lru算法原理
lru近似淘汰算法

lru近似淘汰算法1.引言1.1 概述近似淘汰算法是一种用于缓存管理的重要技术,其中最受欢迎和广泛使用的算法之一就是LRU(Least Recently Used)算法。
LRU算法的基本原理是根据最近使用的时间来决定何时淘汰掉缓存中的数据。
在计算机科学领域,缓存是一种用于存储临时数据的高速存储器。
由于其读写速度快、响应时间低等特点,缓存被广泛应用于各种系统中,如操作系统、数据库系统和网络应用等。
然而,缓存的大小是有限的,所以当缓存已满时,就需要采取一种淘汰策略来替换掉一部分旧的数据,以便为新的数据腾出空间。
LRU算法的思想是,当需要淘汰数据时,选择最近最久未使用的数据进行替换。
其基本操作是通过维护一个用于排序访问顺序的链表或者双向队列来实现的。
每当访问一个数据时,该数据就会被移动到链表的头部或者队列的头部,以表示这是最近被使用的数据。
当需要淘汰数据时,只需要将链表或者队列的尾部数据替换掉即可。
LRU近似淘汰算法相比于其他淘汰策略具有一些独特的优势。
首先,LRU算法能够充分利用最近的访问模式,因此能够相对准确地判断哪些数据是频繁访问的。
其次,LRU算法具有较高的缓存命中率,即能够更有效地将经常访问的数据保留在缓存中,从而提高系统的性能和响应速度。
另外,LRU算法的实现相对简单,容易理解和调试,因此广泛应用于实际系统中。
综上所述,本文将对LRU近似淘汰算法进行详细的介绍和探讨。
首先,将解释LRU算法的原理和基本操作。
然后,将探讨LRU近似淘汰算法相比其他淘汰策略的优势和适用性。
最后,将总结该算法的重要性和应用前景。
通过对LRU近似淘汰算法的深入理解,我们能够更好地应用该算法来提升系统的性能和效率。
文章结构部分的内容可以按照以下方式来撰写:1.2 文章结构本文将按照以下结构来展开介绍LRU近似淘汰算法:第一部分为引言,旨在概述本文的背景和目的。
首先,我们将对LRU 算法进行简要介绍,阐述其原理和应用场景。
lru 页面置换算法

LRU 页面置换算法1. 简介LRU(Least Recently Used)页面置换算法是一种常用的操作系统内存管理算法,用于在内存不足时决定哪些页面应该被置换出去以腾出空间给新的页面。
LRU算法基于一个简单的原则:最近最少使用的页面应该被置换。
在计算机系统中,内存是有限的资源,而运行程序所需的内存可能超过可用内存大小。
当系统发现没有足够的空闲内存来加载新页面时,就需要选择一些已经在内存中的页面进行替换。
LRU算法就是为了解决这个问题而设计的。
2. 原理LRU算法基于一个简单的思想:如果一个页面最近被访问过,那么它将来可能会再次被访问。
相反,如果一个页面很久没有被访问过,那么它将来可能不会再次被访问。
根据这个思想,LRU算法将最近最少使用的页面置换出去。
具体实现上,可以使用一个数据结构来记录每个页面最近一次被访问的时间戳。
当需要替换一页时,选择时间戳最早(即最久未访问)的页面进行替换即可。
3. 实现方式LRU算法的实现可以基于多种数据结构,下面介绍两种常见的实现方式。
3.1 使用链表一种简单的实现方式是使用一个双向链表来记录页面的访问顺序。
链表头部表示最近访问过的页面,链表尾部表示最久未被访问过的页面。
每当一个页面被访问时,将其从原位置移动到链表头部。
当需要替换一页时,选择链表尾部的页面进行替换。
这种实现方式的时间复杂度为O(1),但空间复杂度较高,为O(n),其中n为内存中可用页面数。
class Node:def __init__(self, key, value):self.key = keyself.value = valueself.prev = Noneself.next = Noneclass LRUCache:def __init__(self, capacity):self.capacity = capacityself.cache = {}self.head = Node(0, 0)self.tail = Node(0, 0)self.head.next = self.tailself.tail.prev = self.headdef get(self, key):if key in self.cache:node = self.cache[key]self._remove(node)self._add(node)return node.valueelse:return -1def put(self, key, value):if key in self.cache:node = self.cache[key]node.value = valueself._remove(node)self._add(node)else:if len(self.cache) >= self.capacity:del self.cache[self.tail.prev.key] self._remove(self.tail.prev)node = Node(key, value)self.cache[key] = nodeself._add(node)def _remove(self, node):prev = node.prevnext = node.nextprev.next = nextnext.prev = prevdef _add(self, node):head_next = self.head.nextself.head.next = nodenode.prev = self.headnode.next = head_nexthead_next.prev = node3.2 使用哈希表和双向链表另一种实现方式是使用一个哈希表和一个双向链表。
伪lru替换算法 -回复

伪lru替换算法-回复伪LRU替换算法是一种用于在计算机操作系统中管理页面置换的算法。
LRU是“最近最久未使用”(Least Recently Used)的缩写,伪LRU则是一种近似于LRU的替换算法。
本文将详细解释伪LRU替换算法的原理和步骤,以及它在操作系统中的应用。
一、算法原理伪LRU替换算法是基于页面访问模式的思想设计的。
它模拟了LRU算法中的页面置换过程,但是通过使用一种更加高效的数据结构来实现,以减少算法的时间复杂度。
在LRU算法中,每个页面都有一个时间戳,表示它最后一次被访问的时间。
当需要替换页面时,算法会选择时间戳最久远的页面进行置换。
然而,为了实现这一功能,需要维护页面的访问时间戳,并且在每次访问页面时更新这个时间戳,这样算法的时间复杂度较高。
伪LRU算法通过使用二叉树来代替时间戳,来降低时间复杂度。
二叉树的每个节点都代表一个页面,通过比较节点的数值来判断页面是否为最近使用的页面。
根节点代表最近使用的页面,左子节点代表较旧的页面,右子节点代表更旧的页面。
当需要替换页面时,算法将选择树的最深的路径,并将该页面替换掉。
根据这个逻辑,伪LRU算法在维护树的过程中,只需要比较树的节点,不需要维护时间戳,从而减少了时间复杂度。
二、算法步骤伪LRU替换算法的步骤如下:1. 初始化:为每个页面分配一个二叉树节点,并初始化树的叶子节点为空。
2. 页面访问:当有页面被访问时,算法将按照以下步骤进行操作:a. 如果页面已经在树中,将该页面对应的节点标记为最近使用,然后转到步骤d。
b. 如果页面不在树中,需要进行页面置换。
首先,找到树中最深的非叶子节点的子路径。
这个子路径上的节点都是连续被访问的页面,而且这个子路径的深度大于等于树的高度的一半。
在这个子路径中,如果左子节点的深度大于右子节点的深度,将页面替换为左子节点所代表的页面,否则替换为右子节点。
然后将新访问的页面的节点标记为最近使用,转到步骤d。
lru算法的原理

lru算法的原理
LRU(Least Recently Used)算法是一种常用的缓存淘汰算法,其原理是根据数据的访问时间来进行决策。
LRU算法假设最近被访问过的数据在未来一段时间内也有很大的可能性被再次访问,因此将最近使用过的数据保留在缓存中,而淘汰掉最久未被使用的数据。
具体来说,LRU算法维护一个数据访问历史记录,当需要淘汰数据时,选择最久未被使用的数据进行淘汰。
具体步骤如下:
1. 当访问某个数据时,将该数据移动到历史记录的最前面,表示该数据最近被使用过。
2. 当需要淘汰数据时,选择历史记录的最后一个数据进行淘汰,即最久未被使用的数据。
LRU算法可以通过数据结构实现,常用的实现方式是使用一个双向链表和一个哈希表。
双向链表按照数据的访问时间顺序维护数据,链表头部是最近访问的数据,链表尾部是最久未被访问的数据。
哈希表用于快速查找数据在链表中的位置,通过数据的键来索引链表中的节点。
LRU算法的优点是简单高效,适用于各种数据访问模式。
然而,实现LRU算法需要额外的数据结构和操作,会增加一定的空间和时间复杂度。
lru页面置换算法例题详解

lru页面置换算法例题详解LRU(Least Recently Used)页面置换算法是一种常用的内存管理算法,其基本思想是:当内存空间不足时,优先淘汰最近最少使用的页面。
下面是一个LRU页面置换算法的详细例子:假设我们有3个物理块,当前内存中已经装入了页面1、页面2和页面3。
现在,我们按照顺序依次访问页面4、页面3、页面2、页面1、页面4、页面3、页面5和页面4,我们需要使用LRU算法来决定哪些页面应该被淘汰。
步骤1:装入页面4。
此时内存中有页面1、页面2、页面3和页面4,下一次访问时,将页面4标记为最近使用。
步骤2:访问页面3。
由于页面3在内存中,将其标记为最近使用。
步骤3:访问页面2。
同样,页面2也在内存中,将其标记为最近使用。
步骤4:访问页面1,内存已满,需要淘汰一个页面。
根据LRU算法,应该淘汰最久未使用的页面,即页面3。
因此,将页面1装入内存中,并标记为最近使用,同时将页面3淘汰。
步骤5:访问页面4,内存已满,需要淘汰一个页面。
根据LRU算法,应该淘汰最久未使用的页面,即页面2。
因此,将页面4装入内存中,并标记为最近使用,同时将页面2淘汰。
步骤6:访问页面3,内存已满,需要淘汰一个页面。
根据LRU算法,应该淘汰最久未使用的页面,即页面1。
因此,将页面3装入内存中,并标记为最近使用,同时将页面1淘汰。
步骤7:访问页面5,内存已满,需要淘汰一个页面。
根据LRU算法,应该淘汰最久未使用的页面,即页面1。
因此,将页面5装入内存中,并标记为最近使用,同时将页面1淘汰。
在上述过程中,我们按照LRU算法依次淘汰了页面3、页面2、页面1和页面1,最终实现了页面的置换。
lru算法及例题讲解

lru算法及例题讲解
摘要:
1.LRU算法简介
2.LRU算法原理
3.LRU算法应用
4.例题讲解
5.总结与拓展
正文:
一、LRU算法简介
最近最少使用(Least Recently Used,简称LRU)算法是一种缓存置换策略,用于决定在内存有限的情况下,如何淘汰已失效的缓存数据。
LRU算法基于一个假设:最近访问过的数据很可能会在不久的将来再次被访问。
因此,当内存有限且需要腾出空间时,优先淘汰最近访问过的数据。
二、LRU算法原理
LRU算法通过维护一个访问顺序来实现。
当一个数据被访问时,将其放入一个队列(或栈)中,并按照访问顺序进行排序。
当需要淘汰缓存时,从队尾(或栈顶)移除最近访问过的数据。
三、LRU算法应用
LRU算法广泛应用于计算机科学领域,如操作系统、浏览器缓存、数据库等领域。
通过使用LRU算法,可以有效提高缓存利用率,提高系统性能。
四、例题讲解
题目:一个含有n个元素的缓存,采用LRU算法进行缓存置换,求第k个访问的元素在缓存中的位置。
解题思路:
1.初始化一个长度为n的数组,表示每个元素在缓存中的位置。
2.模拟访问过程,每次访问一个元素,按照LRU算法进行置换,并记录访问顺序。
3.当访问第k个元素时,找到其在访问顺序中的位置,即为在缓存中的位置。
五、总结与拓展
LRU算法作为一种高效的缓存置换策略,在实际应用中具有重要意义。
了解LRU算法的原理和应用,可以帮助我们更好地解决实际问题。
lru算法的实现过程,python

LRU算法是一种常用的缓存淘汰策略,LRU全称为Least Recently Used,即最近最少使用。
它的工作原理是根据数据的历史访问记录来淘汰最近最少使用的数据,以提高缓存命中率和性能。
在Python中,可以通过各种数据结构和算法来实现LRU算法,例如使用字典和双向链表来实现LRU缓存。
一、LRU算法的基本原理LRU算法是基于"最近最少使用"的原则来淘汰缓存中的数据,它维护一个按照访问时间排序的数据队列,当缓存空间不足时,会淘汰最近最少使用的数据。
LRU算法的基本原理可以用以下步骤来说明:1. 维护一个有序数据结构,用来存储缓存中的数据和访问时间。
2. 当数据被访问时,将其移动到数据结构的最前面,表示最近被使用过。
3. 当缓存空间不足时,淘汰数据结构最后面的数据,即最近最少使用的数据。
二、使用Python实现LRU算法在Python中,可以使用字典和双向链表来实现LRU算法。
其中,字典用来存储缓存数据,双向链表用来按照访问时间排序数据。
1. 使用字典存储缓存数据在Python中,可以使用字典来存储缓存数据,字典的键值对可以用来表示缓存的键和值。
例如:```cache = {}```2. 使用双向链表按照访问时间排序数据双向链表可以按照访问时间对数据进行排序,使得最近被访问过的数据在链表的最前面。
在Python中,可以使用collections模块中的OrderedDict来实现双向链表。
例如:```from collections import OrderedDict```3. 实现LRU算法的基本操作在Python中,可以通过对字典和双向链表进行操作来实现LRU算法的基本操作,包括缓存数据的存储、更新和淘汰。
以下是LRU算法的基本操作示例:(1)缓存数据的存储当缓存数据被访问时,可以将其存储到字典中,并更新双向链表的顺序。
例如:```def put(key, value):if len(cache) >= capacity:cache.popitem(last=False)cache[key] = value```(2)缓存数据的更新当缓存数据被再次访问时,可以更新其在双向链表中的顺序。
lru替换算法命中率例题

lru替换算法命中率例题
LRU(Least Recently Used)替换算法是一种常见的页面置换算法,用于缓存淘汰策略。
它的主要思想是根据页面的历史访问记录来进行页面置换,即当缓存空间不足时,将最近最少使用的页面替换出去。
假设有一个缓存空间可以存储3个页面,初始状态为空。
现在按照以下访问顺序访问页面,A, B, C, D, A, D, B, E, A, B。
请计算使用LRU替换算法后的命中率。
首先,按照访问顺序模拟LRU替换算法的过程:
1. A 缓存,A,命中率,0/1。
2. B 缓存,A, B,命中率,1/2。
3. C 缓存,A, B, C,命中率,2/3。
4. D 缓存,B, C, D,命中率,2/4。
5. A 缓存,C, D, A,命中率,3/5。
6. D 缓存,D, A, B,命中率,3/6。
7. B 缓存,A, B, D,命中率,4/7。
8. E 缓存,B, D, E,命中率,4/8。
9. A 缓存,D, E, A,命中率,5/9。
10. B 缓存,E, A, B,命中率,6/10。
根据上述模拟,最终命中率为6/10,即60%。
从另一个角度来看,LRU替换算法的命中率受到访问页面顺序的影响。
在这个例子中,访问了A、B、C、D、A、D、B、E、A、B这10个页面,其中有6次命中,4次未命中。
命中率的计算公式为命中次数除以总的访问次数,即6/10,结果为60%。
综上所述,使用LRU替换算法后的命中率为60%。
深圳鹏芯微笔试题目

鹏芯微是一家位于深圳的芯片设计公司,专注于提供高性能、低功耗的处理器解决方案。
他们的笔试题目通常涵盖了从基础知识到实践技能的广泛范围。
下面我将为你介绍一些可能出现的题目,并提供相关参考内容,以帮助你准备鹏芯微的笔试。
1.问题:请简述和解释CMOS技术及其在芯片设计中的应用。
参考内容:CMOS技术是一种基于互补金属-氧化物-半导体(Complementary Metal-Oxide-Semiconductor)的集成电路设计和制造技术。
其特点是低功耗、高集成度和高可靠性。
在芯片设计中,CMOS技术被广泛应用于各种数字电路和模拟电路,如处理器、存储器、传感器等。
CMOS技术的重要组成部分包括MOSFET(Metal-Oxide-Semiconductor Field Effect Transistor)、逻辑门电路、时钟电路等。
2.问题:请列举几种常见的处理器架构并简述其特点。
参考内容:常见的处理器架构包括CISC(Complex Instruction Set Computer)和RISC(Reduced Instruction Set Computer)两种。
CISC架构的特点是指令集复杂、指令长度不一致,执行一条指令通常需要多个时钟周期。
而RISC架构的特点是指令集简洁、指令长度一致,执行效率较高。
在实际应用中,RISC架构逐渐取代了CISC架构,成为主流的处理器设计。
3.问题:请解释流水线(Pipeline)技术在处理器设计中的作用和原理。
参考内容:流水线技术是一种将指令执行过程划分为多个阶段,并在各个阶段并行处理的技术。
它可以提高处理器的运行速度和效率。
流水线的阶段通常包括指令取指、指令译码、执行、访存、写回等。
当一个阶段的处理完成后,数据就会传送到下一个阶段,而前一个阶段则可以开始处理下一个指令。
这种并行处理的方式可以减少指令的延迟,提高处理器的吞吐量。
4.问题:请列举几种常见的缓存替换算法并简要介绍其原理。
lru页面置换算法实验c语言总结

LRU页面置换算法实验C语言总结1.引言在计算机科学中,页面置换算法是解决主存容量有限的情况下,如何有效地管理页面(或称为内存块)的一种重要方法。
L RU(L ea st Re ce nt ly Us e d)页面置换算法是其中一种经典的策略,通过淘汰最久未使用的页面来提高内存的利用率。
本文将总结使用C语言实现L RU页面置换算法的相关实验。
2.算法原理L R U页面置换算法的核心思想是:最近被访问的页面可能在未来继续被访问,而最久未被使用的页面可能在未来也不再被访问。
基于这一思想,L R U算法维护一个页面访问的时间顺序链表,每次发生页面置换时,选择链表头部(即最久未使用)的页面进行淘汰。
3.实验设计本次实验旨在使用C语言实现LR U页面置换算法,并通过模拟页面访问的过程来验证算法的正确性。
具体设计如下:3.1数据结构为了实现LR U算法,我们需要定义几个关键的数据结构:3.1.1页面节点结构t y pe de fs tr uc tP age{i n tp ag eI D;//页面I Ds t ru ct Pa ge*n ex t;//下一个节点指针s t ru ct Pa ge*p re v;//上一个节点指针}P ag e;3.1.2内存块结构t y pe de fs tr uc tM emo r y{i n tc ap ac it y;//内存块容量i n ts iz e;//当前存储的页面数量P a ge*h ea d;//内存块链表头指针P a ge*t ai l;//内存块链表尾指针}M em or y;3.2实验步骤本次实验主要包括以下几个步骤:3.2.1初始化内存块根据实际需求,设置内存块的容量,并初始化链表头指针和尾指针。
3.2.2页面置换每次发生页面访问时,检查访问的页面是否已经在内存块中。
如果在,将该页面移动到链表尾部;如果不在,执行页面置换。
3.2.3页面淘汰当内存块已满时,选择链表头部的页面进行淘汰,将新访问的页面加入链表尾部。
置换算法lru模拟设计

置换算法lru模拟设计一、概述置换算法(Replacement Algorithm)是一种常用的缓存管理策略,其中 LRU (Least Recently Used)算法是一种常见的策略,用于决定何时淘汰最不常用的数据。
本篇文章将详细介绍如何使用模拟设计实现 LRU 算法。
二、算法原理LRU 算法的基本原理是,当缓存满时,选择最不常用的数据淘汰。
在计算机科学中,常用的 LRU 算法实现方式有三种:FIFO(First In First Out,先进先出)、LFU(Least Frequently Used,最不常用)和基于时间的 LRU。
其中基于时间的 LRU 算法由于其简单易实现,得到了广泛的应用。
三、模拟设计本节将介绍如何使用模拟设计实现 LRU 算法。
模拟设计通常使用一个数组和两个指针来实现。
其中,数组用于存储缓存中的数据,两个指针分别指向最不常用数据和当前头部的位置。
每次有新的数据被插入缓存时,都需要判断其是否已经在缓存中存在,如果存在则移动到尾部,如果不存在则插入到头部。
同时,需要更新头部的指针。
当需要淘汰数据时,选择头部指针所指向的数据进行淘汰。
四、代码实现以下是一个简单的 Python 代码实现:```pythonclass LRUCache:def __init__(self, capacity):self.capacity = capacityself.cache = {}self.head = Noneself.tail = Nonedef get(self, key):if key not in self.cache:return -1self.cache[key].move_to_head()return self.cache[key].valuedef put(self, key, value):if key in self.cache:self.cache[key].move_to_tail()new_node = Node(key, value)if self.head is None:self.head = new_nodeself.tail = new_nodeelse:new_node.move_to_head()prev_node = self.headwhile prev_node.next:prev_node = prev_node.nextprev_node.next = new_nodeself.tail = new_nodeself.cache[key] = new_nodeif len(self.cache) > self.capacity:tail = self.tail.prevdel self.cache[tail.key]if tail == self.head:self.head = Noneself.tail = None```在这个实现中,我们使用了一个 Node 类来表示缓存中的数据节点,其中包含了键值、值和位置信息。
常用缓存淘汰算法(LFU、LRU、ARC、FIFO、MRU)

常⽤缓存淘汰算法(LFU、LRU、ARC、FIFO、MRU)
缓存算法是指令的⼀个明细表,⽤于决定缓存系统中哪些数据应该被删去。
常见类型包括LFU、LRU、ARC、FIFO、MRU。
最不经常使⽤算法(LFU):
这个缓存算法使⽤⼀个计数器来记录条⽬被访问的频率。
通过使⽤LFU缓存算法,最低访问数的条⽬⾸先被移除。
这个⽅法并不经常使⽤,因为它⽆法对⼀个拥有最初⾼访问率之后长时间没有被访问的条⽬缓存负责。
最近最少使⽤算法(LRU):
这个缓存算法将最近使⽤的条⽬存放到靠近缓存顶部的位置。
当⼀个新条⽬被访问时,LRU将它放置到缓存的顶部。
当缓存达到极限时,较早之前访问的条⽬将从缓存底部开始被移除。
这⾥会使⽤到昂贵的算法,⽽且它需要记录“年龄位”来精确显⽰条⽬是何时被访问的。
此外,当⼀个LRU缓存算法删除某个条⽬后,“年龄位”将随其他条⽬发⽣改变。
⾃适应缓存替换算法(ARC):
在IBM Almaden研究中⼼开发,这个缓存算法同时跟踪记录LFU和LRU,以及驱逐缓存条⽬,来获得可⽤缓存的最佳使⽤。
先进先出算法(FIFO):
FIFO是英⽂First In First Out 的缩写,是⼀种先进先出的数据缓存器,他与普通存储器的区别是没有外部读写地址线,这样使⽤起来⾮常简单,但缺点就是只能顺序写⼊数据,顺序的读出数据,其数据地址由内部读写指针⾃动加1完成,不能像普通存储器那样可以由地址线决定读取或写⼊某个指定的地址。
最近最常使⽤算法(MRU):
这个缓存算法最先移除最近最常使⽤的条⽬。
⼀个MRU算法擅长处理⼀个条⽬越久,越容易被访问的情况。
常用缓存淘汰算法(LFU、LRU、ARC、FIFO、MRU)介绍和实现

LRU(Least Recently Used):最近最少使用页面置换算法,也就是首先淘汰最长时间未被使用的页面。关键是看页面最后一次被使用到发生调度
的时间长短。
LFU(Least Frequently Used):最近最不常用页面置换算法,也就是淘汰一定时期内被访问次数最少的页。关键是看一定时间段内页面被使用的频
率。
ARC(Adaptive Replacement Cache):是一种适应性Cache算法, 它结合了LRU与LFU。
FIFO (First In First Out):先进先出算法。
MRU (Most recently used):正好和LRU算法相反,最近最常使用算法。
LRU算法原理解析

LRU算法原理解析LRU是Least Recently Used的缩写,即最近最少使⽤,常⽤于页⾯置换算法,是为虚拟页式存储管理服务的。
现代操作系统提供了⼀种对主存的抽象概念虚拟内存,来对主存进⾏更好地管理。
他将主存看成是⼀个存储在磁盘上的地址空间的⾼速缓存,在主存中只保存活动区域,并根据需要在主存和磁盘之间来回传送数据。
虚拟内存被组织为存放在磁盘上的N个连续的字节组成的数组,每个字节都有唯⼀的虚拟地址,作为到数组的索引。
虚拟内存被分割为⼤⼩固定的数据块虚拟页(Virtual Page,VP),这些数据块作为主存和磁盘之间的传输单元。
类似地,物理内存被分割为物理页(Physical Page,PP)。
虚拟内存使⽤页表来记录和判断⼀个虚拟页是否缓存在物理内存中:如上图所⽰,当CPU访问虚拟页VP3时,发现VP3并未缓存在物理内存之中,这称之为缺页,现在需要将VP3从磁盘复制到物理内存中,但在此之前,为了保持原有空间的⼤⼩,需要在物理内存中选择⼀个牺牲页,将其复制到磁盘中,这称之为交换或者页⾯调度,图中的牺牲页为VP4。
把哪个页⾯调出去可以达到调动尽量少的⽬的?最好是每次调换出的页⾯是所有内存页⾯中最迟将被使⽤的——这可以最⼤限度的推迟页⾯调换,这种算法,被称为理想页⾯置换算法,但这种算法很难完美达到。
为了尽量减少与理想算法的差距,产⽣了各种精妙的算法,LRU算法便是其中⼀个。
LRU原理LRU 算法的设计原则是:如果⼀个数据在最近⼀段时间没有被访问到,那么在将来它被访问的可能性也很⼩。
也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
根据所⽰,假定系统为某进程分配了3个物理块,进程运⾏时的页⾯⾛向为 7 0 1 2 0 3 0 4,开始时3个物理块均为空,那么LRU算法是如下⼯作的:基于哈希表和双向链表的LRU算法实现如果要⾃⼰实现⼀个LRU算法,可以⽤哈希表加双向链表实现:设计思路是,使⽤哈希表存储 key,值为链表中的节点,节点中存储值,双向链表来记录节点的顺序,头部为最近访问节点。
lru原理

lru原理
LRU是Least Recently Used的缩写,是一种页面置换算法,用
于减少缓存命中率低的情况。
缓存是指计算机存储介质中的一种高速
存储器,它存放了最近与被访问的内容。
在缓存中,存储器块的数量
是有限制的。
当存储器块已经被占满,而需要进一步存储新数据时,
就需要将其中的一些存储器块释放出来。
在LRU算法中,每一个存储器块都有一个使用时间。
当需要替换
掉一个存储器块时,LRU算法选择最久没有被使用的存储器块进行置换。
例如,如果有4个存储器块,分别为A、B、C、D,它们的访问时间(从最近到最远)分别为D、C、B、A。
当需要替换掉一个存储器块时,LRU算法会将A块置换掉,因为它是最早访问的块。
LRU算法适用于缓存的场景,如网站缓存、数据库缓存等。
它能
够有效地提高缓存命中率,减少缓存的不命中率。
LRU算法在计算机系统中应用广泛,包括操作系统、数据库管理系统、Web服务器等领域。
cache缓存淘汰算法--LRU算法
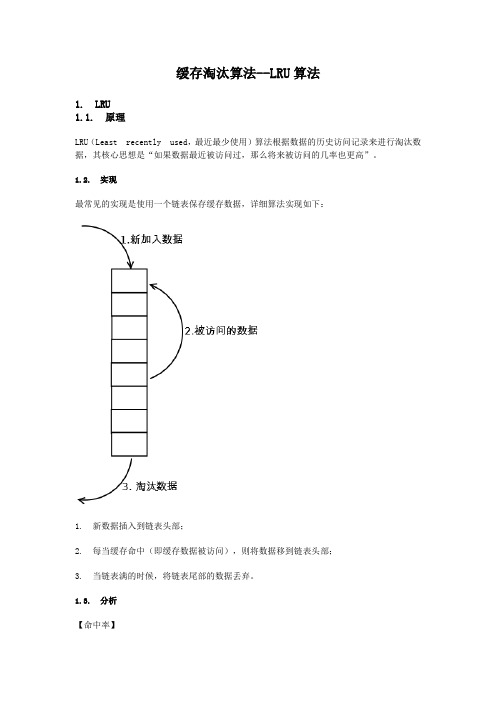
缓存淘汰算法--LRU算法1. LRU1.1. 原理LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.2. 实现最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:1. 新数据插入到链表头部;2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;3. 当链表满的时候,将链表尾部的数据丢弃。
1.3. 分析【命中率】当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】实现简单。
【代价】命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
2. LRU-K2.1. 原理LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。
LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2.2. 实现相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
只有当数据的访问次数达到K次的时候,才将数据放入缓存。
当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
详细实现如下:1. 数据第一次被访问,加入到访问历史列表;2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;4. 缓存数据队列中被再次访问后,重新排序;5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
lru算法和lfu算法

lru算法和lfu算法
LRU算法和LFU算法都是常用的缓存淘汰算法,用于解决缓存满了之后需要淘汰一些不常用或者不重要的缓存数据的问题。
LRU算法是Least Recently Used的缩写,即最近最少使用算法。
其核心思想是,当缓存满了之后,会淘汰最近最少使用的缓存数据,也就是最久没有被使用过的数据。
这样做的好处是可以保留最常用的缓存数据,提高缓存的命中率。
LFU算法是Least Frequently Used的缩写,即最近不经常使用算法。
其核心思想是,当缓存满了之后,会淘汰使用频率最低的缓存数据,也就是最不常用的数据。
这样做的好处是可以保留最常被使用的缓存数据,提高缓存的命中率。
两种算法的实现方式略有不同,但都需要记录每个缓存数据的访问时间和访问频率,以便根据规则进行淘汰。
在实际应用中,需要根据具体情况选择合适的算法,以提高缓存的效率和性能。
- 1 -。
自定义lru算法缓存

自定义lru算法缓存要说起LRU缓存,可能很多小伙伴一听就懵了。
哎呀,啥是LRU?咋听着有点像“老百姓认不住”的缩写?LRU可不是个让你摸不着头脑的东西,它指的是“最近最少使用”算法,英文全称就是Least Recently Used。
简单来说,就是一个缓存策略,用来管理有限的内存空间,避免内存被占满导致程序卡顿,或者最可怕的崩溃。
你想啊,咱们手机里不也是这么管理内存的吗?微信、QQ这些社交软件,有时候打开的速度就慢得让人抓狂。
这不,你一关掉几个常用APP,剩下的才能跑得飞快。
LRU缓存就差不多是这个原理。
它的基本规则就是:咱们存储的数据越多,越容易发生拥挤。
这时候,LRU会“聪明”地决定哪些数据不重要,哪些是最近没怎么用过的,反正占个地方也没啥用,那就淘汰掉。
想象一下你在家里,有一堆书。
每天都有人借,借来借去。
你最爱的那本《三国演义》,当然得放在书架最显眼的地方,一拿就能用。
而那些放在角落里,半年都没人碰的书,早晚会被清理掉。
LRU就像你的家庭图书管理员,专门记住哪个书是最常借的,哪个书你再看也没兴趣,最后把它们“清空”掉,腾出地方给新书。
好吧,咱们不说那么多抽象的东西,咱从生活中的小事儿聊聊。
比如你去超市,买了一大堆东西。
结果,卡车后备箱太小,最后你只能选择把最不重要的几个东西放弃。
这就是LRU的简化版:只有有限的空间,聪明地挑选哪些东西该留下,哪些该丢掉。
这个LRU算法本质上就是依靠时间来判断的。
你用过的数据,时间一长自然会被认定为“冷门”数据,而最近用过的就成了“热门”数据。
你能想象吧,就像你手机里的那几款APP,哪个最常用,哪个用得少,一眼就能看出来,完全不用问。
LRU的核心思想就是:缓存中始终保存最“热门”的数据,而那些被丢到一边很久的,不值一提的就“淘汰”掉。
说到这里,也许你会问:“那这LRU缓存和我们平时电脑上缓存有啥不一样?”这俩没什么太大差别。
你可以把LRU当作是一种“聪明”的缓存策略,能够最大化地利用有限的内存空间。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
lru算法原理
LRU算法原理
LRU(Least Recently Used)算法是一种常见的页面置换算法,在操作系统中被广泛应用于缓存管理、虚拟内存等领域。
LRU算法的基本思想是根据页面的历史访问情况,将最长时间未被使用的页面置换出去,以腾出空间给新的页面使用。
LRU算法的核心原理是“最近使用的页面很可能在未来也会被使用”,因此,当系统需要置换页面时,选择最长时间未被使用的页面进行置换,以提高页面命中率,减少缺页中断。
具体来说,LRU算法维护一个页面访问历史的顺序链表。
每当一个页面被访问时,就将该页面移到链表的头部,表示该页面是最近使用的。
当需要置换页面时,选择链表尾部的页面进行置换,即选择最长时间未被使用的页面。
为了更好地实现LRU算法,可以使用双向链表和哈希表的数据结构。
双向链表用于维护页面的访问顺序,而哈希表用于快速查找页面在链表中的位置。
每当一个页面被访问时,可以通过哈希表快速定位到该页面在链表中的位置,并将其移动到链表头部。
当需要置换页面时,只需将链表尾部的页面移除即可。
在实际应用中,LRU算法可以根据不同的需求进行优化。
例如,可
以使用近似LRU算法(Approximate LRU)来减少算法的开销。
近似LRU算法通过将页面分组,只记录每个页面组的最近使用状态,从而减少了对每个页面的访问历史的维护。
LRU算法还可以通过设置合适的缓存大小来提高算法的效率。
过小的缓存大小会导致频繁的缺页中断,而过大的缓存大小则会浪费内存资源。
因此,在实际使用中,需要根据系统的特点和需求来确定合适的缓存大小。
总结起来,LRU算法是一种基于页面访问历史的页面置换算法。
通过将最长时间未被使用的页面置换出去,LRU算法可以提高页面命中率,减少缺页中断。
在实际应用中,可以根据需求进行优化,如使用近似LRU算法、设置合适的缓存大小等。
LRU算法的原理简单明了,但在实际实现中需要考虑多个因素,以达到最佳的性能和资源利用效果。