MapReduce中shuffle优化与重构
简述mapreduce的shuffle过程。

简述mapreduce的shuffle过程。
MapReduce是一种用于处理大规模数据的并行计算模型,其核心思想是将任务分为两个阶段:Map阶段和Reduce阶段。
在Map阶段,数据被划分为多个独立的片段,每个Map任务对每个数据片段进行处理并生成若干键值对。
而在Reduce阶段,输入键值对按照键的哈希值被分配给特定的Reduce任务进行处理。
而在MapReduce的过程中,Shuffle过程是连接Map阶段和Reduce 阶段的重要步骤。
Shuffle过程主要负责将Map任务生成的中间键值对按照键重新分发给特定的Reduce任务,以便进行后续的处理。
Shuffle过程涉及到三个主要的操作:分区(Partitioning),排序(Sorting)和合并(Merging)。
首先,分区操作用于确定每个中间键值对应该被发送给哪个Reduce 任务。
通常情况下,分区操作会根据中间键的哈希值和Reduce任务的数量进行计算,以确保相同键的键值对被发送到同一个Reduce任务。
这个过程可以保证相同键的键值对在Reduce阶段被正确地聚合和处理。
其次,排序操作用于对每个分区中的键值对进行排序。
这是为了确保Reduce任务能够按照键的顺序进行处理,从而方便后续的聚合操作。
排序可以提高Reduce任务的处理效率,因为相同键的键值对会被连续地处理,减少了数据的读取和写入操作。
最后,合并操作用于将排序后的键值对进行合并,以减少数据的传输量和磁盘IO。
合并操作会将具有相同键的键值对进行合并,生成更少的键值对。
这样可以减少Reduce任务之间的数据传输量,并提高整个MapReduce过程的效率。
总的来说,Shuffle过程在MapReduce中起到了连接Map阶段和Reduce阶段的桥梁作用。
通过分区、排序和合并操作,Shuffle过程可以确保中间键值对被正确地分发给特定的Reduce任务,并按照键的顺序进行处理,从而提高整个MapReduce过程的效率。
sparkshuffle原理、shuffle操作问题解决和参数调优

Spark Shuffle原理、Shuffle操作问题解决和参数调优Spark Shuffle原理、Shuffle操作问题解决和参数调优摘要:1 shuffle原理1.1 mapreduce的shuffle原理1.1.1 map task端操作1.1.2 reduce task端操作1.2 spark现在的SortShuffleManager2 Shuffle操作问题解决2.1 数据倾斜原理2.2 数据倾斜问题发现与解决2.3 数据倾斜解决方案3 spark RDD中的shuffle算子3.1 去重3.2 聚合3.3 排序3.4 重分区3.5 集合操作和表操作4 spark shuffle参数调优内容:1 shuffle原理概述:Shuffle描述着数据从map task输出到reduce task输入的这段过程。
在分布式情况下,reducetask需要跨节点去拉取其它节点上的maptask结果。
这一过程将会产生网络资源消耗和内存,磁盘IO的消耗。
1.1 mapreduce的shuffle原理1.1.1 map task端操作每个,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
Spill过程:这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。
整个缓冲区有个溢写的比例spill.percent(默认是memory写,同时溢写线程锁定已用memory,先对key(序列化的字节)做排序,如果client程序设置了Combiner,那么在溢写的过程中就会进行局部聚合。
Merge过程:每次溢写都会生成一个临时文件,在maptask真正完成时会将这些文件归并成一个文件,这个过程叫做Merge。
1.1.2 reducetask端操作当某台TaskTracker上的所有map task执行完成,对应节点的reduce task开始启动,简单地说,此阶段就是不断地拉取(Fetcher)每个maptask所在节点的最终结果,然后不断地做merge形成reducetask的输入文件。
mapreduce的shuffle机制

标题:探秘MapReduce的Shuffle机制:数据传输的关键环节在现代大数据处理领域,MapReduce框架已经成为一种常见的数据处理模式,而其中的Shuffle机制则是整个数据传输过程中的关键环节。
本文将深入探讨MapReduce的Shuffle机制,从简单到复杂、由浅入深地介绍其原理、作用和优化方法,让我们一起来揭开这个神秘的面纱。
1. Shuffle机制的基本概念在MapReduce框架中,Shuffle机制是指在Mapper阶段产生的中间结果需要传输给Reducer节点进行后续处理的过程。
简单来说,就是将Map阶段的输出结果按照特定的方式进行分区、排序和分组,然后传输给对应的Reducer节点。
这一过程包括数据分区、数据传输和数据合并三个关键步骤,是整个MapReduce任务中耗时和开销较大的部分。
2. Shuffle机制的作用和重要性Shuffle机制在MapReduce框架中起着至关重要的作用。
它决定了数据传输的效率和速度,直接影响整个任务的执行时间。
Shuffle过程的优化可以减少网络开销和磁盘IO,提升整体系统的性能。
而且,合理的Shuffle策略还能够减少数据倾斜和提高任务的容错性。
对Shuffle机制的深入理解和优化,对于提高MapReduce任务的执行效率和性能有着非常重要的意义。
3. Shuffle机制的具体实现方式在实际的MapReduce框架中,Shuffle机制的实现涉及到数据的分区、排序和分组等具体细节。
其中,数据分区决定了数据如何被划分到不同的Reducer节点;数据传输则涉及了数据的网络传输和磁盘读写操作;数据合并则是在Reducer端对来自不同Mapper的数据进行合并和排序。
不同的MapReduce框架会采用不同的Shuffle实现方式,如Hadoop使用的是基于磁盘的Shuffle,而Spark则采用了内存计算的Shuffle优化。
4. Shuffle机制的优化方法为了提高MapReduce任务的执行效率和性能,研究人员和工程师们提出了许多针对Shuffle机制的优化方法。
mapreduce处理数据的工作流程

mapreduce处理数据的工作流程一、简介MapReduce是一种分布式计算模型,用于处理大规模数据集。
它将计算任务分解为可并行处理的小任务,并在多台计算机上执行这些任务。
本文将介绍MapReduce的处理数据的工作流程。
二、MapReduce的基本概念1. Map函数:将输入数据分割成小块,每个小块都由一个Mapper进行处理。
Mapper根据业务逻辑对输入数据进行转换和过滤,输出<key, value>键值对。
2. Shuffle阶段:将Mapper输出的<key, value>键值对按照key进行排序,并将相同key的value聚合在一起。
3. Reduce函数:对Shuffle阶段输出的结果进行归并和汇总,生成最终结果。
三、MapReduce处理数据的工作流程1. 输入数据切片MapReduce会自动将输入文件切成若干个大小相等的块,每个块大小默认为64MB。
切片完毕后,每个块都会被分配给一个Mapper进行处理。
2. Mapper函数执行对于每个切片,MapReduce都会创建一个Mapper实例来执行map 函数。
Mapper首先读取输入文件中与该Mapper实例所负责处理的切片相关联的数据。
然后根据业务逻辑对数据进行转换和过滤,并输出<key, value>键值对。
3. Shuffle阶段Shuffle阶段是MapReduce的核心阶段,它将Mapper输出的<key, value>键值对按照key进行排序,并将相同key的value聚合在一起。
Shuffle阶段会自动将数据分发到不同的Reducer实例上,并根据key值进行排序。
4. Reduce函数执行对于每个key,MapReduce都会创建一个Reducer实例来执行reduce函数。
Reducer首先接收所有与该key相关联的value值,然后根据业务逻辑对数据进行归并和汇总,并输出最终结果。
简述 mapreduce 中的 shuffle 过程

MapReduce中的Shuffle过程1. 概述Shuffle是MapReduce中的一个重要过程,它负责将Map阶段产生的中间数据按照Key进行分组并传递给Reduce阶段进行处理。
Shuffle过程在整个MapReduce作业的性能和效率中起着至关重要的作用。
2. Shuffle过程的作用Shuffle过程主要有以下几个作用: - 数据传输:将Map阶段产生的中间数据按照Key进行分组,并将相同Key的数据传递给对应的Reduce任务进行处理。
- 数据排序:将传输给Reduce任务的数据按照Key进行排序,以便Reduce任务能够更高效地进行处理。
- 数据合并:将相同Key的多个数据合并为一个数据,降低网络传输的开销。
- 数据压缩:对传输的数据进行压缩,减少网络带宽的消耗。
3. Shuffle过程的详细步骤Shuffle过程主要包括三个步骤:分区(Partition)、排序(Sort)和合并(Merge)。
3.1 分区(Partition)在Map阶段,每个Map任务会将产生的中间数据按照Key进行分区,分成多个片段,每个片段对应一个Reduce任务。
分区的目的是为了将相同Key的数据发送给同一个Reduce任务进行处理。
分区的实现方式一般是通过Hash函数将Key映射到指定的分区。
Hash函数可以是系统提供的默认实现,也可以是用户自定义的。
每个Reduce任务会预先知道自己负责的分区,因此Map任务只需要将数据发送给对应的分区即可。
3.2 排序(Sort)在分区之后,每个Reduce任务会接收到多个分区的中间数据。
为了能够高效地处理这些数据,需要对其进行排序。
排序的目的是为了将具有相同Key的数据放在一起,方便后续的处理。
排序可以分为两个阶段:局部排序(Partial Sort)和全局排序(Total Sort)。
局部排序是在每个Map任务内部进行的,它将每个分区的数据按照Key进行排序。
shuffle过程解析
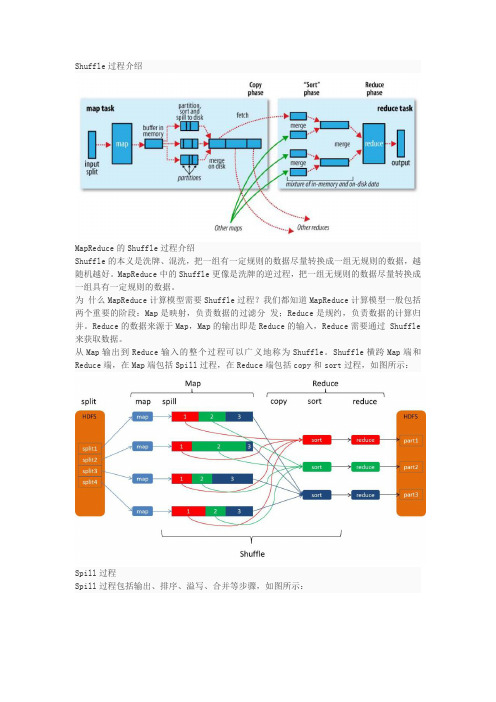
Shuffle过程介绍MapReduce的Shuffle过程介绍Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。
MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。
为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。
Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle 来获取数据。
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。
Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示:Spill过程Spill过程包括输出、排序、溢写、合并等步骤,如图所示:Collect每个Map任务不断地以对的形式把数据输出到在内存中构造的一个环形数据结构中。
使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫Kvbuffer,名如其义,但是这里面不光放置了数据,还放置了一些索引数据,给放置索引数据的区域起了一个Kvmeta的别名,在Kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。
数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次Spill之后都会更新一次。
初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:Kvbuffer的存放指针bufindex是一直闷着头地向上增长,比如bufindex初始值为0,一个Int型的key写完之后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8。
shuffle过程

shuffle过程Shuffle过程Shuffle是指将数据打乱并重新分配的过程。
在大数据处理中,shuffle 是一个非常重要的步骤,因为它可以使得数据更加均匀地分布在各个节点上,从而提高并行处理的效率。
本文将详细介绍shuffle的过程。
一、什么是ShuffleShuffle是指将Map阶段产生的中间结果按照Key值进行排序,并将相同Key值的Value值合并在一起形成一个列表。
然后将这些列表按照Hash算法重新分配到Reduce节点上进行进一步处理。
Shuffle包括三个主要步骤:Partition、Sort和Combine。
二、PartitionPartition是指根据Key值对中间结果进行划分,使得相同Key值的Value值被分配到同一个Reducer节点上进行处理。
具体来说,Partition会根据用户自定义的Partitioner类对Key值进行哈希,并返回一个整型数作为该Key所属Reducer节点的编号。
默认情况下,使用HashPartitioner类对Key进行哈希。
三、SortSort是指对中间结果按照Key值进行排序,以便于后续合并操作。
MapReduce框架默认使用快速排序算法对中间结果进行排序。
四、CombineCombine是指对每个Reducer节点上的相同Key值的Value值进行合并操作,以减少网络传输量和降低Reduce端负载压力。
Combine 操作可以在Map端进行,也可以在Reduce端进行。
默认情况下,MapReduce框架会使用Reducer的Combiner函数对中间结果进行合并操作。
五、Shuffle过程Shuffle过程是指将Partition、Sort和Combine三个步骤结合起来,完成数据打乱和重新分配的过程。
具体来说,Shuffle过程包括以下几个步骤:1. Map阶段:Map任务将输入数据按照用户自定义的Mapper类进行处理,并生成中间结果<key, value>。
hive mapreduce shuffle原理

hive mapreduce shuffle原理Hive是一个建立在Hadoop框架上的数据仓库解决方案,它提供了类SQL查询语言,可以将数据存储在Hadoop的HDFS分布式文件系统中,并通过MapReduce进行处理。
而MapReduce是Hadoop中用于分布式计算的编程模型。
在Hive MapReduce作业中,shuffle是指将Map阶段的输出结果(key-value对)根据key进行排序和分组,以便将相同key 的value聚合在一起,然后传递给Reduce阶段进行处理。
shuffle过程对于MapReduce作业的性能和效率非常重要。
shuffle主要包括三个步骤:分区(partition)、排序(sort)和合并(merge)。
1. 分区(Partition): 在Map阶段结束后,Shuffle会将Map输出的key-value对根据Partitioner函数进行分割,并将相同Partitioner函数输出的结果存储到同一个分区中。
分区的目的是为了使具有相同key值的数据能够发送到同一个Reducer节点上进行处理。
2. 排序(Sort): 在分区之后,shuffle会对每个分区内的数据进行排序操作。
排序是为了将具有相同key值的数据聚合在一起,以便Reduce阶段能够更高效地进行处理。
排序操作可以通过Hadoop的默认排序算法(按照key值进行排序)或自定义排序算法来实现。
3. 合并(Merge): 在排序之后,shuffle会将相同key值的value进行合并操作,以减少数据传输和I/O操作的开销。
合并操作可以有效地降低数据的传输量,并提高MapReduce作业的性能。
合并操作可以在Map端进行,也可以在Reduce端进行。
总结起来,Hive MapReduce Shuffle的原理就是将Map阶段输出的数据根据key进行分区、排序和合并操作,以便将相同key的value聚合在一起,并传递给Reduce阶段进行处理。
mapreduce词频统计过程

MapReduce是一种用于分布式计算的编程模型,它能够对大规模数据进行高效处理和分析。
MapReduce词频统计是MapReduce模型中常见的一个应用场景,它可以对大规模文本数据进行词频统计,从而帮助用户分析文本数据中词汇的使用情况和热词分布。
MapReduce词频统计过程主要包括分为三个步骤:Map阶段、Shuffle阶段和Reduce阶段。
下面我们将逐步介绍MapReduce词频统计的详细过程。
一、 Map阶段在Map阶段,数据被划分成多个小块,并分配给不同的Map任务进行处理。
对于词频统计任务,Map任务首先会将输入的文本数据按行划分,然后对每一行文本进行处理。
具体的Map函数会进行以下操作:1. 读取一行文本数据:Map任务首先会从分配给自己的数据块中读取一行文本数据。
2. 分词和映射:接下来,Map任务会对这行文本数据进行分词操作,将文本数据拆分成单词,并将每个单词映射为键值对<单词, 1>。
“Hello world, hello MapReduce”会被映射为<Hello, 1>、<world, 1>、<hello, 1>、<MapReduce, 1>。
3. 输出键值对:Map任务将映射得到的键值对<单词, 1>作为中间结果输出,以便后续的Shuffle和Reduce阶段进行处理。
二、 Shuffle阶段在Shuffle阶段,Map阶段输出的中间结果<单词, 1>会经过分区、排序和合并等操作,然后传递给Reduce任务。
Shuffle阶段的具体过程如下:1. 分区:Map任务输出的中间结果会被按照键进行哈希分区,不同键的键值对会被分配到不同的分区中。
这样可以保证相同键的键值对会被发送到同一个Reduce任务进行处理。
2. 排序:在每个分区内部,键值对会按照键的自然顺序进行排序,这样可以方便Reduce任务对相同键的键值对进行合并和计算。
简述 mapreduce 中的 shuffle 过程

简述 mapreduce 中的 shuffle 过程【实用版3篇】目录(篇1)1.概述 MapReduce 中的 Shuffle 过程2.Shuffle 过程的作用3.Shuffle 过程的具体实现4.Shuffle 过程的优化5.总结正文(篇1)一、概述 MapReduce 中的 Shuffle 过程MapReduce 是一种分布式计算模型,用于处理大规模数据集。
在MapReduce 中,Shuffle 过程是连接 Map 任务和 Reduce 任务的重要环节。
Shuffle 过程负责将 Map 任务的输出数据按照特定的规则进行分区和排序,然后将分区后的数据传输到相应的 Reduce 任务节点进行处理。
二、Shuffle 过程的作用Shuffle 过程在 MapReduce 计算模型中具有重要作用,主要体现在以下几点:1.数据分区:Shuffle 过程将 Map 任务的输出数据按照不同的分区(partition)进行划分,使得具有相同键值的数据被划分到同一个分区中。
2.数据排序:在每个分区内,Shuffle 过程会对数据进行排序,确保具有相同键值的数据在排序后相邻。
3.数据传输:Shuffle 过程将排序后的数据从 Map 任务节点传输到相应的 Reduce 任务节点,为后续的 Reduce 任务提供输入数据。
三、Shuffle 过程的具体实现Shuffle 过程主要分为两个阶段:Map 端和 Reduce 端。
1.Map 端:在 Map 任务中,Shuffle 过程主要涉及输入数据的划分和排序。
Map 任务将输入数据分成多个分区,并在每个分区内对数据进行排序。
排序后的数据会被存储到本地磁盘,形成一个临时文件。
2.Reduce 端:在 Reduce 任务中,Shuffle 过程主要涉及从 Map 任务节点获取分区数据并将其合并。
Reduce 任务会从所有 Map 任务节点获取对应的分区数据,然后将这些数据进行合并和排序,最终输出处理结果。
2.简述shuffle工作流程。(12分)

Shuffle是在MapReduce运算中非常重要的一个过程,它主要负责将Map阶段输出的数据按照key进行分区和排序,以便Reduce阶段能够高效地进行数据处理。
下面将详细介绍shuffle的工作流程。
1. 分区(Partitioning)在Map阶段输出的数据需要按照key进行分区,以便后续能够将相同key的数据发送到同一个Reducer节点上。
这个过程一般由Partitioner负责,Partitioner会根据key的哈希值将数据分配到不同的分区中,这样相同key的数据就会被分配到同一个分区,然后发送给相同的Reducer节点。
2. 排序(Sorting)在分区之后,每个Reducer节点会收到来自不同Map节点的数据,这些数据需要进行排序以便后续的数据处理。
这个过程会由Map端的内部排序(In-Mapper Sorting)和Reduce端的排序(External Sorting)来完成。
内部排序会在Map阶段对输出的数据进行局部排序,然后将局部有序的数据发送给Reducer节点;而在Reduce阶段,会再次对这些局部有序的数据进行合并排序,使得整体有序。
3. 传输(Shuffling)一旦数据经过分区和排序之后,Map节点就会将数据发送给对应的Reducer节点。
这个过程涉及到数据的网络传输,Map节点需要将数据发送给Reducer节点。
在大规模的数据处理中,这个过程是非常耗时和复杂的,需要考虑网络带宽、传输速度等因素。
4. 缓存(Caching)为了提高效率,Shuffle过程中可以使用缓存技术,将中间结果缓存在内存或磁盘中,以便后续能够更快地访问和处理。
这些缓存的数据可以是分区后的数据、已经排序好的数据等,能够有效地减少数据传输和排序的开销。
5. 性能优化(Performance Tuning)对于Shuffle过程,很多优化方法都可以应用。
比如可以通过Combiner来减少数据的传输量,可以通过压缩技术减少数据的存储空间,还可以通过调节参数来优化网络传输等。
mapreduce的shuffle机制的构成

MapReduce的shuffle机制主要由以下几个部分构成:
1. 分区(Partitioning):将map阶段输出的数据按照key值进行分区,通常使用Partitioner组件来实现。
分区的主要目的是将数据划分为多个分区,以便于后续的排序和分组操作。
2. 排序(Sorting):对分区后的数据进行排序,以便于reduce阶段能够按照key值顺序处理数据。
排序操作是在map阶段和reduce阶段之间完成的。
3. 局部聚合(Local Aggregation):在shuffle过程中,对数据进行局部聚合操作,以减少需要传输的数据量。
局部聚合通常在map阶段完成,通过使用Combiner组件可以实现。
4. 缓存(Caching):在shuffle过程中,使用缓存来存储中间数据,以提高数据处理的效率。
缓存可以被map任务和reduce任务共享。
5. 拉取(Pulling):从map任务中拉取数据,并将其发送到reduce 任务中。
拉取操作是由reduce任务发起的,reduce任务通过向map 任务发送请求来获取需要的数据。
6. 合并(Merging):在shuffle过程中,对来自不同map任务的分区数据进行合并操作,以便于reduce任务能够处理完整的输入数据。
合并操作通常在reduce阶段之前完成。
mapreduce shuffle 排序算法

mapreduce shuffle 排序算法在 MapReduce 计算框架中,"shuffle" 是指在 map 和 reduce 阶段之间对数据进行重新分配的过程。
Shuffle 的目标是确保每个 reduce 函数只接收其感兴趣的数据(根据数据的 key 值),因此,它涉及将数据重新排序并分组。
默认的 shuffle 排序算法如下:1. 全排序(Total Sort):首先,MapReduce 会将所有的 key 值按照从小到大的顺序进行排序。
然后,它会将这些 key 值和对应的 value 值一起发送给 Reduce 阶段。
全排序意味着在所有 MapReduce 作业完成后,Reduce 函数就可以按照 key 的顺序对数据进行处理。
这种排序方法对于小型数据集来说效率较高,但是对于大型数据集来说,其计算量巨大,效率较低。
2. 部分排序(Partial Sort):对于大型数据集,全排序可能并不实际。
因此,MapReduce 可能会采用部分排序算法。
在这种算法中,MapReduce 会将 key 值分成多个部分,并为每个部分生成一个相应的 reduce 任务。
然后,MapReduce 会将每个部分中的 key 值和对应的 value 值发送给相应的 reduce 任务。
这种方法比全排序更有效,因为它只需要对一部分数据进行排序,而不是全部数据。
3. 基于散列的排序(Hash-based Sort):对于某些 key 值,我们可能无法对其进行有效的比较或排序。
在这种情况下,MapReduce 可以采用基于散列的排序算法。
在这种算法中,MapReduce 会为每个 key 值生成一个散列值,并根据散列值将 key 值和对应的 value 值发送给相应的 reduce 任务。
这种方法比全排序和部分排序更有效,因为它不需要对数据进行实际的比较或排序。
以上就是 MapReduce shuffle 的一些主要排序算法。
简述mapreduce中的shuffle过程

简述mapreduce中的shuffle过程MapReduce是一种用于处理大规模数据的分布式计算模型。
在MapReduce中,shuffle是其核心过程之一,主要用于将Map阶段的输出结果按照指定的键进行分组和排序,然后传递给Reduce阶段进行后续处理。
本文将详细介绍MapReduce中的shuffle过程。
1. Map阶段:在MapReduce中,输入数据被分为多个切片,每个切片由一个Map任务处理。
Map任务会将输入数据进行处理,并产生一系列键值对。
这些键值对被称为中间键值对(Intermediate Key-Value Pairs),其中键是可以使用的任意类型,值是由Map任务生成的对应于键的数据。
2. 分区(Partition):分区是shuffle过程的第一步,主要是根据键对中间键值对进行分组,将具有相同键的中间键值对分配到相同的分区中。
分区的数量通常由Reduce任务的数量决定,每个分区对应一个Reduce任务。
3. 排序(Sort):排序是shuffle过程的第二步,主要是对每个分区中的中间键值对按照键进行排序。
这里的排序可以根据键的自然顺序或者使用用户指定的比较函数进行。
合并是shuffle过程的可选步骤,主要是在Map任务内部对分区中的中间键值对进行合并操作。
合并可以减少数据的传输量和磁盘I/O操作以提高性能。
5. 传输(Transfer):传输是shuffle过程的核心步骤,它将排序好的中间键值对从Map任务传输到Reduce任务。
这个过程通常包括两个子步骤:复制(Copy)和排序(Sort)。
- 复制:每个Map任务将自己的中间键值对复制到对应的Reduce任务所在的节点上。
如果有多个Reduce任务在同一个节点上运行,则会将相同键的中间键值对复制到每个对应的Reduce任务上。
- 排序:将来自不同Map任务的中间键值对按照键进行排序。
这样,Reduce任务可以按照顺序读取中间键值对,并按照键的相同顺序进行处理。
简述mapreduce中的shuffle过程

简述mapreduce中的shuffle过程MapReduce是Google发表的一种分布式计算模式,用于大规模数据的处理和并行计算。
在MapReduce中,shuffle过程是非常重要的一个环节,它负责将Map阶段产生的中间结果进行合并和排序,并将结果传递给Reduce阶段进行后续处理。
shuffle过程主要分为三个步骤:分区(partition)、排序(sorting)和合并(merging)。
下面将详细介绍这三个步骤的工作原理和功能。
1. 分区(Partition)在Map阶段,计算框架会根据默认或自定义的分区规则,将各个Map任务的输出结果根据一些属性进行分组,并将相同属性值的结果发送到相同的Reduce任务进行处理。
分区的作用是确保具有相同属性值的结果能够有序地发送到同一Reduce任务,以便后续的排序和合并操作。
分区的实现方式是将Map任务的输出结果按照分区规则进行哈希运算,得到一个分区号,然后将结果发送给对应的Reduce任务。
分区规则一般是根据键值对中的键进行哈希运算,因为分组是根据键值对中的一些属性来进行的。
2. 排序(Sorting)在Map阶段,每个Map任务会输出一组键值对作为中间结果,而Reduce阶段需要对这些结果进行合并和排序。
排序的目的是将具有相同属性值的键值对相邻地放置在一起,以便Reduce任务能够更高效地处理相关的键值对。
排序的实现方式是将Map任务的输出结果按照键进行排序,可以使用内存排序、外部排序等算法。
在排序时,可以充分利用计算节点的内存负载情况和网络传输的带宽来提升整体性能。
3. 合并(Merging)在Map阶段,Map任务可以并行地生成多个中间结果,而Reduce阶段需要将这些结果进行合并和处理。
合并的目的是将具有相同属性值的键值对合并成一个更大的键值对集合,以减少Reduce任务的输入数据量和网络传输的负载。
合并的实现方式是将具有相同属性值的键值对进行聚合和压缩。
简述reduce端的shuffle过程。

简述reduce端的shuffle过程。
reduce端的shuffle过程是在reduce task之前和map task之后进行的,它主要用于将map输出的结果按key进行排序并分组,然后将相同key的数据聚集在一起,以便reduce task能够对数据进行进一步的处理。
具体来说,reduce端的shuffle过程包括以下几个步骤:
1. 从每个map task获取数据:在reduce task启动后,它会向每个map task 发送请求,请求它们的数据。
每个map task会将自己的输出结果分成若干个分区,并将每个分区按key排序后发送给reduce task。
2. 合并排序:在收到所有map task的结果后,reduce task会对它们进行合并排序,以确保所有数据按key有序,并且相同key的数据在同一个分区内。
3. 分组聚合:在完成合并排序后,reduce task会将相同key的数据归为一组,并将它们交给reduce函数进行进一步的处理。
这个过程称为分组聚合。
4. 输出:最后,reduce task会将处理后的数据写入到输出文件。
需要注意的是,shuffle过程的性能对整个MapReduce作业的性能有着重要影响。
因为shuffle过程涉及网络传输和磁盘I/O等开销较大的操作,所以在设计
MapReduce作业时需要尽可能减少数据的传输和磁盘读写,以提高整个作业的效率。
简述shuffle工作流程.

在计算机科学中,shuffle阶段通常指的是在数据处理过程中,对数据进行的重新排序和混合的过程。
具体来说,shuffle过程通常发生在数据处理流水线的某个阶段,例如在机器学习或数据挖掘的任务中,对数据进行排序、分组或混洗的操作。
在MapReduce框架中,shuffle阶段发生在Map阶段和Reduce阶段之间。
Map阶段将输入数据转换成一系列的键值对,然后shuffle阶段将这些键值对进行排序和分组,以便在Reduce阶段进行处理。
具体的shuffle过程包括以下几个步骤:
1. Sort阶段:根据键值对进行排序。
2. Partition阶段:根据键的哈希值进行分组,将相同键的键值对分配到同一组。
3. Reduce阶段:对每组进行归约操作,将每组的键值对处理成最终的结果。
通过shuffle过程,MapReduce框架能够将大规模的数据处理任务划分为许多小的任务,并将这些任务分配给不同的计算节点进行处理。
shuffle过程是MapReduce框架中非常重要的一环,它能够保证数据处理任务的正确性和效率。
MapReduce中combine、partition、shuffle的作用是什么

MapReduce中combine、partition、shuffle的作⽤是什么概括:combine和partition都是函数。
中间的步骤应该仅仅有shuffle!binecombine分为map端和reduce端,作⽤是把同⼀个key的键值对合并在⼀起,能够⾃⼰定义的。
combine函数把⼀个map函数产⽣的<key,value>对(多个key,value)合并成⼀个新的<key2,value2>.将新的<key2,value2>作为输⼊到reduce函数中这个value2亦可称之为values,由于有多个。
这个合并的⽬的是为了降低⽹络传输。
详细实现是由Combine类。
实现combine函数,该类的主要功能是合并同样的key键。
通过job.setCombinerClass()⽅法设置。
默觉得null,不合并中间结果。
实现map 函数详细调⽤:(下图是调⽤reduce,合并map的个数)难点:不知道这个reduce和mapreduce中的reduce差别是什么?以下简单说⼀下:后⾯慢慢琢磨:在mapreduce中。
map多,reduce少。
在reduce中因为数据量⽐較多。
所以⼲脆。
我们先把⾃⼰map⾥⾯的数据归类,这样到了reduce的时候就减轻了压⼒。
这⾥举个样例:map与reduce的样例map理解为销售⼈员,reduce理解为销售经理。
每⼀个⼈(map)仅仅管销售,赚了多少钱销售⼈员不统计。
也就是说这个销售⼈员没有Combine,那么这个销售经理就累垮了。
由于每⼀个⼈都没有统计,它须要统计全部⼈员卖了多少件。
赚钱了多少钱。
这样是不⾏的。
所以销售经理(reduce)为了减轻压⼒,每⼀个⼈(map)都必须统计⾃⼰卖了多少钱,赚了多少钱(Combine),然后经理所做的事情就是统计每⼀个⼈统计之后的结果。
这样经理就轻松多了。
所以Combine在map所做的事情。
mapreduce中shuffle过程

mapreduce中shuffle过程MapReduce 中的 Shuffle 过程,就像是一场数据的大冒险!你想啊,在 MapReduce 这个庞大的数据处理世界里,Shuffle 可不是个小角色。
它就像一个神奇的桥梁,连接着 Map 阶段和 Reduce 阶段。
在 Map 阶段,数据被切割、处理,就好像是把一堆杂乱无章的拼图碎片准备好。
那这些碎片怎么到 Reduce 阶段去拼成完整的图画呢?这就得靠 Shuffle 啦!Shuffle 首先要做的就是对 Map 输出的结果进行分区。
这分区就好比把不同类型的水果放进不同的篮子里。
比如说,苹果放一个篮子,香蕉放另一个篮子。
这样,相同类型的数据就能被分到一起,为后续的处理做好准备。
然后呢,Shuffle 还得对数据进行排序。
这排序可重要了,就像给一群小朋友按照身高排好队,整整齐齐的,方便管理。
经过排序的数据,在 Reduce 阶段处理起来可就轻松多啦!还有啊,Shuffle 还得负责把数据从 Map 端传输到 Reduce 端。
这传输过程就像是快递员送包裹,得保证包裹不丢失、不损坏,准时准点地送到目的地。
你说,要是 Shuffle 过程出了岔子,会怎么样?那可不得了!就好比快递员送错了包裹,或者把包裹弄丢了,整个数据处理的流程不就乱套了嘛!所以啊,Shuffle 过程可得精心设计和优化。
比如说,合理设置分区的数量,让数据分布更均匀;优化排序的算法,提高效率;加强数据传输的可靠性,确保数据的安全。
总之,Shuffle 过程在 MapReduce 中起着至关重要的作用,它就像是一个默默无闻的幕后英雄,为数据处理的顺利进行保驾护航。
咱们可不能小瞧了它!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Iptom t nuFr a 产生的。然后框架为这个任务 Iptpi中 nuS l t 每个键值对调用 1 m pWral o a b , ia l 次 a( ib C mpr l Wf b , t e ae t e O tu o et , eot ) u t lc r R p r r pC l o e 操作。Ma r的输 出被排序  ̄e
Jb o fe u R dcTssn 设定一个作业中 rdc oC n.t m eue a ( t sN k i) eue 任务的数 目。如果 MaR ue没有规约要求,那么设 pe c d 置 r ue e c 任务的数 目是 0 是合法的。 d , 这种情况下 , p a m 任务的输出会直接被写入由 stu u a (a ) e t t t Pt  ̄定的 O pPh h 输出路径 。 框架在把它们写入 F eyt iS s m之前没有对它 l e 们进行排序。
21 第4 0卷 2 月 第7 年 4期
中 国 科 技 论 文 CHIA S I N P PE N C E CE A R
V L o4 O 7N .
Ap . 2 1 r 02
MaR d c p eu e中 su e h f 优化与重构 l
彭 辅权 ,金 苍 宏 , 吴明 晖 2 ,应 晶 , 2
O tu o et ,R pr r 法 【。其 中 用 户 可 以 通 过 u t lc r eot) pC l o e方 o J
收集输出和 向用户传递作业结果 。
MaR dc 的构成要素如表 1 p eue 所示 。
表 1 Ma R d c p eu e的构成要素
T b e 1 E e n so a Re u e a l l me t f M p d c
要
素
负责处理
用户
作业 配置
输入分割和派遣 接受分割的输入后 ,启动每个 ma 任务 p
对于每 个键 值对 ma p函数 被调 用 1 次 混 淆、分 割和排 序 ma p的输 出块
的分 解与 结果的 汇总 ”【 j J 。
一
1 Ma - 2 p端
Mapr是将输入键值对映射到一组中间格式的键 pe 值对集合 。 aop p eu 框架为每个 hp tpt H d o MaR dc e l sl 产 u i 生 1个 m p任务 ,而每个 I uS l 由该作业容错性 , 已经是目前 云计算平台的主流。MaR d c 作为 H do 的核心框 p eue aop
架之一 ,如何提升 MaR dc p eue运算性能,已经是学术
1 MaR d c 框架 介绍 p eu e
H d o p eu 是一个使用简易的软件框架 , aopMaR d c e
的数 目通常是由输入数据的大小决定的, 一般为所有文
件 的总块 数 。 1 R d c 端 . eue 3
责调度构成一个作业的所有任务 , 这些任务分布在不 同的 s v l e上,ma e 监控它们的执行 ,重新执行 已 a sr t 经失败 的任务 。而 s v 仅负责执行由 mat 指派的 le a sr e
序, 然后把结果输入给 rd c 任务。通常作业的输入 eue 和输出都会被存储在文件系统中。 整个框架负责任务 的调度 和监控 以及重新执 行已经失败 的任务 。 MaR d c 框架由一个单独的 mat jb rce 和每 p eu e s ro Tak r e
个集群 节点的一个 s v ak rce 组成 。mat 负 l et Takr a s sr e
界和工业界都非常关注的一个热点问题 。MaR dc J p eue
收稿 日期:2 1-21 0 1 .5 1
基于它写 出来的应用程序能够运行在 由成千上万个商
基金项 目:清华一 腾讯互联 网创新技术联合实验室资助项  ̄(0 18 2 1—)
作者简 介 :彭辅权 ( 8 一 ) 1 7 9 ,男 ,硕士研究生 ,主要研究方向 :海量数据处理 、分布式 计算 通 信联 系人 :应晶 ,教授 ,主要研究方向 :软件工程 ,y g u c d . i j c. u n n @z e c
H do aop能够很好地用于海量数据的存储和计算,由于
框架, 然后具体分析了 su e h f 阶段流程 , l 并分别从 Ma p
端数据压缩、重构远程数据拷贝传输协议和 R dc eue端
内存分配优化 3个方面优化和重构 su l,以提升 hfe
MaR dc 计算性能 。 p eue
(.浙江 大学计算机 学院,杭州 3 02 ;2 浙 江大学城 市学院 ,杭 州 3 0 1 ) 1 107 . 10 5
摘 要 :详细介绍 ̄M p eue aRdc编程框架 , 具体分析了 M印R dc中 e e e u 阶段流程。分别从Ma端数据压缩、重构 p 远程 数据拷贝传输协议 、Rdc端 内存分配优化三方面来优化和重构Su l eu e hf 。最后通 过搭建H do 集群 ,运用 e aop Ma eue p d c分布式算法测试实验数据。实验结果证 明 R 优化重构后的s e h 能显著提高MaRdc计算性能。 衄 p eue 关键词 :云计算 ;H do ; p eue hfe aop MaR dc;su l
1 MaR dc 构成要素 . 1 p eue 用户可 以配置和向框架提交 MaR d c p eue任务。一 个 MaR dc 任务包括 m p任务、混淆过程、排序过 p eue a 程和一套 rdc 任务。框架会管理作业的分配和执行, eue
要传递一个 Jb o f oC n 参数,目的是完成 r u e 的初始 e c d r 化工作。框架为成组的输人数据 中的每个< e, s o ky 1t f ( i vl s 对调用一次 rdc( ib C m a b ,t a r a e) u > eue t l o pr l Ir o, Wra e ae et
prtnr a i e 来控制哪个 ky被分配给哪个 r ue。用户 to i e e cr d
可 选 择 通 过 Jb o.to bnr l s l s ̄ 定 一 个 oC fe m i Ca ( a ) sC e sC s
cm i r o b e,它负责对中间过程的输 出进行本地的聚集 , n 这有助于降低从 m pe 到 rdcr a pr eue 数据传输量 。m p a
Pe g F q a JnCa g o g , W u M i g u Yig Jn n u u n , i n h n n h i, n i g ,
(. p r n o o p t S i c, h in nvri , a g h u 10 7 C i ; 1De at tfC m ue c neZ e agU i sy H n z o 0 2 , h a me r e j e t 3 n
rc nt c n h poo o u e o o yte a om teM叩 e d te d c n a do t z gme r llct no eo s u t gte rtc l sdt cp h d t r h r i af n t h Reu ee d n pi i o , min moya o a o n i
22 4
中 国科 技 论 文
CH N CIN P P R IA S E CE A E
第7 第4 卷 期
21 0 2年 4月
用机器组成的大型集群上 , 并以一种可靠容错的方式并 行处理上 T级别的数据集。 p eue MaR d c 把运行在大规模
集群上的并行计算过程抽象为 2 个函数: p r ue ma 和 e c, d 也就是映射和规约。简单地说, p eue MaR dc 就是 “ 任务
个 MaR d c p e ue作业( b通常会把输入的数据 j ) o
集切分为若干个独立的数据块 , m p 由 a 任务以完全并
行的方式处理它们。框架会对 ma 的输 出先进行排 p
后, 就被划分给每个 rdcr 分块的总数 目和 1 e ue, 个作业
的 r ue任务数相同。用户可 以通过实现 自定义的 e c d
框架内部性能提升很重要的一个部分是对 su l hfe阶段
的优化和重构。本文首先详细介绍了 MaR d c p eue计算
题 已经开始暴露出来,包括数据的安全性、数据传输的 瓶颈、 云服务的不兼容等。云计算的所有问题都起因于 海 量数据 ,而 由 A ah 软件基金 会开发 和推 出的 p ce
中图分类号 :T 3 1 P 1. 5 文献标 志码 :A 文章编号 :2 9 —2 8 (020 —0 4 —5 0 5 7 32 1)4 2 1
Optm i a i n a d r c n t u to hu ei a i z to n e o s r c i n s f n M pRe u e l d c
任 4。 ]
R d cr将一个 ky关联的一组中间数值集规约 eu e e ( d c) r ue e 为一个更小的数值集。对 rdc 的实现者需要 e ue r
重 写 Jb o f ualcn g r Jb o f oC ni rb . f ue oC n) g eoi ( 方法 , 该方 法需
h e o srce m . t erc n tu tds u e h
K e r s co d c m p t g; H a o p; M a Re uc y wo d : l u o ui n do p d e; s uf e h f l