多个样本率地卡方检验及两两比较 之 spss 超简单
用SPSS进行不同变量多组间两两比较卡方检验.pdf
用SPSS进行变量多组之间两两比较卡方检验福建省教育科学研究所林斯坦用SPSS进行不同变量的卡方检验中,如果检验后多组间有显著性差异,说明观察指标在各组之间不完全相同,这时要知道到底是哪两组或哪几组有差异,就需要进行两两比较,但遗憾的是,SPSS未提供卡方检验的多组之间的两两检验的直接方案。
网络上很多人讨论,但均没有简便可行的办法,有人提出用卡方分割法(partitions of X2method),或者用Scheffe'可信区间法和SNK法等等,比较复杂。
现将一种比较简单的,可直接在SPSS中进行两两比较的方法举例如下。
例:您是否赞成教师聘任实行“双向选择”?(单选)1.赞成;2.不赞成为了解乡镇、县城和城市中不同教师对这个问题的看法是否有实质性的不同,则需先进行整体性的卡方检验。
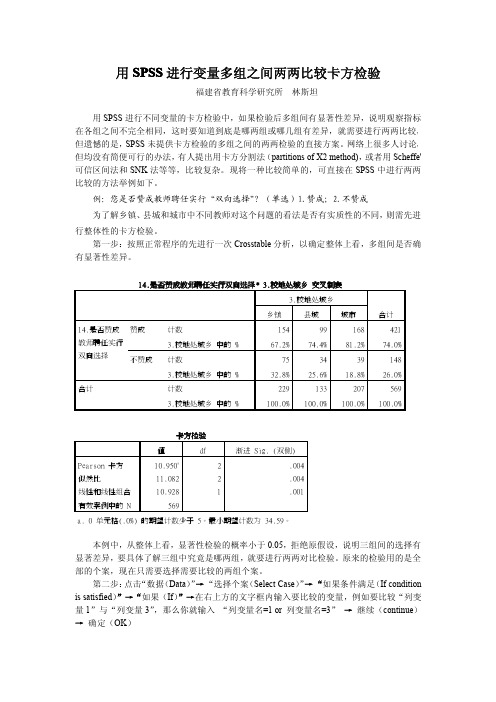
第一步:按照正常程序的先进行一次Crosstable分析,以确定整体上看,多组间是否确有显著性差异。
本例中,从整体上看,显著性检验的概率小于0.05,拒绝原假设,说明三组间的选择有显著差异,要具体了解三组中究竟是哪两组,就要进行两两对比检验。
原来的检验用的是全部的个案,现在只需要选择需要比较的两组个案。
第二步:点击“数据(Data)”→“选择个案(Select Case)”→“如果条件满足(If condition is satisfied)”→“如果(If)”→在右上方的文字框内输入要比较的变量,例如要比较“列变量1”与“列变量3”,那么你就输入“列变量名=1or列变量名=3”→继续(continue)→确定(OK)第三步:按照常规做交叉表(Crosstable)检验,此刻得到的是1与3比较的结果成所有想比较的三组数据。
最后,要对多重比较的概率和与对照比较的概率进行比较,以判断是否有差异性。
有人认为,如果进行两两比较的话,应该结合联合概率进行分割,一般应降低检验水准,若总共要比较3次,就把检验水准降低为0.05/3,即0.017,而不是原来的0.05,卡方分量的个数最多也不得超过总卡方的自由度。
多个样本率的卡方检验及两两比较 之 spss 超简单

多个样本率的卡方检验及两两比较之s p s s超简单(总22页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--SPSS:多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS 教程”,小伙伴们都掌握了吗如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
用SPSS进行不同变量多组间两两比较卡方检验

用SPSS进行不同变量多组间两两比较卡方检验在使用SPSS进行不同变量多组间两两比较卡方检验时,我们可以按照以下步骤进行操作:一、实验设计在进行卡方检验之前,需要明确变量的分类和分组情况。
假设我们有一个调查数据集,其中包含一个自变量(X)和一个因变量(Y),分别有三个水平(A、B、C)和四个水平(D、E、F、G)。
我们的目标是检验自变量(X)的不同水平对因变量(Y)的影响是否显著。
二、导入数据将收集到的数据导入SPSS软件。
确保数据格式正确,变量的水平设置正确。
三、设置分析参数在SPSS的菜单栏选择“分析(Analyze)” - “描述统计(Descriptive Statistics)” - “交叉表(Crosstabs)”。
四、选择变量在交叉表对话框中,将因变量(Y)拖入“行”框中,自变量(X)拖入“列”框中。
点击“统计”按钮。
五、设置统计参数在统计对话框中,选择需要计算的统计量。
在这里,我们需要进行卡方检验,因此选择“卡方(Chi-square)”选项。
点击“继续”按钮。
六、进行卡方检验点击“OK”按钮,SPSS将生成卡方检验结果表格。
此表格显示了各个变量水平之间的卡方值、自由度和显著性水平。
七、结果解读根据卡方检验结果表格,我们可以判断各个变量水平之间的差异是否显著。
卡方值越大,说明差异越显著;相应地,显著性水平(p-value)越小,说明差异越显著。
如果p-value小于设定的显著性水平(通常为0.05),则可以拒绝原假设,即认为变量之间存在显著差异。
八、结果报告根据卡方检验结果生成一个简明的报告。
报告应包括所使用的统计方法,统计检验结果和结论。
可以用表格或图表展示数据,以便更直观地描述结果。
以上是使用SPSS进行不同变量多组间两两比较卡方检验的步骤。
通过这些步骤,我们可以得出结论,确定各个变量水平之间是否存在显著差异。
这为我们研究相关问题提供了可靠的数据支持。
多个样本率的卡方检验及两两比较 之 spss 超简单

SPSS:多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢?3、思维导图4、SPSS操作4.1 数据加权在进行正式操作之前,我们需要先对数据加权,如下:(1)在主页面点击Data→Weight Cases弹出下图:(2)点击Weight cases by,激活Frequency Variable窗口(3)将freq变量放入Frequency Variable栏(4)点击OK4.2 检验假设5数据加权之后,我们要判断研究数据是否满足样本量要求,如下:(1)在主页面点击Analyze→Descriptive Statistics→Crosstabs弹出下图:(2)将变量intervention和risk_level分别放入Row(s)栏和Column(s)栏(3)点击Statistics,弹出下图:(4)点击Chi-square(6)点击Counts栏中的Expected选项经上述操作,SPSS输出预期频数结果如下:该表显示,本研究最小的预测频数是24.7,大于5,满足假设5,具有足够的样本量。
多个样本率的卡方检验及两两比较之spss超简单

:多个样本率的卡方检验及两两比拟来自:医咖会医咖会之前推送过“两个率的比拟(卡方检验)及准确检验的教程〞,小伙伴们都掌握了吗?如果不止两个分组,又该如何进展卡方检验以及之后的两两比拟呢?来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者承受的干预方法〔〕和试验完毕时胆固醇的风险程度〔〕等变量信息,并按照分类汇总整理,局部数据如下:注释:本研究将胆固醇浓度分为“高〞和“正常〞两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比拟各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验完毕时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组〔>2个〕,如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回忆性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进展卡方检验(2×C)呢?3、思维导图4、操作4.1 数据加权在进展正式操作之前,我们需要先对数据加权,如下:(1)在主页面点击→弹出下列图:(2)点击,激活窗口(3)将变量放入栏(4)点击4.2 检验假设5数据加权之后,我们要判断研究数据是否满足样本量要求,如下:(1)在主页面点击→→弹出下列图:(2)将变量和分别放入(s)栏和(s)栏(3)点击,弹出下列图:(4)点击(5)点击→(6)点击栏中的选项(7)点击→经上述操作,输出预期频数结果如下:该表显示,本研究最小的预测频数是,大于5,满足假设5,具有足够的样本量。
多个样本率的卡方检验及两两比较之spss超简单

多个样本率的卡方检验及两两比较之s p s s超简单Document number【SA80SAB-SAA9SYT-SAATC-SA6UT-SA18】S P S S:多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
SPSS如何实现多个样本率多重比较

SPSS实现多组率的两两比较多组率的比较是在医学研究中常常会遇到的问题,其通常被列为R×2表进行χ2检验,其结果仅能说明多个率间的差别有统计学意义,并不能对两两之间差别做出检验。
而将其分割成2 ×2表虽可行两两比较,但不宜用独立四格表的显著界值。
针对这个问题,本文就如何使用国际通用SPSS软件实现该方法,给出具体解决方案。
如图1一组病例资料。
拟对上述资料进行统计分析。
将上述资料按图2进行SPSS录入。
要求:将各组按观察率从小到大排列,本例有效率恰好已是升序排列,故无需再排序。
经过交叉表对三组资料进行卡方检验后,具有统计学意义。
下一步进行两两比较。
操作步骤①权变量:由于“数据”变量中数据并非真正的每条记录数据,而是频数资料,所以要加权,其步骤如下:Data→Weight Case→选择⊙weight case by单选按钮→将“数据”变量添加到Frequency Variable框内→OK。
②选择记录:根据杜养志法,需分别将G1组与第Gi ( i = 2, 3, ⋯⋯k)组进行非独立2 ×2表,步骤如下:Data→Select Case→选择⊙If condition is satisfied单选按钮→点击其下方的If⋯⋯按钮→在右上方框体内录入引号内的内容:“行变量= 1 or行变量= i”( i根据所比的具体组的序数而定) →continue→OK。
③卡方检验: Analyze →Descrip tive Statisics →Crosstable→将“行变量”放入Row框体中→将“列变量”放入column框体中→Statisics→选择Chi - square→continue→OK。
④重复选择记录步骤,选择新的比较组,再行卡方检验,直到所有组均与G1比较过为止。
经过分析后,得出下图结果。
然后根据下图“杜养志非独立的2 ×2表的χ2 值著界值表”确定界值。
多个样本率地卡方检验及两两比较之spss超简单

SPSS 多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过“两个率的比较(卡方检验)及Fisher 精确检验的SPSS 教程”,小伙 伴们都掌握了吗?如果不止两个分组, 又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度, 少体重及改善饮食习惯等。
该医生招募了 150位高胆固醇、生活习惯差的受试者, 并将其随机分成 3组。
其中一组 给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过 6个月的试验后,该医 生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention )和试验结束时胆固醇的风险程度(risk_level )等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代 表临床诊断结果。
如增强体育锻炼、减2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验但需要先满足5项假设:饮食和运动(2 X C),假设类变量。
1 :观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设干扰。
3 :具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互4:研究设计必须满足: 假设的人群中随机抽取150位受试者;本研究中将受试者随机分成3组, (a)样本具有代表性,如本研究在高胆固醇、生活习惯差(b)目的分组,可以是前瞻性的,也可以是回顾性的,如分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2 X C) 呢?3、思维导图4、SPSS操作4.1数据加权在进行正式操作之前,我们需要先对数据加权,如下: ⑴ 在主页面点击Data 7 Weight Cases弹出下图:@1 Ooi not wrieight cases O Weight M&es byFll '!!二 I'-' 311^1:-* -----------------------Current Status* Weight cafi&s by fr&q(2) 点击 Weight cases by ,激活 Frequency Variable 窗口吗 Weigiht Cases©0 natweigtit cases.jIBMIBJM IIMJIM MUBJII■ ■ ■ ■ ■ |©(WeiglTl cases byjFrequency Va'rii3 QI e:Current Stains. Weigh! cases Dy fr&q(3) 将 freq 变量放入 Frequency Variable 栏绘 Weight CasesO Do not 術eight cases. @ Weight cases by■ Requancy Variabls-Current Status: Weiont cases Dy ITeqif ---------- ' ----------- 1 (— f[Paste J J [Cane 巳I HelpWeight CasesR&set CancelHelpIgjjj interventfcridi risfcjeveiOKPaste 11 ResetCancel HelpR intervention cjj TisKJ 列创炉 freq诳)intE“erition d riskjevelOK(4)点击OK 4.2检验假设5数据加权之后,我们要判断研究数据是否满足样本量要求,如下:(1) 在主页面点击Analyze f Descriptive Statistics 弹出下图: T Crosstabs駅Crosstabs□Difiplav dusiered parcharts□Suppress tablesX匕]Fj兰Reset I Cancel Help(2)将变量intervention 和risk_level 分别放入Row(s)栏和Column(s)栏呛Crosstabs-Layer 1 of1□Display clustered bar charts□Suppress ta&lesROMS'):Exact...■「isK_lev&lStatistics... 1CeIJs. 11 JColumn(sJ< Form at...|intervention鼬底“ 1XC - [L I-J; lj;r Jl -J |rj _-| ■_■_ f I T J - IOK ]J'Paste Ke set Cancel* IHelp(3)点击Statistics ,弹出下图: Crosstabs: Statist!cs□ iChi-square■ ■ - n [ IT ■-nilin-iniii i —ii—■■■■! □Correlations r Nominal rOrdinaln Continig,en cy coeUcienitI'【Phi and Cramer's V二 LambdaC Uncertainty coefFicient 匚I GaTTiirnaLJ Somers' d□ Kendalls iau*b □ Kendall's tau< Nominal Dy Interval□ .Eta □ !<appa□ Risk □ McWernar I ' I Cghr ■即‘5 and Maitel -Haenszel st 苹ti 了tiosJIl iii_ - d I ,1-1] - Continue] Canc&l | [ H&lp(4)点击 Chi-square © Crosstabs: Statist!C5 ■ ■ ■ ■ ■ ■ ■ ■ ■ ■H ■ ■ ■ ■ ■ H ■ ■ ■ ■ HB ■ H ■ ■ HHiChi-square!• r•.. ■■■■ —ni——p■■■ i —nIL ■■■ •・o ・r'i □Correlations r Nominal rOrdifia l□ ContingencycoefficientLJ Phi and Cramers V □ Lamnda □ Uncert^inbr coefficient !?_. Garnrnai' Somers' d■ ----r Kendalls lau*b C Kendall's tau-c Nomiinal by Interval □ Eta□ Kappa □ RiskWcNemarL I Cochran's and Mantel-Haenszel statistics IIill[Centinue] Cancel ]Help(5)点击 Continue CellsC ounts ------------ ■ 11 ■― ■ 111 l-ni ll^^lll I —II ■IIFT1II閘也 tJSEFVEd\■ • • • — H ■ ■ ■ H ■ . . . —H ■ ■ XD ^peeled□ Hide small countsLess than 匸□Unsta ndardi 军匸I □Standard'ilzed □Adjusted standardized■Noninteger Wsi ght s -------------- -@ Round cell counts O Round case weights O Truncate c&y 匚ounts O Truncale ca&e weights O No adjustments「P &rcentages rResidualsContinue Cancel HElp(6)点击Counts栏中的Expected 选项 -Z'test'n Compare column proportions0 -C. IJ'^I |A 孙三 II-H :l I 1□ gciw □ Column □ lolal(1)⑺点击Continue OK经上述操作,SPSS输出预期频数结果如下:Level of cholesterol risk: "High" & "Normal*'* Type of intervention: "Drug'",'■Diet'* 5. "EKGrcisG" CrosstabulationEKpectedl CountType ofintervenlion: "Drug", “Di或’& "ExerdsG"该表显示,本研究最小的预测频数是24.7,大于5,满足假设5,具有足够的样本量。
多个样本率间的两两比较方法

多个样本率间的两两比较方法
你想啊,有时候我们会遇到好几个不同的样本,每个样本都有自己的率,那怎么知道这些样本率之间到底有没有差别呢?这就需要两两比较啦。
一种常见的方法就是卡方分割法。
这个方法就像是把一块大蛋糕(总的卡方值)按照一定的规则切成小块(每个两两比较的部分)。
它的原理呢,就是根据总的自由度,合理地分配给每个两两比较的部分。
不过这里面有个小讲究哦,要注意调整检验水准,不然就容易出错啦。
就像我们分蛋糕的时候,如果不小心分错了,那每个人吃到的量就不对了。
还有一种Bonferroni法。
这个方法就比较简单粗暴啦,它是直接把总的检验水准除以两两比较的次数。
比如说,我们要做3次两两比较,那每个比较的检验水准就会比原来的小很多。
这就好比是我们有一笔钱(总的检验水准),要分给好几个地方(两两比较),那每个地方能拿到的就少了。
但是这种方法有时候会过于保守,可能会错过一些实际上有差异的情况。
另外呢,还有Sidak法。
它和Bonferroni法有点像,但是又稍微有点不同。
它在计算的时候会更精确一点,就像是在计算分配东西的时候,考虑得更细致一些。
这些方法在不同的情况下都有自己的用处。
比如说,如果样本量比较小的时候,可能某种方法就更合适;如果我们想要更保守一点,不轻易得出有差异的结论,那又可以选择另外一种方法。
多个样本率的卡方检验与两两比较之spss超简单(2020年整理).pptx

(1)
弹出下图:学海Βιβλιοθήκη 涯(2)学海无 涯
(3)
(4)
学海无 涯
(5) 点击Percentage 栏中的Column 选项
(6) 4.4 组间比较 (1)
学海无 涯
弹出下图:
学海无 涯
(2) 点击Cells,弹出下图:
学海无 涯
(3) 点击 z-test 栏中的 Compare column proportions 和 Adjust p-values (Bonferroni method)选项
学海无 涯
注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临 床诊断结果。
2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动 干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2×C), 但需要先满足 5 项假设: 假设 1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分 类变量。 假设 2:存在多个分组(>2 个),如本研究有 3 个不同的干预组。
学海无 涯
弹出下图:
学海无 涯
(2) 将变量 intervention 和 risk_level 分别放入 Row(s)栏和 Column(s)栏
学海无 涯
(3) 点击 Statistics,弹出下图:
(4) 点击Chi-square
学海无 涯
(5) 点击Continue→Cells
学海无 涯
即在本研究中,没有小于 5 的预测频数,可以直接进行卡方检验(2×C)。那么,如果存 在预测频数小于 5 的情况,我们应该怎么办呢?一般来说,如果预测频数小于 5,就需要进 行 Fisher 精确检验(2×C),我们将在后面推送的内容中向大家详细介绍。
SPSS实现多组率的两两比较

SPSS实现多组率的两两比较SPSS实现多组率的两两比较在医学研究中,多组率的比较是一个常见的问题。
通常,这些比较会被列为R×2表进行χ2检验,但是这种方法只能说明多个率之间的差异具有统计学意义,而不能对两两之间的差异进行检验。
将其分割成2×2表虽然可以进行两两比较,但是不宜使用独立四格表的显著界值。
因此,本文将介绍如何使用国际通用的SPSS软件来解决这个问题。
首先,我们有一组病例资料,如图1所示。
我们需要对这些数据进行统计分析。
根据图2的方式,将这些数据录入SPSS中。
需要注意的是,要将各组按观察率从小到大排列。
在本例中,有效率已经是升序排列,因此无需再排序。
通过交叉表对三组资料进行卡方检验后,发现具有统计学意义。
下一步是进行两两比较。
下面是操作步骤:1.权变量:由于“数据”变量中的数据并非真正的每条记录的数据,而是频数资料,因此需要加权。
具体步骤如下:Data→Weight Case→选择⊙weight case by单选按钮→将“数据”变量添加到Frequency Variable框内→OK。
2.选择记录:根据杜养志法,需要分别将G1组与第Gi ( i = 2.3,⋯⋯k)组进行非独立2 ×2表。
具体步骤如下:Data→Select Case→选择⊙If n is satisfied单选按钮→点击其下方的If⋯⋯按钮→在右上方框体内录入引号内的内容:“行变量= 1 or行变量= i”( i根据所比的具体组的序数而定)→continue→OK。
3.卡方检验:XXX→Descriptive XXX→XXX→将“行变量”放入Row框体中→将“列变量”放入column框体中→Statistics→选择Chi-XXX→continue→OK。
4.重复选择记录步骤,选择新的比较组,再行卡方检验,直到所有组均与G1比较过为止。
经过分析后,得出下图结果。
然后根据下图“XXX非独立的2×2表的χ2值的显著界值表”确定界值。
多个样本率的卡方检验及两两比较 之 spss 超简单教学内容

多个样本率的卡方检验及两两比较之s p s s超简单SPSS:多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢?3、思维导图4、SPSS操作4.1 数据加权在进行正式操作之前,我们需要先对数据加权,如下:(1)在主页面点击Data→Weight Cases弹出下图:(2)点击Weight cases by,激活Frequency Variable窗口(3)将freq变量放入Frequency Variable栏(4)点击OK4.2 检验假设5数据加权之后,我们要判断研究数据是否满足样本量要求,如下:(1)在主页面点击Analyze→Descriptive Statistics→Crosstabs弹出下图:(2)将变量intervention和risk_level分别放入Row(s)栏和Column(s)栏(3)点击Statistics,弹出下图:(4)点击Chi-square(5)点击Continue→Cells(6)点击Counts栏中的Expected选项(7)点击Continue→OK经上述操作,SPSS输出预期频数结果如下:该表显示,本研究最小的预测频数是24.7,大于5,满足假设5,具有足够的样本量。
如何进行多组卡方检验的两两比较_多组卡方检验spss

用SPSS进行变量多组之间两两比较卡方检验 点击“数据(Data)”→“选择个案(SelectCase)”→“如果条件满足(Ifconditionissatisfied)”→“如果(If)”→在右上方的文字框内输入要比较的 变量,例如要比较“列变量1”与“列变量3”,那么你就输入“列变量名=1or列变量名=3”→继续(continue)→确定(OK数据分析培训
请您及时更换请请请您正在使用的模版将于2周后被下线请您及时检验 spss
如何进行多组卡方检验的两两比较_多组卡方检验spss
如有三组数据,组别为A、B、C,先进行三组间的卡方检验,现想对三组间进行两两检验比较,如何进行呢?可否分别对两组进行卡方检 验?会不会降低检验效能呢?
先检验整体,如果整体存在差异不需要, 如过不存在,需要
假设需要,如何进行,是单独进行A与B、A与C、B与C再用卡方检验?还是有一种参数设置,直接得出A、B两组、A、C两组或B、C两组 间检验的卡方统计量和P值?
一个简单但是Conservative的方法是用Bonferroni方法来调整每个检验的检验水平。在这里你要进行两两比较,那么就有3个假设检验需要 进行推断,如果整体的检验水平为alpha的话,每个假设检验的检验水平为alpha/3. 这样做是为了控制第一类错误率。因为如果不调整检验水平 的话,你的检验过程将inflate第一类错误率。
多个样本率的卡方检验及两两比较之spss超简单

多个样本率的卡方检验及两两比较之s p s s超简单文件排版存档编号:[UYTR-OUPT28-KBNTL98-UYNN208]S P S S:多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
多个样本率的卡方检验及两两比较之spss超简单

S P S S:多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢3、思维导图4、SPSS操作数据加权在进行正式操作之前,我们需要先对数据加权,如下:(1)在主页面点击Data→Weight Cases弹出下图:(2)点击Weight cases by,激活Frequency Variable窗口(3)将freq变量放入Frequency Variable栏(4)点击OK检验假设5数据加权之后,我们要判断研究数据是否满足样本量要求,如下:(1)在主页面点击Analyze→Descriptive Statistics→Crosstabs弹出下图:(2)将变量intervention和risk_level分别放入Row(s)栏和Column(s)栏(3)点击Statistics,弹出下图:(4)点击Chi-square(5)点击Continue→Cells(6)点击Counts栏中的Expected选项(7)点击Continue→OK经上述操作,SPSS输出预期频数结果如下:该表显示,本研究最小的预测频数是,大于5,满足假设5,具有足够的样本量。
多个样本率地卡方检验及两两比较 之 spss 超简单

SPSS:多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢?3、思维导图4、SPSS操作4.1 数据加权在进行正式操作之前,我们需要先对数据加权,如下:(1)在主页面点击Data→Weight Cases弹出下图:(2)点击Weight cases by,激活Frequency Variable窗口(3)将freq变量放入Frequency Variable栏(4)点击OK4.2 检验假设5数据加权之后,我们要判断研究数据是否满足样本量要求,如下:(1)在主页面点击Analyze→Descriptive Statistics→Crosstabs弹出下图:(2)将变量intervention和risk_level分别放入Row(s)栏和Column(s)栏(3)点击Statistics,弹出下图:(4)点击Chi-square(5)点击Continue→Cells(6)点击Counts栏中的Expected选项(7)点击Continue→OK经上述操作,SPSS输出预期频数结果如下:该表显示,本研究最小的预测频数是24.7,大于5,满足假设5,具有足够的样本量。
多个样本率的卡方检验及其两两比较之spss超简单

*SPSS :多个样本率的卡方检验及两两比较来自:医咖会医咖会之前推送过 两个率的比较(卡方检验)及Fisher 精确检验的SPSS 教程”小伙 伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来 看详细教程吧!1、问题与数据某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、 减少体重及改善饮食习惯等。
该医生招募了 150位高胆固醇、生活习惯差的受试者,并将其随机分成 3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过 6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention )和试验结束时胆固醇的风险程度(risk_level )等变量信息,并按照分类汇总整理,部分数据如下:[ndividual scores for eoch parrtdp^niTotal count (frequencies)注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2 >C),但需要先满足5项假设:假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组 (>2 个),如本研究有3 个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150 位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3 组,分别给予降胆固醇药物、饮食和运动干预。
用SPSS进行不同变量多组间两两比较卡方检验
用SPSS进行变量多组之间两两比较卡方检验福建省教育科学研究所林斯坦用SPSS进行不同变量的卡方检验中,如果检验后多组间有显著性差异,说明观察指标在各组之间不完全相同,这时要知道到底是哪两组或哪几组有差异,就需要进行两两比较,但遗憾的是,SPSS未提供卡方检验的多组之间的两两检验的直接方案。
网络上很多人讨论,但均没有简便可行的办法,有人提出用卡方分割法(partitions of X2method),或者用Scheffe'可信区间法和SNK法等等,比较复杂。
现将一种比较简单的,可直接在SPSS中进行两两比较的方法举例如下。
例:您是否赞成教师聘任实行“双向选择”?(单选)1.赞成;2.不赞成为了解乡镇、县城和城市中不同教师对这个问题的看法是否有实质性的不同,则需先进行整体性的卡方检验。
第一步:按照正常程序的先进行一次Crosstable分析,以确定整体上看,多组间是否确有显著性差异。
本例中,从整体上看,显著性检验的概率小于0.05,拒绝原假设,说明三组间的选择有显著差异,要具体了解三组中究竟是哪两组,就要进行两两对比检验。
原来的检验用的是全部的个案,现在只需要选择需要比较的两组个案。
第二步:点击“数据(Data)”→“选择个案(Select Case)”→“如果条件满足(If condition is satisfied)”→“如果(If)”→在右上方的文字框内输入要比较的变量,例如要比较“列变量1”与“列变量3”,那么你就输入“列变量名=1or列变量名=3”→继续(continue)→确定(OK)第三步:按照常规做交叉表(Crosstable)检验,此刻得到的是1与3比较的结果成所有想比较的三组数据。
最后,要对多重比较的概率和与对照比较的概率进行比较,以判断是否有差异性。
有人认为,如果进行两两比较的话,应该结合联合概率进行分割,一般应降低检验水准,若总共要比较3次,就把检验水准降低为0.05/3,即0.017,而不是原来的0.05,卡方分量的个数最多也不得超过总卡方的自由度。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS:多个样本率的卡方检验及两两比较来自:医咖会
医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧!
1、问题与数据
某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。
该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。
其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。
经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。
该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:
注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。
2、对问题的分析
研究者想判断干预后多个分组情况的不同。
如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。
针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设:
假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。
假设2:存在多个分组(>2个),如本研究有3个不同的干预组。
假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。
假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。
假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。
经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢?
3、思维导图
4、SPSS操作
4.1 数据加权
在进行正式操作之前,我们需要先对数据加权,如下:(1)在主页面点击Data→Weight Cases
弹出下图:
(2)点击Weight cases by,激活Frequency Variable窗口
(3)将freq变量放入Frequency Variable栏
(4)点击OK
4.2 检验假设5
数据加权之后,我们要判断研究数据是否满足样本量要求,如下:(1)在主页面点击Analyze→Descriptive Statistics→Crosstabs
弹出下图:
(2)将变量intervention和risk_level分别放入Row(s)栏和Column(s)栏
(3)点击Statistics,弹出下图:
(4)点击Chi-square
(5)点击Continue→Cells
(6)点击Counts栏中的Expected选项
(7)点击Continue→OK
经上述操作,SPSS输出预期频数结果如下:
该表显示,本研究最小的预测频数是24.7,大于5,满足假设5,具有足够的样本量。
Chi-Square Tests 表格也对该结果做出提示,如下标注部分:
即在本研究中,没有小于5的预测频数,可以直接进行卡方检验(2×C)。
那么,如果存在预测频数小于5的情况,我们应该怎么办呢?一般来说,如果预测频数小于5,就需要进行Fisher精确检验(2×C),我们将在后面推送的内容中向大家详细介绍。
4.3 卡方检验(2×C)的SPSS操作
(1)
弹出下图:
(2)
(3)
(4)
(5)点击Percentage栏中的Column选项
(6)
4.4 组间比较(1)
弹出下图:
(2)点击Cells,弹出下图:
(3)点击z-test栏中的Compare column proportions和Adjust p-values (Bonferroni method)选项
(4)
5、结果解释
5.1 统计描述
在进行卡方检验(2×C)的结果分析之前,我们需要先对研究数据有个基本的了解。
SPSS 输出结果如下:
该表提示,本研究共有150位受试者,根据干预方式均分为3组。
在试验结束时,药物干预组的50位受试者中有16位胆固醇浓度高,饮食干预组的50位受试者中有28位胆固醇浓度高,而运动干预组的50位受试者中有30位胆固醇浓度高,如下标注部分:
由此可见,药物干预比饮食或运动干预的疗效更好。
同时,该表也提示,药物干预组的50位受试者中有34位胆固醇浓度下降,饮食干预组的50位受试者中有22位胆固醇浓度下降,而运动干预组的50位受试者中只有20位胆固醇浓度下降,如下标注部分:
但是,当各组样本量不同时,频数会误导人们对数据的理解。
因此,我们推荐使用频率来分析结果,如下标注部分:
该表提示,药物干预组的50位受试者中68%胆固醇浓度下降,饮食干预组的50位受试者中44%胆固醇浓度下降,而运动干预组的50位受试者中只有40%胆固醇浓度下降,提示药物干预比饮食和运动干预更有效。
但是这种直接的数据比较可能受到抽样误差的影响,可信性不强,我们还需要进行统计学检验。
5.2 卡方检验(2×C)结果
本研究中任一预测频数均大于5,所以根据Chi-Square Tests表格分析各组的差别。
SPSS输出检验结果如下:
卡方检验(2×C)结果显示χ2=9.175,P = 0.010,说明本研究中各组之间率的差值与0的差异具有统计学意义,提示药物干预与饮食、运动干预在降低受试者胆固醇浓度的作用上存在不同。
如果P>0.05,那么就说明各组之间率的差值与0的差异没有统计学意义,即不认为各组之间存在差异。
5.3 卡方检验(2×C)中的成对比较分析
如果卡方检验(2×C)的P<0.05,说明至少有两组之间的差异存在统计学意义。
SPSS输出的risk_level * intervention Crosstabulation表格通过数字标记提示了两两比较的结果,如下标注部分:
大家可能会注意到,每组数据的标记相同(即上下两行的标记相同),那么我们只要知道组间标记的作用即可。
那么,risk_level * intervention Cross tabulation表格的标记是什么意思呢?第一种情况,各组间无差异,如下:
如上图,各组间标记一致,说明各组之间无差异。
第二种情况,任意两组之间均存在差异,如下:
即每组标记字母均不相同,说明任意两组之间的差异均存在统计学意义。
第三种情况,有些组之间存在差异,而另一些组之间的差异没有统计学意义,如下:
如果任两组之间标记字母相同,说明这两组之间的差异没有统计学意义;如果两组标记字母不同,说明这两组之间的差异存在统计学意义。
根据这一原则,分析本研究结果如下:
该表说明,在本研究中,药物干预的降胆固醇作用(“a”)与饮食干预的降胆固醇作用(“b”)的差异存在统计学意义(P<0.05),药物干预的降胆固醇作用(“a”)也与运动干预的降胆固醇作用(“b”)的差异存在统计学意义(P<0.05),而饮食干预(“b”)与运动干预(“b”)在降胆固醇的作用上没有差异。
6、撰写结论
6.1 若卡方检验(2×C)的P<0.05
本研究招募150位高胆固醇、生活习惯差的受试者,随机分组后分别给予药物、饮食和运动干预。
试验结束时,药物干预组有34位(68%)胆固醇浓度下降,饮食干预组有22位(44%)胆固醇浓度下降,而运动干预组有20位(40%)胆固醇浓度下降,三组差异具有统计学意义(P=0.010)。
成对比较结果提示,药物干预的降胆固醇效果好于饮食或运动干预(P<0.05),而饮食与运动干预在降低胆固醇浓度上的作用无差异(P>0.05)。
6.2 若卡方检验(2×C)的P≥0.05
本研究招募150位高胆固醇、生活习惯差的受试者,随机分组后分别给予药物、饮食和运动干预。
试验结束时,药物干预组有24位(48%)胆固醇浓度下降,饮食干预组有22位(44%)胆固醇浓度下降,而运动干预组有20位(40%)胆固醇浓度下降,三组结果的差异没有统计学意义(P=0.620)。