编译原理 第二章习题答案
西电编译原理_第二章习题解答

最终的正规式: 1* | 1*(01|0)* = 1*(01|0)*
© 西安电子科技大学 · 软件学院
5
1. 根据模式写出正规式
习题2.4 (2) 所有不含有子串 011 的01串 思路2:考虑包含 011 的串,然后构造没有011的串 ① 含有 子串 011 的最简单的串:
© 西安电子科技大学 · 软件学院
?
| (01|10) (00|11)* (01|10) )*
4
1. 根据模式写出正规式
习题2.4 (2) 所有不含有子串 011 的01串 思路1:简单例子,观察规律 (1) 最简单的串: 0 , 1, 11, 00, 10, 01, 010, …
(2) 上述各串重复: (0 | 00 | 01 | 010 )* = (01 | 0)*
© 西安电子科技大学 · 软件学院
7
2.依据NFA/DFA,给出正规式
思路1: 回顾“正规式 与 FA的关系”
正规集 描述 正规式 识别 有限自动机
正规式、FA是从两个不同的侧面表示一个集合(即正 规集)。所以,根本的方法是以正规集为桥梁, - 先分析清楚 FA 识别的集合之结构特征, - 然后再设计此集合的正规式。
© 西安电子科技大学 · 软件学院
2
1. 根据模式写出正规式
一般思路:(1)分析题意 (2)列举一些最简单的例子 (3)寻找统一规律*,考虑所有可能情况**
习题2.4 (1) 由偶数个0和奇数个1构成的01串
解:① 最简单的串有 0个0和1个1组成的串: 1 2个0和1个1组成的串:010 ,001,100 ② 在上述串的中间、两头添加偶数个0和/或偶数个1,即可 得到满足题意的其他串。 设偶数个0/偶数个1组成的串,可用正规式 A 表示,则最 终正规式: A1A | A0A1A0A
编译原理第二章习题解答

部分习题解答
© 西安电子科技大学 ·软件学院
难点
第2章习题
1. 根据模式,写出正规式 2. 依据 NFA/DFA,写出正规式
计算量大
3. 正规式NFA 4. NFADFA: ε_闭包,smove 5. DFA最小化
© 西安电子科技大学 ·软件学院
2
1. 根据模式写出正规式
一般思路:(1)分析题意 (2)列举一些最简单的例子 (3)寻找统一规律*,考虑所有可能情况**
© 西安电子科技大学 ·软件学院
13
其它
习题2.9 构造 10*1 的最小DFA
解: 活用 Thompson 算法
(1) 分解为三部分:1,0*,1;
(2) 画出三者的状态转换图:
1
0
1
0 2
1
3
4
(3) 连接运算:子图首尾相连
1
0 1
0
11
4
这已经是最小的DFA
© 西安电子科技大学 ·软件学院
14
11
其它
关于:正规式 -> NFA -> DFA -> DFA最小化: 说明:(一般)逐步计算 正规式->NFA: (1)呆板Thompson算法:
自上而下分解正规式—— 语法树, 自下而上构造NFA —— 后续遍历; 特点:每个运算对应一次构造,繁琐! (2)活用Thompson算法: 分解正规式:得到若干规模适中的子正规式; 为每个子正规式:画出其最简的状态转换图(子图); 按Thompson算法,将子图组合,得到完整的图。
长度为4:0011, 1100,
? 0101, 0110, 1001, 1010
b) 前4个串: 由00和11组成的串 正规式B*, B= 00 | 11
编译原理第二版作业答案_第2章

第二章 文法和语言p48 4、6(6)、11、 12(2)(6)、18(2)4 证明文法G=({E,O},{(,),+,*,v ,d},P ,E )是二义的,其中P 为 E → EOE | (E) | v | d O → + | * 证明:因为E=〉 EOE =〉EOEOE =〉EOEOv =〉EOE+v=〉EOv+v =〉E*v+v =〉v*v+v , 句子v*v+v 有两棵不同的语法树所以文法G 是二义的。
问题:1)只有文字说明,比如v*v+v 有两棵语法树,但没有画出语法树或者最左(最右)推导过程2)给出的是不同句子(v*v+d v+v*d )的语法树 6、已知文法G :EEEE OO v*v+ vE EE E O O v+v* v〈表达式〉∷=〈项〉|〈表达式〉+〈项〉〈项〉∷=〈因子〉|〈项〉*〈因子〉〈因子〉∷=(〈表达式〉)| i试给出下述表达式的推导及语法树(6)i+i*i推导过程:〈表达式〉=〉〈表达式〉+〈项〉E=〉E+T =〉〈表达式〉+〈项〉*〈因子〉=〉E+ T*F=〉〈表达式〉+〈项〉* i =〉E+ T*i=〉〈表达式〉+ 〈因子〉* i =〉E+F*i=〉〈表达式〉+ i* i =〉E+i*i=〉〈项〉+ i* i =〉T +i*i=〉〈因子〉+ i* i =〉F +i*i=〉i +i*i =〉i +i*i 共8步推导语法树:〈表达式〉+〈因子〉〈项〉i 〈因子〉i〈项〉〈项〉〈因子〉i*11、一个上下文无关文法生成句子abbaa的推导树如下:(1)给出该句子相应的最左推导和最右推导(2)该文法的产生式集合P可能有哪些元素?(3)找出该句子的所有短语、简单短语、句柄。
(1)最左推导:S=〉ABS=〉aBS=〉aSBBS=〉aBBS=〉abBS=〉abbS =〉abbAa=〉abbaa最右推导:S =〉ABS=〉ABAa=〉ABaa=〉ASBBaa=〉ASBbaa=〉ASbbaa=〉Abbaa=〉abbaa(2)该文法的产生式集合P可能有下列元素:S→ABS | Aa|εA→a B→SBB|b(3)因为字符串中的各字符有相对的位置关系,为了能相互区别,给相同的字符标上不同的数字。
(完整word版)编译原理课后答案

第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。
编译原理教程课后习题答案第二章
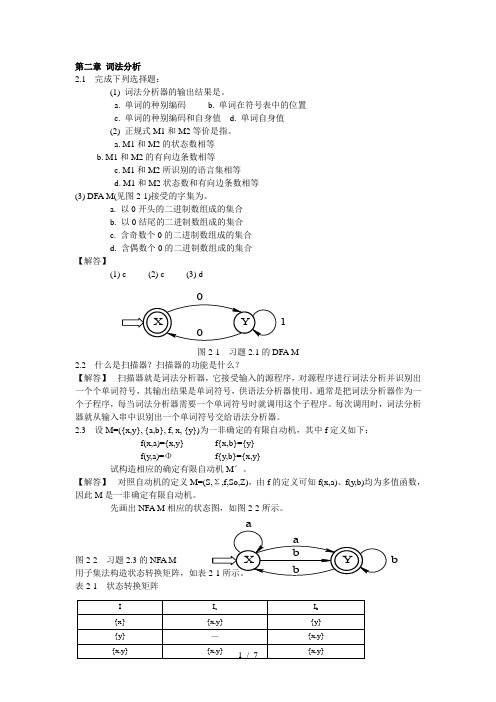
第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指。
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。
《编译原理》课后习题答案第二章

有代表性的符号串:a,a0,aa,a00,a0a,aa0
习题2
3.(1)E T T/F F/F (E)/F (E+T)/F (T+T)/F (F+F)/F (i+i)/i
(2)E E+T E+T+T E+T*F+F E+T*F+i E+T*T*F+i
M:M(0,a)=1 M(0,b)=2
M(1,a)=1 M(1,b)=4
M(2,a)=1 M(2,b)=3
M(3,a)=3 M(3,b)=2
M(4,a)=0 M(4,b)=5
M(5,a)=5 M(5,b)=1
化简:
1.分化
① {0,1} {2,3,4,5}
② {0,1} {2,4} {3,5}
2.合并
=M(M(D,1),1011)
=M(M(C,1),011)
=M(M(F,0),11)
=M(M(E,1),1)
=M(C,1)
=F
∴DFA D能接受字符串0011011
8.解:将状态转换图列表,即:
由左图可知,该状态转换图直接对应的是确定有穷状态自动机DFA
DFA D=({0,1,2,3,4,5},{a,b},M,0,{0,1})
A::=bc|bAc
(2)Z::=AB
A::=ab|aAb
B::=b|Bb
7. 解:题中要求文法是:
Z::=1|3|5|7|9|Z1|Z3|Z5|Z7|Z9|A1|A3|A5|A7|A9
A::=2|4|6|8|A0|A2|A4|A6|A8|Z0|Z2|Z4|Z6|Z8
编译原理习题解答(第2-3章)_吴蓉

P39 12.试分别构造产生下列语言的文法: 试分别构造产生下列语言的文法: 试分别构造产生下列语言的文法 (1){ abna | n=0,1,2,3……} ) , , , (3){ aban | n≥1} ) (5){ anbmcp | n,m,p≥0} ) , , 解: (1)G={VN,VT,P,S},VN={S,A },VT= ) = , , , , {a,b}, , , P:S∷=aAa : ∷ 或 S∷=aB ∷ A∷=bA |ε B∷=bB | a ∷ ∷ (3)G={VN,VT,P,S},VN={S,A },VT= ) = , , , , {a,b}, , , P:S∷=abA : ∷ 或 S∷=Sa | aba ∷ A∷=aA | a ∷
P41 27. 给 出 一 个 产 生 下 列 语 言 L ( G ) = {W|W∈{a,b}*且W中含 的个数是 个数两倍的前 中含a的个数是 ∈ 且 中含 的个数是b个数两倍的前 后文无关文法。 后文无关文法。 解:文法G=({S, A, B}, {a, b}, P, S) 文法 P: S::=AAB|ABA|BAA|ε A::=aS B::=bS 或者 S::=Saab|aSab|aaSb|aabS|Saba|aSba|abSa|abaS|Sbaa |bSaa|baSa|baaS|ε 或者 S::=aaB|aBa|Baa|ε B::=SbS
1 0 S 0
A
0 Z 0
1
解题思路二: 写出其正规表达式 解题思路二 : 写出其正规表达式(0|10)*(10|0|1)【 如果仅有 【 (0|10)*的话推导不出 ,因为是连接关系,后面缺了 的话 的话推导不出1,因为是连接关系,后面缺了10的话 的话推导不出 就会以1结尾 同样的道理还要推导出0, 结尾, 就会以 结尾 , 同样的道理还要推导出 , 所以得到此正规 画出转换系统,然后根据转换系统来推导出文法。 式 】 , 画出转换系统 , 然后根据转换系统来推导出文法 。 也可以根据正规表达式直接写文法,例如正规表达式 (0|10)*(10|0|1)可以看成是 可以看成是a*b,推导出 可以看成是 ,推导出A::= (0|10)A|10|0|1, , 即A::= 0A|1B|10|0|1,其中 ,其中B::=0A,但是 此项不符合正规 ,但是10此项不符合正规 文 法 的 选 项 , 可 以 进 行 改 写 从 而 得 到 A::= 0A|1B|0|1 B::=0A|0。 。
编译原理第二章习题答案

第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2.文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D……D3.已知文法G[S]:Sf dAB Af aA|a B|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法? [答案]正规式是daa*b* ;相应的正规文法为(由自动机化简来):G[S]:S —dA A —a|aB B —aB|a|b|bC C —bC|b也可为(观察得来):G[S]:S —dA A —a|aA|aB B —bB| &4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}5.给出语言{a n b n c1 n>=1,m>=0}的上下文无关文法。
[分析]本题难度不大,主要是考上下文无关文法的基本概念。
上下文无关文法的基本定义是:A-> B ,A € Vn ,B€( VnU Vt) *,注意关键问题是保证a n b n的成立,即“ a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解决。
[答案]构造上下文无关文法如下:S->AB|AA->aAb|abB->Bc|c[扩展]凡是诸如此类的题都应按此思路进行,本题可做为一个基本代表。
基本思路是这样的:要求符合a n b n c m,因为a与b要求个数相等,所以把它们应看作一个整体单元进行,而c m做为另一个单位,初步产生式就应写为S->AB,其中A推出a n b n,B推出c m。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}==============================================2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D===============================================3.已知文法G[S]:S→dAB A→aA|a B→ε|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法?[答案]正规式是daa*b*;相应的正规文法为(由自动机化简来):G[S]:S→dA A→a|aB B→aB|a|b|bC C→bC|b也可为(观察得来):G[S]:S→dA A→a|aA|aB B→bB|ε===================================================================== ==========4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}===================================================================== =========5.给出语言{a n b n c m|n>=1,m>=0}的上下文无关文法。
[分析]本题难度不大,主要是考上下文无关文法的基本概念。
上下文无关文法的基本定义是:A->β,A∈Vn,β∈(Vn∪Vt)*,注意关键问题是保证a n b n的成立,即“a与b的个数要相等”,为此,可以用一条形如A->aAb|ab的产生式即可解决。
[答案]构造上下文无关文法如下:S->AB|AA->aAb|abB->Bc|c[扩展]凡是诸如此类的题都应按此思路进行,本题可做为一个基本代表。
基本思路是这样的:要求符合a n b n c m,因为a与b要求个数相等,所以把它们应看作一个整体单元进行,而c m做为另一个单位,初步产生式就应写为S->AB,其中A推出a n b n,B推出c m。
因为m可为0,故上式进一步改写为S->AB|A。
接下来考虑A,凡是要求两个终结符个数相等的问题,都应写为A->aAb|ab形式,对于B就很容易写成B->Bc|c了。
===================================================================== =========6 .写一文法,使其语言是偶正整数集合。
要求:(1)允许0开头;(2)不允许0开头。
[答案](1)允许0开头的偶正整数集合的文法E->NT|G|SFMT->NT|GN->D|1|3|5|7|9D->0|GG->2|4|6|8S->NS|εF->1|3|5|7|9|GM->M0|0(2)不允许0开头的偶正整数集合的文法E->NT|DT->FT|GN->D|1|3|5|7|9D->2|4|6|8F->N|0G->D|0===================================================================== ========7.已知文法G:E->E+T|E-T|TT->T*F|T/F|FF->(E)|i试给出下述表达式的推导及语法树(1)i; (2)i*i+i (3)i+i*i (4)i+(i+i)[答案](1)E=>T=>F=>i(2)E=>E+T=>T+T=>T*F+T=>F*F+T=>i*F+T=>i*i+T=>i*i+F=>i*i+i(3)E=>E+T=>T+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*i(4)E=>E+T=>T+T=>F+T=>i+T=>i+F=>i+(E)=>i+(E+T)=>i+(T+T)=>i+(F+T)=>i+(i+T)=>i+(i+F)=>i+(i+i)8 .为句子i+i*i构造两棵语法树,从而证明下述文法G[<表达式>]是二义的。
〈表达式〉->〈表达式〉〈运算符〉〈表达式〉|(〈表达式〉)|i〈运算符〉->+|-|*|/[答案]可为句子i+i*i构造两个不同的最右推导:最右推导1〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉i=>〈表达式〉* i=>〈表达式〉〈运算符〉〈表达式〉* i=>〈表达式〉〈运算符〉i * i=>〈表达式〉+ i * i=> i + i * i最右推导2〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉〈运算符〉〈表达式>=>〈表达式〉〈运算符〉〈表达式〉〈运算符〉 i=>〈表达式〉〈运算符〉〈表达式〉 * i=> 〈表达式〉〈运算符〉i * i=>〈表达式〉+ i * i=> i + i * i所以,该文法是二义的。
================================================================= =====9. 文法G[S]为:S->Ac|aBA->abB->bc该文法是否为二义的?为什么?[答案]对于串abc(1)S=>Ac=>abc(2)S=>aB=>abc即存在两不同的最右推导所以,该文法是二义的。
===================================================================== ======10.考虑下面上下文无关文法:S->SS*|SS+|a(1)表明通过此文法如何生成串aa+a*,并为该串构造语法树。
(2) G[S]的语言是什么?[答案](1)此文法生成串aa+a*的最右推导如下S=>SS*=>SS*=>Sa*=>SS+a*=>Sa+a*=>aa+a*(2)该文法生成的语言是即加法和乘法的逆波兰式,===================================================================== =========11. 令文法G[E]为:E->E+T|E-TT->T*F|T/F|FF->(E)|I证明E+T*F是它的一个句型,指出这个句型的所有短语、直接短语和句柄。
[答案]此句型对应语法树如右,故为此文法一个句型。
或者:因为存在推导序列: E=>E+T=>E+T*F,所以 E+T*F句型此句型相对于E的短语有:E+T*F;相对于T的短语有T*F,直接短语为:T*F;。
句柄为:T*F12.已知文法G[E]:E→ET+|T T→TF* | F F→F^ | a试证:FF^^*是文法的句型,指出该句型的短语、简单短语和句柄.[答案]该句型对应的语法树如下:该句型相对于E的短语有FF^^*;相对于T的短语有FF^^*,F;相对于F的短语有F^;F^^;简单短语有F;F^;句柄为F.13.一个上下文无关文法生成句子abbaa的推导树如下:(1)给出串abbaa最左推导、最右推导。
(2)该文法的产生式集合P可能有哪些元素?(3)找出该句子的所有短语、直接短语、句柄。
(1)串abbaa最左推导:S=>ABS=>aBS=>aSBBS=>aεBBS=>aεbBS=>aεbbS=>aεbbAa=>aεbbaa 最右推导:S=>ABS=>ABAa=>ABaa=>ASBBaa=>ASBbaa=>ASbbaa=>Aεbbaa=>aεbbaa (2)产生式有:S→ABS |Aa|εA→aB→SBB|b(3)该句子的短语有a1b1b2a2a3、a1、b1、b2、b1b2、a2a3、a2;直接短语有a1、b1、b2、a2;句柄是a1。
===================================================================== 14.给出生成下列语言的上下文无关文法。
(1){ a n b n a m b m |n,m>=0} (2) { 1n0m 1m0n| n,m>=0}(3){WaW r|W属于{0|a}*,W r表示W的逆}[答案](1){a n b n a m b m| n,m>=0}S->AAA->aAb|ε(2) { 1n0m 1m0n| n,m>=0}S->1S0|AA->0A1|ε(3){WaW r|W属于{0|a}*,W r表示W的逆}S->0S0|1S1|ε=================================================================== 15 .给出生成下列语言的三型文法。
(1){ a n|n >=0 }(2){ a n b m|n,m>=1 }(3){a n b m c k|n,m,k>=0 }[答案](1) { a n|n >=0 }的三型文法为:S->aS|ε(2){ a n b m|n,m>=1 }的三型文法为:S->aAA->aA|bBB->bB|ε(3){a n b m c k|n,m,k>=0 }的三型文法为:A->aA|bB|cC|εB->bB|cC|εC->cC|ε===================================================================== =====16.构造一文法产生任意长的a,b串,使得|a|<=|b|<=2|a|其中,“|a|”表示a字符的个数;“|b|”表示b字符的个数。