Proc gplot
Sas学习笔记

Sas学习笔记人文社会科学学院高等教育学专业张宁S100081674整个SAS程序结构可以分为两个部分,数据data步与过程proc步。
data步1:输入数据(包括手动输入数据、从文本文件中导入数据)a使用手动方法输入数据基本形式是:Data 数据集;Input 变量名(包括格式设置);/*在input语句中需要指定的格式必须和cards中数据的格式一致,需要考虑字符型与数值型数据的不同,以及是否是标准数据,根据实际情况调整数据格式设定*//* 同时在读入数据的时候,需要参考数据的形式,指定输入的起始位置与字符数,包括使用@指针控制、指定起始列终止列、指定字符数等*/其他语句;/*循环语句,选择语句等*//*sas表达式:sas运算符(包括算数、比较、逻辑)sas函数(包括算数函数、常用函数等)*/Cards ;数据;/*其中数据之间默认为空格作为分隔符,如果分隔符为其他符号,则要在input语句中指定delimiter=‘’*/Run;b使用文本文件导入法基本形式是:Data 数据集;变量属性设定;Infile‘文件地址’(firstobs=,obs= ,missover);Input;其他语句;/*循环语句,选择语句,sas表达式*/Run;当然输入数据的时候可以直接使用sas导入数据选项,根据情况设定形式,导入数据。
c总之在data步中常见的语句有:DA TA语句PUT语句——输出语句SET语句——读取观测语句ATTRIB语句——设定变量属性赋值语句——计算SAS表达式,给变量赋值DROP语句——删除变量语句KEEP语句——保留变量语句IF语句——条件语句DO-END语句——循环语句DELETE语句——删除语句OUTPUT语句——输出到数据集语句COMMENT语句——注释语句ARRAY语句——数组语句在实际操作中,可以灵活的使用这些语句实现数据处理。
2:同时在数据步中可以使用语句实现数据集的加工、合并和拼接a数据集排序/*事先对SAS数据集进行排序,是其它SAS程序通过使用BY语句直接调用该数据集及对数据集进行合并或串接的前提*/PROC SORT OPTIONS ;BY 〔DESCENDING〕变量名列表;END;b数据集串联/*在串联中必须要求同一个变量在不同数据集中数据形式一致,如果不一致,则需使用put函数将数据形式转换*/Concatenate方式Data 新数据集;Set 输入数据集1 输入数据集2 ……;/*可以使用(in=变量k)的形式检测来自哪个数据集*/Run;Interleave方式:Data 新数据集;Set 输入数据集1 输入数据集2 ……;By by-variables ;/*必须排序*/Run;c数据集并联/*用MERGE 语句并接SAS数据集*/MERGE (一对一合并)DATA 新数据集;MERGE 输入数据集1 输入数据集2 ……;RUN;MATCH MERGE(匹配合并)DATA 新数据集;MERGE 输入数据集1 输入数据集2 ……;BY by-variables ;RUN;d修改数据集modify/*modify语句修改数据集,并且此过程不能形成新的数据集,并且不需要排序*/data主数据集名称;modify 主数据集名称更新数据集名称;run;Update/*可以产生新的数据集,需要使用by排序*/data 数据集名称update 主数据集名称更新数据集名称;by变量名称;/*该语句必须出现,而且必须在该data步之前对update语句中的数据集进行排序*/run;Proc步该过程常用的sas语句有:V AR语句—指定分析变量MODEL语句—指定统计建模的模型/*一般采用‘因变量=自变量/选项’的形式*/BY语句—指定分组变量/*使用之前一般要使用proc sort语句进行排序*/CLASS语句—指定分类变量OUTPUT语句—指定输出结果存放的数据集FREQ语句—指定一个重复数变量WEIGHT语句—指定一个权重变量ID语句—指定用来标识观测的变量WHERE语句—选择输入数据集的一个行子集进行分析LABEL语句—为变量指定一个临时标签FORMAT语句—为变量输出规定一个输出格式/*过程步中规定的格式只是在本次运算中起作用,而数据步中规定的实行在整个数据集中永久存在*/1:使用proc print语句输出表格PROC FORMAT;V ALUE ;/*使用该语句定义用户格式*/PROC PRINT DATA 数据集SPLIT='*' ;/*使用该语句控制显示中的格式,使其按要求换行*/ID 变量名; /*把指定的变量在取消obs 的情况下排在表格最左列*/V AR 变量列表;/*需要输出的变量*/WHERE 条件表达式…;SUM 变量序列;/*变量需要处理的形式*/BY 变量名; /*在先前进行排序的情况下,对数据进行分组并要求每组进行小计*/PAGEBY 变量序列;/*是报告表格按组分页*/TITLEn'语句';/*使用该语句控制表头显示可以最多有十个标注*/FOOTNOTEn语句';LABEL 变量1= ‘label(标*签)’……;/*控制表头显示,可使用起始中split=定义的方式美化表格*/FORMA T ;/*用户自定格式的使用*/RUN;2:使用proc tabulate语句输出汇总表格PROC FORMAT;V ALUE ;/*使用该语句定义用户格式*/PROC TABULATE data 数据集options;CLASS /*分类变量,可以是数值型也可以是字符型*/;V AR ;/*分析变量,必须是数值型*/FORMAT ;/*用户自定格式的使用*/TABLE page-v,row-v,colum-v / options;/*table语句中使用的变量必须是class与var中定义过的变量*//*包括元素与操作符,根据操作符的不同控制表格格式,无=每个变量占一单独列;,=两个表达式产生一个二维列表分别代表行和列;两个,=三维列表分别是页行列;*隔开两个表示交叉列表*//*options选项控制表格其他形式,如使用rts控制第一列宽度*/KEYLABEL ;/*使用该语句为all类变量以及所有的统计量加标记*/TITLEn'语句';/*使用该语句控制表头显示可以最多有十个标注*/FOOTNOTEn语句';LABEL 变量1= ‘label(标*签)’……;/*控制表头显示,可使用起始中split=定义的方式美化表格*/RUN;3:使用proc gplot语句绘制散点及折线图PROC GPLOT DATA=数据集;PLOT 纵坐标变量*横坐标变量/选项;/*控制坐标轴:HAXIS=Values|Axisn定义水平轴的刻度;VAXIS=Values|Axisn定义垂直轴的刻度;NOAXIS取消坐标轴及相关的文字;CAXIS=Color定义坐标轴的颜色;CTEXT=Color定义坐标轴文本的颜色*//*加框:FRAME加框;CFRAME= Color给坐标轴包围的区域填色*/ SYMBOL V=I=W=C=;/*V=NONE;PLUS'+';STAR'*';SQUARE'方块';DIAMOND'菱形';TRIANGLG'三角形'*//*I= NONE ;JOIN'直线连接';SPLINE'光滑曲线连接';NEEDLE'从数据到横坐标画垂直线'*//*C=RED;GREEN;BLUE;ORANGE*/LABEL ; 变量1= ‘label(标*签)’……;/*控制表头显示,可使用起始中split=定义的方式美化表格*/TITLE C=颜色H=高度及单位F=字体;/*使用该语句控制表头显示可以最多有十个标注*/FOOTNOTE C=颜色H=高度及单位F=字体;RUN;4:使用proc gcharts语句绘制饼图及柱状图PATTERN c=颜色v=花纹;PROC GCHART DA TA=数据集;VBAR|HBAR|PIE|STAR|BLOCK/*垂直柱状图/水平柱状图/圆饼图/星形图/立体柱状图*/分类变量名列/选项;/*DISCRET/*指定分类方式*/MIDPOINT=列举值/*指定分组中点*/ SUMV AR=变量名/*指定分析变量*/TYPE=FREQ|SUM|MEAN|PCT /*指定统计量(无SUMVAR时缺省为FREQ,否则为SUM )*/GROUP=变量名/*指定分组作图*/SUBGROUP=变量名/*指定柱内分组*/FILL=S(SOLID)|X(CROSS)/*设定饼图的花纹*/*/LABEL ; 变量1= ‘label(标*签)’……;/*控制表头显示,可使用起始中split=定义的方式美化表格*/TITLE C=颜色H=高度及单位F=字体;/*使用该语句控制表头显示可以最多有十个标注*/FOOTNOTE C=颜色H=高度及单位F=字体;RUN;5:使用proc univariate、means、freq语句进行定量资料的统计描述PROC UNIV ARIATE DATA= 数据集名options;/*NOPRINT禁止统计报告在OUTPUT视窗中输出PLOT 绘出茎叶图、箱式图和正态概率图FREQ 给出频数表NORMAL 对变量进行正态性检验*/V AR 变量名列;BY 变量名列; /*排序*/FREQ 变量名;WEIGHT 变量名;ID 变量名;OUTPUT OUT= 数据集名关键字= 新变量名列.../*常用关键字有:基本统计量:N MEAN STD(标准差)CV(变异系数)SUM VAR(方差)RANG 百分位数描述:MIN P1 P5 P10 Q1 MEDIAN Q3 P90 P95 P99MAX与假设检验有关的统计量有:STDMEAN(标准误)T */pctlpts=百分位数, ...pctlpre=新变量名列;Run;PROC MEANS [ DATA= 数据集名选项统计量关键字列表;/*选项有:NOPRINT 禁止统计在OUTPUT视窗中输出MAXDEC=n 给出列表输出的最大小数位数,缺省值为2*/V AR 变量名列;BY 变量名列;CLASS 变量名列;FREQ 变量名;WEIGHT 变量名;ID 变量名列;OUTPUT OUT= 数据集名关键字= 新变量名列... ;/*关键字有:基本统计量有:N MEAN STD(标准差)CV(变异系数)SUM VAR(方差)RANG MIN MAX;与假设检验有关的统计量有:STDERR(标准误)T PRT(与t对应的p值) LCLM(可信区间下限) UCLM(可信区间上限)*/Run;PROC FREQ data+;TABLES 请求式/ 选项;/* 常用选项有ORDER=FREQ 按频数递减顺序排列ORDER=DATA 按数据集中出现的顺序排列ORDER=INTERNAL 按内部值排列(缺省) ORDER=FORMATTED 按外部格式值排列*/WEIGHT 变量名;BY 变量名列;Run;6:使用proc corr过程进行相关系数计算(相关关系散点图可以参照gplot语句)PROC CORR DATA=数据集OPTIONS;/*PEARSON 计算皮尔逊相关系数(缺省值);SPEARMAN 计算斯皮尔曼等级相关系数;NOSIMPLE 不打印输出各变量的描述性统计量;NOPROB 省略检验统计量p-值;COV(COVARIANCE) 打印协方差矩阵;NOCCORR 储存时省略相关系数;OUTP=指定皮尔逊相关系数存储的数据集;OUTS= 指定斯皮尔曼相关系数存储的数据集*/ V AR 变量名列;WITH 变量名列;/*计算with指定变量与var指定变量之间的相关系数*/PARTIAL 变量名列;RUN;7:使用proc reg过程进行回归分析PROC REG DATA= 数据集名OPTIONS;/*SIMPLE 计算并打印各变量的基本描述性统计量;SXORR 打印各变量的相关行列式;NOPRINT不打印输出;OUTEST=数据集名指定回归值输出的数据集;COVOUT=数据集名将所估计的协方差阵存入数据集;OUTSSCP=数据集名指定相关矩阵输出的数据集*/V AR 变量名列;BY 变量名列;FREQ 变量名列;MODEL 因变量=自变量/OPTIONS;/*model语句的作用可分为以下四个方面:1.关于报表打印的选项NOPRINT不打印MODEL语句所界定的分析结果;ALL 打印MODEL语句所有分析结果*//*2.界定参数估计值的选项STB 打印标准化回归系数;COVB 输出估计值的协方差阵;VIF 输出方差膨胀因子;COLLIN 进行多元共线性分析*//*3.关于预测值、预测误差的选项P计算每一个观测值y的期望值及其标准误;R 在P选项的基础上对预测误差做进一步分析;CLI 输出单个预测值95﹪的置信区间;CLM 输出预测值均值95﹪的置信区间;INFLUENCE 分析观测值对参数估计和模型预测值的影响*//*4.关于界定回归模型的选项SELECTION=none|forward|backward|stepwise|cp |rsquare|adjrsq 指定自动进行变量选择的方法;NOINT 规定回归模型中不包含截距项.*/OUTPUT OUT=数据集名关键字=新变量名列;RUN;PROC GPLOT DA TA=数据集;/*做回归图*/PLOT 纵轴变量名*横轴变量名;SYMBOL V=符号C=颜色I=none|rl|rq|rc /*不加线线性二次三次*/其他选项;RUN;。
sas期末考试试题

sas期末考试试题SAS期末考试试题一、选择题(每题2分,共20分)1. 在SAS中,以下哪个命令用于创建数据集?A. PROC SORTB. DATASETSC. SETD. INPUT2. 下列哪个选项不是SAS数据集中的变量属性?A. 长度B. 格式C. 标签D. 颜色3. SAS中的PROC FREQ过程用于:A. 描述性统计分析B. 频率分布分析C. 回归分析D. 时间序列分析4. 以下哪个命令用于在SAS中生成随机数?A. RANDB. RANDOMC. RNDD. UNIVARIATE5. 在SAS中,如何使用PROC GPLOT创建图形?A. 使用PLOT语句B. 使用SGPLOT过程C. 使用GPLOT语句D. 使用GRAPH语句二、简答题(每题10分,共30分)1. 解释SAS中的宏语言及其用途。
2. 描述如何使用SAS进行数据清洗的基本步骤。
3. 简述SAS中PROC UNIVARIATE过程的功能和应用场景。
三、编程题(每题25分,共50分)1. 编写SAS程序,从一个名为“sales_data”的数据集中提取出所有销售额超过平均销售额的产品,并计算这些产品的总销售额。
```sasdata sales_data;set sales_data;if sales > mean(sales);run;proc means data=sales_data mean;var sales;output out=avg_sales mean=avg_sales;run;data top_sales;set sales_data;where sales > avg_sales.avg_sales;run;proc sql;select sum(sales) into: total_salesfrom top_sales;quit;```2. 编写SAS程序,使用PROC REG过程对一个名为“education_data”的数据集进行线性回归分析,预测学生的考试成绩(变量名为“score”)基于其学习时间(变量名为“study_hours”)。
学习使用SAS进行数据分析的基础教程

学习使用SAS进行数据分析的基础教程一、SAS介绍与安装SAS(全称Statistical Analysis System,统计分析系统)是一种非常强大的数据分析软件。
它提供了丰富的统计分析、数据挖掘和数据管理功能。
在学习使用SAS之前,首先需要下载并安装SAS软件。
在安装过程中,需要根据操作系统选择相应的版本,并按照安装向导进行操作。
安装完成后,可以通过启动菜单找到SAS软件并打开它。
二、SAS基本语法与数据集1. SAS语法基础SAS语法是一种类似于编程语言的语法。
在SAS中,每一个语句都以分号作为结尾。
常用的SAS语句包括DATA、PROC和RUN。
DATA语句用于创建数据集,PROC语句用于执行数据分析过程,RUN语句用于执行SAS语句的运行。
2. SAS数据集SAS数据集是SAS中最重要的数据组织形式。
它可以包含多个数据变量,并且每个变量可以拥有不同的数据类型,如字符型、数值型、日期型等。
通过DATA语句可以创建一个新的SAS数据集,并通过INPUT语句指定每个变量的属性。
使用SET语句可以将现有的数据集读入到SAS数据集中,以供后续分析使用。
三、SAS数据清洗与变换1. 数据清洗数据清洗是数据分析的第一步,其目的是去除数据中的错误或无效信息,保证数据质量。
在SAS中,可以使用IF和WHERE语句来筛选出符合条件的数据观测值,并使用DELETE和KEEP语句删除或保留特定的变量。
2. 数据变换数据变换是对原始数据进行转换,以满足具体的分析需求。
在SAS中,常用的数据变换操作包括缺失值处理、变量重编码、数据排序和数据合并等。
可以使用IF、ELSE和DO语句进行逻辑判断和循环操作,通过FORMAT语句对数据进行格式化。
四、SAS统计分析1. 描述统计分析描述统计分析是对数据的基本特征进行分析,包括均值、标准差、中位数、分位数和频数等。
在SAS中,可以使用PROC MEANS进行基本统计分析,使用PROC FREQ进行频数分析。
讲义6(SAS制图)

VAXIS=Values|Axisn 定义垂直轴的刻度
NOAXIS
取消坐标轴及相关的文字
CAXIS=Color 定义坐标轴的颜色
CTEXT=Color 定义坐标轴文本的颜色
②加框:
FRAME
加框(一般默认有框)
CFRAME= Color 给坐标轴包围的区域填色
(2)symboln语句可以通过选项定义第n个系列(没有n时默认定义第
可以使用图形选择语句后面的一些选项,来控制在语句中指定的图
形变量的分组,下面的选项可控制如何进行分组: DISCRETE——把一个数字变量当成离散变量,而不是连续变量。
把每一个数字值作为图形的一个分开的条形或线段。如果省略该选项, 过程则假定变量都是连续的。如果没有规定选项MIDPOINTS=或 LEVELS=,过程自动选择图表的间隔。
9415.6
1980
2140.0
1992
10993.7
1981
2350.0
1993
12462.1
1982
2570.0
1994
16264.7
1983 1984 1985 1986 1987 1988 1989
2849.4 3376.4 4305.0 4950.0 5820.0 7440.0 8101.4
计频数。 TYPE=PCT——统计图形变量各个给定值或落入给定区间的观测数
的百分比。 TYPE=CPCT——统计图形变量各个给定值或落入给定区间观测数
的累计百分比。
TYPE=SUM——统计图形变量所有值的总和。 TYPE=MEAN——统计图形变量所有值的平均值。 注:无SUMVAR选项时缺省type默认统计量为FREQ,有SUMVAR 选项时缺省type默认统计量为SUM。
数据分析(梅长林)习题题答案
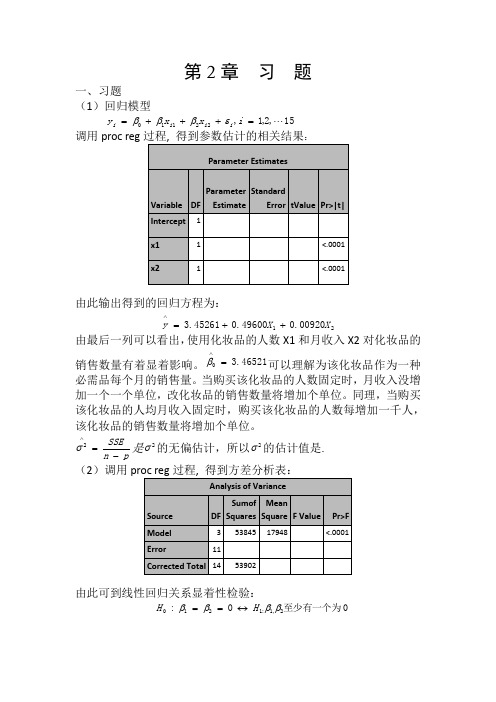
第2章 习 题一、习题(1)回归模型15,2,1,22110 =+++=i x x y i i i i εβββ调用proc reg :由此输出得到的回归方程为:2100920.049600.045261.3X X y ++=∧由最后一列可以看出,使用化妆品的人数X1和月收入X2对化妆品的销售数量有着显着影响。
46521.30=∧β可以理解为该化妆品作为一种必需品每个月的销售量。
当购买该化妆品的人数固定时,月收入没增加一个一个单位,改化妆品的销售数量将增加个单位。
同理,当购买该化妆品的人均月收入固定时,购买该化妆品的人数每增加一千人,该化妆品的销售数量将增加个单位。
pn SSE-=∧2σ是2σ的无偏估计,所以2σ的估计值是. (2)调用由此可到线性回归关系显着性检验:0至少有一个为0:2,1:1210ββββH H ↔==的统计量/(1)/()SSR p MSRF SSE n p MSE-==-的观测值47.56790=F ,检验的p 值0001.0)(000<>==F F p p H另外9989.053902538452===SST SSR R ,2R 描述了由自由变量的线性关系函数值所能反映的Y 的总变化量的比例。
2R 越大,表明线性关系越明显。
这些结果均表明Y 与X1,X2之间的回归关系高度显着。
(3)若置信水平05.0=α,由17881.2)12(975.0=t ,利用参数估计值得到21,0,βββ的置信区间分别为:对,0β2942.54516.343065.21781.245216.3±=⨯±,即)7458.8,8426.1(-) 对1β:01318.049600.000605.01781.249600.0±=⨯±,即)50198.0,48282.0( 2β:0021.000920.00009681.01781.200920.0±=⨯±,即)00113.0,0071.0(-(4)首先检验X1对Y 是否有显着性影:假设其约简模型为:15,2,1,220 =++=i x y i i i εββ 由观测数据并利用proc reg 过程拟合此模型求得:88137.484)(=R SSE 13215=-=R f 88357.56)(=F SSE 12315=-=R f由[()()]()()/R F FSSE R SSE F f f F SSE F f --=求得检验统计量的值为:3.9012/88357.5688357.5688137.4840=-=F05.0))13,1(()(0000<>==>==F F P F F p p H由此拒绝原假设,所以x2对Y 有显着影响。
SAS讲义-第二十课散布图、折线图和层次图

第二十课散布图、折线图和层次图SAS系统中绘制散布图、折线图和层次图,使用PROC PLOT过程和PROC GPLOT过程。
PROC PLOT过程是用来画易生成的低分辩率的图形,输出在OUTPUT窗口。
而PROC GPLOT过程是用来生成定制的、高分辨率的图形,输出在GRAPH窗口,并且还可以对输出的图形进行编辑修改。
一.PROC PLOT过程使用PLOT过程可以在两个不同的坐标系中对两个变量作散布图、折线图、半对数图和层次图。
用于数据处理中,直观地了解数据的变化趋势和数据间的相互关系等。
它的一般形式为:Proc Plot DA TA=数据集</选项列表> ;Plot 纵坐标变量Y*横坐标变量X……</选项列表>;Run ;1PROC PLOT语句PROC PLOT语句中的选项列表主要分成三类:有关图形的坐标轴选项、有关外观的选项和有关图形大小的选项。
其中图形大小的两个选项较为常用:●VPCT=百分比列表——规定产生图形在垂直方向占一页的百分比。
例如VPCT=33表示这张输出图占一页的33%,即占一页的1/3,所以一页可以纵向打印3张图。
VPCT=50 25 25表示每一页在纵向打印3张图,第一张占全页的一半,第二和第三张各占1/4页。
VPCT=200表示要求输出图占2页的长度。
●HPCT=百分比列表——规定产生图形在水平方向占一页的百分比。
2PLOT语句PLOT语句里首先要规定数据集中的哪两个变量作为图形中的垂直变量和水平变量,以及在图形中用于画点的作图字符。
PLOT语句的几种使用格式如下:plot y*x ;plot y*x =’+’;plot y*x=符号变量;plot y*x $ 标记变量=’+’;plot y*x=’+’b*a=’*’ /overlay;第一条语句作图符号用缺省形式,依此用英文大写字母A、B、C…Z作为作图符号。
当观测的条数较多时,低分辩率图不可能画出所有观测的点,所以当图中的某一点表示有一条观测的点时,用作图符号A;当图中的某一点表示有二条观测的点时,用作图符号B;以此类推。
SAS统计分析教程方法总结

SAS统计分析教程方法总结SAS(Statistical Analysis System)是一种流行的统计分析软件,被广泛应用于各个领域的数据分析和决策支持中。
本文将总结SAS统计分析教程的方法,以帮助读者更好地理解和应用SAS软件。
1.数据导入与数据清洗:在进行统计分析之前,首先需要将数据导入SAS软件中。
SAS支持多种数据格式,如Excel、CSV等。
可以使用INFILE和INPUT语句读取数据,并使用DATA步骤定义变量。
在导入数据后,通常需要对数据进行清洗,包括处理缺失值、异常值等。
SAS提供了多种数据处理函数,如MEAN、SUM等,可以帮助完成数据清洗和处理工作。
2.描述性统计分析:描述性统计分析可以了解数据的特征和分布情况。
例如,可以使用PROCMEANS计算数据的均值、标准差、最小值、最大值等;使用PROCFREQ计算离散变量的频数和频率等。
此外,SAS还提供了PROCUNIVARIATE、PROCSUMMARY等过程,可以方便地进行更加复杂的描述性统计分析。
3.统计图表绘制:统计图表是数据分析中常用的可视化工具,能够直观地展示数据的特征和趋势。
SAS提供了PROC SGPLOT和PROC GPLOT等过程,可以绘制各种类型的统计图表,如直方图、散点图、柱状图等。
通过调整图形参数,可以使图表更加美观和易读。
此外,SAS还支持使用ODS(OutputDelivery System)输出图表到不同的输出格式中。
4.假设检验与推断统计:假设检验是统计分析中常用的方法,可以用来判断数据之间是否存在显著差异。
在SAS中,可以使用PROCTTEST、PROCANOVA等过程进行单样本、双样本和多样本假设检验。
此外,SAS还支持非参数检验方法,如PROCNPAR1WAY等。
除了假设检验,推断统计也是重要的统计分析方法,用于对总体参数进行估计和推断。
在SAS中,可以使用PROCMEANS、PROCREG等过程进行点估计和区间估计。
金融数据库——SAS编程与数据处理2-18章复习题

SAS编程与数据处理2-18章复习题朱世武著.《SAS编程技术与金融数据处理》.清华大学出版社. 2003.7第2章SAS系统快速入门1.SAS系统的特点。
2.简述SAS的三类功能与相应的模块举例。
3.SAS技术水平的三个层次.4.缺省情况下SAS系统的五个功能窗口及各自的作用是什么?怎样定义激活这些窗口的快捷键?5.SAS程序的一般特点。
6.SAS日志窗口的信息构成。
7.会使用工具菜单的options选项。
8.在显示管理系统下,切换窗口和完成各种特定的功能等,有四种发布命令的方式:即,在命令框直接键入命令;使用下拉菜单;使用工具栏;按功能键。
试举例说明这些用法。
9.理解SAS逻辑库、临时库和永久库的概念。
会用菜单方式新建SAS永久库。
10.说明下面SAS命令的用途:keys, dlglib, libname, dir, var, options, submit, recall.11.怎样增加和删除SAS工具?12.会用菜单方式导入(Import)和导出SAS数据集(Export)。
13.会用菜单方式创建查询。
14.会用SAS的INSIGHT模块进行简单的数据分析。
15.简述SAS逻辑库的作用。
第3章数据步创建SAS数据集1.理解SAS语句的信息构成。
举例说明。
2.SAS名的种类及命名规则。
什么是SAS关键词?3.理解Data步的Proc步。
4.SAS变量的类型和属性。
举例说明SAS自动变量。
5.理解SAS程序。
SAS程序的书写规则。
给一个简单SAS 程序的例子,适当应用SAS的注释语句。
6.SAS数据集中变量列表时,X1-Xn表示什么?特殊SAS变量列表_numeric_, _character_和_all_的含义。
7.怎样提交SAS程序?程序执行过程中,LOG窗口显示的信息结构。
8.怎样查看SAS程序的输出结果。
9.SAS表达式定义及其构成元素。
10.构成SAS表达式的操作对象和操作符有哪些?11.SAS常数及其类型。
Sas代码作图详解(图文并茂)

Sas代码作图详解SAS/Graph太强大了,本文主要讲一些常用且功能强大的Graph相关的过程步。
1 proc gplot的简单例子proc gplot data=sashelp.shoes;plot Returns * Sales ;run;结果:2 我们也可以只画出符合条件的数据的图形。
proc gplot data=sashelp.shoes;where Region in("United States", "Eastern Europe");plot Returns * Sales ;run;结果:3 输出的图像都是默认的黑色的小十字,因此我们不能区分来自不同地区的数据,下面的程序就是为了解决这一问题proc gplot data=sashelp.shoes;where Region in("United States", "Eastern Europe");plot Returns * Sales= Region;run;结果:这里红色的来自美国,黑色的来自东欧,当然我们也可以自己设定颜色(SAS基本颜色有:black, red, green, blue, cyan, magenta, grey, pink, orange, brown, and yellow)。
4 设定坐标轴和所有文字和颜色proc gplot data=sashelp.shoes;where Region in("United States", "Eastern Europe");plot Returns * Sales= Region/caxis=bluectext=redgrid;run;结果:5 如果要对网格进行更精细地设置,则要用到AUTOHREF和AUTOVREF选项。
AUTOHREF中,LHREF设置水平线的线类型,CHREF设置水平线的线颜色;AUTOVREF中,LVREF设置垂直线的线类型,CVREF设置垂直线的线颜色。
如何使用SAS进行数据分析

如何使用SAS进行数据分析数据分析是现代社会中不可或缺的一项技能。
而SAS(统计分析系统)作为一种广泛应用于商业和学术领域的数据分析工具,为我们提供了许多强大的功能和方法。
在本文中,我将介绍如何使用SAS进行数据分析的基本步骤和技巧,希望能为初学者提供一些帮助。
一、数据准备在开始数据分析之前,首先需要准备好数据。
这包括数据的收集、整理和清洗等步骤。
SAS提供了丰富的数据导入和处理功能,可以方便地从各种数据源中导入数据。
在导入数据时,我们需要确保数据格式正确并进行必要的数据转换和处理。
二、数据探索数据分析的第一步是对数据进行探索。
我们可以使用SAS的统计分析和可视化工具来了解数据的基本特征和分布。
例如,可以使用PROC MEANS来计算数据的平均值、标准差等统计指标,使用PROC FREQ来计算数据的频数和比例,使用PROC UNIVARIATE来进行数据的单变量分析等。
此外,SAS还提供了多种数据可视化方法,如PROC SGPLOT和PROC GPLOT等,可以帮助我们更直观地了解数据的特征。
三、数据预处理在数据分析过程中,往往需要对数据进行预处理。
这包括数据的缺失值处理、异常值处理、变量转换等。
SAS提供了一系列函数和过程来帮助我们完成这些任务。
例如,可以使用PROC MI来处理缺失值,使用PROC TTEST来检测异常值,使用PROC TRANSPOSE来进行变量转换等。
在进行数据预处理时,需要根据具体情况选择适当的方法和技巧。
四、数据建模数据建模是数据分析的核心部分。
在SAS中,我们可以使用PROC REG或PROC LOGISTIC等过程来进行线性回归分析和逻辑回归分析;使用PROC GLM或PROC ANOVA等过程来进行方差分析;使用PROC CLUSTER或PROC FACTOR等过程来进行聚类分析和因子分析等。
选择适当的模型和方法是数据分析的关键,需要根据具体问题和数据特点进行判断。
时间序列分析第二章王燕第四到第六题习题解答

时间序列分析习题解答
第二章 P.33 2.3 习 题
2.4 若序列长度为 100,前 12 个样本自相关系数如下:
1 =0.02
7 =0.12
^
^
2 =0.05
8 =-0.06
图 a2. 输出的时序图:
y 30
20
10
0
-10
-20
-30 JAN69 APR69 JUL69 OCT69 JAN70 APR70 JUL70 OCT70 JAN71 APR71 JUL71 OCT71 JAN72 APR72 JUL72 OCT72 JAN73 APR73 JUL73 OCT73 JAN74 APR74 JUL74 OCT74 time
图 b. 基本统计信息和自相关图:
图 c.
白噪声检验结果:
附
SAS 程序如下:
data ex2_5; input sales@@; time=intnx('month','01jan2000'd,_n_-1); format time MONYY5.; cards; 153 134 145 117 ; proc gplot data=ex2_5; plot sales*time=1; symbol1 c=black v=star i=join; run; proc arima data=ex2_5; identify var=sales; run; 187 175 203 178 234 243 189 149 212 227 214 178 300 298 295 248 221 256 220 202 201 237 231 162 175 165 174 135 123 124 119 120 104 106 85 96 85 87 67 90 78 74 75 63
用REG过程进行回归分析

一、用REG过程进行回归分析SAS/STAT中提供了几个回归分析过程,包括REG(回归)、RSREG(二次响应面回归)、ORTHOREG(病态数据回归)、NLIN(非线性回归)、TRANSREG(变换回归)、CALIS(线性结构方程和路径分析)、GLM(一般线性模型)、GENMOD(广义线性模型),等等。
我们这里只介绍REG过程,其它过程的使用请参考《SAS 系统――SAS/STAT软件使用手册》。
REG过程的基本用法为:PROC REG DATA=输入数据集选项;VAR 可参与建模的变量列表;MODEL 因变量=自变量表 / 选项;PRINT 输出结果;PLOT 诊断图形;RUN;REG过程是交互式过程,在使用了RUN语句提交了若干个过程步语句后可以继续写其它的REG 过程步语句,提交运行,直到提交QUIT语句或开始其它过程步或数据步才终止。
例如,我们对SASUSER.CLASS中的WEIGHT用HEIGHT和AGE建模,可以用如下的简单REG 过程调用:proc reg data=sasuser.class;var weight height age;model weight=height age;run;就可以在输出窗口产生如下结果,注意程序窗口的标题行显示“PROC REG Running”表示REG 过程还在运行,并没有终止。
See outputAGE的作用不显著,所以我们只要再提交如下语句:model weight=height;run;就可以得到第二个模型结果:See output事实上,REG提供了自动选择最优自变量子集的选项。
在MODEL语句中加上“SELECTION= 选择方法”的选项就可以自动挑选自变量,选择方法有NONE(全用,这是缺省)、FORWARD (逐步引入法)、BACKWARD(逐步剔除法)、STEPWISE(逐步筛选法)、MAXR(最大增量法)、MINR(最小增量法)、RSQUARE(选择法)、ADJRSQ(修正选择法)、CP(Mallows的统计量法)。
时间序列分析第二章王燕第一到第三题习题解答

proc arima data=ex2_2; identify var=CO2 Nlag=24; run;
2.3 1945-1950 年费城月度降雨量数据如下(单位:mm)见下表。 —————————————————————————————————— 69.3 80.0 40.9 74.9 84.6 101.1 225.0 95.3 100.6 48.3 144.5 128.3 38.4 52.3 68.6 37.1 148.6 218.7 131.6 112.8 81.8 31.0 47.5 70.1 96.8 61.5 55.6 171.7 220.5 119.4 63.2 181.6 73.9 64.8 166.9 48.0 137.7 80.5 105.2 89.9 174.8 124.0 86.4 136.9 31.5 35.3 112.3 143.0 160.8 97.0 80.5 62.5 158.2 7.6 165.9 106.7 92.2 63.2 26.2 77.0 52.3 105.4 144.3 49.5 116.1 54.1 148.6 159.3 85.3 67.3 112.8 59.4 ____________________________________________________________________
(3) 白噪声检验输出结果为:
观察上面结果,由于延迟 6,12,18,24 时,0.14<P<0.37,所以该序列为非白 噪声序列,但相关性不够显著。
附 SAS 程序(画时序图、计算相关系数和白噪声检验)如下:
data ex2_3; input rainfall@@; time=intnx('month','01jan1975'd,_n_-1); format time MONYY5.; cards; 69.3 80.0 40.9 74.9 84.6 101.1 225.0 95.3 100.6 48.3 144.5 128.3 38.4 52.3 68.6 37.1 148.6 218.7 131.6 112.8 81.8 31.0 47.5 70.1 96.8 61.5 55.6 171.7 220.5 119.4 63.2 181.6 73.9 64.8 166.9 48.0 137.7 80.5 105.2 89.9 174.8 124.0 86.4 136.9 31.5 35.3 112.3 143.0 160.8 97.0 80.5 62.5 158.2 ; proc gplot ; plot rainfall*time=1; symbol1 c=black v=star i=join; run; proc arima ; identify var=rainfall nlag=24; run; 7.6 165.9 106.7 92.2 63.2 26.2 77.0 52.3 105.4 144.3 49.5 116.1 54.1 148.6 159.3 85.3 67.3 112.8 59.4
《时间序列分析》第二章 时间序列预处理习题解答[1]
![《时间序列分析》第二章 时间序列预处理习题解答[1]](https://img.taocdn.com/s3/m/afd770ef524de518964b7d1f.png)
ppm 342 341 340 339 338 337 336 335 334 333 332 331 330 329 328 01JAN75 01MAY75 01SEP75 01JAN76 01MAY76 01SEP76 01JAN77 01MAY77 01SEP77 01JAN78 01MAY78 01SEP78 01JAN79 01MAY79 01SEP79 01JAN80 01MAY80 01SEP80 01JAN81 time
习题 2.3
1.考虑时间序列{1,2,3,4,5,…,20}: (1)判断该时间序列是否平稳; (2)计算该序列的样本自相关系数 ρ k (k=1,2,…,6); (3)绘制该样本自相关图,并解释该图形. 解: (1)根据时序图可以看出,该时间序列有明显的递增趋势,所以它一定不是 平稳序列, 即可判断该时间序是非平稳序列,其时序图程序见后。
∧
330.97 330.05 332.46 330.87 333.23 332.41 335.07 334.39 336.44 335.71 338.16 337.19 331.64 328.58 333.36 329.24 334.55 331.32 336.33 332.44 337.63 333.68 339.88 335.49 332.87 328.31 334.45 328.87 335.82 330.73 337.39 332.25 338.54 333.69 340.57 336.63 333.61 329.41 334.82 330.18 336.44 332.05 337.65 333.59 339.06 335.05 341.19 337.74 333.55 330.63 334.32 331.50 335.99 333.53 337.57 334.76 338.95 336.53 340.87 338.36 ; proc gplot data=example2; plot ppm*time=1; symbol1 c=black v=star i=join; run;
sas知识点总结

sas知识点总结SAS(Statistical Analysis System)是一种统计分析软件,由美国SAS公司开发。
SAS软件主要用于数据管理、数据分析、统计建模、商业智能等各种领域的数据分析。
SAS是业界领先的数据分析软件,被广泛应用于金融、医疗、零售、制造、政府等各个领域。
本文将对SAS软件的一些主要知识点进行总结,包括数据导入导出、数据清洗、数据处理、数据分析、统计建模和报告生成等内容,以便读者能够全面了解并掌握SAS软件的使用。
一、数据导入导出1. 数据导入SAS软件支持多种数据格式的导入,包括CSV、Excel、SPSS、STATA等常见格式。
可以通过DATA步骤或PROC IMPORT来导入数据。
例如,使用DATA步骤来导入CSV文件:```SASDATA dataset;INFILE 'input.csv' DLM=',';INPUT var1 var2 var3;RUN;```2. 数据导出SAS软件同样支持多种数据格式的导出,可以通过DATA步骤或PROC EXPORT来导出数据。
例如,使用PROC EXPORT来导出数据为Excel文件:```SASPROC EXPORT DATA=datasetOUTFILE='output.xlsx'DBMS=EXCEL REPLACE;RUN;```二、数据清洗数据清洗是数据分析的重要步骤,用于处理数据中的错误、缺失、重复等问题,使数据符合分析要求。
1. 缺失值处理SAS软件提供多种方法来处理缺失值,包括删除、填充、插值等。
```SASDATA dataset;SET dataset;IF var1=. THEN var1=0; /*填充缺失值为0*/RUN;```2. 异常值处理SAS软件可以通过PROC UNIVARIATE或PROC MEANS来检测异常值,并采取适当的处理方法。
SAS讲义 第二十课散布图、折线图和层次图

第二十课散布图、折线图和层次图SAS系统中绘制散布图、折线图和层次图,使用PROC PLOT过程和PROC GPLOT过程。
PROC PLOT过程是用来画易生成的低分辩率的图形,输出在OUTPUT窗口。
而PROC GPLOT过程是用来生成定制的、高分辨率的图形,输出在GRAPH窗口,并且还可以对输出的图形进行编辑修改。
一.PROC PLOT过程使用PLOT过程可以在两个不同的坐标系中对两个变量作散布图、折线图、半对数图和层次图。
用于数据处理中,直观地了解数据的变化趋势和数据间的相互关系等。
它的一般形式为:Proc Plot DA TA=数据集</选项列表> ;Plot 纵坐标变量Y*横坐标变量X……</选项列表>;Run ;1PROC PLOT语句PROC PLOT语句中的选项列表主要分成三类:有关图形的坐标轴选项、有关外观的选项和有关图形大小的选项。
其中图形大小的两个选项较为常用:●VPCT=百分比列表——规定产生图形在垂直方向占一页的百分比。
例如VPCT=33表示这张输出图占一页的33%,即占一页的1/3,所以一页可以纵向打印3张图。
VPCT=50 25 25表示每一页在纵向打印3张图,第一张占全页的一半,第二和第三张各占1/4页。
VPCT=200表示要求输出图占2页的长度。
●HPCT=百分比列表——规定产生图形在水平方向占一页的百分比。
2PLOT语句PLOT语句里首先要规定数据集中的哪两个变量作为图形中的垂直变量和水平变量,以及在图形中用于画点的作图字符。
PLOT语句的几种使用格式如下:plot y*x ;plot y*x =’+’;plot y*x=符号变量;plot y*x $ 标记变量=’+’;plot y*x=’+’b*a=’*’ /overlay;第一条语句作图符号用缺省形式,依此用英文大写字母A、B、C…Z作为作图符号。
当观测的条数较多时,低分辩率图不可能画出所有观测的点,所以当图中的某一点表示有一条观测的点时,用作图符号A;当图中的某一点表示有二条观测的点时,用作图符号B;以此类推。
SAS画折线图PROCGPLOT

SAS画折线图PROCGPLOT虽然最后做成PPT⾥的图表会被要求⽤EXCEL画,但当我们只是在分析的过程中,想看看数据的⾛势,直接在SAS⾥画会⽐EXCEL画便捷的多。
修改起来也会更加的简单,,不⽤不断的修改程序然后刷新EXCEL⾥的透视表,,甚⾄有时还是需要重新插⼊图表等等⿇烦的操作。
以下将介绍折线图(PROC GPLOT的⽤法):先看代码:AXIS1 ORDER=(1990 TO 2012 BY 5) MINOR=(NUMBER=1);AXIS2 ORDER=(13000 TO 20000 BY 1000) MINOR=(HEIGHT=5 NUMBER=1);AXIS3 MAJOR=(height=10 NUMBER=20) MINOR=(NUMBER=1);SYMBOL INTERPOL=JOIN VALUE=DOT HEIGHT=10;PROC GPLOT DATA=EX.SALES_YEAR;TITLE 'YEARLY AMOUNT IN NORTH AMERICA';PLOT N_AMOUNT*YEAR/LEGEND HAXIS=AXIS1 VAXIS=AXIS2;PLOT2 N_Transactions*YEAR/LEGEND VAXIS=AXIS3;RUN;QUIT;GOPTIONS RESET=ALL;以上的例⼦⼏乎可以满⾜所有画折线图的需求。
画⼀个简单的折线图必须⽤到的关键有SYMBOL、PLOT、QUIT;1、关键字SYMBOL,是设置折线的样式的。
其中INTERPOL=join表⽰将散点⽤线连接起来,VALUE=dot规定数据点的样式(dot表⽰⽤点表⽰),HEIGHT 表⽰数据点的⼤⼩(⼀般这⾥不写HEIGHT,使⽤默认⼤⼩为1)。
另外若在⼀张图⾥画多条折线的话,不同折线的样式要求不⽤则是SYMBOL1对应PLOT1 即,设置多个SYMBOLN对应PLOTN;2、关键字PLOT,规定画折线图的数据字段(纵坐标字段*横坐标字段)。
Proc gplot

Proc Gplot:运用Gplot作图Proc Gplot:运用Gplot作图原文地址:/proceedings/sugi31/239-31.pdf转载请注明出处:/s/blog_5d3b177c0100b68a.htmlData如下,为一个时间序列数据。
这个数据是自己编的,只是为了方便测试程序。
data t112;input nh_tot fg_tot year;cards;90 90 1970120 100 1971170 110 1972240 120 1973330 130 1974440 140 1975560 150 1976690 160 1977850 170 19781090 180 19791290 190 19801590 200 1981;run;1 基本用法:proc gplot data=t112;plot nh_tot*year;run;结果:2 Gplot的一些基本设置goptions ftext='Arial' htext=2 gunit=pct;symbol1 value=dot interpol=join;title "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982";footnote "Source: Health-United States-2003";proc gplot data=t112;plot nh_tot*year;run;结果:3 改变标题title和脚注footnotegoptions ftext='Arial' htext=2 gunit=pct;symbol1 v=dot i=join;title height=4 "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote justify=right "Source: Health-United States-2003"; proc gplot data=t112;plot nh_tot*year;run;4 改变横坐标的label设置和纵坐标的显示尺度设置options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct;symbol1 v=dot i=join;axis1 label=(angle=90 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 2) minor=(n=4);title h=4 "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982";footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot nh_tot*year/vaxis=axis1 haxis=axis2;format nh_tot comma.;run;5 对各文字和横纵坐标加颜色options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green;symbol1 v=dot i=join c=blue h=2.5;axis1 label=(angle=90 "AMOUNT (IN BILLIONS)") minor=(n=3) color=blue; axis2 order=(1970 to 1982 by 2) minor=(n=4) color=blue;title1 h=4 "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982";footnote1 j=right "Source: Health-United States-2003";proc gplot data=t112;plot nh_tot*year/vaxis=axis1 haxis=axis2;format nh_tot comma.;run;6 将所有的文字设置为绿色,而图形和坐标轴设置为蓝色options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green;symbol1 v=dot i=join c=blue h=2.5;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3) ;axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 font='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot nh_tot*year/vaxis=axis1 haxis=axis2 caxis=blue;format nh_tot comma.;run;7 增加别外一个图像,图像叠加:options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green;symbol1 v=dot i=join c=blue h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3);axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue; format nh_tot comma.;run;8 设置曲线的样式:options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; symbol1 v=dot i=join c=blue h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3);axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue;format nh_tot comma.;run;9 增加一个legend,也可以对legend进行调整:options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue;symbol1 v=dot i=join h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3);axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue legend; format nh_tot comma.;run;10 对默认的legend进行修改:options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; symbol1 v=dot i=join h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);legend1 label=none value=(j=left "TOTAL" j=left "FEDERAL GOVT")mode=protect position=(top inside left)cborder=blue cshadow=blueacross=1 shape=line(10);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue legend=legend1;format nh_tot comma.;run;11 对曲线进行标注:data my_labels;retain xsys ysys '2' function 'label'position '1' style "'Arial/bo'"color 'blue' cborder 'blue';set t112 end=last;if last then do;text=' FEDERAL GOVERNMENT '; x=year; y=fg_tot; output;text=' TOTAL ' ; x=year; y=nh_tot; output;end;run;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; options validvarname=upcase;symbol1 f=marker v='C' i=join h=1.25;symbol2 f=marker v='U' i=join h=1.25;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue annotate=my_labels;format nh_tot comma.;run;12 生成一个GIF图像文件options validvarname=upcase;goptions device=gif gsfname=gout xpixels=1024 ypixels=768ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; symbol1 f=marker v='C' i=join h=1.25;symbol2 f=marker v='U' i=join h=1.25;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);legend1 label=none value=(j=left "TOTAL" j=left "FEDERAL GOVT")mode=protect position=(top inside left)cborder=blue cshadow=blueacross=1 shape=symbol(6,1.25);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-2000"; footnote j=right "Source: Health-United States-2003";filename gout 'c:\healthexp.gif';proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue legend=legend1;format exp comma.;run;13 noframe选项,使得图像能自动调整适合的大小options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; symbol1 v=dot i=join h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 5) minor=(n=4) offset=(2,2);legend1 label=none value=(j=left "TOTAL" j=left "FEDERAL GOVT")mode=protect position=(top inside left)cborder=blue cshadow=blueacross=1 shape=line(10);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue legend=legend1 noframe;format nh_tot comma.;run;SAS/Graph实用基础教程(Gplot、Gchart)An Introduction to the Simplicity and Power of SAS/Graph®SAS/Graph实用基础教程(Gplot、Gchart)原文地址:/proceedings/sugi30/262-30.pdf转载请注明出处:/s/blog_5d3b177c0100bams.htmlSAS/Graph太强大了,本文主要讲一些常用且功能强大的Graph相关的过程步。
基于农药毒力计算的6个统计分析软件比较

基于农药毒力计算的6个统计分析软件比较常菊花;何月平【摘要】选用了能够用于农药毒力数据机率值分析的通用软件(SAS、SPSS和DPS)和专门程序(Polo、BA和EPA机率值分析程序),以二化螟对三唑磷的室内毒力数据为例,比较分析不同统计分析软件的计算结果.结果表明,当对照组死亡率为0时,6个软件程序计算得到的LD值(LD5 、LD50和LD95)、截距和斜率等基本相等,但是LD值的95%置信限有差异.当对照组死亡率不为0时,发现6个程序计算得到的毒力资料数值都有差异,其中LD(LD5 LD50和LD95)、截距和斜率的数值相差较小,但是LD值的95%置信限差异较大.【期刊名称】《安徽农业科学》【年(卷),期】2014(000)003【总页数】4页(P746-748,802)【关键词】SAS;SPSS;Polo;EPA;DPS;BA【作者】常菊花;何月平【作者单位】长江大学生命科学学院,湖北荆州434025;华中农业大学植物科学技术学院,湖北武汉430070【正文语种】中文【中图分类】S127在农药生物测定中,致死中量(LD50)或有效中量(ED50)和回归线的斜率(b值)是表示药剂对生物效力的代表性数值。
为了要测定LD50或b值,通常采用的统计分析方法是机率值分析法(Probit Analysis)[1]。
机率值分析法和计算致死中量的方法很多,但传统的手工计算方法十分复杂,不仅要花费大量时间,而且很容易出错。
随着电子计算机技术的发展,出现了不少软件或程序应用于生物测定数据的机率值分析和致死中量的计算,在很大程度上简化了运算程序[2-6]。
笔者采用机率值分析软件(Polo、BA、EPA)和生物统计软件(SPSS、SAS、DPS)计算农药毒力数据,比较分析不同程序的计算结果,拟推荐出可供广泛使用且结果精确的程序或软件用于生物测定数据的统计分析。
1.1 程序和测试数据以室内采用毛细管点滴法测定三唑磷对水稻二化螟幼虫的室内毒力数据为例(表1),采用SAS 8.1、SPSS 19.0、DPS 7.05版、PoloPlus (Probit and Logit Analysis, LeOra Software)、EPA (EPA probit analysis program used for calculation LC/EC values version 1.5)、BA(Bioassay Data Processing and Management System)6个统计分析软件,计算毒力回归方程、LD5、LD50、LD95 及其95%置信限,以及卡平方值和相关系数等,比较分析不同程序的计算结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Proc Gplot:运用Gplot作图Proc Gplot:运用Gplot作图原文地址:/proceedings/sugi31/239-31.pdf转载请注明出处:/s/blog_5d3b177c0100b68a.htmlData如下,为一个时间序列数据。
这个数据是自己编的,只是为了方便测试程序。
data t112;input nh_tot fg_tot year;cards;90 90 1970120 100 1971170 110 1972240 120 1973330 130 1974440 140 1975560 150 1976690 160 1977850 170 19781090 180 19791290 190 19801590 200 1981;run;1 基本用法:proc gplot data=t112;plot nh_tot*year;run;结果:2 Gplot的一些基本设置goptions ftext='Arial' htext=2 gunit=pct;symbol1 value=dot interpol=join;title "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982";footnote "Source: Health-United States-2003";proc gplot data=t112;plot nh_tot*year;run;结果:3 改变标题title和脚注footnotegoptions ftext='Arial' htext=2 gunit=pct;symbol1 v=dot i=join;title height=4 "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote justify=right "Source: Health-United States-2003"; proc gplot data=t112;plot nh_tot*year;run;4 改变横坐标的label设置和纵坐标的显示尺度设置options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct;symbol1 v=dot i=join;axis1 label=(angle=90 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 2) minor=(n=4);title h=4 "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982";footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot nh_tot*year/vaxis=axis1 haxis=axis2;format nh_tot comma.;run;5 对各文字和横纵坐标加颜色options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green;symbol1 v=dot i=join c=blue h=2.5;axis1 label=(angle=90 "AMOUNT (IN BILLIONS)") minor=(n=3) color=blue; axis2 order=(1970 to 1982 by 2) minor=(n=4) color=blue;title1 h=4 "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982";footnote1 j=right "Source: Health-United States-2003";proc gplot data=t112;plot nh_tot*year/vaxis=axis1 haxis=axis2;format nh_tot comma.;run;6 将所有的文字设置为绿色,而图形和坐标轴设置为蓝色options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green;symbol1 v=dot i=join c=blue h=2.5;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3) ;axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 font='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot nh_tot*year/vaxis=axis1 haxis=axis2 caxis=blue;format nh_tot comma.;run;7 增加别外一个图像,图像叠加:options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green;symbol1 v=dot i=join c=blue h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3);axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue; format nh_tot comma.;run;8 设置曲线的样式:options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; symbol1 v=dot i=join c=blue h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3);axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue;format nh_tot comma.;run;9 增加一个legend,也可以对legend进行调整:options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue;symbol1 v=dot i=join h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3);axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue legend; format nh_tot comma.;run;10 对默认的legend进行修改:options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; symbol1 v=dot i=join h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);legend1 label=none value=(j=left "TOTAL" j=left "FEDERAL GOVT")mode=protect position=(top inside left)cborder=blue cshadow=blueacross=1 shape=line(10);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue legend=legend1;format nh_tot comma.;run;11 对曲线进行标注:data my_labels;retain xsys ysys '2' function 'label'position '1' style "'Arial/bo'"color 'blue' cborder 'blue';set t112 end=last;if last then do;text=' FEDERAL GOVERNMENT '; x=year; y=fg_tot; output;text=' TOTAL ' ; x=year; y=nh_tot; output;end;run;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; options validvarname=upcase;symbol1 f=marker v='C' i=join h=1.25;symbol2 f=marker v='U' i=join h=1.25;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue annotate=my_labels;format nh_tot comma.;run;12 生成一个GIF图像文件options validvarname=upcase;goptions device=gif gsfname=gout xpixels=1024 ypixels=768ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; symbol1 f=marker v='C' i=join h=1.25;symbol2 f=marker v='U' i=join h=1.25;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 2) minor=(n=4) offset=(2,2);legend1 label=none value=(j=left "TOTAL" j=left "FEDERAL GOVT")mode=protect position=(top inside left)cborder=blue cshadow=blueacross=1 shape=symbol(6,1.25);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-2000"; footnote j=right "Source: Health-United States-2003";filename gout 'c:\healthexp.gif';proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue legend=legend1;format exp comma.;run;13 noframe选项,使得图像能自动调整适合的大小options validvarname=upcase;goptions ftext='Arial' htext=2 gunit=pct ctext=green csymbol=blue; symbol1 v=dot i=join h=2.5 l=1;symbol2 v=dot i=join h=2.5 l=3;axis1 label=(angle=90 rotate=0 "AMOUNT (IN BILLIONS)") minor=(n=3); axis2 order=(1970 to 1982 by 5) minor=(n=4) offset=(2,2);legend1 label=none value=(j=left "TOTAL" j=left "FEDERAL GOVT")mode=protect position=(top inside left)cborder=blue cshadow=blueacross=1 shape=line(10);title h=4 f='Arial/bo' "NATIONAL HEALTH CARE EXPENDITURES: 1970-1982"; footnote j=right "Source: Health-United States-2003";proc gplot data=t112;plot (nh_tot fg_tot)*year/overlay vaxis=axis1 haxis=axis2 caxis=blue legend=legend1 noframe;format nh_tot comma.;run;SAS/Graph实用基础教程(Gplot、Gchart)An Introduction to the Simplicity and Power of SAS/Graph®SAS/Graph实用基础教程(Gplot、Gchart)原文地址:/proceedings/sugi30/262-30.pdf转载请注明出处:/s/blog_5d3b177c0100bams.htmlSAS/Graph太强大了,本文主要讲一些常用且功能强大的Graph相关的过程步。