java培训-Hibernate的缓存解读
JAVAWEB面试题(含答案)

1、jsp和servlet的区别、共同点、各自应用的范围??JSP是Servlet技术的扩展,本质上就是Servlet的简易方式。
JSP编译后是“类servlet”。
Servlet和JSP最主要的不同点在于,Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML里分离开来。
而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。
JSP侧重于视图,Servlet主要用于控制逻辑。
在struts框架中,JSP位于MVC设计模式的视图层,而Servlet位于控制层.2、cookie和session的作用、区别、应用范围,session的工作原理Cookie:主要用在保存客户端,其值在客户端与服务端之间传送,不安全,存储的数据量有限。
Session:保存在服务端,每一个session在服务端有一个sessionID作一个标识。
存储的数据量大,安全性高。
占用服务端的内存资源。
3、jstl是什么?优点有哪些??JSTL(JSP Standard Tag Library,JSP标准标签库)是一个不断完善的开放源代码的JSP标签库,由四个定制标记库(core、format、xml和sql)和一对通用标记库验证器(ScriptFreeTLV和PermittedTaglibsTLV)组成。
优点有:最大程序地提高了WEB应用在各应用服务器在应用程序服务器之间提供了一致的接口,最大程序地提高了1、在应用程序服务器之间提供了一致的接口,之间的移植。
2、简化了JSP和WEB应用程序的开发。
3、以一种统一的方式减少了JSP中的scriptlet代码数量,可以达到没有任何scriptlet 代码的程序。
在我们公司的项目中是不允许有任何的scriptlet代码出现在JSP中。
4、允许JSP设计工具与WEB应用程序开发的进一步集成。
相信不久就会有支持JSTL的IDE 开发工具出现。
4、j2ee的优越性主要表现在哪些方面?MVC模式a、J2EE基于JAVA技术,与平台无关b、J2EE拥有开放标准,许多大型公司实现了对该规范支持的应用服务器。
hibernate框架的工作原理

hibernate框架的工作原理Hibernate框架的工作原理Hibernate是一个开源的ORM(Object-Relational Mapping)框架,它将Java对象映射到关系型数据库中。
它提供了一种简单的方式来处理数据持久化,同时也提供了一些高级特性来优化性能和可维护性。
1. Hibernate框架的基本概念在开始讲解Hibernate框架的工作原理之前,需要先了解一些基本概念:Session:Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
SessionFactory:SessionFactory是一个线程安全的对象,它用于创建Session对象。
通常情况下,应用程序只需要创建一个SessionFactory对象。
Transaction:Transaction是对数据库操作进行事务管理的接口。
在Hibernate中,所有对数据库的操作都应该在事务中进行。
Mapping文件:Mapping文件用于描述Java类与数据库表之间的映射关系。
它定义了Java类属性与数据库表字段之间的对应关系。
2. Hibernate框架的工作流程Hibernate框架主要分为两个部分:持久化层和业务逻辑层。
其中,持久化层负责将Java对象映射到数据库中,并提供数据访问接口;业务逻辑层则负责处理业务逻辑,并调用持久化层进行数据访问。
Hibernate框架的工作流程如下:2.1 创建SessionFactory对象在应用程序启动时,需要创建一个SessionFactory对象。
SessionFactory是一个线程安全的对象,通常情况下只需要创建一个即可。
2.2 创建Session对象在业务逻辑层需要进行数据访问时,需要先创建一个Session对象。
Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
2.3 执行数据库操作在获取了Session对象之后,就可以执行各种数据库操作了。
Java中的缓存技术

Java中的缓存技术缓存技术在软件开发中起着至关重要的作用。
它可以提高系统性能、降低对底层资源的访问频率,从而减轻服务器负载并改善用户体验。
在Java开发中,有许多可供选择的缓存技术。
本文将介绍几种常见的Java缓存技术,以及它们的应用场景和原理。
一、内存缓存内存缓存是最常见的缓存技术之一,它将数据保存在内存中,以提高读取速度。
在Java中,可以使用集合框架中的Map接口的实现类来实现内存缓存,如HashMap、ConcurrentHashMap等。
这些类提供了快速的Key-Value存储,通过Key快速查找对应的Value,以实现快速访问缓存数据。
内存缓存适用于数据读取频繁但不经常更新的场景,例如字典数据、配置信息等。
需要注意的是,内存缓存的容量是有限的,当缓存数据超过容量限制时,需要采取一些策略来处理,如LRU(最近最少使用)算法将最久未访问的数据移出缓存。
二、分布式缓存分布式缓存是一种将数据存储在多台服务器节点上的缓存技术。
Java中有多种分布式缓存框架可供选择,如Redis、Memcached等。
这些框架提供了高性能、可扩展的分布式缓存服务,可以在集群中存储大量的数据,并提供分布式缓存的管理和查询接口。
分布式缓存适用于需要同时服务大量客户端并具有高并发读写需求的场景,例如电商网站的商品信息、社交网络的用户数据等。
通过将数据存储在多台服务器上,可以提高系统的可用性和扩展性。
三、页面缓存页面缓存是将网页内容保存在缓存中,以减少对数据库或后端服务的访问频率,从而提高页面的加载速度。
在Java中,可以通过使用Web服务器或反向代理服务器的缓存功能,例如Nginx、Varnish等,来实现页面缓存。
页面缓存适用于内容相对静态或者不经常变化的场景,例如新闻网站的文章、博客网站的页面等。
通过将网页内容保存在缓存中,可以避免每次请求都重新生成页面,大大提高响应速度和系统的并发能力。
四、数据库缓存数据库缓存是将数据库查询结果保存在缓存中,以减少对数据库的频繁查询,提高系统的响应速度和并发能力。
三大框架

Hibernate1.Hibernate 的初始化.读取Hibernate 的配置信息-〉创建Session Factory1)创建Configeration类的实例。
它的构造方法:将配置信息(Hibernate config.xml)读入到内存。
一个Configeration 实例代表Hibernate 所有Java类到Sql数据库映射的集合。
2)创建SessionFactory实例把Configeration 对象中的所有配置信息拷贝到SessionFactory的缓存中。
SessionFactory的实例代表一个数据库存储员源,创建后不再与Configeration 对象关联。
缓存(cache):指Java对象的属性(通常是一些集合类型的属性--占用内存空间。
SessionFactory的缓存中:Hibernate 配置信息。
OR映射元数据。
缓存-大:重量级对象小:轻量级对象3)调用SessionFactory创建Session的方法1】用户自行提供JDBC连接。
Connection con=dataSource.getConnection(); Session s=sessionFactory.openSession(con);2】让SessionFactory提供连接Session s=sessionFactory.openSession();4)通过Session 接口提供的各种方法来操纵数据库访问。
Hibernate 的缓存体系一级缓存:Session 有一个内置的缓存,其中存放了被当前工作单元加载的对象。
每个Session 都有自己独立的缓存,且只能被当前工作单元访问。
二级缓存:SessionFactory的外置的可插拔的缓存插件。
其中的数据可被多个Session共享访问。
SessionFactory的内置缓存:存放了映射元数据,预定义的Sql语句。
Hibernate 中Java对象的状态1.临时状态(transient)特征:1】不处于Session 缓存中2】数据库中没有对象记录Java如何进入临时状态1】通过new语句刚创建一个对象时2】当调用Session 的delete()方法,从Session 缓存中删除一个对象时。
java二级缓存原理

java二级缓存原理Java二级缓存原理随着互联网的发展和应用程序的复杂化,对于数据的访问和处理速度要求也越来越高。
在Java中,缓存技术被广泛应用于提高系统的性能和响应速度。
其中,二级缓存是一种常用的缓存技术,可以有效地减少对数据库等资源的访问次数,提高系统的性能。
一、什么是二级缓存二级缓存是指在应用程序和数据库之间添加一层缓存,用于存储频繁访问的数据。
通常情况下,二级缓存会将数据存储在内存中,以提高数据的访问速度。
相比一级缓存(即应用内存中的缓存),二级缓存具有更大的容量和更高的性能。
二、为什么需要二级缓存在大多数应用程序中,对于频繁访问的数据,每次都直接从数据库中读取会导致较高的数据库负载和较慢的响应速度。
而通过使用二级缓存,可以将这些数据缓存在内存中,减少对数据库的访问次数,从而提高系统的性能和响应速度。
三、二级缓存的实现原理1. 缓存的数据结构二级缓存通常使用哈希表或者红黑树等数据结构来存储缓存数据。
这些数据结构具有快速的查找和插入操作,可以提高数据的访问效率。
2. 缓存的更新策略为了保证缓存数据的及时性和准确性,二级缓存需要实现一定的更新策略。
常见的更新策略有以下几种:- 缓存失效策略:当缓存中的数据过期或者被修改时,将其标记为失效状态,并在下次访问时更新缓存数据。
- 定时刷新策略:定期清理缓存中的失效数据,并从数据库中重新加载最新的数据。
- 主动更新策略:当数据库中的数据发生变化时,通过数据库触发器或者消息队列等机制,自动更新缓存中的数据。
3. 缓存的淘汰策略当缓存中的数据量超过一定的限制时,为了避免内存溢出,需要实现一定的淘汰策略。
常见的淘汰策略有以下几种:- 先进先出(FIFO)策略:将最早进入缓存的数据淘汰出去。
- 最少使用(LFU)策略:将最少被访问的数据淘汰出去。
- 最近最少使用(LRU)策略:将最近最少被访问的数据淘汰出去。
4. 缓存的一致性由于缓存数据是存储在内存中的,可能会出现缓存与数据库数据不一致的情况。
hibernate缓存机制详细分析(一级、二级、查询缓存,非常清晰明白)

hibernate缓存机制详细分析(⼀级、⼆级、查询缓存,⾮常清晰明⽩)您可以通过点击右下⾓的按钮来对⽂章内容作出评价, 也可以通过左下⽅的关注按钮来关注我的博客的最新动态。
如果⽂章内容对您有帮助, 不要忘记点击右下⾓的推荐按钮来⽀持⼀下哦如果您对⽂章内容有任何疑问, 可以通过评论或发邮件的⽅式联系我:****************/**********************如果需要转载,请注明出处,谢谢!!在本篇随笔⾥将会分析⼀下hibernate的缓存机制,包括⼀级缓存(session级别)、⼆级缓存(sessionFactory级别)以及查询缓存,当然还要讨论下我们的N+1的问题。
随笔虽长,但我相信看完的朋友绝对能对hibernate的 N+1问题以及缓存有更深的了解。
⼀、N+1问题⾸先我们来探讨⼀下N+1的问题,我们先通过⼀个例⼦来看⼀下,什么是N+1问题:list()获得对象: /** * 此时会发出⼀条sql,将30个学⽣全部查询出来*/ List<Student> ls = (List<Student>)session.createQuery("from Student").setFirstResult(0).setMaxResults(30).list();Iterator<Student> stus = ls.iterator();for(;stus.hasNext();){Student stu = (Student)stus.next();System.out.println(stu.getName());}如果通过list()⽅法来获得对象,毫⽆疑问,hibernate会发出⼀条sql语句,将所有的对象查询出来,这点相信⼤家都能理解Hibernate: select student0_.id as id2_, student0_.name as name2_, student0_.rid as rid2_, student0_.sex as sex2_ from t_student student0_ limit ?那么,我们再来看看iterator()这种情况iterator()获得对象 /** * 如果使⽤iterator⽅法返回列表,对于hibernate⽽⾔,它仅仅只是发出取id列表的sql* 在查询相应的具体的某个学⽣信息时,会发出相应的SQL去取学⽣信息* 这就是典型的N+1问题* 存在iterator的原因是,有可能会在⼀个session中查询两次数据,如果使⽤list每⼀次都会把所有的对象查询上来* ⽽是要iterator仅仅只会查询id,此时所有的对象已经存储在⼀级缓存(session的缓存)中,可以直接获取*/ Iterator<Student> stus = (Iterator<Student>)session.createQuery("from Student").setFirstResult(0).setMaxResults(30).iterate();for(;stus.hasNext();){Student stu = (Student)stus.next();System.out.println(stu.getName());}在执⾏完上述的测试⽤例后,我们来看看控制台的输出,看会发出多少条 sql 语句:Hibernate: select student0_.id as col_0_0_ from t_student student0_ limit ?Hibernate: select student0_.id as id2_0_, student0_.name as name2_0_, student0_.rid as rid2_0_, student0_.sex as sex2_0_ from t_student student0_ where student0_.id=?沈凡Hibernate: select student0_.id as id2_0_, student0_.name as name2_0_, student0_.rid as rid2_0_, student0_.sex as sex2_0_ from t_student student0_ where student0_.id=?王志名Hibernate: select student0_.id as id2_0_, student0_.name as name2_0_, student0_.rid as rid2_0_, student0_.sex as sex2_0_ from t_student student0_ where student0_.id=?叶敦.........我们看到,当如果通过iterator()⽅法来获得我们对象的时候,hibernate⾸先会发出1条sql去查询出所有对象的 id 值,当我们如果需要查询到某个对象的具体信息的时候,hibernate此时会根据查询出来的 id 值再发sql语那么这种 N+1 问题我们如何解决呢,其实我们只需要使⽤ list() ⽅法来获得对象即可。
Java缓存机制

在软件开发中,缓存是一种常用的优化技术,用于存储频繁访问的数据,使得下一次访问时可以更快地获取数据。
而在Java中,也存在着各种不同的缓存机制,用于提升程序的性能与效率。
一、内存缓存内存缓存是最常见的缓存机制之一。
在Java中,可以使用各种数据结构来实现内存缓存,比如Hashtable、HashMap、ConcurrentHashMap等。
使用内存缓存的好处是可以将数据存储在内存中,而不是频繁地访问数据库或者其他外部存储介质,从而提升访问速度。
同时,内存缓存还可以减轻数据库的负载,提高系统的并发能力。
二、CPU缓存CPU缓存是指CPU内部的高速缓存,用于暂时存储处理器频繁访问的数据。
在Java中,可以通过使用局部变量和静态变量来利用CPU缓存。
局部变量存储在方法栈帧中,相对于对象的实例变量来说,访问局部变量的速度更快。
因此,在开发过程中,应该尽量使用局部变量来存储频繁访问的数据。
静态变量是存储在方法区中的,与对象的实例无关。
由于静态变量只有一个副本,所以可以减少对CPU缓存的竞争,提高程序的性能。
三、磁盘缓存磁盘缓存是将数据存储在磁盘中,并使用相应的缓存算法来提高数据的读写速度。
在Java中,可以通过使用文件缓存或者数据库缓存来实现磁盘缓存。
文件缓存是将数据存储在本地文件系统中,比如将一些配置文件加载到内存中进行处理。
数据库缓存是将数据存储在数据库中,并使用缓存算法来提高数据的访问速度。
一般情况下,数据库缓存会使用LRU(最近最少使用)算法来决定何时移除某个数据。
四、网络缓存网络缓存是将数据存储在网络中,通过网络进行传输。
在Java中,可以通过使用HTTP缓存或者CDN来实现网络缓存。
HTTP缓存是浏览器和服务器之间的缓存,用于存储HTTP请求和响应的数据。
通过合理设定HTTP头信息,可以实现数据的缓存,减少带宽的消耗。
CDN(内容分发网络)是一种将数据分布到全球多台服务器的网络架构,用于存储静态文件,提供更快的数据访问速度。
jpa二级缓存设置专业资料

共 12 页
第 2 页
sheagle@
ehcache 缓存设置
缓存的软件实现 在 Hibernate 的 Session 的实现中包含了缓存的实现 由第三方提供, Hibernate 仅提供了缓存适配器(CacheProvider)。 用于把特定的缓存插件集成到 Hibernate 中。 启用缓存的方式 只要应用程序通过 Session 接口来执行保存、更新、删除、加载和查 询数据库数据的操作,Hibernate 就会启用第一级缓存,把数据库中的数据以对象的形式拷 贝到缓存中,对于批量更新和批量删除操作,如果不希望启用第一级缓存,可以绕过 Hibernate API,直接通过 JDBC API 来执行指操作。 用户可以在单个类或类的单个集合的 粒度上配置第二级缓存。 如果类的实例被经常读但很少被修改, 就可以考虑使用第二级缓存。 只有为某个类或集合配置了第二级 缓存,Hibernate 在运行时才会把它的实例加入到第二 级缓存中。 用户管理缓存的方式 第一级缓存的物理介质为内存,由于内存容量有限,必须通过恰 当的检索策略和检索方式来限制加载对象的数目。 Session 的 evit()方法可以显式清空缓存 中特定对象,但这种方法不值得推荐。 第二级缓存的物理介质可以是内存和硬盘,因此第 二级缓存可以存放大量的数据, 数据过期策略的 maxElementsInMemory 属性值可以控制内存 中 的对象数目。管理第二级缓存主要包括两个方面:选择需要使用第二级缓存的持久类, 设置合适的并发访问策略:选择缓存适配器,设置合适的数据过期策略。
2.3.5 配置二级缓存的主要步骤: 1) 选择需要使用二级缓存的持久化类,设置它的命名缓存的并发访问策略。这是最值 得认真考虑的步骤。 2) 选择合适的缓存插件,然后编辑该插件的配置文件。
Java应用中的数据缓存与持久化

Java应用中的数据缓存与持久化在Java应用开发中,数据的缓存和持久化是两个重要的概念。
数据缓存指的是将数据存储在内存中,以提高数据读写的效率;而数据持久化则是将数据永久地存储在磁盘等非易失性介质上,以保证数据的长久保存。
本文将针对Java应用中的数据缓存与持久化的相关技术进行探讨。
一、数据缓存数据缓存在Java应用中起到了承上启下的重要作用。
它可以将频繁访问的数据存储在内存中,减少了对数据库等外部存储的访问次数,提高了系统的响应速度。
1.1 内存缓存内存缓存是最常见的数据缓存方式之一。
在Java应用中,我们可以使用诸如HashMap、ConcurrentHashMap等数据结构来实现内存缓存。
这些数据结构可以将数据存储在内存中,并且提供了高效的读写操作。
在使用内存缓存时,需要注意内存的使用情况。
如果缓存的数据量过大,有可能导致内存溢出的问题。
因此,需要根据实际业务需求和系统资源来选择合适的内存缓存方案。
1.2 分布式缓存在分布式系统中,数据缓存往往需要考虑多台服务器之间的数据同步和一致性。
这时,我们可以使用分布式缓存来解决这个问题。
分布式缓存基于一致性哈希算法等技术,将数据分布到多个节点上,并且提供了数据同步和故障恢复的机制。
常用的分布式缓存框架有Redis、Memcached等。
它们提供了丰富的功能,如数据的存储、读写操作、数据过期策略等。
通过使用分布式缓存,可以有效利用多台服务器的资源,提高系统的性能和可扩展性。
二、数据持久化尽管数据缓存可以提高系统的性能,但在某些场景下,仅依靠内存缓存还是不够的。
数据持久化在Java应用中的作用就显得尤为重要。
它可以将数据永久地存储在硬盘等非易失性介质上,以保证数据的长久保存。
2.1 关系型数据库关系型数据库是一种常用的数据持久化方式。
Java应用可以通过JDBC技术与关系型数据库进行交互,实现数据的读写操作。
常见的关系型数据库有MySQL、Oracle、SQL Server等。
Hibernate

a. Session.evict
将某个特定对象从内部缓存中清楚
b. Session.clear
清空内部缓存
当批量插入数据时,会引发内存溢出,这就是由于内部缓存造成的。例如:
For(int i=0; i<1000000; i++){
For(int j=0; j<1000000; j++){
session.iterate(…)方法和session.find(…)方法的区别:session.find(…)方法并不读取ClassCache,它通过查询语句直接查询出结果数据,并将结果数据put进classCache;session.iterate(…)方法返回id序列,根据id读取ClassCache,如果没有命中在去DB中查询出对应数据。
User user = new User();
user.setUserName(“gaosong”);
user.setPassword(“123”);
session.save(user);
}
}
在每次循环时,都会有一个新的对象被纳入内部缓存中,所以大批量的插入数据会导致内存溢出。解决办法有两种:a 定量清除内部缓存 b 使用JDBC进行批量导入,绕过缓存机制。
user.setLoginName("jonny");
mit();
session2 .close();
这种方式,关联前后是否做修改很重要,关联前做的修改不会被更新到数据库,
比如关联前你修改了password,关联后修改了loginname,事务提交时执行的update语句只会把loginname更新到数据库
hibernate高级用法

hibernate高级用法Hibernate是一种Java持久化框架,用于将对象转换为数据库中的数据。
除了基本的用法,Hibernate还提供了一些高级的用法,以下是一些常见的Hibernate高级用法:1、继承Hibernate支持类继承,可以让子类继承父类的属性和方法。
在数据库中,可以使用表与表之间的关系来实现继承,例如使用一对一、一对多、多对一等关系。
使用继承可以让代码更加简洁、易于维护。
2、聚合Hibernate支持聚合,可以将多个对象组合成一个对象。
例如,一个订单对象可以包含多个订单行对象。
在数据库中,可以使用外键来实现聚合关系。
使用聚合可以让代码更加简洁、易于维护。
3、关联Hibernate支持关联,可以让对象之间建立关联关系。
例如,一个订单对象可以关联一个客户对象。
在数据库中,可以使用外键来实现关联关系。
使用关联可以让代码更加简洁、易于维护。
4、延迟加载Hibernate支持延迟加载,可以在需要时才加载对象。
延迟加载可以减少数据库的负担,提高性能。
Hibernate提供了多种延迟加载的策略,例如按需加载、懒惰加载等。
5、事务Hibernate支持事务,可以确保数据库的一致性。
事务是一组数据库操作,要么全部成功,要么全部失败。
Hibernate提供了事务管理的方法,例如开始事务、提交事务、回滚事务等。
6、缓存Hibernate支持缓存,可以减少对数据库的访问次数,提高性能。
Hibernate提供了多种缓存策略,例如一级缓存、二级缓存等。
使用缓存需要注意缓存的一致性和更新问题。
7、HQL查询语言Hibernate提供了HQL查询语言,可以让开发人员使用面向对象的查询方式来查询数据库。
HQL查询语言类似于SQL查询语言,但是使用的是Java类和属性名,而不是表名和列名。
HQL查询语言可以更加灵活、易于维护。
以上是一些常见的Hibernate高级用法,它们可以帮助开发人员更加高效地使用Hibernate进行开发。
ehcache 缓存参数

ehcache 缓存参数Ehcache 是一个快速、开源、Java 缓存框架,用于提高应用程序的性能和扩展性。
它提供了许多用于配置和优化缓存的参数。
在本文中,我们将深入研究Ehcache 缓存参数,了解它们的作用和如何配置它们以达到最佳性能。
1. 最大缓存元素数量(maxEntries)maxEntries 参数用于设置缓存最多可以容纳的元素数量。
当缓存中的元素数量达到此值时,便会触发缓存淘汰策略,以释放空间存储新的元素。
配置此参数时,需要根据应用程序的内存使用情况和硬件资源来决定。
2. 缓存过期时间(timeToLiveSeconds 和 timeToIdleSeconds)使用 timeToLiveSeconds 参数可以设置缓存元素的全局过期时间。
一旦设置的时间到达,缓存中所有的元素将被清除。
timeToIdleSeconds 参数用于设置元素的闲置时间,默认情况下,元素不会因为闲置而过期,只有在访问时才会更新其闲置时间。
根据应用程序的业务需求,可以根据元素的特性来配置这两个参数。
3. 内存存储策略(memoryStoreEvictionPolicy)Ehcache 提供了多种内存存储策略,用于确定在缓存空间不足时如何选择要移除的元素。
其中包括 LRU(最近最少使用)、LFU(最不常用)和FIFO(先进先出)等。
选择合适的存储策略很重要,因为它直接影响了缓存的性能和存储效率。
4. 磁盘存储策略(overflowToDisk 和 maxEntriesLocalDisk)如果缓存元素的数量超过了内存容量的限制,那么 Ehcache 将使用磁盘存储策略来保存溢出的元素。
可以通过设置overflowToDisk 参数为true 来启用磁盘存储。
为了控制缓存使用的磁盘空间,可以使用 maxEntriesLocalDisk 参数设置最大磁盘存储元素的数量。
5. 堆外缓存(offheap)Ehcache 还提供了堆外缓存的支持。
Hibernate的工作原理

Hibernate的工作原理Hibernate是一个开源的Java持久化框架,它能够将Java对象映射到关系型数据库中,并提供了一套简单而强大的API,使得开辟人员能够更加方便地进行数据库操作。
Hibernate的工作原理主要包括以下几个方面:1. 对象关系映射(ORM):Hibernate使用对象关系映射技术将Java对象与数据库表之间建立起映射关系。
开辟人员只需要定义好实体类和数据库表之间的映射关系,Hibernate就能够自动地将Java对象持久化到数据库中,或者将数据库中的数据映射成Java对象。
2. 配置文件:Hibernate通过一个配置文件来指定数据库连接信息、映射文件的位置以及其他一些配置信息。
配置文件通常是一个XML文件,其中包含了数据库驱动类、连接URL、用户名、密码等信息。
开辟人员需要根据自己的数据库环境进行相应的配置。
3. SessionFactory:Hibernate的核心组件是SessionFactory,它负责创建Session对象。
SessionFactory是线程安全的,通常在应用程序启动时创建一次即可。
SessionFactory是基于Hibernate配置文件和映射文件来构建的,它会根据配置文件中的信息来创建数据库连接池,并加载映射文件中的映射信息。
4. Session:Session是Hibernate的另一个核心组件,它代表了与数据库的一次会话。
每一个线程通常会有一个对应的Session对象。
Session提供了一系列的方法,用于执行数据库操作,如保存、更新、删除、查询等。
开辟人员通过Session对象来操作数据库,而不直接与JDBC打交道。
5. 事务管理:Hibernate支持事务的管理,开辟人员可以通过编程方式来控制事务的提交或者回滚。
在Hibernate中,事务是由Session来管理的。
开辟人员可以通过调用Session的beginTransation()方法来启动一个事务,然后根据需要进行提交或者回滚。
浅谈Hibernate的flush机制

浅谈Hibernate的flush机制随着Hibernate在Java开发中的广泛应用,我们在使用Hibernate进行对象持久化操作中也遇到了各种各样的问题。
这些问题往往都是我们对 Hibernate缺乏了解所致,这里我讲个我从前遇到的问题及一些想法,希望能给大家一点借鉴。
这是在一次事务提交时遇到的异常。
an assertion failure occured (this may indicate a bug in Hibernate, bu t is more likely due to unsafe use of the session)net.sf.hibernate.AssertionFailure: possible nonthreadsafe access to sessi on注:非possible non-threadsafe access to the session (那是另外的错误,类似但不一样)这个异常应该很多的朋友都遇到过,原因可能各不相同。
但所有的异常都应该是在flush或者事务提交的过程中发生的。
这一般由我们在事务开始至事务提交的过程中进行了不正确的操作导致,也会在多线程同时操作一个Session时发生,这里我们仅仅讨论单线程的情况,多线程除了线程同步外基本与此相同。
至于具体是什么样的错误操作那?我给大家看一个例子(假设Hibernate配置正确,为保持代码简洁,不引入包及处理任何异常)SessionFactory sf = new Configuration().configure().buildSessionFactory() ;Session s = sf.openSession();Cat cat = new Cat();Transaction tran = s.beginTransaction(); (1)s.save(cat); (2) (此处同样可以为update delete)s.evict(cat); (3)mit(); (4)s.close();(5)这就是引起此异常的典型错误。
Hibernete基本概念
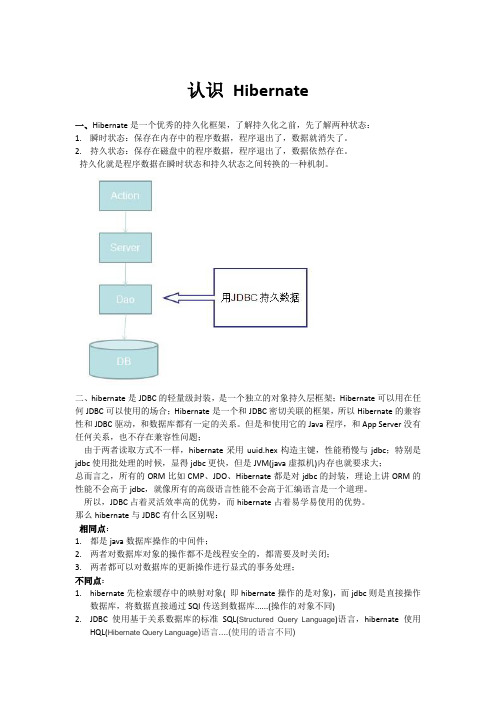
认识Hibernate一、Hibernate是一个优秀的持久化框架,了解持久化之前,先了解两种状态:1.瞬时状态:保存在内存中的程序数据,程序退出了,数据就消失了。
2.持久状态:保存在磁盘中的程序数据,程序退出了,数据依然存在。
持久化就是程序数据在瞬时状态和持久状态之间转换的一种机制。
二、hibernate是JDBC的轻量级封装,是一个独立的对象持久层框架;Hibernate可以用在任何JDBC可以使用的场合;Hibernate是一个和JDBC密切关联的框架,所以Hibernate的兼容性和JDBC驱动,和数据库都有一定的关系。
但是和使用它的Java程序,和App Server没有任何关系,也不存在兼容性问题;由于两者读取方式不一样,hibernate采用uuid.hex构造主键,性能稍慢与jdbc;特别是jdbc使用批处理的时候,显得jdbc更快,但是JVM(java虚拟机)内存也就要求大;总而言之,所有的ORM比如CMP、JDO、Hibernate都是对jdbc的封装,理论上讲ORM的性能不会高于jdbc,就像所有的高级语言性能不会高于汇编语言是一个道理。
所以,JDBC占着灵活效率高的优势,而hibernate占着易学易使用的优势。
那么hibernate与JDBC有什么区别呢:相同点:1.都是java数据库操作的中间件;2.两者对数据库对象的操作都不是线程安全的,都需要及时关闭;3.两者都可以对数据库的更新操作进行显式的事务处理;不同点:1.hibernate先检索缓存中的映射对象( 即hibernate操作的是对象),而jdbc则是直接操作数据库,将数据直接通过SQl传送到数据库......(操作的对象不同)2.JDBC使用基于关系数据库的标准SQL(Structured Query Language)语言,hibernate使用HQL(Hibernate Query Language)语言....(使用的语言不同)3.Hibernate操作的数据是可持久化的,也就是持久化的对象属性的值,可以和数据库中保持一致,而jdbc操作数据的状态是瞬时的,变量的值无法和数据库中一致....(数据状态不同)三、ORM(Object Relational Mapping)对象关系映射完成对象数据到关系型数据映射的机制,称为:对象·关系映射,简ORM总结:Hibernate是一个优秀的对象关系映射机制,通过映射文件保存这种关系信息;在业务层以面向对象的方式编程,不需要考虑数据的保存形式。
关于Hibernate缓存机制的研究

关于Hibernate缓存机制的研究摘要:Hibernate是一个开源的对象关系框架,它对JDBC进行了封装,java程序员可以通过Hibernate框架用对象编程的方式操纵数据库。
而使用Hibernate缓存,减少了项目当中应用程序与数据库的交互,从一定程度上提高了项目运行的效率。
主要探讨Hibernate框架的缓存实现机制与相关的应用策略。
关键词:Hibernate;Session缓存;SessionFactory缓存;持久层1 Hibernate的缓存机制缓存是用于存放数据的内存区域,当应用系统与数据库交互时,把交互过的数据保存到缓存中,当应用系统再次从数据库中读取相同的数据时,就可以从缓存中直接取出数据,而不用再次同数据库交互,从而减少了与数据库交互的次数,提高了应用系统的运行效率,当数据库中的数据被修改或被删除时,那缓存中与之对应的数据也会被修改或被删除,这样可以将缓存中的数据与数据库中的数据同步,保证缓存数据的有效性。
1.1 Hibernate一级缓存Hibernate一级缓存也称为Session缓存,通过将数据存放在Session对象中实现,Session缓存不能通过应用程序或者相关配制人为取消,因此Hibernate一级缓存是事务级别缓存,当session所存在的事务结束时,缓存中的所有数据都会丢失。
一级缓存是Session对象维护一个Key-value型的Map对象,当通过Session存储实体对象时,Session会将实体对象的类型或标识存储到Map对象的key中,将实体对象存储到Map对象的Value 中,当通过Session读取实体对象数据时,Session会跟据实体对象的类型或标识到Map对象中查找,查看是否已存储过这个对象,如果找到则返回这个实体对象,找不到则从数据库中查询。
Hibernate一级缓存是全自动的,不能人为对其干预,但可以通过Session中的方法对它进行管理,包括以下两种:①使用evict()方法从缓存中移除缓存对象,当缓存对象被移出时,该对象的状态会从持久化状态变为托管状态;②使用clear()将缓存中的所有对象全部清除。
使用缓存数据PPT课件

}
7
15.2 一级缓存
3.在一个Session中先save,再执行load查询
@Tes在t 测试类HibernateTest中添加testSessionCache_3()方
法pu,bl并ic 使vo用id@tTeessttSe注ss解io加nCa以ch修e_3饰(),{ 在一个session中先执行save
@Test 1.一个session中发出两次get查询 public将vo项id目tehsitbSeesrsniaotneCa-c1h0e复_1(制){并命名为“hibernate-11”,
User u1=(User)session.get(User.class, 1);
再导入Sys到teMm.yoEuctl.ipprisnet开ln(发"用环户境名中:"。+u在1.g项et目LoghiinbNearmen(a)t)e;-10的测试 类HibUeserrnaut2e=(TUessetr)中se添ssi加ont.egestt(SUessers.icolnaCssa,ch1e)_;1()方法,并使用 @}TestS注yst解em加.ou以t.修pr饰int,ln在("用同户一名个:s"e+sus2.igoent中Log发in出Na两me(次))g;et查询。
要经缓常到存数和据外库置里缓查询存,。那就没有必要用缓存了。
务的生Se(命s1s周) i事期on,务的当范事围缓务:存结缓束存是时只内,能缓被置存当的也前,就事结务不束访能生问命。被周缓卸期存。的载在生,此命范周也围期被下依,赖称缓于为存事 的介H质i是be内rn存a。te的第一级缓存。SessionFactory的缓存又被称为
java hibernate面试题

java hibernate面试题1. 介绍Hibernate框架Hibernate是一个开源的对象关系映射(ORM)框架,用于在Java应用程序和数据库之间建立映射关系。
它提供了一种面向对象的编程模型,将Java对象与数据库表之间进行映射,从而使开发人员可以直接使用Java对象进行数据库操作。
Hibernate直接通过简单的配置,实现了对底层数据库的统一访问,大大简化了数据库操作代码。
2. Hibernate框架的特点和优势- 透明性: Hibernate隐藏了底层数据库的细节,使开发人员能够专注于业务逻辑而不用关心数据库操作。
- 高度可定制性: Hibernate提供了丰富的配置选项和灵活的映射策略,可以根据项目需求进行定制。
- 数据库无关性: Hibernate支持多种数据库,使用统一的API进行开发,使得应用程序可以无缝切换数据库。
- 缓存管理: Hibernate提供了缓存机制,可以提高应用程序的性能和扩展性。
- 对象关系映射: Hibernate将Java对象与数据库表之间建立映射关系,简化了数据库操作的代码编写。
- 事务管理: Hibernate支持事务管理,可以保证数据的一致性和完整性。
3. Hibernate中的持久化状态在Hibernate中,实体对象可以存在三种状态:瞬时态、持久态和脱管态。
- 瞬时态(Transient): 对象在内存中创建,但没有与会话关联。
对该对象进行更改不会影响数据库。
- 持久态(Persistent): 对象与会话关联,并且Hibernate会自动跟踪该对象的变化,并在事务提交时同步到数据库中。
- 脱管态(Detached): 对象与会话分离,再次与会话关联时需要手动进行合并或者更新操作。
4. Hibernate中的对象关系映射Hibernate通过注解或者XML文件来描述Java对象与数据库表之间的映射关系。
常用的映射关系有以下几种:- 一对一(One-to-one): 一个对象与另一个对象之间存在唯一对应关系。
jetcache 二级缓存原理

jetcache 二级缓存原理
JetCache 是一个开源的缓存解决方案,它主要用于解决 Java 应用的缓存问题。
JetCache 主要由本地缓存、分布式缓存和二级缓存三部分组成。
其中,二级缓存是指将数据缓存在应用服务器上,以提高数据访问速度。
JetCache 的二级缓存原理如下:
1. 缓存数据:当某个数据被访问时,如果该数据不在本地缓存中,则会从分布式缓存中获取数据,并将其存储在本地缓存中。
同时,将数据存储在应用服务器的本地磁盘上,以实现二级缓存。
2. 缓存失效:当某个数据被更新时,JetCache 会将该数据的缓存失效,即
从本地缓存和二级缓存中删除该数据。
这样,下次访问该数据时,需要重新从分布式缓存中获取数据,并重新将其存储到本地缓存和二级缓存中。
3. 数据同步:为了保证数据的实时性,JetCache 提供了数据同步功能。
当
某个数据被更新时,JetCache 会将该数据的最新值同步到其他应用服务器上。
这样,其他应用服务器上的本地缓存和二级缓存中的数据也会被更新,以保证数据的一致性。
总的来说,JetCache 的二级缓存原理主要是通过将数据缓存在应用服务器上,以提高数据访问速度。
同时,通过缓存失效和数据同步机制,保证数据的实时性和一致性。
ehcache原理

ehcache原理Ehcache是一个开源的、高性能的Java缓存库,它可以被用于在Java应用程序中进行缓存数据以提高性能。
以下是Ehcache的原理。
1.缓存机制:Ehcache将数据存储在内存中,以提高访问速度。
它使用一个固定的内存空间作为缓存区域,当缓存被填满时,它会使用一种LRU(最近最少使用)策略来替换最旧的缓存项。
Ehcache还可以将缓存项存储在磁盘上,以便在应用程序重启时持久化缓存数据。
2.键值对存储:Ehcache使用键值对的方式存储缓存项。
每个缓存项都有一个唯一的键和一个对应的值。
通过键,应用程序可以在缓存中查找和访问相应的值。
3.缓存策略:Ehcache提供了多种缓存策略来满足不同的需求。
例如,可以通过设置缓存的存活时间来控制缓存项的有效期,一旦超过了指定的时间,缓存项将会过期并被移出缓存区域。
此外,Ehcache还支持基于空间大小的缓存策略,通过设置缓存的最大容量,可以限制缓存中存储的缓存项数量,以防止缓存过度填充。
4.缓存失效:Ehcache提供了多种缓存失效的方式。
除了根据时间或空间来失效缓存项之外,Ehcache还支持手动失效缓存项,即应用程序可以通过指定键来从缓存中移除特定的缓存项。
5.缓存管理:Ehcache允许应用程序对缓存进行管理和配置。
可以通过配置文件或程序代码来设置缓存的属性,例如存活时间、最大容量等。
Ehcache还提供了监控和统计功能,以便了解缓存的使用情况和性能。
6.缓存同步:Ehcache支持多线程环境下的缓存同步。
当多个线程同时访问同一个缓存项时,Ehcache会通过锁机制来确保只有一个线程更新缓存数据。
其他线程将等待更新完成后再获取数据,以保证数据的一致性。
7.分布式缓存:Ehcache还支持分布式缓存,在集群环境下可以将缓存数据存储在多个节点上。
Ehcache使用RMI机制来实现节点之间的通信和缓存数据的同步。
分布式缓存可以提高应用程序的可伸缩性和容错性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hibernate的缓存解读缓存是介于物理数据源与应用程序之间,是对数据库中的数据复制一份临时放在内存中的容器,其作用是为了减少应用程序对物理数据源访问的次数,从而提高了应用的运行性能。
缓存是介于物理数据源与应用程序之间,是对数据库中的数据复制一份临时放在内存中的容器,其作用是为了减少应用程序对物理数据源访问的次数,从而提高了应用的运行性能。
Hibernate在进行读取数据的时候,根据缓存机制在相应的缓存中查询,如果在缓存中找到了需要的数据(我们把这称做“缓存命中"),则就直接把命中的数据作为结果加以利用,避免了大量发送SQL语句到数据库查询的性能损耗。
Hibernate缓存分类:一、Session缓存(又称作事务缓存):Hibernate内置的,不能卸除。
缓存范围:缓存只能被当前Session对象访问。
缓存的生命周期依赖于Session的生命周期,当Session被关闭后,缓存也就结束生命周期。
二、SessionFactory缓存(又称作应用缓存):使用第三方插件,可插拔。
缓存范围:缓存被应用范围内的所有session共享。
这些session有可能是并发访问缓存,因此必须对缓存进行更新。
缓存的生命周期依赖于应用的生命周期,应用结束时,缓存也就结束了生命周期,二级缓存存在于应用程序范围。
Hibernate一些与一级缓存相关的操作(时间点):数据放入缓存:1. save()。
当session对象调用save()方法保存一个对象后,该对象会被放入到session的缓存中。
2. get()和load()。
当session对象调用get()或load()方法从数据库取出一个对象后,该对象也会被放入到session 的缓存中。
3. 使用HQL和QBC等从数据库中查询数据。
例如:数据库有一张表如下:使用get()或load()证明缓存的存在:1.public class Client2.{3.public static void main(String[] args)4. {5. Session session = HibernateUtil.getSessionFactory().openSession();6. Transaction tx = null;7.try8. {9./*开启一个事务*/10. tx = session.beginTransaction();11./*从数据库中获取id="402881e534fa5a440134fa5a45340002"的Customer对象*/12. Customer customer1 = (Customer)session.get(Customer.class, "402881e534fa5a440134fa5a45340002");13. System.out.println("customer.getUsername is"+customer1.getUsername());14./*事务提交*/15. mit();16.17. System.out.println("-------------------------------------");18.19./*开启一个新事务*/20. tx = session.beginTransaction();21./*从数据库中获取id="402881e534fa5a440134fa5a45340002"的Customer对象*/22. Customer customer2 = (Customer)session.get(Customer.class, "402881e534fa5a440134fa5a45340002");23. System.out.println("customer2.getUsername is"+customer2.getUsername());24./*事务提交*/25. mit();26.27. System.out.println("-------------------------------------");28.29./*比较两个get()方法获取的对象是否是同一个对象*/30. System.out.println("customer1 == customer2 result is "+(customer1==customer2));31. }32.catch (Exception e)33. {34.if(tx!=null)35. {36. tx.rollback();37. }38. }39.finally40. {41. session.close();42. }43. }44.}程序控制台输出结果:1.Hibernate:2. select3. customer0_.id as id0_0_,4. customer0_.username as username0_0_,5. customer0_.balance as balance0_0_6. from7. customer customer0_8. where9. customer0_.id=?10.customer.getUsername islisi11.-------------------------------------12.customer2.getUsername islisi13.-------------------------------------14.customer1 == customer2 result is true输出结果中只包含了一条SELECT SQL语句,而且customer1 == customer2 result is true说明两个取出来的对象是同一个对象。
其原理是:第一次调用get()方法, Hibernate先检索缓存中是否有该查找对象,发现没有,Hibernate 发送SELECT语句到数据库中取出相应的对象,然后将该对象放入缓存中,以便下次使用,第二次调用get()方法,Hibernate先检索缓存中是否有该查找对象,发现正好有该查找对象,就从缓存中取出来,不再去数据库中检索。
数据从缓存中清除:1. evit()将指定的持久化对象从缓存中清除,释放对象所占用的内存资源,指定对象从持久化状态变为脱管状态,从而成为游离对象。
2. clear()将缓存中的所有持久化对象清除,释放其占用的内存资源。
其他缓存操作:1. contains()判断指定的对象是否存在于缓存中。
2. flush()刷新缓存区的内容,使之与数据库数据保持同步。
Hibernate使用二级缓存适合存放到第二级缓存中的数据:1. 很少被修改的数据。
2. 不是很重要的数据,允许出现偶尔并发的数据。
3. 不会被并发访问的数据。
4. 参考数据,指的是供应用参考的常量数据,它的实例数目有限,它的实例会被许多其他类的实例引用,实例极少或者从来不会被修改。
不适合存放到第二级缓存的数据:1. 经常被修改的数据。
2. 财务数据,绝对不允许出现并发。
3. 与其他应用共享的数据。
Hibernate如何将数据库中的数据放入到二级缓存中?注意,你可以把缓存看做是一个Map对象,它的Key用于存储对象OID,Value用于存储POJO。
首先,当我们使用Hibernate从数据库中查询出数据,获取检索的数据后,Hibernate 将检索出来的对象的OID放入缓存中key中,然后将具体的POJO放入value中,等待下一次再次向数据查询数据时,Hibernate根据你提供的OID先检索一级缓存,若没有且配置了二级缓存,则检索二级缓存,如果还没有则才向数据库发送SQL语句,然后将查询出来的对象放入缓存中。
为Hibernate配置二级缓存:在主配置文件中hibernate.cfg.xml1.<property name="e_second_level_cache">true</property>2.<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>配置ehcache.xml1.<?xml version="1.0"encoding="UTF-8"?>2.<ehcache>3.<!--4.缓存到硬盘的路径5. -->6.<diskStore path="d:/ehcache"></diskStore>7.8. <!--9.默认设置10. maxElementsInMemory : 在內存中最大緩存的对象数量。
11. eternal : 缓存的对象是否永远不变。
12. timeToIdleSeconds :可以操作对象的时间。
13. timeToLiveSeconds :缓存中对象的生命周期,时间到后查询数据会从数据库中读取。
14. overflowToDisk :内存满了,是否要缓存到硬盘。
15. -->16.<defaultCache maxElementsInMemory="200"eternal="false"17.timeToIdleSeconds="50"timeToLiveSeconds="60"overflowToDisk="true"></defaultCache>18.19. <!--20.指定缓存的对象。
21.下面出现的的属性覆盖上面出现的,没出现的继承上面的。
22. -->23.<cache name="com.suxiaolei.hibernate.pojos.Order"maxElementsInMemory="200"eternal="false"24.timeToIdleSeconds="50"timeToLiveSeconds="60"overflowToDisk="true"></cache>25.26.</ehcache>在需要被缓存的对象中hbm文件中的<class>标签下添加一个<cache>子标签1.<hibernate-mapping>2.<class name="com.suxiaolei.hibernate.pojos.Order"table="orders">3.<cache usage="read-only"/>4.5.<id name="id"type="string">6.<column name="id"></column>7.<generator class="uuid"></generator>8.</id>9.10.<property name="orderNumber"column="orderNumber"type="string"></property>11.<property name="cost"column="cost"type="integer"></property>12.13.<many-to-one name="customer"class="com.suxiaolei.hibernate.pojos.Customer"14.column="customer_id"cascade="save-update">15.</many-to-one>16.</class>17.</hibernate-mapping>若存在一对多的关系,想要在在获取一方的时候将关联的多方缓存起来,需要再集合属性下添加<cache>子标签,这里需要将关联的对象的hbm文件中必须在存在<class>标签下也添加<cache>标签,不然Hibernate只会缓存OID。