Cache Coherence Protocols for Sequential Consistency
多核cache亲和性

多核cache亲和性综述概述利用亲和性这种特性可以降低进程转移带来的性能损失,提高cache命中率,同时利用该特性可以充分利用片上所有的cache来加速串行程序的执行。
但要利用该特性需要操作系统调度程序的支持,同时要求有一定的硬件的支持。
经过研究,cache亲和性对单核多处理器的性能提升不大,但对于多核多处理器能带来很大的性能提升。
该文主要介绍了亲和性的定义,亲和性对性能的影响,最后怎样利用操作系统及硬件支持来充分利用该特性。
引言芯片多处理器(CMP)的已成为当今高性能的多处理器主要形式之一。
对影响性能的关键因素之一便是高速缓存的利用率。
传统的对于高速缓存,每个核心是有自己的私有L1高速缓存,并在同一芯片上所有核心共享的较大二级缓存。
为了提高缓存利用率,我们需要考虑在缓存中的数据重用,在所有核心上共享缓存缓存访问的争夺,和私有缓存间的连贯性缺失率。
亲和性定义:亲和性指进程在给定的cpu或cpu核上运行尽量长的时间而不被转移到别的处理器的倾向性。
在Linux里,内核进程调度器天生就具有软亲和性(soft affinity)的特性,这意味着进程通常不会在处理器或者内核之间频繁迁移。
这种情况是我们希望的,因为进程迁移的频率低意味着产生的负载小,具有更好的性能表现。
在对称多处理(SMP)上,操作系统的进程调度程序必须决定每个CPU上要运行哪些进程。
这带来两项挑战:调度程序必须充分利用所有处理器,避免当一个进程已就绪等待运行,却有一个CPU核心闲置一旁,这显然会降低效率。
然而一个进程一旦被安排在某个CPU核心上运行,进程调度程序也会将它安排在相同的CPU核心上运行。
这会使性能更好,因为将一个进程从一个处理器迁移到另一个处理器是要付出性能代价的。
一般进程会在相同的核或CPU上运行,只会在负载极不均衡的情况下从一个核移往另一个核。
这样可以最小化缓存区迁移效应,同时保证系统中处理器负载均衡。
亲和性程序性能的影响多核处理器的处理器与处理器之间的cache亲和力是通过观察缓存方面积累了一定的进程的状态,即数据或指令后才进行考察的。
适用于多核环境的混合Cache一致性协议

需要在高速缓冲 中为处理器 内核 中的 C c e ah 数据 副本创建较
多的 目录项 ,占用了大量 的存储空间 ,因此在 目录较大时 , 查询时延也较大 。
个处理器 内核 的私有 Cce a ,内核时刻监听总线 是否有请 求 h 送达 ,所有处理器 内核 发出的请求 以广播方式发送到其他 处 理器 内核节点 ,共享总线保证所有处理器 内核 的数据请求串 行执行 。典型 的监听协议有 ME I J S 协议和 M SF E I 协议 。
3 小容量 目录 D C ce - ah
本文协议为克服监听协议无差别发送广播的缺 点,在系 统结构 中引入 了一个 目录 cce a ——DC ce —ah 通过 h —ah ,DC ce 互联结构 和处理器 内核的私 有 L1 ah 互联。带有 D C c e ce C — ah
监听协议的优点是结构比较简单, 但因为总线是独占性 资源,当总线上互联的处理器内核节点较多时, 协议的效率 会急剧下降 。处理器内核的一致性数据请求事务都要无差 别地在总线上广播,并且所有监听到请求的 C ce ah 控制器都 要查找 C ce ah 中是否包含了请求数据 的副本 ,即使不包含远 程请求数据副本的 C ce ah 也需要执行 查找操作 ,无谓地消耗
如是 ,进行下一步处理 。
() 有请求 数据 的 目的 内核 将数据 副本 以点对 点方 式 2含 发送给源请求 内核 ,并进行数据副本状态维护 。
() 3 目的内核向 D C ce发送确认 ,D— ah 维护 目录。 — ah Cce
状态 ;C r—u e 为数据块 副本所在 内核编号 。 oen mb r
多核处理器cache一致性

一.多核处理器cashe一致性 (2)二.基于无锁机制的事务存储 (3)1.事务的基本概念 (3)2.实现流程-design (4)3.缓存状态 (5)4.事务行为 (5)5. 回退机制 (6)三.TCC模型 (6)1.编程模型 (6)2.TCC系统 (7)四.ASTM (7)1.背景 (7)2.STM设计 (8)2.1. 急迫申请与懒惰申请 (8)2.2.元数据结构 (8)2.3. 间接引用对象 (8)3.基本ASTM设计 (9)五.参考文献 (10)一.多核处理器cache一致性由于后续章节要用到多处理器cashe一致性的协议,这里先简单阐述一下!维持多处理器cashe一致性的协议叫做cashe一致性协议。
而实现cashe一致性协议的关键就是要跟踪一个共享数据块的任何状态。
目前有两种协议,分别使用不同的技术来跟踪共享状态。
一种是基于目录的,一个物理内存中数据块的共享状态保存在一个位置,叫做目录。
另外一种就是snooping协议。
我们先来看看snooping协议的具体实现。
Snooping的做法是,每个cashe不仅保存着一份物理内存的拷贝,而且保存着数据块的共享状态的拷贝。
通过广播介质这些cashe可以被访问,所有的cashe控制器通过介质检测来决定自己是否拥有一份来自总线请求的数据块的拷贝。
目前多处理器普遍采用写无效协议来维持一致性的需求。
它的核心思想就是一个处理器在写数据之前必须确保它对该数据块的互斥访问。
如果一个读操作紧随一个写操作之后,由于写操作是互斥的,它在写之前必须对无效化所有该数据块在其它cashe上的拷贝,当读发生时,它获得一个读缺失而被迫去获取新的拷贝。
如果两个写操作试图对同一数据同时操作,那么只有一个获胜,获胜方使得其它处理器种的cashe拷贝无效化,其它操作要完成它的写操作必须先获得数据的新拷贝,也就是更新的数据的拷贝,因此写无效协议实际上实现了写的序列化。
实现写无效协议的关键是使用总线(bus),或者其它的广播介质来执行无效操作。
cache一致性问题和解决方法

cache一致性问题和解决方法作者辽宁工程技术大学摘要高速缓冲存储器一致性问题是指高速缓冲存储器中的数据必须与内存中的数据保持同步(一致) 。
多核处理器将一个以上的计算内核集成在一个处理器中,通过多个核心的并行计算技术,增强处理器计算性能。
单片多处理器结构(CMP—ChipMultiprocessor)又是该领域中备受关注的问题。
本文简要论述了CMP的多级Cache存储结构,多级结构引起了Cache一致性问题,一致性协议的选取对CMP系统的性能有重要影响。
使用何种Cache一致性模型以及它的设计方案是本文重点研究的内容。
关键词:CMP;Cache一致性;存储器;协议;替换策略Cache consistency problem and solving methodAbstract Cache consistency refers to the data in the cache memory must be synchronized with the data in memory (the same).Multi·core processor was the integration of multiple computing cores on a single processoL which improved processor computing ability through the parallelcomputing Technology of multi-coreprocessors.Single chip multi-processorarchitecture(CMP-ChipMulfiprocessor)was hot spots in this area.The CMPmulti-level Cache storage structure was briefly discussed in this paper,which led to Cache coherence problem,the selection of consistency protocol had a major impact on the performance of the CMP system.The selection of model of theCache Coherence and methods of its design will have a significant impact ofoverall design and development of CMPKey words:CMP Cache; consistency; memory; protocol; replacement strategy1引言在过去的二十年中,计算机处理器设计工艺和处理器体系结构发展迅速,计算机也能够完成所赋予它的大部分任务。
多核Cache一致性

x’
core1
x’
core2
……
x’
core3
I表示无效
4.写无效的问题 主要开销在两个方面: (1)作废各Cache副本的开销; (2)由作废引起缺失造成的开销,即处理 机需要访问已经作废的数据时将引起Cache的 缺失。
后果: 如果一个Core经常对某个块连续写,且Core 间对共享块的竞争较小,这时写无效策略维护 一致性的开销是很小的。如发生严重竞争,即 Core之间对某个地址的共享数据竞争,将产生 较多的作废,引起更多的作废缺失。结果是共 享数据在各Cache间倒来倒去,产生颠簸现象, 当缓存块比较大时,这种颠簸现象更为严重。
5. Write-Once一致性协议状态转移表
current command state P-Read P-Write 有效 有效 next state status action
P-Write
保留
必是局部进行, 有效 Read-hit 不影响有效状态 第一次写命中,用 保留 Write-hit 写通过法。同时修 改本地和主存副本 并广播Write-inv 使所有副本失效 第二次写命中,用 重写 Write-hit 写回法。但不修改 主存的副本
5. 写更新的问题 由于更新时,所有的副本均需要更新,开 销很大。
1.1 Cache Coherence问题 1.2 监听总线协议
1.2.1 写一次协议
1.3 基于目录的Cache一致性协议 1.4 三种Cache一致性策略
1.2 监听总线协议(Snoopy protocol)
通过总线监听机制实现Cache和共享存储 器之间的一致性。 适用性分析: 适用于具有广播能力的总线结构多Core系 统,允许每个Core监听其它Core的存储器访 问情况。 只适用于小规模的多Core系统。
AppH

Introduction Interprocessor Communication: The Critical Performance Issue Characteristics of Scientific Applications Synchronization: Scaling Up Performance of Scientific Applications on Shared-Memory Multiprocessors Performance Measurement of Parallel Processors with Scientific Applications Implementing Cache Coherence The Custom Cluster Approach: Blue Gene/L Concluding Remarks
H.2
Interprocessor Communication: The Critical Performance Issue
I
H-3
cessor node. By using a custom node design, Blue Gene achieves a significant reduction in the cost, physical size, and power consumption of a node. Blue Gene/L, a 64K-node version, is the world’s fastest computer in 2006, as measured by the linear algebra benchmark, Linpack.
H-2 H-3 H-6 H-12 H-21 H-33 H-34 H-41 H-44
多Cache一致性目录协议监听协议

多Cache一致性目录协议监听协议协议名称:多Cache一致性目录协议监听协议1. 引言本协议旨在定义多Cache一致性目录协议(Multi-Cache Coherence Directory Protocol)的监听协议,以确保多个Cache之间的数据一致性和协同操作。
监听协议是指在多Cache系统中,各个Cache之间通过监听其他Cache的操作来实现一致性目录的更新和维护。
2. 监听协议的目的监听协议的目的是确保多Cache系统中的一致性目录能够及时更新,并保持一致性。
通过监听其他Cache的操作,可以实现以下目标:- 检测其他Cache的读写操作,以更新一致性目录中的数据状态- 监听其他Cache的写入操作,以更新本地Cache中的数据- 同步各个Cache之间的数据,保持数据的一致性3. 监听协议的基本原则本监听协议遵循以下基本原则:- 监听是异步的,各个Cache之间通过消息传递来实现监听- 监听的优先级是有序的,按照一定的优先级顺序处理监听消息- 监听的粒度是细粒度的,即对于每个数据块都进行监听- 监听的操作是可配置的,可以根据具体需求配置监听的操作类型(读、写、失效等)4. 监听协议的实现步骤本监听协议的实现步骤如下:4.1 注册监听每个Cache在加入多Cache系统时,需要向一致性目录注册自己,并申请监听其他Cache的权限。
注册时需要提供Cache的唯一标识符和监听权限的配置信息。
4.2 监听消息的传递4.2.1 监听消息的格式监听消息的格式包括:消息类型、源Cache标识符、目标Cache标识符、数据块地址等信息。
消息类型包括读请求、写请求、失效请求等。
4.2.2 监听消息的传递方式监听消息通过消息传递机制在各个Cache之间传递。
可以使用广播、点对点等方式传递消息,具体方式根据系统需求进行配置。
4.3 监听消息的处理4.3.1 监听消息的接收与解析每个Cache需要实现监听消息的接收和解析功能,根据接收到的消息类型进行相应的处理。
CACHE COHERENCY PROTOCOL IN A DATA PROCESSING SYST
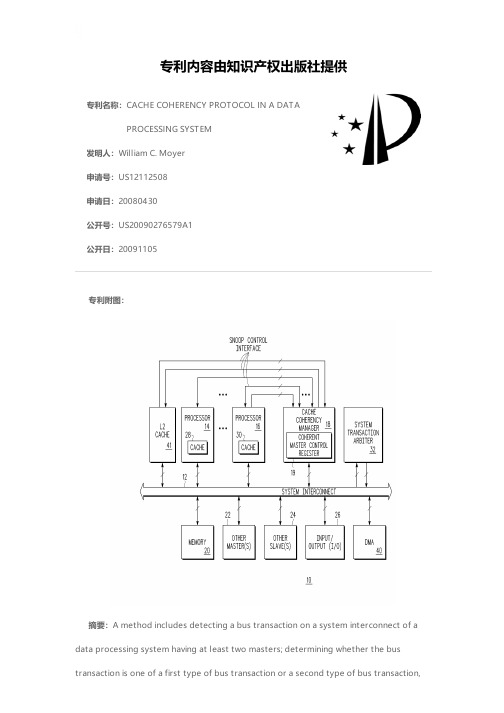
专利名称:CACHE COHERENCY PROTOCOL IN A DATAPROCESSING SYSTEM发明人:William C. Moyer申请号:US12112508申请日:20080430公开号:US20090276579A1公开日:20091105专利内容由知识产权出版社提供专利附图:摘要:A method includes detecting a bus transaction on a system interconnect of a data processing system having at least two masters; determining whether the bustransaction is one of a first type of bus transaction or a second type of bus transaction,where the determining is based upon a burst attribute of the bus transaction; performing a cache coherency operation for the bus transaction in response to the determining that the bus transaction is of the first type, where the performing the cache coherency operation includes searching at least one cache of the data processing system to determine whether the at least one cache contains data associated with a memory address the bus transaction; and not performing cache coherency operations for the bus transaction in response to the determining that the bus transaction is of the second type.申请人:William C. Moyer地址:Dripping Springs TX US国籍:US更多信息请下载全文后查看。
高速缓存一致性协议MESI与内存屏障

⾼速缓存⼀致性协议MESI与内存屏障⼀、CPU⾼速缓存简单介绍 CPU⾼速缓存机制的引⼊,主要是为了解决CPU越来越快的运⾏速度与相对较慢的主存访问速度的⽭盾。
CPU中的寄存器数量有限,在执⾏内存寻址指令时,经常需要从内存中读取指令所需的数据或是将寄存器中的数据写回内存。
⽽CPU对内存的存取相对CPU⾃⾝的速度⽽⾔过于缓慢,在内存存取的过程中CPU只能等待,机器效率太低。
为此,设计者在CPU与内存之间引⼊了⾼速缓存。
CPU中寄存器的存储容量⼩,访问速度极快;内存存储容量很⼤,但相对寄存器⽽⾔访问速度很慢。
⽽⾼速缓存的存储⼤⼩和访问速度都介于⼆者之间,作为⼀个缓冲桥梁来填补寄存器与主存间访问速度过⼤的差异。
引⼊⾼速缓存后,CPU在需要访问主存中某⼀地址空间时,⾼速缓存会拦截所有对于内存的访问,并判断所需数据是否已经存在于⾼速缓存中。
如果缓存命中,则直接将⾼速缓存中的数据交给CPU;如果缓存未命中,则进⾏常规的主存访问,获取数据交给CPU的同时也将数据存⼊⾼速缓存。
但由于⾼速缓存容量远⼩于内存,因此在⾼速缓存已满⽽⼜需要存⼊新的内存映射数据时,需要通过某种算法选出⼀个缓存单元调度出⾼速缓存,进⾏替换。
由于对内存中数据的访问具有局部性,使⽤⾼速缓存能够极⼤的提⾼CPU访问存储器的效率。
⼆、⾼速缓存⼀致性问题⾼速缓存与内存的⼀致性问题 ⾼速缓存在命中时,意味着内存和⾼速缓存中拥有了同⼀份数据的两份拷贝。
CPU在执⾏修改内存数据的指令时如果⾼速缓存命中,只会修改⾼速缓存中的数据,此时便出现了⾼速缓存与内存中数据不⼀致的问题。
这个不⼀致问题在早期单核CPU环境下似乎不是什么⼤问题,因为所有的内存操作都来⾃唯⼀的CPU。
但即使是单核环境下,为了减轻CPU在I/O时的负载、提⾼I/O效率,先进的硬件设计都引⼊了DMA机制。
DMA芯⽚在⼯作时会直接访问内存,如果⾼速缓存⾸先被CPU 修改和内存不⼀致,就会出现DMA实际写回磁盘的内容和程序所需要写⼊的内容不⼀致的问题。
浅谈并行系统中cache一致性问题和解决方法

浅谈并行系统中cache一致性问题和解决方法班级:0920 姓名:储俊学号:09419022摘要:高速缓冲存储器一致性问题是指高速缓冲存储器中的数据必须与内存中的数据保持同步(一致) 这个问题常发生在CPU内核与另一个设备异步访问内存时。
关键词:cache一致性,监听CACHE协议,基于CACHE目录的协议1.Cache一致性问题的发现本项目的目标板为:处理器采用ARM芯片S3C44B0X,存储器采用2片Flash 和1片SDRAM,在调试的时候输入采用键盘,输出采用显示器,用RS232串口实现通信。
在项目的开发过程中,经软件仿真调试成功的程序,烧入目标板后,程序却发生异常中止。
通过读存储器的内容发现,程序不能正常运行在目标板上,是因为存储器中写入的数据与程序编译生成的数据不一致,总是出现一些错误字节。
经过一段时间的调试发现,只要在程序中禁止Cache的使用,存储器中写入的数据将不再发生错误,程序可以正常运行,但速度明显减慢。
经过分析,认为问题是由于Cache数据与主存数据的不一致性造成的。
Cache数据与主存数据不一致是指:在采用Cache的系统中,同样一个数据可能既存在于Cache中,也存在于主存中,两者数据相同则具有一致性,数据不相同就叫做不一致性。
如果不能保证数据的一致性,那么,后续程序的运行就要出现问题2.分析Cache的一致性问题要解释Cache的一致性问题,首先要了解Cache的工作模式。
Cache的工作模式有两种:写直达模式(write-through)和写回模式(copyback)。
写直达模式是,每当CPU把数据写到Cache中时,Cache控制器会立即把数据写入主存对应位置。
所以,主存随时跟踪Cache的最新版本,从而也就不会有主存将新数据丢失这样的问题。
此方法的优点是简单,缺点是每次Cache内容有更新,就要对主存进行写入操作,这样会造成总线活动频繁。
S3C44B0X 中的Cache就是采用的写直达模式(write-through)。
多核处理器cache一致性技术综述

多核处理器cache一致性技术综述摘要:本文介绍了实现多核处理器cache一致性的基本实现技术,并分析了其存在的问题。
根据存在的问题,介绍了几种最新的解决方案。
关键词:cache 一致性监听协议目录协议性能能耗1 基本实现技术:实现cache一致性的关键在于跟踪所有共享数据块的状态。
目前广泛采用的有以下2种协议,它们分别使用不同的技术跟踪共享数据:1.监听协议( Snooping)处理器在私有的缓存中保存共享数据的复本。
同时处理器对总线进行监听,如果总线上的请求与自己相关,则进行处理,否则忽略总线请求信号。
2.目录式(Directory based)使用目录来存放各节点cache中共享数据的信息,把cache一致性请求只发给存放有相应数据块的节点,从而支持cache的一致性。
下面分别就监听协议和目录协议做简单的介绍:1.1 监听协议监听协议通过总线监听机制实现cache和共享内存之间的数据一致性。
因为其可以通过内存的总线来查询cache的状态。
所以监听协议是目前多核处理器主要采用的一致性技术。
监听协议有两种。
一种称为写无效协议(write invalidate protocol) ,它在处理器写数据块之前通过总线广播使其它该数据的共享复本(主要存储在其它处理器的私有缓存中)变为无效,以保证该处理器能独占访问数据块,实现一致性。
另一种称为写更新(write update) ,它在处理器写入数据块时更新该数据块所有的副本。
因为在基于总线的多核处理器中总线和内存带宽是最紧张的资源,而写无效协议不会给总线和内存带来太大的压力,所以目前处理器实现主要都是应用写无效协议。
读请求:如果处理器在私有缓存中找到数据块,则读取数据块。
如果没有找到数据块,它向总线广播读缺失请求。
其它处理器监听到读缺失请求,则检查对应地址数据块状态:无效状态下,向总线发读缺失,总线向内存请求数据块;共享状态下,直接把数据发送给请求处理器;独占状态下,远端处理器节点把数据回写,状态改为共享,并将数据块发送给请求处理器。
DS2208数字扫描器产品参考指南说明书

-05 Rev. A
6/2018
Rev. B Software Updates Added: - New Feedback email address. - Grid Matrix parameters - Febraban parameter - USB HID POS (formerly known as Microsoft UWP USB) - Product ID (PID) Type - Product ID (PID) Value - ECLevel
-06 Rev. A
10/2018 - Added Grid Matrix sample bar code. - Moved 123Scan chapter.
-07 Rev. A
11/2019
Added: - SITA and ARINC parameters. - IBM-485 Specification Version.
No part of this publication may be reproduced or used in any form, or by any electrical or mechanical means, without permission in writing from Zebra. This includes electronic or mechanical means, such as photocopying, recording, or information storage and retrieval systems. The material in this manual is subject to change without notice.
缓存一致性问题(CacheCoherency)

缓存⼀致性问题(CacheCoherency)引⾔ 现在越来越多的系统都会⽤到缓存,只要使⽤缓存就可能涉及到缓存数据与数据库数据之间双写双存储,只要双写就会遇到数据⼀致性的问题,除⾮只有⼀个数据库服务器,数据⼀致性问题也就不存在了。
缓存的作⽤ 1. 临时存储,⽤于提⾼数据查询速度。
⽐如CPU的L1⾼速缓存和L2⾼速缓存,缓存主要是为CPU和内存提供⼀个⾼速的数据缓存区域。
CPU读取数据的百顺序是:先在缓存中寻找,找到后就直接进⾏读取,如果未能找到,才从主内存中进⾏读取。
2. 降低系统反应时间,提⾼并发能⼒。
数据⼀致性的问题的原因 主要是由于两次操作时间不同步导致的数据⼀致性问题。
⽐如Mysql主从复制到时候,master数据在同步slave给数据到过程中会有数据不⼀致的时刻。
如何保证缓存与数据库双写⼀致性 ⼀. 缓存与数据库读写模式(Cache aside pattern) 分两种情况,读数据和写数据(更新) 1. 读数据:读数据时候先读取缓存,如果缓存没有(miss hit)就读取数据库,然后在从数据库中取出数据并添加到缓存中,最后在返回数据给客户端。
2. 更新数据: 先更新数据库数据在删除缓存(也有⼈认为先删除缓存在更新数据库)。
那么为什么在更新数据库同时在删除缓存呢? 这⾥主要考虑⼏个点: 1)缓存懒加载。
有些缓存出来的数据是应⽤在⽐较复杂的场景中,这些缓存存在的时候,不是简单的从数据库取出数据,⽐如更新了数据表中某个字段的值,有⼀条缓存数据值是这个字段的值与另外多个表中字段的值进⾏计算后的结果,当每次该字段被更新的时候都要与其他表多个字段去运算然后得到这个缓存数据,所以这样场景下更新缓存的代价很⾼。
所以要不要实时更新缓存视具体情况来定,⽐如这个字段⼀分钟内修改60次,那么跟该字段相关缓存也跟着要计算60次,但是该缓存⼀分钟内只被访问1次,当缓存真正被访问的时候在进⾏计算,这⼀分钟内缓存只计算了⼀次,开销就⼤幅减少。
高速缓冲存储器一致性

感谢观看
I(Invalid):这行数据无效。
在该协议的作用下,虽然各cache控制器随时都在监听系统总线,但能监听到的只有读未命中、写未命中以 及共享行写命中三种情况。读监听命中的有效行都要进入S态并发出监听命中指示,但M态行要抢先写回主存;写 监听命中的有效行都要进入I态,但收到RWITM时的M态行要抢先写回主存。总之监控逻辑并不复杂,增添的系统 总线传输开销也不大,但MESI协议却有力地保证了主存块脏拷贝在多cache中的一致性,并能及时写回,保证 cache主存存取的正确性 。
在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。
E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中。
S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中。
一个完整的一致性模型包括高速缓存一致性及存储同一性两个方面,且这两个是互补的:高速缓存一致性定 义了对同一个存储进行的读写操作行为,而存储同一性模型定义了访问所有存储的读写行为。在共享存储空间中, 多个进程对存储的不同单元做并发的读写操作,每个进程都会看到一个这些操作被完成的序。
cache笔记:MemoryCoherence和MemoryConsistency

cache笔记:MemoryCoherence和MemoryConsistencyAt this point we should formally discuss memory coherence and memory consistency, terms that speak to the ordering behavior of operations on the mem-ory system. We illustrate their defi nitions within the scope of the race condition example and then discuss them from the perspective of their use in modern multiprocessor systems design.Memory Coherence(⼀致性):The principle of memory coherence indicates that the memory system behaves rationally. (理性的,有条理的)For instance, a value written does not disappear (fail to be read at a later point) unless that value is explicitly overwritten.Write data cannot be buffered indefinitely; any write data must eventually become visible to subsequent reads unless overwritten. Finally, the system must pick an order. If it is decidedthat write X comes before write Y, then at a later point, the system may not act as if Y came before X.Memory Consistency(前后⼀致,连贯性)Whereas coherence defines rational behavior, the consistency model indicates how long and in what ways the system is allowed to behave irrationally with respect to a given set of references. A memory-consistency model indicates how the memory system inter-leaves read and write accesses, whether they are to the same memory location or not. If two refer-ences refer to the same address, their ordering is obviously important. On the other hand, if two references refer to two different addresses, there can be no data dependencies between the two, and it should, in theory, be possible to reorder them as one sees fi t. This is how modern DRAM memory controllers operate, for instance. How-ever, as the example in Figure 4.6 shows, though a data dependence may not exist between two variables, a causal dependence may nonethe-less exist, and thus it may or may not be safe to reorder the accesses. Therefore, it makes sense to defi ne allowable orderings of references to differ-ent addresses. In the race condition example, depending on ne’s consistency model, the simple code fragment。
CACHET an adaptive cache coherence protocol for distributed shared-memory systems

CACHET:An Adaptive Cache Coherence Protocol for Distributed Shared-Memory Systems Computation Structures Group Memo 414October 1998(Revised:March 1999)Xiaowei Shen,Arvind and Larry Rudolphxwshen,arvind,rudolph@To appear in Proceedings of the 13th ACM-SIGARCH International Conference on Super-computing,Rhodes,Greece,June 1999.This paper describes research done at the Laboratory for Computer Science of the Mas-sachusetts Institute of Technology.Funding for this work is provided in part by the AdvancedResearch Projects Agency of the Department of Defense under the Office of Naval Researchcontract N00014-92-J-1310and Ft Huachuca contract DABT63-95-C-0150.CACHET:An Adaptive Cache Coherence Protocol for Distributed Shared-MemorySystemsXiaowei Shen,Arvind and Larry RudolphLaboratory for Computer ScienceMassachusetts Institute of Technologyxwshen,arvind,rudolph@AbstractAn adaptive cache coherence protocol changes its ac-tions to address changing program behaviors.We present an adaptive protocol called Cachet for distributed shared-memory systems.Cachet is a seamless integration of several micro-protocols,each of which has been optimized for a par-ticular memory access pattern.Cachet embodies both intra-protocol and inter-protocol adaptivity,and exploits adap-tivity to achieve high performance under changing memory access patterns.Cachet is presented in the context of a mechanism-oriented memory model,Commit-Reconcile& Fences(CRF),which is a generalization of sequential con-sistency and other weaker memory models in use today.A protocol to implement CRF is automatically a correct im-plementation of any memory model whose programs can be expressed as CRF programs.1IntroductionShared-memory programs have various access patterns, and empirical evidence suggests that nofixed cache coher-ence protocol works well for all access patterns[1,4,5,12]. For example,an invalidation-based MESI-like protocol as-sumes no correlation between processors that access the same address before and after a write operation.Further-more,the protocol behaves as if the processor that modifies an address is likely to modify the same address again in near future.Needless to say,such a protocol is not desirable for many other common access patterns.Previous research has classified memory access patterns into a number of specific sharing patterns,e.g.,the producer-consumer pattern and the migratory pattern[1].Adaptive shared-memory systems allow multiple coherence protocols to run at the same time,or allow the coherence protocol to adapt to some identifiable access patterns[3,11].The main difference in these systems is regarding what and how ac-cess patterns are detected.Some heuristic mechanisms have been proposed to predict and trigger appropriate protocol behavior[8].The implementation of an adaptive cache coherence pro-tocol involves two issues:what adaptivity can be embod-ied in the protocol,and how and when such adaptivity can be invoked.This paper addresses thefirst issue and at-tacks the adaptivity problem from a new perspective.It proposes a cache coherence protocol,Cachet,that provides a wide scope for adapting to changing program behaviors. Cachet is especially suitable for large Distributed Shared-Memory(DSM)systems,and applicable to a wide variety of programmer-centric memory models.Cachet consists of three micro-protocols,each of which is optimized for some common access pattern.Even though each micro-protocol is a complete protocol,we refer to them as such because they constitute parts of the full adaptive pro-tocol.When something is known about the access pattern for a particular address region,the system can employ an appropriate micro-protocol for that region.Moreover,there is scope for adaptive behavior within each micro-protocol based on voluntary rules which can be triggered by some observation regarding the access pattern.Such actions can affect performance but not the correctness and liveness of the protocol.Another level of adaptivity is introduced when, based on some observed program behavior or resource sit-uation,the system automatically switches from one micro-protocol to another in a seamless and efficient manner.Cachet is not just a toy example of an adaptive protocol. It is a sophisticated protocol with some interesting prop-erties.For example,Cachet can function in the presence of limited directory resources in a DSM system,simply by switching to an appropriate micro-protocol when it runs out of directory space.Not all interesting properties of Cachet are necessarily a consequence of adaptivity.For example, Cachet allows write operations to be performed without the exclusive ownership.This not only alleviates potential cache thrashing due to false sharing,but also reduces the average latency of write operations.These advantages make Ca-Processor RulesCstate ActionCRF-Loadl Loadl(a)Cell(a,v,Clean)Cell(a,v,Dirty)retire LoadlCRF-Storel Storel(a,v)Cell(a,v,Dirty)Cell(a,-,Dirty)retire StorelCRF-Commit Commit(a)Cell(a,v,Clean)a sache retire CommitCRF-Reconcile Reconcile(a)Cell(a,v,Dirty)a sache retire ReconcileRule Name Cstate Next MstateCell(a,v)Cell(a,v,Clean)CRF-Writeback Cell(a,v,Dirty)Cell(a,v)Cell(a,v)a sacheMicro-protocol Commit on Dirty Cache Misspurge local clean copyCachet-WriterPush purge all clean copies retrieve data from memory update memorycommit an address that is cached in the Dirty state. Cachet-Migratory:When an address is exclusively ac-cessed by one processor for a reasonable time period,it makes sense to give the cache the exclusive ownership so that all instructions on the address become local operations. This is reminiscent of the exclusive state in conventional MESI-like protocols.The protocol ensures that an address can be cached in at most one cache at any time.Therefore, a Commit instruction can complete even when the address is cached in the Dirty state,and a Reconcile instruction can complete even when the address is cached in the Clean state.The exclusive ownership can migrate among different caches whenever necessary.Different micro-protocols are optimized for different ac-cess patterns.Cachet-Base is ideal when the location is randomly accessed by multiple processors,and only nec-essary commit and reconcile operations are invoked.A conventional implementation of release consistency usually requires that all addresses be indistinguishably committed before a release,and reconciled after an acquire.Such ex-cessive use of commit and reconcile operations can result in performance degradation under Cachet-Base.Cachet-WriterPush is appropriate when certain proces-sors are likely to read an address many times before another processor writes the address.A reconcile operation per-formed on a clean copy causes no purge operation,regardless of whether the reconcile is necessary.Thus,subsequent load operations to the address can continually use the cached data without causing any cache miss.Cachet-Migratoryfits well when one processor is likely to read and write an address many times before another processor accesses the address. Adaptivity:Each micro-protocol contains some voluntary rules that are not triggered by any specific instruction or protocol message.A voluntary action can be initiated at either the cache or memory side.For example,at any time, a cache engine can write a dirty copy back to the memory or purge a clean copy from the cache.It can also send a cache request to the memory for an uncached address. The memory engine can voluntarily supply some data to a cache,if the memory contains the most up-to-date data.It can also send a writeback or purge request to a cache to request the data copy of some specific address to be written back or purged.Exact details of voluntary actions may vary for different micro-protocols.The voluntary rules provide enormous scope for intra-protocol adaptivity which can be exploited to achieve better performance.Different addresses can employ different micro-protocols.It is also possible to dynamically switch the micro-protocol that is operating on an address.In general, the same micro-protocol is used for an address in multiple caches.With appropriate handling,Cachet-Base can co-exist with Cachet-WriterPush or Cachet-Migratory for the same address.This is because Cachet-Base always writes the dirty data back on a commit,and purges the clean copy on a reconcile(thus the subsequent load operation has to retrieve the data from the memory).This gives the memory an opportunity to take proper actions whenever necessary, regardless of how the address is cached in other caches at the time.The micro-protocols form an access privilege hierarchy. Cachet-Migratory has the most privilege in the sense that both commit and reconcile operations have no impact on the cache,while Cachet-Base has the least privilege in the sense that both commit and reconcile operations may require proper actions to be taken on the cache.Cachet-WriterPush has more privilege than Cachet-Base but less privilege than Cachet-Migratory.A cache can voluntarily downgrade a cache cell to a less privileged protocol,while the memory can voluntarily upgrade a cache cell to a more privileged protocol under proper circumstances.The upgrade opera-tion may need to coordinate with other caches.Heuristic messages and soft states can be used as hints to invoke desired adaptive actions.A heuristic message is a suggestion that some voluntary action or protocol switch be invoked at a remote site.Soft states can be used later as hints to invoke local voluntary actions,or choose between different micro-protocols.4Details of Micro-protocolsA coherence protocol that implements the CRF model in DSM systems must deal with at least two following is-sues.First,some operations of CRF(i.e.,the background rules)involve simultaneous state changes in both memory and cache.In DSM systems where cache and memory com-municate via message passing,only those rules whose effect is local are feasible.Second,the system may often need to move into some specific direction in order to avoid deadlock or livelock.For example,on a cache miss,the cache must convey some request information to the memory so that the memory can supply the requested data in time.These prob-lems are solved by employing proper protocol messages, and various cache and memory states.We assume FIFO message passing throughout the paper. Although the memory appears as one component,in DSM systems,different addresses can be distributed in different sites(homes).By FIFO message passing,we mean that messages between a cache site and a home in the memory are always received in the same order in which they are issued. FIFO only applies to messages with the same address.We use state transition tables to describe protocols infor-mally.Each table consists of three sets of rules,processor rules,cache engine rules and memory engine rules.Each processor rule deals with one memory instruction on a spe-cific cache state.The action usually involves completing(retiring)the instruction,or issuing certain protocol mes-sage in order to process the instruction.A Loadl instruction is retired after the data is supplied to the processor,and a Storel instruction is retired after the cache is modified. The processor rules are all mandatory,thus,if a memory instruction can be executed,it must be executed and retired infinite time.An instruction is stalled if it cannot be retired in the current cache state.This can happen,for example, when the cache has to issue a message to the memory and the instruction cannot be processed before the corresponding re-ply or acknowledgment is received.The stalled instruction remains unchanged and is retried later.Note that a stalled instruction only means the instruction itself cannot be processed at the time.It does not necessar-ily block other memory instructions on the same processor from being processed.Indeed,since instructions can be reordered,another instruction can be processed before the stalled instruction completes.Cache coherence and instruc-tion reordering are,however,completely orthogonal issues.The cache engine and memory engine rules are further classified as mandatory and voluntary rules.In general, a mandatory cache engine rule deals with a protocol mes-sage from the memory,and a mandatory memory engine rule deals with a protocol message from some cache site. If an incoming message can be processed,it must be pro-cessed and consumed sooner or later.Once a mandatory rule is applied,the triggering message must be consumed. In contrast,a voluntary rule involves no incoming protocol message,thus the cache or memory state becomes the only predicate that determines whether the rule can be invoked.Notation:The notation‘cmd,a,v’represents a message with command cmd,address a and value v(optional).The source and destination of a message can be either a cache site identifier(id)or the memory(Home).A message received at the memory side is always from site id,while a message received at a cache is always from Home.The notation‘msg Home’means sending the message to the memory,while the notation‘msg dir’means sending the message to a set of cache sites indicated by the directory dir.4.1The Cachet-Base ProtocolFigure3gives the set of rules for the Cachet-Base pro-tocol.When an instruction cannot be processed,Cachet-Base requires the cache engine to take proper action so that the stalled instruction can eventually complete.On a cache miss,the cache sends a cache-request message to the memory to request the data;the cache state becomes CachePending until the requested data is received.When a Commit instruction is performed on a dirty copy,the cache writes the data back to the memory,but requires a transient state WbPending because an acknowledgment is required from the memory.The Commit cannot be retired until the writeback acknowledgment is received.When a Reconcile instruction is performed on a clean copy,the cache purges the cell to allow the Reconcile to complete.The memory maintains no directory state for cached copies.It handles the writeback and cache-request mes-sages from caches as follows.When a writeback message is received,the memory updates the memory with the commit-ted data and sends an acknowledgement to the cache.When a cache-request message is received,the memory sends a cache-reply message with the requested data to the request-ing site.Note that an incoming message can be serviced instantly.We mention in passing that Cachet-Base can be further optimized.For example,a Storel instruction on a cache miss can be retired by creating a new cache cell with the stored value.There is no need tofirst retrieve the data from the memory and then overwrite the data.Note such an optimization is possible because the memory maintains no directory information.Voluntary rules:A cache can purge a clean cell at any time. It can write the data of a dirty cell back to the memory via a writeback message.A cache can send a cache request to the memory to request the data if the address is not cached.V oluntary rules can be used to improve the performance without destroying the correctness and liveness properties of the protocol.For example,a cache can evict a cell by purging or byfirst writing back and then purging if it decides that the data is unlikely to be accessed later.Similarly,a cache can prefetch data by issuing a cache-request message.One subtle point worth noting is that it is not safe for the memory to send data that has not been requested by a cache.4.2The Cachet-WriterPush ProtocolIn Cachet-Base,a reconcile operation on a clean cell forces the cached copy to be purged before the reconcile can complete.The motivation behind Cachet-WriterPush is to allow a reconcile operation to complete even when the address is cached in the Clean state,so that the subsequent load operation can use the data in the cache without causing a cache miss.A cache cell never needs to be purged unless the address has been updated by another processor or the cache gets full.The Cachet-WriterPush protocol ensures that a clean cell always contains the same data as the memory.To maintain this invariant,the memory location cannot be updated by a writeback operation before all clean copies have been purged from other caches.This protocol becomes attractive when Reconcile/Loadl operations are more frequent than Storel/Commit operations.Figure4gives the set of rules for Cachet-WriterPush. For each address,the memory maintains a directory state,Processor RulesCstate ActionLoadl(a)Cell(a,v,Clean)Cell(a,v,Dirty)retire LoadlCell(a,-,CachePending) Cell(a,-,Clean)retire StorelCell(a,v,Dirty)a cache CacheReq,a HomeCommit(a)Cell(a,v,Clean)Cell(a,v,Dirty)Wb,a,v Homea cacheCell(a,-,Clean)retire ReconcileCell(a,v,Dirty)a cache retire ReconcileNext CstateCell(a,-,Clean)Cell(a,v,WbPending)a cache CacheReq,a HomeMessage from Home Next CstateCell(a,-,CachePending)WbAck,a Cell(a,v,Clean)Mandatory M-engine RulesMstate ActionCacheReq,a Cell(a,v)Cell(a,-)WbAck,a idProcessor RulesCstate ActionLoadl(a)Cell(a,v,Clean)Cell(a,v,Dirty)retire LoadlCell(a,-,CachePending)Cell(a,-,Clean)retire StorelCell(a,v,Dirty)a cache CacheReq,a HomeCommit(a)Cell(a,v,Clean)Cell(a,v,Dirty)Wb,a,v Homea cacheCell(a,v,Clean)retire ReconcileCell(a,v,Dirty)a cache retire ReconcileNext CstateCell(a,-,Clean)Purged,a HomeCell(a,v,WbPending)a cache CacheReq,a HomeMessage from Home Next Cstatea cacheCell(a,v,Clean)Cell(a,v,WbPending)WbAckFlush,a a cacheCell(a,-,Clean)Purged,a HomeCell(a,v,WbPending)Cell(a,-,CachePending)Cell(a,v,WbPending)a cacheNext MstateCell(a,v,C[dir])(id dir)Cache,a,v idCell(a,v,T[dir,])Mandatory M-engine RulesMstate ActionCacheReq,a Cell(a,v,C[id dir])Cell(a,v,C[dir])(id dir)Wb,a,v1Cell(a,v,T[dir,Wb(id,v1)]) Cell(a,v,T[id dir,sm])Purged,a Cell(a,v,C[dir])Cell(a,v,T[id dir,sm])Cell(a,v,T[,sm])Cell(a,-,T[,Wb(id,v)])WbAck,a idCell(a,v,C[])Figure4.The Cachet-WriterPush Protocoltory to remember the number of acknowledgments expected from caches.It can also save space by immediately updat-ing the memory and not saving the value in the suspended message.A cache responds to a purge request on a clean cell by purging the clean data and sending a Purged message.If the cached copy is dirty,the dirty data is forced to be written back via a writeback message.In data-race-free programs, a cache cannot receive a purge request on a dirty cell unless the request is issued voluntarily from the memory.A protocol message received at a cache engine can al-ways be processed and consumed immediately.However, when the memory engine receives a cache request while the address is in the transient state,the request message cannot be processed.It is critical that a stalled message not block other protocol messages from being received and processed.A fair scheduling mechanism is needed to ensure that every stalled message is eventually processed.It is worth noting that Cachet-WriterPush can be opti-mized further.An instruction is stalled when the address is in some transient state in the cache.This constraint can be relaxed under certain circumstances.For example,a Recon-cile instruction can be retired when the address is cached in the CachePending state.The optimization is useful since a cache may voluntarily send a cache request to the memory to prefetch the data.It is desirable that such a voluntary action not block subsequent instructions from being completed. Voluntary rules:At any time,a cache can purge a clean cell,and notify the memory of the purge operation via a Purged message.It can also write the data of a dirty cell back to the memory via a writeback message.Furthermore, a cache can send a message to the memory to request a data copy for any uncached address,even though no Loadl or Storel instruction is performed by the processor.The memory can voluntarily send a data copy of any address to any cache,provided the directory shows that the address is not cached in that cache.Thus a cache may receive a data copy even though it has not requested it.Additional rules are needed to handle a data copy that is received while the address is not in the CachePending state.The memory can also voluntarily initiate a purge request to purge clean copies of any address.We show how to enhance Cachet-WriterPush with the up-date capability to demonstrate the utility of voluntary rules. This requires introducing some soft states at the memory. When the memory is notified that a cache copy has been purged,it records that site identifiter when the mem-ory is updated and all suspended writeback messages are acknowledged,it multicasts the new data to those sites in which the address was just purged.The correctness follows trivially from the fact that the memory can voluntarily send a data copy to a cache in which the directory shows that the address is not cached.4.3The Cachet-Migratory ProtocolWhen a memory location is accessed predominantly by one processor,all the operations performed by the processor should be inexpensive.Figure5gives the set of rules for the Cachet-Migratory protocol,which is suitable for this situation.It allows each address to be cached in at most one cache so that both commit and reconcile operations can complete at that site regardless of the cache state of the address.Memory accesses from another site may incur a large expense since the exclusive copy has to be migrated to that site before the accesses can be performed.The memory maintains which site currently has cached the location.When the memory receives a cache request while the address is cached in another cache,it sends aflush request to the cache to force it toflush its copy.The transient state T[id,sm]is used to record the site where the address is currently cached,and the suspended cache request(only the source needs to be recorded).The suspended request will be resumed when a Purged or Flushed message is received.Similar to Cachet-WriterPush,when the memory re-ceives a cache request while the address is in some transient state,the request message must be stalled.A stalled mes-sage should not block other incoming messages from being processed.Voluntary rules:At any time,a cache can purge a clean copy,and notify the memory of the purge operation via a Purged message.It can alsoflush a dirty copy and write the data back to the memory via a Flushed message.It is worth noting that no acknowledgment is needed from the memory for theflush operation.In addition,a cache can send a request to the memory to request an exclusive copy for an uncached address.The memory can voluntarily send an exclusive copy to a cache,if the address is currently not cached by any cache.If the memory state indicates that an address is cached in some cache,the memory can voluntarily send aflush request to the cache to force the data to beflushed from the cache.5Integration of Micro-protocolsIt is easy to see that different addresses can employ dif-ferent micro-protocols without any interference.The pro-grammer or the compiler can inform both the cache and the memory about which protocol is to be used on each address. One way to implement this idea is to tag every state and message command with the name of the protocol.We use subscripts b,w and m to represent the Cachet-Base,Cachet-WriterPush and Cachet-Migratory protocols,respectively. Thus,the Clean state will be replaced by the Clean b,Clean wProcessor RulesCstate ActionLoadl(a)Cell(a,v,Clean)Cell(a,v,Dirty)retire LoadlCell(a,-,CachePending) Cell(a,-,Clean)retire StorelCell(a,v,Dirty)a cache CacheReq,a HomeCommit(a)Cell(a,v,Clean)Cell(a,v,Dirty)retire Commita cacheCell(a,v,Clean)retire ReconcileCell(a,v,Dirty)a cache retire ReconcileNext CstateCell(a,-,Clean)Purged,a Homea cachea cache CacheReq,a HomeMessage from Home Next Cstatea cacheCell(a,v,Clean)Cell(a,-,Clean)Purged,a Homea cacheCell(a,-,CachePending)a cacheVoluntary M-engine RulesMstate ActionCell(a,v,C[id])Cell(a,v,C[id])FlushReq,a idMessage from id Next MstateCell(a,v,C[])Cache,a,v idCell(a,v,C[id])Cell(a,v,C[id1])(id1id)FlushReq,a id1Flushed,a,v Cell(a,v,C[])Cell(a,-,T[id,sm])Purged,a Cell(a,v,C[])Cell(a,v,T[id,sm])Cell(a,v,C[id])Cell(a,v,T[,])or Clean m state,and the Cache message by the Cache b, Cache w or Cache m message,etc.With slight modification,we can let the memory choose the micro-protocol for each address.A cache request can be generated without a micro-protocol tag,and the mem-ory system can respond with a Cache b,Cache w or Cache m message.The cache can then have the data cached in the Clean b,Clean w or Clean m state depending upon the type of the response received.The memory,however,cannot dy-namically switch from one micro-protocol to another on an address without some other significant modifications.The Cachet-Base micro-protocol can coexist with either Cachet-WriterPush or Cachet-Migratory on the same ad-dress,but Cachet-WriterPush and Cachet-Migratory cannot coexist with each other.Cachet-Base gives the memory an opportunity to take appropriate actions whenever necessary, because a dirty copy is always written back on a commit, and a clean copy is always purged on a reconcile so that the subsequent load operation has to retrieve the data from the memory.The lack of space does not allows us to present the complete Cachet protocol.In the rest of this section, we present a protocol that seamlessly integrates the Cachet-Base and Cachet-WriterPush micro-protocols.Figure6gives the rules for the integrated protocol,most of which are taken directly from the two micro-protocols. One critical observation is that the micro-protocols share the cache state Invalid and the memory state C[].The com-mon Invalid state indicates that a cache draws no distinction between different micro-protocols for an uncached address. The common C[]state means that the address is not cached in Cachet-WriterPush,but may be cached in Cachet-Base. Since the memory maintains no information about which caches have the address cached in Cachet-Base,it should al-ways assume that some caches contain Cachet-Base copies.Certain critical invariants are maintained to ensure the correctness of the protocol.As in Cachet-Base,the mem-ory cannot send a Cache b message to a cache unless it re-ceives a cache request from that site.Furthermore,before the memory sends a Cache b copy,it must make sure that no Cachet-WriterPush copy has been sent to the cache re-garding the same address.As in Cachet-WriterPush,the memory cannot be updated when the directory shows that Clean w copies exist in some caches.Thus,if an address is cached in the Clean w state,the cached value must be the same as the memory value.Some unexpected cases must be dealt with properly in the integrated protocol.For example,the memory can re-ceive a Wb b message while the directory shows that the ad-dress is cached in Cachet-WriterPush in some caches.The Wb b message must be suspended until all Clean w copies are purged.Similarly,a cache can receive a Cache w message while a Cachet-Base copy is cached.If the cache state is Clean b,it can be upgraded to Clean w with the cache updated.If the cache state is Dirty b,the cache sends a Purged mes-sage to the memory to inform the memory that the Cache w copy is not accepted.If a cache has an address cached in the Clean w state,it can send a Purged message to the memory,and downgrade the Clean w state to Clean b.This can happen either voluntarily when the cache intends to downgrade a cell from Cachet-WriterPush to Cachet-Base,or mandatorily when it receives a purge request from the memory.The actual purge of the data can be delayed until the next reconcile point.This lazy-purge technique can be useful in reducing potential cache thrashing due to false sharing.Note that when the memory receives a cache request while the address is in some transient state with suspended writeback messages,the memory can service the cache re-quest by supplying a Cachet-Base copy to the requesting site.Thus,unlike Cachet-WriterPush,no message needs to be buffered(or retried)at the memory side.It is also worth noting that the WbAckFlush w message has been merged with the WbAck b message for they carry the same informa-tion.As an example of how the adaptivity can be exploited, consider a DSM system with limited directory space.When the memory receives a cache request,it can respond under either Cachet-Base or Cachet-WriterPush.One reasonable strategy is to always supply a Cachet-WriterPush copy ex-cept when the directory is full,in which case it supplies a Cachet-Base copy.Moreover,the memory can send a purge request to a cache to downgrade a cache cell from Cachet-WriterPush to Cachet-Base so that the resumed directory space can be used for other Cachet-WriterPush copies.This simple adaptivity will allow an address to be resident in more caches than the number of cache identifier slots in the directory.6ConclusionCachet is one cache coherence protocol,although for pedagogic reasons it has been presented as an integration of several micro-protocols.It is also possible to treat Cachet as a family of protocols because of the presence of voluntary rules that can be invoked without an instruction or protocol message.Cachet’s voluntary rules provide enormous ex-tensibility in the sense that various heuristic messages and soft states can be employed to invoke these rules.One can consider each heuristic and associated soft state as giving rise to a new protocol.One way to think of Cachet is that its rules define a toolkit of coherence primitives that can be used to build coherence protocols on-the-fly.When an instruction or protocol mes-sage is received,the protocol engine can execute any of the legal coherence actions,without the fear of destroying the correctness and liveness.This is completely different from。
CacheCoherence文献综述

Cache Coherence文献综述文献阅读背景如何选择高速缓存一致性的解决方案一直以来都是设计共享存储器体系结构的关键问题。
相对于维护高速缓存一致性而言,数据的传输也显得简单了。
高速缓存一致性协议致力于保证每个处理器的数据一致性。
一致性通常是在高速缓存总线或者网线上得到保证。
高速缓存的缺失可以从内存中得到数据,除非有些系统(处理器或者输入输出控制器)设备修改了高速缓存总线。
为了进行写操作,该处理器必须进行状态的转换,通常是转换为独占的状态,而总线上其他的系统设备都必须将他们的数据无效化,目前该数据块的拥有者就成为了数据来源。
因此,当其他设备提出需要此数据块时,该数据块的拥有者,而不是内存,就必须提供数据。
只有当该数据块的拥有者必须腾出空间用以存放其他的数据时,才将最新的数据重新写回内存中。
当然,在这方面,各种协议也有区别,上文所诉只是最基本的一些解决方案1。
并且,协议也包括基于硬件的以及基于软件的协议两个种类。
也有写无效和写更新的区别。
下面概述性地介绍下体系结构中所采用的两种主要的一致性方案:监听式(也称广播式)协议:所有的地址都送往所有的系统设备中。
每个设备在本地缓存中检查(监听)高速缓存总线的状态,系统在几个时钟周期后决定了全局的监听结果。
广播式协议提供了最低的可能延迟,尤其当缓存之间的传输是基本的传输方式。
监听式协议传输数据的带宽也是有一定限制的,通常被限制在:带宽=缓存总线带宽×总线时钟周期/每次监听的时钟周期数。
这将在下文中详细提到。
目录式(也称点对点式)协议:每个地址都被送往系统设备中对缓存数据感兴趣的那些设备。
物理存储器的共享状态放在一个地点,称之为目录。
目录式一致性的开销更大,尤其在延时等方面,因为协议本身的复杂性。
但是整体的带宽可以比监听式协议高很多,往往应用于比较大型的系统,最主要的应用是分布式系统。
这将在下文详细提到。
缓存一致性涉及的体系结构主要有如下几种:第一种类型是集中式存储体系结构,也称作为对称(共享存储器)多处理器系统(SMPs),这种体系结构也称为均匀存储器访问(UMA),这是因为所有的处理器访问存储器都有相同的时延。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
6.823 L18- 16 Arvind
⇒ either all children can have Sh copies
or one child can have an Ex copy
• Once a parent gives an Ex copy to a child, the parent’s data is considered stale • A processor cannot overwrite data in Sh state in L1 • By definition all addresses in the home are in the Ex state
• Only a parent and its children can communicate directly • Inclusion property is maintained between a parent and its children, i.e.,
⇒ a ∈ Li+1
a ∈ Li
November 14, 2005
6.823 L18- 10 Arvind
Data Propagation Between Caches
Child c Child c
Parent
m
Parent
m
Caching rules • Read caching rule • Write caching rule
L2
Interconnect
M
aka Home
Assumptions: Caches are organized in a hierarchical manner • Each cache has exactly one parent but can have
zero or more children
msetData(a, c.data(a));
c.setState(a, Sh);
• Invalidate rule R(dir) == m.state(a) & idc ∈ dir & Sh == c.state(a) → m.setState(a, R(dir - idc))
c.invalidate(a);
November 14, 2005
6.823 L18- 6 Arvind
Cache State Implications
Sh ⇒ cache’s siblings and decedents can only have Sh copies Ex ⇒ each ancestor of the cache must be in Ex
<guard predicate> → {set of state updates that must occur atomically with respect to other rules}
• E.g.:
m.state(a) == R(dir) & idc ∉ dir → m.setState(a, R(dir+ idc)), c.setState(a, Sh); c.setData(a, m.data(a));
– ultimately all actions are triggered by some processor
November 14, 2005
6.823 L18- 14 Arvind
Protocol Design
*Note*
We will not be able to finish this part today.
• sibling info: do my siblings have a copy of address a - Ex (means no), Sh (means may be) • children info: has this address been passed on to any of my children - W(id) means child id has a writable version - R(dir) means only children named in the directory dir have copies
(The rest of the material will be covered during the next lecture.)
November 14, 2005
6.823 L18- 15 Arvind
Protocol Processors
P
p2m m2p c2m m2c in
an abstract view
November 14, 2005
6.823 L18- 4 Arvind
Maintaining Cache Coherence
Hardware support is required such that
• only one processor at a time has write permission for a location • no processor can load a stale copy of the location after a write
November 14, 2005
6.823 L18- 5 Arvind
State Encoding
P (Sh, ∈) a P a
(Sh, ∈) 2
5 3
P L1 L2
6
7 4
P L1
8
P L1
9
P L1
a
(Sh, R(6))
Interconnect
1
a
(Ex, R(2,4))
Each address in a cache keeps two types of state info
1
Cache Coherence Protocols
for
Sequential Consistency
Arvind
Computer Science and Artificial Intelligence Lab
M.I.T.
Based on the material prepared by
November 14, 2005
6.823 L18- 13 Arvind
Making the Rules Local & Reactive
Child c idc
Parent
m
idp
• Some rules require observing and changing the state of multiple caches simultaneously (atomically).
write request:
⇒
The address is invalidated in all other caches before the write is performed
read request:
If a dirty copy is found in some cache, a write-back is performed before the memory is read
November 14, 2005
6.823 L18- 7 Arvind
Cache State Transitions
Inv invalidate load Sh store optimizations Ex flush
store write-back
This state diagram is helpful as long as one remembers that each transition involves cooperation of other caches and the main memory.
P
L1
PP
interconnect
out
m2p c2m m2c
p2m
PP
L1
PP
m
• Each cache has 2 pairs of queues
– one pair (c2m, m2c) to communicate with the memory – one pair (p2m, m2p) to communicate with the processor
• Messages format: msg(idsrc,iddest,cmd,priority,a,v) • FIFO messages passing between each (src,dest) pair except a Low priority (L) msg cannot block a high priority (H) msg
November 14, 2005
6.823 L18- 8 Arvind
High-level Invariants in Protocol Design
November 14, 2005
6.823 L18- 9 Arvind
Guarded Atomic Actions
• Rules specified using guarded atomic actions:
Arvind and Krste Asanovic
November 14, 2005
6.823 L18- 2 Arvind
Systems view
snooper
(WbReq, InvReq, InvRep)
load/store buffers CPU
Cache
(I/Sh/Ex)
pushout (WbRep) (ShRep, ExRep) (ShReq, ExReq)