第三章构造LR表课堂练习题介绍
数据结构第3章+特殊线表习题解析(答)

第三章特殊线表习题一、选择题1、若用单链表来表示队列,则应该选用。
A、带尾指针的非循环链表B、带尾指针的循环链表C、带头指针的非循环链表D、带头指针的循环链表2、若用一个大小为6的数组来实现循环队列,且当rear和front的值分别为0和3。
当从队列中删除一个元素,再加入两个元素后,rear 和front的值分别是。
A、1和5B、2和4C、4和2D、5和13、设栈的输入序列为1、2、3、4,则不可能是其出栈序列。
A、1243B、2134C、1432D、4312E、32144、已知一算术表达式的中缀形式为A+B*C-D/E,后缀形式为ABC*+DE/-,其前缀形式为。
A、-A+B*C/DEB、-A+B*CD/EC、-+*ABC/DED、-+A*BC/DE5、设栈的输入序列是1、2、…、n,若输出序列的第一个元素是n,则第i个输出元素是。
A、不确定B、n-i+1C、iD、n-i6、假定一个顺序循环队列的队首和队尾指针分别用front 和rear表示,则判队空的条件是。
A、front+1==rearB、front==rear+1C、front==0D、front==rear7、假定一个顺序循环队列存储于数组A[n]中,其队首和队尾指针分别用front 和rear表示,则判断队满的条件是。
A、(rear-1)%n==frontB、(rear+1)%n==frontC、rear==(front-1)%nD、rear==(front+1)%n8、一个栈的的输入序列为12345,则下列序列中不可能是栈的输出序列的是。
A、23415B、54132C、23145D、154329、若一个栈的输入序列是1、2、3、…、n,输出序列的第一个元素是i,则第i个输出元素是。
A、i-j-1B、i-jC、j-i+1D、不确定10、用单链表表示的链式队列的队头在链表的位置。
A、链头B、链尾C、链中11、设计一个判别表达式中左、右括号是否配对出现的算法,采用数据结构最佳。
课后习题讲解(数据结构)

课后习题讲解(数据结构)第 1 章绪论课后习题讲解1. 填空⑴()是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
【解答】数据元素⑵()是数据的最小单位,()是讨论数据结构时涉及的最小数据单位。
【解答】数据项,数据元素【分析】数据结构指的是数据元素以及数据元素之间的关系。
⑶ 从逻辑关系上讲,数据结构主要分为()、()、()和()。
【解答】集合,线性结构,树结构,图结构⑷ 数据的存储结构主要有()和()两种基本方法,不论哪种存储结构,都要存储两方面的内容:()和()。
【解答】顺序存储结构,链接存储结构,数据元素,数据元素之间的关系⑸ 算法具有五个特性,分别是()、()、()、()、()。
【解答】有零个或多个输入,有一个或多个输出,有穷性,确定性,可行性⑹ 算法的描述方法通常有()、()、()和()四种,其中,()被称为算法语言。
【解答】自然语言,程序设计语言,流程图,伪代码,伪代码⑺ 在一般情况下,一个算法的时间复杂度是()的函数。
【解答】问题规模⑻ 设待处理问题的规模为n,若一个算法的时间复杂度为一个常数,则表示成数量级的形式为(),若为n*log25n,则表示成数量级的形式为()。
【解答】Ο(1),Ο(nlog2n)【分析】用大O记号表示算法的时间复杂度,需要将低次幂去掉,将最高次幂的系数去掉。
2. 选择题⑴ 顺序存储结构中数据元素之间的逻辑关系是由()表示的,链接存储结构中的数据元素之间的逻辑关系是由()表示的。
A 线性结构B 非线性结构C 存储位置D 指针【解答】C,D【分析】顺序存储结构就是用一维数组存储数据结构中的数据元素,其逻辑关系由存储位置(即元素在数组中的下标)表示;链接存储结构中一个数据元素对应链表中的一个结点,元素之间的逻辑关系由结点中的指针表示。
⑵ 假设有如下遗产继承规则:丈夫和妻子可以相互继承遗产;子女可以继承父亲或母亲的遗产;子女间不能相互继承。
则表示该遗产继承关系的最合适的数据结构应该是()。
数据结构第三章习题答案解析

第三章习题1.按图3.1(b)所示铁道(两侧铁道均为单向行驶道)进行车厢调度,回答:⑴如进站的车厢序列为123,则可能得到的出站车厢序列是什么?⑵如进站的车厢序列为123456,能否得到435612和135426的出站序列,并说明原因。
(即写出以“S”表示进栈、以“X”表示出栈的栈操作序列)。
2.设队列中有A、B、C、D、E这5个元素,其中队首元素为A。
如果对这个队列重复执行下列4步操作:(1)输出队首元素;(2)把队首元素值插入到队尾;(3)删除队首元素;(4)再次删除队首元素。
直到队列成为空队列为止,得到输出序列:(1)A、C、E、C、C (2) A、C、E(3) A、C、E、C、C、C (4) A、C、E、C3.给出栈的两种存储结构形式名称,在这两种栈的存储结构中如何判别栈空与栈满?4.按照四则运算加、减、乘、除和幂运算(↑)优先关系的惯例,画出对下列算术表达式求值时操作数栈和运算符栈的变化过程:A-B*C/D+E↑F5.试写一个算法,判断依次读入的一个以@为结束符的字母序列,是否为形如‘序列1& 序列2’模式的字符序列。
其中序列1和序列2中都不含字符’&’,且序列2是序列1的逆序列。
例如,‘a+b&b+a’是属该模式的字符序列,而‘1+3&3-1’则不是。
6.假设表达式由单字母变量和双目四则运算算符构成。
试写一个算法,将一个通常书写形式且书写正确的表达式转换为逆波兰式。
7.假设以带头结点的循环链表表示队列,并且只设一个指针指向队尾元素结点(注意不设头指针),试编写相应的队列初始化、入队列和出队列的算法。
8.要求循环队列不损失一个空间全部都能得到利用, 设置一个标志域tag , 以tag为0或1来区分头尾指针相同时的队列状态的空与满,请编写与此结构相应的入队与出队算法。
9.简述以下算法的功能(其中栈和队列的元素类型均为int):(1)void proc_1(Stack S){ int i, n, A[255];n=0;while(!EmptyStack(S)){n++; Pop(&S, &A[n]);}for(i=1; i<=n; i++)Push(&S, A[i]);}(2)void proc_2(Stack S, int e){ Stack T; int d;InitStack(&T);while(!EmptyStack(S)){ Pop(&S, &d);if (d!=e) Push( &T, d);}while(!EmptyStack(T)){ Pop(&T, &d);Push( &S, d);}}(3)void proc_3(Queue *Q){ Stack S; int d;InitStack(&S);while(!EmptyQueue(*Q)){DeleteQueue(Q, &d);Push( &S, d);}while(!EmptyStack(S)){ Pop(&S, &d);EnterQueue(Q,d)}}实习题1.回文判断。
数据结构第三章的习题答案

数据结构第三章的习题答案数据结构第三章的习题答案在学习数据结构的过程中,习题是巩固知识和提高能力的重要方式。
第三章的习题主要涉及线性表、栈和队列的实现和操作。
本文将对这些习题进行解答,并给出详细的步骤和思路。
1. 第一题要求实现一个线性表的插入操作。
线性表是一种常用的数据结构,它的特点是元素之间存在一对一的关系。
要实现插入操作,首先需要定义线性表的数据结构,可以使用数组或链表来实现。
然后,根据插入位置,将插入位置之后的元素依次后移,为要插入的元素腾出空间。
最后,将要插入的元素放入插入位置。
2. 第二题要求实现一个栈的压栈和出栈操作。
栈是一种后进先出(LIFO)的数据结构,可以使用数组或链表来实现。
压栈操作就是将元素放入栈顶,出栈操作就是将栈顶元素取出并删除。
要实现这两个操作,可以使用一个指针来指示栈顶位置,每次压栈时将指针加一,出栈时将指针减一。
需要注意的是,栈满时不能再进行压栈操作,栈空时不能进行出栈操作。
3. 第三题要求实现一个队列的入队和出队操作。
队列是一种先进先出(FIFO)的数据结构,同样可以使用数组或链表来实现。
入队操作就是将元素放入队尾,出队操作就是将队头元素取出并删除。
与栈不同的是,队列需要维护队头和队尾两个指针。
每次入队时将元素放入队尾,并将队尾指针后移一位;出队时将队头元素取出,并将队头指针后移一位。
需要注意的是,队列满时不能再进行入队操作,队列空时不能进行出队操作。
4. 第四题要求实现一个栈的括号匹配算法。
括号匹配是一种常见的应用场景,例如编程语言中的括号匹配。
要实现这个算法,可以使用栈来辅助。
遍历字符串中的每个字符,如果是左括号,则将其压入栈中;如果是右括号,则将栈顶元素取出并判断是否与右括号匹配。
如果匹配,则继续遍历下一个字符;如果不匹配,则说明括号不匹配,返回错误。
最后,如果栈为空,则说明括号匹配成功;如果栈不为空,则说明括号不匹配,返回错误。
5. 第五题要求使用栈实现一个逆波兰表达式的计算器。
编译原理第三章练习题答案

编译原理第三章练习题答案编译原理第三章练习题答案编译原理是计算机科学中的重要课程之一,它研究的是将高级语言程序转化为机器语言的过程。
在编译原理的学习过程中,练习题是提高理解和应用能力的重要途径。
本文将为大家提供编译原理第三章的练习题答案,希望能够对大家的学习有所帮助。
1. 什么是词法分析?请简要描述词法分析的过程。
词法分析是编译过程中的第一个阶段,它的主要任务是将源程序中的字符序列划分为有意义的词素(token)序列。
词法分析的过程包括以下几个步骤:1)扫描:从源程序中读取字符序列,并将其转化为内部表示形式。
2)识别:根据预先定义的词法规则,将字符序列划分为不同的词素。
3)分类:将识别出的词素进行分类,如关键字、标识符、常量等。
4)输出:将分类后的词素输出给语法分析器进行进一步处理。
2. 什么是正则表达式?请给出一个简单的正则表达式示例。
正则表达式是一种用于描述字符串模式的工具,它由一系列字符和操作符组成。
正则表达式可以用于词法分析中的词法规则定义。
以下是一个简单的正则表达式示例:[a-z]+该正则表达式表示匹配一个或多个小写字母。
3. 请简要描述DFA和NFA的区别。
DFA(Deterministic Finite Automaton)和NFA(Nondeterministic Finite Automaton)是有限状态自动机的两种形式。
它们在词法分析中常用于构建词法分析器。
DFA是一种确定性有限状态自动机,它的状态转换是确定的,每个输入符号只能对应一个状态转换。
相比之下,NFA是一种非确定性有限状态自动机,它的状态转换是非确定的,每个输入符号可以对应多个状态转换。
4. 请简要描述词法分析器的实现过程。
词法分析器的实现过程包括以下几个步骤:1)定义词法规则:根据编程语言的语法规范,定义词法规则,如关键字、标识符、常量等。
2)构建正则表达式:根据词法规则,使用正则表达式描述不同类型的词素。
3)构建有限状态自动机:根据正则表达式,构建DFA或NFA来识别词素。
编译原理课后复习题答案(陈火旺+第三版)

第二章P36-6(1)L G ()1是0~9组成的数字串(2)最左推导:N ND NDD NDDD DDDD DDD DD D N ND DD D N ND NDD DDD DD D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒0010120127334556568最右推导:N ND N ND N ND N D N ND N D N ND N ND N D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒77272712712701274434886868568P36-7G(S)O N O D N S O AO A AD N→→→→→1357924680|||||||||||P36-8文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/P36-9句子iiiei 有两个语法树:S iSeS iSei iiSei iiiei S iS iiSeS iiSei iiiei ⇒⇒⇒⇒⇒⇒⇒⇒P36-10/**************)(|)(|S T TTS S →→***************/P36-11/*************** L1:ε||cC C ab aAb A AC S →→→ L2:bcbBc B aA A AB S ||→→→εL3:εε||aBb B aAb A AB S →→→ L4:AB B A A B A S |01|10|→→→ε ***************/第三章习题参考答案P64–7(1)确定化:最小化:{,,,,,},{}{,,,,,}{,,}{,,,,,}{,,,}{,,,,},{},{}{,,,,}{,,}{,,,},{},{},{}{,,,}{,012345601234513501234512460123456012341350123456012310100==== 3012312401234560110112233234012345610101}{,,,}{,,}{,},{,}{},{},{}{,}{}{,}{,}{,}{}{,}{}{},{},{,},{},{},{}=====P64–8(1)01)0|1(*(2))5|0(|)5|0()9|8|7|6|5|4|3|2|1|0)(9|8|7|6|5|4|3|2|1(*(3)******)110|0(01|)110|0(10P64–12(a)确定化:给状态编号:最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}012301101223032330123a ba b ====(b)已经确定化了,进行最小化最小化:{{,}, {,,,}}012345011012423451305234523452410243535353524012435011012424{,}{}{,}{,}{,,,}{,,,}{,,,}{,,,}{,}{,}{,}{,}{,}{,}{,}{,}{{,},{,},{,}}{,}{}{,}{,}{,}a b a b a b a b a b a =============={,}{,}{,}{,}{,}{,}{,}10243535353524 b a baP64–14(2):给状态编号:最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}0123011012231323301230101====第四章P81–1(1) 按照T,S 的顺序消除左递归ε|,)(||^)(T S T TS T T a S S G '→''→→' 递归子程序: procedure S; beginif sym='a' or sym='^' then abvance else if sym='('then beginadvance;T;if sym=')' then advance;else error;endelse errorend;procedure T;beginS;'Tend;procedure 'T;beginif sym=','then beginadvance;S;'Tendend;其中:sym:是输入串指针IP所指的符号advance:是把IP调至下一个输入符号error:是出错诊察程序(2)FIRST(S)={a,^,(}FIRST(T)={a,^,(}FIRST('T)={,,ε}FOLLOW(S)={),,,#}FOLLOW(T)={)}FOLLOW('T)={)}预测分析表是LL(1)文法P81–2文法:|^||)(|*||b a E P F F F P F T T T F T E E E T E →'→''→→''→+→''→εεε(1)FIRST(E)={(,a,b,^} FIRST(E')={+,ε} FIRST(T)={(,a,b,^} FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^} FIRST(F')={*,ε} FIRST(P)={(,a,b,^} FOLLOW(E)={#,)} FOLLOW(E')={#,)} FOLLOW(T)={+,),#} FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#} FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:'→+'→'→'→E E T T F F P E a b ||*|()|^||εεεFIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φ FIRST(*F')∩FIRST(ε)={*}∩{ε}=φFIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φ FIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ 所以,该文法式LL(1)文法.(4)procedure E;beginif sym='(' or sym='a' or sym='b' or sym='^' then begin T; E' endelse errorendprocedure E';beginif sym='+'then begin advance; E endelse if sym<>')' and sym<>'#' then error endprocedure T;beginif sym='(' or sym='a' or sym='b' or sym='^' then begin F; T' endelse errorendprocedure T';beginif sym='(' or sym='a' or sym='b' or sym='^' then Telse if sym='*' then errorendprocedure F;beginif sym='(' or sym='a' or sym='b' or sym='^' then begin P; F' endelse errorendprocedure F';beginif sym='*'then begin advance; F' endendprocedure P;beginif sym='a' or sym='b' or sym='^'then advanceelse if sym='(' thenbeginadvance; E;if sym=')' then advance else error endelse errorend;P81–3/***************(1) 是,满足三个条件。
第三章书后答案详解
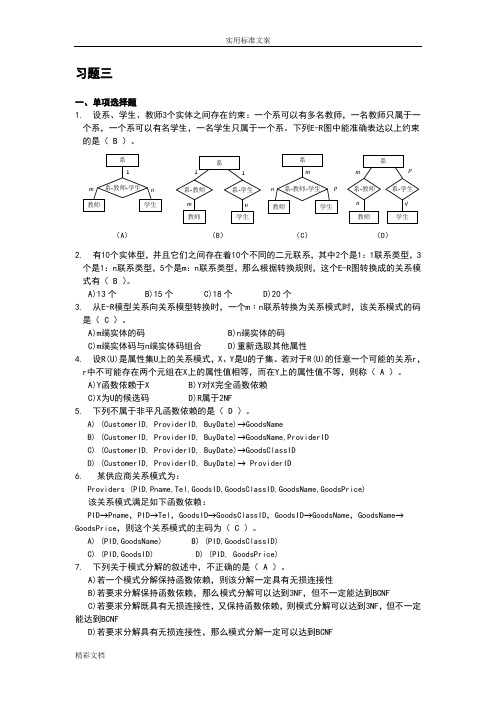
习题三一、单项选择题1.设系、学生、教师3个实体之间存在约束:一个系可以有多名教师,一名教师只属于一个系,一个系可以有名学生,一名学生只属于一个系。
下列E-R图中能准确表达以上约束的是( B )。
PID→Pname,PID→Tel,GoodsID→GoodsClassID,GoodsID→GoodsName,GoodsName→GoodsPrice,则这个关系模式的主码为( C )。
A) (PID,GoodsName) B) (PID,GoodsClassID)C) (PID,GoodsID) D) (PID, GoodsPrice)7.下列关于模式分解的叙述中,不正确的是( A )。
A)若一个模式分解保持函数依赖,则该分解一定具有无损连接性B)若要求分解保持函数依赖,那么模式分解可以达到3NF,但不一定能达到BCNFC)若要求分解既具有无损连接性,又保持函数依赖,则模式分解可以达到3NF,但不一定能达到BCNFD)若要求分解具有无损连接性,那么模式分解一定可以达到BCNF8.下列关于部分函数依赖的叙述中,正确的是( C )。
A)若 X→Y,且存在属性集 Z,Z⋂Y≠φ,X→Z,则称 Y 对 X 部分函数依赖B)若 X→Y,且存在属性集 Z,Z⋂Y=φ,X→Z,则称 Y 对 X 部分函数依赖C)若 X→Y,且存在 X 的真子集 X′,X′→Y,则称 Y 对 X 部分函数依赖D)若 X→Y,且对于 X 的任何真子集 X′,都有 X′→Y,则称 Y 对 X 部分函数依赖9.设U是所有属性的集合,X、Y、Z 都是 U 的子集,且 Z=U-X-Y,下列关于多值依赖的叙述中,正确的是( D )。
此题不用做Ⅰ. 若 X→→Y,则 X→Y Ⅱ. X→Y,则 X→→YⅢ .若 X→→Y,且 Y'→→Y,则 X→→ Y' Ⅳ .若 X→→Y,则 X→→ZA)只有Ⅱ B)只有Ⅲ C)Ⅰ和Ⅲ D)Ⅱ和Ⅳ10.设有关系模式SC(Sno, Sname, Sex, Birthday, Cno, Cname, Grade, Tno, Tname)满足函数依赖集:{Sno→Sname, Sno→Sex, Sno→Birthday, Cno→Cname, (Sno, Cno)→Grade, Tno→Tname}。
第三章习题解答

第三章 语法分析
对产生式V′→ε |[E] 有:FIRST(ε)∩FIRST(‘[’]= Φ; FIRST(‘[’)∩FOLLOW(V′)={[}∩{#,+,]}=Φ;
对E′→ε | +E 有:FIRST(ε)∩FIRST(‘+’)= Φ; FIRST(‘+’)∩FOLLOW(E′)={+}∩{ ] }=Φ。 故文法G[V′]为LL(1)文法。
第三章 语法分析 表3-12 习题3.24的SLR(1)分析表
状态
ACTION
GOTO
b
d
i
#
T
E
H
0
r3
s3
1
2
1
acc
2
s4
3
r2
4
r6
s6
r6
5
5
s7
r1
6
r4
r4
7
s8
8
r5
r5
第三章 语法分析
序号 状态栈 符号栈 产生式 输入串
10
#
E→ε bibi# 归约 r3
2 02
#E
bibi# 移进
第三章 语法分析
表3-8 优先关系表
a
b
c
a
⋖⋗
⋖≡
⋗
b
⋖
⋖⋗
≡
c
⋗
⋗
由于表中的优先关系不唯一,故文法G[S]不是算符优 先文法。
第三章 语法分析 (4) 消除文法G[S]的左递归: S→aSb | P P→bPc | bQc Q→aQ′ Q′→aQ′| ε 提取公共左因子后得到文法G′[S]: S→aSb | P P→bP′ P′→Pc | Qc Q→aQ′ Q′→aQ′| ε
编译原理教程课后习题答案——第三章

第三章语法分析3.1 完成下列选择题:(1) 文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c. xnyxn(n≥0)d. x*yx*(2) 如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同(3) 采用自上而下分析,必须。
a. 消除左递 a. 必有ac归b. 消除右递归c. 消除回溯d. 提取公共左因子(4) 设a、b、c是文法的终结符,且满足优先关系ab和bc,则。
b. 必有cac. 必有bad. a~c都不一定成立(5) 在规范归约中,用来刻画可归约串。
a. 直接短语b. 句柄c. 最左素短语d. 素短语(6) 若a为终结符,则A→α·aβ为项目。
a. 归约b. 移进c. 接受d. 待约(7) 若项目集Ik含有A→α· ,则在状态k时,仅当面临的输入符号a∈FOLLOW(A)时,才采取“A→α· ”动作的一定是。
a. LALR文法b. LR(0)文法c. LR(1)文法d. SLR(1)文法(8) 同心集合并有可能产生新的冲突。
a. 归约b. “移进”/“移进”c.“移进”/“归约”d. “归约”/“归约”【解答】(1) c (2) a (3) c (4) d (5) b (6) b (7) d (8) d3.2 令文法G[N]为G[N]: N→D|NDD→0|1|2|3|4|5|6|7|8|9(1) G[N]的语言L(G[N])是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
【解答】(1) G[N]的语言L(G[N])是非负整数。
(2) 最左推导:NNDNDDNDDDDDDD0DDD01DD012D0127NNDDD3D34NNDNDDDDD5DD56D568最右推导:NNDN7ND7N27ND27N127D1270127NNDN4D434NNDN8ND8N68D685683.3 已知文法G[S]为S→aSb|Sb|b,试证明文法G[S]为二义文法。
编译原理教程课后习题答案——第三章
第三章语法分析3.1 完成下列选择题:(1) 文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c. xnyxn(n≥0)d. x*yx*(2) 如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同(3) 采用自上而下分析,必须。
a. 消除左递 a. 必有ac归b. 消除右递归c. 消除回溯d. 提取公共左因子(4) 设a、b、c是文法的终结符,且满足优先关系ab和bc,则。
b. 必有cac. 必有bad. a~c都不一定成立(5) 在规范归约中,用来刻画可归约串。
a. 直接短语b. 句柄c. 最左素短语d. 素短语(6) 若a为终结符,则A→α·aβ为项目。
a. 归约b. 移进c. 接受d. 待约(7) 若项目集Ik含有A→α· ,则在状态k时,仅当面临的输入符号a∈FOLLOW(A)时,才采取“A→α· ”动作的一定是。
a. LALR文法b. LR(0)文法c. LR(1)文法d. SLR(1)文法(8) 同心集合并有可能产生新的冲突。
a. 归约b. “移进”/“移进”c.“移进”/“归约”d. “归约”/“归约”【解答】(1) c (2) a (3) c (4) d (5) b (6) b (7) d (8) d3.2 令文法G[N]为G[N]: N→D|NDD→0|1|2|3|4|5|6|7|8|9(1) G[N]的语言L(G[N])是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
【解答】(1) G[N]的语言L(G[N])是非负整数。
(2) 最左推导:NNDNDDNDDDDDDD0DDD01DD012D0127NNDDD3D34NNDNDDDDD5DD56D568最右推导:NNDN7ND7N27ND27N127D1270127NNDN4D434NNDN8ND8N68D685683.3 已知文法G[S]为S→aSb|Sb|b,试证明文法G[S]为二义文法。
LR(0)和SLR分析表的构造

此文略长。
我也没想到这写起来这么多,但对构造过程绝对清楚,一步步慢慢看吧。
LR的第一个L和LL的第一个L含义相同,即从左到右扫描句子,第二个R表示Ri ght most最右推导。
在通常的描述中,后面还有一个括号里面的数字如,LR(0)、LR(1)这样,括号里面的数字表示用于决策所需的后续token分词数。
首先看一下LR分析器的模型图可惜看出,LR分析器最关键的部分就是LR分析表了,而LR分析表的构建是由已构造出的LR(0)项目集规范族来进行构造的。
LR分析法貌似是不要求掌握的,而且这部分比我想象的还要复杂,今天看了好多。
才勉强搞清楚这个项目集规范族的构造,但是用来锻炼思维确实不错啊。
项目集,那么字面上看就是项目的集合了,项目是什么呢。
这个也确实不好说,书上是说在文法G中每个产生式的右部适当位置添加一个圆点构成LR(0)项目,举个例子吧。
比如对于A->xyz这条产生式可以构造的LR(0)项目就有4个A->.xyz A->x.yz A->xy.z A->xyz.这样很清楚了吧,就是用.分割。
这个分割产生的四个项目在进行真正的语法分析的时候对应不同的操作,比如规约还是移位。
这里不讨论。
重点是项目集规范族的构造,在知道了LR(0)项目后,可以来看看项目集规范族的定义,对于构成识别一个文法活前缀的DFA项目集(状态)的全体我们称之为这个文法的LR(0)项目集规范族。
至于什么是活前缀呢,定义如下对于任一文法G[S],若S’经过任意次推导得到αAω,继续经过一次推导得到αβω,若γ是αβ的前缀,则称γ是G的一个活前缀。
现在知道了LR(0)项目,了解了活前缀,和项目集规范族的定义,还须引入LR(0)项目集的闭包函数CLOSURE和状态转换函数GO两个概念,先给出数学上的定义,如果你觉得麻烦可以跳过,后面会给出一道例题。
①闭包函数CLOSURE(I)的定义如下:a)I的项目均在CLOSURE(I)中。
数据结构与算法教程习题答案作者朱明方吴及第3章习题解答

第3章习题解答3.1与顺序表相比线性链表有哪些优点?又有哪些局限?若线性表为空,对应的链表是否一定没有结点?[解答]与顺序表相比线性链表的明显优点是:1能够灵活利用存储空间,因为它不是依靠线性表中的数据元素在内存中的相互位置关系来表示数据元素间的逻辑关系,因此它的存储空间可以不连续,从而有利于离散空间的充分利用;2由于在线性链表中是通过结点中的指针来指示数据元素之间的逻辑关系的,因此在作插入、删除等操作的时候避免了数据元素平移的操作,从而可以提高运算实现的效率。
3由于线性链表所占的存储空间完全由表结点的个数决定,当需要增加或减少表中的数据元素时,表空间很容易扩充和缩小。
当然也就不会出现顺序表中存在的表空间扩充困难或者是表空间利用不充分的问题。
线性链表的局限主要是:因为它是依靠跟在数据元素后边的指针来表示数据元素之间的逻辑关系的,因此每个数据元素除了本身的存储空间之外还需要有存放指针的空间,即它比顺序表要付出更多的空间代价。
当约定线性链表不带表头结点的情况下,线性表为空时,对应的链表也没有结点。
3.2链式栈和顺序栈在操作上的主要差别是什么?为什么说对于空闲存储空间的管理适宜采用链式栈来实现?[解答]由顺序栈和链式栈的结构特点可知,顺序栈是顺序存储结构,对其实现基本操作是在连续的存储空间上进行的,因此顺序栈的入栈、出栈、读栈顶元素等操作主要是通过控制栈顶指针的位置来实现的,也就是说,移动栈顶指针是实现顺序栈的基本运算的主要操作。
链式栈是一种链式存储结构,因此它具有链式存储结构的基本特点,它的基本运算主要是通过控制栈顶指针和修改栈顶结点的指针域的值来实现,也就是说,链式栈的基本运算主要是通过改变栈顶指针和栈顶结点中的指针来实现的。
对于链式存储结构来说,空闲的存储空间为各链表所共享,当有新元素要加入链表时,需要从空闲空间取得结点,再把新元素放入空闲结点,然后把新结点加入到链表中;相反地,当从链表中删除元素时,要释放被删除结点到空闲空间。
编译原理课程设计(LR(0)分析表的构造)

引言《编译原理》是计算机专业的一门重要的专业课程,其中包含大量软件设计思想。
通过课程设计,实现一些重要的算法,或设计一个完整的编译程序模型,能够进一步加深理解和掌握所学知识,对提高自己的软件设计水平具有十分重要的意义。
语法分析是编译过程的第二阶段,是编译器前端的核心组成部分,在编译系统中起到了至关重要的作用。
自底向上的语法分析与自顶向下的语法分析相比,对将要分析的源程序有着更大的分析空间,从而受到了广泛的运用。
LR(0)分析是自底向上LR类语法分析的基础,自底向上语法分析方法是一种移进-规约过程,在当前分析的栈顶符号串形成句柄时就采取规约动作,因此最终目标是如何在分析过程中确定句柄。
LR分析法是给出一种能根据当前分析栈中的符号串和向右顺序查看k个符号串就可以唯一地确定分析器动作:是移进还是规约,采用哪条产生式。
LR(0)分析器是在分析过程中,不需要向后查看输入串符号,因此它对文法的限制较大。
对绝大多数高级语言语法分析器是不适用的,但是它是构造其他LR分析器的基础。
LR(0)最终存在的问题和需要解决的问题是在构造LR(0)分析表的时候,在LR(0)项目集规范族中,有移进项目和规约项目、规约项目和规约项目同时存在的现象,形成移进-规约冲突和规约-规约冲突,直接导致语法分析器无法在某一状态进行移进还是规约。
为了能够解决这一问题,我们需要再向后查看一个输入字符(也就是当前字符的FOLLOW集)以确定下一步操作是否能够进行。
我班选择的是老师给的LR(1)语法分析构造器的设计,即对任意给定的文法G构造LR(1)项目集规范族,其中要实现CLOSURE(I)、GO(I,X)、FIRST集合等。
在此基础上,构造了LR(1)分析表。
然后对输入的句子进行语法分析,给出接受或出错报告。
程序采用文件输入输出方式。
其中包括两个输入文件:文法grammar.txt,以及输入串input.txt;两个输出文件:项目集items.txt和文法的LR(1)分析表action_table.txt。
数据结构第三章习题课

1. 一个栈的输入序列为1 2 3 4 5,则下列序列中不可能是栈的输出序列的是()。
A. 2 3 4 1 5B. 5 4 1 3 2C. 2 3 1 4 5D. 1 5 4 3 22. 一个栈的输入序列为123…n,若输出序列的第一个元素是n,输出第i (1<=i<=n)个元素是()。
A. 不确定B. n-i+1C. iD. n-i3. 若栈采用顺序存储方式存储,现两栈共享空间V[1..m],top[i]代表第i个栈( i =1,2)栈顶,栈1的底在v[1],栈2的底在V[m],则栈满的条件是()。
A. |top[2]-top[1]|=0B. top[1]+1=top[2]C. top[1]+top[2]=mD. top[1]=top[2]4. 栈在()中应用。
A. 递归调用B. 子程序调用C. 表达式求值D. A,B,C5. 执行完下列语句段后,i值为:()int f(int x){ return ((x>0) ? x* f(x-1):2);}int i ;i =f(f(1));A.2 B. 4 C. 8 D. 无限递归6. 表达式3* 2^(4+2*2-6*3)-5求值过程中当扫描到6时,对象栈和算符栈为(),其中^为乘幂。
A. 3,2,4,1,1;(*^(+*-B. 3,2,8;(*^-C. 3,2,4,2,2;(*^(-D. 3,2,8;(*^(-7. 用链接方式存储的队列,在进行删除运算时()。
A. 仅修改头指针B. 仅修改尾指针C. 头、尾指针都要修改D. 头、尾指针可能都要修改8. 循环队列存储在数组A[0..m]中,则入队时的操作为()。
A. rear=rear+1B. rear=(rear+1) mod (m-1)C. rear=(rear+1) mod mD. rear=(rear+1)mod(m+1)9. 设栈S和队列Q的初始状态为空,元素e1,e2,e3,e4,e5和e6依次通过栈S,一个元素出栈后即进队列Q,若6个元素出队的序列是e2,e4,e3,e6,e5,e1则栈S的容量至少应该是( )。
E-R图课堂练习

E_R图课堂练习题
2015.3.8
1.设有系、教师、学生、课程等实体,其中每一个系包括系名、系址、
系主任姓名、办公电话等属性,教师实体包括工作证号码、教师名、出生日期、党派等属性。
学生实体包括学号、姓名、出生日期、性别等属性。
课程实体包括课程号、课程名、预修课号等属性。
设一个系可以有多名教师,每个教师教多门课程,一门课程由一个教师教。
其中有的教师指导
多个研究生。
每一个学生可选多门课程,每门课程只有一个预修课程,每一个学生选修一门课程有一个成绩,试根据以上语义画出E-R图。
2. 某公司的业务规则如下:
(1)每位职工可以参加几个不同的工程,且每个工程有多名职工参与;
(2)每位职工有一个职位,且多名职工可能有相同的职位;
(3)职位决定小时工资率,公司按职工在每一个工程中完成的工时,计算酬金;
(4)职工的属性有职工号、姓名、职位和小时工资率;
(5)工程的属性有工程号和工程名称。
试根据上述业务规则,设计ER模型.。
LR分析课堂练习解答
LR(1)分析练习解答过程
答: Step 1. 对原文法进行拓广 (添加产生式S->S’)
SV=E SE V*E V id EV
S S’ SV=E SE V*E V id EV
Step 2: 构建识别(拓广)文法活前缀的DFA
LR(1)分析练习解答过程
id
指向I11
LR(1)分析练习解答过程
构建分析表 首先,为表达式编号
[0] S S’ [1] S V = E [2] S E [3] V * E [4] V id [5] E V
然后,计算action表和goto表
LR(1)分析练习解答过程
构建分析表 Action(0,*)=s4, action(0,id)=s5 Goto(0,S)=1, goto(0,V)=2, goto(0,E)=3 Action(1,$)=acc Action(2,=)=s6 Goto(2,V)=7 Action(3,$)=r2 Action(4,*)=s4, action(4,id)=s5 Goto(4,E)=8, goto(4,V)=9 …
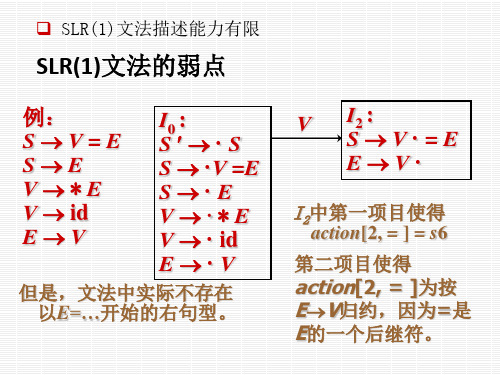
SLR(1)文法描述能力有限
SLR(1)文法的弱点
例: SV=E SE V*E V id EV
I0 : S· S S · =E V S· E V· E * V· id E· V
V
I2 : SV· E = EV·
I2中第一项目使得
action[2, = ] = s6
I5:
S'S · SV · =E EV · SE · V* · E E · V V · *E V · id Vid ·
I6:
I7: I8: I9:
数据结构第3单元课后练习答案

//解法三 不用栈,也不用数组,只用一个计数器top bool match(char a[],int n) { int top=-1; for (int i=0;i<n;i++) if (a[i]=='(') top++; else if (a[i]==')') if (top>-1) top--; //继续检查 else return true; //不匹配 if (top>-1) return true; //不匹配 return false; //匹配 }
//构造函数 template <class T> LinkedStack<T>::LinkedStack() { top=NULL; } //析构函数 template <class T> LinkedStack<T>::~LinkedStack() { Node<T> *q; while (top) { q=top->link; delete top; top=q; } }
template <class T> bool LinkedStack<T>::Push(const T& x) { Node <T> *q=new Node<T>; q->data=x; q->link=top; top=q; return true; } template <class T> bool LinkedStack<T>::Pop() { Node<T> *q=top; if (IsEmpty()) { cout<<"Empty stack"<<endl; return false; } top=top->link; delete q; return true; }
E-R图的练习复习

E-R图的练习复习数据库系统原理复习一、概念1.数据库的三大特点都是什么?(结构化、独立性和共享性)2.数据库的三级结构与独立性是什么?(物理独立性和逻辑独立性)3.人们利用计算机管理数据的方式,经历了哪三个阶段?(人工数据管理、文件系统、数据库系统)4.常用的数据模型有几种?(层次模型、网络模型、关系模型和对象模型)5.数据库的模式有哪三种?(模式、存储模式和子模式)6.什么是关系模型?什么是关系,它有什么特点?(用表格数据来表示实体和实体间联系的模型叫做关系模型,关系是元组的集合)7.实体之间的各种联系经过抽象化之后可以归成哪三大类?(一对一、一对多,多对多)8.反映实体与实体之间联系的是什么模型?(实体模型)E-R图是描述什么联系的图形?(实体、实体属性和实体之间的联系)9.关系代数中的特殊关系运算包括哪些?(投影、选择和连接)10.什么是自然连接?(当两个关系含有公共属性名时才能进行,从两个关系的笛卡尔积中选出公共属性值相等的那些元组构成新关系。
公共属性名只保留一个。
)11.解释函数依赖、部分函数依赖、完全函数依赖。
会做函数依赖图。
12.设R是K1度的关系,S是K2度的关系,则R和S的笛卡尔积的度为多少?13.设R是基数为L1的关系,S是基数为L2的关系,则R和S的笛卡尔积的基数是多少?14.什么是规范化?关系数据库定义了哪些范式?解释第一范式、第二范式、第三范式。
(一个低一级的关系模式,通过投影运算可以转换为若干个高一级的范式的关系模式的集合,这个过程称为规范化。
第一范式、第二范式、第三范式、BC范式。
第一范式:关系模式R的任一具体关系r的每个属性值都是不可分的最小数据单位。
第二范式:首先是第一范式,它的任一非主属性都完全函数依赖于每一个候选码,即消除了部分函数依赖。
第三范式:首先是第二范式,消除了传递函数依赖。
)15.数据库设计分为哪些步骤?(需求描述和分析、概念结构设计、逻辑结构设计、物理结构设计、数据库实施、运行和维护)16.概念设计的主要任务是什么?答:要会画E-R图。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
但是,文法中实际不存在 以E=…开始的右句型。
第二项目使得 action[2, = ]为按 EV归约,因为=是 E的一个后继符。
拓广文法G的LR(0)项目集规范族为:
I0: S' · S S · V=E S · E V · *E V · id E · V
I1: I2: I3: I4:
I1
I3 S E
识别产生式文法活前缀的DFA
I1 S start I 0 R L id I5 I2 = id I6 R L I9
*
id I4 * L R
I8
*
I3
I7
LR(1)分析练习题目
基于LR(1)项目来构造识别G活前缀的DFA,并基于DFA构建分析表.
SV=E SE V*E V id EV
SLR(1)文法描述能力有限
SLR(1)文法的弱点
例: SV=E SE V*E V id EV
I0 : S ·S S· V =E S ·E V· *E V ·id E ·V
V
I2 : S V ·= E EV·
I2中第一项目使得
action[2, = ] = s6
I5:
S'S · SV · =E EV · SE · V* · E E · V V · *E V · id Vid ·
I6:
I7: I8: I9:
SV= · E E · V V · *E V · id V*E · EV · SV=E ·
识别产生式文法活前缀的DFA
I0 S' S S V=E SE V *E V id EV id I5 E V id I6 S V = E E S V=E EV I9 id V *E V I3 S V =E = V id I2 E V V * * V * E I4 E V V E V I8 V id E id V * E V *E I7 S' S * S
action = *
s4 s6 s4 r4 s12 r3 r5 s11 r3 r5 r1 r5 r4 s12 s11 r3 s5 r4
goto id
s5 acc r5 r2 8 10 7 9
$
S
0
13
8
人有了知识,就会具备各种分析能力, 明辨是非的能力。 所以我们要勤恳读书,广泛阅读, 古人说“书中自有黄金屋。 ”通过阅读科技书籍,我们能丰富知识, 培养逻辑思维能力; 通过阅读文学作品,我们能提高文学鉴赏水平, 培养文学情趣; 通过阅读报刊,我们能增长见识,扩大自己的知识面。 有许多书籍还能培养我们的道德情操, 给我们巨大的精神力量, 鼓舞我们前进。
I 1: I 0: S’->S· ,$ S’->· S, $ S->· V=E, $ I2: V S->V S->· E, $ · =E, $ V->· *E, =/$ E->V· ,$ V->· id, =/$ E E->· V, $ I 3: S->E· ,$
0 1 2 3 4 5
S S’ SV=E SE V*E V id EV
id
I 5: V->id· , =/$
*
E V * id
I 7: V->*E· , =/$ I 8: E->V· , =/$ 指向I5
I 4: V->*· E, =/$ E->· V, =/$ V->· *E, =/$ V->· id, =/$
id
指向I11
状态 0 1 2 3 4 5 6 7 8 9 10 11 12 13
S
=
E I 9: I 6: S->V=E· ,$ S->V=· E, $ E->· V, $ V I10: V->· *E, $ E->V· ,$ V->· id, $ id I11: * V->id· ,$
I12 : E I13: V->*· E, $ V->*E· ,$ E->· V, $ V V->· *E, $ 指向I10 * V->· id, $
LR(1)分析练习解答过程
答: Step 1. 对原文法进行拓广 (添加产生式S->S’)
SV=E SE V*E V id EV
0 1 2 3 4 5
S S’ SV=E SE V*E V id EV
Step 2: 构建识别(拓广)文法活前缀的DFA
LR(1)分析练习解答过程