时间序列分析课程设计报告 (1)
时间序列分析课程设计

游程检验
Zscore(居民消费指数) 检验值
a
.000000 21 13 34 10 -2.423 .015
案例<检验值 案例>= 检验值 案例总数 Runs 数 Z 渐近显著性(双侧) a. 均值
表2
时间序列数据是否平稳的游程检验结果
在表 2 中,概率的 P 值为 0.015,如果显著性水平为 0.05,由于概率 P 值小 于显著性水平,因此拒绝零假设,即认为样本值的出现不是随机的,即原序列不 平稳。
时间序列分析课程设计
部分是从 1980 年到 2009 年,第二部分是从 2010 年到 2013 年。将第一部分的 数据作为原始数据,用于对模型进行估计,第二部分的数据则作为实验数据,用 以检验预测的正确性。 最后再对 2014~2016 年的居民消费价格指数作事后预测。 本文的数据是在原数据基础上减 100 以简化计算。
2 问题分析
时间序列是指同一种现象在不同时间上的相继观察值排列而成的一组数字 序列。时间序列预测方法的基本思想是:预测一个现象的未来变化时,用该现象 的过去行为来预测未来。即通过时间序列的历史数据揭示现象随时间变化的规 律,将这种规律延伸到未来,从而对该现象的未来做出预测。对此希望建立相关 居民消费价格指数的数学模型并预测居民消费价格指数的走势。
中南大学数学学院
大学生课程设计
课程设计名称:时间序列分析 专 业 班 级: 题目:居民消费价格指数的时间序列分析 姓名:zgl 学号: 指 导 教 师:唐立
2015 年
6 月
摘要:居民消费价格指数能够反映价格变动趋势和程度,反映通货膨胀水平,在 现代社会经济中占有极为重要的地位。 研究居民消费价格指数的发展变化特征和 未来短期内的发展趋势,把握居民消费价格指数发展变化的动态特征,有利于有 针对性的制定政策措施,维持物价稳定,促进经济的健康发展和社会稳定。本文 以我国 1980 年至 2013 年居民消费价格指数为研究对象, 基于居民消费价格指数 存在明显的非平稳性特征, 运用自回归移动平均模型进行建模分析, 并利用 SPSS 建立了居民消费价格指数时间序列的相关关系模型, 从中选出预测精度相对较高 的模型,并对我国未来一段时间内的居民消费价格指数水平进行了预测。 关键词:消费价格指数 ;时间序列分析;Box-Jenkins;Pandit-Wu;预测
时间序列分析课程设计

时间序列分析课程设计一、课程目标知识目标:1. 让学生理解时间序列分析的基本概念,掌握时间序列数据的结构特征和常见的时间序列模型。
2. 使学生掌握时间序列平稳性检验和自相关函数、偏自相关函数的绘制与分析方法。
3. 帮助学生了解时间序列预测的常用算法,如ARIMA模型、指数平滑等,并掌握其应用场景。
技能目标:1. 培养学生运用时间序列分析方法处理实际问题的能力,学会运用统计软件进行时间序列数据的分析、建模和预测。
2. 提高学生运用所学知识解决实际问题时的时间序列模型选择和参数估计能力。
情感态度价值观目标:1. 培养学生对时间序列分析的兴趣,激发学生主动探索和研究的精神。
2. 引导学生认识到时间序列分析在实际问题中的应用价值,提高学生的数据分析和解决实际问题的能力。
3. 培养学生的团队合作意识,提高学生在团队中沟通、协作的能力。
课程性质分析:本课程为数据分析方向的专业课程,旨在帮助学生掌握时间序列分析的基本理论和方法,培养学生运用时间序列分析解决实际问题的能力。
学生特点分析:学生为高年级本科生,已具备一定的数学基础和统计分析能力,对时间序列分析有一定的了解,但尚需深化理论知识,提高实际操作能力。
教学要求:1. 结合实际案例,注重理论与实践相结合,提高学生的实际操作能力。
2. 采取启发式教学,引导学生主动参与课堂讨论,培养学生的创新思维。
3. 强化课堂互动,关注学生的个体差异,提高教学效果。
二、教学内容1. 时间序列分析基本概念:时间序列的定义、时间序列数据的组成、时间序列的分类及性质。
教材章节:第一章 时间序列分析概述2. 时间序列数据的预处理:数据清洗、数据变换、平稳性检验。
教材章节:第二章 时间序列数据的预处理3. 时间序列模型:自回归模型(AR)、移动平均模型(MA)、自回归移动平均模型(ARMA)、自回归积分滑动平均模型(ARIMA)。
教材章节:第三章 时间序列模型4. 时间序列预测方法:指数平滑法、季节性模型、周期性模型。
时间序列分析课程设计报告

安徽建筑大学时间序列分析课程设计报告书院系数理学院专业统计学班级统计学三班学号 11207040302 姓名朱敏指导教师俞泽鹏基于时间序列分析的股票预测模型研究摘要在现代金融浪潮的推动下,越来越多的人加入到股市,进行投资行为,以期得到丰厚的回报,这极大促进了股票市场的繁荣。
而在这种投资行为的背后,越来越多的投资者逐渐意识到股市预测的重要性。
所谓股票预测是指:根据股票现在行情的发展情况地对未来股市发展方向以及涨跌程度的预测行为。
这种预测行为只是基于假定的因素为既定的前提条件为基础的。
但是在股票市场中,行情的变化与国家的宏观经济发展、法律法规的制定、公司的运营、股民的信心等等都有关联,因此所谓的预测难于准确预计。
即使是证券分析师的预测也只能作为股民入市操作的一般参考意见。
时间序列数据因为接受到许多偶然因素的影响,会常常表现出随机性,在统计学上称之为序列的依赖关系。
时间序列分析是经济预测领域研究的重要工具之一,它描述历史数据随时间变化的规律,并用于预测经济数据。
在股票市场上,时间序列预测法常用于对股票价格趋势进行预测,为投资者和股票市场管理管理方提供决策依据。
本文主要介绍了时间序列分析方法的概念,性质,特点以及时间序列模型,包括建模时对数据时间序列的预处理、模型识别、参数估计、模型检验、模型优化以及模型预测等。
并根据道琼斯指数对收盘价进行短期预测,通过对时间序列分析理论的实证研究分析,建立时间序列模型,说明时间序列分析的方法对于股票价格的预测趋势有一定的参考价值。
关键词:股票,预测,时间序列分析,AR(1 )模型ABSTRACTIn the modern financial wave, more and more people join the stock market to invest, expecting to get rich return, which has greatly promoted the stock market’s prosperity. While under this behavior, an increasing large number of people become to realize the importance of stock forecast. The so-called stock forecast is defined: with the help of the stock’s recent condition, we’ll predict the future stock’s development, including its later development directions and fluctuations. This prediction based on the assumption of behavior is the prerequisite for established factor basis. But the stock’s index is always changing with the country’s macroeconomic development, the formulation of laws and regulations, the company’s operations, the confidence of investors and so on, which results in that it is very difficult to accurately predict. Even securities analysts’forecast results can only be operated as a general reference. Time-series data often show some kinds of randomness and dependence between each other because of the influence of various accidental factors. Time series analysis is one of the most important tools for economy research, and it describe the variation of data with time, and used to forecast economic data.Time series analysis is often used to predict the stock price, which provides decision-making basis for investors and the stock market managers. This thesis mainly introduces time series analysis theory, including its notion, character as well as the expression and description of some models derived from it ,including method of data simulation, method of parameter estimation and method of testing degree of fitting and arrange them by the numbers. And according to the Dow Jonesindex, we may predict the closing price trend for short-term with the help of time series analysis theory. Therefore we can establish some models, we could prove that the method has some value for predicting the stock’s trend by means of model fitting effect and error analysis.Keywords: stock, predict, time series analysis, AR(1)model目录一、引言1.1研究背景1.2研究意义1.3选题依据二、基于时间序列分析的股票预测模型的实例分析2.1绘制时序图2.2平稳性检验2.3纯随机性检验2.4模型的识别与拟合2.5模型的检验2.6序列预测一、引言股票是股份公司(包括有限公司和无限公司)在筹集资本时向出资人发行的股份凭证,代表着其持有者(即股东)对股份公司的所有权。
时间序列分析课程设计结论

时间序列分析课程设计结论一、课程目标知识目标:1. 让学生掌握时间序列分析的基本概念,如趋势、季节性和周期性;2. 培养学生运用时间序列分析方法对数据进行预处理、建模和预测的能力;3. 使学生了解时间序列分析在不同领域的应用,如经济学、气象学等。
技能目标:1. 培养学生运用统计软件进行时间序列数据分析和处理的能力;2. 培养学生根据实际问题时选择合适的时间序列模型进行分析的能力;3. 培养学生运用时间序列模型进行数据预测和决策的能力。
情感态度价值观目标:1. 激发学生对时间序列分析的兴趣,培养其主动探索和研究的意识;2. 培养学生严谨的科学态度,注重数据分析的客观性和准确性;3. 增强学生的团队合作意识,使其在合作学习中相互启发、共同进步。
课程性质分析:本课程为数据分析相关学科,旨在培养学生运用时间序列分析方法解决实际问题的能力。
结合学生特点和教学要求,课程设计注重理论与实践相结合,强调学生的动手操作能力和创新思维。
学生特点分析:学生具备一定的数学基础和统计知识,对数据分析有一定了解,但可能对时间序列分析的具体应用和方法掌握不足。
教学要求分析:1. 注重引导学生从实际问题中提炼出时间序列分析的关键要素;2. 强调学生对时间序列模型的建立、参数估计和预测方法的掌握;3. 通过案例分析和课堂讨论,提高学生的实际操作能力和解决问题的能力。
二、教学内容1. 时间序列分析基本概念:介绍时间序列的定义、组成要素(趋势、季节性、周期性、随机性)以及相关统计指标。
教材章节:第一章 时间序列分析概述2. 时间序列预处理:讲解时间序列数据的收集、整理、可视化等预处理方法,以及平稳性检验和差分等方法。
教材章节:第二章 时间序列数据的预处理3. 时间序列模型:介绍自回归模型(AR)、移动平均模型(MA)、自回归移动平均模型(ARMA)和自回归差分移动平均模型(ARIMA)等常见时间序列模型及其适用场景。
教材章节:第三章 时间序列模型及其应用4. 模型参数估计与检验:讲解时间序列模型的参数估计方法、拟合优度检验和预测误差分析等。
时间序列分析实验报告

引言概述:
时间序列分析是一种用于研究时间数据的统计方法,主要关注数据随时间的变化趋势、季节性和周期性等特征。
时间序列分析应用广泛,可以用于金融预测、经济分析、气象预测等领域。
本实验报告旨在介绍时间序列分析的基本概念和方法,并通过实例分析来展示其应用。
正文内容:
1.时间序列分析基本概念
1.1时间序列的定义
1.2时间序列的模式
1.3时间序列分析的目的
2.时间序列分析方法
2.1随机游走模型
2.2移动平均模型
2.3自回归移动平均模型
2.4季节性模型
2.5ARCH和GARCH模型
3.时间序列数据预处理
3.1数据平稳性检验
3.2数据平滑
3.3缺失值填补
3.4离群值检测
3.5数据变换
4.时间序列模型建立与评估
4.1模型的选择
4.2参数估计
4.3拟合优度检验
4.4模型诊断
4.5预测准确性评估
5.实例分析:某公司销售数据时间序列分析
5.1数据收集与预处理
5.2模型建立与评估
5.3预测分析与结果解释
5.4预测精度评估
5.5结果讨论与进一步改进方向
总结:
时间序列分析是一种重要的统计方法,可用于预测和分析时间相关的数据。
本报告介绍了时间序列分析的基本概念和方法,并通
过实例分析展示了其应用过程。
通过时间序列分析,可以更好地理解数据的趋势和周期性,并进行准确的预测。
时间序列分析也面临着多样的挑战,如数据质量问题和模型选择困难等。
因此,在实际应用中,需要综合考虑多种因素,灵活运用合适的方法和技巧,以提高预测准确性和分析可靠性。
时间序列分析的实验报告-实验一

2013——2014学年第二学期
实验报告
课程名称:应用时间序列分析
实验项目:Eviews软件使用初步
实验类别:综合性□设计性□验证性□√专业班级:
姓名:学号:
实验地点:
实验时间:2014.5. 4
指导教师:成绩:
吉首大学数学与统计学院
一、实验目的:
掌握应用Eviews软件完成以下任务:(1)工作文件及建立;
(2)掌握数据分析的常用操作;(3)进行OLS回归;(4)预测二、实验内容:
用拟合的线性回归模型对数据集进行线性趋势拟合;数据来源是1996年黑龙江省伊春林区16个林业局的年木材采伐量和相关伐木剩余物数据。
三、实验方案(程序设计说明)
四. 实验步骤或程序(经调试后正确的源程序)
五.程序运行结果
六、实验总结
学生签名:
年月日
七、教师评语及成绩
教师签名:
年月日
1。
时间序列课程设计(一)

10.56
54
10.50
92
12.74
130
13.02
17
10.48
55
11.00
93
12.73
131
13.25
18
10.77
56
10.98
94
12.76
132
13.12
1911.335710.6195
12.92
133
13.26
20
10.96
58
10.48
96
12.64
134
13.11
21
11.16
0.307
0.321
0.323
0.328
0.321
0.289
0.295
根据表格看, ARMA(p,q)取(1,1)时,AIC最小
同时,对ARMA(2,3)进行残差自相关函数与偏自相关函数分析,看是否满足白噪声过程,结果如图
图五:ARMA(2,3)相关图
由图五可知,残差对应的自相关函数与偏自相关函数均在置信区间内,故称该残差为白噪声过程,从而检验通过。
附件(原始数据、图表)
obs
X1
obs
X1
obs
X1
obs
X1
1
10.01
39
11.05
77
10.87
115
13.39
2
10.07
40
11.11
78
10.67
116
13.59
3
10.32
41
11.01
79
11.11
117
13.27
4
9.75
时间序列的课程设计报告

时间序列的课程设计报告一、课程目标知识目标:1. 学生能理解时间序列的概念,掌握时间序列的基本组成和特点。
2. 学生能够运用所学知识,分析时间序列数据,识别其变化趋势和模式。
3. 学生能够运用时间序列预测方法,对给定数据进行短期预测。
技能目标:1. 学生能够运用统计软件或编程工具,对时间序列数据进行处理和分析。
2. 学生能够运用图表、报告等形式,清晰、准确地表达时间序列分析结果。
3. 学生能够运用时间序列模型,解决实际问题,提高数据分析能力。
情感态度价值观目标:1. 学生通过学习时间序列知识,培养对数据的敏感性和探究精神,增强数据分析的兴趣。
2. 学生在小组合作中,学会倾听、沟通、协作,培养团队精神和责任感。
3. 学生能够认识到时间序列分析在实际生活中的应用价值,提高学以致用的意识。
课程性质分析:本课程为数据分析相关学科,旨在帮助学生掌握时间序列分析的基本方法和技巧,提高解决实际问题的能力。
学生特点分析:本年级学生具备一定的数学基础和数据分析能力,对新鲜事物充满好奇,但可能缺乏实际应用经验。
教学要求:1. 结合课本知识,注重理论与实践相结合,提高学生的实际操作能力。
2. 注重启发式教学,引导学生主动探究,培养学生的创新思维。
3. 关注学生的个体差异,因材施教,提高教学质量。
二、教学内容1. 时间序列基本概念:时间序列的定义、组成元素、分类及应用场景。
2. 时间序列的特性:平稳性、趋势、季节性、周期性及随机性。
3. 时间序列预处理:数据清洗、缺失值处理、异常值检测与处理。
4. 时间序列分析方法:- 趋势分析:线性趋势、非线性趋势。
- 季节性分析:季节指数、季节性分解。
- 周期性分析:自相关函数、偏自相关函数。
- 随机分析:白噪声检验、ARIMA模型。
5. 时间序列预测方法:- 简单平均法、移动平均法、指数平滑法。
- ARIMA模型及其扩展模型。
- 机器学习方法:如神经网络、支持向量机等。
6. 实际案例分析与操作:结合课本案例,运用所学方法进行时间序列分析及预测。
时间序列分析课程设计总结

时间序列分析课程设计总结一、课程目标知识目标:1. 理解时间序列分析的基本概念,掌握其基本原理和应用领域;2. 学会运用时间序列分析方法对给定数据进行预处理、建模和分析;3. 掌握时间序列模型的选择、参数估计及预测评估方法;4. 了解时间序列分析软件包及其在实践中的应用。
技能目标:1. 能够独立运用时间序列分析方法处理实际数据,进行数据分析和预测;2. 掌握运用统计软件进行时间序列建模、预测及结果分析的技巧;3. 能够根据实际问题,选择合适的时间序列模型,并进行合理的参数估计;4. 提高运用时间序列分析解决实际问题的能力和逻辑思维能力。
情感态度价值观目标:1. 培养学生对时间序列分析的兴趣,激发学生主动探索精神;2. 培养学生的团队协作意识,提高沟通和交流能力;3. 引导学生关注时间序列分析在实际生活中的应用,认识到数学知识在解决实际问题中的价值;4. 培养学生严谨、客观、科学的态度,形成正确的价值观。
本课程针对高年级学生,结合其已掌握的数学知识和实际应用能力,注重理论与实践相结合。
课程目标旨在使学生掌握时间序列分析的基本知识和技能,提高解决实际问题的能力,同时培养其情感态度和价值观,为今后的学术研究和工作实践打下坚实基础。
二、教学内容1. 时间序列分析基本概念:时间序列的定义、特点和应用领域;2. 时间序列预处理:数据清洗、平稳性检验、季节性分解;3. 时间序列模型:自回归模型(AR)、移动平均模型(MA)、自回归移动平均模型(ARMA)、自回归积分滑动平均模型(ARIMA)等;4. 模型参数估计与检验:最小二乘估计、极大似然估计、模型诊断与优化;5. 时间序列预测:预测方法、预测误差分析、预测评估;6. 时间序列软件应用:介绍常用时间序列分析软件包及其操作方法;7. 实践案例:结合实际案例,运用时间序列分析方法解决具体问题。
教学内容根据课程目标,遵循科学性和系统性原则,安排如下:第一周:时间序列分析基本概念及预处理方法;第二周:自回归模型及其应用;第三周:移动平均模型及其应用;第四周:自回归移动平均模型及其应用;第五周:模型参数估计与检验;第六周:时间序列预测及预测评估;第七周:时间序列软件应用及实践案例。
应用时间序列实验报告

河南工程学院课程设计《时间序列分析课程设计》学生姓名学号:学院:理学院专业班级:专业课程:时间序列分析课程设计指导教师:2017年6 月2 日目录1. 实验一澳大利亚常住人口变动分析 (1)1.1 实验目的 (1)1.2 实验原理 (1)1.3 实验内容 (2)1.4 实验过程 (3)2. 实验二我国铁路货运量分析 (8)2.1 实验目的 (8)2.2 实验原理 (8)2.3 实验内容 (9)2.4 实验过程 (10)3. 实验三美国月度事故死亡数据分析 (14)3.1 实验目的 (14)3.2 实验原理 (15)3.3 实验内容 (15)3.4 实验过程 (16)课程设计体会 (19)1.实验一澳大利亚常住人口变动分析1971年9月—1993年6月澳大利亚常住人口变动(单位:千人)情况如表1-1所示(行数据)。
表1-1(1)判断该序列的平稳性与纯随机性。
(2)选择适当模型拟合该序列的发展。
(3)绘制该序列拟合及未来5年预测序列图。
1.1 实验目的掌握用SAS软件对数据进行相关性分析,判断序列的平稳性与纯随机性,选择模型拟合序列发展。
1.2 实验原理(1)平稳性检验与纯随机性检验对序列的平稳性检验有两种方法,一种是根据时序图和自相关图显示的特征做出判断的图检验法;另一种是单位根检验法。
(2)模型识别先对模型进行定阶,选出相对最优的模型,下一步就是要估计模型中未知参数的值,以确定模型的口径,并对拟合好的模型进行显著性诊断。
(3)模型预测模型拟合好之后,利用该模型对序列进行短期预测。
1.3 实验内容(1)判断该序列的平稳性与纯随机性时序图检验,根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常识值附近波动,而且波动的范围有界。
如果序列的时序图显示该序列有明显的趋势性或周期性,那么它通常不是平稳序列。
对自相关图进行检验时,可以用SAS 系统ARIMA 过程中的IDENTIFY 语句来做自相关图。
时序分析实验报告
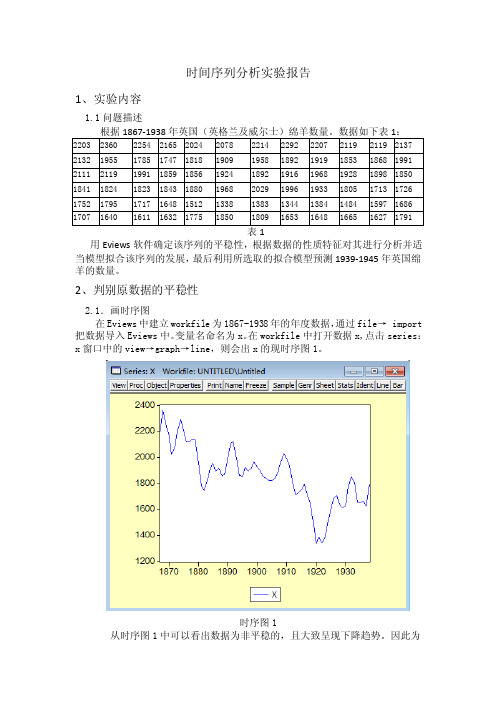
时间序列分析实验报告1、实验内容1.1问题描述用Eviews软件确定该序列的平稳性,根据数据的性质特征对其进行分析并适当模型拟合该序列的发展,最后利用所选取的拟合模型预测1939-1945年英国绵羊的数量。
2、判别原数据的平稳性2.1.画时序图在Eviews中建立workfile为1867-1938年的年度数据,通过file→ import 把数据导入Eviews中。
变量名命名为x。
在workfile中打开数据x,点击series:x窗口中的view→graph→line,则会出x的现时序图1。
时序图1从时序图1中可以看出数据为非平稳的,且大致呈现下降趋势。
因此为经一步说明该数据的平稳性,做相关分析。
2.2.自相关分析继续在该时序图窗口中点击view→correlogram,在弹出的correlogram Specification 的对话框中的lags to include中输入12,点击OK。
则x的自相关图2如下。
自相关图2从自相关图的autocorrelation的一栏可以看出自相大部分都关超出了(至少第三个自相关值要落入两倍的标准差中则为平稳的)两倍的标准差。
则可以进一步认为该数据为非平稳的。
为作出最终的判断,对数进行单位根检验。
2.3.单位根检验同样在自相关图2的窗口中点击view→unit root test在弹出的unit root test 的对话空中的automatic selection的下拉框中选择Schwarz Info,并在Include in test equation中选择intercept点击ok则有如下结果输出单位根表3。
单位根表3从表3中以看所有的ADF值没有都小于值临界值,因此结合时序图和自相关图可以判断出该数据为非平稳的。
3、对数据进行平稳化3.1.对数据做一阶差分在代码窗口中输入genr dx=d(x)并按回车键则在workfile窗体中新生成变量为dx的数据该数据即为x的一阶差分。
时间序列分析试验报告

季平均值为:7058。1 5649.3 4909。6 6597.7
年平均值为:5873.0 5875.0 5853.3 6073.7 6262。5 6384。5
每个季度的数据的散点图:
图1城市居民季度用煤消耗量散点图
(2)分解回归直线趋势。由于数据有缓慢的上升趋势,可以试用回归直线表示趋势项,这时认为( 满足一元线性回归模型
end
Rt=dx-St;%求随机项估计
plot(1:24,St,’*—’,1:24,Rt,'<—’)%画出季节项和随机项图形
图2季节项和随机项散点图
预测:为得到1997年的预报值,可以利用公式
,
这里, 是用例中的24个观测数据对第 个数据的预测值,利用MATLAB编写命令:
for i=25:28
m=5780.1+21。9*(i)+s(i-24)%计算1997年四个季度的预测值
1.0371 —0.3936 -1.1552 0.5110
即季节项估计为
分解随机项:利用原始数据 减去趋势项的估计 和季节项的估计 后得到的数据就是随机项的估计 .
在Matlab命令窗口中继续输入下列命令:
for j=1:6
for k=1:4
St(k+4*(j—1))=s(k);%求季节项值St
end
6384.5
季平均
7058。1
5649。3
4909.6
6597。7
(1)由表8.1.1中每年每季的数据计算年平均值与季平均值,并绘出1991~1996年中每个季度的数据的散点图。
(2)用回归直线趋势法对序列进行分解。
(3)若1997年四季的数据分别为:7720。5 5973。3 5304。4 7075。1,运用(2)对1997年数据作预测并分析误差。
时间序列分析课程报告

时间序列分析课程报告概述时间序列分析是一种广泛应用于经济学、金融学、天气预报、工业生产等领域的方法,用于研究时间序列数据的规律性和预测未来趋势。
本报告将介绍时间序列分析的基本概念、常用方法以及实际应用。
时间序列数据的特点时间序列数据是按照时间顺序排列的一系列观测值的集合。
与传统的数据分析不同,时间序列数据具有以下几个特点:1.时间相关性:时间序列数据中的观测值之间存在时间上的相关性,前一时刻的观测值可能对后一时刻的观测值产生影响。
2.季节性:某些时间序列数据可能在特定的季节或时间周期内呈现出重复的模式或规律。
3.非平稳性:时间序列数据在统计意义上可能不满足平稳性假设,即均值和方差可能随时间变化。
时间序列分析的步骤时间序列分析通常包括以下几个步骤:1.数据收集和整理:获取时间序列数据,并进行清洗和整理,确保数据的准确性和完整性。
2.可视化和描述统计:通过绘制时间序列图、计算统计指标如均值、方差等来对数据进行初步分析,了解数据的基本特征。
3.模型拟合和参数估计:根据数据的特点选择合适的时间序列模型,并通过最大似然估计等方法估计模型的参数。
4.模型诊断和验证:检验拟合的模型是否满足假设条件,包括残差分析、模型诊断图、假设检验等。
5.预测和评估:使用拟合的模型进行未来趋势的预测,并对预测结果进行评估和调整。
常用的时间序列分析方法时间序列分析涉及许多方法和模型,常见的方法包括:•平稳性检验:通过对时间序列数据进行单位根检验,判断其是否满足平稳性假设。
•自相关函数(ACF)和偏自相关函数(PACF):用于探索时间序列数据的自相关性和偏相关性,帮助确定合适的AR、MA模型阶数。
•自回归移动平均模型(ARMA):是一种结合了自回归和移动平均的线性模型,用于拟合时间序列数据。
•季节性自回归移动平均模型(SARMA):是ARMA模型在具有季节性的时间序列数据上的拓展,用于处理季节性数据。
•自回归积分移动平均模型(ARIMA):是ARMA模型在经过差分处理后的数据上的拓展,用于处理非平稳时间序列数据。
时间序列分析实验报告(1)

《时间序列分析》课程实验报告练习题:1.Input语句数据输入格式有:列表方式或自由格式、列方式、格式化方式、命名方式,分别给出程序例子和运行结果,并分析运行结果。
(1)自由格式data lianxi1_1;input name$ sex$ age@@;cards;naw ÄÐ 22 ejniw Å® 23 dhfÄÐ 23 husi Å® 21 huh Å® 24;proc print data=lianxi1_1;run;(2)列方式data lianxi1_2;input name$2-5 sex$6-8 age 9-12;cards;naw ÄÐ 22ejniw Å® 23dhf ÄÐ 23husi Å® 21huh Å® 24;proc print data=lianxi1_2;run;(3)格式化方式data lianxi1_3;input name$5. sex$ age 2.;cards;naw ÄÐ 22ejniw Å® 23dhf ÄÐ 23husi Å® 21huh Å® 24;proc print data=lianxi1_3;run;(4)命名方式data lianxi1_4;Input id name=$ age=;Cards;200012 name=marry age=15200015 age=16 name=join200011 age=16 name=smith;proc print data=lianxi1_4;run;分析:由以上结果及程序可知,自由方式的input后必须加“@@”表示连续输入,而下面的数据可以随意排列;列方式中每个列名后必须加这个列是下面数据的第几个字节到第几个字节,并且输入的数据要对应整齐;格式化方式中在列名后加“数字.”表示这个列取到第几位(数字表示位数),输入的数据也要一行一行对齐不能多加几列上去;而命名方式在列名后要加“=”,并且在输入数据时要把对应的数据都写成“列名=数据”的形式,输入时可以与自由方式一样进行输入,不一定要整齐。
时间序列分析实验报告

时间序列分析实验报告时间序列分析实验报告一、引言时间序列分析是一种用于研究时间序列数据的统计方法,通过对时间序列数据的分析和建模,可以揭示数据背后的规律和趋势,为预测和决策提供依据。
本报告旨在通过对某一时间序列数据的分析和建模,展示时间序列分析的基本原理和方法。
二、数据描述本次实验所使用的时间序列数据为某公司每月销售额的数据,共计12个月的数据。
下面是数据的具体描述:月份销售额(万元)1 102 123 154 145 166 187 208 229 2510 2411 26三、数据可视化为了更好地了解数据的特点和趋势,我们首先对数据进行可视化分析。
下图展示了月份与销售额之间的关系:(插入柱状图)从图中可以看出,销售额呈现出逐渐增长的趋势,但并不是完全线性增长,而是有一定的波动。
四、平稳性检验在进行时间序列分析之前,需要先对数据的平稳性进行检验。
平稳性是指时间序列数据的均值和方差在时间上保持不变的性质。
我们使用单位根检验来检验数据的平稳性。
对于本次实验的数据,我们使用ADF检验进行单位根检验。
检验结果显示,数据的ADF统计量为-2.456,显著性水平为0.05时的临界值为-3.605。
由于ADF统计量大于临界值,我们无法拒绝原假设,即数据存在单位根,不具备平稳性。
五、差分处理由于数据不具备平稳性,我们需要对数据进行差分处理,以消除趋势和季节性的影响。
差分处理可以通过计算当前观测值与前一观测值之间的差异来实现。
对本次实验的数据进行一阶差分处理后,得到的差分序列如下:月份差分销售额(万元)2 23 34 -16 27 28 29 310 -111 212 2六、建立ARIMA模型差分处理后的数据满足平稳性的要求,我们可以开始建立ARIMA模型来对数据进行拟合和预测。
ARIMA模型是一种常用的时间序列模型,它包括自回归(AR)、差分(I)和移动平均(MA)三个部分。
通过对差分序列的自相关图(ACF)和偏自相关图(PACF)的分析,我们选择了ARIMA(1,0,1)模型来拟合数据。
时间序列分析教学设计

时间序列分析教学设计时间序列分析是指对一系列按时间顺序排列的数据进行统计分析和预测的方法。
时间序列分析在实际应用中具有广泛的应用,例如经济预测、股票价格预测、气象预测等。
因此,时间序列分析在统计学和经济学等领域都具有重要的地位。
为了帮助学生理解和掌握时间序列分析的基本方法和技巧,下面设计了一个关于时间序列分析的教学活动。
教学目标:1.了解时间序列分析的基本概念和方法。
2.掌握时间序列数据的可视化和描述统计分析方法。
3.学会利用时间序列数据进行预测和建模。
教学内容:1.时间序列分析概述2.时间序列数据的可视化和描述统计分析3.时间序列预测模型教学方法:1.理论讲解2.案例分析3.实例操作教学过程设计:第一节:时间序列分析概述1.引导学生了解时间序列分析的定义和应用领域。
2.介绍时间序列分析的基本原理和方法。
3.举例说明时间序列分析在实际中的应用。
第二节:时间序列数据的可视化和描述统计分析1.讲解如何利用统计软件对时间序列数据进行可视化展示。
2.介绍时间序列数据的描述统计分析方法,如平均值、方差等指标。
3.利用实例让学生掌握时间序列数据分析的基本步骤和技巧。
第三节:时间序列预测模型1.介绍时间序列预测模型的基本原理和方法,如移动平均法、指数平滑法等。
2.讲解如何建立时间序列预测模型以及评估模型的准确性。
3.通过案例分析,让学生掌握时间序列预测模型的建立和应用技巧。
实例操作:1.要求学生收集一组时间序列数据,如某股票的价格数据、某产品的销售量数据等。
2.引导学生利用统计软件对所收集的时间序列数据进行可视化展示和描述统计分析。
3.要求学生利用学习所掌握的时间序列预测模型方法对数据进行预测,并评估预测模型的准确性。
教学评价:1.通过课堂作业和实例操作,评估学生对时间序列分析概念和方法的掌握程度。
2.通过模拟实际案例,评估学生运用时间序列分析方法解决实际问题的能力。
以上教学设计旨在帮助学生掌握时间序列分析的基本概念、方法和应用技巧。
时间序列分析报告

时间序列分析报告时间序列分析报告一、引言时间序列分析是一种通过统计方法对按照时间顺序排列的数据进行分析和预测的方法。
时间序列数据广泛应用于金融、经济、气象、股票市场等领域。
本报告将以某公司销售数据为例,使用时间序列分析方法分析其销售趋势并进行未来销售预测。
二、数据收集和预处理数据集包含了某公司从2010年1月到2020年12月的销售数据。
首先,我们对数据进行预处理,包括消除季节性波动、删除离群值、平滑处理等。
在这一步骤中,我们使用了平均绝对偏差(MAD)和离散度指数(DPI)等统计量来评估数据的质量,并对异常数据进行剔除。
经过预处理后的数据可以更好地反映销售的趋势和周期性变化。
三、趋势分析为了分析销售的趋势,我们采用了两种常用的方法:移动平均法和线性趋势法。
移动平均法通过计算相邻时间段内销售数据的平均值,来平滑数据并识别出趋势。
线性趋势法采用最小二乘法来拟合数据,并通过拟合曲线来描述趋势的变化。
移动平均法的结果显示,销售数据整体呈现出增长趋势。
然而,使用线性趋势法的拟合曲线更能准确地描述趋势的变化情况。
根据线性趋势法的拟合结果,我们可以看到销售呈现出逐年递增的趋势。
四、季节性分析为了识别销售数据中的季节性变化,我们使用了季节性指数和自相关函数等工具。
季节性指数是用来衡量在某个时间段内销售数据相对于全年平均值的波动程度。
自相关函数可以用来分析销售数据在不同时间段之间的相关性。
根据季节性指数的计算结果,我们可以看到销售数据在年底有一个明显的增长期。
此外,自相关函数显示了销售数据在每年的同一时间段之间存在一定的相关性。
这些结果都表明销售数据具有明显的季节性变化。
五、预测模型为了进行未来销售预测,我们使用了时间序列分析中的ARIMA模型。
ARIMA模型可以用来描述时间序列数据的自相关性、趋势性和季节性变化,并生成未来的预测结果。
根据ARIMA模型的拟合结果,我们可以得到未来几个月的销售预测值。
预测结果显示销售数据将继续呈现增长趋势,并在每年的年底出现高峰。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中国铁路客运量的时间序列分析辜予薇1303050225统计0502摘要首先,本文对中国铁路客运的现状及影响客运量的因素作了简要的分析,并说明了运用时间序列分析方法对中国铁路客运量作预测的现实意义。
接下来,文中收集到了从2002年1月至2008年10月中国铁路客运量的数据,经过一系列分析,对野值进行了相应的替换,并通过平稳化和零均值化将原序列转化为适宜建立时间序列模型的新序列X。
然后,本文用Box-Jekins方法对序列X进行初步识别,拟合出基本模型,并使用F检验定阶法和最佳准则函数定阶法确定模型的阶数,建立了AR(1)模型。
其后,本文还使用Pandit-Wu方法建立起了ARMA(4,3)模型,并将此模型与之前的AR(1)模型作了简单的对比。
在模型建立后,本文分别用两个模型进行了内插和外推预测,比较了它们的预测误差,最后肯定了ARMA(4,3)模型的优越性,并对预测结果进行了简单的分析,提出了自己的建议。
关键词平稳化 Box-Jekins F检验最佳准则函数 Pandit-Wu 预测1引言铁路由于具有运距长、全天候、安全性强、运能大、受自然铁条件影响小的优点,在众多的交通工具中具有得天独厚的优势,无论在货运和客运上,都受到社会公众的亲睐。
[1]而铁路客运又是我国交通运输体系中与老百姓联系最紧密的运输方式,无论远赴他乡的学子,还是行色匆匆的打工仔,都于长长的列车有着不解之缘。
而我们知道,在高峰时期购票难的问题一直困扰着广大的出行者,现时值春运,国家和有关部门及时获取信息,有效地统筹安排铁道和列车资源就显得尤为重要。
我们认为,在众多的信息中,打算乘火车出行的人数是一个关键,它直接关系着有关部门需要开派多少车的问题。
如果车派少了,必然有部分的出行者由于无法买到车票而耽误行程,造成社会公众的不满;但另一方面,如果开派的列车数超过了实际需要,就会有过度“不满员”的情况,不仅加大了列车的运行成本,还造成了资源的浪费。
但由于有关部门也不可能精确地知道未来究竟有多少人打算乘火车出行,所以只有根据历史的规律结合当下的实际情况进行预测。
时间序列分析正是这样一种立足于历史,以预测和控制未来现象的方法,在处理这个问题上是有一定的可行性的。
2问题分析从理论上来讲,影响一个时期铁路客运量的因素有很多,我认为最重要的应该有下面几个:A:节假日分布。
一般来讲,节假日分布密集的时期的出行的人数会较一般时段有所增加,如春节前后主要是农民工和学生构成强大的客流,而“五一”和“十一”黄金周外出旅游的人也会大大增加铁路客运压力。
B:外部竞争因素。
这主要是指飞机和汽车等交通工具的票价高低。
如果某一时段飞机票价居高不下,而一些时间较充裕或购买力不够强的旅客则会选择乘火车出行;另一方面,一般短途旅客都偏好于乘坐汽车,因为较方便。
但如果此时的火车票价远低于汽车票价,使旅客感觉到乘坐火车的期望效用较高,便会舍弃汽车这种交通方式。
C:整个宏观经济环境。
虽然这不是一个关键的因素,但是也在很大程度上影响了客流量。
举例来说,在经济不景气的时期,各行各业会缩减其业务量,那么外出公干的人员自然会减少,而这一部份人也是构成客流量的因素,即铁路客流量也会较往常减少。
当然,还有很多的因素会影响铁路客流量,如个人偏好,天气状况等,但它们对铁路客运量的影响较之前的三个因素就较小,这里便不再作具体的分析。
而我们可以看到,因素A即节假日分布对客运量的影响相对稳定,也是具有一定周期性的。
对此,我们可以了解它的周期,并且建立ARMA模型对客运状况进行分析,对未来的客运量进行预测,解决我们在前面提到的问题。
3数据的收集为了增加分析的准确性,我们需要将数据的统计时期精准到月。
在中华人民共和国统计局网站[2]上,我们可以找到2002年1月至2008年10月的中国全社会客货运输量的月度报表,而其中就有一项就是铁路客运量。
经过整理,可以得到中国铁路客运量的月度时间序列数据(见附录1)。
4数据预处理4.1 数据的录入(1)创建Workfile:点击File/New/Workfile,输入起始年2002年,终止年2008年,并选择Frequency下拉菜单中的Monthly。
(2)建立object输入数据:点击object/new object,定义数据文件名Y并逐个录入数据。
4.2 画时序数据图:将序列Y(单位为亿人)1打开为列表,点击Workfile中的1以后无如特别说明,所有序列单位都为亿人View/line graph ,可以得到下面的图形图4.1 客运量的时间序列图观察上图,我们看到2003年5月的Y 值偏离其它点的距离较大,初步怀疑它为离群点。
下面计算Y 序列的均值和方差:图4.2 Y 序列的均值与方差从图4.2中可以得到0.98Y =,()0.19S Y ==,而2003年5月这个时点上的Y 值为0.33。
取k=3,则3Y Y S <-,故此点确为离群点。
所以,令112t t t Y Y Y ∧+-=-可以计算出这个时点上Y 的替代值为20.710.830.59⨯-=,更新数据并保代表会,便得到剔除野值的Y 序列(见附录2)。
接下来,再画出新时间序列Y 的时序图如下:图4.3 经处理过野值的客运量的时间序列图可以初步看出,铁路客运量的时间序列呈线性增长趋势,即非平稳的。
此外,这个序列还存在一定的周期性。
下面,我们定量地检验此序列地平稳性。
4.3 Unit Root Test :点击View/Unit Root Test ,可以得到以下的结果:表4.1 客运量序列单位根检验的结果Null Hypothesis: Y has a unit root Exogenous: ConstantLag Length: 8 (Automatic based on SIC, MAXLAG=11)t-Statistic Prob.*Augmented Dickey-Fuller test statistic 0.148421 0.9673Test critical values:1% level-3.5228875% level -2.90177910% level -2.588280*MacKinnon (1996) one-sided p-values.从上面的结果,我们可以看出:ADF_T=0.1484>-3.5228,则Y序列非平稳。
由于序列存在周期性,故我们用季节差分将其平稳化。
4.4 季节差分将序列平稳化:在Procs/Generate by Equation中输入X=Y-Y(-12),作一次季节差分(差分后序列X的具体数据见附录3)。
然后点击View/Desriptive Satistics/Histogram and stas,可得到X的均值为0.065143,已非常接近零,故可认为X为零均值序列。
再作ADF检验,可以得到以下的结果:表4.2 X序列的单位根检验结果Null Hypothesis: X has a unit rootExogenous: ConstantLag Length: 0 (Automatic based on SIC, MAXLAG=10)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -4.736238 0.0002Test critical values: 1% level -3.5285155% level -2.90419810% level -2.589562*MacKinnon (1996) one-sided p-values.从上面的结果,我们可以看出:ADF_T=-4.7362<-3.5285,则X序列已经是平稳序列。
可作出X序列的时间序列图如下:从上面的图上,我们也可以判断出此时的X序列是平稳的,可以在此基础上建立模型。
5Box-Jinkins识别模型求自相关系数和偏自相关系数,并画出图形:点击View/correlogram,可以得到以下结果:图5.1 X 序列的自相关和偏自相关图N=70,=8.37。
则当K>1时,2,23,3ϕϕϕ∧∧∧,,中满足||0.1195kk ϕ∧>== 的数量比例为2,不超过31.7%。
故可判断kk ϕ∧呈现1步截尾现象,而 k ρ∧序列被负指数函数控制收敛于零,呈拖尾现象,故可初步判定序列X 适合AR(1)模型。
6 F 检验定阶法和最佳准则函数定阶法6.1 不同阶数模型的拟合:点击Quick/Estimate equation 输入类似X AR(1) AR(2) AR(3)形式的各种不同模型。
首先,输入X AR(1) AR(2) AR(3),拟合AR(3)模型,得到下面的结果:表6.1 X序列的AR(3)模型拟合结果Dependent Variable: XMethod: Least SquaresDate: 12/24/08 Time: 01:12Sample (adjusted): 2003M04 2008M10Included observations: 67 after adjustmentsConvergence achieved after 3 iterationsVariable Coefficient Std. Error t-Statistic Prob.AR(1) 0.575401 0.124535 4.620398 0.0000AR(2) 0.028915 0.144250 0.200451 0.8418AR(3) 0.052077 0.124284 0.419017 0.6766R-squared 0.197830 Mean dependent var 0.066418Adjusted R-squared 0.172762 S.D. dependent var 0.123149S.E. of regression 0.112008 Akaike info criterion -1.496759Sum squared resid 0.802924 Schwarz criterion -1.398041Log likelihood 53.14141 Durbin-Watson stat 2.011555Inverted AR Roots .72 -.07+.26i -.07-.26i从上表可以看出,AR(2)和AR(3)的系数都很小,而且没有通过显著性检验,故而接着拟合AR(2)模型,得到下面的结果:表6.2 X序列的AR(2)模型拟合结果Dependent Variable: XMethod: Least SquaresDate: 12/24/08 Time: 01:18Sample (adjusted): 2003M03 2008M10Included observations: 68 after adjustmentsConvergence achieved after 3 iterationsVariable Coefficient Std. Error t-Statistic Prob.AR(1) 0.581491 0.122810 4.734875 0.0000AR(2) 0.051100 0.122702 0.416454 0.6784R-squared 0.200450 Mean dependent var 0.064853Adjusted R-squared 0.188335 S.D. dependent var 0.122906S.E. of regression 0.110729 Akaike info criterion -1.534487Sum squared resid 0.809224 Schwarz criterion -1.469208Log likelihood 54.17256 Durbin-Watson stat 2.006811Inverted AR Roots.66-.08从表6.2的结果也可以看出,AR(2)的系数也很小,也没有通过显著性检验,进而继续拟合AR(1)模型,得下面的结果:表6.3 X 序列的AR(1)模型拟合结果Dependent Variable: X Method: Least Squares Date: 12/24/08 Time: 01:22Sample (adjusted): 2003M02 2008M10 Included observations: 69 after adjustments Convergence achieved after 2 iterationsVariable Coefficient Std. Error t-Statistic Prob. AR(1)0.6087420.0955146.373346 0.0000R-squared 0.197447 Mean dependent var 0.064348 Adjusted R-squared 0.197447 S.D. dependent var 0.122071 S.E. of regression 0.109358 Akaike info criterion -1.573993 Sum squared resid 0.813224 Schwarz criterion -1.541614 Log likelihood 55.30275 Durbin-Watson stat 2.051691Inverted AR Roots.61此时,参数1ϕ就较为显著了。