storm实战教程 storm培训视频9、storm案例开发-计算网站PV
51CTO学院-实时计算开发-Storm从入门到精通视频课程

实时计算开发-Storm从入门到精通视频课程适用人群中级IT从业人员课程简介课程目标:1、storm基本概念和组件介绍2、storm分组策略3、storm安装4、Storm 记录级容错原理5、Storm 配置详解6、storm基本api介绍7、Storm Topology的并发度8、Storm消息机制原理讲解9、Storm DRPC实战讲解10、Storm Transaction 原理+实战讲解11、Storm 实现滑动窗口计数和TopN排序12、Storm流聚合13、Storm的新利器Pluggable Scheduler适合对象:大数据研究方向人员学习条件:有一定java基础和linux基础,掌握分布式的基本概念课程1Storm基础知识[免费观看]27分钟storm基础知识讲解,包括实时计算需要解决一些什么问题,怎么实现一个实时计算系统,stor m的基本概念,storm应用场景,storm的分组机制。
2storm集群安装-121分钟详细讲述storm集群的安装,手把手教授安装流程并排除问题.3Storm集群安装-234分钟详细讲述storm集群的安装,手把手教授安装流程并排除问题.4Storm-starter打包运行测试Storm集群23分钟详细讲解storm-starter打包部署运行的全过程,同时进行storm集群验证。
5Storm 配置文件配置项讲解14分钟详细讲解storm配置文件对应的参数,以及用法。
6Maven 环境快速搭建教程7分钟讲述maven环境的搭建过程,以及常用命令。
7storm基本api介绍21分钟storm基本api介绍8Storm Topology的并发度11分钟Storm Topology的并发度9Storm消息机制原理讲解24分钟Storm消息机制原理讲解10Storm DRPC实战讲解15分钟Storm DRPC实战讲解。
stormproxies的使用方法

stormproxies的使用方法(实用版3篇)目录(篇1)1.引言2.StormProxies 的概念和背景3.StormProxies 的使用方法3.1 创建 StormProxies 实例3.2 配置 StormProxies3.3 启动 StormProxies3.4 关闭 StormProxies4.StormProxies 的应用场景5.总结正文(篇1)一、引言随着互联网的发展,数据挖掘和分析的需求越来越大。
在大数据时代,分布式计算框架应运而生,其中 Storm 是一种实时的大数据处理系统。
为了使 Storm 处理速度更快,StormProxies 应运而生。
本文将介绍StormProxies 的使用方法。
二、StormProxies 的概念和背景StormProxies 是 Netflix 开发的一个用于加速 Storm 计算的代理应用。
它可以在 Storm 集群中代替 Nimbus 和 Supervisor,从而提高整个集群的性能。
StormProxies 通过代理 Nimbus 和 Supervisor 的通信,减少了集群中的网络延迟和负载,使得 Storm 处理速度更快。
三、StormProxies 的使用方法1.创建 StormProxies 实例要使用 StormProxies,首先需要创建一个 StormProxies 实例。
可以通过以下命令创建一个 StormProxies 实例:```java -jar stormproxies.jar```2.配置 StormProxies在创建 StormProxies 实例后,需要对其进行配置。
可以通过修改stormproxies.jar 中的 resources 文件夹下的配置文件进行配置。
配置文件名为 stormproxies.conf。
以下是一个配置示例:```imbus.host="localhost"imbus.port=6627supervisor.host="localhost"supervisor.port=10808```其中,nimbus.host 和 nimbus.port 分别表示 Nimbus 的 IP 地址和端口,supervisor.host 和 supervisor.port 分别表示 Supervisor 的 IP 地址和端口。
storm教程

storm教程Storm是一个开源的实时大数据处理系统,由Apache基金会开发和维护。
它旨在解决实时处理大规模数据的需求,可以用于处理实时流数据、分布式计算和分布式消息传递。
本教程将向您介绍Storm的基本概念和使用方法。
Storm的基本概念包括Topology、Spout、Bolt和Stream。
Topology是一个实时计算任务的有向无环图,由一系列Spout和Bolt组成。
Spout用于从数据源读取输入数据,并将数据发送给Bolt进行处理。
Bolt是具体的计算单元,可以执行各种数据处理操作。
Stream是数据在Spout和Bolt之间传递的流。
首先,您需要配置Storm集群。
您可以在多台服务器上部署Storm,并通过ZooKeeper来进行协调和管理。
建议使用分布式文件系统来存储Storm的配置和数据。
接下来,您需要按照以下步骤编写和运行一个Storm拓扑:1. 创建一个Topology对象,并设置它的名称。
2. 创建一个Spout对象,并实现Spout接口的nextTuple方法。
在这个方法中,您可以从数据源读取数据,并将每条数据发送给下一个Bolt。
3. 创建一个或多个Bolt对象,并实现Bolt接口的execute方法。
在这个方法中,您可以对接收到的数据进行处理,并发送处理结果给下一个Bolt。
4. 将Spout和Bolt对象添加到Topology中,并定义它们之间的连接关系。
5. 配置Topology的并行度,即每个Bolt的并行处理数量。
6. 提交Topology到集群中运行。
您可以使用Storm提供的命令行工具来提交和监控Topology的运行状态。
在拓扑运行期间,您可以根据需要进行监控和调试。
Storm提供了各种监控工具和命令,包括Storm UI、Log Viewer和Storm Shell等。
此外,Storm还提供了可扩展性和容错性机制。
当集群中的节点发生故障时,Storm可以自动重新分配任务并保证数据的完整性。
02、Storm入门到精通storm3-1

Storm深入学习
• Storm 数据模型(topology)
为了在storm做实时计算,必须创建topology。topology是计算图。 topology中的每个节点包含一个处理逻辑,节点之间的链接表明了数 据如何在节点之间被传输。
运行topology非常直接了当:首先将你的代码和依赖打包为一个 jar,接着运行以下命令即可:
• spouts和bolts实现 spouts负责输出新消息到topology。TestWordSpout输出从列表
m深入学习
• Storm 数据模型(topology)
stream: storm的核心是"stream"。stream是无边界的tuple序列。storm以分布、
可靠的方式为转换一个stream到新的stream提供了基本组件。 storm为stream的转换提供的基本组件是spouts和bolts。spouts和bolt
Storm深入学习
• Storm 数据模型(topology)
此topology包含一个spout和两个bolts。spout输处word,每个bolt 追加"!!!"到输出。node排列成一行:spout输出到第一个bolt,此bolt输 出到第二个bolt。
定义node的代码使用了setSpout和setBolt方法。这些方法接收用 户自定义ID输入,一个包含处理逻辑的对象和node的并行度。包含处 理 逻辑的对象实现了IRichSpout和IRichBolt接口。最后一个参数:node 的并行度,是可选的,它指定了在集群中多少个线程被创建来执行此 组件,如果忽略,storm会为每个Node分配一个线程。
Storm深入学习
Storm深入学习
storm项目实战教程 storm开发实例 7、实例讲解Grouping策略及并发度

并发度
场景分析: 单线程下:加减乘除,和任何处理类Operate,汇总 多线程下: 1、局部加减乘除 2、做处理类Operate,如split 3、持久化,如入DB 以WordCountTopology.java 为例讲解 思考题:如何计算:word总数和word个数 ?并且在高并发下完成 前者是总行数,后者是去重word个数 类似企业场景:计算网站PV和UV Storm流计算从入门到精通 课程链接: /goods-427.html
Spout读文件:学习用,其他无用 读文件:1、分布式应用无法读;2、spout开并发会重复读
Stream grouping 策略
stream grouping就是用来定义一个stream应该如果分配给Bolts上面的多个 Executors(多线程,并发度) 注:不是一个spout或bolt emit到多个bolt(广播方式)。 storm里面有6种类型的stream grouping。 单线程下均等同于All Grouping 1.Shuffle Grouping 轮询,平均分配。随机派发stream里面的tuple,保证每个bolt接收到的tuple数目相同。 2. Non Grouping: 无分组, 这种分组和Shuffle grouping是一样的效果,多线程下不 平均分配。 3. Fields Grouping:按Field分组,比如按word来分组, 具有同样word的tuple会被分 到相同的Bolts, 而不同的word则会被分配到不同的Bolts。 作用:1、过滤,从源端(Spout或上一级Bolt)多输出Fields中选择某些Field 2、相同的tuple会分发给同一个Executer或task处理 典型场景: 去重操作、Join
欢迎访问我们的官方网站
storm的用法总结大全

storm的用法总结大全- Storm是一个开源的实时大数据处理系统,用于处理实时数据流。
它可以与Hadoop 集成,提供高性能的实时数据处理能力。
- Storm可以用于实时分析和处理大规模数据流,如日志数据、传感器数据等。
它可以处理来自不同数据源的数据流,并将数据流分发到不同的处理单元进行处理。
- Storm使用一种称为拓扑(Topology)的方式来描述数据处理流程。
拓扑是由多个处理单元(称为Bolt)和连接它们的数据流(称为Spout)组成的。
- Spout可以从数据源中读取数据,并将数据流发射给Bolt进行处理。
Bolt可以对数据进行转换、过滤、聚合等操作,并将结果发射给下一个Bolt进行处理。
多个Bolt可以并行地执行不同的处理任务。
- Storm的拓扑可以灵活地配置,可以按照需要添加、删除、修改Bolt和Spout。
它支持高可靠性、高吞吐量的数据流处理,并且可以实现在不同的节点之间进行任务的负载均衡。
- Storm提供了可扩展性和容错性,可以通过水平扩展集群节点来处理更大规模的数据流,并且在节点故障时能够保证处理的连续性。
- Storm提供了丰富的API和工具,可以方便地开发和调试数据处理拓扑。
它支持多种编程语言,如Java、Python等,并提供了强大的拓扑调试和可视化工具,方便监控和管理拓扑的运行状态。
- Storm可以与其他大数据处理框架(如Hadoop、Hive、HBase等)集成,在数据处理过程中实现数据的交换和共享。
它还可以与消息中间件(如Kafka、RabbitMQ等)和实时数据库(如Redis、Cassandra等)集成,实现与其他系统的无缝连接。
- Storm有广泛的应用场景,如实时推荐系统、实时风控系统、实时数据分析、实时监控和报警等。
它在互联网、金融、电信、物联网等领域都有着广泛的应用。
w3cschool-Storm入门教程

w3cschool-Storm⼊门教程1.什么是stormStorm是Twitter开源的分布式实时⼤数据处理框架,被业界称为实时版Hadoop。
随着越来越多的场景对Hadoop的MapReduce⾼延迟⽆法容忍,⽐如⽹站统计、推荐系统、预警系统、⾦融系统(⾼频交易、股票)等等,⼤数据实时处理解决⽅案(流计算)的应⽤⽇趋⼴泛,⽬前已是分布式技术领域最新爆发点,⽽Storm更是流计算技术中的佼佼者和主流。
按照storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。
Hadoop提供了map、reduce原语,使我们的批处理程序变得简单和⾼效。
同样,Storm也为实时计算提供了⼀些简单⾼效的原语,⽽且Storm的Trident是基于Storm原语更⾼级的抽象框架,类似于基于Hadoop的Pig框架,让开发更加便利和⾼效。
2.storm应⽤场景推荐系统(实时推荐,根据下单或加⼊购物车推荐相关商品)、⾦融系统、预警系统、⽹站统计(实时销量、流量统计,如淘宝双11效果图)、交通路况实时系统等等。
3.storm的⼀些特性1.适⽤场景⼴泛: storm可以实时处理消息和更新DB,对⼀个数据量进⾏持续的查询并返回客户端(持续计算),对⼀个耗资源的查询作实时并⾏化的处理(分布式⽅法调⽤,即DRPC),storm的这些基础API可以满⾜⼤量的场景。
2. 可伸缩性⾼: Storm的可伸缩性可以让storm每秒可以处理的消息量达到很⾼。
扩展⼀个实时计算任务,你所需要做的就是加机器并且提⾼这个计算任务的并⾏度。
Storm使⽤ZooKeeper来协调集群内的各种配置使得Storm的集群可以很容易的扩展。
3. 保证⽆数据丢失:实时系统必须保证所有的数据被成功的处理。
那些会丢失数据的系统的适⽤场景⾮常窄,⽽storm保证每⼀条消息都会被处理,这⼀点和S4相⽐有巨⼤的反差。
4. 异常健壮: storm集群⾮常容易管理,轮流重启节点不影响应⽤。
Storm 波浪软件说明
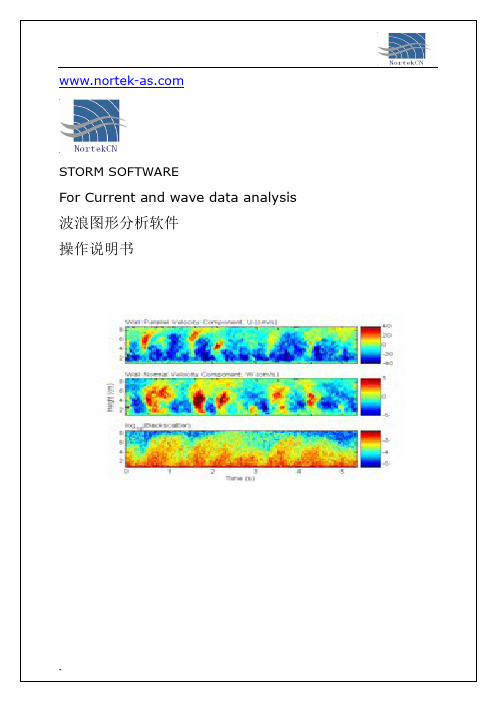
-STORM SOFTWAREFor Current and wave data analysis波浪图形分析软件操作说明书1.介绍:简介:Storm软件是专为Nortek多普勒系列测量仪器使用的,用于测量数据管理、后处理、和图形显示工具。
安装:与普通的软件安装一样,使用者从程序安装光盘中运行Setup.exe文件来开始安装步骤,按照操作说明直到安装完毕。
建议在安装软件之前关闭所有的操作。
PC系统要求:•英特尔奔腾Intel Pentium® III 500 MHz 处理器或接近。
•内存128 MB RAM以上•操作系统Windows 98, Windows NT 4.0 SP3, Windows Me, Windows 2000 or Windows XP•Super VGA Monitor running at 800x600 x 256 colors (1024x768 x High (16-bit) Color recommended)•网络浏览器4.0或以上Internet Explorer 4.0 or higher•光盘驱动器CD-ROM drive•鼠标或其他点击操作设施Mouse or other pointing device2.软件基本组成:工作区域:程序操作者只要在一个集成了数据处理、显示和输出文件功能的窗口、工具、菜单、工具框和其它操作界面就可以完成全部工作。
用户界面使用标准的Windows界面的功能,随着添加附加功能,使您的开发环境,易于使用。
这些基本特征,你最经常使用的是窗口和数据显示,工具栏,菜单和键盘快捷键。
您可以自定义用户界面,以适合您的偏好。
除了自定义设置,您可以创建一个与其他特殊项目需要相关的窗口布局。
您也可以创建自定义工具栏,菜单和快捷键。
这里是一些最常用的组件:•菜单栏(Menu bar)包含命令菜单,让您以不同的方式,视图设置选项来检查数据,自定义用户界面和访问一些通用操作,例如,控制数据处理。
storm的用法总结大全

storm的用法总结大全想了解storm的用法吗?今天就给大家带来了storm的用法,希望能够帮助到大家,下面就和大家分享,来欣赏一下吧。
\ storm的用法总结大全storm的意思n. 暴风雨,暴风雪,[军]猛攻,冲击,骚乱,动荡vi. 起风暴,下暴雨,猛冲,暴怒vt. 袭击,猛攻,暴怒,怒骂,大力迅速攻占变形:过去式: stormed; 现在分词:storming; 过去分词:stormed;storm用法storm可以用作名词storm的基本意思是“风暴,暴风雨”,指由于大气翻动,特别是伴有雨、雪、雹等现象的大气的旋转运动而形成的风暴或暴风雨,是可数名词,有复数形式。
storm引申可作“强烈如暴(风)雨般的东西,(生活中的)风波”,如情感、声音等的猛烈爆发,常与of连用。
storm的基本意思是“袭击”,指用武力攻取,包含一次攻击中所有的冲锋和激战,常常带有孤注一掷的感情色彩,竭尽全力避免失败和毁灭。
storm用作名词的用法例句In the storm I took shelter under the tree.暴风雨时,我正在树下躲避。
A storm arose during the night.夜间起风暴了。
The clouds threatened a big storm.乌云预示着暴风雨即将来临。
storm可以用作动词storm的基本意思是“袭击”,指用武力攻取,包含一次攻击中所有的冲锋和激战,常常带有孤注一掷的感情色彩,竭尽全力避免失败和毁灭。
storm既可用作及物动词,也可用作不及物动词。
用作及物动词时,可接名词或代词作宾语; 用作不及物动词时,表示“起风暴,刮大风下大雨”,这时常以it作主语。
storm还可表示“狂怒,咆哮”,其后可接about,表示“气愤地谈(某事)”; 接at表示“对…大发雷霆”; 接into表示“非常气愤地进入”; 接out表示“非常气愤地出去”。
storm用作动词的用法例句Help was lacking at sea during the storm.起风暴时海上无处可求援。
Storm知识点学习

Storm知识第一节Storm介绍........................... . (2)概念 (2)原理 (2)Storm的主要特点 (2)主要名词解释 (3)Storm配置 (4)操作模式 (5)1、本地模式 (5)2、远程模式 (5)Stream grouping分类 (6)第二节Spout知识 (6)Spout方法说明 (6)第三节Bolt知识 (8)Bolt组件介绍 (8)Bolt方法说明 (8)Bolt开发技巧 (9)1、锚定(译者注:原文为Anchoring) (9)2、多数据流 (9)3、多锚定 (9)4、使用IBasicBolt自动确认 (10)5、IBasicBolt与IRichBolt比较 (10)第四节数据分流与合并 (10)1、分流 (11)A、发送相同tuple (11)B、发送不同的tuple (11)2、数据流合并 (13)第五节ACK机制 (14)1、应用场景 (14)2、ACK机制说明 (14)3、ACK机制的使用 (14)4、ACK的原理 (15)第六节Storm开发注意事项 (15)第七节Storm的应用场景 (15)1、流聚合 (15)第八节Storm集群组件 (16)主控节点(Master Node) (16)工作节点(Work Node) (16)第九节如何向集群提交任务 (17)第十节常见问题以及解决方式 (17)第十一节其他相关知识 (17)什么是“大数据”? (17)第一节Storm介绍概念Storm是Twitter开源的一个类似于Hadoop的实时数据处理框架,是一个分布式的,可靠的,容错的数据流处理系统。
它会把工作任务委托给不同类型的组件,每个组件负责处理一项简单特定的任务。
Storm集群的输入流由一个被称作spout的组件管理,spout 把数据传递给bolt,bolt要么把数据保存到某种存储器,要么把数据传递给其它的bolt。
大数据、云计算系统高级架构师课程学习路线图

大数据、云计算系统高级架构师课程学习路线图大数据之Linux+大数据开发篇项目部分大数据之阿里云企业级认证篇大数据之Java企业级核心技术篇大数据之PB级别网站性能优化篇项目部分大数据之数据挖掘\分析&机器学习篇项目部分大数据之运维、云计算平台篇项目部分c:\iknow\docshare\data\cur_work\javascript:open53kf()课程体系北风大数据、云计算系统架构师高级课程课程一、大数据运维之Linux基础本部分是基础课程,帮大家进入大数据领域打好Linux基础,以便更好地学习Hadoop,hbase,NoSQL,Spark,Storm,docker,openstack等众多课程。
因为企业中的项目基本上都是使用Linux环境下搭建或部署的。
1)Linux系统概述2)系统安装及相关配置3)Linux网络基础4)OpenSSH实现网络安全连接5)vi文本编辑器6)用户和用户组管理7)磁盘管理8)Linux文件和目录管理9)Linux终端常用命令10)linux系统监测与维护课程二、大数据开发核心技术- Hadoop 2。
x从入门到精通本课程是整套大数据课程的基石:其一,分布式文件系统HDFS用于存储海量数据,无论是Hive、HBase或者Spark数据存储在其上面;其二是分布式资源管理框架YARN,是Hadoop 云操作系统(也称数据系统),管理集群资源和分布式数据处理框架MapReduce、Spark应用的资源调度与监控;分布式并行计算框架MapReduce目前是海量数据并行处理的一个最常用的框架。
Hadoop 2。
x的编译、环境搭建、HDFS Shell使用,YARN 集群资源管理与任务监控,MapReduce编程,分布式集群的部署管理(包括高可用性HA)必须要掌握的。
1)大数据应用发展、前景2)Hadoop 2。
x概述及生态系统3)Hadoop 2。
x环境搭建与测试1)HDFS文件系统的架构、功能、设计2)HDFS Java API使用3)YARN 架构、集群管理、应用监控4)MapReduce编程模型、Shuffle过程、编程调优1)分布式部署Hadoop2.x2)分布式协作服务框架Zookeeper3)HDFS HA架构、配置、测试4)HDFS 2.x中高级特性5)YARN HA架构、配置6)Hadoop 主要发行版本(CDH、HDP、Apache)1)以【北风网用户浏览日志】数据进行实际的分析 2)原数据采集 3)数据的预处理(ETL) 4)数据的分析处理(MapReduce)课程三、大数据开发核心技术—大数据仓库Hive精讲hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
Storm入门的Demo教程

Storm⼊门的Demo教程Storm介绍Storm是Twitter开源的分布式实时⼤数据处理框架,最早开源于github,从0.9.1版本之后,归于Apache社区,被业界称为实时版Hadoop。
随着越来越多的场景对Hadoop的MapReduce⾼延迟⽆法容忍,⽐如⽹站统计、推荐系统、预警系统、⾦融系统(⾼频交易、股票)等等,⼤数据实时处理解决⽅案(流计算)的应⽤⽇趋⼴泛,⽬前已是分布式技术领域最新爆发点,⽽Storm更是流计算技术中的佼佼者和主流。
Storm的核⼼组件Nimbus:即Storm的Master,负责资源分配和任务调度。
⼀个Storm集群只有⼀个Nimbus。
Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,⼀个Supervisor节点中包含多个Worker进程。
Worker:⼯作进程,每个⼯作进程中都有多个Task。
Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若⼲个任务(tasks)来执⾏。
每个任务都与⼀个执⾏线程相对应。
Topology:计算拓扑,Storm 的拓扑是对实时计算应⽤逻辑的封装,它的作⽤与 MapReduce 的任务(Job)很相似,区别在于MapReduce 的⼀个 Job 在得到结果之后总会结束,⽽拓扑会⼀直在集群中运⾏,直到你⼿动去终⽌它。
拓扑还可以理解成由⼀系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。
Stream:数据流(Streams)是 Storm 中最核⼼的抽象概念。
⼀个数据流指的是在分布式环境中并⾏创建、处理的⼀组元组(tuple)的⽆界序列。
数据流可以由⼀种能够表述数据流中元组的域(fields)的模式来定义。
Spout:数据源(Spout)是拓扑中数据流的来源。
⼀般 Spout 会从⼀个外部的数据源读取元组然后将他们发送到拓扑中。
大数据在线培训课之storm的学习

大数据在线培训课之storm的学习大数据在线培训课之storm的学习,时代的发展催促着我们不断地学习,不断地进步。
大数据技术以迅雷不及掩耳之势冲击着我们的生活,学习大数据正是当下我们需要做的。
今天千锋小编给大家分享的就是大数据的核心技术之storm的学习。
Why use Storm?Apache Storm是一个免费的开源的分布式实时计算系统。
Storm使得可靠的实时处理无边界的数据量变得很容易,就如同Hadoop做批处理那样。
Storm很简单,可以用任意的编程语言。
Storm有许多使用案例:实时分析、在线机器学习、持续的计算、分布式RPC、ETL等等。
Storm很快速:每个节点每秒钟可以处理一百万个元组。
它是可伸缩的、容错的,保证你的数据将会被处理,并且很容易操作。
Storm集成了队列和数据库技术。
一个Storm拓扑结构以任意复杂的方式消费并处理数据流,在计算的每一个阶段会重新分区数据流。
ConceptsTopologies一个实时应用程序的逻辑被打包成一个Storm topology。
Storm topology 和MapReduce的Job很类似。
一个最关键的不同在于,一个MapReduce的Job最终会结束,而一个topology是永远运行的(除非你手动杀死它)。
一个topology是一个由spouts和bolts以及将它们连接起来的stream grouping 构成的图。
StreamsStream是Storm中的核心抽象。
一个Stream是一个无边界的元组序列。
Stream是由元组中的命名字段被定义的。
默认情况下,元组可以包含integers, longs, shorts, bytes, strings, doubles, floats, booleans, and byte arrays。
你也可以定义自己的序列化方式。
每一个Stream在被声明的时候都会给定一个id。
Spouts在一个topology中,spouts是流的来源。
storm原理

Storm原理一、什么是StormStorm是一种开源的、分布式的实时计算系统。
它可以在大规模的集群环境下处理数据流,并提供了可靠的容错机制。
Storm具有高度可伸缩性和可编程性,使用户能够灵活地处理实时数据。
二、Storm的基本概念在深入探讨Storm的原理之前,我们需要先了解一些Storm的基本概念。
1. Topology(拓扑)在Storm中,拓扑(Topology)是指实时计算的一个任务或应用程序。
拓扑由多个组件组成,每个组件负责一部分计算任务。
拓扑中的组件可以是数据源、数据处理器、数据存储器等。
拓扑可以包含多个层次和多个任务,形成一个复杂的计算图。
2. Spout(喷口)Spout是拓扑中的数据源组件,它从外部数据源接收数据,并将数据发送给下游的Bolt组件。
Spout可以从文件、消息队列、Socket等数据源中读取数据,并实时地将数据发送给Bolt进行处理。
3. Bolt(螺栓)Bolt是拓扑中的数据处理组件,它接收Spout发送的数据,并对数据进行处理。
Bolt可以执行各种计算任务,例如过滤、聚合、计数等。
Bolt可以有多个实例,每个实例只处理一部分数据,并可以进行并行计算。
4. Tuple(元组)在Storm中,数据以Tuple的形式在组件之间传递。
Tuple是一个数据结构,可以包含多个字段。
每个Tuple都有一个唯一的ID和标识符,用于在拓扑中进行传递和追踪。
5. Stream(数据流)Stream是由一系列Tuple组成的序列。
在拓扑中,数据流用于将数据在组件之间传递。
每个数据流都有一个唯一的ID和标识符,用于在拓扑中进行传递和追踪。
三、Storm的工作原理Storm的工作原理可以分为两个阶段:拓扑发布和拓扑执行。
1. 拓扑发布拓扑发布是指将编写好的拓扑提交到Storm的集群环境中运行的过程。
在拓扑发布阶段,Storm会将拓扑的代码、配置信息等发布到集群的各个节点上,并启动拓扑的执行。
《大数据实时分析Storm》培训课程(KZL)

课程名称:大数据实时分析(Storm)课程内容:一、流式实时数据处理:1. 从MapReduce到流计算2. Storm的起源及其主要特点3. 流计算在互联网和运营商中应用案例4. 其他流式数据处理系统:JStorm、Heron、Spark Streaming、Flink、GearPump二、S torm的系统模型:1. Storm流计算的典型架构实例2. 部署模式单机/分布式部署本地模式3. Storm组件:Zookeeper、nimbus、supervisor、UI三、P AXOS协议与Zookeeper初探1. PAXOS协议简介2. Zookeeper基本原理与ZAB协议3. Zookeeper的安装与使用初步4. Zookeeper演示实验四、S torm集群部署和配置1. Storm的依赖组件2. Storm的部署环境3. 部署Storm服务4. 启动Storm5. Storm的守护进程6. 部署Storm的其他节点7. 提交T opology五、S torm中的Grouping六、J ava语言补充1. 基本结构2. 类、继承与接口七、S torm的数据源编程单元:Spout1. Spout的接口与实现Spout与接口层次结构ISpout和IComponent接口接口的实现类及实例2. Spout编程示例八、S torm的数据处理编程单元:Bolt1. Bolt的接口与实现Bolt与接口层次IBolt和IComponent接口接口的实现类及实例2. Bolt程序开发示例九、K afka Spout1. Kafka简介2. Kafka集群的搭建、配置与基本操作3. Kafka High Level API与Low Level API4. High Level API5. 利用High Level API实现Kafka Spout十、消息的可靠处理1. Storm中的At Least Once2. Spout与数据的可靠性3. Bolt与数据的可靠性4. Kafka Low Level API与Kafka Spout的At Least Once机制十一、一致性事务a) Storm一致性事务的基本思路b) Google MillWheel中的Exactly Once机制c) Transactional Topologies与Trident十二、分布式RPC十三、Storm与Redisa) Redis简介与安装b) Redis的基本操作c) Jedis接口d) 从Bolt中将计算结果输出到Redis中十四、Storm与Pythona) Storm中的non-JVM语言接口b) Python简介c) 利用Python开发Storm拓扑十五、Storm实践经验选讲十六、Storm应用开发实例:一个千亿级的Storm流计算平台。
storm课程设计

storm课程设计一、教学目标本课程的教学目标是使学生掌握Storm分布式计算框架的基本原理和应用方法,能够独立完成基于Storm的大数据处理任务。
具体分为以下三个部分:1.知识目标:学生需要了解Storm框架的架构和原理,包括Topology的创建、Bolts和Spouts的使用、acker和fler的设置等。
2.技能目标:学生能够熟练使用Storm进行大数据处理,包括实时数据处理、离线数据处理等。
3.情感态度价值观目标:通过课程的学习,培养学生对大数据处理技术的兴趣,提高学生解决实际问题的能力。
二、教学内容教学内容主要包括Storm框架的介绍、Topology的创建、Bolts和Spouts的使用、acker和fler的设置等。
具体安排如下:1.第一章:Storm框架的介绍,包括其原理和架构。
2.第二章:Topology的创建,介绍如何构建一个基本的数据处理流程。
3.第三章:Bolts和Spouts的使用,讲解如何在Topology中使用Bolts和Spouts进行数据处理。
4.第四章:acker和fler的设置,介绍如何处理Topology中的错误和失败。
5.第五章:实战案例,讲解如何使用Storm进行实时数据处理和离线数据处理。
三、教学方法为了激发学生的学习兴趣和主动性,我们将采用多种教学方法,包括讲授法、讨论法、案例分析法、实验法等。
1.讲授法:用于讲解Storm框架的基本原理和概念。
2.讨论法:用于讨论Topology的创建、Bolts和Spouts的使用等实际问题。
3.案例分析法:通过分析实际案例,使学生掌握Storm的应用方法。
4.实验法:让学生动手实践,完成实际的数据处理任务。
四、教学资源我们将提供丰富的教学资源,包括教材、参考书、多媒体资料、实验设备等,以支持教学内容和教学方法的实施,丰富学生的学习体验。
1.教材:选用《Storm实战》作为主要教材,介绍Storm框架的基本原理和应用方法。
storm 知识点

Storm 知识点Storm 是一款开源的分布式实时计算系统,它能够处理海量的实时数据,并以高效、可靠的方式进行大规模的实时数据处理。
本文将从基础概念、架构、使用场景和案例等方面逐步介绍 Storm 的知识点。
1. Storm 简介Storm 是由 Twitter 公司开发并开源的一款分布式实时计算系统,它提供了高性能的数据流处理能力。
Storm 的设计目标是处理实时数据流,并能够保证数据的低延迟和高可靠性。
2. Storm 架构Storm 的架构中包含以下几个核心组件:2.1 NimbusNimbus 是 Storm 集群的主节点,它负责协调集群中的各个组件,并进行任务的分配和调度。
Nimbus 还负责监控集群的状态,并处理故障恢复等操作。
2.2 SupervisorSupervisor 是 Storm 集群的工作节点,它负责运行实际的计算任务,并按照Nimbus 的指示进行数据的处理和传输。
每个 Supervisor 节点可以运行多个Worker 进程,每个 Worker 进程负责一个具体的计算任务。
2.3 TopologyTopology 是 Storm 中的一个概念,它表示实际的数据处理流程。
Topology 中包含了 Spout 和 Bolt 两种组件,Spout 负责数据的输入,Bolt 负责对输入数据进行处理和转换。
2.4 ZooKeeperZooKeeper 是一个分布式协调服务,Storm 使用 ZooKeeper 来管理集群中的各个组件。
ZooKeeper 负责维护集群的状态信息,并提供分布式锁等功能,用于实现Storm 的高可靠性和容错能力。
3. Storm 使用场景Storm 在实时数据处理领域有着广泛的应用场景,以下是一些常见的使用场景:3.1 实时数据分析Storm 可以对实时数据进行分析和处理,帮助企业快速了解和响应数据的变化。
例如,可以利用 Storm 进行实时的用户行为分析,及时发现用户的偏好和趋势,并根据分析结果做出相应的调整。
storm 面试题

storm 面试题Storm面试题Storm是一款开源的分布式实时计算系统,能够处理高容量的流式数据。
面试中可能会涉及到与Storm相关的问题,下面将针对这些问题进行详细讨论。
1. Storm的定义和特点Storm是由Twitter开发的分布式实时计算系统,它能够处理大容量的流数据,并能够在秒级别内生成可靠的结果。
与传统的批处理系统相比,Storm具有以下特点:- 低延迟:Storm以毫秒级的速度处理数据,是一种实时、低延迟的计算系统。
- 可扩展性:Storm可以在大规模集群中进行部署,能够处理海量数据并达到较高的吞吐量。
- 容错性:Storm具备容错机制,能够自动处理节点故障,并保证系统的可用性和数据的完整性。
- 兼容性:Storm可以与其他开源组件进行集成,如Kafka、Hadoop等,提供更强大的功能。
2. Storm的架构和组件Storm的架构分为Master节点和Worker节点,其中Master节点负责监控和协调整个系统的运行,Worker节点则负责实际的数据处理。
Storm包含以下核心组件:- Nimbus:Nimbus是Storm的Master节点,负责分配拓扑(Topology)的任务给Worker节点,并监控整个集群的运行状态。
- Supervisor:Supervisor是Worker节点的守护进程,负责运行和监控Worker进程,并与Nimbus保持心跳连接。
- Worker:Worker是Storm的工作进程,负责具体的数据处理任务,每个Worker在物理机上运行一个或多个Executor线程。
- ZooKeeper:Storm使用ZooKeeper来管理集群中各个节点的状态信息,保证系统的高可用性和一致性。
- Topology:Topology是Storm中任务的逻辑表示,由Spout和Bolt组成。
Spout负责产生数据流,Bolt负责对数据流进行处理和转换。
3. Storm的数据模型和流处理Storm采用了Tuple数据模型来表示数据流,并通过Spout和Bolt进行处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
欢迎访问我们的官方网站
可行的方案(类似WordCount的计算去重word总数): bolt1通过fieldGrouping 进行多线程局部汇总,下一级blot2进行单线程保存 session_id和count数到Map,下一级blot3进行Map遍历,可以得到: Pv、UV、访问深度(每个session_id 的浏览数) Storm流计算从入门到精通 课程链接: /goods-427.html
Storm流计算从入门到精通 —技术篇
9、案例开发——计算网站PV
讲师:Cloudy(性能问题? Bolt分拆的依据: 1、性能考虑 2、线程安全考虑
需求分析
网站最常用的两个指标: PV(page views): count (session_id) UV(user views): count(distinct session_id) 多线程下,注意线程安全问题 一、PV统计 方案分析 如下是否可行? 1、定义static long pv, Synchronized 控制累计操作 Synchronized 和 Lock在单JVM下有效,但在多JVM下无效
可行的两个方案: 1、shuffleGrouping下,pv * Executer并发数 2、bolt1进行多并发局部汇总,bolt2单线程进行全局汇总 线程安全:多线程处理的结果和单线程一致
需求分析
二、UV统计 方案分析 如下是否可行? 1、把session_id 放入Set实现自动去重,Set.size() 获得UV