User de ned coverage - a tool supported methodology for design veri cation
GSPBOX_-Atoolboxforsignalprocessingongraphs_

GSPBOX_-Atoolboxforsignalprocessingongraphs_GSPBOX:A toolbox for signal processing on graphsNathanael Perraudin,Johan Paratte,David Shuman,Lionel Martin Vassilis Kalofolias,Pierre Vandergheynst and David K.HammondMarch 16,2016AbstractThis document introduces the Graph Signal Processing Toolbox (GSPBox)a framework that can be used to tackle graph related problems with a signal processing approach.It explains the structure and the organization of this software.It also contains a general description of the important modules.1Toolbox organizationIn this document,we brie?y describe the different modules available in the toolbox.For each of them,the main functions are brie?y described.This chapter should help making the connection between the theoretical concepts introduced in [7,9,6]and the technical documentation provided with the toolbox.We highly recommend to read this document and the tutorial before using the toolbox.The documentation,the tutorials and other resources are available on-line 1.The toolbox has ?rst been implemented in MATLAB but a port to Python,called the PyGSP,has been made recently.As of the time of writing of this document,not all the functionalities have been ported to Python,but the main modules are already available.In the following,functions pre?xed by [M]:refer to the MATLAB implementation and the ones pre?xed with [P]:refer to the Python implementation. 1.1General structure of the toolbox (MATLAB)The general design of the GSPBox focuses around the graph object [7],a MATLAB structure containing the necessary infor-mations to use most of the algorithms.By default,only a few attributes are available (see section 2),allowing only the use of a subset of functions.In order to enable the use of more algorithms,additional ?elds can be added to the graph structure.For example,the following line will compute the graph Fourier basis enabling exact ?ltering operations.1G =gsp_compute_fourier_basis(G);Ideally,this operation should be done on the ?y when exact ?ltering is required.Unfortunately,the lack of well de?ned class paradigm in MATLAB makes it too complicated to be implemented.Luckily,the above formulation prevents any unnecessary data copy of the data contained in the structure G .In order to avoid name con?icts,all functions in the GSPBox start with [M]:gsp_.A second important convention is that all functions applying a graph algorithm on a graph signal takes the graph as ?rst argument.For example,the graph Fourier transform of the vector f is computed by1fhat =gsp_gft(G,f);1Seehttps://lts2.epfl.ch/gsp/doc/for MATLAB and https://lts2.epfl.ch/pygsp for Python.The full documentation is also avail-able in a single document:https://lts2.epfl.ch/gsp/gspbox.pdf1a r X i v :1408.5781v 2 [c s .I T ] 15 M a r 2016The graph operators are described in section4.Filtering a signal on a graph is also a linear operation.However,since the design of special?lters(kernels)is important,they are regrouped in a dedicated module(see section5).The toolbox contains two additional important modules.The optimization module contains proximal operators,projections and solvers compatible with the UNLocBoX[5](see section6).These functions facilitate the de?nition of convex optimization problems using graphs.Finally,section??is composed of well known graph machine learning algorithms.1.2General structure of the toolbox(Python)The structure of the Python toolbox follows closely the MATLAB one.The major difference comes from the fact that the Python implementation is object-oriented and thus allows for a natural use of instances of the graph object.For example the equivalent of the MATLAB call:1G=gsp_estimate_lmax(G);can be achieved using a simple method call on the graph object:1G.estimate_lmax()Moreover,the use of class for the"graph object"allows to compute additional graph attributes on the?y,making the code clearer as its MATLAB equivalent.Note though that functionalities are grouped into different modules(one per section below) and that several functions that work on graphs have to be called directly from the modules.For example,one should write:1layers=pygsp.operators.kron_pyramid(G,levels)This is the case as soon as the graph is the structure on which the action has to be performed and not our principal focus.In a similar way to the MATLAB implementation using the UNLocBoX for the convex optimization routines,the Python implementation uses the PyUNLocBoX,which is the Python port of the UNLocBoX. 2GraphsThe GSPBox is constructed around one main object:the graph.It is implemented as a structure in Matlab and as a class in Python.It stores the nodes,the edges and other attributes related to the graph.In the implementation,a graph is fully de?ned by the weight matrix W,which is the main and only required attribute.Since most graph structures are far from fully connected, W is implemented as a sparse matrix.From the weight matrix a Laplacian matrix is computed and stored as an attribute of the graph object.Different other attributes are available such as plotting attributes,vertex coordinates,the degree matrix,the number of vertices and edges.The list of all attributes is given in table1.2Attribute Format Data type DescriptionMandatory?eldsW N x N sparse matrix double Weight matrix WL N x N sparse matrix double Laplacian matrixd N x1vector double The diagonal of the degree matrixN scalar integer Number of verticesNe scalar integer Number of edgesplotting[M]:structure[P]:dict none Plotting parameterstype text string Name,type or short descriptiondirected scalar[M]:logical[P]:boolean State if the graph is directed or notlap_type text string Laplacian typeOptional?eldsA N x N sparse matrix[M]:logical[P]:boolean Adjacency matrixcoords N x2or N x3matrix double Vectors of coordinates in2D or3D.lmax scalar double Exact or estimated maximum eigenvalue U N x N matrix double Matrix of eigenvectorse N x1vector double Vector of eigenvaluesmu scalar double Graph coherenceTable1:Attributes of the graph objectThe easiest way to create a graph is the[M]:gsp_graph[P]:pygsp.graphs.Graph function which takes the weight matrix as input.This function initializes a graph structure by creating the graph Laplacian and other useful attributes.Note that by default the toolbox uses the combinatorial de?nition of the Laplacian operator.Other Laplacians can be computed using the[M]:gsp_create_laplacian[P]:pygsp.gutils.create_laplacian function.Please note that almost all functions are dependent of the Laplacian de?nition.As a result,it is important to select the correct de?nition at? rst.Many particular graphs are also available using helper functions such as:ring,path,comet,swiss roll,airfoil or two moons. In addition,functions are provided for usual non-deterministic graphs suchas:Erdos-Renyi,community,Stochastic Block Model or sensor networks graphs.Nearest Neighbors(NN)graphs form a class which is used in many applications and can be constructed from a set of points (or point cloud)using the[M]:gsp_nn_graph[P]:pygsp.graphs.NNGraph function.The function is highly tunable and can handle very large sets of points using FLANN[3].Two particular cases of NN graphs have their dedicated helper functions:3D point clouds and image patch-graphs.An example of the former can be seen in thefunction[M]:gsp_bunny[P]:pygsp.graphs.Bunny.As for the second,a graph can be created from an image by connecting similar patches of pixels together.The function[M]:gsp_patch_graph creates this graph.Parameters allow the resulting graph to vary between local and non-local and to use different distance functions [12,4].A few examples of the graphs are displayed in Figure1.3PlottingAs in many other domains,visualization is very important in graph signal processing.The most basic operation is to visualize graphs.This can be achieved using a call to thefunction[M]:gsp_plot_graph[P]:pygsp.plotting.plot_graph. In order to be displayable,a graph needs to have2D(or3D)coordinates(which is a?eld of the graph object).Some graphs do not possess default coordinates(e.g.Erdos-Renyi).The toolbox also contains routines to plot signals living on graphs.The function dedicated to this task is[M]:gsp_plot_ signal[P]:pygsp.plotting.plot_signal.For now,only1D signals are supported.By default,the value of the signal is displayed using a color coding,but bars can be displayed by passing parameters.3Figure 1:Examples of classical graphs :two moons (top left),community (top right),airfoil (bottom left)and sensor network (bottom right).The third visualization helper is a function to plot ?lters (in the spectral domain)which is called [M]:gsp_plot_filter [P]:pygsp.plotting.plot_filter .It also supports ?lter-banks and allows to automatically inspect the related frames.The results obtained using these three plotting functions are visible in Fig.2.4OperatorsThe module operators contains basics spectral graph functions such as Fourier transform,localization,gradient,divergence or pyramid decomposition.Since all operator are based on the Laplacian de? nition,the necessary underlying objects (attributes)are all stored into a single object:the graph.As a ?rst example,the graph Fourier transform [M]:gsp_gft [P]:pygsp.operators.gft requires the Fourier basis.This attribute can be computed with the function [M]:gsp_compute_fourier_basis[P]:/doc/c09ff3e90342a8956bec0975f46527d3240ca692.html pute_fourier_basis [9]that adds the ?elds U ,e and lmax to the graph structure.As a second example,since the gradient and divergence operate on the edges of the graph,a search on the edge matrix is needed to enable the use of these operators.It can be done with the routines [M]:gsp_adj2vec[P]:pygsp.operators.adj2vec .These operations take time and should4Figure 2:Visualization of graph and signals using plotting functions.NameEdge derivativefe (i,j )Laplacian matrix (operator)Available Undirected graph Combinatorial LaplacianW (i,j )(f (j )?f (i ))D ?WV Normalized Laplacian W (i,j ) f (j )√d (j )f (i )√d (i )D ?12(D ?W )D ?12V Directed graph Combinatorial LaplacianW (i,j )(f (j )?f (i ))12(D ++D ??W ?W ?)V Degree normalized Laplacian W (i,j ) f (j )√d ?(j )?f (i )√d +(i )I ?12D ?12+[W +W ?]D ?12V Distribution normalized Laplacianπ(i ) p (i,j )π(j )f (j )? p (i,j )π(i )f (i )12 Π12PΠ12+Π?12P ?Π12 VTable 2:Different de?nitions for graph Laplacian operator and their associated edge derivative.(For directed graph,d +,D +and d ?,D ?de?ne the out degree and in-degree of a node.π,Πis the stationary distribution of the graph and P is a normalized weight matrix W .For sake of clarity,exact de?nition of those quantities are not given here,but can be found in [14].)be performed only once.In MATLAB,these functions are called explicitly by the user beforehand.However,in Python they are automatically called when needed and the result stored as an attribute. The module operator also includes a Multi-scale Pyramid Transform for graph signals [6].Again,it works in two steps.Firstthe pyramid is precomputed with [M]:gsp_graph_multiresolution [P]:pygsp.operators.graph_multiresolution .Second the decomposition of a signal is performed with [M]:gsp_pyramid_analysis [P]:pygsp.operators.pyramid_analysis .The reconstruction uses [M]:gsp_pyramid_synthesis [P]:pygsp.operators.pyramid_synthesis .The Laplacian is a special operator stored as a sparse matrix in the ?eld L of the graph.Table 2summarizes the available de?nitions.We are planning to implement additional ones.5FiltersFilters are a special kind of linear operators that are so prominent in the toolbox that they deserve their own module [9,7,2,8,2].A ?lter is simply an anonymous function (in MATLAB)or a lambda function (in Python)acting element-by-element on the input.In MATLAB,a ?lter-bank is created simply by gathering these functions together into a cell array.For example,you would write:51%g(x)=x^2+sin(x)2g=@(x)x.^2+sin(x);3%h(x)=exp(-x)4h=@(x)exp(-x);5%Filterbank composed of g and h6fb={g,h};The toolbox contains many prede?ned design of?lter.They all start with[M]:gsp_design_in MATLAB and are in the module[P]:pygsp.filters in Python.Once a?lter(or a?lter-bank)is created,it can be applied to a signal with[M]: gsp_filter_analysis in MATLAB and a call to the method[P]:analysis of the?lter object in Python.Note that the toolbox uses accelerated algorithms to scale almost linearly with the number of sample[11].The available type of?lter design of the GSPBox can be classi?ed as:Wavelets(Filters are scaled version of a mother window)Gabor(Filters are shifted version of a mother window)Low passlter(Filters to de-noise a signal)High pass/Low pass separationlterbank(tight frame of2lters to separate the high frequencies from the low ones.No energy is lost in the process)Additionally,to adapt the?lter to the graph eigen-distribution,the warping function[M]:gsp_design_warped_translates [P]:pygsp.filters.WarpedTranslates can be used[10].6UNLocBoX BindingThis module contains special wrappers for the UNLocBoX[5].It allows to solve convex problems containing graph terms very easily[13,15,14,1].For example,the proximal operator of the graph TV norm is given by[M]:gsp_prox_tv.The optimization module contains also some prede?ned problems such as graph basis pursuit in[M]:gsp_solve_l1or wavelet de-noising in[M]:gsp_wavelet_dn.There is still active work on this module so it is expected to grow rapidly in the future releases of the toolbox.7Toolbox conventions7.1General conventionsAs much as possible,all small letters are used for vectors(or vector stacked into a matrix)and capital are reserved for matrices.A notable exception is the creation of nearest neighbors graphs.A variable should never have the same name as an already existing function in MATLAB or Python respectively.This makes the code easier to read and less prone to errors.This is a best coding practice in general,but since both languages allow the override of built-in functions,a special care is needed.All function names should be lowercase.This avoids a lot of confusion because some computer architectures respect upper/lower casing and others do not.As much as possible,functions are named after the action they perform,rather than the algorithm they use,or the person who invented it.No global variables.Global variables makes it harder to debug and the code is harder to parallelize.67.2MATLABAll function start by gsp_.The graph structure is always therst argument in the function call.Filters are always second.Finally,optional parameter are last.In the toolbox,we do use any argument helper functions.As a result,optional argument are generally stacked into a graph structure named param.If a transform works on a matrix,it will per default work along the columns.This is a standard in Matlab(fft does this, among many other functions).Function names are traditionally written in uppercase in MATLAB documentation.7.3PythonAll functions should be part of a module,there should be no call directly from pygsp([P]:pygsp.my_function).Inside a given module,functionalities can be further split in differentles regrouping those that are used in the same context.MATLAB’s matrix operations are sometimes ported in a different way that preserves the efciency of the code.When matrix operations are necessary,they are all performed through the numpy and scipy libraries.Since Python does not come with a plotting library,we support both matplotlib and pyqtgraph.One should install the required libraries on his own.If both are correctly installed,then pyqtgraph is favoured unless speci?cally speci?ed. AcknowledgementsWe would like to thanks all coding authors of the GSPBOX.The toolbox was ported in Python by Basile Chatillon,Alexandre Lafaye and Nicolas Rod.The toolbox was also improved by Nauman Shahid and Yann Sch?nenberger.References[1]M.Belkin,P.Niyogi,and V.Sindhwani.Manifold regularization:A geometric framework for learning from labeled and unlabeledexamples.The Journal of Machine Learning Research,7:2399–2434,2006.[2] D.K.Hammond,P.Vandergheynst,and R.Gribonval.Wavelets on graphs via spectral graph theory.Applied and ComputationalHarmonic Analysis,30(2):129–150,2011.[3]M.Muja and D.G.Lowe.Scalable nearest neighbor algorithms for high dimensional data.Pattern Analysis and Machine Intelligence,IEEE Transactions on,36,2014.[4]S.K.Narang,Y.H.Chao,and A.Ortega.Graph-wavelet?lterbanks for edge-aware image processing.In Statistical Signal ProcessingWorkshop(SSP),2012IEEE,pages141–144.IEEE,2012.[5]N.Perraudin,D.Shuman,G.Puy,and P.Vandergheynst.UNLocBoX A matlab convex optimization toolbox using proximal splittingmethods.ArXiv e-prints,Feb.2014.[6] D.I.Shuman,M.J.Faraji,and P.Vandergheynst.A multiscale pyramid transform for graph signals.arXiv preprint arXiv:1308.4942,2013.[7] D.I.Shuman,S.K.Narang,P.Frossard,A.Ortega,and P.Vandergheynst.The emerging?eld of signal processing on graphs:Extendinghigh-dimensional data analysis to networks and other irregular domains.Signal Processing Magazine,IEEE,30(3):83–98,2013.7[8] D.I.Shuman,B.Ricaud,and P.Vandergheynst.A windowed graph Fourier transform.Statistical Signal Processing Workshop(SSP),2012IEEE,pages133–136,2012.[9] D.I.Shuman,B.Ricaud,and P.Vandergheynst.Vertex-frequency analysis on graphs.arXiv preprint arXiv:1307.5708,2013.[10] D.I.Shuman,C.Wiesmeyr,N.Holighaus,and P.Vandergheynst.Spectrum-adapted tight graph wavelet and vertex-frequency frames.arXiv preprint arXiv:1311.0897,2013.[11] A.Susnjara,N.Perraudin,D.Kressner,and P.Vandergheynst.Accelerated?ltering on graphs using lanczos method.arXiv preprintarXiv:1509.04537,2015.[12] F.Zhang and E.R.Hancock.Graph spectral image smoothing using the heat kernel.Pattern Recognition,41(11):3328–3342,2008.[13] D.Zhou,O.Bousquet,/doc/c09ff3e90342a8956bec0975f46527d3240ca692.html l,J.Weston,and B.Sch?lkopf.Learning with local and global consistency.Advances in neural informationprocessing systems,16(16):321–328,2004.[14] D.Zhou,J.Huang,and B.Sch?lkopf.Learning from labeled and unlabeled data on a directed graph.In the22nd international conference,pages1036–1043,New York,New York,USA,2005.ACM Press.[15] D.Zhou and B.Sch?lkopf.A regularization framework for learning from graph data.2004.8。
uppaal-tutorial

A Tutorial on Uppaal4.0Updated November28,2006Gerd Behrmann,Alexandre David,and Kim rsenDepartment of Computer Science,Aalborg University,Denmark{behrmann,adavid,kgl}@cs.auc.dk.Abstract.This is a tutorial paper on the tool Uppaal.Its goal is to bea short introduction on theflavour of timed automata implemented inthe tool,to present its interface,and to explain how to use the tool.Thecontribution of the paper is to provide reference examples and modellingpatterns.1IntroductionUppaal is a toolbox for verification of real-time systems jointly developed by Uppsala University and Aalborg University.It has been applied successfully in case studies ranging from communication protocols to multimedia applications [35,55,24,23,34,43,54,44,30].The tool is designed to verify systems that can be modelled as networks of timed automata extended with integer variables,struc-tured data types,user defined functions,and channel synchronisation.Thefirst version of Uppaal was released in1995[52].Since then it has been in constant development[21,5,13,10,26,27].Experiments and improvements in-clude data structures[53],partial order reduction[20],a distributed version of Uppaal[17,9],guided and minimal cost reachability[15,51,16],work on UML Statecharts[29],acceleration techniques[38],and new data structures and memory reductions[18,14].Version4.0[12]brings symmetry reduction[36], the generalised sweep-line method[49],new abstraction techniques[11],priori-ties[28],and user defined functions to the mainstream.Uppaal has also gen-erated related Ph.D.theses[50,57,45,56,19,25,32,8,31].It features a Java user interface and a verification engine written in C++.It is freely available at /.This tutorial covers networks of timed automata and theflavour of timed automata used in Uppaal in section2.The tool itself is described in section3, and three extensive examples are covered in sections4,5,and6.Finally,section7 introduces common modelling patterns often used with Uppaal.2Timed Automata in UppaalThe model-checker Uppaal is based on the theory of timed automata[4](see[42] for automata theory)and its modelling language offers additional features such as bounded integer variables and urgency.The query language of Uppaal,usedto specify properties to be checked,is a subset of TCTL (timed computation tree logic)[39,3].In this section we present the modelling and the query languages of Uppaal and we give an intuitive explanation of time in timed automata.2.1The Modelling LanguageNetworks of Timed Automata A timed automaton is a finite-state machine extended with clock variables.It uses a dense-time model where a clock variable evaluates to a real number.All the clocks progress synchronously.In Uppaal ,a system is modelled as a network of several such timed automata in parallel.The model is further extended with bounded discrete variables that are part of the state.These variables are used as in programming languages:They are read,written,and are subject to common arithmetic operations.A state of the system is defined by the locations of all automata,the clock values,and the values of the discrete variables.Every automaton may fire an edge (sometimes misleadingly called a transition)separately or synchronise with another automaton 1,which leads to a new state.Figure 1(a)shows a timed automaton modelling a simple lamp.The lamp has three locations:off ,low ,and bright .If the user presses a button,i.e.,synchronises with press?,then the lamp is turned on.If the user presses the button again,the lamp is turned off.However,if the user is fast and rapidly presses the button twice,the lamp is turned on and becomes bright.The user model is shown in Fig.1(b).The user can press the button randomly at any time or even not press the button at all.The clock y of the lamp is used to detect if the user was fast (y <5)or slow (y >=5).press?‚‚‚‚‚press!(a)Lamp.(b)User.Fig.1.The simple lamp example.We give the basic definitions of the syntax and semantics for the basic timed automata.In the following we will skip the richer flavour of timed automata supported in Uppaal ,i.e.,with integer variables and the extensions of urgent and committed locations.For additional information,please refer to the helpmenu inside the tool.We use the following notations:C is a set of clocks and B (C )is the set of conjunctions over simple conditions of the form x ⊲⊳c or x −y ⊲⊳c ,where x,y ∈C ,c ∈N and ⊲⊳∈{<,≤,=,≥,>}.A timed automaton is a finite directed graph annotated with conditions over and resets of non-negative real valued clocks.Definition 1(Timed Automaton (TA)).A timed automaton is a tuple (L,l 0,C,A,E,I ),where L is a set of locations,l 0∈L is the initial location,C is the set of clocks,A is a set of actions,co-actions and the internal τ-action,E ⊆L ×A ×B (C )×2C ×L is a set of edges between locations with an action,a guard and a set of clocks to be reset,and I :L →B (C )assigns invariants to locations. In the previous example on Fig.1,y:=0is the reset of the clock y ,and the labels press?and press!denote action–co-action (channel synchronisations here).We now define the semantics of a timed automaton.A clock valuation is a function u :C →R ≥0from the set of clocks to the non-negative reals.Let R C be the set of all clock valuations.Let u 0(x )=0for all x ∈C .We will abuse the notation by considering guards and invariants as sets of clock valuations,writing u ∈I (l )to mean that u satisfies I (l ).0000000001111111110001110000000000000000000000000000000000000000000000001111111111111111111111111111111111111111111111110000000000000000000000000000000000000000000000000000000011111111111111111111111111111111111111111111111111111111000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000011111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111110000111100001111<B,x=1><A,x=2><A,x=3><A,x=3>action transition delay(+1) transition delay(+2) transition state: <A,x=1>actiontransitionOK invalid action transition invalid state: invariant x<3 violatedFig.2.Semantics of TA:different transitions from a given initial state.Definition 2(Semantics of TA).Let (L,l 0,C,A,E,I )be a timed automaton.The semantics is defined as a labelled transition system S,s 0,→ ,where S ⊆L ×R C is the set of states,s 0=(l 0,u 0)is the initial state,and →⊆S ×(R ≥0∪A )×S is the transition relation such that:–(l,u )d−→(l,u +d )if ∀d ′:0≤d ′≤d =⇒u +d ′∈I (l ),and –(l,u )a −→(l ′,u ′)if there exists e =(l,a,g,r,l ′)∈E s.t.u ∈g ,u ′=[r →0]u ,and u ′∈I (l ′),3where for d∈R≥0,u+d maps each clock x in C to the value u(x)+d,and [r→0]u denotes the clock valuation which maps each clock in r to0and agrees with u over C\r. Figure2illustrates the semantics of TA.From a given initial state,we can choose to take an action or a delay transition(different values here).Depending of the chosen delay,further actions may be forbidden.Timed automata are often composed into a network of timed automata over a common set of clocks and actions,consisting of n timed automata A i= (L i,l0i,C,A,E i,I i),1≤i≤n.A location vector is a vector¯l=(l1,...,l n). We compose the invariant functions into a common function over location vec-tors I(¯l)=∧i I i(l i).We write¯l[l′i/l i]to denote the vector where the i th element l i of¯l is replaced by l′i.In the following we define the semantics of a network of timed automata.Definition3(Semantics of a network of Timed Automata).Let A i= (L i,l0i,C,A,E i,I i)be a network of n timed automata.Let¯l0=(l01,...,l0n)be the initial location vector.The semantics is defined as a transition system S,s0,→ , where S=(L1×···×L n)×R C is the set of states,s0=(¯l0,u0)is the initial state,and→⊆S×S is the transition relation defined by:–(¯l,u)d−→(¯l,u+d)if∀d′:0≤d′≤d=⇒u+d′∈I(¯l).−−→l′i s.t.u∈g,–(¯l,u)a−→(¯l[l′i/l i],u′)if there exists l iτgru′=[r→0]u and u′∈I(¯l[l′i/l i]).–(¯l,u)a−→(¯l[l′j/l j,l′i/l i],u′)if there exist l i c?g i r i−−−−→l′i and−−−−→l′j s.t.u∈(g i∧g j),u′=[r i∪r j→0]u and u′∈I(¯l[l′j/l j,l′i/l i]).l j c!g j r jAs an example of the semantics,the lamp in Fig.1may have the follow-ing states(we skip the user):(Lamp.off,y=0)→(Lamp.off,y=3)→(Lamp.low,y=0)→(Lamp.low,y=0.5)→(Lamp.bright,y=0.5)→(Lamp.bright,y=1000)...Timed Automata in Uppaal The Uppaal modelling language extends timed automata with the following additional features(see Fig.3:Templates automata are defined with a set of parameters that can be of any type(e.g.,int,chan).These parameters are substituted for a given argument in the process declaration.Constants are declared as const name value.Constants by definition cannot be modified and must have an integer value.Bounded integer variables are declared as int[min,max]name,where min and max are the lower and upper bound,respectively.Guards,invariants,and assignments may contain expressions ranging over bounded integer variables.The bounds are checked upon verification and violating a bound leads to an invalid state that is discarded(at run-time).If the bounds are omitted,the default range of-32768to32768is used.4Fig.3.Declarations of a constant and a variable,and illustration of some of the channel synchronisations between two templates of the train gate example of Section4,and some committed locations.5Binary synchronisation channels are declared as chan c.An edge labelled with c!synchronises with another labelled c?.A synchronisation pair is chosen non-deterministically if several combinations are enabled. Broadcast channels are declared as broadcast chan c.In a broadcast syn-chronisation one sender c!can synchronise with an arbitrary number of receivers c?.Any receiver than can synchronise in the current state must do so.If there are no receivers,then the sender can still execute the c!action,i.e.broadcast sending is never blocking.Urgent synchronisation channels are declared by prefixing the channel decla-ration with the keyword urgent.Delays must not occur if a synchronisation transition on an urgent channel is enabled.Edges using urgent channels for synchronisation cannot have time constraints,i.e.,no clock guards. Urgent locations are semantically equivalent to adding an extra clock x,that is reset on all incoming edges,and having an invariant x<=0on the location.Hence,time is not allowed to pass when the system is in an urgent location. Committed locations are even more restrictive on the execution than urgent locations.A state is committed if any of the locations in the state is commit-ted.A committed state cannot delay and the next transition must involve an outgoing edge of at least one of the committed locations.Arrays are allowed for clocks,channels,constants and integer variables.They are defined by appending a size to the variable name,e.g.chan c[4];clock a[2];int[3,5]u[7];.Initialisers are used to initialise integer variables and arrays of integer vari-ables.For instance,int i=2;or int i[3]={1,2,3};.Record types are declared with the struct construct like in C.Custom types are defined with the C-like typedef construct.You can define any custom-type from other basic types such as records.User functions are defined either globally or locally to templates.Template parameters are accessible from local functions.The syntax is similar to C except that there is no pointer.C++syntax for references is supported for the arguments only.Expressions in Uppaal Expressions in Uppaal range over clocks and integer variables.The BNF is given in Fig.33in the appendix.Expressions are used with the following labels:Select A select label contains a comma separated list of name:type expressions where name is a variable name and type is a defined type(built-in or custom).These variables are accessible on the associated edge only and they will takea non-deterministic value in the range of their respective types.Guard A guard is a particular expression satisfying the following conditions: it is side-effect free;it evaluates to a boolean;only clocks,integer variables, and constants are referenced(or arrays of these types);clocks and clock differences are only compared to integer expressions;guards over clocks are essentially conjunctions(disjunctions are allowed over integer conditions).A guard may call a side-effect free function that returns a bool,although clock constraints are not supported in such functions.6Synchronisation A synchronisation label is either on the form Expression!or Expression?or is an empty label.The expression must be side-effect free, evaluate to a channel,and only refer to integers,constants and channels. Update An update label is a comma separated list of expressions with a side-effect;expressions must only refer to clocks,integer variables,and constants and only assign integer values to clocks.They may also call functions. Invariant An invariant is an expression that satisfies the following conditions:it is side-effect free;only clock,integer variables,and constants are referenced;it is a conjunction of conditions of the form x<e or x<=e where x is a clock reference and e evaluates to an integer.An invariant may call a side-effect free function that returns a bool,although clock constraints are not supported in such functions.2.2The Query LanguageThe main purpose of a model-checker is verify the model w.r.t.a requirement specification.Like the model,the requirement specification must be expressed in a formally well-defined and machine readable language.Several such logics exist in the scientific literature,and Uppaal uses a simplified version of TCTL. Like in TCTL,the query language consists of path formulae and state formulae.2 State formulae describe individual states,whereas path formulae quantify over paths or traces of the model.Path formulae can be classified into reachability, safety and liveness.Figure4illustrates the different path formulae supported by Uppaal.Each type is described below.State Formulae A state formula is an expression(see Fig.33)that can be evaluated for a state without looking at the behaviour of the model.For instance, this could be a simple expression,like i==7,that is true in a state whenever i equals7.The syntax of state formulae is a superset of that of guards,i.e.,a state formula is a side-effect free expression,but in contrast to guards,the use of disjunctions is not restricted.It is also possible to test whether a particular process is in a given location using an expression on the form P.l,where P is a process and l is a location.In Uppaal,deadlock is expressed using a special state formula(although this is not strictly a state formula).The formula simply consists of the keyword deadlock and is satisfied for all deadlock states.A state is a deadlock state if there are no outgoing action transitions neither from the state itself or any of its delay successors.Due to current limitations in Uppaal,the deadlock state formula can only be used with reachability and invariantly path formulae(see below).Reachability Properties Reachability properties are the simplest form of properties.They ask whether a given state formula,ϕ,possibly can be satisfied3Notice that A ϕ=¬E3¬ϕ8there should exist a maximal path such thatϕis always true.4In Uppaal we write A[]ϕand E[]ϕ,respectively.Liveness Properties Liveness properties are of the form:something will even-tually happen,e.g.when pressing the on button of the remote control of the television,then eventually the television should turn on.Or in a model of a communication protocol,any message that has been sent should eventually be received.In its simple form,liveness is expressed with the path formula A3ϕ,mean-ingϕis eventually satisfied.5The more useful form is the leads to or response property,writtenϕ ψwhich is read as wheneverϕis satisfied,then eventu-allyψwill be satisfied,e.g.whenever a message is sent,then eventually it will be received.6In Uppaal these properties are written as A<>ϕandϕ-->ψ, respectively.2.3Understanding TimeInvariants and Guards Uppaal uses a continuous time model.We illustrate the concept of time with a simple example that makes use of an observer.Nor-mally an observer is an add-on automaton in charge of detecting events without changing the observed system.In our case the clock reset(x:=0)is delegated to the observer for illustration purposes.Figure5shows thefirst model with its observer.We have two automata in parallel.Thefirst automaton has a self-loop guarded by x>=2,x being a clock,that synchronises on the channel reset with the second automaton.The second automaton,the observer,detects when the self loop edge is taken with the location taken and then has an edge going back to idle that resets the clock x.We moved the reset of x from the self loop to the observer only to test what happens on the transition before the reset.Notice that the location taken is committed(marked c)to avoid delay in that location.The following properties can be verified in Uppaal(see section3for an overview of the interface).Assuming we name the observer automaton Obs,we have:–A[]Obs.taken imply x>=2:all resets offx will happen when x is above2.This query means that for all reachable states,being in the locationObs.taken implies that x>=2.–E<>Obs.idle and x>3:this property requires,that it is possible to reach-able state where Obs is in the location idle and x is bigger than3.Essentially we check that we may delay at least3time units between resets.The result would have been the same for larger values like30000,since there are no invariants in this model.x>=2reset!‚‚‚‚‚246824"time"c l o c k x (a)Test.(b)Observer.(c)Behaviour:one possible run.Fig.5.First example with anobserver.x>=2reset!246824"time"c l o c k x(a)Test.(b)Updated behaviour with an invariant.Fig.6.Updated example with an invariant.The observer is the same as in Fig.5and is not shown here.We update the first model and add an invariant to the location loop ,as shown in Fig.6.The invariant is a progress condition:the system is not allowed to stay in the state more than 3time units,so that the transition has to be taken and the clock reset in our example.Now the clock x has 3as an upper bound.The following properties hold:–A[]Obs.taken imply (x>=2and x<=3)shows that the transition is takenwhen x is between 2and 3,i.e.,after a delay between 2and 3.–E<>Obs.idle and x>2:it is possible to take the transition when x is be-tween 2and 3.The upper bound 3is checked with the next property.–A[]Obs.idle imply x<=3:to show that the upper bound is respected.The former property E<>Obs.idle and x>3no longer holds.Now,if we remove the invariant and change the guard to x>=2and x<=3,you may think that it is the same as before,but it is not!The system has no progress condition,just a new condition on the guard.Figure 7shows what happens:the system may take the same transitions as before,but deadlock may also occur.The system may be stuck if it does not take the transition after 3time units.In fact,the system fails the property A[]not deadlock .The property A[]Obs.idle imply x<=3does not hold any longer and the deadlock can also be illustrated by the property A[]x>3imply not Obs.taken ,i.e.,after 3time units,the transition is not taken any more.10x>=2 && x<=3reset!246824"time"c l o c k x(a)Test.(b)Updated behaviour with a guard and no invariant.Fig.7.Updated example with a guard and no invariant.P0P1P2Fig.8.Automata in parallel with normal,urgent and commit states.The clocks are local,i.e.,P0.x and P1.x are two different clocks.Committed and Urgent Locations There are three different types of loca-tions in Uppaal :normal locations with or without invariants (e.g.,x<=3in the previous example),urgent locations,and committed locations.Figure 8shows 3automata to illustrate the difference.The location marked u is urgent and the one marked c is committed.The clocks are local to the automata,i.e.,x in P0is different from x in P1.To understand the difference between normal locations and urgent locations,we can observe that the following properties hold:–E<>P0.S1and P0.x>0:it is possible to wait in S1of P0.–A[]P1.S1imply P1.x==0:it is not possible to wait in S1of P1.An urgent location is equivalent to a location with incoming edges reseting a designated clock y and labelled with the invariant y<=0.Time may not progress in an urgent state,but interleavings with normal states are allowed.A committed location is more restrictive:in all the states where P2.S1is active (in our example),the only possible transition is the one that fires the edge outgoing from P2.S1.A state having a committed location active is said to11be committed:delay is not allowed and the committed location must be left in the successor state(or one of the committed locations if there are several ones). 3Overview of the Uppaal ToolkitUppaal uses a client-server architecture,splitting the tool into a graphical user interface and a model checking engine.The user interface,or client,is imple-mented in Java and the engine,or server,is compiled for different platforms (Linux,Windows,Solaris).7As the names suggest,these two components may be run on different machines as they communicate with each other via TCP/IP. There is also a stand-alone version of the engine that can be used on the com-mand line.3.1The Java ClientThe idea behind the tool is to model a system with timed automata using a graphical editor,simulate it to validate that it behaves as intended,andfinally to verify that it is correct with respect to a set of properties.The graphical interface(GUI)of the Java client reflects this idea and is divided into three main parts:the editor,the simulator,and the verifier,accessible via three“tabs”. The Editor A system is defined as a network of timed automata,called pro-cesses in the tool,put in parallel.A process is instantiated from a parameterised template.The editor is divided into two parts:a tree pane to access the different templates and declarations and a drawing canvas/text editor.Figure9shows the editor with the train gate example of section4.Locations are labelled with names and invariants and edges are labelled with guard conditions(e.g.,e==id), synchronisations(e.g.,go?),and assignments(e.g.,x:=0).The tree on the left hand side gives access to different parts of the system description:Global declaration Contains global integer variables,clocks,synchronisation channels,and constants.Templates Train,Gate,and IntQueue are different parameterised timed au-tomata.A template may have local declarations of variables,channels,and constants.Process assignments Templates are instantiated into processes.The process assignment section contains declarations for these instances.System definition The list of processes in the system.The syntax used in the labels and the declarations is described in the help system of the tool.The local and global declarations are shown in Fig.10.The graphical syntax is directly inspired from the description of timed automata in section2.12Fig.9.The train automaton of the train gate example.The select button is activated in the tool-bar.In this mode the user can move locations and edges or edit labels. The other modes are for adding locations,edges,and vertices on edges(called nails).A new location has no name by default.Two textfields allow the user to define the template name and its eful trick:The middle mouse button is a shortcut for adding new elements,i.e.pressing it on the canvas,a location,or edge adds a new location,edge,or nail,respectively.The Simulator The simulator can be used in three ways:the user can run the system manually and choose which transitions to take,the random mode can be toggled to let the system run on its own,or the user can go through a trace (saved or imported from the verifier)to see how certain states are reachable. Figure11shows the simulator.It is divided into four parts:The control part is used to choose andfire enabled transitions,go through a trace,and toggle the random simulation.The variable view shows the values of the integer variables and the clock con-straints.Uppaal does not show concrete states with actual values for the clocks.Since there are infinitely many of such states,Uppaal instead shows sets of concrete states known as symbolic states.All concrete states in a sym-bolic state share the same location vector and the same values for discretevariables.The possible values of the clocks is described by a set of con-Fig.10.The different local and global declarations of the train gate example.We superpose several screen-shots of the tool to show the declarations in a compact manner.straints.The clock validation in the symbolic state are exactly those that satisfy all constraints.The system view shows all instantiated automata and active locations of the current state.The message sequence chart shows the synchronisations between the differ-ent processes as well as the active locations at every step.The Verifier The verifier“tab”is shown in Fig.12.Properties are selectable in the Overview list.The user may model-check one or several properties,8insert or remove properties,and toggle the view to see the properties or the comments in the list.When a property is selected,it is possible to edit its definition(e.g., E<>Train1.Cross and Train2.Stop...)or comments to document what the property means informally.The Status panel at the bottom shows the commu-nication with the server.When trace generation is enabled and the model-checkerfinds a trace,the user is asked if she wants to import it into the simulator.Satisfied properties are marked green and violated ones red.In case either an over approximation or an under approximation has been selected in the options menu,then it may happen that the verification is inconclusive with the approximation used.In that casethe properties are marked yellow.Fig.11.View of the simulator tab for the train gate example.The interpretation of the constraint system in the variable panel depends on whether a transition in the transition panel is selected or not.If no transition is selected,then the constrain system shows all possible clock valuations that can be reached along the path.If a transition is selected,then only those clock valuations from which the transition can be taken are shown.Keyboard bindings for navigating the simulator without the mouse can be found in the integrated help system.3.2The Stand-alone VerifierWhen running large verification tasks,it is often cumbersome to execute these from inside the GUI.For such situations,the stand-alone command line verifier called verifyta is more appropriate.It also makes it easy to run the verification on a remote UNIX machine with memory to spare.It accepts command line arguments for all options available in the GUI,see Table3in the appendix.4Example1:The Train Gate4.1DescriptionThe train gate example is distributed with Uppaal.It is a railway control system which controls access to a bridge for several trains.The bridge is a critical shared resource that may be accessed only by one train at a time.The system is defined as a number of trains(assume4for this example)and a controller.A train can not be stopped instantly and restarting also takes time.Therefor,there are timing constraints on the trains before entering the bridge.When approaching,15。
华为 AC6005 无线访问控制器数据手册说明书

HuaweiWireless Access Controller Datasheetand network status instantly.Monitoring interfaceConfiguration interfaceOne-click diagnosis solves 80% of common network problems.The web system supports real-time and periodic one-click intelligent diagnosis from the dimensions of users, APs, and ACs, and provides feasible suggestions for troubleshooting the faults.Figure 1-4 Intelligent diagnosisBuilt-in application identification serverˉSupports Layer 4 to Layer 7 application identification and can identify over 1600 applications, including common office applications and P2P download applications, such as Lync, FaceTime, YouTube, and Facebook.ˉSupports application-based policy control technologies, including traffic blocking, traffic limit, and priority adjustment policies.ˉSupports automatic application expansion in the application signature database.Comprehensive reliability designˉSupports the Boolean port for environmental monitoring and the intra-board temperature probe, which monitors the operating environment of the AC6005 in real time.ˉSupports AC 1+1 HSB, and N+1 backup, ensuring uninterrupted services.ˉSupports port backup based on the Link Aggregation Control Protocol (LACP) or Multiple Spanning Tree Protocol (MSTP).Large-capacity and high-performance designˉThe AC6005 can manage up to 256 APs, meeting requirements o f small and medium campuses.ˉAn AC6005 has eight GE interfaces, and provides a 20 Gbit/s switching capacity and a 4 Gbit/s forwarding capability (the highest among all similar products of the industry).ˉThe AC6005 can manage up to 2048 users, allowing 100 users on an AP to transmit data simultaneously.Various rolesˉThe AC6005 provides PoE power on eight interfaces or PoE+ power on four interfaces and can supply power to directly connected APs, requiring no additional PoE switch for AP power supplies.ˉThe AC6005 has a built-in Portal/AAA server and can provide Portal/802.1x authentication for 1K users.Flexible networkingˉThe AC can be deployed in inline, bypass, bridge, and Mesh network modes, and supports both centralized and local forwarding.ˉThe AC and APs can be connected across a Layer 2 or Layer 3 network. In addition, NAT can be deployed when APs are deployed on the private network and the AC is deployed on the public network.ˉThe AC is compatible with Huawei full-series 802.11n and 802.11ac APs and supports hybrid networking of 802.11n and 802.11ac APs for simple scalability.Multiple interface supportˉSix GE and tow GE combo interfacesˉOne RJ45 serial maintenance interfaceˉOne Mini USB serial maintenance interfaceFeature Description Scalability Licenses are available for managing 1, 8, or 32 APs.Flexible networking The AC and APs can be connected across a Layer 2 or Layer 3 network. NAT can be deployed in configurations where APs are deployed on an internal network and the AC is deployed on an external network.Services can be mapped between VLANs and Service Set Identifiers (SSIDs). The number of service VLANs and number of SSIDs can be in a ratio of 1:1 or 1:N based on service requirements. You can assign user VLANs based on SSIDs, physical locations, or services.The AC can be deployed in inline, bypass, and WDS/Mesh networks.Flexible forwarding The AC6005 allows you to easily configure local or centralized forwarding based on Virtual Access Points (VAPs) according to network traffic and service control requirements.• Centralized forwarding meets the requirements of most network configurations; however, when bandwidth demands from users connected to the same AP steadily increase, traffic switching loads will increase.• Local forwarding improves bandwidth efficiency; however, user authentication cannot be controlled by the AC in local forwarding mode.The AC6005 solves this problem with support for centralized authentication in local forwarding to accommodate changing needs.Radio management The AC6005 supports automatic selection and calibration of radio parameters in AP regions, including these features:• Automatic signal level adjustment and channel selection on power-up• Automatic signal re-calibration in the event of signal interferenceˉPartial calibration: Adjusts a specific AP to optimal signal levels.ˉGlobal calibration: Adjusts all APs in a specified region for optimal signal levels.• When an AP is removed or goes offline, the AC6005 increases the power of neighboring APs to compensate for reduced signal strength.Flexible user rights management The AC6005 uses Access Control Lists (ACLs) based on APs, VAPs, or SSIDs and provides isolation and bandwidth-limiting for each option. The AC6005 also provides access controls for users, and user roles, to meet enterprise requirements regarding permissions, authentication, and authorization, as well as bandwidth limitations per user and user group.• The AC6005 implements per-user access control based on ACLs, VLAN IDs, and bandwidth limits sent from the RADIUS server.• User groups are defined with access control policies. An ACL, user isolation policy, and bandwidth limitations can be applied to user groups for additional access control.• Inter-group user isolation or intra-group user isolation can also be configured.AC6005 featuresFeature DescriptionWDS The AC6005 provides STA access and wireless bridge management functions, as well as network bridge management when in Fit AP mode.The AC6005 supports these networking modes: point-to-multipoint bridging, single-band/dual-band multi-hop relay, dual-band WDS bridging + WLAN access, and single-band WDS bridging + WLAN access.The AC6005 can also function as a wireless bridge between a central campus network and multiple branch campuses. This configuration works well for deployments with no wired network or where cable routing is inconvenient.High reliability Multiple ACs can be configured in a network to increase WLAN reliability. If an active AC experiences a fault or the link between the active AC and APs disconnects, the APs can switch to a standby AC.The AC6005 system provides N+1 active/standby mode, which allows multiple active ACs to share the same standby AC. This feature provides high reliability at reduced cost.Load balancing • Inter-AP load balancing: When an STA is in the coverage area of multiple APs, the AC6005 connects the STA to the AP with the lightest load, delivering STA-based or traffic-based load balancing.• Inter-STA resource balancing: The AC6005 can dynamically and evenly allocate bandwidth resources to prevent some STAs from overusing available bandwidth due to network adapter performance or special applications, such as BT Total Broadband.• The AC6005 first utilizes the 5 GHz band to increase overall utilization of bandwidth.Visualized WLAN network management and maintenance The AC6005 and APs use Fit AP + AC networking and standard Link Layer Discovery Protocol (LLDP) for centralized AP management and maintenance. When paired with Huawei’s eSight network management tool, the AC6005 provides network topology displays to easily manage and optimize network performance.System security • Application identification: Use the service awareness technology to identify packets of dynamic protocols such as HTTP and RTP by checking Layer 4 to Layer 7 information in the packets, helping implement fine-grained QoS management.• URL filtering: URL filtering regulates online behavior by controlling which URLs users can access.• Antivirus: The antivirus function depends on the powerful and constantly updated virus signature database to secure the network and system data.• Intrusion prevention:Intrusion prevention detects intrusions, such as buffer overflow attacks, Trojan horses, and worms, by analyzing network traffic and takes actions to quickly terminate the intrusions. In this way, intrusion prevention protects the information system and network architecture of enterprises.Item SpecificationsTechnical specifications • Dimensions (H x W x D):43.6 mm x 320 mm x 233.6 mm• Weight: 2.9 kg• Operating temperature: –5o C to 50o C• Storage temperature: –40o C to +70o C• Humidity: 5% to 95%• Input voltage: 100 V AC to 240 V AC; 50/60 Hz• Maximum voltage range: 90 V AC to 264 V AC, 47 Hz to 63 Hz• Maximum power consumption: 163.6 W (device power consumption: 39.6 W, PoE: 124 W)Interface type • 8 x GE interfaces, among which the last two are multiplexed with two optical interfaces as combo interfaces• One RJ45 serial maintenance interface• One Mini USB serial maintenance interfaceLED indicator • Power module indicator (PWR): indicates the power-on status of the device.• System running status indicator (SYS): indicates the running status of the device.• Service network port indicator: indicates the data transmission status, interface rate, and PoE status of a network port.Number of managed APs256Number of SSIDs16KNumber of APs controlled byeach license1, 8, 32 Number of access users Entire device: 2KUser group management The AC supports 128 user groups:• Each user group can reference a maximum of 8 ACLs.• Each user group can associate with a maximum of 128 ACL rules.Number of MAC addresses4KNumber of VLANs4KNumber of ARP entries4KNumber of routing entries8KNumber of multicast forwardingentries2KNumber of DHCP IP address pools64 IP address pools, each containing a maximum of 8K IP addressesAC6005 specificationsFeature DescriptionNetwork management and maintenance Device management and statistics• Command line management based on SSH/Telnet/Console• SNMPv2/v3• Web management• Standard MIBs and Huawei proprietary MIBs• Syslog• AP and station statistics• Alarms with different severity levelsCentralized AP configuration and management• Group-based AP management• Centralized version management and automatic version file load • Built-in AP type and customized AP additionGraphic AP deployment and topology displays• AP LLDP• AC LLDPWireless protocols IEEE 802.11a, 802.11b, 802.11g, 802.11d, WMM/802.11e, 802.11h, 802.11k, 802.11n, 802.11acWLAN deployment AP-AC networking• AP-AC Layer 2/3 networking• AC Layer 2 forwarding or Layer 3 routing• NAT traversal (APs are deployed on a private network and ACs are deployed on the public network) Data forwarding• AP-AC CAPWAP tunnel and DTLS encryption• VAP-based forwarding (centralized forwarding and local forwarding)• Centralized authentication and local forwardingVLAN deployment• Mapping between SSIDs and VLANs, and VLAN assignment based on SSIDs or physical locations WDS deployment• Point-to-point and point-to-multipoint• Automatic topology detection and loop prevention (STP)AC active/standby mode• Dual-linked active and standby ACs with Virtual Router Redundancy Protocol (VRRP)• N:1 active/standby deploymentWireless featuresFeature DescriptionRadio management Channel and power configuration• Centralized or static channel power configuration• Automatic channel allocation to implement global radio calibration or partial radio calibration • Automatic power adjustment to implement coverage hole compensation• AP region-based configuration and managementLoad balancing• Load balancing based on the traffic volume on each radio• Load balancing based on the number of usersWireless service control Extended Service Set (ESS)-based service management• ESS-based SSID hiding and AP isolation at Layer 2• Maximum number of access users and associated aging time settings in an ESS• ESSs to service VLANs mapping• ESS associations with a security profile or a QoS profile• Internet Group Management Protocol (IGMP) support for APs in an ESSWireless roaming• Layer 2 roaming• Inter-VLAN Layer 3 roaming• Pairwise Master Key (PMK) caching, rapid key negotiation• Identity check on users who request to reassociate with the AC to reject reassociation requests of unauthorized users• Delayed clearing of user information after a user goes offline so that the user can rapidly go online again DHCP service control• Built-in DHCP server• Support for DHCP snooping on APs• Support for DHCP relay and DHCP snooping on ACMulticast service management• IGMP snooping• IGMP proxyWireless user management WLAN user management• User blacklist and whitelist• User access number limit• User disconnection• Support for multiple queries including online user information and statistics User group management• ACLs based on user groups• Isolation based on user groupsFeature DescriptionEthernet features • 802.1p, QinQ, Smart Link, LLDP• Storm suppression, port isolation, and link aggregationEthernet loop protection • Spanning Tree Protocol (STP)/Rapid Spanning Tree Protocol (RSTP)/Multiple Spanning Tree Protocol (MSTP)• Bridge Protocol Data Unit (BPDU) protection, root protection, and loop protection• Partitioned STP and BPDU tunnels• Rapid Ring Protection Protocol (RRPP)• Hybrid networking of RRPP rings and other ring networksWired featuresFeature DescriptionWireless security and authentication Authentication and encryption• OPEN/WEP/PSK/WPA(2) + 802.1x• WEP/TKIP/AES(CCMP)• WAPIUser authentication and control• MAC address authentication, Portal authentication, and 802.1x authentication • MAC + Portal authentication• PEAP/TLS/MD5/CHAPSecurity and defense• ACLs based on interface, users, and user groups• Isolation based on VAPs and user groups• IP source guard for STAs• Detection of unauthorized APs and alarm function• User blacklist and whitelistAAA• Local authentication/local accounts (MAC addresses and accounts)• RADIUS authentication• Multiple authentication serversWireless QoS control Flow control• VAP-based rate limiting• User-group-based rate limiting• Rate limiting for a specified user• Dynamic traffic control, preventing resources from being wasted by STAsPriority mapping and scheduling• Mapping QoS settings of encapsulated data packets to 802.1p and DSCP fields of outer tunnel packets • Mapping between DSCP, 802.1p, and 802.11e10Huawei AC6005Wireless Access Controller Datasheet ComponentPart Number Name Description AC+license02356813AC6005-8-PWR-8AP AC6005-8-PWR-8AP Bundle(Including AC6005-8-PWR,Resource License 8 AP)AC+license 02356816AC6005-8-8AP AC6005-8 -8AP Bundle(Including AC6005-8,Resource License 8 AP)License 88031VEB L-AC6005-1AP Software Charge,AC6005,L-AC6005-1AP ,AC6005 Access ControllerAP Resource License(1 AP)88031VEAL-AC6005-8APSoftware Charge,AC6005,L-AC6005-8AP ,AC6005 Access ControllerAP Resource License(8 AP)Power moduleSee the ordering guide.Power cableOptical moduleOptical jumperNetwork cableGround bar AC6005 purchase and accessory informationFeatureDescription IP routingUnicast routing protocols: RIP , OSPF, BGP , and IS-IS Device reliabilityVirtual Router Redundancy Protocol (VRRP)QoS features Traffic classifier, traffic behavior, queue scheduling, congestion avoidance, and outbound interfacerate limitingLink detection BFDEFM OAM, CFM OAM, and Y .1731IP service controlARPBuilt-in DHCP serverRADIUS clientBuilt-in FTP serverDHCP relay and DHCP snoopingProfessional Service and SupportHuawei Professional Services provides expert network design and service optimization tasks to help customers:ˉDesign and deploy a high-performance network that is reliable and secure.ˉMaximize return on investment and reduce operating expenses.Company AddendumFor more information, please visit /en/ or contact your local Huawei office.Copyright © Huawei Technologies Co., Ltd. 2016. All rights reserved.No part of this document may be reproduced or transmitted in any form or by any means without prior written consent of Huawei Technologies Co., Ltd.Trademark Notice, HUAWEI, and are trademarks or registered trademarks of Huawei Technologies Co., Ltd.Other trademarks, product, service and company names mentioned are the property of their respective owners.General DisclaimerThe information in this document may contain predictive statements including,without limitation, statements regarding the future financial and operating results,future product portfolio, new technology, etc. There are a number of factors thatcould cause actual results and developments to differ materially from thoseexpressed or implied in the predictive statements. Therefore, such information isprovided for reference purpose only and constitutes neither an offer nor anacceptance. Huawei may change the information at any time without notice.。
博科BrocadeSAN交换机常用命令

博科Brocade SAN交换机常用命令1.查看IP地址命令 (2)2.查看firmware版本 (2)3.查看交换机状态 (2)4.查看交换机license-id (3)5.配置ZONE (3)6.查看zone配置文件 (4)7.查看ZONE (5)8.查看系统日志信息 (6)9.关机 (6)10.设置博科Brocade交换机IP地址 (6)11.博科brocade交换机查看OS版本信息 (6)12.博科brocade交换机添加license授权信息 (7)13.查看博科brocade交换机license授权信息 (7)14.博科Brocade Slikworm 300交换机license (7)15.博科Brocade交换机修改密码命令 (7)16.博科 brocade SAN交换机密码重置 (8)17.登陆后是用passwddefault命令恢复出厂密码 (9)18.交换机升级 (9)19.帮助信息 (13)1.查看IP地址命令swd77:admin> ipaddrshowSWITCHEthernet IP Address: 10.77.77.77Ethernet Subnetmask: 255.255.255.0Fibre Channel IP Address: noneFibre Channel Subnetmask: noneGateway IP Address: noneDHCP: Offswd77:admin>2.查看firmware版本swd211:admin>swd211:admin> firmwareshowAppl Primary/Secondary Versions------------------------------------------FOS v6.2.1v6.2.13.查看交换机状态swd211:admin> switchoshowrbash: switchoshow: command not foundswd211:admin> switchshowswitchName: swd211switchType: 34.0switchState: OnlineswitchMode: NativeswitchRole: PrincipalswitchDomain: 1switchId: fffc01switchWwn: 10:00:00:05:1e:02:a2:10zoning: ON (FC01)switchBeacon: OFFArea Port Media Speed State Proto=====================================0 0 id N2 Online F-Port 50:08:05:f3:00:1b:4e:911 1 id N4 Online F-Port 10:00:00:00:c9:53:b2:8d2 2 id N4 Online F-Port 10:00:00:00:c9:53:b3:c13 3 id N4 Online F-Port 10:00:00:00:c9:53:b3:c24 4 id N4 Online F-Port 50:06:0b:00:00:66:00:c45 5 id N4 Online F-Port 50:06:0b:00:00:66:01:1e6 6 id N2 Online F-Port 50:05:08:b3:00:93:b2:817 7 -- N4 No_Module8 8 id N4 Online F-Port 50:01:43:80:04:c7:87:d89 9 id N4 Online F-Port 50:01:43:80:04:c7:87:dc10 10 id N4 Online F-Port 50:01:43:80:06:31:cf:7c11 11 -- N4 No_Module12 12 -- N4 No_Module13 13 -- N4 No_Module14 14 -- N4 No_Module15 15 -- N4 No_Moduleswd211:admin>4.查看交换机license-idswd211:admin>swd211:admin> licenseidshow10:00:00:05:1e:02:a2:10swd211:admin>5.配置ZONE案例:1) Create Aliases>alicreate “Eng_Host”,“1,0”>alicreate “Eng_Stor”,“1,4; 1,5”>alicreate “Mkt_Host”,“Mktwwn”>alicreate “Mkt_Stor”,“s3wwn; s4wwn; s5wwn”2) Create Zones>zonecreate “Zone_Eng”,“Eng_Host; Eng_Stor”>zonecreate “Zone_Mkt”,“Mkt_Host; Mkt_Stor”3) Create Configuration>cfgcreate “Cfg_EngMkt”,“Zone_Eng; Zone_Mkt”sw4100:admin> cfgshowDefined configuration:cfg: Cfg_EngMktZone_Eng; Zone_Mktzone: Zone_Eng Eng_Host; Eng_Storzone: Zone_Mkt Mkt_Host; Mkt_Storalias: Eng_Stor 1,4; 1,5alias: Eng_Host 1,0alias: Mkt_Stor 21:00:00:20:37:87:49:29; 21:00:00:20:37:87:e5:20; 21:00:00:20:37:87:20:c5alias: Mkt_Host 21:00:00:20:37:87:23:e2Effective configuration:no configuration in effect4) Enable Configuration>cfgenable “Cfg_EngMkt”sw4100:admin> cfgshowDefined configuration:cfg: Cfg_EngMktone_Eng; Zone_Mktzone: Zone_Eng Eng_Host; Eng_Storzone: Zone_Mkt Mkt_Host; Mkt_Storalias: Eng_Stor 1,4; 1,5alias: Eng_Host 1,0alias: Mkt_Stor 21:00:00:20:37:87:49:29; 21:00:00:20:37:87:e5:20; 21:00:00:20:37:87:20:c5alias: Mkt_Host 21:00:00:20:37:87:23:e2Effective configuration:cfg: Cfg_EngMktzone: Zone_Eng 1,0; 1,4; 1,5zone: Zone_Mkt 21:00:00:20:37:87:23:e2; 21:00:00:20:37:87:e5:20; 21:00:00:20:37:87:49:29; 21:00:00:20:37:87:20:c56.查看zone配置文件swd211:admin>swd211:admin> cfgshowDefined configuration:cfg: FC01 OADB_ML6030; SPC_MSA1000; SFDB_EVA4400; SFDB04_MSA1500; SFEVA4400_SMAzone: OADB_ML60301,7; 1,14; 1,15zone: SFDB04_MSA15001,10; 1,6zone: SFDB_EVA44001,3; 1,4; 1,5; 1,7; 1,8; 1,9zone: SFEVA4400_SMA1,8; 1,9; 1,11zone: SPC_MSA10001,0; 1,1; 1,2; 1,7Effective configuration:cfg: FC01zone: OADB_ML60301,71,141,15zone: SFDB04_MSA15001,101,6zone: SFDB_EVA44001,31,41,51,71,81,9zone: SFEVA4400_SMA1,81,91,11zone: SPC_MSA10001,01,11,21,7swd211:admin>swd211:admin>7.查看ZONEswd211:admin> zoneshowDefined configuration:cfg: FC01 OADB_ML6030; SPC_MSA1000; SFDB_EVA4400; SFDB04_MSA1500; SFEVA4400_SMAzone: OADB_ML60301,7; 1,14; 1,15zone: SFDB04_MSA15001,10; 1,6zone: SFDB_EVA44001,3; 1,4; 1,5; 1,7; 1,8; 1,9zone: SFEVA4400_SMA1,8; 1,9; 1,11zone: SPC_MSA10001,0; 1,1; 1,2; 1,7Effective configuration:cfg: FC01zone: OADB_ML60301,71,141,15zone: SFDB04_MSA15001,101,6zone: SFDB_EVA44001,31,41,51,71,81,9zone: SFEVA4400_SMA1,81,91,11zone: SPC_MSA10001,01,11,21,7swd211:admin>8.查看系统日志信息swd211:admin> supportshow日志比较多,建议log出来查看.9.关机swd211:admin> sysshutdown10.设置博科Brocade交换机IP地址博科交换机的默认IP地址是10.77.77.77,在命令行模式下可以通过ipaddrset命令对交换机的IP地址进行设置和修改swd77:admin> ipaddrsetEthernet IP Address [10.77.77.77]: #输入交换机需要设置的IP地址Ethernet Subnetmask [255.255.255.0]: #输入掩码Fibre Channel IP Address [none]:Fibre Channel Subnetmask [none]:Gateway IP Address [none]: # 输入网关DHCP [Off]: #是否开启DHCPswd77:admin>11.博科brocade交换机查看OS版本信息swd77:admin> versionKernel: 2.6.14.2 //linux内核版本Fabric OS: v6.1.0a // 交换机OS版本Made on: Thu Apr 17 21:45:31 2008 // 生产日期Flash: Tue Jan 13 23:33:44 2009BootProm: 4.6.6swd77:admin>12.博科brocade交换机添加license授权信息swd77:admin> licenseadd XXXXXXXX(博科的激活号)13.查看博科brocade交换机license授权信息在命令行模式下使用licenseshow命令可以查看博科交换机的授权情况,使用licenseadd 命令可以添加授权。
ANSYS官方帮助文件05-udf

ANSYS官⽅帮助⽂件05-udfTutorial:Modeling Uniform Fluidization in2D Fluidized BedIntroductionThe prediction of pressure drop in an uniformly?uidized bed is a problem of long standing interest in the process industry.The Eulerian models in ANSYS FLUENT provide an impor-tant modeling tool for studying dense phase particulate?ow involving complex inter-phase momentum transfer.Despite rigorous mathematical modeling of the associated physics,the drag laws used in the model continue to be semi-empirical in nature.Therefore,it is crucial to use a drag law that correctly predicts the incipient or minimum?uidization conditions where the bed of particles is essentially in a state of suspension as a result of the balance between interfacial drag and body forces.The purpose of this tutorial is to study the hydrodynamics and bubble formation in a ?uidized bed over a period of time.It also demonstrates how to customize a drag law for granular gas-solid?ow.This tutorial demonstrates how to do the following:Customize a drag law for granular gas-solidow.Use the Eulerian models to predict the pressure drop in an uniformlyuidized bed.Solve the case using appropriate solver settings.Postprocess the resulting data.PrerequisitesThis tutorial is written with the assumption that you have completed Tutorial1from the ANSYS FLUENT12.0Tutorial Guide,and that you are familiar with the ANSYS FLUENT navigation pane and menu structure.Some steps in the setup and solution procedure will not be shown explicitly.This tutorial will not cover the mechanics of using the Eulerian models.It will focus on the application of these models.For more information refer to Section24.5Setting Up the Eulerian Model in the ANSYS FLUENT User’s Guide.For information about user-de?ned fucntions(UDF)refer to the ANSYS FLUENT UDF Manual.Modeling Uniform Fluidization in2D Fluidized BedProblem DescriptionThe default drag law in ANSYS FLUENT is the Syamlal-O’Brien drag law.This law works for a large variety of problems,but has to be tuned properly for predicting the minimum ?uidization conditions accurately.The default Syamlal-O’brien is as follows:The?uid-solid exchange coe?cient isK sl=3αsαlρl4v2r,s d sC DRe sv r,s| v s? v l|where v2r,s is the terminal velocity coe?cient for the solid phase.v r,s=0.5 A?0.06Re s+ (0.06Re s)2+0.12Re s(2B?A)+A2with A=α4.14l and B=0.8α1.28lforαl≤0.85and with B=α2.65lforαl>0.85The default constants of0.8and2.65predict a minimum?uidization of21cm/s.The experimentally observed minimum? uidization for this particular case is8cm/s.Therefore, by changing the constants we can tune the drag law to predict minimum? uidization at 8cm/s.After some mathematical manipulation,these constants come out to be0.281632and9.07696respectively.Therefore,these values have to be used to predict the correct bed behavior and are passed to the code through user-de?ned functions.The problem considered is a1m x0.15m?uidized bed as shown in Figure1.The inlet air enters in at0.25m/s and the top is modeled as a pressure outlet.The bed is packed with granular solids at0.55volume fraction(close topacking).Figure1:Problem Speci?cationModeling Uniform Fluidization in2D Fluidized Bed Preparation1.Copy the?les,bp.msh.gz and bp drag.c to the working folder./doc/7ae06ac9a1c7aa00b52acba0.html e FLUENT Launcher to start the2D version of ANSYS FLUENT.For more information about FLUENT Launcher see Section1.1.2Starting ANSYS FLU-ENT Using FLUENT Launcher in the ANSYS FLUENT12.0User’s Guide.3.Enable Double-Precision in the Options list.4.Click the UDF Compiler tab and make sure that Setup Compilation Environment forUDF is enabled.The path to the.bat?le which is required to compile the UDF will be displayed as soon as you enable Setup Compilation Environment for UDF.If the UDF Compiler tab does not appear in the FLUENT Launcher dialog box by default, click the Show Additional Options>>button to view the additional settings.Note:The Display Options are enabled by default.Therefore,after you read in the mesh,it will be displayed in the embedded graphics window.Setup and SolutionNote:All entries in setting up this case are in SI units,unless otherwise speci?ed.Step1:Mesh1.Read the mesh?le bp.msh.gz.File?→Read?→Mesh...Figure2:Graphics Display of the MeshModeling Uniform Fluidization in2D Fluidized BedStep2:General1.Check the mesh.General?→CheckANSYS FLUENT will perform various checks on the mesh and will report the progress in the console.Ensure that the minimum volume reported is a positive number.2.Enable the transient solver by selecting Transient from the Time list.General?→TransientStep3:Models1.Select the Eulerian multiphase model.Models?→Multiphase?→Edit...(a)Select Eulerian from the Model selection list.(b)Retain the default settings and close the Multiphase Model dialog box.Step4:Materials1.Modify the properties for air.Materials?→air?→Create/Edit...(a)Enter1.2kg/m3for Density.(b)Enter1.8e-05kg/m-s for Viscosity.(c)Click Change/Create.2.De?ne a material called solids.Modeling Uniform Fluidization in2D Fluidized Bed(a)Enter solids for Name.(b)Enter2600kg/m3for Density and1.7894e-05kg/m-s for Viscosity.(c)Click Change/Create.A Question dialog box will appear asking if you want to overwrite air.Click No.3.Close the Create/Edit Materials dialog box.Step5:Compile the UDFThe UDF contains two arguments s col and f col.These refer to the indices of the phases appearing in the second and?rst columns of the table in the interaction dialog box respec-tively.Therefore in this case s col refers to the index of gas phase which is0and f col refers to the index for solids which is equal to1.De?ne?→User-De?ned?→Functions?→Compiled...1.Click the Add...button in the Source Files section to open the Select File dialog.2.Select the?le bp drag.c.3.Enter lib drag for Library Name.4.Click Build.A Warning dialog box will appear,warning you to make sure that the UDF source?lesare in the same folder that contains the case and data?les.Click OK to close the Warning dialog box.You can view the compilation history in the log?le that is saved in your working folder.5.Click Load to load the library.Modeling Uniform Fluidization in2D Fluidized BedStep6:Phases1.De?ne primary phase.Phases?→phase-1?→Edit...(a)Enter gas for Name.(b)Ensure air is selected from the Phase Material drop-down list.(c)Click OK to close the Primary Phase dialog box.2.De?ne secondary phase.Phases?→phase-2?→Edit...Modeling Uniform Fluidization in2D Fluidized Bed(a)Enter solid for Name.(b)Select solids from the Phase Material drop-down list.(c)Enable Granular.(d)Enter0.0003m for Diameter,and select syamlal-obrien from the Granular Viscositydrop-down list.(e)Retain the default values for the other parameters.(f)Click OK to close the Secondary Phase dialog box.Check the column numbers where the two phases appear in the Phase Interaction dialog box.In this case solid and gas appear in the?rst and second columns respectively.These columns are used to specify the phase indices in the argument list for the UDF.3.Set the drag coe?cient.(a)Select gas from the Phases selection list and click the Interaction...button toopen the Phase Interaction dialog box.i.Select user-de?ned from the drop-down list in the Drag Coe?cient group box.Modeling Uniform Fluidization in2D Fluidized BedA.Ensure that custom drag syam::lib drag is selected.B.Click OK to close the User-De?ned Functions dialog boxii.Click OK to close the Phase Interaction dialog box.(b)Similarly select the user de?ned function for solid(custom drag syam::lib drag).Step7:Boundary Conditions1.Set the boundary conditions for vinlet zone.Boundary Conditions?→vinlet(a)Select gas from the Phase drop-down list and click Edit....i.Select Components from the Velocity Speci?cation Method drop-down list.ii.Enter0.25m/s for Y-Velocity.iii.Click OK to close the Velocity Inlet dialog box.(b)Select solid from the Phase drop-down list and click the Edit...button to openthe Velocity Inlet dialog box.i.Click the Multiphase tab.ii.Ensure that Volume Fraction is0.iii.Click OK to close the Velocity Inlet dialog box.Modeling Uniform Fluidization in2D Fluidized Bed Step8:Operating ConditionsBoundary Conditions?→Operating Conditions...1.Enable Gravity and enter-9.81m/s2for Gravitational Acceleration in the Y direction.2.Enable Speci?ed Operating Density,and enter1.2kg/m3for Operating Density.3.Click OK to close the Operating Conditions dialog box.Step9:Solution1.Mark a region for adaption.Adapt?→Region...Modeling Uniform Fluidization in2D Fluidized Bed(a)Enter0.15m for X Max and Y Max respectively in the Input Coordinates groupbox.(b)Click Mark to mark the cells for re?nement.Note:Click Adapt to perform the re?nement immediately.(c)Close the Region Adaption dialog box.2.Set the solution control parameters.Solution Controls(a)Enter0.5for Pressure in the Under-Relaxation Factors group box.(b)Enter0.2for Momentum.(c)Enter0.4for Volume Fraction.3.Initialize the?ow with default values.Solution Initialization?→InitializeModeling Uniform Fluidization in2D Fluidized Bed 4.Patch the solids volume fraction for hexahedron-r0.Solution Initialization?→Patch...(a)Select solid from the Phase drop-down list.(b)Select Volume Fraction from the Variable selection list.(c)Enter0.55for Value.(d)Select hexahedron-r0from the Registers to Patch selection list.If you wish to patch a constant value,enter that value in the Value?eld.If you want to patch a previously-de?ned?eld function,enablethe Use Field Function option and select the appropriate function inthe Field Function list.(e)Click Patch and close the Patch dialog box.5.Enable autosaving of the data?les for every100time steps.Calculation Activities(a)Enter100for Autosave Every(Time Steps).6.Set up commands for animation.Calculation Activities(Execute Commands)?→Create/Edit...Modeling Uniform Fluidization in2D Fluidized Bed(a)Set2for De?ned Commands.(b)Enable Active for both commands.(c)Set10for Every for both commands.(d)Select Time Step from the When drop-down list for both.(e)Enter/display/contour/solid/vof for command-1.(f)Enter/display/hardcopy"vof-solids-%t.tiff"for command-2.(g)Click OK to close the Execute Commands dialog box.7.Set the graphics hardcopy format.File?→Save Picture...(a)Select TIFF from the Format list.(b)Select Color from the Coloring list.(c)Click Apply and close the Save Picture dialog box.8.Set up the contours display.Graphics and Animations?→Contours?→Set Up...(a)Enable Filled from the Options group box.(b)Select solid from the Phase drop-down list.(c)Select Phases...and Volume Fraction from the Contours of drop-down lists.(d)Click Display and close the Contours dialog box.9.Save the case?le(bp.cas.gz).File?→Write?→Case...10.Start the calculation.Run Calculation.(a)Enter0.001sec for Time Step Size.(b)Enter1400for Number of Time Steps.(c)Enable Extrapolate Variables.(d)Click Calculate.11.Save the data?le(bp.dat.gz).File?→Write?→Data...Modeling Uniform Fluidization in2D Fluidized BedStep10:Postprocessing1.Display contours of volume fraction.(a)Read the data?le for the200th time step(bp-1-00200.dat).File?→Read?→Data...(b)Display?lled contours of volume fraction for solid,at0.2sec(Figure3).Graphics and Animations?→Contours?→Set Up...Figure3:Contours of Volume Fraction of solid(t=0.2s)(c)Similarly display contours at0.9sec(Figure4),and1.4sec(Figure5).Figure4:Contours of Volume Fraction of solid(t=0.9s)Modeling Uniform Fluidization in2D Fluidized BedFigure5:Contours of Volume Fraction of solid(t=1.4s)2.View the animation for the?uidization process using the.tiff?les.ResultsTypically,the constants set to0.8and2.65in the default drag law have to be modi?ed to balance the interfacial drag with the weight of the bed at minimum?uidization.If this is not done,the correct bubbling pattern will not be predicted,leading toincorrect predictions of pressure drop which is the most important objective of such simulations.。
FLACSlope 用户手册英文版

1FLAC/Slope1.1Introduction1.1.1OverviewFLAC/Slope is a mini-version of FLAC that is designed specifically to perform factor-of-safety calculations for slope-stability analysis.This version is operated entirely from FLAC’s graphical interface(the GIIC)which provides for rapid creation of models for soil and/or rock slopes and solution of their stability condition.FLAC/Slope provides an alternative to traditional“limit equilibrium”programs to determine factor of safety.Limit equilibrium codes use an approximate scheme—typically based on the method of slices—in which a number of assumptions are made(e.g.,the location and angle of interslice forces).Several assumed failure surfaces are tested,and the one giving the lowest factor of safety is chosen.Equilibrium is only satisfied on an idealized set of surfaces.In contrast,FLAC/Slope provides a full solution of the coupled stress/displacement,equilibrium and constitutive equations.Given a set of properties,the system is determined to be stable or unstable. By automatically performing a series of simulations while changing the strength properties(“shear strength reduction technique”—see Section1.5),the factor of safety can be found corresponding to the point of stability,and the critical failure(slip)surface can be located.FLAC/Slope does take longer to determine a factor of safety than a limit equilibrium program. However,with the advancement of computer processing speeds(e.g.,1GHz and faster chips), solutions can now be obtained in a reasonable time.This makes FLAC/Slope a practical alternative to a limit equilibrium program,and provides advantages over a limit equilibrium solution(e.g.,see Dawson and Roth,1999,and Cala and Flisiak,2001):1.Any failure mode develops naturally;there is no need to specify a range oftrial surfaces in advance.2.No artificial parameters(e.g.,functions for inter-slice force angles)need to begiven as input.3.Multiple failure surfaces(or complex internal yielding)evolve naturally,if theconditions give rise to them.4.Structural interaction(e.g.,rock bolt,soil nail or geogrid)is modeled realisti-cally as fully coupled deforming elements,not simply as equivalent forces.5.The solution consists of mechanisms that are feasible kinematically.(Notethat the limit equilibrium method only considers forces,not kinematics.)1.1.2Guide to the FLAC/Slope ManualThis volume is a user’s guide to FLAC/Slope.The following sections in the introduction,Sec-tions1.1.3through1.1.5,discuss the various features available in FLAC/Slope,outline the analysis procedure,and provide information on how to receive user support if you have any questions about the operation of FLAC/Slope.Also,in Section1.1.6,we describe the concept of mini-versions of FLAC and our plans for future mini-versions.Section1.2describes the step-by-step procedure to install and start up FLAC/Slope,and provides a tutorial(in Section1.2.2)to help you become familiar with its operation.We recommend that you run this tutorialfirst to obtain an overall understanding of the operation of FLAC/Slope.The components of FLAC/Slope are described separately in Section1.3.This section should be consulted for detailed descriptions on the procedures of operating FLAC/Slope.Several slope stability examples are provided in Section1.4.These include comparisons to limit analysis and limit-equilibrium solutions.FLAC/Slope uses the procedure known as the“strength reduction technique”to calculate a factor of safety.The basis of this procedure and its implementation in FLAC/Slope are described in Section1.5.1.1.3Summary of FeaturesFLAC/Slope can be applied to a wide variety of conditions to evaluate the stability of slopes and embankments.Each condition is defined in a separate graphical tool.1.The creation of the slope boundary geometry allows for rapid generation of linear,nonlin-ear and benched slopes and embankments.The Bound tool provides separate generationmodes for both simple slope shapes and more complicated non-linear slope surfaces.Abitmap or DXF image can also be imported as a background image to assist boundarycreation.2.Multiple layers of materials can be defined in the model at arbitrary orientations andnon-uniform yers are defined simply by clicking and dragging the mouseto locate layer boundaries in the Layers tool.3.Materials and properties can be specified manually or from a database in the Materialtool.At present,all materials obey the Mohr-Coulomb yield model,and heterogeneousproperties can be assigned.Material properties are entered via material dialog boxes thatcan be edited and cloned to create multiple materials rapidly.4.With the Interface tool,a planar or non-planar interface,representing a joint,fault orweak plane,can be positioned at an arbitrary location and orientation in the model.Theinterface strength properties are entered in a properties dialog;the properties can bespecified to vary during the factor-of-safety calculation,or remain constant.5.An Apply tool is used to apply surface loading to the model in the form of either an arealpressure(surface load)or a point load.6.A water table can be located at an arbitrary location by using the Water tool;the water tabledefines the phreatic surface and pore pressure distribution for incorporation of effectivestresses and the assignment of wet and dry densities in the factor-of-safety calculation.7.Structural reinforcement,such as soil nails,rock bolts or geotextiles,can be installedat any location within the model using the Reinforce tool.Structural properties can beassigned individually for different elements,or groups of elements,through a propertiesdialog.Please be aware that FLAC/Slope is limited to slope configurations with sub-horizontal layering and no more than one interface.For analyses which involve multiple(and intersecting)interfaces and sub-vertical layering or weak planes,full FLAC should be used.1.1.4Analysis ProcedureFLAC/Slope is specifically designed to perform multiple analyses and parametric studies for slope-stability projects.The structure of the program allows different models in a project to be easily created,stored and accessed for direct comparison of model results.A FLAC/Slope analysis project is divided into four stages.The modeling-stage tool bars for each stage are shown and described below.Models StageEach model in a project is named and listed in a tabbed bar in the Models stage.Thisallows easy access to any model and results in a project.New models can be added tothe tabbed bar or deleted from it at any time in the project study.Models can also berestored(loaded)from previous projects and added to the current project.Note that theslope boundary is also defined for each model at this stage.Build StageFor a specific model,the slope conditions are defined in the Build stage.This includes:changes to the slope geometry,addition of layers,specification of materials and weakplane(interface),application of surface loading,positioning of a water table and instal-lation of reinforcement.The conditions can be added,deleted and modified at any timeduring this stage.Solve StageIn the Solve stage,the factor-of-safety is calculated.The resolution of the numerical meshis selectedfirst(coarse,medium,fine or user-specified),and then the factor-of-safetycalculation is performed.Different strength parameters can be selected for inclusion inthe strength reduction approach to calculate the safety factor.By default,the materialcohesion and friction angle are used.Plot StageAfter the solution is complete,several output selections are available in the Plot stagefor displaying the failure surface and recording the results.Model results are availablefor subsequent access and comparison to other models in the project.All models created within a project,along with their solutions can be saved,the projectfiles can be easily restored and results viewed at a later time.1.1.5User SupportWe believe that the support that Itasca provides to code users is a major reason for the popularity of our software.We encourage you to contact us when you have a modeling question.We pro-vide a timely response via telephone,electronic mail or fax.General assistance in installation of FLAC/Slope on your computer,plus answers to questions concerning capabilities of the various features of the code,are provided free of charge.Technical assistance for specific user-defined problems can be purchased on an as-needed basis.We can provide support in a more timely manner if you include an example FLAC/Slope model that illustrates your question.This can easily be done by including the project savefile(i.e.,the file with the extension“*.PSL”)as an email attachment with your question.See Section1.3.2for a description of the“*.PSL”file.If you have a question,or desire technical support,please contact us at:Itasca Consulting Group,Inc.Mill Place111Third Avenue South,Suite450Minneapolis,Minnesota55401USAPhone:(+1)612-371-4711Fax:(+1)612·371·4717Email:software@Web:We also have a worldwide network of code agents who provide local technical support.Details may be obtained from Itasca.1.1.6FLAC Mini-VersionsThe basis for FLAC/Slope is FLAC,Itasca’s numerical modeling code for advanced geotechnical analysis of soil,rock and structural support in two dimensions.FLAC/Slope actually runs FLAC,and the GIIC limits access to only specific features in FLAC used for the slope stability calculations. That is why we call FLAC/Slope a mini-version of FLAC.We plan to develop several different mini-versions of FLAC for a variety of different geo-engineering applications.When you install FLAC/Slope,the full version of FLAC is also installed.If you wish,you may start-up FLAC and evaluate its operation and features.See the installation and start-up instructions given below in Section1.2.1.The solve facility is turned off in this evaluation version.If you decide to upgrade to the full FLAC,it is only necessary to upgrade your hardware lock to operate FLAC as well as FLAC/Slope.Then,the full power of FLAC will also be available to you.1.2Getting Started1.2.1Installation and Start-Up ProceduresSystem Requirements—To install and operate FLAC/Slope be sure that your computer meets the following minimum requirements:1.At least35MB of hard disk space must be available to install FLAC/Slope.We recom-mend that a minimum of100MB disk space be available to save model projectfiles.2.For efficient operation of FLAC/Slope,your computer should have at least128MB RAM.3.The speed of calculation is directly related to the clock speed of your computer.We rec-ommend a computer with at least a1GHz CPU for practical applications of FLAC/Slope.4.FLAC/Slope is a32-bit software product.Any Intel-based computer capable of runningWindows95or later is suitable for operation of the code.By default,plots from FLAC/Slope are sent directly to the Windows native printer.Plots can also be directed to the Windows clipboard,orfiles encoded in PostScript,Enhanced Metafile format, and several bitmap formats(PCX,BMP or JPEG).Instructions on creating plots are provided in Section1.3.11.Installation Procedure—FLAC/Slope is installed in Windows from the Itasca CD-ROM using standard Windows procedures.Insert the Itasca CD in the appropriate drive.The installation procedure will begin automatically,if the“autorun”feature on the drive is enabled.If not,enter “[cd drive]:\start.exe”on the command line to begin the installation process.The installation program will guide you through the installation.Make your selections in the dialogs that follow. Please note that the installation program can install all of Itasca’s software products.You must click on the FLAC box in the Select Components dialog in order to install FLAC/Slope on your computer(note that selecting the FLAC box is the correct choice for both FLAC and FLAC/Slope installations).*By default,the electronic FLAC/Slope manual will be copied to your computer during the installation of FLAC/Slope.(After FLAC has been selected in the Select Components dialog,the option not to install the manual can be set by using the Change button.)To use the electronic manual,click on the FLAC Slope Manual icon in the“Itasca Codes”group on the“Start”menu.All electronic volumes of the FLAC manual(including the FLAC/Slope manual)are PDFfiles that require the Adobe Acrobat Reader(R)in order to be ers who do not have the Reader may install it from the Itasca CD.*The full version of FLAC will also be installed when FLAC/Slope is installed.You may start-up full FLAC and operate the code in GIIC mode to evaluate the features in the full version.Please note that the solve facility is turned off in the evaluation version.If you decide to upgrade to the full FLAC,it is only necessary to upgrade your hardware lock to operate FLAC as well as FLAC/Slope.The FLAC/Slope package can be uninstalled via the Add/Remove Programs icon in the Windows Control Panel.A default directory structure will be created when using the install program.The root directory is“\ITASCA”;the sub-directories and their contents are summarized in Table1.1and described below.Table1.1Contents of Itasca directories for FLAC/SlopeDirectory Sub-directory Section FilesFLACEXE executable codesFLAC SLOPE projectfiles for examples in manualGUI Graphical User Interface—JA V A classfilesJRE JA V A runtime environmentMANUALS FLAC FLAC electronic manualSYSTEM hardware key drivers,FLAC.CFGUTILITY READMEfiles,UPDATE.EXE•The“\FLAC”directory contains thefiles related to the operation of FLAC/Slope.Thereare three sub-directories:“FLAC\EXE”contains the executable code that is loaded torun FLAC/Slope;“FLAC\FLAC SLOPE”contains the examplefiles described in thismanual;and“FLAC\GUI”containsfiles used in the operation of the GIIC.•The“\JRE”directory contains the JA V A(TM)Runtime Environment(standard edition1.2.2)that is used for operating the GIIC.•The“\MANUALS\FLAC”directory contains the complete FLAC manual,which in-cludes the FLAC/Slope manual.•The“\SYSTEM”directory contains thefiles related to the hardware lock.•The“UPDATE.EXE”file located in the“\UTILITY”directory is used to upgrade thehardware key if the full version of FLAC is purchased.Thefirst time you load FLAC/Slope you will be asked to specify a customer title.This title will appear on all hardcopy output plots generated by FLAC/Slope.The title information is written to afile named“FLAC.CFG,”which is located in“ITASCA\SYSTEM.”If you wish to rename the customer title at a later time,delete“FLAC.CFG”and restart FLAC/Slope.Finally,be sure to connect the FLAC/Slope hardware key to your LPT1port before beginning operation of the code.Start-Up—The default installation procedure creates an“Itasca Codes”group with icons forFLAC/Slope and FLAC.To load FLAC/Slope,simply click on the FLAC/Slope icon.The code willstart-up and you will see the main window as shown in Figure1.1.The code name and current version number are printed in the title bar at the top of the window,and a main menu bar is positioned just below the title bar.The main menu contains File,Show, Tools,View and Help menus.Beneath the main menu bar is the Modeling Stage tool bar containing modeling-stage tabs for each of the stages:Models,Build,Solve and Plot.When you clickon a modeling-stage tab,a set of tools becomes available:these tools are used to create and run theslope-stability model.Separate sets of tools are provided for the models stage,the build stage,thesolve stage and the plot stage(as discussed previously in Section1.1.4).Figure1.1The FLAC/Slope main windowBeneath the Modeling Stage tool bar is the model-view pane.*The model-view pane shows agraphical view of the model.*If you are a user of full FLAC,you will also have access to a Console pane and Record pane.TheConsole pane shows text output and echos the FLAC commands that are created when operatingFLAC/Slope.This pane also allows command-line input(at the bottom of the pane).The Recordpane contains a list of all the FLAC commands,which can be exported to a datafile for input intofull FLAC.The Console and Record panes are activated from the Show/Resources menu item.Directly above the model-view pane is a View tool bar.You can use the View tools to manipulate the model-view pane(e.g.,translate or rotate the view,increase or decrease the size of the view, turn on and off the model axes).The View tools are also available in the View menu. Whenever you start a new project,a Model Options dialog will appear,as shown in Figure1.1.You have the option to include different features,such as an interface(weak plane),a water table or reinforcement,in the model and specify the system of units for your project with this dialog.The menus and tools are described in detail in Section1.3.An overview of the FLAC/Slope operation is provided in the Help menu.This menu also contains a list of Frequently Asked Questions about FLAC/Slope and an index to all GIIC Helpfiles.1.2.2A Simple TutorialThis section presents a simple tutorial to help you begin using FLAC/Slope right away.By working through this example,you will learn the recommended procedure to(1)define a project that includes different models,(2)build the slope conditions into each model,(3)calculate the factor of safety for each model,and(4)view the results.The example is a simple slope in a layered soil.Figure1.2illustrates the conditions of the slope. The purpose of the project is to evaluate the effect of the water table on the stability of the slope. The project consists of two models:one model with a water table and one without.In the following sections we discuss the four stages in the solution procedure for this problem.If you have not done so already,start up FLAC/Slope following the instructions in Section1.2.1. You will see the main FLAC/Slope window as shown in Figure1.1.You can now begin the tutorial.Figure1.2Conditions of the simple slopeDefining the Project—We begin the project by checking the Include water table?box in the Model Options dialog.The water table tool will be made available for our analysis.We also select the SI: meter-kilogram-second system of units.Press OK to include these options in the project analysis. We now click on File/Save Project As...to specify a project title,a working directory for the project and a project savefile.The Project Save dialog opens,as shown in Figure1.3,and we enter the project title and project savefile names.The working directory location for the project is selected in this dialog.In order to change to a specific directory,we press?in this dialog.An Open dialog appears to allow us to change to the working directory of our choice.We specify a project savefile name of“SLOPE”and note that the extension“.PSL”is assigned automatically—i.e.,the file“SLOPE.PSL”is created in our working directory.We click OK to accept these selections.Figure1.3Project Save dialogWe next click on the Models tool and enter the Models stage to specify a name for thefirst model in our project.We click on New and use the default model name Model1that appears in the New Model dialog.There will be two models in our project:Model1which does not contain a water table,and Model2which does.We will create Model2after we have completed the factor-of-safety calculation for Model1.(Note that,alternatively,we can create both modelsfirst before performing the calculation.)There are several types of model boundaries available to assist us in our model generation.For this tutorial,we select the Simple boundary button.When we press OK in the New Model dialog,an Edit slope parameters dialog opens and we enter the dimensions for our model boundary,as shown in Figure1.4.Note that we click on Mirror Layout to reverse the model layout to match that shown in Figure1.2.We click OK to view the slope boundary that we have created.We can either edit the boundary further or accept it.We press OK to accept the boundary for Model1.The layout for the Model1slope is shown in Figure1.5*.A tab is also created with the model name(Model1)at the bottom of the view.Also,note that an icon is shown in the upper-left corner of the model view indicating the direction and magnitude of the gravity vector.The project savefile name,title and model name are listed in the legend to the model view. Additional information will be added as we build the model.*We have increased the font size of the text in the model view.We click on the File/Preference Settings...menu item and change the font size to16in the Preference settings dialog.Figure1.4Edit Slope Parameters dialogFigure1.5Model1layoutBuilding the Model—We click on the Build tool tab to enter the Build stage and begin adding the slope conditions and materials to Model1.Wefirst define the two soil layers in the model.By clicking on the Layers button we open the Layers tool.(See Figure1.6.)A green horizontal line with square handles at each end is shown when we click on the mouse inside the slope boundary;this line defines the boundary between two layers.We locate this line at the level y=9m by right-clicking on one of the end handles and entering9.0in the Enter vertical level dialog.We press OK in the dialog and then OK in the Layers tool to create this boundary between the two layers.The result is shown in Figure1.7.Figure1.6Layers toolFigure1.7Two layers created by the Layers toolThere are two materials in the slope.These materials are created and assigned to the layers using the Material tool.After entering this tool,wefirst click on the Create button which opens the Define Material dialog.We create the two materials,upper soil and lower soil,and assign the densities and strength properties using this dialog.(Note that after one material is created,it can be cloned using the Clone button,and then the properties can be modified to create the second material.)The properties assigned for the upper soil material are shown in Figure1.8.(A Class,or classification name,is not specified;this is useful if materials are stored in a database—see Section1.3.5.)Figure1.8Properties input in the Define Material dialog for upper soilAfter the materials are created,they are assigned to the two layers.We highlight the material in the List pane and then click on the model view inside the layer we wish to assign the material.The material will be assigned to this layer,and the name of the material will be shown at the position that we click on the mouse inside this layer.The result after both materials are assigned is shown in Figure1.9.We press OK to accept these materials in Model1.Figure1.9Materials assigned to the two layers in the Material toolCalculating a Factor of Safety—We are now ready to calculate the factor of safety.We click on the Solve tool tab to enter the factor-of-safety calculation stage.When we enter this stage,we must first select a numerical mesh for our analysis.We choose a“coarse-grid”model by pressing the Coarse button,and the grid used for the FLAC solution appears in the model view.See Figure1.10.Figure1.10Coarse-grid for Model1We now press the Solve FoS button to begin the calculation.A Factor of Safety parameters dialog opens(Figure1.11),we accept the default solution parameters,and press OK.FLAC/Slope beginsthe calculation mode,and a Model cycling dialog provides a status of the solution process.When the calculation is complete,the calculated factor of safety is printed;in this case the value is1.68.Figure1.11Factor of Safety parameters dialogViewing the Results—We now click on the Plot tool tab to view the results.An fc button is shown,corresponding to the solution conditions(coarse grid,friction angle and cohesion included in the calculation).When we click on this button,we view the failure plot for this model,as shown in Figure1.12.Figure1.12Failure plot for coarse-grid Model1This plot shows the failure surface that develops for these model conditions(delineated by the shear strain-rate contours and velocity vectors).The value for factor of safety is also printed in the plot legend.Performing Multiple Analyses—We wish to compare this result to the case with a water table. We click on the Models tool tab to create the second model.We will start with Model1conditions by clicking on the Clone button.An Input dialog will appear again,but this time the default model name is Model2.We accept this name by pressing OK.A Model2tab is now shown at the bottom of the view.All the model conditions from Model1have been copied into Model2.The only remaining condition to add is the water table.We go to the Build stage and click on the Water button.A blue horizontal line with square handles is shown in the Water tool.We position this line to match the location of the water table as shown in Figure1.2.The line can either be re-positioned by left-clicking the mouse on the line and dragging the line to the water-table location,or by right-clicking the mouse on the line,which opens a dialog to specify coordinates of the water table.We define the water table by four points at coordinates:(0,10),(15,8),(30,3)and(40,3).The result is shown in Figure1.13.Figure1.13Positioning water table in the Water toolWe are now ready to solve Model2,so we go to the Solve stage,select the coarse-grid model and press the Solve FoS button.We follow the same procedure as before to determine the factor of safety.A factor of1.53is shown when the calculation stops.We now go to the Plot stage to produce the failure plot for this model.The result is shown in Figure1.14.Note that the water table is added to this plot by opening a Failure plot items dialog via the Items button.The results for Model2can easily be compared to those for Model1by clicking on the model-name tabs at the bottom of the model view.Figure1.14Failure plot for coarse-grid Model2Making Hardcopy Plots—Several different printer formats are available to create plots from FLAC/Slope.We click on the Setup button in the Plot tool bar to open a Print setup dialog,as shown in Figure1.15.Figure1.15Print setup dialogFor example,we have two choices if we wish to create a plot in an enhanced metafile format for insertion into a Microsoft Word document:(1)We can click on the Enhanced Metafile radio button.We select the name of thefile and thedirectory in which to save thefile by using the File radio button.As shown in thefigure,we save the failure plot to afile named“MODEL2.EMF.”We press OK to save theseprinter settings.Then,we press Print in the Plot tool to send the plot to thisfile.(2)Alternatively,we can copy the plot to the clipboard,by clicking the Clipboard button.Wepress OK to save this setting.Then,press Print in the Plot tool to send the plot to theclipboard andfinally paste the plot directly into the Word document.The plot is shown in Figure1.16.Note that hardcopy plots are formatted slightly differently from the screen plots.Figure1.16Hardcopy plot for Model2resultThis completes the simple tutorial.We recommend that you try additional variations on this project to help increase your understanding.For example,if you wish to evaluate the effect of zoning on the calculated safety factor,return to the Solve stage for Model1and click on the Medium button.This will create afiner mesh than the coarse mesh model.After solving for the factor of safety,a new plot button will be added in the Plot tool bar for Model1.You can then compare this result for a medium mesh directly with the coarse mesh result by clicking on the plot buttons.See Section1.3 for more information on the components of FLAC/Slope and recommended procedures to perform slope-stability calculations.。
摩托罗拉 accessories 编程软件说明书

Motorola Accessory Programming SoftwareTable of Contents1.Introduction2.What's New in this Release3.Requirements4.Installation and Removal5.Open Issues Summary6.Legal Notice7.Publicly Available Software Legal Notices1. IntroductionThe Accessory Programming Software provides organizations with the ability to upgrade and manage the accessory devices.The Accessory Programming Software application contains an upgrade tool that can be used to upgrade one or multiple accessory devices at a time and a retrieve log tool to retrieve the device logs.2. What's New in this ReleaseVersion Notes1.0Initial release allows a user to upgrade their Mission critical and Operations critical wirelessaccessory devices.2.0This release allows a user to upgrade their XE RSM accessory devices.2.8This release allows a user to upgrade their GPS RSM as well as wireless devices.APS R2.8must beused for firmware upgrade to Mission Critical Wireless R01.04.00and Operations Critical WirelessR01.03.01or later firmware.3.0This release allows a user to upgrade their WRSM accessory devices4.0This release allows a user to recognize the name for Long Range OCW Wireless RSM as OCWWRSM.4.1This release allows a user to upgrade and manage their XE500Model1and Model1.5accessorydevices4.2This release allows a user to set codeplug to enable channel knob position broadcast duringpower up for their accessory devices.4.3This release allows a user to set Volume Channel codeplug for their XE500accessory devices.4.4This release allows a user to set Kodiak Device Operation Mode for their OCW WRSM accessorydevices.4.5This release allows a user to set Kodiak Device Operation Mode for their OCW WPOD accessorydevices.4.6This release allows a user to set the Radio,Wave and Kodiak Device Operation Mode for theirWRSM accessory devices.4.7This release allows a user to set the Send Channel Control Powerup for XVE500,XVP850andVolume Control Feature codeplug for XVE500,XVE NO KNOB,XVP850/830,XVN500RSMaccessory devices for FDNY support.4.8This release allows a user to upgrade XV RSM(PMMN4123A and PMMN4145A)accessorydevices.4.9This release fixes the XE500Model1volume configuration missing in version4.8and allows auser to disable over temperature reporting status for XVN500RSM accessory devices.4.10This release allows a user to set Volume and Channel codeplug for their XVE DIV1accessorydevices.4.11This release allows a user to set Extra Loud Earpiece Compatible codeplug for their WM800accessory devices.3. RequirementsOperating Systems●Microsoft®Windows®7Home/Professional Edition●Microsoft®Windows®8.1Home/Professional Edition●Microsoft®Windows®10Home/Professional EditionNote●Please see the application help file for information on how to use the Accessory Programming Software4. Installation and RemovalInstallationAdministrative rights on the PC in which the software is to be installed are required.To download the Accessory Programming Software,please visit the Motorola Solutions MOL website.After downloading the software,please refer to the“APS User Guide.pdf”for instructions to install the software.If a previous version of Accessory Programming Software has already been installed,please remove the software first and install the new software.RemovalIn the Control Panel,select the"Programs and Features"option.Select the Accessory ProgrammingSoftware item from the list of programs and click the Uninstall button.5. Open Issues SummaryOn rare occasion,after completion of the firmware upgrade user may get the following WARNING:"The device has been upgraded successfully but fails to reset.Please disconnect and reconnect the USB cable to reset the device."User can IGNORE this warning since the device was upgraded successfully.6. Legal NoticeMotorola Solutions is a registered trademark of Motorola Solutions,IncMicrosoft®and Windows®are registered trademarks of Microsoft Inc.7. Publicly Available Software Legal NoticesThis media,or Motorola Solutions Product,may include Motorola Solutions Software,Commercial Third Party Software,and Publicly Available Software.The Motorola Solutions Software that may be included on this media,or included in the Motorola Solutions Product,is Copyright(c)by Motorola Solutions,Inc.,and its use is subject to the licenses,terms and conditions of the agreement in force between the purchaser of the Motorola Solutions Product and Motorola Solutions,Inc.The Commercial Third Party Software that may be included on this media,or included in the Motorola Solutions Product,is subject to the licenses,terms and conditions of the agreement in force between the purchaser of the Motorola Solutions Product and Motorola Solutions,Inc.,unless a separate Commercial Third Party Software License is included,in which case,your use of the Commercial Third Party Software will then be governed by the separate Commercial Third Party License.The Publicly Available Software that may be included on this media,or in the Motorola Solutions Product,is listed below.The use of the listed Publicly Available Software is subject to the licenses,terms and conditions of the agreement in force between the purchaser of the Motorola Solutions Product and Motorola Solutions,Inc.,as wellas,the terms and conditions of the license of each Publicly Available Software package.Copies of the licenses for the listed Publicly Available Software,as well as,all attributions,acknowledgements,and software information details,are included below.Motorola Solutions is required to reproduce the software licenses,acknowledgments and copyright notices as provided by the Authors and Owners,thus,all such information is provided in its native language form,without modification or translation.For instructions on how to obtain a copy of any source code being made publicly available by Motorola Solutions related to software used in this Motorola Solutions Product you may send your request in writing to:Motorola Solutions,INC.Government&Public Safety BusinessPublicly Available Software Management1301E.Algonquin RoadSchaumburg,IL60196USA.In your request,please include the Motorola Solutions Product Name and Version,along with the Publicly Available Software specifics,such as the Publicly Available Software Name and Version.Note,the source code for the Publicly Available Software may be resident on the Motorola Solutions Product Installation Media,or on supplemental Motorola Solutions Product Media.Please reference and review the entire Motorola Solutions Publicly Available Software Notifications/EULA for the details on location of the source code.Note,dependent on the license terms of the Publicly Available Software,source code may not be provided.Please reference and review the entire Motorola Solutions Publicly Available Software Notifications/EULA for identifying which Publicly Available Software Packages will have source code provided.To view additional information regarding licenses,acknowledgments and required copyright notices for Publicly Available Software used in this Motorola Solutions Product,please select Legal Notices display from the GUI(if applicable),or review the Notifications/EULA File/ReadMe,on the Motorola Solutions Install Media,or resident in the Motorola Solutions Product.Motorola Solutions and the Stylized M logo are registered in the US Patent and Trademark Office.All other trademarks,logos,and service marks("Marks")are the property of the respective third party owners.You are not permitted to use the Marks without the prior written consent of Motorola Solutions or such third party which may own the Marks.===========================================================================PUBLICLY AVAILABLE SOFTWARE LIST===========================================================================Name:Microsoft WPF ToolkitVersion: 3.5.40619.1Description:The WPF Toolkit is a collection of WPF features and components that are being made available outside of the Framework ship cycle.The WPF Toolkit not only allows users to get new functionality more quickly,but allows an efficient means for giving feedback to the product team. Many of the features will be released with full source code as well.SoftwareSite:/wpfSourceNo Source Distribution Obligations.Code:License:Microsoft Public License(Ms-PL)Microsoft Public License(Ms-PL)This license governs use of the accompanying software.If you use the software,you accept this license.If you do not accept the license,do not use the software.1.DefinitionsThe terms"reproduce,""reproduction,""derivative works,"and"distribution"have the same meaning here as under U.S.copyright law.A"contribution"is the original software or any additions or changes to the software.A"contributor"is any person that distributes its contribution under this license."Licensed patents"are a contributor's patent claims that read directly on its contribution.2.Grant of Rights(A)Copyright Grant-Subject to the terms of this license,including the license conditions and limitations in section 3,each contributor grants you a non-exclusive,worldwide,royalty-free copyright license to reproduce its contribution,prepare derivative works of its contribution,and distribute its contribution or any derivative works that you create.(B)Patent Grant-Subject to the terms of this license,including the license conditions and limitations in section3, each contributor grants you a non-exclusive,worldwide,royalty-free license under its licensed patents to make, have made,use,sell,offer for sale,import,and/or otherwise dispose of its contribution in the software or derivative works of the contribution in the software.3.Conditions and Limitations(A)No Trademark License-This license does not grant you rights to use any contributors'name,logo,or trademarks.(B)If you bring a patent claim against any contributor over patents that you claim are infringed by the software, your patent license from such contributor to the software ends automatically.(C)If you distribute any portion of the software,you must retain all copyright,patent,trademark,and attribution notices that are present in the software.(D)If you distribute any portion of the software in source code form,you may do so only under this license by including a complete copy of this license with your distribution.If you distribute any portion of the software in compiled or object code form,you may only do so under a license that complies with this license.(E)The software is licensed"as-is."You bear the risk of using it.The contributors give no express warranties, guarantees or conditions.You may have additional consumer rights under your local laws which this license cannotchange.To the extent permitted under your local laws,the contributors exclude the implied warranties of merchantability,fitness for a particular purpose and non-infringement.。
Demo of EMMA coverage tool(使用dos命令)
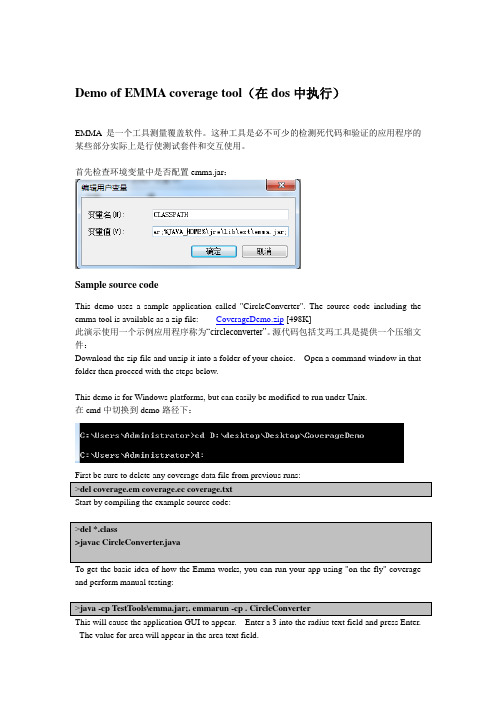
Demo of EMMA coverage tool(在dos中执行)EMMA是一个工具测量覆盖软件。
这种工具是必不可少的检测死代码和验证的应用程序的某些部分实际上是行使测试套件和交互使用。
首先检查环境变量中是否配置emma.jar:Sample source codeThis demo uses a sample application called "CircleConverter". The source code including the emma tool is available as a zip file: CoverageDemo.zip [498K]此演示使用一个示例应用程序称为“circleconverter”。
源代码包括艾玛工具是提供一个压缩文件:Download the zip file and unzip it into a folder of your choice. Open a command window in that folder then proceed with the steps below.This demo is for Windows platforms, but can easily be modified to run under Unix.在cmd中切换到demo路径下:First be sure to delete any coverage data file from previous runs:>del coverage.em coverage.ec coverage.txtStart by compiling the example source code:>del *.class>javac CircleConverter.javaTo get the basic idea of how the Emma works, you can run your app using "on the fly" coverage and perform manual testing:>java -cp TestTools\emma.jar;. emmarun -cp . CircleConverterThis will cause the application GUI to appear. Enter a 3 into the radius text field and press Enter. The value for area will appear in the area text field.翻译:输入以上命令后将会出现一个图形用户界面,输入半径3并按回车,将会在area中显示出面积值。
(Sho06)Sequences of Games A Tool for Taming Complexity in Security Proofs

Sequences of Games:A Tool for Taming Complexity in Security Proofs∗Victor Shoup†January18,2006AbstractThis paper is brief tutorial on a technique for structuring security proofs as sequences games.1IntroductionSecurity proofs in cryptography may sometimes be organized as sequences of games.In certain circumstances,this can be a useful tool in taming the complexity of security proofs that might otherwise become so messy,complicated,and subtle as to be nearly impossible to verify.This technique appears in the literature in various styles,and with various degrees of rigor and formality.This paper is meant to serve as a brief tutorial on one particular“style”of employing this technique,which seems to achieve a reasonable level of mathematical rigor and clarity,while not getting bogged down with too much formalism or overly restrictive rules.We do not make any particular claims of originality—it is simply hoped that others might profit from some of the ideas discussed here in reasoning about security.At the outset,it should be noted that this technique is certainly not applicable to all security proofs.Moreover,even when this technique is applicable,it is only a tool for organizing a proof—the actual ideas for a cryptographic construction and security analysis must come from elsewhere.1.1The Basic IdeaSecurity for cryptograptic primitives is typically defined as an attack game played between an adversary and some benign entity,which we call the challenger.Both adversary and challenger are probabilstic processes that communicate with each other,and so we can model the game as a probability space.Typically,the definition of security is tied to some particular event S.Security means that for every“efficient”adversary,the probability that event S occurs is“very close to”some specified“target probabilty”:typically,either0, 1/2,or the probability of some event T in some other game in which the same adversary is interacting with a different challenger.∗First public version:Nov.30,2004†Computer Science Dept.NYU.shoup@In the formal definitions,there is a security parameter:an integer tending to infinity,and in the previous paragraph,“efficient”means time bounded by a polynomial in the security parameter,and“very close to”means the difference is smaller than the inverse of any polynomial in the security parameter,for sufficiently large values of the security parameter. The term of art is negligibly close to,and a quantity that is negliglibly close to zero is just called negligible.For simplicity,we shall for the most part avoid any further discussion of the security parameter,and it shall be assumed that all algorithms,adversaries,etc.,take this value as an implicit input.Now,to prove security using the sequence-of-games approach,one prodceeds as follows. One constructs a sequence of games,Game0,Game1,...,Game n,where Game0is the original attack game with respect to a given adversary and cryptographic primitive.Let S0 be the event S,and for i=1,...,n,the construction defines an event S i in Game i,usually in a way naturally related to the definition of S.The proof shows that Pr[S i]is negligibly close to Pr[S i+1]for i=0,...,n−1,and that Pr[S n]is equal(or negligibly close)to the “target probability.”From this,and the fact that n is a constant,it follows that Pr[S]is negligibly close to the“target probability,”and security is proved.That is the general framework of such a proof.However,in constructing such proofs, it is desirable that the changes between succesive games are very small,so that analyzing the change is as simple as possible.From experience,it seems that transitions between successive games can be restricted to one of three types:Transitions based on indistinguishability.In such a transition,a small change is made that,if detected by the adversary,would imply an efficient method of distinguishing be-tween two distributions that are indistinguishable(either statistically or computationally). For example,suppose P1and P2are assumed to be computationally indistinguishable dis-tributions.To prove that|Pr[S i]−Pr[S i+1]|is negligible,one argues that there exists a distinguishing algorithm D that“interpolates”between Game i and Game i+1,so that when given an element drawn from distribution P1as input,D outputs1with probability Pr[S i], and when given an element drawn from distribution P2as input,D outputs1with prob-abilty Pr[S i+1].The indistinguishability assumption then implies that|Pr[S i]−Pr[S i+1]| is ually,the construction of D is obvious,provided the changes made in the transition are minimal.Typically,one designs the two games so that they could easily be rewritten as a single“hybrid”game that takes an auxilliary input—if the auxiallary input is drawn from P1,you get Game i,and if drawn from P2,you get Game i+1.The distinguisher then simply runs this single hybrid game with its input,and outputs1if the appropriate event occurs.Transitions based on failure events.In such a transition,one argues that Games i and i+1proceed identically unless a certain“failure event”F occurs.To make this type of argument as cleanly as possible,it is best if the two games are defined on the same underlying probability space—the only differences between the two games are the rules for computing certain random variables.When done this way,saying that the two games proceed identically unless F occurs is equivalent to saying thatS i∧¬F⇐⇒S i+1∧¬F,that is,the events S i∧¬F and S i+1∧¬F are the same.If this is true,then we can use thefollowing fact,which is completely trivial,yet is so often used in these types of proofs that it deserves a name:Lemma1(Difference Lemma).Let A,B,F be events defined in some probability dis-tribution,and suppose that A∧¬F⇐⇒B∧¬F.Then|Pr[A]−Pr[B]|≤Pr[F]. Proof.This is a simple calculation.We have|Pr[A]−Pr[B]|=|Pr[A∧F]+Pr[A∧¬F]−Pr[B∧F]−Pr[B∧¬F]|=|Pr[A∧F]−Pr[B∧F]|≤Pr[F].The second equality follows from the assumption that A∧¬F⇐⇒B∧¬F,and so in particular,Pr[A∧¬F]=Pr[B∧¬F].Thefinal inequality follows from the fact that both Pr[A∧F]and Pr[B∧F]are numbers between0and Pr[F].2So to prove that Pr[S i]is negligibly close to Pr[S i+1],it suffices to prove that Pr[F]is negligible.Sometimes,this is done using a security assumption(i.e.,when F occurs,the adversary has found a collision in a hash function,or forged a MAC),while at other times, it can be done using a purely information-theoretic argument.Usually,the event F is defined and analyzed in terms of the random variables of one of the two adjacent games.The choice is arbitrary,but typically,one of the games will be more suitable than the other in terms of allowing a clear proof.In some particularly challenging circumstances,it may be difficult to analyze the event F in either game.In fact,the analysis of F may require its own sequence of games sprouting offin a different direction,or the sequence of games for F may coincide with the sequence of games for S,so that Pr[F]finally gets pinned down in Game j for j>i+1.This technique is sometimes crucial in side-stepping potential circularities.Bridging steps.The third type of transition introduces a bridging step,which is typically a way of restating how certain quantities can be computed in a completely equivalent way. The change is purely conceptual,and Pr[S i]=Pr[S i+1].The reason for doing this is to prepare the ground for a transition of one of the above two types.While in principle,such a bridging step may seem unnecessary,without it,the proof would be much harder to follow.As mentioned above,in a transition based on a failure event,it is best if the two successive games are understood to be defined on the same underlying probability space. This is an important point,which we repeat here for emphasis—it seems that proofs are easiest to understand if one does not need to compare“corresponding”events across distinct and(by design)quite different probability spaces.Actually,it is good practice to simply have all the games in the sequence defined on the same underlying probability space.However,the Difference Lemma generalizes in the obvious way as follows:if A, B,F1and F2are events such that Pr[A∧¬F1]=Pr[B∧¬F2]and Pr[F1]=Pr[F2],then |Pr[A]−Pr[B]|≤Pr[F1].With this generalized version,one may(if one wishes)analyze transitions based on failure events when the underlying probability spaces are not the same.1.2Some Historical Remarks“Hybrid arguments”have been used extensively in cryptography for many years.Such an argument is essentially a sequence of transitions based on indistinguishability.An early example that clearly illustrates this technique is Goldreich,Goldwasser,and Micali’s paper [GGM86]on constructing pseudo-random functions(although this is by no means the ear-liest application of a hybrid argument).Note that in some applications,such as[GGM86], one in fact makes a non-constant number of transitions,which requires an additional,prob-abilistic argument.Although some might use the term“hybrid argument”to include proofs that use transi-tions based on both indistinguishability and failure events,that seems to be somewhat of a stretch of terminology.An early example of a proof that is clearly structured as a sequence of games that involves transitions based on both indistinguishability and failure events is Bellare and Goldwasser’s paper[BG89].Kilian and Rogaway’s paper[KR96]on DESX initiates a somewhat more formal ap-proach to sequences of games.That paper essentially uses the Difference Lemma,specialized to their particular setting.Subsequently,Rogaway has refined and applied this technique in numerous works with several co-authors.We refer the reader to the paper[BR04]by Bellare and Rogaway that gives a detailed introduction to the methodology,as well as references to papers where it has been used.However,we comment briefly on some of the differences between the technique discussed in this paper,and that advocated in[BR04]:•In Bellare and Rogaway’s approach,games are programs and are treated as purely syntactic objects subject to formal manipulation.In contrast,we view games as probability spaces and random variables defined over them,and do not insist on any particular syntactic formalism beyond that convenient to make a rigorous mathemat-ical argument.•In Bellare and Rogaway’s approach,transitions based on failure events are restricted to events in which an executing program explicitly sets a particular boolean variable to true.In contrast,we do not suggest that events need to be explicitly“announced.”•In Bellare and Rogaway’s approach,when the execution behaviors of two games are compared,two distinct probability spaces are involved,and probabilities of“corre-sponding”events across probability spaces must be compared.In contrast,we sug-gest that games should be defined on a common probability space,so that when discussing,say,a particular failure event F,there is literally just one event,not a pair of corresponding events in two different probability spaces.In the end,we think that the choice between the style advocated in[BR04]and that suggested here is mainly a matter of taste and convenience.The author has used proofs organized as sequences of games extensively in his own work [Sho00,SS00,Sho01,Sho02,CS02,CS03b,CS03a,GS04]and has found them to be an indispensable tool—while some of the proofs in these papers could be structured differently, it is hard to imagine how most of them could be done in a more clear and convincing way without sequences of games(note that all but thefirst two papers above adhere to the rule suggested here of defining games to operate on the same probability space).Other authorshave also been using very similar proof styles recently[AFP04,BK04,BCP02a,BCP02b, BCP03,CPP04,DF03,DFKY03,DFJW04,Den03,FOPS04,GaPMV03,KD04,PP03, SWP04].Also,Pointcheval[Poi04]has a very nice introductory manuscript on public-key cryptography that illustrates this proof style on a number of particular examples.The author has also been using the sequence-of-games technique extensively in teaching courses in cryptography.Many“classical”results in cryptography can be fruitfully analyzed using this technique.Generally speaking,it seems that the students enjoy this approach, and easily learn to use and apply it themselves.Also,by using a consistent framework for analysis,as an instructor,one can more easily focus on the ideas that are unique to any specific application.1.3Outline of the Rest of the PaperAfter recalling some fairly standard notation in the next section,the following sections illustrate the use of the sequence-of-games technique in the analysis of a number of classical cryptographic pared to many of the more technically involved examples in the literature of this technique(mentioned above),the applications below are really just “toy”examples.Nevertheless,they serve to illustrate the technique in a concrete way,and moreover,we believe that the proofs of these results are at least as easy to follow as any other proof,if not more so.All of the examples,except the last two(in§§7-8),are presented at an extreme level of detail;indeed,for these examples,we give complete,detailed descriptions of each and every game.More typically,to produce a more compact proof,one might simply describe the differences between games,rather than describing each game in its entirety(as is done in§§7-8).These examples are based mainly on lectures in courses on cryptography taught by the author.2NotationWe make use of fairly standard notation in what follows.In describing probabilistic processes,we writex c|←Xto denote the action of assigning to the variable x a value sampled according to the dis-tribution X.If S is afinite set,we simply write s c|←S to denote assignment to s of an element sampled from the uniform distribution on S.If A is a probabilistic algorithm and x an input,then A(x)denotes the output distribution of A on input x.Thus,we write y c|←A(x)to denote the action of running algorithm A on input x and assigning the output to the variable y.We shall writePr[x1c|←X1,x2c|←X2(x1),...,x n c|←X n(x1,...,x n−1):φ(x1,...,x n)]to denote the probability that when x1is drawn from a certain distribution X1,and x2is drawn from a certain distribution X2(x1),possibly depending on the particular choice ofx1,and so on,all the way to x n,the predicateφ(x1,...,x n)is true.We allow the predicate φto involve the execution of probabilistic algorithms.If X is a probability distribution on a sample space X,then[X]denotes the subset of elements of X that occur with non-zero probability.3ElGamal Encryption3.1Basic DefinitionsWefirst recall the basic definition of a public-key encryption scheme,and the notion of semantic security.A public-key encryption scheme is a triple of probabilistic algorithms(KeyGen,E,D). The key generation algorithm KeyGen takes no input(other than an implied security pa-rameter,and perhaps other system parameters),and outputs a public-key/secret-key pair (pk,sk).The encryption algorithm E takes as input a public key pk and a message m, selected from a message space M,and outputs a ciphertextψ.The decryption algorithm takes as input a secret key sk and ciphertextψ,and outputs a message m.The basic correctness requirement is that decryption“undoes”encryption.That is,for all m∈M,all(pk,sk)∈[KeyGen()],allψ∈[E(pk,m)],and all m ∈[D(sk,ψ)],we have m=m .This definition can be relaxed in a number of ways;for example,we may only insist that it is computationally infeasible tofind a message for which decryption does not “undo”its encryption.The notion of semantic security intuitively says that an adversary cannot effectively dis-tinguish between the encryption of two messages of his choosing(this definition comes from [GM84],where is called polynomial indistinguishability,and semantic security is actually the name of a syntactically different,but equivalent,characterization).This is formally defined via a game between an adversary and a challenger.•The challenger computes(pk,sk)c|←KeyGen(),and gives pk to the adversary.•The adversary chooses two messages m0,m1∈M,and gives these to the challenger.•The challenger computesb c|←{0,1},ψc|←E(pk,m b)and gives the“target ciphertext”ψto the adversary.•The adversary outputsˆb∈{0,1}.We define the SS-advantage of the adversary to be|Pr[b=ˆb]−1/2|.Semantic security means that any efficient adversary’s SS-advantage is negligible.3.2The ElGamal Encryption SchemeWe next recall ElGamal encryption.Let G be a group of prime order q,and letγ∈G be a generator(we view the descriptions of G andγ,including the value q,to be part of a set of implied system parameters).The key generation algorithm computes(pk,sk)as follows:x c|←Z q,α←γx,pk←α,sk←x.The message space for the algorithm is G.To encrypt a message m∈G,the encryption algorithm computes a ciphertextψas follows:y c|←Z q,β←γy,δ←αy,ζ←δ·m,ψ←(β,ζ).The decryption algorithm takes as input a ciphertext(β,ζ),and computes m as follows:m←ζ/βx.It is clear that decryption“undoes”encryption.Indeed,ifβ=γy andζ=αy·m,then ζ/βx=αy m/βx=(γx)y m/(γy)x=γxy m/γxy=m.3.3Security AnalysisElGamal encryption is semantically secure under the Decisional Diffie-Hellman(DDH) assumption.This is the assumption that it is hard to distinguish triples of the form (γx,γy,γxy)from triples of the form(γx,γy,γz),where x,y,and z are random elements of Z q.The DDH assumption is more precisely formulated as follows.Let D be an algorithm that takes as input triples of group elements,and outputs a bit.We define the DDH-advantage of D to be|Pr[x,y c|←Z q:D(γx,γy,γxy)=1]−Pr[x,y,z c|←Z q:D(γx,γy,γz)=1]|.The DDH assumption(for G)is the assumption that any efficient algorithm’s DDH-advantage is negligible.We now give a proof of the semantic security of ElGamal encryption under the DDH assumption,using a sequence of games.Game0.Fix an efficient adversary A.Let us define Game0to be the attack game against A in the definition of semantic security.To make things more precise and more concrete, we may describe the attack game algorithmically as follows:x c|←Z q,α←γxr c|←R,(m0,m1)←A(r,α)b c|←{0,1},y c|←Z q,β←γy,δ←αy,ζ←δ·m bˆb←A(r,α,β,ζ)In the above,we have modeled the adversary A is a deterministic algorithm that takes as input“random coins”r sampled uniformly from some set R.It should be evident that this algorithm faithfully represents the attack game.If we define S0to be the event that b=ˆb,then the adversary’s SS-advantage is|Pr[S0]−1/2|.Game1.[This is a transition based on indistinguishability.]We now make one small change to the above ly,instead of computingδasαy,we compute it asγz for randomly chosen z∈Z q.We can describe the resulting game algorithmically as follows: x c|←Z q,α←γxr c|←R,(m0,m1)←A(r,α)b c|←{0,1},y c|←Z q,β←γy,z c|←Z q,δ←γz,ζ←δ·m bˆb←A(r,α,β,ζ)Let S1be the event that b=ˆb in Game1.Claim1.Pr[S1]=1/2.This follows from the fact that in Game2,δis effectively a one-time pad,and as such,the adversary’s outputˆb is independent of the hidden bit b.To prove this more rigorously,it will suffice to show that b,r,α,β,ζare mutually independent, since from this,it follows that b andˆb=A(r,α,β,ζ)are independent.First observe that by construction,b,r,α,β,δare mutually independent.It will suffice to show that conditioned on anyfixed values of b,r,α,β,the conditional distribution ofζis the uniform distribution over G.Now,if b,r,α,βarefixed,then so are m0,m1,since they are determined by r,α; moreover,by independence,the conditional distribution ofδis the uniform distribution on G,and hence from this,one sees that the conditional distribution ofζ=δ·m b is the uniform distribution on G.Claim2.|Pr[S0]−Pr[S1]|= ddh,where ddh is the DDH-advantage of some efficient algorithm(and hence negligible under the DDH assumption).The proof of this is essentially the observation that in Game0,the triple(α,β,δ)is of the form(γx,γy,γxy),while in Game1,it is of the form(γx,γy,γz),and so the adversary should not notice the difference,under the DDH assumption.To be more precise,our distinguishing algorithm D works as follows:Algorithm D(α,β,δ)r c|←R,(m0,m1)←A(r,α)b c|←{0,1},ζ←δ·m bˆb←A(r,α,β,ζ)if b=ˆbthen output1else output0Algorithm D effectively“interpolates”between Games0and1.If the input to D is of the form(γx,γy,γxy),then computation proceeds just as in Game0,and thereforePr[x,y c|←Z q:D(γx,γy,γxy)=1]=Pr[S0].If the input to D is of the form(γx,γy,γz),then computation proceeds just as in Game1, and thereforePr[x,y,z c|←Z q:D(γx,γy,γz)=1]=Pr[S1].From this,it follows that the DDH-advantage of D is equal to|Pr[S0]−Pr[S1]|.That completes the proof of Claim2.Combining Claim1and Claim2,we see that|Pr[S0]−1/2|= ddh,and this is negligible.That completes the proof of security of ElGamal encryption.3.4Hashed ElGamalFor a number of reasons,it is convenient to work with messages that are bit strings,say,of length ,rather than group elements.Because of this,one may choose to use a“hashed”version of the ElGamal encryption scheme.This scheme makes use of a family of keyed“hash”functions H:={H k}k∈K,where each H k is a function mapping G to{0,1} .The key generation algorithm computes(pk,sk)as follows:x c|←Z q,k c|←K,α←γx,pk←(α,k),sk←(x,k).To encrypt a message m∈{0,1} ,the encryption algorithm computes a ciphertextψas follows:y c|←Z q,β←γy,δ←αy,h←H k(δ),v←h⊕m,ψ←(β,v).The decryption algorithm takes as input a ciphertext(β,v),and computes m as follows:m←H k(βx)⊕v.The reader may easily verify that decryption“undoes”encryption.As for semantic security,this can be proven under the DDH assumption and the as-sumption that the family of hash functions H is“entropy smoothing.”Loosely speaking, this means that it is hard to distinguish(k,H k(δ))from(k,h),where k is a random element of K,δis a random element of G,and h is a random element of{0,1} .More formally, let D be an algorithm that takes as input an element of K and an element of{0,1} ,and outputs a bit.We define the ES-advantage of D to be|Pr[k c|←K,δc|←G:D(k,H k(δ))=1]−Pr[k c|←K,h c|←{0,1} :D(k,h)=1]|.We say H is entropy smoothing if every efficient algorithm’s ES-advantage is negligible.It is in fact possible to construct entropy smoothing hash function families without ad-ditional hypothesis(the Leftover Hash Lemma may be used for this[IZ89]).However,these may be somewhat less practical than ad hoc hash function families for which the entropy smoothing property is only a(perfectly reasonable)conjecture;moreover,our definition also allows entropy smoothers that use pseudo-random bit generation techniques as well.We now sketch the proof of semantic security of hashed ElGamal encryption,under the DDH assumption and the assumption that H is entropy smoothing.Game0.This is the original attack game,which we can state algorithmically as follows:x c|←Z q,k c|←K,α←γxr c|←R,(m0,m1)←A(r,α,k)b c|←{0,1},y c|←Z q,β←γy,δ←αy,h←H k(δ),v←h⊕m bˆb←A(r,α,k,β,v)We define S0to be the event that b=ˆb in Game0.Game1.[This is a transition based on indistinguishability.]Now we transform Game0 into Game1,computingδasγz for random z∈Z q.We can state Game1algorithmically as follows:x c|←Z q,k c|←K,α←γxr c|←R,(m0,m1)←A(r,α,k)b c|←{0,1},y c|←Z q,β←γy,z c|←Z q,δ←γz,h←H k(δ),v←h⊕m bˆb←A(r,α,k,β,v)Let S1be the event that b=ˆb in Game1.We claim that|Pr[S0]−Pr[S1]|= ddh,(1) where ddh is the DDH-advantage of some efficient algorithm(which is negligible under the DDH assumption).The proof of this is almost identical to the proof of the corresponding claim for“plain”ElGamal.Indeed,the following algorithm D“interpolates”between Game0and Game1, and so has DDH-advantage equal to|Pr[S0]−Pr[S1]|:Algorithm D(α,β,δ)k c|←Kr c|←R,(m0,m1)←A(r,α,k)b c|←{0,1},h←H k(δ),v←h⊕m bˆb←A(r,α,k,β,v)if b=ˆbthen output1else output0Game 2.[This is also a transition based on indistinguishability.]We now transform Game1into Game2,computing h by simply choosing it at random,rather than as a hash. Algorithmically,Game2looks like this:x c|←Z q,k c|←K,α←γxr c|←R,(m0,m1)←A(r,α,k)b c|←{0,1},y c|←Z q,β←γy,z c|←Z q,δ←γz,h c|←{0,1} ,v←h⊕m bˆb←A(r,α,k,β,v)Observe thatδplays no role in Game2.Let S2be the event that b=ˆb in Game2.We claim that|Pr[S1]−Pr[S2]|= es,(2) where es the ES-advantage of some efficient algorithm(which is negligible assuming H is entropy smoothing).This is proved using the same idea as before:any difference between Pr[S1]and Pr[S2] can be parlayed into a corresponding ES-advantage.Indeed,it is easy to see that the fol-lowing algorithm D “interpolates”between Game1and Game2,and so has ES-advantage equal to|Pr[S1]−Pr[S2]|:Algorithm D (k,h)x c|←Z q,α←γxr c|←R,(m0,m1)←A(r,α,k)b c|←{0,1},y c|←Z q,β←γy,v←h⊕m bˆb←A(r,α,k,β,v)if b=ˆbthen output1else output0Finally,as h acts like a one-time pad in Game2,it is evident thatPr[S2]=1/2.(3) Combining(1),(2),and(3),we obtain|Pr[S0]−1/2|≤ ddh+ es,which is negligible,since both ddh and es are negligible.This proof illustrates how one can utilize more than one intractability assumption in a proof of security in a clean and simple way.4Pseudo-Random Functions4.1Basic DefinitionsLet 1and 2be positive integers(which are actually polynomially bounded functions in a security parameter).Let F:={F s}s∈S be a family of keyed functions,where each functionF s maps{0,1} 1to{0,1} 2.LetΓ1, 2denote the set of all functions from{0,1} 1to{0,1} 2.Informally,we say that F is pseudo-random if it is hard to distinguish a random functiondrawn from F from a random function drawn fromΓ1, 2,given black box access to such afunction(this notion was introduced in[GGM86]).More formally,consider an adversary A that has oracle access to a function inΓ1, 2,and suppose that A always outputs a bit.Define the PRF-advantage of A to be|Pr[s c|←S:A F s()=1]−Pr[f c|←Γ1, 2:A f()]=1|.We say that F is pseudo-random if any efficient adversary’s PRF-advantage is negligible.4.2Extending the Input Length with a Universal Hash FunctionWe now present one construction that allows one to stretch the input length of a pseudo-random family of functions.Let be a positive integer with > 1.Let H:={H k}k∈K be a family of keyed hash functions,where each H k maps{0,1} to{0,1} 1.Let us assume that H is an uh-universal family of hash functions,where uh is negligible.This means that for all w,w ∈{0,1} with w=w ,we havePr[k c|←K:H k(w)=H k(w )]≤ uh.There are many ways to construct such families of hash functions.Now define the family of functionsF :={F k,s}(k,s)∈K×S,where each Fk,s is the function from{0,1} into{0,1} 2that sends w∈{0,1} to F s(H k(w)).We shall now prove that if F is pseudo-random,then F is pseudo-random.Game0.This game represents the computation of an adversary given oracle access to a function drawn at random from F .Without loss of generality,we may assume that the adversary makes exactly q queries to its oracle,and never repeats any queries(regardless of the oracle responses).We may present this computation algorithmically as follows: k c|←K,s c|←Sr c|←Rfor i←1...q dow i←A(r,y1,...,y i−1)∈{0,1}x i←H k(w i)∈{0,1} 1y i←F s(x i)∈{0,1} 2b←A(r,y1,...,y q)∈{0,1}output bThe idea behind our notation is that the adversary is modeled as a deterministic al-gorithm A,and we supply its random coins r∈R as input,and in loop iteration i,the adversary computes its next query w i as a function of its coins and the results y1,...,y i−1 of its previous queries w1,...,w i−1.We are assuming that A operates in such a way that the values w1,...,w q are always distinct.Let S0be the event that the output b=1in Game0.Our goal is to transform this game into a game that is equivalent to the computation of the adversary given oracle access to a random element ofΓ ,2,so that the probability that b=1in the latter game is negligibly close to Pr[S0].Game1.[This is a transition based on indistinguishability.]We now modify Game0so that we use a truly random function from 1bits to 2bits,in place of F s.Intuitively, the pseudo-randomness property of F should guarantee that this modification has only a negligible effect on the behavior of the adversary.Algorithmically,Game1looks like this:。
matcont的使用说明

Yuri A. Kuznetsov
1
Introduction
dx = f (x, α) dt
We consider a dynamical system of the form (1)
with x ∈ IRn , f (x, α) ∈ IRn , and α a vector of parameters. We call f the object function of (1). To analyze the behaviour of (1) it is often useful to compute branches of equilibria, Hopf points, limit points etcetera if an appropriate number of parameters (codimension of the type plus one) is freed. The existing software packages such as auto [2], content [5] require the user to rewrite his/her models in a specific format; this complicates the export of results, graphical representation etcetera. Also, these packages require a careful installation and handling. If you have Matlab 6.5 or higher on your computer and an internet connection then you can be running matcont in a few minutes. The aim of matcont is to provide a continuation environment which is compatible with the standard Matlab ODE representation of differential equations. This toolbox is developed with the following targets in mind:
linux内核配置make menuconfig菜单详解

LINUX内核配置MAKE MENUCONFIG菜单详解我们在linux内核裁剪过程中,进入内核所在目录,键入 make menuconfig 就会看到一堆的配置菜单,它们具体代表什么含义呢?我们该如何取舍呢?这里把近期收集到的一些信息做一个总结。
1、General setup代码成熟度选项,它又有子项:1.1、prompt for development and/or incomplete code/drivers该选项是对那些还在测试阶段的代码,驱动模块等的支持。
一般应该选这个选项,除非你只是想使用 LINUX 中已经完全稳定的东西。
但这样有时对系统性能影响挺大。
1.2、Cross-compiler tool prefix交叉编译工具前缀,例如:Cross-compiler tool prefix值为: (arm-linux-)1.3、Local version - append to kernel release内核显示的版本信息,填入 64字符以内的字符串,你在这里填上的字符口串可以用uname -a 命令看到。
1.4、Automatically append version information to the version string自动在版本字符串后面添加版本信息,编译时需要有perl以及git仓库支持1.5、Kernel compression mode (Gzip) --->有四个选项,这个选项是说内核镜像要用的压缩模式,回车一下,可以看到gzip,bzip2,lzma,lxo,一般可以按默认的gzip,如果要用bzip2,lzma,lxo要先装上支持1.6、Support for paging of anonymous memory (swap)使用交换分区或交换文件来做为虚拟内存,一定要选上。
1.7、System V IPC表示系统的进程间通信Inter Process Communication,它用于处理器在程序之间同步和交换信息,如果不选这项,很多程序运行不起来,必选。
Cleanix:A Big Data Cleaning Parfait

Cleanix:A Big Data Cleaning ParfaitHongzhi Wang Harbin Institute of Technology wangzh@Mingda LiHarbin Institute of Technologylimingda@Yingyi BuUniversity of California,Irvineyingyib@Jianzhong Li Harbin Institute of Technology lijzh@Hong GaoHarbin Institute of Technologyhonggao@Jiacheng ZhangHarbin Institute of Technologychinahitzjc@ABSTRACTIn this demo,we present Cleanix,a prototype system for cleaning relational Big Data.Cleanix takes data integrated from multiple data sources and cleans them on a shared-nothing machine cluster. The backend system is built on-top-of an extensible andflexible data-parallel substrate—the Hyracks framework.Cleanix supports various data cleaning tasks such as abnormal value detection and correction,incomplete datafilling,de-duplication,and conflict res-olution.We demonstrate that Cleanix is a practical tool that sup-ports effective and efficient data cleaning at the large scale.1.INTRODUCTIONRecent popular Big Data analytics applications are motivating both industry and academia to design and implement highly scal-able data management tools.However,the value of data not only depends on the quantity but also relies on the quality.On one side, due of the high volume and the high variation,those Big Data ap-plications suffer way more data quality issues than traditional ap-plications.On the other side,efficiently cleaning a huge amount of data in a shared-nothing architecture has not been well studied yet. Therefore,to improve the data quality is an important yet challeng-ing taskMany data cleaning tools[6]have been proposed to help users to detect and repair errors in the data.Although these systems could clean data effectively for many datasets,they are not suitable for cleaning Big Data due to the following three reasons.First,none of the existing systems can scale out to hundreds and thousands of machines in a shared-nothing manner.Second,various error types such as incompleteness,inconsistency,duplication,and value conflicting may co-exist in the Big Data while most existing sys-tems are ad-hoc and only focus on a specific error type.As exam-ples,CerFix[4]focus on inconsistency while AJAX[5]is for de-duplication and conflict resolution.The last but not least,the exist-ing systems often require users to have specific data cleaning exper-tise.For example,CerFix[4]require users to understand the con-cept of conditional functional dependency(CFD),while AJAX[5] lets users express data cleaning tasks with a declarative language. However,many real-world users do not have a solid data cleaning Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage,and that copies bear this notice and the full ci-tation on thefirst page.Copyrights for third-party components of this work must be honored.For all other uses,contact the owner/author(s).Copyright is held by the author/owner(s).CIKM’14,November3–7,2014,Shanghai,China.ACM978-1-4503-2598-1/14/11./10.1145/2661829.2661837.background nor understand the semantics of a specific data clean-ing language.In order to address the fundamental issues in existing systems and support data cleaning at a very large scale,we design and im-plement a new system called Cleanix.We list the key features of Cleanix as follows.•Scalability.Cleanix performs data quality reporting tasks and data cleaning tasks in parallel on a shared-nothing com-midity machine cluster.The backend system is built on-top-of Hyracks[1],an extensible,flexible,scalable and general-purpose data parallel execution engine,with our user-defined data cleaning second-order operators andfirst-order functions.•Unification.Cleanix unifies various automated data repair-ing tasks for errors by integrating them into a single parallel dataflow.New cleaning functionalities for newly discovered data quality issues could be easily added to the Cleanix dataflow as ei-ther user-defined second-order operators orfirst-order functions.•Usability.Cleanix does not require users to be data cleaning ex-perts.It provides a simple and friendly graphical user interface for users to select rules with intuitive meanings and high-level descriptions.Cleanix also provides a bunch of visualization util-ities for users to better understand error statistics,easily locate the errors andfix them.The main goal of this demonstration is to present the Cleanix sys-tem architecture and execution process by performing a series of data integration and cleaning tasks.We show how the data clean-ing operators are used to clean the data integrated from multiple data sources.2.SYSTEM OVERVIEWWe give a system overview in this section.First,we discuss the data cleaning tasks in Section2.1.Then,Section2.2briefly introduces the Hyracks execution engine and illustrates why Hyracks is chosen as the Cleanix backend.Finally,we discuss the Cleanix architecture of the system in Section2.3.2.1Data Cleaning TasksCleanix aims to handle four types of data quality issues in a uni-fied way:•Abnormal value detection and correcting is tofind the anomalies according to the users’options of rules and modify them to a near value that coincides with the rules.•Incomplete datafilling is tofind the empty attributes in the data andfill them with proper values.•De-duplication is to merge and remove duplicated data.•Conflict resolution is tofind conflicting attributes in the tuples referring to the same real-world entity andfind the true values for these attributes.We believe that these four data cleaning tasks cover most data qual-ity issues.Note that even though some data errors could not be pro-cessed directly such as non-concurrency and inconsistency,one can take care of them by dynamically deploying newfirst-order user-defined functions into our system.For example,non-concurrency can be processed as conflict resolutions among the data referring to the same real-world entity.2.2The Hyracks Execution EngineWe use Hyracks as the Cleanix backend to accomplish the above tasks efficiently at large scales Hyracks is a data-parallel execution engine for Big Data computations on shared-nothing commodity machine pared to MapReduce[3],Hyracks has the following advantages:•Extensibility.It allows users to add data processing operators and connectors,and orchestrate them into whatever DAGs.How-ever,in the MapReduce world,we need to cast the data cleaning semantics into a scan(map)—group-by(reduce)framework.•Flexibility.Hyracks supports a variety of materialization poli-cies for repartitioning connectors,while MapReduce only has the localfile system blocking-materialization policy and the HDFS materialization policy.This allows Hyracks to be elastic to dif-ferent cluster configurations.•Efficiency.The extensibility andflexibility together lead to sig-nificant efficiency potentials.Several cloud computing vendors are developing non-MapReduce parallel SQL enginesto support fast Big Data analytics.However, these systems are like“onions"[2]—one cannot directly use their internal Hyracks-like engines under the SQL skin for data cleaning. However,the Hyracks software stack is like a layered“parfait"[2] and Cleanix is yet-another parfait layer on-top-of the core Hyracks layer.2.3Cleanix ArchitectureCleanix provides web interfaces for users to input the informa-tion of data sources,parameters and rule selections.Data from mul-tiple data sources are preprocessed and loaded into a distributedfile system—HDFS1.Then each slave machine reads part of the data to start the cleaning.The data cleaning dataflow containing second-order operators and connectors is executed on slaves according to the user specified parameters and rules(e.g.,first-order functions). At the end of the dataflow,the cleaned data are written to HDFS. Finally,the cleaned data are extracted from HDFS and loaded into the desired target database.3.THE SYSTEM INTERNALSIn this section,we discuss the details of the Cleanix data cleaning pipeline,the algorithmic operators and the profiling mechanism.3.1Data Processing OrderingTo make the discussion brief,we use A,I and D and C to rep-resent the modules of the process of abnormal value detection and correcting,incomplete datafilling,de-duplication and conflict res-olution,respectively.The order of four tasks of data cleaning in Cleanix is determined with the consideration of effectiveness and efficiency.These four modules could be divided into two groups. 1/wiki/Apache_Hadoop Module A and I are in the same group(Group1)sharing the same detection phase since the detection of abnormal values and empty attributes can be accomplished in a single scan of the data.Module D and C are in the same group(Group2)since the identifications of entities with the entity resolution operator are required for both de-duplication and conflict resolution.De-duplication merges tu-ples with the same entity identification while conflict resolution is tofind true values for conflicting attributes for the different tuples referring the same entity identification.The reason why Group1is executed before Group2is that the repairation of abnormal values and empty attributed will increase the accuracy of entity resolu-tion.In Group1,Module A is before I since abnormal values in-terfere the incomplete attributefiling and lead to incorrectfillings. In Group2,Module D is before C since only when different tuples referring to the same entity are found and grouped,the true values of conflicting attributes could be found.3.2Dataflow DetailsThe dataflow graph is shown in Figure1.The dataflow has8 algorithmic operators and4stages,where the computation of each stage is“local"to each single machine and the data exchange(e.g., broadcast or hash repartitioning)happens at the stage boundaries. In the following part,we illustrate the algorithmic operators and the rules for each stage in the topological order in Figure1. Stage1.This stage is performed on each slave machine.•DataRead.It scans incomingfile splits from the HDFS.The data are parsed and translated into the Cleanix internal format.•Correct.This is blocking operator—data are checked accord-ing to the rules selected by users to detect the abnormal values and incomplete tuples.When an abnormal value is detected,it is corrected according to corresponding revision rules(first-order functions).When an incomplete tuple is encountered,it is iden-tified for further processing.•BuildNullGram.This operator builds an inverted list for all in-complete tuples for the imputation based on similar tuples.The inverted list is called the gram table.It is a hash table in which the k-gram is the key and the id set of tuples containing such a k-gram is the value.Stage2.The incoming broadcast connector to this stage broadcasts the gram tables such that all slaves share the same global gram table.•Fill.For each tuple with incomplete attribute,similar tuples are found according to the gram table.The incomplete attribute is filled with the aggregated value of the corresponding attribute in similar tuples according to the imputation rules(first-order functions)selected by users such as average,max or the most frequent.•BuildGram.A local gram table is built for the local data for the attributes potentially containing duplications or conflicts,which are chosen by users.Since a local gram table has been built with BuildNullGram operator,only the newlyfilled values of corresponding attributes are scanned in this step.Stage3.The local gram tables are broadcast to make all slaves share the same global gram table.Note that in this stage,only the updated values in local gram tables are broadcast.•ComputeSimilarity.The similarities between each local tuple and other tuples are computed according to the global gram ta-ble.When the similarity between two tuples is larger than a threshold,they are added to the same group.After local data are scanned,many groups are obtained.Stage 3Data Movement in Single Machine Broadcast HDFS Read/WriteFigure1:The Cleanix Dataflow GraphStage4.The groups are partitioned according to the hashing value of bloomfilter of the union of gram sets in this group.•De-duplication.A weighted graph G is built to describe the sim-ilarity between tuples in each group.Similar vertices are merged iteratively in G until no pairs of vertices can be merged[7].This step is executed iteratively until the ratio between the number of shared connected vertices and the number of the adjacent ver-tices of each vertex is smaller than a threshold.The tuples corre-sponding to all merged vertices are considered as duplications.•Conflict Resolution.Tuples corresponding to the merged ver-tices are merged.During the merging,when an attribute with conflicting values is detected,it is resolved with voting accord-ing to the selected rules chosen by users.The options(first-order functions)include max,min,average and the most frequent. 3.3ProfilingEach stage sends a corresponding profiling report back to the Hyracks master machine by using the Hyracks management events. When the master machine receives the profiling reports,it redirects them to the Cleanix graphical user interface such that users can see the error exploration report,the data quality report and the data cleaning result review.4.DEMONSTRATIONSIn this section we describe the user interfaces of Cleanix in de-tails and explain the aims of our demonstration.Specifying Parameters.Thefirst step in using Cleanix is to load data from data sources into the ers simply need to provide the name,port,username and password of the data sources. Our system also supports databases on the web with a reachable IP address.The interface for user inputting parameters is generated accord-ing to the schema of databases.Our system requires users to input three kinds of required information for each attribute:(1)whether the attribute should be checked;(2)whether the attribute is allowed to be null;(3)the data type of an attribute.Error Exploration.Our system shows the error in the data ex-ploration interface for users to review data errors.In this demon-stration we show the following features.•How the users can explore the data with error identifications. The errors in data are distinguished with different colors in this interface.The user can then further select a tuple in a table.Then the details of the data errors are shown.In this way,users can identify the reasons why the tuple is marked as an error tuple.•How the users explore the data by means of data errors.When the user selects an data error,its corresponding tuples will be displayed in a table.A user could further select a data error de-tection or correction rule and the tuples with attributes violating the rules are shown with the desired attribute highlighted.Data Quality Report.Statistics of data quality information are summarized and shown to users to check the data quality in high level.In the demonstration we show:•The data quality problem in table and attribute level.In partic-ular,this component computes various data quality problem in quantity by means of data sources,tuples and attributes shown in histogram.A similar categorization exists at both the attribute and tuple level.•How the violations are distributed among the data.Cleanix com-putes various statistical measures and reports statistics regarding to the selected rules.The user can choose to retrieve this infor-mation at different levels.Data Cleaning Results Review.In thefinal part of the demonstration,we illustrate the exploration of data cleaning re-sults and interaction of user and the system.More specifically,we compare the repaired data with the original ones.The original and modified data are distinguished in different colors.When the user selects a modified value,the modifications are shown.Additionally, the user could modify the data.The modifications are merged when the cleaned data is transmitted from HDFS to the target database If the input value has some errors,they will be identified and sug-gested correct modifications close to the input value are shown for selection.In the interface,the revised tuples and the revision results are highlighted.Acknowledgements.This paper was partially supported by NGFR973grant2012CB316200and NSFC grant61472099. 5.REFERENCES[1]Vinayak R.Borkar,Michael J.Carey,Raman Grover,Nicola Onose,and Rares Vernica.Hyracks:Aflexible and extensible foundation for data-intensive computing.In ICDE,pages1151–1162,2011.[2]Vinayak R.Borkar,Michael J.Carey,and Chen Li.Inside“Big Datamanagement":ogres,onions,or parfaits?In EDBT,pages3–14,2012.[3]Jeffrey Dean and Sanjay Ghemawat.MapReduce:Simplified dataprocessing on large clusters.In OSDI,pages137–150,2004.[4]Wenfei Fan,Jianzhong Li,Shuai Ma,Nan Tang,and Wenyuan Yu.CerFix:A system for cleaning data with certainfixes.PVLDB,4(12):1375–1378,2011.[5]Helena Galhardas,Daniela Florescu,Dennis Shasha,Eric Simon,andCristian-Augustin Saita.Declarative data cleaning:Language,model, and algorithms.In VLDB,pages371–380,2001.[6]Thomas N.Herzog,Fritz J.Scheuren,and William E.Winkler.Dataquality and record linkage techniques.Springer,2007.[7]Lingli Li,Hongzhi Wang,Hong Gao,and Jianzhong Li.EIF:Aframework of effective entity identification.In WAIM,pages717–728, 2010.。
matpower介绍

12IEEE TRANSACTIONS ON POWER SYSTEMS, VOL. 26, NO. 1, FEBRUARY 2011MATPOWER: Steady-State Operations, Planning, and Analysis Tools for Power Systems Research and EducationRay Daniel Zimmerman, Member, IEEE, Carlos Edmundo Murillo-Sánchez, Member, IEEE, and Robert John Thomas, Life Fellow, IEEEAbstract—MATPOWER is an open-source Matlab-based power system simulation package that provides a high-level set of power flow, optimal power flow (OPF), and other tools targeted toward researchers, educators, and students. The OPF architecture is designed to be extensible, making it easy to add user-defined variables, costs, and constraints to the standard OPF problem. This paper presents the details of the network modeling and problem formulations used by MATPOWER, including its extensible OPF architecture. This structure is used internally to implement several extensions to the standard OPF problem, including piece-wise linear cost functions, dispatchable loads, generator capability curves, and branch angle difference limits. Simulation results are presented for a number of test cases comparing the performance of several available OPF solvers and demonstrating MATPOWER’s ability to solve large-scale AC and DC OPF problems. Index Terms—Load flow analysis, optimal power flow, optimization methods, power engineering, power engineering education, power system economics, power system simulation, power systems, simulation software, software tools.I. INTRODUCTIONTHIS paper describes MATPOWER, an open-source Matlab power system simulation package [1]. It is used widely in research and education for AC and DC power flow and optimal power flow (OPF) simulations. It also includes tools for running OPF-based auction markets and co-optimizing reserves and energy. Included in the distribution are numerous example power flow and OPF cases, ranging from a trivial four-bus example to real-world cases with a few thousand buses. MATPOWER consists of a set of Matlab M-files designed to give the best performance possible while keeping the code simple to understand and customize. Matlab has become a popular tool for scientific computing, combining a high-level language ideal for matrix and vector computations, a cross-platform runtime withManuscript received December 22, 2009; revised April 19, 2010; accepted May 17, 2010. Date of publication June 21, 2010; date of current version January 21, 2011. This work was supported in part by the Consortium for Electric Reliability Technology Solutions and the Office of Electricity Delivery and Energy Reliability, Transmission Reliability Program of the U.S. Department of Energy under the National Energy Technology Laboratory Cooperative Agreement No. DE-FC26-09NT43321. Paper no. TPWRS-00995-2009. R. D. Zimmerman and R. J. Thomas are with the Department of Applied Economics and Management and the School of Electrical and Computer Engineering, Cornell University, Ithaca, NY 14853 USA (e-mail: rz10@; rjt1@). C. E. Murillo-Sánchez is with the Universidad Autónoma de Manizales, and with Universidad Nacional de Colombia, both in Manizales, Colombia (e-mail: carlos_murillo@). Digital Object Identifier 10.1109/TPWRS.2010.2051168robust math libraries, an integrated development environment and GUI with excellent visualization capabilities, and an active community of users and developers. As a high-level scientific computing language, it is well suited for the numerical computation typical of steady-state power system simulations. The initial motivation for the development of the Matlabbased power flow and OPF code that would eventually become MATPOWER arose from the computational requirements of the PowerWeb platform [3], [4]. As a web-based market simulation platform used to test electricity markets, PowerWeb requires a “smart market” auction clearing software that uses an OPF to compute the allocations and pricing. Having the clear potential to be useful to other researchers and educators, the software was released in 1997 via the Internet as an open-source power system simulation package, now distributed under the GNU GPL [2]. Even beyond its initial release, much of the ongoing development of MATPOWER continued to be driven in large part by the needs of the PowerWeb project. This at least partially explains the lack of a graphical user interface used by some related tools such as PSAT [5]. While it is often employed as an end-user tool for simply running one-shot simulations defined via an input case file, the package can also be quite valuable as a library of functions for use in custom code developed for one’s own research. At this lower level, MATPOWER provides easy-to-use functions for and matrices, calculating forming standard network power transfer and line outage distribution factors (PTDFs and LODFs), and efficiently computing first and second derivatives of the power flow equations, among other things. At a higher level, the structure of the OPF implementation is explicitly designed to be extensible [6], allowing for the addition of user-defined variables, costs, and linear constraints. The default OPF solver is a high-performance primal-dual interior point solver implemented in pure-Matlab. This solver has application to general nonlinear optimization problems outside of MATPOWER and comes with a convenience wrapper function to make it trivial to set up and solve linear programming (LP) and quadratic programming (QP) problems. To help ensure the quality of the code, MATPOWER includes an extensive suite of automated tests. Some may find the testing framework useful for creating automated tests for their own Matlab programs. A number of Matlab-based software packages related to power system simulation have been developed by others. A nice summary of their features is presented in [5]. The primary distinguishing characteristics of MATPOWER, aside from0885-8950/$26.00 © 2010 IEEEZIMMERMAN et al.: MATPOWER: STEADY-STATE OPERATIONS, PLANNING, AND ANALYSIS TOOLS13With the series admittance element in the model denoted by , the branch admittance matrix can be written (2) If the four elements of this matrix for branch are labeled as follows: (3)Fig. 1. Branch model.being one of the first to be publicly and freely available as open-source, are the extensible architecture of the OPF formulation and its ease of use as a toolbox of functions to incorporate into one’s own programs. It is also compatible with Octave. This paper describes the MATPOWER package as it stands at version 4, detailing the component modeling in Section II, the power flow and optimal power flow formulations in Sections III and IV, and some additional functionality in Section V. Some example results and conclusions are presented in Section VI. II. MODELING MATPOWER employs all of the standard steady-state models typically used for power flow analysis. The AC models are described first, then the simplified DC models. Internally, the magnitudes of all values are expressed in per unit and angles of complex quantities are expressed in radians. Due to the strengths of the Matlab programming language in handling matrices and vectors, the models and equations are presented here in matrix and vector form. A. Data Formats The data files used by MATPOWER are Matlab M-files or MAT-files which define and return a single Matlab struct. The M-file format is plain text that can be edited using any standard text editor. The fields of the struct are baseMVA, bus, branch, gen, and optionally gencost, where baseMVA is a scalar and the rest are matrices. In the matrices, each row corresponds to a single bus, branch, or generator. The columns are similar to the columns in the standard IEEE CDF and PTI formats. The number of rows in bus, branch, and gen are , , and , respectively. B. Branches All transmission lines, transformers, and phase shifters are modeled with a common branch model, consisting of a standard transmission line model, with series impedance and total charging capacitance , in series with an ideal phase shifting transformer. The transformer, whose tap ratio has magnitude and phase shift angle , is located at the from end of the branch, as shown in Fig. 1. The complex current injections and at the from and to ends of the branch, respectively, can be expressed in terms of the 2 2 branch admittance matrix and the respective terminal voltages and (1)then four vectors , , , and can be constructed, where the th element of each comes from the corresponding element of . Furthermore, the sparse connection maand used in building the system admittance matrices th element of and trices can be defined as follows. The the th element of are equal to 1 for each branch , where branch connects from bus to bus . All other elements of and are zero. C. Generators A generator is modeled as a complex power injection at a specific bus. For generator , the injection is (4) be the vector of these generator Let generator connection matrix injections. A sparse can be defined such that its th element is 1 if generator is located at bus and 0 otherwise. The vector of all bus injections from generators can then be expressed as (5) D. Loads Constant power loads are modeled as a specified quantity of real and reactive power consumed at a bus. For bus , the load is (6) and denotes the vector of complex loads at all buses. Constant impedance and constant current loads are not implemented directly, but the constant impedance portions can be modeled as a shunt element described below. Dispatchable loads are modeled as negative generators and appear as negative values in . E. Shunt Elements A shunt connected element such as a capacitor or inductor is modeled as a fixed impedance to ground at a bus. The admittance of the shunt element at bus is given as (7) denotes the and admittances at all buses. F. Network Equations For a network with buses, all constant impedance elements of the model are incorporated into a complex bus advector of shunt14IEEE TRANSACTIONS ON POWER SYSTEMS, VOL. 26, NO. 1, FEBRUARY 2011mittance matrix that relates the complex nodal current into the complex node voltages : jections (8) branches, the system Similarly, for a network with and relate the bus voltages to branch admittance matrices the vectors and of branch currents at the from and to ends of all branches, respectively: (9) (10) vector and If is used to denote an operator that takes an creates the corresponding diagonal matrix with the vector elements on the diagonal, these system admittance matrices can be formed as follows: (11) (12) (13) The current injections of (8)–(10) can be used to compute the corresponding complex power injections as functions of the complex bus voltages : (14) (15) (16) The nodal bus injections are then matched to the injections from loads and generators to form the AC nodal power balance equations, expressed as a function of the complex bus voltages and generator injections in complex matrix form as (17) G. DC Modeling The DC formulation [11] (with more detailed derivations in [1]) is based on the same parameters, but with the following three additional simplifying assumptions. • Branches can be considered lossless. In particular, branch resistances and charging capacitances are negligible: (18) • All bus voltage magnitudes are close to 1 p.u. (19) • Voltage angle differences across branches are small enough that (20) By combining (1) and (2) with (18) and (19), the complex current flow in a branch can be approximated as (21)Furthermore, using (19) and this approximate current to compute the complex power flow, then extracting the real part and applying the last of the DC modeling assumptions from (20) yields (22) As expected, given the lossless assumption, a similar derivation . for leads to The relationship between the real power flows and voltage angles for an individual branch can then be summarized as (23)where,, andisdefined in terms of the series reactance and tap ratio for that . branch as With a DC model, the linear network equations relate real power to bus voltage angles, versus complex currents to comvector plex bus voltages in the AC case. Let the be constructed similar to , where the th element is and let be the vector whose th element is equal to . Then the nodal real power injections can be expressed vector of bus voltage angles as a linear function of , the (24) where . Similarly, the branch flows at the from ends of each branch are linear functions of the bus voltage angles (25) and, due to the lossless assumption, the flows at the to ends are given by . The construction of the system matrices is analogous to the system matrices for the AC model: (26) (27) The DC nodal power balance equations for the system can be expressed in matrix form as (28) where approximates the amount of power consumed by the constant impedance shunt elements under the voltage assumption of (19). III. POWER FLOW The standard power flow or loadflow problem involves solving for the set of voltages and flows in a network corresponding to a specified pattern of load and generation. MATPOWER includes solvers for both AC and DC power flow problems, both of which involve solving a set of equations of the form (29)ZIMMERMAN et al.: MATPOWER: STEADY-STATE OPERATIONS, PLANNING, AND ANALYSIS TOOLS15constructed by expressing a subset of the nodal power balance equations as functions of unknown voltage quantities. All of MATPOWER’s solvers exploit the sparsity of the problem and, except for Gauss-Seidel, scale well to very large systems. Currently, none of them include any automatic updating of transformer taps or other techniques to attempt to satisfy typical OPF constraints, such as generator, voltage, or branch flow limits. A. AC Power Flow In MATPOWER, by convention, a single generator bus is typically chosen as a reference bus to serve the roles of both a voltage angle reference and a real power slack. The voltage angle at the reference bus has a known value, but the real power generation at the slack bus is taken as unknown to avoid overspecifying the problem. The remaining generator buses are classified as PV buses, with the values of voltage magnitude and and generator real power injection given. Since the loads are also given, all non-generator buses are PQ buses, with real , , and and reactive injections fully specified. Let denote the sets of bus indices of the reference bus, PV buses, and PQ buses, respectively. In the traditional formulation of the AC power flow problem, the power balance equation in (17) is split into its real and reactive components, expressed as functions of the voltage angles and magnitudes and generator injections and , where the load injections are assumed constant and given: (30) (31) For the AC power flow problem, the function from (29) is formed by taking the left-hand side of the real power balance equations (30) for all non-slack buses and the reactive power balance equations (31) for all PQ buses and plugging in the reference angle, the loads and the known generator injections and voltage magnitudes: (32) The vector consists of the remaining unknown voltage quantities, namely the voltage angles at all non-reference buses and the voltage magnitudes at PQ buses: (33)updated value of by factorizing this Jacobian. This method is described in detail in many textbooks. Also included are solvers based on variations of the fastdecoupled method [8], specifically, the XB and BX methods described in [9]. These solvers greatly reduce the amount of computation per iteration, by updating the voltage magnitudes and angles separately based on constant approximate Jacobians which are factored only once at the beginning of the solution process. These per-iteration savings, however, come at the cost of more iterations. The fourth algorithm is the standard GaussSeidel method from Glimm and Stagg [10]. It has numerous disadvantages relative to the Newton method and is included primarily for academic interest. By default, the AC power flow solvers simply solve the problem described above, ignoring any generator limits, branch flow limits, voltage magnitude limits, etc. However, there is an option that allows for the generator reactive power limits to be respected at the expense of the voltage setpoint. This is done by adding an outer loop around the AC power flow solution. If any generator has a violated reactive power limit, its reactive injection is fixed at the limit, the corresponding bus is converted to a PQ bus, and the power flow is solved again. This procedure is repeated until there are no more violations. B. DC Power Flow For the DC power flow problem [11], the vector the set of voltage angles at non-reference buses consists of (34) and (29) takes the form (35) where is the matrix obtained by simply eliminating from the row and column corresponding to the slack bus and reference angle, respectively. Given that the generator injections are specified at all but the slack bus, can be formed directly from the non-slack rows of the last four terms of (28). The voltage angles in are computed by a direct solution of the set of linear equations. The branch flows and slack bus generator injection are then calculated directly from the bus voltage angles via (25) and the appropriate row in (28), respectively. C. Linear Shift FactorsThis yields a system of nonlinear equations with equations and unknowns, where and are the number of PV and PQ buses, respectively. After solving for , the remaining real power balance equation can be used to compute the generator real power injection at the slack bus. Similarly, the remaining reactive power balance equations yield the generator reactive power injections. MATPOWER includes four different algorithms for solving the AC power flow problem. The default solver is based on a standard Newton’s method [7] using a polar form and a full Jacobian updated at each iteration. Each Newton step involves computing the mismatch , forming the Jacobian based on the sensitivities of these mismatches to changes in and solving for anThe DC power flow model can also be used to compute the sensitivities of branch flows to changes in nodal real power injections, sometimes called injection shift factors (ISF) or generation shift factors [11]. These sensitivity matrices, also called power transfer distribution factors or PTDFs, carry an implicit assumption about the slack distribution. If is used to denote a PTDF matrix, then the element in row and column , , represents the change in the real power flow in branch given a unit increase in the power injected at bus , with the assumption that the additional unit of power is extracted according to some specified slack distribution: (36)16IEEE TRANSACTIONS ON POWER SYSTEMS, VOL. 26, NO. 1, FEBRUARY 2011This slack distribution can be expressed as an vector of non-negative weights whose elements sum to 1. Each element specifies the proportion of the slack taken up at each bus. For the special case of a single slack bus , is equal to the vector . The corresponding PTDF matrix can be constructed by first matrix creating the (37) and then inserting a column of zeros at column . Here are obtained from and , respectively, by eliminating their reference bus columns and, in the case of , removing row corresponding to the slack bus. The PTDF matrix , corresponding to a general slack dis, tribution , can be obtained from any other PTDF, such as by subtracting from each column, equivalent to the following simple matrix multiplication: (38) These same linear shift factors may also be used to compute sensitivities of branch flows to branch outages, known as line outage distribution factors or LODFs [12]. Given a PTDF matrix , the corresponding LODF matrix can be constructed as follows, where is the element in row and column , representing the change in flow in branch (as a fraction of its initial flow) for an outage of branch . First, let represent the matrix of sensitivities of branch flows to branch flows, found by multplying the PTDF matrix by the node-branch incidence matrix: (39) If is the sensitivity of flow in branch with respect to flow in branch , then can be expressed as (40) MATPOWER includes functions for computing both the DC PTDF matrix and the corresponding LODF matrix for either a single slack bus or a general slack distribution vector . IV. OPTIMAL POWER FLOW MATPOWER includes code to solve both AC and DC versions of the optimal power flow problem. The standard version of each takes the following form: (41) (42) (43) (44) A. Standard AC OPF The optimization vector for the standard AC OPF problem consists of the vectors of voltage angles and magni-and the tudes power injectionsandvectors of generator real and reactive :(45)The objective function (41) is simply a summation of individual and of real and reactive power polynomial cost functions injections, respectively, for each generator: (46) The equality constraints in (42) are simply the full set of nonlinear real and reactive power balance equations from (30) and (31). The inequality constraints (43) consist of two sets of branch flow limits as nonlinear functions of the bus voltage angles and magnitudes, one for the from end and one for the to end of each branch: (47) (48) The flows are typically apparent power flows expressed in MVA, but can be real power or current flows, yielding the following three possible forms for the flow constraints: (49)where is defined in (9), in (15), , and the vector of flow limits has the appropriate units for the type of constraint. It is likewise for . The variable limits (44) include an equality constraint on any reference bus angle and upper and lower limits on all bus voltage magnitudes and real and reactive generator injections: (50) (51) (52) (53) B. Standard DC OPF When using DC network modeling assumptions and limiting polynomial costs to second order, the standard OPF problem above can be simplified to a quadratic program, with linear constraints and a quadratic cost function. In this case, the voltage magnitudes and reactive powers are eliminated from the problem completely and real power flows are modeled as linear functions of the voltage angles. The optimization variable is (54)ZIMMERMAN et al.: MATPOWER: STEADY-STATE OPERATIONS, PLANNING, AND ANALYSIS TOOLS17and the overall problem reduces to (55)–(60) at the bottom of the page. C. Extended OPF Formulation MATPOWER employs an extensible OPF structure [6] to allow the user to modify or augment the problem formulation without rewriting the portions that are shared with the standard OPF formulation. This is done through optional input parameters, preserving the ability to use pre-compiled solvers. The standard formulation is modified by introducing additional optional user-defined costs , constraints, and variables and can be written in the following form: (61) (62) (63) (64) (65) (66) The user-defined cost function is specified in terms a set of parameters in a pre-defined form described in detail in [6]. This form provides the flexibility to handle a wide range of costs, from simple linear functions of the optimization variables to scaled quadratic penalties on quantities, such as voltages, lying outside a desired range, to functions of linear combinations of variables, inspired by the requirements of price coordination terms found in the decomposition of large loosely coupled problems encountered in our own research. D. Standard Extensions In addition to making this extensible OPF structure available to end users, MATPOWER also takes advantage of it internally to implement several additional capabilities. 1) Piecewise Linear Costs: The standard OPF formulation in (41)–(44) does not directly handle the non-smooth piecewise linear cost functions that typically arise from discrete bids and offers in electricity markets. When such cost functions are convex, however, they can be modeled using a constrained cost variable (CCV) method. The piecewise linear cost function is replaced by a helper variable and a set of linear constraints that form a convex “basin” requiring the cost variable to lie in the epigraph of the function .A convex -segment piecewise linear cost function. . .. . .(67), can be defined by a sequence of points where denotes the slope of the th segment, (68)and and . The “basin” corresponding to this cost function is formed by the following constraints on the helper cost variable : (69) The cost term added to the objective function in place of is simply the variable . For an AC or DC OPF, MATPOWER uses this CCV approach internally to automatically generate the appropriate helper variable, cost term, and corresponding set of constraints for any piecewise linear generator costs. 2) Dispatchable Loads: A simple approach to dispatchable or price-sensitive loads is to model them as negative real power injections with associated negative costs. This is done by specifying a generator with a negative output, ranging from a minimum injection equal to the negative of the largest possible load to a maximum injection of zero. With this model, if the negative cost corresponds to a benefit for consumption, minimizing of generation is equivalent to maximizing social the cost welfare. With an AC network model, there is also the question of reactive dispatch for such loads. In MATPOWER, it is assumed that dispatchable loads maintain a constant power factor and an additional equality constraint is automatically added to enforce this requirement for any “negative generator” being used to model a dispatchable load. 3) Generator Capability Curves: The typical AC OPF formulation includes simple box constraints on a generator’s real and reactive injections. However, the true - capability curves of physical generators usually involve some tradeoff between real and reactive capability. If the user provides the parameters defining this tradeoff for a generator, MATPOWER automatically constructs the corresponding constraints. 4) Branch Angle Difference Limits: The difference between the bus voltage angle at the from end of a branch and the(55) (56) (57) (58) (59) (60)18IEEE TRANSACTIONS ON POWER SYSTEMS, VOL. 26, NO. 1, FEBRUARY 2011TABLE I OPF TEST CASESangle at the to end can be bounded above and below to act as a proxy for a transient stability limit, for example. If these limits are provided, MATPOWER creates the corresponding constraints on the voltage angle variables. E. Solvers Early versions of MATPOWER relied on Matlab’s Optimization Toolbox [13] to provide the NLP and QP solvers needed to solve the AC and DC OPF problems, respectively. While they worked reasonably well for very small systems, they did not scale well to larger networks. Eventually, optional packages with additional solvers were added to improve performance, typically relying on Matlab extension (MEX) files implemented in Fortran or C and pre-compiled for each machine architecture. For DC optimal power flow, there is a MEX build [14] of the high performance BPMPD solver [15] for LP/QP problems. For the AC OPF problem, the MINOPF [16] and TSPOPF [17] packages provide solvers suitable for much larger systems. The former is based on MINOS [18] and the latter includes the primal-dual interior point and trust region based augmented Lagrangian methods described in [19]. Beginning with version 4, MATPOWER also includes its own primal-dual interior point solver (MIPS) implemented in pureMatlab code, derived from the MEX implementation of the corresponding algorithms in [19]. If no optional packages are installed, the MIPS solver will be used by default for both the AC OPF and as the QP solver used by the DC OPF. The AC OPF solver also employs a unique technique for efficiently forming the required Hessians via a few simple matrix operations. The MIPS solver has application to general nonlinear optimization problems outside of MATPOWER and comes with a convenience wrapper function to make it trivial to set up and solve LP and QP problems. V. ADDITIONAL FUNCTIONALITY As mentioned earlier, MATPOWER was birthed out of a need for an OPF-based electricity auction clearing mechanism for a “smart market”. In this context, offers to sell and bids to buy power from generators and loads define the “costs” for the OPF that determines the allocations and prices used to clear the auction. MATPOWER includes code that takes bids and offers for real or reactive power, sets up and runs the corresponding OPF, and returns the cleared bids and offers. The standard OPF formulation described above includes no mechanism for completely shutting down generators which are very expensive to operate. Instead they are simply dispatched attheir minimum generation limits. MATPOWER includes the capability to run an OPF combined with a unit de-commitment for a single time period, which allows it to shut down these expensive units and find a least cost commitment and dispatch using an algorithm similar to dynamic programming. In some cases, it may be desirable to further constrain an OPF solution with the requirement to hold a specified level of capacity in reserve to cover contingencies. MATPOWER includes OPF extensions that allow it to co-optimize energy and reserves, subject to a set of fixed zonal reserve requirements. This code also serves as an example of how to customize the standard OPF with additional variables, costs, and constraints. VI. RESULTS AND CONCLUSIONS Several example cases are used to compare the performance of the various OPF solvers on example networks ranging in size from nine buses and three generators to tens of thousands of buses, thousands of generators and tens of thousands of additional user variables and constraints. Table I summarizes the test cases in terms of the order of the cost function (quadratic or linear), numbers of buses, generators and branches ( , , and ), numbers of variables and constraints ( and ) for both AC and DC OPF formulations, and the number of binding lower voltage limits and branch flow limits for for the DC case. the AC problem and flow limits For each case, six different AC OPF solvers and four different DC OPF solvers were used to solve the problem on a laptop with a 2.33-GHz Intel Core 2 Duo processor running Matlab 7.9. Table II gives the run times in seconds for the solvers which were successful, with the fastest time highlighted in bold for each example. The first algorithm listed for each is from Matlab’s Optimization Toolbox, in the case of the AC OPF and or for the DC problem. Next are the standard and step-controlled variants of the pure-Matlab implementation of the primal-dual interior point method, and last are some of the C and Fortran-based MEX solvers distributed as MATPOWER optional packages. For small systems, the clear winners are MINOPF for AC and BPMPD for DC, both Fortran-based MEX files. For larger systems, the primal-dual interior point solvers have the clear advantage, with the pure-Matlab implementation offering respectable performance relative to the C-based MEX versions. MATPOWER provides a high-level set of power flow and optimal power flow tools for researchers, educators, and students. The optimal power flow is extensible, allowing for easy。
idea unit test with coverage取消标记 -回复

idea unit test with coverage取消标记-回复Unit Testing with CoverageUnit testing is an essential process in software development that involves the testing of individual components or units of a program to ensure their functionality. Code coverage, on the other hand, measures the amount of code that is being exercised by the unit tests. By combining unit testing with coverage analysis, developers can gain valuable insights into their codebase and identify potential areas of improvement.In this article, we will explore the concept of unit testing with coverage and how it can benefit developers in creatinghigh-quality software. We will go step by step in explaining the process, its importance, and how to effectively implement it in your development workflow.Step 1: Understanding Unit TestingUnit testing focuses on testing individual units of code, such as functions, modules, or classes, in isolation. The goal is to ensure that each unit works as intended and produces the expectedoutput for a given set of inputs. By testing units independently, developers can identify and fix bugs early in the development cycle, leading to more robust and maintainable code.Unit tests typically follow a simple structure: they set up the necessary inputs, call the unit under test, and verify the output against expected results. These tests are automated and can be run repeatedly, providing quick feedback on the code's behavior. Unit testing frameworks, such as JUnit for Java or XCTest for Swift, provide tools and conventions to simplify this process.Step 2: Introducing Code CoverageCode coverage measures the extent to which the source code is being executed by tests. It helps developers understand how much of their code is actually being exercised and helps identify areas that might have been overlooked during testing. Code coverage is often expressed as a percentage, where 100 coverage means that every line of code has been executed at least once.There are different levels of code coverage, including line coverage, branch coverage, and statement coverage. Line coverage measuresthe percentage of lines executed, while branch coverage focuses on the number of conditional branches. Statement coverage, on the other hand, ensures that each statement in the code has been executed.Step 3: Benefits of Unit Testing with CoverageCombining unit testing with coverage analysis offers several benefits to developers and the software development process as a whole. These benefits include:1. Early bug detection: Unit tests help in identifying and fixing bugs early in the development cycle. The coverage analysis ensures that each code path is tested, reducing the risk of undetected issues.2. Improved code quality: By aiming for high code coverage, developers are encouraged to write more modular, testable, and maintainable code. Thorough unit testing ensures that code changes and refactoring do not introduce regressions.3. Regression testing: Unit tests can be used as a safety net when making changes to the codebase. By running existing tests aftermodifications, developers can quickly identify if any previous functionality has been broken unintentionally.4. Documentation and understanding: Unit tests can serve as living documentation, providing insights into how the code is intended to work. New developers can refer to these tests to understand the codebase quickly.Step 4: Implementing Unit Testing with CoverageTo implement unit testing with coverage effectively, follow these steps:1. Set up a testing framework: Choose a unit testing framework that supports your programming language and create a test suite to write and run tests. Ensure that the framework provides coverage analysis capabilities.2. Write meaningful tests: Create test cases that cover different scenarios and verify the expected behavior of each unit. Use assertions and test doubles, such as mocks or stubs, to isolate dependencies.3. Measure code coverage: Use the coverage analysis tools provided by your testing framework to measure code coverage. Monitor the percentage of code covered and identify any areas that need improvement.4. Continuous integration: Integrate unit testing with coverage into your development workflow. Automate the execution of tests and coverage analysis as part of your continuous integration (CI) pipeline.5. Set coverage goals: Define coverage goals based on your project's requirements and complexity. Aim for high coverage, but also consider the trade-off between time spent on testing and the risks associated with uncovered code.In conclusion, unit testing with coverage is a powerful approach to improve software quality and reduce bugs in the development process. By systematically testing individual units of code and measuring the coverage of these tests, developers gain confidence in their codebase and can make informed decisions about areasthat need improvement. Implementing unit testing with coverage requires discipline, but the benefits far outweigh the effort invested. So, embrace this practice and start writing better software today!。
Software-Funktion_DCM_en

October 2009Software FunctionDCMDynamic CollisionMonitoring for iTNC 5302Complex machine motions, especially during multiaxis machining, and steadily increasing rapid-traverse and machining speeds make it diffi cult for the machine operator to foresee axis movements.Integrated Dynamic Collision Monitoring (DCM) is a powerful function of theiTNC 530 for preventing collisions between the tool and machine components, or between the tool and fi xtures. This is possible in both the Program Run modes and set-up mode when the machine axes are moved manually by the operator: The iTNC 530 detects when the tool is in danger of causing a collision and stops the axis movements while issuing an errormessage. In addition, the machine operator can have the iTNC display all defi ned collision objects in order to show a simplifi ed depiction of "machine versus tool," including tool carriers and measured fi xtures. In this view, the iTNC displays the colliding objects in a different color. T his helps to prevent machine damage and costly downtimes. Unattended shifts become safer and more reliable.Since its introduction at the endof 2005, Dynamic Collision Monitoring (DCM) has been in use on more than 3000 iTNC-controlled machine tools with differing confi gurations, where it has been providing reliable protection against collision.Safe Setup and MachiningIntegrated Dynamic Collision Monitoring (DCM)3The machine tool builder must defi ne the machine components to be monitored by the iTNC. The working space and the collision objects are described usinggeometric bodies such as planes, cuboids and cylinders. Complex machinecomponents can be modeled with multiple geometric bodies. The tool is automatically considered a cylinder of the tool radius (defi ned in the tool table). For tiltingdevices, the machine tool builder can use the tables for the machine kinematics also to defi ne the collision objects. T his ensures that all components that are attached to the machine are always considered during collision monitoring.HEIDENHAIN offers the KinematicsDesign software tool to help you create andvisually check collision objects quickly and simply. This software tool allows the machine tool builder to use interactive graphics to describe the kinematics and the collision objects that are attached to the machine as early as during the design phase of the machine tool.Confi guring the MachineMachine Components Can Be Defi ned as Collision Objects by the Machine T ool BuilderFixture and T ool-Carrier Management User-Defi nable Collision ObjectsFixture managementThe collision monitoring function of the iTNC 530 also takes into account fi xtures that must be measured by the user with a 3-D touch probe according to the requirements of the fi xture designer. This enables you to detect collisions between the tool and fi xtures in time, so that they can be avoided. HEIDENHAIN or the machine tool builder provides parameterized descriptions of standardfi xtures. The FixtureWizard, which is available in set-up mode on the iTNC, enables you to use these standard fi xtures for describing your own fi xtures.In the Manual Operation mode, the fi xture management function is used to set up the fi xtures in the machine's work envelope. The procedure is simple and similar to probing a workpiece. An interactive menu allows you to use the integrated measuring cycles to measure and automatically transfer the fi xture data, and to defi ne thevariable input values, such as the jawdistance of a vise. The type and sequenceof the individual steps depend on therespective fi xture and cannot be changed.This prevents unnecessary entries andensures that the fi xture can be set up asquickly and easily as possible.Y ou can also have the iTNC create a testprogram after the measuring process. Inthe Program Run, Full Sequence mode theiTNC moves to defi ned test points andevaluates them. If the actual values of thetest points exceed the tolerance that canbe defi ned for the nominal values, then theiTNC issues corresponding errormessages. The measurement result ofeach test point is displayed on the screenand is also available in a log fi le.T ool-carrier management (available as ofNC software 340 49x-06)T ool carriers are managed in a way similarto fi xtures. T ool-carrier templates can bedefi ned by parameters in the control, whichmakes it easy to integrate them in collisionmonitoring. Even angle heads can bedefi ned simply and graphically interactively.In the tool table, you simply assign theassociated tool carrier to the respectivetool so that the iTNC also considers thetool carrier in the tool call. In this manner,the 3-D touch probes from HEIDENHAINcan also be integrated completely incollision monitoring. HEIDENHAIN naturallyprovides the corresponding descriptions forthe collision objects.45Collision test in T est Run modeIn order to avoid machine downtime, you can check for collisions in the T est Run mode before actually machining a part. The iTNC displays the machine kinematics confi guration defi ned by the machine tool builder with all defi ned collision objects, including the fi xtures if they have already been measured. As usual, the screen layout can be adjusted in such a way that the machine kinematics confi guration appears at the right of the NC program, or takes up the whole screen in the same manner as has been possible forworkpiece simulation on the iTNCs for many years now. If there is a collision, the iTNC displays an error message and marks the colliding objects in red. By shifting the datum, you can move the workpiece to a position where no collision can occur during machining.During T est Run, other kinematics models can be activated too, even if a program is being run on the machine at the same time. This is an especially interesting feature for machines with head-changing systems.Safe in Any SituationDynamic Collision Monitoring on the iTNCSafe manual traverse of the machine axesMany collisions occur during set-up mode when the wrong axis-direction key isaccidentally pressed in the daily hustle and bustle at work. The Dynamic Collision Monitoring function of the iTNC provides excellent protection in such a case, because it monitors the tool and all defi ned collision objects for collision with each other. If two collision objects move toward each other, the iTNC fi rst reduces the feed rate and then stops machine movement completely if the distance becomes too small. In these cases, it is especially useful that the operator can retract the machine axes only in the direction in which the distance between the collision objects actually increases. This seems to be easily manageable, but fi ve-axis machining with a tilted tool requires complex calculations that are taken care of by the iTNCautomatically in real time. Strain on the operator is reduced and safety is considerably increased.Full control over the machining process In Automatic mode, the iTNC monitors the movement of all objects with respect to each other. If a collision is impending, the iTNC interrupts the machining process and issues an error message with the names of the colliding objects. In addition, the colliding objects are highlighted in a different color so that they can easily be identifi ed by the machine operator.6Process reliability is increased by machine simulation software, especially if the simulation software uses virtualTNC. virtualTNC is the software kernel of the iTNC, which can be integrated in the machine simulation software. Please see page 8 for more information on virtualTNC.Process reliability is increased even more if collision tests can be performed both before actual machining and when the machine operator begins to set up the machine. This is possible in real time with the Dynamic Collision Monitoring (DCM) function that is integrated in the iTNC 530, offering the following benefi ts in particular:Manual positioningIn set-up mode, the machine operator moves the machine manually with the axis-direction keys or with the electronic handwheel. External simulation ofmachine operations, meaning the manual movement of the axes by the machine operator, is not possible beforehand. This is where only DCM – as a function that is integrated in the control – provides real protection and considerably reduces the danger of collision.DCM Provides Safety in Real TimeAdvantages over External Simulation SystemsAll common CAM systems alreadyprevent collisions between the tool or tool holder and the workpiece during CAM programming. Some systems alsosimulate the movement of rotary axes and graphically display the tilting mechanics (swivel head and/or rotary tilting table).CAM systems that are even more powerful can show the complete virtual machine as well as the machining process in the actual (virtual) machine environment.These systems do not yet simulate the machine-specifi c NC program that is later run by the NC control, butmachine-neutral, CAM-system-internal traverse paths that are converted to an actual NC program by a postprocessor after successful simulation. Only after conversion by the postprocessor does the NC program contain all control-specifi c and machine-specifi c commands thatare translated into actual axis movements by the NC control during machining. Maximum process reliability is therefore achieved by simulating the actual NC program together with the actualtool-compensation values, actual datums, actual machine settings, and the actual control software, taking into account further machine components in the work envelope of the machine (e.g. vise, tool measuring devices, partitions, etc.).Actual clamping positionThe actual clamping position of the workpiece is unambiguously defi ned by manually setting the machine datum. The workpiece alignment (basic rotation) is also not exactly defi ned until the workpiece has been probed. In the worst case, a collision or a violation of a software limit switch is not detected until the part is beingmachined. This occurs especially when a workpiece takes up the entire workenvelope of the machine. Sometimes the workpieces are even measured fullyautomatically during the machining process by means of touch probe cycles, which do not determine the datum and workpiece position unambiguously until program run has been started. Again, only an integrated system, such as DCM, which checks all required positions in real time during the machining process, provides optimum collision protection.Global program settingsT ransformations (shifts, rotations, axis swapping) can be defi ned in global program settings, which add to and are superimposed over the transformations defi ned in the NC program. The user can defi ne or cancel transformations at any time during the machining process. This means that only the control is aware of these transformations, and potentialcollisions can therefore only be prevented byDCM.Actual tool-compensation dataT ool-compensation values sometimes deviate from the value simulated beforehand. The actual values are not entered into the tool table of the iTNC until the tool changer is fi lled, and do not become effective until a tool is called. Sometimes further compensation values (delta values), which the user can add to the tool call, also apply. It is useful if the external simulation system can access the tool presetter. It is also possible to use tool touch probes or lasers to determine the actual compensation values for length and radius during the machining process and save them in the compensation-value tables of the iTNC. This means that, in the worst case, collisions cannot be detected before program run. Once again, DCM puts you on the safe side.Inserting a replacement toolWhen the tool life has expired, fully automated tool changes can take place at any point in the program. The iTNC inserts the replacement tool defi ned by the user. Especially in fi ve-axis milling, this requires complex traverse motions that are controlled via special macros and cannot be simulated externally. However, DCM detects possible collisions in time.Simulation of complex control functionsComplex control functions that are used,for example, to calculate compensationmovements in linear and rotary axesdepending on the active kinematicsconfi guration, cannot be simulated exactlyby external simulation systems. This caneven affect machining operations with atilted tool that are executed with thePLANE function, i.e. 2.5-D operations.DCM also helps you avoid possiblecollisions if you use other functions thatcannot be simulated externally, such as:FUNCTION TCPM AXIS SPAT: Inclined-tool•machining with 45° swivel headsFUNCTION TCPM PATHCTRL VECTOR:•Vector interpolation between the startingand end position, independent ofkinematics confi gurationM140 MB: Retraction function•LN blocks: NC programs with surface•normal vectors automatically position therotary axes of a machine according tointernal rules.Confi guration-dependent behaviorThe machine operator and machine toolbuilder have numerous possibilities foradapting the control's behavior in variousfunctions to their individual requirementsby using machine parameters. Forexample, different positioning movementswithin or at the end of cycles, the effect ofcoordinate transformations, the positioningbehavior, etc. can be defi ned and adapted.Unambiguous external simulation of thesesettings is also not possible. In addition,these types of settings can temporarily bechanged during run time of the NCprogram. Collisions can therefore only bedetected by the DCM function in thecontrol.PLC functionsThe machine tool builder uses the PLC(programmable logic controller) to adaptthe iTNC to the machine. This makes itpossible to realize any machine-dependentfunctions, such as a tool change, headchange or pallet change, and much more.These types of traverse motions defi nedby the machine tool builder are usually nottaken into account by external simulationsoftware, unless virtualTNC (see page 8)is used as a control kernel for simulation.The integral solution proves its strength inthis area too, because it also monitorsthese types of movements.7DR. JOHANNES HEIDENHAIN GmbH Dr.-Johannes-Heidenhain-Straße 583301 Traunreut, Germany {+49 8669 31-0|+49 8669 5061E-mail: info@heidenhain.dewww.heidenhain.deFor catalogs, brochures andProduct Information sheets, visit www.heidenhain.de/docu689 241 · 00 · A · 02 · 10/2009 · PDFThe virtualTNC software for PCs makes it possible to use the iTNC 530 as a control component for machine-simulationapplications (virtual machines) on external computer systems.With virtualTNC, machine-simulationapplications (virtual machines) are capable of the complete simulation of production units to optimize production processes in the fi eld beforehand. virtualTNC can control the axes of a virtual machine as if it were a real system. Users program and operate the control in the same way as they do an actual HEIDENHAIN iTNC 530.virtualTNC is the programming station software of the iTNC 530 with a special interface for transmitting the nominalposition values of the axes to the machine simulation software. This makes it possible to simulate all control functions just as they will later be executed on an actualmachine. The PLC can also be integrated in virtualTNC so that even machine-specifi c traverse motions (e.g. tool change or pallet change) can be simulated as if they were real.virtualTNCPC Software for Control of Virtual MachinesMore information:Catalog: • iTNC 530Brochures: • HEIDENHAIN DNC, Remo-T ools SDK, virtualTNC。
mcb包的说明说明书

Package‘mcb’October13,2022Type PackageTitle Model Confidence BoundsVersion0.1.15Author Yang Li,Yichen Qin,Heming DengMaintainer Heming Deng<***************.cn>Description When choosing proper variable selection methods,it is important to consider the uncer-tainty of a certain method.The model confidence bound for variable selection identi-fies two nested models(upper and lower confidence bound models)contain-ing the true model at a given confidence level.A good variable selec-tion method is the one of which the model confidence bound under a certain confi-dence level has the shortest width.When visualizing the variability of model selection and com-paring different model selection procedures,model uncertainty curve is a good graphi-cal tool.A good variable selection method is the one of whose model uncer-tainty curve will tend to arch towards the upper left corner.This function aims to ob-tain the model confidence bound and draw the model uncertainty curve of certain sin-gle model selection method under a coverage rate equal or little higher than user-given confiden-tial level.About what model confidence bound is and how it work please see Li,Y.,Luo,Y.,Fer-rari,D.,Hu,X.and Qin,Y.(2019)Model Confidence Bounds for Variable Selection.Biomet-rics,75:392-403.<DOI:10.1111/biom.13024>.Besides,'flare'is needed only you ap-ply the SQRT or LAD method('mcb'totally has8methods).Al-though'flare'has been archived by CRAN,you can still get it in<https:///package=flare>and the latest version is useful for'mcb'.License GPL(>=2)Encoding UTF-8LazyData trueImports parallel,methods,leaps,lars,MASS,glmnet,ncvreg,smoothmest,ggplot2,reshape2Depends R(>=3.6.0)Suggestsflare,testthatNeedsCompilation noRepository CRANDate/Publication2020-06-0513:00:02UTC12mcb R topics documented:Diabetes (2)mcb (2)pare (4)Index6 Diabetes DiabetesDescriptionThis diabetes data set has n=352samples and there are p=6predictors:lamotrigine(ltg),total serum cholesterol(tc),total cholesterol(tch),low-and high-density lipoprotein(ldl and hdl)and glucose(glu).The response variable is the measurement of the disease progression one year after baseline.UsageDiabetesFormatA dataframe containing352recordsReferencesB.Efron,T.Hastie,I.Johnstone,and R.Tibshirani.Least angle regression.Annals of statistics,32(2):407–499,2004.mcb Model Confidence BoundDescriptionWhen choosing proper variable selection methods,it is important to consider the uncertainty of a certain method.The MCB for variable selection identifies two nested models(upper and lower confidence bound models)containing the true model at a given confidence level.A good variable selection method is the one of which the MCB under a certain confidence level has the shortest width.When visualizing the variability of model selection and comparing different model selection procedures,Model uncertainty curve is a good graphical tool.A good variable selection method is the one of whose MUC will tend to arch towards the upper left corner.This function aims to obtain the MCB and draw the MUC of certain single model selection method under a coverage rate equal or little higher than user-given confidential level.mcb3Usagemcb(x,y,B=200,lambda=NA,method= Lasso ,level=0.95,seed=122)Argumentsx input matrix;each column is an observation vector of certain independent vari-able,and will be given a name automatically in the order of x1,x2,x3...y y is a matrix of one column which presents the response vector B number of bootstrap replicates to perform,default value is200.B number of bootstrap replicates to perform;Default value is200.lambda A user supplied lambda value.It is the penalty tuning parameter for the variable selection method tested.The default value is the optimization outcome automat-ically computed in consideration of the specific case.method Default value is‘Lasso;user can choose from’aLasso’,’Lasso’,’SCAD’,’MCP’,’stepwise’,’LAD’,’SQRT’level a positive value between0and1,like the concept of confidence level for point estimation;Default value is0.95seed seed for bootstrap procedures;Default value is122;ValueThe mcb method returns an object of class“mcb”The generic accessor functions mcb,mucplot and mcbframe extract various useful features of the value returned by mcb.An object of class“mcb”isa list containing at least the following components:mcb a list containing the bootstrap coverage rate(which is the closest to the user-given confidence level)and the corresponding model confidence bound of theuser-chosen variable selection method in the form of lower confidence boundand upper confidence bound.mucplot plot of the model uncertainty curve for this specific user-chosen variable selec-tionmethod.mcbframe a dataframe containing all the information about MCBs for the specific variable selectionmethod under all bootstrap coverage rates including width(w),lowerconfidence bound(lcb)and upper confidence bound(ucb)for each bootstrap cov-erage rate(bcr)ReferencesLi,Y.,Luo,Y.,Ferrari,D.,Hu,X.and Qin,Y.(2019)Model Confidence Bounds for Variable Selec-tion.Biometrics,75:392-403.Examplesdata(Diabetes)#load datax<-Diabetes[,c( S1 , S2 , S3 , S4 , S5 )]y<-Diabetes[,c( Y )]x<-data.matrix(x)y<-data.matrix(y)result<-mcb(x=x,y=y)#plot of the model uncertainty curveresult$mucplot#a list containing the bootstrap coverage rate and mcbresult$mcb#a dataframe containing all the information about MCBsresult$mcbframepare Comparisons of Model Confidence Bounds for Different Variable se-lection MethodsDescriptionThis function is a supplement of the function mcb.It is used to compare different variable selection methods and would return all the MUCs on same canvas.A good variable selection method’s MUC will tend to arch towards the upper left corner.Usagepare(x,y,B=200,lambdas=NA,methods=NA,level=0.95,seed=122) Argumentsx input matrix presenting independent variables as in mcb.y response vector as in mcb.B number of bootstrap replicates to perform;Default value is200.lambdas A vector of penalty tuning parameters for each variable selection method.The default values are the optimal choices for each selection method computed au-tomatically.methods a vector including all variable selection methods the user wants to test and com-pare.The default value is c(’aLasso’,’Lasso’,’SCAD’,’MCP’,’stepwise’,’LAD’,’SQRT’)level user-defined confidence level as in mcb;Default value is0.95.seed Default value is122.ValueThe pare method returns an object of class“pare”An object of class"pare "is a list containing at least the following components:mcb a list containing the bootstrap coverage rate and the corresponding model confi-dence bound for all user-given variable selection methods.mucplot plot of the model uncertainty curves for all variable selection methods and could be used to choose the best method.mcbframe a list containing all the information about MCBs for all variable selection meth-ods under all available bootstrap coverage rates.ReferencesLi,Y.,Luo,Y.,Ferrari,D.,Hu,X.and Qin,Y.(2019)Model Confidence Bounds for Variable Selec-tion.Biometrics,75:392-403.Examplesdata(Diabetes)#load datax<-Diabetes[,c( S1 , S2 , S3 , S4 , S5 )]y<-Diabetes[,c( Y )]x<-data.matrix(x)y<-data.matrix(y)result<pare(x=x,y=y)#plot of the model uncertainty curves for all variable selection methodsresult$mucplot#a list containing the bootstrap coverage rate and mcb which based on Lassoresult$mcb$Lasso#a dataframe containing all the information about MCBs which based on Lassoresult$mcbframe$LassoIndexDiabetes,2mcb,2pare,46。
DMARC 设置指南说明书

3. Test your DMARC record through a DMARC check tool
Note: You usually have to wait 24-48 hrs. for replication DMARC check tool
The “txt” DMARC record should be named similar to “_dmarc.your_ .”
Example: “v=DMARC1;p=none; rua=mailto:dmarcreports@your_ ”
If you manage the DNS for your domain, create a “p=none” (monitoring mode) DMARC record in the same manner as the SPF and DKIM records.
DKIM is an email authentication standard that uses public/private key cryptography to sign email messages.
DKIM is used to verify that the email came from the domain that the DKIM key is associated with, and that the email had not been modified in transit.
01: STEP UP SPF
HOW TO SET UP SPF:
Nilfisk-Advance A S 多功能吸尘器 Multi 20 Multi 30 用户手册说

Multi 20 Multi 30User manualCopyright © 2013 Nilfisk-Advance A/SMultiEnglish ...............................................6 - 9Deutsch ...........................................10 - 13Français ...........................................14 - 17Español............................................18 - 21Português ........................................22 - 25Italiano .............................................26 - 29Nederlands ......................................30 - 33Svenska ...........................................34 - 37Norsk ...............................................38 - 41Dansk ..............................................42 - 45Suomi ..............................................46 - 49ǼȜȜȘȞȚțȐ..........................................50 - 53 Türkçe..............................................54 - 57ýeština ............................................58 - 60 Slovenski .........................................61 - 64Magyar.............................................65 - 68Română.............................................69 - 72ɛɴɥɝɚɪɫɤɢ........................................73 - 76 Polska ..............................................77 - 80 Slovenskému ...................................81 - 84Ɋɨɫɫɢɸ............................................85 - 88 Eesti.................................................89 - 92 Lietuvos ...........................................93 - 96 LatvijƗ ..............................................97 - 100中国的............................................101 - 1044MultiMulti56MultiOpriginal InstructionsDE FR ES PT IT NL SV NO DA FI EL TR CS SL HU RO BL PL SK RU ET LT LV ENZHDear Nil Þ sk customerCongratulations on the purchaseof your new Nil Þ sk vacuum cleaner.Prior to using the appliance for the Þ rst time, be sure to read this document through and keep it ready to hand.The vacuum cleaner is suitable for private use, e.g. forhousehold, hobby workshops, car cleaning - sucking up non-hazardous dust and non-ß ammable liquids.WARNINGDanger that can lead to serious injuries and d amage.WARNING• No changes to the mechanical, electrical or thermal safety devices must be made.• This appliance can be used by children aged from 8 years and above and persons with reduced physical, sensory or men-tal capabilities or lack of experience and knowledge if they have been given supervi-sion or instruction concerning use of the appliance in a safe way and understand the hazards involved.• Children shall be supervised to make sure that they do not play with the appliance. • Cleaning and user maintenance shall not be made by children without supervision.• Never spray water on the upper section of the vacuum cleaner. Danger for persons, risk or short-circuiting.• Never use the vacuum cleaner if the Þ lter is damaged.• T he vacuum cleaner features a blow func-tion. Do not blow the air out in the open space. Only use the blow function with a clean tube. Dust may be harmful to health.WARNINGVacuuming up hazardous materials can lead to serious or even fatal injuries.The following materials must not be picked up by the vacuum cleaner:• hazardous dust• hot materials (burning cigarettes, hot ashes etc.) • ß ammable, explosive, aggressive liquids (e.g. petrol, solvents, acids, alkalis, etc.)• ß ammable, explosive dust (e.g. magne-sium or aluminium dust etc.)WARNING• Before using the vacuum cleaner makesure that the voltage shown on the rating plate of the vacuum cleaner corresponds to the voltage of the local mains power supply.• It is recommended that the vacuum cleaner should be connected via a residual current circuit breaker.• The vacuum cleaner must not be used if the electrical c able or plug shows any sign of damage. Regularly inspect the cable and the plug for damage. If the power cord is damaged, it must be replaced by Nil Þ sk Service or an electrician to avoid danger before use of the vacuum cleaner is c ontinued.• Do not handle the electrical cable or plug with wet hands.• Do not unplug by pulling on cable. Tounplug, grasp the plug, not the cable. The plug must always be removed from the socket outlet before starting any service or repair work of the machine or cable.Always remove the electric plug from the socket be-fore carrying out maintenance work on the machine.The packaging materials can be recycled. Please recycle the components instead of throwing them in your household rubbish. You can also leave the packaging directly at your Nil Þ sk location to be p roperly recycled from there.As speci Þ ed in European Directive 2002/96/EC on old electrical and electronic appliances, used electri-cal goods must be collected separately and r ecycled ecologically. Contact your local authorities or yournearest dealer for further information.MultiOpriginal Instructions DE FR ES PT IT NL SV NO DA FI EL TR CS SL HU RO BL PL SK RU ET LT LV EN ZHNilÞ sk guarantees vacuum cleaners for domestic usefor 2 years. If your vacuum cleaner or accessoriesis/are handed in for repair, a copy of the receipt mustbe enclosed.Guarantee repairs are being made on the followingconditions:• that defects are attributable to ß aws or defects inmaterials or workmanship. (wear and tear as wellas misuse are not covered by the guarantee).• that the directions of this instruction manual havebeen thoroughly observed.• that repair has not been carried out or attemptedby other than NilÞ sk-trained service staff.• that only original accessories have been applied.• that the product has not been exposed to abusesuch as knocks, bumps or frost.• that the vacuum cleaner has not been used forrental nor used commercially in any other way. Batteries, lamps and wearing parts are excludedfrom the warranty.In the event of defects arising during the duration ofthe warranty and of which NilÞ sk is given notice, Nil-Þ sk will, of their own choice, either repair the defects, replace the unit or refund the purchase price uponreturn of the unit. Opening the unit housing causesthe warranty to become void. Further claims may notbe made on the basis of the warranty. The statutorywarranty rights of the c ustomer remain unaffected.Manufacturer warranty claims shall be made to themanufacturer. Statutory warranty rights also remainunaffected in this case.Addendum Australia:Our goods come with guarantees that cannot be ex-cluded under the Australian Consumer Law. You areentitled to a replacement or refund for a major failureand for compensation for any other reasonablyforeseeable loss or damage. You are also entitled tohave the goods repaired or replaced if the goods failto be of acceptable quality and the failure does notamount to a major failure.NilÞ sk vacuum cleaners for domestic use are war-ranted for 2 years from the date of purchase by:NilÞ sk-Advance Pty LtdUnit 1/13 Bessemer StreetBlacktown NSW 2148Phone: 1300 556 710E-mail: sales@nilÞ .auFind your local service agent here:http://www.nilÞ .au.The bene Þ ts under this warranty are in addition toyour national law of sale.Before liquids are picked up, always remove theÞ lter bag. Insert Þ lter for wet operation. Check that the ß oat works properly. If foam develops or liquid emerges from the machine, stop work immediately and empty the dirt tank.Use the socket on the vacuum cleaner for the pur-pose deÞ ned in the operating instructions only. Be-fore plugging an appliance into the appliance socket:1. Switch off the vacuum cleaner.2. Switch off the appliance to be connected. CAU-TION! Follow the operating instructions andsafety instructions for appliances connected tothe power tool socket. Always unwind the cable of the vacuum cleaner completely before use. The power consumption of the connected appliance must never exceed the value stated on the type plate of the vacuum cleaner.The operating voltage shown on the rating plate must correspond to the voltage of the mains power supply.A. On/off switchB. Filter cleaningC. Cable rewind*D. Speed regulation*E. Connection of powertool*F. Connection of suction hoseG. Connection to blow functionH. Water drain*I. Accessory storageJ. Hose and cable storageK. Quick park* Varies depending on model.78MultiOpriginal InstructionsDE FR ES PT IT NL SV NODA FI EL TR CS SL HU RO BL PL SK RU ET LT LV ENZHSwitching on the vacuum cleanerOn/Off - position “A” (ref. page 7)Switch “0-I”Switch p ositionFunction I On 0OffSwitch “I-0-II”, auto functionSwitch p ositionFunction I On 0Off IIPowertoolAuto on/OffFilter Clean (ref. illu. 3, page 4)When the suction performance drops:1. Connect the power supply.2. Turn the speed regulation to “max” (ref. page 7) (depending on model).3. Close the suction hose opening with the palm of your hand.4. Make a hard/fast push to the Filter clean button (ref. pos. “B” page 7). Repeat pushing 3 times. The resulting stream of air cleans the Þ lter.Cable rewind function1. Disconnect the power supply. Always clean cablebefore rewind using a wet/damp cloth.2. Rewind the cable using the cable rewind button(ref. pos. “C” page 7).ModelMulti 20Multi 30CRT (CR / Inox)CR T (CR / INOX)INOXT VSC (CR / INOX)INOXT VSC (CR / INOX)Voltage (V)220 - 240220 - 240P IEC (W)1150 (ZA 1200)1150 (ZA 1200)P max (W)14001400Power socket max (W)NA EU, AU/NZ: 2000GB: 1800CH: 1100CN: 1050NAEU, AU/NZ: 2000GB: 1800CH: 1100CN: 1050IPX4WARNINGWhen activating the automatic cord rewind, care must be taken as the plug at the end of the cord can swing during the last part of the rewinding. It is recommended that you hold on to the plug while rewinding.Filter change (ref. illu. 4, page 4)1. Disconnect the power supply.2. Turn the Þ lter disc counter-clockwise. Carefully re-move the Þ lter and check it for damages. Replace the Þ lter if necessary and dispose the Þ lter accord-ing to legal regulations. Using wet and dry Þ lter, clean the Þ lter by compressed air (keep proper distance in order not to damage the Þ lter with the air stream) or rinse in water. Dry Þ lter before use.3. Carefully clean the Þ lter sealing areas, mount the Þ lter and tighten the Þ lter clockwise.Changing Þ lter bag1. Disconnect the power supply.2. Carefully remove the Þ lter bag from the container and close the small slider in the top of the Þ lter bag. Dispose the Þ lter bag in accordance with legal regulations.3. Insert the new Þ lter bag in the container and press it gently on the inlet Þ tting using both hands. Nil-Þ sk always recommends the use of a Þ lter bag for Þ ne dust.9MultiOpriginal InstructionsDE FR ES PT IT NL SV NO DA FI EL TRCS SL HU RO BL PL SK RU ET LT LV EN ZHProduct:Vacuum cleaner for wet and dry operation Model:Multi 20, Multi 30Description:230 V 1~, 50 Hz, 1150 W220-240 V 1~, 50/60 Hz, 1150 W IP X4The design of the a ppliance corre-sponds to the follow-ing pertinent regula-tions:EC Low-voltage Directive 2006/95/ECEC EMC Directive 2004/108/EC RoHS Directive 2011/65/ECApplied harmonized standards:EN 60335-1:2010EN 60335-2-2:2010EN 55014-1:2006 + A1:2009EN 55014-2:1997 + A1:2001 + A2:2008EN 61000-3-2:2006EN 61000-3-3:2008Name and address of the person autho-rised to compile the technical Þ le:Anton SørensenGeneral Manager, Technical Operations EAPC Nilfisk-Advance A/S Sognevej 25DK-2605 BrøndbyIdentity and signa-ture of the person e mpowered to draw up the declaration on behalf of themanufacturer:Anton SørensenGeneral Manager, Technical Operations EAPC Nilfisk-Advance A/S Sognevej 25DK-2605 BrøndbyPlace and date of the declaration:Hadsund, 21-11-2013http://www.nilfi HEAD QUARTERDENMARKNilfi sk-Advance GroupSognevej 25DK-2605 BrøndbyT el.: (+45) 4323 8100E-mail: @nilfi SALES COMPANIESAUSTRALIANilfi sk-Advance48 Egerton St.P.O. Box 6046Silverwater, N.S.W. 2128Website: www.nilfi .au AUSTRIANilfi sk-Advance GmbH Metzgerstrasse 685101 Bergheim bei Salzburg Website: www.nilfi sk.atBELGIUMNilfi sk-Advance n.v-s.a.Riverside Business ParkBoulevard Internationalelaan 55Bâtiment C3/C4 GebouwBruxelles 1070Website: www.nilfi CHILENilfi sk-Advance de ChileSan Alfonso 1462SantiagoWebsite: www.nilfi CHINANilfi sk-Advance (Suzhou)Building 18, Suchun Industrial Estate Suzhou Industrial Park215021 SuzhouWebsite: www.nilfi CZECH REPUBLICNilfi sk-AdvanceVGP Park Horní PoþerniceDo ýertous 1/2658193 00 Praha 9Website: www.nilfi DENMARKNilfi sk-Advance NORDIC A/S Sognevej 252605 BrøndbyT el.: (+45) 4323 4050E-mail: kundeservice.dk@nilfi FINLANDNilfi sk-Advance Oy AbKoskelontie 23 E02920 EspooWebsite: www.nilfi sk.fiFRANCENilfi sk-Advance26 Avenue de la BaltiqueVillebon sur Yvette91978 Courtabouef Cedex Website: www.nilfi sk.frGERMANYNilfi sk-AdvanceGuido-Oberdorfer-Strasse 1089287 BellenbergWebsite: www.nilfi sk.deGREECENilfi sk-Advance A.E.ǹȞĮʌĮȪıİȦȢ 29ȀȠȡȦʌȓȉ.Ȁ. 194 00Website: www.nilfi sk.gr HOLLANDNilfi sk-AdvanceVersterkerstraat 51322 AN AlmereWebsite: www.nilfi sk.nlHUNGARYNilfi sk-Advance Kereskedelmi Kft.II. Rákóczi Ferenc út 102310 Szigetszentmiklos-LakihegyWebsite: www.nilfi sk.huINDIANilfi sk-Advance India LimitedPramukh Plaza, ‘B’ Wing, 4th fl oor, Unit No. 403Cardinal Gracious Road, ChakalaAndheri (East) Mumbai 400 099Website: www.nilfi IRELANDNilfi sk-Advance1 Stokes PlaceSt. Stephen’s GreenDublin 2Website: www.nilfi ITAL YNilfi sk-Advance SpAStrada Comunale della Braglia, 1826862 Guardamiglio (LO)Website: www.nilfi sk.itJAPANNilfi sk-Advance Inc.1-6-6 Kita-shinyokohama, Kouhoku-kuY okohama, 223-0059Website: www.nilfi MALAYSIANilfi sk-Advance Sdn BhdSd 14, Jalan KIP 11T aman Perindustrian KIPSri Damansara52200 Kuala LumpurWebsite: www.nilfi MEXICONilfi sk-Advance de Mexico, S. de R.L. de C.V.Agustín M. Chavez No. 1, PB ofi cina 004Col. Centro de Ciudad Santa Fe01210 Mexico, D.F.Website: www.nilfi NEW ZEALANDNilfi sk-AdvanceDanish House6 Rockridge AvenuePenrose, Auckland 1135Website: www.nilfi NORWAYNilfi sk-Advance ASBjørnerudveien 241266 OsloT el.: (+47) 22 75 17 70E-mail: info.no@nilfi POLANDNilfi sk-Advance Sp. Z.O.O.ul. 3 Maja 805-800 PruszkówWebsite: www.nilfi sk.plPORTUGALNilfi sk-AdvanceSintra Business ParkZona Industrial Da AbrunheiraEdifi cio 1, 1° AP2710-089 SintraWebsite: www.nilfi sk.ptRUSSIAɇɢɥɮɢɫɤ-ɗɞɜɚɧɫ127015 Ɇɨɫɤɜɚȼɹɬɫɤɚɹɭɥ. 27, ɫɬɪ. 7ɊɨɫɫɢɹWebsite: www.nilfi sk.ruSOUTH AFRICAWAP South Africa12 Newton StreetSpartan 1630Website: www.nilfi SOUTH KOREANilfi sk-Advance Korea3F Duksoo B/D, 317-15Sungsoo-Dong 2Ga, Sungdong-GuSeoulWebsite: www.nilfi SPAINNilfi sk-Advance S.A.T orre d’Ara, Planta 908302 MataróBarcelonaWebsite: www.nilfi sk.esSWEDENNilfi sk-Advance ABAminogatan 18431 53 MölndalWebsite: www.nilfi sk-alto.seSWITZERLANDNilfi sk-AdvanceRingstrasse 19Kircheberg/Industri Stelzl9500 WilWebsite: www.nilfi sk-alto.chTAIWANNilfi sk-Advance T aiwan Branch1F, No. 193, sec. 2, Xing Long Rd.T aipeiT el.: (+88) 6227 002 268Website: www.nilfi sk-alto.twTHAILANDNilfi sk-Advance Co. Ltd.89 Soi Chokechai-RuammitrViphavadee-Rangsit RoadLadyao, Jatuchak, Bangkok 10900Website: www.nilfi TURKEYNilfi sk-Advance A.S.Serifali Mh. Bayraktar Bulv. Sehit Sk. No:7ÜmraniyeIstanbulWebsite: www.nilfi UNITED KINGDOMNilfi sk (A Division of Nilfi sk-Advance Ltd.)Bowerbank WayGilwilly Industrial Estate, PenrithCumbria CA11 9BQT el: 01768 868995Website: www.nilfi UNITED ARAB EMIRATESNilfi sk-Advance Middle East BranchSAIF-ZoneP.O. Box 122298SharjahWebsite: www.nilfi VIETNAMNilfi sk-Advance Representative Offi ceNo. 51 Doc Ngu Str.Ba Dinh Dist.HanoiWebsite: www.nilfi 。
钓鱼岛到底藏了多少石油

钓鱼岛到底藏了多少石油[27125]人参与钓鱼岛海域到底有多少石油资源一直是焦点导语面对钓鱼岛危机,台湾富商郭台铭17日“突发奇想”,建议大陆、日本、台湾3方民间组织共同合作,开发钓鱼岛资源,可能的话,在资源共享方面,3方各以3成来均分钓鱼岛的资源,另1成作保留。
…[详细]郭台铭的异想天开,自然让网友们非常愤怒。
不过,由此也引出一个话题——到底钓鱼岛有多少石油资源呢?+收听01钓鱼岛附近有石油只是科学推测钓鱼岛附近蕴藏石油来自1969年一份科研报告,并非人们真钻出了油气美国海洋学教授埃默里的报告引发人们对钓鱼岛石油狂热猜想一说到钓鱼岛的自然资源,非石油莫属。
而在新闻中,人们常常看到这样一句话,“1969年,联合国亚洲和远东经济委员会认为,该地区的海床拥有大量石油和天然气资源。
”事实上,钓鱼岛有石油这件事从来没有被确认过。
1961年、1967年,一位叫埃默里(K.O.Emery)的美国海洋学教授和日本东海大学教授新野弘两次发表科研论文,认为包括钓鱼岛在内的东海可能蕴藏油气资源,但是都来自纸上谈兵式的推论。
而所谓的联合国1969年的报告,其实是这两位教授联合中国台湾和韩国的学者一起做的。
他们在1968年10月到11月,在相当于泰国、柬埔寨、越南加起来大的东海海域,进行了为期49天的科考,用科研仪器探测海底地质结构。
而1969年,他们发布了考察成果,《黄海及中国东海地质构造及海水性质测勘》。
这份报告提到一个关键点:在中国台湾和日本之间的浅海区域可能蕴藏着非常丰富的油气储备。
最关键的是,报告原文有一句话:“最有可能的区域是台湾东北部20万平方公里的海域。
”而人们普遍认为这指的是钓鱼岛附近海域。
需要说明的是,埃默里本身师从“海洋地质学之父”谢帕德教授。
而这次科研行动中,日本和中国台湾石油公司的工作人员也都参与了进来,所以,毫无疑问,这个活动就是找油的,才会引起那么大反响。
…[详细]科研报告的可能性依据来自这一地区有生成油气的地质条件海洋石油的形成(图片来源:中科院科普网站)比较主流的海洋油气形成过程的学说是,史前生物的尸体被一层又一层的泥沙给埋了起来,经过漫长的地质时期,就转换成了石油。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
35 Design Automation Conference ® Copyright ©1998 ACM 1-58113-049-x-98/0006/$3.50 DAC98 - 06/98 San Francisco, CA USA
th
and it is used to check that every aspect of the functionality is tested. Therefore, functional coverage is design and implementation speci c, and is much harder to measure. Currently, functional coverage is done mostly manually. The manual process through which one gains con dence that testing has been thorough, is composed of the following steps: rst, one prepares a list of testing requirements in a test plan which contains the events that have to happen during testing. Then, one executes the tests and checks that for every requirement there is a test in which the particular event happened and that this test has been executed successfully. In general, this is a very labor intensive e ort, as the tests are crafted in order to ful ll speci c requirements. If a test ful lled a requirement by chance", it will usually not be noticed. Automation can be added to this process in the following way: a coverage task, a binary function on a test or a trace which speci es whether an event occurs or not, is created for each test requirement. Examples of coverage tasks are: statement 534 was executed", and the instructions in the rst two stages of a pipe were add and divide writing to the same target". A cohesive group of coverage tasks is called a coverage model. The second example of a coverage task can be generalized into coverage models over attributes. Each task is an instantiation of these attributes and the coverage model is the cross product of the possible values. For example, rst instruction, second instruction is a coverage model over two attributes, and ADD, DIV is a task in that model. Comet uses coverage models of this type. In order to nd out if a coverage task happens in a test, we create a trace called event trace. Rows in the event trace usually contain the values of the attributes at the time the row was produced. Coverage is measured by activating the coverage models on the event trace. We divide coverage models into two types: snapshot and temporal. Snapshot models are coverage models whose attributes are taken from a single row in the event trace, for example, the combination of two instructions that are at di erent stages of a pipe at the same time. Temporal coverage models are coverage models whose attributes are taken from di erent rows in the event trace. A coverage task in these models is a speci c scenario that occur during the test, for example, the combination of two instructions that were fetched by the processor with a distance of less than 5 cycles between them. Often, some of the tasks in the coverage model, de ned by the cross product of the attributes, are illegal tasks, that is, coverage tasks that should not occur. For example, two instructions that write to the same resource should never be in the write-back stages of pipes in the same cycle. Comet reports to the user on any illegal tasks found in the event trace. It also reports coverage statistics on which tasks out of the task coverage list TCL, a list of all the legal tasks in the coverage model, have been covered. 3 User De ned Coverage Coverage measurement and the use of coverage as an indicator of the quality of testing and reliability of the design are growing rapidly. More tools for coverage measurement are becoming available, both for software and hardware testing. These tools provide the user with many features that are necessary for an e cient coverage measurement, such as data gathering, updating of the coverage task list, and reports on the coverage status.
User De ned Coverage - A Tool Supported Methodology for Design Veri cation
Raanan Grinwald, Eran Harel, Michael Orgad, Shmuel Ur, Avi Ziv ห้องสมุดไป่ตู้BM Research Lab in Haifa MATAM Haifa 31905, Israel email: fgrinwald, harel, orgad, sur, aziv@g
therefore, very hard to tune the tools to areas which the user thinks are of signi cance. To overcome this problem, some domain dependent tools have been developed which measure speci c functional events 3 . In all the tools we are familiar with, the coverage models are hard-coded. Therefore, the user is forced to use a tool that does not t his needs, or put a lot of e ort into developing a new tool for his coverage needs. In this paper, we present a new methodology for coverage that was developed at IBM's Haifa Research Lab, and a coverage measurement tool called Comet COverage MEasurement Tool that was developed to support this methodology. The main idea behind the new methodology is separation of the coverage model de nition from the tool. This separation enables the user to use a single tool for most of his coverage needs. The user can de ne coverage models that t the design in the best way, while enjoying all the bene ts of a coverage tool, such as data collection and processing, creation of coverage reports, and generation of regression suites with high coverage. Moreover, the user can change the scope or depth of coverage during the veri cation process, starting from simple coverage models in the early stages of veri cation and, based on those models, de ne deeper and more complex models later on. Our coverage methodology and Comet are used by several sites in IBM in designs ranging from systems, to microprocessors, and ASICs. The tool is currently used in many di erent domains, such as architectural veri cation of microprocessors, micro-architecture veri cation of units in a processor, system and unit veri cation of a communication ASIC, and veri cation of coherency and bus protocols. The rest of the paper is organized as follows: In Section 2, we describe the functional coverage process and provide some terminology used in this paper. In Section 3, we describe our new coverage methodology in detail. In Section 4, we describe Comet, our coverage tool, and the coverage process as is done in Comet. Finally, Section 5 concludes the paper. 2 Functional Coverage Process Coverage, in general, can be divided into two types: programbased and functional. Program-based coverage concentrates on measuring syntactic properties in the execution, for example, that each statement was executed, or each transition in a state machine taken. This makes syntactic coverage a generic method which is usually easy to measure. Functional coverage focuses on the functionality of the program,