基于SPSS分析的对云南省人口预测
SPSS1人口的预测分析

用SPSS软件进行预测该立体城市2023年的人口基数的分析可知,其准确性低,却这能预测未来短时间的人口变化,而不能预测十年后的人口数量,因此我们采用最小二乘法您合并采用MATLAB 软件得出了该立体城市2023年的人口基数为3690万(包括外来人口)GDP达58500亿元;交叉相关性序列对:带有 V1 的北京滞后交叉相关标准误差a-10 -.239 .707-9 -.338 .577-8 -.287 .500-7 .024 .447-6 .161 .408-5 .171 .378-4 .566 .354-3 .968 .333-2 .551 .354-1 .287 .3780 .257 .4081 -.028 .4472 -.233 .5003 -.253 .5774 -.307 .7075 .000 .0006 .000 .0007 .000 .0008 .000 .0009 .000 .00010 .000 .000a. 基于以下假设:序列不具有交叉相关性,并且其中一个序列是白噪音。
以下是用MATLAB 做进行运算的程序;function f=fun1(a,t)f=exp(a(1)*x+a(2));t=2004:1:2013;x=[1356 4095 6060 4283 7720 13698 11865.9 13777.94 17801 19500.6]; plot(t,x,'*',t,x);a0=[0.001,1];a=curvefit('fun1',a0,t,x)ti=1790:5:2020;xi=fun1(a,ti);hold onplot(ti,xi);t1=2010;x1=fun1(a,t1)hold off图如下;空气污染指数为0-50,空气质量级别为I 级,空气质量状况属于优。
此时不存在空气污染问题,对公众的健康没有任何危害。
空气污染指数为51-100,空气质量级别为Ⅱ级,空气质量状况属于良。
《统计软件SPSS》考查试题库

1.请使用SPSS计算21名从事某作业工人的血红蛋白量(g%)的均数、标准差、标准误、最大值、最小值、全距、几何均数。
数据如下:14.8 15.4 13.7 14.1 14.4 15.3 14.2 14.8 14.9 12.8 15.6 15.9 14.7 14.4 13.7 15.4 16.4 12.5 17.0 14.4 14.42.试用SPSS对下述数据进行正态性检验。
50例链球菌咽峡炎患者的潜伏期频数分布表潜伏期(小时)12~24~36~48~60~72~84~96~108~120病例数 1 7 11 11 7 5 4 2 2⑴把上述数据库文件转换成SPSS的数据文件;⑵生成两个新变量:理论课成绩:其值为主观和客观考试成绩之和,格式为整数;总评成绩:其值为理论成绩70%+实验课成绩30%,格式为小数点后保留一位;4.将钩端螺旋体病人的血清分别用标准株和水生株作凝溶试验,测得稀释倍数如下,问两组的平均效价有无差别?标准株(11人):100 200 400 400 400 400 800 1600 1600 1600 3200水生株( 9人):100 100 100 200 200 200 200 400 4005.52例麻疹患者恢复期血清麻疹病毒特异性1gG荧光抗体滴度的频数分布如下,求平均抗体滴度。
抗体滴度1:40 1:80 1:160 1:320 1:640 1:1280例数 3 2 17 19 0 16.A、B两因素伴随3H-TdR掺入对K562细胞抑制情况的试验结果如下表,相对抑制值越大,表明抑制能力越强。
试进行分析。
A:氧浓度重复试验编号B(药物)B1 B2 B3 B4A1(含氧3%) 1 0.31 0.46 0.29 0.492 0.18 0.39 0.18 0.513 0.12 0.40 0.12 0.624 0.13 0.34 0.13 0.53A2(含氧20%) 1 0.29 0.65 0.87 0.742 0.27 0.84 0.39 0.783 0.29 0.45 0.57 1.454 0.28 0.63 0.64 1.417.某医师研究A、B和C三种药物治疗肝炎的效果,将32只大白鼠感染肝炎后,按性别相同、体重接近的条件配成8个配伍组,然后将各配伍组中4只大白鼠随机分配到各组:对照组不给药物,其余三组分别给予A、B和C药物治疗。
基于GIS的云南省人口空间分布研究

Study on Spatial Distribution of Population in Yunnan Province Based on GIS 作者: 魏康洪;陈晓平;殷亮
作者机构: 云南大学资源环境与地球科学学院,云南昆明650091
出版物刊名: 绵阳师范学院学报
页码: 96-105页
年卷期: 2016年 第11期
主题词: 人口密度 地统计 GIS 云南省
摘要:为了解云南省2000-2010年人口空间变化的动态特征,以及量化人口在空间和数量上分布的不均衡性.文章利用2000年和2010年云南省各县级行政单元的人口密度数据,借助Arc GIS地统计学的方法对人口密度数据作探索性数据分析.结果表明,近十年间人口密度的空间分布均为高狭峰型正偏态分布;人口密度趋势自西向东呈增加趋势,人口密度在南北向的空间分布格局中表现为中部高,南北低;通过交叉验证法得到研究区域的人口密度空间分布的最优拟合模型;对数克里格法插值图结果显示人口密度分布不均匀,空间分布格局划分明显;基于人口密度分级及各人口密度分布等级区域的差异研究表明,整体人口密度呈增加趋势,人口空间分布有向东部、南部扩展延伸的趋向,云南近1/3的人口集中分布于不到1/10的国土面积上,接近2/3的国土面积上居住不到1/3的人口,揭示了云南省人口分布的不均衡性空间规律.。
spss人口预测-二次函数模型预测
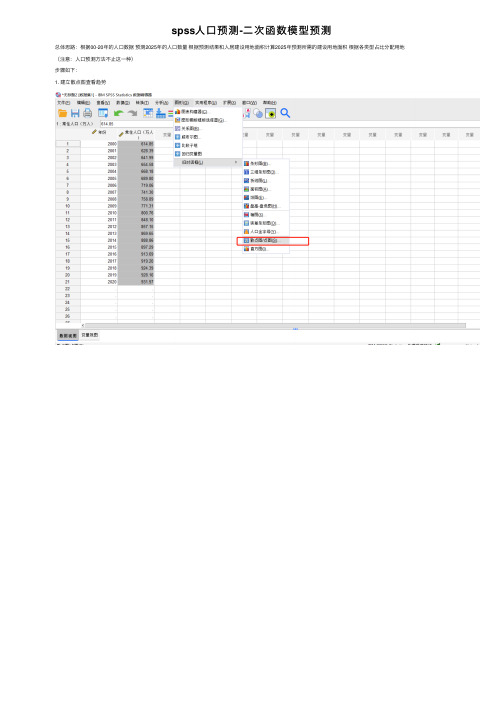
2. 用曲线估算预测
3.根据曲线估算结果,决定采用二次函数模型,
4.根据列表,列出数学公式
5.根据人均建设用地占地面积计算 建设用地需求总量
6.根据比例计算各类型的建设用地所需面积
end 。
网络错误3请刷新页面重试持续报错请尝试更换浏览器或网络环境
spss人口预测 -二次函数模型预测
总体思路:根据00-20年的人口数据 预测2025年的人口数量 根据预测结果和人居建设用地面积计算2025年预测所需的建设用地面积 根据各类型占比分配用地 (注意:人口预测方法不止这一种) 步骤如下: 1. 建立散点图查看趋势
基于VAR模型的云南省人口城市化与经济增长的关联性研究

基于VAR模型的云南省人口城市化与经济增长的关联性研究【摘要】本研究基于VAR模型,探讨了云南省人口城市化与经济增长的关联性。
首先介绍了VAR模型的原理,然后分析了云南省人口城市化和经济增长的现状。
接着讨论了VAR模型在人口城市化和经济增长关联性研究中的应用,并进行了关联性分析。
通过VAR模型对云南省人口城市化与经济增长进行了预测。
研究发现,人口城市化水平的提高对经济增长有积极影响,同时经济增长也推动了人口城市化的进程。
最后总结了研究成果,并展望了未来的研究方向。
通过本研究的深入分析,可以为云南省的经济发展和城市化进程提供重要参考依据和决策支持。
【关键词】VAR模型、云南省、人口城市化、经济增长、关联性研究、研究背景、研究意义、现状分析、应用、关联性分析、预测、研究成果总结、研究展望1. 引言1.1 研究背景在当今快速发展的经济社会环境下,人口城市化和经济增长问题一直备受关注。
作为中国西南地区的重要省份,云南省一直以其独特的区位优势和丰富的资源禀赋吸引着众多投资者和移民。
随着城市化进程的不断推进,云南省的经济也取得了长足的发展。
人口城市化和经济增长之间的关联性及相互影响依然有待深入研究。
通过对云南省人口城市化与经济增长之间的关联性开展研究,可以更好地了解城市化进程对经济发展的影响,找出云南省在城市化和经济增长中存在的问题和矛盾,为相关部门提供科学的决策建议。
本研究将运用VAR模型对云南省人口城市化和经济增长之间的关联性进行深入分析,探讨二者之间的内在联系,为推动云南省经济可持续发展提供理论支撑和实践指导。
1.2 研究意义本研究的重要意义主要包括以下几个方面:云南省是我国西南地区重要的经济和人口聚集地,其人口城市化进程与经济增长密切相关。
通过对云南省人口城市化和经济增长之间的关联性进行研究,可以帮助政府部门更好地制定人口政策和城市规划,推动经济发展。
VAR模型是一种有效的多变量时间序列分析方法,可以用于揭示人口城市化和经济增长之间的动态关系。
Logistic人口预测模型的SPSS拟合方法分析

Logistic人口预测模型的SPSS拟合方法分析【摘要】本研究以Logistic人口预测模型为基础,采用SPSS软件进行拟合方法分析。
在对背景、研究意义和研究目的进行了介绍。
正文部分包括Logistic回归分析原理、SPSS在人口预测模型中的应用、数据收集与处理、模型拟合及结果解读以及模型评价与优化。
结论部分强调了SPSS软件在人口预测模型中的重要性,讨论了模型的预测能力和局限性,并展望了未来研究方向。
通过本研究,可以更深入了解Logistic人口预测模型的拟合方法,为人口预测领域提供参考和启示。
【关键词】Logistic人口预测模型、SPSS拟合方法分析、Logistic回归分析、数据收集与处理、模型拟合、结果解读、模型评价、模型优化、SPSS软件、预测能力、局限性、未来研究展望1. 引言1.1 背景介绍【Logistic人口预测模型的SPSS拟合方法分析】Logistic人口预测模型是一种基于Logistic函数的统计模型,常用于解决二分类问题。
在人口预测领域,Logistic人口预测模型可以帮助研究人员根据已有的人口数据,预测未来的人口分布和趋势。
通过对人口的特征和影响因素进行分析,Logistic回归可以帮助我们理解人口变化的规律和趋势。
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于社会科学研究、商业决策等领域。
在人口预测模型中,SPSS提供了强大的数据分析和建模工具,可以帮助研究人员构建Logistic人口预测模型,并进行模型拟合、预测和评估。
本文旨在探讨Logistic人口预测模型在SPSS软件中的拟合方法和分析过程。
通过对Logistic回归的原理和SPSS软件的应用进行介绍,帮助读者了解如何利用SPSS进行人口预测模型的建模和分析。
我们将会对数据的收集与处理、模型的拟合与结果解读、模型的评价与优化等方面进行深入探讨,最终总结出SPSS在人口预测模型中的重要性,以及模型的预测能力及局限性。
SPSS数据分析我国各省城镇和农村居民人均收入数据分析

SPSS数据分析我国各省城镇和农村居民人均收入数据分析SPSS(Statistical Package for the Social Sciences)是一种用于数据分析和统计的软件。
在本次数据分析中,我们将使用SPSS来分析我国各省城镇和农村居民的人均收入数据。
首先,我们需要准备好要分析的数据集。
该数据集应包含各省城镇和农村居民的人均收入数据,并按省份进行分类。
接下来,我们将通过使用SPSS来执行一些统计分析和可视化方法。
首先,我们可以计算出我国各省城镇和农村居民的人均收入的平均值、中位数和标准差等统计指标。
对于这些统计指标,我们可以使用SPSS的描述性统计功能。
通过选择“统计”菜单下的“描述性统计”选项,我们可以指定要计算的统计指标和变量。
在这个案例中,我们选择人均收入作为变量,并勾选“平均值”、“中位数”和“标准差”等选项。
运行之后,SPSS将输出各省城镇和农村居民的人均收入的平均值、中位数和标准差。
接下来,我们可以使用SPSS的相关性分析功能来探索我国各省城镇和农村居民人均收入之间的关系。
相关性分析可以用于确定两个变量之间的相关程度。
通过选择“分析”菜单下的“相关”选项,我们可以指定要进行相关性分析的变量。
在这个案例中,我们选择城镇和农村居民人均收入作为变量。
运行之后,SPSS将输出相关系数和p值,用于确定城镇和农村居民人均收入之间的相关关系。
除了通过统计指标和相关性分析来了解数据之外,我们还可以使用SPSS的可视化功能来更好地理解数据。
通过选择“图表”菜单下的“散点图”选项,我们可以生成城镇和农村居民人均收入的散点图。
这将帮助我们看到城镇和农村居民人均收入之间的分布情况,并可能发现一些趋势或异常值。
最后,在我们完成了数据分析后,我们可以使用SPSS的报告功能来生成一个简单的报告,概述我们的分析结果和发现。
通过选择“报告”菜单下的“自动报告”选项,我们可以选择生成的报告样式和内容。
在这个案例中,我们可以包括统计指标和相关系数的结果,以及散点图的图像。
人口数量spss线性回归模型建模步骤

人口数量spss线性回归模型建模步骤线性模式
线性模式不仅处理线性问题,主要是处理线性化的非线性模型:
线性模式是简单的比例关系,要求各个自变量彼此独立,才能利用最小二乘技术求线性模型的参数;而非线性则是对简单比例关系的偏离,各变量相互作用。
指数模型、对数模型、幂指数模型、双曲线模型、抛物线模型、正态分布模型等常用的非线性数学模型,也可以借助不数变换或者是变量替换表示为线性函数形式:此次实验主要利用线性
函数、指数函数、双曲线函数和Logistic增长函数的线性化模型预
测中国人口。
开展一般的回归分析,首先要作散点图(scatterplot),然后选择表达式,最后采用适当的拟合方法。
预测结果不能出现违背基本逻辑的结论,同时预测结果要有现实意义。
云南省人口预测及合理容量研究

云南社会主义学院学报 2012年第5期 NO.5,2012云南社会主义学院学报JO U R N A L O F Y U N N A N I N S T I T U T E O F S O C I A L I S M 288云南省人口预测及合理容量研究陈 宇(云南师范大学 数学学院,云南 昆明 650500)摘 要:随着第六次全国人口普查数据陆续公布,云南省人口数量呈现出什么样的规律性,如何预测未来人口总数及合理人口容量,对云南省能否科学实施城镇化、顺利实现小康等具有重要意义。
本文以历年中国及云南省人口统计数据为基础,在对女性生育率、死亡率、年龄结构、男女比例等影响人口增长的因素对比和分析,分别采用Leslie 人口预测模型和经济适度人口模型来预测云南省未来人口总数及人口的合理容量,预测未来30年内云南省人口总数将达到5550万人,人口合理容量5680万人。
关键词:人口预测;城镇化;合理容量()()t LX t X =+1其中L 为Leslie 矩阵;n 为人口按年龄划分级别数;s i (t )表示第t 年第i 年龄级上个体存活率;f i (t )表示第t 年第i 年龄级上的妇女生育率。
令 ()()t w t b f i i i =;w i (t )表示第t 年时第i 年龄级上女性人口比例;b i (t )表示第t 年时第i 年龄级上出生率。
得到Leslie 人口预测模型。
则人口预测模型的矩阵简化为:⎟⎟⎟⎟⎟⎟⎠⎞⎜⎜⎜⎜⎜⎜⎝⎛=−−000000000001211321n n n s s s f f f f f L LM M M M M M L L L 0根据Leslie 人口预测模型 ()()t LX t X =+1,得 第一个分量(0-14岁人口)()()()()t x b w t x b w t x b w t x n n n +++=+L 11100001,第二个分量(15-19岁人口) ()()t x s t x 0011=+,……, 第n 个分量(60岁以上人口) ()()t x s t x n n n 111−−=+, 从而可算出2011年各年龄段的人口总数,利用matlab 软件可推算出2015到2040各年的人口总数。
基于时间序列分析的云南省人口数量模型

2. 文献综述
人口问题是一个世界性问题,这影响到社会的方方面面,从而对人口的有效预测也就成了一个非常 重要的问题。田飞[1]对人口预测的方法体系进行的研究,总结出人口预测模型发展的历程:较早期的模 型有指数增长模型、 Logistic 模型和线性回归模型, 随着模糊数学和统计学的发展出现了灰色系统 GM (1,1) 模型和时间序列模型,而生物医学和计算机的发展为此带来了神经网络算法[2],这些算法各有优缺点, 在模型的选取上应该结合不同数据的特点选择合适的模型。 人口的预测模型应结合当地人口发展的特点来选取。云南省的人口特点除了包含当期人口规模受前 期人口影响较大这个几乎所有人口都有的特点以外,还呈现接近线性方式增长的特点,第一个适用于 ARIMA 模型,第二个适用于线性趋势模型。这两个模型应该都十分广泛,其中第二个模型就是普通的以 时间序号为自变量的一元线性模型,易于理解不做过多介绍。 时间序列模型在分析前期对当期有影响的数据时具有非常广泛的应用。如李子奈等[3]使用时间序列 模型分析和预测了我国的通货膨胀情况,结果表明时间序列模型的精度高。张松林等[4]使用时间序列模 型分析我国的城市化水平,并给出高精确度的预测结果;唐毅[5]在传统时间序列模型的基础上,从样本 序列的动态选取及模型识别两方面进行优化,提出了一种能动态调整模型参数的改进时间序列模型。而 在近两年的研究中,时间序列的应用有了更广泛的实际应用,如王莉等[6]使用时间序列模型结合残差控 制图分析了兰州市的空气质量指数,证实了将时间序列模型与残差控制图结合预测监控大气污染的有效 性。刘自强等[7]运用关键词群分析、社会网络分析和时间序列模型分析预测其研究热点的发展趋势,结 果表明该方法的有效性。这也进一步表明了传统的时间序列模型与新方法的结合能有效克服传统时间序 列模型缺陷,有效解决时代发展的新问题。
基于GIS的云南省人口空间分布研究

0 引 言
人 口分 布是 指 人 E l 过程 在 地理 空 间 的表 现 形式 及其 发 展演 变 情况 J , 然而 , 研究 区域人 口分 布格 局 的 空间性 、 认 识其 时空 演变 机制 和揭 示 其 规 律 性 , 将 有 力 地促 进 人 口、 资源、 环 境 与 社 会 经 济 的协 调 健 康 发 展 .有关 云南 省人 口分 布方 面 的研 究 : 何 明 较 早地 分析 了 昆明地 区城 市化 所 引起 的人 V 1 分 布 的 阶段 性 变 化特 点 ; 曹彦 波等 基 于 多源数 据 分析 了云 南 省人 口分 布 与地 貌 形 态 、 坡度 、 地 形起 伏 度 以及 土 地 利用
的人 口迁 移路 径 ; 施 本植 等 研 究 了云南 省 人 口分布 的 区域差 异性 ; 曹洪 华 等¨ 。 。 通过 对 云南省 1 2 9个 区县
的人 口集聚度指标值 的数据计算和聚类分析 , 诠释和分析 了云南人 口分布状况 .陈璇璇等 ¨ 认为云南省 人 口分布的差异性与资源概况、 地理环境条件以及经济水平等是否形成 良好 的有机组合密切相关 .
第3 5 卷 第 l 1 期 2 0 1 6年 1 1月
绵 阳师范学院学报
J o u r n M o f Mi a n y a n g T e a c h e r s ’C o l l e g e
V0 1 . 3 5 No .1 1 No v ., 201 6
基 于 GI S的 云 南 省 人 口空 间分 布 研 究
第1 1 期
研 究 区域概 况及 数 据 来 源
1 . 1 研 究 区域 概况
பைடு நூலகம்
云南 省地 处 中国西 南边 陲 , 北 接 四川 、 西频 西藏 、 东 与广 西 和 贵州 毗邻 、 南 部 与缅 甸 、 老 挝 和越 南 接壤 ,
人口预测中线性回归分析简单步骤

人口预测中线性回归分析简单步骤:
一、进行回归分析
SPSS-regression-linear
Dependent ——因变量这里应该为人口
Independent ——自变量这里可以为年份,也可以为GDP或其他认为可以引起人口变动的自变量
用箭头添加到相应的框中,然后点击ok,生成结果。
二、结果检验
Model Summary
a Predictors: (Constant), V1
R2=0.11,模型拟合效果不好(此数应该越接近1越好,如果在0.7以上均可认为模型拟合效果较好)
ANOVA(b)
a Predictors: (Constant), V1
b Dependent Variable: V2
sig=0.771,模型线性特征不显著(如果该值小于0.05,可认为线性关系较为显著)
Coefficients(a)
a Dependent Variable: V2
每个参数的sig分别为0.772和0.771,表示参数也不显著(如果该值小于0.05,可认为线性关系较为显著)
列出的一元一次方程为y=88.709x-176626.982。
将x=??带入方程,得到y=??,则??年人口为??。
但由于未通过显著性检验,模型拟合效果也不好,所以该方法预测的结果应当去掉。
(这里如果前面的拟合度和显著性检验效果均较好的话,就应当保留该方法预测的结果。
基于SPSS的社会调查数据分析与预测

基于SPSS的社会调查数据分析与预测社会调查是一项非常重要的研究方法,它可以用来了解人们对特定话题的看法、态度、习惯和行为等信息,并通过对这些信息进行分析和解读来提供有益的洞察和预测。
SPSS(统计分析系统)则是一款功能强大的统计分析软件,它被广泛应用于社会科学、商业、教育和公共卫生等领域,被许多研究人员和学生用来进行定量分析和数据可视化。
在本文中,我将探讨如何使用SPSS进行社会调查数据的分析和预测。
一、数据预处理在进行数据分析之前,需要先进行数据预处理,包括数据清洗、变量选择和缺失数据处理等。
数据清洗是指在数据集中删除或修复错误或不完整的数据。
变量选择则是指选择对分析目标最具影响力的变量。
缺失数据处理则是指使用填充值、插值或删除等方法来处理缺失数据。
二、描述性分析描述性分析是指对数据集中每个变量的分布和分散进行描述和汇总。
其中,中心趋势和离散程度是描述一个数据集的重要统计量。
中心趋势包括平均值、中位数和众数等,而离散程度则包括方差、标准偏差和范围等。
此外,还可以计算每个变量的简单频数和百分比来了解每种回答选项的相对比例。
三、相关性分析相关性分析是指检验不同变量之间是否存在相关性的统计方法。
在SPSS中,可以用相关矩阵或散点图来分析两个变量之间的相关性。
此外,还可以通过克拉姆的V系数来衡量两个分类变量之间的关联程度。
四、回归分析回归分析是指通过建立一个线性或非线性模型来预测因变量与自变量之间的关系。
在SPSS中,可以使用多元回归分析来预测因变量的取值,同时考虑多个自变量之间的相互作用和影响。
在回归建模之前,需要对数据进行变换或调整,以使其符合线性回归的前提条件,例如正态分布、同方差性和线性相关性。
五、因子分析因子分析是指对数据集中的多个变量进行分类,以确定哪些变量对同一概念或构念具有类似的影响力。
在SPSS中,可以使用因子分析来缩减变量的数量,同时识别可能存在的潜在因素或维度。
因子分析的结果可以帮助研究人员了解调查数据中存在的复合概念或潜在动机。
基于SPSS分析的对云南省人口预测

云南大学滇池学院 经济学院经济学专业2014~2015学年SPSS 应用统计软件实验论文基于spss 分析的云南省人口预测模型摘要本文利用云南省2011年统计年鉴中云南总人口数的历史数据,借助统计软件SPSS 分别建立了线性回归模型和Logistic 人口模型,根据模型首先对云南省2008—2009年总人口数进行了预测,并与实际值进行了对比,结果显示模型拟合效果很好,然后运用模型对2012—2014年云南省总人口数进行了预测,两个模型得到的预测结果分别为(10192.27,10252.615,10312.96)和(10007.86,10058.41,10120.73),最后结合预测结果对云南省人口增长和经济建设协调发展提出建议。
关键字:线性回归 Logistic 人口模型 协调发展AbstractIn this paper, the use of historical data Yunnan 2011 Statistical Yearbook of the total population in Yunnan, with the statistical software SPSS linear regression models were established and Logistic population model, the first of a total population of Yunnan Province in 2008-2009 were predicted based on models and values were compared with the actual results show that the model works well fitted, and then use the model of the total population in Yunnan Province in 2012-2014 were predicted, predicted results were obtained in two models (10192.27,10252.615,10312.96) and(10007.86,10058.41,10120.73), the final results of the combined forecasts of population growth and economic development of Yunnan coordinated development proposals.Keywords: Logistic regression model for the coordinated development of population 一、问题的提出云南是少数民族的重要集聚地,自古以来人口密集。
云南省人口预测及合理容量研究
云南社会主义学院学报 2012年第5期 NO.5,2012云南社会主义学院学报JO U R N A L O F Y U N N A N I N S T I T U T E O F S O C I A L I S M 288云南省人口预测及合理容量研究陈 宇(云南师范大学 数学学院,云南 昆明 650500)摘 要:随着第六次全国人口普查数据陆续公布,云南省人口数量呈现出什么样的规律性,如何预测未来人口总数及合理人口容量,对云南省能否科学实施城镇化、顺利实现小康等具有重要意义。
本文以历年中国及云南省人口统计数据为基础,在对女性生育率、死亡率、年龄结构、男女比例等影响人口增长的因素对比和分析,分别采用Leslie 人口预测模型和经济适度人口模型来预测云南省未来人口总数及人口的合理容量,预测未来30年内云南省人口总数将达到5550万人,人口合理容量5680万人。
关键词:人口预测;城镇化;合理容量()()t LX t X =+1其中L 为Leslie 矩阵;n 为人口按年龄划分级别数;s i (t )表示第t 年第i 年龄级上个体存活率;f i (t )表示第t 年第i 年龄级上的妇女生育率。
令 ()()t w t b f i i i =;w i (t )表示第t 年时第i 年龄级上女性人口比例;b i (t )表示第t 年时第i 年龄级上出生率。
得到Leslie 人口预测模型。
则人口预测模型的矩阵简化为:⎟⎟⎟⎟⎟⎟⎠⎞⎜⎜⎜⎜⎜⎜⎝⎛=−−000000000001211321n n n s s s f f f f f L LM M M M M M L L L 0根据Leslie 人口预测模型 ()()t LX t X =+1,得 第一个分量(0-14岁人口)()()()()t x b w t x b w t x b w t x n n n +++=+L 11100001,第二个分量(15-19岁人口) ()()t x s t x 0011=+,……, 第n 个分量(60岁以上人口) ()()t x s t x n n n 111−−=+, 从而可算出2011年各年龄段的人口总数,利用matlab 软件可推算出2015到2040各年的人口总数。
SPSS1人口的预测分析
用SPSS软件进行预测该立体城市2023年的人口基数的分析可知,其准确性低,却这能预测未来短时间的人口变化,而不能预测十年后的人口数量,因此我们采用最小二乘法您合并采用MATLAB 软件得出了该立体城市2023年的人口基数为3690万(包括外来人口)GDP达58500亿元;交叉相关性序列对:带有 V1 的北京滞后交叉相关标准误差a-10 -.239 .707-9 -.338 .577-8 -.287 .500-7 .024 .447-6 .161 .408-5 .171 .378-4 .566 .354-3 .968 .333-2 .551 .354-1 .287 .3780 .257 .4081 -.028 .4472 -.233 .5003 -.253 .5774 -.307 .7075 .000 .0006 .000 .0007 .000 .0008 .000 .0009 .000 .00010 .000 .000a. 基于以下假设:序列不具有交叉相关性,并且其中一个序列是白噪音。
以下是用MATLAB 做进行运算的程序;function f=fun1(a,t)f=exp(a(1)*x+a(2));t=2004:1:2013;x=[1356 4095 6060 4283 7720 13698 11865.9 13777.94 17801 19500.6]; plot(t,x,'*',t,x);a0=[0.001,1];a=curvefit('fun1',a0,t,x)ti=1790:5:2020;xi=fun1(a,ti);hold onplot(ti,xi);t1=2010;x1=fun1(a,t1)hold off图如下;空气污染指数为0-50,空气质量级别为I 级,空气质量状况属于优。
此时不存在空气污染问题,对公众的健康没有任何危害。
空气污染指数为51-100,空气质量级别为Ⅱ级,空气质量状况属于良。
利用SPSS拟合非线性回归模型

利用SPSS拟合非线性回归模型——以S型曲线为例1.原始数据下表给出了某地区1971—2000年的人口数据(表1)。
试用SPSS软件对该地区的人口变化进行曲线拟合,并对今后10年的人口发展情况进行预测。
表1 某地区人口变化数据年份时间变量t=年份-1970人口y/人1971133 8151972233 9811973334 0041974434 1651975534 2121976634 3271977734 3441978834 4581979934 49819801034 47619811134 48319821234 48819831334 51319841434 49719851534 51119861634 52019871734 50719881834 50919891934 52119902034 51319912134 51519922234 51719932334 51919942434 51919952534 52119962634 5211997 27 34 523 1998 28 34 525 1999 29 34 525 20003034 527根据上表中的数据,做出散点图,见图1。
,337003380033900340003410034200343003440034500346001970197219741976197819801982198419861988199019921994199619982000年份人口图1 某地区人口随时间变化的散点图从图1可以看出,人口随时间的变化呈非线性过程,而且存在一个与横坐标轴平行的渐近线,近似S 曲线。
下面,我们用SPSS 软件进行非线性回归分析拟合计算。
2.用SPSS 进行回归分析拟合计算在SPSS 中可以直接进行非线性拟合,步骤如下(假定已经进行了数据输入,关于数据输入方法见SPSS 相关基础 教程):Analysis->Regression->Cubic,在弹出的对话框(见图一)中选择拟合的变量和自变量,本例分别选择y (人口),t (时间变量)为变量(Dependent )和自变量(Independent)。
昆明市人口预测模型研究

昆明市人口预测模型研究
龙承星;张波
【期刊名称】《云南民族大学学报(自然科学版)》
【年(卷),期】2011(020)004
【摘要】通过对1949~2000年昆明市人口总量的分析,以及从2000年第5次全国人口普查中昆明市的相关情况,重点考察了昆明市生育状况、死亡状况、年龄和性别状况,找出昆明市人口存在的问题.通过运用马尔萨斯人口模型和Logistic模型以及提出的线性回归模型对昆明市未来10年的人口进行预测,并进行模型之间的比较,进而得出昆明市未来10年人口的发展状况.
【总页数】4页(P258-261)
【作者】龙承星;张波
【作者单位】湖南人文科技学院数学系,湖南娄底417000;云南大学数学与统计学院,云南昆明650091
【正文语种】中文
【中图分类】O212;C921
【相关文献】
1.基于EXCEL建立人口灰色预测模型的研究——以天津市农业人口为例 [J], 常淑玲
2.“村改居”社区流动人口社会融入问题调查研究--以昆明市王家营社区为例 [J], 王艳
3.昆明市业余排球人口调查研究 [J], 华艳玲
4.基于Logistic人口预测模型的内蒙古地区人口发展趋势研究 [J], 提云哲;金良;张文娟;山琦;阿如娜
5.昆明市不同血糖情况孕妇人口统计学特征、孕期保健及围生期结局的比较研究[J], 张燕;杜明钰;王名芳;马润玫;刘琳
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
云南大学滇池学院经济学院经济学专业
2014~2015学年SPSS应用统计软件
实验论文
基于spss分析的云南省人口预测模型
摘要
本文利用云南省2011年统计年鉴中云南总人口数的历史数据,借助统计软件SPSS分别建立了线性回归模型和Logistic人口模型,根据模型首先对云南省2008—2009年总人口数进行了预测,并与实际值进行了对比,结果显示模型拟合效果很好,然后运用模型对2012—2014年云南省总人口数进行了预测,两个模型得到的预测结果分别为(10192.27,10252.615,10312.96)和(10007.86,10058.41,10120.73),最后结合预测结果对云南省人口增长和经济建设协调发展提出建议。
关键字:线性回归 Logistic人口模型协调发展
Abstract
In this paper, the use of historical data Yunnan 2011 Statistical Yearbook of the total population in Yunnan, with the statistical software SPSS linear regression models were established and Logistic population model, the first of a total population of Yunnan Province in 2008-2009 were predicted based on models and values were compared with the actual results show that the model works well fitted, and then use the model of the total population in Yunnan Province in
2012-2014 were predicted, predicted results were obtained in two models (10192.27,10252.615,10312.96) and (10007.86,10058.41,10120.73), the final results of the combined forecasts of population growth and economic development of Yunnan coordinated development proposals.
Keywords: Logistic regression model for the coordinated development of population
一、问题的提出
云南是少数民族的重要集聚地,自古以来人口密集。
新中国成立后人口的增长速度进一步提高。
1953 年第一次人口普查时云南省总人口为4 425万人, 2009 年增加到9 967万人, 2010 年7 月云南的总人口破千万大关,成为我国重要人口增长的省份。
人口是经济发展的基础,但也可能成为经济发展和实现社会和谐的包袱。
改革开放以来,云南省的人口压力不仅始终存在,而且持续增大。
计划生育政策的实施,目前云南人口形势依然不乐观。
解决好人口可持续发展问题,
依然是云南省今后许多年的重点工作之一。
人口是制约经济发展的一个重要因素,如何协调人口发展与经济建设之间的关系,实现中原崛起有着重要的现实意义。
下面将利用云南省2011年统计年鉴中云南总人口数的历史数据,通过建模对2012—2014年云南省总人口数进行预测。
二、模型的基本假设及数据预处理 基本假设:
(1)行政区域保持不变; (2)社会经济平稳发展;
(3)所研究人口为封闭人口(不考虑流动人口);
(4)未来人口的死亡模式不变(不考虑战争、瘟疫及自然灾害等灾难的影响)。
数据的预处理:
由于1958—1978年之间的历史数据不连续,另外由于1978年以来实行家庭联产承包制导致人口快速增加,因此建立模型时没有使用1958—1977年之间的数据。
三、模型的建立与求解 (一)线性回归模型[1] 1、线性回归模型的建立
人口发展的某一短暂时期会呈现线性增长,即每年的自然增长率大致一直,因此可以用一元线性回归模型对未来短期进行人口预测。
一元线性回归模型如下:
()P t a bt =+ (1)
其中t 为年份,()P t 为t 年的人口总数,a 、b 为模型参数。
2、线性回归模型参数的确定
一元线性回归模型的求解比较简单,根据历史数据利用最小二乘法就可以确定a 、b 的值:
()a P t bt =- (2)
22()(())
[(())]
()
[()]
t P t tP t n b t t n
-
=
-∑∑∑∑∑ (3) 其中n 为样本容量,其余与(1)式中一样。
利用附录中云南省历年总人口数据,分别以1988—2007年(20个样本)、1998—2007年(10个样本),借助SPSS 软件拟合出两个个云南省人口一元线性回归模型,结果见表一:
表一:一元线性回归模型
由拟合优度2R 可以看出两个模型都比较好,在此选取模型二对云南省2008—2009年的人口进行预测并与实际值进行比较,结果如表二:(单位:万人)
由上可以看出预测结果比较合理,可以用此模型进行预测,表三为用该模型对云南省2012—2014年人口总数的预测:(单位:万人)
(二)Logistic 人口模型 1、Logistic 人口模型的建立
Logistic 曲线是荷兰生物学家Verhulst 为研究人口发展过程于1837年提出的,Logistic 人口模型考虑到了人口发展的有限性及人口增长规律:随着人口增加,增长率逐渐下降。
因此可以很好的对人口总数进行预测,Logistic 人口模型的一般表达式为:
2()
()()dP t rP t qP t dt
=- (4) 式中q 为约束参数,对上式求解并进行数学变换后得到如下表达式:
()/(1)bt
m P t P ae =+ (5)
式中()P t 为t 年的人口总数,m P 为人口上限,a 、b 为模型参数。
2、模型参数值的确定
P是模型在Logistic 模型的参数求解过程中,合理地确定极限人口规模
m
拟合精度的关键。
从式中可以看出,Logistic 模型有三个参数,普通的回归无法实现数据的拟合。
一个比较简单常用的Logistic模型求解方法是三点法,但是三点法存在模型拟合精度较低的问题。
另一个有效的办法是估计一个初始的人P,将其带入(5)式进行回归分析,然后反复调整Pm值,直到模
口极限规模
m
型的拟合优度接近最大值,如优选法、0.168 搜索法。
根据云南省人口历史数据大致可以确定云南省人口上限在10000—12000万
P=10450时达到最优,输出结果如人之间,利用SPSS软件反复选值拟合,知当
m
下:
上述模型的拟合优度达到99.7%,用模型表达式为:
0.929
()10450/(1 1.957)t
=+(6)
P t e-
利用上述模型,对云南省2008—2009年的人口总数进行预测并与实际值进行对比,结果如表四:
表四:云南省2008—2009年的人口总数预测值与实际值
可以看出,拟合效果很好,用此模型对云南省2012—2014年人口总数进行预测结果如表五:
表五:云南省2012—2014年人口总数预测值
未来二十年是我省人口转变、经济转轨、社会转型的关键时期,为最大限度地利用人口转变带来的人口“红利”和历史机遇,积极应对可能产生的风险和矛盾,促进人口与经济社会协调和可持续发展,为全面建设小康社会、实现中原崛起创造良好的人口环境,就必须积极探索新时期解决人口与发展问题的新思路、新措施。
1.树立“优先投资于人”的新人口发展观
2.确保控制人口的投入规模不断增长
3.进一步完善计划生育管理和服务工作
4.实施人力资源综合开发战略
5.建立和完善利益导向机制
参考文献
[1] 胡科,石培基区域研究中的常用人口预测模型西北人口2009年第1期第30卷
[2] 欧继中,刘殿敏人口增长对经济发展的影响教育学院学报(哲学社会科学版)2006年第3期第25卷
附录。