L18_Friendship_Between_Animals
综合项目—简易专家系统
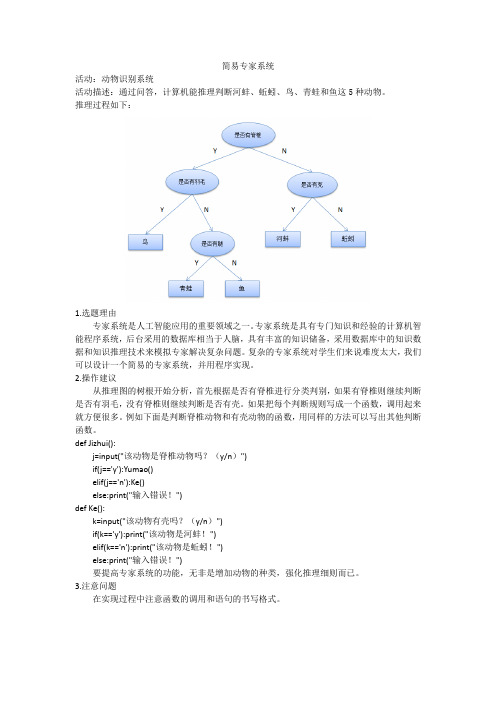
简易专家系统
活动:动物识别系统
活动描述:通过问答,计算机能推理判断河蚌、蚯蚓、鸟、青蛙和鱼这5种动物。
推理过程如下:
1.选题理由
专家系统是人工智能应用的重要领域之一。
专家系统是具有专门知识和经验的计算机智能程序系统,后台采用的数据库相当于人脑,具有丰富的知识储备,采用数据库中的知识数据和知识推理技术来模拟专家解决复杂问题。
复杂的专家系统对学生们来说难度太大,我们可以设计一个简易的专家系统,并用程序实现。
2.操作建议
从推理图的树根开始分析,首先根据是否有脊椎进行分类判别,如果有脊椎则继续判断是否有羽毛,没有脊椎则继续判断是否有壳。
如果把每个判断规则写成一个函数,调用起来就方便很多。
例如下面是判断脊椎动物和有壳动物的函数,用同样的方法可以写出其他判断函数。
def Jizhui():
j=input("该动物是脊椎动物吗?(y/n)")
if(j=='y'):Yumao()
elif(j=='n'):Ke()
else:print("输入错误!")
def Ke():
k=input("该动物有壳吗?(y/n)")
if(k=='y'):print("该动物是河蚌!")
elif(k=='n'):print("该动物是蚯蚓!")
else:print("输入错误!")
要提高专家系统的功能,无非是增加动物的种类,强化推理细则而已。
3.注意问题
在实现过程中注意函数的调用和语句的书写格式。
2020年智慧树知道网课《深度学习之瑞士军刀-pytorch入门》课后章节测试满分答案

第一章测试1【多选题】(3分)已知某函数的参数为35.8,执行后结果为35,可能是以下函数中的()。
A.floorB.roundC.intD.abs2【单选题】(2分)以下表达式中,()的运算结果是False。
A.3<4and7<5or9>10B.24!=32C.(10is11)==0D.’abc’<’ABC’3【单选题】(2分)在以下Python循环中,foriinrange(1,3):foriinrange(2,5):print(i*j)语句print(i*j)共执行了()次。
A.6B.5C.3D.24【单选题】(2分)在Python中,对于函数中return语句的理解,的是()。
A.return可以带返回参数B.return可以不带返回参数C.可以有多条return语句,但只执行一条D.一定要有return语句5【判断题】(2分)一个直接或间接地调用自身的算法称为递归,它有两个条件,一个是要直接或间接地调用自身,另一个是必须有出口。
A.对B.错6【单选题】(2分)关于递归函数的描述,以下选项中正确的是()。
A.函数内部包含对本函数的再次调用B.函数比较复杂C.包含一个循环结构D.函数名称作为返回值7【单选题】(2分)关于形参和实参的描述,以下选项中正确的是()。
A.程序在调用时,将形参复制给函数的实参B.函数定义中参数列表里面的参数是实际参数,简称实参。
实验报告-中文分词

实验报告1 双向匹配中文分词•小组信息目录摘要--------------------------------------------------------------------------------------- 1理论描述--------------------------------------------------------------------------------- 1算法描述--------------------------------------------------------------------------------- 2详例描述--------------------------------------------------------------------------------- 3软件演示--------------------------------------------------------------------------------- 4总结--------------------------------------------------------------------------------------- 6•摘要这次实验的内容是中文分词,现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
而我们用到的分词算法是基于字符串的分词方法(又称机械分词方法)中的正向最大匹配算法和逆向匹配算法。
一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。
统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
•理论描述中文分词指的是将一个汉字序列切分成一个一个单独的词。
[全套55讲] 鱼C论坛小甲鱼Python课后题
![[全套55讲] 鱼C论坛小甲鱼Python课后题](https://img.taocdn.com/s3/m/a2492d417c1cfad6185fa75c.png)
第1课0.Python 是什么类型的语言?Python是脚本语言脚本语言(Scripting language)是电脑编程语言,因此也能让开发者藉以编写出让电脑听命行事的程序。
以简单的方式快速完成某些复杂的事情通常是创造脚本语言的重要原则,基于这项原则,使得脚本语言通常比C语言、C++语言或Java 之类的系统编程语言要简单容易。
也让脚本语言另有一些属于脚本语言的特性:•语法和结构通常比较简单•学习和使用通常比较简单•通常以容易修改程序的“解释”作为运行方式,而不需要“编译”•程序的开发产能优于运行性能一个脚本可以使得本来要用键盘进行的相互式操作自动化。
一个Shell脚本主要由原本需要在命令行输入的命令组成,或在一个文本编辑器中,用户可以使用脚本来把一些常用的操作组合成一组串行。
主要用来书写这种脚本的语言叫做脚本语言。
很多脚本语言实际上已经超过简单的用户命令串行的指令,还可以编写更复杂的程序。
1. IDLE 是什么?IDLE是一个Python Shell,shell的意思就是“外壳”,基本上来说,就是一个通过键入文本与程序交互的途径!像我们Windows那个cmd窗口,像Linux那个黑乎乎的命令窗口,他们都是shell,利用他们,我们就可以给操作系统下达命令。
同样的,我们可以利用IDLE这个shell与Python进行互动。
2. print() 的作用是什么?print() 会在输出窗口中显示一些文本(在这一讲中,输出窗口就是IDLE shell 窗口)。
3. Python 中表示乘法的符号是什么?Python中的乘号是*(星号)。
4. 为什么>>>print('I love ' * 5) 可以正常执行,但>>>print('I love ' + 5) 却报错?在Python 中不能把两个完全不同的东西加在一起,比如说数字和文本,正是这个原因,>>>print('I love ' + 5) 才会报错。
深度学习题集

深度学习题集一、选择题1. 下列关于神经网络基础的说法中,正确的是()A. 神经网络是一种基于规则的机器学习方法。
B. 神经网络只能处理线性可分的问题。
C. 神经网络通过调整神经元之间的连接权重来学习数据中的模式。
D. 神经网络的训练过程不需要大量的数据。
答案:C。
神经网络是一种基于数据的机器学习方法,它可以处理线性不可分的问题,并且需要大量的数据进行训练。
通过调整神经元之间的连接权重,神经网络能够学习到数据中的复杂模式。
2. 在深度学习中,神经网络的层数越多,性能一定越好吗?()A. 是,层数越多表示模型越复杂,性能必然更好。
B. 不一定,层数过多可能会导致过拟合等问题。
C. 否,层数多会降低计算效率,性能反而变差。
D. 取决于数据集的大小,数据集大则层数多性能好。
答案:B。
虽然增加神经网络的层数可以增加模型的表达能力,但层数过多可能会导致过拟合、计算资源需求增加、训练困难等问题,所以神经网络的层数并非越多性能就一定越好。
3. 激活函数在神经网络中的主要作用是什么?()A. 增加神经网络的复杂度。
B. 提高神经网络的计算速度。
C. 引入非线性,使神经网络能够学习复杂的函数。
D. 减少神经网络的参数数量。
答案:C。
激活函数的主要作用是引入非线性,使得神经网络能够学习和表示复杂的函数关系。
如果没有激活函数,神经网络将只能学习线性函数,无法处理复杂的现实问题。
4. 下列哪个激活函数在输入为负数时输出为零?()A. Sigmoid 函数。
B. Tanh 函数。
C. ReLU 函数。
D. Softmax 函数。
答案:C。
ReLU(Rectified Linear Unit)函数在输入为负数时输出为零,在输入为正数时输出等于输入。
Sigmoid 函数和Tanh 函数在输入为负数时输出不为零,Softmax 函数主要用于多分类问题,不是在输入为负数时输出为零的函数。
5. 对于深度神经网络,以下哪种说法是正确的?()A. 深度神经网络的训练时间与网络层数成正比。
L18_Friendship_Between_Animals

2. The egret helps the rhino stay healthy by cleaning its skin.
白鹭通过帮助犀牛清洗皮肤来帮助它保持健康 。 by 介词通过(某种方式)by + doing/n./代词
1.Let’s start the lesson bysinging _______ a song.
• (4)___________ truly has no boundaries.
How warm and gentle they are!
•Do you think friendship only exists between human?
What is friendship?
Friendship is staying together. Friendship is playing together.
practise 1. I used to___on Sundays. A. going fish B. go fishing c. going fishing D. go fish 2. 过去我吃完晚饭经常会去散布。 to have a walk after supper. I used _______ 3. 你怎样邮寄信件,是通过航空邮件 还是普通邮件? by How did you send the letter, __ by ordinary mail? airmail or ___
Friendship Between Animals
Why?
The birds can clean its skin. skin
The deer let the small birds sit on its back.
Mplus应用说明B_T_002_02基础语法与应用第一篇

Mplus应⽤说明B_T_002_02基础语法与应⽤第⼀篇1. 基础语法与应⽤1.1.建⽴因变量和潜变量之间的逻辑关系。
也就是打算建⽴的模型结构。
按照模型结构梳理数据,准备好数据⽂件,编写模型代码和估计⽅式,运⾏,获取各路径的参数,分析结果,推出结论。
因此,Mplus运⾏的逻辑就是从关系模型到运算结果,中间采⽤Mplus程序进⾏逻辑组织,也就是从逻辑代码出发或者利⽤Diagrammer(Mplus提供的关系图制作⼯具)从关系图出发,运⾏结果,并标注到关系图上,以便为相关研究提供结论。
Mplus提供了向导⼯具,对SEM,EFA等采集必要信息,⾃动⽣成模型代码,供运⾏查阅结果。
具体见Mplus->Language Generator下各菜单功能。
算是⼀个发展⽅向。
Diagrammer可以直观构建模型,并同步编写代码。
1.2. MplusMplus采⽤标志段加简单语句构成语⾔结构,不是通⽤语⾔结构,不能进⾏特定算法逻辑表达,可以看作是内部实现的运算功能的参数表。
标志段,Mplus称为命令(command),冒号隔开后按照命令的种类提供相应参数,⽤分号将各参数设置隔开。
代码段每⾏最多不得超过90个字符,如果超过,将被截断,⽽且截断后报错语句不完整。
Data、Variable是所有Mplus分析程序必须有的两个命令。
!*作为注释开头,直到*!,⾸尾之间内容都是注释,不进⾏解释运⾏。
在编辑器中使⽤时,他不会识别到全部注释并以正确的颜⾊标记,但是不影响正常使⽤(单⾏注释是没有问题的)。
这个bug可以给Muthén兄弟还是⽗⼦俩提提。
命令和参数都可以简写成四个字以上的形式。
变量、关键字没有⼤⼩写区分,也就是⼤⼩写随意。
例如定义变量时:Vari: names are Y1 XY1-XY4;model: y1 on xy1,xy3-xy4;“-”作为序列关键字,不论是在定义变量名称还是在模型使⽤名称时,都可以⽤他来简写序列名称,如XVal1-XVal3和XVal1 XVal2 XVal3等价。
新视野大学英语第三版第一册课件Unit8-part1

Questionnaire
5. What do you think are the differences between male and female friends?
A. Male friends enjoy doing activities together instead of sharing feelings.
Questionnaire
Do the following questionnaire on friendship and then work in groups and discuss how differently you treat male and female friends.
Questionnaire
Short answer questions
2. Have you ever noticed any gender differences in your friendship with others?
Tips
• Men are from Mars, women are from Venus. • Intimate, caring, understanding; • Sensitive to one’s feelings; • Reluctant to express one’s true feelings; • Be more restrained with emotional expressions.
Compound dictation Listen to a short passage about friendship and fill in the missing information.
Our friends give us _w__a_rn_i_n_g_s_ against danger. True friends share not only joy but, more often than not, they share s_o_r_r_o_w_. With friendship, life is happy and _h_a_r_m_o_n__io_u_s_. Without friendship, life is hostile tion Listen to a short passage about friendship and fill in the missing information.
青岛理工大学-《Python》练习题及答案

一、填空题1.Python源代码程序编译后的文件扩展名为_________。
答案:pyc2.使用pip工具升级科学计算扩展库numpy的完整命令是_________________。
答案:pip install -- upgrade numpy3.使用pip工具查看当前已安装的Python扩展库的完整命令是_____________。
答案:pip list4.查看变量类型的Python内置函数是________________。
答案:type( )5.使用运算符测试集合包含集合A是否为集合B的真子集的表达式可以写作_______。
答案:A<B6.语句x = 3==3, 5执行结束后,变量x的值为_____________。
答案:(True, 5)7.已知x = 3,那么执行语句x += 6 之后,x的值为_______________。
答案:98.假设列表对象aList的值为[3, 4, 5, 6, 7, 9, 11, 13, 15, 17],那么切片aList[3:7]得到的值是______________________。
答案:[6, 7, 9, 11]9.使用列表推导式生成包含10个数字5的列表,语句可以写为_______________。
答案:[5 for i in range(10)]10.假设有列表a = ['name', 'age', 'sex']和b = ['Dong', 38, 'Male'],请使用一个语句将这两个列表的内容转换为字典,并且以列表a中的元素为“键”,以列表b中的元素为“值”,这个语句可以写为_____________________。
答案:c = dict(zip(a, b))11.已知 a = [1, 2, 3]和 b = [1, 2, 4],那么id(a[1])==id(b[1])的执行结果为___________。
2018中国农业大学821考研数据结构真题

中国农业大学2018 年821 数据结构真题回忆版一、选择题( 20 分)1.下面程序段的时间复杂度为( )for (i=1,s=0;i<=n;i++ ){t=1;for(j=1;j<=i;j++) t=t*j;s= s+t;}A O(n)B O(n^2)C O(n^3)D O(n^4)2.有一个二维数组 A [ m ][ n ] ,假设 A [0][0]存放位置在644 (10) , A A [2][2] 存放位置在676 (10) ,每个元素占一个空间,问A [3][3] (10) 存放在什么位置?脚注(10) 表示用10 进制表示。
A.688 B.678 C.692 D.6963.对关键码序列{7,34,55,25,64,46,20,10}进行Hash 存储时,如果选用H(key)=key%9 作为Hash 函数,则Hash地址为 1 的元素有( )个。
A. 1B. 2C. 3D. 44.一个栈的入栈序列是A,B,C,D,E, 则栈的不可能输出序列是( )。
A.EDCBA B.DECBA C.DCEAB D.ABCDE5.当n=5 时,下列函数的返回值是( )。
intfoo(int n){if(n<2) return n;return foo(n-1)+foo(n-2);}A. 5B. 7C. 8D. 16.已知一颗二叉树,如果先序遍历顺序是ADCEFGHB,中序遍历顺序是CDFEGHAB则, 后序遍历顺序是() 。
A .CFHGEBDA B .CDFEGHBAC .FGHCDBA D.CFHGEDBA7.下列()数据结构,同时具有较高的查找,插入和删除性能。
A.有序数组B.有序链表C.AVL 树D.Hash 表8.下列排序算法中,()在任何情况下时间复杂度不会超过n*1og 2n 表示用10 进制表示。
A.快速排序 B. 堆排序 C. 简单选择排序 D. 冒泡排序9.初始序列为{1,8,6,2,5,4,7,3} 的一组采用堆排序,当构建小根堆完毕时,堆所对应的二叉树中序遍历序列为()A.8 3 2 5 1 6 4 7 B. 3 2 8 5 1 4 6 7C. 3 8 2 5 1 6 7 4D. 8 2 3 5 1 4 7 610..某段文本中各个字母出现的频率分别是 {a:4,b:3, o:12,h:7,i:10},使用哈夫曼编码, 则哪种是可能的编 码()A a(0 0 0) b(0 0 1) h(01) i(10) o(00)B a(0 0 0 0) b(0001) h(001) o(01) i(1)C a(0 1 1) b(0 1 0) h(00) i(01) o(11)D a(0 0 0 0) b(0 0 0 1) h(001) o(0001) i(1)二、填空( 20 分)1. 假定一个线性表为 (12,23,74,55,63,40,82,36),若按 key%3 条件进行划分,使得同一余数的元素成为一个 子表,则得到的三个子表分别是 _______ · 和 ______ 。
信息管理专业英语教程第三版Unit8课后习题答案

信息管理专业英语教程第三版Unit8课后习题答案1、31.That's ______ interesting football game. We are all excited. [单选题] *A.aB.an(正确答案)C.theD./2、The man lost his camera and he ______ it now.()[单选题] *A. foundB. is findingC. is looking forD. looks for(正确答案)3、I live a very quiet and peaceful life. [单选题] *A. 宁静的(正确答案)B. 舒适的C. 和平的D. 浪漫的4、16.Lily is a lovely girl. We all want to ________ friends with her. [单选题] *A.haveB.make(正确答案)C.doD.take5、—What ______ your sister ______ this Saturday?—Something special, because it’s her birthday. ()[单选题] *A. are; going to doB. is; going to do(正确答案)C. does; doD. did do6、More than one student_____absent from the class yesterday due to the flu. [单选题] *A.areB.hasC.isD.was(正确答案)7、85.You’d better? ? ? ? ? a taxi, or you’ll be late. [单选题] *A.take(正确答案)B.takingC.tookD.to take8、I hope to see you again _______. [单选题] *A. long long agoB. long beforeC. before long(正确答案)D. long9、95--Where and when _______ you _______ it? [单选题] *A. did; buy(正确答案)B. do; buyC. have; boughtD. will; buy10、He prefers to use the word “strange”to describe the way()she walks. [单选题] *A. in which(正确答案)B. by whichC. in thatD. by that11、His mother’s _______ was a great blow to him. [单选题] *A. diedB. deadC. death(正确答案)D. die12、The Internet is an important means of()[单选题] *A. conversationB. communication(正确答案)C. speechD. language13、76.—Could you tell me ________the bank?—Turn right and it's on your right. [单选题]* A.how get toB.how to getC.how getting toD.how to get to(正确答案)14、If people _____ overanxious about remembering something, they will forget it. [单选题] *A. will beB. would beC. wereD. are(正确答案)15、Sorry, I can't accept your invitation. [单选题] *A. 礼物B. 观点C. 邀请(正确答案)D. 好意16、A?pen _______ writing. [单选题] *A. is used toB. used toC. is used for(正确答案)D. used for17、How can I _______ the nearest supermarket? [单选题] *A. get offB. get upC. get to(正确答案)D. get on18、Jim wants to hang out with his friends at night, but his parents don’t allow him ______ so. ()[单选题] *A. doB. doneC. to do(正确答案)D. doing19、49.________ is the price of the product? [单选题] *A.HowB.How muchC.What(正确答案)D.How many20、---Excuse me sir, where is Room 301?---Just a minute. I’ll have Bob ____you to your room. [单选题] *A. show(正确答案)B. showsC. to showD. showing21、____ is standing at the corner of the street. [单选题] *A. A policeB. The policeC. PoliceD. A policeman(正确答案)22、E-mail is _______ than express mail, so I usually email my friends. [单选题] *A. fastB. faster(正确答案)C. the fastestD. more faster23、This message is _______. We are all _______ at it. [单选题] *A. surprising; surprisingB. surprised; surprisedC. surprising; surprised(正确答案)D. surprised; surprising24、You can't rely on Jane as she is _____ changing her mind and you will never know what she isgoing to do next. [单选题] *A. occasionallyB. rarelyC. scarcelyD. constantly(正确答案)25、Have you done something _______ on the weekends? [单选题] *A. special(正确答案)B. soreC. convenientD. slim26、—Can you play tennis? —______, but I’m good at football.()[单选题] *A. Yes, I can(正确答案)B. Yes, I doC. No, I can’tD. No, I don’t27、—Where are you going, Tom? —To Bill's workshop. The engine of my car needs _____. [单选题] *A. repairing(正确答案)B. repairedC. repairD. to repair28、_____ to wait for hours,she brought along a book to read. [单选题] *A. ExpectedB. Expecting(正确答案)C. ExpectsD. To expect29、_____ yuan a month _____ not enough for a family of three to live on today. [单选题] *A. Five hundred; is(正确答案)B. Five hundreds; areC. Five hundred; areD.Five hundreds; is30、We are very hungry now. Can you _______ us something to eat? [单选题] *A. carryB. takeC. borrowD. bring(正确答案)。
A survey of statistical network models

A Survey of Statistical Network ModelsAnna Goldenberg University of Toronto Alice X.Zheng Microsoft Research Stephen E.Fienberg Carnegie Mellon UniversityEdoardo M.Airoldi Harvard UniversityDecember 2009a r X i v :0912.5410v 1 [s t a t .M E ] 29 D e c 2009这篇文章从机器学习的角度讲网络,非常有意思。
Goldenberg, A., Zheng, A.X., Fienberg, S.E., & Airoldi E.M. (2009). A survey of statistical network models.Foundations and Trends in Machine Learning, 2, 129-233.2ContentsPreface1 1Introduction31.1Overview of Modeling Approaches (4)1.2What This Survey Does Not Cover (7)2Motivation and Dataset Examples92.1Motivations for Network Analysis (9)2.2Sample Datasets (10)2.2.1Sampson’s“Monastery”Study (11)2.2.2The Enron Email Corpus (12)2.2.3The Protein Interaction Network in Budding Yeast (14)2.2.4The Add Health Adolescent Relationship and HIV Transmission Study142.2.5The Framingham“Obesity”Study (16)2.2.6The NIPS Paper Co-Authorship Dataset (17)3Static Network Models213.1Basic Notation and Terminology (21)3.2The Erd¨o s-R´e nyi-Gilbert Random Graph Model (22)3.3The Exchangeable Graph Model (23)3.4The p1Model for Social Networks (27)3.5p2Models for Social Networks and Their Bayesian Relatives (29)3.6Exponential Random Graph Models (30)3.7Random Graph Models with Fixed Degree Distribution (32)3.8Blockmodels,Stochastic Blockmodels and Community Discovery (33)3.9Latent Space Models (36)3.9.1Comparison with Stochastic Blockmodels (38)4Dynamic Models for Longitudinal Data414.1Random Graphs and the Preferential Attachment Model (41)4.2Small-World Models (44)4.3Duplication-Attachment Models (46)4.4Continuous Time Markov Chain Models (47)i4.5Discrete Time Markov Models (50)4.5.1Discrete Markov ERGM Model (51)4.5.2Dynamic Latent Space Model (52)4.5.3Dynamic Contextual Friendship Model(DCFM) (53)5Issues in Network Modeling57 6Summary61 Bibliography65iiPrefaceNetworks are ubiquitous in science and have become a focal point for discussion in everyday life.Formal statistical models for the analysis of network data have emerged as a major topic of interest in diverse areas of study,and most of these involve a form of graphical rep-resentation.Probability models on graphs date back to1959.Along with empirical studies in social psychology and sociology from the1960s,these early works generated an active “network community”and a substantial literature in the1970s.This effort moved into the statistical literature in the late1970s and1980s,and the past decade has seen a burgeoning network literature in statistical physics and computer science.The growth of the World Wide Web and the emergence of online“networking communities”such as Facebook,MyS-pace,and LinkedIn,and a host of more specialized professional network communities has intensified interest in the study of networks and network data.Our goal in this review is to provide the reader with an entry point to this burgeoning literature.We begin with an overview of the historical development of statistical network modeling and then we introduce a number of examples that have been studied in the network literature.Our subsequent discussion focuses on a number of prominent static and dynamic network models and their interconnections.We emphasize formal model descriptions,and pay special attention to the interpretation of parameters and their estimation.We end with a description of some open problems and challenges for machine learning and statistics.12Chapter1IntroductionMany scientificfields involve the study of networks in some works have been used to analyze interpersonal social relationships,communication networks,academic paper coauthorships and citations,protein interaction patterns,and much more.Popular books on networks and their analysis began to appear a decade ago,[see,e.g.,24;50;318;319;68] and online“networking communities”such as Facebook,MySpace,and LinkedIn are an even more recent phenomenon.In this work,we survey selective aspects of the literature on statistical modeling and analysis of networks in social sciences,computer science,physics,and biology.Given the volume of books,papers,and conference proceedings published on the subject in these differentfields,a single comprehensive survey would be impossible.Our goal is far more modest.We attempt to chart the progress of statistical modeling of network data over the past seventy years and to outline succinctly the major schools of thought and approaches to network modeling and to describe some of their interconnections.We also attempt to identify major statistical gaps in these modeling efforts.From this overview one might then synthesize and deduce promising future research directions.Kolaczyk[177]provides a complementary statistical overview.The existing set of statistical network models may be organized along several major axes.For this article,we choose the axis of static vs.dynamic models.Static network models concentrate on explaining the observed set of links based on a single snapshot of the network,whereas dynamic network models are often concerned with the mechanisms that govern changes in the network over time.Most early examples of networks were single static snapshots.Hence static network models have been the main focus of research for many years.However,with the emergence of online networks,more data is available for dynamic analysis,and in recent years there has been growing interest in dynamic modeling.In the remainder of this chapter we provide a brief historical overview of network modeling approaches.In subsequent chapters we introduce some examples studied in the network literature and give a more detailed comparative description of select modeling approaches.31.1Overview of Modeling ApproachesAlmost all of the“statistically”oriented literature on the analysis of networks derives from a handful of seminal papers.In social psychology and sociology there is the early work of Simmel and Wolff[268]at the turn of the last century and Moreno[221]in the1930s as well as the empirical studies of Stanley Milgram[215;298]in the1960s;in mathematics/probability there is the Erd¨o s-R´e nyi paper on random graph models[94].There are other papers that dealt with these topics contemporaneously or even earlier.But these are the ones that appear to have had lasting impact.Moreno[221]invented the sociogram—a diagram of points and lines used to represent relations among persons,a precursor to the graph representation for networks.Luce and others developed a mathematical structure to go with Moreno’s sociograms using incidence matrices and graphs(see,e.g.,[202;200;201;203;244;282;11]),but the structure they explored was essentially gram gave the name to what is now referred to as the”Small World”phenomenon—short paths of connections linking most people in social spheres—and his experiments had provocative results:the shortest path between any two people for completed chains has a median length of around6;however,the majority of chains initiated in his experiments were never completed!(His studies provided the title for the play and movie Six Degrees of Separation,ignoring the compleity of his results due to the censoring.)White[321]and Fienberg and Lee[100]gave a formal Markov-chain like model and analysis of the Milgram experimental data,including information on the uncompleted gram’s data were gathered in batches of transmission,and thus these models can be thought of as representing early examples of generative descriptions of dynamic network evolution.Recently,Dodds et al.[86]studied a global“replication”variation on the Milgram study in which more than60,000e-mail users attempted to reach one of18target persons in13countries by forwarding messages to acquaintances.Only384of24,163chains reached their targets but they estimate the median length for completions to be7,by assuming that attrition occurs at random.The social science network research community that arose in the1970s was built upon these earlier efforts,in particular the Erd¨o s-R´e nyi-Gilbert model.Research on the Erd¨o s-R´e nyi-Gilbert model(along with works by Katz et al.[166;168;167])engendered thefield of random graph theory.In their papers,Erd¨o s and R´e nyi worked withfixed number of vertices, N,and number of edges,E,and studied the properties of this model as E increases.Gilbert studied a related two-parameter version of the model,with N as the number of vertices and p thefixed probability for choosing edges.Although their descriptions might atfirst appear to be static in nature,we could think in terms of adding edges sequentially and thus turn the model into a dynamic one.In this alternative binomial version of the Erd¨o s-R´e nyi-Gilbert model,the key to asymptotic behavior is the valueλ=pN.There is a“phase change”associated with the value ofλ=1,at which point we shift from seeing many small connected components in the form of trees to the emergence of a single“giant connected component.”Probabilists such as Pittel[243]imported ideas and results from stochastic processes into the random graph literature.Holland and Leinhardt[149]’s p1model extended the Erd¨o s-R´e nyi-Gilbert model to allow4for differential attraction(popularity)and expansiveness,as well as an additional effect due to reciprocation.The p1model was log-linear in form,which allowed for easy computation of maximum likelihood estimates using a contingency table formulation of the model[101;102]. It also allowed for various generalizations to multidimensional network structures[103]and stochastic blockmodels.This approach to modeling network data quickly evolved into the class of p∗or exponential random graph models(ERGM)originating in the work of Frank and Strauss[110]and Strauss and Ikeda[287].A trio of papers demonstrating procedures for using ERGMs[316;241;254]led to the wide-spread use of ERGMs in a descriptive form for cross sectional network structures or cumulative links for networks—what we refer to here as static models.Full maximum likelihood approaches for ERGMs appeared in the work of Snijders and Handcock and their collaborators,some of which we describe in chapter3.Most of the early examples of networks in the social science literature were relatively small (in terms of the number of nodes)and involved the study of the network at afixed point in time or cumulatively over time.Only a few studies(e.g.,Sampson’s1968data on novice monks in the monastery[259])collected,reported,and analyzed network data at multiple points in time so that one could truly study the evolution of the network,i.e.,network dynamics.The focus on relatively small networks reflected the state-of-art of computation but it was sufficient to trigger the discussion of how one might assess thefit of a network model.Should one focus on“small sample”properties and exact distributions given some form of minimal sufficient statistic,as one often did in other areas of statistics,or should one look at asymptotic properties,where there is a sequence of networks of increasing size? Even if we have“repeated cross-sections”of the network,if the network is truly evolving in continuous time we need to ask how to ensure that the continuous time parameters are estimable.We return to many of these question in subsequent chapters.In the late1990s,physicists began to work on network models and study their properties in a form similar to the macro-level descriptions of statistical physics.Barab´a si,Newman, and Watts,among others,produced what we can think of as variations on the Erd¨o s-R´e nyi-Gilbert model which either controlled the growth of the network or allowed for differential probabilities for edge addition and/or deletion.These variations were intended to produce phenomena such as“hubs,”“local clustering,”and“triadic closures.”The resulting models gave usfixed degree distribution limits in the form of power laws—variations on preferential attachment models(“the rich get richer”)that date back to Yule[329]and Simon[269](see also[218])—as well as what became known as“small world”models.The small-world phenomenon,which harks back to Milgram’s1960s studies,usually refers to two distinct properties:(1)small average distance and(2)the“clustering”effect,where two nodes with a common neighbor are more likely to be adjacent.Many of these authors claim that these properties are ubiquitous in realistic networks.To model networks with the small-world phenomenon,it is natural to utilize randomly generated graphs with a power law degree distribution,where the fraction of nodes with degree k is proportional to k−a for some positive exponent a.Many of the most relevant papers are included in an edited collection by Newman et al.[231].More recently this style of statistical physics models have been used to detect community structure in networks,e.g.,see Girvan and Newman[122]and5Backstrom et al.[20],a phenomenon which has its counterpart description in the social science network modeling literature.The probabilistic literature on random graph models from the1990s made the link with epidemics and other evolving stochastic phenomena.Picking up on this idea,Watts and Strogatz[320]and others used epidemic models to capture general characteristics of the evolution of these new variations on random networks.Durrett[91]has provided us with a book-length treatment on the topic with a number of interesting variations on the theme. The appeal of stochastic processes as descriptions of dynamic network models comes from being able to exploit the extensive literature already developed,including the existence and the form of stationary distributions and other model features or properties.Chung and Lu [69]provide a complementary treatment of these models and their probabilistic properties.One of the principal problems with this diverse network literature that we see is that, with some notable exceptions,the statistical tools for estimation and assessing thefit of “statistical physics”or stochastic process models is lacking.Consequently,no attention is paid to the fact that real data may often be biased and noisy.What authors in the network literature have often relied upon is the extraction of key features of the related graphical network representation,e.g.,the use of power laws to represent degree distributions or mea-sures of centrality and clustering,without any indication that they are either necessary or sufficient as descriptors for the actual network data.Moreover,these summary quantities can often be highly misleading as the critique by Stouffer et al.[285,286]of methods used by Barab´a si[25]and V´a zquez et al.[304]suggest.Barab´a si claimed that the dynamics of a number of human activities are scale-free,i.e.,he specifically reported that the probability distribution of time intervals between consecutive e-mails sent by a single user and time delays for e-mail replies follow a power-law with exponent−1,and he proposed a priority-queuing process as an explanation of the bursty nature of human activity.Stouffer et al. [286]demonstrated that the reported power-law distribution was solely an artifact of the analysis of the empirical data and used Bayes factors to show that the proposed model is not representative of e-mail communication patterns.See a related discussion of the poorfit of power laws in Clauset et al.[74].There are several works,however,that try to address modelfitting and model comparison.For example,the work of Williams and Martinez[323] showed how a simple two-parameter model predicted“key structural properties of the most complex and comprehensive food webs in the primary literature”.Another good example is the work of Middendorf et al.[214]where the authors used network motif counts as input to a discriminative systematic classification for deciding which configuration model the actual observed network came from;they looked at power law,small-world,duplication-mutation and duplication-mutation-complementation and other models(seven in total)and concluded that the duplication-mutation-complementation model described the protein-protein inter-action data in Drosophila melanogaster species best.Machine learning approaches emerged in several forms over the past decade with the empirical studies of Faloutsos et al.[97]and Kleinberg[173,172,174],who introduced a model for which the underlying graph is a grid—the graphs generated do not have a power law degree distribution,and each vertex has the same expected degree.The strict6requirement that the underlying graph be a cycle or grid renders the model inapplicable to webgraphs or biological networks.Durrett[91]treats variations on this model as well. More recently,a number of authors have looked to combine the stochastic blockmodel ideas from the1980s with latent space models,model-based clustering[137]or mixed-membership models[9],to provide generative models that scale in reasonable ways to substantial-sized networks.The class of mixed membership models resembles a form of soft clustering[95] and includes the latent Dirichlet allocation model[41]from machine learning as a special case.This class of models offers much promise for the kinds of network dynamical processes we discuss here.1.2What This Survey Does Not CoverThis survey focuses primarily on statistical network models and their applications.As a consequence there are a number of topics that we touch upon only briefly or essentially not at all,such as•Probability theory associated with random graph models.The probabilistic literature on random graph models is now truly extensive and the bulk of the theorems and proofs,while interesting in their own right,are largely unconnected with the present exposition.For excellent introductions to this literature,see Chung and Lu[69]and Durrett[91].For related results on the mathematics of graph theory,see Bollob´a s[43].•Efficient computation on networks.There is a substantial computer science litera-ture dealing with efficient calculation of quantities associated with network structures, such as shortest paths,network diameter,and other measures of connectivity,central-ity,clustering,etc.The edited volume by Brandes and Erlebach[48]contains good overviews of a number of these topics as well as other computational issues associated with the study of graphs.•Use of the network as a tool for sampling.Adaptive sampling strategies modify the sampling probabilities of selection based on observed values in a network structure.This strategy is beneficial when searching for rare or clustered populations.Thompson and Seber[296]and Thompson[293]discuss adaptive sampling in detail.There is also related work on target sampling[294]and respondent-driven sampling[258;305].•Neural networks.Neural networks originated as simple models for connections in the brain but have more recently been used as a computational tool for pattern recognition(e.g.,Bishop[38]),machine learning(e.g.,Neal[228]),and models of cognition(e.g.,Rogers and McClelland[257]).•Networks and economic theory.A relatively new area of study is the link between network problems,economic theory,and game theory.Some useful entrees to this literature are Even-Dar and Kearns[96],Goyal[131],Kearns et al.[169],and Jackson7[160],whose book contains an excellent semi-technical introduction to network concepts and structures.•Relational networks.This is a very popular area in machine learning.It uses proba-bilistic graphical models to represent uncertainty in the data.The types of“networks”in this area,such as Bayes nets,dependency diagrams,etc.,have a different meaning than the networks we consider in this review.The main difference is that the net-works in our work are considered to“be given”or arising directly from properties of the network under study,rather than being representative of the uncertainty of the relationships between nodes and node attributes.There is a multitude of literature on relational networks,e.g.,see Friedman et al.[112],Getoor et al.[117],Neville and Jensen[229];Neville et al.[230],and Getoor and Taskar[116].•Bi-partite graphs.These are graphs that represent measurement on two populations of objects,such as individuals and features.The graphs in this context are seldom the best representation of the data,with exception perhaps of binary measurements or when the true populations have comparable sizes.Recent work on exchangeable Rasch matrices is related to to this topic and potentially relevant for network analysis. Lauritzen[186,187];Bassetti et al.[29]suggest applications to bipartite graphs.•Agent-based modeling.Building on older ideas such as cellular automata,agent-based modeling attempts to simulate the simultaneous operations of multiple agents,in an effort to re-create and predict the actions of complex phenomena.Because the inter-est is often on the interaction among the agents,this domain of research has been linked with network ideas.With the recent advances in high-performance computing, simulations of large-scale social systems have become an active area of research,e.g., see[46].In particular,there is a strong interest in areas that revolve around national security and the military,with studies on the effects of catastrophic events and bio-logical warfare,as well as computational explorations of possible recovery strategies [57;59].These works are the contemporary counterparts of more classical work at the interface between artificial intelligence and the social sciences[54;56;55].8Chapter2Motivation and Dataset Examples2.1Motivations for Network AnalysisWhy do we analyze networks?The motivation behind network analysis is as diverse as the origin of network problems within differing academicfields.Before we delve into details of the“how”of statistical network modeling,we start with some examples of the“why.”This chapter also includes descriptions of popular datasets for interested readers who may wish to exercise their modeling muscles.Social scientists are often interested in questions of interpretation such as the meanings of edges in a social network[181].Do they arise out of friendliness,strategic alliance,obligation, or something else?When the meaning of edges are known,the object is often to characterize the structure of those relations(e.g.,whether friendships or strategic alliances are hierarchical or transitive).A large volume of statistically-oriented social science literature is dedicated to modeling the mechanisms and relations of network properties and testing hypotheses about network structure,see,e.g.,[280].Physicists,on the other hand,tend to be interested in understanding parsimonious mech-anisms for network formation[28;235].For example,a common modeling goal is to explain how a given network comes to have its particular degree distribution or diameter at time t.Several network analysis concepts have found niches in computational biology.For ex-ample,work on protein function classification can be thought of asfinding hidden groups in the protein-protein interaction network[7;8]to gain better understanding of underlying bi-ological bel propagation(node similarity)in networks can be harnessed to help with functional gene annotation[226].Graph alignment can be used to locate subgraphs that are common among species,thus advancing our understanding of evolution[105].Mo-tiffinding,or more generally the search for subgraph patterns,also has many applications [17].Combining networks from heterogeneous data sources helps to improve the accuracy of predicted genetic interactions[327].Heterogeneity of network data sources in biology introduces a lot of noise into the global network structure,especially when networks created for different purposes(such as protein co-regulation and gene co-expression)are combined. [225]addresses network de-noising via degree-based structure priors on graphs.For a review9of biological applications of networks,please see[332].The task offinding hidden groups is also relevant in analyzing communication networks, e.g.,in detecting possible latent terrorist cells[30].The related task of discovering the“roles”of individual nodes is useful for identity disambiguation[36]and for business organization analysis[207].These applications often take the machine learning approach of graph parti-tioning,a topic previously known in social science and statistics literature as blockmodeling [199;89].A related question is functional clustering,where the goal is not to statistically cluster the network,but to discover members of dynamic communities with similar functions based on existing network connectivity[122;232;234;266].In the machine learning community,networks are often used to predict missing informa-tion,which can be edge related,e.g.,predicting missing links in the network[238;73;198], or attribute related,e.g.,predicting how likely a movie is to be a box office hit[229].Other applications include locating the crucial missing link in a business or a terrorist network,or calculating the probability that a customer will purchase a new product,given the pattern of purchases of his friends[142].The latter question can more generally be stated as predict-ing individual’s preferences given the preferences of her“friends”.This research direction has evolved into an area of its own under the name of recommender systems,which has recently received a lot of media attention due to the competition by the largest online movie rental company Netflix.The company has awarded a prize of one million dollars to a team of researchers that were able to predict customer ratings of movies with higher than10% accuracy than their own in-house system[290].The concept of information propagation alsofinds many applications in the network domain,such as virus propagation in computer networks[310],HIV infection networks[222; 163;164],viral marketing[87]and more generally gossiping[170].Here some work focuses onfinding network configurations optimal for routing,while other research assumes that the network structure is given and focus on suitable models for disease or information spread.2.2Sample DatasetsA plethora of data sets are available for network analysis,and more are emerging every year. We provide a quick guided tour of the most popular datasets and applications in eachfield.In his ground-breaking paper,Milgram[215]experimented with the construction of in-terpersonal social networks.His result that the median length of completed chains was approximately6led to the pop-culture coining of the phrase“six degrees of separation.”Subjects of subsequent studies ranged from social interactions of monks[259],to hierar-chies of elephants[209;303],to sexual relationships between adults of Colorado[176],to friendships amongst elementary school students[141;299].While a lot of biological applications focus on the study of protein-protein interaction networks[114;115;184;248;328],metabolic networks[158],functional and co-expression gene similarity networks and gene regulatory networks[111;309],computer science applica-tions revolve around e-mail[207],the internet[97;63;151],the web[152;13],academic paper co-authorship[127]and citation networks[204;216].Citation networks have a long history10of modeling in different areas of research starting with the seminal paper of de Solla Price [83]and more recently in physics[190].With the recent rise of online networks,computer science and social science researchers are also starting to examine blogger networks such as LiveJournal,social networks found on Friendster,Facebook,Orkut,and dating networks such as .Terrorist networks(often simulated)and telecommunication networks have come under similar scrutiny,especially since the events of September11,2001(e.g.,see[182;250;249; 62]).There has also been work on ecological networks such as foodwebs[323;16],neuronal networks[188],network epidemiology[306],economic trading networks[123],transporta-tion networks(roads,railways,airplanes;e.g.,[113]),resource distribution networks,mobile phone networks[92]and many others.Several network data repositories are available on public websites and as part of packages. For example,UCINet1includes a lot of well known smaller scale datasets such as the Davis Southern Club Women dataset[80],Zachary’s karate club dataset[330],and Sampson’s monk data[259]described below.Pajek2contains a larger set of small and large networks from domains such as biology,linguistics,and food-web.Additional datasets in a variety of domains include power grid networks,US politics,cellular and protein networks and others3.A collection of large and very large directed and undirected networks in the areas of communication,citation,internet and others are available as part of Stanford Network Analysis Package(SNAP)4.We now introduce six examples of networks studied in the literature,describing the data in reasonable detail and including graphs depicting the networks wherever feasible.For each network example we articulate specific questions of interest.2.2.1Sampson’s“Monastery”StudyA classic example of a social network is the one derived from the survey administered by Samspon and published in his doctoral dissertation[259].Figure2.1displays the network derived from the“whom do you like”sociometric relations in this dataset.Sampson spent several months in a monastery in New England,where a number of novices were preparing to join a monastic order.Sampson’s original analysis was rooted in direct anthropological ob-servations.He strongly suggested the existence of tight factions among the novices:the loyal opposition(whose members joined the monasteryfirst),the young turks(whose members joined later on),the outcasts(who were not accepted in either of the two main factions),and the waverers(who did not take sides).The events that took place during Sampson’s stay at the monastery supported his observations.For instance,John and Gregory,two members of the young turks,were expelled over religious differences,and other members resigned 1/ucinet/2http://vlado.fmf.uni-lj.si/pub/networks/data/3/~mejn/netdata//cdg/datasets/~networks/resources.htm4/data/11。
java英文(第八版)十三章答案

import java.util.Scanner;public class Exercise13_2 {public static void main(String[] args) {Scanner input = new Scanner(System.in);boolean done = false;int number1 = 0;int number2 = 0;// Enter two integersSystem.out.print("Enter two integers: ");while (!done) {try {number1 = input.nextInt();number2 = input.nextInt();done = true;}catch (Exception ex) {System.out.print("Incorrect input and re-enter two integers: ");input.nextLine(); // Discard input}}System.out.println("Sum is " + (number1 + number2));}}public class Exercise13_4{public static void main(String[] args) {try {new NewLoan(7.5, 30, 100000);NewLoan m = new NewLoan(-1, 3, 3);new NewLoan(7.5, 30, 20000);}catch (Exception ex){System.out.println(ex);}System.out.println("End of program");}}class NewLoan {private double annualInterestRate;private int numOfYears;private double loanAmount;/** Default constructor */public NewLoan() {this(7.5, 30, 100000);}/** Construct a NewLoan with specified annual interest rate,number of years and loan amount*/public NewLoan(double annualInterestRate, int numOfYears,double loanAmount) {if (annualInterestRate <= 0)throw new IllegalArgumentException("Annual interest rate must be positive.");if (numOfYears <= 0)throw new IllegalArgumentException("Number of years must be positive.");if (loanAmount <= 0)throw new IllegalArgumentException("Loan amount must be positive."); setAnnualInterestRate(annualInterestRate);setNumOfYears(numOfYears);setLoanAmount(loanAmount);}/** Return annualInterestRate */public double getAnnualInterestRate() {return annualInterestRate;}/** Set a new annualInterestRate */public void setAnnualInterestRate(double annualInterestRate) {if (annualInterestRate <= 0)throw new IllegalArgumentException("Annual interest rate must be positive.");this.annualInterestRate = annualInterestRate;}/** Return numOfYears */public int getNumOfYears() {return numOfYears;}/** Set a new numOfYears */public void setNumOfYears(int numOfYears){if (numOfYears <= 0)throw new IllegalArgumentException("Number of years must be positive.");this.numOfYears = numOfYears;}/** Return loanAmount */public double getLoanAmount() {return loanAmount;}/** Set a newloanAmount */public void setLoanAmount(double loanAmount) {if (loanAmount <= 0)throw new IllegalArgumentException("Loan amount must be positive.");this.loanAmount = loanAmount;}/** Find monthly payment */public double monthlyPayment() {double monthlyInterestRate = annualInterestRate / 1200;return loanAmount * monthlyInterestRate / (1 -(Math.pow(1 / (1 + monthlyInterestRate), numOfYears * 12)));}/** Find total payment */public double totalPayment() {return monthlyPayment() * numOfYears * 12;}}public class Exercise13_6 {public static void main(String[] args) {System.out.println(parseHex("A5"));System.out.println(parseHex("FAA"));System.out.println(parseHex("T10"));System.out.println(parseHex("ABC"));System.out.println(parseHex("10A"));}public static int parseHex(String hexString) {int value = convertHexToDec(hexString.charAt(0));for (int i = 1; i < hexString.length(); i++) {value = value * 16 + hexString.charAt(i) - '0';}return value;}static int convertHexToDec(char ch) {if (ch == 'A') {return 10;}else if (ch == 'B') {return 11;}else if (ch == 'C') {return 12;}else if (ch == 'D') {return 13;}else if (ch == 'E') {return 14;}else if (ch == 'F') {return 15;}else if (ch <= '9' && ch >= '0')return ch - '0';elsethrow new NumberFormatException("Illegal character: " + ch);}}public class Exercise13_8 {public static void main(String[] args) throws HexFormatException {System.out.println(parseHex("A5"));System.out.println(parseHex("FAA"));System.out.println(parseHex("T10"));System.out.println(parseHex("ABC"));System.out.println(parseHex("10A"));}public static int parseHex(String hexString) throws HexFormatException { int value = convertHexToDec(hexString.charAt(0));for (int i = 1; i < hexString.length(); i++) {value = value * 16 + hexString.charAt(i) - '0';}return value;}static int convertHexToDec(char ch) throws HexFormatException {if (ch == 'A') {return 10;}else if (ch == 'B') {return 11;}else if (ch == 'C') {return 12;}else if (ch == 'D') {return 13;}else if (ch == 'E') {return 14;}else if (ch == 'F') {return 15;}else if (ch <= '9' && ch >= '0')return ch - '0';elsethrow new HexFormatException("Illegal hex character: " + ch); }}class HexFormatException extends Exception { HexFormatException() {super("Illegal hex character");}HexFormatException(String message) {super(message);}}public class Exercise13_10 {public static void main(String[] args) {try {int[] list = new int[20000000];}catch (Error ex) {ex.printStackTrace();System.out.println("You are running out of memory.");}System.out.println("GO");javax.swing.JOptionPane.showMessageDialog(null, "Wait"); }}。
广东省江门市培英初级中七级英语《uint4》案(无答案)人教新目标

广东省江门市培英初级中七级英语《uint4》案(无答案)人教新目标把该单词置入对话中,熟读对话后,创设情景,表演。
2、听力训练:part2二、基础语言点导学:1、看P983a比较同一时间的两种表达方法,简单说出pat与to的差别。
2、总结:时间的表达分为直接表达及借助pat或to表达。
(1)、直接表达:先说小时,后说分钟Eg:2:00TwoO`clock3:15threefifteen(2)、借助于pat或to表达当分钟数小于或等于30分钟时用pat:“分钟+pat+几小时”;Eg:6:10tenpati某7:25twentypateven当分钟超过30分钟用to:“差多少分钟不到60分钟+to+下一小时”Eg:5:55fivetoi某11:40twentytotwelve(3)aquarterpat+几小时:表示几小时过了多少分钟5:15__________________12:15_______________7:15________________aquarterto+几小时:表示差多少分钟到几点钟2:45_________________9:45_________________3:45______________ ____(4)根据所给的时间口述:8:008:054:154:459:2910:301:355:59【训练检测目标探究】1、汉译英:(1)、让我们去动物园吧!(2)、你愿意和我们一起去吗?(3)、什么事啊?2、时间表达训练:(1)、3:15_______________4:15______________2:45____________9:00_______ ______(2)、tenpateight________,aquarterto twelve_________eighto’clock__________单选小练:()1.—____iit—It’i某o’clock.A.WhatB.WhatcolorD.How()2.“12:45”read____.A.aquarterpattwelveB.aquartertotwelveC.twelveforty-fiveD.threequarterpattwelve—Let’at8:30tomorrowmorning.A.meetB.tomeetC.meetD.meetingSectionB学习目标1.知识目标2.情感目标学会认读时间,体会时间的宝贵,珍惜现在的光阴,刻苦学习。
ACCESS题库全部选择题

ACCESS题库全部选择题1、用Access创建的数据库文件,其扩展名是______。
A:.adp B:.dbf C:.frm D:.mdb答案:D2、数据库系统的核心是______。
A:数据模型B:数据库管理系统C:数据库D:数据库管理员答案:B3、数据库系统是由数据库、数据库管理系统、应用程序、______、用户等构成的人机系统。
A:数据库管理员B:程序员C:高级程序员D:软件开发商答案:A4、在数据库中存储的是______。
A:信息B:数据C:数据结构D:数据模型答案:B5、在下面关于数据库的说法中,错误的是______。
A:数据库有较高的安全性B:数据库有较高的数据独立性C:数据库中的数据可以被不同的用户共享D:数据库中没有数据冗余答案:D6、下面关于新型数据库的说法中,错误的是______。
A:数据仓库不是一个新的平台,仍然使用传统的数据库管理系统,而是一个新的概念B:分布式数据库是一个数据在多个不同的地理位置存储的数据库C:面向对象数据库仍然采用传统的关系型数据库管理系统D:空间数据库是随着地理信息系统gis的开发和应用而发展起来的数据库新技术答案:C7、不是数据库系统特点的是______。
A:较高的数据独立性B:最低的冗余度C:数据多样性D:较好的数据完整性答案:C8、在下列数据库管理系统中,不属于关系型的是______。
A:Micorsoft Access B:SQL serverC:Oracle D:DBTG系统答案:D9、Access是______数据库管理系统。
A:层次B:网状C:关系型D:树状答案:C10、在Access中,数据库的基础和核心是______。
A:表B:查询C:窗体D:宏答案:A11、在下面关于Access数据库的说法中,错误的是______。
A:数据库文件的扩展名为mdbB:所有的对象都存放在同一个数据库文件中C:一个数据库可以包含多个表D:表是数据库中最基本的对象,没有表也就没有其他对象答案:B12、在一个单位的人事数据库,字段"简历"的数据类型应当为______。
数据库原理与应用选择题

单项选择题,(选择一个正确的答案,将相应的字母填入题内的括号中)1。
数据库系统的核心是( B)。
A)数据库B)数据库管理系统C)操作系统D)文件2.数据库(DB)、数据库系统(DBS)和数据库管理系统(DBMS)之间的关系是( A ).A)DBS包括DB和DBMSB)DBMS包括DB和DBSC)DB包括DBS和DBMSD)DBS就是DB,也就是DBMS3。
在数据管理技术的发展过程中,数据独立性最高的是( A)阶段.A)数据库系统B)文件系统C)人工管理D)数据项管理4。
数据库系统是由数据库、数据库管理系统(及其开发工具)、应用系统、( D)和用户构成.A)DBMSB)DBC)DBSD)DBA(数据库管理员)5。
文字、图形、图像、声音、学生的档案记录、货物的运输情况等,这些都是( A )。
A)DATAB)INFORMATIONC)DBD)其他6.( C)是长期存储在计算机内有序的、可共享的数据集合。
A)DATAB)INFORMATIONC)DBD)DBS7。
( A)是位于用户与操作系统之间的一层数据管理软件.数据库在建立、使用和维护时由其统一管理、统一控制。
A)DBMSB)DBC)DBSD)DBA8。
概念设计的结果是( B )A)一个与DBMS相关的要领模型B)一个与DBMS无关的概念模型C)数据库系统的公用视图D)数据库系统的数据字典9.E-R方法的三要素是(C)A)实体、属性、实体集B)实体、键、联系C)实体、属性、联系D)实体、域、候选区10。
要保证数据库的数据独立性,需要修改的是( C )A)模式与外模式B)模式与内模式C)三级模式之间的两层映射D)三级模式11.描述数据库全体数据的全局逻辑结构和特性的是( A)A)模式B)内模式C)外模式D)全模式12。
在数据库管理技术发展的3个阶段中,没有专门的软件对数据进行管理的阶段是(D)I.人工管理阶段 II.文件系统阶段 III.数据库阶段A)I 和 IIB)只有 IIC)II 和 IIID)只有 I13.下列四项中,不属于数据库系统特点的是( C )A)数据共享B)数据完整性C)数据冗余度高D)数据独立性高14。
深度学习试题500问

深度学习试题500问1.1标量、向量、张量之间的联系 1 [填空题]_________________________________1.2张量与矩阵的区别? 1 [填空题]_________________________________1.3矩阵和向量相乘结果 1 [填空题]_________________________________1.4向量和矩阵的范数归纳 1 [填空题]_________________________________1.5如何判断一个矩阵为正定? 2 [填空题]_________________________________1.6导数偏导计算 3 [填空题]_________________________________1.7导数和偏导数有什么区别? 3 [填空题]_________________________________1.8特征值分解与特征向量 3 [填空题]_________________________________1.9奇异值与特征值有什么关系? 4 [填空题]_________________________________1.10机器学习为什么要使用概率? 4 [填空题]_________________________________1.11变量与随机变量有什么区别? 4 [填空题]_________________________________1.12常见概率分布? 5 [填空题]_________________________________1.13举例理解条件概率 9 [填空题]_________________________________1.14联合概率与边缘概率联系区别? 10 [填空题]_________________________________1.15条件概率的链式法则 10 [填空题]_________________________________1.16独立性和条件独立性 11 [填空题]_________________________________1.17期望、方差、协方差、相关系数总结 11 [填空题] *_________________________________2.1 各种常见算法图示 14 [填空题]_________________________________2.2监督学习、非监督学习、半监督学习、弱监督学习? 15 [填空题] _________________________________2.3 监督学习有哪些步骤 16 [填空题]_________________________________2.4 多实例学习? 17 [填空题]_________________________________2.5 分类网络和回归的区别? 17 [填空题]_________________________________2.6 什么是神经网络? 17 [填空题]_________________________________2.7 常用分类算法的优缺点? 18 [填空题]_________________________________2.8 正确率能很好的评估分类算法吗? 20 [填空题]_________________________________2.9 分类算法的评估方法? 20 [填空题]_________________________________2.10 什么样的分类器是最好的? 22 [填空题]_________________________________2.11大数据与深度学习的关系 22 [填空题]_________________________________2.12 理解局部最优与全局最优 23 [填空题]_________________________________2.13 理解逻辑回归 24 [填空题]_________________________________2.14 逻辑回归与朴素贝叶斯有什么区别? 24 [填空题] _________________________________2.15 为什么需要代价函数? 25 [填空题]_________________________________2.16 代价函数作用原理 25 [填空题]_________________________________2.17 为什么代价函数要非负? 26 [填空题]_________________________________2.18 常见代价函数? 26 [填空题]_________________________________2.19为什么用交叉熵代替二次代价函数 28 [填空题]_________________________________2.20 什么是损失函数? 28 [填空题]_________________________________2.21 常见的损失函数 28 [填空题]_________________________________2.22 逻辑回归为什么使用对数损失函数? 30 [填空题] _________________________________0.00 对数损失函数是如何度量损失的? 31 [填空题] _________________________________2.23 机器学习中为什么需要梯度下降? 32 [填空题] _________________________________2.24 梯度下降法缺点? 32 [填空题]_________________________________2.25 梯度下降法直观理解? 32 [填空题]_________________________________2.23 梯度下降法算法描述? 33 [填空题]_________________________________2.24 如何对梯度下降法进行调优? 35 [填空题]_________________________________2.25 随机梯度和批量梯度区别? 35 [填空题]_________________________________2.26 各种梯度下降法性能比较 37 [填空题]_________________________________2.27计算图的导数计算图解? 37 [填空题]_________________________________2.28 线性判别分析(LDA)思想总结 39 [填空题] _________________________________2.29 图解LDA核心思想 39 [填空题]_________________________________2.30 二类LDA算法原理? 40 [填空题]_________________________________2.30 LDA算法流程总结? 41 [填空题]_________________________________2.31 LDA和PCA区别? 41 [填空题]_________________________________2.32 LDA优缺点? 41 [填空题]_________________________________2.33 主成分分析(PCA)思想总结 42 [填空题] _________________________________2.34 图解PCA核心思想 42 [填空题]_________________________________2.35 PCA算法推理 43 [填空题]_________________________________2.36 PCA算法流程总结 44 [填空题]_________________________________2.37 PCA算法主要优缺点 45 [填空题]_________________________________2.38 降维的必要性及目的 45 [填空题]_________________________________2.39 KPCA与PCA的区别? 46 [填空题]_________________________________2.40模型评估 47 [填空题]_________________________________2.40.1模型评估常用方法? 47 [填空题]_________________________________2.40.2 经验误差与泛化误差 47 [填空题]_________________________________2.40.3 图解欠拟合、过拟合 48 [填空题]_________________________________2.40.4 如何解决过拟合与欠拟合? 49 [填空题] _________________________________2.40.5 交叉验证的主要作用? 50 [填空题]_________________________________2.40.6 k折交叉验证? 50 [填空题]_________________________________2.40.7 混淆矩阵 50 [填空题]_________________________________2.40.8 错误率及精度 51 [填空题]_________________________________2.40.9 查准率与查全率 51 [填空题]_________________________________2.40.10 ROC与AUC 52 [填空题]_________________________________2.40.11如何画ROC曲线? 53 [填空题]_________________________________2.40.12如何计算TPR,FPR? 54 [填空题]_________________________________2.40.13如何计算Auc? 56 [填空题]_________________________________2.40.14为什么使用Roc和Auc评价分类器? 56 [填空题]_________________________________2.40.15 直观理解AUC 56 [填空题]_________________________________2.40.16 代价敏感错误率与代价曲线 57 [填空题]_________________________________2.40.17 模型有哪些比较检验方法 59 [填空题]_________________________________2.40.18 偏差与方差 59 [填空题]_________________________________2.40.19为什么使用标准差? 60 [填空题]_________________________________2.40.20 点估计思想 61 [填空题]_________________________________2.40.21 点估计优良性原则? 61 [填空题]_________________________________2.40.22点估计、区间估计、中心极限定理之间的联系? 62 [填空题] _________________________________2.40.23 类别不平衡产生原因? 62 [填空题]_________________________________2.40.24 常见的类别不平衡问题解决方法 62 [填空题] _________________________________2.41 决策树 64 [填空题]_________________________________2.41.1 决策树的基本原理 64 [填空题]_________________________________2.41.2 决策树的三要素? 64 [填空题]_________________________________2.41.3 决策树学习基本算法 65 [填空题]_________________________________2.41.4 决策树算法优缺点 65 [填空题]_________________________________2.40.5熵的概念以及理解 66 [填空题]_________________________________2.40.6 信息增益的理解 66 [填空题]_________________________________2.40.7 剪枝处理的作用及策略? 67 [填空题]_________________________________2.41 支持向量机 67 [填空题]_________________________________2.41.1 什么是支持向量机 67 [填空题]_________________________________2.25.2 支持向量机解决的问题? 68 [填空题]_________________________________2.25.2 核函数作用? 69 [填空题]_________________________________2.25.3 对偶问题 69 [填空题]_________________________________2.25.4 理解支持向量回归 69 [填空题]_________________________________2.25.5 理解SVM(核函数) 69 [填空题]_________________________________2.25.6 常见的核函数有哪些? 69 [填空题]_________________________________2.25.6 软间隔与正则化 73 [填空题]_________________________________2.25.7 SVM主要特点及缺点? 73 [填空题]_________________________________2.26 贝叶斯 74 [填空题]_________________________________2.26.1 图解极大似然估计 74 [填空题]_________________________________2.26.2 朴素贝叶斯分类器和一般的贝叶斯分类器有什么区别? 76 [填空题] _________________________________2.26.4 朴素与半朴素贝叶斯分类器 76 [填空题]_________________________________2.26.5 贝叶斯网三种典型结构 76 [填空题]_________________________________2.26.6 什么是贝叶斯错误率 76 [填空题]_________________________________2.26.7 什么是贝叶斯最优错误率 76 [填空题]_________________________________2.27 EM算法解决问题及实现流程 76 [填空题] _________________________________2.28 为什么会产生维数灾难? 78 [填空题]_________________________________2.29怎样避免维数灾难 82 [填空题]_________________________________2.30聚类和降维有什么区别与联系? 82 [填空题] _________________________________2.31 GBDT和随机森林的区别 83 [填空题]_________________________________2.32 四种聚类方法之比较 84 [填空题] *_________________________________3.1基本概念 88 [填空题]_________________________________3.1.1神经网络组成? 88 [填空题]_________________________________3.1.2神经网络有哪些常用模型结构? 90 [填空题] _________________________________3.1.3如何选择深度学习开发平台? 92 [填空题] _________________________________3.1.4为什么使用深层表示 92 [填空题]_________________________________3.1.5为什么深层神经网络难以训练? 93 [填空题]_________________________________3.1.6深度学习和机器学习有什么不同 94 [填空题]_________________________________3.2 网络操作与计算 95 [填空题]_________________________________3.2.1前向传播与反向传播? 95 [填空题]_________________________________3.2.2如何计算神经网络的输出? 97 [填空题]_________________________________3.2.3如何计算卷积神经网络输出值? 98 [填空题]_________________________________3.2.4如何计算Pooling层输出值输出值? 101 [填空题] _________________________________3.2.5实例理解反向传播 102 [填空题]_________________________________3.3超参数 105 [填空题]_________________________________3.3.1什么是超参数? 105 [填空题]_________________________________3.3.2如何寻找超参数的最优值? 105 [填空题]_________________________________3.3.3超参数搜索一般过程? 106 [填空题]_________________________________3.4激活函数 106 [填空题]_________________________________3.4.1为什么需要非线性激活函数? 106 [填空题]_________________________________3.4.2常见的激活函数及图像 107 [填空题]_________________________________3.4.3 常见激活函数的导数计算? 109 [填空题]_________________________________3.4.4激活函数有哪些性质? 110 [填空题]_________________________________3.4.5 如何选择激活函数? 110 [填空题]_________________________________3.4.6使用ReLu激活函数的优点? 111 [填空题]_________________________________3.4.7什么时候可以用线性激活函数? 111 [填空题]_________________________________3.4.8怎样理解Relu(<0时)是非线性激活函数? 111 [填空题] _________________________________3.4.9 Softmax函数如何应用于多分类? 112 [填空题]_________________________________3.5 Batch_Size 113 [填空题]_________________________________3.5.1为什么需要Batch_Size? 113 [填空题]_________________________________3.5.2 Batch_Size值的选择 114 [填空题]_________________________________3.5.3在合理范围内,增大 Batch_Size 有何好处? 114 [填空题] _________________________________3.5.4盲目增大 Batch_Size 有何坏处? 114 [填空题]_________________________________3.5.5调节 Batch_Size 对训练效果影响到底如何? 114 [填空题] _________________________________3.6 归一化 115 [填空题]_________________________________3.6.1归一化含义? 115 [填空题]_________________________________3.6.2为什么要归一化 115 [填空题]_________________________________3.6.3为什么归一化能提高求解最优解速度? 115 [填空题]_________________________________3.6.4 3D图解未归一化 116 [填空题]_________________________________3.6.5归一化有哪些类型? 117 [填空题]_________________________________3.6.6局部响应归一化作用 117 [填空题]_________________________________3.6.7理解局部响应归一化公式 117 [填空题]_________________________________3.6.8什么是批归一化(Batch Normalization) 118 [填空题] _________________________________3.6.9批归一化(BN)算法的优点 119 [填空题]_________________________________3.6.10批归一化(BN)算法流程 119 [填空题]_________________________________3.6.11批归一化和群组归一化 120 [填空题]_________________________________3.6.12 Weight Normalization和Batch Normalization 120 [填空题] _________________________________3.7 预训练与微调(fine tuning) 121 [填空题]_________________________________3.7.1为什么无监督预训练可以帮助深度学习? 121 [填空题]_________________________________3.7.2什么是模型微调fine tuning 121 [填空题]_________________________________3.7.3微调时候网络参数是否更新? 122 [填空题]_________________________________3.7.4 fine-tuning模型的三种状态 122 [填空题]_________________________________3.8权重偏差初始化 122 [填空题]_________________________________3.8.1 全都初始化为0 122 [填空题]_________________________________3.8.2 全都初始化为同样的值 123 [填空题]_________________________________3.8.3 初始化为小的随机数 124 [填空题]_________________________________3.8.4用1/sqrt(n)校准方差 125 [填空题]_________________________________3.8.5稀疏初始化(Sparse Initialazation) 125 [填空题]_________________________________3.8.6初始化偏差 125 [填空题]_________________________________3.9 Softmax 126 [填空题]_________________________________3.9.1 Softmax定义及作用 126 [填空题]_________________________________3.9.2 Softmax推导 126 [填空题]_________________________________3.10 理解One Hot Encodeing原理及作用? 126 [填空题] _________________________________3.11 常用的优化器有哪些 127 [填空题]_________________________________3.12 Dropout 系列问题 128 [填空题]_________________________________3.12.1 dropout率的选择 128 [填空题]_________________________________3.27 Padding 系列问题 128 [填空题] *_________________________________4.1LetNet5 129 [填空题]_________________________________ 4.1.1模型结构 129 [填空题]_________________________________ 4.1.2模型结构 129 [填空题]_________________________________ 4.1.3 模型特性 131 [填空题]_________________________________ 4.2 AlexNet 131 [填空题]_________________________________ 4.2.1 模型结构 131 [填空题]_________________________________ 4.2.2模型解读 131 [填空题]_________________________________ 4.2.3模型特性 135 [填空题]_________________________________ 4.3 可视化ZFNet-解卷积 135 [填空题] _________________________________ 4.3.1 基本的思想及其过程 135 [填空题] _________________________________ 4.3.2 卷积与解卷积 136 [填空题]_________________________________ 4.3.3卷积可视化 137 [填空题]_________________________________ 4.3.4 ZFNe和AlexNet比较 139 [填空题] _________________________________4.4 VGG 140 [填空题]_________________________________ 4.1.1 模型结构 140 [填空题]_________________________________ 4.1.2 模型特点 140 [填空题]_________________________________ 4.5 Network in Network 141 [填空题] _________________________________ 4.5.1 模型结构 141 [填空题]_________________________________ 4.5.2 模型创新点 141 [填空题]_________________________________ 4.6 GoogleNet 143 [填空题]_________________________________ 4.6.1 模型结构 143 [填空题]_________________________________ 4.6.2 Inception 结构 145 [填空题]_________________________________ 4.6.3 模型层次关系 146 [填空题]_________________________________ 4.7 Inception 系列 148 [填空题]_________________________________ 4.7.1 Inception v1 148 [填空题]_________________________________4.7.2 Inception v2 150 [填空题]_________________________________4.7.3 Inception v3 153 [填空题]_________________________________4.7.4 Inception V4 155 [填空题]_________________________________4.7.5 Inception-ResNet-v2 157 [填空题]_________________________________4.8 ResNet及其变体 158 [填空题]_________________________________4.8.1重新审视ResNet 159 [填空题]_________________________________4.8.2残差块 160 [填空题]_________________________________4.8.3 ResNet架构 162 [填空题]_________________________________4.8.4残差块的变体 162 [填空题]_________________________________4.8.5 ResNeXt 162 [填空题]_________________________________4.8.6 Densely Connected CNN 164 [填空题]_________________________________4.8.7 ResNet作为小型网络的组合 165 [填空题] _________________________________4.8.8 ResNet中路径的特点 166 [填空题]4.9为什么现在的CNN模型都是在GoogleNet、VGGNet或者AlexNet上调整的? 167 [填空题] *_________________________________5.1 卷积神经网络的组成层 170 [填空题]_________________________________5.2 卷积如何检测边缘信息? 171 [填空题]_________________________________5.2 卷积的几个基本定义? 174 [填空题]_________________________________5.2.1卷积核大小 174 [填空题]_________________________________5.2.2卷积核的步长 174 [填空题]_________________________________5.2.3边缘填充 174 [填空题]_________________________________5.2.4输入和输出通道 174 [填空题]_________________________________5.3 卷积网络类型分类? 174 [填空题]_________________________________5.3.1普通卷积 174 [填空题]_________________________________5.3.2扩张卷积 175 [填空题]_________________________________5.3.3转置卷积 176 [填空题]5.3.4可分离卷积 177 [填空题]_________________________________5.3 图解12种不同类型的2D卷积? 178 [填空题]_________________________________5.4 2D卷积与3D卷积有什么区别? 181 [填空题]_________________________________5.4.1 2D 卷积 181 [填空题]_________________________________5.4.2 3D卷积 182 [填空题]_________________________________5.5 有哪些池化方法? 183 [填空题]_________________________________5.5.1一般池化(General Pooling) 183 [填空题]_________________________________5.5.2重叠池化(OverlappingPooling) 184 [填空题]_________________________________5.5.3空金字塔池化(Spatial Pyramid Pooling) 184 [填空题] _________________________________5.6 1x1卷积作用? 186 [填空题]_________________________________5.7卷积层和池化层有什么区别? 187 [填空题]_________________________________5.8卷积核一定越大越好? 189 [填空题]_________________________________5.9每层卷积只能用一种尺寸的卷积核? 189 [填空题]_________________________________5.10怎样才能减少卷积层参数量? 190 [填空题]_________________________________5.11卷积操作时必须同时考虑通道和区域吗? 191 [填空题]_________________________________5.12采用宽卷积的好处有什么? 192 [填空题]_________________________________5.12.1窄卷积和宽卷积 192 [填空题]_________________________________5.12.2 为什么采用宽卷积? 192 [填空题]_________________________________5.13卷积层输出的深度与哪个部件的个数相同? 192 [填空题]_________________________________5.14 如何得到卷积层输出的深度? 193 [填空题]_________________________________5.15激活函数通常放在卷积神经网络的那个操作之后? 194 [填空题] _________________________________5.16 如何理解最大池化层有几分缩小? 194 [填空题]_________________________________5.17理解图像卷积与反卷积 194 [填空题]_________________________________5.17.1图像卷积 194 [填空题]_________________________________5.17.2图像反卷积 196 [填空题]_________________________________5.18不同卷积后图像大小计算? 198 [填空题]_________________________________5.18.1 类型划分 198 [填空题]_________________________________5.18.2 计算公式 199 [填空题]_________________________________5.19 步长、填充大小与输入输出关系总结? 199 [填空题] _________________________________5.19.1没有0填充,单位步长 200 [填空题]_________________________________5.19.2零填充,单位步长 200 [填空题]_________________________________5.19.3不填充,非单位步长 202 [填空题]_________________________________5.19.4零填充,非单位步长 202 [填空题]_________________________________5.20 理解反卷积和棋盘效应 204 [填空题]_________________________________5.20.1为什么出现棋盘现象? 204 [填空题]_________________________________5.20.2 有哪些方法可以避免棋盘效应? 205 [填空题]_________________________________5.21 CNN主要的计算瓶颈? 207 [填空题]_________________________________5.22 CNN的参数经验设置 207 [填空题]_________________________________5.23 提高泛化能力的方法总结 208 [填空题]_________________________________5.23.1 主要方法 208 [填空题]_________________________________5.23.2 实验证明 208 [填空题]_________________________________5.24 CNN在CV与NLP领域运用的联系与区别? 213 [填空题] _________________________________5.24.1联系 213 [填空题]_________________________________5.24.2区别 213 [填空题]_________________________________5.25 CNN凸显共性的手段? 213 [填空题]_________________________________5.25.1 局部连接 213 [填空题]_________________________________5.25.2 权值共享 214 [填空题]_________________________________5.25.3 池化操作 215 [填空题]_________________________________5.26 全卷积与Local-Conv的异同点 215 [填空题]_________________________________5.27 举例理解Local-Conv的作用 215 [填空题]_________________________________5.28 简述卷积神经网络进化史 216 [填空题] *_________________________________6.1 RNNs和FNNs有什么区别? 218 [填空题]_________________________________6.2 RNNs典型特点? 218 [填空题]_________________________________6.3 RNNs能干什么? 219 [填空题]_________________________________6.4 RNNs在NLP中典型应用? 220 [填空题]_________________________________6.5 RNNs训练和传统ANN训练异同点? 220 [填空题] _________________________________6.6常见的RNNs扩展和改进模型 221 [填空题]_________________________________6.6.1 Simple RNNs(SRNs) 221 [填空题]_________________________________6.6.2 Bidirectional RNNs 221 [填空题]_________________________________6.6.3 Deep(Bidirectional) RNNs 222 [填空题]_________________________________6.6.4 Echo State Networks(ESNs) 222 [填空题]_________________________________6.6.5 Gated Recurrent Unit Recurrent Neural Networks 224 [填空题] _________________________________6.6.6 LSTM Netwoorks 224 [填空题]_________________________________6.6.7 Clockwork RNNs(CW-RNNs) 225 [填空题] *_________________________________7.1基于候选区域的目标检测器 228 [填空题]_________________________________7.1.1滑动窗口检测器 228 [填空题]_________________________________7.1.2选择性搜索 229 [填空题]_________________________________7.1.3 R-CNN 230 [填空题]_________________________________7.1.4边界框回归器 230 [填空题]_________________________________7.1.5 Fast R-CNN 231 [填空题]_________________________________7.1.6 ROI 池化 233 [填空题]_________________________________7.1.7 Faster R-CNN 233 [填空题]_________________________________7.1.8候选区域网络 234 [填空题]_________________________________7.1.9 R-CNN 方法的性能 236 [填空题]_________________________________7.2 基于区域的全卷积神经网络(R-FCN) 237 [填空题] _________________________________7.3 单次目标检测器 240 [填空题]_________________________________7.3.1单次检测器 241 [填空题]_________________________________7.3.2滑动窗口进行预测 241 [填空题]_________________________________7.3.3 SSD 243 [填空题]_________________________________7.4 YOLO系列 244 [填空题]_________________________________7.4.1 YOLOv1介绍 244 [填空题]_________________________________7.4.2 YOLOv1模型优缺点? 252 [填空题]_________________________________7.4.3 YOLOv2 253 [填空题]_________________________________7.4.4 YOLOv2改进策略 254 [填空题]_________________________________7.4.5 YOLOv2的训练 261 [填空题]_________________________________7.4.6 YOLO9000 261 [填空题]_________________________________7.4.7 YOLOv3 263 [填空题]_________________________________8.1 传统的基于CNN的分割方法缺点? 269 [填空题]_________________________________8.1 FCN 269 [填空题]_________________________________8.1.1 FCN改变了什么? 269 [填空题]_________________________________8.1.2 FCN网络结构? 270 [填空题]_________________________________8.1.3全卷积网络举例? 271 [填空题]_________________________________8.1.4为什么CNN对像素级别的分类很难? 271 [填空题]_________________________________8.1.5全连接层和卷积层如何相互转化? 272 [填空题]_________________________________8.1.6 FCN的输入图片为什么可以是任意大小? 272 [填空题]_________________________________8.1.7把全连接层的权重W重塑成卷积层的滤波器有什么好处? 273 [填空题] _________________________________8.1.8反卷积层理解 275 [填空题]_________________________________8.1.9跳级(skip)结构 276 [填空题]_________________________________8.1.10模型训练 277 [填空题]_________________________________8.1.11 FCN缺点 280 [填空题]_________________________________8.2 U-Net 280 [填空题]_________________________________8.3 SegNet 282 [填空题]_________________________________8.4空洞卷积(Dilated Convolutions) 283 [填空题] _________________________________8.4 RefineNet 285 [填空题]_________________________________8.5 PSPNet 286 [填空题]_________________________________8.6 DeepLab系列 288 [填空题]_________________________________8.6.1 DeepLabv1 288 [填空题]_________________________________8.6.2 DeepLabv2 289 [填空题]_________________________________8.6.3 DeepLabv3 289 [填空题]_________________________________8.6.4 DeepLabv3+ 290 [填空题]_________________________________8.7 Mask-R-CNN 293 [填空题]_________________________________8.7.1 Mask-RCNN 的网络结构示意图 293 [填空题]_________________________________8.7.2 RCNN行人检测框架 293 [填空题]_________________________________8.7.3 Mask-RCNN 技术要点 294 [填空题]_________________________________8.8 CNN在基于弱监督学习的图像分割中的应用 295 [填空题] _________________________________8.8.1 Scribble标记 295 [填空题]_________________________________8.8.2 图像级别标记 297 [填空题]_________________________________8.8.3 DeepLab+bounding box+image-level labels 298 [填空题]_________________________________8.8.4统一的框架 299 [填空题] *_________________________________9.1强化学习的主要特点? 301 [填空题]_________________________________9.2强化学习应用实例 302 [填空题]_________________________________9.3强化学习和监督式学习、非监督式学习的区别 303 [填空题] _________________________________9.4 强化学习主要有哪些算法? 305 [填空题]_________________________________9.5深度迁移强化学习算法 305 [填空题]_________________________________9.6分层深度强化学习算法 306 [填空题]_________________________________9.7深度记忆强化学习算法 306 [填空题]_________________________________9.8 多智能体深度强化学习算法 307 [填空题]_________________________________9.9深度强化学习算法小结 307 [填空题] *_________________________________10.1 什么是迁移学习? 309 [填空题]_________________________________10.2 什么是多任务学习? 309 [填空题]_________________________________10.3 多任务学习有什么意义? 309 [填空题]_________________________________10.4 什么是端到端的深度学习? 311 [填空题]_________________________________10.5 端到端的深度学习举例? 311 [填空题]_________________________________10.6 端到端的深度学习有什么挑战? 311 [填空题] _________________________________10.7 端到端的深度学习优缺点? 312 [填空题] *_________________________________13.1 CPU和GPU 的区别? 314 [填空题]_________________________________13.2如何解决训练样本少的问题 315 [填空题]_________________________________13.3 什么样的样本集不适合用深度学习? 315 [填空题]_________________________________13.4 有没有可能找到比已知算法更好的算法? 316 [填空题]_________________________________13.5 何为共线性, 跟过拟合有啥关联? 316 [填空题]_________________________________13.6 广义线性模型是怎被应用在深度学习中? 316 [填空题]_________________________________13.7 造成梯度消失的原因? 317 [填空题]_________________________________13.8 权值初始化方法有哪些 317 [填空题]_________________________________13.9 启发式优化算法中,如何避免陷入局部最优解? 318 [填空题]_________________________________13.10 凸优化中如何改进GD方法以防止陷入局部最优解 319 [填空题] _________________________________13.11 常见的损失函数? 319 [填空题]_________________________________13.14 如何进行特征选择(feature selection)? 321 [填空题]_________________________________13.14.1 如何考虑特征选择 321 [填空题]_________________________________13.14.2 特征选择方法分类 321 [填空题]_________________________________13.14.3 特征选择目的 322 [填空题]_________________________________13.15 梯度消失/梯度爆炸原因,以及解决方法 322 [填空题]_________________________________13.15.1 为什么要使用梯度更新规则? 322 [填空题]_________________________________13.15.2 梯度消失、爆炸原因? 323 [填空题]_________________________________13.15.3 梯度消失、爆炸的解决方案 324 [填空题]_________________________________13.16 深度学习为什么不用二阶优化 325 [填空题]_________________________________13.17 怎样优化你的深度学习系统? 326 [填空题]_________________________________13.18为什么要设置单一数字评估指标? 326 [填空题]_________________________________13.19满足和优化指标(Satisficing and optimizing metrics) 327 [填空题] _________________________________13.20 怎样划分训练/开发/测试集 328 [填空题]_________________________________13.21如何划分开发/测试集大小 329 [填空题]_________________________________13.22什么时候该改变开发/测试集和指标? 329 [填空题]_________________________________13.23 设置评估指标的意义? 330 [填空题]_________________________________13.24 什么是可避免偏差? 331 [填空题]_________________________________13.25 什么是TOP5错误率? 331 [填空题]_________________________________13.26 什么是人类水平错误率? 332 [填空题]_________________________________13.27 可避免偏差、几大错误率之间的关系? 332 [填空题] _________________________________13.28 怎样选取可避免偏差及贝叶斯错误率? 332 [填空题] _________________________________13.29 怎样减少方差? 333 [填空题]_________________________________13.30贝叶斯错误率的最佳估计 333 [填空题]_________________________________13.31举机器学习超过单个人类表现几个例子? 334 [填空题] _________________________________13.32如何改善你的模型? 334 [填空题]_________________________________13.33 理解误差分析 335 [填空题]_________________________________13.34 为什么值得花时间查看错误标记数据? 336 [填空题] _________________________________13.35 快速搭建初始系统的意义? 336 [填空题]_________________________________13.36 为什么要在不同的划分上训练及测试? 337 [填空题] _________________________________13.37 如何解决数据不匹配问题? 338 [填空题]_________________________________13.38 梯度检验注意事项? 340 [填空题]_________________________________13.39什么是随机梯度下降? 341 [填空题]_________________________________13.40什么是批量梯度下降? 341 [填空题]_________________________________13.41什么是小批量梯度下降? 341 [填空题]_________________________________13.42怎么配置mini-batch梯度下降 342 [填空题]_________________________________13.43 局部最优的问题 343 [填空题]_________________________________13.44提升算法性能思路 346 [填空题] *_________________________________14.1 调试处理 358 [填空题]_________________________________14.2 有哪些超参数 359 [填空题]_________________________________14.3 如何选择调试值? 359 [填空题]_________________________________14.4 为超参数选择合适的范围 359 [填空题]_________________________________14.5 如何搜索超参数? 359 [填空题] *_________________________________15.1 什么是正则化? 361 [填空题]_________________________________15.2 正则化原理? 361 [填空题]_________________________________15.3 为什么要正则化? 361 [填空题]_________________________________15.4 为什么正则化有利于预防过拟合? 361 [填空题] _________________________________15.5 为什么正则化可以减少方差? 362 [填空题]_________________________________15.6 L2正则化的理解? 362 [填空题]_________________________________15.7 理解dropout 正则化 362 [填空题]_________________________________15.8 有哪些dropout 正则化方法? 362 [填空题]_________________________________15.8 如何实施dropout 正则化 363 [填空题]_________________________________。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5. 团聚,一起 get together 6. 不仅… … 而且… … not just… but also… 7. 一个美好的结局 a very happy ending 8. 打动许多人的心 touch many people’s hearts
4. Do good friends need to say something to show they care?
Read and answer the questions 1. What is the relationship between the egret and the rhino? The egret helps the rhino stay healthy by cleaning its skin. It also makes noise to warn the rhino about coming danger. The rhino helps the egret get food more easily.
2. Who is Owen? Who is Mzee? Owen is a baby hippo. Mzee is a 130-year-old tortoise.
3. How did people feel when they heard the story of friendship between Owen and Mzee?
Read and answer the questions 1. What is the relationship between the egret and the rhino? 2. Who is Owen? Who is Mzee? 3. How did people feel when they heard the story of friendship between Owen and Mzee?
They felt moved.
4. Do good friends need to say something to show they care? No.
Read the text again and do exercises
1. 过去常常认为 used to think used to do sth. 2. 互相帮助 help each other 3. 通过清洁它的皮肤 by cleaning its skin
touch one’s heart
Dig-in
1. Good friends can show they care without words. 2. Friendship truly has no boundaries. 3. Isn’t that interesting?
Summary
Homework
1. Review Lesson 18. 2. Finish the exercises on page 45.
பைடு நூலகம்
How warm and gentle are these pictures!
Do you think there is friendship between animals?
Lesson 18 Friendship Between Animals
Teaching Aims 1. Read and spell the new words correctly 2.Learn how to use the following phrases used to do; warn sb. to do sth. by doing sth. not just…but also…; touch one’s heart 3. Learn how to get on well with others
New words
friendship rhino skin warn insect relationship n. 友情,友谊 n. 犀牛 n. 皮,皮肤 v. 警告,提醒 n. 昆虫 n. 关系,关联
survive hippo tortoise truly boundary
v. 生存,存活 n. 河马 n. 龟 adv. 真正,正确地 n. 分界线,边界