hadoop2.2.0安装笔记
hadoop2安装完整步骤

<value>master1:9000</value>
</property>
<property>
<name>node.rpc-address.hadoop-cluster1.nn2</name>
mkdir -m 755 rlocal
mkdir -m 755 nodemanagerlogs
mkdir -m 755 nodemanagerremote
cd /home/hadoop/hadoop2/etc/hadoop
修改core-site.xml
<configuration>
一、环境准备,参看hadoop安装手顺(一到四章节)
二、找三台机器安装zookeeper,本例中三台服务器为masterha1、masterha2和master2
三、安装hadoop2
1.解压缩hadoop-2.2.0.tar.gz 并改名为hadoop2 添加环境变量HADOOP_HOME、PATH(注意除了bin目录外还有sbin目录)
</property>
<!--cluster1-->
<property>
<name>nodes.hadoop-cluster1</name>
<value>nn1,nn2</value>
</property>
<property>
HADOOP2.2安装部署手册

HA D O O P2.2安装部署手册XXXXX公司2014年5月版本号更新人更新日期V1.0Box2014-5-15目录目录 (I)第1章基础环境 (1)1.1集群规划 (1)1.1.1.修改主机名 (1)1.1.2.职责划分 (1)第2章软件版本 (2)2.1软件 (2)2.2文件目录规划 (2)第3章基础配置 (3)3.1集群SSH无密码互信 (3)3.2配置系统环境变量 (3)第4章HADOOP安装 (4)4.1配置文件修改 (4)4.1.1修改$HADOOP_HOME/etc/Hadoop/hadoop-env.sh (4)4.1.2修改$HADOOP_HOME/etc/Hadoop/slaves (4)4.1.3修改$HADOOP_HOME/etc/Hadoop/core-site.xml (4)4.1.4修改$HADOOP_HOME/etc/Hadoop/hdfs-site.xml (5)4.1.5修改$HADOOP_HOME/etc/Hadoop/mapred-site.xml (6)4.1.6修改$HADOOP_HOME/etc/Hadoop/yarn-site.xml (7)4.1.7分发到各结点 (9)4.2格式化HDFS (9)4.3启动HDFS、YARN (9)4.4检查集群运行状态 (9)第5章ZOOKEEPER安装 (9)5.1修改配置 (9)5.2分发到各结点 (10)5.3启动ZOOKEEPER (10)第6章HBASE安装 (10)6.1修改配置 (10)6.1.1修改$HBASE_HOME/conf/hbase-env.sh (10)6.1.2修改$HBASE_HOME/conf/RegionServer (10)6.1.3修改$HBASE_HOME/conf/hbase-site.xml (11)6.2分发到各结点 (12)6.3启动HBASE (12)第7章安装HIVE (12)7.1安装MYSQL (12)7.1.1检查是否已经安装过MYSQL (12)7.1.2安装MYSQL (13)7.1.3配置MYSQL (13)7.1.4修改root密码 (14)7.1.5创建hive元数据数据库 (14)7.2修改HIVE配置 (15)7.2.1修改$HIVE_HOME/conf/hive-site.xml (15)7.3开启HIVE服务 (16)第8章安装SPARK (17)8.1修改配置 (17)8.1.1修改$SPARK_HOME/spark-env.sh (17)8.1.2修改slaves (17)8.2分发到各结点 (17)8.3启动spark (17)第9章安装SHARK (18)9.1修改配置 (18)9.2进入SHARK控制台 (18)附录A:HADOOP-HBASE兼容表 (18)附录B:问题清单 (19)第1章基础环境[root@ip-172-167-15-226~]#lsb_release-aLSBVersion::core-4.0-amd64:core-4.0-noarch:graphics-4.0-amd64:graphics-4.0-noarch:printing-4.0-amd6 4:printing-4.0-noarchDistributor ID:RedHatEnterpriseServerDescription:Red Hat Enterprise Linux Server release6.2(Santiago)Release: 6.2Codename:Santiago1.1集群规划1.1.1.修改主机名vi/etc/sysconfig/networkHOSTNAME=hadoo201vi/etc/hosts#for hadoop2cluster#pengyq2014.5.13172.167.15.226hadoop201172.167.15.227hadoop202172.167.15.228hadoop203172.167.15.230hadoop204172.167.15.231hadoop2051.1.2.职责划分hadoop201作为namenode、seconderynamenode、HMaster、Spark Masterhadoop202,hadoop203,hadoop204,hadoop205为DataNode、RegionServer、Spark Slaver五台机器都作为Zookeeper节点第2章软件版本2.1软件版本兼容请参照附录A[hadoop@hadoop201hadoop2_cluster]$lsjdk1.7.0_55#JAVA运行基础环境hadoop-2.2.0Zookeeper-3.4.6#hbase依赖(使用hbase0.98.2自带zk安装遇到了问题,所以独立安装zk群)hbase-0.98.2apache-hive-0.13.0-binscala-2.11.0#spark依赖spark-0.9.1-bin-hadoop2shark-0.9.1-bin-hadoop22.2文件目录规划/Hadoop/home/hadoop2_cluster/jdk1.7.0_55/hadoop-2.2.0/Zookeeper-3.4.6/hbase-0.98.2/apache-hive-0.13.0-bin/scala-2.11.0/spark-0.9.1-bin-hadoop2/shark-0.9.1-bin-hadoop2/workspace/dfs/data/#hdfs数据name/#namenode数据hive/#hive querylogmapred/#mapreduce日志tmp/zookeeper/#zookeeper datadir/opt/mysql_data/mysql#mysql数据存放目录第3章基础配置3.1集群SSH无密码互信生成SSH密钥ssh-keygen#分发公钥到受控节点ssh-copy-id-i~/.ssh/id_rsa.pub hadoop@hadoop202ssh-copy-id-i~/.ssh/id_rsa.pub hadoop@hadoop203ssh-copy-id-i~/.ssh/id_rsa.pub hadoop@hadoop204ssh-copy-id-i~/.ssh/id_rsa.pub hadoop@hadoop205出现的问题:Permission denied(publickey,gssapi-with-mic).修改了/etc/ssh/sshd_config中的"PasswordAuthentication"参数值为"no",修改回"yes",重启sshd服务即可。
(完整word版)centos6下安装部署hadoop2.2

centos6下安装部署hadoop2。
2hadoop安装入门版,不带HA,注意理解,不能照抄.照抄肯定出错。
我在安装有centos7(64位)的机器上,使用hadoop2。
5版本,安装验证过,但我没有安装过hadoop2。
2,仅供参考.如果你的(虚拟机)操作系统和JVM/JDK是64位的,就直接安装hadoop 2.5版本,无需按照网上说的去重新编译hadoop,因为它的native库就是64位了;如果你的(虚拟机)操作系统和JVM/JDK是32位的,就直接安装hadoop 2。
4以及之前的版本.安装小技巧和注意事项:1. 利用虚拟机clone的技术。
2. 不要在root用户下安装hadoop,自己先事先建立一个用户。
3。
如果需要方便操作,可以把用户名添加到sudoers文件中,使用sudo命令执行需要root权限的操作。
4。
Linux里面有严格的权限管理,很多事情普通用户做不了,习惯使用windows的同学,需要改变观念。
5。
centos7与之前的版本,在很多命令上有区别,centos与ubuntu有存在很多操作上的差别。
6. Hadoop 2.5版本中的native lib库是64位的,而hadoop 2。
2版本中的native lib库是32位的。
网上教程大多数针对hadoop2。
2写的,如果你是64位的虚拟机,你直接安装Hadoop 2.5版本就行。
7. 确认虚拟机安装并启用了sshd服务后,用xshell客户端连接Linux虚拟机,不要在vmware workstation 里面操作。
用xshell可以非常方便的复制文字和命令等。
学习Hadoop安装的步骤(1)可以先参考网上的资料“虾皮博客”http://www。
/xia520pi/xia520pi/archive/2012/05/16/2503949.html安装一个hadoop 1.2 版本,熟悉一下,搞明白后,再安装hadoop 2.x版本。
hadoop2.2实例安装步骤8-实用

2.3.1、 hadoop2安装手顺一、环境准备,参看hadoop安装手顺(一到四章节 jdk ssh)•服务器规划如下:master1-hadoop2: 192.168.137.23 主机名:master1(active namenode,RM)master1-ha-hadoop2: 192.168.137.24 主机名:masterha1(standby namenode,jn)master2-hadoop2: 192.168.137.31 主机名:master2(active namenode,jn)master2-ha-hadoop2: 192.168.137.40 主机名:masterha2(standby namenode,jn)slave1-hadoop2: 192.168.137.25 主机名:slave1(datanode,nodemanager)slave2-hadoop2: 192.168.137.26 主机名:slave2(datanode,nodemanager)slave3-hadoop2: 192.168.137.27 主机名:slave3(datanode,nodemanager)二、找三台机器安装zookeeper,本例中三台服务器为masterha1、masterha2和master2三、安装hadoop21.解压缩hadoop-2.2.0.tar.gz 并改名为hadoop2 添加环境变量HADOOP_HOME、PATH(注意除了bin目录外还有sbin目录)2.cd ~/hadoop创建以下目录 权限设置为755(mkdir -m 755 xxx)mkdir -m 755 namedirmkdir -m 755 datadirmkdir -m 755 tmpmkdir -m 755 jndirmkdir -m 755 hadoopmrsysmkdir -m 755 hadoopmrlocalmkdir -m 755 nodemanagerlocalmkdir -m 755 nodemanagerlogsmkdir -m 755 nodemanagerremotecd /home/hadoop/hadoop2/etc/hadoophadoop2配置文件.zip配置文件.txt修改core-site.xml<configuration><property><name>fs.defaultFS</name><value>viewfs:///</value></property><property><name>fs.viewfs.mounttable.default.link./tmp</name><value>hdfs://hadoop-cluster1/tmp</value></property><property><name>fs.viewfs.mounttable.default.link./tmp2</name><value>hdfs://hadoop-cluster2/tmp2</value></property></configuration>修改hdfs-site.xml<configuration><!-- 使用federation时,使用了2个HDFS集群。
Hadoop 2.0安装部署方法

✓ 步骤1:下载JDK 1.6(注意区分32位和64位) ✓ 步骤2:安装JDK 1.6(以32位为例)
chmod +x jdk-6u45-linux-i586.bin ./jdk-6u45-linux-i586.bin
✓ 步骤3:验证是否安装成功
以上整个过程与实验环境基本一致,不同的是步骤2中配置文件设置内容以 及步骤3的详细过程。
30
HDFS 2.0的HA配置方法(主备NameNode)
注意事项:
1 主备NameNode有多种配置方法,本课程使用Journal Node方式。为此 ,需要至少准备3个节点作为Journal Node,这三个节点可与其他服务,比 如NodeManager共用节点 2主备两个NameNode应位于不同机器上,这两台机器不要再部署其他 服 务,即它们分别独享一台机器。(注:HDFS 2.0中无需再部署和配置 Secondary Name,备NameNode已经代替它完成相应的功能) 3 主备NameNode之间有两种切换方式:手动切换和自动切换,其中, 自动切换是借助Zookeeper实现的,因此,需单独部署一个Zookeeper集群 (通常为奇数个节点,至少3个)。本课程使用手动切换方式。
Hadoop 2.0安装部署方法
Open Passion Value
目录
1. Hadoop 2.0安装部署流程 2. Hadoop 2.0软硬件准备 3. Hadoop 2.0安装包下载 4. Hadoop 2.0测试环境(单机)搭建方法 5. Hadoop 2.0生产环境(多机)搭建方法 6. 总结
✓ yarn-site.xml:
hadoop安装实验总结

hadoop安装实验总结Hadoop安装实验总结Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。
在本次实验中,我成功安装了Hadoop,并进行了相关的配置和测试。
以下是我对整个过程的总结和经验分享。
1. 环境准备在开始安装Hadoop之前,我们需要确保已经具备了以下几个环境条件:- 一台Linux操作系统的机器,推荐使用Ubuntu或CentOS。
- Java开发环境,Hadoop是基于Java开发的,因此需要安装JDK。
- SSH服务,Hadoop通过SSH协议进行节点之间的通信,因此需要确保SSH服务已启动。
2. 下载和安装Hadoop可以从Hadoop官方网站上下载最新的稳定版本。
下载完成后,解压缩到指定目录,并设置环境变量。
同时,还需要进行一些配置,包括修改配置文件和创建必要的目录。
3. 配置Hadoop集群Hadoop是一个分布式系统,通常会配置一个包含多个节点的集群。
在配置文件中,我们需要指定集群的各个节点的IP地址和端口号,并设置一些重要的参数,如数据存储路径、副本数量等。
此外,还可以根据实际需求调整其他配置参数,以优化集群性能。
4. 启动Hadoop集群在完成集群配置后,我们需要启动Hadoop集群。
这一过程需要先启动Hadoop的各个组件,包括NameNode、DataNode、ResourceManager和NodeManager等。
启动成功后,可以通过Web 界面查看集群的状态和运行情况。
5. 测试Hadoop集群为了验证Hadoop集群的正常运行,我们可以进行一些简单的测试。
例如,可以使用Hadoop提供的命令行工具上传和下载文件,查看文件的副本情况,或者运行一些MapReduce任务进行数据处理。
这些测试可以帮助我们了解集群的性能和可靠性。
6. 故障排除与优化在实际使用Hadoop时,可能会遇到一些故障和性能问题。
为了解决这些问题,我们可以通过查看日志文件或者使用Hadoop提供的工具进行故障排查。
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册前言: (3)一. Hadoop安装(伪分布式) (4)1. 操作系统 (4)2. 安装JDK (4)1> 下载并解压JDK (4)2> 配置环境变量 (4)3> 检测JDK环境 (5)3. 安装SSH (5)1> 检验ssh是否已经安装 (5)2> 安装ssh (5)3> 配置ssh免密码登录 (5)4. 安装Hadoop (6)1> 下载并解压 (6)2> 配置环境变量 (6)3> 配置Hadoop (6)4> 启动并验证 (8)前言:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。
为什么是Hadoop2.2.0,而不是Hadoop2.4.0本文写作时,Hadoop的最新版本已经是2.4.0,但是最新版本的Hbase0.98.1仅支持到Hadoop2.2.0,且Hadoop2.2.0已经相对稳定,所以我们依然采用2.2.0版本。
一. Hadoop安装(伪分布式)1. 操作系统Hadoop一定要运行在Linux系统环境下,网上有windows下模拟linux环境部署的教程,放弃这个吧,莫名其妙的问题多如牛毛。
2. 安装JDK1> 下载并解压JDK我的目录为:/home/apple/jdk1.82> 配置环境变量打开/etc/profile,添加以下内容:export JAVA_HOME=/home/apple/jdk1.8export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar执行source /etc/profile ,使更改后的profile生效。
hadoop2.2.0分布式配置

Hadoop2.2.0分布式配置一、系统环境:IP 账号/主机名功能操作系统192.168.25.150 hadoop@hadoopm nm/rm/sm red hat enterprise linux 6.0 192.168.25.151 hadoop@hadoopd1 dn/rm red hat enterprise linux 6.0 192.168.25.152 hadoop@hadoopd2 dn/rm red hat enterprise linux 6.0二、设置HOST:vi /etc/hosts192.168.25.150 hadoopm192.168.25.151 hadoopd1192.168.25.152 hadoopd2注释掉localhost等配置:#127.0.0.1 localhost.localdomain localhost#::1 localhost6.localdomain6 localhost6设置好后,将此文件直接覆盖到其它主机对应的文件。
三、设置静态IP:查看ip:Ifconfig设置静态ip:vi /etc/sysconfig/networkNETWORKING=yesNETWORKING_IPV6=noHOSTNAME= hadoopm #主机名DEVICE=eth0 #网卡标志ONBOOT=yes #是否自动启动BOOTPROTO=static #是否使用静态IPIPADDR=192.168.25.150 #当前机器的IP地址NETMASK=255.255.255.0 #子网掩码GATEWAY=192.168.25.255 #网关也可以单独修改具体网卡的ip配置:vi /etc/sysconfig/network-scripts/ifcfg-ethoDEVICE=eth0 #网卡标志ONBOOT=yes #是否自动启动BOOTPROTO=static #是否使用静态IPIPADDR=192.168.25.150 #当前机器的IP地址NETMASK=255.255.255.0 #子网掩码GATEWAY=192.168.25.255 #网关使配置生效:/etc/init.d/network restart一台机器修改完毕后,其它机器按照此方式修改,注意要调整hostname和ip地址为正在被修改机器的对应信息。
Hadoop2.2部署文档

MICROSOFTHadoop部署文档Hadoop2.2部署吴汉章2014/12/22本文档是RHEL虚拟机下Hadoop部署文档,提供了Hadoop伪分布安装和Hadoop集群安装。
意在帮助Hadoop初学者快速掌握Hadoop部署步骤。
目录文档控制 (2)1引言 (3)1.1文档概述 (3)1.2背景 (3)1.3术语 (3)2Red Hat Linux基础环境搭建 (3)2.1修改主机名称 (3)2.2设置静态IP地址 (3)2.3设置IP映射关系 (4)2.4安装Java JDK (4)2.5创建Linux用户 (5)3Hadoop伪分布安装配置 (5)3.1配置SSH免密钥登陆 (5)3.2 Hadoop伪分布式配置 (6)3.2.1配置hadoop-env.sh (6)3.2.2配置yarn-env.sh (6)3.2.3配置core-site.xml (6)3.2.4配置hdfs-site.xml (7)3.2.5配置mapred-site.xml (8)3.2.6配置yarn-site.xml (8)3.2.7配置slaves节点列表 (8)3.2.8配置Hadoop环境变量 (9)3.3格式化HDFS文件系统 (9)3.4启动Hadoop系统 (9)3.4.1启动HDFS文件系统 (9)3.4.2启动YARN资源管理器 (10)3.5运行MapReduce程序 (10)3.5.1创建单词文件 (10)3.5.2上传文件到HDFS (11)3.5.3运行WordCount程序 (11)4Hadoop集群安装配置 (12)4.1Hadoop集群概要 (12)4.2克隆Master节点机器 (12)4.2.1修改主机名称 (12)4.2.2设置静态IP地址 (12)4.2.3设置IP映射 (13)4.3配置Master节点 (13)4.3.1删除HDFS格式信息 (13)4.3.2配置slave节点列表 (13)4.4克隆slave节点机器 (14)4.4.1配置salve1节点机器 (14)4.4.2配置salve2节点机器 (14)4.5格式化HDFS文件系统 (15)4.6启动Hadoop系统 (15)4.6.1启动HDFS文件系统 (15)4.6.2启动YARN资源管理器 (16)4.7运行MapReduce程序 (17)附件: (17)文档控制1引言1.1文档概述本文档搭建Hadoop集群使用的hadoop2.2.0版本,操作系统为Red Hat Enterprise Linux Server release 5.4 (Tikanga)。
1 Hadoop安装手册Hadoop2.0

Hadoop2.0安装手册目录第1章安装VMWare Workstation 10 (4)第2章VMware 10安装CentOS 6 (10)2.1 CentOS系统安装 (10)2.2 安装中的关键问题 (13)2.3 克隆HadoopSlave (17)2.4 windows中安装SSH Secure Shell Client传输软件 (19)第3章CentOS 6安装Hadoop (23)3.1 启动两台虚拟客户机 (23)3.2 Linux系统配置 (24)3.2.1软件包和数据包说明 (25)3.2.2配置时钟同步 (25)3.2.3配置主机名 (26)3.2.5使用setup 命令配置网络环境 (27)3.2.6关闭防火墙 (29)3.2.7配置hosts列表 (30)3.2.8安装JDK (31)3.2.9免密钥登录配置 (32)3.3 Hadoop配置部署 (34)3.3.1 Hadoop安装包解压 (34)3.3.2配置环境变量hadoop-env.sh (34)3.3.3配置环境变量yarn-env.sh (35)3.3.4配置核心组件core-site.xml (35)3.3.5配置文件系统hdfs-site.xml (35)3.3.6配置文件系统yarn-site.xml (36)3.3.7配置计算框架mapred-site.xml (37)3.3.8 在master节点配置slaves文件 (37)3.3.9 复制到从节点 (37)3.4 启动Hadoop集群 (37)3.4.1 配置Hadoop启动的系统环境变量 (38)3.4.2 创建数据目录 (38)3.4.3启动Hadoop集群 (38)第4章安装部署Hive (44)4.1 解压并安装Hive (44)4.2 安装配置MySQL (45)4.3 配置Hive (45)4.4 启动并验证Hive安装 (46)第5章安装部署HBase (49)5.1 解压并安装HBase (49)5.2 配置HBase (50)5.2.1 修改环境变量hbase-env.sh (50)5.2.2 修改配置文件hbase-site.xml (50)5.2.3 设置regionservers (51)第1章安装VMWare Workstation 105.2.4 设置环境变量 (51)5.2.5 将HBase安装文件复制到HadoopSlave节点 (51)5.3 启动并验证HBase (51)第6章安装部署Mahout (54)6.1 解压并安装Mahout (54)6.2 启动并验证Mahout (55)第7章安装部署Sqoop (57)7.1 解压并安装Sqoop (57)7.2 配置Sqoop (58)7.2.1 配置MySQL连接器 (58)7.2.2配置环境变量 (58)7.3 启动并验证Sqoop (59)第8章安装部署Spark (61)8.1 解压并安装Spark (61)8.2 配置Hadoop环境变量 (62)8.3 验证Spark安装 (62)第9章安装部署Storm (66)安装Storm依赖包 (66)9.1安装ZooKeeper集群 (66)9.1.1解压安装 (66)9.1.2配置ZooKeeper属性文件 (67)9.1.3 将Zookeeper安装文件复制到HadoopSlave节点 (68)9.1.3启动ZooKeeper集群 (68)9.2安装Storm (69)9.2.1 解压安装 (69)9.2.2修改storm.yaml配置文件 (70)9.2.3 将Storm安装文件复制到HadoopSlave节点 (70)9.2.4启动Storm集群 (70)9.2.5向Storm集群提交任务 (71)第10章安装部署Kafka (73)10.1. 安装Kafka (73)10.1.1下载Kafka安装文件 (73)10.2. 配置Kafka (73)10.3. 启动Kafka (74)第1章安装VMWare Workstation 10第1章安装VMWare 10主要内容安装VMWare Workstation 10第1章安装VMWare Workstation 10 在软件包中找到“software\vmware”目录并进入该目录,如下所示:点击“VMware-workstation-full-10.0.0-1295980.exe”安装2等待安装软件检测和解压以后,出现如下界面,直接单击下一步即可。
hadoop.集群搭建详解

hadoop2.2.0集群搭建PS:apache提供的hadoop-2.2.0的安装包是在32位操作系统编译的,因为hadoop依赖一些C++的本地库,所以如果在64位的操作上安装hadoop-2.2.0就需要重新在64操作系统上重新编译1.准备工作:(参考伪分布式搭建)1.1修改Linux主机名1.2修改IP1.3修改主机名和IP的映射关系1.4关闭防火墙1.5ssh免登陆1.6.安装JDK,配置环境变量等2.集群规划:PS:在hadoop2.0中通常由两个NameNode组成,一个处于active 状态,另一个处于standby状态。
Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。
这里我们使用简单的QJM。
在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。
通常配置奇数个JournalNode这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态3.安装步骤:3.1.安装配置zooekeeper集群3.1.1解压tar -zxvf zookeeper-3.4.5.tar.gz -C /cloud/3.1.2修改配置cd /cloud/zookeeper-3.4.5/conf/cp zoo_sample.cfg zoo.cfgvim zoo.cfg修改:dataDir=/cloud/zookeeper-3.4.5/tmp在最后添加:server.1=hadoop01:2888:3888server.2=hadoop02:2888:3888server.3=hadoop03:2888:3888保存退出然后创建一个tmp文件夹mkdir /cloud/zookeeper-3.4.5/tmp再创建一个空文件touch /cloud/zookeeper-3.4.5/tmp/myid最后向该文件写入IDecho 1 > /cloud/zookeeper-3.4.5/tmp/myid3.1.3将配置好的zookeeper拷贝到其他节点(首先分别在hadoop02、hadoop03根目录下创建一个cloud目录:mkdir /cloud)scp -r /cloud/zookeeper-3.4.5/ hadoop02:/cloud/scp -r /cloud/zookeeper-3.4.5/ hadoop03:/cloud/注意:修改hadoop02、hadoop03对应/cloud/zookeeper-3.4.5/tmp/myid内容hadoop02:echo 2 > /cloud/zookeeper-3.4.5/tmp/myidhadoop03:echo 3 > /cloud/zookeeper-3.4.5/tmp/myid3.2.安装配置hadoop集群3.2.1解压tar -zxvf hadoop-2.2.0.tar.gz -C /cloud/3.2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)将hadoop添加到环境变量中vim /etc/profileexport JAVA_HOME=/usr/java/jdk1.6.0_45export HADOOP_HOME=/cloud/hadoop-2.2.0export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin cd /cloud/hadoop-2.2.0/etc/hadoop3.2.2.1修改hadoo-env.shexport JAVA_HOME=/usr/java/jdk1.6.0_453,2.2.2修改core-site.xml<configuration><!-- 指定hdfs的nameservice为ns1 --><property><name>fs.defaultFS</name><value>hdfs://ns1</value></property><!-- 指定hadoop临时目录--><property><name>hadoop.tmp.dir</name><value>/cloud/hadoop-2.2.0/tmp</value></property><!-- 指定zookeeper地址--><property><name>ha.zookeeper.quorum</name><value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value></property></configuration>3,2.2.3修改hdfs-site.xml<configuration><!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致--><property><name>services</name><value>ns1</value></property><!-- ns1下面有两个NameNode,分别是nn1,nn2 --> <property><name>nodes.ns1</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址--><property><name>node.rpc-address.ns1.nn1</name><value>hadoop01:9000</value></property><!-- nn1的http通信地址--><property><name>node.http-address.ns1.nn1</name><value>hadoop01:50070</value></property><!-- nn2的RPC通信地址--><property><name>node.rpc-address.ns1.nn2 </name><value>hadoop02:9000</value></property><!-- nn2的http通信地址--><property><name>node.http-address.ns1.nn2 </name><value>hadoop02:50070</value></property><!-- 指定NameNode的元数据在JournalNode上的存放位置--><property><name>node.shared.edits.dir<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485 /ns1</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置--><property><name>dfs.journalnode.edits.dir</name><value>/cloud/hadoop-2.2.0/journal</value></property><!-- 开启NameNode失败自动切换--><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置失败自动切换实现方式--><name>dfs.client.failover.proxy.provider.ns1</name><value>node.ha. ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制--><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用隔离机制时需要ssh免登陆--><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value> </property></configuration>3.2.2.4修改slaveshadoop01hadoop02hadoop033.2.3配置YARN3.2.3.1修改yarn-site.xml<configuration><!-- 指定resourcemanager地址--> <property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property><!-- 指定nodemanager启动时加载server的方式为shuffle server --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>3.2.3.2修改mapred-site.xml<configuration><!-- 指定mr框架为yarn方式--><property><name></name><value>yarn</value></property></configuration>3.2.4将配置好的hadoop拷贝到其他节点scp -r /cloud/hadoop-2.2.0/ hadoo02:/cloud/scp -r /cloud/hadoop-2.2.0/ hadoo03:/cloud/3.2.5启动zookeeper集群(分别在hadoop01、hadoop02、hadoop03上启动zk)cd /cloud/zookeeper-3.4.5/bin/./zkServer.sh start查看状态:./zkServer.sh status(一个leader,两个follower)3.2.6启动journalnode(在hadoop01上启动所有journalnode)cd /cloud/hadoop-2.2.0sbin/hadoop-daemons.sh start journalnode(运行jps命令检验,多了JournalNode进程)3.2.7格式化HDFS在hadoop01上执行命令:hadoop namenode -format格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/cloud/hadoop-2.2.0/tmp,然后将/cloud/hadoop-2.2.0/tmp拷贝到hadoop02的/cloud/hadoop-2.2.0/下。
Hadoop安装笔记

最近工作需要,摸索着搭建了HADOop 2.2.0(YARN)集群,中间遇到了一些问题,在此记录,希望对需要的同学有所帮助。
本篇文章不涉及hadoop2.2的编译,编译相关的问题在另外一篇文章《hadoop 2.2.0 源码编译笔记》中说明,本篇文章我们假定已经获得了hadoop 2.2.0的64bit发行包。
由于spark的兼容问题,我们后面使用了Hadoop 2.0.5-alpha的版本(2.2.0是稳定版本),2.0.5的配置有一点细微的差别,文中有特别提示。
1. 简介【本节摘自】Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。
以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和mapreduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。
一个HDFS集群是由一个NameNode和若干个DataNode组成的。
其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。
MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。
主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。
主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。
当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和mapreduce共同组成了HADOop分布式系统体系结构的核心。
HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。
hadoop2.2安装
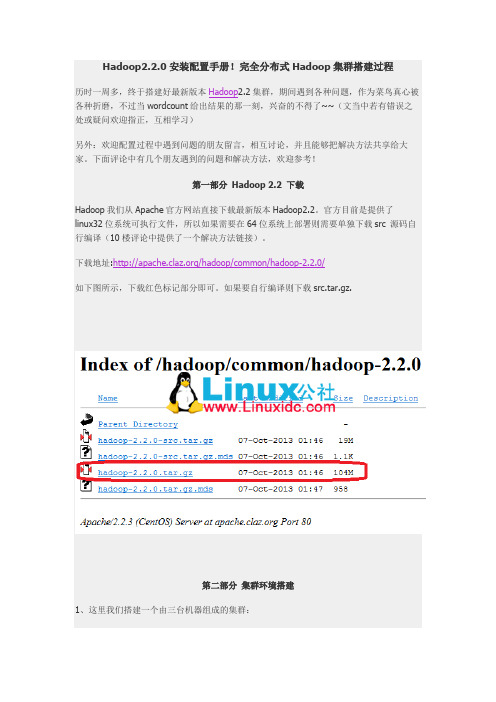
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。
下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
如果要自行编译则下载src.tar.gz.第二部分集群环境搭建1、这里我们搭建一个由三台机器组成的集群:192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。
hadoop安装与配置总结与心得

hadoop安装与配置总结与心得安装与配置Hadoop是一个相对复杂的任务,但如果按照正确的步骤进行,可以顺利完成。
以下是我在安装与配置Hadoop 过程中的总结与心得:1. 首先,确保你已经满足Hadoop的系统要求,并且已经安装了Java环境和SSH。
2. 下载Hadoop的压缩包,并解压到你想要安装的目录下。
例如,解压到/opt/hadoop目录下。
3. 配置Hadoop的环境变量。
打开你的.bashrc文件(或者.bash_profile文件),并添加以下内容:```shellexport HADOOP_HOME=/opt/hadoopexport PATH=$PATH:$HADOOP_HOME/bin```保存文件后,执行source命令使其生效。
4. 配置Hadoop的核心文件。
打开Hadoop的配置文件core-site.xml,并添加以下内容:```xml<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>```5. 配置Hadoop的HDFS文件系统。
打开Hadoop的配置文件hdfs-site.xml,并添加以下内容:```xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>```这里的dfs.replication属性指定了数据块的副本数量,可以根据实际情况进行调整。
6. 配置Hadoop的MapReduce框架。
hadoop2安装笔记

一、准备安装环境:1、Vmware workstation 12 的安装2、虚拟机Red Hat RHEL 6.6[hadoop@master~]$ more /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.150.30 master TST-RHEL66-00192.168.150.31 slave1 TST-RHEL66-01192.168.150.32 slave2 TST-RHEL66-02[hadoop@master~]$2、虚拟机之间可以需要SSH免密码登录## (注意:ssh与-keygen之间没有空格)一路回车即可。
[hadoop@master~]$ cd[hadoop@master~]$pwd/home/hadoop[hadoop@master~]$ ssh-keygen -t rsa##转到.ssh目录 cd ~/.ssh 可以看到生成了id_rsa,和id_rsa.pub两个文件[hadoop@master~]$ cd .ssh/[hadoop@master .ssh]$ lsauthorized_keys id_rsa id_rsa.pub known_hosts## 执行 cp id_rsa.pub authorized_keys[hadoop@master .ssh]$ cp id_rsa.pub authorized_keys## 把Master上面的authorized_keys文件复制到Slave机器的/home/hadoop/.ssh/文件下面[hadoop@master .ssh]$scpauthorized_keys slave1:~/.ssh/[hadoop@master .ssh]$scpauthorized_keys slave2:~/.ssh/## 修改修改.ssh目录的权限以及authorized_keys 的权限(这个必须修改,要不然还是需要密码) sudochmod 644 ~/.ssh/authorized_keyssudochmod 700 ~/.ssh二、Hadoop 2.0稳定版介质/apache//apache/hadoop/core/stable/hadoop-2.7.2.tar.gz1、上传解压文件并创建软链接# tar xzvf hadoop-2.2.0.tar.gz# chown -R hadoop:hadoop hadoop-2.2.0 (-R级联的授权,子目录都有权限)2、配置主机变量配置环境变量(三台主机)添加如下内容到hadoop用户的.bashrc文件:# User specific aliases and functionsexport JAVA_HOME=/usr/java/latestexport CLASSPATH=$CLASSPATH:$JAVA_HOME/libexport HADOOP_DEV_HOME=/home/hadoop/hadoop2export HADOOP_MAPARED_HOME=${HADOOP_DEV_HOME}export HADOOP_COMMON_HOME=${HADOOP_DEV_HOME}export HADOOP_HDFS_HOME=${HADOOP_DEV_HOME}export YARN_HOME=${HADOOP_DEV_HOME}export HADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoopexport HDFS_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoopexport YARN_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop发送到另外两台主机[hadoop@master .ssh]$scp .bashrc slave1:~[hadoop@master .ssh]$scp .bashrc slave2:~3、Hadoop配置有关文件修改hadoop-env.sh和mapred-env.sh文件配置hadoop-env.sh配置mapred-env.sh修改yarn-env.sh和slaves文件~/hadoop2/etc/hadoop/yarn-env.sh配置~/hadoop2/etc/hadoop/slaves修改core-site.xml文件创建hadoop工作目录(临时工作目录,默认是/tmp目录,服务器重启后,文件消失,所以需要另外指定一个目录/hadoop2)修改~/hadoop2/etc/hadoop/core-site.xmlfs_defaultFS是NameNode的IPHadoop.tmp.dir是hadoop的临时目录,刚刚root用户创建的/hadoop2/tmpHadoop.proxyuser.hadoop.hosts中的“.hadoop.”是用户名,我们这里是hadoop,如果使用别的用户,需要用别的用户名,例如:erhadoop.hosts修改hdfs-site.xml文件创建hadoop工作目录(生产环境中的hadoop目录需要指定挂接独立磁盘或独立盘阵的目录。
hadoop安装实验总结

hadoop安装实验总结Hadoop安装实验总结一、引言Hadoop是一个开源的分布式计算平台,用于存储和处理大规模数据集。
在本次实验中,我们将介绍Hadoop的安装过程,并总结一些注意事项和常见问题的解决方法。
二、安装过程1. 确定操作系统的兼容性:Hadoop支持多种操作系统,包括Linux、Windows等。
在安装之前,我们需要确认所使用的操作系统版本与Hadoop的兼容性。
2. 下载Hadoop软件包:我们可以从Hadoop的官方网站或镜像站点上下载最新的稳定版本的Hadoop软件包。
确保选择与操作系统相对应的软件包。
3. 解压缩软件包:将下载的Hadoop软件包解压缩到指定的目录下。
可以使用命令行工具或图形界面工具进行解压缩操作。
4. 配置环境变量:为了方便使用Hadoop命令行工具,我们需要配置环境变量。
在Linux系统中,可以编辑.bashrc文件,在其中添加Hadoop的安装路径。
在Windows系统中,可以通过系统属性中的环境变量设置来配置。
5. 配置Hadoop集群:在Hadoop的安装目录下,找到conf文件夹,并编辑其中的配置文件。
主要包括core-site.xml、hdfs-site.xml 和mapred-site.xml等。
根据实际需求,配置Hadoop的相关参数,如文件系统路径、副本数量、任务调度等。
6. 格式化文件系统:在启动Hadoop之前,需要先格式化文件系统。
使用命令行工具进入Hadoop的安装目录下的bin文件夹,并执行格式化命令:hadoop namenode -format。
7. 启动Hadoop集群:在命令行工具中输入启动命令:start-all.sh(Linux)或start-all.cmd(Windows)。
Hadoop集群将会启动并显示相应的日志信息。
8. 验证Hadoop集群:在启动Hadoop集群后,我们可以通过访问Hadoop的Web界面来验证集群的运行状态。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop 2.2 安装笔记测试环境:硬件:PC 机(12G内存, AMD phenomII x4 CPU,120G SSD硬盘)软件:win7 64位旗舰版操作系统vmware workstation 9.01SSH Secure Shell ClientCentOS-6.4-x86_64-minimaljdk-7u45-linux-x64hadoop-2.2.0第一步Linux 虚拟机安装和配置1.下载好linux操作系统镜像,建立三个空目录用来存放虚机2.建立三个虚拟机,1vcpu,2G内存,20G硬盘。
网络连接模式设置为桥接3.挂载iso镜像,安装系统,主机名分别设置为h1.hadooph2.hadooph3.hadooproot的密码都设成了hadoop由于使用的是centos最小安装镜像,所以各种设置采用默认的即可。
centos 最小安装版镜像地址/centos/6.4/isos/x86_64/4.修改三台虚机的网络配置,设置静态IP(物理机的ip为192.168.1.xx)h1 192.168.1.21h2 192.168.1.22h3 192.168.1.23重启虚机网络service network restart5.关闭防火墙:(非常重要)在三台机器上运行chkconfig iptables off (重启后生效)6.修改三台机器的/etc/hosts文件,加入以下三行192.168.1.21 h1 h1.hadoop192.168.1.22 h2 h2.hadoop192.168.1.23 h3 h3.hadoop7.安装完成后关机,快照。
(防止误操作)第二步,安装JDK1.下载JDK,使用secure file transfer工具上传到三台虚机(由于使用的是centos,我下载的RPM包)JDK下载地址/technetwork/java/javase/downloads/jdk7-downloads-1 880260.html2.在每台虚机上安装JDK[root@h3 ~]# rpm -ivh jdk-7u45-linux-x64.rpm第三步配置SSH 互信1.在每一台机器上创建RSA公钥2.将三台机器的公钥文件id_rsa.pub合并,并拷回每台机器的~/.ssh/,重命名为authorized_keysh1[root@h1 .ssh]# scp ~/.ssh/id_rsa.pub root@h2:~/.ssh/authorized_keysh2[root@h2 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys[root@h2 ~]# scp ~/.ssh/authorized_keys root@h3:~/.ssh/authorized_keysh3[root@h3 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys[root@h3 ~]# scp ~/.ssh/authorized_keys root@h1:~/.ssh/[root@h3 ~]# scp ~/.ssh/authorized_keys root@h2:~/.ssh/3.用每一台机器ssh连接另外两台,确保不用输入密码[root@h1 ~]# ssh h2Last login: Tue Jan 1 17:33:24 2008 from h3[root@h2 ~]# exitlogoutConnection to h2 closed.[root@h1 ~]# ssh h3Last login: Tue Jan 1 17:33:08 2008 from h2[root@h3 ~]# exitlogoutConnection to h3 closed.注意第一次建立连接时会有一个提示,以后就不会有了[root@h1 ~]# ssh h3The authenticity of host 'h3 (192.168.1.23)' can't be established.RSA key fingerprint is ba:26:62:1f:f7:46:24:cd:f9:95:c3:55:82:eb:4e:5a.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'h3,192.168.1.23' (RSA) to the list of known hosts. Last login: Tue Jan 1 17:18:53 2008 from 192.168.1.104第四步安装hadoop1.下载hadoop,由于2.2.x已经发布了稳定版,所以我下载了这个版本下载地址/apache/hadoop/common/hadoop-2.2.0/2.将hadoop-2.2.0.tar.gz 上传到h1节点3.解压安装包[root@h1 ~]# tar -zxvf hadoop-2.2.0.tar.gz4.修改hadoop-env.sh 文件[root@h1 hadoop]# vi /root/hadoop-2.2.0/etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/java/jdk1.7.0_455.修改core-site.xml文件[root@h1 hadoop]# vi core-site.xml<configuration><property><name></name><value>hdfs://h1:9000</value></property><property><name>hadoop.tmp.dir</name><value>/root/hadoop/tmp</value></property></configuration>6.建立hadoop临时目录(同样也要在节点2和节点3上建立)[root@h1 hadoop]# mkdir -p ~/hadoop/tmp7.修改 hdfs-site.xml文件[root@h1 hadoop]# vi hdfs-site.xml<configuration><property><name>dfs.replication</name><value>2</value></property></configuration>8.修改mapred-site.xml文件[root@h1 hadoop]# cp mapred-site.xml.template mapred-site.xml [root@h1 hadoop]# vi mapred-site.xml<configuration><property><name>mapred.job.tracker</name><value>h1:9001</value></property></configuration>9.修改masters文件[root@h1 hadoop]# vi mastersh110.修改slaves文件[root@h1 hadoop]# vi slavesh2h311.将hadoop-2.2.0拷贝到节点2和3[root@h1 ~]# scp -r hadoop-2.2.0 root@h2:~[root@h1 ~]# scp -r hadoop-2.2.0 root@h3:~12.格式化name node[root@h1 bin]# ~/hadoop-2.2.0/bin/hadoop namenode -format13.启动hadoop集群[root@h1 bin]# ./start-all.sh14.验证集群状态h1h2h3总结:1.整个安装步骤基本顺利,hadoop采用了java虚拟机,所以相对于其他系统简单很多。
2.这次安装使用了centos的最精简版,提高系统速度的同时也增加了安装难度,好在本人linux功底还算过得去。
3.ssh互信可能是大多人会遇到的问题,不过只要清楚了原理,问题不大4.本次使用的hadoop的版本是最新的2.2.0,而参考的教学视频和参数配置是针对1.2.1版本的,两个版本间配置文件和可执行文件的目录有些变化。
5.安装完成后虽然集群可以正常启动,但还是有若干报错,同样的环境又配置了一套1.2.1版本的hadoop,没有发现任何问题。
针对这个问题,网上有相关的帖子做出了说明,貌似hadoop2.2.0 在64位linux系统下确实存在一些问题/bamuta/article/details/13506893/question/1051899_134527。