Distributed System Architectures
mp2文档

mp2Abstract:The purpose of this document is to provide an overview of the MP2 (Message Passing Interface 2) protocol. MP2 is a communication protocol used for parallel computing in distributed systems. This document will discuss the features, architecture, and usage of MP2, as well as some common use cases and examples.IntroductionMP2, short for Message Passing Interface 2, is a widely used communication protocol for parallel computing in distributed systems. It is designed to facilitate communication and coordination between processes or nodes in a parallel computing environment. MP2 provides a standardized interface for message passing, which allows different components of a distributed system to exchange data and synchronize their activities efficiently.Features of MP2MP2 offers several important features that make it a preferred choice for parallel computing:1.Portability: MP2 is a portable protocol, which means it can be usedacross various platforms and architectures. It supports a wide range ofoperating systems, including Windows, Linux, and macOS.2.Scalability: MP2 is highly scalable, allowing the addition of morenodes or processes to the system without significant performance degradation.It supports both small-scale and large-scale parallel computing, making itsuitable for a variety of applications.3.Efficiency: MP2 is designed to be highly efficient in terms of bothcommunication overhead and resource utilization. It optimizes data transfer and minimizes latency, allowing for faster and more efficient parallelcomputations.4.Fault-tolerance: MP2 includes mechanisms for fault-tolerance,allowing the system to continue functioning even in the presence of failures. It provides fault detection, recovery, and error handling capabilities to ensure the reliability of parallel computing applications.Architecture of MP2MP2 follows a client-server architecture, where the nodes or processes involved in parallel computing can be categorized as clients or servers. The clients initiate communication by sending messages to servers, and servers respond to these messages accordingly. MP2 uses a message queue to manage the messages, allowing for asynchronous communication between nodes. It also supports both point-to-point and collective communication, providing flexibility in designing parallel algorithms.Usage of MP2To use MP2 for parallel computing, developers need to implement the MP2 library or use existing MP2 libraries available for different programming languages. The MP2 library provides a set of functions and APIs to manage communication, data exchange, and synchronization between processes or nodes. Developers can use these functions to send and receive messages, perform collective operationssuch as broadcast and reduce, and synchronize their activities using barriers or locks.Common Use CasesMP2 is widely used in various fields where parallel computing is required. Some common use cases of MP2 include:1.Scientific Computing: MP2 is used in scientific simulations, wherecomplex calculations are performed in parallel across multiple nodes. It allows scientists to speed up computations and solve larger-scale problems moreefficiently.2.Big Data Processing: MP2 is used in distributed data processingframeworks such as Apache Spark and Hadoop. It enables efficientcommunication and coordination between nodes for processing large volumes of data in parallel.3.High-Performance Computing: MP2 is used in high-performancecomputing clusters, where multiple nodes work together to solvecomputationally intensive problems. It allows for efficient parallelization ofalgorithms and improves overall performance.4.Machine Learning: MP2 is used in distributed machine learningframeworks such as TensorFlow and PyTorch. It enables efficient training and inference across multiple nodes, allowing for faster model development and deployment.Example: Parallel Matrix MultiplicationTo illustrate the usage of MP2, let’s consider an example of parallel matrix multiplication. Suppose we have two matrices A and B, and we want to calculate their product C = A * B. By using MP2, we can distribute the computation across multiple nodes and perform the multiplication in parallel.# Pseudocode for parallel matrix multiplication using MP2import mp2def multiply_matrices(A, B):num_rows = len(A)num_cols = len(B[0])result = [[0] * num_cols for _ in range(num_rows)]# Create MP2 processesprocesses = mp2.create_processes()# Distribute computationmp2.scatter(processes, A, B)# Perform local multiplicationlocal_result = mp2.multiply_local(processes)# Gather resultsmp2.gather(processes, local_result, result)# Synchronize processesmp2.barrier(processes)return result# Usage exampleA = [[1, 2, 3],[4, 5, 6]]B = [[7, 8],[9, 10],[11, 12]]result = multiply_matrices(A, B)print(result)In this example, the computation is divided into multiple processes using the MP2 library. Each process performs a local multiplication of a subset of the matrices, and the results are gathered to obtain the final result. The MP2 barrier function is used to synchronize the processes before returning the result.ConclusionMP2 is a powerful communication protocol for parallel computing in distributed systems. It offers a standardized and efficient way to exchange data and coordinate activities between nodes or processes. With its portability, scalability, efficiency, and fault-tolerance features, MP2 is widely used in various fields for parallel computing applications. This document has provided an overview of the features, architecture, and usage of MP2, as well as a practical example of its usage in parallel matrix multiplication.。
软件工程试卷及答案,英文版

2011~2012学年第二学期期末考试《软件工程(双语)》复习范围注意事项:每个学生必须写上本人的学号、任课教师姓名、姓名、班级,另外所有的答案必须全部写在答卷纸上请不要写的试卷上,试题及答卷一同交上。
Part 1 Select the most appropriate choice to answer the following questions or to complete following statements. (1*15 =15 )1.. Which one of following statement about Client-server architecture is not correct? ca)Set of stand-alone servers which provide specific services such as printing, datamanagement, etc.b)Set of clients which call on these services.c)Most of the data is stored in the most important server.d)Network which allows clients to access servers..2. . Several techniques of Requirements discovery are covered in this book. Which one is not the case? aa)Model-driven engineeringb)Scenariosc)Interviewingd)EthnographyPart 2 Mark the right statement √, the wrong statement×(1*15=15)1.In the software architecture design,using large-grain components improvesperformance and maintainability.2.According Lehman and Belady's ‘laws’ , A program that is used in a real-worldenvironment must necessarily change, or else become progressively less useful inthat environment.Part 3 Fill the blankets: (1*15=15)1.the attributes of good software are are Maintainability , Dependability,Efficiency , Acceptability2.General issues that affect most software are heterogeneity , Business and social change ,Security and trust .3.The reasons of software change are 1 New requirements emerge when the software isused ,The business environment changes ,Errors must be repaired ,Newcomputers and equipment is added to the system;The performance or reliability of the system may have to be improved.4.Generic process models are The waterfall model , Incremental development ,Reuse-oriented software engineering.5. A structured set of activities required to develop a software system, which areSpecification , Design and implementation, Validation _, Evolution.Part 4 Answer the following questions in brief. (4*5=20 )1.What are the program testing goals?Program testing goalsTo demonstrate to the developer and the customer that the software meets its requirements.For custom software, this means that there should be at least one test for everyrequirement in the requirements document.For generic software products, it means that there should be tests for all of the systemfeatures,plus combinations of these features, that will be incorporated in the product release.To discover situations in which the behavior of the software is incorrect, undesirable or does not conform to its specification.Defect testing is concerned with rooting out undesirable system behavior such as system crashes, unwanted interactions with other systems, incorrect computations and data corruption.2.What is architectural patterns?Architectural patterns are a means of reusing knowledge about generic system architectures. They describe the architecture,explain when it may be used and describe its advantages and disadvantages.3.What is the difference between software engineering and computer science?Computer science is concerned with theory and fundamentals; software engineering isconcerned with the practicalities of developing and delivering useful software4.What differences has the web made to software engineering?The web has led to the availability of software services and the possibility of developing highly distributed service-based systems.Web-based systems development has led to important advances in programming languages and software reuse.5.What is Software architecture design?Software architecture designThe design process for identifying the sub-systems making up a system and the framework for sub-system control and communication is architectural designThe output of this design process is a description of the software architectureThe architecture of a packing robot control system6.What is Path testing?The objective of path testing is to ensure that the set of test cases is such that each path through the program is executed at least onceBinary search flow graphPart 5 Solve the following problems(30)1.(5) Based on your experience with a bank A TM, draw an activity diagram that modelsthe data processing involved when a customer withdraws cash from the machine.2.(5) Develop a sequence diagram showing the interactions involved in a application.3.(5) Design the application architecture using the MVC pattern.4.(5)Design a set of test data to accomplish the path testing about the following program(Figure 1).5.(10) Based on the statechart which models a application, describe the whole process indetail.。
6G室内定位技术原理与展望

不同于已经形成广阔且完整的基于全球定位 系统(the global positioning system,GPS)的室外 卫星定位网络,室内环境十分复杂,且随时会因
为人的行为而发生改变。无线信号受室内环境的 影响导致非视距传播(non-line of sight,NLOS), 致使信号不可预测地出现衰减、散射、阴影和盲 点等情况,因而将传统的室外定位网络应用于室 内时无法获得理想的定位效果。目前,常见的室 内定位技术有基于到达时间(time of arrival, TOA)、到达角(angle of arrival,AOA)、接收信 号强度(received signal strength,RSS)和信道状 态信息(channel state information,CSI)等典型测 距技术,也有基于信号指纹的非测距技术。此外, 借助智能手机内置惯性测量单元(inertial measurement unit,IMU)也可实现行人自主定位导航 功能。
y 定位时延:指定位终端到达定位地点与服 务器输出该定位结果之间的时间差,需考 虑服务器输出定位结果的频率(即定位刷 新率)以及被测终端的移动速度。越小的 定位时延即表示越好的追踪效果,6G 场景 下有望实现时延小于 1 ms。
y 定位成本:包括设备成本、功耗成本以及 人力成本。面对 6G 大连接物联网场景,定 位成本往往成为定位技术首要考虑的性能 指标。
操作系统经典书籍推荐

本书第二本和第一本很多地方相似,区别在于第二本理论偏重一些,第一本实例讨论的更多 一些。这两本书别看很厚,但是写的非常流畅,属于比较易读的一类。 3. 现代操作系统(英文版•第2版) Andrew S. Tanenbuam(坦尼伯姆, AST)是第4本书的升级版,里面添加了一些新的操作系统 方面的讨论,原理部分比第四本稍有增强。个人认为,是除了前面两本之外的最好的书。 4. 操作系统: 设计及实现(第二版)(英文影印版) 这个比较有名了,主要是分析 minix 源代码的书,顺带着讲了下原理,应该说是偏于实践的, 可能当年的 linus 的教材就是这本,影响较大,可以帮助你了解一个文件系统或系统调用之 类是如何实现的。当然,和目前的操作系统来讲,稍简单了一些。想做 linux kernel hacker 的同学此书可以一读。 5. 操作系统:现代观点(第二版 实验更新版)(英文版) Operating Systems: A design-Oriented Approach 这两本一般,但是还是比国内抄袭的教 材强很多,可以作为补充阅读的书籍。 6. LINUX 内核源代码情景分析(上册) LINUX 内核源代码情景分析(下册) Understanding Linux Kernel Linux internal 这三本是最 nb 的 linux 内核分析书籍,后两本讲2.2内核,第一本讲2.4。 7. 4.4BSD 操作系统设计与实现(英文影印版) 不说少了,原来 berkeley 那帮写 bsd 的其中几个人写的,经典就是它了。 8. UNIX 操作系统设计(英文版) :古老的 unix 设计方面的书籍,应该说这本书在 unix 世界里面的影 响是十分巨大的,很多后来的 unix 分枝,思想都是缘于此书。里面主要讲解 unix 各个部分
DistributedSystemsPrinciplesandParadigms中文版书名分布

Marcus,Sten : Blueprints for High Availablity
Birman, Reliable Distributed Systems
Byzantine Failure问题:
Pease,M., “Reaching Agreement in the Presence of Faults” J.ACM,1980
Lamport,L.: “Byzantine Generals Problem. ” ACM T ng.syst. 1982
Shooman,M.L: Reliability of Computer Systems and Networks :Fault Tolerance, Analysis, and Design. 2002
Tanisch,P., “Atomic Commit in Concurrent Computing. ” IEEE Concurrency,2000
集中式体系结构:C/S
分布式体系结构:
点对点系统(peer-peer system):DHT(distributed hash table),例如Chord
随机图(random map)
混合体系结构:
协作分布式系统BitTorrent、Globule
自适应软件技术:
①要点分离
②计算映像
③基于组件的设计
Henning,M., “A New Approach to Object-Oriented Middleware”
第11章分布式文件系统
NFS (Network File System):远程访问模型
参考文献——精选推荐

参考⽂献参考⽂献1.B.Kadar,L.Monostori,E.Szelke, An Object-Oriented Framework for Developing Distributed Manufacturing System Design’97,paper2,19972.先进制造技术孙⼤涌屈贤明张松滨机械⼯业出版社3.汪应洛新世纪的⽣产系统-精简、敏捷、柔性⽣产系统中国机械⼯程,V o.,6. No.5. pp.7-9 4.Approaches for commissioning time reduction Rolf Bernhardt Industrial Robot V olume 24.Number1.1997.pp.62-715.PROGRAMMING METHEDS FOR INDUSTRIAL ROBOTS Prof.Dr.-Ing. A.Storr, Dip;.-Inform. H. Schumacher Off-Line Programming of Industrial Robots IFIP,19876.Yoram Regev, The evolution of off-line programming, Industrial Robot,V ol.22,No.3,1995,3.7.NICHOLAS TARNOFF, Graphical Simulation for Sensor Based Robot Programming, Journal of Intelligent and Robotic Systems, No 5, 1992, 49-62.8.Wang, K.S., Computer Graphical Simulation System for Robot Manipulators, Robotics and Autonomous System, No.5, 1989, 183-190.9.A.R. Thangaraj, M. Doelfs, Reduce Downtime With Off-line Programming, Robotics Today, 4(2), 1991, 1-3.10.M.L.Hornick and B.Ravani, Computer-Aided Off-line Planning and Programming of Robot Motion, Int.J,of Robtics Research, 1986, vol 4, No.4,pp.18-31.11.Megahed, M.S., Principles of Robot Modeling and Simulation, John Wiley & Sons, 1993.12.E.Freund,J.Ro mann, Systems Approach to Robots and Automation, Proc,of IEEE Trans. On Robotics and Automation, 1995, vol.1, pp.684-704.13.R.O.Buchal, et al, Simulated Off-line Programming of Welding Robots, Int. J.of Robotic Research, 1989,vol.8,No.3,pp.31-43.14.Maraghy, H.A., Hamid L. Robocell: A Computer-Aided Robots Modeling and Workstation Layout System, The International Journal of Advanced Manufacturing Technology, 2(2), 1987, 43-59.15.B.Ravani, World Modeling for CAD Based Robot Program and Simulation, CAD Based Programming for Sensory Robots, Springer-Verlag Berlin Heidenberg, 1988,pp.67-89.16.L.Levals,et al, WADE:An Object-oriented Environment for Modeling and Simulation of Workcell Application, IEEE Trans. On Robotics and Automation, 1989, vol 5, No.3, pp.324-336.17.E.Trostmann, F. Conrad, L.F. Nielsen and S. Trostmann. ROPSIM, A Robot Off-line Programming and Real-time Simulation System including Dynamics. IFAC Robot Control, Vienna, Austria, 1991.18.何汉武熊有伦胡汉桥⽜喜收⼀个基于微机的机器⼈离线编程系统华中理⼯⼤学学报第20卷第5期1992,1019.徐国桦杨起帆徐毓良沉家正林建勇⼀个装配机器⼈离线编程系统的设计与实现机器⼈V ol.17, No.3,, May, 1995.20.付宜利马云辉赵春霞王树国吴菁机器⼈离线编程与系统组合机床与⾃动化加⼯技术1995年第1期.21.姜⼭程君实包志军⾯向对象机器⼈实时仿真系统的实现22.门⽥安弘着史世民译丰⽥⽣产⽅式的新发展西安交通⼤学出版社23.Richard K M. Survey on Flexible Manufacturing System. Future Technology Survey Inc, 1989. 24.Kusiak A. Intelligent Manufacturing Systems. Prentice-Hall, 1990.25.Lickety-Split. U.S. Production Shifts to Agile Manufacturing. SIGNAL, 1993,(8).26.张曙.全能制造系统。
2012-12-12课程回顾

开卷考试题型
简述和比较题 系统设计题(涉及需求、体系结构、OO设计)
总共7~8题,其中1~2与系统设计相关
课程回顾(八)
2012-11-14 “Software Evolution”
Praintenance Evolution processes Legacy system evolution 2012-11-14 “Component Based Software
课程回顾(六)
2012-10-31 “OO design”
Objects and object classes
An object-oriented design process Design evolution 2012-10-31 “Design Pattern” Creational Patterns Structural Patterns Behavioral Patterns
课程回顾(二)
• 2012-09-26 “Software Processes”
• Software process models • Process iteration • Process activities • The Rational Unified Process • Computer-aided software engineering • 2012-09-26 “Project Management” • Management activities • Project planning • Project scheduling • Risk management
Software inspections
Automated static analysis Cleanroom software development
外文翻译---软件和软件工程

外文翻译:Software and software engineering ----the software appearance and enumeratesAs the decade of the 1980s began, a front page story in business week magazine trumpeted the following headline:” software: the new driving force.”software had come of age—it had become a topic for management concern. during the mid-1980s,a cover story in foreune lamented “A Growing Gap in Software,”and at the close of the decade, business week warned managers about”the Software Trap—Automate or else.”As the 1990s dawned , a feature story in Newsweek asked ”Can We Trust Our Software? ”and The wall street journal related a major software company’s travails with a front page article entitled “Creating New Software Was an Agonizing Task …” these headlines, and many others like them, were a harbinger of a new understanding of the importance of computer software ---- the opportunities that it offers and the dangers that it poses.Software has now surpassed hardware as the key to the success of many computer-based systems. Whether a computer is used to run a business, control a product, or enable a system , software is the factor that differentiates . The completeness and timeliness of information provided by software (and related databases) differentiate one company from its competitors. The design and “human friendliness” of a software product differentiate it from competing products with an otherwise similar function .The intelligence and function provided by embedded software often differentiate two similar industrial or consumer products. It is software that can make the difference.During the first three decades of the computing era, the primary challenge was to develop computer hardware that reduced the cost of processing and storing data .Throughout the decade of the 1980s,advances in microelectronics resulted in more computing power at increasingly lower cost. Today, the problem is different .The primary challenge during the 1990s is to improve thequality ( and reduce the cost ) of computer-based solutions- solutions that are implemented with software.The power of a 1980s-era mainframe computer is available now on a desk top. The awesome processing and storage capabilities of modern hardware represent computing potential. Software is the mechanism that enables us to harness and tap this potential.The context in which software has been developed is closely coupled to almost five decades of computer system evolution. Better hardware performance, smaller size and lower cost have precipitated more sophisticated computer-based syst ems. We’re moved form vacuum tube processors to microelectronic devices that are capable of processing 200 million connections per second .In popular books on “the computer revolution,”Osborne characterized a “new industrial revolution,” Toffer called the advent of microelectronics part of “the third wave of change” in human history , and Naisbitt predicted that the transformation from an industrial society to an “information society” will have a profound impact on our lives. Feigenbaum and McCorduck suggested that information and knowledge will be the focal point for power in the twenty-first century, and Stoll argued that the “ electronic community” created by networks and software is the key to knowledge interchange throughout the world . As the 1990s began , Toffler described a “power shift” in which old power structures( governmental, educational, industrial, economic, and military) will disintegrate as computers and software lead to a “democratization of knowledge.”Figure 1-1 depicts the evolution of software within the context of. computer-based system application areas. During the early years of computer system development, hardware underwent continual change while software was viewed by many as an afterthought. Computer programming was a "seat-of-the-pants" art for which few systematic methods existed. Software development was virtually unmanaged--until schedules slipped or costs began to escalate. During this period, abatch orientation was used for most systems. Notable exceptions were interactive systems such as the early American Airlines reservation system and real-time defense-orientedsystems such as SAGE. For the most part, however, hardware was dedicated to the union of, a single program that in turn was dedicated to a specific application.Evolution of softwareDuring the early years, general-purpose hardware became commonplace. Software, on the other hand, was custom-designed for each application and had a relatively limited distribution. Product software(i.e., programs developed to be sold to one or more customers) was in its infancy . Most software was developed and ultimately used by the same person or organization. You wrote it, you got it running , and if it failed, you fixed it. Because job mobility was low , managers could rest assured that you’d be there when bugs were encountered.Because of this personalized software environment, design was an implicit process performed in one’s head, and action was often nonexistent. During the early years we learned much about the implementation of computer-based systems, but relatively little about computer system engineering .In fairness , however , we must acknowledge the many outstanding computer-based systems that were developed during this era. Some of these remain in use today and provide landmark achievements that continue to justify admiration.The second era of computer system evolution (Figure 1.1) spanned the decade from themid-1960s to the late 1970s. Multiprogramming and multiuse systems introduced new concepts of human-machine interaction. Interactive techniques opened a new world of applications and new levels of hardware and software sophistication . Real-time systems could collect, analyze, and transform data form multiple sources , thereby controlling processes and producing output in milliseconds rather than minutes . Advances in on-line storage led to the first generation of database management systems.The second era was also characterized by the use of product software and the advent of "software houses." Software was developed for widespread distribution in a multidisciplinary market. Programs for mainframes and minicomputers were distributed to hundreds and sometimesthousands of users. Entrepreneurs from industry, government, and academia broke away to "develop the ultimate software package" and earn a bundle of money.As the number of computer-based systems grew, libraries of computer software began to expand. In-house development projects produced tens of thousands of program source statements. Software products purchased from the outside added hundreds of thousands of new statements. A dark cloud appeared on the horizon. All of these programs--all of these source statements-had to be corrected when faults were detected, modified as user requirements changed, or adapted to new hardware that was purchased. These activities were collectively called software maintenance. Effort spent on software maintenance began to absorb resources at an alarming rate.Worse yet, the personalized nature of many programs made them virtually unmentionable. A "software crisis" loomed on the horizon.The third era of computer system evolution began in the mid-1970s and continues today. The distributed system--multiple computers, each performing functions concurrently and communicating with one another- greatly increased the complexity of computer-based systems. Global and local area networks, high-bandwidth digital communications, and increasing demands for 'instantaneous' data access put heavy demands on software developers.The third era has also been characterized by the advent and widespread use of microprocessors, personal computers, and powerful desk-top workstations. The microprocessor has spawned a wide array of intelligent products-from automobiles to microwave ovens, from industrial robots to blood serum diagnostic equipment. In many cases, software technology is being integrated into products by technical staff who understand hardware but are often novices in software development.The personal computer has been the catalyst for the growth of many software companies. While the software companies of the second era sold hundreds or thousands of copies of their programs, the software companies of the third era sell tens and even hundreds of thousands of copies. Personal computer hardware is rapidly becoming a commodity, while software provides the differentiating characteristic. In fact, as the rate of personal computer sales growth flattened during the mid-1980s, software-product sales continued to grow. Many people in industry and at home spent more money on software than they did to purchase the computer on which the software would run.The fourth era in computer software is just beginning. Object-oriented technologies (Chapters 8 and 12) are rapidly displacing more conventional software development approaches in many application areas. Authors such as Feigenbaum and McCorduck [FEI83] and Allman [ALL89] predict that "fifth-generation" computers, radically different computing architectures, and their related software will have a profound impact on the balance of political and industrial power throughout the world. Already, "fourth-generation" techniques for software development (discussed later in this chapter) are changing the manner in which some segments of the software community build computer programs. Expert systems and artificial intelligence software has finally moved from the laboratory into practical application for wide-ranging problems in the real world. Artificial neural network software has opened exciting possibilities for pattern recognition and human-like information processing abilities.As we move into the fourth era, the problems associated with computer software continue to intensify:Hardware sophistication has outpaced our ability to build software to tap hardware's potential.Our ability to build new programs cannot keep pace with the demand for new programs.Our ability to maintain existing programs is threatened by poor design and inadequate resources.In response to these problems, software engineering practices--the topic to which this book is dedicated--are being adopted throughout the industry.An Industry PerspectiveIn the early days of computing, computer-based systems were developed usinghardware-oriented management. Project managers focused on hardware because it was the single largest budget item for system development. To control hardware costs, managers instituted formal controls and technical standards. They demanded thorough analysis and design before something was built. They measured the process to determine where improvements could be made. Stated simply, they applied the controls, methods, and tools that we recognize as hardware engineering. Sadly, software was often little more than an afterthought.In the early days, programming was viewed as an "art form." Few formal methods existed and fewer people used them. The programmer often learned his or her craft by trial and error. The jargon and challenges of building computer software created a mystique that few managers cared to penetrate. The software world was virtually undisciplined--and many practitioners of the clay loved it!Today, the distribution of costs for the development of computer-based systems has changed dramatically. Software, rather than hardware, is often the largest single cost item. For the past decade managers and many technical practitioners have asked the following questions: Why does it take so long to get programs finished?Why are costs so high?Why can't we find all errors before we give the software to our customers?Why do we have difficulty in measuring progress as software is being developed?These, and many other’ questions, are a manifestation of the concern about software and the manner in which it is developed--a concern that has tend to the adoption of software engineering practices.译文:软件和软件工程——软件的出现及列举在二十世纪八十年代的前十年开始的时候, 在商业周刊杂志里一个头版故事大声宣扬以下标题:“软件,我们新的驱动力!”软件带来了一个时代------它成为了一个大家关心的主题。
软件人员推荐书目(都是国外经典书籍!!!)

软件人员推荐书目(都是国外经典书籍!!!)软件测试编程C++CC# .软件人员推荐书目(一) 大师篇一、科学哲学和管理哲学【1】"程序开发心理学"(The Psychology of Computer Programming : Silver Anniversary Edition)【2】"系统化思维导论"(An Introduction to Systems Thinking, Silver Anniversary Edition)【3】 "系统设计的一般原理"( General Principles of Systems Design)【4】"质量?软件?管理(第1卷)—— 系统思维"(Quality Software Management:Systems Thinking)【5】 "成为技术领导者——解决问题的有机方法"(Becoming A Technical Leader:An Organic Problem Solving Approach)【6】"你的灯亮着吗?-发现问题的真正所在"( Are Your Lights On? How to Figure Out What the Problem Really Is)【7】 "程序员修炼之道"(The Pragmatic Programmer)【8】"与熊共舞:软件项目风险管理" (Waltzing With Bears: Managing Risk on Software Projects)【9】 "第五项修炼: 学习型组织的艺术与实务"( The Fifth Discipline)二、计算机科学基础【10】 "计算机程序设计艺术"(The Art of Computer Programming)【11】"深入理解计算机系统"(Computer Systems A Programmer's Perspective )【12】 "算法导论"(Introduction to Algorithms, Second Edition)【13】"数据结构与算法分析—— C语言描述(原书第2版) "(Data Structure & Algorithm Analysis in C, Second Edition)【14】"自动机理论、语言和计算导论(第2版)"(Introduction to Automata Theory, Languages, and Computation(Second Edition))【15】"离散数学及其应用(原书第四版)"(Discrete Mathematics and Its Applications,Fourth Edition)【16】 "编译原理"(Compilers: Principles, Techniques and Tools)【17】 "现代操作系统"(Modern Operating System)【18】 "计算机网络(第4版)"(Computer Networks)【19】"数据库系统导论(第7版)"(An Introduction to Database Systems(Seventh Edition))三、软件工程思想【20】 "人件"(Peopleware : Productive Projects and Teams, 2nd Ed.)【21】 "人件集 —— 人性化的软件开发"( The Peopleware Papers: Notes on the Human Side of Software)【22】 "人月神话"(The Mythical Man-Month)【23】"软件工程— 实践者的研究方法(原书第5版)"(Software Engineering: A Practitioner's Approach, Fifth Edition)【24】"敏捷软件开发-原则、模式与实践"(Agile Software Development: Principles, Patterns, and Practices)【25】 "规划极限编程"( Planning Extreme Programming) 【26】"RUP导论(原书第3版)"(The Rational Unified Process:An Introduction,Third Edition )【27】 "统一软件开发过程"(The Unified Software Development Process)四、软件需求【28】"探索需求-设计前的质量"(Exploring Requirements: Quality Before Design)【29】 "编写有效用例"(Writing Effective Use Cases )五、软件设计和建模【30】 "面向对象方法原理与实践"【31】"面向对象软件构造(英文版.第2版)"(Object-Oriented Software Construction,Second Edition )【32】"面向对象分析与设计(原书第2版)"(Object-Oriented Analysis and Design with Applications,2E )【33】 "UML面向对象设计基础"(Fundamentals of Object-Oriented Design in UML)【34】"UML精粹—— 标准对象建模语言简明指南(第2版)"(UML Distilled: A Brief Guide to the Standard Object Modeling Language (2nd Edition))【35】"UML和模式应用(原书第2版)"(Applying UML and Patterns:An Introduction to Object-Oriented Analysis and Design and the Unified Process,Second Edition )【36】 "设计模式精解"(Design Patterns Explained)【37】 "设计模式:可复用面向对象软件的基础"( DesignPatterns:Elements of Reusable Object-Oriented software)【38】"面向模式的软件体系结构卷1:模式系统"( Pattern-Oriented Software Architecture, Volume 1: A System of Patterns)【39】 "软件设计的艺术"(Bringing Design to Software)六、程序设计【40】 "编程珠矶"(Programming Pearls Second Edition )【41】 "C程序设计语言(第2版?新版)"(The C Programming Language )【42】"C++ 程序设计语言(特别版)"(The C++ Programming Language, Special Edition)【43】 "C++ Primer (3RD)"【44】 "C++语言的设计和演化"(The Design and Evolution of C++)【45】 "C++ 编程思想(2ND)"(Thinking in C++ Second Edition)【46】 "Effective C++" & "More Effective C++"【47】 "C++编程艺术 "(The Art of C++ )【48】 "Java 编程思想:第3版"( Thinking in Java, Third Edition)【49】 "Effective Java"七、软件测试【50】 "测试驱动开发(中文版)"(Test-driven development:by example )【51】"面向对象系统的测试"(Testing Object-Oriented System: Models, Patterns, and Tools)【52】"单元测试之道Java版—— 使用Junit"/ "单元测试之道C#版——使用NUnit" (Pragmatic Unit Testing:In Java with JUnit / Pragmatic Unit Testing:In C# with NUnit)八、软件维护和重构【53】"重构-改善既有代码的设计"(Refactoring: Improving the Design of Existing Code)九、配置管理和版本控制【54】"版本控制之道—— 使用CVS"(程序员修炼三部曲第一部:Pragmatic Version Control Using CVS)十、领域专题(网络、平台、数据库相关)【55】 "TCP/IP详解"( TCP/IP Illustracted)【56】 "Unix网络编程"(UNIX Network Programming)【57】"UNIX环境高级编程"(Advanced Programming in the UNIX Environment)【58】 "UNIX 编程艺术"(The Art of Unix Programming)【59】 "数据访问模式 —— 面向对象应用中的数据库交互"软件人员推荐书目(二) 拾遗篇【1】"系统思考"( 第五项修炼的核心,经理人处理复杂问题的利器) (Seeing the Forest for the Trees: A Manager's Guide to Applying Systems Thinking)【2】 "模式分析的核方法"(Kernel Methods for Pattern Analysis)【3】"计算机科学概论:第8版"(Computer Science : An Overview (8th Edition))【4】"计算机科学导论"(Foundations of Computer Science: From Data Manipulation to Theory of Computation)【5】 "编码的奥秘"(CODE)【6】"具体数学:计算机科学基础(英文版.第2版)"(Concrete Mathematics A Foundation for Computer Science(Second Edition))【7】"数据结构与算法分析C++描述(第2版)(英文影印版)"(Data Structures & Algorithm Analysis in C++(2nd ed.))【8】"数据结构与算法分析—— Java语言描述"(Data Structures and Algorithm Analysis in Java)【9】"数据结构、算法与应用:C++描述"(Data Structures,Algorithms and Applications in C++)【10】"数据结构与算法分析(C++版)第二版" (Practice Introduction to Data Structures and Algorithm Analysis (C++ Edition) (2nd Edition))【11】 "数据结构 C++语言描述"(Data Structures C++)【12】 "图论简明教程"(A Friendly Introduction to Graph Theory )【13】 "操作系统概念(第六版)"(Operating System Concepts,Sixth Edition)【14】"操作系统:设计与实现(第二版)上册、下册(新版)" (OPERATING SYSTEMS:Design and Implementation(Second edition))【15】"分布式系统-原理与范型"(Distributed Systems:Principles and Paradigms )【16】"4.4 BSD操作系统设计与实现(中文版)"(The Design and Implementation of the 4.4BSD Operation System)【17】 "莱昂氏UNIX源代码分析"(Lion' Commentary on UNIX 6th Edition With Source Code)【18】 "Linux内核设计与实现"(Linux Kernel Development)【19】 "编译原理及实践"(Compiler Construction: Principles and Practice)【20】"数据与计算机通信(第七版)"(Data and Computer Communications, Seventh Edition)【21】 "数据库系统概念"(Database System Concepts, Fourth Edition)【22】"数据库管理系统:原理与设计(第3版)" (Database Management Systems(Third Edition))【23】"数据库原理、编程与性能(原书第2版)" (Database-Principles, Programming, and Performance Second Edition )【24】 "最后期限"(The Deadline:a novel about project management)【25】 "死亡之旅(第二版)" (Death March, Second Edition )【26】"技术人员管理— 创新、协作和软件过程"(Managing Technical People:Innovation,Teamwork,and the Software Process)【27】 "个体软件过程"(Introduction to the Personal Software Process)【28】 "小组软件开发过程"(Introduction to the Team Software Process )【29】 "软件工程规范"(A Discipline for Software Engineering)【30】"快速软件开发——有效控制与完成进度计划"(Rapid Development)【31】 "超越传统的软件开发 —— 极限编程的幻象与真实"【32】"敏捷软件开发-使用SCRUM过程(影印版)"(Agile Software Development with Scrum)【33】"解析极限编程:拥抱变化(影印版)"(Extreme Programming Explained:Embrace Change)【34】"敏捷软件开发工具——精益开发方法"(Lean Software Development:An Agile Toolkit )【35】 "敏捷软件开发(中文版)"(Agile Software Development )【36】"特征驱动开发方法原理与实践"(A Practical Guide to Feature-Driven Development )【37】"敏捷建模:极限编程和统一过程的有效实践"(Agile Modeling:Effective Practices for eXtreme Programming and the Unified Process )【38】"敏捷项目管理"(Agile Project Management: Creating Innovative Products)【39】"自适应软件开发—一种管理复杂系统的协作模式" (Adaptive Software Development:a collaborative approach to managing complex systems)【40】"Rational统一过程:实践者指南"(The Rational Unified Process Made Easy: A Practitioner's Guide to the RUP )【41】"CMMI精粹--集成化过程改进实用导论"(CMMI Distilled: A Practical Introduction to Integrated Process Improvement )【42】"CMMI——过程集成与产品改进指南(影印版)"(CMMI : Guidelines for Process Integration and Product Improvement )【43】 "领域驱动开发"(Domain-Driven Design:Tacking Complexity in the heart of software)【44】 "创建软件工程文化"(Creating a Software Engineering Culture)【45】 "过程模式"(More Process Patterns : Delivering Large-Scale Systems Using Object Technology)【46】 "软件工艺"(Software Craftsmanship)【47】 "软件需求"(Software Requirements)【48】"软件需求管理:统一方法"(Managing Software Requirements:A Unified Approach)【49】"软件复用技术:在系统开发过程中考虑复用" (Software Reuse Techniques Adding Reuse to the Systems Development Process )【50】"软件复用:结构、过程和组织"(Software Reuse Architecture,Process and Organization for Business Success )【51】"分析模式:可复用的对象模型" (Analysis Patterns :Reusable Object Models )【52】 "Design by Contract原则与实践"( Design by Contract by Example )【53】 "UML 用户指南"(The Unified Modeling Language User Guide )【54】"UML参考手册"(The Unified Modeling Language Reference Manual)【55】"系统分析与设计(第5版)"(Systems Analysis and Design, Fifth Edition)【56】"软件构架实践(第2版)" (Software Architecture in Practice,Second Edition)【57】"企业应用架构模式"(Patterns of Enterprise Application Architecture )【58】"软件体系结构的艺术"(The Art of Software Architecture:Design Methods and Techniques)【59】"软件构架编档"(Documenting Software Architectures:Views and Beyond)【60】 "OO项目求生法则"(Surviving Object-Oriented Projects)【61】 "OOD启思录" (Object-Oriented Design Heuristics)【62】"对象揭秘:Java、Eiffel和C++"(Objects Unencapsulated: Java, Eiffel and C++)【63】"软件开发的科学与艺术"(The Science and Art of Software Development)【64】 "程序设计实践"(The Practice of Programming)【65】"代码阅读方法与实践"(Code Reading: The Open Source Perspective )【66】 "代码大全"(Code Complete)【67】 "重构手册(中文版)"(Refactoring workbook)【68】"程序设计语言——实践之路"(Programming Language Pragmatics )【69】 "高质量程序设计指南--C++/C语言"【70】 "C程序设计(第二版)"【71】 "C++程序设计"【72】"C++面向对象程序设计"(Object-Oriented Programming in C++ Fourth Edition )【73】 "C++ Gotchas(影印版)"(C++ Gotchas: Avoiding Common Problems in Coding and Design )【74】 "Essential C++ 中文版"(Essential C++)【75】 "C++经典问答"(C++ FAQs (2nd Edition) )【76】 "C++ Templates中文版"(C++ Templates: The Complete Guide )【77】"C++标准程序库—自修教程与参考手册"(The C++ Standard Library)【78】 "C++ STL(中文版)"(C++ Standard Template Library )【79】"泛型编程与STL"(Generic Programming and the STL: Using and Extending the C++ Standard Template Library )【80】 "C++多范型设计"(Multi-Paradigm Design for C++ )【81】"C++设计新思维(泛型编程与设计模式之应用)"(Modern C++ Design : Generic Programming and Design Patterns Applied)【82】 "C++沉思录"(Ruminations on C++)【83】 "Accelerated C++ 中文版"(Accelerated C++)【84】"Advanced C++ 中文版"(Advanced C++ Programming Styles and Idioms )【85】"Exceptional C++(中文版)" "More Exceptional C++(英文版)" (Exceptional C++, More Exceptional C++)【86】"C++编程惯用法—— 高级程序员常用方法和技巧" (C++ Strategies and Tactics )【87】 "深度探索C++对象模型"(Inside The C++ Object Model)【88】"Applied C++ 中文版——构建更佳软件的实用技术"(AppliedC++: practical techniques for building better software )【89】 "C++高效编程:内存与性能优化"(C++ Footprint and Performance Optimization)【90】"提高C++性能的编程技术"(Efficient C++: Performance Programming Techniques)【91】 "代码优化:有效使用内存"(Code Optimization: Effective Memory Usage )【92】 "大规模C++程序设计" ( large-Scale C++ Software Design)【93】"Java编程语言(第三版)"(The Java Programming Language,Third Edition )【94】 "UML Java程序员指南"(UML For Java Programmers)【95】 "最新 Java 2 核心技术"(Core Java 2)【96】 "Java编程艺术"(The Art of Java)【97】"J2EE核心模式(原书第2版)"(Core J2EE Patterns: Best Practices and Design Strategies, Second Edition)【98】 "应用程序调试技术"(Debugging Applications)【99】"软件测试"(Software Testing A Craftsmaj's Approach(Second Edition)【100】"软件测试求生法则"(Surviving the Top Ten Challenges of Software Testing:A People-Oriented Approach)【101】"功能点分析—成功软件项目的测量实践"(Function Point Analysis:Measurement Practices for Successful Software Projects)【102】"走查、审查与技术复审手册—对程序、项目与产品进行评估(第3版)"(Handbook of Walkthroughs,Inspections,and Technical Reviews:Evaluating Programs,Projects,and Products,3rd ed. )【103】 "配置管理原理与实践"(Configuration Management Principles and Practice)【104】 "软件发布方法"(Software Release Methodology)【105】 "Lex 与 Yacc(第二版)"(Lex & Yacc,Second Edition )【106】"用TCP/IP进行网际互联"(TCP/IP网络互联技术)(Internetworking With TCP/IP)【107】 "TCP/IP路由技术"(Routing TCP/IP)【108】"Windows 程序设计(第5版)(上、下册)"(Programming Windows (Fifth Edition) )【109】".NET构架技术与Visual C++编程"(.NET Architecture and Programming using Visual C++ )【110】"Microsoft .NET程序设计技术内幕" (Programming Microsoft.NET)【111】 "Microsoft C# Windows程序设计(上、下册)"【112】"基于C++ CORBA 高级编程"(Advanced CORBA Programming with C++)【113】 "计算机图形学"(Computer Graphics)【114】"计算机图形学:C语言版(第2版"英文影印版)"(Computer Graphics: C Version, Second Edition )【115】 "计算机图形学(第三版)"(Computer Graphics with OpenGL, 3e)【116】"Windows游戏编程大师技巧(第二版)"(Tricks of the Windows Game Programming Gurus, 2nd)【117】 "顶级游戏设计:构造游戏世界"(Ultimate Game Design: Building Game Worlds)【118】 "汇编语言编程艺术"(The Art of Assembly Language )【119】"软件剖析――代码攻防之道"(Exploiting Software:how to break code)【120】 "编写安全的代码"(Writing secure Code)【121】"应用密码学(协议算法与C源程序)"(Applied Cryptography:Protocols,Algorithms,and Source Code in C)【122】"网络信息安全的真相"(Secrets and Lies:Digital Security in a Networked World)【123】 "数据仓库项目管理"(Data Warehouse Project Management)【124】 "数据挖掘概念与技术"(Data Mining:Concepts and Techniques)【125】 "人工智能"(Artifical Intelligence: A new Synthesis)【126】 "神经网络设计" (Neural Network Design)【127】 "网格计算"(Grid Computing)【128】"工作流管理—模型方法和系统"(workflow management:models,methods,and systems)。
软考高级架构师技术选型40题

软考高级架构师技术选型40题1. In a large-scale e-commerce project, which of the following cloud computing services is most suitable for handling the peak traffic during the shopping festival?A. IaaSB. PaaSC. SaaSD. Serverless答案:A。
解析:IaaS( 基础设施即服务)提供了最大的灵活性和对底层基础设施的控制,能够根据需求快速扩展资源以应对高峰流量。
PaaS( 平台即服务)侧重于提供平台环境,对于处理突发的大规模流量扩展相对受限。
SaaS(软件即服务)是已经成型的应用服务,难以针对特定的高峰流量需求进行定制化扩展。
Serverless 适用于一些特定的短时间、低资源需求的任务,对于持续的高峰流量处理可能不够稳定。
2. For a financial company that needs to ensure high data security and compliance, which cloud computing model is the best choice?A. Public cloudB. Private cloudC. Hybrid cloudD. Community cloud答案:B。
解析:Private cloud(私有云)提供了最高级别的控制和安全性,能够满足金融公司对数据安全和合规性的严格要求。
Public cloud( 公有云)共享资源,安全性和合规性可能难以完全满足金融公司的特殊需求。
Hybrid cloud( 混合云)结合了公有云和私有云,但在数据安全和合规方面仍不如私有云直接和可控。
Community cloud( 社区云)共享程度较高,安全性和定制化程度不如私有云。
3. When choosing a cloud computing provider for a startup with limited budget and rapid growth expectations, which factor should be given the highest priority?A. CostB. ScalabilityC. SecurityD. Support services答案:B。
mmcn

A Measurement Study of Peer-to-Peer File Sharing SystemsStefan Saroiu,P.Krishna Gummadi,Steven D.GribbleDept.of Computer Science and Engineering,Univ.of Washington,Seattle,WA,98195-2350ABSTRACTThe popularity of peer-to-peer multimediafile sharing applications such as Gnutella and Napster has created a flurry of recent research activity into peer-to-peer architectures.We believe that the proper evaluation of a peer-to-peer system must take into account the characteristics of the peers that choose to participate.Surprisingly, however,few of the peer-to-peer architectures currently being developed are evaluated with respect to such considerations.In this paper,we remedy this situation by performing a detailed measurement study of the two popular peer-to-peerfile sharing systems,namely Napster and Gnutella.In particular,our measurement study seeks to precisely characterize the population of end-user hosts that participate in these two systems.This characterization includes the bottleneck bandwidths between these hosts and the Internet at large,IP-level latencies to send packets to these hosts,howoften hosts connect and disconnect from the system,howmany files hosts share and download,the degree of cooperation between the hosts,and several correlations between these characteristics.Our measurements showthat there is significant heterogeneity and lack of cooperation across peers participating in these systems.Keywords:Peer-to-Peer,Network Measurements,Wide-Area Systems,Internet Services,Broadband1.INTRODUCTIONThe popularity of peer-to-peerfile sharing applications such as Gnutella and Napster has created aflurry of recent research activity into peer-to-peer architectures.1–6Although the exact definition of“peer-to-peer”is debatable,these systems typically lack dedicated,centralized infrastructure,but rather depend on the voluntary participation of peers to contribute resources out of which the infrastructure is constructed.Membership in a peer-to-peer system is ad-hoc and dynamic:as such,the challenge of such systems is tofigure out a mechanism and architecture for organizing the peers in such a way so that they can cooperate to provide a useful service to the community of users.For example,in afile sharing application,one challenge is organizing peers into a cooperative,global index so that all content can be quickly and efficiently located by any peer in the system.2–4,6 In order to evaluate a proposed peer-to-peer system,the characteristics of the peers that choose to participate in the system must be understood and taken into account.For example,if some peers in afile-sharing system have low-bandwidth,high-latency bottleneck network connections to the Internet,the system must be careful to avoid delegating large or popular portions of the distributed index to those peers,for fear of overwhelming them and making that portion of the index unavailable to other peers.Similarly,the typical duration that peers choose to remain connected to the infrastructure has implications for the degree of redundancy necessary to keep data or index metadata highly available.In short,the system must take into account the suitability of a given peer for a specific task before explicitly or implicitly delegating that task to the peer.Surprisingly,however,few of the architectures currently being developed are evaluated with respect to such considerations.We believe that this is,in part,due to a lack of information about the characteristics of hosts that choose to participate in peer-to-peer systems.We are aware of a single previous study7that measures only one such characteristic,namely the number offiles peers share.In this paper,we remedy this situation by performing a detailed measurement study of the two most popular peer-to-peerfile sharing systems,namely Napster and Gnutella.The hosts that choose to participate in these systems are typically end-users’home or office machines,located at the“edge”of the Internet.Our measurement study seeks to precisely characterize the population of end-user hosts that participate in these two systems.This characterization includes the bottleneck bandwidths between these hosts and the Internet at large,IP-level latencies to send packets to these hosts,howoften hosts connect and disconnect from the system,howmanyfiles hosts share and dow nload,and correlations betw een these characteristics.Our The authors may be contacted at{tzoompy,gummadi,gribble}@measurements—four days for Napster andThere are amount of heterogeneity of sharing vary between three any similar peer-to-peer peers tend to deliberately responsibility depends on peers to tell the truth,or2.METHODOLOGYThe methodology behind our measurements is quite simple.For each of the Napster and Gnutella systems,we proceeded in two steps.First,we periodically crawled each system in order to gather instantaneous snapshots of large subsets of the systems’user population.The information gathered in these snapshots include the IP address and port number of the users’client software,as well as some information about the users as reported by their software.Second,immediately after gathering a snapshot,we actively probed the users in the snapshot over a period of several days to directly measure various properties about them,such as their bottleneck bandwidth.In this section of the paper,wefirst give a brief overview of the architectures of Napster and Gnutella. Following this,we then describe the software infrastructure that we built to gather our measurements,including the Napster crawler,the Gnutella crawler,and the active measurement tools used to probe the users discovered.2.1.The Napster and Gnutella ArchitecturesBoth Napster and Gnutella have similar goals:to facilitate the location and exchange offiles(typically images, audio,or video)amongst a large group of independent users connected through the Internet.In these systems,files are stored on the computers of the individual users or peers,and exchanged through a direct connection between the downloading and uploading peers,over an HTTP-style protocol.All peers in this system are symmetric:they all have the ability to function both as a client and a server.This symmetry distinguishes peer-to-peer systems from many conventional distributed system architectures.Though the process of exchanging files is similar in both systems,Napster and Gnutella differ substantially in howpeers locatefiles(Figure1).In Napster,a large cluster of dedicated central servers maintain an index of thefiles that are currently being shared by active peers.Each peer maintains a connection to one of the central servers,through which thefile location queries are sent.The servers then cooperate to process the query and return a list of matchingfiles and locations.On receiving the results,the peer may choose to initiate afile exchange directly from another peer. In addition to maintaining an index of sharedfiles,the centralized servers also monitor the state of each peer in the system,keeping track of metadata such as the peers’reported connection bandwidth and the duration that the peer has remained connected to the system.This metadata is returned with the results of a query,so that the initiating peer has some information to distinguish possible download sites.There are no centralized servers in Gnutella,however.Instead,Gnutella peers form an overlay network by forging point-to-point connections with a set of neighbors.To locate afile,a peer initiates a controlledflood of the network by sending a query packet to all of its neighbors.Upon receiving a query packet,a peer checks ifany locally storedfiles match the query.If so,the peer sends a query response packet back towards the query originator.Whether or not afile match is found,the peer continues toflood the query through the overlay.To help maintain the overlay as the users enter and leave the system,the Gnutella protocol includes ping and pong messages that help peers to discover other nodes.Pings and pongs behave similarly to query/query-response packets:any peer that sees a ping message sends a pong back towards the originator,and forwards the ping onwards to its own set of neighbors.Ping and query packets thusflood through the network;the scope offlooding is controlled with a time-to-live(TTL)field that is decremented on each hop.Peers occasionally forge newneighbor connections w ith other peers discovered through the ping/pong mechanism.Note that it is possible to have several disjoint Gnutella overlays of Gnutella simultaneously coexisting in the Internet;this contrasts with Napster,in which peers are always connected to the same cluster of central servers.2.2.Crawling the Peer-to-Peer SystemsWe nowdescribe the design and implementation of our Napster and Gnutella craw lers.2.2.1.The Napster CrawlerBecause we did not have direct access to indexes maintained by the central Napster servers,the only way we could discover the set of peers participating in the system at any time was by issuing queries forfiles,and keeping a list of peers referenced in the queries’responses.To discover the largest possible set of peers,we issued queries with the names of popular song artists drawn from a long list downloaded from the web.The Napster server cluster consists of approximately160servers;each peer establishes a connection with only one server.When a peer issues a query,the server the peer is connected tofirst reportsfiles shared by “local users”on the same server,and later reports matchingfiles shared by“remote users”on other servers in the cluster.For each crawl,we established a large number of connections to a single server,and issued many queries in parallel;this reduced the amount of time taken to gather data to3-4minutes per crawl,giving us a nearly instantaneous snapshot of peers connected to that server.For each peer that we discovered during the crawl,we then queried the Napster server to gather the following metadata:(1)the bandwidth of the peer’s connection as reported by the peer herself,(2)the number offiles currently being shared by the peer,(3)the current number of uploads and the number of downloads in progress by the peer,(4)the names and sizes of all thefiles being shared by the peer,and(5)the IP address of the peer.To get an estimate of the fraction of the total user population we captured,we separated the local and remote peers returned in our queries’responses,and compared them to statistics periodically broadcast by the particular Napster server that we queried.From these statistics,we verified that each crawl typically captured between40%and60%of the local peers on the crawled server.Furthermore,this40-60%of the peers that we captured contributed between80-95%of the total(local)files reported to the server.Thus,we feel that our crawler captured a representative and significant fraction of the set of peers.Our crawler did not capture any peers that do not share any of the popular content in our queries.This introduces a bias in our results,particularly in our measurements that report the number offiles being shared by users.However,the statistics reported by the Napster server revealed that the distributions of number of uploads,number of downloads,number offiles shared,and bandwidths reported for all remote users were quite similar to those that we observed from our captured local users.2.2.2.The Gnutella CrawlerThe goal of our Gnutella crawler is the same as our Napster crawler:to gather nearly instantaneous snap-shots of a significant subset of the Gnutella population,as well as metadata about peers in captured subset as reported by the Gnutella system itself.Our crawler exploits the ping/pong messages in the protocol to discover hosts.First,the crawler connects to several well-known,popular peers(such as or ).Then,it begins an iterative process of sending ping messages with large TTLs to known peers,adding newly discovered peers to its list of known peers based on the contents of received pong messages.In addition to the IP address of a peer,each pong message contains metadata about the peer, including the number and total size offiles being shared.We allowed our crawler to continue iterating for approximately two minutes,after which it would typically gather between8,000and10,000unique peers(Figure2).According to measurements reported by Clip2,8this corresponds to at least25%to50%of the total population of peers in the system at any time.After twoFigure2:Number of Gnutella hosts captured by our crawler over timeminutes,we would terminate the crawler,save the crawling results to afile and begin another crawl iteration to gather our next snapshot of the Gnutella population.Unlike our Napster measurements,in which we were more likely to capture hosts sharing popular songs, we have no reason to suspect any bias in our measurements of the Gnutella user population.Furthermore, to ensure that the crawling process does not alter the behavior of the system in any way,our crawler neither forwarded any Gnutella protocol messages nor answered any queries.2.2.3.Crawler StatisticsBoth the Napster and Gnutella crawlers were written in Java,and ran using the IBM Java1.18JRE on Linux 2.2.16.The crawlers ran in parallel on a small number of dual-processor Pentium III700MHz computers with 2GB RAM,and four40GB SCSI disks.Our Napster trace captured four days of activity,from Sunday May 6th,2001through Wednesday May9th,2001.We recorded a total of509,538Napster peers on546,401unique IP addresses.Our Gnutella trace spanned eight days(Sunday May6th,2001through Monday May14th,2001) and captured1,239,487Gnutella peers on1,180,205unique IP-addresses.2.3.Directly Measured Peer CharacteristicsFor each gathered peer population snapshot,we directly measured additional properties of the peers.Our goal was to capture data that would enable us to reason about the fundamental characteristics of the users(both as individuals and as a population)participating in any peer-to-peerfile sharing system.The data collected includes the distributions of bottleneck bandwidths and latencies between peers and our measurement infrastructure, the number of sharedfiles per peer,the distribution of peers across DNS domains,and the“lifetime”of the peers in the system,i.e.,howfrequently peers connect to the systems,and howlong they remain connected.tency MeasurementsGiven the list of peers’IP-addresses obtained by the crawlers,we measured the round-trip latency between the peers and our measurement machines.For this,we used a simple tool that measures the RTT of a40-byte TCP packet exchanged between a peer and our measurement host.Our interest in latencies of the peers is due to the well known feature of TCP congestion control which discriminates againstflows with large round-trip times. This,coupled with the fact that the average size offiles exchanged is in the order of2-4MB,makes latency a very important consideration when selecting amongst multiple peers sharing the samefile.Although we realize that the latency to any particular peer is dependent on the location of the host from which it is measured,we feel the distribution of latencies over the entire population of peers from a given host might be similar(but not identical)from different hosts,and hence,could be of interest.2.3.2.Lifetime MeasurementsTo gather measurements of the lifetime characteristics of peers,we needed a tool that would periodically probea large set of peers from both systems to detect when they were participating in the system.Every peer in bothNapster and Gnutella connects to the system using a unique IP-address/port-number pair;to download afile, peers connect to each other using these pairs.There are therefore three possible states for any participating peer in either Napster or Gnutella:1.offline:the peer is either not connected to the Internet or is not responding to TCP SYN packets becauseit is behind afirewall or NAT proxy.2.inactive:the peer is connected to the Internet and is responding to TCP SYN packets,but it is discon-nected from the peer-to-peer system and hence responds with TCP RST’s.3.active:the peer is actively participating in the peer-to-peer system,and is accepting incoming TCPconnections.We developed a simple tool(which we call LF)using Savage’s“Sting”platform.9To detect the state of a host,LF sends a TCP SYN-packet to the peer and then waits for up to twenty seconds to receive any packets from it.If no packet arrives,we mark the peer as offline.If we receive a TCP RST packet,we mark the peer as inactive.If we receive a TCP SYN/ACK,we label the host as active,and send back a RST packet to terminate the connection.We chose to manipulate TCP packets directly rather than use OS socket calls to achieve greater scalability;this enabled us to monitor the lifetimes of tens of thousands of hosts per workstation.Because we identify a host by its IP address,one limitation in the lifetime characterization of peers our inability of distinguishing hosts sharing dynamic IP addresses(e.g.DHCP).2.3.3.Bottleneck Bandwidth MeasurementsAnother characteristic of peers that we wanted to gather was the speed of their connections to the Internet. This is not a precisely defined concept:the rate at which content can be downloaded from a peer depends on the bottleneck bandwidth between the downloader and the peer,the available bandwidth along the path,and the latency between the peers.The central Napster servers can provide the connection bandwidth of any peer as reported by the peer itself. However,as we will show later,a substantial percentage of the Napster peers(as high as25%)choose not to report their bandwidths.Furthermore,there is a clear incentive for a peer to discourage other peers from downloadingfiles by falsely reporting a low bandwidth.The same incentive to lie exists in Gnutella;in addition to this,in Gnutella,bandwidth is reported only as part of a successful response to a query,so peers that share no data or whose content does not match any queries never report their bandwidths.Because of this,we decided to actively probe the bandwidths of peers.There are two difficult problems with measuring the available bandwidth to and from a large number of hosts:first,available bandwidth can significantlyfluctuate over short periods of time,and second,available bandwidth is determined by measuring the loss rate of an open TCP connection.Instead,we decided to use the bottleneck link bandwidth as afirst-order approximation to the available bandwidth;because our workstations are connected by a gigabit link to the Abilene network,it is likely that the bottleneck link between our workstations and any peer in these systems is last-hop link to the peer itself.This is particularly likely since,as we will show later,most peers are connected to the system using low-speed modems or broadband connections such as cable modems or DSL.Thus,if we could characterize the bottleneck bandwidth between our measurement infrastructure and the peers,we would have a fairly accurate upper bound on the rate at which information could be downloaded from these peers.Bottleneck link bandwidth between two different hosts equals the capacity of the slowest hop along the path between the two hosts.Thus,by definition,bottleneck link bandwidth is a physical property of the network that remains constant over time for an individual path.Although various bottleneck link bandwidth measurement tools are available,10–13for a number of reasons that are beyond the scope of this paper,all of these tools were unsatisfactory for our purposes.Hence,we developed our own tool(called SProbe)14based on the same underlying packet-pair dispersion technique as some of the above-mentioned tools.Unlike other tools,however,SProbe uses tricks inspired by Sting9to actively measure both upstream and downstream bottleneck bandwidths using only a few TCP packets.Our tool also proactively detects cross-traffic that interferes with the accuracy of the packet-pair technique,improving the overall accuracy of our measurements.∗By comparing the reported bandwidths of the peers with our measured ∗For more information about SProbe,refer to .Figure3.Left:CDFs of upstream and downstream bottleneck bandwidths for Gnutella peers;Right:CDFs of down-stream bottleneck bandwidths for Napster and Gnutella peers.bandwidths,we were able to verify the consistency and accuracy of SProbe,as we will demonstrate in Section3.5.2.3.4.A Summary of the Active MeasurementsFor the lifetime measurements,we monitored17,125Gnutella peers over a period of60hours and7,000Napster peers over a period of25hours.For each Gnutella peer,we determined its status(offline,inactive or active) once every seven minutes,and for each Napster peer,once every two minutes.For Gnutella,we attempted to measure bottleneck bandwidths and latencies to a random set of595,974 unique peers(i.e.,unique IP-address/port-number pairs).We were successful in gathering downstream bot-tleneck bandwidth measurements to223,552of these peers,the remainder of which were either offline or had significant cross-traffic.We measured upstream bottleneck bandwidths from16,252of the peers(for various reasons,upstream bottleneck bandwidth measurements from hosts are much harder to obtain than downstream measurements to hosts14).Finally,we were able to measure latency to339,502peers.For Napster,we attempted to measure downstream bottleneck bandwidths to4,079unique peers.We successfully measured2,049peers.In several cases,our active measurements were regarded as intrusive by several monitored systems.Un-fortunately,e-mail complaints received by the computing staffat the University of Washington forced us to prematurely terminate our crawls,hence the lower number of monitored Napster hosts.Nevertheless,we suc-cessfully captured a significant number of data points for us to believe that our results and conclusions are representative for the entire Napster population.3.MEASUREMENT RESULTSOur measurement results are organized according to a number of basic questions addressing the capabilities and behavior of peers.In particular,we attempt to address how many peers are capable of being servers,how many behave like clients,howmany are w illing to cooperate,and also howw ell the Gnutella netw ork behaves in the face of random or malicious failures.3.1.How Many Peers Fit the High-Bandwidth,Low-Latency Profile of a Server?One particularly relevant characteristic of peer-to-peerfile sharing systems is the percentage of peers in the system having server-like characteristics.More specifically,we are interested in understanding what percentage of the participating peers exhibit the server-like characteristics with respect to their bandwidths and latencies. Peers worthy of being servers must have high-bandwidth Internet connections,they should remain highly avail-able,and the latency of access to the peers should generally be low.If there is a high degree of heterogeneity amongst the peers,a well-designed system should pay careful attention to delegating routing and content-serving responsibilities,favoring server-like peers.3.1.1.Downstream and Upstream Measured Bottleneck Link BandwidthsTofit the profile of a high-bandwidth server,a participating peer must have a high upstream bottleneck link bandwidth,since this value determines the rate at which a server can serve content.On the left,Figure3Figure 4.Left:Reported bandwidths For Napster peers;Right:Reported bandwidths for Napster peers,excluding peers that reported “unknown”.presents cumulative distribution functions (CDFs)of upstream and downstream bottleneck bandwidths for Gnutella peers.†From this graph,we see that while 78%of the participating peers have downstream bottleneck bandwidths of at least 100Kbps,only 8%of the peers have upstream bottleneck bandwidths of at least 10Mbps.Moreover,22%of the participating peers have upstream bottleneck bandwidths of 100Kbps or less.Not only are these peers unsuitable to provide content and data,they are particularly susceptible to being swamped by a relatively small number of connections.The left graph in Figure 3reveals asymmetry in the upstream and downstream bottleneck bandwidths of Gnutella peers.On average,a peer tends to have higher downstream than upstream bottleneck bandwidth;this is not surprising,because a large fraction of peers depend on asymmetric links such as ADSL,cable modems or regular modems using the V.90protocol.15Although this asymmetry is beneficial to peers that download content,it is both undesirable and detrimental to peers that serve content:in theory,the download capacity of the system exceeds its upload capacity.We observed a similar asymmetry in the Napster network.The right graph in Figure 3presents CDFs of downstream bottleneck bandwidths for Napster and Gnutella peers.As this graph illustrates,the percentage of Napster users connected with modems (of 64Kbps or less)is about 25%,while the percentage of Gnutella users with similar connectivity is as low as 8%.At the same time,50%of the users in Napster and 60%of the users in Gnutella use broadband connections (Cable,DSL,T1or T3).Furthermore,only about 20%of the users in Napster and 30%of the users in Gnutella have very high bandwidth connections (at least 3Mbps).Overall,Gnutella users on average tend to have higher downstream bottleneck bandwidths than Napster users.Based on our experience,we attribute this difference to two factors:(1)the current flooding-based Gnutella protocol is too high of a burden on low bandwidth connections,discouraging them from participating,and (2)although unverifiable,there is a widespread belief that Gnutella is more popular to technically-savvy users,who tend to have faster Internet connections.3.1.2.Reported Bandwidths for Napster PeersFigure 4illustrates the breakdown of Napster peers with respect to their voluntarily reported bandwidths;the bandwidth that is reported is selected by the user during the installation of the Napster client software.(Peers that report “Unknown”bandwidth have been excluded in the right graph.)As Figure 4shows,a significant percent of the Napster users (22%)report “Unknown”.These users are either unaware of their connection bandwidths,or they have no incentive to accurately report their true bandwidth.Indeed,knowing a peer’s connection speed is more valuable to others rather than to the peer itself;a peer that reports high bandwidth is more likely to receive download requests from other peers,consuming network resources.Thus,users have an incentive to misreport their Internet connection speeds.A well-designed system therefore must either directly measure the bandwidths rather than relying on a user’s input,or create the right†“Upstream”denotes traffic from the peer to the measurement node;“downstream”denotes traffic from the mea-surement node to the peer.Figure 5.Left:Measured latencies to Gnutella peers;Right:Correlation between Gnutella peers’downstream bottleneck bandwidth and latency.incentives for the users to report accurate information to the system.Finally both Figures 3and 4confirm that the most popular forms of Internet access for Napster and Gnutella peers are cable modems and DSLs (bottleneck bandwidths between 1Mbps and 3.5Mbps).3.1.3.Measured Latencies for Gnutella PeersFigure 5(left)shows a CDF of the measured latencies from our measurement nodes to Gnutella peers.Approx-imately 20%of the peers have latencies of at least 280ms,whereas another 20%have latencies of at most 70ms:the closest 20%of the peers are four times closer than the furthest 20%.From this,we can deduce that in a peer-to-peer system where peers’connections are forged in an unstructured,ad-hoc way,a substantial fraction of the connections will suffer from high-latency.On the right,Figure 5shows the correlation between downstream bottleneck bandwidth and the latency of individual Gnutella peers (on a log-log scale).This graph illustrates the presence of two clusters;a smaller one situated at (20-60Kbps,100-1,000ms)and a larger one at over (1,000Kbps,60-300ms).These clusters correspond to the set of modems and broadband connections,respectively.The negatively sloped lower-bound evident in the low-bandwidth region of the graph corresponds to the non-negligible transmission delay of our measurement packets through the low-bandwidth links.An interesting artifact evident in this graph is the presence of two pronounced horizontal bands.These bands correspond to peers situated on the North American East Coast and in Europe,respectively.Although the latencies presented in this graph are relative to our location (Seattle,WA),these results can be extended to conclude that there are three large classes of latencies that a peer interacts with:(1)latencies to peers on the same part of the continent,(2)latencies to peers on the opposite part of a continent and (3)latencies to trans-oceanic peers.As Figure 5shows,the bandwidths of the peers fluctuate significantly within each of these three latency classes.3.2.How Many Peers Fit the High-Availability Profile of a Server?Server worthiness is characterized not only by high-bandwidth and low-latency network connectivity,but also by the availability of the server.If,peers tend to be unavailable frequently,this will have significant implications about the degree of replication necessary to ensure that content is consistently accessible on this system.On the left,Figure 6shows the distribution of uptimes of peers for both Gnutella and Napster.Uptime is measured as the percentage of time that the peer is available and responding to traffic.The “Internet host uptime”curves represent the uptime as measured at the IP-level,i.e.,peers that are in the inactive or active states,as defined in Section 2.3.2.The “Gnutella/Napster host uptime”curves represent the uptime of peers in the active state,and therefore responding to application-level requests.For all curves,we have eliminated peers that had 0%uptime (peers that were never up throughout our lifetime experiment).The IP-level uptime characteristics of peers are quite similar for both systems;this implies that the set of。
协作移动机器人-前因和方向外文文献翻译、中英文翻译、外文翻译

Cooperative Mobile Robotics: Antecedents and DirectionsY. UNY CAOComputer Science Department, University of California, Los Angeles, CA 90024-1596ALEX S. FUKUNAGAJet Propulsion Laboratory, California Institute of Technology, Pasadena, CA 91109-8099ANDREW B. KAHNGComputer Science Department, University of California, Los Angeles, CA 90024-1596Editors: R.C. Arkin and G.A. BekeyAbstract. There has been increased research interest in systems composed of multiple autonomous mobile robots exhibiting cooperative behavior. Groups of mobile robots are constructed, with an aim to studying such issues as group architecture, resource conflict, origin of cooperation, learning, and geometric problems. As yet, few applications of cooperative robotics have been reported, and supporting theory is still in its formative stages. In this paper, we give a critical survey of existing works and discuss open problems in this field, emphasizing the various theoretical issues that arise in the study of cooperative robotics. We describe the intellectual heritages that have guided early research, as well as possible additions to the set of existing motivations.Keywords: cooperative robotics, swarm intelligence, distributed robotics, artificial intelligence, mobile robots, multiagent systems1. PreliminariesThere has been much recent activity toward achieving systems of multiple mobile robots engaged in collective behavior. Such systems are of interest for several reasons:•tasks may be inherently too complex (or im-possible) for a single robot to accomplish, or performance benefits can be gained from using multiple robots;•building and using several simple robots can be easier, cheaper, more flexible and more fault-tolerant than having a single powerful robot foreach separate task; and•the constructive, synthetic approach inherent in cooperative mobile robotics can possibly∗This is an expanded version of a paper which originally appeared in the proceedings of the 1995 IEEE/RSJ IROS conference. yield insights into fundamental problems in the social sciences (organization theory, economics, cognitive psychology), and life sciences (theoretical biology, animal ethology).The study of multiple-robot systems naturally extends research on single-robot systems, butis also a discipline unto itself: multiple-robot systems can accomplish tasks that no single robot can accomplish, since ultimately a single robot, no matter how capable, is spatially limited. Multiple-robot systems are also different from other distributed systems because of their implicit “real-world” environment, which is presumably more difficult to model and reason about than traditional components of distributed system environments (i.e., computers, databases, networks).The term collective behavior generically denotes any behavior of agents in a system having more than one agent. the subject of the present survey, is a subclass of collective behavior that is characterized by cooperation. Webster’s dictionary [118] defines “cooperate” as “to associate with anoth er or others for mutual, often economic, benefit”. Explicit definitions of cooperation in the robotics literature, while surprisingly sparse, include:1. “joint collaborative behavior that is directed toward some goal in which there is a common interest or reward” [22];2. “a form of interaction, usually based on communication” [108]; and3. “[joining] together for doing something that creates a progressive result such as increasing performance or saving time” [137].These definitions show the wide range of possible motivating perspectives. For example, definitions such as (1) typically lead to the study of task decomposition, task allocation, and other dis-tributed artificial intelligence (DAI) issues (e.g., learning, rationality). Definitions along the lines of (2) reflect a concern with requirements for information or other resources, and may be accompanied by studies of related issues such as correctness and fault-tolerance. Finally, definition (3) reflects a concern with quantified measures of cooperation, such as speedup in time to complete a task. Thus, in these definitions we see three fundamental seeds: the task, the mechanism of cooperation, and system performance.We define cooperative behavior as follows: Given some task specified by a designer, a multiple-robot system displays cooperative behavior if, due to some underlying mechanism (i.e., the “mechanism of cooperation”), there is an increase in the total utility of the system. Intuitively, cooperative behavior entails some type of performance gain over naive collective behavior. The mechanism of cooperation may lie in the imposition by the designer of a control or communication structure, in aspects of the task specification, in the interaction dynamics of agent behaviors, etc.In this paper, we survey the intellectual heritage and major research directions of the field of cooperative robotics. For this survey of cooperative robotics to remain tractable, we restrict our discussion to works involving mobile robots or simulations of mobile robots, where a mobile robot is taken to be an autonomous, physically independent, mobile robot. In particular, we concentrated on fundamental theoretical issues that impinge on cooperative robotics. Thus, the following related subjects were outside the scope of this work:•coordination of multiple manipulators, articulated arms, or multi-fingered hands, etc.•human-robot cooperative systems, and user-interface issues that arise with multiple-robot systems [184] [8] [124] [1].•the competitive subclass of coll ective behavior, which includes pursuit-evasion [139], [120] and one-on-one competitive games [12]. Note that a cooperative team strategy for, e.g., work on the robot soccer league recently started in Japan[87] would lie within our present scope.•emerging technologies such as nanotechnology [48] and Micro Electro-Mechanical Systems[117] that are likely to be very important to co-operative robotics are beyond the scope of this paper.Even with these restrictions, we find that over the past 8 years (1987-1995) alone, well over 200papers have been published in this field of cooperative (mobile) robotics, encompassing theories from such diverse disciplines as artificial intelligence, game theory/economics, theoretical biology, distributed computing/control, animal ethology and artificial life.We are aware of two previous works that have surveyed or taxonomized the literature. [13] is abroad, relatively succinct survey whose scope encompasses distributed autonomous robotic systems(i.e., not restricted to mobile robots). [50] focuses on several well-known “swarm” architectures (e.g., SWARM and Mataric’s Behavior-based architecture –see Section 2.1) and proposes a taxonomy to characterize these architectures. The scope and intent of our work differs significantly from these, in that (1) we extensively survey the field of co-operative mobile robotics, and (2) we provide a taxonomical organization of the literature based on problems and solutions that have arisen in the field (as opposed to a selected group of architectures). In addition, we survey much new material that has appeared since these earlier works were published.Towards a Picture of Cooperative RoboticsIn the mid-1940’s Grey Walter, along with Wiener and Shannon, studied turtle-like robots equipped wit h light and touch sensors; these simple robots exhibited “complex social behavior” in responding to each other’s movements [46]. Coordination and interactions of multiple intelligent agents have been actively studied in the field of distributed artificial intelligence (DAI) since the early 1970’s[28], but the DAI field concerned itself mainly with problems involving software agents. In the late 1980’s, the robotics research community be-came very active in cooperative robotics, beginning with projects such as CEBOT [59], SWARM[25], ACTRESS [16], GOFER [35], and the work at Brussels [151]. These early projects were done primarily in simulation, and, while the early work on CEBOT, ACTRESS and GOFER have all had physical implementations (with≤3 robots), in some sense these implementations were presented by way of proving the simulation results. Thus, several more recent works (cf. [91], [111], [131])are significant for establishing an emphasis on the actual physical implementation of cooperative robotic systems. Many of the recent cooperative robotic systems, in contrast to the earlier works, are based on a behavior-based approach (cf. [30]).Various perspectives on autonomy and on the connection between intelligence and environment are strongly associated with the behavior-based approach [31], but are not intrinsic to multiple-robot systems and thus lie beyond our present scope. Also note that a recent incarnation of CEBOT, which has been implemented on physical robots, is based on a behavior-based control architecture[34].The rapid progress of cooperative robotics since the late 1980’s has been an interplay of systems, theories and problems: to solve a given problem, systems are envisioned, simulated and built; theories of cooperation are brought from other fields; and new problems are identified (prompting further systems and theories). Since so much of this progress is recent, it is not easy to discern deep intellectual heritages from within the field. More apparent are the intellectualheritages from other fields, as well as the canonical task domains which have driven research. Three examples of the latter are:•Traffic Control. When multiple agents move within a common environment, they typically attempt to avoid collisions. Fundamentally, this may be viewed as a problem of resource conflict, which may be resolved by introducing, e.g., traffic rules, priorities, or communication architectures. From another perspective, path planning must be performed taking into con-sideration other robots and the global environment; this multiple-robot path planning is an intrinsically geometric problem in configuration space-time. Note that prioritization and communication protocols – as well as the internal modeling of other robots – all reflect possible variants of the group architecture of the robots. For example, traffic rules are commonly used to reduce planning cost for avoiding collision and deadlock in a real-world environment, such as a network of roads. (Interestingly, behavior-based approaches identify collision avoidance as one of the most basic behaviors [30], and achieving a collision-avoidance behavior is the natural solution to collision avoidance among multiple robots. However, in reported experiments that use the behavior-based approach, robots are never restricted to road networks.) •Box-Pushing/Cooperative Manipulation. Many works have addressed the box-pushing (or couch-pushing) problem, for widely varying reasons. The focus in [134] is on task allocation, fault-tolerance and (reinforcement) learning. By contrast, [45] studies two boxpushing protocols in terms of their intrinsic communication and hardware requirements, via the concept of information invariants. Cooperative manipulation of large objects is particularly interesting in that cooperation can be achieved without the robots even knowing of each others’ existence [147], [159]. Other works in the class of box-pushing/object manipulation include [175] [153] [82] [33] [91] [94] [92][114] [145] [72] [146].•Foraging. In foraging, a group of robots must pick up objects scattered in the environment; this is evocative of toxic waste cleanup, harvesting, search and rescue, etc. The foraging task is one of the canonical testbeds for cooperative robotics [32] [151] [10] [67] [102] [49] [108] [9][24]. The task is interesting because (1) it can be performed by each robot independently (i.e., the issue is whether multiple robots achieve a performance gain), and (2) as discussed in Section 3.2, the task is also interesting due to motivations related to the biological inspirations behind cooperative robot systems. There are some conceptual overlaps with the related task of materials handling in a manufacturing work-cell [47]. A wide variety of techniques have been applied, ranging from simple stigmergy (essentially random movements that result in the fortuitous collection of objects [24] to more complex algorithms in which robots form chains along which objects are passed to the goal [49].[24] defines stigmergy as “the production of a certain behaviour in agents as a consequence of the effects produced in the local environment by previous behaviour”. This is actually a form of “cooperation without communication”, which has been the stated object of several for-aging solutions since the corresponding formulations become nearly trivial if communication is used. On the other hand, that stigmergy may not satisfy our definition of cooperation given above, since there is no performance improvement over the “naive algorithm” –in this particular case, the proposed stigmergic algorithm is the naive algorithm. Again, group architecture and learning are major research themes in addressing this problem.Other interesting task domains that have received attention in the literature includemulti-robot security systems [53], landmine detection and clearance [54], robotic structural support systems (i.e., keeping structures stable in case of, say ,an earthquake) [107], map making [149], and assembly of objects using multiple robots [175].Organization of PaperWith respect to our above definition of cooperative behavior, we find that the great majority of the cooperative robotics literature centers on the mechanism of cooperation (i.e., few works study a task without also claiming some novel approach to achieving cooperation). Thus, our study has led to the synthesis of five “Research Axes” which we believe comprise the major themes of investigation to date into the underlying mechanism of cooperation.Section 2 of this paper describes these axes, which are: 2.1 Group Architecture, 2.2 Resource Conflict, 2.3 Origin of Cooperation, 2.4 Learning, and 2.5 Geometric Problems. In Section 3,we present more synthetic reviews of cooperative robotics: Section 3.1 discusses constraints arising from technological limitations; and Section 3.2discusses possible lacunae in existing work (e.g., formalisms for measuring performance of a cooperative robot system), then reviews three fields which we believe must strongly influence future work. We conclude in Section 4 with a list of key research challenges facing the field.2. Research AxesSeeking a mechanism of cooperation may be rephrased as the “cooperative behavior design problem”: Given a group of robots, an environment, and a task, how should cooperative behavior arise? In some sense, every work in cooperative robotics has addressed facets of this problem, and the major research axes of the field follow from elements of this problem. (Note that certain basic robot interactions are not task-performing interactions per se, but are rather basic primitives upon which task-performing interactions can be built, e.g., following ([39], [45] and many others) or flocking [140], [108]. It might be argued that these interactions entail “control and coordination” tasks rather than “cooperation” tasks, but o ur treatment does not make such a distinction).First, the realization of cooperative behavior must rely on some infrastructure, the group architecture. This encompasses such concepts as robot heterogeneity/homogeneity, the ability of a given robot to recognize and model other robots, and communication structure. Second, for multiple robots to inhabit a shared environment, manipulate objects in the environment, and possibly communicate with each other, a mechanism is needed to resolve resource conflicts. The third research axis, origins of cooperation, refers to how cooperative behavior is actually motivated and achieved. Here, we do not discuss instances where cooperation has been “explicitly engineered” into the robots’ behavior since this is the default approach. Instead, we are more interested in biological parallels (e.g., to social insect behavior), game-theoretic justifications for cooperation, and concepts of emergence. Because adaptability and flexibility are essential traits in a task-solving group of robots, we view learning as a fourth key to achieving cooperative behavior. One important mechanism in generating cooperation, namely,task decomposition and allocation, is not considered a research axis since (i) very few works in cooperative robotics have centered on task decomposition and allocation (with the notable exceptions of [126], [106], [134]), (ii) cooperative robot tasks (foraging, box-pushing) in the literature are simple enough that decomposition and allocation are not required in the solution, and (iii) the use of decomposition and allocation depends almost entirely on the group architectures(e.g. whether it is centralized or decentralized).Note that there is also a related, geometric problem of optimizing the allocation of tasks spatially. This has been recently studied in the context of the division of the search of a work area by multiple robots [97]. Whereas the first four axes are related to the generation of cooperative behavior, our fifth and final axis –geometric problems–covers research issues that are tied to the embed-ding of robot tasks in a two- or three-dimensional world. These issues include multi-agent path planning, moving to formation, and pattern generation.2.1. Group ArchitectureThe architecture of a computing sys tem has been defined as “the part of the system that remains unchanged unless an external agent changes it”[165]. The group architecture of a cooperative robotic system provides the infrastructure upon which collective behaviors are implemented, and determines the capabilities and limitations of the system. We now briefly discuss some of the key architectural features of a group architecture for mobile robots: centralization/decentralization, differentiation, communications, and the ability to model other agents. We then describe several representative systems that have addressed these specific problems.Centralization/Decentralization The most fundamental decision that is made when defining a group architecture is whether the system is centralized or decentralized, and if it is decentralized, whether the system is hierarchical or distributed. Centralized architectures are characterized by a single control agent. Decentralized architectures lack such an agent. There are two types of decentralized architectures: distributed architectures in which all agents are equal with respect to control, and hierarchical architectures which are locally centralized. Currently, the dominant paradigm is the decentralized approach.The behavior of decentralized systems is of-ten described using such terms as “emergence” and “self-organization.” It is widely claimed that decentralized architectures (e.g., [24], [10], [152],[108]) have several inherent advantages over centralized architectures, including fault tolerance, natural exploitation of parallelism, reliability, and scalability. However, we are not aware of any published empirical or theoretical comparison that supports these claims directly. Such a comparison would be interesting, particularly in scenarios where the team of robots is relatively small(e.g., two robots pushing a box), and it is not clear whether the scaling properties of decentralization offset the coordinative advantage of centralized systems.In practice, many systems do not conform toa strict centralized/decentralized dichotomy, e.g., many largely decentralized architectures utilize “leader” agents. We are not aware of any in-stances of systems that are completely centralized, although there are some hybrid centralized/decentralized architectures wherein there is a central planner that exerts high-levelcontrol over mostly autonomous agents [126], [106], [3], [36].Differentiation We define a group of robots to be homogeneous if the capabilities of the individual robots are identical, and heterogeneous otherwise. In general, heterogeneity introduces complexity since task allocation becomes more difficult, and agents have a greater need to model other individuals in the group. [134] has introduced the concept of task coverage, which measures the ability of a given team member to achieve a given task. This parameter is an index of the demand for cooperation: when task coverage is high, tasks can be accomplished without much cooperation, but otherwise, cooperation is necessary. Task coverage is maximal in homogeneous groups, and decreases as groups become more heterogeneous (i.e., in the limit only one agent in the group can perform any given task).The literature is currently dominated by works that assume homogeneous groups of robots. How-ever, some notable architectures can handle het-erogeneity, e.g., ACTRESS and ALLIANCE (see Section 2.1 below). In heterogeneous groups, task allocation may be determined by individual capabilities, but in homogeneous systems, agents may need to differentiate into distinct roles that are either known at design-time, or arise dynamically at run-time.Communication Structures The communication structure of a group determines the possible modes of inter-agent interaction. We characterize three major types of interactions that can be sup-ported. ([50] proposes a more detailed taxonomy of communication structures). Interaction via environmentThe simplest, most limited type of interaction occurs when the environment itself is the communication medium (in effect, a shared memory),and there is no explicit communication or interaction between agents. This modality has also been called “cooperation without communication” by some researchers. Systems that depend on this form of interaction include [67], [24], [10], [151],[159], [160], [147].Interaction via sensing Corresponding to arms-length relationships inorganization theory [75], interaction via sensing refers to local interactions that occur between agents as a result of agents sensing one another, but without explicit communication. This type of interaction requires the ability of agents to distinguish between other agents in the group and other objects in the environment, which is called “kin recognition” in some literatures [108]. Interaction via sensing is indispensable for modeling of other agents (see Section 2.1.4 below). Because of hard-ware limitations, interaction via sensing has often been emulated using radio or infrared communications. However, several recent works attempt to implement true interaction via sensing, based on vision [95], [96], [154]. Collective behaviors that can use this kind of interaction include flocking and pattern formation (keeping in formation with nearest neighbors).Interaction via communicationsThe third form of interaction involves explicit communication with other agents, by either directed or broadcast intentional messages (i.e. the recipient(s) of the message may be either known or unknown). Because architectures that enable this form of communication are similar tocommunication networks, many standard issues from the field of networks arise, including the design of network topologies and communications protocols. For ex-ample, in [168] a media access protocol (similar to that of Ethernet) is used for inter-robot communication. In [78], robots with limited communication range communicate to each other using the “hello-call” protocol, by which they establish “chains” in order to extend their effective communication ranges. [61] describes methods for communicating to many (“zillions”) robots, including a variety of schemes ranging from broadcast channels (where a message is sent to all other robots in the system) to modulated retroreflection (where a master sends out a laser signal to slaves and interprets the response by the nature of the re-flection). [174] describes and simulates a wireless SMA/CD ( Carrier Sense Multiple Access with Collision Detection ) protocol for the distributed robotic systems.There are also communication mechanisms designed specially for multiple-robot systems. For example, [171] proposes the “sign-board” as a communication mechanism for distributed robotic systems. [7] gives a communication protocol modeled after diffusion, wherein local communication similar to chemical communication mechanisms in animals is used. The communication is engineered to decay away at a preset rate. Similar communications mechanisms are studied in [102], [49], [67].Additional work on communication can be found in [185], which analyzes optimal group sizes for local communications and communication delays. In a related vein, [186], [187] analyzes optimal local communication ranges in broadcast communication.Modeling of Other Agents Modeling the intentions, beliefs, actions, capabilities, and states of other agents can lead to more effective cooperation between robots. Communications requirements can also be lowered if each agent has the capability to model other agents. Note that the modeling of other agents entails more than implicit communication via the environment or perception: modeling requires that the modeler has some representation of another agent, and that this representation can be used to make inferences about the actions of the other agent.In cooperative robotics, agent modeling has been explored most extensively in the context of manipulating a large object. Many solutions have exploited the fact that the object can serve as a common medium by which the agents can model each other.The second of two box-pushing protocols in[45] can achieve “cooperation without commun ication” since the object being manipulated also functions as a “communication channel” that is shared by the robot agents; other works capitalize on the same concept to derive distributed control laws which rely only on local measures of force, torque, orientation, or distance, i.e., no explicit communication is necessary (cf. [153] [73]).In a two-robot bar carrying task, Fukuda and Sekiyama’s agents [60] each uses a probabilistic model of the other agent. When a risk threshold is exceeded, an agent communicates with its partner to maintain coordination. In [43], [44], the theory of information invariants is used to show that extra hardware capabilities can be added in order to infer the actions of the other agent, thus reducing communication requirements. This is in contrast to [147], where the robots achieve box pushing but are not aware of each other at all. For a more com-plex task involving the placement of five desks in[154], a homogeneous group of four robots share a ceiling camera to get positional information, but do not communicate with each other. Each robot relies on modeling of otheragents to detect conflicts of paths and placements of desks, and to change plans accordingly.Representative Architectures All systems implement some group architecture. We now de-scribe several particularly well-defined representative architectures, along with works done within each of their frameworks. It is interesting to note that these architectures encompass the entire spectrum from traditional AI to highly decentralized approaches.CEBOTCEBOT (Cellular roBOTics System) is a decentralized, hierarchical architecture inspired by the cellular organization of biological entities (cf.[59] [57], [162] [161] [56]). The system is dynamically reconfigurable in tha t basic autonomous “cells” (robots), which can be physically coupled to other cells, dynamically reconfigure their structure to an “optimal” configuration in response to changing environments. In the CEBOT hierarchy there are “master cells” that coordinate subtasks and communicate with other master cells. A solution to the problem of electing these master cells was discussed in [164]. Formation of structured cellular modules from a population of initially separated cells was studied in [162]. Communications requirements have been studied extensively with respect to the CEBOT architecture, and various methods have been proposed that seek to reduce communication requirements by making individual cells more intelligent (e.g., enabling them to model the behavior of other cells). [60] studies the problem of modeling the behavior of other cells, while [85], [86] present a control method that calculates the goal of a cell based on its previous goal and on its master’s goal. [58] gives a means of estimating the amount of information exchanged be-tween cells, and [163] gives a heuristic for finding master cells for a binary communication tree. Anew behavior selection mechanism is introduced in [34], based on two matrices, the priority matrix and the interest relation matrix, with a learning algorithm used to adjust the priority matrix. Recently, a Micro Autonomous Robotic System(MARS) has been built consisting of robots of 20cubic mm and equipped with infrared communications [121].ACTRESSThe ACTRESS (ACTor-based Robot and Equipments Synthetic System) project [16], [80],[15] is inspired by the Universal Modular AC-TOR Formalism [76]. In the ACTRESS system,“robotors”, including 3 robots and 3 workstations(one as interface to human operator, one as im-age processor and one as global environment man-ager), form a heterogeneous group trying to per-form tasks such as object pushing [14] that cannot be accomplished by any of the individual robotors alone [79], [156]. Communication protocols at different abstraction levels [115] provide a means upon which “group cast” and negotiation mechanisms based on Contract Net [150] and multistage negotiation protocols are built [18]. Various is-sues are studied, such as efficient communications between robots and environment managers [17],collision avoidance [19].SWARM。
CCF推荐国际学术会议
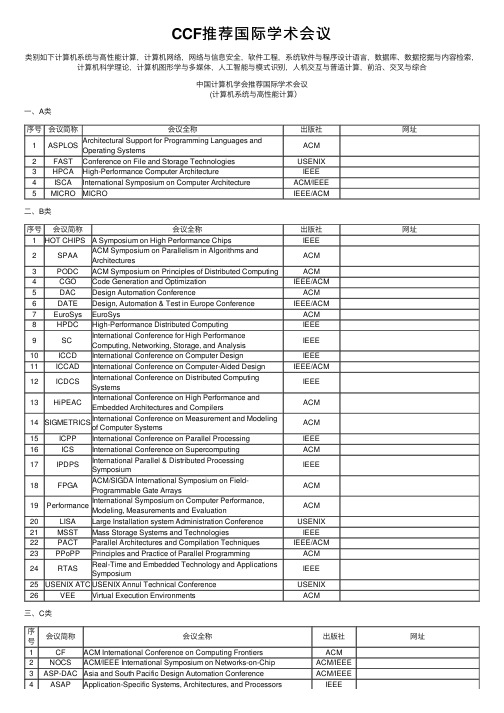
CCF推荐国际学术会议类别如下计算机系统与⾼性能计算,计算机⽹络,⽹络与信息安全,软件⼯程,系统软件与程序设计语⾔,数据库、数据挖掘与内容检索,计算机科学理论,计算机图形学与多媒体,⼈⼯智能与模式识别,⼈机交互与普适计算,前沿、交叉与综合中国计算机学会推荐国际学术会议 (计算机系统与⾼性能计算)⼀、A类序号会议简称会议全称出版社⽹址1ASPLOS Architectural Support for Programming Languages andOperating SystemsACM2FAST Conference on File and Storage Technologies USENIX3HPCA High-Performance Computer Architecture IEEE4ISCA International Symposium on Computer Architecture ACM/IEEE5MICRO MICRO IEEE/ACM⼆、B类序号会议简称会议全称出版社⽹址1HOT CHIPS A Symposium on High Performance Chips IEEE2SPAA ACM Symposium on Parallelism in Algorithms andArchitecturesACM3PODC ACM Symposium on Principles of Distributed Computing ACM4CGO Code Generation and Optimization IEEE/ACM 5DAC Design Automation Conference ACM6DATE Design, Automation & Test in Europe Conference IEEE/ACM 7EuroSys EuroSys ACM8HPDC High-Performance Distributed Computing IEEE9SC International Conference for High PerformanceComputing, Networking, Storage, and AnalysisIEEE10ICCD International Conference on Computer Design IEEE 11ICCAD International Conference on Computer-Aided Design IEEE/ACM12ICDCS International Conference on Distributed ComputingSystemsIEEE13HiPEAC International Conference on High Performance andEmbedded Architectures and CompilersACM14SIGMETRICS International Conference on Measurement and Modelingof Computer SystemsACM15ICPP International Conference on Parallel Processing IEEE 16ICS International Conference on Supercomputing ACM17IPDPS International Parallel & Distributed ProcessingSymposiumIEEE18FPGA ACM/SIGDA International Symposium on Field-Programmable Gate ArraysACM19Performance International Symposium on Computer Performance,Modeling, Measurements and EvaluationACM20LISA Large Installation system Administration Conference USENIX 21MSST Mass Storage Systems and Technologies IEEE 22PACT Parallel Architectures and Compilation Techniques IEEE/ACM 23PPoPP Principles and Practice of Parallel Programming ACM24RTAS Real-Time and Embedded Technology and Applications SymposiumIEEE25USENIX ATC USENIX Annul Technical Conference USENIX26VEE Virtual Execution Environments ACM三、C类序号会议简称会议全称出版社⽹址1CF ACM International Conference on Computing Frontiers ACM2NOCS ACM/IEEE International Symposium on Networks-on-Chip ACM/IEEE3ASP-DAC Asia and South Pacific Design Automation Conference ACM/IEEE4ASAP Application-Specific Systems, Architectures, and Processors IEEE5CLUSTER Cluster Computing IEEE6CCGRID Cluster Computing and the Grid IEEE7Euro-Par European Conference on Parallel and Distributed Computing Springer 8ETS European Test Symposium IEEE9FPL Field Programmable Logic and Applications IEEE 10FCCM Field-Programmable Custom Computing Machines IEEE 11GLSVLSI Great Lakes Symposium on VLSI Systems ACM/IEEE12HPCC IEEE International Conference on High Performance Computing and CommunicationsIEEE13MASCOTS IEEE International Symposium on Modeling, Analysis, andSimulation of Computer and Telecommunication SystemsIEEE14NPC IFIP International Conference on Network and Parallel Computing Springer15ICA3PP International Conference on Algorithms and Architectures for Parallel ProcessingIEEE16CASES International Conference on Compilers, Architectures, and Synthesisfor Embedded SystemsACM17FPT International Conference on Field-Programmable Technology IEEE18CODES+ISSSInternational Conference on Hardware/Software Codesign & SystemSynthesisACM/ IEEE19HiPC International Conference on High Performance Computing IEEE/ ACM 20ICPADS International Conference on Parallel and Distributed Systems IEEE 21ISCAS International Symposium on Circuits and Systems IEEE 22ISLPED International Symposium on Low Power Electronics and Design ACM/IEEE 23ISPD International Symposium on Physical Design ACM 24ITC International Test Conference IEEE25HotInterconnectsIEEE26VTS IEEE中国计算机学会推荐国际学术会议 (计算机⽹络)⼀、A类序号会议简称会议全称出版社⽹址1MOBICOM ACM International Conference on Mobile Computing and NetworkingACM2SIGCOMM ACM International Conference on the applications,technologies, architectures, and protocols for computer communicationACM3INFOCOM IEEE International Conference on ComputerCommunicationsIEEE⼆、B类序号会议简称会议全称出版社⽹址2CoNEXT ACM International Conference on emerging Networking EXperiments and TechnologiesACM3SECON IEEE Communications Society Conference on Sensor andAd Hoc Communications and NetworksIEEE4IPSN International Conference on Information Processing inSensor NetworksIEEE/ACM5ICNP International Conference on Network Protocols IEEE6MobiHoc International Symposium on Mobile Ad Hoc Networking andComputingACM/IEEE7MobiSys International Conference on Mobile Systems, Applications,and ServicesACM8IWQoS International Workshop on Quality of Service IEEE9IMC Internet Measurement Conference ACM/USENIX10NOSSDAV Network and Operating System Support for Digital Audio andVideoACM11NSDI Symposium on Network System Design and Implementation USENIX三、C类序号会议简称会议全称出版社⽹址序号会议简称会议全称出版社⽹址1ANCS Architectures for Networking and Communications Systems ACM/IEEE2FORTE Formal Techniques for Networked and Distributed Systems Springer3LCN IEEE Conference on Local Computer Networks IEEE4Globecom IEEE Global Communications Conference, incorporating theGlobal Internet SymposiumIEEE5ICC IEEE International Conference on Communications IEEE6ICCCN IEEE International Conference on ComputerCommunications and NetworksIEEE7MASS IEEE International Conference on Mobile Ad hoc andSensor SystemsIEEE8P2P IEEE International Conference on P2P Computing IEEE9IPCCC IEEE International Performance Computing andCommunications ConferenceIEEE10WoWMoM IEEE International Symposium on a World of WirelessMobile and Multimedia NetworksIEEE11ISCC IEEE Symposium on Computers and Communications IEEE 12WCNC IEEE Wireless Communications & Networking Conference IEEE 13Networking IFIP International Conferences on Networking IFIP14IM IFIP/IEEE International Symposium on Integrated Network ManagementIFIP/IEEE15MSWiM International Conference on Modeling, Analysis andSimulation of Wireless and Mobile SystemsACM16NOMS Asia-Pacific Network Operations and ManagementSymposiumIFIP/IEEE17HotNets The Workshop on Hot Topics in Networks ACM中国计算机学会推荐国际学术会议 (⽹络与信息安全)⼀、A类序号会议简称会议全称出版社⽹址1CCS ACMConferenceonComputerand CommunicationsSecurityACM2CRYPTO International Cryptology Conference Springer 3EUROCRYPT European Cryptology Conference Springer 4S&P IEEESymposiumonSecurityandPrivacy IEEE5USENIXSecurityUsenix Security SymposiumUSENIXAssociation⼆、B类序号会议简称会议全称出版社⽹址1ACSAC Annual Computer Security ApplicationsConferenceIEEE2ASIACRYPT Annual International Conference on the Theory andApplication of Cryptology and Information SecuritySpringer3ESORICS EuropeanSymposiumonResearchinComputerSecuritySpringer4FSE Fast Software Encryption Springer5NDSS ISOC Network and Distributed System SecuritySymposiumISOC6CSFW IEEE Computer Security FoundationsWorkshop 7RAID International Symposium on Recent Advancesin Intrusion DetectionSpringer8PKC International Workshop on Practice and Theory in PublicKey CryptographySpringer9DSN The International Conference on DependableSystems and NetworksIEEE/IFIP10TCC Theory of Cryptography Conference Springer11SRDS IEEE International Symposium on Reliable DistributedSystemsIEEE12CHES Springer三、C类序号会议简称会议全称出版社⽹址1WiSec ACM Conference on Security and PrivacyinWireless and Mobile NetworksACM2ACMMM&SECACM Multimedia and Security Workshop ACM3SACMAT ACM Symposium on Access Control Modelsand TechnologiesACM4ASIACCS ACM Symposium on Information, Computerand Communications SecurityACM5DRM ACM Workshop on Digital Rights Management ACM 6ACNS Applied Cryptography and Network Security Springer7ACISP AustralasiaConferenceonInformation SecurityandPrivacySpringer8DFRWS Digital Forensic Research Workshop Elsevier 9FC Financial Cryptography and Data Security Springer10DIMVA Detection of Intrusions and Malware &Vulnerability AssessmentSIDAR、GI、Springer11SEC IFIP International Information SecurityConferenceSpringer12IFIP WG11.9IFIP WG 11.9 International Conferenceon Digital ForensicsSpringer13ISC Information Security Conference Springer14SecureCommInternational Conference on Security andPrivacy in Communication NetworksACM15NSPW New Security Paradigms Workshop ACM 16CT-RSA RSA Conference, Cryptographers' Track Springer 17SOUPS Symposium On Usable Privacy and Security ACM 18HotSec USENIX Workshop on Hot Topics in Security USENIX 19SAC Selected Areas in Cryptography Springer20TrustCom IEEE International Conference on Trust, Securityand Privacy in Computing andCommunicationsIEEE中国计算机学会推荐国际学术会议 (软件⼯程、系统软件与程序设计语⾔)⼀、A类序号会议简称会议全称出版社⽹址1FSE/ESEC ACM SIGSOFT Symposium on the Foundation ofSoftware Engineering/ European Software Engineering ConferenceACM2OOPSLA Conference on Object-Oriented Programming Systems, Languages, and ApplicationsACM3ICSE International Conference on SoftwareEngineeringACM/IEEE4OSDI USENIX Symposium on Operating SystemsDesign and ImplementationsUSENIX5PLDI ACM SIGPLAN Symposium on Programming LanguageDesign & ImplementationACM6POPL ACM SIGPLAN-SIGACT Symposium on Principles of Programming LanguagesACM7SOSP ACM Symposium on Operating Systems Principles ACM⼆、B类序号会议简称会议全称出版社⽹址1ECOOP European Conference on Object-Oriented Programming AITO2ETAPS European Joint Conferences on Theory and Practice ofSoftwareSpringer3FM Formal Methods, World Congress FME IEEE International Conference on Program4ICPC IEEE International Conference on ProgramComprehensionIEEE5RE IEEE International Requirement Engineering Conference IEEE6CAiSE International Conference on Advanced InformationSystems EngineeringSpringer7ASE International Conference on Automated SoftwareEngineeringIEEE/ACM8ICFP International Conf on Function Programming ACM9LCTES International Conference on Languages, Compilers, Toolsand Theory for Embedded SystemsACM10MoDELS International Conference on Model Driven Engineering Languages and SystemsACM, IEEE11CP International Conference on Principles and Practice ofConstraint ProgrammingSpringer12ICSOC International Conference on Service Oriented Computing Springer 13ICSM International. Conference on Software Maintenance IEEE14VMCAI International Conference on Verification,Model Checking, and Abstract InterpretationSpringer15ICWS International Conference on Web Services(Research Track)IEEE16SAS International Static Analysis Symposium Springer17ISSRE International Symposium on Software ReliabilityEngineeringIEEE18ISSTA International Symposium on Software Testing andAnalysisACMSIGSOFT19Middleware Conference on middleware ACM/IFIP/ USENIX20WCRE Working Conference on Reverse Engineering IEEE21HotOS USENIX Workshop on Hot Topics in Operating Systems USENIX三、C类序号会议简称会议全称出版社⽹址1PASTE ACMSIGPLAN-SIGSOFTWorkshoponProgram AnalysisforSoftwareToolsandEngineeringACM2APLAS Asian Symposium on Programming Languages and Systems Springer3APSEC Asia-Pacific Software EngineeringConferenceIEEE4COMPSAC International Computer Software and ApplicationsConferenceIEEE5ICECCS IEEE International Conference on Engineeringof Complex Computer SystemsIEEE6SCAM IEEE International Working Conferenceon Source Code Analysis and ManipulationIEEE7ICFEM International Conference on FormalEngineering MethodsSpringer8TOOLS International Conference on Objects, Models,Components, PatternsSpringer9PEPM ACM SIGPLAN Symposium on Partial Evaluation andSemantics Based Programming ManipulationACM10QSIC International Conference on Quality Software IEEE11SEKE International Conference on Software Engineering and Knowledge EngineeringKSI12ICSR International Conference on Software Reuse Springer 13ICWE International Conference on Web Engineering Springer14SPIN International SPIN Workshop on ModelChecking of SoftwareSpringer15LOPSTR International Symposium on Logic-basedProgram Synthesis and TransformationSpringer16TASE International Symposium on Theoretical Aspects of Software EngineeringIEEE17ICST The IEEE International Conference on Software Testing, Verification and ValidationIEEE18ATVA International Symposium on Automated Technology for Verification and AnalysisVerification and Analysis19ESEM International Symposium on Empirical Software Engineeringand MeasurementACM/IEEE20ISPASSSystems and SoftwareIEEE21SCC International Conference on Service Computing IEEE22ICSSP International Conference on Software and System Process ISPA中国计算机学会推荐国际学术会议 (数据库,数据挖掘与内容检索)⼀、A类序号会议简称会议全称出版社⽹址1SIGMOD ACM Conference on Management ofDataACM2SIGKDD ACM Knowledge Discovery and DataMiningACM3SIGIR International Conference on ResearchanDevelopment in Information RetrievalACM4VLDB International Conference on Very LargeData BasesMorganKaufmann/ACM5ICDE IEEE International Conference on Data EngineeringIEEE⼆、B类序号会议简称会议全称出版社⽹址1CIKM ACM International Conference onInformationand Knowledge ManagementACM2PODS ACM SIGMOD Conference on Principlesof DB SystemsACM3DASFAA Database Systems for AdvancedApplicationsSpringer4ECML-PKDDEuropean Conference on Principles andPractice of Knowledge Discovery inDatabasesSpringer5ISWC IEEE International Semantic WebConferenceIEEE6ICDM IEEE International Conference on DataMiningIEEE7ICDT International Conference on DatabaseTheorySpringer8EDBT International Conference on ExtendingDBTechnologySpringer9CIDR International Conference on InnovationDatabase ResearchOnlineProceeding10WWW International World Wide WebConferencesSpringer11SDM SIAM International Conference on DataMiningSIAM三、C类序号会议简称会议全称出版社⽹址1WSDM ACM International Conference on Web Search and Data MiningACM2DEXA Database and Expert SystemApplicationsSpringer3ECIR European Conference on IR Research Springer4WebDB International ACM Workshop on Weband DatabasesACM5ER International Conference on Conceptual ModelingSpringerModeling6MDM International Conference on Mobile Data ManagementIEEE7SSDBM International Conference on Scientificand Statistical DB ManagementIEEE8WAIM International Conference on Web Age Information ManagementSpringer9SSTD International Symposium on Spatial and Temporal DatabasesSpringer10PAKDD Pacific-Asia Conference on Knowledge Discovery and Data MiningSpringer11APWeb The Asia Pacific Web Conference Springer12WISE Web Information Systems Engineering Springer13ESWC Extended Semantic Web Conference Elsevier中国计算机学会推荐国际学术会议(计算机科学理论)⼀、A类序号会议简称会议全称出版社⽹址1STOC ACM Symposium on Theory of Computing ACM2FOCS IEEE Symposium on Foundations ofComputer ScienceIEEE3LICS IEEE Symposium on Logic in ComputerScienceIEEE⼆、B类序号会议简称会议全称出版社⽹址1SoCG ACM Symposium on ComputationalGeometryACM2SODA ACM-SIAM Symposium on DiscreteAlgorithmsSIAM3CAV Computer Aided Verification Springer4CADE/IJCAR Conference on Automated Deduction/The International Joint Conference onAutomated ReasoningSpringer5CCC IEEE Conference on Computational Complexity IEEE6ICALP International Colloquium on Automata,Languages and ProgrammingSpringer7CONCUR International Conference onConcurrency TheorySpringer三、C类序号会议简称会议全称出版社⽹址1CSL Computer Science Logic Springer2ESA European Symposium on Algorithms Springer3FSTTCS Foundations of Software Technologyand Theoretical Computer ScienceIndianAssociationfor Researchin ComputingScience4IPCO International Conference on Integer Programming and CombinatorialOptimizationSpringer5RTA International Conference on Rewriting Techniques and ApplicationsSpringer6ISAAC International Symposium onAlgorithms and ComputationSpringer7MFCS Mathematical Foundations ofComputer ScienceSpringer8STACS Symposium on Theoretical Aspectsof Computer ScienceSpringer9FMCAD Formal Method in Computer-Aided Design ACM 10SAT Theory and Applications of Springer10SAT Theory and Applications ofSatisfiability TestingSpringer中国计算机学会推荐国际学术会议(计算机图形学与多媒体)⼀、A类序号会议简称会议全称出版社⽹址1ACM MM ACM International Conference on Multimedia ACM2SIGGRAPH ACM SIGGRAPH Annual Conference ACM3IEEE VIS IEEE Visualization Conference IEEE⼆、B类序号会议简称会议全称出版社⽹址1ICMR ACM SIGMM International Conference on MultimediaRetrievalACM2i3D ACM Symposium on Interactive 3D Graphics ACM 3SCA ACM/Eurographics Symposium on Computer Animation ACM 4DCC Data Compression Conference IEEE5EG EurographicsWiley/ Blackwell6EuroVis Eurographics Conference on Visualization ACM7SGP Eurographics Symposium on Geometry ProcessingWiley/ Blackwell8EGSR Eurographics Symposium on RenderingWiley/ Blackwell9ICME IEEE International Conference onMultimedia &ExpoIEEE10PG Pacific Graphics: The Pacific Conference on ComputerGraphics and ApplicationsWiley/Blackwell11SPM Symposium on Solid and Physical Modeling SMA/Elsevier三、C类序号会议简称会议全称出版社⽹址1CASA Computer Animation and Social Agents Wiley2CGI Computer Graphics International Springer3ISMAR International Symposium on Mixed and AugmentedRealityIEEE/ACM4PacificVis IEEE Pacific Visualization Symposium IEEE5ICASSP IEEE International Conference on Acoustics, Speechand SPIEEE6ICIP International Conference on Image Processing IEEE7MMM International Conference on Multimedia Modeling Springer8GMP Geometric Modeling and Processing Elsevier9PCM Pacific-Rim Conference on Multimedia Springer10SMI Shape Modeling International IEEE中国计算机学会推荐国际学术会议(⼈⼯智能与模式识别)⼀、A类序号会议简称会议全称出版社⽹址1AAAI AAAI Conference on Artificial Intelligence AAAI2CVPR IEEE Conference on Computer Vision andPattern RecognitionIEEE3ICCV International Conference on ComputerVisionIEEE4ICML International Conference on MachineLearningACM5IJCAI International Joint Conference on Artificial Morgan Kaufmann5IJCAI⼆、B类序号会议简称会议全称出版社⽹址1COLT Annual Conference on ComputationalLearning TheorySpringer2NIPS Annual Conference on Neural InformationProcessing SystemsMIT Press3ACL Annual Meeting of the Association for Computational LinguisticsACL4EMNLP Conference on Empirical Methods in Natural Language ProcessingACL5ECAI European Conference on ArtificialIntelligence IOS Press6ECCV European Conference on Computer Vision Springer7ICRA IEEE International Conference on Roboticsand AutomationIEEE8ICAPS International Conference on AutomatedPlanning and SchedulingAAAI9ICCBR International Conference on Case-BasedReasoningSpringer10COLING International Conference on Computational LinguisticsACM11KR International Conference on Principles ofKnowledge Representation and ReasoningMorgan Kaufmann12UAI International Conference on Uncertaintyin Artificial IntelligenceAUAI13AAMAS International Joint Conferenceon Autonomous Agents and Multi-agentSystemsSpringer三、C类序号会议简称会议全称出版社⽹址1ACCV Asian Conference on Computer Vision Springer2CoNLL Conference on Natural Language Learning CoNLL3GECCO Genetic and Evolutionary ComputationConferenceACM4ICTAI IEEE International Conference on Tools with Artificial IntelligenceIEEE5ALT International Conference on AlgorithmicLearning TheorySpringer6ICANN International Conference on Artificial Neural NetworksSpringer7FGR International Conference on Automatic Faceand Gesture RecognitionIEEE8ICDAR International Conference on DocumentAnalysis and RecognitionIEEE9ILP International Conference on Inductive Logic ProgrammingSpringer10KSEM International conference on KnowledgeScience,Engineering and ManagementSpringer11ICONIP International Conference on NeuralInformation ProcessingSpringer12ICPR International Conference on PatternRecognitionIEEE13ICB International Joint Conference on Biometrics IEEE14IJCNN International Joint Conference on NeuralNetworksIEEE15PRICAI Pacific Rim International Conference onArtificial IntelligenceSpringer16NAACL The Annual Conference of the NorthAmerican Chapter of the Associationfor Computational LinguisticsNAACL17BMVC British Machine Vision Conference VisionAssociation中国计算机学会推荐国际学术会议(⼈机交互与普适计算)⼀、A类序号会议简称会议全称出版社⽹址1CHI ACM Conference on Human Factors in ComputingSystemsACM2UbiComp ACM International Conference on Ubiquitous Computing ACM⼆、B类序号会议简称会议全称出版社⽹址1CSCW ACM Conference on Computer Supported CooperativeWork and Social ComputingACM2IUI ACM International Conference on Intelligent UserInterfacesACM3ITS ACM International Conference on Interactive Tabletopsand SurfacesACM4UIST ACM Symposium on User Interface Software andTechnologyACM5ECSCW European Computer Supported Cooperative Work Springer6MobileHCI International Conference on Human Computer Interactionwith Mobile Devices and ServicesACM三、C类序号会议简称会议全称出版社⽹址1GROUP ACM Conference on Supporting Group Work ACM2ASSETS ACM Conference on Supporting Group Work ACM3DIS ACM Conference on Designing InteractiveSystemsACM4GI Graphics Interface conference ACM5MobiQuitous International Conference on Mobile and Ubiquitous Systems:Computing, Networking and ServicesSpringer6PERCOM IEEE International Conference onPervasive Computing and CommunicationsIEEE7INTERACT IFIP TC13 Conference on Human-ComputerInteractionIFIP8CoopIS International Conference on Cooperative Information Systems Springer9ICMI ACM International Conference on MultimodalInteractionACM10IDC Interaction Design and Children ACM 11AVI International Working Conference on Advanced User Interfaces ACM12UIC IEEE International Conference on UbiquitousIntelligence and ComputingIEEE中国计算机学会推荐国际学术会议(前沿、交叉与综合)⼀、A类序号会议简称会议全称出版社⽹址1RTSS Real-Time Systems Symposium IEEE⼆、B类序号会议简称会议全称出版社⽹址1EMSOFT International Conference on Embedded Software ACM/IEEE/IFIP2ISMB International conference on Intelligent Systems forMolecular BiologyOxford Journals3CogSci Cognitive Science Society Annual Conference Psychology Press4RECOMB International Conference on Research inSpringer4RECOMB International Conference on Research inComputational Molecular BiologySpringer5BIBM IEEE International Conference on Bioinformaticsand Biomedicine IEEE三、C类序号会议简称会议全称出版社⽹址1AMIA American Medical Informatics Association Annual SymposiumAMIA2APBC Asia Pacific Bioinformatics Conference BioMed Central3COSIT International Conference on Spatial InformationTheoryACM。
deserializeusing用法 -回复

deserializeusing用法-回复"DeserializeUsing" is a term commonly used in programming to describe the process of converting data that has been serialized (or transformed into a specific format) back into its original form. This process is essential for transmitting data between systems, storing data in databases, and ensuring the integrity and consistency of the information being transferred.In this article, we will delve deep into the concept of deserialization, exploring its uses, advantages, challenges, and common practices. We will start with an overview of serialization and then move on to discussing the purpose, steps, and best practices of deserialization.Serialization, as mentioned earlier, is the transformation of data into a format that can be easily stored or transmitted. This process involves converting the data structures and objects in a program into a binary or text-based format, making it portable and compatible across different platforms and languages. Serialization is crucial for scenarios where the state of an object needs to be preserved or transferred, such as remote procedure calls, distributed systems, and object persistence.Once data is serialized, it needs to be deserialized to retrieve its original structure and state. Deserialization is the reverse process of serialization that reconstructs the serialized data back into its original form. This process is vital to ensure that the data can be accurately interpreted and utilized by the receiving system or application.The deserialization process typically involves several steps. Let's explore these steps in detail:1. Identify the Serialized Data Format: The first step in the deserialization process is to determine the format in which the data has been serialized. Common formats include JSON, XML, Protocol Buffers, YAML, and MessagePack, among others. Each format has its own rules and syntax for serialization and deserialization.2. Retrieve the Serialized Data: Once the format is known, the serialized data needs to be obtained. It can be fetched from a file, a network response, or any other source from which the data was initially serialized.3. Initialize the Deserialization Context: Before deserialization can occur, a deserialization context or environment needs to be established. This context typically involves setting up the necessary objects, libraries, or modules required to perform the deserialization process successfully.4. Parse and Validate the Serialized Data: Once the context is prepared, the serialized data is parsed and validated to ensure that it adheres to the expected format and structure. This step is crucial for error handling and preventing potential security vulnerabilities, such as injection attacks or data corruption.5. Map Serialized Data to Target Data Structures: Deserialization involves mapping the serialized data to the appropriate data structures or objects in the receiving system. This step requires a clear understanding of the structure and type information of the original serialized data.6. Reconstruct Objects and Restore State: Using the mapped data, the deserialization process reconstructs the original objects and restores their state. This step involves creating instances of classes,assigning values to their properties, and recreating the relationships between different objects, if applicable.7. Handle Data Transformation and Conversion: During deserialization, it is common to encounter data transformation or conversion requirements. This may involve converting data types, applying business rules, or transforming the structure of the data to match the receiving system's requirements.8. Implement Error Handling and Exception Management: Deserialization can potentially encounter errors or exceptions, such as malformed or corrupted data, missing dependencies, or incompatible versions. Robust error handling and exception management mechanisms should be implemented to ensure graceful recovery and fault tolerance.9. Validate Deserialized Data: Once the deserialization process is complete, it is advisable to validate the deserialized data to ensure its integrity and correctness. This validation can involve domain-specific checks, comparison against expected values, or running business rules to confirm the accuracy of the deserialized data.Deserializing data has numerous benefits in the field of software development. It allows for the seamless transfer of data between different systems, facilitates interoperation between applications written in different languages, and enables the preservation of state when persisting objects to databases or storage systems. Deserialization also plays a significant role in distributed systems, microservices architectures, and message-based communication.However, deserialization is not without challenges. It can introduce security risks if not handled properly. Deserialization vulnerabilities, such as deserialization of untrusted data, can lead to remote code execution, denial of service attacks, or data manipulation. Developers should be aware of these risks and implement security measures such as input validation, data filtering, and sandboxing to mitigate potential threats.In conclusion, deserialization is a critical process in software engineering that allows data to be transformed back into its original form after serialization. By understanding the steps involved, developers can ensure the correct interpretation and utilization of serialized data, enabling efficient and reliable dataexchange across systems. However, it is important to handle deserialization securely to prevent potential security vulnerabilities and attacks.。
基于LSTM的电影评论情感分析研究

Technology Study技术研究DCW27数字通信世界2021.020 引言互联网的迅速发展以及通信工具的兴起,导致网络用户的信息交互渠道大量增加。
网络用户通过各种方式来表达自己对热点事件的观点,这使得在互联网上充斥着大批的由网民所参与的,对于事物、事件等有重大研究性的评论。
但是这些观点以及评论信息大多数都基于个人的主观意见,因此,情感分析的主要目的就是研究如何可以提取与情感相关的信息。
伴随着生活水平的逐渐提高以及群众对自己身心的放松,极大多数的人会选择在闲暇时间去观看一场自己喜欢的电影。
然而,面对逐渐扩大的电影市场以及众多但质量参差不齐的电影,消费者们通常难以抉择,他们对影片的期望值越大往往失望值也越大,花钱看“烂片”的现象不在少数。
因此,在选择电影之前,消费者们通常会关注已经看过该影片观众的评论,这些评论主要涉及到评论者对电影本身表达的情感信息,以及评论者对电影中的人物态度观点等。
但是由于每个人的喜好不同,过度的自我观点会对其他消费者造成潜移默化的影响,极大地提高了对有价值信息的获取难度。
所以快速并且有效地获取、处理这些电影的评论是极其重要的。
1 相关工作情感分析又称作观点发掘,隶属于数据挖掘,因其当前的巨大数字量形式记录,文本情感分析的研究工作发展十分迅速。
情感分析属于自然语言处理中的一个子领域,且通常是对携带主观性的文本进行处理,并且分析其中所包含的主观意见或者个人态度等。
对于情感分析,国外研究起源较早,Riloff 等通过构建了一些情感词典为之后的情感分析建立了良好的基础。
国内对于情感分析也做了众多的研究,常晓龙等通过融合中文语义特点来构建中文的情感词典;梁军等人尝试使用机器学习的方法进行特征提取,在降低了人工成本的同时也极大地提高了准确率。
群众对于各种热点事件有着各自的观点,对其进行情感分析可以有效解决所带来的问题,尤其当前的互联网环境当中充斥着大量的文本数据,对其进行情感分析是十分重要的工作。
体系结构设计英语

体系结构设计英语Designing System ArchitecturesThe field of system architecture has become increasingly crucial in the modern technology landscape. As the complexity of software and hardware systems continues to grow, the need for robust and efficient architectural designs has become paramount. System architecture encompasses the fundamental organization and structure of a system, including its components, their interactions, and the principles that govern its design and evolution.One of the key aspects of system architecture is the ability to decompose a complex system into manageable and well-defined subsystems. This modular approach allows for better scalability, maintainability, and flexibility, as changes can be made to individual components without disrupting the entire system. By identifying the appropriate level of abstraction and defining clear interfaces between subsystems, system architects can create architectures that are easier to understand, develop, and evolve over time.Another crucial aspect of system architecture is the consideration of non-functional requirements such as performance, security, reliability,and scalability. These requirements often have a significant impact on the overall design and can influence the selection of specific architectural patterns and technologies. For example, a system designed for high-performance computing may prioritize parallel processing and distributed computing, while a system focused on secure data storage may emphasize encryption and access control mechanisms.The process of designing a system architecture typically involves several key steps. First, the system's requirements and goals must be clearly defined, taking into account both functional and non-functional requirements. This often involves a thorough analysis of the problem domain, stakeholder needs, and any existing constraints or limitations.Next, the system architect must identify the appropriate architectural styles and patterns that can effectively address the identified requirements. This may involve exploring various architectural approaches, such as client-server, microservices, event-driven, or n-tier architectures, and evaluating their suitability for the specific system being designed.Once the architectural style has been selected, the system architect must define the high-level components and their interactions. This may involve creating detailed component diagrams, data flowdiagrams, and other visual representations to ensure a clear understanding of the system's structure and behavior.As the design process progresses, the system architect must also consider the deployment and operational aspects of the system. This may include defining the infrastructure requirements, such as hardware, software, and network configurations, as well as the processes and tools needed for deployment, monitoring, and maintenance.Throughout the design process, the system architect must also engage in ongoing communication and collaboration with various stakeholders, including developers, project managers, and end-users. This ensures that the system architecture remains aligned with the evolving needs and constraints of the project, and that any changes or refinements can be effectively incorporated into the design.In conclusion, system architecture is a critical discipline that underpins the success of complex software and hardware systems. By leveraging modular design, considering non-functional requirements, and engaging in a structured design process, system architects can create architectures that are scalable, maintainable, and adaptable to the ever-changing technological landscape. As the demand for sophisticated and reliable systems continues to grow, the role of the system architect will become increasingly essential in drivinginnovation and ensuring the long-term success of technology-driven organizations.。
BASEON

BASEONIntroductionThe BASEON framework is a widely-recognized approach to software development that emphasizes flexibility, scalability, and fault tolerance. It stands for Basic Availability, Soft-state, Eventual consistency, and No consistency.In this document, we will explore the key concepts and principles of BASEON, understand how it differs from the traditional ACID (Atomicity, Consistency, Isolation, Durability) model, and discuss its benefits and use cases.Understanding BASEONBasic AvailabilityThe basic availability principle in BASEON states that a system should guarantee a certain level of availability even in the face of partial failures. In traditional ACID systems, availability often relies on all parts of the system functioning correctly. However, BASEON acknowledges that failures are inevitable and focuses on making the system available despite these failures.Soft-stateThe soft-state principle recognizes that system states can change over time and do not necessarily need to be consistent across all nodes at any given moment. BASEON systems allowfor temporary inconsistencies, and the overall system state converges over time.Eventual ConsistencyEventual consistency is a fundamental aspect of BASEON, which acknowledges that achieving absolute consistency in a distributed system is often impractical or inefficient. Instead, BASEON aims for eventual consistency, where all replicas will eventually converge to the same state. It allows for a trade-off between consistency and system performance.No ConsistencyNo consistency means that BASEON systems do not enforce strong consistency guarantees, such as those provided by ACID systems. Instead, the focus is on providing availability and performance by relaxing the strict consistency requirements.BASEON vs ACIDWhile ACID provides strong consistency guarantees, it often comes at the cost of availability and scalability. BASEON, on the other hand, emphasizes availability and performance by relaxing the consistency requirements. This makes BASEON more suitable for distributed systems and large-scale applications where high availability is critical.ACID systems typically require immediate consistency across all nodes, which can be difficult to achieve in distributed systems due to network latency and partial failures. BASEON, with its eventual consistency model, allows for more flexible and scalable system architectures.BASEON also allows for optimistic concurrency control, where conflicts are resolved after the fact rather than preventing them in advance. This approach is more suitable for systems with high write throughput as it reduces coordination overhead.Benefits of BASEONHigh AvailabilityThe BASEON model ensures that the system is always available for user requests, even in the face of partial failures. By allowing temporary inconsistencies, the system can continue to operate and serve requests. This is particularly useful for critical applications that cannot afford downtime.ScalabilityBASEON provides scalability by relaxing the strict consistency requirements of ACID and allowing for eventual consistency. This allows for the distribution and replication of data across multiple nodes, providing the ability to handle large amounts of data and high transaction rates.Fault ToleranceBy embracing the potential for partial failures, BASEON systems are inherently more fault-tolerant. Even if individual components fail, the system can continue to operate, and data can be replicated and recovered from other nodes.Use Cases for BASEONBASEON is well-suited for various scenarios where high availability and scalability are critical. Some common use cases include:•Social media platforms: BASEON allows social media platforms to accommodate a large number of concurrentusers and handle high write and read throughput.•E-commerce applications: In e-commerce applications, where consistent inventory availability andorder processing are essential, BASEON can ensure highavailability while allowing for temporary inconsistencies.•Collaborative document editing: BASEON can be used to facilitate collaborative document editing wheremultiple users can make changes simultaneously. Eventual consistency ensures that all users eventually see the same version of the document.ConclusionBASEON provides a flexible and scalable approach to software development that prioritizes availability and performance. By relaxing strict consistency requirements, BASEON allows for distributed systems that can handle high transaction rates and recover from partial failures.Understanding the basic principles of BASEON and its differences from traditional ACID systems can help developers make informed decisions when designing and implementing distributed applications.。
SAP专业教材资料Incident_Management_10_18Ps

SAP标准事件管理1 管理概述管理复杂性,风险,费用以及技能和资源是执行关键任务支持的SAP为中心的解决方案的核心。
复杂性甚至进一步上升在outtasking和外包的趋势下。
为了帮助客户管理他们的SAP为中心的解决方案,SAP提供一整套业务标准解决方案的。
出于这样的标准,事件管理标准描述了事件的解决过程。
这有助于客户加快事件的解决,增加IT可用性解决方案,尽量减少消极业务影响,并获得100%的问题和挑战的透明度。
本文档提供有关事件的细节管理水平。
它解释了标准的基本概念,描述了流程的不同步骤,并提供有关标准的实施细节。
这包括对方法和有关资料所需的配置说明。
2 SAP Standards for E2E Solution Operations关键任务Operation是一个挑战。
随着SAP-centric solutions的灵活性的增加,客户必须去有效的管理复杂性、风险、成本以及技能和资源。
客户必须运行以及逐渐的改进IT Solution 来确保solution landscape的平稳操作。
这包括有效性、性能、流程、和数据透明性、数据一致性、IT流程一致性的管理以及其他的任务。
一般情况下,客户组织中的多个团队与这些需求的实现有关。
他们属于关键organizational areas Business Unit and IT.尽管每个公司的组织名称可能不同,但是他们的Function一般来说都是相同的。
他们根据公司战略和corporate policies以及组织目标来运行他们的活动(例如,公司管制、一致、安全)。
Figure 2.1: Organizational model for end-to-end solution operations不同的团队专门进行某些任务的执行:在业务方,End User使用已实现的Functionality 去运行他们的日常业务。
Key User为他们的同事提供First Level Support。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
A client-server system
Computers in a C/S network
Layered application architecture
Presentation layer Concerned with presenting the results of a computation to system users and with collecting user inputs. Application processing layer Concerned with providing application specific functionality e.g., in a banking system, banking functions such as open account, close account, etc. Data management layer Concerned with managing the system databases.
A client-server ATM system
Three-tier architectures
In a three-tier architecture, each of the application
architecture layers may execute on a separate processor. Allows for better performance than a thin-client approach and is simpler to manage than a fat-client approach. A more scalable architecture -as demands increed.
Middleware
Software that manages and supports the different
components of a distributed system. In essence, it sits in the middle of the system. Middleware is usually off-the-shelf rather than specially written software. Examples
architectures between clients and servers. Each distributable entity is an object that provides services to other objects and receives services from other objects. Object communication is through a middleware system called an object request broker. However, distributed object architectures are more complex to design than C/S systems.
Fat-client model In this model, the server is only responsible for data management. The software on the client implements the application logic and the interactions with the system user.
Virtually all large computer-based systems are
now distributed systems. Information processing is distributed over several computers rather than confined to a single machine. Distributed software engineering is therefore very important for enterprise computing systems.
System types
Personal systems that are not distributed and that are
designed to run on a personal computer or workstation. Embedded systems that run on a single processor or on an integrated group of processors. Distributed systems where the system software runs on a loosely integrated group of cooperating processors linked by a network.
Topics covered
Multiprocessor architectures Client-server architectures Distributed object architectures
Inter-organisational computing
Distributed systems
Application layers
Thin and fat clients
Thin-client model In a thin-client model, all of the application processing and data management is carried out on the server. The client is simply responsible for running the presentation software
A 3-tier C/S architecture
An internet banking system
Use of C/S architectures
2. Distributed Object Architectures
There is no distinction in a distributed object
More processing is delegated to the client as the
application processing is locally executed. Most suitable for new C/S systems where the capabilities of the client system are known in advance. More complex than a thin client model especially for management. New versions of the application have to be installed on all clients.
Scalability Increased throughput by adding new resources. Fault tolerance The ability to continue in operation after a fault has occurred.
Distributed system disadvantages
Distributed system characteristics
Resource sharing Sharing of hardware and software resources.
Openness Use of equipment and software from different vendors. Concurrency Concurrent processing to enhance performance.
Thin and fat clients
Thin client model
Used when legacy systems are migrated to client
server architectures.
The legacy system acts as a server in its own right with a
Unpredictability Unpredictable responses depending on the system organisation and network load.
Generic Types of Distributed Systems Architectures
are provided by servers and a set of clients that use these services. Clients know of servers but servers need not know of clients. Clients and servers are logical processes The mapping of processors to processes is not necessarily 1 : 1.
graphical interface implemented on a client.
A major disadvantage is that it places a heavy
processing load on both the server and the network.
Fat client model
Distributed object architectures No distinction between clients and servers. Any object on the system may provide and use services from other objects.