Hadoop集群安装与部署v2
大数据Hadoop集群安装部署文档

大数据Hadoop集群安装部署文档一、背景介绍大数据时代下,海量数据的处理和分析成为了一个重要的课题。
Hadoop是一个开源的分布式计算框架,能够高效地处理海量数据。
本文将介绍如何安装和部署Hadoop集群。
二、环境准备1.集群规模:本文以3台服务器组成一个简单的Hadoop集群。
2.操作系统:本文以Linux作为操作系统。
三、安装过程1.安装JavaHadoop是基于Java开发的,因此需要先安装Java。
可以通过以下命令安装:```sudo apt-get updatesudo apt-get install openjdk-8-jdk```2.安装Hadoop```export HADOOP_HOME=/opt/hadoopexport PATH=$PATH:$HADOOP_HOME/bin```保存文件后,执行`source ~/.bashrc`使配置生效。
3.配置Hadoop集群在Hadoop安装目录中的`etc/hadoop`目录下,有一些配置文件需要进行修改。
a.修改`hadoop-env.sh`文件该文件定义了一些环境变量。
可以找到JAVA_HOME这一行,将其指向Java的安装目录:```export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64```b.修改`core-site.xml`文件```<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>```c.修改`hdfs-site.xml`文件```<property><name>dfs.replication</name><value>3</value></property>```其中,`dfs.replication`定义了数据的副本数,这里设置为34.配置SSH免密码登录在Hadoop集群中,各个节点之间需要进行通信。
(完整word版)centos6下安装部署hadoop2.2

centos6下安装部署hadoop2。
2hadoop安装入门版,不带HA,注意理解,不能照抄.照抄肯定出错。
我在安装有centos7(64位)的机器上,使用hadoop2。
5版本,安装验证过,但我没有安装过hadoop2。
2,仅供参考.如果你的(虚拟机)操作系统和JVM/JDK是64位的,就直接安装hadoop 2.5版本,无需按照网上说的去重新编译hadoop,因为它的native库就是64位了;如果你的(虚拟机)操作系统和JVM/JDK是32位的,就直接安装hadoop 2。
4以及之前的版本.安装小技巧和注意事项:1. 利用虚拟机clone的技术。
2. 不要在root用户下安装hadoop,自己先事先建立一个用户。
3。
如果需要方便操作,可以把用户名添加到sudoers文件中,使用sudo命令执行需要root权限的操作。
4。
Linux里面有严格的权限管理,很多事情普通用户做不了,习惯使用windows的同学,需要改变观念。
5。
centos7与之前的版本,在很多命令上有区别,centos与ubuntu有存在很多操作上的差别。
6. Hadoop 2.5版本中的native lib库是64位的,而hadoop 2。
2版本中的native lib库是32位的。
网上教程大多数针对hadoop2。
2写的,如果你是64位的虚拟机,你直接安装Hadoop 2.5版本就行。
7. 确认虚拟机安装并启用了sshd服务后,用xshell客户端连接Linux虚拟机,不要在vmware workstation 里面操作。
用xshell可以非常方便的复制文字和命令等。
学习Hadoop安装的步骤(1)可以先参考网上的资料“虾皮博客”http://www。
/xia520pi/xia520pi/archive/2012/05/16/2503949.html安装一个hadoop 1.2 版本,熟悉一下,搞明白后,再安装hadoop 2.x版本。
Hadoop集群安装详细步骤亲测有效

Hadoop集群安装详细步骤亲测有效第一步:准备硬件环境- 64位操作系统,可以是Linux或者Windows-4核或更高的CPU-8GB或更高的内存-100GB或更大的硬盘空间第二步:准备软件环境- JDK安装:Hadoop运行需要Java环境,所以我们需要先安装JDK。
- SSH配置:在主节点和从节点之间建立SSH连接是Hadoop集群正常运行的前提条件,所以我们需要在主节点上生成SSH密钥,并将公钥分发到从节点上。
第四步:配置Hadoop- core-site.xml:配置Hadoop的核心参数,包括文件系统的默认URI和临时目录等。
例如,可以将`hadoop.tmp.dir`设置为`/tmp/hadoop`。
- hdfs-site.xml:配置Hadoop分布式文件系统的参数,包括副本数量和块大小等。
例如,可以将副本数量设置为`3`。
- yarn-site.xml:配置Hadoop的资源管理系统(YARN)的参数。
例如,可以设置YARN的内存资源分配方式为容器的最大和最小内存均为1GB。
- mapred-site.xml:配置Hadoop的MapReduce框架的参数。
例如,可以设置每个任务容器的内存限制为2GB。
第五步:格式化Hadoop分布式文件系统在主节点上执行以下命令,格式化HDFS文件系统:```hadoop namenode -format```第六步:启动Hadoop集群在主节点上执行以下命令来启动Hadoop集群:```start-all.sh```此命令将启动Hadoop的各个组件,包括NameNode、DataNode、ResourceManager和NodeManager。
第七步:测试Hadoop集群可以使用`jps`命令检查Hadoop的各个进程是否正常运行,例如`NameNode`、`DataNode`、`ResourceManager`和`NodeManager`等进程都应该在运行中。
Hadoop集群安装详细步骤

Hadoop集群安装详细步骤|Hadoop安装配置文章分类:综合技术Hadoop集群安装首先我们统一一下定义,在这里所提到的Hadoop是指Hadoop Common,主要提供DFS(分布式文件存储)与Map/Reduce的核心功能。
Hadoop在windows下还未经过很好的测试,所以笔者推荐大家在linux(cent os 5.X)下安装使用。
准备安装Hadoop集群之前我们得先检验系统是否安装了如下的必备软件:ssh、rsync和Jdk1.6(因为Hadoop需要使用到Jdk中的编译工具,所以一般不直接使用Jre)。
可以使用yum install rsync来安装rsync。
一般来说ssh是默认安装到系统中的。
Jdk1.6的安装方法这里就不多介绍了。
确保以上准备工作完了之后我们就开始安装Hadoop软件,假设我们用三台机器做Hadoop集群,分别是:192.168.1.111、192.168.1.112和192.168.1.113(下文简称111,112和113),且都使用root用户。
下面是在linux平台下安装Hadoop的过程:在所有服务器的同一路径下都进行这几步,就完成了集群Hadoop软件的安装,是不是很简单?没错安装是很简单的,下面就是比较困难的工作了。
集群配置根据Hadoop文档的描述“The Hadoop daemons are N ameNode/DataNode and JobTracker/TaskTracker.”可以看出Hadoop核心守护程序就是由NameNode/DataNode 和JobTracker/TaskTracker这几个角色构成。
Hadoop的DFS需要确立NameNode与DataNode角色,一般NameNode会部署到一台单独的服务器上而不与DataNode共同同一机器。
另外Map/Reduce服务也需要确立JobTracker和TaskTracker的角色,一般JobTracker与NameNode共用一台机器作为master,而TaskTracker与DataNode同属于slave。
Hadoop 2.0安装部署方法

✓ 步骤1:下载JDK 1.6(注意区分32位和64位) ✓ 步骤2:安装JDK 1.6(以32位为例)
chmod +x jdk-6u45-linux-i586.bin ./jdk-6u45-linux-i586.bin
✓ 步骤3:验证是否安装成功
以上整个过程与实验环境基本一致,不同的是步骤2中配置文件设置内容以 及步骤3的详细过程。
30
HDFS 2.0的HA配置方法(主备NameNode)
注意事项:
1 主备NameNode有多种配置方法,本课程使用Journal Node方式。为此 ,需要至少准备3个节点作为Journal Node,这三个节点可与其他服务,比 如NodeManager共用节点 2主备两个NameNode应位于不同机器上,这两台机器不要再部署其他 服 务,即它们分别独享一台机器。(注:HDFS 2.0中无需再部署和配置 Secondary Name,备NameNode已经代替它完成相应的功能) 3 主备NameNode之间有两种切换方式:手动切换和自动切换,其中, 自动切换是借助Zookeeper实现的,因此,需单独部署一个Zookeeper集群 (通常为奇数个节点,至少3个)。本课程使用手动切换方式。
Hadoop 2.0安装部署方法
Open Passion Value
目录
1. Hadoop 2.0安装部署流程 2. Hadoop 2.0软硬件准备 3. Hadoop 2.0安装包下载 4. Hadoop 2.0测试环境(单机)搭建方法 5. Hadoop 2.0生产环境(多机)搭建方法 6. 总结
✓ yarn-site.xml:
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
hadoop集群安装配置的主要操作步骤-概述说明以及解释

hadoop集群安装配置的主要操作步骤-概述说明以及解释1.引言1.1 概述Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。
它提供了高度可靠性、容错性和可扩展性的特性,因此被广泛应用于大数据处理领域。
本文旨在介绍Hadoop集群安装配置的主要操作步骤。
在开始具体的操作步骤之前,我们先对Hadoop集群的概念进行简要说明。
Hadoop集群由一组互联的计算机节点组成,其中包含了主节点和多个从节点。
主节点负责调度任务并管理整个集群的资源分配,而从节点则负责实际的数据存储和计算任务执行。
这种分布式的架构使得Hadoop可以高效地处理大规模数据,并实现数据的并行计算。
为了搭建一个Hadoop集群,我们需要进行一系列的安装和配置操作。
主要的操作步骤包括以下几个方面:1. 硬件准备:在开始之前,需要确保所有的计算机节点都满足Hadoop的硬件要求,并配置好网络连接。
2. 软件安装:首先,我们需要下载Hadoop的安装包,并解压到指定的目录。
然后,我们需要安装Java开发环境,因为Hadoop是基于Java 开发的。
3. 配置主节点:在主节点上,我们需要编辑Hadoop的配置文件,包括核心配置文件、HDFS配置文件和YARN配置文件等。
这些配置文件会影响到集群的整体运行方式和资源分配策略。
4. 配置从节点:与配置主节点类似,我们也需要在每个从节点上进行相应的配置。
从节点的配置主要包括核心配置和数据节点配置。
5. 启动集群:在所有节点的配置完成后,我们可以通过启动Hadoop 集群来进行测试和验证。
启动过程中,我们需要确保各个节点之间的通信正常,并且集群的各个组件都能够正常启动和工作。
通过完成以上这些操作步骤,我们就可以成功搭建一个Hadoop集群,并开始进行大数据的处理和分析工作了。
当然,在实际应用中,还会存在更多的细节和需要注意的地方,我们需要根据具体的场景和需求进行相应的调整和扩展。
Hadoop集群的搭建方法与步骤

Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
Hadoop集群部署(2.X版本)

1前期工作1.1新建用户:以下步骤在master、slave服务器上都需要执行。
为普通用户设置sudo1.2修改/etc/hosts 文件,增加集群机器的ip和hostname的映射关系:以下步骤在master、slave服务器上都需要执行。
红色部分以实际情况为准1.3关闭SELinux1.4关闭防火墙1.5设置ssh1.6JDK安装配置:以下步骤在master、slave服务器上都需要执行。
先卸载RedHat自带安装的jdk:下载相应版本的JDK,放到虚拟机上目录:/usr/jdk64下(实际上这里是32位的),解压:2Hadoop安装配置(本点除了有特殊说明,否则只需要在master机器上执行)准备好安装包:hadoop-2.4.1.tar.gz创建几个后面需要用到的目录:把下载好的Hadoop安装包hadoop-2.4.1.tar.gz放到/home/apps目录,解压:配置Hadoop,一共有7个文件需要配置,2.4.1版本中这些文件路径是:1234567配置完成!3slave服务器复制hadoop以下步骤在master服务器上执行。
4格式化分布式文件系统5启动hadoop以下步骤在master服务器上执行。
使用apps用户登录。
./sbin/start-all.sh这个命令可以一次启动下面的dfs、yarn,一般启动时,输入这个命令即可。
1启动dfs2检测守护进程3启动yarn4查看启动情况如果有dead的要kill进程后重启datanode,使用apps用户:在浏览器上输入:http://192.168.0.201:8088/cluster/apps/KILLED可以看到到启动情况,以及相关nodes6Hive安装配置以下步骤在一台slave服务器(DataN1)上执行即可。
因为master节点负荷比较大,故Hive安装配置到任意slave节点上,本系统安装在hadoop2虚拟机中。
hadoop2.2安装
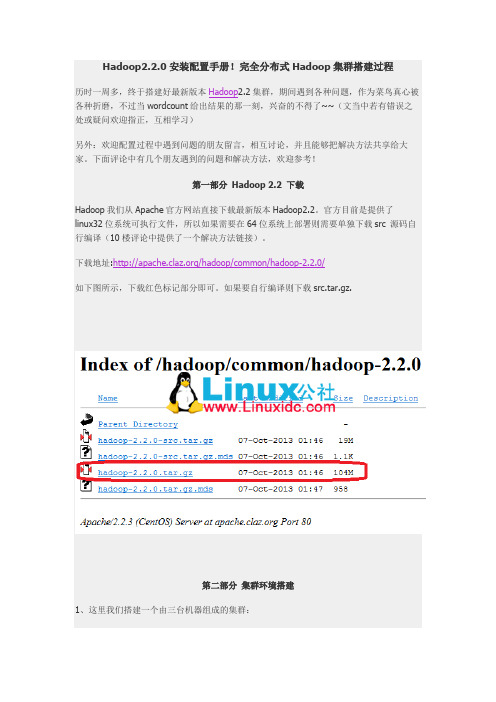
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。
下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
如果要自行编译则下载src.tar.gz.第二部分集群环境搭建1、这里我们搭建一个由三台机器组成的集群:192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。
hadoop集群部署(部署)及配置实验

hadoop集群部署(部署)目录一、安装配置步骤 (3)1.1 虚拟机的准备工作 (3)1.2 安装和配置JDK环境 (3)1.3 配置SSH免密码登录 (4)1.4 编辑etc/hosts文件 (6)1.5 配置hadoop (7)1.6 将master上的Hadoop安装包拷贝到数据节点上 (9)1.7 编辑master主机的etc/profile文件 (10)1.8 格式化hadoop (10)1.9 启动hadoop (10)二、验证hadoop群集 (11)2.1 通过hadoop dfsadmin -report命令验证 (11)2.2 通过web访问hadoop验证 (12)三、Hadoop的使用 (14)3.1 Hadoop中的命令(Command)使用 (14)3.2 运行.jar代码 (15)3.3 使用web界面查看信息 (17)四、Hadoop相关资源 (21)一、安装配置步骤1.1 虚拟机的准备工作1、新建四台虚拟机,并安装好centos6.2,接着把四台虚拟机分别命名为Master、DataNode1、DataNode2、DataNode3;2、四台VM配置好IP地址;3、四台VM均要配置好相同的hadoop管理用的用户名,本次实验是:jntest01。
1.2 安装和配置JDK环境四台VM均需要安装JDK 1.6,并设置环境变量准备工作:1、先下载好JDK 1.6(oracle官网可以下载);2、把下载好的JDK 1.6上传到四台VM中,可以用winSCP工具上传。
若是在虚拟机能上网,直接在虚拟机里下载好即可,就可以免了上传文件这一步。
具体步骤:1、用jntest01登录到VM,切换到JDK存放的路径,然后安装jdk,具体命令操作如下:su //需临时切换到root权限,但前提是要只是root密码password: //输入root的密码chmod u+x jdk-6u26-linux-x64-rpm.bin //授予jdk安装包用户具有执行的权限./ jdk-6u26-linux-x64-rpm //安装jdk2、安装jdk过程都是自动的,安装完后,会提示按enter键继续,此时jdk安装完毕;3、安装完jdk后,此时jdk的环境还没生效,我们可以在命令行输入java –version查看,此时会linux的java版本还是系统自带的open java版本;4、设置环境变量,使java环境生效,具体操作如下:vi /etc/profile //用vi编辑工具编辑etc/profile文件,在文件的最后那里输入如下命令#set java environmentexport JAVA_HOME=/usr/java/jdk1.6.0_26export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_HOME/binexport JAVA_HOME CLASSPATH PATH5、编辑完etc/profile文件后,保存好之后还需输入下面这个命令使其马上生效source /etc/profile6、为java建立符号链接,具体如下操作如下cd /usr/bin //切换目录ln -s -f /usr/java/jdk1.6.0_26/jre/bin/java //建立符号连接ln -s -f /usr/java/jdk1.6.0_26/bin/javac //建立符号连接至此JDK的安装和配置完成,我们可以通过java –version命令查看是否安装成功,如下图所示:1.3 配置SSH免密码登录准备工作:使用jntest01登陆1、确保四台虚拟机的用户家目录下有.ssh目录,并且确保.ssh的权限是700(即rwr)默认情况下会建立,如下图所示:2、如果没有,则需要手动新建,如下:确保已经在家目录下,使用mkdir .ssh命令创建目录,如下图:3、另外还需要确认创建出来的.ssh目录要确保权限是700。
hadoop集群的相关步骤

hadoop集群的相关步骤搭建一个Hadoop集群是进行大数据处理和分析的关键步骤之一。
Hadoop是一个开源的分布式计算框架,可以处理大规模数据集并提供高可靠性和高性能的数据存储和处理能力。
下面将介绍搭建Hadoop集群的相关步骤。
第一步是准备硬件设备。
搭建Hadoop集群需要至少两台服务器,一台作为主节点(NameNode),负责管理整个集群的文件系统和任务调度,其他服务器作为从节点(DataNode),负责存储和处理数据。
确保服务器之间可以互相通信,并且具备足够的存储空间和计算能力。
第二步是安装Hadoop软件。
在每台服务器上安装Hadoop软件包,并进行必要的配置。
配置文件包括core-site.xml、hdfs-site.xml和mapred-site.xml等,用于指定集群的各项参数,如文件系统的存储路径、副本数量、任务调度等。
确保所有服务器上的Hadoop配置文件一致。
第三步是配置SSH免密登录。
为了方便集群节点之间的通信和管理,需要配置SSH免密登录。
在主节点上生成SSH密钥,并将公钥分发到所有从节点上,以实现无密码登录。
这样可以方便地进行集群节点的管理和维护。
第四步是格式化Hadoop文件系统。
在主节点上执行格式化命令,将文件系统初始化为Hadoop可识别的格式。
这一步会清空文件系统中的所有数据,请确保在执行此命令之前已备份重要数据。
第五步是启动Hadoop集群。
在主节点上启动Hadoop服务,包括NameNode、DataNode和ResourceManager等。
通过启动脚本或命令行工具,可以监控集群的运行状态,并查看日志信息以排查问题。
第六步是验证集群的正常运行。
通过访问Hadoop的Web界面,可以查看集群的状态和运行情况。
确保所有节点都正常加入集群,并且文件系统和任务调度功能正常工作。
最后一步是进行数据处理和分析。
通过编写MapReduce程序或使用Hive、Pig等工具,可以对大规模数据进行处理和分析。
Hadoop集群的搭建和配置

Hadoop集群的搭建和配置Hadoop是一种分布式计算框架,它可以解决大数据处理和分析的问题。
Hadoop由Apache软件基金会开发和维护,它支持可扩展性、容错性、高可用性的分布式计算,并且可以运行在廉价的硬件设备上。
Hadoop集群的搭建和配置需要多个步骤,包括安装Java环境、安装Hadoop软件、配置Hadoop集群、启动Hadoop集群。
以下是这些步骤的详细说明。
第一步:安装Java环境Hadoop运行在Java虚拟机上,所以首先需要安装Java环境。
在Linux系统下,可以使用以下命令安装Java环境。
sudo apt-get install openjdk-8-jdk在其他操作系统下,安装Java环境的方式可能有所不同,请查阅相应的文档。
第二步:安装Hadoop软件Hadoop可以从Apache官方网站上下载最新版本的软件。
下载后,解压缩到指定的目录下即可。
解压缩后的目录结构如下:bin/:包含了Hadoop的可执行文件conf/:包含了Hadoop的配置文件lib/:包含了Hadoop的类库文件sbin/:包含了Hadoop的系统管理命令share/doc/:包含了Hadoop的文档第三步:配置Hadoop集群配置Hadoop集群需要编辑Hadoop的配置文件。
其中最重要的是hadoop-env.sh、core-site.xml、hdfs-site.xml和mapred-site.xml。
hadoop-env.sh:这个文件定义了Hadoop集群的环境变量。
用户需要设置JAVA_HOME、HADOOP_HOME等环境变量的值。
core-site.xml:这个文件定义了Hadoop文件系统的访问方式。
用户需要设置、hadoop.tmp.dir等参数的值。
hdfs-site.xml:这个文件定义了Hadoop分布式文件系统的配置信息。
用户需要设置.dir、dfs.data.dir等参数的值。
Hadoop的安装部署

Hadoop的安装部署Hadoop的安装部署对于云计算的概念,世界知名的几大IT厂商都推出了各自的云计算平台,比如Amazon的AWS、微软的Azure和IBM的蓝云等,但他们都是商业平台,不适合广大对云计算有兴趣的研究者,而Hadoop是google云计算的开源实现,并且是完全免费的。
Hadoop是一个分布式系统基础架构,是Apache下的一个项目,由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成。
其中,HDFS和MapReduce是两个最基础最重要的成员。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力高速运算和存储。
简单地说来,Hadoop 是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop框架中最核心的设计就是:MapReduce和HDFS。
MapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。
HDFS是Hadoop分布式文件系统(HadoopDistributedFileSystem)的缩写,为分布式计算存储提供了底层支持。
MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。
这不是什么新思想,其实在前面提到的多线程,多任务的设计就可以找到这种思想的影子。
不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执行;另一种是任务之间有相互的依赖,先后顺序不能够颠倒,这类任务是无法并行处理的。
回到大学时期,教授上课时让大家去分析关键路径,无非就是找最省时的任务分解执行方式。
在分布式系统中,机器集群就可以看作硬件资源池,将并行的任务拆分,然后交由每一个空闲机器资源去处理,能够极大地提高计算效率,同时这种资源无关性,对于计算集群的扩展无疑提供了最好的设计保证。
如何部署Hadoop集群

如何部署Hadoop集群Hadoop集群是一种可以处理大量数据的分布式系统,它是由Apache基金会开发的开源软件。
Hadoop集群可以在低成本的硬件上运行,它可以使用节点管理系统来管理各个节点,实现任务调度,从而实现大数据处理。
在本篇文章中,我将向您介绍如何部署Hadoop集群,以便更好地处理大数据。
第一步:选购硬件在开始部署Hadoop集群之前,首先需要购买合适的硬件设备。
通常情况下,Hadoop集群需要至少三台服务器来工作,其中一个作为主节点,其他服务器作为从节点。
一些有用的硬件要求如下:- 中央处理器:Hadoop集群需要强大的中央处理器来支持高效的数据处理和存储。
- 内存:Hadoop需要大量的内存来处理和存储数据。
- 存储:需要足够的存储空间来存储数据和执行任务。
- 网络连接:网络连接应该足够快以提供高效的数据传输。
第二步:安装操作系统在购买并配置好所需的硬件后,需要安装合适的操作系统。
大多数情况下,Linux是Hadoop集群的首选操作系统,因为它稳定、可靠、易于维护,并且开发了很多用于Hadoop集群的工具。
第三步:安装JavaHadoop是用Java编写的,因此需要安装Java来运行Hadoop。
安装Java的过程非常简单。
只需要前往Java官方网站下载最新版本的Java并按照安装向导操作即可。
第四步:安装Hadoop一旦Java已成功安装,就可以开始安装Hadoop了。
Hadoop的安装过程也很简单。
只需前往Hadoop官方网站,下载最新版本的Hadoop并按照安装向导操作即可。
第五步:配置Hadoop安装Hadoop后,需要对其进行一些配置,以便它能够与其他节点通信并执行任务。
配置Hadoop时需要注意以下几个方面:- Hadoop配置文件:Hadoop的核心配置文件位于目录下的 conf 文件夹中。
- 网络配置:Hadoop需要使用网络进行节点之间的通信。
因此,需要为每个节点指定一个唯一的IP地址,并确保它们都能够相互通信。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop集群安装与部署目录1.目的: (4)2.集群构成: (4)2.1.集群构成图: (4)2.2.集群构成明细: (4)3.Hadoop安装前的准备: (8)3.1.安装JDK (8)3.2.修改/etc/hosts文件 (9)3.3.增加Hadoop集群专有用户............. 错误!未定义书签。
3.4.安装和配置SSH (10)4.安装和配置Hadoop集群 (13)4.1.在NameNode节点安装Hadoop (13)4.2.修改search用户环境设置文件 (13)4.3.在NameNode节点配置Hadoop (14)4.3.1配置hadoop-env.sh文件 (15)4.3.2配置core-site.xml文件 (15)4.3.3配置mapred-site.xml文件 (16)4.3.4配置hdfs-site.xml文件 (17)4.3.5配置yarn-site.xml文件 (18)4.3.6配置主、从节点列表文件 (18)4.4.远程复制Hadoop到集群其他节点 (18)5.启动Hadoop集群 (19)5.1.系统格式化 (19)5.2.启动集群 (19)5.2.1启动HDFS分布式文件系统 (19)5.2.2启动YARN资源管理器 (20)5.2.3验证集群运行状况 (20)6 mapreduce 测试1.目的:本手册旨在熟悉Hadoop2.X(hadoop-2.7.3)集群的安装与配置过程。
通过本手册的内容,使用户可以搭建一个拥有三个节点的Hadoop集群。
2.集群构成:2.1.集群构成图:Secondary NameNode 192.168.82.109:50090DataNodeDataNode 192.168.82.1072.2.集群构成明细:该集群一共有三个安装了64位CentOS7系统的服务器节点。
如下:Node:Name Node的主机名IP地址为:master(192.168.80.100);2.Secondary NameNode & DataNode1:DataNode1同时兼做Secondary NameNode使用。
它的主机名IP 地址为:slaver1(192.168.80.101);3.DataNode2:DataNode2的主机名IP地址为:slaver2(192.168.80.102)。
网卡配置(所有节点)配置网卡(Master节点)配置网卡(Slaver1 节点)网卡配置文件改名禁止可预测网卡命名规则(所有节点)激活grub文件修改主机名(master节点)修改主机名(slaver1 节点)修改hosts文件(所有节点)# reboot 重启系统(所有节点)查看主机名已修改查看网卡名称被修改3.Hadoop安装前的准备:3.1.安装JDKNamenode和datanode节点建议安装SUN公司提供的标准版Java7的JDK 包。
首先在用root用户登录master的系统后,通过以下命令(红字部分)检查系统已安装的JDK包的名称:接下来从Oracle官网下载64的JDK1.7的RPM安装包到/opt目录下后安装它。
这里使用的安装包是:jdk-7u79-linux-x64.rpm。
到这里为止就完成了master上的标准JDK的安装工作。
JDK的默认安装目录为” /usr/java/jdk1.7.0_79/”。
在slaver1和slaver2中参照以上步骤,同样完成标准JDK的替换安装工作。
3.2.修改/etc/hosts文件在每一个节点中,通过修改/etc/hosts文件,实现集群中所有节点之间的主机名互访。
Master节点修改后的/etc/hosts文件内容如下:Slaver1 节点的/etc/hosts文件内容如下:3.3 关闭防火墙(master节点)3.4安装和配置SSH集群中所有节点必须安装并配置SSH,保证各节点之间可以通过认证密钥互相免密访问,以便Hadoop 脚本可以管理远端各节点中运行的Hadoop 守护进程。
因为我们在各节点中安装CentOS7时已经勾选了安装SSH,接下来只需要配置SSH认证即可。
1)首先在master节点生成root用户的公钥,并将该密钥作为远端访问用的认证密钥。
具体操作如下所示:查看生成的公钥和私钥修改认证密钥文件的许可权限为644:(这一步默认也是此权限)2)接下来在slaver1节点中以root用户登录后,运行同样的公钥生成命令:如果slave1节点是从master节点克隆来的,首先在slaver1节点删除/root/.ssh/目录下的内容,再重新生成自己的公钥和密钥。
执行命令“rm -rf /root/.ssh/*”3)把master节点中的认证密钥远程拷贝到slaver1节点中:在slaver1节点查看拷贝过来的authorized_keys文件,并把自己的公钥文件id_rsa.pub添加到授权文件中,并将授权文件复制回master节点查看两个节点的授权文件内容一致,均含有两个节点的公钥3)验证ssh无密码公钥认证登录在master节点登录slaver1在slaver1节点登录master4.安装和配置Hadoop集群4.1.在NameNode节点安装Hadoop首先在NameNode中安装Hadoop,从官网下载最新的Hadoop发行版二进制格式文件hadoop-2.7.3 .tar.gz到/opt目录下。
通过下述命令把文件解压到/目录下:Hadoop是解压即安装。
在NameNode中安装完Hadoop后先不要着急在其他DataNode节点上解压安装Hadoop,而是等NameNode中所有Hadoop 集群相关配置完成之后,再把NameNode上整个Hadoop目录(~/ hadoop-2.7.3)远程拷贝到其他各个节点的相同路径下,就可以完成其他节点的Hadoop安装与配置。
4.2.修改用户环境设置文件在master节点中,修改全局环境变量脚本/etc/profile,追加Java根目录、Hadoop根目录、Hadoop执行脚本所在路径等相关环境变量信息:JA V A_HOME=/usr/java/jdk1.7.0_79HADOOP_HOME=/opt/hadoop-2.7.3PATH=$PATH:$HOME/bin:$JA V A_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport JA VA_HOME HADOOP_HOME PATH由于所有的Hadoop执行脚本基本都在NameNode上运行,因此可以不在其他节点的环境配置文件中追加以上环境变量。
其修改后的完整内容如下:执行环境变量/etc/profile脚本,验证环境变量是否设置成功4.3.在master节点配置HadoopHadoop2.X的配置文件路径为:$HADOOP_HOME/etc/hadoop/。
本手册中的$HADOOP_HOME为” /opt/hadoop-2.7.3”。
在接下来描述的所有配置文件,如无特殊说明都存在于/opt/hadoop-2.7.3/etc/hadoop路径下需要修改的配置文件一共有4个,分别为环境变量脚本文件hadoop-env.sh;核心配置文件core-site.xml;HDFS配置文件hdfs-site.xml以及MapReduce配置文件mapred-site.xml4.3.1.配置hadoop-env.sh文件修改hadoop-env.sh文件中的Java根目录变量和Log文件输出目录变量。
以下红字部分为hadoop-env.sh需要修改的内容:虽然在全局环境变量配置文件中已经配置了”JAVA_HOME”变量的值,但在这里还是需要明确Java根目录的绝对路径。
否则可能会在Hadoop脚本执行过程中出现找不到Java根目录的错误。
Log文件输出目录定义为”/opt/hadoop-2.7.3/log”,如果该目录不存在会在第一次被使用时由Hadoop自动创建。
4.3.2.配置core-site.xml文件在core-site.xml文件的” <configuration>”标签中追加描述集群中缺省文件系统的URI(包括协议、主机名称、端口号)属性(属性名为” fs.defaultFS”),及Hadoop系统临时目录属性(属性名为:” hadoop.tmp.dir”),如以下红字所示内容:URI的协议为”HDFS”、主机名称为NameNode的名称”master”、端口号定义为”9000”;而Hadoop系统的临时目录设置为” /opt/hadoop-2.7.3/tmp”,如果该目录不存在会在第一次被使用时由Hadoop自动创建。
4.3.3.配置mapred-site.xml文件缺省不存在此文件。
因此首先需要通过mapred-site.xml.template文件通过以下命令来复制一份mapred-site.xml文件:在mapred-site.xml文件的” <configuration>”标签中追加描述MapReduce 本地计算用目录属性,如以下红字内容所示:Hadoop从2.0开始取消了Jobtracker,因此没有必要再在该配置文件中定义” mapred.job.tracker”属性了。
取而代之的是通过定义””属性的值为”yarn”来指定MapReduce计算的缺省运行框架。
MapReduce本地计算用目录为” /opt/hadoop-2.7.3/var”,如果该目录不存在会在第一次被使用时由Hadoop自动创建。
如果本地计算使用多个目录时,各目录路径名称之间用逗号进行分隔。
4.3.4.配置hdfs-site.xml文件在hdfs-site.xml文件的” <configuration>”标签中追加描述Secondary NameNode(包括主机名及端口)属性以及数据保存目录属性。
其中NameNode元数据保存路径定义为” /opt/hadoop-2.7.3/ dfs/name”目录,而DataNode数据保存路径为” /opt/hadoop-2.7.3/ dfs/data”目录。
这两个目录属性都可以定义成包含多个路径。
各路径名称之间只要用逗号进行分隔即可。
同样,如果这些目录不存在,也会在第一次被使用时由Hadoop自动创建。
具体增加内容如以下红字部分所示:4.3.5.配置yarn-site.xml文件在yarn-site.xml文件的” <configuration>”标签中追加NodeManager上运行的附属服务属性的描述。