Sql Server 2005分区表设计
SQL Server2005数据库应用技术第5章 创建与管理数据表

5.2.5 使用T-SQL语句重命名表
可以使用sp_rename存储过程对表进行重命 名,基本语法格式如下: sp_rename 原表名 , 新表名
5.2.6 使用T-SQL语句删除表
删除表的语句格式如下: DROP TABLE 表名
5.3 使用完整性约束
5.3.1 数据完整性分类
– 实体完整性:实体完整性也称为行完整性,要 求表中的所有行有一个唯一的标识符,
【例】在数据库“StudentElective”中创建课程表 “Course”。
USE StudentElective GO CREATE TABLE Course (cno char(10) not null, cname varchar(40) not null, credit tinyint )
5.1.2 表的类型
(3)已分区表 已分区表是将数据水平划分成多个单元的表, 这些单元可以分散到数据库中多个文件组里面, 实现对单元中数据的并行访问。
(4)系统表 系统表储存了有关SQL Server服务器的配置、 数据库配置、用户和表对象的描述等系统信息。
5.1.3 设计表
在创建表之前,需要规划并确定表的下列特征:
5.1.2 表的类型
在SQL Server 2005系统中把表分成了4种类 型,即普通表、临时表、已分区表和系统表。
(1)普通表 普通表就是通常提到的数据库中存储数据的 数据表,是最重要、最基本的表。
(2)临时表 临时表是临时创建的、不能永久生存的表。 临时表被创建之后,可以一直存储到SQL Server 实例断开连接为止。
5.2 修改表
5.2.1使用SSMS修改表结构
使用SQL Server Management Studio修改表 结构 的基本操作步骤演示。
SQL Server 2005 表分区操作详解

SQL Server 2005 表分区操作详解SQL Server数据库表分区操作过程由三个步骤组成:1. 创建分区函数2. 创建分区架构3. 对表进行分区下面将对每个步骤进行详细介绍。
步骤一:创建一个分区函数此分区函数用于定义你希望SQL Server如何对数据进行分区的参数值([u]how[/u])。
这个操作并不涉及任何表格,只是单纯的定义了一项技术来分割数据。
我们可以通过指定每个分区的边界条件来定义分区。
例如,假定我们有一份Customer s表,其中包含了关于所有客户的信息,以一一对应的客户编号(从1到1,000,000)来区分。
我们将通过以下的分区函数把这个表分为四个大小相同的分区:这些边界值定义了四个分区。
第一个分区包括所有值小于250,000的数据,第二个分区包括值在250,000到49,999之间的数据。
第三个分区包括值在500,000到7499,999之间的数据。
所有值大于或等于750,000的数据被归入第四个分区。
请注意,这里调用的"RANGE RIGHT"语句表明每个分区边界值是右界。
类似的,如果使用"RANGE LEFT"语句,则上述第一个分区应该包括所有值小于或等于250,000的数据,第二个分区的数据值在250,001到500,000之间,以此类推。
步骤二:创建一个分区架构一旦给出描述如何分割数据的分区函数,接着就要创建一个分区架构,用来定义分区位置([u]where[/u])。
创建过程非常直截了当,只要将分区连接到指定的文件组就行了。
例如,如果有四个文件组,组名从"fg1"到"fg4",那么以下的分区架构就能达到想要的效果:注意,这里将一个分区函数连接到了该分区架构,但并没有将分区架构连接到任何数据表。
这就是可复用性起作用的地方了。
无论有多少数据库表,我们都可以使用该分区架构(或仅仅是分区函数)。
SQL Server 2005分区表技术的研究与实现

() 建 分 区函 数 4创
能, 但并没 有为数据 修改带来好 处 。S lsre 0 0中 , q e r2 0 v 增加
的基础表 的功能 。 尽管 S L Sre 7 Q e r . S L Sre 00的功 能大 大改 v 0和 Q e r2 0 v
l rd t aead go p t a 了可 以直 接对分 区视 图进 行数据修 改 ,通过视 图定位 到相应 组 的数据位于 同一个文件组 中。使用 a e a bs d ru
0 引言
随着各类 数据 库应用分析系统数据量 的增大 , 处理要求 日 益复 杂 , 而性能要 求却不断 提高 。 这一矛盾越来越突出。数据库
分区架构来来创立分 区的功能 , 分区架构可 以将表对 象映射到
一
个或 多个 文件组 上 ; 围绕表结构 设计 了几 种新功能 , 为分区
表的长期管理提供 了大量 的可选项 。
合视 图访问多个 表时 的总计 划成本 。改善 了 S l t e c 语句 的性 e
()创建文件组并将文件添加 至文 件组 3
每个分区需要映射到一个 文件组 上去 , 虽然一个 文件组可
以由多个 分区使 用 , 但为 了更好地管理数 据 ( 如为 了更精确地 备份控制 )应 该精 心设计分区表 , , 以便 只有 相关数据或逻辑分 可以向数据库 中添加文件组 。 多个文件放置一个分区表可以获得更好的 I / O平衡 。接着 通过 a e a b e ad fe S L语句 向文件组 中添加一到 多 l rd t a d l Q t as i
SQL Server 2005中的分区表

(一):什么是分区表?为什么要用分区表?如何创建分区表?如果你的数据库中某一个表中的数据满足以下几个条件,那么你就要考虑创建分区表了。
1、数据库中某个表中的数据很多。
很多是什么概念?一万条?两万条?还是十万条、一百万条?这个,我觉得是仁者见仁、智者见智的问题。
当然数据表中的数据多到查询时明显感觉到数据很慢了,那么,你就可以考虑使用分区表了。
如果非要我说一个数值的话,我认为是100万条。
2、但是,数据多了并不是创建分区表的惟一条件,哪怕你有一千万条记录,但是这一千万条记录都是常用的记录,那么最好也不要使用分区表,说不定会得不偿失。
只有你的数据是分段的数据,那么才要考虑到是否需要使用分区表。
3、什么叫数据是分段的?这个说法虽然很不专业,但很好理解。
比如说,你的数据是以年为分隔的,对于今年的数据而言,你常进行的操作是添加、修改、删除和查询,而对于往年的数据而言,你几乎不需要操作,或者你的操作往往只限于查询,那么恭喜你,你可以使用分区表。
换名话说,你对数据的操作往往只涉及到一部分数据而不是所有数据的话,那么你就可以考虑什么分区表了。
那么,什么是分区表呢?简单一点说,分区表就是将一个大表分成若干个小表。
假设,你有一个销售记录表,记录着每个每个商场的销售情况,那么你就可以把这个销售记录表按时间分成几个小表,例如说5个小表吧。
2009年以前的记录使用一个表,2010年的记录使用一个表,2011年的记录使用一个表,2012年的记录使用一个表,2012年以后的记录使用一个表。
那么,你想查询哪个年份的记录,就可以去相对应的表里查询,由于每个表中的记录数少了,查询起来时间自然也会减少。
但将一个大表分成几个小表的处理方式,会给程序员增加编程上的难度。
以添加记录为例,以上5个表是独立的5个表,在不同时间添加记录的时候,程序员要使用不同的SQL 语句,例如在2011年添加记录时,程序员要将记录添加到2011年那个表里;在2012年添加记录时,程序员要将记录添加到2012年的那个表里。
SQL Server 2005基础教程 第6章 表

2019年5月11日
第10页
SQL Server 2005基础教程
更该列的数据类型
清华大学出版社
使用ALTER TABLE语句除了可以增加新 列和删除列之外,还可以对列的属性进行 更改。本节主要讲述如何更改列的数据类 型。使用ALTER TABLE语句更该列的数 据类型的基本语法形式如下所示:
IDENTITY属性的语法形式如下所示:
– IDENTITY (seed, increment)
2019年5月11日
第13页
SQL Server 2005基础教程
清华大学出版社
ROWGUIDCOL列
ROWGUIDCOL列是全局唯一标识符列。 每一个表中最多可以创建一个 ROWGUIDCOL列。从理论上来看,分布 在Internet上的两个不同的计算机中的 ROWGUIDCOL列的值出现相同的现象的 概率是微乎其微的。在创建表时,可以使 用UNIQUEIDENTIFIER数据类型定义 ROWGUIDCOL列。
样的索引?
2019年5月11日
第4页
SQL Server 2005基础教程
清华大学出版社
6.2 表的基本特点和类型
本节讲述两方面的内容,首先分析和描述 表的基本特点,然后讨论表的分类方式和 表的类型。
2019年5月11日
第5页
SQL Server 2005基础教程
表的基本特点
清华大学出版社
表是关系模型中表示实体的方式,是用来 组织和存储数据、具有行列结构的数据库 对象。
– 普通表 – 已分区表 – 临时表 – 系统表
每一种类型的表都有自己的作用和特点。
2019年5月11日
第7页
SQL Server 2005基础教程
sql2005分区表功能的知识要点(一):rangeleft与rangeright

sql2005分区表功能的知识要点(一):rangeleft与rangeright(一).为范围分区创建分区函数范围分区必须使用边界条件进行定义。
而且,即使通过CHECK 约束对表进行了限制,也不能消除该范围任一边界的值。
为了允许定期将数据移入该表,需要创建最后一个空分区。
在范围分区中,首先定义边界点:如果存在五个分区,则定义四个边界点值,并指定每个值是第一个分区的上边界(LEFT) 还是第二个分区的下边界(RIGHT)。
根据LEFT 或RIGHT 指定,始终有一个空分区,因为该分区没有明确定义的边界点。
具体来讲,如果分区函数的第一个值(或边界条件)是'20001001',则边界分区中的值将是:对于LEFT第一个分区是所有小于或等于'20001001' 的数据第二个分区是所有大于'20001001' 的数据对于RIGHT第一个分区是所有小于'20001001' 的数据第二个分区是所有大于或等于'20001001' 数据由于范围分区可能在datetime 数据中进行定义,因此必须了解其含义。
使用datetime 具有某种含义:即总是同时指定日期和时间。
未定义时间值的日期表示时间部分为“0”的12:00A.M。
如果将LEFT 与此类数据结合使用,则日期为10 月1 日12:00 A.M. 的数据将位于第一个分区,而10 月份的其他数据将位于第二个分区。
从逻辑上讲,最好将开始值与RIGHT 结合使用,而将结束值与LEFT 结合使用。
下面的三个子句将创建逻辑上相同的分区结构:RANGE LEFT FOR V ALUES ('20000930 23:59:59.997','20001231 23:59:59.997','20010331 23:59:59.997','20010630 23:59:59.997')或RANGE RIGHT FOR V ALUES ('20001001 00:00:00.000', '20010101 00:00:00.000', '20010401 00:00:00.000', '20010701 00:00:00.000')或RANGE RIGHT FOR V ALUES ('20001001', '20010101','20010401', '20010701')注意:此处使用datetime 数据类型确实增加了一定的复杂性,但您需要确保设置正确的边界情况。
实验4 SQL Server 2005创建数据类型和表

实验4创建数据类型和表4.1课堂练习:创建数据类型目标本次课堂练习的目标是能够创建基于系统提供的类型的别名类型。
您将使用SQL Server Management Studio 中的对象资源浏览器或使用CREATE TYPETransact-SQL 语句创建别名类型。
本次课堂练习将使用这两种技术在AdventureWorks 数据库中创建别名类型。
使用SQL Server Management Studio 创建别名类型执行以下步骤以使用SQL Server Management Studio 创建别名数据类型:1.单击“开始”,指向“所有程序”,指向“Micr osoft SQL Server 2005”,然后单击“SQL Serv er Manag ement Studio”。
2.在“连接到服务器”对话框中,指定下表中的值,然后单击“连接”。
属性值服务器类型数据库引擎服务器名称本地服务器身份验证Windows 身份验证3.如果“对象资源管理器”不可见,则单击“视图”菜单上的“对象资源管理器”。
4.在对象资源管理器中,依次展开“数据库”、“Adv e ntureWork s”、“可编程性”和“类型”。
5.右键单击“用户定义数据类型”,然后单击“新建用户定义数据类型”。
6.在“新建用户定义数据类型”对话框中,输入下表中的详细信息,然后单击“确定”。
属性值架构dbo名称Countr yCode数据类型char长度2允许空值选中7. 验证CountryCode 数据类型是否已显示在“用户定义数据类型”列表中。
使用Transact-SQL 创建别名类型执行以下步骤以使用Transact-SQL 创建用户定义数据类型:1.在SQL Server Management Studio 中,单击工具栏上的“新建查询”按钮。
2.在新的空白查询窗口中,创建一个数据类型为nvarchar(50),它的别名为“dbo.EmailAddress”。
SQL SERVER利用分区对大数据表处理操作手册

SQL SERVER 2005利用分区对大数据表处理操作手册超大型数据库的大小常常达到数百GB,有时甚至要用TB来计算。
而单表的数据量往往会达到上亿的记录,并且记录数会随着时间而增长。
这不但影响着数据库的运行效率,也增大数据库的维护难度。
除了表的数据量外,对表不同的访问模式也可能会影响性能和可用性。
这些问题都可以通过对大表进行合理分区得到很大的改善。
当表和索引变得非常大时,分区可以将数据分为更小、更容易管理的部分来提高系统的运行效率。
如果系统有多个CPU或是多个磁盘子系统,可以通过并行操作获得更好的性能。
所以对大表进行分区是处理海量数据的一种十分高效的方法。
本文通过一个具体实例,介绍如何创建和修改分区表,以及如何查看分区表。
SQL Server 2005是微软在推出SQL Server 2000后时隔五年推出的一个数据库平台,它的数据库引擎为关系型数据和结构化数据提供了更安全可靠的存储功能,使用户可以构建和管理用于业务的高可用和高性能的数据应用程序。
此外SQL Server 2005结合了分析、报表、集成和通知功能。
这使企业可以构建和部署经济有效的BI解决方案,帮助团队通过记分卡、Dashboard、Web Services 和移动设备将数据应用推向业务的各个领域。
无论是开发人员、数据库管理员、信息工作者还是决策者,SQL Server 2005都可以提供出创新的解决方案,并可从数据中获得更多的益处。
它所带来的新特性,如T-SQL的增强、数据分区、服务代理和与.NetFramework的集成等,在易管理性、可用性、可伸缩性和安全性等方面都有很大的增强。
表分区的具体实现方法:表分区分为水平分区和垂直分区。
水平分区将表分为多个表。
每个表包含的列数相同,但是行更少。
例如,可以将一个包含十亿行的表水平分区成12个表,每个小表表示特定年份内一个月的数据。
任何需要特定月份数据的查询只需引用相应月份的表。
而垂直分区则是将原始表分成多个只包含较少列的表。
SqlServer2005对现有数据进行分区具体步骤
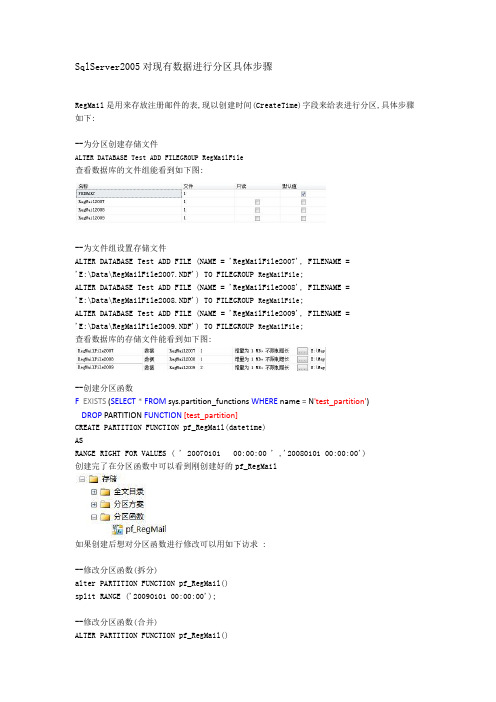
SqlServer2005对现有数据进行分区具体步骤RegMail是用来存放注册邮件的表,现以创建时间(CreateTime)字段来给表进行分区,具体步骤如下:--为分区创建存储文件ALTER DATABASE Test ADD FILEGROUP RegMailFile查看数据库的文件组能看到如下图:--为文件组设置存储文件ALTER DATABASE Test ADD FILE (NAME = 'RegMailFile2007', FILENAME ='E:\Data\RegMailFile2007.NDF') TO FILEGROUP RegMailFile;ALTER DATABASE Test ADD FILE (NAME = 'RegMailFile2008', FILENAME ='E:\Data\RegMailFile2008.NDF') TO FILEGROUP RegMailFile;ALTER DATABASE Test ADD FILE (NAME = 'RegMailFile2009', FILENAME ='E:\Data\RegMailFile2009.NDF') TO FILEGROUP RegMailFile;查看数据库的存储文件能看到如下图:--创建分区函数F EXISTS (SELECT*FROM sys.partition_functions WHERE name = N'test_partition')DROP PARTITION FUNCTION[test_partition]CREATE PARTITION FUNCTION pf_RegMail(datetime)ASRANGE RIGHT FOR VALUES ( ' 20070101 00:00:00 ' ,'20080101 00:00:00')创建完了在分区函数中可以看到刚创建好的pf_RegMail如果创建后想对分区函数进行修改可以用如下访求 :--修改分区函数(拆分)alter PARTITION FUNCTION pf_RegMail()split RANGE ('20090101 00:00:00');--修改分区函数(合并)ALTER PARTITION FUNCTION pf_RegMail()MERGE RANGE ('20080101 00:00:00');--创建分区方案/*看分区方案是否存在,若存在先drop掉*/IF EXISTS (SELECT*FROM sys.partition_schemes WHERE name = N'test_scheme') DROP PARTITION SCHEME test_schemeCREATE PARTITION SCHEME ps_RegMailAS PARTITION pf_RegMail TO (RegMail2007,RegMail2008,RegMail2009)CREATE PARTITION SCHEME MonthDateRangeSchemeASPARTITION MonthDateRangeALL TO ([PRIMARY])如果想去分区方案进行修改--修改分区方案ALTER PARTITION SCHEME ps_RegMailNEXT USED RegMail2010;--创建分区表CREATE TABLE [dbo].[PARTITIONERegMail]([id] [int] IDENTITY(1,1) NOT NULL,[CreateTime] [datetime] NOT NULLCONSTRAINT [PK_PARTITIONERegMail] PRIMARY KEY NONCLUSTERED([id] ASC)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]) ON [ps_RegMail]([CreeateTime])--此为关键步骤,将现有数据存入上面所建的文件中ALTER TABLE [dbo].[RegMail]WITH NOCHECK ADDCONSTRAINT [PK_RegMail] PRIMARY KEY CLUSTERED([CreateTime]) ON [ps_RegMail]([CreateTime])--如果原来的表里有主键哪就要执行下面语句:alter table RegEmail drop constraint PK_RegEmail--将表的主键删除--4. --对已经存在的表进行分区设置ALTER TABLE dbo.d_depot_inoutDROP CONSTRAINT PK_d_depot_inoutWITH(MOVE TO ps_d_depot_inout(statdate))ALTER TABLE d_depot_inoutADDPRIMARY KEY NONCLUSTERED(depot,statdate,itemno)ON ps_d_depot_inout(statdate)GO--查寻数据所在文件组--最后看看结果。
SQL Server 2005 中的分区表和索引

SQL Server 2005 中的分区表和索引SQL Server 2005发布日期: 3/24/2005 | 更新日期: 3/24/2005Kimberly L. Tripp 的创始人适用于:SQL Server 2005摘要:SQL Server 2005 中基于表的分区功能为简化分区表的创建和维护过程提供了灵活性和更好的性能。
追溯从逻辑分区表和手动分区表的功能到最新分区功能的发展历程,探索为什么、何时以及如何使用SQL Server 2005 设计、实现和维护分区表。
(本文包含一些指向英文站点的链接。
)关于本文本文所描绘的功能和计划是下一版本SQL Server 的开发方向。
它们并非本产品的说明书,如有更改,恕不另行通知。
对于最终产品是否具有这些功能不做任何明示或暗示的保证。
对于某些功能,本文假设读者熟悉SQL Server 2000 功能和服务。
有关背景信息,请访问SQL Server 网站或SQL Server 2000 资源工具包。
这并不是产品说明书。
下载相关的代码示例SQL2005PartitioningScripts.exe。
本页内容为什么要进行分区?分区的发展历史定义和术语创建分区表的步骤融会贯通:案例研究总结为什么要进行分区?什么是分区?为什么要使用分区?简单的回答是:为了改善大型表以及具有各种访问模式的表的可伸缩性和可管理性。
通常,创建表是为了存储某种实体(例如客户或销售)的信息,并且每个表只具有描述该实体的属性。
一个表对应一个实体是最容易设计和理解的,因此不需要优化这种表的性能、可伸缩性和可管理性,尤其是在表变大的情况下。
大型表是由什么构成的呢?超大型数据库(VLDB) 的大小以数百GB 计算,甚至以TB 计算,但这个术语不一定能够反映数据库中各个表的大小。
大型数据库是指无法按照预期方式运行的数据库,或者运行成本或维护成本超出预定维护要求或预算要求的数据库。
这些要求也适用于表;如果其他用户的活动或维护操作限制了数据的可用性,则可以认为表非常大。
数据库应用技术SQLServer2005基础篇课程设计

数据库应用技术SQLServer2005基础篇课程设计一、课程设计目的本次课程设计旨在让学生通过实际操作,掌握SQLServer2005基础知识,并能运用学过的知识进行实际操作与解决问题,提高学生的数据库应用水平。
二、课程设计内容1. 环境搭建使用SQLServer2005 Management Studio(简称SSMS)进行环境搭建,包括创建数据库、数据表、视图等。
2. SQL语言基础讲解SQL语言基础知识,包括DDL(数据定义语言)、DML(数据操作语言)、DCL(数据控制语言)等,让学生了解数据库的基本操作。
3. 数据表设计讲解数据表设计的基本原则和方法,包括数据类型、字段约束、数据表关系等,让学生能够熟练地设计出符合要求和规范的数据表。
4. SQL查询讲解SQL查询的基本语法,包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等关键字。
并通过实例让学生了解SQL查询的应用场景和技巧。
5. 数据库备份与还原通过讲解SQLServer的备份和还原功能,让学生了解备份和还原数据库的方法和注意事项,以防止数据丢失和恢复数据。
三、课程设计要求1. 实验环境要求•操作系统:Windows 7及以上•数据库软件:SQLServer2005及以上•SSMS(SQLServer Management Studio)2. 实验过程•独立完成实验,不得抄袭和剽窃。
•所有实验均需要提交实验报告,包含实验目的、实验步骤、实验结果以及总结等内容。
•实验过程中需记录操作步骤和注意事项。
四、课程设计实验题目实验一:环境搭建1.安装SQLServer2005和SSMS。
2.创建一个名为。
MICROSOFTSQL SERVER2005的分区新功能

关键词 : S QL S E RV E R 2 0 0 5 表 分 区 索引 死 锁 中图 分 类 号 : T P 3 文献 标 识 码 : A
文章编 号 : 1 0 0 7 — 9 4 1 6 ( 2 0 1 3 ) 0 1 — 0 1 3 7 — 0 1
随着数据库使用的深入 , 我们 面临着数据库越 来越 大的问题 。 S C HE ME AS P A RTI T I O N p a r f u n c TO ( [ F GI 】 , [ F G 2 】 , [ F G3 ] ) ; 为了解决这一 问题 , 数据库厂家引入 了分区 ( P a r t i t i o n i n g ) 的概念 。 ORAC L E 从8 i 开始就引入了初步 的范 围分 区功 能 , 到1 l g 就扩展 了 I n t e r v a 1 分区- # b 键分 区、 虚拟列 分区、 引入 了分 区建议器等扩展功
括 斗 铹
㈧ l l
设 计 开 发
MI C R OS O F T S Q L S E R V E R 2 0 0 5 的分区新功能
孙 砚 立
( 天津市中医药研究院 天津 3 0 0 1 2 0 )
摘要 : 本 文介绍 了分 区在 微软 数据 库S QL S e r v e r 2 0 0 5 中的 实施和 应 用 , 尤其是 应 用在 海量数 据 的数 据库 上 时 , 可优 化 文件 均衡放 置 , 加快 查
由于在S Q L S e r v e r Ma n a g e me n t S t u d i o ( S S MS ) 中没有 实施
分 区 的 图形 界 面 , 只 能 由我 们进 行 手 工 写 S Q L i  ̄句 进 行 与 分 区有 关 的操 作 。 具体操作步骤 如下 :
SQL Server 2000和SQL Server 2005的分区

SQL Server 2000里的分区--(SQL Server 2005里面的分区技术,为大部分朋友所熟知,但对于SQL Server 2000里面的表分区,很多朋友可能有些迷糊,本方将为大家描述一下SQL Server 2000及SQL Server 20005的分区技术。
其实SQL Server 2000里面本没有真正的分区,但为了弥补这一缺陷,人们利用视图和触发器的组合,创造出一种分区方案,对于这样种分区方案,姑且称之为“伪分区”。
)---------------------------------------------------------------------准备1SELECT * INTO CustomersGer FROM Customers WHERE Customers.Country='Germany'SELECT * INTO CustomersMex FROM Customers WHERE Customers.Country='Mexico'GO--准备2CREATE VIEW v_Customers_Ger_MexASSELECT * FROM CustomersGerUNIONSELECT * FROM CustomersMexGO--创建INSTEAD OF触发器CREATE TRIGGER tr_Customers_Update ON v_Customers_Ger_MexINSTEAD OF UPDATEASDECLARE @Country nvarchar(15)SET @Country=(SELECT Country FROM inserted)IF @Country='Germany'BEGINUPDATE CustomersGer SET CustomersGer.Phone=Inserted.Phone FROM CustomersGerJOIN Inserted ON CustomersGer.CustomerID=Inserted.CustomerIDENDELSE IF @Country='Mexico'BEGINUPDATE CustomersMex SET CustomersMex.Phone=Inserted.Phone FROM CustomersMexJOIN Inserted ON CustomersMex.CustomerID=Inserted.CustomerIDENDGO--测试UPDATE v_Customers_Ger_Mex SET Phone='030-007xfxx' WHERE CustomerID='ALFKI'SELECT CustomerID,Phone FROM v_Customers_Ger_Mex WHERE CustomerID='ALFKI'SELECT CustomerID,Phone FROM CustomersGer WHERE CustomerID='ALFKI'SELECT CustomerID,Phone FROM CustomersMex WHERE CustomerID='ALFKI'GO--------------------------------------------------------------------- SQL Server 2005里的分区---------------------------------------------------------------------创建实验用数据库USE masterCREATE DATABASE Sales ON PRIMARY (NAME = 'Sales_Data',FILENAME='C:\Databases\Sales_dat.mdf', SIZE=3MB,MAXSIZE=10MB,FILEGROWTH=10%),FILEGROUP FG1(NAME = 'File1',FILENAME = 'C:\Databases\File1_dat.ndf', SIZE = 1MB,MAXSIZE = 10MB,FILEGROWTH = 10%),FILEGROUP FG2(NAME = 'File2',FILENAME = 'C:\Databases\File2_dat.ndf', SIZE = 1MB,MAXSIZE = 10MB,FILEGROWTH = 10%),FILEGROUP FG3(NAME = 'File3',FILENAME = 'C:\Databases\File3_dat.ndf', SIZE = 1MB,MAXSIZE = 10MB,FILEGROWTH = 10%)LOG ON(NAME = 'Sales_Log',FILENAME = 'C:\Databases\Sales_Log.ldf', SIZE = 1MB,MAXSIZE = 10MB,FILEGROWTH = 10%)--创建分区函数,假定当前为2002年USE SalesCREATE PARTITION FUNCTION pf_OrderDate (datetime)AS RANGE RIGHT FOR VALUES('2003/01/01', '2004/01/01')GO--USE Sales--ALTER PARTITION FUNCTION pf_OrderDate ()--SPLIT RANGE ('2005/01/01')--GO--创建分区方案USE SalesGOCREATE PARTITION SCHEME ps_OrderDateAS PARTITION pf_OrderDate TO(FG1, FG2, FG3)GO--创建实验用数据表,并将其绑定到分区方案上USE SalesGOCREATE TABLE dbo.Orders(OrderID int identity(10000,1),OrderDate datetime NOT NULL,CustomerID int NOT NULL,CONSTRAINT PK_Orders PRIMARY KEY (OrderID, OrderDate))ON ps_OrderDate (OrderDate)GOCREATE TABLE dbo.OrdersHistory(OrderID int identity(10000,1),OrderDate datetime NOT NULL,CustomerID int NOT NULL,CONSTRAINT PK_OrdersHistory PRIMARY KEY (OrderID, OrderDate) )ON ps_OrderDate (OrderDate)GO-- SELECT * FROM sys.partition_schemes-- SELECT * FROM sys.partitions--向数据表中写入2002年的范例数据USE SalesGOINSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/6/25', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/8/13', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/8/25', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2002/9/23', 1000)GOSELECT * FROM OrdersSELECT * FROM dbo.OrdersHistoryGO--2003年年初利用分区交换执行快速的数据归档USE SalesGOALTER TABLE dbo.Orders SWITCH PARTITION 1 TO dbo.OrdersHistory PARTITION 1 GOSELECT * FROM OrdersSELECT * FROM dbo.OrdersHistoryGO--可以通过以下代码确认数据归档是否成功:--SELECT * FROM dbo.Orders--SELECT * FROM dbo.OrdersHistory--向数据表中写入2003年的范例数据USE SalesGOINSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/6/25', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/8/13', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/8/25', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2003/9/23', 1000)GOSELECT * FROM OrdersSELECT * FROM dbo.OrdersHistoryGO--2004年年初利用分区交换执行快速的数据归档USE SalesGOALTER TABLE dbo.Orders SWITCH PARTITION 2 TO dbo.OrdersHistory PARTITION 2 GOSELECT * FROM OrdersSELECT * FROM dbo.OrdersHistoryGO--对2002年数据分区和2003年数据分区进行合并USE SalesGOALTER PARTITION FUNCTION pf_OrderDate() MERGE RANGE ('2003/01/01')GO--SELECT * FROM sys.partition_schemes--SELECT * FROM sys.partitions--使用分区分裂功能准备2005年的数据分区USE SalesGOALTER PARTITION SCHEME ps_OrderDate NEXT USED FG2ALTER PARTITION FUNCTION pf_OrderDate() SPLIT RANGE ('2005/01/01') GO--可使用以下代码检查各分区中的数据行数:SELECT $PARTITION.pf_OrderDate(OrderDate) AS Partition,COUNT(*) AS [COUNT] FROM dbo.OrdersGROUP BY $PARTITION.pf_OrderDate(OrderDate)ORDER BY Partition ;GOSELECT $PARTITION.pf_OrderDate(OrderDate) AS Partition,COUNT(*) AS [COUNT] FROM dbo.OrdersHistoryGROUP BY $PARTITION.pf_OrderDate(OrderDate)ORDER BY Partition ;GO-----------------------USE SalesGOINSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2004/6/25', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2004/8/13', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2004/8/25', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2004/9/23', 1000) GOINSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2005/6/25', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2005/8/13', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2005/8/25', 1000) INSERT INTO dbo.Orders (OrderDate, CustomerID) VALUES ('2005/9/23', 1000) GO。
sqlserver 2005 如何创建分区表

注意:分区函数还允许将函数作为分区函数定义的一部分。您可以使用 DATEADD(ms,-3,'20010101'),而不是使用 '20001231 23:59:59.997' 明确定义时间。
要在四个活动分区(每个分区代表一个日历季度)中存储四分之一的 Orders 数据,并创建第五个分区以备将来使用(还是作为占位符,用于在分区表中移入和移出数据),请将 LEFT 分区函数与以下四个边界条件结合使用:
[SubTotal] [money] NULL,
[Status] [tinyint] NOT NULL ,
[RevisionNumber] [tinyint] NULL ,
[ModifiedDate] [datetime] NULL ,
[ShipMethodID] [tinyint] NULL,
创建分区函数后,必须将其与分区架构相关联,以便将分区定向至特定的文件组。定义分区架构时,即使多个分区位于同一个文件组中,也必须为每个分区指定一个文件组。对于前面创建的范围分区 (OrderDateRangePFN),存在五个分区;最后一个空分区将在 PRIMARY 文件组中创建。因为此分区永远不包含数据,所以不需要指定特殊的位置。
边界点 '20010630 23:59:59.997':
第四个分区将包含所有大于 '20010331 23:59:59.997' 但小于或等于 '20010630 23:59:59.997' 的值
最后,第五个分区将包含所有大于 '20010630 23:59:59.997' 的值。
创建分区架构
CREATE PART
MICROSOFT SQL SERVER2005的分区新功能

MICROSOFT SQL SERVER2005的分区新功能摘要:本文介绍了分区在微软数据库sqlserver2005中的实施和应用,尤其是应用在海量数据的数据库上时,可优化文件均衡放置,加快查询速度。
关键词:sql server 2005 表分区索引死锁中图分类号:tp3 文献标识码:a 文章编号:1007-9416(2013)01-0137-01随着数据库使用的深入,我们面临着数据库越来越大的问题。
为了解决这一问题,数据库厂家引入了分区(partitioning)的概念。
oracle从8i开始就引入了初步的范围分区功能,到11g就扩展了interval分区-外键分区、虚拟列分区、引入了分区建议器等扩展功能。
微软从microsoft sql7.0开始通过分区视图实现各种分区方式,到2005版对大型数据库的分区又大大的前进了一步。
通过使用分区,我们能把数据库工作表或索引放置在提前设置的文件组上。
这项新功能可以让表和索引的指定片放置在独立的文件组里,这样能有效的管理比较脆弱工作表的输入和输出。
[u1]改善了这些工作表以及具有各种访问模式的表的可伸缩性和可管理。
尤其表现在数以百gb甚至以tb计算的大型数据库里,单个的工作表也可能非常大,性能严重下降,数据查询反应较慢。
如采取提前设计和分区实现,能大大缓解数据库的查询反应慢、数据死锁、备份时间较长等问题。
由于在sql server management studio(ssms)中没有实施分区的图形界面,只能由我们进行手工写sql语句进行与分区有关的操作。
具体操作步骤如下:1 创建一个分区函数语句如下:creat parition functionpartition_funtction_name(input_parameter_type) as range [left|reght] for values([boundary_value[,,,n]])我们首先要为分区函数提供一个符合对象标识规则的名称,然后说明输入参数的类型。
SQL Server 2005---分区表和分区函数

SQL Server 2005------分区表和分区函数在谈论分区表这个话题之前,先和大家分享一个案例:2008年秋天的某天,我的团队接到成都市XX局一个SQL调优的ESS单子。
客户反映查询统计一次各地市局上报的数据汇总,需要6到15秒才能获得真正想要的数据,当我和销售人员赶到客户数据中心现场后,发现里面布置了很多柜式服务器,每台服务器都是8核16G内存。
和相关技术负责人沟通以及演示业务系统之后,可以肯定不是服务器性能的问题,我详细分析了他们的数据库,统计慢的几张表往往一周的上报数据便会增加1百多万行,导致他们这个系统刚上线没多久,某些表产生的数据已经在2000万行以上,最终我提出了优化方案,业务逻辑层采用存储过程代替普通的SQL语句,并启用相关开发平台的缓存技术;数据库系统中采用增强索引和规划分区表进行优化,最终问题解决。
事实上数据库性能优化是每个优秀的数据库工程师必须具备的素质之一,而这一节讨论的分区表便是性能调优的一种技术。
在企业级应用系统中,一个表存储2千万行的数据很常见,不可预期的数据也会在逐渐增长,所以数千万级别的表DBA会常常碰到,而TB级别的数据最终也在所难免,因此了解和掌握性能调优的18般兵器非常重要。
我计划用三篇博文介绍分区表这个主题,分别为:1,分区表理论解析2,实战分区表3,分区表前传大凡在应用系统和数据库系统中行走江湖多年的朋友,都会面临数据统计、分析以及归档的问题,企业信息化进程加速了各种数据的极具增长,商务智能(BI)的出现和实施着实给信息工作者和决策者带来了绝妙的体验,但从 OLTP 向 OLAP 系统加载数据是很头疼的事,常常需要数分钟或数小时,解决这一问题的技术之一便是分区表,一旦实施了分区表,这样的操作往往只需几秒钟,太让人兴奋了。
而大型表或索引经过分区后更容易进行管理,因为这样可以快速高效地管理和访问数据子集,同时维护数据集合的完整性。
分区表的数据分布于一个数据库中的多个文件组单元中,数据是按水平方式分区的(数据分区的多种方式会在分区表前传中阐述),因此一个表的某些行映射到某个分区,而另外一些行映射到另外某个分区,以此类推。
SQL2005分区表

SQL2005分区表分区表有利于管理海量数据的表和索引,在分区中引入了一个分区键的概念,分区键用于根据某个区间值,特定值列表或散列函数执行数据的聚集.使用分区表有如下好处:1.提高数据的高用性:可用性的提高源自每个分区的独立性.优化器知道这种分区机制,会相应的从查询计划中除去未引用的分区.2.减轻管理员负担.3.改善某些查询性能,在只读查询的性能方面,分区对两类操作起作用.●分区消除:处理查询时,不考虑某些分区.●并行操作:并行全表扫描和并行索引区间扫描.4.减少资源竞争.脚本:--首先手工创建文件分组、物理文件;脚本方式创建后边介绍---- 创建分区函数--go--create partition function MineDateRange(datetime)--as--range right(left) for values (--'2010-01-01',--'2011-01-01',--'2012-01-01')--go------ 创建分区方案--go--create partition scheme Mine_Orders--as--partition MineDateRange--to (test2010, test2011, test2012,test2013)--go-- 创建分区表--go--create table dbo.OrdersTest--(-- OrderID int not null-- ,CustomerID varchar(10) not null-- ,EmployeeID int not null-- ,OrderDate datetime not null--)--on Mine_Orders(OrderDate)--go-- 创建聚集分区索引--create clustered index IXC_OrdersTest on dbo.OrdersTest(OrderDate) --go--插入数据--INSERT INTO [HyMineSecurityMonitor].[dbo].[OrdersTest]-- ([OrderID]-- ,[CustomerID]-- ,[EmployeeID]-- ,[OrderDate])-- VALUES-- (7-- ,'ffff',7-- ,'2015-10-10 12:20:23')--查询数据--select * from OrdersTest--查看每个分区的数据分布情况--SELECT partition = $partition .MineDateRange(OrderDate), rows = count(*), minval = min(OrderDate), maxval = max(OrderDate)--FROM dbo.OrdersTest--GROUP BY $partition .MineDateRange(OrderDate)--ORDER BY partition--------------------------------------------修改分区------------------------------------------------------添加文件分组--ALTER DATABASE HyMineSecurityMonitor ADD FILEGROUP [test2014]--添加物理文件--ALTER DATABASE HyMineSecurityMonitor--ADD FILE--(NAME = N'test2014',FILENAME =N'D:\DataBase\testDB\test2014.ndf',SIZE = 5MB,MAXSIZE =100MB,FILEGROWTH = 5MB)--TO FILEGROUP [test2014]--修改分区函数新增一个分区--go--alter partition function MineDateRange()--split range('2013-01-01')--go--修改分区方案新增一个文件--go--alter partition scheme Mine_Orders next used [test2014]--go--修改分区函数合并一个分区--go--alter partition function PF_Orders_OrderDateRange()--merge range('2013-01-01')--go--------------------------------------------------------分区表数据迁移---------------------------------------------SQL Server 2005 分区表分区切换的三种形式:----1. 切换分区表的一个分区到普通数据表中:Partition to Table;(普通表:dbo.Orders_1998)-- create table dbo.Orders_1998-- (-- OrderID int not null-- ,CustomerID varchar(10) not null-- ,EmployeeID int not null-- ,OrderDate datetime not null-- ) on [test2012]---- alter table dbo.OrdersTest switch partition 3 to dbo.Orders_1998--1). 普通表必须建立在分区表切换分区所在的文件组上。
SQLServer数据库分区分表(水平分表)详细步骤

SQLServer数据库分区分表(⽔平分表)详细步骤⽬录1、需求说明2、实现思路2.1分区原理2.2 ⽔平分区优点2.3 实现思路3、实现步骤3.1代码创建分区表3.1.1 创建数据库3.1.2 添加⽂件组3.1.3 添加⽂件3.1.4 定义分区函数3.1.5 定义分区架构3.1.6 定义分区表3.2 界⾯向导表分区3.2.1 创建数据库3.2.2 创建⽂件组3.2.3 添加⽂件3.2.4 定义分区表3.2.5 添加分区函数和分区架构3.3 动态添加分割点4、测试数据4.1 添加测试数据4.1.1 新建测试表4.1.2 编写T-SQL添加测试数据5、补充说明5.1 分区分表理解5.2 ⽔平分区分表疑惑5.3 其它说明1、需求说明将数据库Demo中的表按照⽇期字段进⾏⽔平分区分表。
要求数据⽂件按⼀年⼀个⽂件存储,且分区的分割点会根据时间的增长⾃动添加(例如现在是2017年1⽉1⽇,将其作为⼀个分割点,即将2017年1⽉1⽇之前的数据存储到数据⽂件A中,将2017年1⽉1⽇的之后的数据存储到数据⽂件B中;当时间到2018年1⽉1⽇时,⾃动将2018年1⽉1⽇添加为⼀个新的分区分割点,并将2017年1⽉1⽇⾄2018年1⽉1⽇的数据存储在数据⽂件B中,将2018年1⽉1⽇之后的数据存储在⼀个新的数据⽂件C中,以此类推)。
2、实现思路2.1分区原理要实现这⼀功能,⾸先要了解数据库对⽔平分区表进⾏分区存储的原理。
所谓⽔平分区分表,就是把逻辑上的⼀个表,在物理上按照你指定的规则分放到不同的⽂件⾥,把⼀个⼤的数据⽂件拆分为多个⼩⽂件,还可以把这些⼩⽂件放在不同的磁盘下。
这样把⼀个⼤的⽂件拆分成多个⼩⽂件,便于我们对数据的管理。
2.2 ⽔平分区优点l 便于存档l 便于管理:备份恢复时可以单⼀的备份或者恢复某⼀个分区l 提⾼可⽤性:⼀个分区故障,不影响其他分区的正常使⽤l 提⾼性能:提升查询数据的速度2.3 实现思路①创建数据库②在创建的数据库中添加⽂件组③在⽂件组中添加新的⽂件④定义分区函数⑤定义分区架构⑥定义分区表⑦定义代理作业,⾃动添加分区分割点⑧测试数据注意:² 分区表依赖于分区架构,⽽分区架构⼜依赖与分区函数,所以在穿件分区函数、分区架构、分区表是要按照对应的顺序创建。
sql2005分区表效率实验

分区前itemDetail耗时目标记录数无条件2:357631400指定字段1:117631400指定字段0:242543814指定条件指定字段0:001指定条件itemDetailleft joincljg无条件6:027631400指定字段1:507631400指定字段0:382543814指定条件指定字段0:001指定条件分区后itemDetail耗时目标记录数无条件2:547631400指定字段1:547631400指定字段0:392543814指定条件指定字段0:001指定条件itemDetailleft joincljg无条件6:027631400指定字段1:587631400指定字段0:402543814指定条件指定字段0:001指定条件语句select * from itemDetailselect fId,xh,i02,i03,i04,i05 from itemDetailselect fId,xh,i02,i03,i04,i05 from itemDetail where fId>=121133 and fId<=242266select fId,xh,i02,i03,i04,i05 from itemDetail where fId=111111select * from itemDetail id left join cljg c on id.fid = c.fidselect c.fId,xh,i02,i03,i04,i05,jg01,jg02,jg45 from itemDetail id left join cljg c on id.fid = c.fi select id.fId,xh,i02,i03,i04,i05,jg01,jg02,jg45 from itemDetail id left join cljg c on id.fid = c.f select id.fId,xh,i02,i03,i04,i05,jg01,jg02,jg45 from itemDetail id left join cljg c on id.fid = c.f 语句select * from itemDetailselect fId,xh,i02,i03,i04,i05 from itemDetailselect fId,xh,i02,i03,i04,i05 from itemDetail where fId>=121133 and fId<=242266select fId,xh,i02,i03,i04,i05 from itemDetail where fId=111111select * from itemDetail id left join cljg c on id.fid = c.fidselect c.fId,xh,i02,i03,i04,i05,jg01,jg02,jg45 from itemDetail id left join cljg c on id.fid = c.fi select id.fId,xh,i02,i03,i04,i05,jg01,jg02,jg45 from itemDetail id left join cljg c on id.fid = c.f select id.fId,xh,i02,i03,i04,i05,jg01,jg02,jg45 from itemDetail id left join cljg c on id.fid = c.fd.fid = c.fidjg c on id.fid = c.fid where id.fId>=121133 and id.fId<=242266 jg c on id.fid = c.fid where id.fId=111111g c on id.fid = c.fidjg c on id.fid = c.fid where id.fId>=121133 and id.fId<=242266 jg c on id.fid = c.fid where id.fId=111111。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目录一、基本说明 (2)1.可以做分区表的情况 (2)2.分区表的优点 (2)3.分区表的目的 (2)4.能使用分区操作的SQL版本软件 (2)二、具体操作 (2)1.分区表建立的步骤 (2)2.举例 (3)3.创建文件组 (3)4.创建文件 (4)5.创建分区函数 (5)6.创建分区方案 (6)7.创建分区表 (7)三、操作分区表 (8)1.插入数据 (8)2.查询数据所在物理分区表 (9)3.修改分区表数据 (11)4.将普通表转换为分区表 (11)四、删除(合并)一个分区表 (15)五、添加分区 (16)六、将已分区表转换成普通表 (18)一、基本说明1.可以做分区表的情况a.数据库中某个表中的数据很多,多到在查询数据时能明显感觉到速度变慢时就要考虑分区表了。
b.当一张表的数据会经常使用,且不管年份之类的因素经常对其进行增删改查操作时最好不要分区。
c.数据是分段的数据,比如以年为分隔的数据,对于今年的数据而言,经常进行增删改查的操作,而对于往年的数据而言,几乎不需要什么操作,或者对往年的操作往往只限于查询,那么可以使用分区表。
换名话说,对数据的操作往往只涉及到一部分数据而不是所有数据的话,那么就可以考虑分区表了。
2.分区表的优点将一个数据量很多的数据表分成几个小表的处理方式,会给程序员增加编程上的难度。
以添加记录为例,5个独立的表,在不同时间添加记录的时候,程序员要使用不同的SQL语句,例如在2011年添加记录时,程序员要将记录添加到2011年那个表里;在2012年添加记录时,程序员要将记录添加到2012年的那个表里。
这样,程序员的工作量会增加,出错的可能性也会增加。
使用分区表就可以很好的解决以上问题。
a.分区表可以从物理上将一个大表分成几个小表,但是从逻辑上来看,还是一个大表。
b.对于具有多个CPU的系统,分区可以对表的操作通过并行的方式进行,这对于提升性能是非常有帮助的3.分区表的目的使用分区表的主要目的,是为了改善大型表以及具有各种访问模式的表的可伸缩性和可管理性。
4.能使用分区操作的SQL版本软件Sql server2000是不能建立分区表的,需要使用SQL Server2005及以上版本的SQL二、具体操作1.分区表建立的步骤1.创建数据库文件组2.创建数据库文件3.创建分区函数4.创建分区方案5.创建分区表2.举例在本文档中以单元计费表作为例子,单元计费中记录着各个单元(房间)在每月的计费金额,我们将这个表分成5个小表,2008年以前作为一个表,2009年的记录作为一个表,2010年作为一个表,2011年的记录作为一个表,2011年以后作为一个表,总共是做5个表。
3.创建文件组创建分区表的第一步是创建数据库文件组,因为系统原本有默认的文件组PRIMARY文件,所以这一步也是可以省略的,不过为了方便管理,还是可以先创建几个文件组,这样可以将不同的小表放在不同的文件组里,既便于理解又可以提高运行速度。
创建文件组的方法步骤一:SQL Server Management Studio→选择要分区的数据库→右键鼠标→【属性】步骤二:在数据库属性界面中选择文件组→单击【添加】,每添加一个文件组都单击一次【添加】4.创建文件创建数据库文件的目的是为了将分区的小表放在硬盘上的文件里。
创建文件的方法步骤一:在创建文件组的数据库属性界面中选择【文件】→单击【添加】,输入文件信息,如下图在添加文件时需要注意:1.将不同的文件放在文件组中,当然一个文件组中也可以包含多个不同的文件。
2.将不同的文件放在不同的硬盘分区里,最好是放在不同的独立硬盘里。
要知道IQ的速度往往是影响SQL Server运行速度的重要条件之一。
将不同的文件放在不同的硬盘上,可以加快SQL Server的运行速度。
5.创建分区函数以单元计费表作为例子,对其建立分区函数--分区函数create partition function fununitcharge(datetime)as range right for values('20090101','20100101','20110101','20120101')其中a.Create partition function表示要创建一个分区函数b.Fununitcharge是分区函数名,可自行定义c.Fununitcharge()括号中是分区的列的数据类型,当用作分区列时,除text、ntext、image、xml、timestamp、varchar(max)、nvarchar(max)、varbinary(max)、别名数据类型或CLR用户定义数据类型外,所有数据类型均有效。
d.left|right指定当间隔值由数据库引擎按升序从左到右排序时,values属于每个边界值间隔的哪一侧(左侧还是右侧)。
如果未指定,则默认值为LEFT,LEFT的意思是将等于这个值的数据放在左边的那个表里,RIGHT的意思是将等于这个值的数据放在右边的那个表里,以所举函数为例,使用RIGHT 后结果是:小于2009-01-01的数据放在一个表中大于或等于2009-01-01小于2010-01-01的数据放在一个表中大于或等于2010-01-01小于2011-01-01的数据放在一个表中大于或等于2011-01-01小于2012-01-01的数据放在一个表中大于或等于2012-01-01之后的数据放在一个表中Values中,'20090101','20100101','20110101','20120101',这些都是分区的条件。
'20090101'代表2009年1月1日,在小于这个值的记录,都会分在一个小表中,如表1;而大于或等于'20090101'并且小于'20100101'的值,会放在另一个表中,如表2。
以此类推,到最后,所有大小或等于'20120101'的值会放在另一个表中,如表5。
6.创建分区方案分区方案的作用是将分区函数生成的分区映射到文件组中去,也就是说分区方案是告诉SQL Server将已分区的数据放在哪个文件组中。
以单元计费表为例,其分区方案的代码如下所示:--分区方案create partition scheme schunitchargeas partition fununitchargeto(fq2008,fq2009,fq2010,fq2011,fq2012)其中a.Create partition scheme表示要创建一个分区方案b.Schunitcharge是分区方案的名称,可自行定义c.as partition fununitcharge说明该分区方案所使用的数据划分条件(也就是所使用的分区函数)为fununitcharged.To()括号中的内容是指fununitcharge分区函数划分出来的数据对应存放的文件组此时分区函数和分区方案已经建立好了,若要查看他们可以在数据库的【存储】中查看,如图7.创建分区表创建分区表和创建普通表的方法类似,代码如下--创建分区表create table unitcharge([计费id][int]NOT NULL,[单元编号][nvarchar](50)NOT NULL,[收费项目id][int]NOT NULL,[应计金额][money]NOT NULL DEFAULT(0),[实收金额][money]NOT NULL DEFAULT(0),[计费起始日期][datetime]NULL,[计费终止日期][datetime]NULL,[计费人][nvarchar](50)NULL,[收款终止日期][smalldatetime]NULL)on schunitcharge(计费起始日期)其中a.create table是新建一个数据表b.Unitcharge是数据表的名称,可自行定义c.Unitcharge()括号里的是表中的字段,在这里需要注意的是分区表不能再创建聚集索引。
因为聚集索引可以将记录在物理上顺序存储,而分区表是将数据分别存储在不同的表中,这两个概念是冲突的,所以,在创建分区表的时候就不能再创建聚集索引了。
d.ON schunitcharge()说明使用名为schunitcharge的分区方案。
e.schunitcharge()括号中的内容是用于分区条件的字段是计费起始日期。
经过以上的操作分区表unitcharge已经是一个物理上分离,逻辑上是一体的分区表了。
查看该表的属性,可以看到该表已经属于分区表了。
三、操作分区表1.插入数据创建完分区表后,分区表还是一个空表,我们可以向分区表直接插入数据,而不用去管它这些数据放在哪个物理上的数据表中,现在我们对其插入一些数据--插入语句insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(1,'0101101',2,'262.65','0','2008-12-31 ','2009-01-31','system','2009-02-01')insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(2,'0101102',2,'125.62','125.62',' 2009-01-01','2009-02-01','system','2010-02-21')insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(3,'0101103',5,'200','125.62','2009-01-31 ','2009-02-27','system','2009-03-01')insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(4,'0101101',45,'278.65','278.65','2010-01-01','2010-02-01','system', '2010-02-28')insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(5,'0101102',34,'225.62','125',' 2010-01-31','2010-02-01','system','2010-03-01')insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(6,'0101103',23,'212','25.62',' 2011-01-01','2011-02-01','system','2011-02-01')insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(7,'0101101',2,'262.65','0',' 2011-01-31','2011-02-01','system','2011-02-01')insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(8,'0101102',2,'125.62','125.62',' 2012-01-01','2012-02-27','system','2012-03-01')insert into unitcharge([计费id],[单元编号],[收费项目id],[应计金额],[实收金额],[计费起始日期],[计费终止日期],[计费人],[收款终止日期])values(9,'0101102',2,'125.62','125.62',' 2012-01-31','2012-02-27','system','2012-03-01')由上面的语句我们对unitcharge表插入了9条数据使用select*from unitcharge得出下面的结果由查询的结果可知第一条数据在1分区表,第二、三条数据在2分区表,第四、五条数据在3分区表,第六、七条数据在4分区表,第八、九条数据在5分区表2.查询数据所在物理分区表在分区表中使用一般的select语句是无法知道数据是分别存放在几个不同的物理表中,若要知道数据分别存放的物理表,我们需要使用到$PARTITION函数,这个函数可以调用分区函数,并返回数据所在物理分区的编号。