提升HBase性能的几个地方
如何提高HBase性能

提高HBase 性能使用LSI® Nytro™ WarpDrive® 闪存加速卡主要结果LSI 进行的测试表明:部署具备Nytro WarpDrive 卡的HBase BucketCache 功能为HBase 环境带来明显的性能优势。
测试结果中,对于数据统一分布,每秒操作数提高达40 倍,平均延迟降低达17 倍。
Apache HBase™是一种横向扩展分布式数据库,旨在实现不间断实时访问大量非结构化大数据的容错能力。
HBase的可扩展性在于支持包含数十亿行以及数百万列的海量数据库表。
分布数据和延迟基于Hadoop Distributed File System (HDFS),HBase用于为服务器集群的分散式HDFS 数据的并行处理提供低延迟随机存取和极其快速的插入和更新的性能。
然而,如果数据集超过可用的DRAM 高速缓存,这种分布式数据可对HBase读访问操作带来明显的性能损失。
挑战在于利用硬盘驱动器(HDD)体系结构有限的读写响应能力来优化低延迟随机及大批量吞吐速率。
满足对HBase的性能需求为了满足对HBase部署项目的严格性能需求,采用了多种方法,但每种方法都有自己的挑战。
打破成本和复杂性障碍的一个解决方案是采用固态PCIe®闪存存储。
每秒I/O数超过硬盘驱动器200倍的固态存储,SSD为打破HBase系统的性能瓶颈提供了现实的解决方案。
为了利用闪存的高性能,HBase的架构中集成了具备独特BucketCache功能的闪存存储。
BucketCache 为主机内存提供补充缓存,作为从主机DRAM(LRU)缓存退出数据的临时缓存。
一方面增加额外的主机内存有助于提高性能,基于闪存的缓存可成倍提高用于HBase Region Server的DRAM有效容量。
这样能够实现更大的工作集,从而比单独使用DRAM和硬盘驱动器更快地处理更大的数据集。
而增加额外内存的方案的每千兆成本比闪存高出约25 倍,易丢失数据,且显著增加服务器能耗,同时由于Java 缓存管理的低效和管理开销,降低了缓存能力。
Hbase关键的几个点

Hbase关键的几个点荐书进行时•架构犹如探险,眼界必须超前(留言送书)一. 什么时候需要HBase1. 半结构化或非结构化数据对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用HBase。
当业务发展需要增加存储比如一个用户的email,phone,address信息时RDBMS需要停机维护,而HBase支持动态增加.2. 记录非常稀疏RDBMS的行有多少列是固定的,为null的列浪费了存储空间。
而如上文提到的,HBase为null的Column不会被存储,这样既节省了空间又提高了读性能。
3. 多版本数据根据Row key和Column key定位到的Value可以有任意数量的版本值,因此对于需要存储变动历史记录的数据,用HBase就非常方便了。
对于某一值,业务上一般只需要最新的值,但有时可能需要查询到历史值。
4. 超大数据量当数据量越来越大,RDBMS数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。
随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。
随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。
经历过这些事的人都知道过程是多么的折腾。
采用HBase就简单了,只需要加机器即可,HBase会自动水平切分扩展,跟Hadoop 的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce)。
二. HTable一些基本概念1. Row key行主键,HBase不支持条件查询和Order by等查询,读取记录只能按Row key(及其range)或全表扫描,因此Row key需要根据业务来设计以利用其存储排序特性(Table按Row key字典序排序如1,10,100,11,2)提高性能。
Hbase2.x新特性Hbase常见问题性优化小总结

Hbase2.x新特性Hbase常见问题性优化⼩总结在很早之前,我曾经写过两篇关于Hbase的⽂章:如果你没有看过,推荐收藏看⼀看。
另外,在我的CSDN有专门的HBase专栏可以系统学习,参考:《Hbase专栏》本⽂在上⾯⽂章的基础上,新增了更多的内容,并且增加了Hbase2.x版本的新功能。
Hbase常见问题集合问: Hbase⼤量写⼊很慢,⼀个列族,每个200多列,⼀秒写30000条数据,使⽤mutate添加数据,clientbuffer缓存⼤⼩为10M,四台测试机,128G内存,分配60G给Hbase,该怎么优化?答:可以使⽤bulkload⽅式写⼊,通过mr程序⽣产hfile⽂件,直接⽤bulkload导⼊⽣成的hfile⽂件,速度⾮常快。
问: hbase⼤规模的丢数据,整个数据库系统都挂掉了,然后发错误⽇志,说Hdfs内部的配置⽂件,hbase.version,丢失了。
⼤家有遇到过类似的问题吗?⾃建的集群。
答:检查⼀下⼀些服务的端⼝有没有暴露到公⽹,是不是集群被攻击了。
⾃建还是有⼀些风险的。
然后检查下⾃⼰的hbase配置。
看看数据的备份情况。
问: start-hbase.sh中有这么⼀段:if [ "$distMode" == 'false' ]then"$bin"/hbase-daemon.sh --config "${HBASE_CONF_DIR}" $commandToRun master $@else"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" $commandToRun zookeeper"$bin"/hbase-daemon.sh --config "${HBASE_CONF_DIR}" $commandToRun master"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" \--hosts "${HBASE_REGIONSERVERS}" $commandToRun regionserver"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" \--hosts "${HBASE_BACKUP_MASTERS}" $commandToRun master-backupfidistMode为false时表⽰单机,true时表⽰集群,看脚本好像是单机只启动master,是否是说单机环境下不需要zookeeper,regionserver这些的意思,可是⽹上搜了下⼜有⼈说单机环境下master和 zookeeper会运⾏在同⼀个jvm。
HBase性能优化方法总结

HBase性能优化方法总结本文主要是从HBase应用程序设计与开发的角度,总结几种常用的性能优化方法。
1. 表的设计1.1 Pre-Creating Regions默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。
一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。
有关预分区,详情参见:Table Creation: Pre-Creating Regions,下面是一个例子:[html]view plain copy1.public static boolean createTable(HBaseAdmin admin, HTableDescriptor table, byte[][] splits)2.throws IOException {3. try {4. admin.createTable(table, splits);5. return true;6. } catch (TableExistsException e) {7. ("table " + table.getNameAsString() + " already exists");8. // the table already exists...9. return false;10. }11.}12.13.public static byte[][] getHexSplits(String startKey, String endKey, int numRegions) {14. byte[][] splits = new byte[numRegions-1][];15. BigInteger lowestKey = new BigInteger(startKey, 16);16. BigInteger highestKey = new BigInteger(endKey, 16);17. BigInteger range = highestKey.subtract(lowestKey);18. BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));19.lowestKey = lowestKey.add(regionIncrement);20. for(int i=0; i <numRegions-1;i++) {21. BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));22. byte[] b = String.format("%016x", key).getBytes();23. splits[i] = b;24. }25. return splits;26.}1.2 Row KeyHBase中row key用来检索表中的记录,支持以下三种方式:•通过单个row key访问:即按照某个row key键值进行get操作;•通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;•全表扫描:即直接扫描整张表中所有行记录。
hbase 使用场景

hbase 使用场景
HBase是一个分布式的、面向列的数据库,它在大数据存储和分析领域有着广泛的应用。
以下是 HBase 的一些使用场景:
1. 实时数据处理:HBase 支持高并发的读写操作,可以快速处理海量的实时数据。
一些实时数据处理场景,例如实时日志分析、实时数据监控等,都可以使用 HBase 实现。
2. 大数据存储:HBase 适合存储大规模的结构化数据,例如用户行为数据、日志数据等。
由于 HBase 是分布式的,可以轻松地实现数据的横向扩展,支持 PB 级别的数据存储。
3. 数据库缓存:HBase 可以作为数据库的缓存层,将数据缓存在内存中,提高访问速度和效率。
在读写频繁的场景下,使用 HBase 作为缓存层可以有效减轻数据库的负担。
4. 时序数据存储:HBase 支持按时间顺序存储数据,特别适合存储时间序列数据,例如传感器数据、股票行情数据等。
5. 图数据库:HBase 支持快速的图遍历和查询操作,可以作为图数据库使用。
在社交网络、推荐系统等场景中,使用 HBase 作为图数据库可以提高查询效率。
总之,HBase 在大数据存储和分析领域有着广泛的应用,可以满足各种不同的数据存储需求。
- 1 -。
hbase概述

hbase概述HBase是Apache Hadoop生态系统中的一个分布式非关系型数据库。
它是以Google的Bigtable为基础实现的,旨在为大规模分布式系统提供高可靠性、高性能的数据存储和处理能力。
HBase的设计目标是适用于海量数据环境下的随机实时读写,并能够容忍硬件故障。
HBase的特点和优势主要包括以下几个方面:1.分布式架构:HBase使用分布式架构来存储数据,数据可以水平扩展到数千台机器上。
它采用了Hadoop的HDFS(Hadoop Distributed File System)作为底层存储,可以自动在集群中多节点上复制数据,实现分布式存储和高可靠性。
2.高可扩展性:由于HBase采用分布式架构,可以通过简单地增加集群中的机器来扩展系统的容量和性能。
通过添加更多的Region Server节点,HBase能够支持PB级别的数据规模。
3.列式存储:HBase将数据以列式存储在磁盘上,相比传统的行式数据库,这种存储方式在某些场景下可以提供更好的查询性能。
此外,HBase还支持列族的概念,可以将相关的列进行组织,提高查询效率。
4.高性能读写:HBase支持高性能的读写操作,可以满足实时查询和更新的需求。
HBase的数据模型和存储方式使得它在随机读写方面表现出色,适合处理大量的随机访问操作。
5.强一致性:HBase提供强一致性的数据一致性模型,即读取操作总是可以看到最新的数据。
这种特性使得HBase适用于许多需要数据一致性的应用场景,如金融、电信等领域。
6.数据复制和容错:HBase采用副本机制来实现数据的复制和容错。
可以将数据副本存储在不同的Region Server上,以提高系统的容错能力和可靠性。
当某个副本节点发生故障时,可以自动切换到其他副本节点进行读写操作。
7.可伸缩的数据模型:HBase数据模型是非常灵活和可伸缩的,可以存储具有不同结构的数据。
HBase支持动态添加和删除列族,以及在行级别上进行事务处理。
阐述hbase的基本特点和概念。

HBase是一个分布式的、面向列的开源数据库存储系统,具有高可靠性、高性能和可伸缩性,它可以处理分布在数千台通用服务器上的PB级的海量数据。
以下是HBase的基本特点和概念:1.高可靠性:HBase使用Hadoop分布式文件系统(HDFS)作为其文件存储系统,具有高可靠性。
它利用Zookeeper作为协同服务,确保在系统出现故障时,数据不会丢失。
2.高性能:HBase具有高性能,可以在廉价的PC Server上搭建大规模结构化存储集群。
它使用Hadoop MapReduce来处理海量数据,确保数据能够快速地被访问和处理。
3.面向列:HBase是一个面向列的数据库,这意味着它以列族的形式存储数据,而不是以行的形式存储。
这使得HBase非常适合于处理大型数据集,因为它可以更快地访问和过滤数据。
4.可伸缩性:HBase可以轻松地扩展到数千台服务器,使其能够处理PB级别的数据。
这使得HBase成为处理大规模数据的理想选择。
5.适合非结构化数据存储:HBase不限制存储的数据的种类,允许动态的、灵活的数据模型。
它适合于存储非结构化数据,如文本、图像或音频等。
6.主从架构:HBase是主从架构,其中HMaster作为主节点,HRegionServer作为从节点。
HMaster负责协调和分配任务给各个HRegionServer,而HRegionServer则负责处理和存储数据。
7.多版本数据:HBase为null的记录不会被存储,同时它也支持多版本号数据。
这使得HBase可以方便地存储变动历史记录,比如用户的Address变更。
总的来说,HBase是一个非常强大和灵活的数据库系统,适用于处理大规模的非结构化数据。
hbase高可用原理

hbase高可用原理HBase(Hadoop数据库)的高可用原理包括以下几个方面:1. 数据复制:HBase使用Hadoop的HDFS作为底层存储,HDFS自身提供了数据复制机制。
当一个数据块被写入HDFS时,会自动对其进行多次复制,默认情况下是3次。
这样可以确保即使在某个节点出现故障时,仍然可以从其他节点读取数据。
2. HBase主从复制:在HBase中,一个RegionServer可以托管多个Region,而每个Region有多个副本。
HBase使用主从复制机制,将主副本存储在不同的RegionServer上。
当主副本所在的RegionServer发生故障时,HBase可以通过切换到副本来保证数据的可用性。
3. ZooKeeper:HBase使用ZooKeeper来实现分布式协调和管理。
ZooKeeper 可以监控HBase集群中各个节点的状态,并在节点发生故障时进行快速的故障检测和恢复。
通过ZooKeeper,HBase可以实现集群的自动故障转移和负载均衡。
4. RegionServer故障转移:当一个RegionServer发生故障时,HBase会通过ZooKeeper检测到该故障,并将该RegionServer上的Region重新分配到其他正常的RegionServer上。
这样可以确保整个HBase集群中的数据在某个节点故障时仍然可以持续可用。
5. 自动负载均衡:HBase会根据集群中各个RegionServer的负载情况,动态将Region分配到不同的RegionServer上,以实现负载均衡。
这样可以确保各个RegionServer的负载相对均衡,提高整个集群的运行效率和可用性。
总之,HBase的高可用性主要是通过数据复制、主从复制、ZooKeeper、故障转移和负载均衡等机制来实现的。
这些机制可以确保在节点故障或负载不平衡时,HBase集群仍然能够提供高可用和高性能的数据访问服务。
hbase数据库特点及应用场景

hbase数据库特点及应用场景HBase是一个基于Hadoop的分布式、面向列的NoSQL数据库,被设计用来存储大规模的结构化和半结构化数据。
以下是HBase数据库的特点及其应用场景的相关参考内容。
特点:1. 高可靠性:HBase使用了Hadoop的HDFS作为底层文件系统,数据会被自动复制到集群中其他节点上,可以保证数据的可靠性和容错性。
2. 高扩展性:HBase具有横向扩展的特性,可以通过增加节点来实现更高的吞吐量和存储容量。
3. 高性能:HBase使用了内存和硬盘结合的方式进行数据存储,同时支持数据的并发读写操作,可以满足实时性要求较高的应用场景。
4. 面向列的存储:HBase将数据按列族进行存储,可以灵活地增加、删除和修改列,提供了更好的灵活性和可扩展性。
5. 灵活的数据模型:HBase的数据模型类似于一个稀疏的多维表格,可以方便地存储和查询具有不同列的数据。
6. 复杂查询:HBase提供了强大的查询功能,支持复杂的过滤器和多维范围查找,可以进行高效的数据分析和计算。
应用场景:1. 日志处理:由于HBase具有高可靠性和高扩展性的特点,适合用于大规模日志的存储和分析。
可以存储各种类型的日志数据,并通过HBase提供的查询功能进行实时分析和统计。
2. 个性化推荐系统:个性化推荐系统通常需要存储大量的用户行为数据和物品数据,HBase的高性能和高扩展性使其成为一个理想的选择。
可以将用户的行为日志和个人信息存储在HBase中,并通过数据分析算法进行实时的推荐计算。
3. 时序数据存储:HBase对于时序数据的存储和查询有着很好的支持,适用于物联网、电力、金融等领域的实时监控和分析。
可以将具有时间属性的数据存储在HBase中,通过按时间范围进行查询和聚合分析。
4. 在线教育平台:在线教育平台通常需要存储大量的学生课程数据和学习行为数据,HBase的高性能和灵活的数据模型适合存储和查询这些数据。
可以将学生的课程信息和学习记录存储在HBase中,并通过数据分析提供个性化的学习推荐和统计报表。
hbase数据库特点及应用场景

hbase数据库特点及应用场景HBase数据库(Hadoop数据库)是一个基于Hadoop分布式文件系统的分布式列式数据库。
它是Apache Hadoop生态系统的一部分,为海量数据提供了高可靠性、高性能和高扩展性的存储解决方案。
以下是HBase数据库的特点及应用场景的相关参考内容。
特点:1. 分布式存储:HBase使用Hadoop分布式文件系统(HDFS)作为底层存储,数据以分布式方式存储在不同的节点上,可以实现海量数据的高效存储和处理。
2. 列式存储:HBase采用列式存储模式,将数据按列进行存储,这种模式相比传统的行式存储更适合于大数据环境下的查询和分析。
3. 高可靠性:HBase通过数据的副本机制确保数据的高可靠性。
每个数据都会在集群的多个节点上存储多个副本,当某个节点出现故障时,可以快速恢复数据。
4. 高性能:HBase支持读写操作的快速响应,可以实现数据的实时查询和快速写入。
它采用了内存和硬盘的混合存储方式,在内存中缓存热数据,提高了查询的性能。
5. 高扩展性:HBase通过横向扩展的方式支持集群的扩展,可以轻松地添加或删除节点来适应数据的增长。
同时,HBase还支持数据的自动分区和负载均衡,提高了存储和查询的效率。
应用场景:1. 日志处理:HBase适用于大规模的日志数据处理,如网络日志、应用日志等。
它可以快速地写入和查询日志数据,并且可以通过分析日志数据来提取有价值的信息。
2. 物联网(IoT)数据存储:随着物联网的发展,大量的传感器和设备产生的数据需要进行存储和分析。
HBase可以作为IoT数据的存储引擎,支持高吞吐量的数据写入和实时查询。
3. 在线实时分析(OLAP):HBase具有快速的写入和查询性能,适合用于在线实时分析场景。
它可以处理大量的数据并提供快速的响应,可以支持实时的数据分析和决策。
4. 社交网络分析:HBase适用于存储和分析社交网络中的大量数据。
例如,可以使用HBase存储用户关系数据、用户行为数据等,并通过分析这些数据了解用户的兴趣和行为。
phoenix hbase原理

phoenix hbase原理Phoenix是一种在HBase上构建关系型数据库的开源工具。
它是基于HBase的列式存储和分布式计算能力构建的,提供了对HBase数据的SQL查询和事务功能。
以下是Phoenix与HBase的原理:1. 数据模型:Phoenix将HBase的列式存储模型转化为行式存储模型,通过将一组相关的列数据组织在一起,形成行数据。
这使得可以在HBase中执行类似关系数据库中的查询和事务操作。
2. 压缩和优化:Phoenix利用HBase的行键排序和压缩机制来提高查询性能。
它将相邻的行数据存储在相邻的HBase Region服务器上,以便在查询时可以快速定位并检索数据。
3. 查询计划和优化:Phoenix使用SQL查询语句来查询HBase 数据,并根据查询语句解析构建查询计划。
它使用一种称为Cost-Based Optimizer的优化器来选择最佳的查询计划。
该优化器使用统计信息和查询成本估算来选择最有效的执行路径。
4. 查询执行:一旦查询计划确定,Phoenix将查询发送到HBase集群中的相应Region服务器上执行。
结果会被返回给客户端进行处理。
5. 事务支持:Phoenix提供了ACID事务的功能,使多个查询和更新可以作为一个原子操作执行。
它利用HBase的事务特性来实现事务一致性和隔离性。
6. 索引支持:Phoenix支持在HBase表上创建索引,以加速查询操作。
它使用了类似于传统关系数据库的B树索引来提高查询性能。
总的来说,Phoenix利用HBase的分布式存储和计算能力,在HBase之上构建了一个关系型数据库。
它提供了SQL查询、事务和索引等功能,使得在HBase上操作数据更加方便和高效。
hbase知识点总结

hbase知识点总结HBase的特点:1. 高可靠性:HBase采用了分布式架构,数据被分布存储在多个节点上,因此可以提高系统的可靠性,即使某些节点发生故障,也能保证系统的正常运行。
2. 高性能:HBase支持并发访问、扩展性好,可以处理大规模数据,并提供快速的读写性能。
3. 灵活的数据模型:HBase采用列存储的模式,数据存储在表中的列族中,可以动态地增加列族和列,适合存储半结构化、非结构化的数据。
4. 水平扩展:HBase可以通过增加或减少节点的方式进行扩展,可以适应数据规模的增长。
HBase的原理:1. 数据模型:HBase的数据模型是面向列族的,数据存储在表中的行和列族中,每个列族包含多个列,每个列有一个时间戳,可以存储多个版本的数据。
这种数据模型适合存储稀疏数据,可以动态地增加列族、列。
2. 分布式存储:HBase采用了分布式存储的方式,数据被分割成多个区域,并存储在不同的RegionServer节点上,每个RegionServer管理多个Region,Region则包含多个Store,每个Store包含一个或多个列族。
3. 架构组件:HBase包含Master节点和RegionServer节点,Master节点负责管理集群的元数据信息、负载均衡、安全性等,RegionServer节点则负责存储和处理数据。
HBase还包含ZooKeeper节点用于协调集群中各个节点的状态和配置信息。
4. 读写操作:HBase的读操作是通过Row Key来获取数据,可以在列族、列和时间戳上进行过滤,支持多版本数据的读取。
写操作则是先将数据写入MemStore,当MemStore的数据达到一定大小时,将数据刷写到磁盘中的HFile文件。
HBase的使用方法:1. 数据模型设计:在使用HBase之前,需要对数据进行合理的数据模型设计,包括表的结构、列族的设计、Row Key的选择等。
要根据实际的业务需求来进行设计,保证数据的高效访问和存储。
HBase性能优化方法总结(四):数据计算

HBase性能优化⽅法总结(四):数据计算本⽂主要是从HBase应⽤程序设计与开发的⾓度,总结⼏种常⽤的性能优化⽅法。
有关HBase系统配置级别的优化,可参考:。
下⾯是本⽂总结的第四部分内容:数据计算相关的优化⽅法。
4. 数据计算4.1 服务端计算运⾏于HBase RegionServer服务端,各个Regions保持对与其相关的coprocessor实现类的引⽤,coprocessor类可以通过RegionServer上classpath中的本地jar或HDFS的classloader进⾏加载。
⽬前,已提供有⼏种coprocessor:Coprocessor:提供对于region管理的钩⼦,例如region的open/close/split/flush/compact等;RegionObserver:提供⽤于从客户端监控表相关操作的钩⼦,例如表的get/put/scan/delete等;Endpoint:提供可以在region上执⾏任意函数的命令触发器。
⼀个使⽤例⼦是RegionServer端的列聚合,这⾥有。
以上只是有关coprocessor的⼀些基本介绍,本⼈没有对其实际使⽤的经验,对它的可⽤性和性能数据不得⽽知。
感兴趣的同学可以尝试⼀下,欢迎讨论。
4.2 写端计算4.2.1 计数HBase本⾝可以看作是⼀个可以⽔平扩展的Key-Value存储系统,但是其本⾝的计算能⼒有限(Coprocessor可以提供⼀定的服务端计算),因此,使⽤HBase时,往往需要从写端或者读端进⾏计算,然后将最终的计算结果返回给调⽤者。
举两个简单的例⼦:PV计算:通过在HBase写端内存中,累加计数,维护PV值的更新,同时为了做到持久化,定期(如1秒)将PV计算结果同步到HBase中,这样查询端最多会有1秒钟的延迟,能看到秒级延迟的PV结果。
分钟PV计算:与上⾯提到的PV计算⽅法相结合,每分钟将当前的累计PV值,按照rowkey + minute作为新的rowkey写⼊HBase中,然后在查询端通过scan得到当天各个分钟以前的累计PV值,然后顺次将前后两分钟的累计PV值相减,就得到了当前⼀分钟内的PV值,从⽽最终也就得到当天各个分钟内的PV值。
HBase写入性能提高

put.add(toByte("fam1"), toByte("qualifier4"), toByte(UUID.randomUUID().toString()));
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
}
public static void main(String[] args) {
PerformanceComparison test = new PerformanceComparison();
try {
test.createTable();
long start = System.currentTimeMillis();
put.add(toByte("fam1"), toByte("qualifier1"), toByte(UUID.randomUUID().toString()));
put.add(toByte("fam1"), toByte("qualifier2"), toByte(UUID.randomUUID().toString()));
tableDesc.addFamily(new HColumnDescriptor("fam1"));//family
HBase 数据库检索性能优化策略大数据培训

HBase 数据库检索性能优化策略兄弟连IT教育作为国内领先的培训机构,迄今已有10年的教育历史。
8大特色课程:PHP培训、安卓培训、JAVAEE+大数据、UI设计、HTML5培训、云计算架构师,虚拟现实VR培训,机器人教育培训,在目前IT市场特别火,每门课程都由名师牵头,以认认真真的态度做教育。
HBase 数据表介绍HBase 数据库是一个基于分布式的、面向列的、主要用于非结构化数据存储用途的开源数据库。
其设计思路来源于 Google 的非开源数据库”BigTable”。
HDFS 为 HBase 提供底层存储支持,MapReduce 为其提供计算能力,ZooKeeper 为其提供协调服务和failover(失效转移的备份操作)机制。
Pig 和 Hive 为 HBase 提供了高层语言支持,使其可以进行数据统计(可实现多表 join 等),Sqoop 则为其提供 RDBMS 数据导入功能。
HBase 不能支持 where 条件、Order by 查询,只支持按照主键 Rowkey 和主键的 range 来查询,但是可以通过 HBase 提供的 API 进行条件过滤。
HBase 的 Rowkey 是数据行的唯一标识,必须通过它进行数据行访问,目前有三种方式,单行键访问、行键范围访问、全表扫描访问。
数据按行键的方式排序存储,依次按位比较,数值较大的排列在后,例如 int 方式的排序:1,10,100,11,12,2,20…,906,…。
ColumnFamily 是“列族”,属于 schema 表,在建表时定义,每个列属于一个列族,列名用列族作为前缀“ColumnFamily:qualifier”,访问控制、磁盘和内存的使用统计都是在列族层面进行的。
Cell 是通过行和列确定的一个存储单元,值以字节码存储,没有类型。
Timestamp 是区分不同版本 Cell 的索引,64 位整型。
不同版本的数据按照时间戳倒序排列,最新的数据版本排在最前面。
关于hbase表的特点描述

HBase 表的特点描述
HBase 是一个分布式、可扩展、高性能的列式存储系统,它适用于存储海量的结构化数据。
HBase 表具有以下特点:
1. 海量存储:HBase 适合存储 PB 级别的海量数据,在 PB 级别的数据以及采用廉价 PC 存储的情况下,能在几十到百毫秒内返回数据。
这与 Hbase 的极易扩展性息息相关。
正式因为 Hbase 良好的扩展性,才为海量数据的存储提供了便利。
2. 列式存储:HBase 采用的是列式存储,即根据列族来存储数据。
列族下面可以有非常多的列,列族在创建表的时候就必须指定。
这种存储方式可以节省存储空间,提高查询效率。
3. 极易扩展:HBase 的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加 RegionSever 的机器,进行水平扩展,提升Hbase 上层的处理能力,提升 Hbsae 服务更多 Region 的能力。
同时,通过横向添加 Datanode 的机器,进行存储层扩容,提升 Hbase 的数据存储能力和提升后端存储的读写能力。
4. 高并发:HBase 具有高并发处理能力,能够应对大量的同时访问。
这是因为 HBase 采用了基于列的访问控制和负载均衡技术,使得在并发访问时,能够有效地分配访问请求,提高系统的响应能力。
5. 稀疏:HBase 表具有稀疏特性,即在列数据为空的情况下,不会占用存储空间。
这种特性可以节省存储空间,提高系统的性能。
HBase读写性能优化
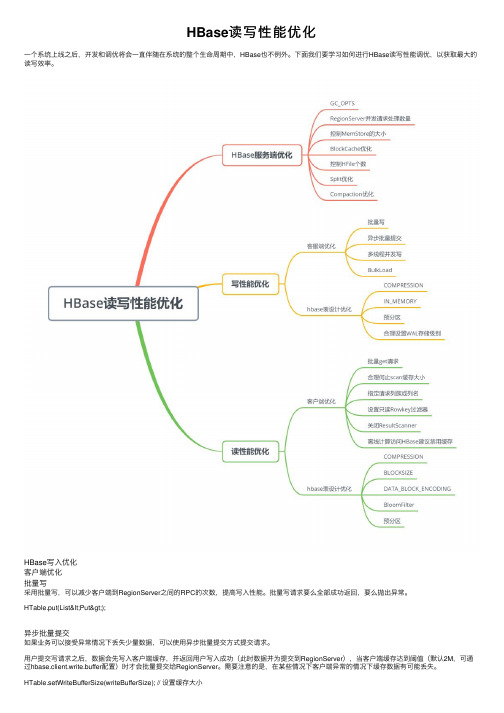
HBase读写性能优化⼀个系统上线之后,开发和调优将会⼀直伴随在系统的整个⽣命周期中,HBase也不例外。
下⾯我们要学习如何进⾏HBase读写性能调优,以获取最⼤的读写效率。
HBase写⼊优化客户端优化批量写采⽤批量写,可以减少客户端到RegionServer之间的RPC的次数,提⾼写⼊性能。
批量写请求要么全部成功返回,要么抛出异常。
HTable.put(List<Put>);异步批量提交如果业务可以接受异常情况下丢失少量数据,可以使⽤异步批量提交⽅式提交请求。
⽤户提交写请求之后,数据会先写⼊客户端缓存,并返回⽤户写⼊成功(此时数据并为提交到RegionServer),当客户端缓存达到阈值(默认2M,可通过hbase.client.write.buffer配置)时才会批量提交给RegionServer。
需要注意的是,在某些情况下客户端异常的情况下缓存数据有可能丢失。
HTable.setWriteBufferSize(writeBufferSize); // 设置缓存⼤⼩HTable.setAutoFlush(false);多线程并发写客户端开启多个HTable写线程,每个写线程负责⼀个HTable对象的flush操作,这样结合定时flush和写buffer,可以即保证在数据量⼩的时候,数据可以在较短时间内被flush,同时⼜保证在数据量⼤的时候,写buffer⼀满就即使进⾏flush。
使⽤BulkLoad写⼊在HBase中数据都是以HFile形式保存在HDFS中的,当有⼤量数据需要写⼊到HBase的时候,可以采⽤BulkLoad⽅式完成。
使⽤MapReduce或者Spark直接⽣成HFile格式的数据⽂件,然后再通过RegionServer将HFile数据⽂件移动到相应的Region上去。
写数据表设计调优COMPRESSION配置数据的压缩算法,这⾥的压缩是HFile中block级别的压缩。
HBase(十)HBase性能调优总结

HBase(⼗)HBase性能调优总结⼀. HBase的通⽤优化1 ⾼可⽤在 HBase 中 Hmaster 负责监控 RegionServer 的⽣命周期,均衡 RegionServer 的负载,如果 Hmaster 挂掉了,那么整个 HBase 集群将陷⼊不健康的状态,并且此时的⼯作状态并不会维持太久。
所以 HBase ⽀持对 Hmaster 的⾼可⽤配置。
HBase的⾼可⽤集群搭建参考:2 Hadoop 的通⽤性优化1) NameNode 元数据备份使⽤ SSD2) 定时备份 NameNode 上的元数据每⼩时或者每天备份,如果数据极其重要,可以 5~10 分钟备份⼀次。
备份可以通过定时任务复制元数据⽬录即可。
3) 为 NameNode 指定多个元数据⽬录使⽤ .dir 或者 .dir 指定。
这样可以提供元数据的冗余和健壮性,以免发⽣故障。
4) NameNode 的 dir ⾃恢复设置 .dir.restore 为 true,允许尝试恢复之前失败的 .dir⽬录,在创建 checkpoint 时做此尝试,如果设置了多个磁盘,建议允许。
5) HDFS 保证 RPC 调⽤会有较多的线程数属性:node.handler.count解释:该属性是 NameNode 服务默认线程数,默认值是 10,根据机器的可⽤内存可以调整为 50~100属性:dfs.datanode.handler.count解释:该属性默认值为 10,是 DataNode 的处理线程数,如果 HDFS 客户端程序读写请求⽐较多,可以调⾼到 15~20,设置的值越⼤,内存消耗越多,不要调整的过⾼,⼀般业务中,5~10 即可。
hdfs-site.xml6) HDFS 副本数的调整属性:dfs.replication解释:如果数据量巨⼤,且不是⾮常之重要,可以调整为 2~3,如果数据⾮常之重要,可以调整为 3~5。
hdfs-site.xml7) HDFS ⽂件块⼤⼩的调整属性:dfs.blocksize解释:块⼤⼩定义,该属性应该根据存储的⼤量的单个⽂件⼤⼩来设置,如果⼤量的单个⽂件都⼩于 100M,建议设置成 64M 块⼤⼩,对于⼤于 100M 或者达到 GB 的这种情况,建议设置成 256M,⼀般设置范围波动在 64M~256M 之间。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
提升HBase性能的几个地方
1、使用bloomfilter和mapfile_index_interval
注意:在1.9.3版本的hbase中,bloomfilter是不支持的,存在一个bug,可以通过如下的修改加以改正:
(1)、在方法org.apache.hadoop.hbase.regionserver.HStore.createReaders()中,找到如下行
BloomFilterMapFile.Reader reader = file.getReader(fs, false, false);
将其改成
BloomFilterMapFile.Reader reader = file.getReader(fs,
this.family.isBloomfilter(), false);
(2)、在方法org.apache.hadoop.hbase.HColumnDescriptor.toString()中,找到如下的代码行
if (key != null && key.toUpperCase().equals(BLOOMFILTER)) {
// Don't emit bloomfilter. Its not working.
continue;
}
将其注释掉
2、hbase对于内存有特别的嗜好,在硬件允许的情况下配足够多的内存给它。
通过修改hbase-env.sh中的
export HBASE_HEAPSIZE=3000 #这里默认为1000m
3、修改java虚拟机属性
(1)、在环境允许的情况下换64位的虚拟机
(2)、替换掉默认的垃圾回收器,因为默认的垃圾回收器在多线程环境下会有更多的wait 等待
export HBASE_OPTS="-server -XX:NewSize=6m -XX:MaxNewSize=6m
-XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode"
4、增大RPC数量
通过修改hbase-site.xml中的
hbase.regionserver.handler.count属性,可以适当的放大。
默认值为10有点小
5、做程序开发是注意的地方
(1)、需要判断所求的数据行是否存在时,尽量不要用HTable.exists(final byte [] row) 而用HTable.exists(final byte [] row, final byte[] column)等带列族的方法替代。
(2)、不要使用HTable.get(final byte [] row, final byte [] column) == null来判断所求的数据存在,而是用HTable.exists(final byte [] row, final byte[] column)替代
(3)、HTable.close()方法少用.因为我遇到过一些很令人费解的错误
6、记住HBase是基于列模式的存储,如果一个列族能搞定就不要把它分开成两个,关系数据库的那套在这里很不实用.分成多个列来存储会浪费更多的空间,除非你认为现在的硬盘和白菜一个价。
7、如果数据量没有达到TB级别或者没有上亿条记录,很难发挥HBase的优势,建议换关系数据库或别的存储技术。
本文转载自:
/chenjingjing/archive/2010/01/26/1656895.html。