与平均极差的分布有关的数值
定量资料统计描述——集中趋势与离散程度

度量单位不同资料之间离散度的比较; 均数相差悬殊的资料之间离散度的比较。
【例4-11】
某研究收集了100例7岁男孩的身高和体重的资料,身高均数为 123.10cm,标准差为4.71cm;体重均数为22.92kg,标准差为 2.26kg,比较这100例7岁男孩的身高和体重的变异度。
身高 CV
4.71 100 % 3.83 %
M X n1
当n为奇数时,
() 2
, 位置居中的观察值
当n为偶数时,
M
(X n ()
X n )/ ( 1)
2 ,计算出位次居中的两个观察值的均数
2
2
例:7名病人患某病的潜伏期分别为2,3,4,5,6,9,16天,求其中位数。
本例n=7,为奇数
M X 71 X 4 5(天 ) () 2
例:8名患者食物中毒的潜伏期分别为1,2,2,3,5,8,15,24小时,求其中位数。
本例n=8,为偶数
M
1
2
X 8
() 2
X 8
( 1) 2
1 2
X
4
X5
1 3 5 4(小时)
2
(二) 中位数的应用
中位数可用于各种分布的资料,在正态分布资料中,中位数等于 均数,在对数正态分布资料中,中位数等于几何均数。
中位数不受极端值的影响,因此,实际工作中主要用于不对称分 布类型的资料、两端无确切值(>100)或分布不明确的资料。
患者编号:1 2 3 4 5 6 7 8 9 ... 117 118 119 120 住院天数:1 2 2 2 3 3 4 4 5 ... 40 40 42 45
n=120,120*5%=6,为整数:
P5
人教八年级数学平均数、加权平均数、中位数、众数、极差和方差归纳与复习

平均数、加权平均数、中位数、众数、极差和方差归纳与复习一、回顾与梳理。
平均数:一组数据的总和除以这组数据个数所得到的商叫这组数据的平均数。
即x=(x1+x2+……+xn)÷n中位数:将一组数据按大小顺序排列,处在最中间位置的一个数或最中间的两个数的平均数叫做这组数据的中位数。
众数:在一组数据中出现次数最多的数叫做这组数据的众数。
平均数:一组数据的平均值,平均水平.平均数是描述一组数据的一种常用指标,反映了这组数据中各数据的平均大小。
平均数的大小与一组数据里的每个数据都有关系,其中任何数据的变动都会引起平均数的相应变动.平均数一般的计算方法为:用一组数据的总和除以这组数据的个数.平均数的优点。
反映一组数的总体情况比中位数、众数更为可靠、稳定.平均数的缺点。
平均数需要整批数据中的每一个数据都加人计算,因此,在数据有个别缺失的情况下,则无法准确计算,计算的工作量也较大。
平均数易受极端数据的影响,从而使人对平均数产生怀疑。
中位数:在有序排列的一组数据中最居中的那个数据中等水平.中位数是描述数据的另一种指标,如果将一组数按从小到大排列那么中位数的左边和右边恰有一样多的数据。
中位数仅与数据的大小排列位置有关,某些数据的变动对它的中位数没有影响.中位数是将数据按大小顺序依次排列(相等的数也要全部参加排序)后“找”到的.当数据的个数是奇数时,中位数就是最中间的那个数据;当数据的个数是偶数时,就取最中间的两个数据的平均数作为中位数.中位数的优点。
简单明了,很少受一组数据的极端值的影响。
中位数的缺点。
中位数不受其数据分布两端数据的影响,因此中位数缺乏灵敏性,不能充分利用所有数据的信息。
当观测数据已经分组或靠近中位数附近有重复数据出现时,则难以用简单的方法确定中位数。
众数:一组数据中出现次数最多的那个数据。
集中趋势众数告诉我们,这个值出现次数最多,一组数据可以有不止一个众数,也可以没有众数。
众数着眼于对各数据出现的频数的考查,其大小只与这组数据中的部分数据有关.一组数据中的众数不止一个.当一组数据中有相同数据多次出现时,其众数往往是我们关心的.众数的优点。
五种统计学数值方法

五种统计学数值方法统计学是一门研究数据收集、分析和解释的学科。
在统计学中,有许多数值方法可以用来描述和分析数据。
这些方法可以帮助我们更好地理解数据,从而做出更准确的决策。
本文将介绍五种常见的统计学数值方法,包括中心趋势、离散程度、偏态和峰度、相关性和回归分析。
一、中心趋势中心趋势是用来描述数据集中的一组数值。
常见的中心趋势包括平均数、中位数和众数。
1.平均数平均数是指一组数据的总和除以数据的个数。
平均数可以帮助我们了解数据的总体趋势。
例如,如果一组数据的平均数为50,那么我们可以大致认为这组数据的中心趋势在50左右。
2.中位数中位数是指一组数据中间的那个数。
如果一组数据有奇数个数,那么中位数就是这组数据排序后的中间那个数;如果一组数据有偶数个数,那么中位数就是这组数据排序后中间两个数的平均数。
中位数可以帮助我们了解数据的分布情况。
例如,如果一组数据的中位数为50,那么我们可以认为这组数据的一半数值小于50,一半数值大于50。
3.众数众数是指一组数据中出现次数最多的数。
众数可以帮助我们了解数据的集中程度。
例如,如果一组数据的众数为50,那么我们可以认为这组数据中有很多数值都集中在50附近。
二、离散程度离散程度是用来描述数据分散程度的一组数值。
常见的离散程度包括方差、标准差和极差。
1.方差方差是指一组数据与其平均数之差的平方和除以数据的个数。
方差可以帮助我们了解数据的离散程度。
例如,如果一组数据的方差很大,那么这组数据的数值分散程度就很大。
2.标准差标准差是指一组数据与其平均数之差的平方和除以数据的个数再开方。
标准差可以帮助我们了解数据的分布情况。
例如,如果一组数据的标准差很小,那么这组数据的数值分布就比较集中。
3.极差极差是指一组数据中最大值与最小值之差。
极差可以帮助我们了解数据的范围。
例如,如果一组数据的极差很大,那么这组数据的数值范围就很广。
三、偏态和峰度偏态和峰度是用来描述数据分布形态的一组数值。
数据分析极差和方差

如果一组数据的方差较大,可能存在异常值,需 要进一步检查。
预测模型评估
在预测模型中,可以使用历史数据的方差来评估 模型的预测准确性。
方差在数据分析中的作用
描述数据分布
方差可以用来描述数据分布的情况, 了解数据的集中趋势和离散程度。
比较数据集
决策依据
在数据分析中,方差可以作为决策的 依据,例如在市场调研中,可以根据 不同产品的方差大小来决定产品的市 场策略。
提高效率
数据分析有助于优化业务流程,提高工作效率,降低 成本。
极差和方差的定义
极差
极差是一组数据中的最大值和最小值之差,用于描述数 据的离散程度。
方差
方差是一组数据与其平均值之差的平方的平均值,用于 描述数据的离散程度。
02
极差
极差的计算方法
01 极差定义
极差是一组数据中最大值与最小值之差,用于衡 量数据的离散程度。
通过比较不同数据集的方差大小,可 以了解它们之间的差异。
04
极差和方差的比较
极差和方差的优缺点
极差 优点:计算简单,容易理解,能够反
映数据的变化范围。
缺点:对异常值敏感,容易受到极端 值的影响,不能反映数据的离散程度。
方差
优点:能够反映数据的离散程度,不 受极端值影响,可以用于比较不同数 据集的离散程度。
极差和方差的计算方法
目前极差和方差的计算方法主要是基于统计学的理论,未来可以 考虑结合机器学习算法,提高计算效率和准确性。
极差和方差的应用领域
目前极差和方差主要应用于统计学和数据分析领域,未来可以考虑 将其应用ห้องสมุดไป่ตู้其他领域,如金融、医学等。
极差和方差的优化算法
目前极差和方差的计算算法较为简单,未来可以考虑优化算法,提 高计算效率。
【MSA】确定重复性和再现性的指南-平均值和极差法

平均值和极差法(Xbar & R)是一种可同时对测量系统提供重复性和再现性的估计值的研究方法。
与单独的极差法不同,该方法允许将测量系统的变差分解成两个独立的部分:重复性和再现性,但不能确定它们两者的相互作用。
同时,基于评估者与零件/量具交互作用产生的变差也没有计入分析中。
进行研究尽管评价者的人数、测量次数及零件数量均可能会不同,但下面的讨论呈现进行研究的最佳情况。
参见图B6中的GRR数据表,详细的程序如下:1) 取得一个能代表过程变差实际或预期范围的样本,为n> 10个零件44的样本。
2) 给评价者编号为A、B、C等,并将零件从1到n进行编号,但零件编号不要让评价者看到。
3) 对量具进行校准,如果这是正常测量系统程序中的一部分的话。
让评价者A以随机顺序45测量n个零件,并将结果记录在第1行。
4) 让评价者B和C依次测量这些一样的n个零件,不要让他们知道别人的读值,然后将结果分别的记录在第6行和第11行。
5) 用不同的随机测量顺序重复以上循环,并将数据记录在第2、7和12行:注意将数据记录在适当的栏位中,例如:如果首先被测量的是零件7,然后将数据记录在标有零件7的字段中。
如果需要进行三次测量,则重复以上循环,并将数据记录在第3、8和13行中。
6) 当测量大型零件或不可能同时获得数个零件时,第4步到第5步将变更成以下顺序:让评价者A测量第一个零件并将读值记录在第1行;让评价者B测量第一个零件并将读值记录在第6行;让评价者C测量第一个零件并将读值记录在第11行。
让评价者A重新测量第一个零件并将读值记录在第2行;评价者B重新测量第一个零件并将读值记录在第7行;评价者C重复测量第一个零件并将读值记录在第12行。
如果需要进行三次测量,则重复以上循环,并将数值记录在第3、8和13行中。
7) 如果评价者处于不同的班次,可以使用一个替代的方法。
让评价者A 测量所有10个零件,并将读值记录在第1行;然后让评价者A按照不同的顺序重新测量,并把读值记录在第2行和第3行。
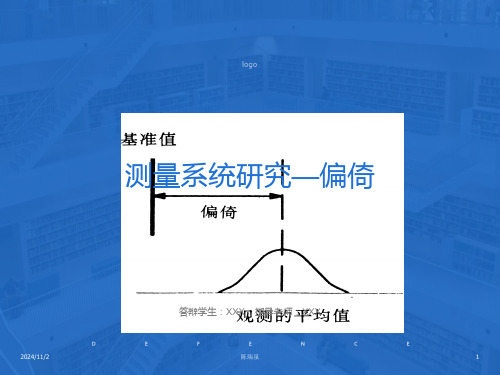
测量系统-偏倚研究

偏倚
0.1153
10.8
0.0067 -0.12157 0.13497
2019/4/1
12
独立样件法 —范例
一名制造工程师评价了一个用于过程监控的新测量系统。 测量设备的一项分析证明该测量系统没有线性误差的问题,该工 程师只需对测量系统的偏倚进行研究和评价。根据过程变差的实 际情况,他从测量系统操作范围内选取了一个零件;通过对该零 件进行了全尺寸测量确定了它的参考值,然后由主要操作者测量 该零件15次。
2019/4/1
23
偏倚研究的分析
如果测量系统偏倚非0,应该可以通过硬件、软件或两项同时 调整再校准达到0,如果偏倚不能调整到0,也仍然可以通过改变程 序(如用偏倚调整每个读数)使用。由于存在评价人较高误差的风 险,应该在取得顾客同意后方可使用这种方法。
2019/4/1
24
σ
2019/4/1
重复性 =
R/ d2*
( d2* 依据m和g ,见附录c)
18
确定偏倚的指南 -控制图法
6.确定偏倚的 t 统计量 (偏倚的不确定度由σ b给出)
其中 ɡ 是 g 和 m的乘积, g代表子组容量,m代表 子组数量。 7.如果 0 落在围绕偏倚值的 1- 置信区间内,偏倚在 水平内可被接受。
2019/4/1
21
控制图法举例
2019/4/1
22
偏倚研究的分析
如果偏倚在统计上非0,寻找以下可能的原因: 标准或基准值误差,检查标准程序; 仪器磨损; 仪器制造尺寸有误; 仪器测量了错误的特性; 仪器未得到完善的校准,评审校准程序; 评价人设备操作不当; 仪器修正验算不正确。
15
独立样件法 —范例
医学统计学第七版课后答案及解析

医学统计学第七版部分课后答案及解析第二章1. 答:统计学中用来描述集中趋势的体系是平均数,包括算术均数,几何均数,中位数。
均数反映了一组观察值的平均水平,适用于单峰对称或近似单峰对称分布资料的平均水平的描述。
几何均数:有些医学资料,如抗体的滴度,细菌计数等,其频数分布呈明显偏态,各观察值之间呈倍数变化(等比关系),此时不宜用算术均数描述其集中位置,而应该使用几何均数(geometric mean)。
几何均数一般用G表示,适用于各变量值之间成倍数关系,分布呈偏态,但经过对数变换后成单峰对称分布的资料。
中位数和百分位数:中位数(median)就是将一组观察值按升序或降序排列,位次居中的数,常用M表示。
理论上数据集中有一半数比中位数小,另一半比中位数大。
中位数既适用于资料呈偏态分布或不规则分布时集中位置的描述,也适用于开口资料的描述。
所谓“开口”资料,是指数据的一端或者两端有不确定值。
百分位数(percentile )是一种位置指标,以P X表示,一个百分位数P X将全部观察值分为两个部分,理论上有X%的观察值比P X小,有(100- X)%观察值比P X大。
故百分位数是一个界值,也是分布数列的一百等份分割值。
显然,中位数即是P50 分位数。
即中位数是一特定的百分位数。
常用于制定偏态分布资料的正常值范围。
2. 答:常用来描述数据离散程度的指标有:极差、四分位数间距、标准差、方差、及变异系数,尤以方差和标准差最为常用。
极差(range ,记为R),又称全距,是指一组数据中最大值与最小值之差。
极差大,说明资料的离散程度大。
用极差反映离散程度的大小,简单明了,故得到广泛采用,如用以说明传染病、食物中毒等的最短、最长潜伏期等。
其缺点是: 1. 不灵敏; 2. 不稳定。
四分位数间距(inter-quartile range )就是上四分位数与下四分位数之差,即:Q=Q U-Q L , 其间包含了全部观察值的一半。
高中数学必修三 18-19 第1章 §4 4.1 平均数、中位数、众数、极差、方差 4.2 标准差

难
(6)样本的标准差和方差都是正数.( )
返 首 页
[解析] (1)×,根据平均数的定义可知错误.
自
当
主 预
(2)×,根据众数定义知众数可以一个,也可以多个.
堂 达
习
标
•
(3)×,由中位数的定义可知错误.
•
探
固
新 知
(4)√,极差与标准差都反映了样本数据的波动性和离散程度.
双 基
(5)×,平均数与数据的波动性无关.
究 •
(4)算出(3)中 n 个平方数的平均数,即为样本方差.
攻
重 难
(5)算出(4)中方差的算术平方根,即为样本标准差.
课 时 分 层 作 业
返 首 页
自
当
主
堂
预
达
习 •
2.标准差(方差)的两个作用:
标 •
探
固
新
(1)标准差(方差)越大,数据的离散程度越大;标准差(方差)越小,数据的 双
知
基
离散程度越小.
达 标
•
•
探
A.茎叶图
B.频率分布直方图
固
新
双
知
C.频率折线图
D.频率分布表
基
合
作
探 究
B [当收集到的数据量很大时,一般用频率分布直方图.]
攻
重 难
(2)根据计算结果判断哪台机床加工零件的质量更稳定.
课 时 分 层 作 业
返 首 页
[解] (1) x 甲=16(99+100+98+100+100+103)=100,
自 主
x 乙=16(99+100+102+99+100+100)=100.
【生物统计】第三章 次数分布和平均数、变异数

3. 条形图; 74
„
4. 饼图; 1 0 9
104
109
1. 方柱形图 适用于表示连续性变数的次数分布; 2. 多边形图 适用于表示连续性变数的次数分布;
以课本p.17的表1.6的分布为例说明。
图1 表.1.6 100 株小麦的次数分布 豫农202不同播期下灌浆速率 Fig 1 Filling rate under different sowing 35 date 中 值 次 数
米粒性状
质量性状的变数资料
红糯
红非
白糯
白非
1. 方柱形图
属性分组
表 1.8 玉米 F2 代两对性状的分离 水稻F2代植株米粒性状分离图
次数(f)
100个麦穗每穗小穗数分布图 Æ « Ç ð » É ·Ì
Æ « ð £ » É Ì Á
适用于表示连续性变数的次数分布; 20个 15个 ·Ì ׫ °É Ç ð 19% 850 56.11 黄色非甜 × °« ð £ 白非 19个 5% 6%É Ì Á16 17% 282 18.61 黄色甜粒 17% 15% 2. 多边形图
100个麦穗每穗小穗数的次数分布表(P37) 每穗小穗数(y) 15 16 17 18 19 20 总次数(n) 次数(f) 6 15 32 25 17 5 100
因为取值个数只有15 、16、17、18、19和20六种, 所以以自然单位分组。
2、若变数可取值个数太多,则可按取值大小,从小 到大相邻若干个值合为一组的方法进行整理(一般 要求组距相等)。
第三章 次数分布和平均数、变异数
第一节 总体及其样本 第二节 次数分布 第三节 平均数 第四节 变异数
第一节 总体与样本 1.数据的变异和趋中性
数据的统计 (标准差,众数、中位数、平均数)

解:用计算器计算可得:
x甲 25.401, x乙 25, 406; s甲 0.037, s乙 0.068.
从样本平均数看,甲生产的零件内径比乙生产 的更接近内径标准(25.40mm),但是差异很小; 从样本标准差看,由于 s甲 s乙 , 因此,甲生产的零件内径比乙的稳定程度高 得多.于是,可以作出判断,甲生产的零件的质 量比乙的高一些.
解: 依题意计算可得 x1=900 x2=900
s1≈23.8
s2 ≈42.6
甲乙两种水稻6年平均产量的平均数相同,但 甲的标准差比乙的小,所以甲的生产比较稳定.
解 : (1) 平均重量约为496.86 g , 标准差约为6.55
(2)重量位于(x-s , x+s)之间有14袋白糖,所占 百分比为66.67%.
分析:每一个工人生产的所有零件的内径尺寸组成一 个总体.由于零件的生产标准已经给出(内径25.40mm), 生产质量可以从总体的平均数与标准差两个角度来衡 量.总体的平均数与内径标准尺寸25.40mm的差异大 时质量低,差异小时质量高;当总体的平均数与标准尺 寸很接近时,总体的标准差小的时候质量高,标准差大 的时候质量低.这样,比较两人的生产质量,只要比较他 们所生产的零件内径尺寸所组成的两个总体的平均数 与标准差的大小即可.但是这两个总体的平均数与标 准差都是不知道的,根据用样本估计总体的思想,我们 可以通过抽样分别获得相应的样体数据,然后比较这 两个样本的平均数、标准差,以此作为两个总体之间 的估计值.
2、中位数 :将一组数据按大小依次排列,把处 在最中间位置的一个数据(或两个数据的平均数) 叫做这组数据的中位数。
3、平均数:一组数据的算术平均数,即
x = (x1+x2+……+xn) /n
统计学第3、4章知识点与习题(含答案)

第三章数据资料的统计描述:统计表和统计图第一节定性资料的统计描述知识点:1、统计分组就是根据统计研究的需要,将统计总体按照一定的标志区分为若干组成部分的一种统计方法。
2、定性数据的频数、频率、百分数、累计频数、累积频率的概念及计算。
3、定性数据频数分布表示方法主要有条形图、扇形图。
第二节定量数据的统计描述知识点:1、定量数据频数分布表的编制:(1)整理原始资料;(2)确定变量数列的形式;(3)编制组距式变量数列。
应注意的问题:确定组距,确定组限。
考查的区间式分组数据按“上组限不在组内”的原则确定。
2、定量数据的频数、频率、百分数、累积频数、累计频率的概念及计算。
3、定量数据频数分布表示方法主要有直方图、折线图和曲线图三种。
第三节探索性数据分析——茎叶图知识点:1、基本茎叶图的理解及编制第四节相关表与相关图知识点:1、相关表,反映定性变量与定量变量之间的相关关系。
2、散点图,反映两个定量变量之间的相关关系。
根据散点图判断两个变量的相关关系。
第四章数据资料的统计描述:数值计算第一节集中趋势知识点:关于单值式分组和区间式分组数据的1、平均数的计算,包括算术平均数,几何平均数,调和平均数2、众数的计算3、中位数、四分位数的计算4、(补充知识点)平均数、众数、中位数三者之间的关系5、百分位数的计算6、截尾均值的计算第二节离散测度知识点:1、极差的计算2、关于单值式分组和区间式分组数据的四分位数差的计算3、关于单值式分组和区间式分组数据的方差、标准差的计算4、变异系数的计算5、(补充知识点)偏度、峰度的含义及计算第三节协方差与相关系数知识点:1、样本协方差的含义及计算2、相关系数的含义及计算第四节相对位置测度与奇异点知识点:1、数据的标准化处理2、奇异点的诊断:利用契比雪夫定理和经验规则第五节探索性分析——5点描述与箱线图知识点:1、5点描述法的理解2、箱线图的理解与运用第三章习题:一、填空题1、在对数据资料进行统计描述时,______反映了各个组中每一项目出现的次数,______反映了各个组中项目发生的比例。
数值变量资料的统计描述(变异程度)

-1
0
准 态 布 标 正 分 -1 1 ~ -1 6 1 6 .9 ~ .9 -2 8 2 8 .5 ~ .5
态 布 正 分 面 或 率 积 概 6 .2 % 8 7 μ σ ± 9 .0 % 5 0 μ 1 6 ± .9 σ 9 .0 % 9 0 μ 2 8 ± .5 σ
三、医学正常值范围的估计
Px
5
复习: 复习:频数表资料的百分位数
在 段 限 P = 所 组 下 值+ x 该 限 的 计 数 (n×x%−至 下 值 累 频 ) 组 × 距 所 组 下 值 上 值 的 数 在 段 限 至 限 间 频 (n×x%−ΣfL) P = L+i × x fm
(n×x%−ΣfL)
下限值L 下限值
i; fm
∋定义:又称参考值范围,是指特定健康人群的解剖、 定义:又称参考值范围,是指特定健康人群的解剖、 生理、生化等各种数据的波动范围。 生理、生化等各种数据的波动范围。习惯上是确定 包括95%的人的界值。 包括95%的人的界值。 95%的人的界值 ∋单双侧:根据指标的实际用途,有的指标有上下界 单双侧:根据指标的实际用途, 值(双侧)。某些指标只需确定上限(单);某些指标 双侧) 某些指标只需确定上限( 只需确定下限( 只需确定下限(单)。
excel描述统计结果解读

excel描述统计结果解读Excel 的描述统计结果可以提供一系列关于数据集的数值,帮助我们理解数据的分布和特性。
以下是对这些数值的详细解读:1.平均值:所有数据点的和除以数据点的数量。
它表示数据集的中心趋势。
2.标准误差:用于衡量样本均值与总体均值之间的差异。
标准误差越小,样本均值越接近总体均值。
3.中值:将数据从小到大排序后,位于中间位置的数。
如果数据量为奇数,中值是中间那个数;如果数据量为偶数,中值是中间两个数的平均值。
中值对于异常值不敏感,因此可以更好地表示数据的中心趋势。
4.众数:数据集中出现次数最多的数。
众数可以反映数据的集中趋势。
5.标准偏差:衡量数据点与平均值之间的差异。
标准偏差越大,数据越分散;标准偏差越小,数据越集中。
6.方差:标准偏差的平方,也表示数据点与平均值之间的差异。
7.峰度:衡量数据分布形态的陡峭程度。
与正态分布相比,峰度大于3的分布更陡峭,峰度小于3的分布更平缓。
8.偏度:衡量数据分布形态的偏斜程度。
偏度大于0表示分布右偏,即右侧尾部更长;偏度小于0表示分布左偏,即左侧尾部更长。
9.极差:数据集中的最大值与最小值之差,反映数据的波动范围。
10.第K大(小)值:输出表的某一行中包含每个数据区域中的第k个最大(小)值,可以反映数据的次序信息。
11.置信度:通常用于表示样本均值与总体均值之间差异的可靠性。
例如,95%的置信度意味着我们有95%的信心认为样本均值在总体均值的某个范围内。
通过解读这些描述统计结果,我们可以对数据集有更深入的了解,并为进一步的数据分析提供基础。
标准偏差

标准偏差标准偏差(也称标准离差或均方根差)是反映一组测量数据离散程度的统计指标。
是指统计结果在某一个时段内误差上下波动的幅度。
是正态分布的重要参数之一。
是测量变动的统计测算法。
它通常不用作独立的指标而与其它指标配合使用。
标准偏差在误差理论、质量管理、计量型抽样检验等领域中均得到了广泛的应用。
因此, 标准偏差的计算十分重要, 它的准确与否对器具的不确定度、测量的不确定度以及所接收产品的质量有重要影响。
然而在对标准偏差的计算中, 不少人不论测量次数多少, 均按贝塞尔公式计算。
[编辑]样本标准差的表示公式数学表达式:•S-标准偏差(%)•n-试样总数或测量次数,一般n值不应少于20-30个•i-物料中某成分的各次测量值,1~n;[编辑]标准偏差的使用方法•在价格变化剧烈时,该指标值通常很高。
•如果价格保持平稳,这个指标值不高。
•在价格发生剧烈的上涨/下降之前,该指标值总是很低。
[编辑]标准偏差的计算步骤标准偏差的计算步骤是:步骤一、(每个样本数据-样本全部数据之平均值)2。
步骤二、把步骤一所得的各个数值相加。
步骤三、把步骤二的结果除以(n - 1)(“n”指样本数目)。
步骤四、从步骤三所得的数值之平方根就是抽样的标准偏差。
[编辑]六个计算标准偏差的公式[1][编辑]标准偏差的理论计算公式设对真值为X的某量进行一组等精度测量, 其测得值为l1、l2、……l n。
令测得值l与该量真值X之差为真差占σ, 则有σ1 = l i− Xσ2 = l2− X……σn = l n− X我们定义标准偏差(也称标准差)σ为(1)由于真值X都是不可知的, 因此真差σ占也就无法求得, 故式只有理论意义而无实用价值。
[编辑]标准偏差σ的常用估计—贝塞尔公式由于真值是不可知的, 在实际应用中, 我们常用n次测量的算术平均值来代表真值。
理论上也证明, 随着测量次数的增多, 算术平均值最接近真值, 当时, 算术平均值就是真值。
于是我们用测得值l i与算术平均值之差——剩余误差(也叫残差)V i来代替真差σ , 即设一组等精度测量值为l1、l2、……l n则……通过数学推导可得真差σ与剩余误差V的关系为将上式代入式(1)有(2)式(2)就是著名的贝塞尔公式(Bessel)。
极差,方差,标准差的概念

极差,方差,标准差的概念平均差:平均差是表示各个变量值之间差异程度的数值之一。
指各个变量值同平均数的离差绝对值的算术平均数。
标准差:是离均差平方的算术平均数的平方根,用σ表示。
标准差是方差的算术平方根。
方差:方差是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。
概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。
极差:极差又称范围误差或全距(Range),以R表示,是用来表示统计资料中的变异量数(measures of variation),其最大值与最小值之间的差距,即最大值减最小值后所得之数据。
是指一组数据内的最大值和最小值之间的差异.区别:1、平均差是说明集中趋势的,标准差是说明一组数据的离中趋势的.平均差是反应各标志值与算术平均数之间的平均差异,是各个数据与平均值差值的绝对值的平均数;标准差是离均差平方和平均后的方根,更能反映一个数据集的离散程度。
2、方差是每个数减去平均数的平方的和,标准差是把方差除以我们的关注的事物的个数,方差=(1/n)[(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2],标准差=方差的算术平方根。
3、平均差是总体所有单位与其算术平均数的离差绝对值的算术平均数。
方差是各个数据与其算术平均数的离差平方和的平均数。
联系:极差越大,平均差的代表性越小,反之亦然;标准差越大,平均差的代表性越小,反之亦然,方差的算术平方根=标准差。
扩展资料:方差的统计学意义当数据分布比较分散(即数据在平均数附近波动较大)时,各个数据与平均数的差的平方和较大,方差就较大;当数据分布比较集中时,各个数据与平均数的差的平方和较小。
因此方差越大,数据的波动越大;方差越小,数据的波动就越小。
样本中各数据与样本平均数的差的平方和的平均数叫做样本方差;样本方差的算术平方根叫做样本标准差。
【精品】定量资料的统计描述

【精品】定量资料的统计描述定量资料的统计描述是指通过定量数据分布的一系列统计量来描述一个样本或总体的特征。
常用的统计量包括中心位置、离散程度、分布形态和相关性等。
中心位置中心位置是指数据分布的平均水平。
常用的中心位置统计量包括平均数、中位数和众数。
平均数是所有数据值的总和除以数据个数。
它具有良好的代表性,但受极端值的影响较大,因此需要谨慎使用。
中位数是将数据按大小排序后位于中间的数值,当数据存在极端值时,中位数比平均数更能正确反映数据的中心位置。
众数是数据中出现次数最多的数值,适用于分布具有明显峰值的情况。
离散程度离散程度是指数据分布的距离平均值的大小。
常用的离散程度统计量包括标准差、方差、极差和四分位数差等。
标准差是数据离均值的平均距离,是最常用的衡量数据分散程度的统计量。
方差是标准差的平方,由于平方的量级较大,因此比标准差不易解释。
极差是数据最大值与最小值之差,不考虑数据内部的分布情况,因此不具有代表性。
四分位数差是在数据中将数值分为四个部分,即25%、50%、75%三个分位点,然后用75%分位点减去25%分位点,用于描述数据离散程度。
分布形态分布形态是指数据分布的偏态和峰态。
常用的分布形态统计量包括偏度和峰度。
偏度是反映数据分布偏斜程度的统计量,正偏分布表示分布的长尾在分布的右侧,负偏分布表示分布的长尾在分布的左侧。
当偏度为0时,表示分布是对称的。
峰度是反映数据分布峰态的统计量,正峰分布表示分布的峰在分布的中心较高,负峰分布表示分布的峰在分布的中心较低。
当峰度为0时,表示分布的峰态基本接近正态分布。
相关性相关性是指两个变量之间的关联程度。
常用的相关性统计量包括相关系数和协方差。
相关系数是反映两个变量之间线性相关程度的统计量,取值范围为-1~1之间,正值表示正相关,负值表示负相关,0表示不相关。
协方差是反映两个变量之间相关性的统计量,数值大小表示两个变量之间的相关程度,但由于单位的影响,不易比较。
测量系统分析-偏倚
仪器磨损。
仪器制造尺寸有误
仪器测量了错误的特性
仪器未得到完善的校准,评审校准程序
评价人设备操作ห้องสมุดไป่ตู้当
仪器修正验算不正确
*
*
偏倚研究的分析
陈瑞泉
如果测量系统偏倚非 0,应该可以通过硬件、软件或两项同时调整再校准达到0,如果偏倚不能调整到0,也仍然可以通过改变程序(如用偏倚调整每个读数)使用。由于存在评价人较高误差的风险,应该在取得顾客同意后方可使用这种方法。
*
*
确定偏倚的指南 - 独立样件法
陈瑞泉
研究程序 1.选取一个样件,得出一个可追溯到相关标准的参考 值。如果不可能,选择一件落在生产测量范围中间的生 产件 ,指定其为偏倚分析的标准样本。在工具室测量这 个零件 n≧10次,并计算出n次读数的平均值;把这个平 均值作为基准值。 2.让一个评价人,以工作状态通常的方法测量这个样件 10次以上。 3.相对于基准值,将数据画出直方图。评审直方图,确 定是否存在特殊原因或出现异常;如果没有,继续分析。
陈瑞泉
计算出偏倚占过程变差的百分率: 偏倚%=100[|偏倚|/过程变差]
对偏倚的分析结果应写出书面报告。
如果偏倚大于10%,应进行原因分析。
*
*
偏倚的分析程序
陈瑞泉
偏倚过大的原因可能是: 基准的误差, 零件的磨损; 量具尺寸不对; 测量了错误的特性; 量具没有正确校准; 评价人量具使用不当等。
针对具体的原因,采取相应的措施,对测量系统进行改进。
*
*
t 统计量
df自由度
显著t值(2尾)查t分布分位表
偏倚
95%偏倚置信区间
低值
高值
测量值
0.1153