Python3速查表
python速查表

Python Basics Hacksheet
文件读写
f = open(filename,mode) | 返回一个文件 对象f,“model = r”表示读文件,“model = w”表示写文件 f.read(size) | 返回包含文件前size个字符 的字符串 f.readline() | 每次读取文件的一行,返回 该行字符串 f.readlines() | 返回包含整个文件内容的列 表,列表的元素为文件的每一行内容所构成的字 符串 f.close() | 关闭文件并释放它所占用的系统 资源
函数
def sum(a,b=1): return a+b
定义求和函数sum(),该函数要求输入位置参数 a,带默认值的参数b为可选参数,其默认值为 1,函数返回结果为a+b的计算结果
sum(1,b=10) | 执行sum()函数,返回结果为11 def sum(*args,**kwargs) | 不定长参数, *args接收包含多个位置参数的元组,**kwargs 接收包含多个关键字参数的字典 obj.methodname | 一个方法是一个“属 于”对象并被命名为obj.methodname的函数
算术运算符
x + 5 | 加,计算结果为7 x - 5 | 减,计算结果为-3 x * 5 | 乘,乘,计算结果为10 x / 5 | 除,Python 2.x版本的计算结果为0, Python 3.x版本的计算结果为0.4 x ** 2 | 幂运算,即 x2,计算结果为4 x += 1 | 将x+1的值赋给x x -= 1 | 将x-1的值赋给x
编码和解码 ASCII | 基于拉丁字母的一套电脑编码系统, 不包含中文、日文等非英语字符
Python3速查表

remove name x …
☝ assignment ⇔ binding of a name with a value 1) evaluation of right side expression value 2) assignment in order with left side names
empty
Non modifiable values (immutables) ☝ expression with only comas →tuple str bytes (ordered sequences of chars / bytes)
'I\'m'
"""X\tY\tZ 1\t2\t3"""
escaped tab ☝ immutables
lst[0]→10 lst[-1]→50
⇒ first one ⇒ last one
lst[1]→20 lst[-2]→40
Access to sub-sequences via lst[start slice:end slice:step]
On mutable sequences (list), remove with del lst[3] and modify with assignment lst[4]=25
☺ ☹
a toto x7 y_max BigOne 8y and for
=
Variables assignment
x=1.2+8+sin(y) a=b=c=0 assignment to same value y,z,r=9.2,-7.6,0 multiple assignments a,b=b,a values swap a,*b=seq unpacking of sequence in *a,b=seq item and list and x+=3 increment ⇔ x=x+3 *= x-=2 /= decrement ⇔ x=x-2 %= x=None « undefined » constant value
Python数据科学速查表 - Seaborn

y="total_bill",
data=tips,
第1步 第3步
aspect=2)
>>> g = (g.set_axis_labels("Tip","Total bill(USD)").
set(xlim=(0,10),ylim=(0,100))) >>> plt.title("title")
第4步
>>> plt.show(g)
>>> h.set(xlim=(0,5), ylim=(0,5), xticks=[0,2.5,5],
设置X与Y轴的限制和刻度
yticks=[0,2.5,5])
图形
>>> plt.title("A Title") >>> plt.ylabel("Survived") >>> plt.xlabel("Sex") >>> plt.ylim(0,100) >>> plt.xlim(0,10) >>> plt.setp(ax,yticks=[0,5]) >>> plt.tight_layout()
绘制条件关系的子图栅格 在分面栅格上绘制分类图 绘制适配分面栅格的数据与回归模型
>>> h = sns.PairGrid(iris) >>> h = h.map(plt.scatter) >>> sns.pairplot(iris) >>> i = sns.JointGrid(x="x",
python列表查询方法

python列表查询方法Python是一种高级编程语言,它提供了许多强大的数据结构和函数,其中之一就是列表。
列表是Python中最常用的数据结构之一,它允许我们存储和操作一组有序的元素。
在本文中,我们将讨论Python 中的列表查询方法。
1. 列表索引列表索引是最基本的列表查询方法之一。
它允许我们通过索引访问列表中的元素。
在Python中,列表的索引从0开始,因此第一个元素的索引为0,第二个元素的索引为1,以此类推。
我们可以使用以下语法来访问列表中的元素:```my_list = [1, 2, 3, 4, 5]print(my_list[0]) # 输出1print(my_list[2]) # 输出3```2. 列表切片列表切片是一种更高级的列表查询方法,它允许我们从列表中获取一个子列表。
我们可以使用以下语法来获取一个子列表:```my_list = [1, 2, 3, 4, 5]print(my_list[1:3]) # 输出[2, 3]```上面的代码将返回一个包含列表中第2个和第3个元素的新列表。
我们可以使用冒号来指定要获取的子列表的起始和结束索引。
请注意,结束索引不包括在结果中。
3. 列表成员运算符列表成员运算符是一种用于测试列表中是否存在特定元素的方法。
它使用in关键字来测试元素是否存在于列表中。
以下是一个例子:```my_list = [1, 2, 3, 4, 5]if 3 in my_list:print("3在列表中")else:print("3不在列表中")上面的代码将输出“3在列表中”,因为3是列表中的一个元素。
4. 列表方法Python提供了许多列表方法,这些方法允许我们对列表进行各种操作。
以下是一些常用的列表方法:- append():在列表末尾添加一个元素- extend():将一个列表中的元素添加到另一个列表中- insert():在指定位置插入一个元素- remove():从列表中删除一个元素- pop():从列表中删除并返回一个元素- index():返回列表中第一个匹配项的索引- count():返回列表中指定元素的出现次数- sort():对列表进行排序- reverse():将列表中的元素反转这些方法可以帮助我们对列表进行各种操作,从而更好地满足我们的需求。
Python Scikit-Learn数据科学速查表说明书

PYTHON FOR DATASCIENCE CHEAT SHEETPython Scikit-LearnP r e p r o c e s s i n gW o r k i n g O n M o d e lP o s t -P r o c e s s i n gI n t r o d u c t i o n•Using NumPy:>>>import numpy as np>>>a=np.array([(1,2,3,4),(7,8,9,10)],dtype=int)>>>data = np.loadtxt('file_name.csv', delimiter=',')•Using Pandas:>>>import pandas as pd>>>df=pd.read_csv file_name.csv ,header =0)D a t a L o a d i n gT r a i n -T e s tD a t aD a t a P r e p a r a t i o n•Standardization>>>from sklearn.preprocessing import StandardScaler>>>get_names = df.columns >>>scaler =preprocessing.StandardScaler()>>>scaled_df = scaler.fit_transform(df)>>>scaled_df =pd.DataFrame(scaled_df, columns=get_names)m•Normalization>>>from sklearn.preprocessing import Normalizer >>>pd.read_csv("File_name.csv")>>>x_array = np.array(df [ Column1 ] #Normalize Column1>>>normalized_X =preprocessing.normalize([x_array])M o d e l C h o o s i n gT r a i n -T e s tD a t aP r e d i c t i o nE v a l u a t e P e r f o r m a n c eUnsupervised Learning Estimator:•Principal Component Analysis (PCA):>>> from sklearn.decomposition import PCA>>> new_pca= PCA(n_components=0.95)•K Means:>>>from sklearn.cluster import KMeans >>> k_means = KMeans(n_clusters=5, random_state=0)Unsupervised :>>> k_means.fit(X_train)>>> pca_model_fit =new_pca.fit_transform(X_train)Supervised Learning Estimator:•Linear Regression:>>>from sklearn.linear_model import LinearRegression >>> new_lr =LinearRegression(normalize=True)•Support Vector Machine:>>> from sklearn.svm import SVC >>> new_svc = SVC(kernel='linear')Supervised:>>>new_ lr.fit(X, y)>>> knn.fit(X_train, y_train)>>>new_svc.fit(X_train, y_train)•Naive Bayes:>>> from sklearn.naive_bayes import GaussianNB>>> new_gnb = GaussianNB()•KNN:>>> from sklearn import neighbors >>>knn=neighbors.KNeighborsClassifier(n_ne ighbors=1)Clustering:1. Homogeneity:>>> from sklearn.metrics import homogeneity_score>>> homogeneity_score(y_true, y_predict)2. V-measure:>>> from sklearn.metrics import v_measure_score>>> metrics.v_measure_score(y_true, y_predict)Regression:1. Mean Absolute Error:>>> from sklearn.metrics import mean_absolute_error >>> y_true = [3, -0.5, 2]>>> mean_absolute_error(y_true, y_predict) 2. Mean Squared Error:>>> from sklearn.metrics import mean_squared_error >>> mean_squared_error(y_test, y_predict) 3. R² Score :>>> from sklearn.metrics import r2_score >>> r2_score(y_true, y_predict)Classification:1. Confusion Matrix:>>> from sklearn.metrics importconfusion_matrix>>> print(confusion_matrix(y_test,y_pred))2. Accuracy Score:>>> knn.score(X_test, y_test) >>> from sklearn.metrics importaccuracy_score>>> accuracy_score(y_test, y_pred)Cross-validation:>>> fromsklearn.cross_validation import cross_val_score >>>print(cross_val_score(knn, X_train, y_train, cv=4))>>>print(cross_val_score(new_lr, X, y, cv=2))Scikit-learn :“sklearn" is a machine learning library for the Python programming language. Simple and efficient tool for data mining, Data analysis and Machine Learning.Importing Convention -import sklearn>>>from sklearn.model_selection import train_test_split>>> X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)M o d e l T u n i n gGrid Search:>>> from sklearn.grid_search import GridSearchCV>>> params = {"n_neighbors": np.arange(1,3), "metric":["euclidean", "cityblock"]}>>> grid = GridSearchCV(estimator=knn, param_grid=params)>>> grid.fit(X_train, y_train)>>> print(grid.best_score_)>>> print(grid.best_estimator_.n_neighbors)Randomized Parameter Optimization:>>> from sklearn.grid_search import RandomizedSearchCV >>> params = {"n_neighbors": range(1,5), "weights": ["uniform", "distance"]}>>> rsearch = RandomizedSearchCV(estimator=knn,param_distributions=params, cv=4, n_iter=8, random_state=5)>>> rsearch.fit(X_train, y_train)>>> print(rsearch.best_score_)Supervised:>>>y_predict =new_svc.predict(np.random.random((3,5)))>>>y_predict = new_lr.predict(X_test)>>>y_predict = knn.predict_proba(X_test)Unsupervised:>>>y_pred = k_means.predict(X_test)FURTHERMORE:Python for Data Science Certification Training Course。
python3+selenium获取列表某一列的值
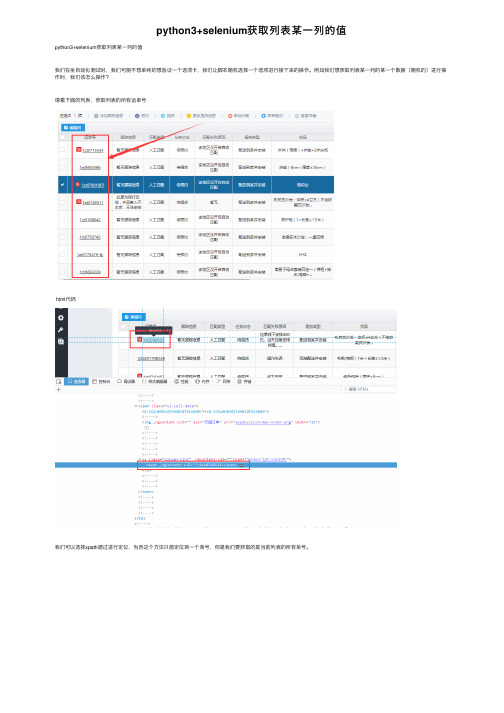
python3+selenium获取列表某⼀列的值python3+selenium获取列表某⼀列的值我们在坐⾃动化测试时,我们可能不想单纯的想验证⼀个选项卡,我们让脚本随机选择⼀个选项进⾏接下来的操作。
例如我们想获取列表某⼀列的某⼀个数据(随机的)进⾏操作时,我们该怎么操作?请看下⾯的列表,获取列表的所有运单号html代码我们可以选择xpath通过进⾏定位,当然这个⽅法只能定位到⼀个单号,但是我们要获取的是当前列表的所有单号。
我们复制下来的⼩path 的内容是 '/html/body/app-root/app-root/ips-root/div[2]/ng-component/ng-component/div/div[3]/ui-grid/p-datatable/div/div[2]/div/div[2]/div/table/tbody/tr[1]/td[2]/span/a/span'上⾯是我们复制第⼀个单号的,接下来我们复制第⼆个单号的xpath路径:'/html/body/app-root/app-root/ips-root/div[2]/ng-component/ng-component/div/div[3]/ui-grid/p-datatable/div/div[2]/div/div[2]/div/table/tbody/tr[2]/td[2]/span/a/span'此时我们仔细观察就会发现,这两个xpath只有⼩部分东西会变那就是最后⾯的tr[1]在变,所以我们把tr[1]中的“[1]”去掉就⾏了。
接下来我们可以通过遍历和.text的⽅法进⾏打印了。
注:⼤家可以看到我截图⾥⾯的代码,我是进⾏了两次定位,只定位⼀次并使⽤.text进⾏打印时是会报错的,其实我也想不明⽩,如果有⼤神看到,请指点⼀下。
python查询语句

python查询语句Python是一种高级编程语言,它支持各种数据库,包括MySQL、Oracle、SQLite、PostgreSQL等。
在Python中使用查询语句可以从数据库中检索所需的数据。
Python中的查询语句主要使用SQL(Structured Query Language)语言,它是一种用于管理关系型数据库的标准语言。
以下是Python中使用SQL查询语句的一些示例:1. 查询表中的所有数据使用SELECT语句可以查询表中的所有数据。
例如,要查询名为“students”的表中的所有数据,可以执行以下查询语句:```SELECT * FROM students;```2. 查询特定列的数据若只需要查询表中特定列的数据,可以使用SELECT语句并指定要查询的列名。
例如,要查询名为“students”的表中学生的姓名和年龄,可以执行以下查询语句:```SELECT name, age FROM students;```3. 查询满足特定条件的数据使用WHERE子句可以查询满足特定条件的数据。
例如,要查询名为“students”的表中年龄大于等于18岁的学生,可以执行以下查询语句:```SELECT * FROM students WHERE age >= 18;```4. 对结果进行排序使用ORDER BY子句可以对查询结果进行排序。
例如,要查询名为“students”的表中学生的年龄,并按照年龄从小到大排序,可以执行以下查询语句:```SELECT age FROM students ORDER BY age ASC;```5. 使用通配符查询数据使用通配符(%)可以模糊匹配数据。
例如,要查询名为“students”的表中所有姓名以“J”开头的学生,可以执行以下查询语句:```SELECT * FROM students WHERE name LIKE 'J%';```以上是Python中使用SQL查询语句的一些常用示例。
Python内置函数速查表一览

Python内置函数速查表⼀览如下所⽰:函数功能abs(x)返回⼀个数的绝对值。
参数可以是⼀个整数或浮点数。
如果参数是⼀个复数,则返回它的模。
all(iterable)如果 iterable 的所有元素为真(或迭代器为空),返回 Trueany(iterable)如果 iterable 的任⼀元素为真则返回 True。
如果迭代器为空,返回 False ascii(object)返回⼀个表⽰对象的字符串bin(x)将⼀个整数转变为⼀个前缀为“0b”的⼆进制字符串bool([x])返回⼀个布尔值,True 或者 False。
breakpoint(*args, **kws)此函数将您放⼊调⽤站点的调试器中bytearray([source[, encoding[, errors]]])返回⼀个新的 bytes 数组bytes([source[, encoding[, errors]]])返回⼀个新的“bytes”对象callable(object)如果参数 object 是可调⽤的就返回 True,否则返回 Falsechar(i)返回 Unicode 码位为整数 i 的字符的字符串格式@classmethod把⼀个⽅法封装成类⽅法compile(source, filename, mode, flags=0,dont_inherit=False, optimize=-1)将 source 编译成代码或 AST 对象complex([real[, imag]])返回值为 real + imag*1j 的复数,或将字符串或数字转换为复数delattr(object, name)如果对象允许,该函数将删除指定的属性dict(**kwarg) dict(mapping, **kwarg) dict(iterable,**kwarg)创建⼀个新的字典dir([object])如果没有实参,则返回当前本地作⽤域中的名称列表。
计算机编程语言速查表

计算机编程语言速查表C语言:- 定义变量:`数据类型变量名;`- 赋值:`变量名 = 值;`- 条件语句: `if (条件) { 执行语句; } else { 其他执行语句; }`- 循环语句: `for (初始化; 条件; 递增) { 执行语句; }`- 函数定义: `返回类型函数名(参数列表) { 执行语句; return 返回值; }`Java语言:- 定义变量:`数据类型变量名 = 值;`- 赋值:`变量名 = 值;`- 条件语句: `if (条件) { 执行语句; } else { 其他执行语句; }`- 循环语句: `for (初始化; 条件; 递增) { 执行语句; }`- 函数定义: `返回类型函数名(参数列表) { 执行语句; return 返回值; }`Python语言:- 定义变量:`变量名 = 值`- 赋值:`变量名 = 值`- 条件语句: `if 条件: 执行语句 else: 其他执行语句`- 循环语句: `for 变量名 in 序列: 执行语句`- 函数定义: `def 函数名(参数列表): 执行语句 return 返回值`JavaScript语言:- 定义变量:`var 变量名 = 值;`- 赋值:`变量名 = 值;`- 条件语句: `if (条件) { 执行语句; } else { 其他执行语句; }`- 循环语句: `for (初始化; 条件; 递增) { 执行语句; }`- 函数定义: `function 函数名(参数列表) { 执行语句; return 返回值; }`总结:编程语言在语法和结构上有所不同,但核心概念相似。
不同的编程语言适用于不同的应用场景,根据项目需求选择合适的编程语言是开发者的重要任务之一。
编程语言速查表可以帮助开发者在需要时快速查找语言特定的语法和用法,提高开发效率。
熟悉不同编程语言的语法和特性,可以使开发者更加灵活地应对各种编程挑战,实现高效的编程工作。
python3自学速查手册

python3自学速查手册《Python3自学速查手册》是一本非常全面的Python3学习手册,包含了Python3的各个方面。
以下是一些主要章节的概述:1. Python3教程:这个章节将介绍Python3的基本概念,包括变量、数据类型、控制流等。
2. Python3基础语法:这个章节将深入探讨Python3的语法,包括函数、模块、类等。
3. 基本数据类型:这个章节将介绍Python3中的基本数据类型,包括数字、字符串、列表、元组和字典等。
4. 解释器:这个章节将介绍Python3的解释器,包括其工作原理和如何使用。
5. 注释:这个章节将介绍如何使用注释来提高代码的可读性。
6. 运算符:这个章节将介绍Python3中的运算符,包括算术运算符、比较运算符和逻辑运算符等。
7. 数字(Number):这个章节将深入探讨Python3中的数字类型,包括整数和浮点数。
8. 字符串:这个章节将深入探讨Python3中的字符串类型,包括字符串的创建、切片和格式化等。
9. 列表:这个章节将深入探讨Python3中的列表类型,包括列表的创建、修改和遍历等。
10. 元组:这个章节将深入探讨Python3中的元组类型,包括元组的创建、修改和遍历等。
11. 字典:这个章节将深入探讨Python3中的字典类型,包括字典的创建、修改和遍历等。
12. 编程第一步:这个章节将介绍如何使用Python3编写一个简单的程序,包括程序的输入和输出。
13. 条件控制:这个章节将介绍如何使用条件语句来控制程序的流程。
14. 循环语句:这个章节将介绍如何使用循环语句来重复执行一段代码。
15. 迭代器与生成器:这个章节将介绍迭代器和生成器的概念,以及如何使用它们来遍历集合和生成序列。
16. 函数:这个章节将深入探讨Python3中的函数,包括函数的定义、参数传递和返回值等。
17. 数据结构:这个章节将介绍Python3中的常见数据结构,包括栈、队列和优先队列等。
python 读取excel表格数据方法

文章标题:Python读取Excel表格数据方法详解一、背景介绍Excel表格是我们日常生活和工作中经常使用的一种数据存储和处理工具。
在使用Python进行数据分析或处理时,我们经常会遇到需要读取Excel表格数据的情况。
本文将介绍如何使用Python读取Excel表格数据的方法,以及一些常用的技巧和注意事项。
二、使用openpyxl库读取Excel表格数据openpyxl是一个Python库,可以用来读取和写入Excel文件。
下面是使用openpyxl库读取Excel表格数据的方法:1. 安装openpyxl库我们需要安装openpyxl库。
在命令行中输入以下命令来安装openpyxl:```pip install openpyxl```2. 打开Excel文件使用openpyxl库可以使用以下代码打开一个Excel文件:```pythonfrom openpyxl import load_workbookwb = load_workbook('example.xlsx')```这样就可以打开名为example.xlsx的Excel文件。
3. 选择工作表接下来,我们需要选择要操作的工作表。
可以使用以下代码选择一个工作表:```pythonws = wb['Sheet1']```这样就可以选择名为Sheet1的工作表。
4. 读取数据一旦选择了工作表,就可以使用openpyxl库来读取其中的数据。
以下代码展示了如何读取单元格的数据:```pythoncell_value = ws['A1'].value```这样就可以获取A1单元格的数据。
5. 遍历数据除了读取单元格的数据外,我们还可以遍历整个工作表来获取所有数据。
以下是遍历整个工作表的示例代码:```pythonfor row in ws.iter_rows(values_only=True):for cell in row:print(cell)```这样就可以遍历并打印出整个工作表中的数据。
python 解析 excel 方法

Python中有许多库可以解析Excel文件,其中最常用的是pandas和openpyxl。
使用pandas库解析Excel文件的方法如下:1.安装pandas库:可以使用pip命令安装,如pip install pandas。
2.导入pandas库:在代码中添加import pandas as pd。
3.读取Excel文件:使用pd.read_excel()函数读取Excel文件,例如df =pd.read_excel('example.xlsx')。
4.处理数据:可以使用pandas提供的方法对数据进行处理,例如筛选、排序、分组等。
5.保存数据:可以使用to_excel()函数将处理后的数据保存为Excel文件,例如df.to_excel('example_processed.xlsx')。
使用openpyxl库解析Excel文件的方法如下:1.安装openpyxl库:可以使用pip命令安装,如pip install openpyxl。
2.导入openpyxl库:在代码中添加from openpyxl import load_workbook。
3.读取Excel文件:使用load_workbook()函数读取Excel文件,例如wb =load_workbook('example.xlsx')。
4.获取工作表:使用wb['Sheet1']获取名为"Sheet1"的工作表,也可以使用工作表的索引号获取工作表。
5.处理数据:可以使用openpyxl提供的方法对数据进行处理,例如读取单元格的值、修改单元格的值等。
6.保存数据:使用save()函数将修改后的工作簿保存为Excel文件,例如wb.save('example_processed.xlsx')。
python的正则表达式速查表与实操手册

正则表达式是一种强大的文本匹配工具,它可以用来搜索、替换和分析文本数据。
Python作为一种流行的编程语言,内置了正则表达式模块re,通过使用re模块,我们可以在Python中轻松地实现正则表达式的功能。
本文将为大家提供Python的正则表达式速查表与实操手册,帮助大家更好地掌握Python正则表达式的用法。
一、基本概念1. 正则表达式的概念正则表达式是用来描述字符串匹配模式的一种工具,它由普通字符和特殊字符组成,可以用来匹配和查找字符串中的特定模式。
2. re模块的使用Python中的re模块为我们提供了操作正则表达式的功能,通过使用re模块,我们可以实现字符串的匹配、查找、替换等操作。
二、基本语法1. 匹配单个字符- .:匹配任意字符(除了换行符)- [ ]:匹配方括号中的任意一个字符- \d:匹配数字- \s:匹配空白字符- \w:匹配字母、数字、下划线2. 匹配多个字符- *:匹配前面的字符0次或多次- +:匹配前面的字符1次或多次- ?:匹配前面的字符0次或1次- {m}:匹配前面的字符m次- {m,n}:匹配前面的字符m到n次3. 边界匹配- ^:匹配字符串开头- $:匹配字符串结尾- \b:匹配单词边界4. 分组和引用- ( ):用来表示一组字符- |:表示或关系- \1, \2:引用匹配到的内容三、实操手册1. 匹配字符串import repattern = 'foo'text = 'foobaz'match = re.match(pattern, text)if match:print('匹配成功', match.group())else:print('匹配失败')2. 查找字符串pattern = 'foo'text = 'foobazfoo'matches = re.findall(pattern, text)for match in matches:print('匹配成功', match)3. 替换字符串pattern = 'foo'text = 'foobazfoo'new_text = re.sub(pattern, 'bar', text)print('替换后的文本', new_text)通过以上实操手册的例子,我们可以清楚地了解到Python中正则表达式的使用方法。
Python3最常用函数(备用查询)

Python3最常用函数(备用查询)介绍•Python ()•Learn X in Y minutes ()•Regex in python (quickref.me)Hello World>>> print('Hello, World!')Hello, World!Python 中著名的“Hello World”程序变量age = 18 # 年龄是 int 类型name = 'John' # name 现在是str 类型print(name)Python 不能在没有赋值的情况下声明变量数据类型str Textint, float, complex Numericlist, tuple, range Sequencedict Mappingset, frozenset Setbool Booleanbytes, bytearray, memoryview Binary查看: Data TypesSlicing String>>> msg = 'Hello, World!'>>> print(msg[2:5])llo查看: StringsListsmylist = []mylist.append(1)mylist.append(2)for item in mylist:print(item) # 打印输出 1,2查看: ListsIf Elsenum = 200if num > 0: print('num is greater than 0')else: print('num is not greater than 0')查看: 流程控制循环for item in range(6): if item == 3: break print(item)else: print('Finally finished!')查看: Loops函数>>> def my_function():... print('来自函数的你好')...>>> my_function()来自函数的你好查看: Functions文件处理with open('myfile.txt', 'r', encoding='utf8') as file: for line in file: print(line)查看: 文件处理算术result = 10 + 30 # => 40result = 40 - 10 # => 30result = 50 * 5 # => 250result = 16 / 4 # => 4.0 (Float Division)result = 16 // 4 # => 4 (Integer Division)result = 25 % 2 # => 1result = 5 ** 3 # => 125/ 表示 x 和 y 的商,// 表示 x 和 y 的底商,另见 StackOverflow 加等于counter = 0counter += 10 # => 10counter = 0counter = counter + 10 # => 10message = 'Part 1.'# => Part 1.Part 2.message += 'Part 2.'f-字符串(Python 3.6+)>>> website = 'Quickref.ME'>>> f'Hello, {website}''Hello, Quickref.ME'>>> num = 10>>> f'{num} + 10 = {num + 10}''10 + 10 = 20'查看: Python F-StringsPython 数据类型字符串hello = 'Hello World'hello = 'Hello World'multi_string = '''Multiline StringsLorem ipsum dolor sit amet,consectetur adipiscing elit '''查看: Strings数字x = 1 # inty = 2.8 # floatz = 1j # complex>>> print(type(x))<class 'int'>布尔值my_bool = True my_bool = Falsebool(0) # => Falsebool(1) # => TrueListslist1 = ['apple', 'banana', 'cherry']list2 = [True, False, False]list3 = [1, 5, 7, 9, 3]list4 = list((1, 5, 7, 9, 3))查看: Lists元组 Tuplemy_tuple = (1, 2, 3)my_tuple = tuple((1, 2, 3))类似于 List 但不可变Setset1 = {'a', 'b', 'c'} set2 = set(('a', 'b', 'c'))一组独特的项目/对象字典 Dictionary>>> empty_dict = {}>>> a = {'one': 1, 'two': 2, 'three': 3}>>> a['one']1>>> a.keys()dict_keys(['one', 'two', 'three'])>>> a.values()dict_values([1, 2, 3])>>> a.update({'four': 4})>>> a.keys()dict_keys(['one', 'two', 'three', 'four'])>>> a['four']4Key:值对,JSON 类对象Casting整数 Integersx = int(1) # x 将是 1y = int(2.8) # y 将是 2z = int('3') # z 将是3浮点数 Floatsx = float(1) # x 将为 1.0y = float(2.8) # y 将是 2.8z = float('3') # z 将为 3.0w = float('4.2') # w 将是 4.2字符串 Stringsx = str('s1') # x 将是 's1'y = str(2) # y 将是 '2'z = str(3.0) # z 将是 '3.0'Python 字符串类数组>>> hello = 'Hello, World'>>> print(hello[1])e>>>print(hello[-1])d获取位置 1 或最后的字符循环>>> for char in 'foo':... print(char)foo遍历单词 foo 中的字母切片字符串┌───┬───┬───┬───┬───┬───┬───┐ | m | y | b | a | c | o | n | └───┴───┴───┴───┴───┴───┴───┘ 0 1 2 3 4 5 6 7-7 -6 -5 -4 -3 -2 -1>>> s = 'mybacon'>>> s[2:5]'bac'>>> s[0:2]'my'>>> s = 'mybacon'>>> s[:2]'my'>>> s[2:]'bacon'>>> s[:2] + s[2:]'mybacon'>>> s[:]'mybacon'>>> s = 'mybacon'>>> s[-5:-1]'baco'>>> s[2:6]'baco'迈着大步>>> s = '12345' * 5>>> s'1234512345123451234512345'>>> s[::5]'11111'>>> s[4::5]'55555'>>> s[::-5]'55555'>>> s[::-1]'5432154321543215432154321'字符串长度>>> hello = 'Hello, World!'>>> print(len(hello))13len() 函数返回字符串的长度多份>>> s = '===+'>>> n = 8>>> s * n'===+===+===+===+===+===+===+===+'检查字符串>>> s = 'spam'>>> s in 'I saw spamalot!'True>>> s not in 'I saw The Holy Grail!'True连接>>> s = 'spam'>>> t = 'egg'>>> s + t'spamegg'>>> 'spam' 'egg''spamegg'格式化name = 'John'print('Hello, %s!' % name)name = 'John'age = 23print('%s is %d years old.' % (name, age))format() 方法txt1 = 'My name is {fname}, I'm {age}'.format(fname='John', age=36)txt2 = 'My name is {0}, I'm {1}'.format('John', 36)txt3 = 'My name is {}, I'm {}'.format('John', 36)Input 输入>>> name = input('Enter your name: ')Enter your name: Tom>>> name'Tom'从控制台获取输入数据Join 加入>>> '#'.join(['John', 'Peter', 'Vicky'])'John#Peter#Vicky' Endswith 以..结束>>> 'Hello, world!'.endswith('!')TruePython F 字符串(自 Python 3.6+ 起)f-Strings 用法>>> website = 'Reference'>>> f'Hello, {website}''Hello, Reference'>>> num = 10>>> f'{num} + 10 = {num + 10}''10 + 10 = 20'>>> f'''He said {'I'm John'}''''He said I'm John'>>> f'5 {'{stars}'}''5 {stars}'>>> f'{{5}} {'stars'}''{5} stars'>>> name = 'Eric'>>> age = 27>>> f'''Hello!... I'm {name}.... I'm {age}.''''Hello!\n I'm Eric.\n I'm 27.'它从 Python 3.6 开始可用,另见: 格式化的字符串文字f-Strings 填充对齐>>> f'{'text':10}' # [宽度]'text '>>> f'{'test':*>10}' # 向左填充'******test'>>> f'{'test':*<10}' # 填写正确'test******'>>> f'{'test':*^10}' # 填充中心'***test***'>>> f'{12345:0>10}' # 填写数字'0000012345'f-Strings 类型>>> f'{10:b}' # binary 二进制类型'1010'>>> f'{10:o}' # octal 八进制类型'12'>>> f'{200:x}' # hexadecimal 十六进制类型'c8'>>> f'{200:X}''C8'>>> f'{345600000000:e}' # 科学计数法'3.456000e+11'>>> f'{65:c}' # 字符类型'A'>>> f'{10:#b}' # [类型] 带符号(基础)'0b1010'>>> f'{10:#o}''0o12'>>> f'{10:#x}''0xa' F-Strings Sign>>> f'{12345:+}' # [sign] (+/-)'+12345'>>> f'{-12345:+}''-12345'>>> f'{-12345:+10}'' -12345'>>> f'{-12345:+010}''-000012345'F-Strings 其它>>> f'{-12345:0=10}' # 负数'-000012345'>>> f'{12345:010}' # [0] 快捷方式(不对齐)'0000012345'>>> f'{-12345:010}''-000012345'>>> import math # [.precision]>>> math.pi3.141592653589793>>> f'{math.pi:.2f}''3.14'>>> f'{1000000:,.2f}' # [分组选项]'1,000,000.00'>>> f'{1000000:_.2f}''1_000_000.00'>>> f'{0.25:0%}' # 百分比'25.000000%'>>> f'{0.25:.0%}''25%'Python Lists定义>>> li1 = []>>> li1[]>>> li2 = [4, 5, 6]>>> li2[4, 5, 6]>>> li3 = list((1, 2, 3))>>> li3[1, 2, 3]>>> li4 = list(range(1, 11))>>> li4[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]生成>>> list(filter(lambda x : x % 2 == 1, range(1, 20)))[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]>>> [x ** 2 for x in range (1, 11) if x % 2 == 1][1, 9, 25, 49, 81]>>> [x for x in [3, 4, 5, 6, 7] if x > 5][6, 7]>>> list(filter(lambda x: x > 5, [3, 4, 5, 6, 7]))[6, 7]添加>>> li = []>>> li.append(1)>>> li[1]>>> li.append(2)>>> li[1, 2]>>> li.append(4)>>> li[1, 2, 4]>>> li.append(3)>>> li[1, 2, 4, 3]List 切片列表切片的语法:a_list[start:end]a_list[start:end:step]切片>>> a = ['spam', 'egg', 'bacon', 'tomato', 'ham', 'lobster']>>> a[2:5]['bacon', 'tomato', 'ham']>>> a[-5:-2]['egg', 'bacon','tomato']>>> a[1:4]['egg', 'bacon', 'tomato']省略索引>>> a[:4]['spam', 'egg', 'bacon', 'tomato']>>> a[0:4]['spam', 'egg', 'bacon', 'tomato']>>> a[2:]['bacon', 'tomato', 'ham', 'lobster']>>> a[2:len(a)]['bacon', 'tomato', 'ham', 'lobster']>>> a['spam', 'egg', 'bacon', 'tomato', 'ham', 'lobster']>>> a[:]['spam', 'egg', 'bacon', 'tomato', 'ham', 'lobster']迈着大步['spam', 'egg', 'bacon', 'tomato', 'ham', 'lobster']>>> a[0:6:2]['spam', 'bacon', 'ham']>>> a[1:6:2]['egg', 'tomato', 'lobster']>>> a[6:0:-2]['lobster', 'tomato', 'egg']>>> a['spam', 'egg', 'bacon', 'tomato', 'ham', 'lobster']>>> a[::-1]['lobster', 'ham', 'tomato', 'bacon', 'egg', 'spam']删除>>> li = ['bread', 'butter', 'milk']>>> li.pop()'milk'>>> li['bread', 'butter']>>> del li[0]>>> li['butter']使用权>>> li = ['a', 'b', 'c', 'd']>>> li[0]'a'>>> li[-1]'d'>>> li[4]Traceback (most recent call last): File '<stdin>', line 1, in <module>IndexError: list index out of range连接>>> odd = [1, 3, 5]>>> odd.extend([9, 11, 13])>>> odd[1, 3, 5, 9, 11, 13]>>> odd = [1, 3, 5]>>> odd + [9, 11, 13][1, 3, 5, 9, 11, 13]排序和反转>>> li = [3, 1, 3, 2, 5]>>> li.sort()>>> li[1, 2, 3, 3, 5]>>> li.reverse()>>> li[5, 3, 3, 2, 1]计数>>> li = [3, 1, 3, 2, 5]>>> li.count(3)2重复>>> li = ['re'] * 3>>> li['re', 're', 're']Python 流程控制基本num = 5if num > 10: print('num is totally bigger than 10.')elif num < 10: print('num is smaller than 10.')else: print('num is indeed 10.')一行>>> a = 330>>> b = 200>>> r = 'a' if a > b else 'b'>>> print(r)aelse ifvalue = Trueif not value: print('Value is False')elif value is None: print('Value is None')else: print('Value is True')Python 循环基础primes = [2, 3, 5, 7]for prime in primes: print(prime)有索引animals = ['dog', 'cat', 'mouse']for i, value in enumerate(animals): print(i, value)Whilex = 0while x < 4: print(x) x += 1 # Shorthand for x = x + 1Breakx = 0for index in range(10): x = index * 10 if index == 5: break print(x)Continuefor index in range(3, 8): x = index * 10 if index == 5: continue print(x)范围for i in range(4): print(i) # Prints: 0 1 2 3for i in range(4, 8): print(i) # Prints: 4 5 6 7for i in range(4, 10, 2): print(i) # Prints: 4 6 8使用 zip()name = ['Pete', 'John', 'Elizabeth']age = [6, 23, 44]for n, a in zip(name, age): print('%s is %d years old' %(n, a))列表理解result = [x**2 for x in range(10) if x % 2 == 0] print(result)# [0, 4, 16, 36, 64]Python 函数基础def hello_world(): print('Hello, World!')返回def add(x, y): print('x is %s, y is %s' %(x, y)) return x + yadd(5, 6) # => 11位置参数def varargs(*args): return argsvarargs(1, 2, 3) # => (1, 2, 3) 关键字参数def keyword_args(**kwargs): return kwargs# => {'big': 'foot', 'loch': 'ness'}keyword_args(big='foot', loch='ness')返回多个def swap(x, y): return y, xx = 1y = 2x, y = swap(x, y) # => x = 2, y = 1默认值def add(x, y=10): return x + yadd(5) # => 15add(5, 20) # => 25匿名函数# => True(lambda x: x > 2)(3)# => 5(lambda x, y: x ** 2 + y ** 2)(2, 1)Python 模块导入模块import mathprint(math.sqrt(16)) # => 4.0从一个模块导入from math import ceil, floorprint(ceil(3.7)) # => 4.0print(floor(3.7)) # => 3.0全部导入from math import *缩短模块import math as m# => Truemath.sqrt(16) == m.sqrt(16)功能和属性import mathdir(math)Python 文件处理读取文件逐行with open('myfile.txt') as file: for line in file: print(line) 带行号file = open('myfile.txt', 'r')for i, line in enumerate(file, start=1): print('Number %s: %s' % (i, line))字符串写一个字符串contents = {'aa': 12, 'bb': 21}with open('myfile1.txt', 'w+') as file: file.write(str(contents))读取一个字符串with open('myfile1.txt', 'r+') as file: contents = file.read()print(contents)对象写一个对象contents = {'aa': 12, 'bb': 21}with open('myfile2.txt', 'w+') asfile: file.write(json.dumps(contents))读取对象with open('myfile2.txt', 'r+') as file: contents = json.load(file)print(contents)删除文件import osos.remove('myfile.txt')检查和删除import osif os.path.exists('myfile.txt'): os.remove('myfile.txt')else: print('The file does not exist')删除文件夹import osos.rmdir('myfolder')Python 类和继承Definingclass MyNewClass: pass# Class Instantiationmy = MyNewClass()构造函数class Animal: def __init__(self, voice): self.voice = voice cat = Animal('Meow')print(cat.voice) # => Meow dog = Animal('Woof') print(dog.voice) # => Woof方法class Dog: # 类的方法 def bark(self): print('Ham-Ham') charlie = Dog()charlie.bark() # => 'Ham-Ham'类变量class MyClass: class_variable = 'A class variable!'# => 一个类变量!print(MyClass.class_variable)x = MyClass() # => 一个类变量!print(x.class_variable)Super() 函数class ParentClass: def print_test(self): print('Parent Method') class ChildClass(ParentClass): def print_test(self): print('Child Method') # 调用父级的 print_test() super().print_test()>>> child_instance = ChildClass()>>> child_instance.print_test()Child MethodParent Methodrepr() 方法class Employee: def __init__(self, name): = name def __repr__(self): return john = Employee('John')print(john) # => John用户定义的异常class CustomError(Exception): pass多态性class ParentClass: def print_self(self): print('A') class ChildClass(ParentClass): def print_self(self): print('B') obj_A = ParentClass()obj_B = ChildClass() obj_A.print_self() # => Aobj_B.print_self() # => B覆盖class ParentClass: def print_self(self): print('Parent') class ChildClass(ParentClass): def print_self(self): print('Child') child_instance = ChildClass()child_instance.print_self() # => Child 继承class Animal: def __init__(self, name, legs): = name self.legs = legs class Dog(Animal): def sound(self): print('Woof!') Yoki = Dog('Yoki', 4)print() # => YOKIprint(Yoki.legs) # => 4Yoki.sound() # => Woof!各种各样的注释# 这是单行注释''' 可以写多行字符串使用三个',并且经常使用作为文档。
python excel 筛选表格

主题:使用Python对Excel表格进行筛选与处理随着信息化时代的到来,数据处理和分析已经成为许多行业中不可或缺的一部分。
而Excel作为最常用的表格处理工具之一,其功能强大,综合,受到了广泛的应用。
而Python作为一种快速、简单、灵活的编程语言,也受到了许多数据分析师和工程师的青睐。
在实际工作中,很多时候我们需要对Excel表格进行筛选和处理,而Python可以帮助我们更高效地完成这些任务。
1. Python对Excel的基本操作在进行Excel表格筛选和处理之前,首先需要了解Python对Excel的基本操作。
Python中有许多库可以用来处理Excel表格,比如pandas、openpyxl、xlrd等。
其中,pandas是一种数据处理和分析的库,具有强大的功能和灵活的操作方式,因此在Excel表格处理中得到了广泛的应用。
2. 使用pandas库进行Excel表格的筛选在使用pandas库对Excel表格进行筛选时,首先需要使用pandas的read_excel()函数将Excel表格读入到Python中,然后利用pandas提供的数据操作和筛选功能对表格进行处理。
可以使用loc[]函数对表格进行条件筛选,使用dropna()函数对缺失值进行处理,使用sort_values()函数对表格进行排序等等。
3. 利用Python进行复杂条件的筛选和处理除了简单的条件筛选之外,有时候我们还需要对Excel表格进行复杂的条件筛选和处理。
需要根据多个条件进行筛选,需要对多个列进行处理,需要进行逻辑运算等等。
在这种情况下,可以利用Python的逻辑运算和函数式编程的特性来完成这些复杂的任务,从而提高工作效率。
4. 将筛选后的结果写入到新的Excel表格在对Excel表格进行筛选和处理之后,有时还需要将处理后的结果写入到新的Excel表格中。
这时可以使用pandas的to_excel()函数将处理后的结果保存为新的Excel表格。
python3 数字类型详解

python3 数字类型详解Python 3 中的数字类型包括整数(int)、浮点数(float)、复数(complex)和布尔值(bool)。
让我们逐一来详细解释这些类型。
首先是整数类型(int)。
在Python 3中,整数没有大小限制,可以是正数、负数或零。
整数可以直接进行加减乘除运算,而且支持整数除法(//)、取余(%)和幂运算()。
整数类型还支持位运算,如按位与(&)、按位或(|)、按位取反(~)等。
其次是浮点数类型(float)。
浮点数用于表示带有小数点的数字。
Python中的浮点数采用双精度浮点数格式,因此支持非常大范围的数值,同时也具有一定的精度。
浮点数可以进行加减乘除运算,但由于浮点数的特性,可能会出现精度问题,因此在比较浮点数时需要谨慎处理。
第三种是复数类型(complex)。
复数由实部和虚部构成,虚部用"j"或"J"表示。
Python中使用"j"来表示虚部,例如3+5j。
复数类型支持复数的加减乘除运算,以及复数的共轭、取模等操作。
最后是布尔值类型(bool)。
布尔值只有两个取值,True和False。
布尔类型通常用于逻辑运算和条件判断,例如if语句中的条件判断就会返回布尔值True或False。
除了以上基本的数字类型外,Python 3还提供了丰富的数学运算库(如math、cmath等),可以进行各种数学运算和复杂的数学操作。
另外,Python 3还支持类型转换,可以通过int()、float()、complex()等函数将其他类型转换为数字类型。
总的来说,Python 3提供了强大而灵活的数字类型,能够满足各种数值计算和处理的需求。
希望以上内容能够全面地解释了Python 3中的数字类型。
整理)python操作excel

整理)python操作excel.Python操作Excel老婆单位有时候有一些很大的Excel统计报表需要处理,其中最恶心的是跨表的JOIN查询。
他们通常采取的做法是,把多个Excel工作簿合成一个工作簿的多个表格,然后再跑函数(VLOOKUP之类)去查。
因为用的函数效率很低,在CPU打满的情况下还要跑几个小时。
为了优化这个过程,作者采用Python+SQLite实现,效果不错。
Python操作Excel的函数库作者主要尝试了3种读写Excel的方法:xlrd、xlwt、xlutils。
其中,xlrd可以读取.xls和.xlsx文件,且效率较高,因此作者选择了它来读取Excel文件;而最终输出的报表格式较复杂,直接操作Excel文件。
Python里的关系型数据库SQLite是一个非常轻量级的关系型数据库,很多语言和平台都内置SQLite支持,也是iOS和Android上的默认数据库。
Python的标准___也包含了sqlite3库,用起来非常方便。
作者将xlrd读取到的Excel数据插入到SQLite数据库中,实现了数据的快速查询和统计。
用xlrd读取Excel并插入数据库样例作者提供了用xlrd读取Excel并插入到SQLite数据库的样例代码,方便读者研究和使用。
device_id。
city))保存更改mit()关闭数据库连接device_city_db.close()如果数据量较小,可以直接使用Python内部的数据结构,如字典和列表。
但是,如果要读取的表格数据量较大,最好先将数据插入数据库进行预处理。
这样可以避免每次调试都要进行耗时较长的Excel文件载入过程,同时也能充分利用数据库的索引和SQL语句强大功能进行快速数据分析。
下面是一个使用SQLite数据库进行数据处理的示例代码。
首先,我们需要打开数据库文件,并创建一个名为device_city的表格。
然后,我们逐行读取设备表格中的数据,并将设备ID和城市信息插入到device_city表格中。
python excel sheet的调用

python excel sheet的调用如何使用Python调用Excel表格导语:Excel表格在日常工作中广泛使用,而Python作为一种强大的编程语言,提供了很多库和工具,可以方便地处理Excel表格。
本文将介绍如何使用Python调用Excel表格,以及一些常用的操作和技巧。
第一步:安装所需的库在使用Python调用Excel表格之前,我们需要安装相关的库。
Python 有多个库可以处理Excel表格,比如`openpyxl`、`xlrd`、`pandas`等。
这里我们选择使用`openpyxl`库,因为它支持读写Excel表格,并且使用简单方便。
使用以下命令可以安装`openpyxl`库:pip install openpyxl第二步:导入所需的库安装好库之后,我们需要在Python脚本中导入相关的库,以便使用其中的函数和方法。
导入`openpyxl`库的方法如下:pythonimport openpyxl第三步:打开Excel表格在Python中调用Excel表格之前,我们需要先打开表格文件。
使用`openpyxl`库的`load_workbook`函数可以打开Excel表格,代码示例:pythonworkbook = openpyxl.load_workbook('example.xlsx')上述代码中的`example.xlsx`为Excel表格的文件名,可以根据实际情况进行修改。
第四步:选择工作表打开Excel表格之后,我们可以选择要操作的工作表。
使用`openpyxl`库的`active`属性可以获取当前活动的工作表,代码示例:pythonsheet = workbook.active如果要选择特定的工作表,可以使用`get_sheet_by_name`方法,如下所示:pythonsheet = workbook.get_sheet_by_name('Sheet1')上述代码中的`Sheet1`为工作表的名称,可以根据实际情况进行修改。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
☺ ☹
a toto x7 y_max BigOne 8y and for
=
Variables assignment
x=1.2+8+sin(y) a=b=c=0 assignment to same value y,z,r=9.2,-7.6,0 multiple assignments a,b=b,a values swap a,*b=seq unpacking of sequence in *a,b=seq item and list and x+=3 increment ⇔ x=x+3 *= x-=2 /= decrement ⇔ x=x-2 %= x=None « undefined » constant value
Base Types integer, float, boolean, string, bytes int 783 0 -192 0b010 0o642 0xF3
float 9.23 0.0 -1.7e-6 -6 ×10 bool True False str "One\nTwo" Multiline string:
→direct access to names, renaming with as ☝ modules and packages searched in python path (cf sys.path)
Conditional Statement
yes ? no yes ? no
not a
True False
indentation !
a or b
logical or one or other
parent statement: statement block 1… ⁝ parent statement: statement block2… ⁝ next statement after block 1
☝ configure editor to insert 4 spaces in place of an indentation tab.
Missing slice indication → from start / up to end. On mutable sequences (list), remove with del lst[3:5] and modify with assignment lst[1:4]=[15,25] Boolean Logic Comparisons : < > <= >= == != (boolean results) ≤ ≥ = ≠ both simultalogical and a and b
lst[:3]→[10,20,30] lst[:-1]→[10,20,30,40] lst[::-1]→[50,40,30,20,10] lst[1:3]→[20,30] lst[1:-1]→[20,30,40] lst[-3:-1]→[30,40] lst[3:]→[40,50] lst[::-2]→[50,30,10] lst[::2]→[10,30,50] lst[:]→[10,20,30,40,50] shallow copy of sequence
negative index positive index positive slice negative slice
-5 0 0 -5 1 -4
-4 1 2 -3
lst=[10, 20, 30, 40, 50]
3 -2 4 -1 5
for lists, tuples, strings, bytes… Items count -3 -2 -1 2 3 4 len(lst)→5 ☝ index from 0 (here from 0 to 4)
☝ keys=hashable values (base types, immutables…)
Identifiers
a…zA…Z_ followed by a…zA…Z_0…9 ◽ diacritics allowed but should be avoided ◽ language keywords forbidden ◽ lower/UPPER case discrimination
escaped '
(key/value associations) {1:"one",3:"three",2:"two",3.14:"π"}
dict {"key":"value"} set {"key1","key2"}
dict(a=3,b=4,k="v") {1,9,3,0}
frozenset immutable set
lst[0]→10 lst[-1]→50
⇒ first one ⇒ last one
lst[1]→20 lst[-2]→40
Access to sub-sequences via lst[start slice:end slice:step]
On mutable sequences (list), remove with del lst[3] and modify with assignment lst[4]=25
escaped new line
zero
binary
octal
◾ ordered sequences, fast index access, repeatable values ["x",11,8.9] list [1,5,9] 11,"y",7.4 tuple (1,5,9)
Container Types ["mot"] [] ("mot",) () "" b"" {} set()
logical not True and False constants
if logical condition: statements block
Can go with several elif, elif... and only one final else. Only the block of first true condition is executed.
☝ floating numbers… approximated values
Operators: + - * / // % ** ab Priority (…) × ÷ @ → matrix × python3.5+numpy (1+5.3)*2→12.6 abs(-3.2)→3.2 round(3.57,1)→3.6 pow(4,3)→64.0 ☝ usual order of operations
Modules/Names Imports from monmod import nom1,nom2 as fct import monmod →access via monmod.nom1 … statement block executed only if a condition is true
del x
remove name x …☝ assignment ⇔ binding of a name with a value 1) evaluation of right side expression value 2) assignment in order with left side names
Conversions type(expression) int("15") → 15 nd int("3f",16) → 63 can specify integer number base in 2 parameter int(15.56) → 15 truncate decimal part float("-11.24e8") → -1124000000.0 round(15.56,1)→ 15.6 rounding to 1 decimal (0 decimal → integer number) bool(x) False for null x, empty container x , None or False x ; True for other x str(x)→ "…" representation string of x for display (cf. formatting on the back) chr(64)→'@' ord('@')→64 code ↔ char repr(x)→ "…" literal representation string of x bytes([72,9,64]) → b'H\t@' list("abc") → ['a','b','c'] dict([(3,"three"),(1,"one")]) → {1:'one',3:'three'} set(["one","two"]) → {'one','two'} separator str and sequence of str → assembled str ':'.join(['toto','12','pswd']) → 'toto:12:pswd' str splitted on whitespaces → list of str "words with spaces".split() → ['words','with','spaces'] str splitted on separator str → list of str "1,4,8,2".split(",") → ['1','4','8','2'] sequence of one type → list of another type (via list comprehension) [int(x) for x in ('1','29','-3')] → [1,29,-3] Sequence Containers Indexing Individual access to items via lst[index]