Mycat-cluster设计简析
Mycat配置及使用详解.

Mycat配置及使⽤详解.⾸先我们来看下什么是Mycat:MyCat:开源分布式数据库中间件, 这⾥定义的很简单, 就是分布式数据库的中间件.其实Mycat 是可以时mysql进⾏集群的中间件, 我们可以对mysql来分库分表来应对⽇益增长的数据量. 每台机器只存少量数据, 数据总和是分布式的机器上数据量总和.例如我们⼀个表中有512条数据(当然实际情况可能有成千上万条数据), 那么现在我们有三台机器装有mysql数据库, 我们想将这些数据按照⼀定规则的存储在三台机器上, 那么我们设定规则:表的id%/512 取的结果按照区间分别存储在三个不同的数据库中, 但是这三个数据库⼜要统⼀的对外提供服务.那么这些分割算法以及统⼀对外提供服务是谁来提供⽀持的呢? 当然就是我们今天要讲的Mycat了.在Linux下连接Mysql:连接Linux中的mysql数据库:(这⾥我们的Linux IP为192.168.200.140)查看表结构:查看1库中的商品ID(这个已经是通过Mycatt分好的)查看1库中的商品ID(这个已经是通过Mycatt分好的)查看1库中的商品ID(这个已经是通过Mycatt分好的)启动Mycat连接Mycat:在项⽬组中设置默认连接为Mycat:(关于这⾥数据库为什么是babasport⽽不是babasport1或babasport2等, 后⾯会说明)Mycat的配置:1, ⽤户名及密码设置:server.xml:2, 逻辑库中的定义表:schema.xml:这⾥需要说⼀下, 因为bbs_color和bbs_brand表中的数据很少, 所以这⾥不需要分库分表, 直接设置成全局表就⾏, 也就是这两个表中的数据在1,2,3 库中都是⼀样的.还有就是childTable, 我们拿bbs_product和bbs_sku来说, 因为商品product和库存bbs_sku是⼀对多的关系, 那么我们就希望商品id为1 的商品所对应的库存都是在同⼀个库中的, 这样查询的话就不⽤跨库了.同样这⾥还有⼀个属性是rule="sharding-by-pattern", 那么接下来我们就要看下这⾥设定的规则了.因为上⾯的schema标签中有定义的那么为babasport, ⽽且dataNode节点⼜分别指向dn1, dn2, dn3, 所以这⾥就可以做到对应了.我们在项⽬连接的时候直接是连接babasport的.3, 查看分⽚规则: rule.xml这⾥指定算法为sharding-by-pattern.查看算法sharding-by-pattern, 这⾥指定算法存储在partition-pattern.txt这⾥是通过PartitionByPattern这个类来实现的, 这⾥是对512进⾏取模, 如果取模过程中出现异常, 那么就放到3库(0,1,2)中进⾏存储.查看算法指定⽂件:这⾥就可以⼀⽬了然的查看到 0-127 是放在1库中, 128-255 是放在2库中, 256-512 是放在3库中.同样Mycat还⽀持动态扩容, 当我们的数据量越来越⼤时我们还可以加机器来分担压⼒, Mycat可以动态的取扩容. 这⾥就不再讲具体的实现原理了.关于Mycat的内容就说到这⾥, 更深层次的东西⼤家可以继续查阅相关资料, 我这⾥只是做⼀个介绍和⼊门.。
MyCat配置详解

MyCat配置详解MyCat配置1. server.xml配置Server.xml保存了mycat需要的所有的系统配置信息,代码映射为SystemConfig类。
标签主要有三个:system,user,firewarll1.1 user标签1.1.1 property标签<user name="test"> <!--⽤户名是test--><property name="password">password</property><!--密码是password--><property name="schemas">TESTDB</property><!-- 使⽤的schema是TESTDB-->⽰例说明test⽤户密码是testdb1, db2可访问的schema有db1,db2true是否只读11111连接上限,降级权值0是否对密码加密默认 0 否如需要开启配置 1,1.1.2 privileges标签对⽤户的 schema以及表进⾏精细化的DML权限控制。
<privileges check="false">check表⽰是否开启DML权限检查。
默认是关闭。
dml顺序说明iinsert,update,select,delete<schema name="db1" dml="0110" ><table name="tb01" dml="0000"></table><table name="tb02" dml="1111"></table></schema>db1的权限是update,select。
MySQL Cluster简介

MySQL Cluster简介1. MySQL Cluster 是什么?答:MySQL Cluster 是一个实时、高度可扩展且符合ACID 要求的事务型数据库,既可以实现99.999%的可用性,又具备开源产品低TCO 的优势。
MySQL Cluster 采用一种分布式的多主机架构,无单点故障。
它可在商业硬件上横向扩展,并且可同时支持读取和写入密集型负载,支持通过SQL 和NoSQL 接口访问。
MySQL Cluster 采用实时设计,可提供可预测的毫秒级响应,每秒可处理数百万次操作。
该集群支持内存中和基于磁盘的数据、自动数据分区(分片)以及负载平衡,无需停机即可在处于运行状态的集群中添加节点,因此可实现线性的数据库可伸缩性,能够处理在应用压力无法预测时、基于Web 的负载。
2. MySQL Cluster 运营商级版本是什么?答: MySQL Cluster 运营商级版本(CGE) 包括用于管理和审计MySQL Cluster 数据库以及监视其安全性的工具,同时还提供Oracle 标准支持服务。
用户可通过订购或者商业许可及服务来获取MySQL Cluster CGE。
3. MySQL Cluster 的最新版本?答:最新GA 版是MySQL Cluster 7.3。
MySQL Cluster 中集成和捆绑了MySQL 5.6。
4MySQL Cluster 对硬件或软件是否有特殊需求?答:没有,MySQL Cluster 被设计为在商用硬件上运行。
使用Infiniband 网络互联等专门硬件可实现更高水平的性能,尤其是针对具有许多节点的大型集群。
5. MySQL Cluster 的系统需求?答:操作系统:请参见最新的受支持平台列表»CPU:Intel/AMD x86、UltraSPARC内存:至少1GB RAM硬盘:3GB网络:至少1 个节点(千兆以太网— TCP/IP)6.MySQL Cluster 的理想应用场景?答:理想应用包括:∙大容量OLTP∙实时分析∙支持欺诈检测的电子商务和金融交易∙移动和小额支付∙会话管理和缓存∙串流派送、分析和推荐∙内容管理和交付∙大型多人在线游戏∙通信和位置服务∙使用者/用户资料管理和授权7. MySQL Cluster 有哪些典型性能指标?答:可用性99.999%(每年停机时间小于5 分钟)∙性能o响应时间:不到5 毫秒(通过SQL 进行同步复制和访问)。
mycat 原理

mycat 原理Mycat原理。
Mycat是一个开源的分布式数据库中间件,它是为了解决MySQL数据库的扩展性和高可用性而设计的。
Mycat可以将多个MySQL数据库组合成一个逻辑的数据库集群,从而实现数据的分片存储和负载均衡。
在本文中,我将介绍Mycat的原理及其工作机制。
Mycat的原理主要包括分片规则、路由规则和SQL解析。
首先,分片规则是指将数据按照一定的规则分散到不同的数据库节点上,这样可以实现数据的水平分片存储。
其次,路由规则是指根据SQL语句的特征将请求路由到相应的数据库节点上,从而实现负载均衡和高效的数据访问。
最后,SQL解析是指解析SQL语句,根据分片规则和路由规则将SQL请求转发到相应的数据库节点上,并将结果返回给客户端。
Mycat的工作机制主要包括SQL拦截、路由分发和结果集合并。
首先,SQL拦截是指Mycat拦截客户端的SQL请求,然后根据路由规则将请求路由到相应的数据库节点上。
其次,路由分发是指Mycat将SQL请求分发到各个数据库节点上,并将结果集合并后返回给客户端。
最后,结果集合并是指Mycat将各个数据库节点返回的结果集进行合并,然后返回给客户端,从而实现透明的数据访问。
总的来说,Mycat的原理和工作机制都是围绕着数据分片存储、负载均衡和高可用性展开的。
通过分片规则、路由规则和SQL解析,Mycat可以实现数据的水平分片存储和高效的数据访问。
通过SQL拦截、路由分发和结果集合并,Mycat 可以实现负载均衡和高可用性。
因此,Mycat在大数据时代具有重要的意义,它可以帮助企业解决数据库的扩展性和高可用性问题,从而提高数据访问的效率和可靠性。
总之,Mycat作为一个开源的分布式数据库中间件,其原理和工作机制都非常复杂和精妙。
通过深入理解Mycat的原理和工作机制,我们可以更好地应用Mycat 来解决数据库的扩展性和高可用性问题,从而更好地满足企业的数据访问需求。
希望本文对你理解Mycat有所帮助。
MyCat读写分离配置

MyCat读写分离配置读写分离在我们配置数据库集群时是必然会考虑的一个点,因为这可以有效的降低主库的负载,并且在读多余写的情况下,绝大部分的读请求都可以分发到各个不同的从库上。
即使从库负载不够,也可以通过增加从库的方式来提升整体的查询效率。
本文主要讲解MyCat如何进行读写分离的配置。
1. 环境搭建为了搭建读写分离数据库架构,这里我们需要准备两个数据库,一个作为主库,一个作为从库。
本文所使用的方式是通过docker搭建的主从架构,因而可以在本机上直接运行。
具体配置如下:关于docker如何搭建MySQL主从数据库,读者朋友可以阅读本人的文章(Docker搭建MySQL主从集群)。
读者朋友也可以通过虚拟机的方式搭建主从数据库,这里就不再赘述。
2. MyCat配置关于MyCat的配置,其主要是需要在某一个数据库节点上同时指定主库和从库。
下面是一个示例:<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="mydb" checkSQLschema="true" sqlMaxLimit="100"><table name="t_user" primaryKey="id" autoIncrement="true" dataNode="dn1"/></schema><dataNode name="dn1" dataHost="dhost1" database="db1"/><dataHost name="dhost1" maxCon="1000" minCon="10" balance="1"writeType="0"switchType="-1" dbType="mysql" dbDriver="native"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="localhost:3306" user="root" password="root"/> <writeHost host="hostS1" url="localhost:3307" user="root" password="root"/> </dataHost></mycat:schema>关于上述配置,主要有如下几点需要说明:xml的配置顺序schema、dataNode和dataHost的顺序不能发生变化;在dataHost中通过writeHost将主库和从库都配置进去,MyCat可以通过show master status来检测具体哪一个是主库,哪一个是从库;在dataHost上有两个参数:balance和switchType。
Mycat开源分布式数据库中间件介绍

Mycat分片方案
范围类分片规则 CATALOG
1. 范围约定 目录 2. 目录 按日期(天)分片 3. 按单月小时拆分 4. 自然月分片
设计目标
平滑移植
大数据
CATALOG目录 目录
兼容MySQL,MYSQL项目很容易移 植到MyCAT上 多种分片算法,100亿大表,秒级并 行查询 透明的读写访问机制,多数据源
应用透明 高可用 高性能
内建数据库集群故障切换机制
支持MySQL主从集群、 Galera Cluster多主同步集群
设计目标
Mycat开源分布式数据库中间件介绍
目目录录
CATALOG目录 目录
第一部分:Mycat • 介绍 • 设计目标
• 应用场景
• 方案对比 • 技术架构
第二部分:集群及规划
目Mycat介绍录
一个彻底开源的,面向企业应用开发的大数据库集群 CATALOG 目录 ACID、可以替代MySQL的加强版数据库 支持事务、 目录 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品 一个新颖的数据库中间件产品
集群能力
企业级特性
Oracle有很多企业级特性以及 MySQL缺乏很多高级的企业级特性,因此关键 完备的工具等,满足苛刻要求 业务领域还无法跟上Oracle,但在大多数业务 的关键业务领域 领域,已经满足需求,特别是互联网领域 Oracle大规模使用下的成本比 较高,包括高端硬件的支出和 运维费用 MySQL的使用费用基本为零,而硬件方面的成 本也相对低很多
MySQL Cluster配置参数详细介绍

c) 2代表本节点参与决策,但是优先权较1低,但是比0高
ArbitrationRank参数不仅仅管理节点有,MySQL节点也有。而且一般来说,所有的管理节点一般都应该设置成1,所有SQL节点都设置成2。
2) [NDB_MGMD]是每个管理节点配置一组,所需配置项如下(下面的参数只能设置在[NDB_MGMD]参数组中):
c) 还可以计入syslog里面如:LogDestination=SYSLOG:facility=syslog;
d) 甚至多种方式共存:LogDestination=CONSOLE;SYSLOG:facility=syslog;FILE:filename=/var/log/cluster-log
MaxNoOfLocalScans:和上面的这个参数相对应,只不过设置的是在本节点上面的并发table scan和range scan数量。如果在系统中有大量的并发而且一般都不使用并行的话,需要注意此参数的设置。默认为MaxNoOfConcurrentScans * node数目;
BatchSizePerLocalScan:该参用于计算在Localscan(并发)过程中被锁住的记录数,文档上说明默认为64;
DataDir:指定本地的pid文件,trace文件,日志文件以及错误日志子等存放的路径,无系统默认地址,所以必须设定;
DataMemory:设定用于存放数据和主键索引的内存段的大小。这个大小限制了能存放的数据的大小,因为ndb存储引擎需属于内存数据库引擎,需要将 所有的数据(包括索引)都load到内存中。这个参数并不是一定需要设定的,但是默认值非常小(80M),只也就是说如果使用默认值,将只能存放很小的数 据。参数设置需要带上单位,如512M,2G等。另外,DataMemory里面还会存放UNDO相关的信息,所以,事务的大小和事务并发量也决定了 DataMemory的使用量,建议尽量使用小事务;
1.Mycat原理解析

1.Mycat原理解析一、常见的数据库中间件对比功能Sharding-JDBCTDDL Amoeba Cobar MyCat基于客户端还是服务端客户端客户端服务端服务端服务端分库分表有有有有有MySQL交互协议JDBCDriverJDBCDriver前端用NIO,后端用JDBC Driver前端用NIO,后端用BIO前后端均用NIO支持的数据库任意任意任意MySQL 任意MyCat是社区爱好者在阿里Cobar基础上进行二次开发,解决了cobar当时存在的一些问题,并且加入了许多新的功能在其中,目前MyCAT社区活跃度很高。
二、架构图1、Sharding-JDBC2、TDDL3、Amoeba4、Cobar5、MyCat总结:1.TDDL 不同于其它几款产品,并非独立的中间件,只能算作中间层,是以 Jar 包方式提供给应用调用。
属于JDBC Shard 的思想,网上也有很多其它类似产品。
2.Amoeba 是作为一个真正的独立中间件提供服务,即应用去连接 Amoeba 操作 MySQL 集群,就像操作3.单个 MySQL 一样。
从架构中可以看来,Amoeba 算中间件中的早期产品,后端还在使用 JDBC Driver。
4.Cobar 是在 Amoeba 基础上进化的版本,一个显著变化是把后端JDBC Driver 改为原生的MySQL 通信协议层。
后端去掉JDBC Driver 后,意味着不再支持JDBC 规范,不能支持Oracle、PostgreSQL 等数据。
但使5.用原生通信协议代替JDBC Driver,后端的功能增加了很多想象力,比如主备切换、读写分离、异步操作等。
6.MyCat 又是在 Cobar 基础上发展的版本,两个显著点是:7.(1)后端由 BIO 改为 NIO,并发量有大幅提高8.(2)增加了对Order By、Group By、limit 等聚合功能的支持(虽然 Cobar 也可以支持 Order By、Group By、Limit 语法,但是结果没有进行聚合,只是简单返回给前端,聚合功能还是需要业务系统自己完成)。
Mycat分片规则详解--范围取模分片

Mycat分⽚规则详解--范围取模分⽚实现⽅式:该算法先进⾏范围分⽚,计算出分⽚组,组内在取模优点:综合了范围分⽚和取模分⽚的优点,分⽚组内使⽤取模可以保证组内的数据分布⽐较均匀,分⽚组之间采⽤范围分⽚可以兼顾范围分⽚的特点,事先规划好分⽚的数量,数据扩容时按照分⽚组扩容,则原有分⽚组的数据不需要迁移,分⽚组内还可以避免热点数据问题。
缺点:在数据范围时固定值(⾮递增值)时,存在不⽅便扩展的情况,例如将 dataNode Group size 从 2 扩展为 4 时,需要进⾏数据迁移才能完成配置⽰例:<tableRule name="auto-sharding-rang-mod"><rule><columns>id</columns><algorithm>rang-mod</algorithm></rule></tableRule><function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod"><property name="mapFile">partition-range-mod.txt</property><property name="defaultNode">0</property></function>相关属性:mapFile:切分规则配置⽂件defaultNode:默认节点,⼩于0表⽰不设置默认节点,⼤于等于0表⽰设置默认节点,如果超出配置的范围,则使⽤默认节点partition-range-mod.txt ⽰例:#range start-end,dataNode group size#K=1000,M=100000-100K=2100K1-200K=2注意:0-100K=2 表⽰在 0-100K范围中,有2个dataNode;如果需要进⾏扩展,则配置新的范围并增加 dataNode 组的数量来进⾏扩展,不需要针对历史数据进⾏迁移。
详解 mycat分片.(DOC)

MYcat 分片规则. 枚举法:通过在配置文件中配置可能的枚举id,自己配置分片,使用规则:<tableRule name="sharding-by-intfile"><rule><columns>user_id</columns><algorithm>hash-int</algorithm></rule></tableRule><function name="hash-int"class="org.opencloudb.route.function.PartitionByFileMap"><property name="mapFile">partition-hash-int.txt</property><property name="type">0</property><property name="defaultNode">0</property></function>partition-hash-int.txt 配置:10000=010010=1DEFAULT_NODE=1上面columns 标识将要分片的表字段,algorithm 分片函数,其中分片函数配置中,mapFile标识配置文件名称,type默认值为0,0表示Integer,非零表示String,所有的节点配置都是从0开始,及0代表节点1/*** defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点*默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点* 如果不配置默认节点(defaultNode值小于0表示不配置默认节点),碰到* 不识别的枚举值就会报错,* like this:can't find datanode for sharding column:column_nameval:ffffffff*/2.固定分片hash算法<tableRule name="rule1"><rule><columns>user_id</columns><algorithm>func1</algorithm></rule></tableRule><function name="func1"class="org.opencloudb.route.function.PartitionByLong"><property name="partitionCount">2,1</property><property name="partitionLength">256,512</property></function>配置说明:上面columns 标识将要分片的表字段,algorithm 分片函数,partitionCount 分片个数列表,partitionLength 分片范围列表分区长度:默认为最大2^n=1024 ,即最大支持1024分区约束 :count,length两个数组的长度必须是一致的。
mycat配置文档分析

Mycat部署文档说明本文档主要对mycat的配置文件进行分析。
配置文件Schema.xml文件在MYCAT/conf/schema.xml中定义逻辑库,表、分片节点等内容。
schema.xml内容如下:<!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://org.opencloudb/"><schema name="dbtest" checkSQLschema="false" sqlMaxLimit="100"><table name="tb_test" dataNode="dn1,dn2" rule="auto-sharding-long" /> </schema><dataNode name="dn1" dataHost="localhost1" database="db1" /><dataNode name="dn2" dataHost="localhost1" database="db1" /><dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="1" dbType="mysql" dbDriver="native"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="192.168.14.204:3306" user="admin" password="123456"><readHost host="hostS1" url="192.168.14.205:3306" user="admin" password="123456"/></writeHost><writeHost host="hostM2" url="192.168.14.211:3306" user="admin" password="123456"><readHost host="hostS2" url="192.168.14.212:3306" user="admin" password="123456"/></writeHost></dataHost></mycat:schema>基本概念:1)table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode,这是通过表格的分片规则定义来实现的,table可以定义其所属的“子表(childTable)”,子表的分片依赖于与“父表”的具体分片地址,简单的说,就是属于父表里某一条记录A的子表的所有记录都与A存储在同一个分片上。
Mycat开源分布式数据库中间件介绍
远程培训服务
通过电话会议、 QQ会议等方式进行远程培训,协助项目组 按次 2 成员掌握Mycat基本技能并集中解答技术问题,每次2小时
现场技术 支持服务
1.现场(Mycat专家 )技术支持服务
4
人天 人天
2.现场(Mycat Leader)技术支持服务
5
目目录录
CATALOG目录 目录
第一部分:Mycat • 介绍 • 设计目标
现场技术 支持服务
1.现场(Mycat专家 )技术支持服务
人天 人天
4
2.现场(Mycat Leader)技术支持服务
5
合作模式
软件项目全生命周期顾问服务 目录
服务项目 描述 标准
咨询服务
提供包括项目风险评估、需求分析、中间件选型、架构设 按半年,年付费 计和评估、 1 POC原型设计、项目管理支持、核心代码研发、 技术攻关、性能测试方案、系统性能优化、数据库优化等 全生命周期技术服
多主同时写入,高可靠性,适合系统中的关键表 Client Galera cluster
帐务表、订单表等
用户表、字典表、常规数据
主从故障切换,可能有数据丢失的问题
Mysql Master/Slave
Mycat
One Schema 日志类的数据
存储大量一次性非业务数据 NoSQL
一个逻辑库
Mycat典型应用场景
成本问题
Mycat分片方案
解决的问题?: CATALOG目录 单库单节点数据过大带来的性能及稳定性 目录
切分后带来问题: -引入分布式事务的问题。 -跨节点Join 的问题。 -跨节点合并排序分页问题。 -数据热点问题
所以: -尽量不切分,架构是进化而来,不是一蹴而就。 -最大可能的找到最合适的切分维度。 -由于数据库中间件对数据Join 实现的优劣难以把握,而且 实现高性能难度极大,业务读取 -尽量少使用多表Join -尽量通过数据冗余,分组避免数据垮库多表join。 -尽量避免分布式事务。 -单表切分数据1000万以内。
mycat读写分离+垂直切分+水平切分+er分片+全局表测试

mycat读写分离+垂直切分+⽔平切分+er分⽚+全局表测试读写分离:利⽤最基础的mysql主从复制,事务性的查询⽆法分离出去(因为会导致数据不⼀致),这样就⽆法做到真正的读写分离,因为有些场景可能⼤部分都是事物性的读。
解决⽅法: galera for mysql 强⼀致性。
好的实例连接:安装使⽤过程遇到的问题:1、mycat启动后报错,进程直接退出: Error: Exception thrown by the agent : .MalformedURLException: Local host name unknown: .UnknownHostException: ys-fs: ys-fs: Name or service not known原因:本机要配置/etc/hosts 127.0.0.1 主机名⼀、垂直切分测试:1、schema.xml⾥⾯加⼊:<schema name="weixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="weixin" /><schema name="yixin" checkSQLschema="false" sqlMaxLimit="100" dataNode="yixin" /><schema name="sms" checkSQLschema="false" sqlMaxLimit="100" dataNode="sms" /><dataNode name="weixin" dataHost="host0" database="weixin" /><dataNode name="yixin" dataHost="host1" database="yixin" /><dataNode name="sms" dataHost="host2" database="sms" /><dataHost name="host0" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="namenode" url="192.168.168.230:3306" user="root" password="youngsun" /></dataHost><dataHost name="host1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hadoop1" url="192.168.168.231:3306" user="root" password="youngsun" /></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"><heartbeat>select user()</heartbeat><!-- can have multi write hosts --><writeHost host="hadoop2" url="192.168.168.232:3306" user="root" password="youngsun" /></dataHost>2、server.xml加⼊:<user name="test_wyh"><property name="password">test</property><property name="schemas">weixin,yixin,sms</property></user>3、遇到问题:1)、Caused by: org.xml.sax.SAXParseException; lineNumber: 106; columnNumber: 16; The content of element type "mycat:schema" must match "(schema*,dataNode*,dataHost*)".原因:要按照schema、datanode 、datahost的顺序放,不能打乱。
MyCat高可用、注解、分片策略详解

MyCat⾼可⽤、注解、分⽚策略详解1.Mycat ⾼可⽤⽬前 Mycat 没有实现对多 Mycat 集群的⽀持,可以暂时使⽤ HAProxy 来做负载。
思路:HAProxy 对 Mycat 进⾏负载。
Keepalived 实现 VIP。
2.Mycat 注解注解的作⽤当关联的数据不在同⼀个节点的时候,Mycat 是⽆法实现跨库 join 的。
举例:如果直接在 150 插⼊主表数据,151 插⼊明细表数据,此时关联查询⽆法查询出来。
-- 150 节点插⼊INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (9, 1000003, 2673, 1, '2019-9-25 11:35:49', '2019-9-25 11:35:49');-- 151 节点插⼊INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (9, 20180001, 2673, 19.99, 1, 1, 1);在 mycat 数据库查询,直接查询没有结果。
select a.order_id,b.price from order_info a, order_detail b where a.nums = b.goods_id;Mycat 作为⼀个中间件,有很多⾃⾝不⽀持的 SQL 语句,⽐如存储过程,但是这些语句在实际的数据库节点上是可以执⾏的。
有没有办法让 Mycat 做⼀层透明的代理转发,直接找到⽬标数据节点去执⾏这些 SQL 语句呢?那我们必须要有⼀种⽅式告诉 Mycat 应该在哪个节点上执⾏。
这个就是 Mycat 的注解。
MycatZK配置文件详解

MycatZK配置⽂件详解1.1修订版。
ZK-Server记录了集群的信息,Mycat-eye、Mycat-Server等从ZK读取配置并协同⼯作。
Mycat安装包中提供⼀个zk-config.bat/sh⼯具,该⼯具从conf/zk-default.txt中加载zk路径到ZK-Server中去,完成ZK-Server数据的初始化过程。
然后Mycat-eye与LB可以⽤ZK来管理集群。
下图是Mycat 1.5 的多中⼼集群⽅案,分布于不同地域(Zone)内的⼀些Mycat Cluster 组成双中⼼多3中⼼⽅案,前提是这些不通中⼼中的Mycat Cluster可以以某种⽅式完成数据库端的数据同步机制。
每个中⼼都有⼀组Mycat负载均衡器LB,这些LB 与同⼀中⼼内的Cluster组成⼀对多关系,即⼀个LB可以服务⼀个中⼼内的所有Cluster的负载均衡请求,也可以是多个LB,每个负担不同的Cluster的流量。
此外建议是每⼀个LB都有⼀个Backup,平时并不连接Cluster,但监测到Master下线以后,就⽴即开始连接Cluster并开始⼯作。
下图是⼀个Mycat Cluster的组成部分,它是位于某个特定中⼼(Zone)的⼀个处理单元,包括,⼀个Mycatcluster包括如下信息:所属的中⼼(Zone),固定不可变的标⽰具有地理位置标⽰,⽐如北京联通机房11个或多个采⽤相同配置(引⽤同⼀个MyCat Schema配置)的Mycat ServerMySQL数据库服务器,是属于⼀个Zone内部的共享资源,不属于Cluster级别的,主要拥有以下关键信息:IP地址、端⼝和名称所在主机Host,为了区分数据迁移⽯时候是否需要复制⽂件MySQL群组,定义⼀组具备主从关系的MySQL服务器之间的关系管理员权限的⽤户名密码等,⽤于⾃动运维操作此外,配置管理部分,我们需要记录集群中所⽤的的主机的信息,包括账号密码等,hostId不可变化,可以理解为内部分配的⼀个编号(不同于主机名),在所有的Zone中保持唯⼀。
Mycat配置分库分表(垂直分库、水平分表)、全局序列
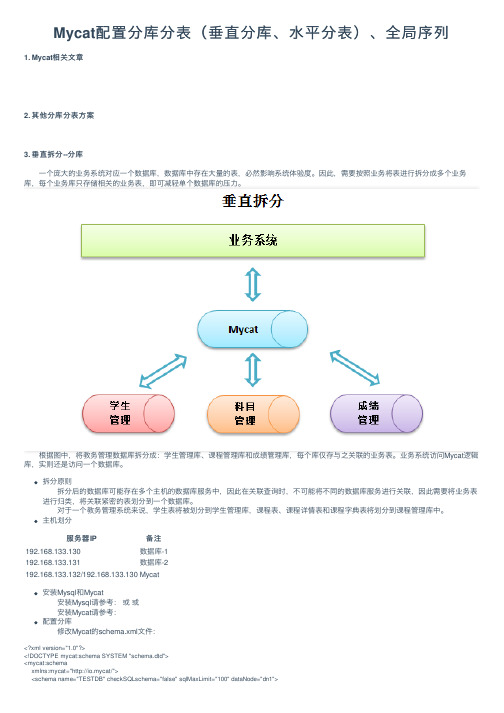
Mycat配置分库分表(垂直分库、⽔平分表)、全局序列1. Mycat相关⽂章2. 其他分库分表⽅案3. 垂直拆分--分库 ⼀个庞⼤的业务系统对应⼀个数据库,数据库中存在⼤量的表,必然影响系统体验度。
因此,需要按照业务将表进⾏拆分成多个业务库,每个业务库只存储相关的业务表,即可减轻单个数据库的压⼒。
根据图中,将教务管理数据库拆分成:学⽣管理库、课程管理库和成绩管理库,每个库仅存与之关联的业务表。
业务系统访问Mycat逻辑库,实则还是访问⼀个数据库。
拆分原则 拆分后的数据库可能存在多个主机的数据库服务中,因此在关联查询时,不可能将不同的数据库服务进⾏关联,因此需要将业务表进⾏归类,将关联紧密的表划分到⼀个数据库。
对于⼀个教务管理系统来说,学⽣表将被划分到学⽣管理库,课程表、课程详情表和课程字典表将划分到课程管理库中。
主机划分服务器IP备注192.168.133.130数据库-1192.168.133.131数据库-2192.168.133.132/192.168.133.130Mycat安装Mysql和Mycat 安装Mysql请参考:或或 安装Mycat请参考:配置分库 修改Mycat的schema.xml⽂件:<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schemaxmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"><table name="t_student" dataNode="dn2"></table></schema><dataNode name="dn1" dataHost="host1" database="education" /><dataNode name="dn2" dataHost="host2" database="education" /><dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="192.168.133.130:3306" user="root" password="123456"></writeHost></dataHost><dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM2" url="192.168.133.131:3306" user="root" password="123456"></writeHost></dataHost></mycat:schema> 对于数据库education,仅把表t_student划分到第⼆个节点,即主机2上,其余的表t_schedule、t_schedule_detail、t_subject_dict默认划分到第⼀个节点。
mycat路由解析开发指南

Mycat路由解析开发指南1切换解析器配置解析器的切换修改server.xml文件中的以下内容:在<system></system>内部加入<!--默认的sql解析器,可选值fdbparser,druidparser --><property name="defaultSqlParser">druidparser</property>druidparser为新解析器,fdbparser为原先的解析器。
2Druid解析器的优势1、性能更高。
druidparser为新解析器,该解析器单独从解析性能上比原解析器(fdbparser)快5倍以上,甚至10倍以上,sql越长,快的倍数越多。
曾经对一个长sql解析测试,能达到40倍左右。
2、支持的语法更多。
下面列举一些fdbparser不支持,但是druidparser支持的语法:(1)Insert into ….on duplicate key update…..(2)Insert into (),()…语句(3)带注释(comment)的create table语句(4)alter table … change….语句;(5)alter table … modify….语句;(6)添加索引时带索引名称的;如alter table coding_rule add unique ux_indexname (prefix);之前很多不支持的语法mycat需要使用hint来支持,现在只需要换成druidparser 就可以了。
3、编码更容易。
Druid解析出路由信息可以有两种方式:visitor方式、statement方式,其api比较方便的提取表名、条件表达式、字段列表、值列表等信息。
而且可以很容易的通过ast语法树改写sql,这对人工智能路由比较有帮助。
3路由解析流程本文采用自顶向下方式,从粗到细逐步展开路由解析流程。
mycat数据库集群系列之mycat读写分离安装配置

mycat数据库集群系列之mycat读写分离安装配置 最近在梳理数据库集群的相关操作,现在花点时间整理⼀下关于mysql数据库集群的操作总结,恰好你⼜在看这⼀块,供⼀份参考。
本次系列终结⼤概包括以下内容:多数据库安装、mycat部署安装、数据库之读写分离主从复制、数据库之双主多重、数据库分库分表。
每⼀个点,有可能会对应⼀篇或者多篇⽂章,由于还要继续上班⼯作,所以本系列分享预计持续时间需要10天左右,有兴趣的您可以持续关注。
我是⼀个菜鸟,如果写的不好的地⽅,望多多指点和包涵。
好了,直接进⼊本次的主题:mycat读写分离模式配置安装。
⼀、简介 mycat是⼲嘛的呢?⾸先我们来简单的了解⼀下mycat到底是⼲嘛的:MyCat 是⽬前最流⾏的基于 java 语⾔编写的数据库中间件,是⼀个实现了 MySQL 协议的服务器,前端⽤户可以把它看作是⼀个数据库代理,MyCat 发展到⽬前的版本,已经不是⼀个单纯的 MySQL 代理了,它的后端可以⽀持MySQL、SQL Server、Oracle、DB2、PostgreSQL 等主流数据库,也⽀持 MongoDB 这种新型NoSQL ⽅式的存储,未来还会⽀持更多类型的存储。
简单的说,Mycat是⼀个数据库集群操作中间件,实现了数据库的:读写分离、主从切换、分库分表等业务,但是对我们程序员在使⽤上来说,是封装的,和平时使⽤单库单表操作⽆差别。
其它的就不在此忽悠了,⽹上介绍多如⽜⽑。
⼆、环境准备1、JDK安装 前⾯已经介绍了mycat是⽤java写的,所以第⼀个环境要求就是要jdk环境,并且jdk是1.8+。
Jdk安装包下载,我最开始在官⽹下载,下载的速度超慢,今天就不推荐官⽹下载地址了,今天给⼤家推荐的是国内华为⼤佬提供的下载地址,当然上⾯包的更新速度没有官⽹及时,但是够⽤了,⽬前是13+。
下载速度但是杠杠的,分分钟下载完毕: 根据⾃⼰的电脑环境,选择对应的包下载即可,由于本次是在win10上实操,所我现在的是win-64。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Mycat-cluster组件设计方案简述
--QING____ Mycat-cluster为Mycat分布式集群基础组件,可以让Mycat存储系统的各个节点server 互相协同,目前Mycat-cluster支持的特性如下:
1) 集群中Mycat节点服务状态跟踪:可以方便的查看集群中各个节点的server状态,以及所有节点之间的网络关系.当节点状态异常时,可以获得通知消息等.
2) Leader选举,以及Follower节点的双向通讯: leader和Follower之前需要进行其他数据通信和消息发送.
3) 集群节点动态管理,比如动态的新增节点/移除节点等.
4) 支持optional配置文件的集群统一管理: 对于非核心配置文件,可以统一管理,对于配置文件变更,可以有效的同步到的所有节点上,并动态加载.
一.整体设计
系统服务的分布式管理,可以使用使用zookeeper作为底层支持,zookeeper作为集群服务管理是比较合适的选择.可能用户的环境并没有zookeeper支持,我们在将来会支持基于IO的cluster管理.
F1. 逻辑组件结构图
每个Mycat节点启动时,都可以选择是否挂载启动zookeeper客户端,zk客户端的主要作用,就是和zookeeper集群通讯,用来参与leader选举,以及响应leader失效/节点变更等事件.
F2. Cluster简析
集群中每个Mycat节点都会和zookeeper集群保持一个TCP长链接.此外每个mycat 节点之间也需要建立一个有向的TCP链接..因为网络环境的复杂性,可能导致mycat与zookeeper之间的网络不通,但是每个mycat之间的网络却是通常的;我们需要确保在zookeeper集群短时间异常的情况下,不能过度的干扰服务的支撑能力.。