赵冲2009911002《马的遍历实验报告》
图的遍历 实验报告

图的遍历实验报告一、引言图是一种非线性的数据结构,由一组节点(顶点)和节点之间的连线(边)组成。
图的遍历是指按照某种规则依次访问图中的每个节点,以便获取或处理节点中的信息。
图的遍历在计算机科学领域中有着广泛的应用,例如在社交网络中寻找关系紧密的人员,或者在地图中搜索最短路径等。
本实验旨在通过实际操作,掌握图的遍历算法。
在本实验中,我们将实现两种常见的图的遍历算法:深度优先搜索(DFS)和广度优先搜索(BFS),并比较它们的差异和适用场景。
二、实验目的1. 理解和掌握图的遍历算法的原理与实现;2. 比较深度优先搜索和广度优先搜索的差异;3. 掌握图的遍历算法在实际问题中的应用。
三、实验步骤实验材料1. 计算机;2. 编程环境(例如Python、Java等);3. 支持图操作的相关库(如NetworkX)。
实验流程1. 初始化图数据结构,创建节点和边;2. 实现深度优先搜索算法;3. 实现广度优先搜索算法;4. 比较两种算法的时间复杂度和空间复杂度;5. 比较两种算法的遍历顺序和适用场景;6. 在一个具体问题中应用图的遍历算法。
四、实验结果1. 深度优先搜索(DFS)深度优先搜索是一种通过探索图的深度来遍历节点的算法。
具体实现时,我们可以使用递归或栈来实现深度优先搜索。
算法的基本思想是从起始节点开始,选择一个相邻节点进行探索,直到达到最深的节点为止,然后返回上一个节点,再继续探索其他未被访问的节点。
2. 广度优先搜索(BFS)广度优先搜索是一种逐层遍历节点的算法。
具体实现时,我们可以使用队列来实现广度优先搜索。
算法的基本思想是从起始节点开始,依次遍历当前节点的所有相邻节点,并将这些相邻节点加入队列中,然后再依次遍历队列中的节点,直到队列为空。
3. 时间复杂度和空间复杂度深度优先搜索和广度优先搜索的时间复杂度和空间复杂度如下表所示:算法时间复杂度空间复杂度深度优先搜索O(V+E) O(V)广度优先搜索O(V+E) O(V)其中,V表示节点的数量,E表示边的数量。
图的遍历的实验报告

图的遍历的实验报告图的遍历的实验报告一、引言图是一种常见的数据结构,它由一组节点和连接这些节点的边组成。
图的遍历是指从图中的某个节点出发,按照一定的规则依次访问图中的所有节点。
图的遍历在许多实际问题中都有广泛的应用,例如社交网络分析、路线规划等。
本实验旨在通过实际操作,深入理解图的遍历算法的原理和应用。
二、实验目的1. 掌握图的遍历算法的基本原理;2. 实现图的深度优先搜索(DFS)和广度优先搜索(BFS)算法;3. 比较并分析DFS和BFS算法的时间复杂度和空间复杂度。
三、实验过程1. 实验环境本实验使用Python编程语言进行实验,使用了networkx库来构建和操作图。
2. 实验步骤(1)首先,我们使用networkx库创建一个包含10个节点的无向图,并添加边以建立节点之间的连接关系。
(2)接下来,我们实现深度优先搜索算法。
深度优先搜索从起始节点开始,依次访问与当前节点相邻的未访问过的节点,直到遍历完所有节点或无法继续访问为止。
(3)然后,我们实现广度优先搜索算法。
广度优先搜索从起始节点开始,先访问与当前节点相邻的所有未访问过的节点,然后再访问这些节点的相邻节点,依此类推,直到遍历完所有节点或无法继续访问为止。
(4)最后,我们比较并分析DFS和BFS算法的时间复杂度和空间复杂度。
四、实验结果经过实验,我们得到了如下结果:(1)DFS算法的时间复杂度为O(V+E),空间复杂度为O(V)。
(2)BFS算法的时间复杂度为O(V+E),空间复杂度为O(V)。
其中,V表示图中的节点数,E表示图中的边数。
五、实验分析通过对DFS和BFS算法的实验结果进行分析,我们可以得出以下结论:(1)DFS算法和BFS算法的时间复杂度都是线性的,与图中的节点数和边数呈正比关系。
(2)DFS算法和BFS算法的空间复杂度也都是线性的,与图中的节点数呈正比关系。
但是,DFS算法的空间复杂度比BFS算法小,因为DFS算法只需要保存当前路径上的节点,而BFS算法需要保存所有已访问过的节点。
马基的实验报告

马基的实验报告引言马基(Machi)实验是一项经典的心理学实验,以其对人类决策行为的洞察力而著名。
该实验以人类集体对待资金的使用方式作为研究对象,从而探究人们在不同情境下的决策倾向。
本实验旨在揭示人们对风险的态度以及人类对预期效用理论的违背程度。
实验设计受试者选择本实验邀请了100名年龄在18至40岁之间、具备一定经济常识的受试者参与。
受试者被随机分成两组,每组50人。
实验材料准备实验以货币为主要材料,使用相对较小但具有一定实际价值的纸币,如10和20纸币。
实验步骤1. 将实验组的50名受试者随机分为两组:正向组和负向组。
2. 正向组受试者接受一项称为“实验A”的任务,目的是给他们提供一个积极的背景。
3. 负向组受试者接受一项称为“实验B”的任务,目的是给他们提供一个消极的背景。
4. 实验A的任务如下:受试者获得1000,并需要在两个决策中选择:A1、将金额增加10%的风险决策,或A2、将金额保持不变的确定性决策。
5. 实验B的任务如下:受试者开始时获得2000,需要在两个决策中选择:B1、将金额增加50%的风险决策,或B2、将金额减少20%的确定性决策。
6. 在每个决策后,受试者将收到实际支付该金额的一半,作为实验的奖励。
实验结果正向组实验结果在正向组中,结果显示80%的受试者选择了A1,只有20%的受试者选择了A2。
这表明正向组受试者更倾向于冒险。
负向组实验结果在负向组中,结果显示有70%的受试者选择了B1,仅30%的受试者选择了B2。
这表明负向组受试者更倾向于冒险。
结论通过分析实验结果,可以得出以下结论:1. 正向组受试者对于获得盈利的决策更倾向于冒险。
2. 负向组受试者对于避免更大亏损的决策更倾向于冒险。
这些结果与预期效用理论存在偏差,该理论假设人们会根据预期盈利或亏损的大小来做出决策。
然而,实验结果表明人们对风险持有不同的态度。
讨论马基实验的结果表明了人们在不同情境下的决策心理。
其中,正向组倾向于冒险的行为可能是基于对盈利机会的乐观估计,而负向组倾向于冒险的行为可能是基于对亏损机会的忧虑。
图的遍历实验报告

图的遍历实验报告图的遍历实验报告一、引言图是一种常见的数据结构,广泛应用于计算机科学和其他领域。
图的遍历是指按照一定规则访问图中的所有节点。
本实验通过实际操作,探索了图的遍历算法的原理和应用。
二、实验目的1. 理解图的遍历算法的原理;2. 掌握深度优先搜索(DFS)和广度优先搜索(BFS)两种常用的图遍历算法;3. 通过实验验证图的遍历算法的正确性和效率。
三、实验过程1. 实验环境准备:在计算机上安装好图的遍历算法的实现环境,如Python编程环境;2. 实验数据准备:选择合适的图数据进行实验,包括图的节点和边的信息;3. 实验步骤:a. 根据实验数据,构建图的数据结构;b. 实现深度优先搜索算法;c. 实现广度优先搜索算法;d. 分别运行深度优先搜索和广度优先搜索算法,并记录遍历的结果;e. 比较两种算法的结果,分析其异同点;f. 对比算法的时间复杂度和空间复杂度,评估其性能。
四、实验结果与分析1. 实验结果:根据实验数据和算法实现,得到了深度优先搜索和广度优先搜索的遍历结果;2. 分析结果:a. 深度优先搜索:从起始节点出发,一直沿着深度方向遍历,直到无法继续深入为止。
该算法在遍历过程中可能产生较长的路径,但可以更快地找到目标节点,适用于解决一些路径搜索问题。
b. 广度优先搜索:从起始节点出发,按照层次顺序逐层遍历,直到遍历完所有节点。
该算法可以保证找到最短路径,但在遍历大规模图时可能需要较大的时间和空间开销。
五、实验总结1. 通过本次实验,我们深入理解了图的遍历算法的原理和应用;2. 掌握了深度优先搜索和广度优先搜索两种常用的图遍历算法;3. 通过实验验证了算法的正确性和效率;4. 在实际应用中,我们需要根据具体问题的需求选择合适的遍历算法,权衡时间复杂度和空间复杂度;5. 进一步研究和优化图的遍历算法,可以提高算法的性能和应用范围。
六、参考文献[1] Cormen, T. H., Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to Algorithms (3rd ed.). MIT Press.[2] Sedgewick, R., & Wayne, K. (2011). Algorithms (4th ed.). Addison-Wesley Professional.。
马步遍历探索

=Hale Waihona Puke (etx ety s p l 同 时 记 录 下 此 时 的 方 向 d(t ): , n x , x_)=t + ; _n e s p k e
fe )= s p O时 ,即 从 1 — 8选 取 方 向 ,并 求 出 此 方 向 的 走 马 位 t — 置 :nx x x ( moex (), etyy ( m v— k。 et = i )+ v_ k n x = i )+ oe Y()
判 断 : 若 1 etx≤n ≤n x_ ,1≤n x y≤m,c es ( e tx et h sb n x_ ,
…
…
B 啊E R G A … … … … … … … … …… … … …… ……… … … … … …… … 一 … …… … …… … … ^ PORM … …
马步遍历探索 =
杨克 昌 刘志
摘 要 :马 步遍 历探 索是 一 个有 难 度 也有 趣 味 的 组合 数 学 问题 。分 别 应 用 回溯 与 贪 心算 法探 索马 步遍 历 n m 棋 盘 。结 果显 示 ,回溯 算 法能 够 求 出 问题 的 所 有 解 ,但 效 率较 低 ,而 贪 心算 法 的 求解
图 1 位于 (,)的马可 走的 8个位置 ×y
设 置 控 制 马 步 规 则 的 数 组 m v x () oe k、moey () v_ k ,若 马
_
/回 溯 探 求 马 步 遍 历 /
# n ld <i s r a . > i cu e o te m h
图的遍历算法实验报告

图的遍历算法实验报告
《图的遍历算法实验报告》
在计算机科学领域,图的遍历算法是一种重要的算法,它用于在图数据结构中
访问每个顶点和边。
图的遍历算法有两种常见的方法:深度优先搜索(DFS)
和广度优先搜索(BFS)。
在本实验中,我们将对这两种算法进行实验,并比较
它们的性能和应用场景。
首先,我们使用深度优先搜索算法对一个简单的无向图进行遍历。
通过实验结
果可以看出,DFS算法会首先访问一个顶点的所有邻居,然后再递归地访问每
个邻居的邻居,直到图中所有的顶点都被访问到。
这种算法在一些应用场景中
非常有效,比如寻找图中的连通分量或者寻找图中的环路。
接下来,我们使用广度优先搜索算法对同样的无向图进行遍历。
通过实验结果
可以看出,BFS算法会首先访问一个顶点的所有邻居,然后再按照距离递增的
顺序访问每个邻居的邻居。
这种算法在一些应用场景中也非常有效,比如寻找
图中的最短路径或者寻找图中的最小生成树。
通过对比实验结果,我们可以发现DFS和BFS算法各自的优势和劣势。
DFS算
法适合用于寻找图中的连通分量和环路,而BFS算法适合用于寻找最短路径和
最小生成树。
因此,在实际应用中,我们需要根据具体的需求来选择合适的算法。
总的来说,图的遍历算法是计算机科学中非常重要的算法之一,它在许多领域
都有着广泛的应用。
通过本次实验,我们对DFS和BFS算法有了更深入的了解,并且对它们的性能和应用场景有了更清晰的认识。
希望通过这篇实验报告,读
者们也能对图的遍历算法有更深入的理解和认识。
数据结构实习报告——国际象棋中马的遍历

数据结构与VC编程实习实习报告学生姓名:学号:专业班级:指导教师:2012年7月14日实习题目在国际象棋棋盘上实现马的遍历一、任务描述及要求国际象棋的棋盘有8×8=64个格子,给它们规定坐标(1,1)到(8,8)。
马在这64个格子的某一个格子上,它的跳动规则是:如果它现在在(x,y)位置,它下一步可以跳到(x±1,y±2)或(x±2,y±1)(所有的“±”之间没有相关性)。
一般来说它下一步可以有八种跳法,但是它不能跳出这64个格子。
设计算法使它不管从哪出发都可以跳遍所有的格子(每个格子只能路过一次)最后回到起点。
1.基本要求:合理设计界面,自行设计国际象棋棋盘,用鼠标选择马的起始位置,起始位置选定后,按“开始”按钮演示马的每一步行走路线。
棋盘和马的显示尽量美观逼真。
功能菜单或按钮自行设计,以合理为目的。
2.扩展要求:对算法进行优化,根据j.c.Warnsdorff规则设计算法,该规则是在所有可跳的方格中,马只可能走这样一个方格:从该方格出发,马能跳的方格数为最少;如果可跳的方格数相等,则从当前位置看,方格序号小的优先。
二、概要设计1.抽象数据类型本次实习中,我主要采用图的深度遍历知识和贪心算法来解决在国际象棋棋盘上实现马的遍历问题。
棋盘上将64个格子视为64个点,将马从一个格子跳到另一个格子视为一条边,则共有168条边,那么可以将棋盘视为一个无向图,马在棋盘上按c.Warnsdorff规则跳动可视为图的深度遍历过程中的一步。
为了实现图的存储,需要建立顶点顺序表和邻接表,这个过程是在图的构造函数里实现的。
图的操作主要包括:给出顶点vertex在表中的位置,给出顶点位置为 v 的第一个邻接顶点的位置,给出顶点v的邻接顶点w的下一个邻接顶点的位置,给出顶点位置为 v 的最优邻接顶点的位置。
图的遍历算法是在视图类里面实现的。
图的抽象数据类型为:ADT Graph{数据:顶点顺序表关系: 邻接表表示了顶点之间的邻接关系操作:①给出顶点vertex在表中的位置②给出顶点位置为 v 的第一个邻接顶点的位置③给出顶点v的邻接顶点w的下一个邻接顶点的位置④给出顶点位置为 v 的最优邻接顶点的位置}由于贪心算法有时不能得到整体最优解,所以我设计了另一种遍历算法。
图的遍历操作实验报告

图的遍历操作实验报告一、实验目的本次实验的主要目的是深入理解图的遍历操作的基本原理和方法,并通过实际编程实现,掌握图的深度优先遍历(DepthFirst Search,DFS)和广度优先遍历(BreadthFirst Search,BFS)算法,比较它们在不同类型图中的性能和应用场景。
二、实验环境本次实验使用的编程语言为 Python,开发环境为 PyCharm。
实验中使用的数据结构为邻接表来表示图。
三、实验原理(一)深度优先遍历深度优先遍历是一种递归的图遍历算法。
它从起始节点开始,沿着一条路径尽可能深地访问节点,直到无法继续,然后回溯到上一个未完全探索的节点,继续探索其他分支。
(二)广度优先遍历广度优先遍历则是一种逐层访问的算法。
它从起始节点开始,先访问起始节点的所有相邻节点,然后再依次访问这些相邻节点的相邻节点,以此类推,逐层展开。
四、实验步骤(一)数据准备首先,定义一个图的邻接表表示。
例如,对于一个简单的有向图,可以使用以下方式创建邻接表:```pythongraph ={'A':'B','C','B':'D','E','C':'F','D':,'E':,'F':}```(二)深度优先遍历算法实现```pythondef dfs(graph, start, visited=None):if visited is None:visited = set()visitedadd(start)print(start)for next_node in graphstart:if next_node not in visited:dfs(graph, next_node, visited)```(三)广度优先遍历算法实现```pythonfrom collections import deque def bfs(graph, start):visited ={start}queue = deque(start)while queue:node = queuepopleft()print(node)for next_node in graphnode:if next_node not in visited:visitedadd(next_node)queueappend(next_node)```(四)测试与分析分别使用深度优先遍历和广度优先遍历算法对上述示例图进行遍历,并记录遍历的顺序和时间开销。
马的遍历课程设计报告

《数据结构》课程设计实验报告——马的遍历学院:长江学院班级:093212学号:09321225姓名:杨海龙指导老师:刘自强指导时间:2010.12.28目录1.流程图: (1)2.问题描述: (2)3.设计思路: (2)4.数据结构设计: (2)5.功能函数算法分析: (3)(1)计算一个点周围有几个点函数int Count(int x,int y) (3)(2)寻找下一个方向函数int Find_Direction(int x,int y) (3)(3)栈的相关函数: (4)(4)骑士遍历函数:void Knight(int x,int y,int v) (5)(5)主函数:void main() (6)(6)棋盘初始化函数void Mark_Che(int v) (7)(7)标记初始化函数void Mark_Dir(int v) (8)6.运行和测试: (8)7.心得体会: (10)马的遍历问题1.流程图:2.问题描述:在中国象棋棋盘上,对任意位置上放置的一个马,均能选择一个合适的路线,使得该棋子(马)能按象棋的规则不重复的走过棋盘上的每一个位置。
要求依次输出所有走过的各位置的坐标。
3.设计思路:首先,中国象棋是10*9的棋盘,马的走法是“马走日”,忽略“蹩脚马”的情况。
其次,这个题目采用的是算法当中的深度优先算法和回溯法:在“走到”一个位置后要寻找下一个位置,如果发生“阻塞”的情况,就是后面走不通的情况,则向后回溯,重新寻找。
在寻找下一步的时候,对周围的这几个点进行比较,从而分出优劣程度,即看它们周围可以走的点谁最少,然后就走那条可走路线最少的那条。
经过这样的筛选后,就会为后面的路径寻找提供方便,从而减少回溯次数。
最后,本程序的棋盘和数组类似,因而采用数组进行存储,同时因为有回溯,所以采用栈的方法,并且为了最后打印方便,采用的是顺序栈的方法。
同时还有八个方向的数组,和为栈设计的每个点周围的八个方向那些可以走的数组。
图的遍历实验报告

图的遍历实验报告数据结构实验报告计科101 冯康 201000814128实验图的基本操作一、实验目的及要求1、使学生1、使学生可以巩固所学的有关图的基本知识。
2、熟练掌握图的存储结构。
3、熟练掌握图的两种遍历算法。
基本要求:以邻接表为存储结构,实现连通无向图的深度优先和广度优先遍历。
以用户指定的结点为起点,分别输出每种遍历下的结点访问序列。
二、算法描述[问题描述]对给定图,实现图的深度优先遍历和广度优先遍历。
【测试数据】由学生依据软件工程的测试技术自己确定。
四、实验报告要求1、实验报告要按照实验报告格式规范书写。
2、实验上要写出多批测试数据的运行结果。
3、结合运行结果,对程序进行分析。
编程思路:深度优先算法:计算机程序的一种编制原理,就是在一个问题出现多种可以实现的方法和技术的时候,应该优先选择哪个更合适的,也是一种普遍的逻辑思想,此种思想在运算的过程中,用到计算机程序的一种递归的思想。
度优先搜索算法:又称广度优先搜索,是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。
Dijkstra单源最短路径算法和Prim 最小生成树算法都采用了和宽度优先搜索类似的思想。
其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。
换句话说,它并不考虑结果的可能位址,彻底地搜索整张图,直到找到结果为止。
以临接链表作为存储结构,结合其存储特点和上面两种算法思想,给出两种遍历步骤: (1)既然图中没有确定的开始顶点,那么可从图中任一顶点出发,不妨按编号的顺序,先从编号小的顶点开始。
中原工学院计算机学院打印时间:2016-4-30 上午 00:04 第1页共4页数据结构实验报告计科101 冯康 201000814128(2)要遍历到图中所有顶点,只需多次调用从某一顶点出发遍历图的算法。
所以,下面只考虑从某一顶点出发遍历图的问题。
(3)为了在遍历过程中便于区分顶点是否已经被访问,设置一个访问标志数组visited[n],n为图中顶点的个数,其初值为0,当被访问过后,其值被置为1。
关于马的实验报告

关于马的实验报告一、引言马是一种优秀的哺乳动物,广泛应用于农业、交通和体育等领域。
了解马的生态和行为,对于人类与马的相处、马的饲养管理以及马的驯养等方面具有重要意义。
本次实验旨在进一步探究马的行为特征、智力水平和适应能力,以及探讨与人类的关系。
二、实验目的1. 了解马的行为特征,包括社交行为、觅食行为和运动行为等;2. 研究马的智力水平,包括学习能力和记忆能力等;3. 探讨马的适应能力,包括对环境的适应和应激反应等;4. 分析人类与马的关系,包括马的驯养和与人类的合作等。
三、实验方法1. 观察法利用直接观察法,对马的行为特征进行记录和分析。
观察包括社交行为、觅食行为和运动行为等方面。
2. 训练法通过驯养与训练,对马的学习能力和记忆能力进行测试。
通过给马一系列口令,并观察其是否能够理解和按照指令执行来评估其学习和记忆能力。
3. 环境变化法改变马的饲养环境和引入新的刺激物,观察马是否能够快速适应和应激反应。
观察期限为7天,记录马在环境变化后的行为变化。
四、实验结果1. 马的行为特征观察结果通过观察,我们发现马是社交性动物,经常与同类进行互动和运动。
在觅食行为中,马具有较强的选择性,能够根据自身需求选择不同的食物。
在运动行为中,马展现出高度的灵活性和协调性。
2. 马的智力水平测试结果经过训练和测试,我们发现马具有较高的学习能力和记忆能力。
它们能够很好地理解人类的口令并按照指令执行,表现出良好的训练效果。
3. 马的适应能力观察结果在环境变化实验中,我们发现马能够快速适应新的饲养环境,并在引入新的刺激物后表现出一定的好奇心和探索欲。
马在适应新环境过程中,也体现出了较强的应激反应能力。
五、讨论与结论通过本次实验我们得到了以下结论:1. 马是社交性动物,喜欢与同类互动和运动。
2. 马具有较高的学习能力和记忆能力,能够很好地理解人类的指令。
3. 马在适应新环境和应对新刺激物方面表现出较强的能力。
在今后的研究中,我们可以进一步探索马的其他行为特征,如繁殖行为和睡眠行为等。
作文关于马字的研究报告400字

作文关于马字的研究报告400字Horses have been an integral part of human history for thousands of years. 马是人类历史上几千年来不可或缺的一部分。
They have been used for transportation, agriculture, warfare, and as loyal companions. 它们被用于交通、农业、战争,以及作为忠诚的伴侣。
Despite the technological advancements that have rendered horses less essential in modern society, they continue to hold a special place in the hearts of many. 尽管科技的进步已经使马在现代社会中的必要性减少,它们依然在许多人心中占据着特殊的地位。
In the Chinese language, the character for horse, 马, is a symbol of strength, power, and vitality. 在汉语中,马字象征着力量、权力和生命力。
The horse is often associated with attributes such as speed, freedom, and grace. 马经常与速度、自由和优雅等属性联系在一起。
This symbolism has been ingrained in Chinese culture for centuries, with horses appearing in myths, legends, and artwork. 这种象征在几个世纪以来已被深深根植于中国文化中,马出现在神话、传说和艺术作品中。
In traditional Chinese medicine, the horse is believed to possess healing properties and is used in various herbal remedies. 在传统的中医中,马被认为具有治疗特性,被用于各种草药疗法中。
马的遍历VC课程设计报告

课程设计报告学院、系:专业名称:网络工程课程设计科目VC++程序课程设计学生姓名:指导教师:完成时间:2010年9月-11月解骑士巡游问题一、设计任务与目标国际象棋中马采用“日”字走法,对棋盘上马所在的结点,一步内到达的结点最多有八个,即假设马所在点的坐标为(i,j),那么其它八个结点的坐标为(i+1,j+2),(i+2,j+1),(i+2,j-1),(i+1,j-2),(i-1,j-2),(i-2,j-1),(i-2,j+1),(i-1,j+2)把这些点看作马所在点的邻接点,所以可以采用类似图的深度优先遍历,以马所在点为初始点对整个棋盘进行遍历。
然后按遍历的顺序输出结点棋盘的规格限制为8*8,输入数据为起始点的位置(0-7)。
输出数据为可以遍历成功的若干方案(本程序设置为至多八种)。
二、方案设计与论证解决马的遍历问题,可以用一个二维数组board[][]来表示棋盘,一开始用来存放步骤号,若走过了则把它赋值为1。
另对马的8种可能走法设定一个顺序,如当前位置在棋盘的(i,j)方格,下一个可能的位置依次为(i+2,j+1)、(i+1,j+2)、(i-1,j+2)、(i-2,j+1)、(i-2,j-1)、(i-1,j-2)、(i+1,j-2)、(i+2,j-1),实际可以走的位置尽限于还未走过的和不越出边界的那些位置。
为便于程序的同意处理,可以引入两个数组mover[]、movec[],分别存储各种可能走法对当前位置的纵横增量。
整形变量step存放步骤号,start存放遍历次数,在numable函数和number函数中的语句k=(i+start)%N;中是用于定位,保证不会超过棋盘范围和八次遍历都不会走同样的路径test 存放遍历成功次数。
在8×8方格的棋盘上,从任意指定的方格出发,为马寻找一条走遍棋盘每一格并且只经过一次的一条路径。
程序框图或流程图,程序清单与调用关系调用函数调用关系 2.重要模块(next否图2.2 流程图三、全部源程序清单#include<iostream.h>#include<iomanip.h>#include<stdlib.h>#define N 8//棋盘行列数#define INF 9999999int mover[]={-2,-1,1,2,2,1,-1,-2};//用来表示要走向该i行,需要移动的格子数int movec[]={1,2,2,1,-1,-2,-2,-1};//用来表示要走向该j列,需要移动的格子数class qi{private :int board[N+1][N+1];//用于保存走的次序int start;//测试次数int ber,bec;//用于保存输入(初始)的行列int step;//走的步数int test;//可以遍历成功的次数int r,c;//当前行列值int i,j;//循环变量int k;//下次可以查找的增量的个数public :qi();qi(int a,int b);int next(int r, int c);int numable(int r,int c,int nexta[]);//返回下次可以查找的增量int number(int r,int c);//返回下次可以查找的增量的个数bool begin(int a,int b);void set(int a,int b);};qi::qi(int a,int b){ber=a;。
算法分析-马的hamilton周游路线问题-实验报告
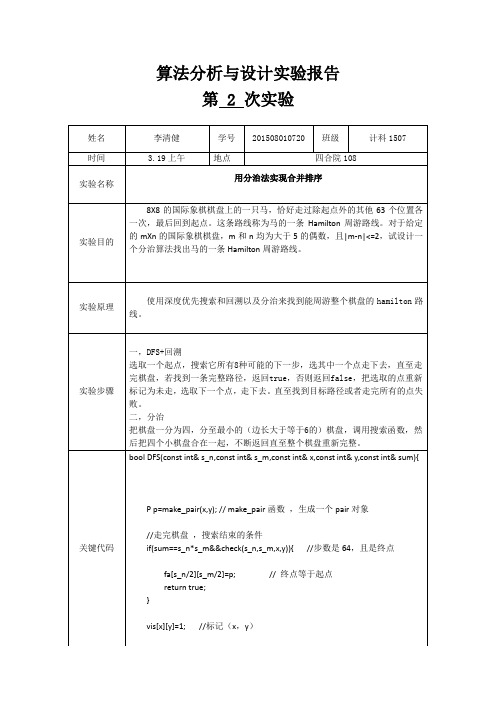
把棋盘一分为四,分至最小的(边长大于等于6的)棋盘,调用搜索函数,然后把四个小棋盘合在一起,不断返回直至整个棋盘重新完整。
关键代码
bool DFS(const int& s_n,const int& s_m,const int& x,const int& y,const int& sum){
if(judgey(s_x+midn-2,i,Map[s_x+midn-2][i].first,Map[s_x+midn-2][i].second,midn,midmm)) {ans++;break;}
}
}
测试结果
实验心得
马的hamilton周游路线问题,是一道很复杂的题目,运用到了图的数据结构,使用深度优先搜索来搜索马的路径。还要使用分治把棋盘分为小棋盘。
//如果找到了正确的路径就true,没有就继续弹出下一个点 ,
while(!q.empty()){
int nx=q.top().x,ny=q.top().y;
q.pop();
fa[nx][ny]=p; // 把p存入fa【】【】
if(DFS(s_n,s_m,nx,ny,sum+1))
return true;
//若此棋盘已经被记录,直接复制不需要重新DFS
if(!seted[s_n][s_m]){
memset(seted,0,sizeof(seted));
memset(vis,0,sizeof(vis));
DFS(s_n,s_m,s_n/2,s_m/2,1);
seted[s_n][s_m]=1;
}
copy(s_x,s_y,s_n,s_m);
马品种的识别实验报告

马品种的识别实验报告实验目的:本实验旨在通过观察和分析马的外貌特征以及主要品种的区别,实现对马品种的准确识别。
实验步骤:1.收集马的样本照片和相关资料;2.选取具有代表性和典型性的马的特征进行观察和记录;3.根据马的颜色、体型、体毛等特征,将样本照片进行分类;4.对每个品种的马的特征进行比较和分析;5.结果记录和总结。
实验结果:经过观察和分析,我们发现马的品种可以根据其颜色、体型和体毛等特征进行准确识别。
主要的马品种包括汗血宝马、花色马、游戏马和体型较小的迷你马等。
1.汗血宝马:这是一种体型较大的马,以其优雅的身姿和灵活的动作而闻名。
它们的体毛通常为纯黑色或纯白色,四肢粗壮,背脊平直。
其特点是颈部较长而修长,眼睛大而明亮。
2.花色马:花色马的外观特征非常个性化和多样化。
它们的体毛可以呈现出各种颜色和斑纹,如黑白相间、棕白相间等。
与其他品种相比,花色马的体型较小,腿部相对细长,尾巴一般呈长而浓密的造型。
3.游戏马:游戏马以其运动和竞技能力而著名。
它们的体型中等,四肢修长而有力,背脊呈弧形。
游戏马的体毛颜色较为丰富,主要有黑色、棕色和灰色等。
与其他品种相比,游戏马的颈部较短而粗壮,背部有明显的肌肉线条。
4.迷你马:迷你马是一种体型较小的马,通常被作为马术比赛中的宠物使用。
它们的体毛颜色多样,包括黑色、棕色、白色等。
迷你马的眼睛大而圆,腿部短且修长,尾巴细长而浓密。
实验结论:通过对马的外貌特征的观察和比较,我们可以准确识别不同品种的马。
汗血宝马、花色马、游戏马和迷你马在体型、颜色、体毛等方面存在明显差异,这些特征能够帮助我们进行马品种的准确识别。
本实验对马的识别和分类有重要意义,对于马术比赛、畜牧业和动物保护等领域具有实际应用价值。
我们深入研究马的外貌特征和品种分类的研究,可以更好地了解和保护这一美丽的动物资源。
解剖马实验报告

一、实验目的1. 了解马的外部形态和解剖结构;2. 掌握马的骨骼、肌肉、血管、神经和内脏等系统的解剖知识;3. 提高动物解剖实践能力。
二、实验原理动物解剖学是研究动物体内各器官系统的形态、结构和功能的一门学科。
通过对马的解剖,可以了解马的外部形态和解剖结构,掌握马的骨骼、肌肉、血管、神经和内脏等系统的解剖知识。
三、实验用品1. 马尸体一具;2. 解剖器械:解剖刀、剪刀、镊子、解剖剪、解剖针、解剖尺等;3. 实验台、解剖镜、解剖图等。
四、实验步骤1. 骨骼系统解剖(1)观察马的骨骼系统,包括头骨、脊柱、胸骨、肋骨、骨盆、四肢骨等。
(2)使用解剖刀和剪刀,逐层分离骨骼与软组织,观察骨骼的形态、大小、连接方式等。
(3)重点观察骨骼的关节、椎骨、颅骨等部位。
2. 肌肉系统解剖(1)观察马的肌肉系统,包括头部、颈部、躯干、四肢等部位的肌肉。
(2)使用解剖刀和剪刀,逐层分离肌肉与软组织,观察肌肉的形态、起止点、作用等。
(3)重点观察马的股四头肌、臀大肌、背阔肌、胸大肌等主要肌肉。
3. 血管系统解剖(1)观察马的血管系统,包括动脉、静脉和毛细血管。
(2)使用解剖刀和剪刀,逐层分离血管与软组织,观察血管的形态、走向、分支等。
(3)重点观察马的颈动脉、股动脉、颈静脉、股静脉等主要血管。
4. 神经系统解剖(1)观察马的神经系统,包括脑、脊髓、神经等。
(2)使用解剖刀和剪刀,逐层分离神经与软组织,观察神经的形态、走向、分支等。
(3)重点观察马的脑、脊髓、颈神经、坐骨神经等主要神经。
5. 内脏系统解剖(1)观察马的内脏系统,包括心脏、肺、肝、脾、胃、肠、肾等。
(2)使用解剖刀和剪刀,逐层分离内脏与软组织,观察内脏的形态、大小、功能等。
(3)重点观察心脏、肺、肝、胃、肠、肾等主要内脏器官。
五、实验结果与分析1. 骨骼系统:马的骨骼系统具有典型的哺乳动物特征,骨骼结构完整,关节连接紧密,为马的运动提供了良好的基础。
2. 肌肉系统:马的肌肉系统发达,主要肌肉具有强大的收缩力,为马的运动提供了动力。
图的遍历操作实验报告

实验三、图的遍历操作一、目的掌握有向图和无向图的概念;掌握邻接矩阵和邻接链表建立图的存储结构;掌握DFS及BFS对图的遍历操作;了解图结构在人工智能、工程等领域的广泛应用。
二、要求采用邻接矩阵和邻接链表作为图的存储结构,完成有向图和无向图的DFS 和BFS操作。
三、DFS和BFS 的基本思想深度优先搜索法DFS的基本思想:从图G中某个顶点Vo出发,首先访问Vo,然后选择一个与Vo相邻且没被访问过的顶点Vi访问,再从Vi出发选择一个与Vi相邻且没被访问过的顶点Vj访问,……依次继续。
如果当前被访问过的顶点的所有邻接顶点都已被访问,则回退到已被访问的顶点序列中最后一个拥有未被访问的相邻顶点的顶点W,从W出发按同样方法向前遍历。
直到图中所有的顶点都被访问。
广度优先算法BFS的基本思想:从图G中某个顶点Vo出发,首先访问Vo,然后访问与Vo相邻的所有未被访问过的顶点V1,V2,……,Vt;再依次访问与V1,V2,……,Vt相邻的起且未被访问过的的所有顶点。
如此继续,直到访问完图中的所有顶点。
四、示例程序1.邻接矩阵作为存储结构的程序示例#include"stdio.h"#include"stdlib.h"#define MaxVertexNum 100 //定义最大顶点数typedef struct{char vexs[MaxVertexNum]; //顶点表int edges[MaxVertexNum][MaxVertexNum]; //邻接矩阵,可看作边表 int n,e; //图中的顶点数n和边数e}MGraph; //用邻接矩阵表示的图的类型//=========建立邻接矩阵=======void CreatMGraph(MGraph *G){int i,j,k;char a;printf("Input VertexNum(n) and EdgesNum(e): ");scanf("%d,%d",&G->n,&G->e); //输入顶点数和边数scanf("%c",&a);printf("Input Vertex string:");for(i=0;i<G->n;i++){scanf("%c",&a);G->vexs[i]=a; //读入顶点信息,建立顶点表}for(i=0;i<G->n;i++)for(j=0;j<G->n;j++)G->edges[i][j]=0; //初始化邻接矩阵printf("Input edges,Creat Adjacency Matrix\n");for(k=0;k<G->e;k++) { //读入e条边,建立邻接矩阵 scanf("%d%d",&i,&j); //输入边(Vi,Vj)的顶点序号G->edges[i][j]=1;G->edges[j][i]=1; //若为无向图,矩阵为对称矩阵;若建立有向图,去掉该条语句}}//=========定义标志向量,为全局变量=======typedef enum{FALSE,TRUE} Boolean;Boolean visited[MaxVertexNum];//========DFS:深度优先遍历的递归算法======void DFSM(MGraph *G,int i){ //以Vi为出发点对邻接矩阵表示的图G进行DFS搜索,邻接矩阵是0,1矩阵 int j;printf("%c",G->vexs[i]); //访问顶点Vivisited[i]=TRUE; //置已访问标志for(j=0;j<G->n;j++) //依次搜索Vi的邻接点if(G->edges[i][j]==1 && ! visited[j])DFSM(G,j); //(Vi,Vj)∈E,且Vj未访问过,故Vj 为新出发点}void DFS(MGraph *G){int i;for(i=0;i<G->n;i++)visited[i]=FALSE; //标志向量初始化for(i=0;i<G->n;i++)if(!visited[i]) //Vi未访问过DFSM(G,i); //以Vi为源点开始DFS搜索}//===========BFS:广度优先遍历=======void BFS(MGraph *G,int k){ //以Vk为源点对用邻接矩阵表示的图G进行广度优先搜索 int i,j,f=0,r=0;int cq[MaxVertexNum]; //定义队列for(i=0;i<G->n;i++)visited[i]=FALSE; //标志向量初始化for(i=0;i<G->n;i++)cq[i]=-1; //队列初始化printf("%c",G->vexs[k]); //访问源点Vkvisited[k]=TRUE;cq[r]=k; //Vk已访问,将其入队。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
马的遍历问题实验报告学院:信科院班级:2009级计本一班姓名:赵冲指导老师:廖凯贤设计时间:2011—12—01马的遍历问题1.问题描述:在中国象棋(10*9)和国际象棋(8*8)的棋盘的任意位置上放一个马,然后按照“马走日”的走法,在没有蹩马脚的限制下,选择一个合适的路线,使得棋子能够不重复的走完棋盘上的每一步。
试设计这样一个算法,能够实现这样的功能,并且能够打印出走过的正确路径。
2.编码实现:#include<stdio.h>#include<stdlib.h>int chessboard[14][13];//棋盘int CanPass[14][13][8];//每个棋子的八个方向哪些可以走typedef struct{//棋盘的八个方向int y,x;}direction;direction dir[8]={{2,1},{1,2},{-1,2},{-2,1},{-2,-1},{-1,-2},{1,-2},{2,-1}};//八个方向//栈的设计typedef struct{int x,y;//走过位置int di;//方向}pathnode;typedef struct{pathnode pa[90];int top;}path;//顺序栈void Init_Path(path *p){//初始化栈p->top=-1;}int Push_Path(path *p,pathnode t,int v) {//压节点及其向下一位移动的方向入栈if(p->top>=63+26*v)return -1;else{p->top++;p->pa[p->top].x=t.x;p->pa[p->top].y=t.y;p->pa[p->top].di=t.di;return 1;}}int Empty(path p){//判断栈是否为空if(p.top<0) return 1;return 0;}int Pop_Path(path *p,pathnode *t){//出栈if(Empty(*p))return -1;else{t->x=p->pa[p->top].x;t->y=p->pa[p->top].y;t->di=p->pa[p->top--].di;return 1;}}int Count(int x,int y){//计算每个节点周围有几个方向可以走int count=0,i=0;for(i=0;i<8;i++)if(chessboard[x+1+dir[i].x][y+1+dir[i].y]==0)count++;return count;}int Find_Direction(int x,int y){//寻找下一个方向int dire,min=9,count,d=9;for(dire=0;dire<8;dire++){if(chessboard[x+1+dir[dire].x][y+1+dir[dire].y]==0&& CanPass[x+1][y+1][dire]==0){count=Count(x+dir[dire].x,y+dir[dire].y);if(min>count){min=count;d=dire;}}}if(d<9)return d;elsereturn -1;}void Knight(int x,int y,int v)//x,y表示出发位置{//骑士遍历函数int num=1,t,i;path p;pathnode f;Init_Path(&p);for(num=1;num<=64+26*v;num++){t=Find_Direction(x,y);if(t!=-1){//正常找到下一个方向的情况下chessboard[x+1][y+1]=num;f.x=x;f.y=y;f.di=t;Push_Path(&p,f,v);x=x+dir[t].x;y=y+dir[t].y;}else if(num==64+26*v&&chessboard[x+1][y+1]==0){//最后一次时t肯定是-1chessboard[x+1][y+1]=num;f.x=x;f.y=y;f.di=t;Push_Path(&p,f,v);}else{if(Pop_Path(&p,&f)==-1){//出栈且栈为空的情况printf("!!!!!!!!!!!!无法为您找到一条适合的路径!!!!!!!!!!!!\n");exit(0);}num-=2;x=f.x;y=f.y;CanPass[x+1][y+1][f.di]=1;}//end else}//根据栈中信息打印出骑士行走路径printf("骑士巡游路径如下:\n ");for(i=0;i<64+26*v;i++){printf("(%2d,%d)->",p.pa[i].x,p.pa[i].y);if((i+1)%(8+v)==0)printf("\b\b \n->");}printf("\b\b \n");printf("根据数组打印结果是:\n");for(i=0;i<8+2*v;i++){//根据棋盘数组来打印for(t=0;t<8+v;t++)printf("%4d",chessboard[i+2][t+2]);printf("\n");}}void Mark_Dir(int v){//由于三维数组赋初值比较困难,因而采用单独的函数实现int i,j,k;for(i=0;i<12+2*v;i++)for(j=0;j<12+v;j++)for(k=0;k<8;k++)CanPass[i][j][k]=0;}void Mark_Che(int v){//标志棋盘函数int i,j;for(i=0;i<12+2*v;i++)//首先全部标记为0for(j=0;j<12+v;j++)chessboard[i][j]=0;for(i=0;i<2;i++)//前面两行标记为1for(j=0;j<12+v;j++)chessboard[i][j]=1;for(j=0;j<2;j++)//前面两列for(i=0;i<12+2*v;i++)chessboard[i][j]=1;for(j=10+v;j<12+v;j++)//后面两列for(i=0;i<12+2*v;i++)chessboard[i][j]=1;for(i=10+2*v;i<12+2*v;i++)for(j=0;j<12+v;j++)//后面两行chessboard[i][j]=1;}void main(){//主函数int x,y,v;char ch='y';while(ch=='y'){ while(1){printf(" *************************************\n");printf(" 2009级计本一班赵冲\n");printf(" *************************************\n");printf(" <版权所有,翻版必究>\n");printf("请选择棋盘类型(0:国际象棋,1:中国象棋):");scanf("%d",&v);if(v!=1&&v!=0)printf("输入错误,请重新输入!\n");elsebreak;}Mark_Che(v);Mark_Dir(v);while(1){printf("请输入入口点横坐标:");scanf("%d",&x);if(x<1||x>8+2*v)printf("输入错误,请重新输入!(横坐标在1-%d之间)\n",8+2*v);elsebreak;}while(1){printf("请输入入口点纵坐标:");scanf("%d",&y);if(y<1||y>8+v)printf("输入错误,请重新输入!(纵坐标在1-%d之间)\n",8+v);elsebreak;}Knight(x,y,v);printf("继续(是:y;否:其他):");fflush(stdin);scanf("%c",&ch);}}3.运行和测试:程序运行开始时,提示用户输入棋盘类型:运行结果如下图示:.实验总结:从这次的上机实践中,我体会到上机的重要性。
编写程序,离不开上机,一段不懂的代码只有经过反复的研读与调试,最终变成自己的代码。
对于接下来的路程,脚踏实地,勤奋努力比什么都重要;代码是枯燥的,但不枯燥的是学习的过程,难得的是学习过程中体会的快乐,有目标的学习与坚持,生活才会更加美好!。