【数据库】 数据的编码、录入与整理
数据库编码规范

数据库编码规范V1.02022-8-28目的范围术语设计概要命名规范(逻辑对象)数据库对象命名脚本注释数据库操作原则常用字段命名(参考)1)目的为了统一公司软件开辟的设计过程中关于数据库设计时的命名规范和具体工作时的编程规范,便于交流和维护,特制定此规范。
2)范围本规范合用于开辟组全体人员,作用于软件项目开辟的数据库设计、维护阶段<3)术语数据库对象:在数据库软件开辟中,数据库服务器端涉及的对象包括物理结构和逻辑结构的对象。
物理结构对象:是指设备管理元素,包括数据文件和事务日志文件的名称、大小、目录规划、所在的服务器计算极名称、镜像等,应该有具体的配置规划。
普通对数据库服务器物理设备的管理规程,在整个项目/产品的概要设计阶段予以规划。
逻辑结构对象:是指数据库对象的管理元素,包括数据库名称、表空间、表、字段/域、视图、索引、触发器、存储过程、函数、数据类型、数据库安全性相关的设计、数据库配置有关的设计以及数据库中其他特性处理相关的设计等。
4)设计概要设计环境<数据库:ORACLE9i、MSSQLSERVER2000 等,操作系统:LINUX7.1 以上版本,显示图形操作界面;RedHat9 以上版本WINDOWS2000SERVER 以上设计使用工具手使用PowerDesigner 做为数据库的设计工具,要求为主要字段做详尽说明。
对于SQLServer 尽量使用企业管理器对数据库进行设计,并且要求对表,字段编写详细的说明(这些将作为扩展属性存入SQLServer 中) 手通过PowerDesigner 定制word 格式报表,并导出word 文档,作为数据字典保存。
(PowerDesignerv10 才具有定制导出word 格式报表的功能)<对于SQLServer 一旦在企业管理器进行数据库设计时加入扩展属性,就可以通过编写简单的工具将数据字典导出。
4 编写数据库建数据库、建数据库对象、初始化数据脚本文件设计原则4 采用多数据文件手禁止使用过大的数据文件,unix 系统不大于2GB,window 系统不超过500MB$oracle 数据库中必须将索引建立在索引表空间里。
编码规则和编码结构

编码规则和编码结构
编码规则和编码结构是一种用来组织数据的方式,它由数字和字母的组合构成。
编码规则和编码结构能够让大容量的数据具有一定的组织性,使用者可根据编码规则和编码结构进行查找和组织数据,从而更加方便地管理和查找某些特定的数据。
一、编码规则:
1. 编码规则是介于数据和人的桥梁,它决定了如何将手工输入的信息应用到数据库中,以及如何将数据库中的文本译码。
2. 编码规则原则上以八位二进制数来表示,从左到右,每八位表示一个字母,且编码完成后可恢复文字。
3. ASCII编码是最常用的编码规则,它在编码规则上有更广泛的应用,并且不同国家使用不同的编码规则,因此需要根据具体情况来确定编码规则。
二、编码结构:
1. 编码结构是数据库结构的一种正式表示方法,它是构成数据库的基础。
2. 无论是把文本信息转化为编码还是把编码的信息转化为文本,编码结构均有关系。
3. 编码结构因应用不同而有所不同,如堆存储、顺序存储和索引存储等,它们的字段搭配大小结构也不尽相同。
4. 合理的编码结构有利于查询和识别数据,有助于数据库的维护和发掘,同时也能减少系统的时空开销。
MySQL中的数据字符编码与排序规则

MySQL中的数据字符编码与排序规则在数据库中,数据字符编码和排序规则是非常重要的概念和设置。
它们决定了数据的存储和排序方式,直接影响了数据的正确性和可用性。
对于MySQL数据库来说,熟悉和正确设置数据字符编码和排序规则是非常重要的。
1. 数据字符编码数据字符编码是用来表示和存储数据字符的方式。
不同的字符编码支持的字符集和字符范围是不同的,而且一些字符编码可能会有乱码或不完全支持某些语言的情况。
在MySQL中,常见的数据字符编码有UTF-8、GBK、Latin1等。
UTF-8是一种Unicode字符编码,它支持世界上大部分语言的字符。
UTF-8使用变长字节表示每个字符,对于英文字符只需要一个字节,而对于中文字符需要三个字节。
在创建MySQL数据库时,强烈建议使用UTF-8字符编码,以确保对各种语言的支持和数据的正确存储。
GBK是一种中文字符编码,它和UTF-8相比只支持中文字符,但是存储空间更小。
如果数据库中的数据主要是中文,可以考虑使用GBK字符编码。
但需要注意的是,在使用GBK编码时,如果有其他非中文的字符存在,可能会出现乱码问题。
Latin1是一种较早的字符编码,它只支持部分字符集,比如英文、法文、西班牙文等。
如果数据库中的数据只包含这些字符集范围内的字符,可以考虑使用Latin1编码。
2. 排序规则排序规则决定了对于字符串和文本数据的排序方式。
在MySQL中,常见的排序规则有utf8_general_ci、utf8_bin、gbk_general_ci等。
utf8_general_ci是最常用的排序规则,它基于Unicode字符编码,对于大多数情况下的排序需求都可以满足。
utf8_general_ci在比较时忽略大小写和重音符号的区别,例如"abc"和"ABC"会被认为是相同的。
utf8_bin是一种严格区分大小写和重音符号的排序规则。
它会将"abc"和"ABC"视为完全不同的字符串。
Access数据库数据录入与查询

Access数据库数据录入与查询在信息化时代,数据库管理系统已经成为各个领域中不可或缺的工具。
Access数据库作为一种常用的关系型数据库管理系统,具有便捷、高效的特点,被广泛应用于数据录入和查询。
本文将介绍Access数据库的数据录入和查询方法,帮助读者更好地利用该数据库管理系统。
一、数据录入1. 打开Access数据库软件,创建新的数据库文件。
2. 在新建的数据库文件中,创建数据表。
可以通过图形界面或者SQL语句进行创建,根据需要定义各个字段的名称和数据类型。
3. 在数据表中录入数据。
可以通过手动输入、复制粘贴、导入文件等方式将数据录入到相应的字段中。
二、数据查询1. 打开已有的数据库文件。
2. 进入查询视图,通过SQL语句或者查询设计来进行数据查询。
- SQL语句查询:在查询视图中选择“SQL”选项,输入相应的SQL 语句,如SELECT、FROM、WHERE等关键词。
根据查询需求,结合条件表达式进行查询,获取符合条件的数据。
- 查询设计:在查询视图中选择“查询设计”选项,通过拖拽字段、设置条件以及排序等操作,构建查询的布局和条件。
运行查询后,系统将按照设定的条件进行搜索,并返回符合条件的数据集合。
三、数据录入与查询的技巧1. 设置主键:在创建数据表时,选择一个字段作为主键。
主键用于唯一标识一条记录,可以加快数据查询的速度。
2. 数据校验:在录入数据时,可以设置数据校验规则,确保录入的数据类型和格式符合要求。
例如,对于日期字段可以设置日期格式,对于数字字段可以设置数据范围。
3. 使用表单:Access数据库提供了表单功能,通过表单可以更方便地录入和查看数据。
可以通过图形界面设计表单,设置表单的布局和字段显示方式,提高数据录入和查询的操作便捷性。
4. 索引优化:对于经常进行查询的字段,可以创建索引以加快查询速度。
通过在相应字段上创建索引,系统将按照索引顺序进行搜索,提高数据库的性能。
5. 备份与恢复:定期对数据库进行备份,防止数据丢失或损坏。
数据录入与整理

数据录入与整理在现代信息社会中,大量的数据被不断产生和积累,对这些数据进行录入与整理成为许多行业和领域中必不可少的任务。
数据录入与整理工作的准确性和效率直接影响着信息处理的质量和决策的科学性。
本文将就数据录入与整理的重要性、方法与技巧以及存在的问题进行探讨。
一、数据录入与整理的重要性数据录入与整理是保证信息处理质量的基础,具有以下几个重要方面的作用。
1. 提供准确的数据基础:数据录入与整理过程中,需要对数据进行逐一检查和核对,确保数据的准确性和完整性。
准确的数据基础为后续的数据分析、挖掘和应用打下了坚实的基础。
2. 保证信息处理的可靠性:数据录入与整理过程中的详尽记录和清晰分类,有助于避免信息的遗漏和混乱,确保信息处理的可靠性和一致性。
3. 改善工作效率:通过合理的数据录入与整理方法和技巧,可以提高工作的效率。
自动化的录入和整理工具能够极大地节省人力成本和时间成本。
二、数据录入与整理的方法与技巧数据录入与整理的方法和技巧可以因具体的工作内容和要求而有所差异,但以下几点是常见的通用方法和技巧。
1. 数据录入的规范化:规范的数据录入方法能够提高数据的准确性和一致性。
例如,约定数据的格式、单位、编码等,以及设定数据录入必填项,防止数据遗漏。
2. 数据整理的分类与归档:合理的分类与归档方式能够帮助保持数据的有序和易于查找。
根据数据的性质或用途,将数据进行分类和归档,方便后续的数据分析和利用。
3. 利用自动化工具:随着科技的进步,很多数据录入和整理工作可以利用专门的软件和工具来完成,如电子表格软件、数据库管理系统等。
合理利用这些工具可以提高工作效率和减少错误。
三、存在的问题与解决方案在数据录入与整理的过程中,可能会遇到一些问题,需要及时解决和改进。
1. 人为因素带来的错误:数据录入和整理过程中,由于疏忽或操作不当等人为因素,可能会导致数据出现错误。
解决这一问题的关键是加强培训和规范操作,同时可采用数据校验机制检查错误。
数据录入与整理

数据录入与整理数据录入与整理是一项重要的工作,它涉及到对大量数据的准确输入和组织,以便为后续的数据分析和决策提供支持。
本文将探讨数据录入与整理的重要性、方法以及需要注意的问题。
一、数据录入的重要性数据录入是数据处理过程中的第一步,它对后续的分析和应用至关重要。
首先,准确的数据录入可以确保数据的质量。
如果数据录入错误,将会大大影响后续的数据分析和决策结果,甚至导致错误的判断。
其次,良好的数据录入可以提高数据的可用性和可操作性。
准确记录的数据可以为日后的查询和使用提供方便,节省时间和精力。
二、数据录入的方法1. 手工录入手工录入是最基本和常用的数据录入方法。
这种方法适用于数据量较小的情况,操作相对简单,但需要投入大量的时间和人力。
在手工录入时,需要注意输入的准确性,避免因为疏忽或者输入错误导致数据的不准确。
2. 自动化录入随着技术的发展,自动化录入成为了一种更为高效的方式。
通过使用特定的软件或设备,可以将纸质文档或者其他形式的数据自动录入到电子系统中。
这种方法大大节省了时间和人力,并且减少了人为错误的可能性。
但是在使用自动化录入时,也需要保证设备的准确性和稳定性。
三、数据整理的步骤数据整理是将散乱的数据按照一定的格式和顺序进行组织和重排的过程。
以下是一般的数据整理步骤:1. 数据清洗在数据录入过程中,常常会出现错误、缺失或不规范的数据。
数据清洗是为了修正这些问题,并确保数据的质量。
数据清洗包括删除重复数据、填补缺失数据、修正错误数据,以及统一数据格式和单位等。
2. 数据分类和标识根据数据的特点和用途,将数据进行分类和标识是一项重要的整理工作。
通过对数据进行分类和标识,可以方便后续的查询和分析。
例如,可以按照时间、地区、产品类型等进行分类。
3. 数据归档和存储数据整理完成后,需要进行归档和存储。
根据数据的敏感程度和使用频率,选择合适的存储介质和方法。
在数据存储过程中,要注意数据的备份和安全性,以防止数据丢失或泄露。
数据库字符集编码和表字符集编码

数据库字符集编码和表字符集编码数据库字符集编码和表字符集编码是数据库中非常重要的概念,它们决定了数据库中存储的数据的字符编码方式。
正确设置字符集编码可以确保数据的正确存储和显示,避免出现乱码等问题。
数据库字符集编码是指数据库服务器使用的字符编码方式,它决定了数据库中所有表的默认字符集编码。
常见的数据库字符集编码有UTF-8、GBK、GB2312等。
UTF-8是一种通用的字符编码方式,支持全球范围内的字符,是目前最常用的字符集编码方式。
GBK和GB2312是中文字符集编码方式,适用于中文环境。
表字符集编码是指每个表在数据库中的字符编码方式,它可以与数据库字符集编码不同。
在创建表时,可以指定表的字符集编码,也可以使用数据库的默认字符集编码。
如果表的字符集编码与数据库的字符集编码不一致,那么在存储和显示数据时就需要进行字符集转换,这可能会导致性能下降和数据损坏。
正确设置数据库字符集编码和表字符集编码非常重要。
首先,它可以确保数据的正确存储和显示。
如果数据库字符集编码和表字符集编码不一致,那么在存储和显示数据时就可能出现乱码等问题,影响用户体验。
其次,它可以提高数据库的性能。
如果数据库字符集编码和表字符集编码一致,那么在存储和显示数据时就不需要进行字符集转换,可以提高数据库的性能。
在设置数据库字符集编码和表字符集编码时,需要考虑以下几个因素。
首先,需要考虑数据库的使用环境。
如果数据库主要用于存储中文数据,那么可以选择中文字符集编码,如GBK或GB2312。
如果数据库需要支持全球范围内的字符,那么可以选择UTF-8字符集编码。
其次,需要考虑数据库的性能和存储空间。
不同的字符集编码对存储空间的占用和性能有不同的影响。
一般来说,UTF-8字符集编码占用的存储空间较大,但支持更多的字符,而GBK和GB2312字符集编码占用的存储空间较小,但只支持中文字符。
最后,需要考虑与其他系统的兼容性。
如果数据库需要与其他系统进行数据交换,那么需要确保数据库字符集编码和表字符集编码与其他系统兼容。
数据编码的基本方式

28
机内码
文档仅供参考,如有不当之处,请联系改正。
GB2312-80统一要求了中文旳基本编码原则,但是 要存储在计算机中与西文编码在计算机中旳表达
)8= ( )16=
文档仅供参考,如有不当之处,请联系改正。
编码
计算机是美国人发明旳,所以计算机旳字 符集中自然包括了英文旳26个字母。
计算机要在全世界通用,必须采用公认旳 原则格式对字符、符号进行编码。
常用旳字符编码有ASCII码、BCD码、西文 字符编码和EBCDIC码。
21
文档仅供参考,如有不当之处,请联系改正。
文档仅供参考,如有不当之处,请联系改正。
二进制数转换为十六进制数
整数部分从低位向高位方向每4位用一种等值旳十六 进制数来替代,即四位并为一位,最终不足4位时在 高位处补0,补够4位;小数部分从高位向低位方向 每4位用一种等值旳十六进制数来替,最终不足4位 时在低位处补0,补够4位。 (1110 0101 1010 . 1011 1001)2 =(E5A.B9)16
78~7E
位 区 1~15
16~55
56~87
88~94
21 22 23 24 25 26 …………7C 7D 7E
7F
1 2 3 4 5 6 ………………91 92 93 94
非中文图形符号(常用符号、数字序号、俄文、 英文、法文、希腊字母、日文平、片假名等)
啊阿埃
一级中文
(3755个)
二级中文(3008个)
23
文档仅供参考,如有不当之处,请联系改正。
西文字符处理起来比较简朴,而中文信息 处理起来就复杂了。中文是图形文字,常 用中文就有3000~6000个,形状和笔画差 别很大。这就决定了中文字符旳编码方案 必须完全不同于西文旳编码方案。
数据库设计规范_编码规范

数据库设计规范_编码规范数据库设计规范包括数据库表结构的设计原则和数据库编码规范。
数据库表结构的设计原则包括表的命名规范、字段的命名规范、主键和外键的设计、索引的使用、约束的定义等。
数据库编码规范包括SQL语句的书写规范、存储过程和函数的命名规范、变量和参数的命名规范、注释的使用等。
1.表的命名规范-表名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:user_info。
- 表名使用单数形式,如:user、order。
2.字段的命名规范-字段名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 字段名使用小写字母,使用下划线(_)作为单词之间的分隔符,如:user_name。
- 字段名要具有描述性,可以清楚地表示其含义,如:user_name、user_age。
3.主键和外键的设计-每张表应该有一个主键,用于唯一标识表中的记录。
- 主键字段的命名为表名加上“_id”,如:user_id。
- 外键字段的命名为关联的表名加上“_id”,如:user_info_id,指向user_info表的主键。
4.索引的使用-对于经常用于查询条件或连接条件的字段,可以创建索引,提高查询性能。
-索引的选择要权衡查询性能和写入性能之间的平衡。
-不宜为每个字段都创建索引,避免索引过多导致性能下降。
5.约束的定义-定义必要的约束,保证数据的完整性和一致性。
-主键约束用于保证唯一性和数据完整性。
-外键约束用于保证数据的一致性和关联完整性。
6.SQL语句的书写规范-SQL关键字使用大写字母,表名和字段名使用小写字母。
-SQL语句按照功能和逻辑进行分行和缩进,提高可读性。
-使用注释清晰地描述SQL语句的功能和用途。
7.存储过程和函数的命名规范-存储过程和函数的命名要具有描述性,可以清楚地表示其功能和用途。
-使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:get_user_info。
数据的编码实验报告

一、实验目的1. 了解数据编码的基本概念和方法。
2. 掌握常用数据编码技术,如ASCII码、Unicode码等。
3. 熟悉数据编码在信息处理中的应用。
二、实验原理数据编码是将数据转换成计算机可识别的二进制形式的过程。
数据编码的主要目的是为了便于计算机存储、处理和传输信息。
常用的数据编码技术有ASCII码、Unicode码、ISO码等。
三、实验内容1. ASCII码编码实验2. Unicode码编码实验3. 数据编码应用实验四、实验步骤1. ASCII码编码实验(1)打开记事本,输入一段文本信息,如:“Hello, World!”。
(2)将记事本保存为文本文件(.txt)。
(3)使用文本编辑器打开该文件,查看其内容。
(4)使用ASCII码表,将每个字符对应的ASCII值找出来,如:H对应65,e对应101,l对应108,如此类推。
(5)将ASCII值转换为二进制形式,如:65的二进制为01000001,101的二进制为11001001,108的二进制为11011000,如此类推。
(6)将所有字符的二进制编码拼接起来,得到该文本的ASCII码编码。
2. Unicode码编码实验(1)打开记事本,输入一段包含中文字符的文本信息,如:“你好,世界!”。
(2)将记事本保存为文本文件(.txt)。
(3)使用文本编辑器打开该文件,查看其内容。
(4)将文本文件转换为UTF-8编码,并保存。
(5)使用文本编辑器打开UTF-8编码的文件,查看其内容。
(6)使用Unicode码表,将每个字符对应的Unicode值找出来,如:“你”的Unicode值为20320,“好”的Unicode值为22909,如此类推。
(7)将Unicode值转换为二进制形式,如:20320的二进制为11100100 00000000,22909的二进制为10010001 10011001,如此类推。
(8)将所有字符的二进制编码拼接起来,得到该文本的Unicode码编码。
数据库设计规范_编码规范

数据库设计规范_编码规范1.命名规范:表名、字段名和约束名应该具有描述性,遵循一致的命名规则。
避免使用保留字作为名称,使用下划线或驼峰命名法。
2.数据类型选择:选择合适的数据类型来存储数据,避免过大或过小的数据类型。
这有助于减小数据库的存储空间,提高查询性能。
3.主键和外键:每个表都应该有一个主键来唯一标识每条记录。
外键用于建立表之间的关系,确保数据的一致性和完整性。
4.表的范式:根据具体需求,遵循规范化设计原则。
将数据分解为多个表,减少数据冗余和更新异常。
5.索引设计:根据查询需求和数据量,设计适当的索引。
避免过多或不必要的索引,以减小索引维护的开销。
6.分区设计:对大型表进行分区,将数据分散存储在不同的物理磁盘上,提高查询性能。
7.安全性设计:为数据库设置适当的权限和访问控制,限制不必要的用户访问和操作。
数据库编码规范:1.编码一致性:统一使用同一种编码方式,如UTF-8,避免不同编码之间的转换问题。
2.参数化查询:使用参数化查询语句,预编译SQL语句。
这样可以防止SQL注入攻击,提高查询性能。
3.事务管理:使用事务控制语句(如BEGIN、COMMIT和ROLLBACK)来管理数据库事务,确保数据的一致性和完整性。
4.错误处理:在代码中捕获和处理数据库错误和异常,提高系统的容错性。
5.SQL语句编写:编写简洁且优化的SQL语句,避免使用多个嵌套的子查询,使用JOIN操作符进行表之间的关联。
6.数据库连接管理:优化数据库连接,避免频繁地打开和关闭数据库连接。
7.缓存机制:对于频繁查询的数据,使用缓存机制来减少数据库的压力。
8.日志记录:记录数据库操作日志,包括增删改查的操作,以便后续的问题跟踪和审计。
综上所述,数据库设计规范和编码规范对于确保数据库系统的性能、安全性和可维护性至关重要。
遵循这些规范能够提高数据库系统的效率和可靠性,减少潜在的问题和风险。
因此,在进行数据库设计和编码时,应该遵循这些规范。
安徽工业大学管理统计学实验报告

安徽工业大学管理统计学实验报告统计学实验报告一、实验步骤总结(一)数据的搜集与整理1. 实验一:数据的收集与整理实验步骤:一、统计数据的整理(一)数据的预处理1、数据的编码及录入(1)数据的编码(2)数据的录入2、数据的审核与筛选3、数据的排序(二)数据的整理对数据进行整理的主要方式是统计分组,并形成频数分布。
既可以使用函数FREQUENCE进行统计分组,也可以借助直方图工具进行统计分组。
二、统计数据的描述(一)运用函数法进行统计描述常用的统计函数函数名称函数功能Average 计算指定序列算数平均数Geomean 计算数据区域的几何平均数 Harmean 计算数据区域的调和平均数Median 计算给定数据集合的中位数Mode 计算给定数据集合的众数Max 计算最大值Min 计算最小值Quartile 计算四分位点Stdev 计算样本的标准差Stdevp 计算总体的标准差 Var 计算样本的方差 Varp 计算总体的方差在Excel中有一组求标准差的函数,一个是求样本标准差的函数Stdev,另一个是求总体标准差的函数Stdevp。
Stdev与Stdevp的不同是:其根号下的分式的分母不是N,而是N-1。
此外,还有两个对包含逻辑值和字符串的数列样本标准差和总体标准差的函数,分别是Stdeva和Stdevpa。
(二)运用“描述统计”工具进行数据描述“描述统计”工具可以生成以下统计指标,按从上到下的顺序为:平均值、标准误差、中位数、众数、样本标准差、样本方差、峰度值、偏度值、级差、最小值、最大值、样本总和、样本个数和一定显著水平下总体均值的置信区间。
三、长期趋势和季节变动测定(一)直线趋势的测定1、移动平均法测定直线趋势2、最小二乘法测定直线趋势(二)曲线趋势的测定(三)季节变动测定1、月(季)平均法2、移动平均趋势剔除法测地归纳季节变动实验数据:2. 实验二:实验步骤:描述数据的图表方法(1)熟练掌握Excel 2003的统计制表功能(2)熟练掌握Excel 2003的统计制图功能(3)掌握各种统计图、表的功能,并能准确的根据不同对象的特点加以应用实验数据:二、实验心得报告成绩:(一)心得体会16个课时的课以来,在老师的帮助下,我进行了系统的统计学操作实验,加深了对统计学各方面只是以及对EXCEL操作软件的应用了解,同时能更好的把实践与理论相结合。
数据的收集和整理

数据的收集和整理数据收集和整理是数据分析和决策制定中的重要步骤。
通过有效地收集和整理数据,我们能够获得准确、完整且合理的数据,并为后续的数据分析提供基础。
本文将探讨数据的收集和整理过程,并提供一些有效的方法和技巧。
一、数据的收集数据的收集是指通过各种手段和途径,获取所需的数据信息。
以下是一些常见的数据收集方法:1. 实地观察:直接到研究对象所在的现场进行观察和记录。
例如,在市场调研中,观察消费者的购买行为和偏好,以及商品陈列和销售环境。
2. 问卷调查:设计和分发调查问卷,收集被调查者的意见、看法和建议。
可以通过纸质问卷、电子调查表格或在线调查平台进行。
注意问卷设计应该简明扼要,问题清晰明确,以确保获得准确的数据。
3. 访谈和采访:与目标人群进行面对面的交流,获得详细和深入的信息。
访谈可以是结构化的,按照预定问题进行;也可以是半结构化的,允许对话的展开和深入。
采访则可以是录音或录像的形式。
4. 数据库和档案:利用现有的数据库和档案,获取已经收集和整理好的数据信息。
例如,政府公开数据、科研机构的研究报告、企业的销售数据等等。
5. 网络和社交媒体:利用互联网和社交媒体平台,获取人们在网上发布的各种信息和数据。
例如,通过舆情分析,了解公众对某一事件或产品的意见和评价。
6. 实验和观察记录:通过实验设计和记录观察数据,来获取实时的数据信息。
例如,在科学研究中,可以进行实验以验证某一假设或推测。
二、数据的整理数据的整理是指将收集到的数据进行编码、分类、清洗和归档,以便后续的数据分析和使用。
以下是一些数据整理的步骤和技巧:1. 数据编码:为了方便管理和分析,对数据进行编码和编号。
可以使用数字、字母或符号来表示不同的类别和变量。
编码应该简洁明了,规范统一,以便后续的数据处理。
2. 数据分类:将数据按照不同的特征和维度进行分类。
例如,按照时间、地点、人群等分类,将数据进行分组。
分类有助于对数据进行比较和分析。
3. 数据清洗:清洗数据是为了确保数据的准确性和完整性。
spss第二章,数据的编码、录入与整理
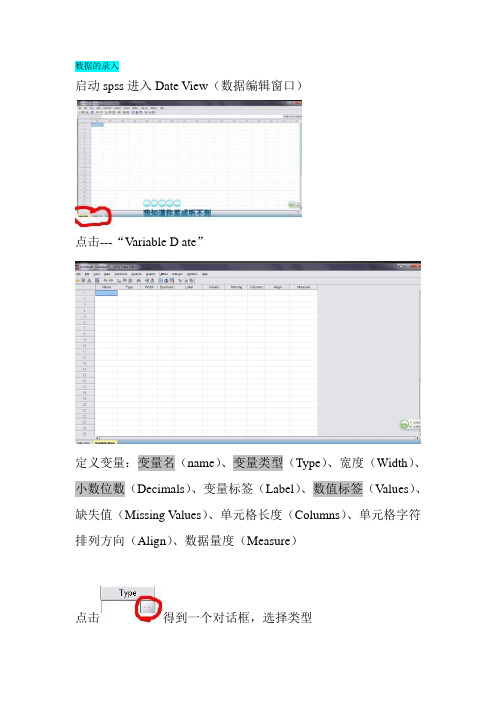
数据的录入启动spss进入Date View(数据编辑窗口)点击---“Variable D ate”定义变量:变量名(name)、变量类型(Type)、宽度(Width)、小数位数(Decimals)、变量标签(Label)、数值标签(Values)、缺失值(Missing V alues)、单元格长度(Columns)、单元格字符排列方向(Align)、数据量度(Measure)点击得到一个对话框,选择类型系统默认宽度为8,小数位2位;一般数字和字符比较常用-------Lable中可以取汉字名字方便查看------Values中可以设定数值标签,既将非数值的记录转换成数值;比如:性别1-女,2-男(一般默认为none)如图填写,点击----“And”----“OK”。
------在Missing中系统默认缺失值“none”用户可自己定义-------其他几项一般都用默认数据的录入-------回到“Date View”中逐个录入数据------“File”--“Save”(或者Ctrl+s)保存到适当的位置内即可数据的导入-----“File”---“Open”---“Date”数据的整理:数据分值转换数据分值的转换时通过对数据的重编码来实现的。
(比如将选项ABCD变成数值进行积分)----数据输入后----“Transform”--“Recode into different Variables”选中其中一个变量将其移到Numeric Variable->Output V ariable在那么中重编码----点击“Change”----“Old And New Values”例如:“Old”中写A----“New”中写1,此时A对应的数值就是1;同理写BCD-------点击“And”----“continue”----回到前一个界面-------将其它需要重编码的都编写一次(不要为了偷懒而一次性写,不会达到相同效果)------编完后-----点击“OK”表2.13前身量表的统分假定一个量表由两个分量表组成,其一为1、2、5、8、9题组成,另一个由3、4、6、7、10题,要求计算出分量表和总量表的分。
统计学中的数据收集和整理

统计学中的数据收集和整理统计学作为一门科学,涉及到数据的收集、整理、分析和解释。
在统计数据的可靠性和准确性上,数据的收集和整理环节起到至关重要的作用。
本文将介绍统计学中数据收集和整理的基本原则和常用方法。
一、数据收集的原则在进行数据收集时,需要遵循以下原则,以保证数据的准确性和可靠性:1. 目标明确性:在数据收集的初期,需要明确研究的目标和所要回答的问题。
只有清楚明确的目标才能帮助我们选择合适的数据收集方法和采样策略。
2. 信度和效度:信度是指数据收集工具的稳定性和一致性,效度是指数据工具是否测量到了研究问题的本质。
为了保证数据的信度和效度,我们需要使用经过验证的测量工具和合适的研究设计。
3. 采样代表性:采样是指从总体中选择一部分观察对象,用于代表整个总体。
采样的目标是保证样本与总体之间的代表性和可比性。
在选择采样方法时,需要根据研究目标和研究对象的特点来确定最合适的采样方式。
二、数据收集的方法1. 问卷调查:问卷调查是一种常用的数据收集方法。
通过设计合适的问卷并发放给样本对象,收集他们的观点和意见。
问卷调查的优势是收集大量数据的效率高,但也存在着回收率低、回答者主观性和误差等问题。
因此,在进行问卷调查时,需要注意问卷设计的合理性和问题的准确性。
2. 访谈调查:访谈是一种直接与被调查对象进行交流的方式,可以深入了解被调查对象的观点和意见。
访谈调查的优势是可以获得详细和全面的数据,但也需要投入更多的时间和人力资源。
在进行访谈调查时,需要掌握良好的沟通技巧,确保信息的准确性和充分性。
3. 观察调查:观察调查是直接观察和记录被调查对象的行为和现象。
观察调查可以减少受访者的主观性和回忆偏差,但观察者的主观性和认知偏差会对数据产生影响。
因此,在进行观察调查时,需要选择合适的观察方法,并确保观察者对被观察对象的行为保持客观性。
三、数据整理的方法数据整理是将收集到的原始数据进行录入、清洗、编码和存储的过程。
SPSS软件的操作与应用第2讲 描述性统计 (1)

直方图
1. 用面积表示各组频数的多少,矩形的高度表示每一组的频数或频率 宽度表示各组的组距; 2. 由于分组数据具有连续性,各矩形通常是连续排列; 3. 主要用于展示数值型数据。
二、频数分析
4. SPSS操作及案例 例一:各门成绩统计 结果保存为:3-StudentScore.spo
二、频数分析
5. SPSS操作及案例分析 根据方差齐性检验结果可以看出,语文成绩按照男女分开的样 本显著性水平Sig.值都大于0.05,表明方差的差异不显著,也就是 说方差是齐性的。
四、探索性分析
5. SPSS操作及案例分析 例五:操作步骤(数据文件:4-Explore.sav ) Analyze→Descriptive Statistics→Explore...
平均值(Mean):即算术平均值(=(X1+X2+…+Xn)/n)。 易受极端值影响。 中位数(Median):把变量的值有序排列,位于中间位置的值即中位数。 是位置平均置,不易受极端值的影响。 众数(Mode):样本中出现次数最多的值,代表数据的集中程序。 求和(Sum):所有变量之和,反映变量的总体水平。
三、基本描述统计量
4. 描述分布形态的统计量 考察数据分布形态特征的统计量,例如,数据分布是否对称、偏 斜程度以及陡缓程度,主要有如下两种统计量: 偏度(Skewness):
偏度值>0,为正偏或右偏;偏度值<0,为负偏或左偏。偏度绝对值越大,偏斜越大。
峰度(Kurtosis):
峰度值>0,数据分布比标准正态分布更陡峭,为尖峰分布;峰度值<0,数据分布比 标准正态分布更平缓,为平峰分布。
四、探索性分析
2. 通过茎叶图(Stem-and-Leaf Plots)描述频度分布
调查资料的编码和录入

②变量值标签 变量值标签是对变量的可能的取值所附
加的进一步说明,一般对分类变量要定义 其取值的标签。
(4)变量格式 变量格式主要包括显示宽度、对齐方式
和缺失值。
2.编码设计的方法
❖ 事前编码设计 ❖ 事后编码设计
事后编码指的是给某个没有事先编码的 答案分配一个代码。通常需要事后编码的 有:封闭式问答题的“其它”项和开放式
问 答题。
二、调查资料的录入
调查资料的录入指的是将问卷或编码表 中的每一项目对应的代码读到磁盘、磁带 中,或通过键盘直接敲入计算机中。
数据录入方式:键盘、扫描仪、光标阅 读器等。
市场调查
(2)变量类型
变量有三种基本类型:数值型、字符型 和日期型。数值型变量又按不同要求分为 五种,共八种类型的变量,分别是: 标准数值型变量 带逗点的数值型变量 圆点数值型变量 科学记数法 带美元符号的数值型变量
自定义型 日期型变量 字符型变量 (3)变量标签和变量值标签 ①变量标签 变量标签是对变量名的附加的进一步说明。
(1)变量8个字符组成,变量名最好不用汉 字。
②首字符是字母,其后可为字或数字或除“?”、 “-”、“!”和“*”以外的字符。但应注意, 不能以下划线“-”和圆点“.”作为变量名的最 后一个字符。
③变量名不能与统计软件保留字相同。
④系统不区分变量名中的大小写字符。例如ABC和abc 被认为是同一个变量。
市场调查
一、资料的编码
1.编码是指将被调查者回答的问卷答案“量 化”成计算机可以接受的语言。 2.编码的作用 ①将定性资料定量化,便于进行统计分析; ②减少数据录入和分析的工作量,节省费 用和时间,有助于提高工作效率。
3 .编码涉及的内容 ❖ 变量名 ❖ 变量类型 ❖ 变量标签和变量值标签 ❖ 变量格式
数据的编码录入与整

第4题-环境
编码
样例
1-相貌;2-文化水准;3-气质风度; 文化 2 4-志同道合;5-人品;6-家庭条件; 水准 7-个人收入;8-其他
1-相貌;2-文化水准;3-气质风度; 志同 4 4-志同道合;5-人品;6-家庭条件; 道合 7-个人收入;8-其他
1-相貌;2-文化水准;3-气质风度; 人品 5 4-志同道合;5-人品;6-家庭条件; 7-个人收入;8-其他
系统缺失值 指计算机默认的缺失方式,如输入数据空缺、输入非法字符等
. 通常把缺失值标记为“ ”
a
8
四、缺失值的处理
3. 缺失值处理方法 替代法:采用统计命令或在相关统计功能中利用参数替代 Transform →Replace Missing Values
剔出法:剔除有缺失值的题目或剔除有缺失值的整份问卷
a
9
五、数据处理中的操作术语
个案(Cases)
一个研究对象就是一个个案;一个个案就是一条记录;在数据表格 中表示为“一行”
每一个个案记录的是一个研究对象各个属性的具体数值,如学生信 息(姓名、性别、年龄等)
每一行为一条记录
每一列为一个字段
学生表
字段
每个记录只能对应一个对象且仅为一个
个案
学号 0604231 0604253 0605321 0606002
1-相貌;2-文化水准;3-气质风度;4-志同道合;5-人品;6-家庭 条件;7-个人收入;8-其他 1-选;0-不选 1-选;0-不选 1-选;0-不选
A B C(A-1,B-2,C-3)
A B C(A-3,B-2,C-1)
样例
男
1
小学
2
文化水准 2
志同道合 4
数据库设计编码规范

SQL Serve数据库设计规范一、数据库命名规范:对象前缀命名:前缀命名一般用小写表的前缀:业务模块组名前缀数据列的前缀:一般采用列的数据类型做前缀存储过程前缀:udp ,系统存储过程(sp)自定义函数前缀:udf(User define function)视图前缀:udv(User Define View)表示用户自定义视图自定义规则前缀:udr(User Define rule)用户自定义规则自定义约束前缀:uck(User Checker)用户自定义约束索引前缀:idx(Index)表示索引主键前缀:pk(primary keys)表示主键数据列的前缀示例:编号 1 2 3 4 5 6 7数据类型char varchar int smallint datetime money numeric 前缀 c vc i si dt m n 编号8 9 10 11 12 13数据类型decimal float bit binary image text前缀 d f b b img tx二、数据库设计规范:1、每个表中都可以考虑添加的的几个有用的字段RecoredID,记录唯一编号,不建议采用业务数据作为记录的唯一编号CreationDate,在SQL Server 下默认为GETDATE()RecordCreator,在SQL Server下默认为NOT NULL DEFAULT USERRecordVersion,记录的版本标记;有助于准确说明记录中出现null 数据或者丢失数据的原因2、数据类型:字符类型一般不建议采用char而采用varchar数据类型,除非当这列数据的长度特别固定时可以考虑用char。
数值类型如果表示金额货币建议用money型数据,如果表示科学记数建议用numeric数据类型记录标识一般采用int类型标识唯一一行记录。
自增or 非自增3、索引:所有的表都应该有一个主键索引,这对提高数据库的性能很有帮助根据使用频率决定哪些字段需要建立索引,选择经常作为连接条件、筛选条件、聚合查询、排序的字段作为索引的候选字段。
数据库字符编码

数据库字符编码
数据库字符编码是用来表示和存储字符数据的编码规则。
在数据库中,字符编码决定了如何将字符转化为数字进行存储和检索。
常见的数据库字符编码包括:
1. ASCII:ASCII字符编码是英语字符和控制字符的标准化编码方式,采用7位二进制编码,可以表示128种字符。
2. Unicode:Unicode字符编码是全球通用的字符编码标准,可以表示几乎所有的字符,包括各种语言的字符、符号和标点符号。
Unicode有不同的实现方式,包括UTF-8、UTF-16和UTF-32等。
3. UTF-8:UTF-8是一种变长编码方式,它可以根据字符的不同使用1到4个字节来表示字符,对于英语字符,使用1个字节就可以表示。
4. UTF-16:UTF-16是一种定长编码方式,使用16位的编码表示一个字符。
常见的数据库,如MySQL、Oracle、SQL Server等都支持不同的字符编码,可以根据实际需要来设置数据库的字符编码。
正确设置数据库字符编码可以确保数据的正确存储和检索,并支持不同语言和字符的处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 编码示例中的第5、6题就是属于数值型编码
– 第5题是正向数值型(被选项的程度越高,分值越大) – 第6题是反向数值型(被选项的程度越高,分值越小)
变量名 第5题 第6题 A B C(A-1,B-2,C-3) A B C(A-3,B-2,C-1) 编码 A A 样例 1 3 16
• 变量(Variable)
– 是指问卷中每一个问题,数据库里字段,数据表格中表示为“一列”
• 量值(Value)
– 是指问卷中的答案,也称为观测值,在SPSS系统里,单元格中的数值 就是变量值
22
三、创建数据文件
23
数据处理的流程
建立数据文件
定义数据文件结构
数据加工整理
录入、修改、保存数据
统计分析
姓名 张三 李四 王五 赵六
性别 男 女 女 男
出生日期 87-1-1 88-6-30 88-8-18 88-12-24
专业编号 01 02 03 02
21
数据处理中的操作术语
• 样本(Sample)
– 是指具有共同属性的所有研究对象,如学生的所有信息 – 样本包含多个个案,在数据表格中表示为“n行”
28
定义变量类型、宽度及小数位数
• 在“Type”下单击单元格,打开变量类型窗口,选择变 量类型 • 常用变量类型有:
– – – – 数值型(Numeric) 日期型(Date) 货币型(Dollar) 字符型(String)
29
定义变量标签和变量值标签
• 定义变量标签
– 在“Label”下单击单元格,输入变量标签 – SPSS允许变量标签长度为255字节
• 数据编码概念
– 数据编码是指把需要加工处理的数据库信息,用特定的数字来表 示的一种技术。 – 根据一定数据结构和目标的定性特征,将数据转换为代码或编码 字符,在数据传输中表示数据的组成,并作为传送、接受和处理 的一组规则和约定。
13
数据问卷量表
序号 调查内容 选项
1
2
您的性别:
你的文化程度:
(1)男 (2)女
– 系统缺失值
• 指计算机默认的缺失方式,如输入数据空缺、输入非法字符等 • 通常把缺失值标记为“.”
19
缺失值处理方法
• 替代法:
– 采用统计命令或在相关统计功能中利用参数替代 – 在SPSS中,执行菜单命令“Transform →Replace Missing Values”来替代缺失值
• 剔出法:
编码类型(多项选择题)
• 多项选择题的编码
– 多项选择题就是题目答案的选项是多选项
变量名 编码 1-相貌;2-文化水准;3-气质风 度;4-志同道合;5-人品;6-家 庭条件;7-个人收入;8-其他 1-相貌;2-文化水准;3-气质风 度;4-志同道合;5-人品;6-家 庭条件;7-个人收入;8-其他 1-相貌;2-文化水准;3-气质风 度;4-志同道合;5-人品;6-家 庭条件;7-个人收入;8-其他 1-选;0-不选 1-选;0-不选 1-选;0-不选 样例 文化 水准 志同 道合 人品 2
10
SPSS数据分析基本步骤
建立数据文件 定义数据文件结构
数据加工整理
录入、修改、保存数据
统计分析
解释分析结果
11
二、数据处理的基本概念
12
数据的编码、录入与整理
• 原理
– 是研究者利用SPSS进行统计分析的必要前提。 – 就是把通过问卷调查获得的资料转变为SPSS能够识别的数据文件 ,为各种统计分析做好准备。
4
5
(1)不感兴趣 (2)感兴趣 (3)非常感兴趣
6
您对学英语感到厌恶:
(1)不厌恶 (2)厌恶 (3)非常厌恶
14
数据问卷编码方案
变量名 第1题 第2题 第3题-1 第3题-2 第3题-3 第4题-工作 1-男 ;0-女 1-没上过学;2-小学;3-初中;4-高中;5-大专以上 1-相貌;2-文化水准;3-气质风度;4-志同道合;5-人品;6-家庭 条件;7-个人收入;8-其他 1-相貌;2-文化水准;3-气质风度;4-志同道合;5-人品;6-家庭 条件;7-个人收入;8-其他 1-相貌;2-文化水准;3-气质风度;4-志同道合;5-人品;6-家庭 条件;7-个人收入;8-其他 1-选;0-不选 编码 男 小学 文化水准 志同道合 人品 选 样例 1 2 2 4 5 1
第4题-学校
第4题-环境 第5题 第6题
1-选;0-不选
1-选;0-不选 A B C(A-1,B-2,C-3) A B C(A-3,B-2,C-1)
不选
选 A A
0
1 1 3 15
编码类型(数值型数据)
• 数值型数据的编码
– 数值型数据的编码就是根据调查问卷的评分标准对变量赋予分值 – 通常采用三点计分、四点计分和五点计分等方式进行评分
31
变量定义的信息复制
• 如果有多个变量的类型相同,可以先定义一个变量,然后 把该变量定义的信息复制给新变量 • 操作步骤:
– 先定义一个变量 – 在该变量行号上单击右键,在快捷菜单中选择“Copy” – 选择同类型新变量所在行,单击右键,在快捷菜单中选择“Paste”
(1)没上过学 (2)小学 (3)初中 (4)高中 (5)大专以上
3
您想选择下列哪些择偶条件(任选三 项):
您购买房屋时,会考虑哪些因素(任 选): 您对心理学感兴趣:
(1)相貌 (2)文化水准 (3)气质风度 (4)志同道合 (5)人品 (6) 家庭条件 (7)个人收入 (8)其他
(1)离工作地点的远近 (2)小孩所就读的学校 (3)居家附近 的环境
• 限定多选项分类法
– 限定了一次最多可以选择项目的个数; – 不能直接对题目进行编码,必须先确定最 多选择,并给每个选项建立一个变量 – 如编码示例中的第3题
第3题-1
第3题-2
4
第3题-3
5
• 任意多项二分法
– 表示每一次可以任选几个选项; – 编码方法把每一个被选项作为一个变量来 定义,每个变量只能选择“1或0” – 如编码示例中的第4题
– 统计分析、数据挖掘 、数据采集 、企业应用服务
• 2010年: IBM收购SPSS之后,各子产品名称统一加上IBM SPSS字样: – 统计分析产品、数据挖掘产品、数据采集产品、企业应用服务7SPSS发展8SPSS发展9
SPSS基础内容
• • • • • • • 第7讲 SPSS数据的编码、录入与整理 第8讲 统计报告 第9讲 描述性统计 第10讲 均值比较 第11讲 散点图、相关系数 第12讲 回归概念、回归系数 第13讲 SPSS综述
• 定义变量值标签
– 变量值标签是对变量的每一可能取值进一步描述,当变量是定类 或定序变量时,非常有用。变量值标签系统默认为None – 在“Values”下单击单元格,打开变量值标签窗口,输入变量值 标签
30
定义缺失值
• 在“Missing”下单击单元格,打开缺失值窗口,输入缺失值
– No missing values:没有缺失值 – Discrete missing values:定义1~3个单一数为缺失值 – Range plus one optional discrete missing values:定义指定范围 为缺失值,同时指定另外一个不在这一范围的单一数为缺失值
编码类型(非数值型数据)
• 非数值型数据的编码
– 非数值型数据的编码,首先要确定编码规则,然后根据规则对变 量赋予分值。
• 双值型变量的编码
– 多采用“0、1”或“1、2”来赋值 – 如编码示例中的第1题
• 多值型变量的编码 • 通常对非数值型数据编码,主要起到分组的作用,不能进 行各种算术运算
变量名 第1题 第2题 1-男 ;0-女 1-没上过学;2-小学;3-初中;4-高中;5-大专以上 编码 男 小学 样例 1 2 17
• • • • • • • • • • 变量名(Name):变量的名称 变量类型(Type):变量的类型 宽度(Width):存储变量值的最大值 小数位数(Decimals):变量为数值类型时,小数后的位数 变量标签(Label):对变量名的注释。光标在变量名上时,会显示该标签 变量值标签(Values):变量标签的取值 缺失值(Missing Values):定义缺失的值,例如,当定义99为缺失值时,当该 变量的值为99时,把它认为是缺失值 显示数据的列宽(Colums):与上面“宽度”不同,它只管显示 对齐方式 (Align):左对齐、右对齐、居中 量度类型(Measure):定比变量(Scale)、定序变量(Ordinal)、定类变量 (Nominal)。只用于统计制图时坐标轴变量的区分和SPSS决策树模块的变 量定义。
SPSS基础与Access数据库
第七讲 数据的编码、录入与整理
1
教师信息
姓 名:郑戟明 电 话:67703855 E-mail:shift_zjm@ 办公室:学院楼B421 部 门:商务信息学院计算机教学部
2
一、SPSS简介
3
SPSS的名称
• 1968年美国斯坦福大学两名研究生研制,原名SPSS,英 文名称社会科学统计软件包(Statistical Package for the Social Sciences)首字母的缩写。 • 1994-1998年间陆续并购SYSTAT等公司,统计软件的3S 指的就是SPSS、SAS、SYSTAT • 2000年改名为“Statistical Product and Service Solutions”,即“统计产品与服务解决方案” • 2010年SPSS公司被IBM并购。
4