编译原理Chapter 5
编译原理chapter5

若S+ …X,则X•>#。
第五章 优先分析法
第二节 简单优先分析方法
三、简单优先分析的基本思想
根据优先关系的定义,将简单优先文法中各 文法符号之间的这种关系用一个矩阵表示,称 作简单优先矩阵。PDA读入一个单词后,比较 栈顶符号和该单词的优先级,若栈顶符号优先 级低于该单词,继续读入;若栈顶符号优先级 高于或等于读入符号,则找句柄进行归约,找 不到句柄就继续读入。直到最后栈内只剩下开 始符号,输入串读到“#”为止。此时识别正 确。
1、自下而上归约
2、规定算符(更一般地说,指终结符)的优先级 及结合规则,以使得分析过程唯一
3、比较相邻两个算符而决定动作
注:1)这里的关键是对所有算符定义某种优先 关系
2)算符优先分析法是仿效四则运算的计算过 程而构造的一种语法分析方法
第五章 优先分析法 第三节 算符优先分析方法 一、基本思想
4、实例 表达式文法:
第五章 优先分析法 第二节 简单优先分析方法
四、简单优先矩阵
用于表示文法符号之间的简单优先关系的矩阵。
注:简单优先矩阵的构造可通过Warshall算法实 现。
第五章 优先分析法 第二节 简单优先分析方法
五、简单优先分析法的优缺点
优点:技术简单 缺点:适用范围小,分析表尺寸太大。
第五章 优先分析法 第三节 算符优先分析方法 一、基本思想
设A1A2…Ai-1AiAi+1…An是文法G的一个句型, 1)、若AiVN,则Ai-1、Ai+1 VT,即不许出现相继两个
非终结符;
第五章 优先分析法
第三节 算符优先分析方法 四、算符优先文法及优先表的构造 3、算符文法和算符优先文法定义的意义
编译原理课件CHAPTER 5(Semantic Analysis and Intermediate Code Generation-3)

2013-6-28
17
例 : A + B * ( C - D ) + E / ( C - D ) ↑N
求: 1.后缀式 2.四元式 3.三元式 4.间接三元式
2013-6-28 18
例 : A + B * ( C - D ) + E / ( C - D ) ↑N
后缀式 : A B C D - * + E C D – N ↑ / + 四元式 : (1) ( - C D T1 ) T2)
2013-6-28
34
5.4
中间代码生成
分析控制流语句的语法制导定义 P493 Fig.8.23
2013-6-28
35
5.4
中间代码生成
控制流语句中布尔表达式的翻译
产生布尔表达式三地址代码的语法制导定义
P494 Fig.8.24 or and not 关系表达式 是 L-属性定义,不能用自底向上的翻译,只能用深 度优先的分析方法 改写语法制导定义为翻译模式
id4
t1 := id2 + id3 t2 := t1 + id4 id1 := t2
id3
2013-6-28
25
5.4
中间代码生成
访问数组元素(Array Elements) 数组被存储在一片连续的空间中,见P482 Fig.8.17 访问数组元素,与以下几个量有关
Base(数组元素的起始地址)— 此值登记在符号表中 数组的维数(dimensional) — 说明时确定 每一维的下界(low)和上界(high),(取值个 数)— 说明时确定 存储方式 — 按行(row-major)还是按列(columnmajor) — 与编译器设计有关
编译原理课件CHAPTER5(SemanticAnalysisandIntermediateCodeGeneration-1)

2019/11/8
6
5.2 语法制导翻译
属性的类型(从分析过程中属性值的计算方法 来分类):
1、综合属性(Synthesized Attributes): 属性值是分析树中该结点的子结点的属性值的 函数
2、继承属性(Inherited Attributes):属 性值是分析树中该结点的父结点和/或兄弟结 点的属性值的函数
Chapter5 Semantic Analysis and Intermediate Code Generation
语义分析概述 语法制导翻译
(Syntax-Directed Translation) 类型确定与类型检查
(Type Checking) 中间代码生成
(Intermediate Code Generation)
31
5.2 语法制导翻译
** Fig.5.16 是 Fig.5.2 的一种具体实 现方法
2019/11/8
32
5.2 语法制导翻译
L -属性定义(L-attributed definitions):
是一种语法制导定义 对于产生式 A→X1X2…Xn 右部 Xj 的继承属性,
它依赖于: 1、 X1,X2,…,Xj-1 ( Xj左边的文法符号)的 属性 2、A 的继承属性
(5.1)是一个适合以深度优先顺序计算属性 的翻译模式
E
T 9 {print(“9”)}
1
2019/11/8
R
-
T
3
{print(“-”)}
R
5 {print(“5”)} + T {print(“+”)} R
2
5
2 {print(“2”)}
编译原理chapter 5 part 1

Handle (cont)
E’ => E => E + n => n + n Viable prefix Parsing Stack 1 2 3 4 5 6 7 $ $n $E $E + $E + n $E $E’ Right sentential form Input n + n$ + n$ + n$ n$ $ $ $ shift reduce E -> n shift shift reduce E -> E + n reduce E’-> E accept Handle Action
Derivation: E’ => E => E + n => n + n
The sequence of symbols on the parsing stack is called a viable prefix of the right sentential from. The n+ is not a viable prefix of n + n. (why ?)
X
A-> α X . η
X is a Token
A-> α . X η
X
A-> α X . η
If X is a token, then this transition corresponds to a shift of X from the input to the top of the stack.
Example 5.1
S’ -> S S -> ( S ) S | ε Parsing Stack 1 2 3 4 5 6 7 $ $( $( S $(S) $(S)S $S $ S’ String: ( ) Derivation: S’=> S => (S) S=> (S) => ( ) Input ( )$ )$ )$ $ $ $ $ shift reduce S -> ε shift reduce S -> ε reduce S -> ( S ) S reduce S’ -> S accept Action
编译原理第5章

二.算符优先分析法的基本思路
是仿照算术表达式的四则运算过程而设计的一 种语法分析方法。
终结符号 运算符 非终结符号 运算对象 算符优先分析法的关键在于用合适的方法去定义 任何两个可能相继出现的结符号a和b(它们之间 可能插有一个非终结符号)之间的优先级。然后利 用这种关系比较相邻运算符之间的优先级来确定 可归约串并进行归约。
bcde#
归约Ab
4
#aA
bcde#
移进
5
#aAb
cde#
归约AAb
6
#aA
cde#
移进
7
#aAc
de#
移进
8
#aAcd
e#
归约Bd
9
#aAcB
e#
移进
10
#aAcBe
# 归约SaAcBe
11
#S
#
接受
5.2算符优先分析法 概述 一. 算符文法的定义 二. 算符优先分析法的基本思想
算符优先分析法概述
第五章 自底向上分析
P94
概论
▪ 思想
• 自下而上的语法分析过程是最右推导的逆过
程(最左归约);即从输入串开始,朝着文 法开始符号进行归约,直至到达文法开始符 号为止的过程。
▪ 核心
• 寻找句型中的“句柄”进行归约,用不同的
方法寻找句柄,就可获得不同的分析方法
5.1 自底向上分析
一、规范归约
•归约 G=(VT,VN,S,P),α, β ∈(VT∪VN)*,A→β∈P,
规范句型的特点:
生式如下:
①S→aAcBe
②A→b
句柄后不会出现非终结符号。
③A→Ab
④B→d
对输入串abbcde#进行分析
编译原理第5章

四元式
四元式:带有四个域的记录结构,算符OP, 第一和第二运算量ARG1和ARG2,运算结果 RESULT。
与三元式相比,四元式更容易优化。 例: A:=-B*(C+D) 表示为:
(1) (2) (3) (4)
OP @ + * :=
ARG1 B C T1 T3
ARG2 D T2 -
RESULT T1 T2 T3 A
语义动作 {print E.VAL}
{E.VAL:= E(1).VAL+E(2).VAL}
{E.VAL:= E(1).VAL*E(2).VAL} {E.VAL:= E(1).VAL} {E.VAL:= LEXVAL}
其中LEXVAL表示由词法分析器送来的n的内部值
湖南农业大学信息科学技术学院 王 奕
湖南农业大学信息科学技术学院 王 奕
5.3.1 逆波兰式
后缀式表示法:波兰逻辑学家Lukasiewicz发明的 一种表示表达式的方法,又称逆波兰表示法。
一个表达式E的后缀形式可以如下定义:
1. 如果E是一个变量或常量,则E的后缀式是E自身。 2. 如果E是E1 op E2形式的表达式,其中op是任何二 元操作符,则E的后缀式为E1 E2 op,其中E1 和 E2 分别为E1 和E2的后缀式。 3. 如果E是(E1)形式的表达式,则E1 的后缀式就是E 的后缀式。
后缀式的计算
用一个栈实现。 一般的计算过程是:自左至右扫描后缀式,每碰到 运算量就把它推进栈。每碰到k目运算符就把它作 用于栈顶的k个项,并用运算结果代替这k个项。
湖南农业大学信息科学技术学院 王 奕
语法制导生成后缀式
产生式 E→E(1)op E(2) E→ (E(1)) E→id
编译原理第5章

语法分析-自下而上分析 语法分析-
E E T | E+T T F | T*F F i | (E) E + T 短语有:i, T * F, E+T * F, E + T * F + i 直接短语有: i, T * F 句柄是:T * F
第7页
E + T F
T *
F
i
编译原理
语法分析-自下而上分析 语法分析-
接短语
*
位于一个句型最左边的直接短语称为句柄. 句型最左边的直接短语称为 位于 句型---> 短语 ---> 直接短语 --->句柄 句型 句柄
注: 每次归约的部分必须是称之为句柄 句柄的字符串(最右 句柄 推导)。 关键的问题是如何识别句柄 如何识别句柄
第6页
编译原理
例:下述文法的另一个句型: 下述文法的另一个句型: E+T * F + i 其短语、直接短语、句柄分别是? 其短语、直接短语、句柄分别是?
第17页
T *
F
i
编译原理 算符优先分析法小结
优点 简单、效率高 能够处理部分二义性文法 缺点 文法书写限制大 占用内存空间大 不规范、存在查不到的语法错误
语法分析-自下而上分析 语法分析-
第18页
编译原理
语法分析-自下而上分析 语法分析-
LR分析法 LR分析法
L表示从左到右扫描输入串,R表示构造一个 表示从左到右扫描输入串, 表示构造一个 表示从左到右扫描输入串 最右推导的逆过程。 最右推导的逆过程。 大多数用上下文无关文法描述的程序语言都 可用LR分析器予以识别 分析器予以识别。 可用 分析器予以识别。 能用I.R分析器分析的文法类 包含能用LL(1) 分析器分析的文法类, 能用 分析器分析的文法类,包含能用 分析器分析的全部文法类, 分析法在自左 分析器分析的全部文法类,LR分析法在自左 至右扫描输入串时就能发现其中的任何错 并能准确地指出出错地点。 误.并能准确地指出出错地点。
编译原理CHAPTER 5(Semantic Analysis and Intermediate Code Generation-2)ppt课件

2018/11/15
12
P 1M ε id1
t1 8
D
id1 : T1 ; proc id2 ; id3 : T2 ; S
D2 5 ; 3 N
2
D1 :
;
T1 proc id2
D3 4 ;
id3 : T2
S
ε
5. t := top ( tblptr ) addwidth ( t, top ( offset ) ) pop ( tblptr ) pop ( offset ) enterproc ( top( tblptr), , t )
2018/11/15
11
P 1M ε id1
t2 t1 4 8
D
id1 : T1 ; proc id2 ; id3 : T2 ; S
D2 ; 3 N
2
D1 :
;
T1 proc id2
D3 4 ;
id3 : T2
S
ε
4. enter ( top( tblptr), , T2.type, top(offset) ) top( offset ) := top(offset) + T2.width
2018/11/15 13
P7 1M ε id1 D
6
D2 5 ; 3 N
id1 : T1 ; proc id2 ; id3 : T2 ; S
2
D1 :
;
T1 proc id2
D3 4 ;
id3 : T2
S
ε
6. 7. addwidth ( top ( tblptr ), top ( offset ) ) pop ( tblptr ) pop ( offset )
编译原理 第五章

一个文法符号串的开始符号集合定义如下: 定义5.1 设G=(VT,VN,S,P)是上下文无关文法 FIRST(α)={a|α aβ,a∈VT,α,β∈V*} 若α ε,则规定ε∈FIRST(α).
不难求出在例5.2文法G2中 FIRST(Ap)={a,c} FIRST(Bq)={b,d} 因此有 FIRST(A)∩(FIRST(B)= 这样文法G2中,关于S的两个产生式的右部虽然都以非 终结符开始,但它们右部的符号串可能推导出的首符号集 合不相交,因而可以根据当前的输入符号是属于哪个产生 式右部的首符号集合而决定选择相应产生式进行推导,因 此仍能构造确定的自顶向下分析。
定义5.4 一个上下文无关文法是LL(1)文法的充分 必要条件是:对每个非终结符A的两个不同产生式, A→α, A→β,满足 SELECT(A→α)∩SELECT(A→β)= 其中α,β不同时能 ε。
LL(1)文法也可定义为: 一个文法G是LL(1)的,当且仅当对于G的每 一个非终结符A的任何两个不同产生式 A→α|β, 下面的条件成立: ① FIRST(α)∩FIRST(β)= ,也就是α和 β推导不出以某个相同的终结符a为首的符号串; 它们不应该都能推出空字ε. ② 假若β ε那么, FIRST(α)∩ FOLLOW(A)= 也就是,若β ε 则α所能推出的串的首符号不应在FOLLOW(A) 中(如例5.3)。这种表示与定义5.4相比计算步骤 少,但不如定义5.4清晰。
编译原理-第五章习题答案

上一页
下一页
11
例:5.3 文法:SaAcBe A bAb B d 句子:abbcde
步骤 (1) (2) (3) (4) (5) (6)
栈
# #a #ab #aA #aAb #aA #aAc #aAcd #aAcB #aAcBe #S
输入 abbcde# bbcde# bcde# bcde# cde# cde#
上一页
下一页
20
5)构造算符优先文法G的优先表的算法
思路:对文法中的每一个产生式的候选式检查,判断句型中相邻符号之间 的关系 来构造优先表; 具体算法: FOR 每条产生式P→X1X2…Xn FOR i=1 TO n-1 IF Xi,Xi+1∈VT,THEN Xi=Xi+1; IF i ≤n-2且Xi,Xi+2∈VT,Xi+1∈VN THEN Xi=Xi+2; IF Xi∈VT,Xi+1∈VN THEN FOR FIRSTVT(Xi+1)中的每个a Xi <. a; NEXT IF Xi∈VN,Xi+1∈VT THEN FOR LASTVT(Xi)中的每个a DO a .> Xi+1; NEXT NEXT NEXT
上一页
下一页
8
例:5.1 P85 文法: E→T|E+T T→F|T*F F→i|(E) 句型:i1*i2+i3其中:短语有i1、i2、i3、i1*i2、 i1*i2+i3 直接短语:i1、i2、i3;句柄:i1 例:5.2 P85 文法如上 E 句型:E+T*F+i 短语:E+T*F+i,E+T*F,T*F,i 直接短语:T*F和i E + 句柄:T*F
编译原理chapter5

•22
a < b, b < c a<c
|– M : int, |– N : int
|– M + N : int
5.2 描述类型系统的语言
类型系统的形式化 类型表达式 定型断言 定型规则
•23
5.2 描述类型系统的语言
5.2.1 断言
断言的形式 |– S S的所有自由变量都声明在中 其中 是一个静态定型环境,如x1:T1, …, xn:Tn S的形式随断言形式的不同而不同 断言有三种具体形式
•30
5.3 简单类型检查器的说明
例: i : integer; j : integer; j := i mod 2000
•31
5.3 简单类型检查器的说明
5.3.2 类型系统 环境规则
(Env )
•32
|– |T, id dom () , id : T |
(Decl Var)
5.1.2 类型化语言和类型系统 类型化的语言
变量的类型 类型化的语言 未类型化的语言 显式类型化语言 类型是语法的一部分
•10
5.1 类型在程序设计语言中的作用
5.1.2 类型化语言和类型系统 类型化的语言
变量的类型 类型化的语言 未类型化的语言 显式类型化语言 隐式类型化的语言
类型系统的形式化 类型系统是一种逻辑系统
有关自然数的逻辑系统 -自然数表达式(需要定义它的语法) a+b, 3 - 合适公式(断言,需要定义它的语法) a+b=3, (d=3)(c<10) - 推理规则
•19
a < b, b < c a<c
5.2 描述类型系统的语言
类型系统的形式化 类型系统是一种逻辑系统
编译原理答案第五章
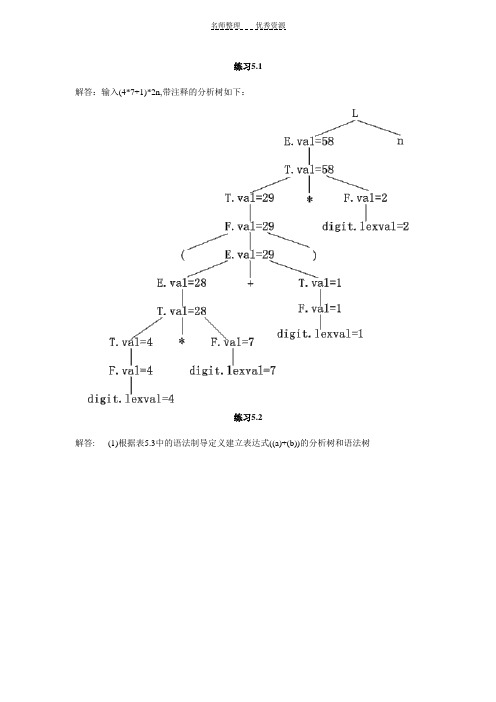
练习5.1解答:输入(4*7+1)*2n,带注释的分析树如下:练习5.2解答: (1)根据表5.3中的语法制导定义建立表达式((a)+(b))的分析树和语法树(2)根据图5.17的翻译模式构造((a)+(b))的分析树和语法树练习5.3解答:设置下面的函数和属性:expr1||expr2:把表达式expr2拼写在表达式expr1后面。
deletep(expr):去掉表达式expr左端的‘(’和右端的‘)’。
E.expr,T.expr,F.expr:属性变量,分别表示E,T,F的表达式。
E.add,T.add,F.add,属性变量,若为true,则表示其表达式中外层有‘+’号,否则无‘+’号。
E.pmark,T.pmark,F.pmark,属性变量,若为true,表示E,T,F的表达式中左端为‘(’,右端是‘)’。
语法制导定义如下:产生式语义规则E -> E1 +T if(T.pmark==true)THEN E.expr=E1.expr||'+'||deletep(T.expr) ELSE E.expr:=E1.expr||'+'||T.expr;E.add:=true;E.pmark:=false;E -> T if(T.pmark==true)THEN E.expr:=deletep(T.expr)ELSE E.expr:=T.expr;E.add:=T.add;E.pmark:=false;T -> T1*F T.expr:=T1.expr||'*'||F.expr; T.add:=false;T.pmark:=false;T -> F T.expr:=F.expr; T.add:=F.add;T.pmark:=F.pmark;F -> (E) if(E.add==false)THEN BEGINF.expr:=E.expr;F.add:=false;F.pmark:=false;ENDELSE BEGINF.expr:='('||E.expr||')';F.add:=true;F.pmark:=true;END;F -> id F.expr:=id.lexval;F.add:=false;F.pmark:=false;练习5.4解答: (1)语法制导定义如下:产生式语义规则E -> E1+T if(E1.type==int) AND (T.type==int) THEN E.type:=intELSE E.type:=real;E -> T E.type:=T.type;T -> num T.type:=int;T -> num.num T.type:=real;(2)设E.pf和T.pf分别是E和T的前缀形式,||是两个字符串的连接,语法制导定义如下:产生式语义规则E -> E1+T if(E1.type==int) AND (T.type==int)THEN E.type:=intELSE BEGINE.type:=real;if(E1.type==int) AND (T.type==real)THEN E1.pf:='inttoreal'||E1.pfELSE if(E1.type==real)AND(T.type==int)THEN T.pf:='inttoreal'||T.pfEND;E.pf:='+'||E1.pf||T.pf;E -> T E.type:=T.type; E.pf:=T.pf;T -> num T.type:=int; T.pf:=int.lexval;T ->num.numT.type:=real; T.pf:=real.lexval;练习5.5解答: (1)用综合属性决定s.val的语法制导定义:产生式语义规则S -> L S.val:=L.val;S ->L1.L2S.val:=L1.val+L2.val*L2.p;L -> B L.val:=B.val; L.p:=2-1;L -> L1B L.val:=L1.val*2+B.val; L.p:=L.p*2-1;B -> 0 B.val:=0;B -> 1 B.val:=1;注:L.p表示恢复L.val的因子。
编译原理_第5章(清华大学)

学习目标: ➢掌握:LL(1)文法的判别,预测分析
法,递归子程序的构造方法 ➢理解:LL(1)文法 ➢了解:不确定的自顶向下分析
语法分析的作用是识别由词法分析给出的单词序 列是否是给定文法的正确句子
分类:
语法分析
自顶向下分析 自底向上分析
确定的
不确定的 算法优先分析(第六章)
进行推导,类似地LL(k)文法需要向前看K个符号才 可以确定选用哪个产生式。
例 有文法G[S]为:
S→aAS
SELECT(S→aAS)= {a}
S→b
SELECT(S→b)= {b}
A→bA
SELECT(A→bA)= {b}
A→ε
SELECT(A→ε)=Follow(A)= {a,b}
Hale Waihona Puke 由于SELECT(A→bA)∩SELECT(A→ε)={b}≠Φ,
此外若可能导出空串,A自动获得匹配,输入符a 有可能与A后的一个符号匹配,所以当a应属于 Follow(A)时,选择产生式A→也是可以的。
直观上说某产生式A→α的选择集合是指遇到哪些输 入符号(包括#)时选用该产生式向下推导。
例 G3[S]: 若α≠>*ε,则SELECT(A→α)=FIRST(α) S→aA 若α=>*ε, 则SELECT(A→α)
例文法G2[S]: S→Ap FIRST(Ap)={a,c}
S→Bq FIRST(Bq)={b,d}
A→a
FIRST(a)={a }
A→cA FIRST(cA)={c}
B→b
FIRST(b)={b}
B→dB FIRST(dB)={d}
由于同一非终结符的两个产生式的右部推导出来的 开始符号集不相交,因此可根据当前输入符属于哪 个产生式右部的开始符号集而决定选哪个产生式进 行推导,可以进行确定的自顶向下分析
编译原理Chapt5

G(E):
E T | E+T T F | T*F F (E) | i
步骤 9 10 11 12 13 14
符号栈 #E+ #E+i3 #E+F #E+T #E #E
输入串 i3# # # # # #
动作 进 进 归,用F→i 归,用T→F 归,用E→E+T 接受
江西财经大学信息管理学院
a1a2ai an# 输入串
Sm
Xm
S1 S0
X1 #
LR分析 程 序 action
江西财经大学信息管理学院
输出
状态 符号 分析栈
goto
LR分析表
LR分析器的核心是一张分析表:
ACTION[s,a]:当状态s面临输入符号a时,
应采取什么动作.
GOTO[s,X]:状态s面对文法符号X时,下
江西财经大学信息管理学院
例:设文法G(S): (1) S aAcBe (2) A b (3) A Ab (4) B d 试对abbcde进行“移进-归约”分析。
e B d B b c c A b S a a
江西财经大学信息管理学院
abbcde bbcde bcde cde de e
G(E):
E T | E+T T F | T*F F (E) | i
步骤 符号栈 输入串 0 # i1*i2+i3# 1 #i1 *i2+i3# 2 #F *i2+i3# 3 #T *i2+i3# 4 #T* i2+i3#
江西财经大学信息管理学院
动作 预备 进 归,用F→i 归,用T→F 进
编译原理-第五章

利用下面的两条规则,可把包含直接左递归的产生式转换成 用扩展BNF表示法表示的产生式。
❖ ① 提公因子
每当一条产生式中有公因子可提的时候,就把它提出来,若
原产生式是
A→x|xy
则可写成 A→x(y|ε),这里把ε当作最后一个候选式。
❖ ② 若 A→x|y|…|z|Av
是一组产生式,且它只有一个直接左递归的右部位于最后,
如果x是一个终结符串,而且h中至多最左符号是终 结符,那么,(q,y,h)是该NDPDA的一个构形,而且
(q,xy,S)├*(q,y,h)
5.2 消除左递归方法
5.2.1 文法的左递归性
❖ 文法的左递归性属文法递归性的一种,在一文法中,所有形
如
A→xAy x,y ∈(∑∪N) *,A∈N
称为递归产生式(或自嵌入产生式)。
U→1|1|…|n
都有 SELECT (U→i)∩SELECT(U→j)= (ij, i, j=1, 2, …, n),则文法G是一个LL(1)文法。
5.3造
1. 设X(VN∪VT),FIRST(X)的构造
❖ ① 若XVT,则FIRST(X)={X};
(可空)。 ❖ δ 是一个转换函数,它将三元组(q,a,Z)映象成对偶集
{(p1,h1),(p2,h2),…},即,δ(q,a,Z)= {(p1,h1),(p2,h2),…} .
5.1.2 PDA的 构形和移动
PDA的一个构形是一个三元组:(q,w,h) ❖ 其中,q∈Q;w∈∑*是尚待扫描的输入串,包括读
第五章 自上而下语法分析
❖ 语法分析是继词法分析之后编译过程的第2阶段。 它的主要任务是对词法分析的输出结果——单词序 列进行分析,识别合法的语法单位。
编译原理 Chapter 5

T
*
F
F.type = int F.place = &c
F
id
id.lexValue = c
id id.lexValue = b
(1) 假设a, b, c是已经 声明的全局变量, a的类型为float,b 和c的类型为int
(2) 中间未标明的T和 F的type和place都 是int和&b
观察inh属性的传递
15
消除直接左递归时语义规则的处理
• 假设
– A A1Y – AX
• 那么
– A XR – R YR1 – Rε
A.a = g(A1.a, Y.y) A.a = f(X.x)
R.i = f(X.x); A.a = R.s R1.i = g(R.i, Y.y); R.s = R1.s R.s = R.i
在调用Xi()之前计算Xi的继承属性值,然后以它们为参 数调用Xi()
在产生式对应代码的最后计算A的综合属性 如果所有的文法符号的属性计算按上面的方式进行,
计算顺序必然和依赖关系一致
24
L属性SDD和自顶向下语法分析 (2)
L属性SDD其属性总可按如下方式计算
L_dfvisit(n) {
for m = 从左到右n的每个子节点 do {
类型结构
• 简化的类型表达式的语法
– TBC
B int | float
– C [num] C | ε
第五章 语法制导的翻译
南京大学计算机系
介绍
使用上下文无关文法引导语言的翻译
CFG的非终结符号代表了语言的某个构造 程序设计语言的构造由更小的构造组合而成 一个构造的语义可以由小构造的含义综合而来
编译原理 课件chapter5

T E E+ E+4 E+F E+T E En L
15 15 1515-4 15-4 15-4 19 19 19
T→ T*F E→ T
F → digit T→ F E→ E+T
L→ En
32
总结: 总结 采用自底向上分析,例如LR分析,首先给出 S-属性定义,然后,把S-属性定义变成可执行 的代码段,这就构成了翻译程序.象一座建筑, 语法分析是构架,归约处有一个"挂钩",语 义分析和翻译的代码段(语义子程序)就挂在 这个钩子上.这样,随着语法分析的进行,归 约前调用相应的语义子程序,完成相应的翻译任 务.
state
val ... A .a
top
... A
定义式 A .a:=f(X.x, Y.y, Z.z)(抽象)变成 val[ntop]:=f(val[top-2],val[top-1],val[top]) (具体可执行代码). 在执行代码段之前执行: ntop:=top-r+1 执行代码段后执行: top:=ntop; r是句柄的长度.
25
例5.9
表达式 a+a*(b-c)+(b-c)*d 的dag
+ + * a b – c
26
* d
5.3 S-属性定义及其自底向上的计算 在分析栈中使用一个附加的域来存放综 合属 性值. 下图为一个带有综合属性值域的分析栈:
top
state ... X Y Z ...
val ... X.x Y.y Z.z ...
3
要求:随着语法分析,分析树逐步被构造出 来,每构造一个子树,和这棵子树结点相联系 的文法符号的属性值都可以根据已有结点属性 值的计算出来的.一个重要的属性定义类称作 "L—属性"定义,满足上述要求.
编译原理chapter5

struct expty expTy (Tr_exp exp; Ty_ty ty) { struct expty e; e.exp=exp; e.ty=ty; return e; }
5.2 Type-Checking Expressions
• 举例:在Tiger语言中,加法表达式e1+e2
– 两个操作数都必须是整型的(类型检查器必须对此检查) – 结果是整型(类型检查器将返回这种类型)
• 用散列表对字典操作(插入、搜索和删除)的平均时间 为Θ(1),此操作在最坏情况下的操作正比于元素个数n。 • 二叉搜索树对字典的基本操作能在O(logn)的时间内完成。
5.1.3 Efficient Functional Symbol Tables
• 二叉搜索树:
m1={bat→1, camel→2, dog→3} m2=m1+{mouse→4}
• 当σ′= σ + { a→τ },是通过以a 作为键值将τ 插入散 列表来实现的。
void insert ( string key, void *binding) { int index = hash(key) % SIZE table[index] = Bucket ( key, binding, table[index]); } unsigned int hash ( char *s0) { unsigned int h=0; char *s; for ( s=s0; *s; s++) h=h*65599 + *s; return h; }
– formals:各个形式参数的类型;
– result:该函数返回的结果的类型(或Void)。
5.2 Tiger编译器的绑定
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
prev
next
步骤三 计算FOLLOW集
dir
上下文无关文法的每一个BVN计算
FOLLOW(B)
prev
开始符号S,置#于FOLLOW(S)中; 若AαBβ是一个产生式,则把 FIRST(β)-{}加至FOLLOW(B)中; 若AαB是一个产生式,把 FOLLOW(A)加至 FOLLOW(B)中; * 若AαBβ是一个产生式而β ( 即 FIRST(β) ),则把 FOLLOW(A)加至 FOLLOW(B)中;
注:#是输入串的结束符
prev next 12
SELECT集
dir
给定上下文无关文法的产生式:
A→α,AVN,αV*, 若α \ ,则SELECT(A→α)=FIRST(α)
* 若α ,则 *
SELECT(A→α)=(FIRST(α)-)
∪FOLLOW(A)
prev next 14
dir
若XV,则FIRST(X)={X} 若XVN,且有产生式Xa…,aV
则把a加入到FIRST(X)中,即
a First ( X )
若XVN,且有产生式X,
则把也加到FIRST(X)中,即
First ( X )
prev next 24
若XVN,
dir
prev
SELECT(S→AB) ∩ SELECT(S→bC)≠ SELECT(A→) ∩ SELECT(A→b)= SELECT(B→) ∩ SELECT(B→aD)= SELECT(C→AD) ∩ SELECT(C→b)≠ SELECT(D→aS) ∩ SELECT(D→c)= 所以本文法不是LL(1)文法
prev next
SELECT(C→AD) ={FIRST(A)-{}}∪FIRST(D) ={a,b,c} SELECT(C→b) ={b}
35
dir
S→AB S→bC A→ A→b B→ B→aD C→AD C→b D→aS D→c
prev next
SELECT(D→aS) ={a}
SELECT(D→c) =FIRST(c)={c}
LL(1)文法
dir
上下文无关文法是LL(1)文法的充分必要条
件是,对每一个非终结符A的两个不同的产 生式,A→α,A→β满足: SELECT(A→α) ∩ SELECT(A→β)= Φ * 其中:α、β不同时能
prev
next 15
dir
LL(1)文法的含义是:第一个L表明自顶向
下分析是从左向右扫描输入串,第二个L表 明分析过程中将用最左推导,1表明只需向 右看1个符号便可决定使用哪个产生式进行 推导 LL(K)文法,即向右看K个字符
prev next
A B S
21
步骤二 计算FIRST集
dir
根据定义计算
设G=( VT, VN, S, P )是上下文无关文法 * FIRST(α)={ a|α aβ,aVT, α,βV*} * 若α,则FIRST(α)
prev
next 23
对每一文法符号XV计算FIRST(X)
非终结符的FIRST集
FIRST(S)= FIRST(A)∪ FIRST(B)∪{b}={a,b,} FIRST(A)={}∪{b}={b,} FIRST(B)={}∪{a}={a,} FIRST(C)={FIRST(A)-{}}∪ FIRST(D)∪{b}={a,b,c} FIRST(D)={a}∪{c}={a,c}
2. 判断两两相交是否为空
SELECT(S→aAS)∩SELECT(S→b)= SELECT(A→bA}∩SELECT(A→)≠
prev
故:G[S]不是LL(1)文法
18
next
5.2 LL(1)文法的判别
dir
使用自顶向下分析方法时,必须首先判别给
定文法是否为LL(1)文法,即需要计算:
37
第五章 自顶向下语法分析方法
dir
5.1 5.2 5.3 5.4
5.5
确定的自顶向下分析思想 LL(1)文法的判别 某些非LL(1)文法到LL(1)文法的等价 变换 不确定的自顶向下分析思想 确定的自顶向下分析方法
5.5.1 递归子程序法 5.5.2 预测分析方法
prev
next 1
36
dir
SELECT(S→AB)={a,b,#} SELECT(A→)={a,c,#} SELECT(B→)={#} SELECT(C→AD)={a,b,c} SELECT(D→aS)={a}
SELECT(S→bC)={b} SELECT(A→b)={b} SELECT(B→aD)={a} SELECT(C→b)={b} SELECT(D→c)={c}
引言
dir
语法分析
是编译程序的核心部分
作用:识别由词法分析给出的单词符号序列是否 是给定文法的正确句子(程序)
语法分析方法
自顶向下分析方法 自底向上分析方法
prev next 2
确定的自顶向下分析方法 不确定的自顶向下分析方法 算符优先分析方法 LR分析方法
自顶向下分析方法概述
dir
自顶向下分析方法
Y1,Y2,…,Yi 都VN,且有产 生式X Y1Y2…Yn。
* 当Y1,..Yi-1 (1≤i≤n),则FIRST(Y1){},…,FIRST(Yi-1)-{},FIRST(Yi)都包 含在FIRST(X)中,即:
First ( X ) (First (Y j ) { }) First (Yi )
First ( ) ( First ( X j ) { }) First ( X i )
j 1 i 1
若FIRST(Xj)(1≤j≤n), 则
First ( ) First ( X j )
j 1
prev next 26
n
dir
prev
S→AB S→bC A→ A→b B→ B→aD C→AD C→b D→aS D→c
面向目标的分析方法
从文法的开始符出发企图推导出与输入的单词 串完全相匹配的句子,若输入串是给定文法的 句子,则必能推出,反之必然出错
prev
next 3
5.1
dir
确定的自顶向下分析思想
确定的自顶向下分析方法,首先要
解决问题
解决从文法的开始符出发,如何根据当前的输入符 号(单词符号)唯一地确定选用哪个产生式替换相 应非终结符往下推导,或构造一棵相应的语法树
prev next
SELECT(S→AB) ={FIRST(A)-{}}∪{FIRST(B)-{}} ∪FOLLOW(S) ={a,b,#} SELECT(S→bC) ={b}
32
dir
S→AB S→bC A→ A→b B→ B→aD C→AD C→b D→aS D→c
prev next
SELECT(A→) =FOLLOW(A) ={a,c,#} SELECT(A→b) ={b}
FIRST集 FOLLOW集 SELECT集
prev
next 19
例5.5 判断下面文法G[S]是否为LL(1)文法
dir
S→AB S→bC A→ A→b B→ B→aD C→AD C→b D→aS D→c
prev
next 20
步骤一
dir
求出能够推出的非终结符
S→AB S→bC A→ A→b B→ B→aD C→AD C→b D→aS D→c
33
dir
S→AB S→bC A→ A→b B→ B→aD C→AD C→b D→aS D→c
prev next
SELECT(B→) =FOLLOW(B) ={#} SELECT(B→aD) ={a}
34
dir
S→AB S→bC A→ A→b B→ B→aD C→AD C→b D→aS D→c
prev
next 9
例5.3 若有文法G[S]:
S
dir
S→aA S→d A→bAS A→ 若输入串w=abd
a
A
b
A
S
d
SaAabASabSabd
prev next 10
FOLLOW集
dir
设G=(VT,
VN, S, P)是上下文无关文法 * FOLLOW(A)={ a | SAβ 且aVT, aFIRST(β), VT* ,βV+ } * 若S Aβ,且β,则#FOLLOW(A) * FOLLOW(A)={ a|S…Aa… ,aVT,} * …A,则#FOLLOW(A) 若S
j 1
i 1
* 若所有Y1,…Yn ,则把加到FIRST(X)中
First ( X ) First (Y j )
j 1
prev
n
next 25
符号串的FIRST集
dir
若符号串αV*,α=X1X2…Xn,
* ,则FIRST(α)=FIRST(X ) 当X1不能 1 若对任何j(1≤j≤i-1,2≤i≤n), FIRST(Xj) 则
prev
next
30
步骤四 计算SELECT集
dir
给定文法的产生式:
A→α AVN,αV*, * 若α \ ,则SELECT(A→α)=FIRST(α) * ,则 若α SELECT(A→α) =(FIRST(α)-) ∪ FOLLOW(A)
prev
next 31
ห้องสมุดไป่ตู้
dir
S→AB S→bC A→ A→b B→ B→aD C→AD C→b D→aS D→c
A c A
p
c
A
a
SApcApccApccap