数据库编码规则
数据库编码规范

数据库编码规范V1.02022-8-28目的范围术语设计概要命名规范(逻辑对象)数据库对象命名脚本注释数据库操作原则常用字段命名(参考)1)目的为了统一公司软件开辟的设计过程中关于数据库设计时的命名规范和具体工作时的编程规范,便于交流和维护,特制定此规范。
2)范围本规范合用于开辟组全体人员,作用于软件项目开辟的数据库设计、维护阶段<3)术语数据库对象:在数据库软件开辟中,数据库服务器端涉及的对象包括物理结构和逻辑结构的对象。
物理结构对象:是指设备管理元素,包括数据文件和事务日志文件的名称、大小、目录规划、所在的服务器计算极名称、镜像等,应该有具体的配置规划。
普通对数据库服务器物理设备的管理规程,在整个项目/产品的概要设计阶段予以规划。
逻辑结构对象:是指数据库对象的管理元素,包括数据库名称、表空间、表、字段/域、视图、索引、触发器、存储过程、函数、数据类型、数据库安全性相关的设计、数据库配置有关的设计以及数据库中其他特性处理相关的设计等。
4)设计概要设计环境<数据库:ORACLE9i、MSSQLSERVER2000 等,操作系统:LINUX7.1 以上版本,显示图形操作界面;RedHat9 以上版本WINDOWS2000SERVER 以上设计使用工具手使用PowerDesigner 做为数据库的设计工具,要求为主要字段做详尽说明。
对于SQLServer 尽量使用企业管理器对数据库进行设计,并且要求对表,字段编写详细的说明(这些将作为扩展属性存入SQLServer 中) 手通过PowerDesigner 定制word 格式报表,并导出word 文档,作为数据字典保存。
(PowerDesignerv10 才具有定制导出word 格式报表的功能)<对于SQLServer 一旦在企业管理器进行数据库设计时加入扩展属性,就可以通过编写简单的工具将数据字典导出。
4 编写数据库建数据库、建数据库对象、初始化数据脚本文件设计原则4 采用多数据文件手禁止使用过大的数据文件,unix 系统不大于2GB,window 系统不超过500MB$oracle 数据库中必须将索引建立在索引表空间里。
数据库字符编码

数据库字符编码
数据库字符编码是用来表示和存储字符数据的编码规则。
在数据库中,字符编码决定了如何将字符转化为数字进行存储和检索。
常见的数据库字符编码包括:
1. ASCII:ASCII字符编码是英语字符和控制字符的标准化编码方式,采用7位二进制编码,可以表示128种字符。
2. Unicode:Unicode字符编码是全球通用的字符编码标准,可以表示几乎所有的字符,包括各种语言的字符、符号和标点符号。
Unicode有不同的实现方式,包括UTF-8、UTF-16和UTF-32等。
3. UTF-8:UTF-8是一种变长编码方式,它可以根据字符的不同使用1到4个字节来表示字符,对于英语字符,使用1个字节就可以表示。
4. UTF-16:UTF-16是一种定长编码方式,使用16位的编码表示一个字符。
常见的数据库,如MySQL、Oracle、SQL Server等都支持不同的字符编码,可以根据实际需要来设置数据库的字符编码。
正确设置数据库字符编码可以确保数据的正确存储和检索,并支持不同语言和字符的处理。
数据库编码规范

数据库编码规范在当今数字化的时代,数据库作为存储和管理数据的核心组件,其重要性不言而喻。
为了确保数据库的高效运行、数据的准确性和一致性,以及便于维护和扩展,制定一套完善的数据库编码规范是至关重要的。
首先,让我们来谈谈数据库命名规范。
数据库中的对象,如表、视图、存储过程等,都应该有清晰、有意义且易于理解的名称。
表名应该准确反映其所存储的数据内容,例如,如果是存储用户信息的表,可以命名为“users”。
避免使用模糊、无意义的名称,如“table1”、“temp_table”等。
同样,视图的名称应该能够表明其提供的数据视图的性质,存储过程的名称应该能够清晰地表达其功能。
对于字段命名,也要遵循相似的原则。
字段名应该具有描述性,使用完整的单词而不是缩写,除非缩写是行业内普遍认可且不会产生歧义的。
例如,“user_name”比“uname”更清晰易懂。
此外,要保持命名的一致性,比如,如果采用了驼峰命名法,就应在整个数据库中都保持这种命名风格。
接下来是数据类型的选择。
正确选择数据类型不仅可以节省存储空间,还能提高数据处理的效率。
对于整数类型,如果值的范围较小,可以选择 tinyint 或 smallint;如果范围较大,则选择 int 或 bigint。
对于字符串类型,如果长度固定且较短,使用 char 类型;如果长度不固定且长度可能较大,使用 varchar 类型。
对于日期和时间类型,根据具体的需求选择 date、datetime 或 timestamp 等。
在设计表结构时,要遵循数据库的范式原则。
通常,达到第三范式是一个比较理想的状态。
这意味着每个表中的非主键字段都完全依赖于主键,且不存在传递依赖。
例如,如果有一个订单表,订单号是主键,而客户信息应该存储在单独的客户表中,通过客户 ID 与订单表关联,而不是直接将客户信息存储在订单表中。
索引的使用也是数据库优化的重要方面。
索引可以大大提高数据查询的效率,但过多或不当的索引也会影响数据的插入、更新和删除操作。
mysql常用的编码集和排序规则 -回复

mysql常用的编码集和排序规则-回复MySQL是一个广泛使用的关系型数据库管理系统,它支持多种编码集和排序规则来适应不同的语言和地区。
本文将一步一步回答关于MySQL常用的编码集和排序规则的问题。
一、什么是编码集和排序规则?编码集是一种字符集,用于存储和处理数据库中的文本数据。
它定义了字符的二进制表示方式。
MySQL中的编码集控制着数据在存储时的编码方式,以及在查询和处理时的字符解码和字符串排序规则。
排序规则是一种定义字符在进行比较和排序时的规则。
它决定了字符的顺序和比较的方式,以及在排序过程中如何处理特殊字符和大小写。
二、MySQL常用的编码集1. UTF-8编码集UTF-8是一种通用的Unicode字符编码,能够表示几乎所有已知的字符。
它支持多种语言和字符集,是互联网和现代软件开发中最常用的字符编码之一。
在MySQL中,UTF-8编码集以utf8或utf8mb4的形式表示。
utf8是MySQL早期版本中使用的UTF-8编码集,但它只支持存储最多3个字节的Unicode字符。
utf8mb4是MySQL 5.5.3及更高版本中引入的扩展版本,支持存储最多4个字节的Unicode字符。
2. GBK和GB2312编码集GBK和GB2312是两种常用的中文字符编码集。
GBK是国标扩展编码,支持存储大部分中文字符,而GB2312只支持最基本的中文字符。
在MySQL中,GBK编码集以gbk的形式表示,而GB2312编码集以gb2312的形式表示。
3. Latin1编码集Latin1是一种较早的字符编码集,也称为ISO 8859-1。
它支持大部分西欧语言的字符,但不支持亚洲字符。
Latin1编码集在MySQL中以latin1的形式表示。
三、MySQL常用的排序规则1. utf8_general_ciutf8_general_ci是UTF-8编码集下最常用的排序规则。
它是不区分大小写的,将字符进行简单的二进制比较,可以同时处理多种语言的字符。
mysql 编码规则

MySQL编码规则是指MySQL数据库中字符集和排序规则的设置。
字符集定义了存储在数据库中的字符数据的类型,而排序规则定义了对这些字符数据的比较和排序方式。
MySQL支持多种字符集和排序规则,其中最常用的是utf8字符集和utf8_general_ci排序规则。
utf8字符集可以存储任何Unicode字符,而utf8_general_ci排序规则则按照字典顺序对字符进行排序。
在MySQL中,可以通过以下命令查看当前数据库的编码规则:
```
SHOW VARIABLES LIKE 'character%';
SHOW VARIABLES LIKE 'collation%';
```
如果需要修改编码规则,可以使用以下命令:
```
ALTER DATABASE database_name CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
```
其中,database_name是要修改编码规则的数据库名称,table_name是要修改编码规则的数据表名称。
SQL编码规范

SQL编码规范1.书写格式 ⽰例代码: 存储过程SQL⽂书写格式例 select c.dealerCode, round(sum(c.submitSubletAmountDLR + c.submitPartsAmountDLR + c.submitLaborAmountDLR) / count(*), 2) as avg, decode(null, 'x', 'xx', 'CNY') from ( select a.dealerCode, a.submitSubletAmountDLR, a.submitPartsAmountDLR, a.submitLaborAmountDLR from SRV_TWC_F a where (to_char(a.ORIGSUBMITTIME, 'yyyy/mm/dd') >= 'Date Range(start)' and to_char(a.ORIGSUBMITTIME, 'yyyy/mm/dd') <= 'Date Range(end)' and nvl(a.deleteflag, '0') <> '1') union all select b.dealerCode, b.submitSubletAmountDLR, b.submitPartsAmountDLR, b.submitLaborAmountDLR from SRV_TWCHistory_F b where (to_char(b.ORIGSUBMITTIME, 'yyyy/mm/dd') >= 'Date Range(start)' and to_char(b.ORIGSUBMITTIME,'yyyy/mm/dd') <= 'Date Range(end)' and nvl(b.deleteflag,'0') <> '1') ) c group by c.dealerCode order by avg desc; C#中⾥的SQL字符串书写格式例 strSQL = "insert into Snd_FinanceHistory_Tb " + "(DEALERCODE, " + "REQUESTSEQUECE, " + "HANDLETIME, " + "JOBFLAG, " + "FRAMENO, " + "INMONEY, " + "REMAINMONEY, " + "DELETEFLAG, " + "UPDATECOUNT, " + "CREUSER, " + "CREDATE, " + "HONORCHECKNO, " + "SEQ) " + "values ('" + draftInputDetail.dealerCode + "', " + "'" + draftInputDetail.requestsequece + "', " + "sysdate, " + "'07', " + "'" + frameNO + "', " + requestMoney + ", " + remainMoney + ", " + "'0', " + "0, " + "'" + draftStruct.employeeCode + "', " + "sysdate, " + "'" + draftInputDetail.honorCheckNo + "', " + index + ")"; 1).缩进 对于C#⾥的SQL字符串,不可有缩进,即每⼀⾏字符串不可以空格开头 2).换⾏ 1>.Select/From/Where/Order by/Group by等⼦句必须另其⼀⾏写 2>.Select⼦句内容如果只有⼀项,与Select同⾏写 3>.Select⼦句内容如果多于⼀项,每⼀项单独占⼀⾏,在对应Select的基础上向右缩进8个空格(C#⽆缩进) 4>.From⼦句内容如果只有⼀项,与From同⾏写 5>.From⼦句内容如果多于⼀项,每⼀项单独占⼀⾏,在对应From的基础上向右缩进8个空格(C#⽆缩进) 6>.Where⼦句的条件如果有多项,每⼀个条件占⼀⾏,以AND开头,且⽆缩进 7>.(Update)Set⼦句内容每⼀项单独占⼀⾏,⽆缩进 8>.Insert⼦句内容每个表字段单独占⼀⾏,⽆缩进;values每⼀项单独占⼀⾏,⽆缩进 9>.SQL⽂中间不允许出现空⾏ 10>.C#⾥单引号必须跟所属的SQL⼦句处在同⼀⾏,连接符("+")必须在⾏⾸ 3).空格 1>.SQL内算数运算符、逻辑运算符连接的两个元素之间必须⽤空格分隔 2>.逗号之后必须接⼀个空格 3>.关键字、保留字和左括号之间必须有⼀个空格 2.不等于统⼀使⽤"<>"。
数据库设计规范_编码规范

数据库设计规范_编码规范数据库设计规范包括数据库表结构的设计原则和数据库编码规范。
数据库表结构的设计原则包括表的命名规范、字段的命名规范、主键和外键的设计、索引的使用、约束的定义等。
数据库编码规范包括SQL语句的书写规范、存储过程和函数的命名规范、变量和参数的命名规范、注释的使用等。
1.表的命名规范-表名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:user_info。
- 表名使用单数形式,如:user、order。
2.字段的命名规范-字段名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 字段名使用小写字母,使用下划线(_)作为单词之间的分隔符,如:user_name。
- 字段名要具有描述性,可以清楚地表示其含义,如:user_name、user_age。
3.主键和外键的设计-每张表应该有一个主键,用于唯一标识表中的记录。
- 主键字段的命名为表名加上“_id”,如:user_id。
- 外键字段的命名为关联的表名加上“_id”,如:user_info_id,指向user_info表的主键。
4.索引的使用-对于经常用于查询条件或连接条件的字段,可以创建索引,提高查询性能。
-索引的选择要权衡查询性能和写入性能之间的平衡。
-不宜为每个字段都创建索引,避免索引过多导致性能下降。
5.约束的定义-定义必要的约束,保证数据的完整性和一致性。
-主键约束用于保证唯一性和数据完整性。
-外键约束用于保证数据的一致性和关联完整性。
6.SQL语句的书写规范-SQL关键字使用大写字母,表名和字段名使用小写字母。
-SQL语句按照功能和逻辑进行分行和缩进,提高可读性。
-使用注释清晰地描述SQL语句的功能和用途。
7.存储过程和函数的命名规范-存储过程和函数的命名要具有描述性,可以清楚地表示其功能和用途。
-使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:get_user_info。
mysql 建库常用编码

mysql 建库常用编码
在MySQL中,常用的字符集和校对规则取决于您的需求和所处理的数据。
以下是一些常用的字符集和校对规则:
1. utf8:支持大部分国际字符,如果只是英文和部分特殊字符,可以选择utf8。
2. utf8mb4:这是utf8的超集,支持更多的国际字符,包括emoji等。
如果需要存储emoji或某些其他特殊字符,建议使用utf8mb4。
3. latin1:这是一个单字节的字符集,支持西欧语言。
4. gbk:支持简体中文。
5. gb2312:支持简体和部分繁体中文。
6. big5:支持繁体中文。
当您创建数据库或表时,可以指定字符集和校对规则。
例如:
```sql
CREATE DATABASE mydb DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
```
或者为特定的表指定:
```sql
CREATE TABLE mytable (id INT, name VARCHAR(255)) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
```
请注意,选择正确的字符集和校对规则对于确保数据的正确存储和检索非常重要。
在处理多语言数据时,应特别注意这一点。
数据库设计规范_编码规范

数据库设计规范_编码规范1.命名规范:表名、字段名和约束名应该具有描述性,遵循一致的命名规则。
避免使用保留字作为名称,使用下划线或驼峰命名法。
2.数据类型选择:选择合适的数据类型来存储数据,避免过大或过小的数据类型。
这有助于减小数据库的存储空间,提高查询性能。
3.主键和外键:每个表都应该有一个主键来唯一标识每条记录。
外键用于建立表之间的关系,确保数据的一致性和完整性。
4.表的范式:根据具体需求,遵循规范化设计原则。
将数据分解为多个表,减少数据冗余和更新异常。
5.索引设计:根据查询需求和数据量,设计适当的索引。
避免过多或不必要的索引,以减小索引维护的开销。
6.分区设计:对大型表进行分区,将数据分散存储在不同的物理磁盘上,提高查询性能。
7.安全性设计:为数据库设置适当的权限和访问控制,限制不必要的用户访问和操作。
数据库编码规范:1.编码一致性:统一使用同一种编码方式,如UTF-8,避免不同编码之间的转换问题。
2.参数化查询:使用参数化查询语句,预编译SQL语句。
这样可以防止SQL注入攻击,提高查询性能。
3.事务管理:使用事务控制语句(如BEGIN、COMMIT和ROLLBACK)来管理数据库事务,确保数据的一致性和完整性。
4.错误处理:在代码中捕获和处理数据库错误和异常,提高系统的容错性。
5.SQL语句编写:编写简洁且优化的SQL语句,避免使用多个嵌套的子查询,使用JOIN操作符进行表之间的关联。
6.数据库连接管理:优化数据库连接,避免频繁地打开和关闭数据库连接。
7.缓存机制:对于频繁查询的数据,使用缓存机制来减少数据库的压力。
8.日志记录:记录数据库操作日志,包括增删改查的操作,以便后续的问题跟踪和审计。
综上所述,数据库设计规范和编码规范对于确保数据库系统的性能、安全性和可维护性至关重要。
遵循这些规范能够提高数据库系统的效率和可靠性,减少潜在的问题和风险。
因此,在进行数据库设计和编码时,应该遵循这些规范。
国家地名数据库界线、界桩编码方法

《国家地名数据库管理系统》界线、界桩代码编制方法按:吉林省是国家地名数据库建设试点省,他们在地名数据库建设中先行一步,取得了丰富的经验。
他们实践中探索总结的《国家地名数据库管理系统》界线、界桩代码编制方法很有实用价值,请各地在建库过程中学习参考。
《国家地名数据库管理系统》中的“界线管理”在录入界线、界桩数据时,需要对界线、界桩进行正确编码,才能保证数据的正确存储和显示。
现对界线、界桩代码编制的方法做简要说明。
一、界线编码在界线数据表中,界线代码共20位,分为3个部分,即:区划1(9位)、区划2(9位)、界线分类代码(2位)组成。
现将界线编码分县级以上界线和县级以下(乡镇级)界线分别做出编码说明。
1、县级以上界线编码在这里以长春—吉林线为例,说明县级以上界线的编码原则。
如图1所示。
图1 长春吉林线编码示意图区划1和区划2是界线毗邻的两个市,即:长春市和吉林市。
区划1的前6位为己方—长春市的行政区划代码(即数据录入者所在的市):220100;后三位是县级以下代码,因为长春—吉林线为地区界,所以不存在县级以下代码,填000。
区划2的前6位为对方—吉林市的行政区划代码(即毗邻方):220200,后三位同样是000。
第三部分的界线分类代码可以直接选择,为地级行政界,选择后系统会自动赋值为02,当然也可以在列表形式下直接输入02。
这样,长春—吉林界线编码即为:220100.000.220200.000.02。
在这里需要说明的是,区划1一定要填写自己所在的市(县、区),很多数据录入者反映录入数据后,再打开时发现数据不见了,就是因为区划1填写的不正确,系统根据区划1的代码将数据分配到其所在的行政区域目录下,只有通过区划1所在的行政区划代码进入系统才能看到数据,并非是数据丢失。
2、县级以下界线编码:县级以下代码以长春市南关区的新立城镇和玉潭镇界线为例进行说明,如图2所示。
图2 新立城镇和玉潭镇界线编码图乡镇界线代码结构跟县级以上界线完全一样,因为是乡镇级的界线,所以区划1和区划2的县级以上代码应该相同,都是长春市南关区代码,即为220102;区划1中的后三位为县级以下代码,即为新立城镇的代码,为100,区划2的后三位同样为县级以下代码,即为玉潭镇代码,为102;第三部分为界线分类代码,可以选择乡级行政界,系统自动赋值为05,这样新立城镇和玉潭镇的界线编码为220102.100.220102.102.05。
地名数据库编码规则

国家地名数据库代码编制规则一、地名数据库代码编制(一)为了统一、规范国家地名数据库代码,满足地名数据库编码工作的需要,特制定本规则。
(二)国家地名数据库代码依据国家标准《中华人民共和国行政区划代码》(GB2260)、《县以下行政区划代码编制规则》(GB10114一88)的编码规则、《民政统计代码编制规则》和《地名分类与类别代码编制规则》(GB/T18521-2001)制定。
(三)国家地名数据库代码应做到不重、不漏,留有备用号。
(四)国家地名数据库代码共有20位数字,分为四段。
第一段由6位数字组成,表示县级以上行政区划代码,执行《中华人民共和国行政区划代码》(GB/T 2260—2002)。
1。
行政区划数字代码(简称数字码)采用三层六位层次码结构,按层次分别表示我国各省(自治区、直辖市、特别行政区)、市(地区、自治州、盟)、县(自治县、县级市、旗、自治旗、市辖区、林区、特区)。
2.数字码码位结构从左至右的含义是:第一层即前两位代码表示省、自治区、直辖市、特别行政区。
第二层即中间两位代码表示市、地区、自治州、盟、直辖市所辖市辖区/县汇总码、省(自治区)直辖县级行政区划汇总码,其中(1)01~20、51~70表示市,01、02还用于表示直辖市所辖市辖区、县汇总码;(2)21~50表示地区、自治州、盟;(3)90表示省(自治区)直辖县级行政区划汇总码.第三层即后两位表示县、自治县、县级市、旗、自治旗、市辖区、林区、特区,其中:(1)01~20表示市辖区、地区(自治州、盟)辖县级市、市辖特区以及省(自治区)直辖县级行政区划中的县级市,01通常表示市辖区汇总码;(2)21~80表示县、自治县、旗、自治旗、林区、地区辖特区(3)81~99表示省(自治区)辖县级市。
3。
为保证数字码的唯一性,因行政区划发生变更而撤销的数字码不再赋予其他行政区划。
4.凡是未经批准,不是国家标准的行政区划单列区、县级单位,代码的第三层即后两位必须设置为以91开始按顺序往下编制。
Oracle数据库编码规范

Oracle数据库编码规范1目的使用统一的命名和编码规范,使数据库命名及编码风格标准化,以便于阅读、理解和继承。
2适用范围本规范适用于公司范围内所有以ORACLE作为后台数据库的应用系统和项目开发工作。
3规范3.1书写规范丑陋的书写规范不仅可读性较差,而且给人以敬而远之的感觉;而良好的书写规范则给人以享受和艺术的体验。
3.1.1大小写风格规则3.1.1.1所有数据库关键字和保留字命名使用大小写不做要求。
3.1.2缩进风格规则3.1.2.1程序块严格采用缩进风格书写,保证代码清晰易读,风格一致,缩进格数统一为2/4个。
必须使用空格,不允许使用【Tab】键。
以免在用不同的编辑器阅读程序时,因【Tab】键所设置的空格数目不同而造成程序布局不整齐。
规则3.1.2.2当同一条语句需要占用多于一行时,每行的其他关键字与第一行的关键字进行右对齐。
IF flag = True THENSelect usernameInto vUserInfoFrom userInfoWhere userId = ‘id’END IF;3.1.3空格及换行规则3.1.3.1不允许把多个语句写在一行中,即一行只写一条语句且一行最长不能超过80字符;规则3.1.3.2避免将复杂的SQL语句写到同一行,建议要在关键字和谓词间换行。
WHERE子句书写时,每个条件占一行。
规则3.1.3.3相对独立的程序块之间必须加空行。
BEGIN、END独立成行。
3.1.4其它规则3.1.4.1确保变量和参数在类型和长度上与表数据列相匹配。
如果与表数据列宽度不匹配,则当较宽或较大的数据传进来时会产生运行异常。
3.2命名规范对于命名规范来说,想要做到完全统一的确是不可能的任务。
命名规范更多的是个人层面的爱好,既使无法完全做到一致,但是我们仍然要尽量去遵守。
3.2.1字段命名规范在此仅提供几种常见的命名方法,如表3-2-1所示。
表3-2-1 命名规范表规则3.2.1.1不建议使用数据库关键字和保留字,原因是为了避免不必要的冲突和麻烦。
mysql数据库设置编码格式

mysql数据库设置编码格式说起数据库编码格式很多程序员都会很头疼,因为对他们而言去创建一个数据库或者说对数据库执行増、删、改、查操作已经不是什么难事,但是在开发过程中经常发生的是乱码问题。
这个问题处理起来让人很烦乱,所以有很多程序员宁愿多做一些编程工作也不愿意将时间浪费到这个上面。
其实针对数据乱码问题我们只要在开发过程中始终遵循一条不变道理——在程序运行的全过程中编码格式统一即可。
我就出现过这样的问题,前几天帮同学调个程序,不论怎么在前台界面与java代码接口处设置编码格式或在java程序与数据库接口处设置编码格式都不起效果,经过一番艰苦的查找发现我的数据库编码格式与我在整个编程过程中地编码格式完全不同,数据库server的编码格式为UTF-8,而开发过程中前台jsp与后台java代码的编码格式均为gb2312,因为数据库的server编码格式是不能够通过执行命令去设置的,所以只能重新装数据库引擎,还好用的是mysql数据库卸载与安装都不是很费事。
下面说一下如何通过命令设置mysql数据库的编码格式:1、通过DOS登录到mysql数据库2、查看当前数据库的编码格式: mysql>status;或者show variables like 'character%';上面显示server characterset :gb2312; 数据库服务器编码格式Db characterset : gb2312; 数据库编码格式Client characterset : gb2312 数据库客户端编码格式Conn. characterset : gb2312数据库连接编码格式3、设置编码格式:set names 'gb2312'通过set命令只能够设置Db、Client、Conn的编码格式,在设置编码格式过程中,如果不知道当前安装的数据库到底有多少种编码格式那么可以通过show character set;命令显示当前数据库的所有编码格式集合。
doc oracle al16utf16编码

1. 什么是AL16UTF16编码?AL16UTF16编码是Oracle数据库中用于支持Unicode字符集的一种编码方式。
Unicode字符集是一种国际标准,用于表示世界上几乎所有语言的字符。
它包含了多种编码方式,其中AL16UTF16是Oracle数据库中常用的一种。
2. AL16UTF16编码的特点AL16UTF16编码特点AL16UTF16编码采用固定长度的编码方式,每个字符占用两个字节。
这种编码方式可以表示Unicode字符集中的所有字符,包括中文、日文、韩文等各种语言的字符。
AL16UTF16编码支持存储大容量的数据,可以满足大规模应用的需求。
它还可以在不同的操作系统和评台之间进行数据转换和交换,保证数据的完整性和一致性。
AL16UTF16编码是Oracle数据库中默认的Unicode字符集编码方式,可以在创建数据库时选择使用它来支持多语言环境下的数据存储和处理。
3. AL16UTF16编码的使用场景AL16UTF16编码主要用于以下场景:多语言环境下的数据存储和处理。
在国际化的应用程序中,通常会涉及到不同语言的数据处理和显示,AL16UTF16编码可以很好地支持这种场景。
跨评台数据交换。
由于AL16UTF16编码可以在不同操作系统和评台之间进行数据转换,因此在数据交换和共享的场景中也经常会用到它。
大容量数据存储和处理。
一些需要处理大容量数据的应用程序,尤其是需要支持多语言的大型企业应用,通常会选择AL16UTF16编码来存储和处理数据。
这样可以保证数据的完整性和一致性。
4. 如何在Oracle数据库中使用AL16UTF16编码?可以以下步骤在Oracle数据库中使用AL16UTF16编码:在创建数据库时选择AL16UTF16编码。
在创建数据库实例或新的数据库时,可以选择AL16UTF16编码来支持Unicode字符集。
修改数据库的字符集。
对于已经创建的数据库,如果需要改变字符集为AL16UTF16编码,可以使用ALTER DATABASE语句来修改数据库的字符集设置。
SQL Server数据库命名与编码规范

SQL Server数据库命名与编码规范一.数据库对象命名基本规范1.总体命名规范●名称的长度不超过32个字符。
●名称采用英文单词、英文单词缩写和数字,单词之间用“_”分隔。
说明:除非用户提供文档化的行业标准(例如,国标或部颁标准),否则不得违反本规范。
●数据库对象名称首字母必须小写。
●不得采用“_”作为名称的起始字母和终止字母。
●名称必须望文知意。
●名称不得与数据库管理系统保留字冲突。
●不要在对象名的字符之间留空格。
2.数据库名数据库名定义为系统名+模块名,或直接采用系统名。
数据库名全部采用小写。
3.数据库文件数据文件命名采用数据库名+_+文件类型+[文件序号].文件后缀,文件序号为1、2、3…9等数值,当数据库中某一文件类型的文件有多个时加上文件序号以区别。
只有一个时可不加。
文件后缀:主数据文件为.mdf,其它数据文件为.ndf,日志文件为.ldf。
文件名全部采用小写。
4.表表命名要遵循以下原则:●采用“系统名+_+t_+模块名+_+表义名”格式构成。
●若单系统单模块开发,命名可采用“t_+表义名”格式构成。
●若数据库中只含有单个模块,命名可采用“系统名+t_+表义名”格式构成。
●整个表名的长度不要超过30个字符。
●系统名、模块名均采用小写字符。
●模块名或表义名均以其英文单词命名,且字符间不加分割符;表义名中单词的首字符大写,其它字符小写,多个单词间也不加任何分割符,单词全部采用单数形式。
●表别名命名规则:取表义名的前3个字符加最后一个字符。
如果存在冲突,适当增加字符(如取表义名的前4个字符加最后一个字符等)。
●关联表命名为Re_表A_表B,Re 是Relative的缩写,表A 和表B均采用其表义名或缩写形式。
5.属性(列或字段)属性命名遵循以下原则:●采用有意义的列名,为实际含义的英文单词,且字符间不加任何分割符, 单词的首字符大写。
●属性名前不要加表名等作为前缀。
●属性后不加任何类型标识作为后缀。
数据库设计、命名、编码规范

4.4 视图名
Pascal 命名规范 视图的名称 如 = "vw_" + 视图内容标识
vw_UserPerm
4.5 触发器名
触发类型 触发标识
----------------------------------Insert Delete Update I D U
触发名=
"tr_"
+模块名称 +
相应的表名 +
查询或其它 存储过程名称 识 如 UP_Sale_Client_I =
S UP_模块名 + 下划线 + 表名 + 存储过程功能标
4.7 变量名
Pascal 命名规范
4.8 游标命名
游标应该以下面的标准来命名: 表名或者对象名字{使用此游标的对象名字}+CURSOR 例如: FiscalMonthCURSOR EmployeeListCURSOR
Sales_FK_Customer
4.12 索引命名
索引的命名应该在表空间内唯一,当查看执行计划时可以有效的对索引进行识 别.. [IX][类型(U 标识 Unique,C 标识 Clustered)][列名(s)] Ø Ø Ø Ø Ø 例如: IXUC_SalesId (clustered unique) 当对单列进行索引时,你可能需要使用列的全名. 当对多列进行索引时,要使用你所能想到的最优的缩写. 当对一个表的所有列进行索引时,使用 ALL 单词. 在多列名中使用下划线以增加可读性. 不要为索引加上序列号
6.
注释
注释可以包含在批处理中。在触发器、存储过程中包含描述性注释将大大增加文本 的可读性和可维护性。 1. 注释语法包含两种情况:单行注释、多行注释 单行注释:注释前有两个连字符(--),一般,对变量、条件子句可以采用该 类注释,在注释代码上一行。 多行注释:符号/*和*/之间的内容为注释内容。对某项完整的操作建议使用该类 注释。 2. 注释以中文为主。 实际应用中,发现以中文注释的 SQL 语句版本在英文环境中不可用。为避免后 续版本执行过程中发生某些异常错误,中文环境下用中文,外包项目一律用英 文。 3、 注释尽可能详细、全面。 创建每一数据对象前,应具体描述该对象的功能和用途。 传入参数的含义应该有所说明。如果取值范围确定,也应该一并说明。取值有 特定含义的变量(如 boolean 类型变量),应给出每个值的含义。 4、 注释简洁,同时应描述清晰。
数据库设计编码规范
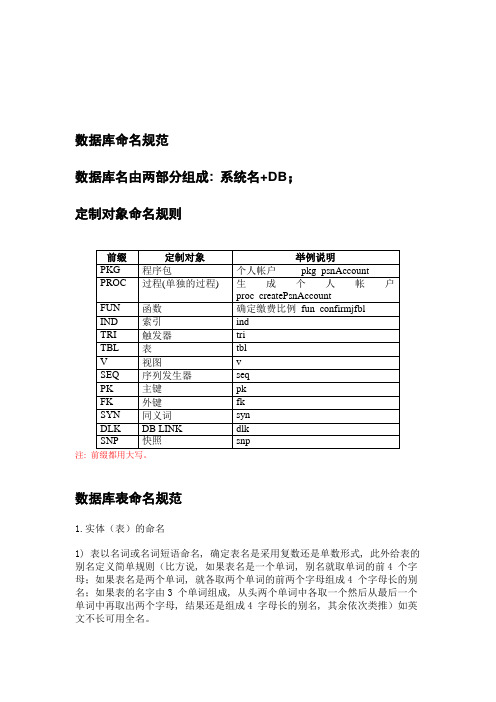
数据库命名规范数据库名由两部分组成: 系统名+DB;定制对象命名规则注:数据库表命名规范1.实体(表)的命名1) 表以名词或名词短语命名, 确定表名是采用复数还是单数形式, 此外给表的别名定义简单规则(比方说, 如果表名是一个单词, 别名就取单词的前4 个字母;如果表名是两个单词, 就各取两个单词的前两个字母组成4 个字母长的别名;如果表的名字由3 个单词组成, 从头两个单词中各取一个然后从最后一个单词中再取出两个字母, 结果还是组成4 字母长的别名, 其余依次类推)如英文不长可用全名。
对工作用表来说, 表名可以加上前缀WORK_ 后面附上采用该表的应用程序的名字。
在命名过程当中, 根据语义拼凑缩写即可。
注意, 由于ORCLE会将字段名称统一成大写或者小写中的一种, 所以要求加上下划线。
举例:定义的缩写 Sales: SAL 销售;Order: ORD 订单;Detail: DTL 明细;则销售订单明细表命名为: TBL_SAL_ORD_DTL;2) 如果表或者是字段的名称仅有一个单词, 那么建议不使用缩写, 而是用完整的单词。
举例:定义的缩写 Material MA 物品;物品表名为: TBL_Material, 而不是 MA.但是字段物品编码则是: MATERIAL_ID3) 关联类通过用下划线连接两个基本类之后, 再加前缀R的方式命名,后面按照字母顺序罗列两个表名或者表名的缩写。
关联表用于保存多对多关系。
如果被关联的表名大于10个字母, 必须将原来的表名的进行缩写。
如果没有其他原因, 建议都使用缩写。
举例: 表Object与自身存在多对多的关系,则保存多对多关系的表命名为:R_OBJECT;表 Depart和Employee;存在多对多的关系;则关联表命名为TBL_R_DEPT_EMP 属性命名规范1.属性(列)的命名1) 采用有意义的列名, 表内的列要针对键采用一整套设计规则。
每一个表都将有一个自动ID作为主健,逻辑上的主健作为第一组候选主健来定义,如果是数据库自动生成的编码, 统一命名为: ID;如果是自定义的逻辑上的编码则用缩写加“ID”的方法命名。
sql 的编码格式-概述说明以及解释

sql 的编码格式-概述说明以及解释1.引言1.1 概述SQL(结构化查询语言)是用于管理和操作关系型数据库的编程语言。
在进行SQL编码时,正确的编码格式对于保证数据的完整性、准确性和安全性至关重要。
本文将详细介绍SQL编码格式的定义、常见的SQL编码格式以及SQL编码格式的重要性。
在编写SQL语句时,需要按照一定的格式和规范来编码,以保证语句的可读性和易维护性。
SQL编码格式主要包括缩进、换行、大小写、注释等方面的规范。
首先,缩进在SQL编码中起到了对语句进行层级划分的作用,使得代码结构清晰可见。
通过缩进,可以清晰地区分出SELECT语句、FROM子句、WHERE子句等不同的部分。
其次,换行在SQL编码中能够使得复杂的SQL语句更易理解。
将不同的子句和关键字放在不同的行上,可以使得语句的层次更加明确,也便于注释和修改。
同时,对于SQL关键字和标识符的大小写,也需要遵循一定的编码规范。
一般来说,SQL关键字建议使用大写,而表名、列名等标识符则建议使用小写。
这样可以增加代码的可读性,并且能够避免与关键字冲突的问题。
此外,在SQL编码时添加注释是十分重要的。
注释能够增加代码的可维护性和可读性,帮助其他人更好地理解意图和功能。
注释可以在语句的前面或是行内进行添加,以帮助开发人员更好地理解该段代码的作用和目的。
综上所述,SQL编码格式在数据库开发中起到了至关重要的作用。
通过正确的缩进、换行、大小写和注释等编码格式,可以使得SQL语句更加易读、易懂,提高代码的可维护性和可读性。
在后续的章节中,本文将进一步讨论常见的SQL编码格式以及SQL编码格式的重要性。
1.2 文章结构本文主要以SQL 的编码格式为主题进行探讨和研究。
为了更好地阐述SQL 编码格式的定义、常见的格式以及其重要性,本文将从以下几个方面进行分析。
首先,将介绍SQL 编码格式的定义。
我们将解释什么是SQL 编码格式,它是一种用于编写SQL 语句的规范和约定。
数据库编码规则

fs表名如果表名超过一个单词第一个单词头字母小写外其它单词的头字母都大写如
数据库编码规则
数据库编码规则
1、 数据库名称:FDAYS + “库名”,如:FDAYSTour 2、 数据表名称:FS + “_” +“表名”,如果表名超过一个单词,第一个单词头字母小写外,其它单词的头字母都大写,如:FS_adminUser 3、 数据表字段命名:“字段名”,如:UserName,注ID字段名为:UserId 4、 视图名称:VI + “_” + “视图名”,如:VI_adminUser 5、 存储过程名称:PR + “_” + “存储过程名”,如:PR_addAdminUser 6、 函数名称:FN + “_”+ “函数名称”,如:FN_getUser 7、 规则名称:RU + “_” + “规则名称”,如:RU_userCode 8、 游标名称:CU + “_” + “游标名称”,如:CU_getUser 9、 触发器名称:TG + “_” + “触发器名称”,如:TG_delUserByDate 10、SQL语句用大写字母书写,如:SELECT * FROM FS_adminUser
navicat导入的编码格式

navicat导入的编码格式导入编码格式是指在使用Navicat软件将数据导入到数据库时,需要确保数据库、数据文件以及导入的方式都是相同的编码格式,以保证数据的完整性和正确性。
在使用Navicat导入数据之前,首先需要确定数据库中使用的编码格式。
常见的编码格式有UTF-8、GBK、ISO-8859-1等。
UTF-8是最常用的编码格式,它可以支持全球各种语言的字符。
GBK是中文编码格式,适用于简体中文和繁体中文。
ISO-8859-1是ISO标准定义的编码格式,适用于简体中文、繁体中文和西欧字符。
在Navicat软件中导入数据时,需要确保数据文件的编码格式与数据库的编码格式一致。
如果数据文件的编码格式与数据库的编码格式不一致,可能会导致乱码或数据丢失。
在导入之前,可以使用文本编辑器(如Notepad++)打开数据文件,查看文件的编码格式,并将其转换成数据库所需的编码格式。
另外,在使用Navicat导入数据时,还需要选择正确的导入方式。
Navicat提供了多种导入方式,例如导入SQL文件、导入Excel文件、导入CSV文件等。
不同的导入方式需要注意的编码格式也不同。
如果使用导入SQL文件的方式,首先需要确保SQL文件是以正确的编码格式保存的。
在导入之前,可以使用文本编辑器打开SQL文件,查看文件的编码格式,并将其转换成数据库所需的编码格式。
然后,通过Navicat的导入功能选择导入SQL文件,根据数据库的编码格式选择正确的字符集。
如果使用导入Excel文件或CSV文件的方式,需要设置正确的字符集。
在导入之前,打开数据文件,选择正确的字符集,确保数据文件中的数据能正确地转换为数据库所需的编码格式。
然后,通过Navicat的导入功能选择导入数据文件,选择正确的字符集即可。
总之,当使用Navicat导入数据时,需要确保数据库、数据文件以及导入的方式都是相同的编码格式。
在导入之前,可以通过文本编辑器查看和转换数据文件的编码格式,然后在Navicat中选择正确的字符集。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
6. 命名规范(逻辑对象)
6.1 数据库结构命名
6.1.1 数据库命名
数据库的命名要求使用与数据库意义相关联的英文字母,即<业务系统名称>
6.1.2 数据库日志设计命名
数据库日志的的命名以<数据库名>_<时间>.log 格式命名。其中,<日志名>为有意义的数据库日志名称。例如: ccnet_20110907.log
3. 术语
3.1 数据库对象:
在数据库软件开发中,数据库服务器端涉及的对象包括物理结构和逻辑结构的对象。
3.2 物理结构对象:
是指设备管理元素,包括数据文件和事务日志文件的名称、大小、目录规划、所在的服务器计算极名称、镜像等,应该有具 体的配置规划。一般对数据库服务器物理设备的管理规程,在整个项目/产品的概要设计阶段予以规划。
3.1 数据库对象:............................................................................................................................................... 4 3.2 物理结构对象:........................................................................................................................................... 4 3.3 逻辑结构对象:........................................................................................................................................... 4 4. 设计原则.............................................................................................................................................................. 4 4.1 设计原则....................................................................................................................................................... 4 4.2 设计的更新................................................................................................................................................... 4 5. 命名总体原则...................................................................................................................................................... 5 6. 命名规范(逻辑对象) ...................................................................................................................................... 5 6.1 数据库结构命名........................................................................................................................................... 5 6.2 数据库对象命名........................................................................................................................................... 6 6.3 参考详细.................................................... 8 7. 脚本注释.............................................................................................................................................................. 8 7.1 存储过程或触发器....................................................................................................................................... 8 7.2 自定义函数................................................................................................................................................... 9 8. 数据库操作原则................................................................................................................................................ 10 8.1 建立、删除、修改库表操作..................................................................................................................... 10 8.2 添加、删除、修改表数据......................................................................................................................... 10
DBA-SEP-001 数据库编码规则说明书
版本:V1.0 日期:2011-09-07
1. 目的
为了统一公司软件开发的设计过程中关于数据库设计时的命名规范和具体工作时的编程规范,便于阅读、理解、继承
交流和维护,特制定此规范。
2. 范围
本规范适用于公司范围内所有以 SQL Server 作为后台数据库的应用系统和项目开发工作
e) 为每一个数据库创建独立的管理员用户,尽量不要使用 sa 或者系统管理员身份进行数据库设计。
4.2 设计的更新
a) 在设计阶段,由数据库管理员或指定的项目组其一成员进行维护。 b) 运行阶段,由数据库管理员进行维护。 c) 如对表结构进行修改,应先在《数据库设计文档》文档进行修改,最后在数据库中进行修改。 d) 修改数据库要通过 SQL,禁止其它方式对数据进行修改
DBA-SEP-001 数据库编码规则说明书
版本:V1.0 日期:2011-09-07
数据库编码规则
版本 V1.0
DBA-SEP-001 数据库编码规则说明书
编写: Bean
校队: ---
版本:V1.0 日期:2011-09-07
审核: ---
修订历史记录
日期
版本
说明
作者
2011-09-07
V1.0
发布版本
Bean
DBA-SEP-001 数据库编码规则说明书
版本:V1.0 日期:2011-09-07
目录
修订历史记录.............................................................................................................................................................. 2 1. 目的...................................................................................................................................................................... 4 2. 范围...................................................................................................................................................................... 4 3. 术语...................................................................................................................................................................... 4
DBA-SEP-001 数据库编码规则说明书
e) 修改数据库的 SQL 要添加说明后保存备查
版本:V1.0 日期:2011-09-07