上海大学875多媒体技术基础考研专业课笔记
最新上海大学计算机专业考研参考科目

2019上海大学计算机专业考研参考科目上海大学是上海市属、国家“211工程”重点建设的综合性大学,国家“双一流”世界一流学科建设高校。
而计算机专业开展与国民经济发展密切相关的计算机科学及应用技术研究。
所以要考上海计算机专业的同学是很明智的选择,本文就来跟大家分享计算机专业考研参考科目。
081200 计算机科学与技术(一)研究方向:1.高性能计算机系统及应用2. 计算机系统结3.并行处理4.容错计算5. 数据库与数据挖掘6.多媒体技术与应用7.计算机网络8.智能信息处理9.信息安全0.系统生物学考试科目:1.101思想政治理论2.201英语一3.301数学一4.832计算机组成原理与数据结构5.C++程序设计、编译原理(复试科目)081200 计算机科学与技术(二)研究方向:1.材料信息与数据科学、材料高通量计算软件考试科目:1.101思想政治理论2.201英语一3.301数学一4.408计算机学科专业基础综合5.复试科目:C++程序设计或编译原理以上就是上海大学计算机专业考研考试科目,你可以到上海大学研究生-招生目录查询。
相信看完的同学对上海大学管理学院个专业考研参考书目有一定的了解了,考研是无场硝烟的战争,希望同学们能够坚持下去取得胜利。
尼采说:“如果这世界上真有奇迹,那只是努力的另一个名字。
生命中最难的阶段不是没有人懂你,而是你不懂你自己。
”不狠一把你都不知道自己的潜力有多大。
只要坚持,胜利的曙光终将属于你。
加油!同时,聚英考研网也将实时更新全国各大高校包括招生简章、招生目录、参考书目、报录比、复试分数线在内的研究生招生信息。
免费提供考研真题资料下载,考研直播课、考研辅导程,以及学长学姐高分经验分享、考研干货等内容,欢迎各位考生加群或者进官网了解。
数字媒体技术专业考研指导
不指定参考书
(02)网络多媒体
三、教育技术专业方向:可以选择数字媒体技术或教育游戏方向或教育影视方向
大学
研究方向
初试科目
复试科目
参考书
南京师范大学
01 视觉文化与信息技术教育
02 教育数据挖掘与智能处理
03 教育游戏与3D建模
①政治
②英语或俄语或日语
③C语言与Web技术
④教学设计或数据结构
(4)数字媒体展示与控制
山东大学
(1)三维建模与渲染
101.思想政治理论
201.英语一
301.数学一
408.计算机学科专业基础综合
不指定参考书
(2)可视媒体计算
(3)数字化艺术与设计
浙江大学
01产品创新技术与系统:
①101政治②201英语01数学(一)④408计算机学科专业基础综合(含数据结构、计算机组成原理、操作系统和计算机网络)
北京师范大学
01教育技术基本理论
02教学设计与绩效技术
03知识媒体
04人工智能教育应用
05信息技术教育
06教育信息管理
07信息技术与课程整合
08数字化学习环境与资源
09职业课程与教学论
华东师范大学
01 教育技术学理论
02 教育测评与信息处理
03 网络远程教育
04 虚拟现实与游戏设计
05 教育培训系统设计
①101政治
②201英语一
③311教育学专业基础综合
复试:①笔试:计算机操作、教育技术学
四川师范大学
01信息化教学资源设计与开发
02教育软件研究与开发
03数字传媒技术与艺术
华南师范大学
上海大学 2013~2014 学年秋季学期研究生专业课课程表
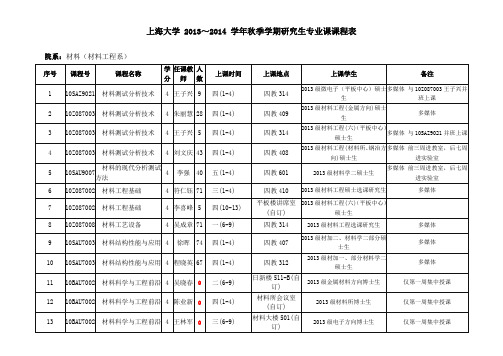
10
10SAU7003
材料结构性能与应用
4
程晓英
67
四(1-4)
四教312
2013级材加一、部分材料学二硕士生
多媒体
11
10BAU7002
材料科学与工程前沿
4
吴晓春
0
二(6-9)
日新楼511-B(自订)
2013级金属材料方向博士生
仅第一周集中授课
12
10BAU7002
材料科学与工程前沿
4
陈业新
多媒体
7
10Z087002
材料工程基础
4
李喜峰
5
四(10-13)
平板楼讲席室(自订)
2013级材料工程(六)(平板中心)硕士生
8
10Z087008
材料工艺设备
4
吴成章
71
一(6-9)
四教314
2013级材料工程选课研究生
多媒体
9
10SAU7003
材料结构性能与应用
4
徐晖
74
四(1-4)
四教407
2013级材加二、材料学二部分硕士生
2
黎军顽
28
四(6-9)
四教407
2013级材料工程(金属方向)硕士生
多媒体 与10SAU7001黎军顽并班上课
43
10SAU7001
专业英语
2
王均安
40
四(6-9)
四教312
2013级材料学二硕士生
多媒体 与10Z087001王均安并班上课
44
10Z087001
专业英语
2
王均安
14
四(6-9)
四教312
网络与新媒体

这个专业的学生,将来可以在各级党政机关、部队、院校、企业等场合从事络新闻宣传、媒介传 播优化等工作。他们可以在国家重点新闻站、各级报社、广播电台、电视台、传媒集团等单位的 信息化管理宣传部门、文化传播公司等机构从事媒介内容生产以及媒介经营管理等工作。他们的 职业道路充满了可能,从最初级的新闻编辑到最高级别的决策者,都有他们的身影。
培养目标
络与新媒体专业是适应社会的需求而设立的,综合性和交叉性为其特色,是“文”和“理”的结 合、艺术与技术的结合、络技术与数字媒体的结合。 专业旨在培养适应传统媒体机构、政府机 关、事业单位、公司等团体组织急需的宽口径、复合型信息传播人才。 教育教学应坚持以马克 思主义为指导,培养学生具有坚定正确的政治方向,以国家政治、经济和文化建设发展需求为基 本原则,以中国高等教育定位和特点为参考框架,同时以行业标准和社会需求为导向,培养坚持 马克思主义新闻观,坚持正确政治立场和方向,具有全媒体新闻传播知识和能力的应用型、复合 型、创新型人才,以及具有全球视野和跨文化传播能力的国际新闻传播人才。
各高校根据自身特点以及师资情况,结合专业教学目标和任务,在课程设置中,应包括页设计与 制作、数字多媒体作品创作、非线性编辑、融合新闻作品创作、新媒体数据分析与应用、新媒体 产品设计与项目管理等。
《多媒体技术基础与应用》期末复习提纲(10-11(二)

《多媒体技术基础与应用》期末复习提纲(2010-2011学年第二学期一、选择题1.媒体中的是为了加工、处理和传输感觉媒体而人为构造出来的一种媒体,如文字、音频、图像和视频等的数字化编码表示等。
A.感觉媒体B.表示媒体C.显示媒体D.存储媒体2.多媒体技术的主要特性有(1多样性(2集成性(3交互性(4实时性A.仅(1B.(1+(2C.(1+(2+(3D.全部3.请根据多媒体的特性判断以下哪些属于计算机多媒体的范畴?(1交互式视频游戏(2有声图书(3彩色画报(4彩色电视A.仅(1B.(1+(2C.(1+(2+(3D.全部4.一般认为,多媒体技术研究的兴起,从开始。
A.1972年,Philips展示播放电视节目的激光视盘B.1984年,美国Apple公司推出Macintosh系列机C.1986年,Philips和Sony公司宣布发明了交互式光盘系统CD-ID.1987年,美国RCA公司展示了交互式数字影像系统DVI5.多媒体技术未来发展的方向是(1高分辨率,提高显示质量(2高速度化,缩短处理时间(3简单化,便于操作(4智能化,提高信息识别能力A.(1+(2+(3B.(1+(2+(4C.(1+(3+(4D.全部6.下列哪些说法正确?(1多媒体技术促进了通信、娱乐和计算机的融合(2多媒体技术可用来制作VCD及影视音响、卡拉OK机(3多媒体技术极大地改善了人—界面(4利用多媒体是计算机产业发展的必然趋势A.(1+(2+(3B.(1+(2+(4.C.(2+(3+(4D.全部7.下列哪些说法正确?(1媒体之间的关系也代表着信息(2任何媒体之间都可直接进行相互转换(3不同的媒体所表达信息的程度不同(4有格式的数据才能表达信息的含义A.(1+(2+(3B.(1+(2+(4C.(1+(3+(4D.全部8.当前光盘存储容量最大的光盘类型是。
A.VCDB.CD-DAC.DVDD.CD-ROM9.将模拟声音信号转变为数字音频信号的数字化过程是。
上海大学广播电视艺术学、电影学考试试题

上海大学2003年攻读硕士学位研究生入学考试试题招生专业:广播电视艺术学、电影学考试科目:影片分析(2004年改在复试中进行,像第三大题100分的影片分析都是当年的热点影片,在专业辅导班上也都提到,不用担心。
)一、简荅题(共20分)1. 电影评论一般可分为哪几种写作类型?5分2. 请列举出传统的或现代的电影批评方法各三种以上。
5分3. 什么叫场面调度?场面高度批评方法分析的基本元素有哪些?二、简析题(共30分)1. 试分析基耶洛夫斯基是怎样在<<蓝色>>中运用蓝色基调及一系列蓝色道具来阐发其作品意义的?15分2. 阿巴斯的<<橄榄树下的情人>>的结尾,有一个长达数分钟的大全景长镜头,表现在一片橄榄树丛中中,男主角对女主角的追逐,而在最后,显然已经追上了女主角的他,则返身奔跑了回来。
结合全片,谈谈你对这个结尾的理解。
15分三、影片分析(共100分)<<和你在一起>>(陈凯歌)<<美丽的大脚>>(杨亚洲)<<寻枪>>(陆川)要求:1. 请在上列影片中任选一部写一篇电影评论。
2. 请自列文章标题,无题者扣分。
3. 文从己出,立论鲜明,论据充分,论证严谨完整。
4. 字数2500—3000字左右。
(注:这些题目在专业辅导班上一般会给定要看影片的范围,这样针对性就很强了。
平常多看些名片或较有影响及每年热点的片子,不会考偏的影片)上海大学2002年攻读硕士学位研究生入学考试试题招生专业:广播电视艺术学考试科目:电视制作基础。
(复试中进行,且报制作方向才要考这一科,报美学,编导或制片方向就可以不看这本书)一、名词解释(每题3分,共30分)1、景深2、电视制作的要素3、相加混色法4、三基色5、景别6、三角照明原则7、脱机编辑8、录像带上的磁迹9、声画对位10、淡变二、简答题(每题5分,共40分)1、声音通过艺术处理可以产生哪些作用?2、摇镜头和移镜头在拍摄时有什么区别?3、组合编辑和插入编辑有什么区别?4、蒙太奇包括哪三层意思?5、什么是人眼的视觉惰性?人眼的视觉残留时间为多少?6、广角镜头与窄角镜头有哪些特征?7、如何通过调白平衡使所摄画面的色调偏红?8、主光,逆光和副光在电视照明中的功能是什么?三、综述题(每题10分,共30分)1、简述画面构图中前景和背景的艺术作用?2、综述非线性编辑的特征。
《传播学》课程笔记

《传播学》课程笔记第一章:引论1.1 传播的定义传播是一种复杂的社会现象,它涉及信息的传递、接收、处理和反馈等一系列过程。
在广义上,传播可以定义为:- 一种社会互动的过程,通过这个过程,个体或群体通过使用共享的符号系统交换信息、思想和情感。
- 一种建立共识、共享意义和文化传承的手段。
传播的几个关键要素包括:- 消息(Message):传播的内容,可以是语言、文字、图像、声音等形式。
- 传播者(Sender/Encoder):发起传播的个人或团体,负责将信息编码以便传递。
- 接收者(Receiver/Decoder):接收并解码信息的个人或团体。
- 通道(Channel):信息传递的媒介或途径,如空气、纸张、电子信号等。
- 反馈(Feedback):接收者对信息的回应,有助于传播者评估传播效果。
1.2 传播的分类传播可以根据不同的标准进行分类,以下是一些常见的传播类型:- 按照传播范围:人际传播、组织传播、大众传播、国际传播。
- 按照传播方向:单向传播、双向传播、多向传播。
- 按照传播内容:信息传播、教育传播、娱乐传播、广告传播。
- 按照传播媒介:口头传播、书面传播、电子传播、网络传播。
1.3 传播的过程传播过程是一个动态的、互动的序列,通常包括以下步骤:- 观念形成:传播者内部产生传播的动机和目的。
- 信息编码:传播者将观念或信息转化为可以传递的符号形式。
- 信息发送:通过选定的通道将编码后的信息发送出去。
- 信息接收:接收者通过感官接收到信息。
- 信息解码:接收者将接收到的符号信息还原为可以理解的意义。
- 信息理解:接收者对信息的意义进行解释和思考。
- 反馈:接收者向传播者提供信息接收和理解的情况,完成传播的循环。
1.4 传播的系统结构传播的系统结构可以从不同的角度来分析,以下是一种常见的模型:- 信源(Source):信息的起点,负责信息的产生和编码。
- 编码器(Encoder):将信息转换成适合传播的信号或符号。
《网络与新媒体概论》课程笔记

《网络与新媒体概论》课程笔记第一章绪论一、人类社会的四次传播革命1. 语言传播:人类最早的传播方式,通过口头语言传递信息。
2. 文字传播:文字的发明使得信息可以记录下来,传播更加广泛和持久。
3. 印刷传播:印刷术的发明使得大量复制和传播信息成为可能,进一步推动了人类文明的进步。
4. 电子传播:电子技术的出现,使得信息传播速度大大提高,传播方式更加多样化。
二、新传播革命的本质新传播革命是指以互联网为核心的信息传播技术革命。
其本质是信息传播的去中心化、互动性和全球化。
三、新传播革命的基本特征1. 数字化:信息以数字形式存储和传播,提高了信息的处理和传输效率。
2. 网络化:互联网连接了全球的计算机和设备,实现了信息的即时共享和交流。
3. 互动性:用户可以参与到信息的生产和传播过程中,形成了一种新型的互动关系。
4. 多媒体:互联网可以传播文字、图片、音频、视频等多种形式的信息,丰富了信息的表达方式。
5. 全球化:互联网打破了地域和国界的限制,实现了全球范围内的信息传播和交流。
四、新传播革命的挑战1. 信息过载:互联网上的信息量巨大,用户难以筛选和处理。
2. 网络安全:互联网上的信息安全和隐私保护问题日益突出。
3. 数字鸿沟:互联网的发展加剧了全球范围内的数字鸿沟问题,不同地区和群体之间的信息获取能力差距加大。
4. 媒体素养:互联网用户需要具备一定的媒体素养,才能正确使用和评价网络信息。
五、互联网发展的两大支点1. 技术创新:互联网的发展离不开技术的不断创新,如云计算、大数据、人工智能等。
2. 商业模式:互联网的商业模式不断创新,推动了互联网的快速发展。
第二章互联网、新媒体与新技术一、互联网的产生与发展1. 互联网的起源:互联网起源于20世纪60年代的美国,最初是为了军事目的而建立的一个网络。
2. 互联网的发展:随着技术的进步和应用的普及,互联网逐渐从军事领域走向民用,形成了全球范围内的信息传播网络。
二、新媒体的基本特征1. 数字化:新媒体的信息以数字形式存储和传播,提高了信息的处理和传输效率。
上海大学硕士研究生考试895现代经济学、833马克思主义政治经济学参考书目及考试大纲

上海大学硕士研究生参考书目
经济学院(理论经济学、应用经济学(一)、统计学(一)),上海研究院(应用经济学(二)),悉尼工商学院(区域经济学(二))初试专业课:895现代经济学
参考书目:
《简明微观宏观经济学》陈宪韩太祥中国人民大学出版社2015年
《微观经济学:现代观点》范里安上海三联书店2015年
《宏观经济学》曼昆中国人民大学出版社2011年
社会科学学部
政治经济学专业
初试专业课:883马克思主义政治经济学
《当代马克思主义政治经济学十五讲》本书编写组中国人民大学出版社2016年
《马克思主义政治经济学概论》马克思主义理论研究和建设工程重点教材高等教育出版社2011版或最新版
上海大学895现代经济学指定的参考书目是范里安和曼昆的版本,有一定难度,政治经济学的初试专业课是考的马克思主义政治经济学。
应用经济学有不容的研究方向,每个方向的复试线都是不同的。
经济学硕的学制是2.5年,招生规模也不小,尤其是应用经济学(一),
2017年的统招人数是72人。
上大考研辅导班:上大上海电影学院考研招生简章

上大考研辅导班:上大上海电影学院考研招生简章一、上大考研辅导班---上大上海电影学院考研专业目录081200 计算机科学与技术(三)上海电影特效工程技术研究中心是由上海市科技委员会综合管理,依托上海大学综合性、多学科交叉优势,引领行业发展的电影技术研发、人才培养、产业服务的省部级特色基地。
中心师资力量雄厚,实验设备先进,有着很好的应用和产业背景。
近年来,先后主持承担了 10 余项国家级和省部级重要课题,获得多个国家科技进步奖、上海市科技进步奖等重要奖项,与中国电影科学技术研究所、上影集团、SMG、清华大学、中科院等龙头企业、科研院所和高校建立密切合作关系,开展产学研用协同创新,在业界的影响力不断提升。
计算机科学与技术为计算机一级学科,涵盖了计算机应用技术、软件与理论和系统结构三个二级学科硕士点,按一级学科招生。
本专业紧密联系计算机发展的最新热点以及上海市计算机行业的发展方向,开展与国民经济发展密切相关的计算机科学及应用技术研究。
本专业的主要研究方向包括新型计算机体系结构、软件工程、数据库、信息管理系统、多媒体技术、计算机网络、智能信息处理、信息安全等,并与上海大学材料基因组工程研究院合作开展材料信息与数据科学研究。
本专业培养具有扎实的计算机硬件、软件基础理论知识,能够从事计算机应用研究与应用开发的高级专门人才,所设课程反映计算机学科的各个领域的当前国内外先进水平,旨在使学生掌握坚实的专业基础和宽广的知识面。
本专业研究力量强,学术梯队结构合理;近年来,先后承担了多项国家技术攻关项目、国家自然科学基金、国防科工委及上海市重大科技项目等,多次获得部、市科技进步奖,经费充裕。
在国内外著名刊物和学术会议上发表大量学术论文,出版过数十本教材和著作,主办过重要的国际学术会议。
在有关研究方向上联合培养了一批外国留学生,还与国内外多所大学签有学术交流、联合培养研究生的协议。
数字电影特效技术为本专业新增方向,主要利用计算机技术对电影领域内的海量音视频数据进行分析和处理。
2024年上海大学研究生入学考试(学硕)艺术学考研真题

2024年上海大学研究生入学考试(学硕)艺术学考研真题业务课名称:艺术学考生须知:1.答案必须写在答题纸上,写在其他纸上无效。
2.答题时必须使用蓝、黑色墨水笔或圆珠笔做答,用其他答题不给分,不得使用涂改液。
643戏剧与影视史一、名词解释(共5道,每道6分,15选5)1.歌颂型喜剧2.《伊万的童年》3.赛博朋克电影4.AIGC5.凤凰卫视6.《唐顿庄园》7.《山羊之歌》8.普劳图斯9.汉堡剧评10.互动电影11.《中国影戏大观》12.残酷戏剧13.《最后的山神》14.时装新戏15.WEAF 网台二、简答(共3道,每道20分,9选3)1.简述美国超级英雄电影的类型特征与背后的意识形态2.简述文艺复兴时期戏剧的艺术特征。
3.简述四级办电视政策。
4.简述邵氏黄梅调电影创作与美学特征、文化意义5.分析曹禺话剧《雷雨》的戏剧结构。
6.简述电影金鸡奖的发展历程、特色及其意义7.简述亚里士多德对悲剧的定义。
8.1990 年代以来的中国纪录片的发展及特点9.简述中国戏剧从古代到现代的转变。
10.简述外国三大流媒体平台及其发展特点。
三、论述题(共2道,每道30分,6选2)1.结合法国新浪潮作者电影,左岸派作家电影中文学对创作的影响,谈谈电影中的文学性2.从技术、美学、文化选择角度阐述电影工业美学,及其如何实现中国电影民族化的影像表达。
3.结合具体实例,阐述温暖现实主义电视剧的内涵、特征、意义4.如何理解没有冲突就没有戏。
5.结合具体实例,谈谈文化类综艺6.结合具体实例,论述戏剧百年发展历程。
878戏剧与影视理论一、名词解释(每道8分,10选5,共40分)1.蒙太奇2.电影类型3.电影语言4.现实主义电影5.第四堵墙6.戏剧冲突7.荒诞性8.互文性9.戏剧语言10.格罗托夫斯基二、简答(1-4题每道15分,4选2;5-6题每道20分,2选1,共50分)1.选择一个影视批评方法分析其有效性和局限性。
2.简述戏剧批评的三种方法3.简述电影作者论的基本发展脉络与内涵4.戏剧的五大基本元素是什么,谈谈你对对其关系的理解5.请从电影工业美学、共同体美学、中国电影学派这三种当下中国电影理论中任选一个,分析并阐述其理论要点。
2017上海大学考研初试参考书目(专业学位)

《社会工作实务》朱眉华
334 新闻与传播专业综合能力
《理论新闻传播学导论》童兵 中国人民大学出版社 2011 年
《传播学通论》戴元光 金冠军主编 上海交通大学出版社 2007年
《新闻传媒业的他律与自律》张咏华 黄挽澜 魏永征 上海外语教育出版社 2007年
注:上述论著如果重印,可以用新版。
《分析化学》刘志广主编 高等教育出版社 2008年
926 物理化学(专)
《物理化学》(第5版)天津大学物理化学教研室编 北京:高等教育出版社 2009年
《物理化学解题指南》(第2版)冯霞 高正虹 陈丽编 北京:高等教育出版社 2009年
927 环境化学(专)
《环境化学》(第2版)戴树桂等编 高等教育出版社 2007年
359 日语翻译基础
《日语综合教程》(第7、8册)季林根 皮细庚 上海外语教学出版社 2008年
《日汉翻译教程》高宁 上海外语教育出版社 2010年6月
《新编汉日翻译教程》高宁 上海外语教育出版社 2003年7月
《新编汉日日汉同声传译教程:从即席翻译到同声传译》(第2版) 宋协毅 外语教学与研究出版社 2011年7月
920 模拟与数字电路(专)
《电子技术基础》(模拟部分)(第 5 版)康华光主编 高等教育出版社 2008 年 2 月
《电子技术基础》(数字部分)(第 5 版)康华光主编 高等教育出版社 2006 年 1 月
921 材料科学基础(专)
《材料科学基础》李见 冶金工业出版社 2000年
《材料科学基础》胡赓祥 上海交通大学出版社 2000年
354 汉语基础(文学院)
《现代汉语》黄伯荣,廖序东 高等教育出版社
《古代汉语》王力 中华书局
上海大学学年秋季学期研究生专业课课程表

上海大学学年秋季学期研究生专业课课程表下文为大家整理带来的上海大学学年秋季学期研究生专业课课程表,希望内容对您有帮助,感谢您得阅读。
上海大学2020~2020学年秋季学期研究生专业课课程表序号课程号课程名称学分任课教师人数上课时间上课地点上课学生备注110SAZ9021材料测试分析技术4王子兴9四(1-4)四教3142020级微电子(平板中心)硕士生多媒体与10Z087003王子兴并班上课210Z087003材料测试分析技术4朱丽慧28四(1-4)四教4092020级材料工程(金属方向)硕士生多媒体310Z087003材料测试分析技术4王子兴5四(1-4)四教3142020级材料工程(六)(平板中心)硕士生多媒体与10SAZ9021并班上课410Z087003材料测试分析技术4刘文庆43四(1-4)四教4082020级材料工程(材料所、钢冶方向)硕士生多媒体前三周进教室,后七周进实验室510SAU9007材料的现代分析测试方法4李强40五(1-4)四教6012020级材料学二硕士生多媒体前三周进教室,后七周进实验室610Z087002材料工程基础4符仁钰71三(1-4)四教4102020级材料工程硕士选课研究生多媒体710Z087002材料工程基础4李喜峰5四(10-13)平板楼讲席室(自订)2020级材料工程(六)(平板中心)硕士生810Z087008材料工艺设备4吴成章71一(6-9)四教3142020级材料工程选课研究生多媒体910SAU7003材料结构性能与应用4徐晖74四(1-4)四教4072020级材加二、材料学二部分硕士生多媒体1010SAU7003材料结构性能与应用4程晓英67四(1-4)四教3122020级材加一、部分材料学二硕士生多媒体1110BAU7002材料科学与工程前沿4吴晓春0二(6-9)日新楼511-B(自订)2020级金属材料方向博士生仅第一周集中授课1210BAU7002材料科学与工程前沿4陈业新0四(1-4)材料所会议室(自订)2020级材料所博士生仅第一周集中授课1310BAU7002材料科学与工程前沿4王林军0三(6-9)材料大楼501(自订)2020级电子方向博士生仅第一周集中授课1410BAU7002材料科学与工程前沿4张阿方0五(1-4)材料大楼801(自订)2020级高分子及外挂博士生仅第一周集中授课1510SAU7002材料物理化学4陈业新40二(6-7),三(6-7)四教208/四教2072020级材料学二硕士生多媒体1610SAU7002材料物理化学4鲁晓刚74四(1-4)四教1142020级材料加工工程一、二硕士生多媒体1710Z087004材料制备方法4李重河71二(6-9)四教2102020级材料工程选课硕士生多媒体1810Z087007复合材料及其应用4李爱军71五(6-9)四教6012020级材料工程选课硕士生多媒体1910SAZ9025复合材料及其应用4曹进9一(10-13)平板楼讲席室(自订)2020级微电子(平板中心)硕士生与10Z087007曹进并班上课2020Z087007复合材料及其应用4曹进5一(10-13)平板楼讲席室(自订)2020级材料工程(六)(平板中心)硕士生与10SAZ9025曹进并班上课2110Z087006工程材料应用4殷录桥5二(10-13)四教6022020级材料工程(六)(平板中心)硕士生多媒体与10SAZ9020殷录桥并班上课2210SAZ9020工程材料应用4殷录桥9二(10-13)四教6022020级微电子(平板中心)硕士生多媒体与10Z087006殷录桥并班上课2310Z087006工程材料应用4金曼71五(1-4)四教6022020级材料工程选课硕士生多媒体2410SAU9010金属材料腐蚀原理与防护技术4李谋成40二(1-4)四教3142020级材料学二硕士生多媒体2510SAU9015金属凝固4宋长江43二(1-4)四教3122020级材料加工工程二硕士生多媒体与10SAV9004并班上课2610SAV9004金属凝固4宋长江22二(1-4)四教3122020级钢铁冶金、有色硕士生多媒体与10SAU9015并班上课2710SAU9003摩擦与磨损4韦习成31二(1-4)四教3092020级材料加工工程一硕士生多媒体2810Z087005数值模拟在材料工程中的应用4黎军顽71三(6-9)四教2042020级材料工程选课硕士生多媒体2910SAZ9022数值模拟在材料工程中的应用4杨连乔9四(6-9)四教4092020级微电子(平板中心)硕士生多媒体与10Z087005杨连乔并班上课3010Z087005数值模拟在材料工程中的应用4杨连乔5四(6-9)四教4092020级材料工程(六)(平板中心)硕士生多媒体与10SAZ9022杨连乔并班上课3110SAZ7002微电子器件原理4李喜峰9三(10-13)平板楼讲席室(自订)2020级微电子(平板中心)硕士生3210SAZ9026微能源技术导论4曾志刚9二(6-9)四教1162020级微电子(平板中心)硕士生多媒体3310BAV7001现代冶金基础理论4任忠鸣0三(6-9)日新楼410(自订)2020级钢铁冶金博士生3410SAU9005新型铝合金材料与成形技术4张恒华31五(1-4)四教6032020级材料加工工程一硕士生多媒体3510SAV9006冶金炉气处理与利用4汪学广22四(6-9)四教4082020级钢铁冶金、有色金属冶金硕士生多媒体与10SAU9017并班上课3610SAU9017冶金炉气处理与利用4汪学广43四(6-9)四教4082020级材料加工工程二硕士生多媒体与10SAV9006并班上课3710SAV7002冶金热力学4吴永全22三(6-9)四教1162020级钢铁冶金和有色金属冶金硕士生多媒体3810SAV9007有色金属湿法冶金4谈定生4四(1-4)四教5072020级有色金属冶金硕士生多媒体3910SAU9002铸造技术原理与应用4杨弋涛31一(1-4)四教5042020级材料加工工程一硕士生多媒体4010SAU7001专业英语2黎军顽31四(6-9)四教4072020级材料加工工程一硕士生多媒体与10Z087001黎军顽并班上课4110SAZ7001专业英语2魏斌9二(1-4)四教2102020级微电子(平板中心)硕士生多媒体与10Z087001魏斌并班上课4210Z087001专业英语2黎军顽28四(6-9)四教4072020级材料工程(金属方向)硕士生多媒体与10SAU7001黎军顽并班上课4310SAU7001专业英语2王均安40四(6-9)四教3122020级材料学二硕士生多媒体与10Z087001王均安并班上课4410Z087001专业英语2王均安14四(6-9)四教3122020级材料工程(材料所方向)硕士生多媒体与10SAU7001王均安并班上课4510Z087001专业英语2魏斌5二(1-4)四教2102020级材料工程(六)(平板中心)硕士生多媒体与10SAZ7001魏斌并班上课。
大学数字媒体艺术专业学习内容和课程有哪些

大学数字媒体艺术专业学习内容和课程有哪些一、数字媒体艺术专业学习内容和课程数字媒体艺术设计主要学:思想政治理论、相关的人文社会科学类、理工类以及艺术、体育、科技、外语、计算机知识、中外设计史、设计概论、设计方法、创新理论、专业领域课堂授课、社会实践、岗位实训、职业实习、专业类社会实践、专业类实训等课程。
二、数字媒体艺术专业未来发展方向数字媒体艺术毕业生主要在各级电视台、影视电影动画制作单位、传媒与广告公司、数码艺术公司、展示设计公司、形象企划公司、多媒体与网页设计、室内装修设计、产品造型设计等行业就业。
毕业生也可以在大专院校、研究所等部门从事教学与科研工作;继续攻读与设计学、网络设计与制作专业相关的学科或交叉学科的研究生。
数字媒体专业的就业范围广阔,毕业生可在各级电视台、影视动画、传媒广告、网络多媒体、网络游戏、电信移动、房地产和工业产品等热门行业就业或广告、动画制作、装潢设计和摄影摄像服务业。
如:广告设计、电子商务网站设计、多媒体远程教育,房地产业的演示动画片制作、室内外装修行业的设计工作、电视电影的特技制作,电子游戏的开发、动漫创作、产品开发及艺术设计等各个行业。
相比国际水平,中国数字媒体艺术仍处于起步和发展阶段,但不能否认的是数字媒体已渗透到我们生活的方方面面,娱乐、信息传播、科学研究都离不开数字媒体。
在越来越多的行业中,如电影、电视、展览展示、广告、包装等,数字媒体艺术扮演着越来越重要的角色。
在这样的时代背景下,无论是实现梦想、施展才华,还是寻找机遇、兴趣爱好,投身到数字媒体艺术领域,具有发展潜力。
三、数字媒体艺术专业开设的大学有哪些序号专业名称学校名称所在省份1 数字媒体艺术中国人民大学北京2 数字媒体艺术清华大学北京3 数字媒体艺术北京交通大学北京4 数字媒体艺术北京工业大学北京5 数字媒体艺术北京化工大学北京6 数字媒体艺术北京工商大学北京7 数字媒体艺术北京服装学院北京8 数字媒体艺术北京邮电大学北京9 数字媒体艺术北京印刷学院北京10 数字媒体艺术北京林业大学北京11 数字媒体艺术北京师范大学北京12 数字媒体艺术首都师范大学北京13 数字媒体艺术中国传媒大学北京14 数字媒体艺术中央美术学院北京15 数字媒体艺术中国戏曲学院北京16 数字媒体艺术北京电影学院北京17 数字媒体艺术北京联合大学北京18 数字媒体艺术北京城市学院北京19 数字媒体艺术北京工商大学嘉华学院北京20 数字媒体艺术北京邮电大学世纪学院北京21 数字媒体艺术北京工业大学耿丹学院北京22 数字媒体艺术天津师范大学天津23 数字媒体艺术天津外国语大学天津24 数字媒体艺术天津美术学院天津25 数字媒体艺术天津天狮学院天津26 数字媒体艺术天津中德应用技术大学天津27 数字媒体艺术天津传媒学院天津28 数字媒体艺术天津师范大学津沽学院天津29 数字媒体艺术天津仁爱学院天津30 数字媒体艺术河北北方学院河北31 数字媒体艺术河北师范大学河北32 数字媒体艺术保定学院河北33 数字媒体艺术唐山师范学院河北34 数字媒体艺术廊坊师范学院河北35 数字媒体艺术邯郸学院河北36 数字媒体艺术唐山学院河北37 数字媒体艺术河北传媒学院河北38 数字媒体艺术河北工程技术学院河北39 数字媒体艺术河北美术学院河北40 数字媒体艺术华北理工大学轻工学院河北41 数字媒体艺术河北师范大学汇华学院河北42 数字媒体艺术保定理工学院河北43 数字媒体艺术燕京理工学院河北44 数字媒体艺术沧州交通学院河北45 数字媒体艺术河北东方学院河北46 数字媒体艺术山西大学山西47 数字媒体艺术太原理工大学山西48 数字媒体艺术山西农业大学山西49 数字媒体艺术山西应用科技学院山西50 数字媒体艺术山西工程科技职业大学山西51 数字媒体艺术晋中信息学院山西52 数字媒体艺术山西师范大学现代文理学院山西53 数字媒体艺术山西工商学院山西54 数字媒体艺术山西传媒学院山西55 数字媒体艺术内蒙古科技大学内蒙古56 数字媒体艺术内蒙古师范大学内蒙古57 数字媒体艺术内蒙古民族大学内蒙古58 数字媒体艺术内蒙古艺术学院内蒙古59 数字媒体艺术沈阳航空航天大学辽宁60 数字媒体艺术大连工业大学辽宁61 数字媒体艺术辽宁工业大学辽宁62 数字媒体艺术辽宁师范大学辽宁63 数字媒体艺术沈阳师范大学辽宁64 数字媒体艺术鲁迅美术学院辽宁65 数字媒体艺术大连大学辽宁66 数字媒体艺术大连理工大学城市学院辽宁67 数字媒体艺术大连工业大学艺术与信息工程学院辽宁68 数字媒体艺术大连科技学院辽宁69 数字媒体艺术大连艺术学院辽宁70 数字媒体艺术大连东软信息学院辽宁71 数字媒体艺术东北电力大学吉林72 数字媒体艺术长春工业大学吉林73 数字媒体艺术吉林建筑大学吉林74 数字媒体艺术东北师范大学吉林75 数字媒体艺术吉林师范大学吉林76 数字媒体艺术长春师范大学吉林77 数字媒体艺术吉林艺术学院吉林78 数字媒体艺术吉林警察学院吉林79 数字媒体艺术长春光华学院吉林80 数字媒体艺术长春工业大学人文信息学院吉林81 数字媒体艺术长春建筑学院吉林82 数字媒体艺术长春科技学院吉林83 数字媒体艺术吉林动画学院吉林84 数字媒体艺术哈尔滨工业大学黑龙江85 数字媒体艺术哈尔滨理工大学黑龙江86 数字媒体艺术哈尔滨师范大学黑龙江87 数字媒体艺术哈尔滨学院黑龙江88 数字媒体艺术黑龙江东方学院黑龙江89 数字媒体艺术黑龙江工程学院黑龙江90 数字媒体艺术哈尔滨石油学院黑龙江91 数字媒体艺术黑龙江工商学院黑龙江92 数字媒体艺术哈尔滨剑桥学院黑龙江93 数字媒体艺术黑龙江工程学院昆仑旅游学院黑龙江94 数字媒体艺术哈尔滨华德学院黑龙江95 数字媒体艺术华东理工大学上海96 数字媒体艺术东华大学上海97 数字媒体艺术上海音乐学院上海98 数字媒体艺术上海戏剧学院上海99 数字媒体艺术上海大学上海100 数字媒体艺术上海工程技术大学上海101 数字媒体艺术上海电机学院上海102 数字媒体艺术上海杉达学院上海103 数字媒体艺术上海第二工业大学上海104 数字媒体艺术上海建桥学院上海105 数字媒体艺术上海视觉艺术学院上海106 数字媒体艺术上海外国语大学贤达经济人文学院上海107 数字媒体艺术上海师范大学天华学院上海108 数字媒体艺术苏州大学江苏109 数字媒体艺术南京工业大学江苏110 数字媒体艺术常州大学江苏111 数字媒体艺术南京邮电大学江苏112 数字媒体艺术江南大学江苏113 数字媒体艺术南京林业大学江苏114 数字媒体艺术江苏大学江苏115 数字媒体艺术南京信息工程大学江苏116 数字媒体艺术南通大学江苏117 数字媒体艺术淮阴师范学院江苏118 数字媒体艺术南京体育学院江苏119 数字媒体艺术南京艺术学院江苏120 数字媒体艺术苏州科技大学江苏121 数字媒体艺术淮阴工学院江苏122 数字媒体艺术常州工学院江苏123 数字媒体艺术扬州大学江苏124 数字媒体艺术三江学院江苏125 数字媒体艺术江苏理工学院江苏126 数字媒体艺术江苏海洋大学江苏127 数字媒体艺术徐州工程学院江苏128 数字媒体艺术南通理工学院江苏129 数字媒体艺术无锡太湖学院江苏130 数字媒体艺术金陵科技学院江苏131 数字媒体艺术南京大学金陵学院江苏132 数字媒体艺术南京航空航天大学金城学院江苏133 数字媒体艺术南京传媒学院江苏134 数字媒体艺术南京理工大学泰州科技学院江苏135 数字媒体艺术南京师范大学泰州学院江苏136 数字媒体艺术南京工业大学浦江学院江苏137 数字媒体艺术无锡学院江苏138 数字媒体艺术江苏师范大学科文学院江苏139 数字媒体艺术南京审计大学金审学院江苏140 数字媒体艺术宿迁学院江苏141 数字媒体艺术江苏第二师范学院江苏142 数字媒体艺术西交利物浦大学江苏143 数字媒体艺术昆山杜克大学江苏144 数字媒体艺术杭州电子科技大学浙江145 数字媒体艺术浙江工业大学浙江146 数字媒体艺术浙江理工大学浙江147 数字媒体艺术浙江农林大学浙江148 数字媒体艺术浙江师范大学浙江149 数字媒体艺术杭州师范大学浙江150 数字媒体艺术浙江工商大学浙江151 数字媒体艺术嘉兴学院浙江152 数字媒体艺术中国美术学院浙江153 数字媒体艺术浙江财经大学浙江154 数字媒体艺术浙江传媒学院浙江155 数字媒体艺术浙江越秀外国语学院浙江156 数字媒体艺术宁波财经学院浙江157 数字媒体艺术浙大宁波理工学院浙江158 数字媒体艺术浙江工业大学之江学院浙江159 数字媒体艺术浙江理工大学科技与艺术学院浙江160 数字媒体艺术浙江工商大学杭州商学院浙江161 数字媒体艺术嘉兴南湖学院浙江162 数字媒体艺术安徽工业大学安徽163 数字媒体艺术安徽工程大学安徽164 数字媒体艺术安庆师范大学安徽165 数字媒体艺术黄山学院安徽166 数字媒体艺术滁州学院安徽167 数字媒体艺术淮南师范学院安徽168 数字媒体艺术铜陵学院安徽169 数字媒体艺术安徽三联学院安徽170 数字媒体艺术蚌埠学院安徽171 数字媒体艺术亳州学院安徽172 数字媒体艺术马鞍山学院安徽173 数字媒体艺术皖江工学院安徽174 数字媒体艺术安徽艺术学院安徽175 数字媒体艺术厦门大学福建176 数字媒体艺术福州大学福建177 数字媒体艺术福建工程学院福建178 数字媒体艺术闽江学院福建179 数字媒体艺术武夷学院福建180 数字媒体艺术泉州师范学院福建181 数字媒体艺术厦门理工学院福建182 数字媒体艺术厦门华厦学院福建183 数字媒体艺术闽南理工学院福建184 数字媒体艺术泉州职业技术大学福建185 数字媒体艺术闽南科技学院福建186 数字媒体艺术福州工商学院福建187 数字媒体艺术阳光学院福建188 数字媒体艺术福州外语外贸学院福建189 数字媒体艺术泉州信息工程学院福建190 数字媒体艺术华东交通大学江西191 数字媒体艺术江西理工大学江西192 数字媒体艺术景德镇陶瓷大学江西193 数字媒体艺术江西农业大学江西194 数字媒体艺术赣南师范大学江西195 数字媒体艺术江西财经大学江西196 数字媒体艺术景德镇学院江西197 数字媒体艺术江西科技师范大学江西198 数字媒体艺术南昌工程学院江西199 数字媒体艺术南昌理工学院江西200 数字媒体艺术江西应用科技学院江西201 数字媒体艺术江西服装学院江西202 数字媒体艺术南昌大学科学技术学院江西203 数字媒体艺术赣东学院江西204 数字媒体艺术赣南科技学院江西205 数字媒体艺术江西财经大学现代经济管理学院江西206 数字媒体艺术江西软件职业技术大学江西207 数字媒体艺术齐鲁工业大学山东208 数字媒体艺术青岛农业大学山东209 数字媒体艺术山东师范大学山东210 数字媒体艺术曲阜师范大学山东211 数字媒体艺术聊城大学山东212 数字媒体艺术滨州学院山东213 数字媒体艺术临沂大学山东214 数字媒体艺术济宁学院山东215 数字媒体艺术山东财经大学山东216 数字媒体艺术山东艺术学院山东217 数字媒体艺术青岛滨海学院山东218 数字媒体艺术枣庄学院山东219 数字媒体艺术山东工艺美术学院山东220 数字媒体艺术山东女子学院山东221 数字媒体艺术潍坊科技学院山东222 数字媒体艺术青岛恒星科技学院山东223 数字媒体艺术青岛黄海学院山东224 数字媒体艺术山东协和学院山东225 数字媒体艺术山东工程职业技术大学山东226 数字媒体艺术烟台理工学院山东227 数字媒体艺术聊城大学东昌学院山东228 数字媒体艺术青岛城市学院山东229 数字媒体艺术潍坊理工学院山东230 数字媒体艺术山东石油化工学院山东231 数字媒体艺术泰山科技学院山东232 数字媒体艺术山东华宇工学院山东233 数字媒体艺术山东外事职业大学山东234 数字媒体艺术青岛工学院山东235 数字媒体艺术青岛农业大学海都学院山东236 数字媒体艺术山东财经大学东方学院山东237 数字媒体艺术烟台科技学院山东238 数字媒体艺术山东青年政治学院山东239 数字媒体艺术青岛电影学院山东240 数字媒体艺术山东农业工程学院山东241 数字媒体艺术郑州轻工业大学河南242 数字媒体艺术河南工业大学河南243 数字媒体艺术南阳师范学院河南244 数字媒体艺术黄淮学院河南245 数字媒体艺术郑州工程技术学院河南246 数字媒体艺术洛阳理工学院河南247 数字媒体艺术河南工学院河南248 数字媒体艺术河南工程学院河南249 数字媒体艺术郑州科技学院河南250 数字媒体艺术郑州师范学院河南251 数字媒体艺术郑州财经学院河南252 数字媒体艺术黄河交通学院河南253 数字媒体艺术信阳学院河南254 数字媒体艺术郑州经贸学院河南255 数字媒体艺术商丘学院河南256 数字媒体艺术郑州升达经贸管理学院河南257 数字媒体艺术郑州西亚斯学院河南258 数字媒体艺术华中科技大学湖北259 数字媒体艺术长江大学湖北260 数字媒体艺术中国地质大学(武汉)湖北261 数字媒体艺术武汉纺织大学湖北262 数字媒体艺术湖北工业大学湖北263 数字媒体艺术华中农业大学湖北264 数字媒体艺术华中师范大学湖北265 数字媒体艺术湖北大学湖北266 数字媒体艺术汉江师范学院湖北267 数字媒体艺术中南财经政法大学湖北268 数字媒体艺术湖北美术学院湖北269 数字媒体艺术湖北工程学院湖北270 数字媒体艺术湖北经济学院湖北271 数字媒体艺术武汉商学院湖北272 数字媒体艺术武汉东湖学院湖北273 数字媒体艺术武昌理工学院湖北274 数字媒体艺术武汉晴川学院湖北275 数字媒体艺术湖北大学知行学院湖北276 数字媒体艺术湖北工业大学工程技术学院湖北277 数字媒体艺术武汉工程大学邮电与信息工程学院湖北278 数字媒体艺术武汉纺织大学外经贸学院湖北279 数字媒体艺术武昌工学院湖北280 数字媒体艺术武汉工商学院湖北281 数字媒体艺术湖北商贸学院湖北282 数字媒体艺术文华学院湖北283 数字媒体艺术武汉学院湖北284 数字媒体艺术武汉工程科技学院湖北285 数字媒体艺术武汉华夏理工学院湖北286 数字媒体艺术武汉传媒学院湖北287 数字媒体艺术武汉设计工程学院湖北288 数字媒体艺术吉首大学湖南289 数字媒体艺术长沙理工大学湖南290 数字媒体艺术湖南师范大学湖南291 数字媒体艺术湘南学院湖南292 数字媒体艺术怀化学院湖南293 数字媒体艺术湖南人文科技学院湖南294 数字媒体艺术南华大学湖南295 数字媒体艺术湖南工程学院湖南296 数字媒体艺术湖南工业大学湖南297 数字媒体艺术湖南涉外经济学院湖南298 数字媒体艺术长沙师范学院湖南299 数字媒体艺术湖南应用技术学院湖南300 数字媒体艺术湖南信息学院湖南301 数字媒体艺术汕头大学广东302 数字媒体艺术华南师范大学广东303 数字媒体艺术广州美术学院广东304 数字媒体艺术深圳大学广东305 数字媒体艺术广东财经大学广东306 数字媒体艺术广东白云学院广东307 数字媒体艺术广州大学广东308 数字媒体艺术广州航海学院广东309 数字媒体艺术仲恺农业工程学院广东310 数字媒体艺术广东金融学院广东311 数字媒体艺术广东工业大学广东312 数字媒体艺术广东外语外贸大学广东313 数字媒体艺术广东东软学院广东314 数字媒体艺术广州软件学院广东315 数字媒体艺术广州南方学院广东316 数字媒体艺术广州华商学院广东317 数字媒体艺术华南农业大学珠江学院广东318 数字媒体艺术广州理工学院广东319 数字媒体艺术北京师范大学珠海分校广东320 数字媒体艺术广州商学院广东321 数字媒体艺术北京理工大学珠海学院广东322 数字媒体艺术广东科技学院广东323 数字媒体艺术东莞城市学院广东324 数字媒体艺术广东第二师范学院广东325 数字媒体艺术桂林电子科技大学广西326 数字媒体艺术桂林理工大学广西327 数字媒体艺术广西艺术学院广西328 数字媒体艺术梧州学院广西329 数字媒体艺术桂林旅游学院广西330 数字媒体艺术贺州学院广西331 数字媒体艺术北海艺术设计学院广西332 数字媒体艺术广西民族大学相思湖学院广西333 数字媒体艺术桂林学院广西334 数字媒体艺术桂林信息科技学院广西335 数字媒体艺术南宁理工学院广西336 数字媒体艺术北京航空航天大学北海学院广西337 数字媒体艺术广西职业师范学院广西338 数字媒体艺术海口经济学院海南339 数字媒体艺术三亚学院海南340 数字媒体艺术重庆邮电大学重庆341 数字媒体艺术重庆师范大学重庆342 数字媒体艺术长江师范学院重庆343 数字媒体艺术四川美术学院重庆344 数字媒体艺术重庆工程学院重庆345 数字媒体艺术重庆城市科技学院重庆346 数字媒体艺术重庆财经学院重庆347 数字媒体艺术重庆移通学院重庆348 数字媒体艺术西南交通大学四川349 数字媒体艺术西南科技大学四川350 数字媒体艺术西华大学四川351 数字媒体艺术四川农业大学四川352 数字媒体艺术四川师范大学四川353 数字媒体艺术西南财经大学四川354 数字媒体艺术四川音乐学院四川355 数字媒体艺术攀枝花学院四川356 数字媒体艺术成都东软学院四川357 数字媒体艺术成都艺术职业大学四川358 数字媒体艺术成都理工大学工程技术学院四川359 数字媒体艺术四川传媒学院四川360 数字媒体艺术成都银杏酒店管理学院四川361 数字媒体艺术成都文理学院四川362 数字媒体艺术西南财经大学天府学院四川363 数字媒体艺术四川大学锦江学院四川364 数字媒体艺术四川文化艺术学院四川365 数字媒体艺术四川电影电视学院四川366 数字媒体艺术吉利学院四川367 数字媒体艺术贵州师范大学贵州368 数字媒体艺术贵州民族大学贵州369 数字媒体艺术六盘水师范学院贵州370 数字媒体艺术贵阳信息科技学院贵州371 数字媒体艺术贵州师范学院贵州372 数字媒体艺术昆明理工大学云南373 数字媒体艺术西南林业大学云南374 数字媒体艺术昭通学院云南375 数字媒体艺术云南财经大学云南376 数字媒体艺术云南艺术学院云南377 数字媒体艺术玉溪师范学院云南378 数字媒体艺术云南经济管理学院云南379 数字媒体艺术云南大学滇池学院云南380 数字媒体艺术云南艺术学院文华学院云南381 数字媒体艺术西北大学陕西382 数字媒体艺术西安工业大学陕西383 数字媒体艺术渭南师范学院陕西384 数字媒体艺术西安美术学院陕西385 数字媒体艺术西安文理学院陕西386 数字媒体艺术西安培华学院陕西387 数字媒体艺术西安财经大学陕西388 数字媒体艺术西安邮电大学陕西389 数字媒体艺术西安欧亚学院陕西390 数字媒体艺术西安翻译学院陕西391 数字媒体艺术西安思源学院陕西392 数字媒体艺术陕西服装工程学院陕西393 数字媒体艺术西北大学现代学院陕西394 数字媒体艺术延安大学西安创新学院陕西395 数字媒体艺术西安明德理工学院陕西396 数字媒体艺术西安科技大学高新学院陕西397 数字媒体艺术西北师范大学甘肃398 数字媒体艺术天水师范学院甘肃399 数字媒体艺术河西学院甘肃400 数字媒体艺术西北民族大学甘肃401 数字媒体艺术兰州文理学院甘肃402 数字媒体艺术青海师范大学青海403 数字媒体艺术新疆师范大学新疆404 数字媒体艺术新疆艺术学院新疆405 数字媒体艺术新疆工程学院新疆。
数字媒体技术导论笔记

数字媒体技术导论笔记一、数字媒体技术概述。
1. 定义。
- 数字媒体技术是通过现代计算和通信手段,综合处理文字、声音、图形、图像等信息,使抽象的信息变成可感知、可管理和可交互的一种技术。
它是计算机技术、通信技术和数字广播技术融合的产物。
2. 发展历程。
- 早期起源于计算机图形学的发展,随着计算机硬件性能的提升,如CPU运算速度加快、存储容量增大等,数字媒体技术逐渐发展起来。
- 互联网的普及更是极大地推动了数字媒体技术的发展,从简单的文本传输到多媒体信息的广泛传播。
3. 应用领域。
- 娱乐产业。
- 游戏开发,包括2D、3D游戏的图形渲染、物理模拟、角色动画等方面。
- 教育领域。
- 制作多媒体教材,通过图像、音频、视频等多种形式呈现知识内容,提高学习的趣味性和效果。
- 在线教育平台,借助数字媒体技术实现实时视频教学、互动式课件等功能。
- 广告传媒。
- 制作吸引人的数字广告,如户外大屏幕上的高清视频广告、网页中的动态广告等。
- 虚拟现实(VR)和增强现实(AR)在广告体验中的应用,让消费者有更直观的感受。
二、数字媒体技术的基础。
1. 数据表示与压缩。
- 数据表示。
- 在数字媒体中,图像用像素矩阵表示。
例如,一个RGB彩色图像,每个像素由红(R)、绿(G)、蓝(B)三个分量组成,每个分量的值通常用8位表示,取值范围是0 - 255。
- 音频数据可以通过采样、量化和编码来表示。
采样频率决定了音频的质量,常见的采样频率有44.1kHz(CD音质)等。
- 数据压缩。
- 无损压缩,如哈夫曼编码,它通过重新编码数据,减少数据的冗余,解压后能完全恢复原始数据。
- 有损压缩,例如JPEG图像压缩和MPEG视频压缩。
JPEG在压缩图像时会根据人眼对不同频率的视觉敏感度,舍弃一些高频信息以减小文件大小;MPEG则是针对视频的时间和空间冗余进行压缩。
2. 数字图像处理。
- 图像获取。
- 可以通过数码相机、扫描仪等设备获取数字图像。
考研数字媒体考试题目及答案

考研数字媒体考试题目及答案# 考研数字媒体考试题目及答案## 一、选择题1. 数字媒体技术中,以下哪项不是数字图像处理的基本操作?A. 缩放B. 旋转C. 裁剪D. 色彩调整答案:D2. 在数字音频编辑中,以下哪个术语描述的是音频信号的频率范围?A. 动态范围B. 采样率C. 比特率D. 频率响应答案:D3. 以下哪个软件不是用于视频编辑的?A. Adobe Premiere ProB. Final Cut ProC. PhotoshopD. Avid Media Composer答案:C## 二、简答题1. 简述数字媒体技术在现代广告中的应用。
数字媒体技术在现代广告中的应用非常广泛,它通过数字化手段增强了广告的吸引力和传播效率。
例如,利用3D建模技术可以创建逼真的产品展示,增强消费者的视觉体验;通过视频编辑软件可以制作动态的广告片,吸引观众的注意力;利用社交媒体平台的数字广告可以精准投放,提高广告的转化率。
2. 解释什么是数字水印技术,并简述其在数字媒体保护中的应用。
数字水印技术是一种将特定信息嵌入到数字媒体文件中的方法,这些信息通常不易被察觉,但可以通过特定的算法检测出来。
在数字媒体保护中,数字水印可以用来追踪媒体文件的来源和版权信息,防止未经授权的复制和分发,保护创作者的知识产权。
## 三、论述题1. 论述数字媒体技术对电影产业的影响。
数字媒体技术对电影产业产生了深远的影响。
首先,数字化拍摄技术使得电影制作更加便捷和经济,降低了电影制作的门槛。
其次,数字后期制作技术,如CGI(计算机生成图像)和视觉特效,极大地丰富了电影的表现形式和视觉体验。
此外,数字分发平台的出现,如在线视频点播服务,改变了电影的发行和观看模式,使得观众可以随时随地享受电影内容。
2. 分析数字媒体技术在教育领域的应用及其带来的变革。
数字媒体技术在教育领域的应用极大地提高了教学的互动性和趣味性。
例如,通过多媒体课件,教师可以结合图像、声音和视频等多种媒体形式,使抽象的概念更加直观易懂。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
������D =
E DF; ������
������D ������ ������D = −
E DF; ������
������D ������������������: ������ ������D
其中: ℎ ������D 为事件������D 的熵 ������ ������D 为事件������D 的信息量 Ø ������ = ������# − ������ ������ ������D 为事件������D 发生的概率
Vsignal:信号电压 Vnoise:量化噪声压
n:采样精度的位数 3、 声音质量与数据率 按频带可将声音质量划分为五个等级: (由低到高) 电话(telephone) 调幅广播(amplitude modulation, AM) 调频广播(frequency modulation, FM) 激光唱片(CD-Audio) 数字录音带(digital audio tape, DAT) P48 表 3-1 声音质量的 MOS 评分: 由若干实验者对声音质量好坏进行评分,求其平均值作为对声音质量的评价,这种方法叫做主观平均判分法。所得的 分数叫做主观平均分(mean opinion score, MOS) 4、 脉冲编码调制(pulse code modulation, PCM) ① PCM 的概念: 输入:模拟声音信号
③信息量(具有确定概率事件的信息的定量度量) ������ ������ = ������������������:
; < =
= −������������������: ������(������),p(x)是事件 x 出现的概率
☆对于等概率事件的集合,其每个事件的信息量=该集合的决策量 ④熵(事件信息的平均值) ������ ������ =
输出:PCM 样本 防失真滤波器:滤除声音频带以外的信号(低通滤波器) 波形编码器:可理解为采样器 量化器:量化阶大小生成器,或量化间隔生成器 ② 均匀量化 概念:采用相等的量化间隔对采样得到的信号进行量化 Ø 为适应幅度大的输入信号,同时又满足精度要求,就需要增加样本位数,但对话音信号来说,大信号出现的机会不多, 增加的样本位数没有充分利用,为克服此不足,便引入了非均匀量化,也叫非线性量化。 ③ 非均匀量化 概念:对输入信号进行量化时,大信号采用大的量化间隔,小的输入信号采用小的量化间隔。 采样输入信号幅度和量化输出数据之间的两种对应关系: ( 1) µ 律压扩算法 运用于北美和日本数字电话通信中 A 律压扩算法(运用于欧洲和中国大陆数字电话通信中) ln (1 + ������|������|) ln (1 + ������)
数据无损压缩
一、数据冗余 ①概念: 人为冗余 冗余 试听冗余 数据冗余 ②决策量(事件数的对数值) ������# = ������������������ (������),其中,n 是事件数(互斥时间) ( 1) ( 2) ( 3) Sh,以 2 为底的对数 Nat,以 e 为底的对数 Hart,以 10 为底的对数
②、30 路制的重要参数
l l l l
每帧由 32 个时间片(信道)组成 每个信息每次传送 8 位代码 数据传输率 R=32×8×8000=2048 kb/s 每一个话路的数据传输率=8000×8=64 kb/s
Ø 由于当信道无数据传输时仍给那个信道分配时间槽,因此线路利用率较低,为解决此问题开发了统计时分多路复用技术 (statistical time division multiplexing, STDM) ,按照每个传输信道的传输需要来分配时间间隔, 提高了传输线路的效率。 6、 增量调制与自适应增量调制 ( 1) 增量调制(delta modulation, DM) 是对实际的采样信号与预测的采样信号之差的极性进行编码,将极性变成“0”和“1”两种可能的取值,若 实际采样信号与预测的采样信号之差为“正” ,则用“1”表示,相反则用“0”表示。 ①斜率过载: 增量调制器的输出不能保持跟踪输入信号的快速变化,一般,当输入 信号的变化速度超过反馈回路输出信号的最大变化速度时就会发生斜率过载(主要原因:量化阶固定不变) ②粒状噪声: 在输入信号缓慢变化部分, 即输入信号与预测信号的差值接近零的区域, 增量调制器的输出出现随机交变的 “ 0” 和“1” ,这种噪声不可消除。 Ø ( 2) 自适应增量调制(adaptive delta modulation, ADM) 基本方法:检测到斜率过载时增大量化阶∆,而在输入信号的斜率减小时降低量化阶∆。 7、 自适应差分脉冲编码调制 ( 1) 自适应差分编码调制(adaptive pulse code modulation, APCM) 基本方法:根据输入信号幅度大小来改变量化阶大小。 瞬时自适应:量化阶大小每隔几个样本就改变 音节自适应:量化阶的大小在较长时间周期里发生改变 改变量化阶大小的两种方法: 前向自适应(forward adaption) 后向自适应(backward adaption) ( 2) 差分脉冲编码调制(differential pulse code modulation, DPCM) 基本方法:利用样本与样本之间存在的信息冗余来进行编码,根据过去的样本来估算下一个样本信号的幅度大小, 这个值成为预测值,然后对实际信号值与预测值之差进行量化编码,从而减少了表示每个样本信号的位数。 ( 3) 自适应差分脉冲编码调制(adaptive differential pulse code modulation, ADPCM) ①、利用自适应的思想改变量化阶大小,即用小的量化阶去编码小的差值,用大的量化阶去编码大的差值。 ②、使用过去的样本值估算下一个输入样本的预测值,使实际样本值和预测值之间的差值总是最小。 8、 子带编码(sub-band coding, SBC) 基本思想:使用一组带通滤波器(band-pass filter, BPF)把输入声音信号的频带划分成若干个连续的频段,每个频段称为子 带,对每个子带的声音信号采用单独的编码方式去编码,在信道上传输时,将每个子带的代码复合起来,接收端译码时,将 每个子带单独译码,然后再进行重组,还原成原来的声音信号。 子带编码的两个好处: ①:对每个子带信号分别进行自适应控制,量化阶的大小可按照每个子带的能量电平加以调节 ②:根据每个子带信号在感觉上的重要性,对每个子带分配不同的位数,用来表示每个样本值。 Ø 由于分割频带的滤波器不是理想滤波器,经过分带、编码、译码后合成输出的声音信号会有混迭效应,采用正交滤波器 (quadrature mirror filter, QMF)来划分频带,混迭效应在最后合成时会消失。 9、 线性预测编码(linear predictive coding, LPC) 宋 :输出不变时量化阶增大 50%,改变时减小 50% 格林弗斯基:连续出现三个同样的值,量化阶加一个较大的增量,反之,加一个较小的增量 增大量化阶 ⟹ 斜率过载改善 ⟹ 粒状噪声加重 减小量化阶 ⟹ 斜率过载严重 ⟹ 粒状噪声改善
1 + ln (������ ������ ) 1 ≤ |������| ≤ 1 1 + ������������������ ������
5、 PCM 在通信中的应用 ( 1) 频分多路复用(frequency-division multiplexing, FDM) 概念:在一条通信线路上使用不同频段同时传送多个独立信号,是模拟载波通信的主要方法。 核心思想:把传输信道划分为 n 个窄带,每个窄带传送一路信号。 ( 2) 时分多路复用(time-division multiplexing, TDM) 概念:在一条通信线路上使用不同时段传送多个独立信号的方法,是数字通信的主要方法。 核心思想:将时间分成等间隔的时段,为每对用户指定一个时间间隔,每个间隔传输信号的一部分,这样便可使多 用户同时使用一条传输线路。 ①、24 路制的重要参数: l l l l l l l 每秒传送 8000 帧,每帧 125������s 12 帧组成 1 复帧(用于同步) 每帧由 24 个时间片(信道)和 1 位同步位组成 每个信道每次传送 8 位代码,1 帧有 24×8+1=193 位 数据传输率 R=8000×8=64 kb/s 每秒传送 8000 帧,每帧 125������s 16 帧组成 1 复帧(用于同步)
⑤数据冗余(决策量超过熵的量) 信息量 I = 数据量 D − 冗余量 R
信息熵就是对于一个不确定事件集合信息量的平均值
二、统计编码 ①香农-范诺编码 目的:产生具有最小冗余的码词 基本思想:产生编码长度可变的码词 估计码词长度的准则:符号出现的概率,概率越大,码词长度越短。 算法: 1、按照符号出现的概率减少的顺序将待编码的符号排成序列 2、将符号分成两组,使两组符号概率近似或相等 3、将第一组赋为 0,第二组赋为 1 4、对每组重复步骤(2) ,直至每组剩下一个信源符号 ②霍夫曼编码 算法: 1、按出现概率排序 2、将两个最小的概率相加作为新的概率与余下的概率重新排队,每次相加都将“0”和“1”赋予相加的两个概率 3、重复步骤(2)直到最后概率相加得 1 Ø Ø 霍夫曼编码没有错误保护功能。 霍夫曼编码是可变长度码, 在编码时不需要在生成码流中附加同步码, 因此也难以随意查找或调用压缩文件中的内容, 然后再译码。 ③算数编码 编码:将整个要编码的数据依照其出现的概率映射到一个位于[0,1)的实数区间中。并且输出一个小于 1 同时大于 0 的小数来 表示全部数据。 1、从实数区间[0,1)开始,按照信源符号的频度将当前区间分割为若干个子区间 2、根据当前输入的符号选择对应的子区间,从选择的子区间中继续下一轮的分割 3、重复步骤(2)知道所有符号编码完毕
ijDkElm iEnDjo
男声 300~3000 Hz 女声 300~3400 Hz 高保真声音(high-fidelity audio) 10—20 KHz
ቤተ መጻሕፍቲ ባይዱ
= 20������������