关于cascade与inverse
JAVA笔试题

JAVA笔试题科目试题类型题干选择题选项A<action name=”individualLoginForm” path=”/individualLo SSH单选题在Struts配置文件中配置了一个实现登陆功能的Action名为IndividualLoginAction,用户提交Hibernate是对JDBC轻量级的封装SSH单选题下列关于Hibernate说法正确的是()identitySSH单选题下列主键生成策略针对自增长Struts的Action类必须实现Action接口SSH单选题关于Action的说法,下列正确的是incrementSSH单选题在hibernate中,以下()主键生成策略不存在Spring是一系列轻量级JavaEE框架的集合SSH单选题下列关于Spring说法错误的是( )。
SSH单选题下面说法正确的是( )。
S pring配置文件的名字一定是applicationContext.xmlhibernate3也实现了依赖注入SSH单选题下面关于依赖注入说法正确的 ( )。
invalidateSSH单选题在ActionForm中,()方法用来验证的使用Struts框架时,这些组件必须继承ActionFormSSH多选题在构建视图(View)层使用的组件时,使用Struts框架和JSF框架有着明显的不同,区别在于()。
(选ActionServletSSH单选题下面哪个是Struts控制器()EJBSSH单选题J2EE规范中指定的J2EEAPI中不包括以下()JarSSH单选题JavaEE应用程序包含了Web组件,它可以被封装为()文件类com.test.LoginForm是org.apache.struts.action.ActionFo SSH单选题在使用Struts框架构建应用系统时,会在配置文件中出现如下配置信息:pageSSH多选题ActionForm的生命周期是()(选两项)SSH多选题以下哪两种状态没有关联数据)(选两项)临时态数据库连接信息SSH多选题下面()不是Hibernate.cfg.xml映射文件中包含的内容(选两项)SSH单选题Struts提供哪些视图层组件标签SSH单选题Struts提供哪些控制层组件标签htmlSSH单选题以下哪组标签不是struts提供的ActionSSH单选题下列哪项不是struts提供的Action类编写类继承ActionFormSSH单选题下面哪项是使用ActionForm不必须的SSH单选题下列哪项不是hibernate中Session类的方法savenativeSSH单选题下列哪项不是hibernate常见的id生成器映射文件名只能以.hbm.xml结尾SSH单选题下列关于hibernate映射文件说法正确的是SSH单选题下列哪项不是bean在hibernate中的状态持久状态load方法可以根据主键加载一个对象SSH单选题关于hibernate session的get,load方法描述错误的是Query对象通过session.createQuery()方法创建SSH单选题下列关于hibernate的Query接口说法错误的是SSH单选题下列关于hql的说法正确的是from关键字后使用类名session的load方法默认会使用延迟加载SSH单选题下列关于hibernate延迟加载说法错误的是依赖注入指的是对象之间的关系在运SSH单选题下列关于依赖注入(DI)说法错误的是before adviceSSH单选题下列哪项不属于Spring的advice类型bean就是被Spring管理的对象SSH单选题下列关于Spring中的bean描述错误的是Hibernate的SessionFactory可以由Spring创造SSH单选题下列关于Hibernate与Spring的整合说法错误的是SSH单选题下列关于Struts Action的execute方法签名描述正确的是execute(ActionMapping mappireset方法用于重新设置ActionForm属性值SSH单选题下列关于Struts ActionForm说法错误的是ActionSSH单选题在Struts实现的MVC框架中,()类是包含了excute方法的控制器类,负责调用模型的方法,控SSH单选题在基于Struts框架的Web应用中,下面关于Action类的说法正确的是Action类属于模型组件ActionForm Bean用来完成一些实际的业务逻辑SSH单选题在基于Struts框架的Web应用中,下面关于ActionForm Bean的说法正确的是this.saveErrors(request, erSSH单选题分析Action Bean的execute方法:p ublicActionForward execute(ActionMapping map<controller>SSH单选题在Struts配置文件中,()元素的processorClass属性用于配置RequestProcessor类。
ssh试题

测试卷(java)一、选择题(60 分)1)在S t r ut s实现的MVC框架中,(a)类是包含了excute 方法的控制器类,负责调用模型的方法,控制应用程序的流程。
a)Actionb)EJBc)ActionServletd)JSP2)在基于Struts 框架的Web 应用中,下面关于Action类的说法正确的是(c)。
a)Action 类属于模型组件b)Action 类主要用来完成实际的业务逻辑c)Action 类负责调用模型的方法,更新模型的状态,并帮助控制应用程序的流程d)在Web 应用启动时会自动加载所有的Action实例3)在基于Struts 框架的Web 应用中,下面关于ActionForm Bean的说法正确的是(b)。
a)ActionForm Bean 用来完成一些实际的业务逻辑b)Struts 框架利用ActionForm Bean 来进行视图和控制器之间表单数据的传递c)ActionForm负责调用模型的方法,更新模型的状态d)ActionForm Bean 包含一些特殊的方法,reset()用于验证表单数据validate()将其属性重新设置为默认值4)分析Action Bean 的execute 方法:public ActionForward execute(ActionMappingmapping, ActionForm form,HttpServletRequest request,HttpServletResponse response) {ActionErrors errors=new ActionErrors();if(!udao.check(loginform)){ errors.add("login", newActionMessage("error.login"));returnmapping.findForward("failure");}}完成以上的功能,应在下划线上填入(c)。
Inverse 和 cascade的区别

Inverse 和cascade的区别实际上,他们是互不相关的概念:inverse是指的关联关系的控制方向,而cascade指的是层级之间的连锁操作。
级联删除在默认情况下,当Hibernate删除一个持久化对象时,不会自动删除与他关联的其他持久化对象,如果希望Hibernate删除Customer对象时,自动删除和Customer关联的Order对象,可以把cascade的属性设置为delete。
注意:在关联的双方的哪一方设置cascade为delete呢?是不是要在双方都要设置呢?这个主要看项目本身。
如果项目是针对一对多的,应该在“one”方设置cascade为delete,不能在“many”方设置cascade为delete 。
提示:所谓删除一个持久化对象,并不是指从内存中删除这个对象,而是从数据库中删除相关的记录。
这个对象依然存在于内存中,只不过由持久化状态转变成为临时状态。
cascade属性可以有多个值,中间用逗号分开,eg:cascade="save-update,delete<set name="orders" cascade="all-delete-orphan" inverse="true"><key column="c_id"></key><one-to-many class="net.mbs.mypack.Order" /></set>Cascade属性的all-delete-orphan值当我们解除Customer和Order对象之间的关系时:customer.getOrdersa().remove(order);order.setCustomer(null);系统会执行update order set c_id=null where id=? //前提:c_id列允许为null如果希望Hibernate自动删除不再和Customer对象关联的Order对象,可以把cascade属性设置为all-delete-orphanall-delete-orphan值的总结1:当保存Customer对象时,级联保存所有关联的Order对象,相当于cascade=“save-update”2:当删除Customer对象时,级联删除所有关联的Order对象,相当于cascade=“delete”. 3;删除不再和Customer对象关联的所有Order对象当关联双方存在父子关系时,就可以把父方的cascade属性设置为“all-delete-orphan”] 所谓父子关系,是指由父方子方的持久化生命周期,子方对象必须和一个父方对象关联如果删除父方对象,应该级联删除所有的关联的子方对象。
自动控制原理重点英文单词+汉语翻译

Closed-loop control systems 闭环控制系统Open-loop control systems开环控制系统Process 过程Linear system线性系统Nonlinear system非线性系统Continuous system 连续系统Discrete system离散系统Stability 稳定性Steady-state performance 稳态性能Transient performance 暂态特性mathematical model 数学模型differential equations 微分方程Transfer function传递函数zeros and poles of transfer function传递函数的零极点Inverse proportion part 比例环节Inertia part惯性环节Integral part 积分环节Derivative part 微分环节Vibrate part震荡环节Delay part 滞后环节Block diagram (Equivalent transformation)方框图(Unit) negative (positive) feedback loop 负(正)反馈回路Mason formula 梅逊公式disturbance 干扰Step signal 阶跃信号Ramp signal(speed function signal) 斜波信号Parabola signal(acceleration signal) 加速度信号pulse signal脉冲信号Sinusoidal signal 正弦信号Delay time延迟时间Rise time 上升时间Peak time峰值时间Settling time 稳定时间Percent overshoot超调量Steady-state error稳态误差position error coefficient Kp speed error coefficient Kv acceleration error coefficient Kafirst-order system一阶系统S econd-order system 二阶系统high-order system 高阶系统Dominant pole主导极点Underdamped欠阻尼Critically Damped临界阻尼Overdamped 过阻尼Undamped无阻尼的Routh-Hurwitz stability criterion劳斯稳定性判据R outh array 劳斯表Character equation 特征方程root locus 根轨迹open-loop zeros and poles 开环零极点Magnitude and angle requirements of root locus幅值与相角frequency character 频率特征(inverse) Laplace transformation 拉普拉斯(反)变换Nyquist plot奈奎斯特图Bode diagram波德图Logarithmic magnitude frequency character对数幅值频率特性Logarithmic phase frequency character对数相频特征Nyquist stability criterion奈奎斯特稳定判据cutoff frequency 剪切频率Phase margin 相位裕量Gain margin 增益裕量Cutoff frequencyCascade phase-lead compensation串联超前矫正Cascade phase-lag compensation 串联滞后校正Cascade phase-lag and -lead compensation串联滞后-超前矫正sample control system 采样控制系统digital control system 数控系统discrete control system离散控制系统Shannon sampling theorem 香农采样定理Zero-order hold 零阶保持sampling period 采样周期Sampling frequency 采样频率Z-transform z变换Z-inverse transform z逆变换pulse transfer function脉冲传递函数bilinear transform双线性变换。
cascade和inverse详解

Hibernate中的inverse在表关系映射中经常应用,inverse的值有两种,“true”和“false”。
inverse="false"是默认的值,如果设置为true 则表示对象的状态变化不会同步到数据库 ;设置成false则相反;inverse的作用:在hibernate中是通过inverse的设置来决定是有谁来维护表和表之间的关系的。
我们说inverse设立不当会导致性能低下,其实是说inverse设立不当,会产生多余重复的SQL语句甚至致使JDBC exception的throw。
这是我们在建立实体类关系时必须需要关注的地方。
一般来说,inverse=true 是推荐使用,双向关联中双方都设置 inverse=false的话,必会导致双方都重复更新同一个关系。
但是如果双方都设立inverse=true的话,双方都不维护关系的更新,这也是不行的,好在一对多中的一端:many-to-one 默认是inverse=false,避免了这种错误的产生。
但是多对多就没有这个默认设置了,所以很多人经常在多对多的两端都使用inverse=true,结果导致连接表的数据根本没有记录,就是因为他们双分都没有责任维护关系。
所以说,双向关联中最好的设置是一端为inverse=true,一端为inverse=false。
一般inverse=false会放在多的一端,那么有人提问了,many-to-many两边都是多的,inverse到底放在哪儿?其实hibernate建立多对多关系也是将他们分离成两个一对多关系,中间连接一个连接表。
所以通用存在一对多的关系,也可以这样说:一对多是多对多的基本组成部分。
cascade 有五个选项分别是:all ,delete ,none,save-update,delete-orphan ;all : 所有情况下均进行关联操作。
none:所有情况下均不进行关联操作。
关于延迟加载(lazy)和强制加载

延迟加载特性的出现,正是为了解决这个问题。所谓延迟加载,就是在需要数据的时候,才真正执行数据加载操作。
对于我们这里的user对象的加载过程,也就意味着,加载user对象时只针对其本身的属性, 而当我们需要获取user对象所关联的address信息时(如执行user.getAddresses时),才
TUser user = (TUser)session.load(TUser.class,new Integer(1));
VO经过Hibernate进行处理,就变成了PO。上面的示例代码session.save(user)中,我们把一个VO “user”传递给Hibernate的Session.save方法进行保存。在save方法中,Hibernate对其进
TUser user =(TUser)userList.get(0);
System.out.println("User name => "+user.getName());
Set hset = user.getAddresses();
session.close();//关闭Session
这里有个问题,如果我们采用了延迟加载机制,但希望在一些情况下,实现非延迟加载时的功能,也就是说,我们希望在Session关闭后,依然允许操作user的addresses
属性。如,为了向View层提供数据,我们必须提供一个完整的User对象,包含其所关联的address信息,而这个User对象必须在Session关闭之后仍然可以使用。
javaSE2.20.试卷A及答案

A卷姓名:_______________ 一.选择题:(每题2分,共62分)61.关于sleep()和wait(),以下描述错误的一项是()A. sleep是线程类(Thread)的方法,wait是Object类的方法;B. sleep不释放对象锁,wait放弃对象锁;C. sleep暂停线程、但监控状态仍然保持,结束后会自动恢复;D. wait后进入等待锁定池,只有针对此对象发出notify方法后获得对象锁进入运行状态。
解答:Dsleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。
调用sleep不会释放对象锁。
wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
62.下面能让线程停止执行的有(多选)( )A. sleep();B. stop();C. notify();D. synchronized();E. yield();F. wait();G. notifyAll();解答:ABDEFsleep:导致此线程暂停执行指定时间stop: 这个方法将终止所有未结束的方法,包括run方法。
synchronized():对象锁yield:当前正在被服务的线程可能觉得cpu的服务质量不够好,于是提前退出,这就是yield。
wait:当前正在被服务的线程需要睡一会,醒来后继续被服务63.下面哪个可以改变容器的布局?( )A. setLayout(aLayoutManager);B. addLayout(aLayoutManager);C. layout(aLayoutManager);D. setLayoutManager(aLayoutManager);解答:AJava设置布局管理器setLayout()64.下面哪个是applet传递参数的正确方式?()A. <applet code=Test.class age=33 width=100 height=100>B. <param name=age value=33>C. <applet code=Test.class name=age value=33 width=100 height=100>D. <applet Test 33>解答:B65.提供Java存取数据库能力的包是()A.java.sql B.java.awt C.ng D.java.swing解答:Ajava.sql是JDBC的编程接口java.awt和java.swing是做图像界面的类库ng: Java 编程语言进行程序设计的基础类66.不能用来修饰interface的有()A.private B.public C.protected D.static解答:ACD修饰接口可以是public和默认67.下列说法错误的有()A.在类方法中可用this来调用本类的类方法B.在类方法中调用本类的类方法时可直接调用C.在类方法中只能调用本类中的类方法D.在类方法中绝对不能调用实例方法解答:ACDA.在类方法中不能使用this关键字C.在类方法中可以调用其它类中的类方法D.在类方法中可以通过实例化对象调用实例方法68.从下面四段(A,B,C,D)代码中选择出正确的代码段()A.abstract class Name {private String name;public abstract boolean isStupidName(String name) {} }B.public class Something {void doSomething () {private String s = "";int l = s.length();}}C.public class Something {public static void main(String[] args) {Other o = new Other();new Something().addOne(o);}public void addOne(final Other o) {o.i++;}}class Other {public int i;}D.public class Something {public int addOne(final int x) {return ++x;}}解答:CA..抽象方法不能有方法体B.方法中定义的是局部变量,不能用类成员变量修饰符private D.final修饰为常量,常量的值不能被改变69.选择下面代码的运行结果:()。
Selig-1994-AIAAJ-CascadeInverseDesign

designer to specify directly the desired trailing-edge angle in the range from 0 deg (a cusped trailing edge) to 180 deg (a rounded trailing edge). A rounded trailing edge raises the Issue of where should the rear stagnation point be located. Although this issue is not addressed here. the ability of the present method to allow for the specification of a rounded trailing edge and also the outlet flow angle paves the way for the introduction of viscous considerations as discussed in Gostelow.' A computer code (CASCADE) has been developed based on the current approach. The design method is analogous to that widely used for multipoint inverse airfoil design described in Refs. 2-5. Thus, it is expected that the current cascade design approach will have similar appeal because it allows for multipoint design and runs rapidly on a personal computer. . To place this work in a broader context. it is helpful to diSCUSS concurrent developments in airfoil and cascade design. Mangler> and LighthilF were the first to resolve the mathematical difficulties believed to be associated with inverse airfoil design.8.9 These theories. which were based on conformal mapping, showed that for the inverse airfoil problem the specified velocity distribution must statisfy certain conditions. In so doing, the conformal transformation connecting the circle and airfoil plane can be found. From this transformation. the airfoil shape can be determined. For the cascade, Lighthill lO made a significant'contribution following along similar lines. In almost analogous fashion to the isolated airfoil problem. he found that the specified velocit~ ~istribution about the cascade blade must satisfy special conditions for the mathematical problem to be well posted. Once these conditions are satisfied. the mapping can be determined to give the cascade geometry. Advancements in airfoil design continued through improvements in numerical techniques and through the use of computers. Added to this was the multipoint design theory of Epple~ (summarized in Ref. 2). Specifically, this theory made It poSSible to divide the airfoil into segments and specify over each segment the desired velocity distribution along with the angle of attack at which that velocitv distribution is to be achieved .. C~nsequently. conformal mapping as applied to the mverse airfOil problem remains in favor owing to the abilitv to solve rapidly and conveniently the multipoi~t design problem. 2 •3 Parallel developments in cascade design through the use of conformal mapping have not been equally successful. In fact. few recent efforts have been aimed at practical cascade design by means of conformal mapping. II In current use for incompressible flow are cascade design methods based on distributed singularity methods. 12- 14 Such methods. however, are
程序员常见的问题解答

程序员常见的问题解答1.Configuration接口的功能,主要作用?创建一个Configuration对象配置和启动hibernate框架创建SessionFactory对象的实例读取hibernate.cfg.xml核心配置文件2.Hibernate持久化操作的七步?1.创建Configuration对象2.创建SessionFactory对象3.创建Session对象4.开始事物5.持久化操作6.提交事物7.关闭Session3.怎么样使用HQL查询方法?创建一个查询createQuery()创建一个Query查询接口的实例,该实例可以利用HQL语言来进行数据库的查询操作。
HOL语句要给createQuery()方法作为参数才可以让Query方法来进行查询操作4.事务具有几个基本特征,都是什么吗?(ACID):1 Atomic(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败。
2 Consistency(一致性):只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初状态。
3 Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。
同时,并行事务的修改必须与其他并行事务的修改相互独立。
4 Durability(持久性):事务结束后,事务处理的结果必须能够得到固化。
5. 如果两个事物并发运行,就可能出现以上五种并发问题,都是什么?1第一类丢失更新(Lost update)2. 脏读取(Dirty Reads):3.虚读(Phantom Reads)4. 不可重复读取(Non-repeatable Reads)5第二类丢失更新(Second lost updates problem)6.hibertnate中的关联关系包括1.一对一的关联模式2.一对多的关联模式3. 多对多的关联模式7. 怎么样把映射表的xml文件配置到Hibernate核心配置文件中:<mapping resource="model/Student.hbm.xml" />8. ORM全称?(Object - Relation Mapping)对象关系映射9.ORM的工作原理?把持久化类映射成数据库中的表把对象映射成数据库中表的一行记录把对象的属性映射成数据库中表的字段10. Session接口的功能它是应用程序与数据库之间交互的但线程对象,一个session同样对应一个数据库,所以它是hibernate提供的与进行持久化操作的对象(持久化操作为增,删,改,查)同时它也是一个事物对象的工厂,及Transaction对象两种创建方式11.session中最常用的几种持久化操作的方法?save()delete()update()load()get()12. Session缓存的作用?1、减少访问数据库的频率。
数据库的表关系图

数据库的表关系图1>:one-to-one(一对一关联)主键关联:一对一关联一般可分为主键关联和外键关联主键关联的意思是说关联的两个实体共享一个主键值,但这个主键可以由两个表产生.现在的问题是:*如何让另一个表引用已经生成的主键值解决办法:*Hibernate映射文件中使用主键的foreign生成机制eg:学生表:<hibernate-mapping><class name="er" table="user" catalog="study"><id name="userid" type="ng.Integer"><column name="userid" /><generator class="native" /></id><property name="username" type="ng.String"><column name="username" length="20" /></property><one-to-one name="card" class="org.wen.beans.Card" cascade="all"></one-to-one></class></hibernate-mapping>添加:<one-to-one name="card"class="org.wen.beans.Card"fetch="join"cascade="all" /><class>元素的lazy属性为true,表示延迟加载,如果lazy设为false,则表示立即加载.以下对这二点进行说明.立即加载:表示在从数据库中取得数据组装好一个对象后,会立即再从数据库取得数据组装此对象所关联的对象延迟加载:表示在从数据库中取得数据组装好一个对象后,不会立即从数据库中取得数据组装此对象所关联的对象,而是等到需要时,才会从数据库取得数据组装此关联对象.<one-to-one>元素的fetch属性可选为select和joinjoin:连接抓取,Hibernate通过在Select语句中使用outer join(外连接)来获得对象的关联实例或者关联集合.select:查询抓取,Hibernate需要另外发送一条select语句抓取当前对象的关联实体或集合.******所以我们一般用连接抓取<join>证件表:<hibernate-mapping><class name="org.wen.beans.Card" table="card" lazy="true" catalog="study"><id name="cardid" type="ng.Integer"><column name="cardid" /><generator class="foreign"><param name="property">user</param></generator></id><!-- id使用外键(foreign)生成机制,引用代号为user的对象的主键作为card表的主键和外键。
Hibernate备课笔记

Hibernate笔记:作者:胡晟源QQ:13128377811. hibernate不能删除全是非空记录表记录。
org.hibernate.PropertyValueException: not-null property references a null or transient value: 在hbm.xml里面写了not-null=“true”,至于什么原因,目前正在寻找。
2.Hql语句:form+对象名。
后面的名字必须和javabean类类名相同。
3配置Myeclipse连接数据库,使之自动生成hibernate.cfg.xml和javabean类。
第一步:成功连接数据库。
第三步:新建一个Web工程项目。
选中该项目然后:MyEclipse-->Project--->add Hibernate Capabilities。
操作之后会出现如下界面:选中myhibernate这个项目。
然后点击:一:Myeclipse二:project capabilities三:add Hibernate Capabilities. 第二步:第三步:第四步:对于这步中,我选中去掉自动生成的HibernatesessionFactory工具类,该工具类就是一个回去Session的单例。
完成后,打开项目就可以看到:第五步:重新回到MyEclipse Database Exploere界面。
选中刚刚配置的SQLServerDriver,右击选中open connection,完成后就会出现如下界面:第六步:在dbo-->table中选中相应的表,右击选中Hibernate Reverse Engineering。
如上。
然后出现:第七步:第八步:4.查询一列:返回的是:List<Object>,查询多列:返回的是List<object[]>数组集合。
●(increment)并发问题。
SSH选择题

1。
下面(D)是框架。
A.JSP B。
Struts标签库 C。
Criteria查询 D.SSH2.MVC设计模式的目的是(C).A.使程序结构更清晰B.使程序更好维护C.保证视图和模型的隔离 D在逻辑上将视图、模型和控制器分开3。
下面信息不在Struts配置文件中配置的是(B).A.Form Bean配置信息 B。
Spring声明式事务C.Action转发路径D.Struts引用的资源文件4。
在Struts中,DispatchAction和普通Action的配置不同的是(B)。
A。
需要多配置一个可选的parameter属性B。
需要多配置一个必须的parameter属性C。
需要多配置一个可选的method属性D。
需要多配置一个必须的method属性5.在Struts中,关于DispatchAction的说法中,错误的是(B)。
A.访问DispatchAction必须提供parameter参数B.DispatchAction中必须实现execute方法C.DispatchAction可以与Spring进行集成D.可通过传入参数的值指定访问DispatchAction中的方法的名称6。
下面关于Struts报错机制说法正确的是(AC)。
A.强制使用国际化B。
错误信息保存在session中C.使用〈html:errors>标签显示错误信息D.也可以使用〈html:messages〉显示错误信息7.某Action Bean中有如下代码:errors.add(”order_count”,new ActionMessage(”error。
biz_ruler。
no_storage"));在页面上显示这条错误信息的代码是(D)。
A。
〈html:error name=”order_count” /〉B。
〈html:error property=”order_count" />C.<html:errors name=”order_count" /〉D。
Java面试经典100题
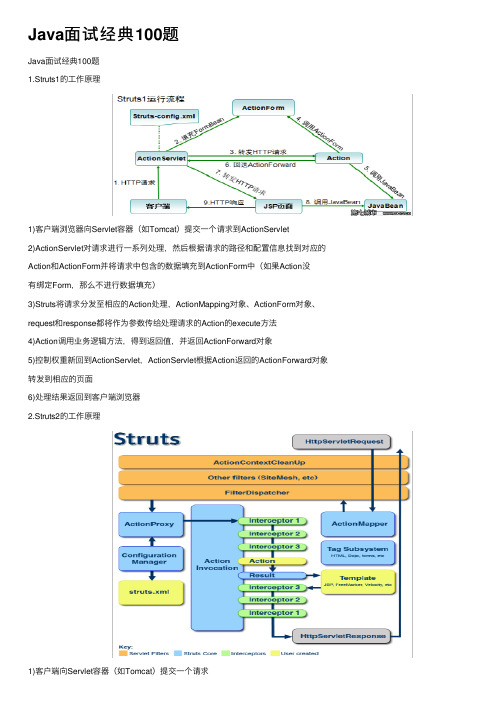
Java⾯试经典100题Java⾯试经典100题1.Struts1的⼯作原理1)客户端浏览器向Servlet容器(如Tomcat)提交⼀个请求到ActionServlet2)ActionServlet对请求进⾏⼀系列处理,然后根据请求的路径和配置信息找到对应的Action和ActionForm并将请求中包含的数据填充到ActionForm中(如果Action没有绑定Form,那么不进⾏数据填充)3)Struts将请求分发⾄相应的Action处理,ActionMapping对象、ActionForm对象、request和response都将作为参数传给处理请求的Action的execute⽅法4)Action调⽤业务逻辑⽅法,得到返回值,并返回ActionForward对象5)控制权重新回到ActionServlet,ActionServlet根据Action返回的ActionForward对象转发到相应的页⾯6)处理结果返回到客户端浏览器2.Struts2的⼯作原理1)客户端向Servlet容器(如Tomcat)提交⼀个请求2)请求经过⼀系列过滤器(如ActionContextCleanUp过滤器等)3)核⼼控制器被调⽤,询问ActionMapper来决定请求是否需要调⽤某个Action4)如果ActionMapper决定需要调⽤某个Action,核⼼控制器把控制权委派给ActionProxy(备注:JSP请求⽆需调⽤Action)5)ActionProxy通过Configuration Manager询问框架的配置⽂件(struts.xml),找到需调⽤的Action类6)ActionProxy创建⼀个ActionInvocation的实例7)ActionInvocation负责调⽤Action,在此之前会依次调⽤所有配置的拦截器8)Action执⾏完毕,ActionInvocation负责根据结果码字符串在struts.xml的配置中找到对应的返回结果页⾯9)拦截器被再次执⾏10)过滤器被再次执⾏11)处理结果返回到客户端浏览器3.Struts1与Struts2的区别1)数据封装:Struts1有From类和Action类,属性封装From类⾥,在Struts2⾥只有Action类,属性直接封装Action类⾥。
hibernate.hbm.xml配置详解

Hibernate中hbm.xml配置说明。
在Hibernate中,各表的映射文件….hbm.xml可以通过工具生成,例如在使用MyEclipse开发时,它提供了自动生成映射文件的工具。
配置文件的基本结构如下:Xml代码1<?xml version="1.0"encoding='UTF-8'?>23<!DOCTYPE hibernate-mapping PUBLIC4"-//Hibernate/Hibernate Mapping DTD 3.0//EN"5"/hibernate-mapping-3.0.dtd">6<hibernate-mapping package="包名">7<class name="类名"table="表名">8<id name="主键在java类中的字段名"column="对应表中字段"type="类型">9<generator class="主键生成策略"/>10</id>1112……13</class>14</hibernate-mapping>1. 主键(id)Hibernate的主键生成策略有如下几种:1) assigned主键由外部程序负责生成,在save() 之前指定。
2) hilo通过hi/lo 算法实现的主键生成机制,需要额外的数据库表或字段提供高位值来源。
3) seqhilo与hilo 类似,通过hi/lo 算法实现的主键生成机制,需要数据库中的Sequence,适用于支持Sequence 的数据库,如Oracle。
4) increment主键按数值顺序递增。
cascade用法

cascade用法1. 什么是cascadeCascade是一个英文单词,翻译成中文可以理解为“级联”的意思。
在计算机科学领域,特别是机器学习和计算机视觉领域中,cascade是一个重要的概念和技术,常常用于解决一些复杂问题。
2. cascade在机器学习中的应用在机器学习中,cascade通常用于级联分类器(cascade classifier)的构建。
级联分类器是一种多阶段的分类器,采用级联的方式对输入数据进行分类。
每个阶段的分类器负责检测和识别特定的特征或模式,当数据通过一个阶段的分类器后,只有通过了该分类器才会被继续传递到下一个阶段进行进一步分类。
这种级联方式可以大大提高分类的准确性和效率。
3. cascade在计算机视觉中的应用Cascade在计算机视觉中也得到了广泛的应用。
其中最著名的应用之一就是人脸检测。
人脸检测是计算机视觉领域中一个非常具有挑战性的问题,而cascade分类器正是在解决这个问题中取得了很大的成功。
在人脸检测中,通常会使用级联分类器来构建人脸检测器。
级联分类器由一系列的强分类器组成,每个强分类器都是由一个或多个弱分类器级联而成。
弱分类器通常是一些简单的特征分类器,如Haar特征分类器或LBP特征分类器。
这些弱分类器只能检测出一些简单的特征,如边缘、角点等。
但是通过级联,强分类器可以逐步地进行更精细的检测,最终实现人脸的准确识别。
4. cascade分类器的训练过程训练一个cascade分类器是一个迭代的过程,需要经过多个阶段的训练。
每个阶段的训练都会增加一些新的强分类器,以提高分类的准确性和效率。
具体的训练过程可以分为以下几个步骤:步骤 1:准备正负样本数据集首先,需要准备一组正样本和一组负样本。
正样本是指待检测的目标,如人脸图像;负样本是指不包含待检测目标的图像。
这些样本数据将用于训练和评估分类器的性能。
步骤 2:选择弱分类器在每个阶段的训练中,需要选择一些弱分类器。
基于深度学习的三维重建算法:MVSNet、RMVSNet、PointMVSNet、Casc。。。

XiaoyaMVSN也把改进7 CVP-MVSNet(CVPR2020)Cost Volume Pyramid Based Depth Inference for Multi-View Stereo澳⼤利亚国⽴和英伟达,github链接:https:///JiayuYANG/CVP-MVSNet也是改的MVSNet_pytorch的代码,和上⼀个cascade MVSNet⽐较类似,也是先预测出深度信息然后⽤来缩⼩更⼤的图⽚的深度,CVP-MVSNet相⽐cascade MVSNet也缩⼩了cost volume的范围。
8 Fast-MVSNet(CVPR2020)Fast-MVSNet: Sparse-to-Dense Multi-View Stereo With Learned Propagationand Gauss-Newton Refifinement,上海科技⼤学也是改的MVSNet_pytorch的代码,github链接:https:///svip-lab/FastMVSNetFast-MVSNet采⽤稀疏的cost volume以及Gauss-Newton layer,⽬的是提⾼MVSNet的速度。
9 CIDER(AAAI 2020)Learning Inverse Depth Regression for Multi-View Stereo with Correlation Cost Volume , 华科的GitHub链接:https:///GhiXu/CIDERCIDER主要采⽤采⽤group的⽅式提出了⼀个⼩的cost volume10 UCSNet(CVPR2020)Deep Stereo using Adaptive Thin Volume Representation with Uncertainty Awarenessgithub链接:https:///touristCheng/UCSNetUCSNet和cascade/CVPMVSnet差不过,只是depth interval可以⾃动调整,最⼤层度的进⾏⽹络层级,通过下采样四分之⼀的深度结果来缩⼩cost volume和深度的范围,从⽽让模型尽可能⼩。
映射关系——精选推荐

映射关系命名策略的例⼦public class MyNamingStrategy extends ImprovedNamingStrategy{public String classToTableName(String className){return StingHelper.unqualify(className).toUpperCase()+'S';}public String propertyToColumnName(String propertyName){return propertyName.toUpperCase();}public String tableName(String tableName){return tableName;}public String columnName(String columnName){return columnName;}public String propertyToTabTableName(String className, String propertyName){return classToTableName(classNmae)+'_'+propertyToColumnName(propertyName);}}设置类的包名<hibernate-mapping package="xxx"><class name="" >...</class></hibernate-mapping>把主键定义为⾃动增长标识符类型:auto-increment:⾃动递增(MySQL)identity(a,b):以a为起始,⾃动增加b个长度。
(MySQL)Sequence:创建⼀个单独的序列。
(Oracle)create sequence XX_ID_SEQ increment by 1 start with 1curval:返回序列的当前值nxtval:先增加序列值,然后返回增加后的序列值Hibernate允许在持久化类中把OID定义为以下整数类型:short:2个字节取值范围 -2^15~2^15-1int:4个字节取值范围 -2^31~2^31-1long:8个字节取值范围 -2^63~2^63-1为了持久化对象的OID的唯⼀性和不变形,通常由Hibernate或底层数据库来给OID赋值。
mvc模拟题1

认证考试笔试试题课程:SCCE阶段:G3-补考卷院校名称:考试日期:准考证号:姓名:注意:1.考试时间1小时,总分100分;2.考试结束试卷必须交回,不交回试卷者成绩无效。
选择题(针对以下题目,选择符合题目要求的答案。
针对每一道题目,全选对,则该题得分;所选答案错误或漏选,则该题不得分。
每题2分。
)1.关于存储过程中的参数,下列说法错误的是()。
A.存储过程不能声明返回值类型,但可以通过传出参数向调用者返回值B. 传入参数可以设置默认值C.定义传出参数时,必须在传出参数之后添加OUT关键字D. 调用带传出参数的存储过程时,必须先定义一个变量,用于接收传出参数的值2.有一名为“列车运营”的实体,该实体属性含有:车次、日期、实际发车时间、实际抵达时间、情况摘要等属性,该实体主键是()。
A.车次B.日期C.车次+日期 D.车次+情况摘要3.在数据库的概念设计中,最常用的数据模型是()。
A. 形象模型B. 物理模型C. 逻辑模型D. 实体联系模型4.SQL Server中,下面用于限制分组函数的返回值的字句是()A.WHEREB. HAVINGC. ORDER BYD. 无法限定分组函数的返回值5.关于数据完整性,以下说法正确的是()。
【选择两项】A.完整性通过主键和外键之间的引用关系实现。
B. 引用完整性通过限制数据类型、检查约束等实现。
C. 数据完整性是通过数据操纵者自身对数据的控制来实现的。
D.如果两个表中存储的信息相互关联,那么只要修改了一个表,另外一个表也要做出相应的修改,则称该这两个表中的数据具备完整性。
6.现有订单表orders,包含用户信息userid, 产品信息productid, 以下()语句能够返回至少被订购过两回的productidA. select productid from orders where count(productid)>1B. select productid from orders where max(productid)>1C. select productid from orders where having count(productid)>1 group by productidD. select productid from orders group by productid having count(productid)>17.考虑本地图书馆的一个图书借阅系统,数据库包含Member(会员),Borrow(借阅)和Book(书籍)表,要求:1)每人可以借阅一本或多本书2)每本书一次只能被借给一个人;3)图书馆没有的书籍不能被借阅;以下()体现了在Borrow和Book表中强制这种引用完整性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
这个异常其时不是多对多中常遇到的,但是这个异常的提示不make sense,所以提一下,是因为id的java对象中
这个问题出现在要删除关系的一头时。如,要删除一个已经和Student有关系的Teacher。当mit();时才会抛出这个异常。
这时一个在关系另一头的Student对象中的Set或是List中把这个Teacher对象显示的remove掉,再session.delete(这个teacher);
一方维护关系,就会使在插入或是删除"一"方时去update"多"方的每一个与这个"一"的对象有关系的对象。而如果让"多"方面维护
关系时就不会有update操作,因为关系就是在多方的对象中的,直指插入或是删除多方对象就行了。当然这时也要遍历"多"方的每
一个对象显示的操作修关系的变化体现到DB中。不管怎样说,还是让"多"方维护关系更直观一些。
的记录来维护关系呢?在用hibernate时,我们不会显示的对TeacherStudent表做操作。对TeacherStudent的操作是hibernate
帮我们做的。hibernate就是看hbm文件中指定的是"谁"维护关系,那个在插入或删除"谁"时,就会处发对关系表的操作。
前提是"谁"这个对象已经知道这个关系了,就是说关系另一头的对象已经set或是add到"谁"这个对象里来了。前面说过inverse默认
cascade和inverse有什么区别?
可以这样理解,cascade定义的是关系两端对象到对象的级联关系;而inverse定义的是关系和对象的级联关系。
net.sf.hibernate.ObjectDeletedException: deleted object would be re-saved by cascade (remove deleted object from associations): 2, of class: Xxxxx
。这是为了防止在Student端有cascade时把这个Teacher对象再存回DB。所以,这个异常的只有在Student的关系定义中有
cascade="...",而且没有像上面说的显示的解除关系时才会出现。所以防止出现这个异常的方法就是:
1,在Student端不用cascade;2,或是用cascade的话,就显示的删除对像中的关系。
到底在哪用inverse="ture"?
inverse属性默认是false的,就是说关系的两端都来维护关系。这个意思就是说,如有一个Student, Teacher和TeacherStudent表,
Student和Teacher是多对多对多关系,这个关系由TeacherStudent这个表来表现。那么什么时候插入或删除TeacherStudent表中
Hibernate通过这个属性来判断一个对象应该save还是update,如果这个对象的id是unsaved-value的话,
那说明这个对象不是persistence object要save(insert);如果id是非unsaved-value的话,那说明这个对象
是persistence object(数据库中已存在),只要update就行了。saveOrUpdate方法用的也是这个机制。
是false,就是关系的两端都维护关系,对其中任一个操作都会处发对表系表的操作。当在关系的一头,如Student中的bag或set中
用了inverse="true"时,那就代表关系是由另一关维护的(Teacher)。就是说当这插入Student时,不会操作TeacherStudent表,
即使Student已经知道了关系。只有当Teacher插入或删除时才会处发对关系表的操作。所以,当关系的两头都用inverse="true"是
的type和hbm文件中定义的不一样,如:java中用long,而hbm中用type="integer",并且generator用的是identity时就会出现
(To be add) 把hibernate遇到常见异常会一点点加上来的
到底在哪用cascade="..."?
cascade属性并不是多对多关系一定要用的,有了它只是让我们在插入或删除对像时更方便一些,只要在cascade的源头上插入或是
删除,所有cascaded-value是个很重要的属性。
不对的,就会导致任何操作都不处发对关系表的操作。当两端都是inverse="false"或是default值是,在代码对关系显示的维护也
是不对的,会导致在关系表中插入两次关系。
在一对多关系中inverse就更有意义了。在多对多中,在哪端inverse="true"效果差不多(在效率上)。但是在一对多中,如果要