LZMA压缩img文件实例
利用Matlab进行数据压缩与加密技术详解

利用Matlab进行数据压缩与加密技术详解在当今科技快速发展的时代,数据压缩与加密技术日趋重要。
随着数字化时代的到来,数据的产生与传输量不断增加,如何高效地存储和传输数据成为了一个亟待解决的问题。
同时,随着信息安全威胁的不断增加,数据加密也成为了保护信息安全的重要手段之一。
在这样的背景下,Matlab作为一个强大的数学计算工具,提供了丰富的数据压缩与加密函数,成为了研究和实践者们的首选。
1. 数据压缩技术数据压缩技术是将大容量的数据通过一定的算法和方法进行转换和编码,以减少所占用的存储空间或传输带宽。
Matlab提供了多种数据压缩的方法和函数。
1.1 无损压缩无损压缩是一种将原始数据转化为压缩文件,但在解压缩时恢复得到与原始数据完全一样的数据的压缩技术。
Matlab中常用的无损压缩方法有哈夫曼编码和Lempel-Ziv-Welch(LZW)算法。
哈夫曼编码是一种用于数据压缩的算法,通过构建霍夫曼树将较高频率的字符用较短的二进制编码表示,而将较低频率的字符用较长的二进制编码表示,从而实现对数据的压缩。
在Matlab中,可以使用`huffmandict`函数生成霍夫曼编码字典,并使用`huffmanenco`和`huffmandeco`函数进行编码和解码。
LZW算法是一种以词典为基础的无损压缩算法,利用词典来对数据进行压缩和解压缩。
在Matlab中,可以使用`lzwenco`和`lzwdeco`函数实现LZW算法的编码和解码。
1.2 有损压缩有损压缩是指在压缩数据的过程中,丢弃部分数据的精确信息,从而得到一个对原始数据的近似表示。
有损压缩可以显著减小数据的存储空间和传输带宽,但也会引入一定的失真。
Matlab提供了多种有损压缩方法和函数,如离散余弦变换(DCT)、小波变换(Wavelet Transform)等。
DCT技术是一种常用的图像压缩方法,它通过将图像划分为非重叠的小块,然后对每个小块进行变换来减少冗余信息。
7-zip的极限压缩算法

7-zip的极限压缩算法
7-Zip 使用了一种名为LZMA 的压缩算法,这是一种非常高效的压缩算法,特别适合处理大型文件和数据流。
LZMA 算法具有极高的压缩比,尤其是在处理大量数据时。
以下是LZMA 算法的一些关键特性:
1.字典编码:LZMA 使用字典编码,这意味着它查找并存储重复的数
据块,而不是简单地存储每个字节。
这种方法能够显著减少重复数据的大小。
2.范围编码:与传统的熵编码方法不同,LZMA 使用范围编码来进一
步提高压缩效率。
范围编码能够更有效地表示数据中的概率分布,从而在压缩过程中实现更高的效率。
3.多线程支持:7-Zip 支持多线程压缩,这使得在多核处理器系统上能
够更快地完成压缩任务。
通过并行处理,可以显著提高压缩大型文件的性能。
4.高压缩比:LZMA 算法提供了非常高的压缩比,尤其是在处理大量
数据时。
这使得7-Zip 在许多场景下成为了一个非常有效的压缩工具。
5.解压缩速度:虽然LZMA 压缩算法相对较慢,但解压缩速度相对较
快。
这意味着当你需要快速访问压缩文件时,解压缩操作不会成为瓶颈。
6.可配置的压缩级别:7-Zip 允许用户选择不同的压缩级别,可以根据
需要平衡压缩时间和压缩比。
这为用户提供了更大的灵活性,可以根据需求选择最适合的压缩设置。
总的来说,7-Zip 的LZMA 算法是一种非常强大且高效的压缩算法,特别适用于处理大型文件和数据流。
其高效的字典编码、范围编码和多线程支持等特性使得它在许多场景下成为了首选的压缩工具。
固件包img文件解压和打包教程——让自己也能做个简单的ROM!

废话不多说直接上教程:VirtualBox下载地址:/html_2/1/59/id=46462&pn=0.html YLMS OS下载地址:/1、在VirtualBox虚拟YLMS OS下安装增强功能及共享WINDOWS文件夹的方法linlong@linlong-laptop:~$ sudo passwd root输入新的UNIX 密码:重新输入新的UNIX 密码:passwd:已成功更新密码linlong@linlong-laptop:~$ su密码:root@linlong-laptop:/home/linlong# mkdir /mnt/cdromroot@linlong-laptop:/home/linlong# sudo mount /dev/cdrom /mnt/cdrommount: 块设备/dev/sr0 写保护,已只读方式挂载root@linlong-laptop:/home/linlong# cd /mnt/cdromroot@linlong-laptop:/mnt/cdrom# ls32Bit VBoxLinuxAdditions-amd64.run VBoxWindowsAdditions.exe64Bit VBoxLinuxAdditions-x86.run VBoxWindowsAdditions-x86.exeAUTORUN.INF VBoxSolarisAdditions.pkgautorun.sh VBoxWindowsAdditions-amd64.exeroot@linlong-laptop:/mnt/cdrom# sudo sh ./VBoxLinuxAdditions-x86.run Verifying archive integrity... All good.Uncompressing VirtualBox 3.2.4 Guest Additions for Linux.........VirtualBox Guest Additions installertar: 记录大小= 8 块Building the VirtualBox Guest Additions kernel modulesBuilding the main Guest Additions module ...done.Building the shared folder support module ...done.Building the OpenGL support module ...doneDoing non-kernel setup of the Guest Additions ...done.Starting the VirtualBox Guest Additions ...done.Installing the Window System driversInstalling Server 1.7 modules ...done.Setting up the Window System to use the Guest Additions ...done.You may need to restart the hal service and the Window System (or just restartthe guest system) to enable the Guest Additions.Installing graphics libraries and desktop services components ...done.root@linlong-laptop:/mnt/cdrom#2、实现共享菜单栏上点击设备然后再弹出的列表中点击分配数据空间出现如下图(不知道的自己百度下)sudo mkdir /home/share (share是要共享的文件夹名字)sudo mount -t vboxsf share /home/(注意空格)3、解包(需要用到的包要放到共享文件目录下)(一)在开始解包之前要做这么几件事:①下载unyaffs包下载地址:/p/unyaffs/downloads/list②执行先执行gcc –o unyaffs unyaffs.c 再执行cp unyaffs /bin(具体看你bin目录在哪个路径下)(二)接下来就开始解压img文件:请不要直接用命令unyaffs system.img,这样的话解开的文件都在当前目录下。
固件包img文件解压和打包教程——让自己也能做个简单的ROM!
废话不多说直接上教程:VirtualBox下载地址:/html_2/1/59/id=46462&pn=0.html YLMS OS下载地址:/1、在VirtualBox虚拟YLMS OS下安装增强功能及共享WINDOWS文件夹的方法linlong@linlong-laptop:~$ sudo passwd root输入新的UNIX 密码:重新输入新的UNIX 密码:passwd:已成功更新密码linlong@linlong-laptop:~$ su密码:root@linlong-laptop:/home/linlong# mkdir /mnt/cdromroot@linlong-laptop:/home/linlong# sudo mount /dev/cdrom /mnt/cdrommount: 块设备/dev/sr0 写保护,已只读方式挂载root@linlong-laptop:/home/linlong# cd /mnt/cdromroot@linlong-laptop:/mnt/cdrom# ls32Bit VBoxLinuxAdditions-amd64.run VBoxWindowsAdditions.exe64Bit VBoxLinuxAdditions-x86.run VBoxWindowsAdditions-x86.exeAUTORUN.INF VBoxSolarisAdditions.pkgautorun.sh VBoxWindowsAdditions-amd64.exeroot@linlong-laptop:/mnt/cdrom# sudo sh ./VBoxLinuxAdditions-x86.run Verifying archive integrity... All good.Uncompressing VirtualBox 3.2.4 Guest Additions for Linux.........VirtualBox Guest Additions installertar: 记录大小= 8 块Building the VirtualBox Guest Additions kernel modulesBuilding the main Guest Additions module ...done.Building the shared folder support module ...done.Building the OpenGL support module ...doneDoing non-kernel setup of the Guest Additions ...done.Starting the VirtualBox Guest Additions ...done.Installing the Window System driversInstalling Server 1.7 modules ...done.Setting up the Window System to use the Guest Additions ...done.You may need to restart the hal service and the Window System (or just restartthe guest system) to enable the Guest Additions.Installing graphics libraries and desktop services components ...done.root@linlong-laptop:/mnt/cdrom#2、实现共享菜单栏上点击设备然后再弹出的列表中点击分配数据空间出现如下图(不知道的自己百度下)sudo mkdir /home/share (share是要共享的文件夹名字)sudo mount -t vboxsf share /home/(注意空格)3、解包(需要用到的包要放到共享文件目录下)(一)在开始解包之前要做这么几件事:①下载unyaffs包下载地址:/p/unyaffs/downloads/list②执行先执行gcc –o unyaffs unyaffs.c 再执行cp unyaffs /bin(具体看你bin目录在哪个路径下)(二)接下来就开始解压img文件:请不要直接用命令unyaffs system.img,这样的话解开的文件都在当前目录下。
MATLAB数据压缩与编码技巧与实例

MATLAB数据压缩与编码技巧与实例引言在现代信息时代,数据的处理与传输是一项重要任务。
然而,随着数据量的不断增加,数据的存储和传输成本也逐渐提高。
为了克服这一问题,数据压缩和编码技巧变得至关重要。
本文将探讨MATLAB中的数据压缩和编码技巧,并提供实际案例。
一、数据压缩方法1. 无损压缩无损压缩是指在数据压缩过程中不会丢失数据。
MATLAB提供了多种无损压缩方法,如GZIP、ZLIB和LZ77算法等。
其中,GZIP是一种广泛使用的压缩工具,可以通过命令行或MATLAB函数进行调用。
例如,可以使用以下MATLAB代码压缩文件。
```matlabinputFile = 'input.txt';outputFile = 'compressed.gz';gzip(inputFile, outputFile);```此代码将输入文件"input.txt"压缩为"compressed.gz"。
2. 有损压缩有损压缩是指在数据压缩过程中会有一定的数据损失。
这种方法适用于某些情况下,例如图像和音频数据。
在MATLAB中,可以使用JPEG和MP3等算法进行有损压缩。
以下是一个示例,演示如何使用JPEG算法对图像进行有损压缩。
inputImage = imread('input.jpg');outputImage = 'compressed.jpg';imwrite(inputImage, outputImage, 'Quality', 80);```这段代码将输入图像"input.jpg"以80%的质量压缩为"compressed.jpg"。
二、数据编码技巧1. 霍夫曼编码霍夫曼编码是一种常用的无损编码方法,广泛应用于数据压缩领域。
在MATLAB中,可以通过"Huffmandict"和"Huffmanenco"函数实现霍夫曼编码。
z i g z a g 压 缩 算 法 ( 2 0 2 0 )

JPEG图片压缩的Python实现文章目录致谢预备知识Python代码这学期有幸参加学习学校韩宇星教授的数字图像工程(全英)课-程,对机器视觉了解更进一步,对韩老师引用世事洞明皆学问,人情练达即文章那节课印象颇深。
课-程期间,通过网络博客资料学习,收获很多。
为表感谢,我记录这篇学习笔记,希望为全世界知识共享迈出一小步。
预备知识感谢这些博主乐于分享知识的无私精神。
Python代码接下来贴出本人的Python代码,程序效果如下:其中amilk.bmp是原图,大小约2652KB;amilk.gpj是程序压缩后存储的文件,大小约380KB;resul.bmp是程序读取amilk.gpj后恢复出来的BMP文件,大小约1990KB,文件大小变化是因为JPEG是有损压缩,这必然导致部分高频信息丢失。
原图效果:根据amilk.gpj反压缩得到的图片效果:python代码如下:import numpy as npimport osfrom PIL import Imageclass KJPEG:def __init__(self):self.__dctA = np.zeros(shape=(8, 8))for i in range(8):c = np.sqrt(1 - 8)c = np.sqrt(2 - 8)for j in range(8):self.__dctA[i, j] = c * np.cos(np.pi * i * (2 * j + 1) - (2 * 8))# 亮度量化矩阵self.__lq = np.array([16, 11, 10, 16, 24, 40, 51, 61,12, 12, 14, 19, 26, 58, 60, 55,14, 13, 16, 24, 40, 57, 69, 56,14, 17, 22, 29, 51, 87, 80, 62,18, 22, 37, 56, 68, 109, 103, 77,24, 35, 55, 64, 81, 104, 113, 92,49, 64, 78, 87, 103, 121, 120, 101,72, 92, 95, 98, 112, 100, 103, 99,# 色度量化矩阵self.__cq = np.array([17, 18, 24, 47, 99, 99, 99, 99,18, 21, 26, 66, 99, 99, 99, 99,24, 26, 56, 99, 99, 99, 99, 99,47, 66, 99, 99, 99, 99, 99, 99,99, 99, 99, 99, 99, 99, 99, 99,99, 99, 99, 99, 99, 99, 99, 99,99, 99, 99, 99, 99, 99, 99, 99,99, 99, 99, 99, 99, 99, 99, 99,# 标记矩阵类型,lt是亮度矩阵,ct是色度矩阵 self.__lt = 0self.__ct = 1# Zig编码表self.__zig = np.array([0, 1, 8, 16, 9, 2, 3, 10,17, 24, 32, 25, 18, 11, 4, 5,12, 19, 26, 33, 40, 48, 41, 34,27, 20, 13, 6, 7, 14, 21, 28,35, 42, 49, 56, 57, 50, 43, 36,29, 22, 15, 23, 30, 37, 44, 51,58, 59, 52, 45, 38, 31, 39, 46,53, 60, 61, 54, 47, 55, 62, 63# Zag编码表self.__zag = np.array([0, 1, 5, 6, 14, 15, 27, 28,2, 4, 7, 13, 16, 26, 29, 42,3, 8, 12, 17, 25, 30, 41, 43,9, 11, 18, 24, 31, 40, 44, 53,10, 19, 23, 32, 39, 45, 52, 54,20, 22, 33, 38, 46, 41, 55, 60,21, 34, 37, 47, 50, 56, 59, 61,35, 36, 48, 49, 57, 58, 62, 63def __Rgb2Yuv(self, r, g, b):# 从图像获取YUV矩阵y = 0.299 * r + 0.587 * g + 0.114 * bu = -0.1687 * r - 0.3313 * g + 0.5 * b + 128v = 0.5 * r - 0.419 * g - 0.081 * b + 128return y, u, vdef __Fill(self, matrix):# 图片的长宽都需要满足是16的倍数(采样长宽会缩小1-2和取块长宽会缩小1-8)# 图像压缩三种取样方式4:4:4、4:2:2、4:2:0fh, fw = 0, 0if self.height % 16 != 0:fh = 16 - self.height % 16if self.width % 16 != 0:fw = 16 - self.width % 16res = np.pad(matrix, ((0, fh), (0, fw)), 'constant',constant_values=(0, 0))return resdef __Encode(self, matrix, tag):# 先对矩阵进行填充matrix = self.__Fill(matrix)# 将图像矩阵切割成8*8小块height, width = matrix.shape# 减少for循环语句,利用numpy的自带函数来提升算法效率shape = (height -- 8, width -- 8, 8, 8)strides = matrix.itemsize * np.array([width * 8, 8, width, 1]) blocks = np.lib.stride_tricks.as_strided(matrix, shape=shape, strides=strides)for i in range(height -- 8):for j in range(width -- 8):res.append(self.__Quantize(self.__Dct(blocks[i,j]).reshape(64), tag))return resdef __Dct(self, block):# DCT变换res = np.dot(self.__dctA, block)res = np.dot(res, np.transpose(self.__dctA))return resdef __Quantize(self, block, tag):res = blockif tag == self.__lt:res = np.round(res - self.__lq)elif tag == self.__ct:res = np.round(res - self.__cq)return resdef __Zig(self, blocks):ty = np.array(blocks)tz = np.zeros(ty.shape)for i in range(len(self.__zig)):tz[:, i] = ty[:, self.__zig[i]]tz = tz.reshape(tz.shape[0] * tz.shape[1]) return tz.tolist()def __Rle(self, blist):for i in range(len(blist)):if blist[i] != 0:res.append(cnt)res.append(int(blist[i]))elif cnt == 15:res.append(cnt)res.append(int(blist[i]))# 末尾全是0的情况if cnt != 0:res.append(cnt - 1)res.append(0)return resdef Compress(self, filename):# 根据路径image_path读取图片,并存储为RGB矩阵 image = Image.open(filename)# 获取图片宽度width和高度heightself.width, self.height = image.sizeimage = image.convert('RGB')image = np.asarray(image)r = image[:, :, 0]g = image[:, :, 1]b = image[:, :, 2]# 将图像RGB转YUVy, u, v = self.__Rgb2Yuv(r, g, b)# 对图像矩阵进行编码y_blocks = self.__Encode(y, self.__lt)u_blocks = self.__Encode(u, self.__ct)v_blocks = self.__Encode(v, self.__ct)# 对图像小块进行Zig编码和RLE编码y_code = self.__Rle(self.__Zig(y_blocks))u_code = self.__Rle(self.__Zig(u_blocks))v_code = self.__Rle(self.__Zig(v_blocks))# 计算VLI可变字长整数编码并写入文件,未实现Huffman部分 tfile = os.path.splitext(filename)[0] + ".gpj"if os.path.exists(tfile):os.remove(tfile)with open(tfile, 'wb') as o:o.write(self.height.to_bytes(2, byteorder='big'))o.flush()o.write(self.width.to_bytes(2, byteorder='big'))o.flush()o.write((len(y_code)).to_bytes(4, byteorder='big'))o.flush()o.write((len(u_code)).to_bytes(4, byteorder='big'))o.flush()o.write((len(v_code)).to_bytes(4, byteorder='big'))o.flush()self.__Write2File(tfile, y_code, u_code, v_code)def __Write2File(self, filename, y_code, u_code, v_code): with open(filename, "ab+") as o:data = y_code + u_code + v_codefor i in range(len(data)):if i % 2 == 0:td = data[i]for ti in range(4):buff = (buff 1) | ((td 0x08) 3)if bcnt == 8:o.write(buff.to_bytes(1, byteorder='big')) o.flush()td = data[i]vtl, vts = self.__VLI(td)for ti in range(4):buff = (buff 1) | ((vtl 0x08) 3)if bcnt == 8:o.write(buff.to_bytes(1, byteorder='big')) o.flush()for ts in vts:if ts == '1':if bcnt == 8:o.write(buff.to_bytes(1, byteorder='big')) o.flush()if bcnt != 0:buff = (8 - bcnt)o.write(buff.to_bytes(1, byteorder='big'))o.flush()def __IDct(self, block):# IDCT变换res = np.dot(np.transpose(self.__dctA), block) res = np.dot(res, self.__dctA)return resdef __IQuantize(self, block, tag):res = blockif tag == self.__lt:res *= self.__lqelif tag == self.__ct:res *= self.__cqreturn resdef __IFill(self, matrix):matrix = matrix[:self.height, :self.width]return matrixdef __Decode(self, blocks, tag):tlist = []for b in blocks:b = np.array(b)tlist.append(self.__IDct(self.__IQuantize(b,tag).reshape(8 ,8)))height_fill, width_fill = self.height, self.widthif height_fill % 16 != 0:height_fill += 16 - height_fill % 16if width_fill % 16 != 0:width_fill += 16 - width_fill % 16rlist = []for hi in range(height_fill -- 8):start = hi * width_fill -- 8rlist.append(np.hstack(tuple(tlist[start: start + (width_fill -- 8)])))matrix = np.vstack(tuple(rlist))res = self.__IFill(matrix)return resdef __ReadFile(self, filename):with open(filename, "rb") as o:tb = o.read(2)self.height = int.from_bytes(tb, byteorder='big')tb = o.read(2)self.width = int.from_bytes(tb, byteorder='big')tb = o.read(4)ylen = int.from_bytes(tb, byteorder='big')tb = o.read(4)ulen = int.from_bytes(tb, byteorder='big')tb = o.read(4)vlen = int.from_bytes(tb, byteorder='big')rlist = []vtl, tb, tvtl = None, None, Nonewhile len(rlist) ylen + ulen + vlen:if bcnt == 0:tb = o.read(1)if not tb:tb = int.from_bytes(tb, byteorder='big')if itag == 0:buff = (buff 1) | ((tb 0x80) 7)if icnt == 4:rlist.append(buff 0x0F)elif icnt == 8:vtl = buff 0x0Ftvtl = vtlbuff = (buff 1) | ((tb 0x80) 7)if tvtl == 0 or tvtl == -1:rlist.append(self.__IVLI(vtl, bin(buff)[2:].rjust(vtl,'0')))y_dcode = rlist[:ylen]u_dcode = rlist[ylen:ylen+ulen]v_dcode = rlist[ylen+ulen:ylen+ulen+vlen]return y_dcode, u_dcode, v_dcodedef __Zag(self, dcode):dcode = np.array(dcode).reshape((len(dcode) -- 64, 64)) tz = np.zeros(dcode.shape)for i in range(len(self.__zag)):tz[:, i] = dcode[:, self.__zag[i]]rlist = tz.tolist()return rlistdef __IRle(self, dcode):rlist = []for i in range(len(dcode)):if i % 2 == 0:rlist += [0] * dcode[i]rlist.append(dcode[i])return rlistdef Decompress(self, filename):y_dcode, u_dcode, v_dcode = self.__ReadFile(filename) y_blocks = self.__Zag(self.__IRle(y_dcode))u_blocks = self.__Zag(self.__IRle(u_dcode))v_blocks = self.__Zag(self.__IRle(v_dcode))y = self.__Decode(y_blocks, self.__lt)u = self.__Decode(u_blocks, self.__ct)v = self.__Decode(v_blocks, self.__ct)r = (y + 1.402 * (v - 128))g = (y - 0.34414 * (u - 128) - 0.71414 * (v - 128)) b = (y + 1.772 * (u - 128))r = Image.fromarray(r).convert('L')g = Image.fromarray(g).convert('L')b = Image.fromarray(b).convert('L')image = Image.merge("RGB", (r, g, b))image.save(".-result.bmp", "bmp")image.show()def __VLI(self, n):# 获取整数n的可变字长整数编码ts, tl = 0, 0ts = bin(n)[2:]tl = len(ts)tn = (-n) ^ 0xFFFFtl = len(bin(-n)[2:])ts = bin(tn)[-tl:]return (tl, ts)def __IVLI(self, tl, ts):# 获取可变字长整数编码对应的整数nif tl != 0:n = int(ts, 2)if ts[0] == '0':n = n ^ 0xFFFFn = int(bin(n)[-tl:], 2)if __name__ == '__main__':kjpeg = KJPEG()press(".-amilk.bmp")kjpeg.Decompress(".-amilk.gpj")一般情况下,使用较多的是小整数,那么较小的整数应使用更少的byte 来编码。
常用的无损压缩算法

常用的无损压缩算法无损压缩是一种在不降低数据质量的情况下减小文件大小的压缩算法。
下面介绍几种常用的无损压缩算法:1. Huffman编码:Huffman编码是一种基于统计概率的压缩算法,通过为出现频率高的字符分配较短的编码,从而减小文件的大小。
该算法广泛应用于图像、音频和视频等领域。
2. Lempel-Ziv-Welch (LZW) 压缩:LZW压缩算法是一种字典压缩算法,它通过构建和维护一个可扩展的字典来压缩数据。
该算法常用于无损图像压缩中,如GIF格式。
3. Run-Length Encoding (RLE) 压缩:RLE压缩算法是一种简单且直观的压缩技术,它通过对连续重复的数据进行计数来减小文件的大小。
该算法常用于压缩像素数据、文本文件等。
4. Burrows-Wheeler Transform (BWT) 压缩:BWT压缩算法是一种基于重排列的压缩技术,通过对数据进行环形重排列来寻找重复的模式,并利用这些模式进行压缩。
BWT常被用于文本压缩和文件压缩。
5. Arithmetic Coding (AC) 压缩:AC压缩算法是一种通过对数据流中的不同符号进行编码来压缩数据的技术。
AC压缩算法通常比Huffman编码更高效,但实现起来更复杂。
6.LZ77和LZ78压缩算法:LZ77和LZ78算法是一对常见的压缩算法,它们通过利用历史数据和字典来寻找数据中的重复模式,并将这些重复模式替换为更短的引用。
LZ77和LZ78算法被广泛应用于无损压缩和解压缩领域。
以上介绍的只是几种常用的无损压缩算法,每种算法都有自己的特点和适用领域。
一般来说,选择最适合数据类型的压缩算法可以提高压缩效率。
此外,还有一些其他的无损压缩算法,如DEFLATE算法(在ZIP和PNG中使用)、LZMA算法(在7z中使用)等。
LZMA压缩img文件实例
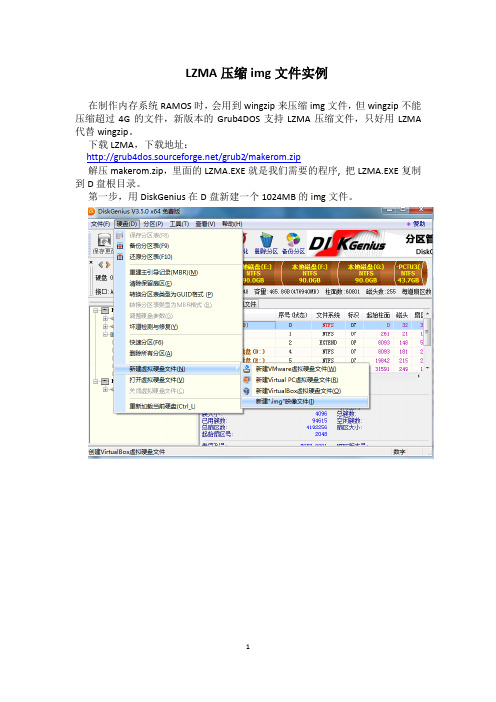
LZMA压缩img文件实例在制作内存系统RAMOS时,会用到wingzip来压缩img文件,但wingzip不能压缩超过4G的文件,新版本的Grub4DOS支持LZMA压缩文件,只好用LZMA 代替wingzip。
下载LZMA,下载地址:/grub2/makerom.zip解压makerom.zip,里面的LZMA.EXE就是我们需要的程序, 把LZMA.EXE复制到D盘根目录。
第一步,用DiskGenius在D盘新建一个1024MB的img文件。
点击左上角的“保存更改”按钮点击“是”按钮第二步,用LZMA.EXE压缩img文件在命令行提示符里运行D:\>lzma /?LZMA 4.57 Copyright (c) 1999-2007 Igor Pavlov 2007-12-06 Error: Incorrect commandUsage: LZMA <e|d> inputFile outputFile [<switches>...]e: encode filed: decode fileb: Benchmark<Switches>-a{N}: set compression mode - [0, 1], default: 1 (max)-d{N}: set dictionary - [0,30], default: 23 (8MB)-fb{N}: set number of fast bytes - [5, 273], default: 128-mc{N}: set number of cycles for match finder-lc{N}: set number of literal context bits - [0, 8], default: 3 -lp{N}: set number of literal pos bits - [0, 4], default: 0-pb{N}: set number of pos bits - [0, 4], default: 2-mf{MF_ID}: set Match Finder: [bt2, bt3, bt4, hc4], default: bt4-mt{N}: set number of CPU threads-eos: write End Of Stream marker-si: read data from stdin-so: write data to stdout找到要用到的参数,e——压缩,-mt{N}——CPU线程数,我的CPU是4核的Q9500,输入命令:D:\>Lzma e D:\1024.img D:\1024.lzma –mt4LZMA 4.57 Copyright (c) 1999-2007 Igor Pavlov 2007-12-06D:\>等待两分钟,压缩完毕。
lzma压缩算法原理

lzma压缩算法原理LZMA(Lempel-Ziv-Markovchain)压缩算法是一种高效的数据压缩方法,目前广泛应用在各种存储媒体和传输网络上。
LZMA是由多个组件构成的,包括Lempel-Ziv(LZ)编码、Markov链编码、Huffman 编码以及字典算法,各个组件结合起来完成良好的数据压缩。
Lempel-Ziv算法Lempel-Ziv编码是一种近似无损压缩算法,由Avi W. Lempel 和Jakob Ziv于1977年提出。
该编码的基本思想是,给定的输入数据序列,从序列的最开始处开始查找,第一个不同的数据项就是压缩编码的起点。
如果在该数据项后面的某个数据项,与起点之前的某个数据项,完全一样,则可以用一个距离参数来描述两个数据项之间的差异,而不需要再次表示这些数据项,从而节省空间。
Markov链编码Markov链编码是一种基于自相关系数的概率编码,它由俄罗斯数学家安德烈马尔科夫提出。
该编码算法基于马尔可夫链建立了一种统计模型,可以根据有限的数据序列预测之后的输入序列,并通过统计学的方法逐渐概括出数据的特征。
该编码通过计算不同数据序列之间的联系,使得预测更准确,利用马尔可夫模型进行编码可以极大地压缩数据,使得压缩效率得到提高。
Huffman编码Huffman编码是一种可变长编码,该编码由David A. Huffman 在1952年提出。
Huffman编码的基本思想是,根据数据的出现的频率,将出现频率高的数据编码用较短的字符串,出现频率低的数据编码用较长的字符串,从而达到压缩的目的。
字典算法字典算法是一种用于压缩字符串的有效算法,其原理是利用字典中的字符串进行匹配,将压缩字符串中出现的标记索引为相应的字符串在字典中的索引,从而节省空间,缩短压缩字符串的长度,提高压缩效率。
LZMA算法LZMA是一种基于Lempel-Ziv算法、Markov链算法、Huffman编码和字典算法的高效数据压缩算法。
lzma 压缩参数

lzma 压缩参数
LZMA是一种高压缩比的压缩算法,参数可以通过调整来获得不同的压缩效果和速度。
常见的LZMA压缩参数包括:
1. -d参数:用于指定压缩字典的大小,字典越大,压缩率越高,但压缩速度会变慢。
可以使用字节大小的数字或K、M、G等后缀来表示大小。
例如,-d24M表示使用24MB的字典大小。
2. -m参数:用于控制压缩器内存使用的限制。
可以指定一个整数值来表示最大使用的内存大小,单位为字节,或者使用百分比%来表示可用内存的比例。
例如,-m512M表示使用最多512MB的内存用于压缩。
3. -lc和-lp参数:用于指定匹配长度和距离的最小传输长度。
可以使用整数指定长度。
4. -pb参数:用于指定LZMA压缩时使用的指针位数。
可以使用0至4之间的整数值。
5. -fb参数:用于指定压缩时使用的未压缩块的大小。
可以使用整数表示文件块大小。
这些参数可以根据具体的需求进行调整,以获得最佳的压缩效果和速度。
lzma压缩解压缩工具命令行用法参考

lzma压缩解压缩工具命令行用法参考听说了一个Graphicsmagick,一个从2002年发布的ImageMagick5.5.2版本分裂出去的图形处理包,和ImageMagick非常相近,而且命令兼容ImageMagick,但号称比ImageMagick更快的处理速度,去官方网站下载了一个包编译下,发现了官方网站提供三种压缩包下载: bzip2, gzip, lzma ,lzma这个格式以前没听说过,所以稍微研究了一下:主要参考了man手册。
LZMA (Lempel-Ziv-Markov chain-Algorithm) 基于著名的LZ77压缩算法改进的压缩/解压工具,特点:高压缩率,高解压速度,低内存消耗,lzma命令行工具使用方式和gzip,bzip2类似,对已经熟悉gzip,bzip2这类工具的用户来说,上手并不难。
对比两大主流压缩工具:gzip,bzip2:1,lzma和bzip2在速度上面远远输给gzip,但在压缩率方面,lzma算法占优势。
2,lzma拥有比gzip,bzip2更高的压缩比率,压缩后文件更小,纯文本文件压缩更加明显,在解压方面比bzip2速度快出数倍,对于想要有较高的压缩率,又不想消耗太多内存,lzma是首先。
3,文件属性,lzma压缩和解压缩能保持文件所有人,权限和修改时间等信息,但是gzip不保存这些信息。
速度: bzip2 < lzma < gzip压缩率: gzip < bzip2 < lzma文件信息:gzip 不保留, bzip2 , lzma 保留这么看来,好像没有太多理由再用bzip2 了?呵呵,不过bzip2仍是我的最爱,目前还没有办法一下子接受lzma,虽然lzma很优秀,但我已经习惯了 tar cjvf 和 tar xjvf 了!lzma在绝大多数Linux和Unix系统中默认安装。
几个主要参数:-d --decompress --uncompress指定解压缩,比如lzma -d test.lzma,该命令相当于unlzma test.lzma-f --force强制解压/压缩,忽略一切问题,比如:目标文件已经存在,直接覆盖等。
lzma 压缩参数

lzma 压缩参数摘要:一、lzma 压缩算法简介1.lzma 压缩算法的起源2.lzma 与其他压缩算法的比较二、lzma 压缩参数介绍1.压缩级别2.字典大小3.最大字典大小4.最小字典大小5.迭代次数6.宽度和高度7.标志位三、lzma 压缩参数对压缩效果的影响1.压缩级别对压缩效果的影响2.字典大小对压缩效果的影响3.最大字典大小对压缩效果的影响4.最小字典大小对压缩效果的影响5.迭代次数对压缩效果的影响6.宽度和高度对压缩效果的影响7.标志位对压缩效果的影响四、如何选择合适的lzma 压缩参数1.根据数据类型选择压缩参数2.根据压缩需求选择压缩参数3.根据硬件资源选择压缩参数正文:lzma 压缩算法是一种高效的压缩算法,广泛应用于各种数据压缩场景。
与其他压缩算法相比,lzma 具有更高的压缩比和更快的压缩速度。
为了获得最佳的压缩效果,我们需要合理设置lzma 压缩参数。
本文将详细介绍lzma 压缩参数及其对压缩效果的影响,并教您如何选择合适的lzma 压缩参数。
一、lzma 压缩算法简介LZMA(Lempel-Ziv-Markov-Adleman)压缩算法起源于俄罗斯,是一种基于字典的压缩算法。
相较于传统的zip、rar 等压缩格式,lzma 压缩算法能提供更高的压缩比和更快的压缩速度。
此外,lzma 算法还被广泛应用于各种开源项目,如7z 压缩格式、Deep Learning Model Optimization 等。
二、lzma 压缩参数介绍在使用lzma 压缩算法时,我们需要设置一系列参数以达到最佳的压缩效果。
以下是一些常用的lzma 压缩参数:1.压缩级别:用于控制压缩过程的复杂度,级别越高,压缩时间越长,但压缩率也越高。
2.字典大小:影响压缩算法选择字典的规模,字典大小越大,压缩率越高,但同时会增加计算复杂度。
3.最大字典大小:限制了字典的最大规模,可以提高压缩速度。
4.最小字典大小:限制了字典的最小规模,可以提高压缩率。
无损压缩和有损压缩的例子

无损压缩和有损压缩的例子
1. 无损压缩呢,就好比把一堆珍贵的积木原封不动地装进一个小盒子里,一点都不损坏它们。
比如说你有一张超高清的照片,无损压缩后还是能完美呈现所有细节,就像你记忆中那片美丽的风景一点都没变!
2. 有损压缩呀,就像是为了能装进小箱子,不得不把一些不太重要的积木小块拆掉。
例如音乐的 MP3 格式,虽然体积变小了,但可能有些超细微的声音就丢失掉了,哎,有得必有失嘛!
3. 无损压缩不就是把一个精致的瓷器小心翼翼地打包起来,到了目的地还能完完整整的。
就像你精心录制的一段视频,无损压缩后再播放,哇,还是那么清晰动人!
4. 想想看,有损压缩如同把一幅画裁剪了一部分来让它变小,虽然整体还在但总觉得少了点啥。
就好比看一个低清晰度的视频,总觉得有些模糊呢,是吧!
5. 无损压缩可以说是对宝贝的细心呵护,把它完整无缺地保存着。
好比你最喜欢的那首无损音乐,每一个音符都那么清晰悦耳,简直是享受啊!
6. 有损压缩不就类似把一块大蛋糕切去了一些边边角角来减小体积嘛。
就像你用手机拍的照片,为了省空间选择有损压缩,哎呀,一些细节就模糊啦!
7. 无损压缩这可是高手的操作啊,让东西安然无恙地缩小。
比如说珍贵的文档,无损压缩后打开,还是那熟悉的一字一句呀!
8. 那有损压缩不就像给一个物品做了简化处理,必然会失去点什么呀。
就如同看那种压缩过度的图片,咦,怎么感觉怪怪的呢!
9. 无损压缩简直就是魔法,能把好东西原封不动地变精炼。
比如无损格式的音频文件,播放的时候你会感叹,哇,真的和原版一模一样啊!所以说嘛,无损压缩能保留完美,有损压缩虽然有损失但能节省空间,各有各的好呀!。
7z压缩算法 嵌入式

7z压缩算法嵌入式
7z压缩算法是一种广泛使用的压缩算法,其中的LZMA算法是其默认的压缩算法。
LZMA算法在压缩效率和速度上都有很好的表现,具有以下主要特征:
1.高压缩比率:LZMA算法能够实现较高的压缩比率,从而有效地减小文件大小。
2.可变的字典大小:LZMA算法支持高达4GB的字典大小,这使得它能够更好地处理大型文件和数
据流。
3.压缩速度:在2 GHz的CPU上,LZMA算法的压缩速度大约为1 MB/s。
4.解压缩速度:同样在2 GHz的CPU上,LZMA算法的解压缩速度大约为10-20 MB/s。
5.较小解压缩内存:LZMA算法在解压缩过程中需要的内存相对较少,这有助于降低系统资源的使
用。
6.较小的解压缩代码:LZMA算法的解压缩代码大小约为5KB,这使得它在嵌入式应用中具有较小
的存储需求。
7.支持多线程:LZMA算法支持多线程处理,从而能够进一步提高压缩和解压缩的速度。
由于以上优点,LZMA压缩算法特别适合用于嵌入式应用。
嵌入式系统通常具有有限的硬件资源和存储空间,因此高效的压缩算法对于减小文件大小和降低系统资源使用至关重要。
LZMA算法的这些特性使得它成为嵌入式应用中一个很好的选择。
请注意,7z压缩算法和LZMA算法都是开源的,并基于GNU LGPL许可协议发布,这意味着你可以自由使用和修改这些算法。
lzma decoding result 10 -回复

lzma decoding result 10 -回复“LZMA解码结果10”的主题可能会是关于压缩算法的应用和优势。
以下是一篇有关该主题的1500-2000字的文章,详细解释了LZMA算法的工作原理、压缩和解压缩过程以及其在计算机领域的应用。
标题:LZMA算法的应用和优势引言:在当今数字化的时代,数据的存储和传输变得愈发重要。
为了有效利用有限的存储空间或减少数据传输时间,压缩算法应运而生。
其中一种被广泛使用的压缩算法是LZMA(Lempel-Ziv-Markov chain Algorithm),它通过一系列的压缩和解压缩步骤来将数据文档缩小到原来的一小部分。
本文将一步一步回答“LZMA解码结果10”的主题,详细介绍LZMA算法的工作原理、压缩和解压缩过程,以及其在计算机领域的应用。
第一部分:LZMA算法的工作原理LZMA算法是一种基于词典的压缩算法,它利用了Lempel-Ziv数据压缩算法和马尔可夫链模型的特点。
该算法通过建立和维护一个动态扩展的词典来对数据进行压缩。
词典是一个存储先前看到的数据模式的数据结构,LZMA算法会不断尝试匹配词典中的模式来找到重复的数据块。
在这种匹配过程中,LZMA算法使用了一种称为滑动窗口的技术,该技术允许算法从输入数据中读取连续的字节,并将其添加到词典中。
第二部分:LZMA算法的压缩过程LZMA算法的压缩过程包括多个步骤。
首先,算法会初始化一个空的词典和滑动窗口,然后它会读取输入数据,并根据词典中已有的模式来查找匹配。
一旦找到匹配,算法会记录匹配的位置和长度,并将其编码为一系列位。
同时,算法会将匹配之后的未压缩数据添加到词典中,以便于后续的匹配过程。
这个压缩过程会不断循环,直到所有的输入数据都被压缩。
第三部分:LZMA算法的解压缩过程LZMA算法的解压缩过程与压缩过程相反。
解压缩开始时,算法会初始化同样的词典和滑动窗口。
然后,它会解码被压缩的位序列,并根据压缩数据的指示来重建词典的状态。
lzma压缩算法

lzma压缩算法LZMA压缩算法是一种非常常见的压缩算法,在许多应用程序和操作系统中被广泛使用。
LZMA算法的名称源于其创始人Lempel–Ziv–Markov Chain Algorithm(LZMA)。
LZMA算法是一种数据压缩算法,它通过在数据中发现重复的模式并使用更短的字节序列来表示这些模式来压缩数据。
下面是LZMA压缩算法的一些详细步骤:1. 字典初始化LZMA算法使用字典作为压缩的前提。
字典是一个固定大小的缓冲区,充当替换原始数据中的重复内容的存储空间。
字典大致等于输入数据的大小。
2. 读取数据LZMA算法将输入数据从开头开始读取,缓冲区大小为字典大小的两倍,这允许算法查找两倍大小的匹配。
3. 前置知识在LZMA算法中,有一些重要的术语,在后续的步骤中可能会提到。
其中最常见的术语包括:i) 匹配:在字典中找到与当前位置匹配的最长字符串。
ii) 距离:在字典中给出匹配字符串的起始位置。
iii) 解压前缀:从字典中取出距离和大小,然后用这些数据解压缩出一个前缀。
iv) 匹配长度:匹配字符串的长度。
v) 字符:压缩过程中输入数据的顺序和字符。
4. 找到匹配字符串一旦开始读取输入数据,LZMA算法将开始搜索字典以查找与当前位置匹配的最长字符串。
这个匹配通常越长,压缩效果越好。
5. 选择匹配字符串当LZMA算法找到一个匹配的字符串时,它需要选择最好的匹配。
LZMA算法使用一个"成本"函数来决定哪个是最好的匹配,成本函数基于解压缩前缀的大小和匹配长度。
6. 输出压缩数据一旦找到了最好的匹配字符串,LZMA算法使用单独的编码过程来输出压缩数据。
LZMA算法使用Range Encoding方法进行压缩,该方法是一种有损压缩算法,可以根据压缩效率的需要对压缩后的数据进行压缩和解压缩。
总之,LZMA算法是一种强大的压缩算法,它结合了多种压缩技术,包括字典匹配、重复动态编码和Range Encoding。
lzma 压缩参数

lzma 压缩参数LZMA是一种高效的压缩算法,它提供了多种压缩参数可以调整以获得不同的压缩效果和速度。
以下是常用的参数及其说明:1. -e或--extreme:启用极限压缩模式,可以获得更高的压缩比,但会显著增加压缩时间。
2. -t<threads>或--threads=<threads>:指定线程数,用于并行压缩或解压缩多个文件。
默认值为CPU核心数。
3. -d<dict-size>或--dictionary=<dict-size>:指定用于压缩的字典大小。
较大的字典大小可以提高压缩率,但会增加内存和压缩时间。
默认值为8MB。
4. -fb<mode>或--match-finder=<mode>:指定匹配查找器的类型。
可用的模式包括BT2(二字节哈希查找器)和BT4(四字节哈希查找器)。
BT4是默认值,通常比BT2更快但消耗更多内存。
5. -lc<mode>或--literal-context-bits=<mode>:指定字面文本上下文位数。
较高的位数可以提高压缩率,但会增加压缩时间。
默认值为3。
6. -lp<mode>或--literal-pos-bits=<mode>:指定字面位置位数。
较高的位数可以提高压缩率,但会增加压缩时间。
默认值为0。
7. -pb<mode>或--pos-bits=<mode>:指定匹配位置位数。
较高的位数可以提高压缩率,但会增加压缩时间。
默认值为2。
以上只是部分常用的压缩参数,LZMA还提供了更多参数可以调整以优化压缩效果和速度。
具体的参数选取需要根据具体的压缩要求和实际情况进行调整。
lzma decoding result 10 -回复

lzma decoding result 10 -回复LZMA (Lempel-Ziv-Markov chain-Algorithm) 是一种数据压缩算法,它以数据编码和解码的形式存在。
本文将以“LZMA解码结果10”为主题,逐步解释LZMA压缩算法的工作原理、解码过程,以及其在实际应用中的重要性。
第一部分:LZMA压缩算法的原理和工作过程(500字)LZMA算法是一种基于字典的无损数据压缩算法,与其他压缩算法相比,它能够产生更高效的压缩率。
LZMA通过使用滑动窗口和字典技术来实现数据的压缩和解压缩。
在LZMA算法中,滑动窗口被用作一个缓冲区,它可以分为两个部分:字典区和匹配区。
字典区是一个固定大小的缓冲区,用于存储之前出现的文本片段。
匹配区是一个可变大小的缓冲区,用于存储当前处理的文本片段。
LZMA算法将滑动窗口划分为多个块,每个块包含一个字典和一个匹配区。
LZMA算法的工作过程可以分为以下几个步骤:1. 初始化:设置滑动窗口的大小和字典的大小。
2. 压缩:将待压缩的数据逐个字符读入滑动窗口,并通过匹配字典中的内容找到最长的匹配串。
然后,将匹配串的位置和长度编码为一个压缩码,存储到输出文件中。
3. 更新字典:将匹配区的内容添加到字典中,更新滑动窗口的状态。
4. 重复上述步骤,直到所有数据都被压缩为止。
第二部分:解码过程(500字)LZMA的解码过程与压缩过程相似,但需注意的是,解码时需要利用压缩码来获取位置和长度信息,从而重构原始数据。
LZMA的解码过程可以简要概括为以下几个步骤:1. 初始化:设置滑动窗口的大小和字典的大小。
2. 读取压缩码:从输入文件中逐个读取压缩码,获取位置和长度信息。
3. 根据压缩码重构匹配串:利用位置和长度信息,在字典中找到相应的匹配串。
4. 将解码得到的字符输出到解压缩文件。
5. 更新字典:将匹配区的内容添加到字典中,更新滑动窗口的状态。
6. 重复上述步骤,直到解码完所有压缩码为止。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1
-d{N}: set dictionary - [0,30], default: 23 (8MB) -fb{N}: set number of fast bytes - [5, 273], default: 128 -mc{N}: set number of cycles for match finder -lc{N}: set number of literal context bits - [0, 8], default: 3 -lp{N}: set number of literal pos bits - [0, 4], default: 0 -pb{N}: set number of pos bits - [0, 4], default: 2 -mf{MF_ID}: set Match Finder: [bt2, bt3, bt4, hc4], default: bt4 -mt{N}: set number of CPU threads -eos: write End Of Stream marker -si: read data from stdin -so: write data to stdout 找到要用到的参数,e——压缩,-mt{N}——CPU线程数,我的CPU是4核的 Q9500,输入命令: D:\>Lzma e D:\1024.img D:\1024.lzma –mt4 LZMA 4.57 Copyright (c) 1999-2007 Igor Pavlov 2007-12-06 D:\> 等待两分钟,压缩完毕。
LZMA压 缩 img文 件 实 例
在制作内存系统RAMOS时,会用到wingzip来压缩img文件,但wingzip不能 压缩超过4G的文件,新版本的Grub4DOS支持LZMA压缩文件,只好用LZMA 代替wingzip。 下载LZMA,下载地址: /grub2/makerom.zip 解压makerom.zip,里面D盘根目录。 第一步,用DiskGenius在D盘新建一个1024MB的img文件。
1
1
点击左上角的“保存更改”按钮
1
点击“是”按钮
第二步,用LZMA.EXE压缩img文件 在命令行提示符里运行 D:\>lzma /? LZMA 4.57 Copyright (c) 1999-2007 Igor Pavlov 2007-12-06 Error: Incorrect command Usage: LZMA <e|d> inputFile outputFile [<switches>...] e: encode file d: decode file b: Benchmark <Switches> -a{N}: set compression mode - [0, 1], default: 1 (max)
1