廖力编译原理课件第4章
编译原理第4章.doc
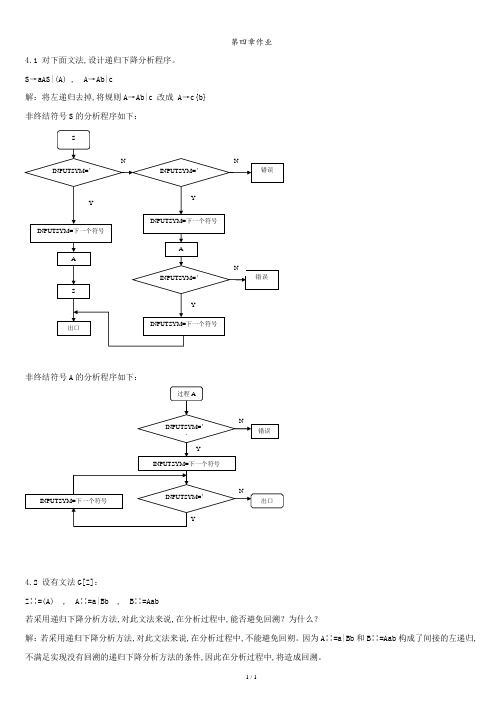
第四章作业4.1 对下面文法,设计递归下降分析程序。
S→aAS|(A) , A→Ab|c解:将左递归去掉,将规则A→Ab|c 改成 A→c{b}非终结符号S的分析程序如下:非终结符号A的分析程序如下:4.2 设有文法G[Z]:Z∷=(A) , A∷=a|Bb , B∷=Aab若采用递归下降分析方法,对此文法来说,在分析过程中,能否避免回溯?为什么?解:若采用递归下降分析方法,对此文法来说,在分析过程中,不能避免回朔。
因为A∷=a|Bb和B∷=Aab构成了间接的左递归,不满足实现没有回溯的递归下降分析方法的条件,因此在分析过程中,将造成回溯。
4.3 若有文法如下,设计递归下降分析程序。
<语句>→<语句><赋值语句>|ε<赋值语句>→ID=<表达式><表达式>→<项>|<表达式>+<项>|<表达式>-<项><项>→<因子>|<项>*<因子>|<项>/<因子><因子>→ID|NUM|(<表达式>)解:首先,去掉左递归(1)<语句>→<语句><赋值语句>|ε改为: <语句>→{<赋值语句>}(3)<表达式>→<项> | <表达式> + <项> | <表达式> - <项> 改为:<表达式>→<项>{(+ | -)<项>}(4)<项>→<因子> | <项> * <因子> | <项> / <因子>改为:<项>→<因子>{(* | /)<因子>}则文法变为:<语句>→{<赋值语句>}<赋值语句>→ID=<表达式><表达式>→<项>{(+ | -)<项>}<项>→<因子>{(* | /)<因子>}<因子>→ID|NUM|(<表达式>)非终结符号 <语句>→{<赋值语句>} 的分析程序如下:非终结符号 <赋值语句>→ID=<表达式> 的分析程序如下:非终结符号<表达式>→<项>{(+ | -)<项>} 的分析程序如下:非终结符号 <项>→<因子>{(* | /)<因子>} 的分析程序如下:非终结符号 <因子>→ID|NUM|(<表达式>) 的分析程序如下:4.4 有文法G[A]:A::=aABe|ε,B::=Bb|b(1)求每个非终结符号的FOLLOW集。
编译原理 第4章1

4.2.2 文法的左递归性和回 溯的消除
第二种情况: 文法中相同左部的规 则,其中某一右部能推出ε串,例如, 文法G: A→ Bx B→ x |ε 其非终结符B有两个右部,第二个右 部能推导出ε串且两个右部左端第一 个符号不相同,但在分析符号串 W=x 时出现回溯。
4.2.2 文法的左递归性和回 溯的消除
FIRST(α) SELECT(A→ α) = FIRST(α)/{ε}∪FOLLOW (A) * 若αε
* 若α / ε
LL(1)文法的判断条件
例 设有文法G[A]: A→aB | d B→bBA | ε
SELECT(A→aB ) = FIRST(aB) = { a } SELECT(A→d ) = FIRST(d) = { d }
LL(1)文法的判断条件
为了建立LL(1)文法的判断条件,需引 进三个相关集: FIRST集
FOLLOW集
SELECT集
LL(1)文法的判断条件
(1) 设α是文法G的任一符号串,定义文 法符号串α的首符号集合。 * FIRST(α) = { a | α a…且 a∈V }
T
* ε ,则规定 ε∈ FIRST(α) 若α
4.2.2 文法的左递归性和回 溯的消除
2. 回溯的消除 在自上而下分析过程中,由于回 溯,需要推翻前面的分析,包括已做 的一大堆语义工作,重新去进行试探, 这样大大降低了语法分析器的工作效 率,因此,需要消除回溯。
4.2.2 文法的左递归性和回 溯的消除
我们分析发现引起回溯的原因是: 在 文法中,当某个非终结符A有多个候选式时: A → α1 | α2 | α3 |∙∙∙∙∙∙| αn
LL(1)文法的判断条件
S → aAb A → de | d ∵ SELECT(A→de)= FIRST(de)={d} SELECT(A→d)= FIRST(d)={d} ∴ SELECT(A→de)∩SELECT(A→d) ≠Φ
编译原理课件CHAPTER 4(Syntax Analysis-3)

初态是活前缀 ε 的有效项目集 活前缀γ的有效项目集是从初态出发经过γ道路 所到达的那个状态所代表的项目集 分析过程中分析栈中的活前缀的有效项目集是 栈顶状态 Sm 所代表的那个集合,栈顶状态体 现了栈里一切有用的信息
32
2013-9-10
4.5
LR分析
例:文法G’ S’ E E T + E E T T int * T T int T (E)
例: 求 closure ( { E’ ·E } )
E’ E EE+T | T TT*F | F F ( E ) | id
2013-9-10
28
4.5
LR分析
goto 函数
goto ( I, X ) goto ( I, X ) = closure (A→αX·β),其中 A→α·Xβ在 I 中
0
a
c
B
6 9
8
aAcBe b Ab d
分析句子的过程可以看作在上面这个 DFA 上运 行的过程
13
2013-9-10
例子:
步骤 1 0 栈 输入串 abbcde$ ACTION S2 GOTO
S
1 * 2
b
A c B
4 3
b e
0
a
6
5
d
2013-9-10
7
9
14
8
例子:
步骤 1 2 0 0a2 栈 输入串 abbcde$ bbcde$ ACTION S2 S4 GOTO
例子:
分析句子:abbcde
2013-9-10
6
编译原理第四章

FIRST( F ) = { (, id
}
FIRST( T ) = FIRST( F ) = { (, id } FIRST( E ) = FIRST( T ) = { (, id } FIRST( E' ) = { +,ε }
FIRST( T' ) = { *, ε }
定义
教学进度
FOLLOW( A ) 的计算法(P67)
计算机科学与工程系
表达式文法直接左递归的消除
E → E + T|T T → T * F|F F → ( E )|id
E E' T T' F → → → → → T + F * ( E' T E'|ε T' F T'|ε E )|id
教学进度
计算机科学与工程系
把直接左递归改为直接右递归:
将规则A →A1|A2|...|Am|1|2|...|n 改写为: A → 1 A’ |2 A’ |...|n A’ A’ → 1A’|2 A’ |...|m A’ | ε
• top down parsing:推导
• bottom up parsing:归约
教学进度
4.2 自顶向下语法分析
• 基本思想:
计算机科学与工程系
• 从文法的开始符号出发,向下推导出句子; • 试图用一切可能的办法,从文法开始符号出发, 自上而下地为输入串建立一课语法树;(寻找一 个最左推导) • 此分析过程本质上是一种试探过程。 • 非确定的自上而下分析法实际上采用的是一种 穷尽一切可能的试探法。
• E → T E' • E'→ + T E'|ε • T → F T' • T'→ * F T'|ε • F → ( E )|id 按照最左推导过程,构造分析树
ppt编译原理4章444

4.3 确定的自顶向下分析思想
一、算法思想: 文法特点: (1)每个产生式的 对于任一输入符号串,从文法的识别符号出发,根据 右部都由终结符号开始;(2) 当前的输入符号,唯一的确定一个产生式,用产生式的右 两个产生式若左部相同,则 部的符号串替代相应的非终结符往下推导,或构造一棵语 其右部以不同的终结符号开 始;(3)无空产生式U 法树。若能推导出输入串或构造语法树成功则输入串是句 子,否则不是。 S 二、举例: (1)文法G[S]: SpA |qB AcAd|a 输入串 w=pccadd 对应最左推导:
4.5 非LL(1)文法转换为LL(1)文法
对某个语言来说其文法不一定是LL(1)文法,而非LL(1) 文法将无法采用确定的自顶向下分析方法进行分析,但我 们可以通过对文法进行等价变换,在有些情况下使其成为 LL(1)文法。 一、提取左公共因子: 设文法中有Uxy|xw( UVN, x,y,wV*)形式的产生式,从 而导致了: First(xy)First(xw)=First(x)Ф 因而使: Select(Uxy) Select(Uxw) Ф 1.方法:若有产生式Uxy|xw|…|xz , 则提取左公共因 若在y,w,…,z中仍然有左公 子并用EBNF表示为: Ux(y|w|…|z) 共因子,可以再次提取。 注意,若有:Uxy|x 再引入另一个非终结符号V,将产生式变为: 则提取后:Ux(y|) UxV V y|w|…|z
2.举例: 设有产生式:S→if B then S1 else S2 | if B then S1 其中,S表示两种类型的条件语句。 提取公因子,改成: S→if B then S1 ( else S2 | ) 引入非终结符号R: S→if B then S1 R R→else S2 |ε 文法中,if , then, elseVT
编译原理课件Chapter_4

NFA构造文法的例子
• A0 aA0 | bA0 | aA1 • A1 bA2 • A2 bA3 • A3 ε
• 考虑baabb的推导和接受过程可知:NFA接受一个句子 的运行过程实际就是该文法推导出该句子的过程
b
(a|b)*abb
22
文法及其生成的语言
语言是从文法的开始符号出发,能推导得到的所 有句子的集合
将文法的非终结符号排序为A1, A2, …, An for i = 1 to n do {
for j = 1 to i – 1 do { 将形如Ai Ajγ的产生式替换为Ai δ1γ | δ2γ | … | δkγ, 其中Aj δ1 | δ2 | … | δk是以Aj为左部的所有产生式
} 消除Ai的立即左递归 }
23
设计文法 (1)
文法能够描述程序设计语言的大部分语法
但不是全部,比如,标识符的先声明后使用则无法用 上下文无关文法描述
因此语法分析器接受的语言是程序设计语言的超集; 必须通过语义分析来剔除一些符合文法、但不合法的 程序
24
设计文法 (2)
在进行高效的语法分析之前,需要对文法做以下 处理
6
上下文无关文法的例子
• 简单算术表达式的文法
– 终结符号:id, +, –, *, /, (, )
– 非终结符号:expression, term, factor
– 开始符号:expression
– 产生式集合
expression expression + term
expression expression – term
消除二义性
二义性:文法可以为一个句子生成多颗不同的分析树
消除左递归
编译原理课件第四章

中间代码生成的过程和方法
过程
中间代码生成是将源代码转换为中间表示形式的过 程,可以使用三地址码等中间代码表示。
方法
中间代码生成可以应用常见的优化技术,如常量折 叠、公共子表达式消除等。
编译优化的基本原理和技术
基本原理
编译优化的基本原理包括消除冗余、提高并行度和改进数据局部性等。
技术
编译优化的常用技术有指令调度、循环优化和内函数等。
编译原理课件第四章
在这一章中,我们将介绍编译原理课件中的第四章内容。我们将探讨编译器 前端和后端的概念,以及它们各自的任务和流程。
编译器前端和后端
1
编译器后端
2
编译器后端负责中间代码生成、代码优 化和目标代码生成等任务。
编译器前端
编译器前端负责词法分析、语法分析和 语义分析等任务。
语法分析器的作用和原理
1 作用
语法分析器用于分析源代码的语法结构,并生成抽象语法树。
2 原理
语法分析器使用文法规则和语法分析算法进行解析,如LL(1)分析和LR分析。
语法制导翻译的概念和实现
概念
语法制导翻译是在语法分析的同时进行翻译,通过 语法规则和语义动作实现。
实现
语法制导翻译可以使用语义动作和符号表等技术来 实现语义分析和中间代码生成。
编译原理_第4章_第3节_LR分析法63页PPT文档

❖ 采用自底向下语法分析方法,在分析过程中的每一步,都会面 对两个关键问题:
(1)如何确定句柄 (2)找出的句柄应规约到哪一个非终结符
解决方法:(移进-规约法) (1)引入一个先进后出的符号栈来存放符号,按照顺序把当前
输入符号入栈(移进),然后查看栈顶符号串是否形成一个句柄。 (2)形成一个句柄时,便对此句柄直接规约,把它代替为相
(s0 s1…sms, #X1X2…Xmai, ai+1…an#)
(2) Action[sm, ai]=rn: {Aβ},且s=Goto[sm-|β|, A],则三元式变为:
(s0 s1…sm-|β|s, #X1X2…Xm-|β|A, aiai+1…an#) (3) Action[sm, ai]=acc,宣布接受,三元式不再变化。 (4) Action[sm, ai]=err,报错,三元式不再变化。
A c
d
3
EaA•
Ac•A A•d A•cA
d Ad•
4A c
5
6 AcA•
例:识别acd
状态栈 0 02
024 0245 0246 023
01 0
活前缀栈 当前符号
#
a
#a
c
#ac
d
#acd
#
#acA
#
#aA
#
#E
#
#S
#
输入串 cd# d# #
0
E
S•E E•aA
a
1
SE•
2 Ea•A A•d A•cA
A c
d
3
EaA•
Ac•A A•d A•cA
d Ad•
4A c
5
6 AcA•
编译原理课件chapter4

三地址代码的生成
总结词
三地址代码是一种常见的中间代码形式,它由一系列的三元 式组成,每个三元式包含一个操作符和两个操作数。
详细描述
三地址代码的生成是编译过程中的一个重要步骤,它通过对 源代码进行语法分析和语义分析,将高级语言转换为一系列 的三元式。这些三元式表示了源代码中的运算和数据传输操 作,可以进一步转换为目标代码。
常见的寄存器分配算法包括基于 图的方法、线性扫描算法和遗传
算法等。
目标代码的生成
01
02
03
04
目标代码的生成通常涉及指令 选择、指令调度和代码优化等
步骤。
指令选择是根据中间代码选择 合适的目标指令的过程,需要 考虑指令集架构、语义等约束
。
指令调度是为了确定指令的执 行顺序,以充分利用处理器资
源并提高指令级并行度。
为了能够处理连续输入的字符流,词 法分析器需要使用一个输入缓冲区来 存储尚未处理的字符。
设计状态转换图
根据正则表达式的规则,可以设计出 一个状态转换图,用于描述如何将输 入的字符转换为相应的词法单元。
词法分析器的实现
编写词法分析器程序
根据状态转换图和输入缓冲区的处理 逻辑,可以编写出相应的词法分析器 程序。
循环展开
将循环体多次执行,减 少循环次数,提高程序
运行效率。
循环优化
通过优化循环结构,减 少循环次数,提高程序
运行效率。
函数内联
将函数调用替换为函数 体中的代码,减少函数
调用的开销。
循环优化
01
02
03
04
循环展开
将循环体多次执行,减少循环 次数,提高程序运行效率。
循环合并
将多个循环合并为一个循环, 减少循环次数,提高程序运行
编译原理第4章PPT课件

4
§4.2自上而下面临的问题
二、举例: 自上而下方法的分析过程本质上
是一种试探过程,是反复使用不同产生 式谋求匹配输入串的过程。
5
§4.பைடு நூலகம்自上而下面临的问题
例:文法 SxAy A**|*
输入串α :x*y
(1)把文法G的所有VN按任一种顺序排列成 P1,P2,…,Pn;按此顺序执行; (2)FOR i = 1 To n Do
Begin For j :=1 To i-1 Do 把形如PiPjγ的规则改写成 Piδ1γ|δ2γ|…|δkγ 其中Pjδ1|δ2|…|δk是关 于Pj的所有规则; 消除关于Pi规则的直接左递归性
F T’ + T
iℇ
E’ ℇ
F(E) |i
F
T’
输入串:i+i; 如右图所示
i
ℇ
19
§4.3LL(1)分析法
2、由上分析是不是就意味着:当非终结符 A面临输入符号a,且a不属于A的任意候 选首符集,但A的某个候选首符集包含ℇ时, 就一定可以使A自动匹配?
分析:只有当a是在文法的某个句型中允许跟在A 后的终结符时,才可能允许A自动匹配,否则,a 在这里的出现是一种语法错误。
14
§4.3LL(1)分析法
2、当不得回溯时,对文法有什么要求?
∀ 非终结符A的各个候选的首符集的交集均为空。
分析:Aα
first(α)={a|α⇒* a…,a∈ VT} 若α⇒* ℇ ,则规定ℇ∈ first(α)
即:first(α)是α的所有可能推导的开头终结符或可能
的ℇ。
此时,当要求A匹配输入串时,A根据它所面临的第
编译技术原理及方法 课件 第四章 语法分析1

具体的说,语法分 析是在单词流的基础 上建立一个层次结构
标识符 a
——语法树
=
表达式
标识符 +
表达式
b
标识符 *ቤተ መጻሕፍቲ ባይዱ标识符
c
d
4-1语法分析概述
一、语法分析的主要任务
举例 a=b+c*d
语法分析 任务:将词法分析后所有单词组成句子,根据不同高级语言
不同语法规则来分析这些句子乃至程序是否正确。
如果写成 a=b+-c*d 会不会发现?
cad
S
i
ScAd c A d cabd a b
4-1语法分析概述 二、自顶向下语法分析概述
2、分析方法
若按自上而下语法分析程序的步骤进行分析判断,其过程如下:
P: S∷=cAd A∷=ab|a
(3)此时子树A最左端末结点a 与i所指的符号a匹配。于是 再调整i使其指向下一输入符 号d,并试图用A的最右末端 结点b与之匹配。但它们不 匹配,因此,子树A的匹配 失败,这意味着选用A的第 一个候选式对此时的情况不 适合,不能构造出输入串x 的语法树。
4-2自顶向下语法分析
4.2.1消除回溯和左递归
一、消除回溯
2、运气不好的情况——同一个非终结符的不同候选式的不以终 结符号开头 : 通过求FIRST集分析路标
不难总结出,构造FIRST集的方法步骤如下—— 对任一符号X(X∈VN∪VT),构造FIRST(X)时,只要连续使用下列规则,直至每个FIRST
ScAd c
A
d
4-1语法分析概述 二、自顶向下语法分析概述
2、分析方法
若按自上而下语法分析程序的步骤进行分析判断,其过程如下:
P: S∷=cAd A∷=ab|a
精品课件-编译原理(第四版)-第4章

我们再举一例说明属性文法。一简单变量类型说明的文法G[D] 如下:
G[D]:D→int L∣float L
L→L, id∣id
其对应的属性文法为
(1)D→TL
L.in=T.type
(2)T→int
T.type=int
(3)T→float
T.type=float
(4)L→L(1),id L(1).in=L.in; addtype ( id.entry, L.in )
(1)赋值语句:左部 表达式
(2)条件语句:表达式 语句1 语句2
与抽象语法相对应的语法树称为抽象语法树或抽象树, 如赋值语句x=a−b*c的抽象语法树如图4-4(a) 所示,而图4-4(b) 则是该赋值语句的普通语法树。
图4–4 x=a−b*c的语法树
(a) 抽象语法树;(b) 普通语法树 图
语义栈 _ __ _7 _7_ _7_ _ _7_9 _7_9_ _7_9_ _ _7_9_5 _7_45 _52
输入串 7+9*5#
+9*5# +9*5#
9*5# *5# *5# 5# # # # #
主要动作 s3 r4 s4 s3 r4 s5 s3 r4 r2 r1 acc
Hale Waihona Puke 4.2 属 性 文 法一个源程序经过词法分析、语法分析之后,表明该源程序 在书写上是正确的,并且符合程序语言所规定的语法。但是语 法分析并未对程序内部的逻辑含义加以分析,因此编译程序接 下来的工作是语义分析,即审查每个语法成分的静态语义。如 果静态语义正确,则生成与该语言成分等效的中间代码,或者 直接生成目标代码。直接生成机器语言或汇编语言形式的目标 代码的优点是编译时间短且无需中间代码到目标代码的翻译, 而中间代码的优点是使编译结构在逻辑上更为简单明确,特别 是使目标代码的优化比较容易实现。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一节 下推自动机(PDA)
例:试给出接受语言L={ancbn|n>=0}的下推自动机。 解: 1、生成L语言相应文法的产生式为S → aSb|c 2、生成相应的PDA M=(Q ,Σ,H,δ,q0,z0,F) PDA M=({q},{a,b,c},{S,a,b,c}, δ ,q,S,{q}) 其中δ 为:1) δ(q,a,a)= (q, ε) 2) δ(q,b,b)= (q, ε) 3) δ(q,c,c)= (q, ε) 4) δ (q, ε S)={(q,aSb),(q,c)}
1,3
第四章 自上而下语法分析 22
第二节 自上而下分析法的一般问题 二、一般方法
例 文法产生式如下,请分析符号串x*y#的过程 1) S → xAy 2) A →** 3)A → * x*y # # 语法分析程序 语法表
1,3
第四章 自上而下语法分析 23
第二节 自上而下分析法的一般问题 二、一般方法
第四章 自上而下语法分析 30
第二节 自上而下分析法的一般问题 三、不带回溯的自上而下分析算法
3 、消除左递归算法 注:1)此算法适用于消除不含形如P →P的产生式,也不 含以ε为右部的产生式的文法。 2)这里第二步所做的工作是: a)若产生式出现直接左递归则用消除直接左递归的 方法消除掉。 b)若产生式右部最左符号是非终结符且其序号大于 左部的非终结符,则不处理。 c)若序号小于左部的非终结符,则将这序号小的非 终结符用其右部串来取代,然后消除新的直接左递归。
x*y # x A y # 语法分析程序 语法表
1
第四章 自上而下语法分析 16
第二节 自上而下分析法的一般问题 二、一般方法
例 文法产生式如下,请分析符号串x*y#的过程 1) S → xAy 2) A →** 3)A → * x*y # A y # 语法分析程序 语法表
1
第四章 自上而下语法分析 17
例:文法产生式如下,请分析符号串x*y#的过程 1) S → xAy 2) A →** 3)A → *
x*y # 语法分析程序 语法表
S #
输出带
第四章 自上而下语法分析 15
第二节 自上而下分析法的一般问题 二、一般方法
例 文法产生式如下,请分析符号串x*y#的过程 1) S → xAy 2) A →** 3)A → *
第四章 自上而下语法分析 7
back
• 设CFG G=(VN, Σ,P,S),相应的不确定的PDA M=(Q ,Σ,H,δ,q0,z0,F) ,其中: • 1)Q=F={q0}; • 2)H= VN ∪ Σ; • 3) z0 =S; • 4) δ映射关系为: – 对于形如A→ω的产生式,有δ(q, ε,A)=(q, ω),这称为 推导。 – 有 δ(q, a,a)=(q, ε )称为匹配,其中a∈Σ。 • 5)输入串能为PDA所接受,仅当输入串读完,下推栈 为空。
第二节 自上而下分析法的一般问题 二、一般方法
2、算法 (1)若栈顶符号x是非终结符,查询语法表,找出一 个以x作为左பைடு நூலகம்的产生式,x出栈,并将其右部反序 入栈,且输出带记下产生式编号——推导。 (2)若栈顶符号x是终结符,且读头下的符号也是x, 则x出栈,读头指向下一个符号——匹配。 (3)若栈顶符号x是终结符,但读头下的符号不是x, 则匹配失败。这说明可能前面推导时选错了候选式, 退回到上次推导现场(包括栈顶符号、读头的指针和 输出带上信息)——回溯。
第四章 自上而下语法分析 10
第二节 自上而下分析法的一般问题
一、自上而下语法分析定义 – 从文法的开始符号开始,反复使用不同产生式进行 推导以谋求与输入符号串相匹配。 注:此处的输入符号串是指词法分析结果的一串二元式。 二、一般方法 试探法:带回溯的自上而下分析法。
第四章 自上而下语法分析 11
注:4)正规文法和有限自动机仅适合于描述和识别高级 语言的各类单词,语句可用上下文无关文法来描述,而 下推自动机又恰好能识别上下文无关文法所能描述的语 言,因此上下文无关文法及其对应的下推自动机就成为 编译技术中语法分析的理论基础。
第四章 自上而下语法分析 5
第一节 下推自动机(PDA) 二、下推自动机的形式定义
3、带回溯的自上而下分析法的缺陷 1)如果文法存在左递归,语法分析会无限循环下去。 2)若产生式存在多个候选式,选择哪个进行推导完全 是盲目的。 3)回溯会引起时间和空间的大量消耗。 4)如果被识别的语句是错的,算法无法指出错误的确 切位置。
第四章 自上而下语法分析 24
第二节 自上而下分析法的一般问题 三、不带回溯的自上而下分析算法
第四章 自上而下语法分析 13
第二节 自上而下分析法的一般问题 二、一般方法
2、算法 (4)回溯后选取另一候选式进行推导,若没有候选式可 选,则进一步回溯。若回溯到开始符号又已无候选式 可选,则识别失败。 (5)若栈内仅剩下“#”,且读头也指向“#”,则识别成 功。
第四章 自上而下语法分析 14
第二节 自上而下分析法的一般问题 二、一般方法
例 文法产生式如下,请分析符号串x*y#的过程 1) S → xAy 2) A →** 3)A → * x*y # * y # 语法分析程序 语法表
1,3
第四章 自上而下语法分析 21
第二节 自上而下分析法的一般问题 二、一般方法
例 文法产生式如下,请分析符号串x*y#的过程 1) S → xAy 2) A →** 3)A → * x*y # y # 语法分析程序 语法表
第四章 自上而下语法分析
廖力 xobjects@ 3793235
第四章 自上而下语法分析 1
引言
1、语法分析的地位 – 是编译程序的核心部分。 2、语法分析的任务 – 识别由词法分析得出的单词序列是否是给定文法的 句子。 3、语法分析的理论基础 – 上下文无关文法和下推自动机
第四章 自上而下语法分析 2
输入带 输出带
下 推 栈
有限状态 控制器
注:1)PDA和FA的模型相比,多了一个下推栈。 2)PDA的动作由三个因素来决定:当前状态、读头 所指向符号、下推栈栈顶符号。 3)一个输入串能被PDA所接受,仅当输入串读完, 下推栈变空;或输入串读完,控制器到达某些终态。
第四章 自上而下语法分析 4
第一节 下推自动机(PDA) 一、下推自动机模型
1 、消除左递归 • 1)什么是左递归 + – 左递归:文法存在产生式P →Pa – 直接左递归: P →Pa + – 间接左递归: P →Aa , A→Pb • 2)消除左递归 – 消除直接左递归 – 消除间接左递归
第四章 自上而下语法分析 25
第二节 自上而下分析法的一般问题 三、不带回溯的自上而下分析算法
第四章 自上而下语法分析 29
第二节 自上而下分析法的一般问题 三、不带回溯的自上而下分析算法
3 、消除左递归算法 1)把文法G的所有非终结符按任意顺序排列成 P1,P2,…,Pn,然后按此顺序执行步骤2。 2) For (I=1,I<=n,I++) {for (k=1,k<=I-1,k++) {把形如Pi →Pkγ的规则改写为 Pi →δ1 γ |δ 2 γ |……| δn γ /* 其中Pk →δ1| δ2|……| δn*/ } 消除Pi规则的直接左递归;} 3)删去从文法开始符号不可达的非终结符产生式。
第四章 自上而下语法分析 28
第二节 自上而下分析法的一般问题 三、不带回溯的自上而下分析算法
1 、消除左递归 • 1)什么是左递归 + – 左递归:文法存在产生式P →Pa – 直接左递归: P →Pa + – 间接左递归: P →Aa , A→Pb • 2)消除左递归 – 消除直接左递归 – 消除间接左递归
1、定义: PDA是一个七元组:M=(Q ,Σ,H,δ,q0,z0,F) – H:下推栈内字母表 – z0 :下推栈的栈初始符,是H中的元素。 – δ :Q×(Σ ∪{ε})×H到Q×H*的有限子集映射。 例如: δ (q,a,z)={(q1,r1),(q2,r2)……(qn,rn)},其意义 是:设控制器当前状态为q,下推栈顶符号为a,输入符号 为a(可为空),则状态转换到序偶集{(q1,r1),(q2 , r2)……(qn,rn)}(qi为下一状态, ri为代替z的栈顶符号串) – F⊆Q是控制器的终态集
第四章 自上而下语法分析 26
例:文法G: (1)E → E+T|T (2)T → T*F|F (3)F →(E)| i 转化为G`: (1) → E →TE` (2) → T →FT` (3) → F →(E)| i
第四章 自上而下语法分析 27
E` →+TE`| ε T` →*FT`| ε
例:文法G:P → PaPb|BaP 转化为:P →BaPP` P` →aPbP`| ε 注:只有最左边的P参加变换。
第四章 自上而下语法分析 9
aaacbb# 有限状态控制器 输出带
S #
其分析过程: (q,aacbb,S) ┣1(q,aacbb,aSb) ┣(q,acbb,Sb) ┣1(q,acbb,aSbb) ┣(q,cbb,Sbb) ┣2(q,cbb,cbb) ┣(q,bb,bb) ┣(q,b,b) ┣(q, ε, ε)
第四章 自上而下语法分析 6
第一节 下推自动机(PDA) 二、下推自动机的形式定义
注:1)由此定义的PDA肯定是不确定的PDA。这给语法 分析会带来不确定性。我们在构造PDA M的算法的时 候,要对PDA做一些限制。 2) PDA采用“┣”来表示PDA做了一步动作。 3)有时,下推自动机还配置输出带,以记录推导或 归约过程所用的产生式编号。
第二节 自上而下分析法的一般问题 二、一般方法
1、基本构成 设下推栈的初始状态包含两个符号:‘#S’,其中‘#’ 为栈底,‘S’为文法开始符号。整个分析过程在语法分 析程序控制下进行。在语法分析中用到的文法产生式 的表,称为语法表。 a+b……# 语法分析程序 语法表 输出带