CANOCO之CCA排序中文完整版
Canoca4.5正版软件使用教程(简单版)
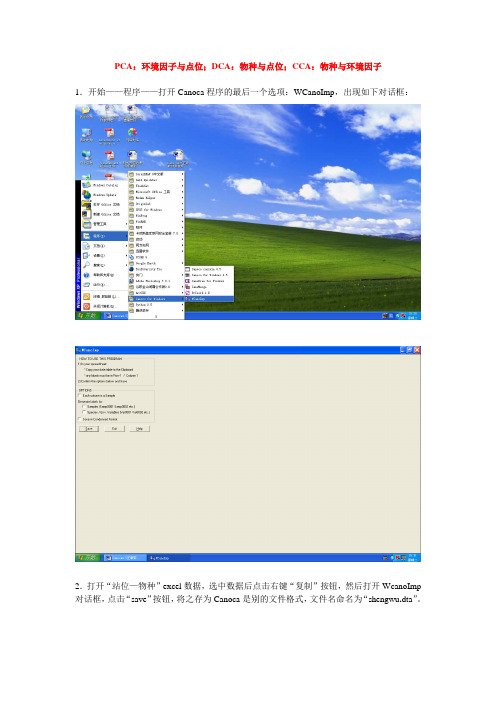
PCA:环境因子与点位;DCA:物种与点位;CCA:物种与环境因子
1.开始——程序——打开Canoca程序的最后一个选项:WCanoImp,出现如下对话框:
2.打开“站位—物种”excel数据,选中数据后点击右键“复制”按钮,然后打开WcanoImp 对话框,点击“save”按钮,将之存为Canoca是别的文件格式,文件名命名为“shengwu.dta”。
3.打开“站位—环境”excel数据,选中数据后点击右键“复制”按钮,然后打开WcanoImp 对话框,点击“save”按钮,将之存为Canoca是别的文件格式,文件名命名为“huanjing.env”。
4.这样,各点位生物和环境的数据就都变成了Canoco识别的格式了。
5.开始——程序——打开Canoca程序:Canoca for windows 4.5,点击Newproject选项。
6.选择:species and environmental data available,后点击下一步,分别输入生物和环境的数据,再将输出文件的位置定义好。
点击下一步。
7. 点击“Analyze”,然后“FS Summary”按钮变亮,点击“FS Summary”按钮,再点击“Copy”,再贴入记事本中,就可以显示各环境因子的P值(显著性)了。
8.开始——程序——打开Canoca程序:Canoca Draw for Windows。
输入计算好的文件,就可以画图了。
9.要想编辑CCA排序图中符号的格式,点击一下想要编辑的符号,再点击“F5键”,就可以进行编辑了。
CANOCOCCA分析最简明教程

Canoco基本操作
1、打开excel文档,如下图所示,包含环境变量(12个)和生物因子(7种N转化生物)。
共是12个处理,每个处理三个重复,总共是36个土壤样品。
然后打开canoco 软件中WcanoIMP,如下图所示。
然后选中save in condensed format,分别选中环境变量和生物因子(包括前面的数字),点击复制,然后点击save。
保存形成两个dat文件
这俩文件都可以用文本文档打开
此时打开canoco 软件,得到下面的界面。
点击project如图,选择species and environmental date available、
3.点下一步后,有三个brown窗口,前2个分别选择environ.dta 和species.dta. 第三个选择软件自带合适的处理方法(如CCA和RDA等)。
本文是选用CCA分析。
一直下一步,
这里选择both above tests
我这个软件只能在xp上用,windows7 里面运行回报vf错误,但是可以用RunAsDate.exe帮忙,百度搜索绿色版,完美可用。
但作图没问题
5.点击create 窗口,如下图所示。
得到最后的结果。
保存
然后create-。
基于Canoco的CCA数据处理过程解析

基于Canoco的CCA数据处理过程解析1、数据处理1、数据格式要求在Excel表格里面,你必须将数据做成矩形形式。
默认的方式(也是常用的方式)是一行代表一个样方,一列代表一个变量。
表格左顶格最好是空着。
最好第一列和第一行分别有样方编号和变量的名称。
必须注意的是名称不能超过8个字符,如果超过8个字符,CANOCO会自动截取前8个字符作为名称。
变量名称最好是英文字母、数字、圆点或是连字符,空格也可以。
除了第一行和第一列,表格内剩下的填充内容必须是数字或是空着,绝对不能使用字符型数据。
定性变量(因子)必须转换为哑变量(0‐1数据)方可进入CANOCO分析。
当数据在Excel表格里按要求整理好后,将包含数据的矩形方阵选定,然后选择“复制”按钮,此时数据便复制到剪贴板中。
WCanoImp 便可以从剪贴板中读取数据。
如图1‐2a所示,WCanoImp可以从“开始”菜单中Canoco for windows下来菜单中打开。
此时会弹出WCanoImp对话框,上半部分包含如何使用该程序的简短信息,下半部分是一些可选框。
如果在Excel表格数据是按照默认方式组织你的数据,第一选项不必选,相反,如果是数据结构正好相反,以列代表样方,以行代表变量,必须选中这个“Eachcolumn is a Sample”选项。
除非你的数据是样方很少而变量很多(Excel表格里面列数不能超过256列),否则不推荐用这种方式组织数据。
如果你没有样方或是变量没有编号或是名称,可以选择下面两个选框,程序会帮你给各行各列附上默认名称(Sample1,)。
最后一个选项是问你是否存为压缩型数据类型,除非你觉得硬盘空间不够大,否则不必选这个选项,是否选这个选项中对于分析结果毫不影响。
当你确定所以的选择是正确的,你就可以按下save按钮,系统弹出新的对话框让你选择保存新文件地方和取个文件名,之后会让你给这个文件加个标注,这个标注内容将显示在新文件的数据内容第一行,以便日后数据内容的识别。
canoco4.5中文教程

Canoco for Windows 4.5 中文简明教程2009-9第一章 CANOCO简介一 软件功能Canoco for Windows 是新一代的 CANOCO 软件,是生态学应用软件中用于约束与非约束排序的最流行工具。
Canoco for Windows 整合了排序以及回归和排列方法学,以便得到健全的生态数据统计模型。
Canoco for Windows 包括线性和曲线单峰方法。
使用 Canoco for Windows 进行排序,能够洞察:● 生物群落结构● 植物与动物群落以及它们的环境之间的联系● 一个对环境和(或)其生物群落的假设冲击所能造成的影响● 在生物群落上进行的复杂生态学和生态毒理学实验的相关处理所能造成的影响一个排序被计算出来后,排序图可以立即显示在显示器上。
Canoco 具体独特的能力,可以说明用协变量表示的背景变异,而用它的扩展工具来进行排列测试,包括测试的互动效果。
这些独特的特性使得Canoco for Windows 能特别有效的解决应用研究方面的问题。
二 软件模块The Canoco for Windows软件包主要包含以下几个模块:● Canoco for Windows:软件包的核心,用来指定要分析的数据和排序模型,排序方法以及分析结果的查看等基本操作命令均被集中在该模块的对话框中● WcanoImp:将以电子表格形式(Excel等)保存的外部数据转化为CANOCO识别的形式● CanoDraw 4.0 for Windows:用来绘制各种类型的排序图,同时也可以生成多种等值线和回归模型图,并进一步深层次发掘排序结果,该模块可以直接从主程序界面工具栏激活● CanoMerge:合并Canoco识别的dta类型数据文件,并可以将数据文件以带制表分隔符的文本形式输出(基本常用统计软件均兼容该类型文件),同时该模块具有滤掉低频率物种的功能● PrCoord:对特定数据集进行主坐标分析以及冗余分析三 统计方法这里只简要阐述CANOCO具有的统计分析方法,不做赘述,后面章节将详细论述操作步骤。
使用CANOCO进行CCA或RDA教程分析

使用CANOCO进行CCA或RDA教程分析在生态学和环境科学研究中,多元统计分析是非常重要的手段之一。
通过分析数据之间的关系,我们可以更好地理解生态系统的结构和功能。
而Canonical Correspondence Analysis (CCA)和Redundancy Analysis (RDA)是几种常用的多元统计方法之一,用于研究环境因子与物种组成之间的关系。
CANOCO是一个非常流行的用于执行CCA和RDA的统计软件。
本教程将向您介绍如何使用CANOCO进行CCA或RDA分析,以帮助您更好地理解生态数据。
第一步:数据准备在进行CCA和RDA分析之前,首先需要准备好您的数据。
数据应该是一个表格矩阵,包括环境因子(如温度、湿度、土壤pH等)和物种组成数据。
确保数据格式正确,可以导入到CANOCO中进行进一步的分析。
第二步:导入数据打开CANOCO软件并导入您准备好的数据。
在菜单栏中选择“File” -> “Import data”,然后选择您的数据文件进行导入。
CANOCO支持多种数据格式,包括txt、csv等。
第三步:选择分析方法在导入数据后,您需要选择进行CCA还是RDA分析。
在CANOCO中,可以通过菜单栏中的“Analysis” -> “Cononical Correspondence Analysis”或“Redundancy Analysis”来选择相应的分析方法。
第四步:设置参数在选择了分析方法后,需要设置相应的参数。
首先要选择变量类型(环境因子或生物物种),然后可以选择如何对数据进行标准化等设置。
第五步:运行分析设置好参数后,点击“Run”按钮开始运行分析。
CANOCO会生成相应的结果,并提供图形展示和统计结果。
您可以根据生成的结果图表来更好地理解数据之间的关系。
第六步:结果解读最后,根据CANOCO生成的结果来解读环境因子和物种组成之间的关系。
通过对结果图表的分析,可以深入了解生态系统的结构和功能,为生态学研究提供更多有益信息。
使用CANOCO进行CCA或RDA

8、进入“Data Editing Choices”对话框。这个对话框是用于对数据 进行选择操作的。指定后点击下一步。
在分析中删除 不想要分析的 物种数据
用于在分析中 排除不想要分 析的环境变量
如果数据都是想要分析的,则直接选择下一步即可。
精品课件
9、进入“Forward selection of ……”对话框。这个对话框是用于对 环境数据进行预先选择操作的。指定后点击下一步。
物种数据量纲相同时选 择这个。
物种数据量纲不相同时 选择这个。
对于样方,中心化和标准化并不总是必要的;对于物种数据,中心化是必要的, 标准化不一定是必要的。 但是当物种数据量纲不同时,该数据一定要进行标准化! 而当物种数据量纲相同时,不标准化物种数据可能比较好,因为当不同物种的 平均丰度差别较大时,标准化会使得精品罕课见件物种的权重变大。
前面若在”Available Data"对话框 中选择了间接梯度排序,在此处 就可以选择这几种方法
因为我们前面在”Available Data"对话框 中选择了直接梯度排序,在此处只能选 择几种直接梯度排序的方法,包括CCA、 RDA。
精品课件
5、进入“Scaling: Linear Methods”对话框,此处参数的选择见 Multivariate Analysis of Ecological Data Using Canoco的P55,选 择后对图解释方式的影响见P152-153。指定后点击下一步。
精品课件
11、出现Project对话框,点选Analyze即开始分析。
精品课件
12、前面如果选择了手动预选,则此时进入"Forward Selection Step"
Canoco中文简明教程1

Canoco for Windows 4.5 中文简明教程2009-9第一章 CANOCO简介一 软件功能Canoco for Windows 是新一代的 CANOCO 软件,是生态学应用软件中用于约束与非约束排序的最流行工具。
Canoco for Windows 整合了排序以及回归和排列方法学,以便得到健全的生态数据统计模型。
Canoco for Windows 包括线性和曲线单峰方法。
使用 Canoco for Windows 进行排序,能够洞察:● 生物群落结构● 植物与动物群落以及它们的环境之间的联系● 一个对环境和(或)其生物群落的假设冲击所能造成的影响● 在生物群落上进行的复杂生态学和生态毒理学实验的相关处理所能造成的影响一个排序被计算出来后,排序图可以立即显示在显示器上。
Canoco 具体独特的能力,可以说明用协变量表示的背景变异,而用它的扩展工具来进行排列测试,包括测试的互动效果。
这些独特的特性使得Canoco for Windows 能特别有效的解决应用研究方面的问题。
二 软件模块The Canoco for Windows软件包主要包含以下几个模块:● Canoco for Windows:软件包的核心,用来指定要分析的数据和排序模型,排序方法以及分析结果的查看等基本操作命令均被集中在该模块的对话框中● WcanoImp:将以电子表格形式(Excel等)保存的外部数据转化为CANOCO识别的形式● CanoDraw 4.0 for Windows:用来绘制各种类型的排序图,同时也可以生成多种等值线和回归模型图,并进一步深层次发掘排序结果,该模块可以直接从主程序界面工具栏激活● CanoMerge:合并Canoco识别的dta类型数据文件,并可以将数据文件以带制表分隔符的文本形式输出(基本常用统计软件均兼容该类型文件),同时该模块具有滤掉低频率物种的功能● PrCoord:对特定数据集进行主坐标分析以及冗余分析三 统计方法这里只简要阐述CANOCO具有的统计分析方法,不做赘述,后面章节将详细论述操作步骤。
生态学课件5群落排序

对应分析法整个处理过程由两部分组成:表格和关联图。
CCA排序图解
CCA排序图解释:箭头 表示环境因子,箭头所 处的象限表示环境因子 与排序轴之间的正负相 关性,箭头连线的长度 代表着某个环境因子与 研究对象分布相关程度 的大小,连线越长,代 表这个环境因子对研究 对象的分布影响越大。 箭头连线与排序轴的家 教代表这某个环境因子 与排序轴的相关性大小,
排序的类型
直接排序(直接梯度分析或梯度分析)
利用环境因素的排序称为直接排序,即以群落生境或其中某一生态因 子的变化排定样地生境 的位序。 间接排序(间接梯度分析或组成分析) 利用植物群落本身属性(如种的出现与否,种的频度、盖度等等)排 定群落样地的位序,称为间接排序。
主成分分析
主成分分析
是将一个综合考虑许多性状(例如P个)的问题(P各属性就是P 维空间),在尽量少损失原有信息的前提下,找出1至3个主分量,然 后将各个实体在一个2维或3维空间中表示出来,从而达到直观明了地 排序实体的目的。 大量的应用证明PCA法是一种非常有效的排序方法,它既适用于 数量数据,也可用于二元数据,在许多应用中,往往只取前二、三个 主分量就可以反映原数据离差的40%--90%。
对应分析的作用
对应分析的基本思想是将一个联列表的行和列中各元素的
比例结构以点的形式在较低维的空间中表示出来。它最大 特点是能把众多的样品和众多的变量同时作到同一张图解 上,将样品的大类及其属性在图上直观而又明了地表示出 来,具有直观性。另外,它还省去了因子选择和因子轴旋 转等复杂的数学运算及中间过程,可以从因子载荷图上对 样品进行直观的分类,而且能够指示分类的主要参数(主 因子)以及分类的依据,是一种直观、简单、方便的多元 统计方法。 对应分析法中的表格是一个二维的表格,由行和列组成。 每一行代表事物的一个属性,依次排开。列则代表不同的 事物本身,它由样本集合构成,排列顺序并没有特别的要 求。在关联图上,各个样本都浓缩为一个点集合,而样本 的属性变量在图上同样也是以点集合的形式显示出来。
使用CANOCO进行CCA或RDA教程分析

使用CANOCO进行CCA或RDA教程分析CANOCO(Canonical Correspondence Analysis and Redundancy Analysis)是一种常用于生态学和环境科学领域的多元统计分析软件,用于研究物种与环境因子之间的相互关系。
本篇文章将介绍使用CANOCO进行CCA(Canonical Correspondence Analysis)或RDA (Redundancy Analysis)的教程分析方法。
一、简介CCA和RDA都是多元统计分析方法,用于探究物种组成与环境因子之间的关系。
它们同时考虑物种对环境的响应以及环境因子对物种组成的解释。
CCA适用于物种组成与连续型环境因子的分析,而RDA 适用于物种组成与定性和/或数量型环境因子的分析。
二、数据准备在进行CCA或RDA分析前,需要准备两个数据文件:物种数据和环境数据。
物种数据包括物种丰度或物种相对丰富度信息。
环境数据包括与物种组成相关的环境因子,如土壤pH、温度、湿度等。
在数据准备过程中,要确保数据的格式正确,数据项对应准确,并且缺失数据已经进行处理。
对于不同类型的环境因子,需要进行转换或标准化处理,以保证数据的可比性和准确性。
三、导入数据在CANOCO中,可以通过导入数据按钮或者使用数据向导来导入物种数据和环境数据。
在导入数据时,请注意选择正确的数据文件和数据格式,并按照软件的要求进行字段匹配。
四、选择分析方法在导入数据后,需要选择适合的分析方法:CCA或RDA。
如果环境因子为连续型变量,则选择CCA;如果环境因子包括分类变量或数量型变量,则选择RDA。
五、执行分析在选择完分析方法后,点击执行分析按钮,CANOCO将自动计算并生成相应的结果。
分析过程可能需要一定的时间,取决于数据集的大小和复杂程度。
六、解读结果分析完成后,可以查看生成的结果图表和统计数据。
结果图表通常包括轴排序图、环境响应图、环境相关性图等。
CANOCO之CCA排序(中文完整版)
Canoco for Windows 4.5 之 CCA 排序以下为软件使用的详细步骤,具体探讨如何使用Canoco for Windows 4.5 软件包完成Canonical Correspondence Analysis (CCA)分析,软件包的大部分程序都将在步骤中涉及,鉴于分析中所采用的公用数据集,大家可以基于Canoco 测试版重做这些分析。
(提醒: Canoco 测试版默认安装路径为C:\Canoco ,如果您在别的地方重新安装,请恰当的调整文件夹路径。
)步骤共划分为四个过程:借助 WCanolmp 导入电子表数据借助 Canoco for Windows 进行 CCA 排序借助 CanoDraw 画出排序图修正 CanoDraw 排序图一、借助 WCanoImp 导入电子表数据1.打开路径C:\Canoco\Samples\dune_env.xls 中的 Excel 文件,当然也可以使用其他可读形式。
在 Excel 表中,要选择整个矩形区域的数据,包括第一行(含变量名称)和第一列(含样本名称),然后复制数据到剪贴板(也可使用Excel 中的 Edit → Copy 菜单命令),之后,从快捷菜单中打开Canoco for Windows 的子菜单WCanoImp (见图 1)。
图1 从快捷菜单中打开 WCanoImp2.此时, WCanoImp 程序已经开始运行,这里我们选择保存数据为Condensed 格式(如果数据包括很多0 值的话,而且这对于物种数据还很常见,那么浓缩格式可以节省文件空间)。
核对以下选项后,就可以点击保存按钮了(见图2)。
图 2 WcanoImp 的文件保存3.此时出现一个文件选择框,选择文件路径为 C:\Canoco\Samples ,同时输入文件名duneenv2.dta,此时不要输入 duneenv.dta,因为这个文件已经存在,如果你保存的话将会覆盖(当然前提需要你的确认),之后,点击“Save”按钮。
Canoco for Windows 4.5 中文简明教程

Canoco for Windows 4.5 中文简明教程2009-9第一章 CANOCO简介一 软件功能Canoco for Windows 是新一代的 CANOCO 软件,是生态学应用软件中用于约束与非约束排序的最流行工具。
Canoco for Windows 整合了排序以及回归和排列方法学,以便得到健全的生态数据统计模型。
Canoco for Windows 包括线性和曲线单峰方法。
使用 Canoco for Windows 进行排序,能够洞察:● 生物群落结构● 植物与动物群落以及它们的环境之间的联系● 一个对环境和(或)其生物群落的假设冲击所能造成的影响● 在生物群落上进行的复杂生态学和生态毒理学实验的相关处理所能造成的影响一个排序被计算出来后,排序图可以立即显示在显示器上。
Canoco 具体独特的能力,可以说明用协变量表示的背景变异,而用它的扩展工具来进行排列测试,包括测试的互动效果。
这些独特的特性使得Canoco for Windows 能特别有效的解决应用研究方面的问题。
二 软件模块The Canoco for Windows软件包主要包含以下几个模块:● Canoco for Windows:软件包的核心,用来指定要分析的数据和排序模型,排序方法以及分析结果的查看等基本操作命令均被集中在该模块的对话框中● WcanoImp:将以电子表格形式(Excel等)保存的外部数据转化为CANOCO识别的形式● CanoDraw 4.0 for Windows:用来绘制各种类型的排序图,同时也可以生成多种等值线和回归模型图,并进一步深层次发掘排序结果,该模块可以直接从主程序界面工具栏激活● CanoMerge:合并Canoco识别的dta类型数据文件,并可以将数据文件以带制表分隔符的文本形式输出(基本常用统计软件均兼容该类型文件),同时该模块具有滤掉低频率物种的功能● PrCoord:对特定数据集进行主坐标分析以及冗余分析三 统计方法这里只简要阐述CANOCO具有的统计分析方法,不做赘述,后面章节将详细论述操作步骤。
canoco4.5进行CCA分析
canoco4.5进⾏CCA分析Canoco 4.5 做CCA分析1.canoco 4.5 包括很多模块,我们⼀般使⽤到的就是WCanolmp,canoco for Windows 4.5,canoDraw for Windows这三个。
2. ⾸先我们打开WCanolmp,将环境因⼦和物种信息分别保存为.dat⽂件。
2.1 ⽤Excel打开环境因⼦⽂件同样⽤Excel 打开物种信息⽂件需要注意的是,两个dat⽂件的数据组数要⼀样,也就是enviro.dat⾥⾯复制保存了5列,spice.dat⾥⾯也要复制保存同样名称的5列,这5列⼀定包括图中红⾊区域。
否则后⾯就会出现错误。
见3.22.2 如果我们的数据⼀列表⽰⼀组数据,那么我们就要选择eachcolumn is a sample。
2.3 保存好两个.dat⽂件后,不要着急打开⼯程模块,先新建⼀个⽂本⽂档,将⽂档后缀名改成sol,后⾯要⽤到。
3.3.1 打开canoco for Windows4.5模块,通过图中红⾊区域的图标新建⼀个project,或者打开file—new project。
选择spices and environment data available,点下⼀步。
3.2 按照要求点击Browse,将两个dat⽂件分别输⼊,最下⾯⼀栏将之前新建的sol⽂件输⼊。
点击下⼀步。
这时如果保存的数据组数不⼀样,就会出现错误。
这个问题改好后,重新建⼀个project,不然会⼀直跳出来这个错误。
之后⼀直下⼀步就好,最后点完成后出现con⽂件,命名后保存。
3.4 在project中点击Analyze进⾏分析。
3.5 分析后出现下图,点击CanoDraw,保存cdw⽂件,跳到作图3.6 点击create-biplots and joint plots-samples and env. Variables作图。
出现下图,这时发现样点序号不是⾃⼰的标注,需要进⾏更改。
典范对应分析

zj =
∑x
i =1 p i =1
p
ij
yj
Zj为样方排序值
7
∑x
ij
得到一组样方排序值,并用下式调试,使得Zj的最大值为 100,最小值为0,这是为了阻止排序坐标值在迭代过程 中逐步变小
zj
(a)
= 100 ×
z j − min z j max z j − min z j
第三步:再用加权平均法求样方新值,得: (2.09,2.57,2.24,2.2.5,2.17,2.30,2.11)
典范对应分析 CCA DCCA
引言
◆CCA方法简介 ◆CCA方法优缺点 ◆CCA排序的基本步骤 ◆DCCA排序
2
一、CCA方法简介 CCA方法简介
◆ 典范对应分析(canonical correspondence analysis, CCA), 典范对应分析( CCA), 是基于对应分析发展而来的一种排序方法, 是基于对应分析发展而来的一种排序方法,将对应分析与多元 回归分析相结合,每一步计算均与环境因子进行回归, 回归分析相结合,每一步计算均与环境因子进行回归,又称多 元直接梯度分析。其基本思路是在对应分析的迭代过程中, 元直接梯度分析。其基本思路是在对应分析的迭代过程中,每 次得到的样方排序坐标值均与环境因子进行多元线性回归。 次得到的样方排序坐标值均与环境因子进行多元线性回归。 CCA要求两个数据矩阵 一个是植被数据矩阵, 要求两个数据矩阵, CCA要求两个数据矩阵,一个是植被数据矩阵,一个是环境数 据矩阵。首先计算出一组样方排序值和种类排序值( 据矩阵。首先计算出一组样方排序值和种类排序值(同对应分 ),然后将样方排序值与环境因子用回归分析方法结合起来 然后将样方排序值与环境因子用回归分析方法结合起来, 析),然后将样方排序值与环境因子用回归分析方法结合起来, 这样得到的样方排序值即反映了样方种类组成及生态重要值对 群落的作用,同时也反映了环境因子的影响, 群落的作用,同时也反映了环境因子的影响,再用样方排序值 加权平均求种类排序值, 加权平均求种类排序值,使种类排序坐标值值也间接地与环境 因子相联系。其算法可由Canoco软件快速实现。 Canoco软件快速实现 因子相联系。其算法可由Canoco软件快速实现。
Canoco中文简明教程1
Canoco for Windows 4.5 中文简明教程2009-9第一章 CANOCO简介一 软件功能Canoco for Windows 是新一代的 CANOCO 软件,是生态学应用软件中用于约束与非约束排序的最流行工具。
Canoco for Windows 整合了排序以及回归和排列方法学,以便得到健全的生态数据统计模型。
Canoco for Windows 包括线性和曲线单峰方法。
使用 Canoco for Windows 进行排序,能够洞察:● 生物群落结构● 植物与动物群落以及它们的环境之间的联系● 一个对环境和(或)其生物群落的假设冲击所能造成的影响● 在生物群落上进行的复杂生态学和生态毒理学实验的相关处理所能造成的影响一个排序被计算出来后,排序图可以立即显示在显示器上。
Canoco 具体独特的能力,可以说明用协变量表示的背景变异,而用它的扩展工具来进行排列测试,包括测试的互动效果。
这些独特的特性使得Canoco for Windows 能特别有效的解决应用研究方面的问题。
二 软件模块The Canoco for Windows软件包主要包含以下几个模块:● Canoco for Windows:软件包的核心,用来指定要分析的数据和排序模型,排序方法以及分析结果的查看等基本操作命令均被集中在该模块的对话框中● WcanoImp:将以电子表格形式(Excel等)保存的外部数据转化为CANOCO识别的形式● CanoDraw 4.0 for Windows:用来绘制各种类型的排序图,同时也可以生成多种等值线和回归模型图,并进一步深层次发掘排序结果,该模块可以直接从主程序界面工具栏激活● CanoMerge:合并Canoco识别的dta类型数据文件,并可以将数据文件以带制表分隔符的文本形式输出(基本常用统计软件均兼容该类型文件),同时该模块具有滤掉低频率物种的功能● PrCoord:对特定数据集进行主坐标分析以及冗余分析三 统计方法这里只简要阐述CANOCO具有的统计分析方法,不做赘述,后面章节将详细论述操作步骤。
canoco 教程

(4)约束性排序(直接排序):在特定的梯度上 (环境轴)上探讨物种的变化情况。例如:RDA, CCA,DCCA等。 (5)非约束性排序(间接排序):寻求潜在的或 在间接的环境梯度来解释物种数据的变化。 (6)偏分析:预先剔除物种变化中由协变量产生 的效应,再通过排序揭示剩下物种变化的排序方 法。 (7)混合排序分析:前面若干轴采用约束排序, 而剩下的轴是非约束性排序的梯度分析方法。
(4)结果
2.1.2 DCA
(1) DCA一般都用区间去趋势“by segments ” ;DCCA一般用多项式去趋势 “by polynomials” 。 (2) 多项式去趋势阶数的选择标准:环境因子 小于10个,选2阶;小于13个,选3阶,大于 13个,选4阶。 (3) 注意:对于约束排序,去趋势一般是不必 要的。
3 专业术语
生态学原始数据一般由两个部分构成,一 组是响应变量 (response variable),另外一组是解 释变量(explanatory variables)。 (1)解释变量:相当于自变量,又称预测变量, 经常分为主环境变量和协环境变量。
(2)响应变量:相当于因变量,又称物种数据。
(3)梯度分析:即通常所说的排序分析,是揭 示物种组成数据与实测或潜在环境因子之间关系 的方法的总称。包括约束性排序和非约束性排序。
(2) WCanoImp
这个程序的功能构建数据。但这个程序用 法受到了window的剪贴板和电子表格文件的限 制。比如在Excel2003以前的版本,列数仅有 256列,这就意味着样方数或物种数不能两个 同时超过256个,否则需要分割。当然行数宽 松点,但不能超过65536行。如果你的数据超 过这个限制,你可以将你的数据分割为几个部 分,经过WCanoImp转化后,再用CanoMerge程 序拼接起来。
collate排序规则

创建数据库通过collate指定数据库中数据的排序规则,对于密码有严格大小写要求的很有必要设定--使用collate指定排序规则之前,一定要先知道排序规则名,可以通过以下SQL语句查询select * from ::fn_helpcolltations()使用方法:create database erpon( --表示主数据文件name='erp_data', --文件逻辑名。
这是参考档案时在SQL Server 中使用的逻辑名称。
logical_file_name 在资料库中必须是唯一的,且必须符合识别码的规则。
filename='d:\erp.mdf', --文件的物理位置和名字size=5mb, --初始大小maxsize=unlimited, --文件增长到磁盘充满。
指定为不限制增长的日志文件的最大大小为2 TB,而数据文件的最大大小为16 TBfilegrowth=20% --文件增长比例)log on( --日志文件name='erp_log',filename='d:\erp.log',size=5mb,maxsize=20mb, --最大为20Mfilegrowth=10%)collate Chinese_PRC_CS_AI; --collate Chinese_PRC_CS_AI 查询时区分大小写--collate Chinese_PRC_CI_AI 查询是不区分大小写(默认)--Chinese_PRC 表示中文简体--Chinese_TaiWan 表示的是繁体中文也可以在查询是指定排序规则select * from temp collate Chinese_PRC_CS_AI;在默认情况下,sql 2008中是不区分大小写的,这样对于用户密码中的大小写字母就失去了意义,所以指定排序规则是很有必要的数据库创建完后也可以在数据库的属性—>选项—>排序规则中修改排序规则:_BIN 二进制排序、_CI_AI 不区分大小写、不区分重音、不区分假名类型、不区分全半角_CI_AI_WS 不区分大小写、不区分重音、不区分假名类型、区分全半角_CI_AI_KS 不区分大小写、不区分重音、区分假名类型、不区分全半角_CI_AI_KS_WS 不区分大小写、不区分重音、区分假名类型、区分全半角_CI_AS 不区分大小写、区分重音、不区分假名类型、不区分全半角_CI_AS_WS 不区分大小写、区分重音、不区分假名类型、区分全半角_CI_AS_KS 不区分大小写、区分重音、区分假名类型、不区分全半角_CI_AS_KS_WS 不区分大小写、区分重音、区分假名类型、区分全半角_CS_AI 区分大小写、不区分重音、不区分假名类型、不区分全半角_CS_AI_WS 区分大小写、不区分重音、不区分假名类型、区分全半角_CS_AI_KS 区分大小写、不区分重音、区分假名类型、不区分全半角 _CS_AI_KS_WS 区分大小写、不区分重音、区分假名类型、区分全半角 _CS_AS 区分大小写、区分重音、不区分假名类型、不区分全半角_CS_AS_WS 区分大小写、区分重音、不区分假名类型、区分全半角 _CS_AS_KS 区分大小写、区分重音、区分假名类型、不区分全半角_CS_AS_KS_WS 区分大小写、区分重音、区分假名类型、区分全半角。
dcca排序法

DCCA排序法是一种植被环境关系多元分析技术,它在去趋势对应分析(DCA)的基础上改进而成。
在每一轮样方值—物种值的加权平均叠带运算后,用样方环境因子值与样方排序值做一次多元线性回归,用回归系数与环境因子原始值计算出样方分值在用于新一轮叠带计算,这样得出的排序轴代表环境因子的一种线性组合,称此方法为环境约束的对应分析(CCA)。
然后加入去趋势算法去掉因第一,二排序轴间的相关性产生的"弓形效应"而成为DCCA。
因为DCCA排序法结合物种构成和环境因子的信息计算样方排序轴,结果更理想,并可以直观地把环境因子、物种、样方同时表达在排序轴的坐标平面上,已成为上世纪90年代以来植被梯度分析与环境解释的趋势性方法。
Canoco for Windows作CCA图

首先excel原始数据,按如下格式录入。
下表为底栖种类列表。
行为样点,列为底栖种类,每一种用一个数代表。
1代表有这个物种,0代表未采集到物种。
如果为底栖多样性或者丰度、密度、生物量等,将数字1的位置替换为数即可。
(数据整理:物种数据,列采样点;行生物数据。
环境数据,列采样点;行环境因子。
注:数据(物种和环境数据)之间差别较大,如数量级之间的差别,需进行lg(x+1)转换,pH不需要进行lg转换。
)表1:底栖种类表2:底栖生物量保存为species文件。
保存为environment文件。
数据录入后,选中,复制。
开始—Canoco for Windows—WcanoImp—以管理员身份运行—选中Each column is a Sample 和Save in Condensed Format,然后点击save。
保存数据。
打开Canoco for Windows 4.5 右键—以管理员身份运行新建—选择species and environment data available—下一步第一栏,点击Browse—文件类型All Files—选择对应的数据文件—Canoco solution file name输入CCA—下一步后面一串都直接点击“下一步”—完成输入文件名,点击保存。
点击Analysis展开可以看到数据分析在这些数据结果中框出来的部分为各环境因子与第一轴和第二轴的关系。
Table 3 Summary of the CCA ordinations. % variance indicates percentage variance of macrobenthos(species, abundance, biomass)-environment relations explained by the first two ordination axes. Correlations indicate intra-set correlations of environmental factors with the first two ordination axes.Macrobenthic speciesAxis 1Axis 2StatisticsEigenvalue0.8860.791Species-environment correlations0.9830.957% variance a9.518.0CorrelationsAbove-ground Biomass0.2300.770**Below-ground Biomass-0.0760.843**Vegetation Coverage-0.378*0.674**Moisture Content0.884**0.181Bulk Density-0.547**-0.455**Pt0.545**0.461**Soil pH0.485**-0.127Soil Salinity-0.607**-0.055Soil Hardness-0.820**0.354*Organic Matter-0.2760.558**Correlations indicate intra-set correlations of abiotic factors with the first two ordination axesP < 0.05; ** P < 0.01a Percentage variance of species-environment relations explained by the first two ordination axes所得数据并没有加“*”,需要查“相关系数显著性检验表”或者叫“相关系数界值表”,有多少个样方,就是自由度为多少。
canoco 简介

基于CANOCO的生态学数据的多元统计分析著者:Jan Leps 捷克南波希米亚大学植物学系和捷克科学院昆虫研究所生态学教授Petr Smilauer 捷克南波希米亚大学多元统计分析讲师译者:赖江山 中国科学院植物研究所生物多样性与生物安全研究组助理研究员这本书目的主要在于帮助生态学者分析野外观测数据和实验获得的数据。
本书对于学生或研究人员处理复杂的生态学问题非常有用,比如生物群落随环境条件的如何变化,或是生物群落在控制实验中的变化。
在简单介绍排序原理之后,本书的着重介绍约束排序方法(RDA和CCA)和置换统计检验在多元数据中的应用。
同时介绍了如何利用分类的方法及现代回归技术(GLM,GAM,loess)来正确解读排序图。
最后,用CANOCO软件分析了7个难度不同的研究案例。
这些案例对于大家选择排序方法及分析排序结果很有帮助。
案例的数据均可以从网络本书的主页(http://regent.bf.jcu.cz/maed/)上获得。
原书前言群落的组成的多维数据,比如种群的属性,或是环境因子的属性,是生态学家研究生涯的面包与黄油。
这些数据被分析时候需要考虑它们的多维性。
用多元统计的方法来分析群落数据是比较适合的。
在这本书,我们尽量使用一套一致的方法来回答生态学家在研究中常遇到的问题。
然而,我们也经常用自己观点来表述一些内容,同时,我们也关注一些非参数的方法,比如非度量多维尺度分析(NMDS)的算法等等。
我们并不要是强调不同的方法对于分析多元数据的差异,而是想说明要解决一个问题,可以用很多方法。
在本书主要内容讲排序的方法,但并不意味着分类的方法没有用(译者注:排序与分类密不可分,分类分析群落的间断分布,排序分析群落的连续分布 )。
同时,我们也对回归方做了一些总结,包括最新发展的内容比如广义可加模型(generalized additive models)。
在这本书的所描述的方法可以广泛被研究植物、动物和土壤的研究人员利用,当然也可以是水生生物方面的人员。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
.Canoco for Windows 4.5之CCA排序以下为软件使用的详细步骤,具体探讨如何使用Canoco for Windows 4.5软件包完成Canonical Correspondence Analysis (CCA) 分析,软件包的大部分程序都将在步骤中涉及,鉴于分析中所采用的公用数据集,大家可以基于Canoco测试版重做这些分析。
(提醒:Canoco测试版默认安装路径为C:\Canoco,如果您在别的地方重新安装,请恰当的调整文件夹路径。
)步骤共划分为四个过程:借助WCanolmp导入电子表数据借助Canoco for Windows进行CCA排序借助CanoDraw画出排序图修正CanoDraw 排序图一、借助WCanoImp导入电子表数据1.打开路径C:\Canoco\Samples\dune_env.xls中的Excel文件,当然也可以使用其他可读形式。
在Excel表中,要选择整个矩形区域的数据,包括第一行(含变量名称)和第一列(含样本名称),然后复制数据到剪贴板(也可使用Excel中的Edit→Copy菜单命令),之后,从快捷菜单中打开Canoco for Windows的子菜单WCanoImp(见图1)。
WCanoImp从快捷菜单中打开1 图格式(如CondensedWCanoImp程序已经开始运行,这里我们选择保存数据为此时,2.值的话,而且这对于物种数据还很常见,那么浓缩格式可以节省文件空果数据包括很多0 。
核对以下选项后,就可以点击保存按钮了(见图2)间)2 WcanoImp图的文件保存..3.此时出现一个文件选择框,选择文件路径为C:\Canoco\Samples,同时输入文件名duneenv2.dta,此时不要输入duneenv.dta,因为这个文件已经存在,如果你保存的话将会覆盖(当然前提需要你的确认),之后,点击“Save”按钮。
4.之后弹出一个小型窗口,可以输入一段描述性的文字(最多80 字节),此时由WCanoImp生成的一段文字被突出显示(蓝色阴影),可以默认,也可以通过输入文字直接替换。
然后点击“OK”按钮,有提示框提醒“你的文件成功创建”,最后再次点击“OK”按钮后,又回到WCanoImp 窗口,可以关闭。
二、借助Canoco for Windows进行CCA排序1.从快捷菜单中打开Canoco for Windows的子菜单(见数据导入第1个步骤),此时选择Canoco for Windows项,打开的时候会有日期提醒(已转换系统日期的除外),关闭后继续。
此时,Canoco for Windows的工作区还是空的,在开始分析之前,我们必须创建一个新的项目,如可以通过工具栏上的“New project”快捷键创建(图3)。
图3 Canoco for Windows新项目的创建2.点击“New project”按钮之后,会出现新的项目窗口(Project View)和登录窗口(Log View),同时项目建立向导也会自动启动(以下主要是对各向导页面的说明)。
CCA试图通过环境数据解释物种关系,如果我们想同时分析物种数据(主数据)、环境数据(从数据)以及相应的梯度关系,则必须首先选择第一个向导页的复选框(图4),确认后点击向导页下方的“Next”按钮。
图4 数据关系的选择3.下一页,主要是选择2个文件作为排序结果的储存部分(Canoco结果文件)。
但由于前一页的选择,所以两个选项(协变量和补充性环境变量)是非激活的。
此时,你可以直接..在默认路径中输入文件名,也可以使用“Browse”按钮去查询数据文件所在(图5),原则上应该按照下图填写路径,除非你的Canoco安装目录不在C:\Canoco。
图5 数据文件的选择4.点击“Next”按钮后,向导页出现了分析方法的选择,这里选择CCA,当然你也可以尝试单击向导页右上方的“?”按钮,点击后你的鼠标变成一个问号标志,放到任何一个标签上面都可以得到具体信息,如想获得整个向导页的说明,则可以点击向导页底部的“Help”按钮。
5.下一页,需要选择分类排序的比例,此时保持默认值,如想更清楚了解这一选择,你也可以尝试阅读“Help”文本。
6.继续下一页,给我们提供物种数据转换的几种方法,对于我们的数据,物种数值大体处于对数比例,因此我们保持默认的“不转换”,继续点击“Next”。
7.这一页“数据编辑选择”(图6)是数据分析的核心部分,通过选择特定的复选框,你可以通过分析移除某些样本、物种或是环境变量,改变它们的比重或是让它们作为补充成分。
此外,你也可以通过Define Interactions(原始环境变量的动力和产量)扩展解释变量。
但在步骤中,为尽量保证我们的展示简单,我们没有选择任何一个复选框且忽略了大部分的向导页说明。
图6 数据编辑选择8.下一页允许进行环境变量的预选,除了手动预选之外,也可以借助CANOCO 3.x的自动预选,它可以为个体解释变量的微量和受制约的影响提供快速的概括(见The Package:The Canoco for Windows module)。
在此时说明中,我们依然保持默认状态(即使不采用预选),继续点击“下一步”。
..9.下一页“Global Permutation Test”主要涉及蒙特卡洛置换检验,我们将为之展示Canocofor Windows最简单的置换检验。
首先选择左边页的最后一个选项“Both above tests”,同时让排列数和排列类型选择保持默认状态(图7)。
图7 Global Permutation Test10.下一页,继续保持默认设置。
当然也可以采取违背最简排序方法(自由排列),如通过协变量分析,确定已有样本/实验设计的程序结构,因此那些来自不同结构的样本并没有在排列中转换,可见The Package: The Canoco for Windows module以获取更多信息。
11.最终页终于出现了,这里友情提醒,此时你或许需要回头检查下当初的选择并按照要求进行修正,当然也可以在排序分析完成后检查,最后能重复和提高已有分析结果,如果确定的话,点击“Finish”按钮。
12.这样,一个标题为“Canoco Project”的文件保存对话框出现了,需要你输入一个名字并保存,比如我们把文件tutorial.con保存路径为C:\Canoco\Samples(图8)。
图8 con文件的保存13.点击“OK”按钮之后,已有项目得以保存,界面又回归到Canoco for Windows 工作区,同时项目窗口被突出显示,而登录窗口成为背景(图9)。
14.点击项目窗口中的“Analyze”按钮,计算过程(包括蒙特卡洛排序)呈现在弹出(pop-up)窗口,在这个窗口消失之后,你又将回到Canoco for Windows工作区,此时登录窗口填满了分析的主要结果。
若想检查排序结果,可通过点击窗口查看,当然也可以点击F3或点击转换工具栏按钮。
..图14 Canoco for Windows主界面15.在登录窗口,你可以看到蒙特卡洛排序检验、排序总体情况以及一些附加信息,这些信息在Canoco for Windows中有细致展示(图15),也可借助右手边的“scrollbar”收起登录窗口。
图15 登录窗口的详细信息三、借助CanoDraw画出排序图1.有两种方法打开CanoDraw,一是从快捷菜单中打开Canoco for Windows的子菜单(见数据导入第1个步骤),此时选择CanoDraw项;二是在项目窗口执行“Project→CanoDraw”命令。
刚开始的时候,CanoDraw for Windows基于现有的活动项目(.con file)、排序结果和输入数据文件创建了一个新的项目,此时需确认项目名称(和Canoco project一样,但以cdw作为扩展名),点击“保存”按钮,然后从Project→Nominal variables子菜单中选择环境变量,同时选择SF, BF, HF, NM 变量(图16)2.为创建图表,从Create→Biplots and Joint Plots子菜单中选择“Species and env.variables”项(图17),最终生成排序图。
用“File”子菜单中的“Save”命令保存,并给与命名,当然,在本文的后一部分,将主要介绍如何修正排序图。
..图16 CanoDraw中的变量选择图17 排序图的生成四、修正CanoDraw 排序图1.原则上,对排序图的修正,可以通过选择图表的不同部分(如符号、标签、线条、箭头)来完成。
但是在很多分析中,因为排序图初次建立时的选择是比较恰当的,所以对图表的修正往往事倍功半。
2.如果想修正的话,可通过使用“View”菜单中的“Visual Attributes”命令。
选择后,会弹出如下会话框,首先应选择菜单左边的图表类型,然后尝试改变初始图表分布(图18)。
图18 CanoDraw图形修正菜单..3.以上的修订命令适用很广泛,基本可适用于所有基于Canoco分析所创建的CanoDraw项目,但还有一些特别的设置方法,如“Project→Settings”命令,通过此方法,你可以选择个体是否贴上标签,一个图表究竟建立怎样的属性等等(图19)。
图19 Project Settings 具体分布4.为表明图表中物种间差异,我们不妨来改变物种标签的颜色,既然物种的特征符号为蓝色,那么我们不妨让它们的标签亦为蓝色,而原始标签默认为黑色。
通过左键点击其中一个物种的标签,一个红色框就出现在标签的周围,把鼠标放在这个框内并点击右键,一个系列菜单就出现了(图20)。
图20 图形修正的右键菜单5.从这些菜单中,选择第一个“Select Suchlike”命令,这样CanoDraw就选择了该物种所有剩下部分的标签,因为它们采用的是同样大小和型号的字体,如果你想选择图中的所有物种而无视它们的差异,那么可以选择菜单中第二个“Select Similar”命令。
6.现在点击F5(或者选择View→Properties Sheet命令),然后会出现下图所示对话框(图21)。
..图21 标签色彩修改(属性)对话框(一)7.这是CanoDraw图表修正的核心,允许你改变一个或多个选择对象的属性,之前所有关于图表的属性选项此时都处于激活状态,举例来说,在我们的分析中,Color、line、Fill和Font页就是激活的,但Symbol页因为对标签没有意义而没有被激活。
此时我们选择颜色页的蓝色按钮,然后点击“Apply”(见上图)。
8.请注意,在改变图表的选择或转换到另外CanoDraw 项目时,你没有必要关掉这个属性表,你可以简单的转换边上的窗口,还可在CanoDraw窗口内点击某些部位,比如你可以点击物种Symbol并通过“Select Suchlike”命令再一次选择它们,点回属性表并选择Symbol页,此时Symbol 页就是激活的。