[VIP专享]DATA BLOCK内部结构的解析
block原理

block原理block原理是指通过在计算机系统中添加特定的控制机制,来实现对某些操作或事件的阻止或限制。
这种机制可以用于各种场景,例如网络安全、操作系统、数据库等,以保护系统的稳定性和安全性。
本文将从网络安全的角度,探讨block原理的应用和工作原理。
在网络安全领域,block原理通常用于阻止恶意攻击、拒绝服务攻击、垃圾邮件等不良行为。
它通过检测和识别恶意的网络流量或行为,然后将其拦截或限制,以防止对系统的破坏或滥用。
这种阻止机制可以应用于网络设备、防火墙、入侵检测系统等。
block原理的工作原理主要分为两个步骤:检测和拦截。
首先,系统会通过各种手段,如网络流量分析、行为模式识别等,对流经系统的数据进行检测。
如果检测到异常或恶意行为,系统会触发拦截机制,将相关的数据流或行为阻止或限制。
具体来说,检测阶段可以包括以下几个步骤。
首先,系统会对网络流量进行实时监控,收集相关的数据包信息。
然后,系统会根据预设的规则或算法,对这些数据包进行分析和比对,以判断是否存在异常或恶意行为。
最后,系统会根据分析结果,触发相应的拦截机制。
拦截阶段是block原理的核心步骤,它通过各种手段来阻止或限制恶意行为的继续进行。
常见的拦截方法包括:断开与攻击者的连接、封锁攻击者的IP地址、限制网络带宽等。
这些方法可以有效地防止攻击者继续对系统进行攻击或滥用。
除了网络安全领域,block原理还可以应用于操作系统和数据库等其他领域。
在操作系统中,block原理可以用于管理进程和资源的访问权限,以保证系统的安全性和稳定性。
在数据库中,block原理可以用于实现事务的原子性和隔离性,以保证数据的完整性和一致性。
总结起来,block原理是一种通过在计算机系统中添加特定的控制机制,来阻止或限制某些操作或事件的发生。
它在网络安全、操作系统和数据库等领域都有广泛的应用。
通过检测和拦截恶意行为,block原理可以保护系统的稳定性和安全性。
在未来的发展中,随着网络攻击和滥用的不断增加,block原理将会发挥更加重要的作用,为计算机系统提供更强大的保护。
block的底层原理

block的底层原理
block的底层原理是使用了区块链技术。
区块链是一种分布式数据库系统,它将数据以区块的形式按照时间顺序连接,形成一个不可篡改的链式结构。
每个block包含以下几个主要的数据部分:1. 区块头(block header):包含了区块的元数据,例如区块的版本号、时间戳、难度目标等信息。
2. Merkle根哈希(Merkle root hash):将区块内的所有交易数据通过hash算法生成一个唯一的哈希值,保证了数据的完整性。
3. 交易数据(transactions):包含了该区块内的所有交易记录,例如转账、合约调用等操作。
4. 前一个区块的哈希(previous block hash):记录了上一个区块的哈希值,实现了链式连接。
block的底层原理可以简单描述为以下步骤:1. 新的交易记录进入网络,节点在验证交易的有效性后,将其打包到一个新的区块中。
2. 节点通过计算交易数据的Merkle根哈希,将区块头与交易数据组合成一个完整的block。
3. 节点将这个新的block 广播给网络中的其他节点。
4. 其他节点接收到这个block后,会对其进行验证,并将其添加到各自的本地区块链中。
5. 当一个block被添加到区块链的末尾后,它就是不可更改的,因为改变该block中的任何数据,都会导致其对应的哈希值不匹配,从而被其他节点拒绝。
通过使用加密算法、共识机制等技术,block的底层原理实现了去中心化、不可篡改、安全可信的数据传输和存储。
这种机制使得block可以被广泛应用于加密货币、智能合约、数字资产等领域。
datacube基本逻辑组件设计

datacube基本逻辑组件设计(原创版)目录1.数据立方体的基本概念2.数据立方体的基本逻辑组件设计3.数据立方体的应用场景正文【数据立方体的基本概念】数据立方体,是一种用于描述数据关系的多维数据模型。
它将数据按照不同的维度进行组织,从而形成一个多维的、可扩展的数据模型。
数据立方体通常由三个或更多的维度组成,这些维度相互交叉,形成一个多维空间,以方便对数据进行分析和处理。
【数据立方体的基本逻辑组件设计】数据立方体的基本逻辑组件主要包括以下几个部分:1.维度:数据立方体的维度是描述数据的属性,通常包括事实维度、时间维度、地理位置维度等。
维度是数据立方体的重要组成部分,它们定义了数据立方体的结构和数据关系。
2.粒度:数据立方体的粒度是指数据的详细程度。
不同的粒度可以提供不同详细程度的数据,以满足不同层次的数据分析需求。
3.度量:数据立方体的度量是指数据的度量单位。
度量可以是数量、金额、时间等,它们定义了数据的大小和单位。
4.明细数据:数据立方体的明细数据是指具体的数据记录。
明细数据通常存储在事实表中,它们描述了业务过程的具体细节。
5.事实表:事实表是数据立方体的核心部分,它包含了所有的明细数据。
事实表通常包含度量和维度的交叉,以提供多维的数据分析功能。
【数据立方体的应用场景】数据立方体广泛应用于数据仓库和商业智能领域,它可以提供多维的数据分析和决策支持。
以下是数据立方体的一些应用场景:1.报表分析:数据立方体可以提供丰富的数据维度,方便用户生成各种报表,如销售额报表、库存报表等。
2.数据挖掘:数据立方体可以提供多维的数据模型,方便用户进行数据挖掘和分析。
3.决策支持:数据立方体可以提供实时的数据分析和决策支持,帮助用户做出更好的决策。
block原理

block原理在计算机科学中,block是一个常用的概念,它在不同的领域中都有着重要的作用。
从数据存储到网络通信,block都扮演着重要的角色。
本文将从block的基本原理出发,介绍其在不同领域中的应用和意义。
首先,我们来看一下block的基本原理。
在计算机中,block通常指的是一组连续的数据。
这些数据可以是存储在磁盘上的文件,也可以是通过网络传输的数据包。
在存储设备中,block通常是存储和读取的最小单位,它的大小可以根据具体的存储设备而有所不同。
在网络通信中,block也常常用于划分数据包,以便于传输和处理。
在数据存储领域,block的原理主要涉及到磁盘的物理结构和文件系统的管理。
磁盘被划分为许多的扇区,每个扇区包含一定数量的block。
文件系统会将文件存储在磁盘的block中,并记录这些block的位置和关联关系。
当需要读取文件时,文件系统会根据记录的信息找到相应的block,并将其读取到内存中。
同样,当需要写入文件时,文件系统会找到空闲的block,并将数据写入其中。
这样的设计可以有效地管理磁盘上的数据,提高数据的读写效率。
在网络通信领域,block的原理主要涉及到数据包的划分和传输。
在网络通信中,数据往往需要被划分为多个block进行传输,以适应网络的传输特性和提高传输效率。
这些block通常会被加上一些额外的信息,如校验和、序号等,以确保数据的完整性和可靠性。
接收端会根据这些额外的信息对接收到的block进行验证和重组,以确保数据的正确性和完整性。
这样的设计可以有效地保证数据在网络中的可靠传输。
除了在数据存储和网络通信中的应用,block的原理还在许多其他领域中发挥着重要的作用。
比如,在加密算法中,block通常被用来作为加密和解密的基本单位。
在数据库系统中,block通常被用来作为数据的存储和管理单位。
在图像处理中,block通常被用来作为图像的处理和压缩单位。
可以说,block的原理贯穿了计算机科学的方方面面,是计算机科学中的一个重要概念。
block实现原理

block实现原理block是一种在计算机科学和编程中常用的数据结构和算法,在不同的领域有不同的实现原理。
以下是几种常见的block实现原理。
1. 阻塞队列(blocking queue):阻塞队列是一种线程安全的队列,能够实现在队列为空时等待元素,或者在队列已满时等待空间的特性。
阻塞队列的实现原理通常基于同步机制,如锁和条件变量。
当队列为空时,出队操作将被阻塞,直到有新的元素入队;当队列已满时,入队操作将被阻塞,直到有元素出队。
通过这种方式,阻塞队列能够实现线程间的同步和协调。
2. 逻辑阻塞(blocking):逻辑阻塞是指在编程中通过条件判断实现的阻塞操作。
在多线程或并发编程中,当某个线程需要等待满足特定条件时,可以使用逻辑阻塞来实现。
具体实现原理基于条件变量和锁的概念,通过条件判断和轮询等方式来判断是否需要阻塞或唤醒线程。
3. 文件阻塞(blocking I/O):文件阻塞是在输入/输出操作中常见的一种阻塞方式。
在进行文件读写时,如果没有足够的数据供应或者无法将数据写入到文件中,操作系统会将当前线程阻塞,等待数据的准备或空间的释放。
文件阻塞通常基于操作系统的文件系统和设备驱动程序来实现。
4. 网络阻塞(blocking networking):网络阻塞是指在网络通信中发生的阻塞情况。
当一个应用程序通过网络发送或接收数据时,如果无法立即完成该操作,操作系统会将调用线程阻塞,直到数据发送或接收完成。
网络阻塞的实现原理基于底层的网络协议栈和操作系统的网络API。
需要注意的是,在不同的上下文中,block的实现原理可能会有所不同,这是因为block这个概念在计算机科学中具有广泛的应用,适用于不同的领域和问题。
以上提到的几种实现原理只是常见的例子,并不能涵盖所有的情况。
不同的block实现原理可以根据具体的需求和场景来选择和设计。
DataBlockScanner

DataBlockScanner由于每一个磁盘或者是网络上的I/O操作可能会对正在读写的数据处理不慎而出现错误,所以HDFS提供了下面两种数据检验方式,以此来保证数据的完整性,而且这两种检验方式在DataNode节点上是同时工作的:一.校验和检测损坏数据的常用方法是在第一次进行系统时计算数据的校验和,在通道传输过程中,如果新生成的校验和不完全匹配原始的校验和,那么数据就会被认为是被损坏的。
二.数据块检测程序(DataBlockScanner)在DataNode节点上开启一个后台线程,来定期验证存储在它上所有块,这个是防止物理介质出现损减情况而造成的数据损坏。
关于校验和,HDFS以透明的方式检验所有写入它的数据,并在默认设置下,会在读取数据时验证校验和。
正对数据的每一个校验块,都会创建一个单独的校验和,默认校验块大小是512字节,对应的校验和是4字节。
DataNode节点负载在存储数据(当然包括数据的校验和)之前验证它们收到的数据,如果此 DataNode节点检测到错误,客户端会收到一个CheckSumException。
客户端读取DataNode节点上的数据时,会验证校验和,即将其与DataNode上存储的校验和进行比较。
每一个DataNode节点都会维护着一个连续的校验和和验证日志,里面有着每一个Block的最后验证时间。
客户端成功验证Block之后,便会告诉DataNode节点,Datanode节点随之更新日志。
这一点也就涉及到前面说的DataBlockScanner了,所以接下来我将主要讨论DataBlockScanner。
还是先来看看与DataBlockScanner相关联的类吧!dataset:数据块管理器;blockInfoSet:数据块扫描信息集合,按照上一次扫描时间和数据块id 升序排序,以便快速获取验证到期的数据块;blockMap:数据块和数据块扫描信息的映射,以便能够根据数据块快速获取对应的扫描信息;totalBytesToScan:一个扫描周期中需要扫描的总数据量;bytesLeft:一个扫描周期中还剩下需要扫描的数据量;throttler:扫描时I/O速度控制器,需要根据totalBytesToScan和bytesLeft信息来衡量;verificationLog:数据块的扫描验证日志记录器;scanPeriod:一个扫描周期,可以由Datanode的配置文件来设置,配置项是:dfs.datanode.scan.period.hours,单位是小时,默认的值是21*24*60*60*1000 ms。
Data_Cube之概念解释
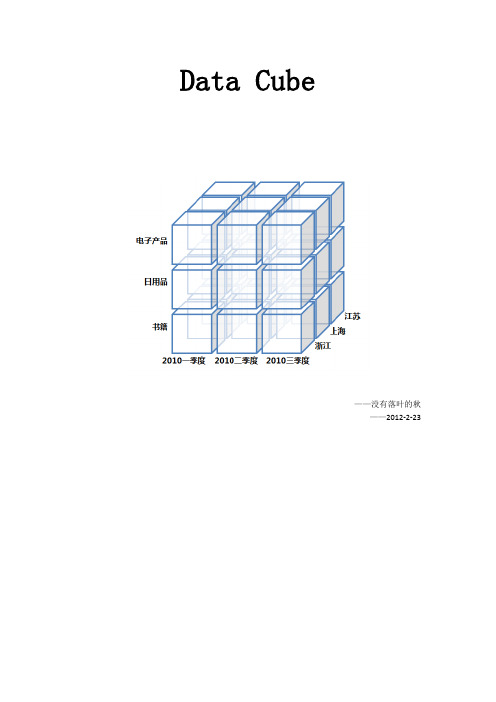
Data Cube——没有落叶的秋——2012-2-23各种数据库、网络技术、web开发参考:/database/basis/201112/32141.htm数据库设计与数据仓库设计1.业务数据和分析数据普通的数据库_业务处理直接用于业务处理,需要严格约束表和表之间的关系,保证了数据完整性。
数据库的设计:一般通过实体关系模型确定数据库中需要存储数据的表,再通过数据规范化方法(如第1、2、3范式等)改变这些表的结构,确定表的主外键,并以主外键为依据,在表之间建立起一对一或一对多的关系。
列举:adventureworks业务数据库中购买订单、买入商品运送方法和商品提供商等数据表关系如下:从业务数据库中的表间的关系示例图总可以看出,对于购买订单报头这个表(purchaseOrderHeader)而言,与供货商(Vendor)表、购买订单详情表(purchaseOrderDetail)运输方法表(ShipMethod)之间的关系是根据实际业务操作中应该有的关系来确定的,这样的数据库系统结构设计用于业务操作的信息化很合适。
商务分析数据库_多维商务分析需要的数据库与业务数据库不同,用于OLAP(On-Line Analytical Processing)的数据应该是多维度的。
下图为购买地区、购买时间和产品名称3个视角分析购买订单时需要的一种数据立方。
数据立方体又称为多维数据集,是使用分析数据的典型方式。
2.数据仓库中的立方体数据立方体与数学中的X、Y、Z坐标轴表示3个空间创建一个立方体是一样的,可以将不同的商业视角作为维度建立一个商业智能分析用的立方体。
通过不同的坐标抽(数据属性如:时间、地方等)的灵活组合,可以构成各种各样的数据立方体。
使用时间仓库时的数据立方体也不都是三维的,由于商务视角的多样性,大多数情况下数据立方体是以三维以上的方式组成的。
数据立方体中多个维度的值是商务需求中需要观察的目标,这个目标的值一般叫度量值。
NANDFlash的底层结构

NANDFlash的底层结构NAND Flash是一种非易失性存储器(Non-Volatile Memory,NVM),广泛应用于各种设备中,如SSD、USB闪存驱动器、嵌入式系统、智能手机等。
NAND Flash的底层结构是一种非常复杂的技术,以下将详细介绍其底层结构。
1. 位线(Word Line)和单元(Cell):NAND Flash内部被划分为一个个单元,每个单元中包含一个或多个存储位,用于存储二进制信息。
单元通过位线与外部控制电路进行交互。
位线是一组金属导线,位于存储芯片的水平方向上。
2. 页(Page)和块(Block):NAND Flash内的存储单元被组织成页和块的形式。
页是最小的擦除和编程单位,通常为2KB到16KB不等。
块则是由多个页组成的,典型大小为128页或256页。
擦除操作是将一个块内的所有页清除为逻辑1状态,只能整块执行。
编程操作是将数据写入到单个页中。
3. 交错擦除(Interleaved Erase):为了提高擦除和编程的性能,NAND Flash采用了交错擦除结构。
即将多个块交错放置在一起,使得擦除和编程操作可以同时进行,提高了整体的吞吐量和响应时间。
4.擦除和编程控制:擦除和编程操作是通过在位线上加电压来实现的。
擦除操作是将位线上的电压加高,使得存储单元内的电荷被抽离,将其置为逻辑1状态。
编程操作则是通过施加较高的电压将电荷注入存储单元,即将其置为逻辑0状态。
5. 位选择器(Bit Selector):NAND Flash中的每一位单元与位线之间有一个位选择器。
位选择器作为二极管的形式存在,在正向偏置下,连通位线与存储单元;在反向偏置下,阻断位线和存储单元之间的连接。
6. 芯片选择器(Chip Selector):用于选择与读写操作所涉及的存储芯片。
多个NAND Flash芯片可以通过芯片选择器进行并联或级联,以扩展存储容量。
7. 控制逻辑:NAND Flash芯片还包含一些控制逻辑,用于对存储操作进行控制和管理。
fabric block结构

fabric block结构
Fabric中的区块结构(Block类型)包括区块头(Header)、交易数据集合(Data)以及区块元数据(Metadata)三个部分。
1. 区块头(Header):封装了区块号、前一个区块的哈希值、当前区块的哈希值。
其中,区块号用于标识该区块在账本中的位置,前一个区块的哈希值是当前区块的前一个区块的唯一标识,当前区块的哈希值是该区块内容的唯一标识。
2. 交易数据集合(Data):封装了打包的交易集合。
3. 区块元数据(Metadata):封装了四个元数据索引项,包括:
BlockMetadataIndex_SIGNATURES:区块签名;
BlockMetadataIndex_LAST_CONFIG:最新配置区块的区块号;
BlockMetadataIndex_TRANSACTIONS_FILTER:最新交易过滤器,封装了交易数据集合中所有交易对应的交易验证码,标识其交易的有效性; BlockMetadataIndex_ORDERER:Orderer配置信息,如Kafka共识组件的初始化参数。
以上内容仅供参考,如需更专业的解释,可咨询区块链领域的技术人员或查阅相关技术文档。
kv 数据库 block 结构

kv 数据库 block 结构
KV数据库(Key-Value Database)是一种简单的数据库模型,它使用键值对的形式来存储数据。
而"block"结构通常指的是数据库中的一种数据存储方式,通常用于提高数据的读取和写入性能。
在KV数据库中,数据以键值对的形式存储,其中键用于唯一标识数据,而值则存储实际的数据内容。
而"block"结构则是一种数据的组织方式,它通常指的是将数据划分为固定大小的块(block),以便进行高效的读写操作。
在实际的KV数据库中,采用block结构可以带来一些优势。
首先,通过将数据划分为固定大小的块,可以更加高效地利用存储空间,减少空间的浪费。
其次,block结构可以提高数据的读取和写入性能,因为数据库系统可以更加高效地管理和操作固定大小的数据块。
另外,block结构还可以与缓存、索引等技术结合,进一步提高数据库的性能。
例如,数据库系统可以使用缓存来缓存常用的数据块,以减少磁盘IO操作,从而提高读取性能。
同时,数据库系统也可以利用索引来快速定位和访问特定的数据块,以提高写入和查
询操作的效率。
总的来说,KV数据库中的block结构是一种用于提高数据存储和操作性能的技术手段,它通过合理划分数据块,并结合缓存、索引等技术,可以有效地提升数据库系统的整体性能和效率。
data store memory 结构体-概述说明以及解释

data store memory 结构体-概述说明以及解释1.引言1.1 概述在数据存储领域中,数据存储内存起着关键作用。
数据存储内存是一种用于临时存储和快速访问数据的存储设备,其具有高速读写速度、低延迟和高带宽特性。
本文将重点探讨数据存储内存的定义、作用以及优势,以帮助读者深入了解该关键技术在数据存储系统中的重要性。
通过本文的阐述,读者将能够更好地理解数据存储内存的特点和价值,从而为未来的技术发展和应用提供重要参考。
1.2 文章结构本文分为三个部分:引言,正文和结论。
- 引言部分将介绍数据存储内存的概念和本文的目的,为读者提供一个整体的了解。
- 正文部分将详细展开数据存储内存的定义、作用和优势,深入探讨其在数据存储中的重要性和价值。
- 结论部分将对数据存储内存的重要性进行总结,展望其未来的发展趋势,并结束全文。
编写文章1.2 文章结构部分的内容1.3 目的:本文的主要目的是探讨数据存储内存的重要性和优势。
通过对数据存储内存的定义、作用和优势进行深入分析,旨在帮助读者更好地了解数据存储内存在计算机系统中的地位和作用。
同时,通过展望数据存储内存的未来发展,为读者提供对数据存储内存技术的前瞻性认识,帮助他们在未来的学习和工作中更好地应用和理解数据存储内存相关的知识。
最终,通过本文的内容,希望能够强调和强调数据存储内存在现代计算机系统中的重要性,促进数据存储内存技术的进一步发展和应用。
2.正文2.1 数据存储内存的定义数据存储内存是一种用于存储和操作数据的计算机内存结构。
它通常被用来存储临时数据和临时结果,以便在程序执行过程中快速访问和修改数据。
数据存储内存通常包括内存单元、存储器控制器和数据通路等组成部分,能够提供高速的数据访问和读写操作。
数据存储内存的定义还可以扩展到包括硬件存储器和软件存储器等方面,用于满足不同应用场景的数据存储需求。
在计算机系统中,数据存储内存扮演着至关重要的角色,可以直接影响系统的性能和运行效率。
flash擦写block结构

flash擦写block结构
Flash擦写block是Flash存储器中逻辑上的最小可擦写单位,由多个扇区组成。
每个Flash擦写block包括一定数量的页,每页包含多个字节(通常为256或512字节)。
Flash擦写block包含一个擦除计数器,在Flash擦写操作时被递增和更新。
Flash擦写block还有一个标志位,用于指示它是否已被擦除。
如果一个Flash擦写block中的所有页都被擦除,则该标志位为“1”,否则为“0”。
Flash擦写block的结构通常如下所示:
++
Flash擦写block header
++
页1
++
页2
++
...
++
页n
++
Flash擦写block header由擦除计数器和标志位组成。
一页通常由数据区和校验区组成。
Flash擦写block的大小和页大小可能因不同的Flash存储器而异。
由于Flash存储器中对Flash擦写操作的限制,Flash擦写block通常需要被完全擦除才能被写入新数据,这也是Flash存储器相较于其他存储器的一个主要缺点。
data matrix code的方格矩阵

数据矩阵代码(Data Matrix code)是一种二维条码,由一系列黑白方格按照特定规则排列而成。
它常被用于商业领域中的自动识别和跟踪系统中,也被广泛用于包装、制造和物流行业。
其具有高密度编码、易扫描和可靠性高等特点,在现代社会中发挥着重要作用。
下面将从几个方面来介绍数据矩阵代码的方格矩阵:1. 方格矩阵的结构特点数据矩阵代码由一系列黑色和白色方块组成,这些方块按照特定的布局规则排列在一个固定大小的网格中。
每个方块代表一个二进制数,黑色方块代表1,白色方块代表0。
这种特殊的排列方式使得数据矩阵代码具有高度的纠错能力和信息密度,即使受损也能够确保信息的完整性和准确性。
2. 方格矩阵的编码原理数据矩阵代码的编码原理是通过将文本或数字信息转换成一系列二进制数,并按照特定规则排列成方格矩阵。
在编码过程中,系统会自动计算出纠错编码,并将其嵌入到方格矩阵中。
这种编码方式不仅能够确保信息的安全传输,还能够提高扫描和识别的速度和准确性。
3. 方格矩阵的应用领域数据矩阵代码的方格矩阵在各个行业中都有着广泛的应用。
在物流和制造领域,数据矩阵代码能够用于追踪和管理产品的生产和流通过程;在医疗保健领域,数据矩阵代码能够用于医药品的追踪和管理;在零售领域,数据矩阵代码能够用于商品的售后跟踪和管理等。
数据矩阵代码的方格矩阵凭借其高度纠错能力和信息密度,在自动识别和跟踪系统中发挥着重要作用。
4. 方格矩阵的发展趋势随着信息技术的不断发展,数据矩阵代码的方格矩阵也在不断演进和完善。
未来,数据矩阵代码将会更加智能化、多样化和个性化,能够更好地满足不同行业的需求。
在人工智能和大数据的推动下,数据矩阵代码的方格矩阵也将有更广阔的应用前景,为各个行业带来更多的创新和价值。
数据矩阵代码的方格矩阵作为一种重要的二维条码,其结构特点、编码原理和应用领域均具有重要意义。
随着信息技术的不断发展,数据矩阵代码的方格矩阵也将不断演进和完善,为各个行业带来更多的创新和价值。
datacache组成原理

datacache组成原理数据缓存是计算机系统中常用的一种优化技术,它通过存储计算机程序运行过程中频繁访问的数据,以提高程序的执行速度和系统的整体性能。
数据缓存的组成原理可以从硬件和软件两个方面来解释。
一、硬件组成原理:在计算机系统的硬件部分,数据缓存通常由高速缓存(Cache)和内存组成。
高速缓存是一种容量较小但速度较快的存储器,它位于处理器与主内存之间,用于存储最近使用的数据。
具体来说,高速缓存由三个层次组成:L1、L2和L3、L1高速缓存位于处理器核心内部,速度最快但容量最小,通常用于存储指令级别的数据。
L2高速缓存位于L1缓存之后,速度较慢但容量较大,用于存储更多的数据。
L3高速缓存则位于处理器芯片之外,速度较L1和L2更慢,但容量更大。
这种层次结构的设计是为了兼顾处理速度和存储容量的平衡。
数据缓存的作用是在处理器的内部存储一些最近访问的数据,当程序需要读取数据时,首先查询缓存中是否已存在所需数据。
如果存在,就可以直接从缓存读取数据,避免了从主内存中加载数据的时间开销;如果不存在,会从主内存中加载数据到缓存,并保证数据的一致性,即缓存中的数据与主内存中的数据保持同步。
另外,数据缓存还通过使用高速缓存的方式来提高数据访问的命中率。
高速缓存通过一种称为缓存行(Cache Line)的方式来存储数据,即将连续的若干个字节或数据块作为一个缓存行。
当程序需要读取或写入数据时,缓存控制器会首先查询所需数据所在的缓存行,如果存在,则称为缓存命中(Cache Hit);如果不存在,则称为缓存失效(Cache Miss)。
命中率是指缓存行命中所占的比例,高的命中率意味着缓存更加有效地提供了所需数据,从而提高了程序的执行效率。
二、软件组成原理:在软件部分,数据缓存的组成原理主要涉及到程序设计和访存优化。
1.程序设计:良好的程序设计可以减少数据的访存次数和数据重复读写的情况,从而减少对缓存的不命中。
例如,合理使用局部性原理,即将相关的数据尽可能存储在连续的内存位置上,以便利用高速缓存的局部性特性进行访问。
SD原理及内部结构

1、简介:SDxx(Secure Digital Memory Card)是一种为满足xx、容量、性能和使用环境等各方面的需求而设计的一种新型存储器件,SDxx允许在两种模式下工作,即SD模式和SPI模式,本系统采用SPI模式。
本小节仅简要介绍在SPI模式下,STM32处理器如何读写SDxx,如果读者如希望详细了解SDxx,可以参考相关资料。
SD xx内部结构及引脚如下图所示:SDxx内部图.JPG 2、SDxx管脚图:SDxx.JPG3、SPI模式下SD各管脚名称为:sd 卡:SPI模式下SD各管脚名称为.JPG注:一般SD有两种模式:SD模式和SPI模式,管脚定义如下:(A)、SD MODE 1、CD/DATA3 2、CMD 3、VSS1 4、VDD 5、CLK 6、VSS2 7、DATA0 8、DATA1 9、DATA2(B)、SPI MODE 1、CS2、DI 3、VSS 4、VDD 5、SCLK 6、VSS2 7、DO8、RSV 9、RSVSD xx主要引脚和功能为:CLK:时钟信号,每个时钟周期传输一个命令或数据位,频率可在0~25MHz之间变化,SDxx的总线管理器可以不受任何限制的自由产生0~25MHz 的频率;CMD:双向命令和回复线,命令是一次主机到从xx操作的开始,命令可以是从主机到单xx寻址,也可以是到所有xx;回复是对之前命令的回答,回复可以来自单 xx或所有xx;DAT0~3:数据线,数据可以xx向主机也可以从主机传向xx。
SDxx以命令形式来控制SDxx的读写等操作。
可根据命令对多块或单块进行读写操作。
在SPI模式下其命令由6个字节构成,其中高位在前。
SDxx命令的格式如表1所示,其中相关参数可以查阅SDxx规范。
4、MicroSDxx管脚图:MicroSDxx管脚图.JPG5、MicroSDxx管脚名称:MicroSDxx管脚名称.JPGSD xx与MicroSDxx仅仅是封装上的不同,MicroSDxx更小,大小上和一个SIMxx差不多,但是协议与SDxx相同。
HDFS中的数据块(Block)

HDFS中的数据块(Block)我们在分布式存储原理总结中了解了分布式存储的三⼤特点:1. 数据分块,分布式的存储在多台机器上2. 数据块冗余存储在多台机器以提⾼数据块的⾼可⽤性3. 遵从主/从(master/slave)结构的分布式存储集群HDFS作为分布式存储的实现,肯定也具有上⾯3个特点。
HDFS分布式存储:在HDFS中,数据块默认的⼤⼩是128M,当我们往HDFS上上传⼀个300多M的⽂件的时候,那么这个⽂件会被分成3个数据块:所有的数据块是分布式的存储在所有的DataNode上:为了提⾼每⼀个数据块的⾼可⽤性,在HDFS中每⼀个数据块默认备份存储3份,在这⾥我们看到的只有1份,是因为我们在hdfs-site.xml中配置了如下的配置:<property><name>dfs.replication</name><value>1</value><description>表⽰数据块的备份数量,不能⼤于DataNode的数量,默认值是3</description></property> 我们也可以通过如下的命令,将⽂件/user/hadoop-twq/cmd/big_file.txt的所有的数据块都备份存储3份:hadoop fs -setrep 3 /user/hadoop-twq/cmd/big_file.txt我们可以从如下可以看出:每⼀个数据块都冗余存储了3个备份在这⾥,可能会问这⾥为什么看到的是2个备份呢?这个是因为我们的集群只有2个DataNode,所以最多只有2个备份,即使你设置成3个备份也没⽤,所以我们设置的备份数⼀般都是⽐集群的DataNode的个数相等或者要少⼀定要注意:当我们上传362.4MB的数据到HDFS上后,如果数据块的备份数是3个话,那么在HDFS上真正存储的数据量⼤⼩是:362.4MB * 3 = 1087.2MB注意:我们上⾯是通过HDFS的WEB UI来查看HDFS⽂件的数据块的信息,除了这种⽅式查看数据块的信息,我们还可以通过命令fsck来查看数据块的实现在HDFS的实现中,数据块被抽象成类org.apache.hadoop.hdfs.protocol.Block(我们以下简称Block)。
详解data,bdata,idata,pdata,xdata,code存储类型与存储区

bit是在内部数据存储空间中 20H .. 2FH 区域中一个位的地址,或者 8051 位可寻址 SFR 的一个位地址。
code是在0000H .. 0FFFFH 之间的一个代码地址。
data是在 0 到 127 之间的一个数据存储器地址,或者在 128 .. 255 范围内的一个特殊功能寄存器(SFR)地址。
idata是0 to 255 范围内的一个 idata 存储器地址。
xdata 是 0 to 65535 范围内的一个 xdata 存储器地址。
指针类型和存储区的关系详解一、存储类型与存储区关系data ---> 可寻址片内rambdata ---> 可位寻址的片内ramidata ---> 可寻址片内ram,允许访问全部内部rampdata ---> 分页寻址片外ram (MOVX @R0) (256 BYTE/页)xdata ---> 可寻址片外ram (64k 地址范围)code ---> 程序存储区 (64k 地址范围),对应MOVC @DPTR二、指针类型和存储区的关系对变量进行声明时可以指定变量的存储类型如:uchar data x和data uchar x相等价都是在内ram区分配一个字节的变量。
同样对于指针变量的声明,因涉及到指针变量本身的存储位置和指针所指向的存储区位置不同而进行相应的存储区类型关键字的使用如:uchar xdata * data pstr是指在内ram区分配一个指针变量("*"号后的data关键字的作用),而且这个指针本身指向xdata区("*"前xdata关键字的作用),可能初学C51时有点不好懂也不好记。
没关系,我们马上就可以看到对应“*”前后不同的关键字的使用在编译时出现什么情况。
......uchar xdata tmp[10]; //在外ram区开辟10个字节的内存空间,地址是外ram 的0x0000-0x0009......第1种情况:uchar data * data pstr;pstr=tmp;首先要提醒大家这样的代码是有bug的, 他不能通过这种方式正确的访问到tmp空间。
ios block的类型

ios block的类型
在iOS中,block(块)主要有三种类型:栈block、堆block
和全局block。
1. 栈Block(Stack Block):栈Block是在栈上分配内存的,它可以访问外部的局部变量,并且在Block内部对局部变量的修改也会影响到外部的变量。
栈Block的生命周期仅限于定义它的作用域内,一旦超出作用域,栈Block将被销毁。
栈Block的定义方式如下:
int multiplier = 3; int (^block)(int) = ^(int num) { return num * multiplier; };
栈Block常用于封装一段需要访问外部局部变量的代码,并作为参数传递给其他函数或方法。
2. 堆Block(NSMallocBlock):堆block在堆上分配内存,用于存储在block作用域内创建的对象。
堆block的生命周期与程序的生命周期相同,直到程序退出才会被释放。
3. 全局Block(Global Block):全局block是在程序运行时
定义的,可以被多个对象所共享。
全局block不持有任何外部变量,因此在Block内部无法访问外部的局部变量。
全局block的生命周期
与程序的生命周期相同,直到程序退出才会被释放。
全局block的定义方式如下:
^{ // Block内部的代码 }
全局block主要用于一些无需访问外部变量的简单操作,例如对数组进行遍历或对字符串进行处理等。
rcle体系结构简介

Oracle体系结构简介一、数据库(Database)数据库是一个数据的集合,不仅是指物理上的数据,也指物理、存储及进程对象的一个组合。
Oracle是关系型数据库治理系统(RDBMS)。
二、实例(Instance)数据库实例(也称为服务器Server)就是用来访问一个数据库文件集的一个存储结构及后台进程的集合。
它使一个单独的数据库可以被多个实例访问(也就是ORACLE并行服务器-- OPS)。
实例和数据库的关系如下决定实例的组成及大小的参数存储在init.ora文件中。
三、内部结构表、列、数据类型(Table、Column、Datatype)Oracle中是以表的形式存储数据的,它包含若干个列;列是表的属性的描述;列由数据类型和长度组成;Oracle中定义的数据类型主要有CHAR、VARCHAR2、NUMBER、DATE、LONG、LOB、BFILE等,具体的数据类型情况将在本栏目的相关文档中具体介绍。
约束条件(Constraint)表中以及表间可以存在一些数据上的逻辑关系、限制,也就是约束。
Oracle中的约束主要有主键(PK)、外键(FK)、检查(CHECK)、唯一性(UNIQUE)等几种;拥有约束的表中每条数据均必须符合约束条件。
抽象数据类型(Abstract Datatype)可以利用CREATE TYPE命令创建自定义的抽象数据类型。
分区(Partition)可以利用分区将大表分隔成若干个小的存储单元,逻辑上仍然是一个完整的独立单一实体,以减小访问时数据的查找量,提高访问、存储效率用户(User)用户不是一个物理结构,但是它与数据库的对象拥有非常重要的关系--用户拥有数据库对象,以及对象的使用权。
模式(Schema)用户帐号拥有的对象集合称为模式。
索引(Index)数据库中每行记录的物理位置并不重要,Oracle为每条记录用一个ROWID来标识,ROWID记录了记录的准确位置。
索引是供用户快速查找到记录的数据库结构。
yaffs2 结构 -回复

yaffs2 结构-回复YAFFS2 结构YAFFS2(Yet Another Flash File System 2)是一种用于嵌入式系统的文件系统,特别适用于闪存设备。
它的灵感来自于早期的YAFFS文件系统,但在架构和功能上有所改进。
YAFFS2提供了高效的数据存储和管理方式,使闪存设备在读写操作方面更加稳定和可靠。
YAFFS2的主要结构包括:块(Block)、页(Page)、幸存页(Spare Page)和节点(Node)。
首先,让我们从块开始。
块是YAFFS2中最小的存储单元,它由连续的页组成。
每个块的大小通常为128KB或256KB。
闪存设备的数据存储是以块为单位进行的,这意味着当我们需要存储一个文件或一个数据块时,实际上是将其存储到一个或多个连续的块中。
在每个块中,数据被分为多个页。
每个页的大小通常为2KB或4KB。
这样的设计使得YAFFS2能够更高效地进行读写操作,因为闪存设备的读写速度是以页为单位的。
幸存页是指在每个块中用于存储元数据的页。
元数据包括节点、标志位、CRC等信息。
幸存页的存在使得YAFFS2能够更好地管理闪存设备的使用情况,并使得数据的读写更加可靠。
最后,我们来看一下节点。
节点对于YAFFS2来说非常重要,它是文件系统中的基本单位。
每个节点对应着一个文件或目录。
节点存储了文件的元数据,如文件名、文件大小、文件权限等。
除此之外,节点还存储了指向文件数据在闪存设备上位置的指针。
通过以上的结构,YAFFS2实现了对闪存设备的高效管理和读写。
当我们在闪存设备上创建一个文件时,YAFFS2会为该文件创建一个对应的节点,并将其相关信息存储在该节点中。
当我们写入数据时,YAFFS2将数据分为页,并将这些页存储在连续的块中。
为了保证数据的完整性,YAFFS2还会计算并存储CRC等校验信息。
在读取数据时,YAFFS2会通过节点找到数据的位置,并将其读取到应用程序中。
此外,YAFFS2还具备一些高级功能,如快照(Snapshot)和压缩(Compression)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LRBA: [0x0.0.0] LSCN: [0x0.0] HSCN: [0xffff.ffffffff] HSUB: [1]
Block dump from disk:
buffer tsn: 7 rdba: 0x01800087 (6/135)
scn: 0x0000.0015a3eb seq: 0x01 flg: 0x06 tail: 0xa3eb0601frmt: 0x02 chkval: 0xec19 type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x00002B70E9566A00 to 0x00002B70E9568A00
2B70E9566A00 0000A206 01800087 0015A3EB 06010000 [................]
2B70E9566A10 0000EC19 00000001 00012CBB 0015A3EA [.........,......]
2B70E9566A20 00000000 0032F802 01800080 000F0004 [......2.........]
2B70E9566A30 00000346 00C00793 002200BB 00002001 [F.........".. ..]
2B70E9566A40 0015A3EB 00000000 00000000 00000000 [................]
2B70E9566A50 00000000 00000000 00000000 00000000 [................]
2B70E9566A60 00000000 00010100 0014FFFF 1F781F8C [..............x.]
2B70E9566A70 00001F78 1F8C0001 00000000 00000000 [x...............]
2B70E9566A80 00000000 00000000 00000000 00000000 [................] Repeat 502 times
2B70E95689F0 0202012C 410502C1 41414141 A3EB0601 [,......AAAAA....] 1.数据块头
Block header dump: 0x01800087
Object id on Block? Y
seg/obj: 0x12cbbcsc: 0x00.15a3eaitc: 2flg: Etyp: 1 - DATA
brn: 0 bdba: 0x1800080 ver: 0x01 opc: 0
inc: 0 exflg: 0
seg/obj: 0x12cbb --16进制转成10进制76987
SQL> select object_id from dba_objects where object_name='T1' and wner='GYJ';
OBJECT_ID
----------
76987
csc: 0x00.15a3ea --cleanoutSCN,块清除时的SCN
itc: 2 --指向第二个事务槽
flg: E --指用的是ASSM,如果是O表示用的是free list
typ: 1 - DATA --类型是数据
2.事务槽
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0004.00f.00000346 0x00c00793.00bb.22 --U- 1 fsc 0x0000.0015a3eb
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
Itl: ITL事务槽号的流水编号
Xid:transac[X]tion identified(事务ID),由und的段号+undo的槽号+undo槽号的覆盖次数三部分组成Uba:undo block address记录了最近一次的该记录的前镜像(修改前的值)
Flag:C是提交,U是快速提交,---是未提交
Lck:锁住了几行数据,对应有几个行锁
Scn/Fsc:Scn=SCN of commited TX; Fsc=Free space credit(bytes)
这里fsc 0x0000.0015a3eb是指提交的scn,这个值大于上次清除块时的scn=csc: 0x00.15a3ea(此scn是这个块中最小的SCN of commited)
3.用户数据头
bdba: 0x01800087
data_block_dump,data header at 0x2b70e9566a64
===============
tsiz: 0x1f98
hsiz: 0x14
pbl: 0x2b70e9566a64
76543210
flag=--------
ntab=1
nrow=1
frre=-1
fsbo=0x14
fseo=0x1f8c
avsp=0x1f78
tosp=0x1f78
0xe:pti[0] nrow=1 ffs=0
0x12:pri[0] ffs=0x1f8c
bdba: 0x01800087 --数据块的地址:16进制转成2进制取前10位二进制为文件号0000 0001 1000 ..... 0000000110=5号文件,后面剩于的部分表示块号,0X87转成10进制为135号块
tsiz: 0x1f98 --top of size块的总大小即8088个字节
fb: (Flag byte)--H-FL指H(Head piece of row)F(First data piece) L(Last data piece)
lb: 0x1 --Lock byte和上面的ITL的lck相对应,表示这行是否被lock了
cc: 2 --表示有两列,即这个表有两个字段
col 0: [ 2]c1 02--第一行的第一个字段长度和值
col 1: [ 5]41 41 41 41 41--第一行的第二个字段长度和值
把字符转成16进制
SQL> select * from t1;
ID NAME
------ ---- -----
1 AAAAA
SQL> select dump(01,'16') from dual;
DUMP(01,'16')
-----------------
Typ=2 Len=2: c1,2
SQL> select dump('AAAAA','16') from dual;
DUMP('AAAAA','16')
----------------------------
Typ=96 Len=5: 41,41,41,41,41
反过来把16进制转成字符
SQL> select chr(to_number(substr(replace('41 41 41 41 41',' '),2*rownum-1,2),'xxxxxxxx')) from dba_objects where rownum<=5;
CH
--
A
A
A
A
A
不过对数值类型的不能这样转化,要写过比较复杂的过程把各种字符都考虑进去。
数据块的最后四字节tail: 0xa3eb0601=scnBASE+flg+seq,如果不相等会报块损坏!!!scn: 0x0000.0015a3eb seq: 0x01 flg: 0x06。