目标分割和分类研究
医学图像分割的意义、概念、分类和研究现状

第1章绪论1.1 引言当今社会,是知识经济的社会,高新科技飞速发展。
入们在迅速发展新科技的同时,也越来越关注自身的生活环境与医疗条件。
健康,越来越成为每一个入倾心关注和孜孜追求的意境。
然焉,群学技术是一把双刃剑,它带给人们得到的同时也在破坏着我们赖以生存的环境,从而严重威害人类的健康。
堪愧的环境,沉重的压力以及激烈的竞争,都侵入们的健康走入低餐,从而健康成为全人类共同关注的目标。
因此医学的发展面临严重的挑战,作为医生诊断和治疗重要手段的医学影像学也得到了相应的发展。
现今,医学图像在医疗诊断中起着不可低估的重要作用。
计算机断层扫描、核磁共振(Magnetic Resonance,MR)、超声(Ultras叫nd)以及其它成像技术等,都是无侵害性的器宫体外成像的有力手段。
但是,医学图像还有一个显著的特点,由于受成像设备的影响、局部体效应(同一个体素中包含多种组织)、患者的体位运动和检查床的匀速直线运动,使得医学图像不可避免地盘现噪声和伪影,边缘模糊和信号强度不均匀现缓,例如信号强度在同一种组织中会出现大幅度的变化或在同一个物体中也不均匀。
此外,在图像形成和传输的过程中,图像的像质也会受到一定的影响,这些都给医生下达准确的诊断造成了一定的障碍。
为了提高医学图像的可读性,使得医生可以对人体的解割结构以及病变部位进行更有效的观察和诊断,提离诊断的准确率,医学图像处理从而成为了一门应用性很强的学科而且得到了长足的发展。
1.2 医学图像分割的意义、分类及其研究现状1.2.1 医学图像分割的意义医学图像分割在医学研究、临床诊断、病理分析、手术计划、影像信息处理、计算机辅助手术等医学研究与实践领域中有着广泛的应用和研究价值,具体表现为以下几个方面:(1) 用于感兴趣区域提取,便于医学图像的分析和识别。
如不同形式或来源的医学图像配准与融合,解剖结构的定量度量、细胞的识别与计数、器官的运动跟踪及同步等;(2)用于人体器官、组织或病灶的尺寸、体积或容积的测量。
基于迁移学习的图像分割与分类算法研究

基于迁移学习的图像分割与分类算法研究摘要:随着深度学习的快速发展,图像分割和分类在计算机视觉领域得到了广泛应用。
然而,由于标注样本的成本和困难度,传统的深度学习方法往往在数据相对较少的领域表现欠佳。
为了解决这一问题,迁移学习成为了图像分割与分类领域的研究热点。
本文深入探讨了基于迁移学习的图像分割与分类算法的研究现状,并提出了一种新的算法来提高图像分割与分类的性能。
第一章绪论1.1 研究背景图像分割和分类是计算机视觉领域的两个重要问题。
随着深度学习的兴起,许多基于深度学习的方法在图像分割和分类任务上取得了巨大成功。
然而,传统的深度学习方法往往需要大量的标注样本来训练模型,而在某些领域中,标注样本的获取成本昂贵且困难。
因此,如何在数据较少的情况下提高图像分割和分类的性能成为了一个重要的研究问题。
1.2 研究目标本文旨在研究基于迁移学习的图像分割与分类算法,以提高在数据不足的情况下的性能表现。
通过借用源任务的知识或模型,迁移学习可以帮助目标任务在数据较少的情况下取得更好的效果。
第二章相关研究综述2.1 图像分割算法综述本章将介绍图像分割算法的发展历程。
从传统的基于阈值的分割算法到基于深度学习的端到端分割算法,对各种方法的原理和优缺点进行详细的介绍。
2.2 图像分类算法综述本章将介绍图像分类算法的研究现状。
从传统的基于特征提取和分类器的方法到基于深度学习的端到端分类算法,对各种方法的原理和优缺点进行详细的介绍。
2.3 迁移学习在图像分割与分类中的应用本章将介绍迁移学习在图像分割与分类领域的应用情况。
从迁移学习的基本原理到各种迁移学习方法的综述,对其在图像分割与分类中的优势和不足进行详细的分析。
第三章基于迁移学习的图像分割与分类算法3.1 算法原理本章将介绍基于迁移学习的图像分割与分类算法的原理。
该算法基于源任务的模型,在目标任务上进行微调,以获得更好的性能。
3.2 算法实现本章将介绍基于迁移学习的图像分割与分类算法的具体实现。
高光谱图像地物分类和分割方法研究的开题报告

高光谱图像地物分类和分割方法研究的开题报告一、研究背景高光谱遥感技术是遥感技术中的一种新型技术,它可以对地表的物质成分进行精细化的探测。
高光谱图像具有较高的光谱分辨率,能够获取到地物的大量光谱信息。
因此,高光谱图像在地物分类和分割领域有着广泛的应用,例如:城市规划、土地利用、农业生产等。
高光谱遥感图像的分类和分割是高光谱图像处理的重要研究领域,可以通过对图像进行预处理、特征提取和分类方法等方面的优化,提高高光谱图像分类和分割的精度和效率,在实际应用中起到重要的作用。
二、研究内容1. 高光谱图像的预处理对高光谱图像进行预处理,包括了噪声去除、波段选择、数据降维等一系列工作。
其中,波段选择是预处理中的一个重要步骤,可以针对不同的分类和分割对象,选择合适的波段进行分类和分割。
2. 高光谱图像的特征提取特征提取是高光谱图像分类和分割的关键步骤,通常包括了光谱特征和空间特征两个方面。
光谱特征是指通过对不同波段的光谱响应值进行分析和提取,得到具有代表性的特征向量。
空间特征是指通过对图像进行空间分析和处理,提取出与地物分布、形状等相关的特征。
3. 高光谱图像的分类方法分类方法是高光谱图像分类和分割中的核心步骤,通常包括了基于像素的方法、基于目标的方法以及基于深度学习的方法。
目前,基于深度学习的方法在高光谱图像分类和分割领域表现出了较好的效果,成为研究热点之一。
4. 高光谱图像的分割方法高光谱图像分割是指将图像中的像素分成不同的地物分类,通常包括了基于区域的方法、基于像素的方法以及基于深度学习的方法。
其中,基于深度学习的方法表现出了较好的效果,成为研究热点之一。
三、研究意义高光谱图像分类和分割是遥感图像领域的重要研究方向,对于研究地表的物质成分、精准农业、城市规划等领域具有重要的应用价值。
本研究旨在探究高光谱图像分类和分割的关键技术,为高光谱图像的精准应用提供技术支持和理论指导。
四、研究方法本研究将采用实验研究和理论分析相结合的方式,通过对高光谱图像分类和分割方法的分析、实验验证,提出新的高光谱图像分类和分割方法,提高高光谱图像分类和分割的精度和效率。
小目标语义分割 评价指标

小目标语义分割评价指标(原创版)目录1.引言2.小目标语义分割的定义和意义3.评价指标的选择与应用4.实例分析5.结论正文【引言】随着深度学习技术的发展,语义分割在计算机视觉领域取得了显著的进展。
小目标语义分割作为语义分割的一个研究方向,旨在提高模型对小目标的识别和分割能力。
为了衡量小目标语义分割模型的性能,需要选用合适的评价指标。
本文将对小目标语义分割的评价指标进行探讨。
【小目标语义分割的定义和意义】小目标语义分割是指在图像中对尺寸较小的目标进行语义分割,即对图像中的每个像素点进行分类,将其归属到相应的类别中。
相较于传统的语义分割任务,小目标语义分割更具挑战性,因为它需要模型在高分辨率下对目标进行准确的分类。
小目标语义分割在实际应用中具有重要意义,例如在无人机遥感图像分析、医学影像分析等领域。
【评价指标的选择与应用】评价小目标语义分割模型性能的指标主要有以下几种:1.Intersection over Union (IoU):IoU 是常用的评价目标分割质量的指标,计算方法是目标预测区域与真实区域的交集与并集之比。
对于小目标语义分割,可以采用像素级别的 IoU 或者对象级别的 IoU(如mIoU)来评价模型性能。
2.Precision、Recall 和 F1 值:这三个指标是分类问题中经常使用的评价指标,其中 Precision 表示正确预测为正样本的样本占预测为正样本的样本的比例,Recall 表示正确预测为正样本的样本占实际为正样本的样本的比例,F1 值是 Precision 和 Recall 的调和平均值。
对于小目标语义分割,可以采用这些指标来评价模型对不同类别的目标的分割性能。
3.Average Precision (AP):AP 值是目标检测中常用的评价指标,可以用于衡量模型对目标的分割精度。
在小目标语义分割中,可以采用 AP 值来评价模型对不同尺寸目标的分割性能。
4.Mean Intersection over Union (mIoU):mIoU 是基于对象级别的评价指标,计算方法是每个对象预测区域与真实区域的交集与并集之比。
2023目标分割综述

2023目标分割综述目标分割是计算机视觉领域的重要任务之一,旨在将图像中的每个像素分类为特定目标或背景。
目标分割技术在图像识别、自动驾驶、医学图像处理等领域具有广泛应用。
本文将对目前主流的目标分割方法进行综述,介绍它们的原理和应用。
一、传统方法的目标分割传统的目标分割方法 usually 基于图像的低级特征,如颜色、纹理和边缘等。
这些方法使用手动定义的规则和特定算法对图像进行处理。
其中,GrabCut 和 Mean-Shift 算法是常用的基于颜色和纹理的目标分割方法。
然而,这些方法对于复杂场景和目标的鲁棒性较差,无法解决遮挡、光照变化等问题。
二、深度学习方法的目标分割近年来,随着深度学习的发展,基于神经网络的目标分割方法取得了巨大的进展。
这些方法通过训练深度卷积神经网络(DCNN)来学习图像特征,并通过像素级的分类实现目标分割。
其中最具代表性的方法是全卷积网络(FCN)和深度拉伸网络(DSN)。
1.全卷积网络(FCN)全卷积网络是一种将传统的卷积神经网络应用于像素级分类的改进方法。
它通过去掉网络的全连接层,将卷积层和上采样层结合,实现了端到端的像素级分类。
FCN 通过多层次和多尺度的特征融合,有效地提高了目标分割的精度。
2.深度拉伸网络(DSN)深度拉伸网络是一种基于全卷积网络的改进模型,它在 FCN 的基础上引入了拉伸操作。
拉伸操作是通过多个特定比例的上采样层实现的,可以更好地保留细节信息。
DSN 通过反向传播算法训练网络,并使用像素级别的损失函数进行目标分割。
三、目标分割的应用领域目标分割技术在许多领域都有广泛的应用。
以下是目标分割在图像识别、自动驾驶和医学图像处理等领域的应用案例。
1.图像识别目标分割在图像识别中起到了关键作用。
通过将图像中的目标与背景分割开来,可以提取出目标的关键特征,从而实现对目标的准确识别。
在目标检测、人脸识别等领域,目标分割技术被广泛应用。
2.自动驾驶自动驾驶技术需要准确地识别和分割出道路、车辆、行人等目标。
复杂背景下运动目标分割算法研究

P A融合和二值 形态学重构 , C 以提取和更新背景 。将粗分割图像转 换到 H V域 中 , S 采用 V分量 阈值 法消除 阴影 , 应用彩 并
色投影法解决连通体粘连和路面反光问题。实验结果表 明该方法能够结合各种算法的优势 , 而较准确地 提取出运动车 快景提取 ; 运动 目标分割 ; 阴影消除 ; 色投影 彩
Po ci l rh p l dt d cneth onci re adsprs t lt i yt a . xeie— r et na oi m i ap e i onc te net gt gt n pesh g s nn b er d E p r n j o g t s i o s c n a u e ie g h o m
第2 卷 第1期 5 1
文章编号 :06— 3 8 2 0 ) 1 22— 3 10 94 (0 8 1 —0 8 0
基于贝叶斯框架的目标分割方法研究

基于贝叶斯框架的目标分割方法研究摘要:运动目标的检测与分割是视频监控系统的基础,所分割出的目标的完整性对视频的后续处理如目标分类、跟踪及行为理解产生重要影响。
实际场景通常很复杂包括静态的背景和动态的背景及运动目标。
该文提出了基于贝叶斯框架的目标检测方法。
首先求相邻两帧之差,通过自适应阈值把帧差图二值化为变化部分和静止部分。
每个像素维护两个表分别对应静止和运运两种状态,表中表项记录像素最近最重要的概率信息,检索这些概率代入贝叶斯公式,求出当前帧像素点的最大后验概率,根据贝叶斯分类原则,对当前帧的像素进行分类。
最后,对室内、室外拍摄的两个视频做实验进行验证,实验表明该方法在较复杂环境下,也具有较好的目标检测能力。
关键词:贝叶斯;目标分割;中图分类号:tp18 文献标识码:a 文章编号:1009-3044(2013)04-0866-04在视频流中检测和分割前景目标是后续处理如目标分类、目标跟踪和行为理解的基础。
人脑智能所谓的前景通常是自已感兴趣的目标,其他场景成分一概归入背景。
固定的摄像机,分割前景常用的方法有帧差法、背景减除法等,这些方法假设背景都是由静止的物体(其颜色或强度缓慢变化)构成。
然而,当背景中含有目标物体的阴影如车影,运动物体如晃动的树枝,水波以及光照变化给前景目标的正确检测和分割带来挑挑战。
当背景处于或场景缓慢变化时,单高斯就能较好的描述背景像素的噪声。
对于周期运动的背景如摇动的树叶,像素在叶子和叶子后面的地面两种颜色为均值的分布中变化。
像素呈现双峰状态。
基于背景中可能有周期性动用的物体,近来,人们又提出了采用高斯混合模型(多个高斯的线性组合)来描述每个背景像素。
高斯的权重、均值,方差迭代更新以适应环境的变化。
但是,这些方法不能处理光线的缓慢的变化和突变。
如从早到晚的光线变化和开关灯的全局背景光线的突变。
此外,存在前景目标与背景的相互转换的情况如移动背景物体而产生的背景局部变化(如移动凳子)及开车停在停车位,车成为了背景物体。
eCognition中的分割与分类方法研究
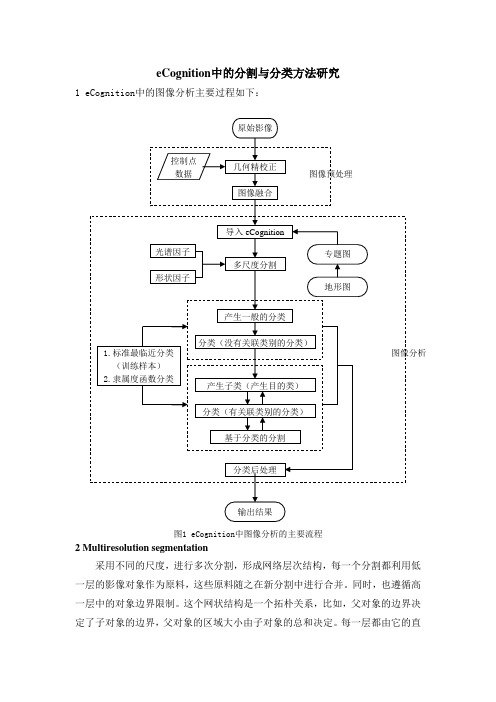
eCognition中的分割与分类方法研究1 eCognition中的图像分析主要过程如下:图1 eCognition中图像分析的主要流程2 Multiresolution segmentation采用不同的尺度,进行多次分割,形成网络层次结构,每一个分割都利用低一层的影像对象作为原料,这些原料随之在新分割中进行合并。
同时,也遵循高一层中的对象边界限制。
这个网状结构是一个拓朴关系,比如,父对象的边界决定了子对象的边界,父对象的区域大小由子对象的总和决定。
每一层都由它的直接的子对象来构成,在下一个高层上,子对象合并为大对象。
这个合并会被已有父对象的边界所限制。
如果是不同的父对象,那么相邻的对象不能进行合并。
图2 影像多尺度分割的网络层次结构从一个单个像元开始,分别与其相邻对象进行计算,若相邻的两个对象和合并后的异质性指标小于给定的域值,则合并,否则不进行合并。
当一轮合并结束后,以上一轮生成的对象为基本单元,继续分别与它的相邻对象进行计算,这一过程将一直持续到在用户指定的尺度上已经不能再进行任何对象的合并为止。
3 Computation of the heterogeneity criterion1)对象的光谱(spectral)异质性指标color h :∑•=cc c color w h σ (1)其中c ω为图层的权重,c σ为图层的标准差,c 为图层数;根据不同的影像特性以及目标区域(interest object)特性,图层间的权重调配亦有所不同,可依使用的需求加以调整。
2)对象的形状(spatial)异质性指标shape h :s compactnes compatness smoothness smoothness shape h h h ⨯+⨯=ωω (2)其中形状的异质性指标是由平滑(smoothness)与紧密(compactness)这两个子异质性指标所构成,smoothness ω与s compactnes ω代表两者间的权重调配,两者的和为1;平滑指标与紧密指标计算如下式所示:(3)(4) 其中,l 为对象的实际边长,b 为对象的最短边长,n 为对象面积;若平滑指标⎪⎪⎭⎫⎝⎛⨯+⨯-⨯=222111Obj Obj Obj Obj Obj Obj Merge Merge Merge smoothnessb l n b l n b l n h ⎪⎪⎭⎫ ⎝⎛⨯+⨯-⨯=222111Obj Obj Obj Obj Obj Obj Merge MergeMerge s compactnes n l n n l n n l n h的权重较高,分割后的对象边界较为平滑,反之,若紧密指标的权重较高,分割后的对象形状较为紧密较接近矩形,根据不同的影像特性以及目标对象(interest object )特性,两者间的权重调配亦有所不同,可依使用者的需求加以调整。
分割算法综述

分割算法是一种广泛应用于图像处理、计算机视觉和数据挖掘等领域的技术。
它可以将一个大的数据集分割成若干个小数据集,以便于更高效地处理和分析。
本文将对分割算法进行综述,介绍其基本原理、分类、应用场景和优缺点,并展望未来研究方向。
一、基本原理分割算法的基本原理是根据某种准则将一个大数据集分割成若干个小数据集。
常见的分割方法包括等分分割、最优值分割、聚类分割等。
等分分割是将大数据集均匀地分割成若干个小数据集,但这种方法往往难以满足实际需求。
最优值分割则根据某种阈值或准则,将大数据集分割成最合适的小数据集。
聚类分割则是通过将数据集中的样本划分为不同的簇,然后将同一簇的样本归为一类。
二、分类分割算法可以根据不同的标准进行分类,例如基于算法类型、应用场景等。
常见的算法分类包括基于聚类的分割算法、基于图的分割算法、基于密度的分割算法等。
基于聚类的分割算法通常通过寻找相似性最高的样本对,进而将它们划分为同一簇。
基于图的分割算法则通过构建一个有向图或无向图来表示数据集中的样本关系,然后通过优化图的结构来实现分割。
基于密度的分割算法则通过检测数据集中的局部密度峰值来实现分割。
三、应用场景分割算法在许多领域都有广泛的应用,例如医学影像分析、计算机视觉、生物信息学、网络安全等。
在医学影像分析中,分割算法可以帮助医生更准确地识别病灶区域,为疾病诊断和治疗提供更可靠的依据。
在计算机视觉中,分割算法可以应用于图像处理、目标检测、人脸识别等领域。
在生物信息学中,分割算法可以帮助研究人员更有效地分析基因组数据,为疾病预防和治疗提供新的思路。
在网络安全领域,分割算法可以用于检测网络流量中的异常行为,提高网络安全防御能力。
四、优缺点分割算法的优点包括高效性、灵活性和可扩展性。
它可以将大数据集分成更小、更易于处理的数据子集,从而提高数据处理效率。
同时,分割算法可以根据不同的应用场景和需求,灵活地选择不同的算法和参数,从而实现更好的性能。
基于激光点云的复杂三维场景多态目标语义分割技术研究

基于激光点云的复杂三维场景多态目标语义分割技术研究一、综述随着激光雷达(LiDAR)技术的快速发展,复杂三维场景的三维信息获取变得更加高效和精确。
在此背景下,多态目标语义分割技术在自动驾驶、无人机应用、城市规划等领域展现出了巨大的潜力和价值。
本文旨在综述当前基于激光点云的三维场景多态目标语义分割技术的研究进展,并分析其在不同应用场景下的优缺点。
激光点云作为三维场景信息的主要来源,其预处理和质量控制对于语义分割的准确性具有关键影响。
常用的数据预处理方法包括滤波降噪、点云配准和多视拼接等,以提高点云的质量和平滑度。
针对不同场景和应用需求,研究者们还提出了一系列点云后处理算法,如分层聚类、表面重建和体素划分等,以提取具有语义信息的点云数据。
为了解决三维场景中的多态目标识别与分类问题,语义分割技术应运而生。
根据其实现原理和方法的不同,现有的语义分割方法大致可以分为以下几类:基于像素的方法、基于特征的方法和基于深度学习的方法。
基于像素的方法主要利用图像处理和计算机视觉中的知识,通过对激光点云中每个点的像素值进行聚类或分类来实现语义分割。
此类方法在大规模场景中对建筑物、道路、植被等功能区域的分割表现出了较好的效果,但在处理复杂场景和动态目标时,其性能可能受到限制。
基于特征的方法通过提取激光点云中物体的边缘、纹理等特征变量来实现多态目标的分割。
这类方法能有效处理复杂的场景结构,并对变化目标具有较好的跟踪能力。
特征提取和分类策略的设计仍然具有一定的主观性,且计算复杂度较高。
随着深度学习技术的迅速发展,基于卷积神经网络(CNN)和循环神经网络(RNN)的模型在三维场景语义分割领域取得了显著的进展。
这类方法能够自动学习激光点云数据的特征表示,并在大规模数据集上表现出优异的性能。
深度学习模型的训练和部署仍面临着高昂的计算成本和模型泛化能力的挑战。
针对现有研究的局限性,未来的研究可以从以下几个方面展开:一是结合多源信息,如颜色、纹理、时间等信息,融合多种传感器的输出以提高语义分割的性能;二是设计更加高效和可解释的特征提取和表示方法,降低算法的计算复杂度和内存消耗;三是研究适应复杂场景变化的目标跟踪与动态目标分割技术;四是推动基于云计算和边缘计算的分布式三维语义分割技术的发展。
深度学习常见任务的一些评价指标总结(如图像分类,目标检测,图像分割等)

深度学习常见任务的一些评价指标总结(如图像分类,目标检测,图像分割等)下面是按照四个部分进行总结,大纲如下。
1.分类、目标检测、语义分割、实例分割的指标评估方法有哪些?2.同一深度学习任务中选择不同评价指标的策略或原因是什么?3.在不同的图像任务中使用相同的指标评价方法有什么区别?4.对单标签及多标签输出指标评估方法有什么不同(可以理解为简单任务vs复杂任务)?1.分类、目标检测、语义分割、案例分割的指标评价方法有哪些?1.1. 分类的指标评估方法图像分类是指将图像中的物体归入某一类别。
分类任务常用的评价指标如下。
•精度 Accuracy•混淆矩阵•查准率(准确率)•查全率(召回率)•PR曲线与AP、mAP•F值•ROC曲线与AUC值(1)精度 Accuracy错误率和精度是分类任务中最常用的两种性能度量,既适用于二分类任务,也适用于多分类任务。
错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例。
精度含义:被正确分类的样本占总样本的比。
公式:优点:简单缺点:精度只是简单地计算出比例,但是没有对不同类别进行区分,因而无法得知具体类别下的错误率和精度。
(2)混淆矩阵(confusion matrix)混淆矩阵也叫错误矩阵(error matrix),混淆矩阵是以模型预测的类别数量统计信息为横轴,真实标签的数量统计信息为纵轴画出的矩阵,如下图所示。
对角线代表了模型预测和数据标签一致的数目,所以准确率也可以用混淆矩阵对角线之和除以测试集图片数量来计算。
对角线上的数字越大越好,代表模型在该类的预测结果更好。
其他地方自然是预测错误的地方,值越小说明模型预测的越好。
分类结果的混淆矩阵由混淆矩阵可以衍生出其它的一些评价指标,如查准率(又称准确率,precision),查全率(又称召回率,recall),True Postitve Rate(真正率),False Positive Rate(假正率),True Negative Rate(真负率),False NegativeRate(假负率)。
医学影像数据的分割与分类方法比较研究

医学影像数据的分割与分类方法比较研究摘要:随着医学影像技术的快速发展,医学影像数据的分割和分类成为医疗领域的热门研究方向。
本文通过比较传统方法和深度学习方法两种不同的医学影像数据分割与分类方法,详细分析了它们的原理、优势与不足,并探讨了它们在医学影像领域中的应用前景。
1.介绍医学影像数据的分割和分类是指在医学影像资料中将感兴趣区域进行分割或将影像进行分类的过程。
该过程对于医生和医学研究人员来说十分重要,因为只有清晰地定义了感兴趣的区域或分类信息,才能更好地进行病灶诊断和治疗。
传统方法和深度学习方法是目前常用的两种医学影像数据分割与分类方法。
2.传统方法传统方法主要利用图像处理和计算机视觉技术对医学影像进行分析。
其中常用的方法包括基于阈值的分割方法、基于边缘检测的分割方法和基于区域生长的分割方法。
这些方法通过对像素值、边缘信息和区域特征进行分析和处理,来实现对医学影像的分割和分类。
传统方法的优势在于算法简单、计算速度快,但其精度和鲁棒性相对较低,对于复杂的医学影像数据往往难以提供准确的结果。
3.深度学习方法深度学习方法是近年来医学影像数据分割与分类领域的热点研究方向。
它基于深度神经网络模型,通过大量的训练样本来学习医学影像的特征。
深度学习方法的核心是卷积神经网络(CNN),其具有良好的特征提取和表示能力。
深度学习方法相较于传统方法具有更高的精度和鲁棒性,能够处理复杂的医学影像数据并提供准确的分割和分类结果。
4.方法比较传统方法和深度学习方法在医学影像数据分割与分类上存在一些差异。
传统方法在算法简单和计算速度上具有一定优势,但在处理复杂的医学影像数据时往往效果不佳。
深度学习方法在算法复杂度和计算时间上较高,但凭借其强大的特征提取和表示能力,能够更好地适应复杂的医学影像数据。
5.应用前景传统方法和深度学习方法在医学影像领域中都有广泛的应用前景。
传统方法在一些简单的医学影像数据分割和分类任务中依然具有一定的价值,而深度学习方法则在处理复杂的医学影像数据和提高分割和分类准确度方面具有优势。
血液细胞图像分割与分类方法研究

血液细胞图像分割与分类方法研究血液细胞图像分割与分类是医学图像处理领域中一项非常重要的任务。
通过提取和分析血液细胞图像,可以帮助医生对患者的健康状况进行评估和诊断。
近年来,随着计算机视觉和机器学习技术的不断发展,血液细胞图像分割与分类方法的研究也取得了显著进展。
图像分割是将图像划分成不同的区域或对象的过程。
对于血液细胞图像,分割的目标是将不同类型的细胞从图像中分离出来,以便进行后续的分类和分析。
在血液细胞图像分割中,常用的方法包括阈值分割、边缘检测和区域生长等。
阈值分割是最简单且常用的图像分割方法之一。
它基于像素灰度值和预设的阈值将图像分为两个或多个区域。
对于血液细胞图像,可以根据细胞的亮度和颜色特征来确定合适的阈值进行分割。
然而,阈值分割方法对于具有复杂纹理和变化的图像可能效果不理想。
边缘检测是通过寻找图像中明显变化的位置来进行分割的方法。
在血液细胞图像中,细胞与背景之间通常存在明显的边缘。
边缘检测方法可以通过梯度算子、模板匹配和边缘追踪等技术来提取细胞的边缘信息。
然而,由于噪声和图像质量的影响,边缘检测方法可能产生不准确或不完整的边缘。
区域生长是一种将图像像素分组为具有相似特征的连通区域的分割方法。
在血液细胞图像中,可以根据细胞的灰度值、纹理特征和形状等来选择种子点,并通过判别准则来增长区域。
区域生长方法具有较好的适应性和抗噪性,适用于各种血液细胞图像。
图像分割之后,需要对细胞图像进行分类,即将细胞分为不同的类型。
血液细胞的分类可以通过提取和分析细胞的形状、颜色、纹理和其他特征来实现。
常用的分类方法包括基于特征的分类和基于深度学习的分类。
基于特征的分类方法需要先提取细胞图像的特征,然后使用机器学习算法进行分类。
特征可以包括形状特征、颜色特征、纹理特征等。
常用的机器学习算法有支持向量机(SVM)、K近邻(KNN)和随机森林(Random Forest)等。
这些方法可根据提取到的特征建立分类模型,从而对细胞进行准确分类。
目标识别 语义分割 变化检测 场景分类 逻辑回归-概述说明以及解释

目标识别语义分割变化检测场景分类逻辑回归-概述说明以及解释1.引言1.1 概述目标识别、语义分割、变化检测、场景分类以及逻辑回归是计算机视觉领域中重要的研究方向。
随着人工智能的快速发展,这些技术在图像处理、视频分析以及自动驾驶等应用中发挥着关键作用。
目标识别是指通过图像或视频中的特征提取和模式匹配技术,将感兴趣的目标从背景中准确定位和识别出来。
它在实时监控、人脸识别和图像检索等领域中有着广泛的应用。
语义分割是将图像分割成语义上有意义的区域,即将每个像素点分配给特定的类别。
通过语义分割,我们可以更好地理解图像中的场景以及不同目标的位置与形状,在自动驾驶、医学影像分析等领域具有很高的研究价值。
变化检测是指通过比较图像序列之间的差异,来检测图像中发生的变化。
变化检测在遥感图像分析、环境监测以及视频监控中具有重要意义,它可以帮助我们及时发现异常情况和变化事件。
场景分类是将图像或视频分为不同的场景类别,例如室内、室外、山地、海滩等。
场景分类在图像检索、智能监控和图像自动标注等方面有广泛的应用,通过对图像的场景分类可以更好地理解图像的语义和内容。
逻辑回归是一种常用的分类算法,通过建立逻辑回归模型,将输入样本映射为一个概率值,并根据概率值进行分类决策。
逻辑回归在广告推荐、信用风险评估以及医疗诊断等领域有着广泛的应用。
本篇文章将重点介绍目标识别、语义分割、变化检测、场景分类和逻辑回归这几个研究方向的要点和方法,并对其在实际应用中的挑战和发展前景进行讨论。
通过对这些技术的深入了解,我们可以更好地理解计算机视觉领域的最新研究动态,并为相关实际问题提供有效的解决方案。
1.2 文章结构文章结构部分的内容可以是对整篇文章的组织和结构进行介绍和概述。
以下是一个可能的编写内容:文章结构本文主要围绕目标识别、语义分割、变化检测、场景分类和逻辑回归这五个主题展开深入研究和讨论。
为了更好地分析和理解这些主题,文章按照以下结构进行组织和呈现。
细胞病理图像的分割及分类识别方法研究

细胞病理图像的分割及分类识别方法研究细胞病理图像的分割及分类识别方法研究摘要:癌症是当今社会健康领域的重点和热点。
通过对细胞病理学图像的特征分析和分类识别,可以为癌症的早期诊断和治疗提供重要依据。
本文旨在研究细胞病理图像的分割及分类识别方法,包括预处理、分割、特征提取和分类识别。
在预处理方面,通过调整图像的亮度、对比度等参数,提高图像质量。
在分割方面,采用改进的分割算法,对细胞图像进行分割,提取有用信息。
在特征提取方面,采用形态学、颜色、纹理等多种方法,提取出不同的特征向量。
最后,采用多分类方法,对细胞图像进行分类识别,取得较好的分类效果。
本文的研究为癌症的早期诊断和治疗提供了一定的理论基础和技术支持。
关键词:细胞病理图像;分割;特征提取;分类识别;癌症一、绪论癌症是一种由于遗传、环境等多种原因引起的疾病。
癌症发病率不断上升,严重威胁人类生命健康。
早期诊断和治疗是预防癌症的关键。
细胞病理学图像是癌症诊断中的重要手段,对其进行分割和分类识别,有助于提高癌症诊断的准确性和效率。
二、预处理预处理是对图像进行去噪和增强的过程。
其中,对比度和亮度的调整可以提高图像的质量。
另外,采用局部直方图均衡化算法,可以增强图像的细节信息。
三、分割分割是将图像中不同的物体分别提取出来的过程。
本文采用改进的分水岭分割算法,可以更准确地分割出图像中的细胞,提取有用信息。
此外,为了消除分割结果中的噪声,还采用了形态学滤波算法。
四、特征提取特征提取是将图像中的特征转化为数学向量的过程。
本文采用颜色、形态学和纹理等多种方法,提取不同的特征向量。
其中,颜色特征是根据像素的颜色值提取出的,形态学和纹理特征是根据图像边缘和纹理等特征提取而来的。
五、分类识别分类识别是将不同的特征向量进行分类的过程。
本文采用多分类方法,将不同的特征向量分别归为不同的类别。
其中,最常用的分类算法包括支持向量机、随机森林等。
六、实验结果本文采用了CAMELYON16数据集进行实验,取得了较好的分类效果。
基于深度学习的目标分割技术研究

基于深度学习的目标分割技术研究第一章绪论近年来随着深度学习在计算机视觉领域取得重要进展,基于深度学习的目标分割技术也受到了广泛关注。
目标分割技术是计算机视觉领域的一个重要研究方向,它旨在从图像中自动地提取感兴趣区域。
而深度学习技术通过神经网络的学习能力,使得目标分割技术得到了极大的提升。
因此,本文将从基础原理、相关算法、应用场景等多个方面展开研究深度学习的目标分割技术。
第二章基本原理图像分割是一项基本任务,它将图像划分成若干区域,每个区域具有相似的特征,并且不同区域之间的特征是不相似的。
在深度学习技术的帮助下,图像分割被分为语义分割和实例分割两种类型。
1. 语义分割语义分割技术将图像分为若干区域,并为每个区域分配一个语义类别,旨在通过像素级别的分类,实现对图像的理解和解释。
此技术常用的卷积神经网络有 FCN、SegNet、DeepLab、PSPNet 等。
2. 实例分割实例分割技术不仅要将图像分成不同的区域,还要为每个区域分配一个唯一的实例标识符。
相比于语义分割,实例分割更具挑战性,对于物体的形态、大小、旋转等具有较高的要求。
常用的卷积神经网络有 Mask R-CNN、YOLACT 等。
第三章相关算法在深度学习技术的帮助下,图像分割的算法得到了迅速发展。
基于深度学习的目标分割技术主要分为两种类型,分别是传统的FCN 系列和在语义分割基础上加入实例分割的Mask R-CNN 系列。
1. FCN 系列算法FCN(Fully Convolutional Network)是深度学习目标分割技术中最为基础的算法。
这种算法针对的是图像的像素级分类,即将原始图片分割成若干的像素级别的分类标签。
该算法提出了 D-Layers,通过多层的下采样和上采样使得网络逐渐扩张,最终实现图像的分割。
2. Mask R-CNN 系列算法Mask R-CNN 是一种深度学习算法,是在 Faster R-CNN 基础上引入实例分割任务的模型。
天文学研究中的机器学习图像识别方法

天文学研究中的机器学习图像识别方法引言:随着科技的迅速发展,机器学习在各个领域都得到了广泛的应用。
天文学作为一门研究宇宙和天体的科学,也受益于机器学习的进展。
在天文学研究中,图像识别是一项关键技术,它能够帮助天文学家更快速、准确地分析观测到的天体图像,并从中获取宝贵的科学信息。
本文将介绍机器学习在天文学图像识别中的应用方法和技术。
一、机器学习在天文图像预处理中的应用在进行天文学图像识别之前,通常需要对图像进行预处理,包括去噪、增强和校正等步骤。
机器学习在这一过程中可以提供有效的解决方案。
其中比较常用的方法之一是卷积神经网络(Convolutional Neural Networks,CNN)。
CNN通过学习图像中的特征,能够很好地解决天文图像中的灰度失真、噪声和伪影等问题。
另外,支持向量机(Support Vector Machines,SVM)也是一种常用的图像分类方法,可以用于图像去噪和分类预测等任务。
二、机器学习在天文目标检测和分类中的应用在天文学中,目标检测和分类是非常重要的任务。
例如,星系分类和行星检测等问题需要对天体进行快速准确的定位和分类。
机器学习中的目标检测算法,如Faster R-CNN、YOLO等,能够实现对天文图像中的天体进行自动检测和识别。
此外,随着深度学习技术的不断发展,神经网络模型如卷积神经网络、循环神经网络(Recurrent Neural Networks,RNN)和变形自编码器(Variational Autoencoders,VAE)等也被广泛应用于天文学目标检测和分类的研究中。
三、机器学习在天文图像分割中的应用天文学图像的分割是指将图像中的各个目标或结构分割出来,以便进行进一步的分析和研究。
机器学习在天文图像分割中发挥了重要作用。
传统的分割方法包括阈值分割、边缘检测和区域生长等,但这些方法对于复杂的天文图像往往效果不佳。
而机器学习方法,如卷积神经网络和支持向量机等,能够自动学习图像中的纹理和形状特征,并实现更准确的分割结果。
医学影像分析中的深度学习方法

医学影像分析中的深度学习方法引言随着科技的不断进步,医学影像学在临床诊断和治疗中扮演着越来越重要的角色。
在众多的医学影像学技术中,深度学习方法作为一种新兴的技术,在医学影像分析中显示出巨大的潜力。
本文将对医学影像分析中的深度学习方法进行介绍和探讨,并分别从图像分类、目标检测、分割和生成等方面进行讨论。
一、图像分类在医学影像学中,图像分类是最常见且最基础的任务之一。
深度学习方法在图像分类中具有很大的优势。
通过使用卷积神经网络(CNN)等深度学习模型,可以自动从医学影像中学习特征,并对影像进行分类。
例如,通过对大量CT扫描图像进行训练,深度学习模型可以准确地识别肺部结节是否为恶性肿瘤,从而辅助医生进行诊断。
二、目标检测在医学影像中,除了进行图像分类外,还需要进行目标检测。
目标检测主要是指在医学影像中检测和标注出特定的结构或病灶。
深度学习方法在目标检测中表现出良好的准确性和鲁棒性。
通过将卷积神经网络与目标检测算法相结合,可以有效地定位和识别医学影像中感兴趣的区域。
例如,通过使用深度学习方法,可以自动检测MRI图像中的肿瘤位置和大小,并提供给医生做进一步诊断。
三、分割在医学影像分析中,分割是指将医学影像中的结构或病灶从背景中分离出来。
深度学习方法在医学影像分割中表现出很强的能力。
通过使用FCN(全卷积神经网络)等深度学习模型,可以对医学影像进行像素级别的分割。
例如,在CT扫描中,可以使用深度学习模型将肺部和肿瘤分割出来,帮助医生更好地理解影像和制定治疗方案。
四、生成医学影像生成是指通过深度学习方法生成与真实医学影像相似的图像。
生成的医学影像可以用于模拟和研究特定疾病的情况,也可以用于辅助医生的培训和教育。
通过使用生成对抗网络(GAN)等深度学习方法,可以生成逼真的医学影像。
例如,可以使用深度学习方法生成眼底图像,供眼科医生进行诊断和治疗。
结论深度学习方法在医学影像分析中显示出巨大的潜力。
通过图像分类、目标检测、分割和生成等技术,在医学影像学中取得了许多重要的进展。
3D点云点云分割、目标检测、分类

3D点云点云分割、⽬标检测、分类3D点云点云分割、⽬标检测、分类原标题Deep Learning for 3D Point Clouds: A Survey作者Yulan Guo, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun导读3D点云学习( Point Clouds)作为近年来的研究热点之⼀,受到了⼴泛关注,每年在各⼤会议上都有⼤量的相关⽂章发表。
当前,点云上的深度学习变得越来越流⾏,⼈们提出了许多⽅法来解决这⼀领域的不同问题。
国防科技⼤学郭裕兰⽼师课题组新出的这篇论⽂对近⼏年点云深度学习⽅法进⾏了全⾯综述,是第⼀篇全⾯涵盖多个重要点云相关任务的深度学习⽅法的综述论⽂,包括三维形状分类、三维⽬标检测与跟踪、三维点云分割等,并对点云深度学习的机制和策略进⾏全⾯的归纳和解读,帮助读者更好地了解当前的研究现状和思路。
也提供了现有⽅法在⼏个可公开获得的数据集上的全⾯⽐较,最后也介绍了未来的研究⽅向。
对于3D点云,数据正在迅速增长。
⼤有从2D向3D发展的趋势,⽐如在opencv中就已经慢慢包含了3D点云的处理的相关模块,在数据⽅⾯点云的获取也是有多种渠道,⽆论是源于CAD模型还是来⾃LiDAR传感器或RGBD相机的扫描点云,⽆处不在。
另外,⼤多数系统直接获取3D点云⽽不是拍摄图像并进⾏处理。
因此,在深度学习⼤⽕的年代,应该如何应⽤这些令⼈惊叹的深度学习⼯具,在3D点云上的处理上达到对⼆维图像那样起到很好的作⽤呢?3D点云应⽤深度学习⾯临的挑战。
⾸先在神经⽹络上⾯临的挑战:(1)⾮结构化数据(⽆⽹格):点云是分布在空间中的XYZ点。
没有结构化的⽹格来帮助CNN滤波器。
(2)不变性排列:点云本质上是⼀长串点(nx3矩阵,其中n是点数)。
在⼏何上,点的顺序不影响它在底层矩阵结构中的表⽰⽅式,例如,相同的点云可以由两个完全不同的矩阵表⽰。
高分辨率图像的多层次分割与分类的开题报告

高分辨率图像的多层次分割与分类的开题报告
一、研究动机和研究目标
高分辨率图像的多层次分割与分类对于许多领域都具有很高的实用价值,如医学图像识别、卫星遥感图像解析、自然景观分类等。
然而,由于高分辨率图像数据量大、噪声干扰多、特征量庞大等特点,因此如何高效地引入多层次分割和分类方法,实现
精准而快速的分析,是一个具有挑战性的问题。
本报告旨在通过研究和分析多种分割和分类算法,设计出一种高效实用的高分辨率图像多层次分割和分类方法,以应对实际应用需求。
二、研究内容和思路
1. 针对高分辨率图像的特点,如数据量大、噪声干扰多、特征量庞大等问题,对常见的图像预处理方法进行研究和分析,如降噪处理、尺度变换、特征提取等。
2. 对于高分辨率图像的多层次分割和分类问题,介绍常见算法,如Canny算法、Sobel算法、基于聚类的方法、基于深度学习的方法等,并分析其优缺点,并对其进行改进和优化。
3. 基于多层次的分割和分类方法,提出一种高效而实用的算法,并通过实验验证其有效性和可靠性。
4. 结合实际应用需求,提出针对特定领域的高分辨率图像多层次分割与分类方法,如医学影像识别、卫星遥感图像解析、自然景观分类等。
三、研究意义和应用价值
高分辨率图像的多层次分割和分类在许多领域都具有很高的应用价值。
例如,在医学中,可以通过对高分辨率医学影像进行多层次分割和分类,实现对不同病灶的快
速定位和准确诊断;在卫星遥感中,可以对大规模的高分辨率图像进行高效地多层次
分割和分类,实现对地物的自动化识别和监测。
本研究通过对高分辨率图像的多层次分割和分类算法的研究和优化,可以提高图像分析的准确性和效率,为实际应用需求提供一种高效、快速的解决方案。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数字图像处理作业题目:目标分割和分类研究学号:姓名:林佰柱导师:陈邦兴学院:电子与信息工程学院专业:通信与信息系统联系方式:摘要随着现代交通迅猛发展和人民的生活水平提高,在地铁等复杂场景的客流安全成为日益重要的问题。
目前,国内人群密集区域密集程度获取和人员安全等都是通过工作人员监控摄像机或者实地监控实现的。
长时间的监控,容易导致工作人员身心疲惫,并严重浪费人力和物力等。
本文对地铁等密集场所信息提取具有实际应用意义。
得益于现代计算机技术的飞速发展,通过计算机技术来解决此问题已成为一种可能。
在复杂场景下通过计算机和视频处理技术,可以获得场景中人群的密度、流量和速度等信息。
该方法只需摄像头、板卡和计算机等硬件设备,维护升级方便。
本文对图像密度等级分类、人脸检测和人脸跟踪技术展开深入研究,分析比较了各种算法的优缺点,并提出了多种改进算法。
本文主要分为三个模块,图像密度等级分类、人脸检测和人脸跟踪。
对于图像密度等级分类模块,根据单位空间人群数量,将图像分为低密度、中低密度、中等密度、中高密度和高密度五个等级。
目前常采用的算法为首先对图像进行特征提取,然后神经网络对特征提取的结果进行分类。
本文主要依据灰度共生矩阵(Grey Level Dependency Matrix, GLDM)来对图像进行特征提取,针对此特征提取算法不足之处,本文提出了特征提取的改进方法,并采用独立成分分析(Independence Component Analysis, ICA)聚类算法对特征结果进行聚类,再应用神经网络对聚类结果进行分类。
对于人脸检测模块,主要应用AdaBoost算法对人脸进行检测,以此来达到计算流量的目的。
在人脸跟踪模块,对人脸平面进行标定,并针对人脸平面标定点较少等难点,本文提出了一种对标定点要求少、简单但是准确性高的标定算法。
根据人脸检测模块得到的结果,使用改进的匹配算法对人脸进行跟踪。
本文主要针对地铁等复杂场景,对图像密度等级分类;通过人脸检测达到计算流量的目的;并对图像进行标定和对人脸进行跟踪来计算人群速度。
大量的现场数据实验结果表明,本文所采用的算法的密度等级分类、流量统计和速度计算的准确率均达到93%以上,具有一定的实用价值。
关键词:复杂场景,密度等级分类,特征提取,人脸检测,人脸跟踪第1章绪论本章主要介绍了课题的选题背景与实际意义,系统介绍了人群密度等级分类、人脸检测和人脸跟踪等技术的发展现状和主要难点,最后介绍本文主要工作、创新以及章节安排。
1.1 研究背景在地铁等人群密集区域,当人群容量一旦超出硬件环境支持的能力和管理调度指挥的承受能力时,将有可能产生人员安全隐患。
因此,如何确保人身安全,做好安全防范意识,日趋重要。
智能交通系统(Intelligent Traffic Systems, ITS)是通过对现行交通进行监控和分析,并进行科学化改造与完善,所达到更和谐、更有效地运用交通来满足社会需求的方式。
对地铁等密集场地视频进行有效信息提取是智能交通的一个组成部分。
ITS是对通信、控制和信息处理技术在运输系统中集成应用的统称,它产生的综合效益表现为挽救生命、时间和节省金钱、降低能耗以及改善环境等。
它有助于最大程度上发挥交通基础设施效能,提高交通运输系统的运行效率和服务水平,为公众提供高效、安全、便捷和舒适的出行服务。
ITS这一概念始于20世纪80年代,其中最具代表性的是美国智能车辆道路系统(IVHS,1992年),欧洲高效安全交通系统计划(PROMETHEUS, 1986年),欧洲交通安全道路体系(DRIVE,1989年)和日本道路交通信息通信系统(VICS,1995年)。
随着我国改革开放不断深入和国民经济快速发展,接踵而来的是交通中由于高人群密度等产生的人员安全和事故需要急待解决,因此在中国发展ITS 势在必行。
随着科技的不断进步,可以将视频处理技术应用在智能交通系统中。
采用视频处理技术的智能交通系统由电子摄像机、图像采集卡和计算机等组成。
与磁感应器等其它检测方式不同,它安装卸载方便,成本低,可以多点布设。
但是它受系统软、硬件限制,受恶劣天气、灯光变化等因素影响检测准确率。
尽管如此,随着图像处理技术的不断进步和硬件条件的不断改善,视频处理智能交通技术将得到深入发展和更为广泛的应用。
基于视频处理技术的智能交通系统占有越来越重要的地位,是未来智能交通发展的重要方向。
目前此种方法无论在室内还是室外都表现出良好的势头,只是在雨雪天、雾天等天气的系统鲁棒性上有待加强。
但是无论如何,基于视频处理技术的智能交通系统已经是大势所趋,因此如何提高视频处理技术的准确率和鲁棒性等是当代智能交通发展的重要研究方面。
随着ITS的不断发展,它涉及的方面越来越广,已经不仅仅局限在道路交通信息检测等,还开始涉及人的主动安全等方面,如汽车自主驾驶,地铁客流量信息检测也是其中主要方面。
地铁客流量信息检测主要检测客流量密度、流量和速度等信息。
它为客流人身安全提供保障,为地铁相关交通部门后续建设提供理论依据。
1.2 国内外研究现状目前密度等级分类是客流量信息检测的一个重要信息量。
人脸检测和人脸跟踪是目标检测和目标跟踪的重要研究方面,为客流流量和速度信息提供基础。
本节对此三个部分的国内外研究现状分别进行介绍。
1.2.1 密度等级研究现状在地铁等复杂场景中,人群密度等级是一个重要信息,在人群密度高于正常密度时发出警报,保障人群安全。
本文所探讨的密度计算主要是根据图像单位面积内人数的多少,将图像分为密度不等的五个等级。
密度等级分类主要目的在于保障人身安全,并为地铁交通相关部门规划地铁布局提供理论依据,因此密度等级分类具有重要研究价值。
通过估计人群密度,可以粗略地知道人群整体所处的状态,从而对人群的行为做出判断,以利于更安全、更有效的管理人群。
除了人群管理外,它还可用于:更合理地安排各个时段的在岗工作人员数;更有效地管理人群流动繁忙场合的交通。
传统的人群监控靠闭路电视通过监控某一场景实现,它需要用户自身对场景图像做出判断。
这种方法主观性很强,不能进行定量分析。
红外传感器方法是有别于图像处理的一种方法。
当红外传感器检测到人体时,可以在图像上体现出来。
密度不同,表现出来的图像也不同。
但是当人群密度高于中等人群密度时,经过红外传感器处理后表现出来的图像已无很大差别,不能再区分密度。
现代数字图像处理技术的发展,为解决上述问题提供了途径。
将图像处理、模式识别、计算机视觉等技术应用在人群监控中,可以达到对人群的自动、客观、实时和定量分析。
自智能化人群监控技术提出以后,人们对其进行了广泛研究,目前已有很多算法,一些实用的系统也开始应用在地铁等场合的客流监控中。
但是,基于视频处理的客流密度分析遇到了一些困难。
密度等级分类的主要难点在于:(1)由于地铁人群密度高于正常密度时,很难判断人群密度具体属于哪种等级;(2)如何避免邻居类间误判也是需要急待解决的问题。
基于视频处理的密度等级分类在近几年有了较大的发展,代表人物是A. N. MARANA等[1,3,4]。
对人群密度等级分类展开深入研究,主要研究理论有两个方面,一方面根据分形算法进行客流的密度等级分类,另一方面根据图像纹理特征提取后对提取的特征向量再分类的概念进行密度等级分类。
分形算法[1]是一种比较简单的获得人群密度的方法。
分形算法可以被广泛的应用在图像处理、图像分析、视觉和模式识别中。
分形维数基于尺度测量的思想,用来衡量一个几何集或自然物体不规则和破碎程度的数,是由标度关系得出的一个定量的值。
分形维数用来计算图像密度等级的主要原理是不同密度等级的图像所表现的边缘图像不同,根据不同膨胀尺寸的边缘图像可以用来计算图像的分形维数。
纹理是一幅图像有别于其它图像的重要特征。
一般来说,纹理图像中灰度分布具有某种周期性及规律性。
人在区分不同图像的密度等级时,也是根据纹理不同来区分。
纹理特征应用广泛,可以用在阴影检测、卫星云图和森林监控等场景中。
目前常用的计算纹理的方法主要有GLDM[2,3,4]、切比雪夫运动场[2]、直线分割[5]、高斯马尔科夫随机场[6]、傅里叶变换[5]和小波变换[7,8]等,其中前四种属于时域的纹理特征提取,傅里叶变换和小波变换是频域的纹理特征提取。
经过纹理特征提取的结果需要经过分类器分类才能得到分类结果。
目前比较常用的分类器有BP神经网络、支持向量机(Support Vector Machine, SVM) [8,9]和自组织神经网络[2]等。
在基于视频处理的密度等级分类算法中,如何保证高密度情况下密度等级分类的准确性是目前密度分类的一个重点和难点。
1.2.2 人脸检测研究现状人脸检测是目标检测的一部分。
人脸检测在视频监控中具有重要的作用,是视频安全监控中一个重要方面,为人脸识别提供基础。
本文通过检测人脸来计算流量。
为了计算单位时间内通过单位横截面的人数,对人脸进行检测是比较直观并且准确性高的一种方法,并且可以为后续的人脸跟踪提供基础。
人脸检测一直是图像处理的一个重点和难点。
人脸检测问题最初来源于人脸识别,人脸检测是自动识别系统中一个关键环节,但早期的人脸识别主要针对具有较强约束条件的人脸图像(如无背景的图像),往往假设人脸位置已知或容易获得,因此人脸检测问题并未受到重视。
随着人脸检测应用场景越来越复杂,有基于内容的检索、数字视频处理和视觉检测等,由此产生的一系列需要解决的问题使得人脸检测开始作为一个独立的课题受到研究者的重视。
人脸是人类具有相当复杂的细节变化的自然结构目标,此类目标的检测问题挑战性在于:(1)人脸由于外貌、表情、肤色等不同,具有模式的可变性;(2)人脸上有可能存在眼镜、胡须等附属物;(3)作为三维物体的人脸的影像不可避免地受由光照产生的阴影影响。
因此,如果能够找到解决这些问题的方法,成功构造出人脸检测与跟踪系统,将为解决其它类似的复杂模式检测问题提供重要线索。
目前,国内外对人脸检测问题的研究很多。
国外比较着名的有MIT,CMU 等;国内有清华大学、中国科学院计算技术研究所和中国科学院自动化研究所等。
并且,MPEG7标准组织已经建立了人脸识别草案小组,人脸检测算法也是一项征集的内容。
随着人脸检测问题研究的深入,国际上发表的有关论文数量也大幅度增长。
根据肤色进行人脸检测是目前较流行的一种算法。
文献[14,15]提出了使用颜色的方法来检测人脸。
文献[14]使用多个神经网络分类器来分类颜色直方图,并对分类结果输入神经网络进行再分类。
文献[15]使用RGB颜色空间来检测人脸,并对候选区域进行眼、嘴、脸型轮廓检测,达到精确检测的目的。
肤色的方法简单易行,但是当非人脸区域颜色与人脸颜色相似的情况下,容易发生误检。
模板匹配也是目前较流行的人脸检测算法。