Server查询优化方法文库
SQLServer数据库性能调优技巧

SQLServer数据库性能调优技巧第一章:SQLServer数据库性能调优概述SQLServer是一种常用的关系型数据库管理系统,在大型企业和云计算环境中广泛应用。
为了确保数据库的高性能和可靠性,进行数据库性能调优非常重要。
本章将介绍SQLServer数据库性能调优的概念和目标。
1.1 数据库性能调优的概念数据库性能调优是指通过分析和优化数据库的结构、查询、索引、存储和配置等方面的问题,以提高数据库系统的效率和性能。
优化数据库性能可以显著提升数据的访问速度、减少系统响应时间和提高数据库的处理能力。
1.2 数据库性能调优的目标数据库性能调优的主要目标是提高数据库的运行效率和用户的体验,具体目标包括:- 提高数据的访问速度:通过合理的查询优化和索引设计,加快数据的检索速度。
- 减少系统响应时间:通过调整数据库配置、优化SQL 查询和提高硬件性能等措施,缩短系统响应时间。
- 提高数据库的处理能力:通过合理的分区设计、并行处理和负载均衡等措施,提高数据库的并发处理能力。
第二章:SQLServer数据库性能调优基础在进行SQLServer数据库性能调优之前,有几个基础概念需要了解,包括数据库的结构、查询执行计划和索引等。
2.1 数据库的结构SQLServer数据库由多个表组成,每个表由多个行和列组成。
表有一定的关系,通过主键和外键来建立关联。
了解数据库的结构对于进行性能调优非常重要。
2.2 查询执行计划查询执行计划是SQLServer数据库执行查询语句时的执行路径和操作过程的详细描述。
通过分析查询执行计划,可以找到潜在的性能问题,并进行相应的优化。
2.3 索引索引是一种特殊的数据库对象,用于加快查询速度。
常见的索引类型包括聚集索引、非聚集索引和全文索引等。
合理设计索引可以提高查询的性能。
第三章:SQLServer数据库性能调优技巧本章将介绍一些常用的SQLServer数据库性能调优技巧,包括查询优化、索引优化、配置优化和硬件优化等。
SQL Server 2005 SQL查询优化

SQL Server 2005SQL 查询优化目录SQL Server 2005:SQL查询优化 .............................................................................................. 错误!未定义书签。
实验安装 (44)练习一:使用SQL Server Profiler工具解决死锁问题 (5)练习二:使用SQL Server Profiler工具隔离运行速度慢的查询语句 (9)练习三:检查执行计划 (11)练习四:使用数据库引擎优化顾问工具(Database Tuning Advisor) (12)SQL Server 2005 SQL查询优化目标注释:本实验侧重于这个模块中的概念,因此不必遵循微软的安全建议。
注释:SQL Server 2005的最新详细资料, 请访问/sql/.完成本实验之后, 你可以实现以下目标:▪使用SQL Server Profiler工具解决死锁问题▪为一个低性能查询制定一个查询计划,并将它以XML格式的文档保存。
▪使用数据库引擎优化顾问工具(Database Tuning Advisor)场景假设你是AdventureWorks数据库的数据库管理员.你的数据库用户经常遇到死锁问题而且你很关心死锁是不是导致系统性能低的一个原因。
你已经隔离了一个经常与死锁有关的查询。
你将使用SQL Server Profiler工具来跟踪导致死锁的事件并详细记录死锁的信息。
追踪到死锁的原因之后,你发现这个原因并不是导致系统性能下降的主要原因,所以你决定检查那些关键的查询。
通过检测为那些关键查询制定的查询计划来分析它们,然后你可以使用索引优化顾问工具来提出最适当的索引。
前提条件▪SQL Server 2000管理任务的基本经验▪熟悉T-SQL语言▪完成SQL Server Management Studio 的动手实验。
SQL SERVER 2000 查询慢的原因和解决方法

sql2000查询速度慢的原因2009年10月13日星期二 10:53查询速度慢的原因很多,常见如下几种:1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2、I/O吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足5、网络速度慢6、查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)7、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)8、sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列10、查询语句不好,没有优化●可以通过如下方法来优化查询 :1、把数据、日志、索引放到不同的I/O设备上,增加读取速度,以前可以将Tempdb 应放在RAID0上,SQL2000不在支持。
数据量(尺寸)越大,提高I/O越重要.2、纵向、横向分割表,减少表的尺寸(sp_spaceuse)3、升级硬件4、根据查询条件,建立索引,优化索引、优化访问方式,限制结果集的数据量。
注意填充因子要适当(最好是使用默认值0)。
索引应该尽量小,使用字节数小的列建索引好(参照索引的创建),不要对有限的几个值的字段建单一索引如性别字段5、提高网速;6、扩大服务器的内存,Windows 2000和SQL server 2000能支持4-8G的内存。
配置虚拟内存:虚拟内存大小应基于计算机上并发运行的服务进行配置。
运行Microsoft SQL Server? 2000 时,可考虑将虚拟内存大小设置为计算机中安装的物理内存的 1.5 倍。
如果另外安装了全文检索功能,并打算运行 Microsoft 搜索服务以便执行全文索引和查询,可考虑:将虚拟内存大小配置为至少是计算机中安装的物理内存的 3 倍。
将 SQL Server max server memory 服务器配置选项配置为物理内存的 1.5 倍(虚拟内存大小设置的一半)。
7、增加服务器CPU个数;但是必须明白并行处理串行处理更需要资源例如内存。
sqlserver数据库 提高效率方法

SQL Server 数据库是一种常见的关系型数据库管理系统,它被广泛应用于企业级应用程序和数据管理系统中。
然而,随着数据库规模的增大和日常操作的复杂性增加,数据库的性能和效率往往成为关注的焦点。
提高SQL Server数据库的效率不仅可以显著改善系统的响应速度和稳定性,也可以节约资源和降低成本。
本文将介绍一些提高SQL Server 数据库效率的方法,帮助管理员和开发人员更好地管理和优化数据库系统。
1. 使用合适的索引索引是数据库中用来加快对表中数据的访问速度的结构,它可以通过创建索引来优化查询的性能。
在SQL Server中,通过对经常进行搜索,排序和过滤的数据列创建合适的索引,可以显著提高查询性能。
定期对索引进行维护和优化也是提高数据库效率的关键步骤。
2. 优化查询语句优化SQL查询语句对于提高数据库效率至关重要。
在编写查询语句时,应避免使用全表扫描,尽量减少数据量,避免使用不必要的连接和子查询,合理使用排序和分组等操作,以及避免使用模糊查询和通配符查询等低效操作。
3. 定期备份和恢复定期备份数据库是保障数据库安全的重要手段,同时备份还能够减少数据库维护的风险。
在备份时,管理员应该选择合适的备份策略,并对备份文件进行存储和管理,以确保数据库在出现故障或灾难时能够快速恢复。
4. 使用存储过程和触发器存储过程和触发器是SQL Server中重要的数据库对象,它们可以提高数据库的安全性和可维护性,同时还能减少网络流量和客户端执行开销,提高数据库的效率。
在编写存储过程和触发器时,应遵循一些最佳实践,如避免多次嵌套存储过程和触发器,减少对数据库的锁定和阻塞。
5. 使用物理分区技术SQL Server支持对数据表进行物理分区,这可以帮助管理员更好地管理数据,并根据需求对数据进行调优。
通过物理分区,可以提高查询和数据加载的性能,同时也方便了数据备份和恢复。
总结通过上述方法,可以显著提高SQL Server数据库的性能和效率,使其能够更好地满足企业应用程序和数据管理系统的需求。
基于SQL Server数据库查询优化的几点思考

、
cut e 于 查 询 速 度 的 提 高会 更 有 效 。 ls rd对 e () 聚集索引 的使用 2非 查询优化器对非聚集索引的支持相对较聚集索引少一些 。当非聚 集索 引具有高选择性 , 也就是说消除了大量的行以后才对查询有用 。 一
模 型 1 :
E po e ( m l e y
S l c fo e ly ewh r mp w e >dt d ( ,1, t t ) ee t r m mp o e e e e yr a ady 一 0g d e e y ea 0
_
Sl t‘ e c 该查询执行所花费的时间( e 毫秒) ’dt i(s ,t t ) 为 = ad m , g d e e f @te a 0
通过设 置分 别在主键(rpn ) en —o上建立 聚集索引 , e _ yr 加 在 mpw e( 参 工 作时 间) 建立非 聚集 索 引与 在主键 ( p n)2 e _ o 建立 非聚 集索 引 , m ] 在 e p wy m er上建立聚集索引两种情况 的耗时对 比,发现并不是在主键 上 建 立聚集索 引都是最好 的选择 。因此 ,有时在 主键约束上设 置 nn o—
一
在 某 种 情 况 下 ,反 而 会 造 成 查 询 速 度 的 减 慢 。 以模 型 2中 的 数 据 表 e poe m l e为例 , y 查询 工龄超 过 1 0年的职工信 息 , 使用下 列代码段查看 查询花费时间 :
DECL ARE @ tdae i tt me
St =edt0 e @tgta e
[ 关键词 ]QLSre 数据库模 型 优化查询 索引 S e r v
随着 计 算 机 技 术 的 飞 速发 展 , 为企 业 级 数 据 库 服 务 器 S evr 作 QLSre 在性 能、 可扩展性等方面对 于数据库 系统提 出了更为严格的要求 。 依据 S LSne 的响应时间 、 Q e r r 吞吐量 和可扩展性等方面来判定其性能 。影 响 S LSre 性能的因素很多 , Q evr 大致 分为 : 应用程序 的体系结构 的设计 、 数 据 库模 型和物理设 计 、事务与 隔离 级别的选择 、 rnat S Tasc QL语句设 - 计、 硬件 资源配置及 S LSre 配置参数设定等几个方面。我们就数据 Q evr 库模 型设计 、rnat- Q Tase S L语句设计 和常用优化技术三方面来讨论。 - 合 理 设 计 数 据 库模 型 设计不 良的数据库模 型会 导致数据查询 、 修改等操作效率 的降低 。 为 了 避免 这 类 问 题 , 以从 以 下几 点 考虑 。 可 1 据 库 模 型 的 范 式 . 数 范式是对关系规范化的约束要求 ,规范化理论将关 系应该满 足的 规范要求分成几级 , 主要包括第一范式( N )第二范式( F 、 三范 1r、 2N )第 式 (N 、 3 F)鲍依斯 一科得范式 ( CN )第 四范式 ( F 和第 五范式 ( B F 、 4N ) 5 N ) 。范式越高 , 能够有效 消除数据冗余 , F等 越 理顺数据隶属关 系, 持 保 数据库的完整性 , 提高数据库的稳定性和扩展性 。 但是越高的范式需要 更多的表 , 在检索 同样信息的查询 中需要 的连接操作也会 更多 , 造成需 要更多的系统机缘来优化执行 ,最终导致数据库 系统 中查 询的性 能的 降低。以下面两个模型为例 , 在模 型 1 使用 一张表代表 职工 ; 模型 2中 将职工表的信息细化成为两张表——职工表和部门表 。
基于SQL SERVER的数据库查询优化浅析

计 算机 与 网络
基 于 S E VE QLS R R硇 数 据 库查 询 优 化 浅析
海 南软件 职业技 术 学院 符 于江 潘 萍
[ 摘 要 ] 管 S LS R E 尽 Q E V R数据库 系统应用很 广, 效率很 高, 但在 实际应 用过程 中还 需要 不断具体优化 , 才能使 S LS R E 的 Q VR E
3物 理结 构 设 计 .
应简化或避免对大型表进行重 复的排序 。 如果排序不可避免 , 则应 尽量 简化它 , 如缩小排序的列的范 围等 。 52使用 ei 谓词代替 i _ xs t n子查 询 子查询含有 ei s x t 谓词时 ,子查 询都只要判断逻辑 的真假 。这样 s D MS的优化器就仅根据索 引就可 以完成 工作。因此 , B 使用 ei s x t 谓词 s 查询效率能 比 I 子查询效率高。此外 , n 尽可能用 nt eis o x t代替 nt n s oi 也可提高查询效能。 53尽量避免相关子查询 _ S L中的嵌套查询分为两种” Q 相关子查询和非相关子查询 。 相关子 查询是 一个 列 的标签 同时在主查 询和 w e 子句 中的查询 中出现 , hr e 执 行时子查询的查询条件 要依 赖于主查询所访问的一个记录行。当主查 询 中的列值改变之后 , 子查询必须重新查 询一次 。查询嵌套层 次越多 , 效率越低 , 因此应 当尽量 避免 这种相关子查询 , 如不能避免时 , 么要 那 在子查询中过滤 掉尽可能多的行。 54尽可能使用 “ ” . : 代替 l e i 子句 k LK I E关键字支持模糊匹配 , 但这种模糊匹配耗时间 。如果可 以替 换, 那么使用“ ” = 操作 符的 WHE E子句性能最好 。 R
21 少连 接 运 算 .减
SqlServer中百万级数据的查询优化

SqlServer中百万级数据的查询优化万级别的数据真的算不上什么⼤数据,但是这个档的数据确实考核了普通的查询语句的性能,不同的书写⽅法有着千差万别的性能,都在这个级别中显现出来了,它不仅考核着你sql语句的性能,也考核着程序员的思想。
公司系统的⼀个查询界⾯最近⾮常慢,界⾯的响应时间在6-8秒钟时间,甚⾄更长。
检查发现问题出现在数据库端,查询⽐较耗时。
该界⾯涉及到多个表中的数据,基本表有150万数据,关联⼦表的最多的⼀个700多万数据,其它表数据也在⼏⼗万到⼏百万之间。
其实按这样的数据级别查询响应时间应该在毫秒级内,不应该有这么长时间。
那么接下来就该进⾏问题排查了。
由于这个这界⾯的功能主要是信息检索,查询⽐较复杂,太多的条件组合,使⽤存储过程太多的局限性,因此查询使⽤的是动态拼接的sql 语句。
查询⽅式是最常⽤的1、获取数据总数2、数据分页。
直接上代码(部分条件)。
select numb=count(distinct t1.tlntcode)from ZWOMMAINM0 t1 inner join ZWOMMLIBM0 t2 on t1.tlntcode=t2.tlntcodejoin ZWOMEXPRM0 cp on t1.tlntcode=cp.tlntcodejoin ZWOMILBSM0 i on i.tlntcode=t1.tlntcodejoin ZWOMILBSM0 p on p.tlntcode=i.tlntcodejoin ZWOMILBSM0 l on l.tlntcode=i.tlntcodewhere isnull(t2.deletefg,'0')='0' and panyn like '%IBM%' and cp.sequence=0and i. mlbscode in('i0100','i0101','i0102','i0103','i0104','i0105','i0106') and i.locatype='10'and p.mlbscode in('p0100','p0102','p0104','p0200','p0600') and p.locatype='10'and l.mlbscode in('l030') and l.locatype='10'查看执⾏时间根据提⽰得知,整个查询耗时花费在了分析和编译为4秒,执⾏为0.7秒。
SQLServer2000数据库优化方案参考

1、6、7、SQL Server 2000 数据库优化方案参考查询速度慢的原因很多,常见如下几种:没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2、I/O 吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足5、网络速度慢查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)8、sp_lock,sp_who, 活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列10、查询语句不好,没有优化可以通过如下方法来优化查询1、把数据、日志、索引放到不同的I/O 设备上,增加读取速度,以前可以将Tempdb应放在RAIDO上,SQL2000不在支持。
数据量(尺寸)越大,提高I/O 越重要.2、纵向、横向分割表,减少表的尺寸(sp_spaceuse)3、升级硬件4、根据查询条件,建立索引,优化索引、优化访问方式,限制结果集的数据量。
注意填充因子要适当(最好是使用默认值0)。
索引应该尽量小,使用字节数小的列建索引好(参照索引的创建),不要对有限的几个值的字段建单一索引如性别字段5 、提高网速;6、扩大服务器的内存,Windows 2000 和SQL server 2000 能支持4-8G 的内存。
配置虚拟内存:虚拟内存大小应基于计算机上并发运行的服务进行配置。
运行Microsoft SQL Server? 2000 时,可考虑将虚拟内存大小设置为计算机中安装的物理内存的1.5 倍。
如果另外安装了全文检索功能,并打算运行Microsoft 搜索服务以便执行全文索引和查询,可考虑:将虚拟内存大小配置为至少是计算机中安装的物理内存的3 倍。
将SQL Server max server memory 服务器配置选项配置为物理内存的1.5 倍(虚拟内存大小设置的一半)。
7、增加服务器CPU 个数;但是必须明白并行处理串行处理更需要资源例如内存。
Windows Server 2008 R2设置与优化
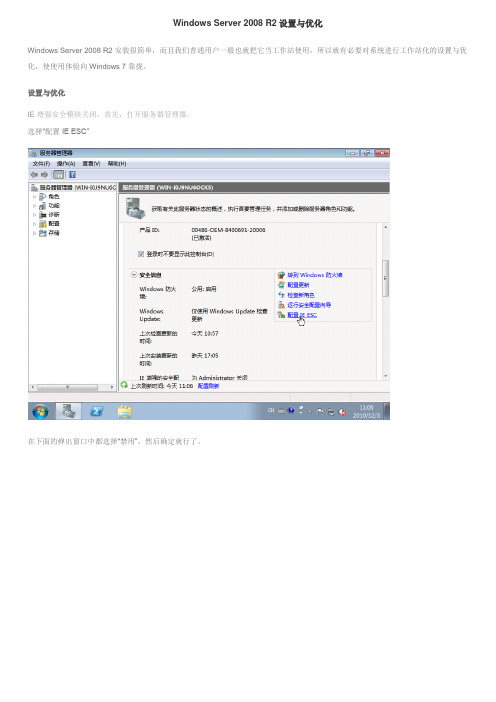
Windows Server 2008 R2设置与优化Windows Server 2008 R2安装很简单,而且我们普通用户一般也就把它当工作站使用,所以就有必要对系统进行工作站化的设置与优化,使使用体验向Windows 7靠拢。
设置与优化IE增强安全模块关闭,首先,打开服务器管理器。
选择“配置IE ESC”在下面的弹出窗口中都选择“禁用”,然后确定就行了。
功能。
选择“无线LAN服务”这样,我们的无线网络就可以使用了。
账户管理系统启动自动登录系统启动禁用“ctrl+alt+del”操作,直接出现用户界面。
关机的时候不再出现“关闭事件跟踪程序”。
打开Windows Server 2008 R2声音系统支持。
开始——》管理工具——》服务找到“Windows Audio”服务。
为Windows Server 2008 R2增加Windows 7的桌面体验支持。
安装完成,重新启动一次。
进入管理工具——》服务——》找到“Themes”服务,启动,重启。
桌面右键——》个性化——》选择“Aero主题”,想获得更多的主题,点击链接:联机获取更多主题。
添加桌面图标,桌面右键——》个性化——》左边栏——》更改桌面图标。
后记到这里,我们Windows Server 2008 R2的简单设置与优化就实现完毕,虽然现在网络上已经出现了像Windows Server 2008 R2 workstation converter这样傻瓜的设置工具,但是毕竟自己掌握一些基本的设置与优化要领还是必要的。
更别说我们在设置或优化的过程中就是一个好的学习方式。
sql server数据库cpu过高 排查方法

sql server数据库cpu过高排查方法摘要:一、问题概述二、排查方法1.查询CPU使用情况2.查询内存使用情况3.查询磁盘使用情况4.查询网络连接情况5.查询SQL Server配置6.查询运行中的查询语句7.查询系统日志三、解决措施1.优化SQL查询语句2.调整SQL Server配置3.优化数据库表结构4.调整服务器硬件配置5.优化网络环境6.定期清理系统日志正文:在日常工作中,SQL Server数据库CPU使用过高是一个常见问题,可能导致服务器性能下降,影响业务正常运行。
为了解决这个问题,我们需要对数据库进行排查,找出导致CPU使用率过高的原因,并采取相应的解决措施。
以下是一些排查方法和解决措施供大家参考。
一、问题概述当SQL Server数据库CPU使用过高时,可能导致以下现象:1.服务器响应变慢。
2.运行查询语句时,查询速度降低。
3.数据库连接数增多,但实际处理能力没有明显提升。
二、排查方法1.查询CPU使用情况:通过系统监控工具或查询SQL Server性能监控表,查看CPU使用情况。
2.查询内存使用情况:检查内存使用是否充足,是否存在内存泄漏现象。
3.查询磁盘使用情况:检查磁盘空间是否充足,是否存在磁盘瓶颈。
4.查询网络连接情况:检查服务器网络连接是否正常,是否存在网络拥堵现象。
5.查询SQL Server配置:检查SQL Server的硬件配置和软件配置,如内存、CPU、磁盘空间等。
6.查询运行中的查询语句:查看当前运行的查询语句,是否存在低效的SQL语句。
7.查询系统日志:分析系统日志,查找可能导致CPU使用率过高的异常信息。
三、解决措施1.优化SQL查询语句:对低效的SQL查询语句进行优化,提高查询效率。
2.调整SQL Server配置:根据实际情况,调整SQL Server的硬件配置和软件配置,如增加内存、升级CPU等。
3.优化数据库表结构:对数据库表进行索引、分区等优化操作,提高数据查询效率。
SQLServer多表查询优化方案总结

SQLServer多表查询优化⽅案总结SQL Server多表查询的优化⽅案是本⽂我们主要要介绍的内容,本⽂我们给出了优化⽅案和具体的优化实例,接下来就让我们⼀起来了解⼀下这部分内容。
1.执⾏路径ORACLE的这个功能⼤⼤地提⾼了SQL的执⾏性能并节省了内存的使⽤:我们发现,单表数据的统计⽐多表统计的速度完全是两个概念.单表统计可能只要0.02秒,但是2张表联合统计就可能要⼏⼗秒了.这是因为ORACLE只对简单的表提供⾼速缓冲(cache buffering) ,这个功能并不适⽤于多表连接查询..数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越⼤,就可以保留更多的语句,当然被共享的可能性也就越⼤了.2.选择最有效率的表名顺序(记录少的放在后⾯)ORACLE的解析器按照从右到左的顺序处理FROM⼦句中的表名,因此FROM⼦句中写在最后的表(基础表 driving table)将被最先处理. 在FROM⼦句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表.当ORACLE处理多个表时, 会运⽤排序及合并的⽅式连接它们.⾸先,扫描第⼀个表(FROM⼦句中最后的那个表)并对记录进⾏派序,然后扫描第⼆个表(FROM⼦句中最后第⼆个表),最后将所有从第⼆个表中检索出的记录与第⼀个表中合适记录进⾏合并.例如:表 TAB1 16,384 条记录表 TAB2 1条记录选择TAB2作为基础表 (最好的⽅法)select count(*) from tab1,tab2 执⾏时间0.96秒选择TAB2作为基础表 (不佳的⽅法)select count(*) from tab2,tab1 执⾏时间26.09秒如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引⽤的表.例如: EMP表描述了LOCATION表和CATEGORY表的交集.1. SELECT *2. FROM LOCATION L ,3. CATEGORY C,4. EMP E5. WHERE E.EMP_NO BETWEEN 1000 AND 20006. AND E.CAT_NO = C.CAT_NO7. AND E.LOCN = L.LOCN将⽐下列SQL更有效率1. SELECT *2. FROM EMP E ,3. LOCATION L ,4. CATEGORY C5. WHERE E.CAT_NO = C.CAT_NO6. AND E.LOCN = L.LOCN7. AND E.EMP_NO BETWEEN 1000 AND 20003.WHERE⼦句中的连接顺序(条件细的放在后⾯)ORACLE采⽤⾃下⽽上的顺序解析WHERE⼦句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最⼤数量记录的条件必须写在WHERE⼦句的末尾.例如:(低效,执⾏时间156.3秒)1. SELECT …2. FROM EMP E3. WHERE SAL > 500004. AND JOB = ‘MANAGER’5. AND 25 < (SELECT COUNT(*) FROM EMP6. WHERE MGR=E.EMPNO);7. (⾼效,执⾏时间10.6秒)8. SELECT …9. FROM EMP E10. WHERE 25 < (SELECT COUNT(*) FROM EMP11. WHERE MGR=E.EMPNO)12. AND SAL > 5000013. AND JOB = ‘MANAGER’;4.SELECT⼦句中避免使⽤'* '当你想在SELECT⼦句中列出所有的COLUMN时,使⽤动态SQL列引⽤ '*' 是⼀个⽅便的⽅法.不幸的是,这是⼀个⾮常低效的⽅法. 实际上,ORACLE在解析的过程中, 会将'*' 依次转换成所有的列名, 这个⼯作是通过查询数据字典完成的, 这意味着将耗费更多的时间.5.减少访问数据库的次数当执⾏每条SQL语句时, ORACLE在内部执⾏了许多⼯作: 解析SQL语句, 估算索引的利⽤率, 绑定变量 , 读数据块等等. 由此可见, 减少访问数据库的次数 , 就能实际上减少ORACLE的⼯作量.⽅法1 (低效)1. SELECT EMP_NAME , SALARY , GRADE2. FROM EMP3. WHERE EMP_NO = 342;4. SELECT EMP_NAME , SALARY , GRADE5. FROM EMP6. WHERE EMP_NO = 291;⽅法2 (⾼效)1. SELECT A.EMP_NAME , A.SALARY , A.GRADE,2. B.EMP_NAME , B.SALARY , B.GRADE3. FROM EMP A,EMP B4. WHERE A.EMP_NO = 3425. AND B.EMP_NO = 291;6.删除重复记录最⾼效的删除重复记录⽅法 ( 因为使⽤了ROWID)1. DELETE FROM EMP E2. WHERE E.ROWID > (SELECT MIN(X.ROWID)3. FROM EMP X4. WHERE X.EMP_NO = E.EMP_NO);7.⽤TRUNCATE替代DELETE当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) ⽤来存放可以被恢复的信息. 如果你没有COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准确地说是恢复到执⾏删除命令之前的状况),⽽当运⽤TRUNCATE时, 回滚段不再存放任何可被恢复的信息.当命令运⾏后,数据不能被恢复.因此很少的资源被调⽤,执⾏时间也会很短.8.尽量多使⽤COMMIT只要有可能,在程序中尽量多使⽤COMMIT, 这样程序的性能得到提⾼,需求也会因为COMMIT所释放的资源⽽减少:COMMIT所释放的资源:a. 回滚段上⽤于恢复数据的信息.b. 被程序语句获得的锁c. redo log buffer 中的空间d. ORACLE为管理上述3种资源中的内部花费(在使⽤COMMIT时必须要注意到事务的完整性,现实中效率和事务完整性往往是鱼和熊掌不可得兼)9.减少对表的查询在含有⼦查询的SQL语句中,要特别注意减少对表的查询.例如:低效:1. SELECT TAB_NAME2. FROM TABLES3. WHERE TAB_NAME = ( SELECT TAB_NAME4. FROM TAB_COLUMNS5. WHERE VERSION = 604)6. AND DB_VER= ( SELECT DB_VER7. FROM TAB_COLUMNS8. WHERE VERSION = 604⾼效:1. SELECT TAB_NAME2. FROM TABLES3. WHERE (TAB_NAME,DB_VER)4. = ( SELECT TAB_NAME,DB_VER)5. FROM TAB_COLUMNS6. WHERE VERSION = 604)Update 多个Column 例⼦:低效:1. UPDATE EMP2. SET EMP_CAT = (SELECT MAX(CATEGORY) FROM EMP_CATEGORIES),3. SAL_RANGE = (SELECT MAX(SAL_RANGE) FROM EMP_CATEGORIES)4. WHERE EMP_DEPT = 0020;⾼效:1. UPDATE EMP2. SET (EMP_CAT, SAL_RANGE)3. = (SELECT MAX(CATEGORY) , MAX(SAL_RANGE)4. FROM EMP_CATEGORIES)5. WHERE EMP_DEPT = 0020;10.⽤EXISTS替代IN,⽤NOT EXISTS替代NOT IN在许多基于基础表的查询中,为了满⾜⼀个条件,往往需要对另⼀个表进⾏联接.在这种情况下, 使⽤EXISTS(或NOT EXISTS)通常将提⾼查询的效率.低效:1. SELECT *2. FROM EMP (基础表)3. WHERE EMPNO > 04. AND DEPTNO IN (SELECT DEPTNO5. FROM DEPT6. WHERE LOC = ‘MELB’)⾼效:1. SELECT *2. FROM EMP (基础表)3. WHERE EMPNO > 04. AND EXISTS (SELECT ‘X’5. FROM DEPT6. WHERE DEPT.DEPTNO = EMP.DEPTNO7. AND LOC = ‘MELB’)(相对来说,⽤NOT EXISTS替换NOT IN 将更显著地提⾼效率)在⼦查询中,NOT IN⼦句将执⾏⼀个内部的排序和合并. ⽆论在哪种情况下,NOT IN都是最低效的 (因为它对⼦查询中的表执⾏了⼀个全表遍历). 为了避免使⽤NOT IN ,我们可以把它改写成外连接(Outer Joins)或NOT EXISTS.例如:1. SELECT …2. FROM EMP3. WHERE DEPT_NO NOT IN (SELECT DEPT_NO4. FROM DEPT5. WHERE DEPT_CAT='A');为了提⾼效率.改写为:(⽅法⼀: ⾼效)1. SELECT ….2. FROM EMP A,DEPT B3. WHERE A.DEPT_NO = B.DEPT(+)4. AND B.DEPT_NO IS NULL5. AND B.DEPT_CAT(+) = 'A'(⽅法⼆: 最⾼效)1. SELECT ….2. FROM EMP E3. WHERE NOT EXISTS (SELECT 'X'4. FROM DEPT D5. WHERE D.DEPT_NO = E.DEPT_NO6. AND DEPT_CAT = 'A');当然,最⾼效率的⽅法是有表关联.直接两表关系对联的速度是最快的!11.识别'低效执⾏'的SQL语句⽤下列SQL⼯具找出低效SQL:1. SELECT EXECUTIONS , DISK_READS, BUFFER_GETS,2. ROUND((BUFFER_GETS-DISK_READS)/BUFFER_GETS,2) Hit_radio,3. ROUND(DISK_READS/EXECUTIONS,2) Reads_per_run,4. SQL_TEXT5. FROM V$SQLAREA6. WHERE EXECUTIONS>07. AND BUFFER_GETS > 08. AND (BUFFER_GETS-DISK_READS)/BUFFER_GETS < 0.89. ORDER BY 4 DESC;(虽然⽬前各种关于SQL优化的图形化⼯具层出不穷,但是写出⾃⼰的SQL⼯具来解决问题始终是⼀个最好的⽅法)关于SQL Server多表查询优化⽅案的相关知识就介绍到这⾥了,希望本次的介绍能够对您有所收获!。
SQLServer数据库的查询优化技巧

SQLServer数据库的查询优化技巧在数据库应用的过程中,查询是最常被执行的操作之一。
因此,优化查询是提高应用性能和效率的一种有效手段。
下面将介绍几种SQLServer数据库查询优化的技巧,帮助您更好地开发和设计SQLServer数据库。
一、创建索引索引是一种数据结构,主要用于快速查找和定位数据。
在SQLServer数据库中,通过为表和视图创建索引,可以提高查询的效率和性能。
对于经常进行查询的表和视图,应该将其关键列进行索引。
同时,还应该注意索引的数量和方案,避免过多或者重复的索引对系统性能的影响。
二、避免使用SELECT *使用SELECT *查询会使系统不必要地返回所有列的数据,对服务器的负载造成很大的开销。
因此,在实际应用中,应该仅返回需要查询的列,以减少系统的负载和查询的时间。
在设计表结构的时候,还可以考虑将常用的列存储在一张表中,而将不常用或者大数据类型的列存储在另外一张表中,以优化查询的效率。
三、减少使用子查询子查询是SQL查询中常见的一种操作,但是其效率通常较低。
在实际应用中,应该尽量避免使用子查询。
对于需要使用子查询的情况,可以通过JOIN等其他方式进行优化。
四、避免使用NOT IN和<>运算符在实际应用中,应该尽量避免使用NOT IN和<>运算符,因为它们会增加查询的开销和时间。
可以使用LEFT OUTER JOIN等其他方式替换这些运算符,以减少查询的时间和负载。
五、使用临时表在SQLServer数据库中,临时表是一种临时存储数据的表,通常用于存储中间结果和临时查询结果。
使用临时表可以减少查询的时间和负载,同时还可以提高查询的效率和性能。
在使用临时表的时候,应该注意清理和释放临时表,以避免对系统性能的影响。
六、使用物化视图物化视图是一种预计算的数据结果集,可以提高查询的效率和性能。
在SQLServer数据库中,可以通过使用物化视图来优化查询,尤其是对于复杂和耗时的查询操作。
Windows Server 2016数据中心操作优化指南说明书

Reconsidere las operaciones para mejorar la eficacia y la seguridadActualmente, las operaciones del centro de datos parecen recibir más escrutinioque los presupuestos. Las aplicaciones nuevas estiran el tejido operacional y creantrabajos pendientes en la infraestructura que pueden frenar los negocios. Se esperaque las organizaciones de TI logren más con menos, pero una infraestructuraantigua con poca automatización se convierte en un impedimento para avanzar .Mientras tanto, las infracciones de seguridad son recurrentes y afectan la reputaciónde las organizaciones.Cuando las organizaciones busquen más allá de la virtualización del servidor paraalcanzar una mayor eficacia, pueden usar las capacidades de Windows Server 2016para satisfacer los desafíos de seguridad y operación, lo que liberará a los recursosde TI para que se dediquen a planificar e innovar futuras soluciones que puedanaumentar el éxito de la empresa.Automatice las operaciones rutinarias del centro de datosSi un objetivo importante es obtener escala sin aumentar el costo, unaestrategia posible es el uso correcto de la automatización. Las organizacionesde TI tienen que ajustar una cantidad cada vez mayor de solicitudes de negociosy mantener , al mismo tiempo, la infraestructura y las aplicaciones existentes. Lasorganizaciones que ya lograron ahorrar todos los costos disponibles mediantela virtualización del servidor pueden considerar virtualizar las redes y elalmacenamiento. De esta forma, podrán disminuir los costos con un hardware máseconómico, eliminar la complejidad y obtener la capacidad de administrar segúnlas políticas, la automatización y la organización en vez de usar configuracionesmanuales y estáticas.Mediante el uso de las capacidades de PowerShell en Windows Server 2016 sepueden lograr eficiencias operacionales importantes, ya que les permite a losadministradores de TI usar una consola para automatizar , implementar , configurar ,administrar y desmantelar aplicaciones, servidores, configuraciones y usuarios enuno o más servidores. El entorno mejorado de Configuración de estado deseadopuede permitirle ahorrar tiempo mediante la definición del estado deseado y elenvío de alertas automáticas y reparaciones si hay problemas. Esta automatizaciónayuda a los administradores de TI a ofrecer infraestructura como servicio a losclientes internos como autoservicio para abordar el ataque de solicitudes deimplementación y configuración.Ahora los administradores de TI tienen nuevas opciones para los entornosvirtualizados, lo que les permite seleccionar e implementar lo más adecuado para aumentar las eficiencias y disminuir el costo.Logre eficiencia con un centro de datos definido por el softwarecon Windows Server 2016Maximice la eficiencia Aquí le presentamos tres formas más en las que Windows Server 2016 ayuda a las organizaciones a mejorar su eficiencia y reducir los costos.Infraestructura hiperintegrada Infraestructura hiperintegrada. La máxima expresión del software: el centro de datos definido integra estrechamente los recursos de informática, redes, almacenamiento, virtualización y hardware en un entorno informático para aumentar la simpleza y escalabilidad. Windows Server 2016 puede ayudar a las organizaciones a descubrir los beneficios de los entornos hiperintegrados.Servidor Nano Sistema operativo eficaz. Disminuya la huella de su centro de datos con el Servidor Nano, una nueva opción de instalación de administración remota para centros de datos y nubes privadas. Minimice la superficie de ataques, aumente la disponibilidad y reduzca el uso de recursos. Actualización gradual del sistema operativo de clústeres Actualizaciones eficaces. Ahora los administradores pueden actualizar los clústeres del servidor de Windows Server 2012 R2 a Windows Server 2016 sin detener las cargas de trabajo de Hyper-V o del Servidor de archivos de escalabilidad horizontal.“ L o que logró Microsoft con los Espacios de almacenamiento directo es nada menos que increíble. Un excelente rendimiento y una gran flexibilidad a un precio muy conveniente. Gracias a la capacidad de usar NVMe o SSD como una memoria caché y SSD o HDD para la capacidad, junto con los adaptadores de red de RDMA, todas las necesidades con respecto al rendimiento quedan satisfechas". – David Knappett, arquitecto técnico de Alternative NetworksMejore la movilidad de la carga de trabajo y el controlde las redesLas infraestructuras tradicionales de red son rígidas y complejas. Las organizacionespueden lograr un escalado rápido y agilidad cuando trasladan la capa de control dered desde el hardware al software para crear una red definida por el software. El controlsegún políticas les permite configurar y administrar de forma centralizada los dispositivosfísicos y de redes virtuales, como enrutadores, conmutadores y gateways en el centro dedatos. Además, trae como resultado el equilibrio en la carga automática y la capacidadde cambiar cargas de trabajo sin configurar conmutadores. Los elementos de la redvirtual, como el Conmutador virtual de Hyper-V , la Virtualización de red de Hyper-V y laGateway de Windows Server , se convierten en elementos integrales de la infraestructurade red definida por software. El equipo de TI puede seguir usando conmutadores,enrutadores y cualquier otro dispositivo de hardware físico existente, siempre que seancompatibles con los controladores virtuales y mientras logren una mayor integraciónentre la red virtual y la red física. Disminuya los costos de almacenamiento En un entorno altamente virtualizado, el sistema subyacente de almacenamiento puede afectar el rendimiento general. Un sistema tradicional de almacenamientoconfigurado de forma manual puede evitar que las organizaciones reciban todoslos beneficios del centro de datos definido por software. Las capacidades dealmacenamiento definido por software en Windows Server 2016, como Espaciosde almacenamiento directo, Réplica de almacenamiento y Calidad de servicio, usanpolíticas y automatización para aumentar la eficiencia del centro de datos y disminuirlos costos de administración del almacenamiento. Ayude a asegurar su futuro en el nivel del sistema operativoLos criminales cibernéticos son más sofisticados que nunca. Usan estrategias inteligentespara infringir la seguridad de su centro de datos y obtener acceso a la información clavede su empresa. Usar herramientas distintas de diversos proveedores para configurarsoluciones solo logra sumar problemas de seguridad. Con Windows Server 2016, lastecnologías de seguridad están integradas en la plataforma de virtualización para ayudara asegurar el bloque de creación básico de la informática virtualizada: la máquinavirtual. Las máquinas virtuales blindadas son ideales para sistemas empresariales clave,incluidos controladores de dominios y servidores de certificados. Las máquinas virtualessolo pueden ejecutarse en hardware designado y los datos se mantienen cifrados,incluso si una de ellas se filtra accidentalmente o un administrador ficticio la roba. Otrascaracterísticas, como Credential Guard y la Integridad de código, ayudan a proteger lascredenciales almacenadas y evitan que se ejecuten los archivos binarios ficticios.Los departamentos de TI también luchan por mantener a los hackers fuera de lasredes corporativas. El nuevo firewall de Virtualización de la función de red integradoen Windows Server 2016 ayuda a las organizaciones a estar más seguras y ser máseficientes, ya que permite que el firewall sea parte integral del entorno de red definidopor software, incluida la automatización y organización de la configuración del firewallcuando el entorno informático cambia. © 2016 Microsoft Corporation. T odos los derechos reservados. Esta hoja de datos tiene únicamente fines informativos. Microsoft no realiza garantías, expresas o implícitas, con respecto a la información que aquí se presenta.Logre eficiencia con un centro de datos definidopor el softwareDé el próximo paso. Más información en/WindowsServer2016Opciones para administrar la infraestructura Microsoft ofrece una variedad de soluciones de administración de la infraestructura para trabajar con cualquier modelo operacional. Microsoft System Center 2016Ya sea que tenga miles de servidores o solo unos pocos, System Center proporciona una función eficaz para laadministración e implementación de sucentro de datos virtualizado y definidopor software para mejorar la agilidady el rendimiento.PowerShell y la Configuración de estado deseado Defina, implemente y administre el entorno del software con el scripting dePowerShell y la Configuración de estadodeseado usando una sola consola.Herramientas de administración del servidor Use las Herramientas de administración del servidor, un servicio gratuito de la nube para administrar instancias de Windows Server locales y en Azure.Operations Management Suite Para administrar y ayudar a proteger las cargas de trabajo en diversos tipos de nube, puede ampliar la administración a los servicios de Operations Management Suite (OMS) para obtener visibilidad y control en los sistemas de Azure, AWS, Windows Server, Linux, VMware y OpenStack.。
sqlserver优化思路

sqlserver优化思路SQL Server的优化思路主要涉及以下几个方面:1. 索引优化:通过创建适当的索引,可以显著提高查询性能。
但是,请注意,索引虽然提高了查询速度,但会降低插入、删除和更新操作的速度,因为数据库需要维护索引结构。
因此,索引应谨慎创建,只在必要和常用查询条件的字段上创建索引。
2. 查询优化:优化查询语句是提高SQL Server性能的重要手段。
应尽量避免在查询中使用复杂的函数和计算,这会导致查询优化器无法有效使用索引。
此外,应尽量减少查询中的数据量,只获取必要的字段,而不是使用SELECT 。
3. 数据库设计优化:良好的数据库设计对于性能至关重要。
这包括合理的数据表结构设计、规范化的数据、合适的数据类型和大小、以及合适的数据分区和归档方法。
4. 硬件和配置优化:硬件性能(如CPU、内存和磁盘I/O)对数据库性能有很大影响。
根据工作负载调整SQL Server的配置参数(如最大内存、自动增长设置等)也是必要的。
5. 并发和事务管理:合理地管理并发事务可以避免资源争用和死锁,从而提高系统吞吐量。
这包括使用适当的锁策略、合理地设计事务、以及在必要时使用乐观或悲观锁定。
6. 定期维护:定期进行数据库维护,如更新统计信息、重建索引、清理旧数据等,可以保持数据库的健康状态和最佳性能。
7. 使用适当的工具和技术:SQL Server提供了一些工具和技术,如SQL Server Profiler、Execution Plans、Table Valued Parameters等,可以帮助开发者诊断和优化性能问题。
请注意,优化是一个持续的过程,需要根据工作负载的变化和技术的进步定期进行。
sql server 全字段模糊查询方法

sql server 全字段模糊查询方法
在 SQL Server 中,你可以使用 `LIKE` 运算符进行模糊查询。
如果你想对所有字段进行模糊查询,你可以将每个字段用 `OR` 连接起来,或者你可以使用 `COALESCE` 函数和 `CONCAT` 函数将多个字段连接成一个字段进行模糊查询。
以下是两种方法的示例:
1. 使用 `OR` 连接每个字段:
```sql
SELECT
FROM your_table
WHERE field1 LIKE '%your_value%'
OR field2 LIKE '%your_value%'
OR field3 LIKE '%your_value%';
```
2. 使用 `COALESCE` 和 `CONCAT` 连接多个字段:
```sql
SELECT
FROM your_table
WHERE CONCAT(COALESCE(field1, ''), COALESCE(field2, ''), COALESCE(field3, '')) LIKE '%your_value%';
```
在第二种方法中,我们使用 `COALESCE` 函数将每个字段的值与空字符串连接起来,然后使用 `CONCAT` 函数将它们连接成一个字符串。
这样,我们就可以对所有字段进行模糊查询,而无需为每个字段编写一个 `LIKE` 子句。
WindowsServer性能监视及优化

• (1)在如图13.2所示监控的图表区域单击鼠标右键,在 弹出的菜单中选中“添加计数器”,弹出如图13.5所示的 “添加计数器”对话框。也可以在快捷工具栏上,单击 “+”按钮,直接打开添加计数器对话框。
• (2)选择相应的选项之后,单击“添加”按钮,将会在 系统性能监控器中出现一个新的监控值,设置相应的监控 参数和显示特性。具体的设置方法是先单击该参数,然后 在 右 键 菜 单 中 选 择 “ 属 性第”22页,/共弹62页出 如 图 1 3 . 6 所 示 的 对 话 框 。
Windows Server 2008中可以通过一个简化的向导界面完成计数器到日志文件的 添加,并确定计数器开始,停止以及持续的时间。
第4页/共62页
13.1Windows Server 2008的性能监视 新特征
• 3.资源查看
Windows Server 2008中新的资源查看界面成为了 Windows可靠性与性能监测器的主页。这个界面提供了 实时的对CPU,磁盘,网络和内存占用情况的查看。通过 将这些受到监控的内容进行扩展,可使系统管理员确认哪 些流程在使用哪些资源。在Windows之前的版本中,这 一实时的根据流程确定的数据只在有限的任务管理器的表 格中存在。
13.4 性能监视器的使用
• 2.选择监视频率
• 对于常规监视,通常可以用超过15分钟的间隔来记录活动。 如果要监视特定的问题,则必须改变时间间隔。如果要在 特定时间内监视特定进程的活动,可以设置较短的更新时 间间隔;反之,若要监视慢速显示的问题(如内存溢出), 则使用较长的间隔。选择时间间隔时,还要考虑要监视的 总时间长度。如果监视不超过4个小时,则每15秒更新一次 比较合理;如果要监视系统8个小时或更长时间,则设置的 间隔不要少于300秒。
基于SQL server数据库优化查询的分析

也可 以作为程序 设 理 的 时 间 开 销 :服 务 器 端 接 收 到 客 户 端 提 交 的 S L请 求 后 , 作为独立 的语言在 终端上以交互方式使用 , Q 会
即 用 执 行 数 据 维护 、 询 等 操 作 。客 户 端 数 据 处 理 的时 间开 销 : 查 客户 计 中 的 子 语 言 使 用 , 嵌 入 到 高 级 语 言 中使 用 , 户 可 以通 过 Q Q 端接 收 到 服 务 器 返 回 的数 据 后 , 要 进 一 步 处 理 , 统 计 、 序 S L语 言 方 便 地 从 数 据 库 中获 得 自 己需 要 的 信 息 。S L语 句 的 需 如 排 等 , 后 将 结 果 通 过 用 户 接 口显 示 给 用 户 。 最
Q 从 在 服 务 器 端 。为 了提 高 数 据 库 应 用 系 统 的 可 靠 性 和 有 效 性 , 需 而 不 良的 S L语 句 则 以 低 效 方 式 访 问数 据 库 , 而 导致 不 必 要
要采 取 合 理 的查 询 优 化 策 略 。 的 数 据 扫 描 和 传 输 不 必 要 的 数 据 , 费大 量 数 据 库 资 源 。 耗
基 于  ̄ S模 式 数 据 库 应 用 系 统 时 间 开 销 在 对 数 据 库 应 用 端 。 / 系 统 进 行 操 作 时 , 除硬 件 配 置 对 系 统 性 能 影 响 时 , 间 开 销 剔 时
主要 由 以下 三 部 分 组 成 :
网络 延 迟 的 时 间开 销 : 统 工 作 于 C/s模 式 , 户 端 向服 书 写 规 范 和 技 巧 。 系 客 务器 端提 交 S L请 求 , 务 器 端 将 处 理 结 果 返 回 客 户 端 。数 据 Q 服 需要 在 网 络 上 传 输 , 然 有 一 定 的 网络 延 迟 。服 务 器 端 数 据 处 必
Windows server 2008R2优化设置

(2)账户图片
08R2中没有账户图片,所以需要copy一份win7的过去,复制到ProgramData\Microsoft\User Account Pictures下
下载 User Account Pictures.rar 请移步至此
/self.aspx/2008R2/User%5E_Account%5E_Pictures.rar
(4)
控制面板\管理工具\计算机管理
打开后,
左侧选择“系统工具\本地用户和组\用户”,右侧在Administrator上面右键,选择“属性”,选中“密码永不过期”
(5)
开始\运行
输入gpedit.msc,打开本地组策略编辑器
打开后,
左侧选择“计算机配置\管理模板\系统”,右侧“显示"关闭事件跟踪程序"” 更改为“ 已禁用”,“在登录时不显示"管理您的服务器"页”更改为“已启用”
登录界面默认为灰囧片,可以通过修改Windows\System32\imageres.dll文件达到美化为win7登录界面的目的
我这个是自己修改的,你也可以自己修改
不能在当前系统替换,需要到winpe或者用安装光盘引导进入修复命令行,然后copy覆盖过去,注意文件权限
下载 bootres.dll请移步至此
(6)
重起后
控制面板\管理工具\服务
“Themes” 启动类型改为“自动”,并且选择“启动”
“Windows Audio” 启动类型改为“自动”,并且选择“启动”
(7)
控制面板\系统,左侧“高级系统设置”,进入里面“高级”选项卡,点击“性能”里面的“设置”
在“性能选项”中,选择“视觉效果”选项卡,“调整为最佳外观”,确定
浅谈SQL server查询优化

范 金 哲
( 黑龙 江农 垦 管 理 干部 学 院信 息 中心 , 黑龙 江 哈 尔滨 1 5 0 0 0 0 ) 摘 要: 简要 分 析 了 S Q L s e r v e r 的 查 询优 化 方 法 。 关键词 : S Q L s e r v e r ; - I - , L q E; 索引; 视图
2 1 枥 图 索引是 常见 的数据库 对象 , 它 的设置好 坏 、 使用 是否得 当 , 极 大地影 视 图是 一 种数据库 对象 ,它足 由用户从 一个或多 个表 中建立 的一 个 响数 据库应用程序和数据库 的 。 在 良好的数 据库没 计基础上 , 能 有效 虚拟 表。 视 是 S Q L查询语 句而 不是 朋数据构造 的。 它 可以用来控制用户 地 陡用索 引是 S Q L S E R V E R取得商 能 的基 础。 如果 对于 — 立索 对 数据的访 问 , 限制用户从表 中所检索 的内容 , 并能简化 数据 的显 示 。而 引的表执行查询操作 , S Q L S E R V E R必须进行表扫描 ,从磁盘上读表的 且 在大多数 f 青 况下用 户所查询 的信 息 , 可能存 储在 多个表 中 , 而对 多表操 每—个数据页, 从而挑选出所有符合条件的数据行。特别是当一个表有很 作 比较繁琐 , 那 么可通过视 图将所需 的伉 皂 、 设 计到一个视 图中 , 以此来 简 多行时 ,就会浪费大量时间 ,效率太低。然而在建立索引之后 , S Q L 化数据查询和处理操作。另外 , 视图中的数据都来 自 于基表, 是在视图被 S E R V E R将根据索引的指示,直接定位到需要查询的数据行,从而加快 引用时动态生成的, 使用视图可以集中、 简化和定制用户的数据库显示 , S Q L S E R V E R的数据检索操作 。这样利用索引可以避免表扫描 , 并减少 用户可 以通过 视图来 访 问数据 , 而不必 直接去访问视 图的基 表。 因查询而造 成的 I / O开 销。 在S Q I S E R V E R中可能通过视 图检索数据 ,对视 图町以使川连 接 、 1 . 1簇索引 G r o u p B y 子句 、 子 查询等 , 以及它们 的任意组合来检 索视图数据 。 簇索引是对磁盘 匕 实际数据重新组织 ,以按指定的一个或多个列的 2 2索引视 图 值排序。 —个簇索引是—个 B 一 树, 其底层包含了表中所有的数据页, 并且 索引视 图在 数据库 中存储 视图结 果集 。索引视图之后 , 视 图的虚拟 成 数据的物理存俐『 婷 与索引顺序完全相同,亦即簇索引的数据是按照一 为真实 : 视图包含数据。 索引视图可缩短对多个表和进行多个复杂连接的 定的物理排序方式来保存的。由于簇索引的索引页面指针指向数据页面, 视 图的查询时 间, 来直接 访问所 需数据 , 成为跨 多个表 格的超索 引。此 外 , 所以使用簇索引检索数据要 比j 隗《 索引快 , 而目 刮 于检索连续键值。 查询优化器开始在查询中使用视图优化器 , 而不是直接从 F r o m子句中命 由于数据存储于数据页中, 所以只能为每个表建立—个簇索引。 而且 名视图, 这样可以从索引视图中检索数据而无需重新编码, 由此为查询带 创建簇索引要求数据库有足够的空问来容纳大约 1 . 2 倍于表中实际数据 来高效率。但基础表更新数据时, S Q L S E R V E R需要更新索引视图中的 的数据 。在簇 索引下 , 数 据在物理 上按顺序排 在数据页上 , 重 复值也排 在 数据 , 这个更新可能 影响性能 。 只有 当视 图的结果检 索速度 的效率超过 了 起, 所以查询时一旦找到符合条件的第—条记录, 具有相同键值或后续 修改所需的开销时, 才应在视图J ‘ - 仓 l 建索引。 键值的行一定在物理上与它连在—起 , 而不必进一步搜索, 从而缩小了查 2 3分 区视 图 询范 围 , 提 高了查询速 度 。每个 表只能建 — 个簇索 引 , 以下 隋况 比较适 合 分区视图可以提高分布式数据的查询效率。在各个区域的服务器中 创建够 誉 嚣 引: ① 用于范围查询的列 ; ② 用于 O r d e r B y或 G r o u p B v查询 都存有本区域仓库信 息的 Wa r e h o u s e 表,这样在本地服务器上进行查询 的列 ; ③ 用于连接} 桑 作的列 ; ④ 返回大量结果集的查询 ; ⑤ 不经常修改 时可以大大地提高检 索的效率 。 使 用这种方法 , 在j 井 j 彳 彳 艮 多查询时 避免了 的列( 对经常变动的列, 列值修改后 , 数据行必须移动到新的位置 ) 。 和其它服务器i 言 。 l 2非簇索 引 但是, 有些查询不仅要访问本地仓库信 息, 还要访问— / 卜 或多个远程 对于非移 索引, 叶级页包括了到数据页和行的行定位器 , 而不像簇索 仓库信 息。 分区视图提供了简单的解决方案 , 因为它是含有分区数据的表 引中那样是真正的数据。它不对表中的物理数据页i 亍 排序。因此 , 创建 的联 合 。每个仓 库 都可 根据 仓库 的 I D来 辨 别属 于哪个 服 务器 。例 如 , 个非簇索引不要求必须有大的剩余空间。—个表最多可建立 2 4 9 个非 S E R V E R 1 服务器 的仓库 的 I D在 1 0 0 0 1 与1 9 9 9 9 之间, S E R V E R 2 服 务 簇索引, 但要注意 , 表中索引数 目太多 , 会影响到其它操作的性能 , 例如 器 的仓库 的 I D在 2 0 0 0 1与 2 9 9 9 9之 问。下 列 的语 句 说明如何 在 U p d a t e , D e l e t e 和I n s e r t 等。因此, 不要试图使用过多的索引, 一般而言 , S E R V E R 1 服务器上为仓库数据创建一个分区视图: Cr e a t e Vi e w Al l wa r e ho us e As 对于—个表拥有一个簇索引和 2—6个非簇索引就已经足够了( 数据仓  ̄f f l # b ) 。每个非簇索引提供访问数据的不同排序J 』 序 。以下为一 J 犍 S e l e c t Fr o m Myd a t a ba s e . t a b l e o wn e r . wm' e h o us e Un i o n a l l 非簇索引比饺合适的场合: ① 用于集合功能的列; ② 外部键; ③ 返回数 据量小 的结果集 的查 询; ④ 经常 要通过在表 连接 中指定 列 的方 式访 问的 Se l e c t Fr o m s e ve r r 2 . My d a t a ba s e  ̄ t a b l e o wn e r wa r e h o us e 信 息, 或者查询 中排序和组合需 要的列 。 因为本地 的查 询很少 需要访 问远 端 的数 据 , 此这 种优化 器大 大地 1 3复 合索 引 提高 了查询 的效率 。例 如下列语 句实现 了 S E R V E R1 服 务器上 的一 个查 复合索 引是 通过两个或 两个 以上 的列创建 的键( 最大列数 为 1 6列 ) , 询: S e l e c t F r o m Al l wa r e h o us e whe r e wa r e h o us e I D=1 0 088 索引值 的最大 长度 为 9 0 0 字节 。 不 要试图创建列数 过多的复合索引 , 过多 的列会影响性能并使索引键变大 ,这样在渎取索引键时要扫描更多的数 分 区视 图使服务器 组 中的多个服务器 之间可 以实现 并行处 理 , 这样 , 据页。在复合 索引中应首先定 义最可能具有 唯一性 的列 。那么 S Q L 数 据可以分 布在多 1 \ 月 艮 务器之 间, 查询时 恨据需要动态 合并 。它提供 了访 S E R V E R何时能充分利用索引的优势, 何时不能使用索引? 问不同地址保存的数据的强大功能, 但是管理和使用视图很复杂, 视图生 当对—个大型表进行操作时, 如果满足下列条件 , 优化器就能充分利 成和使用的规贝 艮 多, 因此 , 只有遵守所有规则, 才可利用其强大特I 生。 用复合索引: ① 复合索引中的第 个字段或所有字段是在 Wh e r e 子句中 3异步查询 引用的字段, 并且包含有用的搜索参数。② 复合索引中的字段, 在 Wh e r e 异 步查 询是 远程数 据库 对象 ( R D 0 l 的一 个特 征 ( R D 0用 于开发 S Q L 子句 中不 参与任伺形式 的计算 。 S E R V E R数据库应用程序) , 它允许直用程序在等待完成长时间运行的查 1 4覆盖索 引 询时, 能够执行其它任务。这样就使得用户在执行其它操作之前 , 不必等 当要查询的所有信 息 都包括在单独的非簇索引( 也即—个复合索引 ) 待查询 的完 成 , 实现 并行操作 。 的索引项中时, 即为覆盖索引。S Q L不用读取数
SQLServer查询速度慢原因及优化方法

SQLServer查询速度慢原因及优化⽅法原⽂地址:SQL Server数据库查询速度慢的原因有很多,常见的有以下⼏种:1、没有索引或者没有⽤到索引(这是查询慢最常见的问题,是程序设计的缺陷)2、I/O吞吐量⼩,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不⾜5、⽹络速度慢6、查询出的数据量过⼤(可以采⽤多次查询,其他的⽅法降低数据量)7、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)8、sp_lock,sp_who,活动的⽤户查看,原因是读写竞争资源。
9、返回了不必要的⾏和列10、查询语句不好,没有优化●可以通过以下⽅法来优化查询 :1、把数据、⽇志、索引放到不同的I/O设备上,增加读取速度,以前可以将Tempdb应放在RAID0上,SQL2000不在⽀持。
数据量(尺⼨)越⼤,提⾼I/O越重要。
2、纵向、横向分割表,减少表的尺⼨(sp_spaceuse)3、升级硬件4、根据查询条件,建⽴索引,优化索引、优化访问⽅式,限制结果集的数据量。
注意填充因⼦要适当(最好是使⽤默认值0)。
索引应该尽量⼩,使⽤字节数⼩的列建索引好(参照索引的创建),不要对有限的⼏个值的字段建单⼀索引如性别字段。
5、提⾼⽹速。
6、扩⼤服务器的内存,Windows 2000和SQL server 2000能⽀持4-8G的内存。
配置虚拟内存:虚拟内存⼤⼩应基于计算机上并发运⾏的服务进⾏配置。
运⾏ Microsoft SQL Server? 2000时,可考虑将虚拟内存⼤⼩设置为计算机中安装的物理内存的1.5倍。
如果另外安装了全⽂检索功能,并打算运⾏Microsoft搜索服务以便执⾏全⽂索引和查询,可考虑:将虚拟内存⼤⼩配置为⾄少是计算机中安装的物理内存的3倍。
将SQL Server max server memory服务器配置选项配置为物理内存的1.5倍(虚拟内存⼤⼩设置的⼀半)。
7、增加服务器CPU个数;但是必须明⽩并⾏处理串⾏处理更需要资源例如内存。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Server查询优化方法文库.txt用快乐去奔跑,用心去倾听,用思维去发展,用努力去奋斗,用目标去衡量,用爱去生活。
钱多钱少,常有就好!人老人少,健康就好!家贫家富,和睦就好。
MS SQL Server查询优化方法查询速度慢的原因很多,常见如下几种1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)2、I/O吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足5、网络速度慢6、查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)7、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)8、sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列10、查询语句不好,没有优化可以通过如下方法来优化查询1、把数据、日志、索引放到不同的I/O设备上,增加读取速度,以前可以将Tempdb应放在RAID0上,SQL2000不在支持。
数据量(尺寸)越大,提高I/O越重要.2、纵向、横向分割表,减少表的尺寸(sp_spaceuse)3、升级硬件4、根据查询条件,建立索引,优化索引、优化访问方式,限制结果集的数据量。
注意填充因子要适当(最好是使用默认值0)。
索引应该尽量小,使用字节数小的列建索引好(参照索引的创建),不要对有限的几个值的字段建单一索引如性别字段5、提高网速;6、扩大服务器的内存,Windows 2000和SQL server 2000能支持4-8G的内存。
配置虚拟内存:虚拟内存大小应基于计算机上并发运行的服务进行配置。
运行Microsoft SQL Server? 2000 时,可考虑将虚拟内存大小设置为计算机中安装的物理内存的 1.5 倍。
如果另外安装了全文检索功能,并打算运行 Microsoft 搜索服务以便执行全文索引和查询,可考虑:将虚拟内存大小配置为至少是计算机中安装的物理内存的 3 倍。
将 SQL Server max server memory 服务器配置选项配置为物理内存的 1.5 倍(虚拟内存大小设置的一半)。
7、增加服务器CPU个数;但是必须明白并行处理串行处理更需要资源例如内存。
使用并行还是串行程是MsSQL自动评估选择的。
单个任务分解成多个任务,就可以在处理器上运行。
例如耽搁查询的排序、连接、扫描和GROUP BY字句同时执行,SQL SERVER根据系统的负载情况决定最优的并行等级,复杂的需要消耗大量的CPU的查询最适合并行处理。
但是更新操作UPDATE,INSERT, DELETE还不能并行处理。
8、如果是使用like进行查询的话,简单的使用index是不行的,但是全文索引,耗空间。
like 'a%' 使用索引 like '%a' 不使用索引用 like '%a%' 查询时,查询耗时和字段值总长度成正比,所以不能用CHAR类型,而是VARCHAR。
对于字段的值很长的建全文索引。
9、DB Server 和APPLication Server 分离;OLTP和OLAP分离10、分布式分区视图可用于实现数据库服务器联合体。
联合体是一组分开管理的服务器,但它们相互协作分担系统的处理负荷。
这种通过分区数据形成数据库服务器联合体的机制能够扩大一组服务器,以支持大型的多层 Web 站点的处理需要。
有关更多信息,参见设计联合数据库服务器。
(参照SQL帮助文件'分区视图')a、在实现分区视图之前,必须先水平分区表b、在创建成员表后,在每个成员服务器上定义一个分布式分区视图,并且每个视图具有相同的名称。
这样,引用分布式分区视图名的查询可以在任何一个成员服务器上运行。
系统操作如同每个成员服务器上都有一个原始表的复本一样,但其实每个服务器上只有一个成员表和一个分布式分区视图。
数据的位置对应用程序是透明的。
11、重建索引 DBCC REINDEX ,DBCC INDEXDEFRAG,收缩数据和日志 DBCC SHRINKDB,DBCC SHRINKFILE. 设置自动收缩日志.对于大的数据库不要设置数据库自动增长,它会降低服务器的性能。
在T-sql的写法上有很大的讲究,下面列出常见的要点:首先,DBMS处理查询计划的过程是这样的:1、查询语句的词法、语法检查2、将语句提交给DBMS的查询优化器3、优化器做代数优化和存取路径的优化4、由预编译模块生成查询规划5、然后在合适的时间提交给系统处理执行6、最后将执行结果返回给用户其次,看一下SQL SERVER的数据存放的结构:一个页面的大小为8K(8060)字节,8个页面为一个盘区,按照B树存放。
12、Commit和rollback的区别 Rollback:回滚所有的事物。
Commit:提交当前的事物. 没有必要在动态SQL里写事物,如果要写请写在外面如: begin tran exec(@s) commit trans 或者将动态SQL 写成函数或者存储过程。
13、在查询Select语句中用Where字句限制返回的行数,避免表扫描,如果返回不必要的数据,浪费了服务器的I/O资源,加重了网络的负担降低性能。
如果表很大,在表扫描的期间将表锁住,禁止其他的联接访问表,后果严重。
14、SQL的注释申明对执行没有任何影响15、尽可能不使用光标,它占用大量的资源。
如果需要row-by-row地执行,尽量采用非光标技术,如:在客户端循环,用临时表,Table变量,用子查询,用Case语句等等。
游标可以按照它所支持的提取选项进行分类:只进必须按照从第一行到最后一行的顺序提取行。
FETCH NEXT 是唯一允许的提取操作,也是默认方式。
可滚动性可以在游标中任何地方随机提取任意行。
游标的技术在SQL2000下变得功能很强大,他的目的是支持循环。
有四个并发选项READ_ONLY:不允许通过游标定位更新(Update),且在组成结果集的行中没有锁。
OPTIMISTIC WITH valueS:乐观并发控制是事务控制理论的一个标准部分。
乐观并发控制用于这样的情形,即在打开游标及更新行的间隔中,只有很小的机会让第二个用户更新某一行。
当某个游标以此选项打开时,没有锁控制其中的行,这将有助于最大化其处理能力。
如果用户试图修改某一行,则此行的当前值会与最后一次提取此行时获取的值进行比较。
如果任何值发生改变,则服务器就会知道其他人已更新了此行,并会返回一个错误。
如果值是一样的,服务器就执行修改。
选择这个并发选项 OPTIMISTIC WITH ROWVERSIONING:此乐观并发控制选项基于行版本控制。
使用行版本控制,其中的表必须具有某种版本标识符,服务器可用它来确定该行在读入游标后是否有所更改。
在 SQL Server 中,这个性能由 timestamp 数据类型提供,它是一个二进制数字,表示数据库中更改的相对顺序。
每个数据库都有一个全局当前时间戳值:@@DBTS。
每次以任何方式更改带有 timestamp 列的行时,SQL Server 先在时间戳列中存储当前的 @@DBTS 值,然后增加 @@DBTS 的值。
如果某个表具有 timestamp 列,则时间戳会被记到行级。
服务器就可以比较某行的当前时间戳值和上次提取时所存储的时间戳值,从而确定该行是否已更新。
服务器不必比较所有列的值,只需比较 timestamp 列即可。
如果应用程序对没有 timestamp 列的表要求基于行版本控制的乐观并发,则游标默认为基于数值的乐观并发控制。
SCROLL LOCKS 这个选项实现悲观并发控制。
在悲观并发控制中,在把数据库的行读入游标结果集时,应用程序将试图锁定数据库行。
在使用服务器游标时,将行读入游标时会在其上放置一个更新锁。
如果在事务内打开游标,则该事务更新锁将一直保持到事务被提交或回滚;当提取下一行时,将除去游标锁。
如果在事务外打开游标,则提取下一行时,锁就被丢弃。
因此,每当用户需要完全的悲观并发控制时,游标都应在事务内打开。
更新锁将阻止任何其它任务获取更新锁或排它锁,从而阻止其它任务更新该行。
然而,更新锁并不阻止共享锁,所以它不会阻止其它任务读取行,除非第二个任务也在要求带更新锁的读取。
滚动锁根据在游标定义的 SELECT 语句中指定的锁提示,这些游标并发选项可以生成滚动锁。
滚动锁在提取时在每行上获取,并保持到下次提取或者游标关闭,以先发生者为准。
下次提取时,服务器为新提取中的行获取滚动锁,并释放上次提取中行的滚动锁。
滚动锁独立于事务锁,并可以保持到一个提交或回滚操作之后。
如果提交时关闭游标的选项为关,则 COMMIT 语句并不关闭任何打开的游标,而且滚动锁被保留到提交之后,以维护对所提取数据的隔离。
所获取滚动锁的类型取决于游标并发选项和游标SELECT 语句中的锁提示。
锁提示只读乐观数值乐观行版本控制锁定无提示未锁定未锁定未锁定更新 NOLOCK 未锁定未锁定未锁定未锁定 HOLDLOCK 共享共享共享更新 UPDLOCK 错误更新更新更新 TABLOCKX 错误未锁定未锁定更新其它未锁定未锁定未锁定更新 *指定 NOLOCK 提示将使指定了该提示的表在游标内是只读的。
16、用Profiler来跟踪查询,得到查询所需的时间,找出SQL的问题所在;用索引优化器优化索引17、注意UNion和UNion all 的区别。
UNION all好18、注意使用DISTINCT,在没有必要时不要用,它同UNION一样会使查询变慢。
重复的记录在查询里是没有问题的19、查询时不要返回不需要的行、列20、用sp_configure 'query governor cost limit'或者SET QUERY_GOVERNOR_COST_LIMIT来限制查询消耗的资源。
当评估查询消耗的资源超出限制时,服务器自动取消查询,在查询之前就扼杀掉。
SET LOCKTIME设置锁的时间。