图论深度优先搜索实验报告
迷宫问题 实验报告

迷宫问题实验报告迷宫问题实验报告引言:迷宫问题一直以来都是计算机科学领域中的研究热点之一。
迷宫是一个具有复杂结构的空间,其中包含了许多死胡同和通道,人们需要找到一条从起点到终点的最短路径。
在这个实验中,我们将通过使用不同的算法和技术来解决迷宫问题,并探讨它们的优缺点。
实验方法:我们首先建立一个虚拟的迷宫模型,使用二维数组来表示。
迷宫包含了墙壁、通道和起点终点。
我们通过设置不同的迷宫大小、起点和终点位置以及障碍物的分布来模拟不同的情况。
1. 广度优先搜索算法:广度优先搜索算法是一种常用的解决迷宫问题的算法。
它从起点开始,逐层地向外扩展搜索,直到找到终点或者遍历完所有的可达点。
在实验中,我们发现广度优先搜索算法能够找到一条最短路径,但是当迷宫规模较大时,算法的时间复杂度会急剧增加,导致搜索时间过长。
2. 深度优先搜索算法:深度优先搜索算法是另一种常用的解决迷宫问题的算法。
它从起点开始,沿着一个方向一直搜索到无法继续前进为止,然后回溯到上一个节点,选择另一个方向进行搜索。
在实验中,我们发现深度优先搜索算法能够快速找到一条路径,但是由于它的搜索策略是“深入优先”,因此无法保证找到的路径是最短路径。
3. A*算法:A*算法是一种启发式搜索算法,它综合了广度优先搜索和深度优先搜索的优点。
在实验中,我们将每个节点的代价定义为从起点到该节点的实际代价和从该节点到终点的预估代价之和。
A*算法通过优先选择代价最小的节点进行搜索,以期望找到一条最短路径。
实验结果表明,A*算法在大多数情况下能够找到最短路径,并且相对于广度优先搜索算法,它的搜索时间更短。
4. 遗传算法:除了传统的搜索算法外,我们还尝试了一种基于进化思想的遗传算法来解决迷宫问题。
遗传算法通过模拟生物进化过程中的选择、交叉和变异等操作来搜索最优解。
在实验中,我们将迷宫路径编码为一个个体,并使用适应度函数来评估每个个体的优劣。
经过多次迭代,遗传算法能够找到一条较优的路径,但是由于算法本身的复杂性,搜索时间较长。
实验四 搜索 实验报告

实验四搜索实验报告一、实验目的本次实验的主要目的是深入了解和掌握不同的搜索算法和技术,通过实际操作和分析,提高对搜索问题的解决能力,以及对搜索效率和效果的评估能力。
二、实验环境本次实验使用的编程语言为 Python,使用的开发工具为 PyCharm。
实验中所需的数据集和相关库函数均从网络上获取和下载。
三、实验原理1、线性搜索线性搜索是一种最简单的搜索算法,它从数据的开头开始,依次比较每个元素,直到找到目标元素或者遍历完整个数据集合。
2、二分搜索二分搜索则是基于有序数组的一种搜索算法。
它每次将数组从中间分割,比较目标值与中间元素的大小,然后在可能包含目标值的那一半数组中继续进行搜索。
3、广度优先搜索广度优先搜索是一种图搜索算法。
它从起始节点开始,逐层地访问相邻节点,先访问距离起始节点近的节点,再访问距离远的节点。
4、深度优先搜索深度优先搜索也是一种图搜索算法,但它沿着一条路径尽可能深地访问节点,直到无法继续,然后回溯并尝试其他路径。
四、实验内容及步骤1、线性搜索实验编写线性搜索函数,接受一个列表和目标值作为参数。
生成一个包含随机数的列表。
调用线性搜索函数,查找特定的目标值,并记录搜索所用的时间。
2、二分搜索实验先对列表进行排序。
编写二分搜索函数。
同样生成随机数列表,查找目标值并记录时间。
3、广度优先搜索实验构建一个简单的图结构。
编写广度优先搜索函数。
设定起始节点和目标节点,进行搜索并记录时间。
与广度优先搜索类似,构建图结构。
编写深度优先搜索函数。
进行搜索并记录时间。
五、实验结果与分析1、线性搜索结果在不同规模的列表中,线性搜索的时间消耗随着列表长度的增加而线性增加。
对于较小规模的列表,线性搜索的效率尚可,但对于大规模列表,其搜索时间明显较长。
2、二分搜索结果二分搜索在有序列表中的搜索效率极高,其时间消耗增长速度远低于线性搜索。
即使对于大规模的有序列表,二分搜索也能在较短的时间内找到目标值。
3、广度优先搜索结果广度优先搜索能够有效地遍历图结构,并找到最短路径(如果存在)。
八数码实验报告

八数码实验报告八数码实验报告引言:八数码,也被称为滑块拼图,是一种经典的益智游戏。
在这个实验中,我们将探索八数码问题的解决方案,并分析其算法的效率和复杂性。
通过这个实验,我们可以深入了解搜索算法在解决问题中的应用,并且探讨不同算法之间的优劣势。
1. 问题描述:八数码问题是一个在3x3的方格上进行的拼图游戏。
方格中有8个方块,分别标有1到8的数字,还有一个空方块。
游戏的目标是通过移动方块,将它们按照从左上角到右下角的顺序排列。
2. 算法一:深度优先搜索(DFS)深度优先搜索是一种经典的搜索算法,它从初始状态开始,不断地向前搜索,直到找到目标状态或者无法继续搜索为止。
在八数码问题中,深度优先搜索会尝试所有可能的移动方式,直到找到解决方案。
然而,深度优先搜索在解决八数码问题时存在一些问题。
由于搜索的深度可能非常大,算法可能会陷入无限循环,或者需要很长时间才能找到解决方案。
因此,在实际应用中,深度优先搜索并不是最优的选择。
3. 算法二:广度优先搜索(BFS)广度优先搜索是另一种常用的搜索算法,它从初始状态开始,逐层地向前搜索,直到找到目标状态。
在八数码问题中,广度优先搜索会先尝试所有可能的一步移动,然后再尝试两步移动,依此类推,直到找到解决方案。
与深度优先搜索相比,广度优先搜索可以保证找到最短路径的解决方案。
然而,广度优先搜索的时间复杂度较高,尤其是在搜索空间较大时。
因此,在实际应用中,广度优先搜索可能不太适合解决八数码问题。
4. 算法三:A*算法A*算法是一种启发式搜索算法,它在搜索过程中利用了问题的启发信息,以提高搜索效率。
在八数码问题中,A*算法会根据每个状态与目标状态之间的差异,选择最有可能的移动方式。
A*算法通过综合考虑每个状态的实际代价和启发式估计值,来评估搜索路径的优劣。
通过选择最优的路径,A*算法可以在较短的时间内找到解决方案。
然而,A*算法的实现较为复杂,需要合适的启发函数和数据结构。
浅谈深度优先搜索算法优化

浅谈深度优先搜索算法优化深度优先算法是一种常用的图算法,其基本思想是从起始节点开始,不断地深入到图的各个分支直到无法继续深入,然后回溯到上一个节点,继续深入其他未探索的分支,直到遍历完整个图。
然而,深度优先算法在应用中可能会面临一些问题,例如空间过大导致的效率低下等。
因此,需要对深度优先算法进行优化。
一种常见的深度优先算法优化方法是剪枝技术。
剪枝是指在过程中对一些节点进行跳过,从而减少空间。
具体来说,可以通过设置一些条件,只符合条件的节点,从而跳过一些不必要的路径。
例如,在解决八皇后问题时,可以设置一些约束条件,如不同行、不同列和不同对角线上不能同时存在两个皇后,然后在过程中只考虑符合条件的节点,这样就能够有效地减少空间,提高效率。
另一种常见的深度优先算法优化方法是使用启发式。
启发式是一种基于问题特征的方法,通过引入评估函数来估计状态的潜在价值,从而指导方向。
启发式在深度优先算法中的应用主要是通过选择有潜在最优解的节点进行,从而减少次数和空间。
例如,在解决旅行商问题时,可以使用贪心算法选择距离当前节点最近的未访问的节点,然后向该节点进行深度,这样就能够更快地找到最优解。
此外,可以通过使用数据结构进行优化。
深度优先算法使用递归的方式进行,但递归在实现上需要使用系统栈,当空间非常大时,会占用大量的内存。
为了解决这个问题,可以使用迭代的方式进行,使用自定义的栈来存储路径。
这样,可以节省内存并提高效率。
另外,也可以使用位运算来替代传统的数组存储状态,从而节省空间。
例如,在解决0-1背包问题时,可以使用一个整数表示当前已经选择了哪些物品,这样就能够大大减小空间,提高效率。
最后,可以通过并行计算来优化深度优先算法。
并行计算是指使用多个处理器或多个线程同时进行计算,从而加快速度。
在深度优先算法中,并行计算可以通过将空间划分为多个子空间,每个子空间由一个处理器或一个线程负责,然后汇总结果,得到最终的解。
这样就能够充分利用计算资源,提高效率。
图的搜索与应用实验报告(附源码)(word文档良心出品)

哈尔滨工业大学计算机科学与技术学院实验报告课程名称:数据结构与算法课程类型:必修实验项目名称:图的搜索与应用实验题目:图的深度和广度搜索与拓扑排序设计成绩报告成绩指导老师一、实验目的1.掌握图的邻接表的存储形式。
2.熟练掌握图的搜索策略,包括深度优先搜索与广度优先搜索算法。
3.掌握有向图的拓扑排序的方法。
二、实验要求及实验环境实验要求:1.以邻接表的形式存储图。
2.给出图的深度优先搜索算法与广度优先搜索算法。
3.应用搜索算法求出有向图的拓扑排序。
实验环境:寝室+机房+编程软件(NetBeans IDE 6.9.1)。
三、设计思想(本程序中的用到的所有数据类型的定义,主程序的流程图及各程序模块之间的调用关系)数据类型定义:template <class T>class Node {//定义边public:int adjvex;//定义顶点所对应的序号Node *next;//指向下一顶点的指针int weight;//边的权重};template <class T>class Vnode {public:T vertex;Node<T> *firstedge;};template <class T>class Algraph {public:Vnode<T> adjlist[Max];int n;int e;int mark[Max];int Indegree[Max];};template<class T>class Function {public://创建有向图邻接表void CreatNalgraph(Algraph<T>*G);//创建无向图邻接表void CreatAlgraph(Algraph<T> *G);//深度优先递归搜索void DFSM(Algraph<T>*G, int i);void DFS(Algraph<T>* G);//广度优先搜索void BFS(Algraph<T>* G);void BFSM(Algraph<T>* G, int i);//有向图的拓扑排序void Topsort(Algraph<T>*G);/得到某个顶点内容所对应的数组序号int Judge(Algraph<T>* G, T name); };主程序流程图:程序开始调用关系:主函数调用五个函数 CreatNalgraph(G)//创建有向图 DFS(G) //深度优先搜索 BFS(G) //广度优先搜索 Topsort(G) //有向图拓扑排序 CreatAlgraph(G) //创建无向图其中 CreatNalgraph(G) 调用Judge(Algraph<T>* G, T name)函数;DFS(G)调用DFSM(Algraph<T>* G , int i)函数;BFS(G) 调用BFSM(Algraph<T>* G, int k)函数;CreatAlgraph(G) 调选择图的类型无向图有向图深 度 优 先 搜 索广度优先搜索 深 度 优 先 搜 索 广度优先搜索拓 扑 排 序程序结束用Judge(Algraph<T>* G, T name)函数。
深度优先搜索实验报告

深度优先搜索实验报告引言深度优先搜索(Depth First Search,DFS)是图论中的一种重要算法,主要用于遍历和搜索图的节点。
在实际应用中,DFS被广泛用于解决迷宫问题、图的连通性问题等,具有较高的实用性和性能。
本实验旨在通过实际编程实现深度优先搜索算法,并通过实际案例验证其正确性和效率。
实验中我们将以迷宫问题为例,使用深度优先搜索算法寻找从入口到出口的路径。
实验过程实验准备在开始实验之前,我们需要准备一些必要的工具和数据。
1. 编程环境:我们选择使用Python语言进行编程实验,因其语法简洁而强大的数据处理能力。
2. 迷宫地图:我们需要设计一个迷宫地图,包含迷宫的入口和出口,以及迷宫的各个路径和墙壁。
实验步骤1. 首先,我们需要将迷宫地图转化为计算机可处理的数据结构。
我们选择使用二维数组表示迷宫地图,其中0表示墙壁,1表示路径。
2. 接着,我们将编写深度优先搜索算法的实现。
在DFS函数中,我们将使用递归的方式遍历迷宫地图的所有路径,直到找到出口或者遇到墙壁。
3. 在每次遍历时,我们将记录已经访问过的路径,以防止重复访问。
4. 当找到出口时,我们将输出找到的路径,并计算路径的长度。
实验结果经过实验,我们成功地实现了深度优先搜索算法,并在迷宫地图上进行了测试。
以下是我们的实验结果:迷宫地图:1 1 1 1 11 0 0 0 11 1 1 0 11 0 0 0 11 1 1 1 1最短路径及长度:(1, 1) -> (1, 2) -> (1, 3) -> (1, 4) -> (2, 4) -> (3, 4) -> (4, 4) -> (5, 4)路径长度:7从实验结果可以看出,深度优先搜索算法能够准确地找到从入口到出口的最短路径,并输出了路径的长度。
实验分析我们通过本实验验证了深度优先搜索算法的正确性和有效性。
然而,深度优先搜索算法也存在一些缺点:1. 只能找到路径的一种解,不能确定是否为最优解。
深度优先搜索(深搜)——DeepFirstSearch【例题:迷宫】
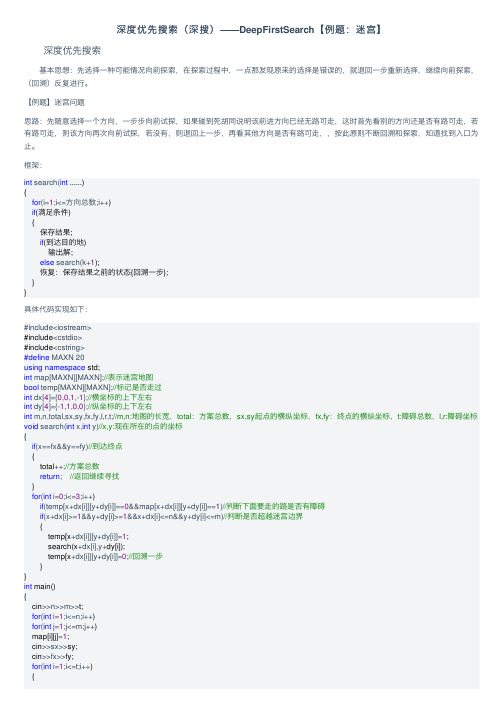
深度优先搜索(深搜)——DeepFirstSearch【例题:迷宫】深度优先搜索 基本思想:先选择⼀种可能情况向前探索,在探索过程中,⼀点那发现原来的选择是错误的,就退回⼀步重新选择,继续向前探索,(回溯)反复进⾏。
【例题】迷宫问题思路:先随意选择⼀个⽅向,⼀步步向前试探,如果碰到死胡同说明该前进⽅向已经⽆路可⾛,这时⾸先看别的⽅向还是否有路可⾛,若有路可⾛,则该⽅向再次向前试探,若没有,则退回上⼀步,再看其他⽅向是否有路可⾛,,按此原则不断回溯和探索,知道找到⼊⼝为⽌。
框架:int search(int ......){for(i=1;i<=⽅向总数;i++)if(满⾜条件){保存结果;if(到达⽬的地)输出解;else search(k+1);恢复:保存结果之前的状态{回溯⼀步};}}具体代码实现如下:#include<iostream>#include<cstdio>#include<cstring>#define MAXN 20using namespace std;int map[MAXN][MAXN];//表⽰迷宫地图bool temp[MAXN][MAXN];//标记是否⾛过int dx[4]={0,0,1,-1};//横坐标的上下左右int dy[4]={-1,1,0,0};//纵坐标的上下左右int m,n,total,sx,sy,fx,fy,l,r,t;//m,n:地图的长宽,total:⽅案总数,sx,sy起点的横纵坐标,fx,fy:终点的横纵坐标,t:障碍总数,l,r:障碍坐标void search(int x,int y)//x,y:现在所在的点的坐标{if(x==fx&&y==fy)//到达终点{total++;//⽅案总数return; //返回继续寻找}for(int i=0;i<=3;i++)if(temp[x+dx[i]][y+dy[i]]==0&&map[x+dx[i]][y+dy[i]]==1)//判断下⾯要⾛的路是否有障碍if(x+dx[i]>=1&&y+dy[i]>=1&&x+dx[i]<=n&&y+dy[i]<=m)//判断是否超越迷宫边界{temp[x+dx[i]][y+dy[i]]=1;search(x+dx[i],y+dy[i]);temp[x+dx[i]][y+dy[i]]=0;//回溯⼀步}}int main(){cin>>n>>m>>t;for(int i=1;i<=n;i++)for(int j=1;j<=m;j++)map[i][j]=1;cin>>sx>>sy;cin>>fx>>fy;for(int i=1;i<=t;i++){cin>>l>>r;map[l][r]=0;}map[sx][sy]=0; search(sx,sy); printf("%d",total); return0;}。
人工智能实验四城市交通图的代价树深度优先搜索

< 人工智能> 实验报告 4一、实验目的:掌握深度优先搜索求解算法的基本思想。
二、实验要求:用C语言实现城市交通图的代价树深度优先搜索求解三、实验语言环境:C语言四、设计思路:解法:采用代价树的深度优先搜索理论: 1. 首先根据交通图,画出代价图代价图 2. 开始搜索open表存放刚刚生成的节点。
closed表存放将要扩展的节点或已经扩展过的节点。
背景:如图是5城市之间交通路线图,A城市是出发地,E城市是目的地,两城市间的交通费用(代价)如图中数字所示,求从A到E 的最小费用路线。
解法:采用代价树的广度优先搜索理论:1. 首先根据交通图,画出代价图代价图如图2. 开始搜索oepn表存放刚刚生成的节点。
closed表存放将要扩展的节点或已经扩展过的节点。
open表结构:[代价]|[节点]|[父节点]closed表结构:[序号]|[节点]|[父节点]1) 把A放入open表open表:0| A | 0Closed表:空2) 把A从open表放入closed表open表:空closed表:1 | A | 03) 扩展A,得C1,B1,放入open表C1的代价:3 B1的代价:4 Open表:3 | C1 | A4 | B1 | Aclosed表:1 | A | 04 | B1 | Aclosed表:1 | A | 02 | C1 | AC1不是目标节点,于是继续扩展5) 把C1扩展得到D1,放入open表D1的代价:3+2=5B1的代价:4open表:4 | B1 | Aclosed表:1 | A | 02 | C1 | A6) 把B1从open放入closed表open表:5 | D1 | C1closed表:1 | A | 02 | C1 | A3 | B1 | AB1不是目标节点,于是继续扩展7) 扩展B1得D2,E1,放入Open表D2的代价:4+4=8E1的代价:4+5=9open表:5 | D1 | C18 | D2 | B19 | E1 | B1closed表:1 | A | 02 | C1 | A8) 把D1从open表放入closed表open表:8 | D2 | B19 | E1 | B1closed表:1 | A | 02 | C1 | A3 | B1 | A4 | D1 | C1D1不是目标节点,于是继续扩展9) 把D1扩展得到E2,B2,放入open表E2的代价:3+2+3=8B2的代价:3+2+4=9D2的代价:8E1的代价:9open表:8 | E2 | D18 | D2 | B19 | B2 | D19 | E1 | B1closed表:2 | C1 | A3 | B1 | A4 | D1 | C110) 把E2从open表放入closed表open表:8 | D2 | B19 | B2 | D19 | E1 | B1closed表:1 | A | 02 | C1 | A3 | B1 | A4 | D1 | C15 | E2 | D1 E2 是目标节点,搜索结束。
深度优先搜索算法详解及代码实现

深度优先搜索算法详解及代码实现深度优先搜索(Depth-First Search,DFS)是一种常见的图遍历算法,用于遍历或搜索图或树的所有节点。
它的核心思想是从起始节点开始,沿着一条路径尽可能深入地访问其他节点,直到无法继续深入为止,然后回退到上一个节点,继续搜索未访问过的节点,直到所有节点都被访问为止。
一、算法原理深度优先搜索算法是通过递归或使用栈(Stack)的数据结构来实现的。
下面是深度优先搜索算法的详细步骤:1. 选择起始节点,并标记该节点为已访问。
2. 从起始节点出发,依次访问与当前节点相邻且未被访问的节点。
3. 若当前节点有未被访问的邻居节点,则选择其中一个节点,将其标记为已访问,并将当前节点入栈。
4. 重复步骤2和3,直到当前节点没有未被访问的邻居节点。
5. 若当前节点没有未被访问的邻居节点,则从栈中弹出一个节点作为当前节点。
6. 重复步骤2至5,直到栈为空。
深度优先搜索算法会不断地深入到图或树的某一分支直到底部,然后再回退到上层节点继续搜索其他分支。
因此,它的搜索路径类似于一条深入的迷宫路径,直到没有其他路径可走后,再原路返回。
二、代码实现以下是使用递归方式实现深度优先搜索算法的代码:```pythondef dfs(graph, start, visited):visited.add(start)print(start, end=" ")for neighbor in graph[start]:if neighbor not in visited:dfs(graph, neighbor, visited)# 示例数据graph = {'A': ['B', 'C'],'B': ['A', 'D', 'E'],'C': ['A', 'F'],'D': ['B'],'E': ['B', 'F'],'F': ['C', 'E']}start_node = 'A'visited = set()dfs(graph, start_node, visited)```上述代码首先定义了一个用于实现深度优先搜索的辅助函数`dfs`。
深度优先搜索算法

深度优先搜索算法深度优先搜索算法(Depth-First Search,DFS)是一种用于遍历或搜索树或图数据结构的算法。
在DFS中,我们会尽可能深地探索一个分支,直到无法继续为止,然后回溯到前一个节点,继续探索其他分支。
DFS通常使用递归或栈数据结构来实现。
在本文中,我们将深入探讨DFS的原理、实现方法、应用场景以及一些相关的扩展主题。
1.原理深度优先搜索算法的原理非常简单。
从图或树的一个起始节点开始,我们首先探索它的一个邻居节点,然后再探索这个邻居节点的一个邻居节点,依此类推。
每次都尽可能深地探索一个分支,直到无法继续为止,然后回溯到前一个节点,继续探索其他分支。
这个过程可以用递归或栈来实现。
2.实现方法在实现DFS时,我们可以使用递归或栈来维护待访问的节点。
下面分别介绍这两种实现方法。
2.1递归实现递归是实现DFS最直观的方法。
我们可以定义一个递归函数来表示探索节点的过程。
该函数接受当前节点作为参数,并在该节点上进行一些操作,然后递归地调用自身来探索当前节点的邻居节点。
这样就可以很容易地实现DFS。
```pythondef dfs(node, visited):visited.add(node)#对当前节点进行一些操作for neighbor in node.neighbors:if neighbor not in visited:dfs(neighbor, visited)```2.2栈实现除了递归,我们还可以使用栈来实现DFS。
我们首先将起始节点入栈,然后循环执行以下步骤:出栈一个节点,对该节点进行一些操作,将其未访问的邻居节点入栈。
这样就可以模拟递归的过程,实现DFS。
```pythondef dfs(start):stack = [start]visited = set()while stack:node = stack.pop()if node not in visited:visited.add(node)#对当前节点进行一些操作for neighbor in node.neighbors:if neighbor not in visited:stack.append(neighbor)```3.应用场景深度优先搜索算法在实际的软件开发中有着广泛的应用。
深度优先搜索算法利用深度优先搜索解决迷宫问题

深度优先搜索算法利用深度优先搜索解决迷宫问题深度优先搜索算法(Depth-First Search, DFS)是一种常用的图遍历算法,它通过优先遍历图中的深层节点来搜索目标节点。
在解决迷宫问题时,深度优先搜索算法可以帮助我们找到从起点到终点的路径。
一、深度优先搜索算法的实现原理深度优先搜索算法的实现原理相当简单直观。
它遵循以下步骤:1. 选择一个起始节点,并标记为已访问。
2. 递归地访问其相邻节点,若相邻节点未被访问,则标记为已访问,并继续访问其相邻节点。
3. 重复步骤2直到无法继续递归访问,则返回上一级节点,查找其他未被访问的相邻节点。
4. 重复步骤2和3,直到找到目标节点或者已经遍历所有节点。
二、利用深度优先搜索算法解决迷宫问题迷宫问题是一个经典的寻找路径问题,在一个二维的迷宫中,我们需要找到从起点到终点的路径。
利用深度优先搜索算法可以很好地解决这个问题。
以下是一种可能的解决方案:```1. 定义一个二维数组作为迷宫地图,其中0代表通路,1代表墙壁。
2. 定义一个和迷宫地图大小相同的二维数组visited,用于记录节点是否已经被访问过。
3. 定义一个存储路径的栈path,用于记录从起点到终点的路径。
4. 定义一个递归函数dfs,参数为当前节点的坐标(x, y)。
5. 在dfs函数中,首先判断当前节点是否为终点,如果是则返回True,表示找到了一条路径。
6. 然后判断当前节点是否越界或者已经访问过,如果是则返回False,表示该路径不可行。
7. 否则,将当前节点标记为已访问,并将其坐标添加到path路径中。
8. 依次递归访问当前节点的上、下、左、右四个相邻节点,如果其中任意一个节点返回True,则返回True。
9. 如果所有相邻节点都返回False,则将当前节点从path路径中删除,并返回False。
10. 最后,在主函数中调用dfs函数,并判断是否找到了一条路径。
```三、示例代码```pythondef dfs(x, y):if maze[x][y] == 1 or visited[x][y] == 1:return Falseif (x, y) == (end_x, end_y):return Truevisited[x][y] = 1path.append((x, y))if dfs(x+1, y) or dfs(x-1, y) or dfs(x, y+1) or dfs(x, y-1): return Truepath.pop()return Falseif __name__ == '__main__':maze = [[0, 1, 1, 0, 0],[0, 0, 0, 1, 0],[1, 1, 0, 0, 0],[1, 1, 1, 1, 0],[0, 0, 0, 1, 0]]visited = [[0] * 5 for _ in range(5)]path = []start_x, start_y = 0, 0end_x, end_y = 4, 4if dfs(start_x, start_y):print("Found path:")for x, y in path:print(f"({x}, {y}) ", end="")print(f"\nStart: ({start_x}, {start_y}), End: ({end_x}, {end_y})") else:print("No path found.")```四、总结深度优先搜索算法是一种有效解决迷宫问题的算法。
有界深度优先搜索算法的实现

实验报告有界深度优先搜索算法的实现一.实验目的(1)熟悉盲目搜索—有界深度优先算法;(2)通过实验实际操作有界深度优先算法的运行,深入理解其内涵;(3)掌握有界深度优先算法,并会在其他问题中运用。
二.实验原理(1)问题描述八数码问题也称为九宫问题。
在3×3的棋盘,摆有八个棋子,每个棋子上标有1至8的某一数字,不同棋子上标的数字不相同。
棋盘上还有一个空格(以数字0来表示),与空格相邻的棋子可以移到空格中。
要求解决的问题是:给出一个初始状态和一个目标状态,找出一种从初始转变成目标状态的移动棋子步数最少的移动步骤。
所谓问题的一个状态就是棋子在棋盘上的一种摆法。
解八数码问题实际上就是找出从初始状态到达目标状态所经过的一系列中间过渡状态。
(2)有界深度优先算法原理它是从根节点开始,首先扩展最新产生的节点,即沿着搜索树的深度发展下去,一直到没有后继结点处时再返回,换一条路径走下去。
就是在搜索树的每一层始终先只扩展一个子节点,不断地向纵深前进直到不能再前进(到达叶子节点或受到深度限制)时,才从当前节点返回到上一级节点,沿另一方向又继续前进。
这种方法的搜索树是从树根开始一枝一枝逐渐形成的。
由于一个有解的问题树可能含有无穷分枝,深度优先搜索如果误入无穷分枝(即深度无限),则不可能找到目标节点。
为了避免这种情况的出现,在实施这一方法时,定出一个深度界限,在搜索达到这一深度界限而且尚未找到目标时,即返回重找,所以,深度优先搜索策略是不完备的。
另外,应用此策略得到的解不一定是最佳解(最短路径)。
三.实验内容1、熟悉了解有界深度优先算法;2、对课堂上讲解的八数码难题的例题(深度界限设为5),编程求解。
四.实验步骤(1)设置深度界限,假设为5;(2)判断初始节点是否为目标节点,若初始节点是目标节点则搜索过程结束;若不是则转到第2步;(3)由初始节点向第1层扩展,得到节点2,判断节点2是否为目标节点;若是则搜索过程结束;若不是,则将节点2向第2层扩展,得到节点3;(4)判断节点3是否为目标节点,若是则搜索过程结束;若不是则将节点3向第3层扩展,得到节点4;(5)判断节点4是否为目标节点,若是则搜索过程结束;若不是则将节点4向第4层扩展,得到节点5;(6)判断节点5是否为目标节点,若是则搜索过程结束;若不是则结束此轮搜索,返回到第2层,将节点3向第3层扩展得到节点6;(7)判断节点6是否为目标节点,若是则搜索过程结束;若不是则将节点6向第4层扩展,得到节点7;(8)判断节点7是否为目标节点,若是则结束搜索过程;若不是则将节点6向第4层扩展得到节点8;(9)依次类推,直到得到目标节点为止;(10)搜索过程见附图2所示。
深度优先搜索和广度优先搜索

深度优先搜索和广度优先搜索深度优先搜索(DFS)和广度优先搜索(BFS)是图论中常用的两种搜索算法。
它们是解决许多与图相关的问题的重要工具。
本文将着重介绍深度优先搜索和广度优先搜索的原理、应用场景以及优缺点。
一、深度优先搜索(DFS)深度优先搜索是一种先序遍历二叉树的思想。
从图的一个顶点出发,递归地访问与该顶点相邻的顶点,直到无法再继续前进为止,然后回溯到前一个顶点,继续访问其未被访问的邻接顶点,直到遍历完整个图。
深度优先搜索的基本思想可用以下步骤总结:1. 选择一个初始顶点;2. 访问该顶点,并标记为已访问;3. 递归访问该顶点的邻接顶点,直到所有邻接顶点均被访问过。
深度优先搜索的应用场景较为广泛。
在寻找连通分量、解决迷宫问题、查找拓扑排序等问题中,深度优先搜索都能够发挥重要作用。
它的主要优点是容易实现,缺点是可能进入无限循环。
二、广度优先搜索(BFS)广度优先搜索是一种逐层访问的思想。
从图的一个顶点出发,先访问该顶点,然后依次访问与该顶点邻接且未被访问的顶点,直到遍历完整个图。
广度优先搜索的基本思想可用以下步骤总结:1. 选择一个初始顶点;2. 访问该顶点,并标记为已访问;3. 将该顶点的所有邻接顶点加入一个队列;4. 从队列中依次取出一个顶点,并访问该顶点的邻接顶点,标记为已访问;5. 重复步骤4,直到队列为空。
广度优先搜索的应用场景也非常广泛。
在求最短路径、社交网络分析、网络爬虫等方面都可以使用广度优先搜索算法。
它的主要优点是可以找到最短路径,缺点是需要使用队列数据结构。
三、DFS与BFS的比较深度优先搜索和广度优先搜索各自有着不同的优缺点,适用于不同的场景。
深度优先搜索的优点是在空间复杂度较低的情况下找到解,但可能陷入无限循环,搜索路径不一定是最短的。
广度优先搜索能找到最短路径,但需要保存所有搜索过的节点,空间复杂度较高。
需要根据实际问题选择合适的搜索算法,例如在求最短路径问题中,广度优先搜索更加合适;而在解决连通分量问题时,深度优先搜索更为适用。
深度优先遍历算法和广度优先遍历算法实验小结

深度优先遍历算法和广度优先遍历算法实验小结一、引言在计算机科学领域,图的遍历是一种基本的算法操作。
深度优先遍历算法(Depth First Search,DFS)和广度优先遍历算法(Breadth First Search,BFS)是两种常用的图遍历算法。
它们在解决图的连通性和可达性等问题上具有重要的应用价值。
本文将从理论基础、算法原理、实验设计和实验结果等方面对深度优先遍历算法和广度优先遍历算法进行实验小结。
二、深度优先遍历算法深度优先遍历算法是一种用于遍历或搜索树或图的算法。
该算法从图的某个顶点开始遍历,沿着一条路径一直向前直到不能再继续前进为止,然后退回到上一个节点,尝试下一个节点,直到遍历完整个图。
深度优先遍历算法通常使用栈来实现。
以下是深度优先遍历算法的伪代码:1. 创建一个栈并将起始节点压入栈中2. 将起始节点标记为已访问3. 当栈不为空时,执行以下步骤:a. 弹出栈顶节点,并访问该节点b. 将该节点尚未访问的邻居节点压入栈中,并标记为已访问4. 重复步骤3,直到栈为空三、广度优先遍历算法广度优先遍历算法是一种用于遍历或搜索树或图的算法。
该算法从图的某个顶点开始遍历,先访问起始节点的所有相邻节点,然后再依次访问这些相邻节点的相邻节点,依次类推,直到遍历完整个图。
广度优先遍历算法通常使用队列来实现。
以下是广度优先遍历算法的伪代码:1. 创建一个队列并将起始节点入队2. 将起始节点标记为已访问3. 当队列不为空时,执行以下步骤:a. 出队一个节点,并访问该节点b. 将该节点尚未访问的邻居节点入队,并标记为已访问4. 重复步骤3,直到队列为空四、实验设计本次实验旨在通过编程实现深度优先遍历算法和广度优先遍历算法,并通过对比它们在不同图结构下的遍历效果,验证其算法的正确性和有效性。
具体实验设计如下:1. 实验工具:使用Python编程语言实现深度优先遍历算法和广度优先遍历算法2. 实验数据:设计多组图结构数据,包括树、稠密图、稀疏图等3. 实验环境:在相同的硬件环境下运行实验程序,确保实验结果的可比性4. 实验步骤:编写程序实现深度优先遍历算法和广度优先遍历算法,进行多次实验并记录实验结果5. 实验指标:记录每种算法的遍历路径、遍历时间和空间复杂度等指标,进行对比分析五、实验结果在不同图结构下,经过多次实验,分别记录了深度优先遍历算法和广度优先遍历算法的实验结果。
深度优先搜索(补充教案)

深度优先搜索(补充教案)一、搜索过程深度优先搜索的搜索过程类似树的先序遍历,也叫回溯法。
搜索过程如下:从源节点开始发现有一节点v,如果v还有未探测到的边,就沿此边继续探测下去,当节点v的所有边都被探测过,搜索过程将回溯到最初发现v点的源节点。
这一过程一直进行到已发现从源节点可达的所有节点为止。
这显然是一个递归过程。
为了在遍历过程中区分顶点是否被访问,往往可以引入一个数组,如以mark[1..n]作为标记。
数组的元素取0和1,初值为0。
当节点被访问时,与节点相应得数组元素为1,每次访问节点时,都得先检查它的标记值,找0值得节点访问,并深度继续。
深度大的先得到扩展,具有“后产生先扩展”的特点,因此在数据结构上采用堆栈来存储(新节点入栈,节点不能扩展时,栈定出栈)。
二、搜索特点1、由于深度搜索过程中有保留已扩展节点,则不致于重复构造不必要的子树系统。
2、深度优先搜索并不是以最快的方式搜索到解,因为若目标节点在第i层的某处,必须等到该节点左边所有子树系统搜索完毕之后,才会访问到该节点,因此,搜索效率还取决于目标节点在解答树中的位置。
3、由于要存储所有已被扩展节点,所以需要的内存空间往往比较大。
4、深度优先搜索所求得的是仅仅是目前第一条从起点至目标节点的树枝路径,而不是所有通向目标节点的树枝节点的路径中最短的路径。
5、适用范围:适用于求解一条从初始节点至目标节点的可能路径的试题。
若要存储所有解答路径,可以再建立其它空间,用来存储每个已求得的解。
若要求得最优解,必须记下达到目前目标的路径和相应的路程值,并与前面已记录的值进行比较,保留其中最优解,等全部搜索完成后,把保留的最优解输出。
三、算法描述1、算法数据结构描述:深度优先搜索时,最关键的是结点扩展(OPEN)表的生成,它是一个栈,用于存放目前搜索到待扩展的结点,当结点到达深度界限或结点不能再扩展时,栈顶结点出栈,放入CLOSE表(存放已扩展节点),继续生成新的结点入栈OPEN表,直到搜索到目标结点或OPEN栈空为止。
深度优先搜索和广度优先搜索的比较和应用场景

深度优先搜索和广度优先搜索的比较和应用场景在计算机科学中,深度优先搜索(DFS)和广度优先搜索(BFS)是两种常用的图搜索算法。
它们在解决许多问题时都能够发挥重要作用,但在不同的情况下具有不同的优势和适用性。
本文将对深度优先搜索和广度优先搜索进行比较和分析,并讨论它们在不同应用场景中的使用。
一、深度优先搜索(DFS)深度优先搜索是一种通过遍历图的深度节点来查找目标节点的算法。
它的基本思想是从起始节点开始,依次遍历该节点的相邻节点,直到到达目标节点或者无法继续搜索为止。
如果当前节点有未被访问的相邻节点,则选择其中一个作为下一个节点继续进行深度搜索;如果当前节点没有未被访问的相邻节点,则回溯到上一个节点,并选择其未被访问的相邻节点进行搜索。
深度优先搜索的主要优势是其在搜索树的深度方向上进行,能够快速达到目标节点。
它通常使用递归或栈数据结构来实现,代码实现相对简单。
深度优先搜索适用于以下情况:1. 图中的路径问题:深度优先搜索能够在图中找到一条路径是否存在。
2. 拓扑排序问题:深度优先搜索能够对有向无环图进行拓扑排序,找到图中节点的一个线性排序。
3. 连通性问题:深度优先搜索能够判断图中的连通分量数量以及它们的具体节点组合。
二、广度优先搜索(BFS)广度优先搜索是一种通过遍历图的广度节点来查找目标节点的算法。
它的基本思想是从起始节点开始,先遍历起始节点的所有相邻节点,然后再遍历相邻节点的相邻节点,以此类推,直到到达目标节点或者无法继续搜索为止。
广度优先搜索通常使用队列数据结构来实现。
广度优先搜索的主要优势是其在搜索树的广度方向上进行,能够逐层地搜索目标节点所在的路径。
它逐层扩展搜索,直到找到目标节点或者遍历完整个图。
广度优先搜索适用于以下情况:1. 最短路径问题:广度优先搜索能够在无权图中找到起始节点到目标节点的最短路径。
2. 网络分析问题:广度优先搜索能够在图中查找节点的邻居节点、度数或者群组。
三、深度优先搜索和广度优先搜索的比较深度优先搜索和广度优先搜索在以下方面有所不同:1. 搜索顺序:深度优先搜索按照深度优先的顺序进行搜索,而广度优先搜索按照广度优先的顺序进行搜索。
DFS深度优先搜索(附例题)

DFS深度优先搜索(附例题)深度优先搜索,简称DFS,算是应⽤最⼴泛的搜索算法,属于图算法的⼀种,dfs按照深度优先的⽅式搜索,通俗说就是“⼀条路⾛到⿊”,dfs 是⼀种穷举,实质是将所有的可⾏⽅案列举出来,不断去试探,知道找到问题的解,其过程是对每⼀个可能的分⽀路径深⼊到不能再深⼊为⽌,且每个顶点只能访问⼀次。
dfs⼀般借助递归来实现例题:⾛迷宫#include <iostream>#include <string.h>using namespace std;int m,n;int sx,sy,ex,ey;//起点终点坐标int mp[20][20];//记录地图int cnt=0;//结果个数int ax[10]={0,0,-1,1};//x的四个⾛向int ay[10]={1,-1,0,0};//y的四个⾛向int vis[20][20];//记录是否来过int dfs(int x,int y){if((x>=0)&&(y>=0)&&(x<n)&&(y<m)&&(mp[x][y]==0)){//坐标合法性if(x==ex&&y==ey){//如果是终点cnt++;return0;}vis[x][y]=1;//将x,y设为已经来过if(vis[x][y]==1){//判断是否相邻顶点可⾛for(int i=0;i<4;i++){int tx=x+ax[i];int ty=y+ay[i];if((tx>=0)&&(ty>=0)&&(tx<n)&&(ty<m)&&(mp[tx][ty]==0)&&vis[tx][ty]==0)//相邻顶点可⾛条件dfs(tx,ty);//递归dfs此点}}vis[x][y]=0;return0;}}int main(){memset(vis,0,sizeof(vis));//将遍历数组全部置0cin>>n>>m;for(int i=0;i<n;i++){for(int j=0;j<m;j++){char c;cin>>c;if(c=='.'){//边输⼊边置mp的0或1,并设置起点坐标和终点坐标mp[i][j]=0;}else if(c=='S'){sx=i;sy=j;mp[i][j]=0;}else if(c=='T'){ex=i;ey=j;mp[i][j]=0;}elsemp[i][j]=1;//'#'为墙壁,⾛不通所以设为1}}dfs(sx,sy);//从起点开始遍历cout<<cnt<<endl;return0;}。
深度优先搜索原理与实践及代码示例

深度优先搜索原理与实践及代码示例深度优先搜索(Depth First Search,简称DFS)是一种用于遍历或搜索树或图的算法。
它通过从根节点开始,沿着树的深度遍历直到某个叶子节点,然后回溯到上一个节点,继续遍历下一个分支。
DFS通常使用递归实现,也可以使用栈来辅助实现。
一、DFS原理深度优先搜索基于“尽可能深入地搜索”的原则。
它从根节点出发,先访问子节点,再访问子节点的子节点,直到达到某个终止条件。
然后回溯到上一个节点,继续访问该节点的其他子节点,直到遍历完整个树或图。
二、DFS实践下面以一个简单的二叉树为例,演示DFS算法的实践过程。
假设有以下二叉树:```1/ \2 3/ \4 5```DFS的遍历顺序是:1 -> 2 -> 4 -> 5 -> 3。
以下是实现DFS遍历二叉树的示例代码:```pythonclass Node:def __init__(self, data):self.data = dataself.left = Noneself.right = Nonedef dfs(node):if node is None:returnprint(node.data)dfs(node.left)dfs(node.right)# 创建二叉树node1 = Node(1)node2 = Node(2)node3 = Node(3)node4 = Node(4)node5 = Node(5)node1.left = node2node1.right = node3node2.left = node4node2.right = node5# DFS遍历二叉树dfs(node1)```运行上述代码,将输出:1 2 4 5 3。
可以看到,DFS按照深度优先的原则遍历二叉树节点。
三、DFS的应用深度优先搜索算法有广泛的应用,包括但不限于以下几个领域:1. 图的连通性判断:可以通过DFS遍历图的所有连通节点,判断图是否连通。
深度优先搜索

深度优先搜索(Depth-First-Search)引例:迷宫问题首先我们来想象一只老鼠,在一座不见天日的迷宫内,老鼠在入口处进去,要从出口出来。
那老鼠会怎么走?当然可以是这样的:老鼠如果遇到直路,就一直往前走,如果遇到分叉路口,就任意选择其中的一条继续往下走,如果遇到死胡同,就退回到最近的一个分叉路口,选择另一条道路再走下去,如果遇到了出口,老鼠的旅途就算成功结束了。
深度优先搜索的基本原则就是这样:按照某种条件往前试探搜索,如果前进中遭到失败(正如老鼠遇到死胡同)则退回头另选通路继续搜索,直到找到满足条件的目标为止。
递归程序设计然而要实现这样的算法,我们需要用到编程的一大利器---递归。
当一个函数直接或者间接的调用了自己本身的时候,则发生了递归。
讲一个更具体的例子:从前有座山,山里有座庙,庙里有个老和尚,老和尚在讲故事,讲什么呢?讲:从前有座山,山里有座庙,庙里有个老和尚,老和尚在讲故事,讲什么呢?讲:从前有座山,山里有座庙,庙里有个老和尚,老和尚在讲故事,讲什么呢?讲:…………。
好家伙,这样讲到世界末日还讲不玩,老和尚讲的故事实际上就是前面的故事情节,这样不断地调用程序本身,就形成了递归。
万一这个故事中的某一个老和尚看这个故事不顺眼,就把他要讲的故事换成:“你有完没完啊!”,这样,整个故事也就嘎然而止了。
我们编程就要注意这一点,在适当的时候,就必须要有一个这样的和尚挺身而出,把整个故事给停下来,或者说他不再往深一层次搜索,要不,我们的递归就会因计算机栈空间大小的限制而溢出,称为stack overflow。
递归的经典实例:int factorial(int n){if (n == 0) //基线条件(base case){return 1;}else{return n * factorial(n - 1); //将问题规模逐渐缩小,或者说转化为更小更简单的子问题 }}再来看另外一个例子---放苹果 (POJ1664):把M个同样的苹果放在N个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法? 5,1,1和1,5,1 是同一种分法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
深度优先遍历
一、实验目的
了解深度优先遍历的基本概念以及实现方式。
二、实验内容
1、设计一个算法来对图的进行深度优先遍历;
2、用C语言编程来实现此算法。
用下面的实例来调试程序:
三、使用环境
Xcode编译器
四、编程思路
深度优先遍历图的方法是,从邻接矩阵出发:访问顶点v;依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;构造一个遍历辅助矩阵visited[]进行比较若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止,并将顶点信息存储在数组Q[]里面。
反复搜索可以通过使用函数的嵌套来实现。
五、调试过程
1.程序代码:
//为方便调试,程序清晰直观删除了邻接矩阵的构造函数,
//并且修改了main()函数,只保留了DFS函数
#include <stdio.h>
#define N 4 //定义顶点数
int a[N][N]=
{
{0,1,1,1}
,{1,0,0,0}
,{1,0,0,1}
,{1,0,0,1}
}; //邻接矩阵由之前程序函给出
int visited[N]={0}; //遍历比较的辅助矩阵,初始化为0矩阵int Q[N]; //用来存储各个顶点的信息
static int last=-1;
void DFS(int G[][N], int s)
{
visited[s] = 1;
Q[++last]=s;
for (int i=0;i<N;i++) //进行遍历
{
if (G[s][i]==1)
{
if(visited[i] == 0)
DFS(G,i); //函数嵌套,完成一次搜索,指向下一个顶点 }
}
}
int main()
{
DFS(a,0);
printf("深度优先搜索为\n");
for (int i=0;i<N;i++) //打印遍历的结果
printf("%d ",Q[i]+1);
return 0;
}2.运行窗口:
输出结果为各顶点按深度优先遍历的排序。