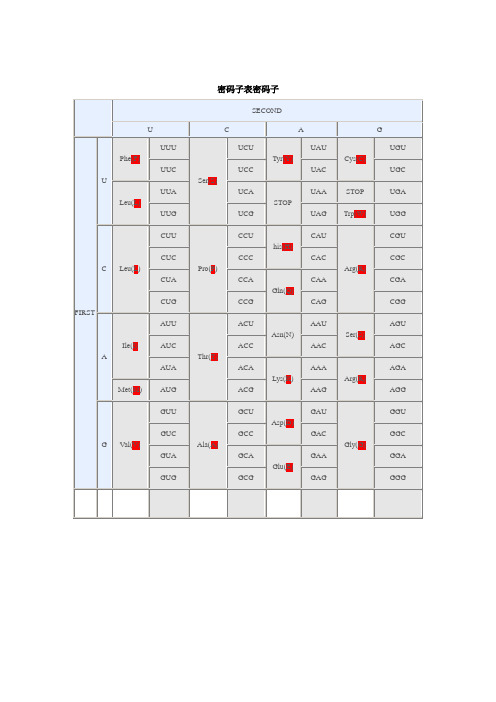
密码子使用偏好性参数汇总
遗传密码子及偏爱性

查看下面这个网址:
/mb/admin/upload/files/wjl/htm/chapter6_4.htm
(关于密码子的使用频率等等的东东,很全)
6.4遗传密码表
6.4.1密码子的特点
①每个密码子三联体(triplet)决定一种氨基酸
除Trp和Met只有1个密码子外,其它18种氨基酸均有1个以上的密码子,Phe、Tyr、His、Gln、Glu、Asn、Asp、Lys、Cys各有2个密码子;Ile有3个密码子;Val、Pro、Thr、Ala、Gly各有4个密码子;Leu、Arg、Ser各有6个密码子。
许多氨基酸的密码子的第1和第2个碱基相同,只有第3个碱基不同,在同一方框内。
如有4个密码子的氨基酸。
有些方框内有两种氨基酸的密码子。
它们的第1、2个碱基均相同,第3个嘌呤或嘧啶分别编码不同氨基酸。
在同义密码子中,有偏爱必有偏废。
在不同物种中,偏废或罕用的密码子,也各不相同。
克隆基因时应注意偏爱密码子。
密码子偏好性

CAC (7.3)
CGC (14.0)
C
CUA (5.6)
CCA (9.1)
CAA (14.4)
CGA (4.8)
A
CUG (37.4)
CCG (14.5)
CAG (26.7)
CGG (7.9)
G
A
AUU (29.6)
ACU (13.1)
AAU (29.3)
AGU (13.2)
U
AUC (19.4)
ACC (18.9)
AAC (20.3)
AGC (14.3)
C
AUA (13.3)
ACA (15.1)
AAA (37.2)
AGA (7.1)
A
AUG (23.7)
ACG (13.6)
AAG (15.3)
AGG (4.0)
G
G
GUU (21.6)
GCU (18.9)
GAU (33.7)
GGU (23.7)
精氨酸
Arginine
Arg
R
CGU,CGC,CGA,CGG,AGA,AGG
天冬酰胺
Asparagine
Asn
N
AAU,AAC
天冬氨酸
Asparticacid
Asp
D
GAU,GAC
半胱氨酸
Cystine
Cys
C
UGU,UGC
谷氨酸
Glutamicacid
Glu
E
GAA,GAG
谷氨酰胺
Glutarnine
A
UUG (12.9)
UCG (4.4)
UAG (0.8)
UGG (13.2)
乌苏里貉MC3R基因密码子偏好性分析

中国畜牧兽医 2024,51(4):1349-1361C h i n aA n i m a lH u s b a n d r y &V e t e r i n a r y Me d i c i n e 乌苏里貉M C 3R 基因密码子偏好性分析李 鑫1,2,李 伟1,2,刘 洁1,2,程静然1,2,刘进军1,2,王朋然1,2,韩学良1,2,任二军1,2,邓露芳3,宗文丽3(1.石家庄市农林科学研究院,石家庄050041;2.河北省毛皮动物养殖技术创新中心,石家庄050041;3.北京三元种业科技有限公司饲料分公司,北京101105)摘 要:ʌ目的ɔ明确乌苏里貉黑素皮质素受体3(m e l a n o c o r t i n 3r e c e p t o r ,M C 3R )基因密码子使用偏好特征和影响因素,了解不同物种间遗传进化和密码子偏好性的关系,为开展M C 3R 基因异源高效表达研究提供理论依据㊂ʌ方法ɔ以乌苏里貉和其他15个物种的M C 3R 基因C D S 序列为材料,应用C o d o nW ㊁E M B O S S 等软件分析M C 3R 基因密码子偏好性的6个参数指标;通过N e u t r a l i t y -p l o t ㊁E N c -p l o t 及P R 2-p l o t 分析探究密码子偏好性形成的影响因素;基于各物种M C 3R 基因C D S 序列信息构建系统发育树,基于同义密码子相对使用度(R S C U )构建不同物种的密码子使用偏好性热图㊂ʌ结果ɔ乌苏里貉M C 3R 基因密码子G C 和G C 3s 均>0.5,密码子偏好使用以G /C 结尾;偏好使用的密码子有25个(R S C U 值>1),其中16个以C 结尾,9个以G 结尾㊂经N e u t r a l i t y -p l o t ㊁E N c -p l o t 及P R 2-pl o t 分析得出,自然选择是M C 3R 基因密码子使用偏好形成的主要影响因素㊂基于基因序列和R S C U 值的聚类分析显示,在系统进化上乌苏里貉与犬属同一分支,后与赤狐㊁北极狐聚为一支;但在密码子使用上乌苏里貉与人㊁黑猩猩及家马聚为一类㊂ʌ结论ɔM C 3R 基因偏好使用以G /C 结尾的密码子;自然选择是导致偏好性产生的主要影响因素;密码子使用虽具有种属特异性,但受其他因素影响亲缘关系相近的物种间密码子使用模式也会有差异㊂关键词:乌苏里貉;M C 3R 基因;密码子偏好性;自然选择中图分类号:S 865.2+4;Q 75文献标识码:AD o i :10.16431/j.c n k i .1671-7236.2024.04.003 开放科学(资源服务)标识码(O S I D ):收稿日期:2023-10-16基金项目:河北省重点研发计划项目(21326357D );石家庄市财政预算专项联系方式:李鑫,E -m a i l :765150371@q q .c o m ㊂通信作者任二军,E -m a i l :r e n e r ju n 2012@163.c o m A n a l y s i s o fC o d o nU s a geB i a s o f M C 3R G e n e i n N y c t e r e u t e s p r o c y o n o i d e s L IX i n 1,2,L IW e i 1,2,L I UJ i e 1,2,C H E N GJ i n g r a n 1,2,L I UJ i n j u n 1,2,WA N GP e n g r a n 1,2,H A N X u e l i a n g 1,2,R E N E r j u n 1,2,D E N GL u f a n g 3,ZO N G W e n l i 3(1.S h i j i a z h u a n g A c a d e m y o f A g r i c u l t u r a l a n dF o r e s t r y S c i e n c e s ,S h i j i a z h a n g 050041,C h i n a ;2.T e c h n o l o g i c a l I n n o v a t i o nC e n t e r f o rF u rA n i m a lB r e e d i n g o f H e b e i ,S h i j i a z h u a n g050041,C h i n a ;3.B e i j i n g S a n y u a nS e e dT e c h n o l o g y Co .,L t d .,F e e dB r a n c h ,B e i j i n g 101105,C h i n a )A b s t r a c t :ʌO b j e c t i v e ɔT h i ss t u d y w a sa i m e dt oi d e n t i f y t h ec o d o n u s a gec h a r a c t e r i s t i ca n d i n f l u e n c i n g f a c t o r so fm e l a n o c o r t i n3r e c e p t o r (M C 3R )g e n ei n N y c t e r e u t e s p r o c yo n o i d e s ,a n d u n d e r s t a n dt h er e l a t i o n s h i p b e t w e e n g e n e t i ce v o l u t i o n a n dc o d o n p r e f e r e n c ea m o n g di f f e r e n t s p e c i e s ,s o a s t o p r o v i d e a t h e o r e t i c a l b a s i s f o r s t u d y i n g t h e h e t e r o l o g o u s h i g h e x p r e s s i o n o f M C 3R g e n e .ʌM e t h o d ɔS i x p a r a m e t e r s o f c o d o n p r e f e r e n c e o f M C 3R g e n eC D Ss e q u e n c e s i n N yc t e r e u t e s p r o c yo n o i d e s a n d15o t h e rs p e c i e sw e r ea n a l y z e du s i n g C o d o n W a n dE M B O S Ss o f t w a r e s ,a n d N e u t r a l i t y -p l o t ,E N c -p l o ta n d P R 2-p l o t w e r eu s e dt oe x pl o r ei n f l u e n c ef a c t o r so fc o d o n b i a s f o r m a t i o no f M C 3R g e n e .T h e p h y l o g e n e t i c t r e ew a s c o n s t r u c t e db a s e do n t h e c l u s t e r a n a l ys i so f中国畜牧兽医51卷M C3R g e n e C D S s e q u e n c ei n f o r m a t i o n,a n dt h e h e a t m a p w a sc o n s t r u c t e d b a s e o n r e l a t i v e s y n o n y m o u s c o d o nu s a g e(R S C U)o fd i f f e r e n t s p e c i e s.ʌR e s u l tɔT h ec o d o n G Ca n dG C3sw e r e b o t h g r e a t e r t h a n0.5o f M C3R g e n e i n N y c t e r e u t e s p r o c y o n o i d e s,a n d t h e c o d o n p r e f e r r e d t o e n d w i t hG/C.T h e r ew e r e25p r e f e r r e d c o d o n s(R S C Uv a l u e>1),o fw h i c h16e n d e d i nCa n d9e n d e d i nG.N e u t r a l i t y-p l o t,E N c-p l o ta n dP R2-p l o ta n a l y s i sr e s u l t ss h o w e dt h a tn a t u r a l s e l e c t i o n w a s t h em a i n i n f l u e n c i n g f a c t o r o f M C3R g e n e c o d o n p r e f e r e n c e f o r m a t i o n.T h e c l u s t e r a n a l y s i s r e s u l t s o f g e n es e q u e n c ea n d R S C U v a l u e ss h o w e dt h a t t h e N y c t e r e u t e s p r o c y o n o i d e s b e l o n g e dt ot h e s a m e c l a d i s t i c g e n u sa s C a n i s l u p u s f a m i l i a r i s i n p h y l o g e n e t i cr e l a t i o n s h i p,a n dt h e nc l u s t e r e d w i t h V u l p e s v u l p e s a n d V u l p e s l a g o p u s.B u tw h e n i t c a m e t o c o d o n u s e,N y c t e r e u t e s p r o c y o n o i d e s w e r e g r o u p e dw i t h H o m o s a p i e n s,P a n t r o g l o d y t e s a n d E q u u s c a b a l l u s.ʌC o n c l u s i o nɔM C3R g e n e p r e f e r e d t ou s e c o d o n s e n d i n g w i t hG/C,a n dn a t u r a l s e l e c t i o nw a s t h em a i n i n f l u e n c i n g f a c t o r o f c o d o n p r e f e r e n c e.T h e c o d o nu s a g e b i a sw a s s p e c i e s-s p e c i f i c,b u t c o d o nu s e p a t t e r n sw e r e d i f f e r e n t a m o n g c l o s e l y r e l a t e d s p e c i e s d u e t oo t h e r f a c t o r s.K e y w o r d s:N y c t e r e u t e s p r o c y o n o i d e s;M C3R g e n e;c o d o nu s a g eb i a s;n a t u r a l s e l e c t i o n黑素皮质素受体3(m e l a n o c o r t i n3r e c e p t o r, M C3R)又称神经性黑素皮质素受体基因,在外周组织和大脑中高度表达[1-2]㊂通常认为,瘦素(l e p t i n, L P)是肥胖基因(o b e s e,o b)的表达产物,由脂肪细胞分泌到血液中,通过减少食欲和改变代谢过程来降低体重[3-4]㊂M C3R存在于L e p t i n信号通路中,是L e p t i n信号传导的下游介质,因此也被认为具有调控采食量和能量稳态的功能[5-6]㊂M C3R参与机体的能量代谢㊁采食行为等生理过程,如M C3R基因可作为影响和控制鹌鹑体重的候选基因[7]; M C3R基因不同基因型可导致犬体型呈现显著差异[8-9];M C3R基因敲除小鼠相比于野生鼠表现出代谢异常㊁体重不变㊁体脂增加,被认为可能参与了能量平衡的调控[10-11];M C3R还可作为乌苏里貉体型性状的候选基因[12]㊂在不同生物体㊁不同基因及不同物种的同一基因中,同义密码子被使用的概率并不是相等或随机的,一些密码子在编码氨基酸时会优先于其他密码子被反复使用[13-14],这种现象叫作密码子使用偏好性(c o d o nu s a g eb i a s,C U B)㊂密码子偏好性在生物体中影响广泛,包括m R N A的稳定性,转录㊁翻译的效率和准确性,以及蛋白质的表达㊁结构㊁功能和翻译折叠等[15-17]㊂密码子偏好性通过影响染色质结构㊁m R N A折叠,调节翻译的延伸率,进而影响转录水平和翻译效率[18]㊂因此,密码子偏差被认为是由基因组对转录和翻译机制的适应而引起的[19]㊂亲缘关系相近的生物以相似的方式使用密码子,因此分析密码子偏好性可以揭示生物之间的水平基因转移和进化关系[20-21]㊂大多数高表达蛋白是由具有最优密码子的基因编码的,因此,可通过基因工程或重组D N A技术对外源基因进行优化,增强外源基因的蛋白表达水平㊂随着高通量测序技术的快速发展,充分分析密码子偏好性有助于理解物种进化㊁环境适应㊁遗传特征等机制[22-23]㊂貉属食肉目犬科,是一种毛皮动物㊂在国内,貉主要有2个品种,即乌苏里貉和白貉,其中乌苏里貉是中国饲养数量最多的品种㊂乌苏里貉属于中国三大亚种中的东北亚种,产于大兴安岭㊁长白山及三江平原等地区㊂貉皮是貉经济价值的体现,皮张尺寸是决定毛皮品质的重要因素之一,而体型大小决定皮张大小㊂M C3R作为貉体型性状的候选基因,研究其特征特性对于改良貉体型性状㊁毛皮尺寸具有重要意义㊂目前,关于M C3R基因的研究多集中在能量代谢㊁稳态调节等功能方面,但针对该基因在密码子水平的研究鲜见报道㊂鉴于此,本研究拟采用生物信息学技术对乌苏里貉M C3R基因的密码子偏好性进行分析,并与其他物种进行比较,以期了解不同物种间的进化关系㊁基因功能及表达水平,为异源高效表达提供理论参考㊂1材料与方法1.1M C3R基因C D S序列信息本研究所有物种的M C3R基因C D S序列信息均通过检索N C B I数据库获得(表1)㊂05314期李鑫等:乌苏里貉M C3R基因密码子偏好性分析表1M C3R基因C D S序列信息T a b l e1C D S s e q u e n c e i n f o r m a t i o no f M C3R g e n e序号N o.物种S p e c i e s登录号A c c e s s i o nN o.序列长度S e q u e n c e l e n g t h/b p 1乌苏里貉N y c t e r e u t e s p r o c y o n o i d e s X M_055343696.19722人H o m o s a p i e n s NM_019888.39723牛B o s t a u r u s X M_010811617.39724犬C a n i s l u p u s f a m i l i a r i s X M_038432837.19725原鸡G a l l u s g a l l u s X M_004947236.59786小鼠M u sm u s c u l u s NM_008561.39727大鼠R a t t u s n o r v e g i c u s NM_001025270.49728北极狐V u l p e s l a g o p u s X M_041732312.19729赤狐V u l p e s v u l p e s X M_026015069.197210野猪S u s s c r o f a NM_001123137.196011家马E q u u s c a b a l l u s NM_001256972.197212黑猩猩P a n t r o g l o d y t e s X M_525362.5108313家猫F e l i s c a t u s X M_023251083.297214绵羊O v i s a r i e s X M_004014450.597215山羊C a p r a h i r c u s X M_005688325.297216斑马鱼D a n i o r e r i o NM_180972.29841.2密码子使用情况分析分别应用C o d o n W软件㊁E M B O S S在线工具(h t t p:ʊv m-b i o i n f o.t o u l o u s e.i n r a.f r/e m b o s s)中的C U S P和C H I P S进行以下分析:①密码子碱基含量:各碱基在密码子第3位上的含量(A3s㊁G3s㊁C3s㊁T3s),C D S区密码子整体G C含量(G C),密码子第1㊁2㊁3位碱基G C含量(G C1s㊁G C2s㊁G C3s)㊂②密码子使用频率和使用分值:密码子使用频率是某一密码子在编码区总密码子中所占比例;密码子使用分值是指某一密码子在编码氨基酸的各个密码子中所占的比例[24]㊂③同义密码子相对使用度(r e l a t i v e s y n o n y m o u s c o d o n u s a g e,R S C U):于1986年由S h a r p等[25]提出,在假设同一氨基酸的所有同义密码子都被平等使用的情况下,通过分析密码子的观察频率与期望频率之比获得R S C U值,该值不受基因长度和氨基酸频率的影响㊂④有效密码子数(e f f e c t i v en u m b e r o f c o d o n s,E N c):于1990年由W r i g h t[26]提出,E N c值量化了基因的同义密码子使用频率,与基因长度或氨基酸组成无关㊂⑤最优密码子使用频率(f r e q u e n c y o fo p t i m a l c o d o n s, F o p):通过将最佳密码子的数量除以基因中同义密码子的总数来计算,该值需要一个高表达基因作参考[27]㊂⑥密码子偏好性指数(c o d o nb i a si n d e x, C B I):被用作评价基因表达的标准,它反映了一个基因中优势密码子高表达的组分情况[28]㊂1.3N e u t r a l i t y-p l o t分析N e u t r a l i t y-p l o t是以G C3s为横坐标㊁G C12为纵坐标绘制散点图并进行相关性分析,其中G C12表示G C1s和G C2s的平均值㊂如果回归曲线斜率接近于1,且G C12与G C3s相关性显著,说明密码子偏倚主要受突变影响;若回归曲线斜率接近于0,且G C12与G C3s不显著相关,说明密码子的使用主要受自然选择影响[29]㊂1.4E N c-p l o t分析E N c-p l o t是以G C3s值为横坐标㊁E N c值为纵坐标绘制散点图㊂E N c值与G C3s值之间的函数关系用一条标准曲线表示,计算公式:E N c=2+G C3s+ 29/(G C3s2+(1-G C3s)2)[30];图中每个点与标准曲线的距离可以反映密码子偏好性形成的原因是碱基突变还是自然选择[31]㊂1.5P R2-p l o t分析奇偶规则(p a r i t y r u l e2,P R2)规定如果D N A 的2条互补链间不存在任何突变或选择效应上的偏倚,那么在碱基含量上应有A=T和G=C[32]㊂计算每个基因的A T含量偏倚[A3/(A3+U3)]和G C 含量偏倚[G3/(G3+C3)],以A3/(A3+U3)为横坐标㊁G3/(G3+C3)为纵坐标进行P R2-p l o t分析㊂当A=T和G=C时,坐标均为0.5的图中心,2条1531中国畜牧兽医51卷D N A链的突变压力和选择压力(A+T+G+C=1)之间没有偏差,突变压力和自然选择的效果是相等的,从中心点发出的矢量表示密码子第3个位置偏好的程度和方向[33]㊂1.6基于R S C U值和亲缘关系的聚类分析基于乌苏里貉㊁人㊁牛㊁犬㊁原鸡㊁小鼠㊁大鼠㊁北极狐㊁赤狐㊁野猪㊁家马㊁黑猩猩㊁家猫㊁绵羊㊁山羊㊁斑马鱼共16个物种M C3R基因R S C U值,去除掉终止密码子T A A㊁T A C㊁T G A,以及编码色氨酸和蛋氨酸的密码子T G G㊁A T G;应用M e g a11.0软件基于邻近法对16个物种M C3R基因C D S序列进行亲缘关系聚类,构建系统进化树;利用H e m I软件对不同物种的59个密码子的R S C U值进行聚类分析并绘制热图㊂2结果2.1乌苏里貉M C3R基因密码子偏好性相关参数分析通过检索N C B I数据库可知,乌苏里貉M C3R 基因C D S区由972个碱基组成,编码323个氨基酸㊂由表2可知,乌苏里貉M C3R基因C D S区E N c值为31.16(<35),F o p和C B I值分别为0.66和0.43;碱基组成分析显示,乌苏里貉M C3R基因C D S区G C值为0.61㊂表2乌苏里貉M C3R基因密码子偏好性参数分析T a b l e2T h e v a l u e o f c o d o nb i a s p a r a m e t e r o f M C3R g e n e i n N y c t e r e u t e s p r o c y o n o i d e s参数P a r a m e t e r s E N c G C G C1s G C2s G C3s A3s C3s G3s T3s F o p C B I 结果R e s u l t s31.160.610.510.370.940.050.740.400.020.660.432.2乌苏里貉M C3R基因密码子R S C U值分析由表3可知,在21种氨基酸中有19种氨基酸在密码子使用时具有偏好性,偏好使用的密码子共有25个(R S C U值>1),其中有19个密码子的R S C U值ȡ2,显示偏好性较强;偏好性最强的是编码亮氨酸(L e u)的密码子C T G(R S C U值为3.66),随后依次是编码苏氨酸(T h r)的密码子A C C (R S C U值为3.43)和终止密码子T A G(R S C U值为3.00)㊂R S C U值为1.00的密码子有2个,分别是编码蛋氨酸(M e t)的密码子A T G和编码色氨酸(T r p)的密码子T G G,提示密码子使用不具有偏好性㊂此外,使用度高的25个密码子全部是由G/C 结尾,其中16个以C结尾,9个以G结尾;使用度较低的密码子(R S C U值<1)大多数以A/T结尾㊂而且使用度高的密码子F r e q u e n c y和F r a c t i o n值也相对较高,编码氨基酸时使用数量也相对较多㊂表3乌苏里貉M C3R基因密码子偏好性分析T a b l e3C o d o nb i a s a n a l y s i s o f M C3R g e n e i n N y c t e r e u t e s p r o c y o n o i d e s氨基酸A m i n o a c i d s密码子C o d o n s数量N u m b e r/个用法频率值U s a g e f r e q u e n c y/ɢ用法分值F r a c t i o n同义密码子相对使用度R S C U丙氨酸A l a G C A13.090.030.14G C C1958.640.662.62G C G618.520.210.83G C T39.260.100.41半胱氨酸C y s T G C1855.561.002.00T G T0000天冬氨酸A s p G A C721.611.002.00G A T0000谷氨酸G l u G A A26.170.220.44G A G721.610.781.56苯丙氨酸P h e T T C2267.901.002.00T T T0000甘氨酸G l y G G A0000G G C927.780.692.77G G G412.350.311.23G G T0000 25313531 4期李鑫等:乌苏里貉M C3R基因密码子偏好性分析续表氨基酸U s a g e f r e q u e n c y/ɢ用法分值R S C UF r a c t i o n同义密码子相对使用度N u m b e r/个用法频率值C o d o n s数量A m i n o a c i d s密码子组氨酸H i s C A C927.781.002.00C A T0000异亮氨酸I l e A T A13.090.040.11A T C2783.330.962.13A T T0000赖氨酸L y s A A A0000A A G515.431.002.00亮氨酸L e u C T A39.260.070.44C T C1340.120.321.90C T G2577.160.613.66C T T0000T T A0000T T G0000蛋氨酸/甲硫氨酸M e t A T G1546.301.001.00天冬氨酸A s n A A C1752.471.002.00A A T0000脯氨酸P r o C C A26.170.180.73C C C721.610.642.55C C G13.090.090.36C C T13.090.090.36谷氨酰胺G l n C A A0000C A G721.611.002.00精氨酸A r g A G A0000A G G26.170.221.33C G A0000C G C39.260.332.00C G G39.260.332.00C G T13.090.110.67丝氨酸S e r A G C1133.950.482.87A G T0000T C A0000T C C824.690.352.09T C G39.260.130.78T C T13.090.040.26苏氨酸T h r A C A0000A C C1237.040.863.43A C G13.090.070.29A C T13.090.070.29缬氨酸V a l G T A13.090.030.13G T C1752.470.532.13G T G1443.210.441.75G T T0000色氨酸T r p T G G39.261.001.00酪氨酸T y r T A C1133.951.002.00T A T0000终止密码子E n d c o d o n T A A0000T A G13.091.003.00T G A0000中国畜牧兽医51卷2.3乌苏里貉与其他物种M C3R基因基于E N c㊁F o p㊁C B I及碱基组成的比较分析由表4可知,各物种E N c值介于29.46~54.80之间,E N c值<35的物种有乌苏里貉(31.16)㊁牛(34.90)㊁犬(31.13)㊁北极狐(30.69)㊁赤狐(30.69)㊁野猪(29.46)㊁家马(34.27)㊁家猫(31.52)㊁绵羊(32.58)㊁山羊(33.17),其中野猪E N c值最小;除此之外,人(35.46)㊁原鸡(54.80)㊁小鼠(36.39)㊁大鼠(35.75)㊁黑猩猩(36.47)㊁斑马鱼(52.80)等E N c 值>35,其中原鸡E N c值最大,斑马鱼次之㊂各物种F o p和C B I值分别介于0.48~0.67㊁0.15~0.46之间,其中斑马鱼F o p和C B I值均为最小,大鼠F o p和C B I值均为最大㊂除原鸡外,其他物种M C3R基因C D S区G C值均>0.5,其中野猪G C值最高;乌苏里貉与犬㊁北极狐和赤狐的G C值相同,均为0.61㊂表4不同物种M C3R基因的密码子偏好性参数T a b l e4T h e c o d o nb i a s p a r a m e t e r o f M C3R g e n e i nd i f f e r e n t s p e c i e s物种S p e c i e s E N c G C G C1s G C2s G C3s G C12A3s C3s G3s T3s F o p C B I 乌苏里貉N y c t e r e u t e s p r o c y o n o i d e s31.160.610.510.370.940.440.050.740.400.020.660.43人H o m o s a p i e n s35.460.570.480.360.860.420.080.680.360.100.600.34牛B o s t a u r u s34.900.580.510.360.860.430.050.650.400.110.590.32犬C a n i s l u p u s f a m i l i a r i s31.130.610.510.370.950.440.040.740.420.020.660.43原鸡G a l l u s g a l l u s54.800.470.400.330.650.370.170.500.320.250.510.18小鼠M u sm u s c u l u s36.390.560.470.370.850.420.040.660.370.140.640.40大鼠R a t t u s n o r v e g i c u s35.750.580.470.380.880.420.040.670.410.100.670.46北极狐V u l p e s l a g o p u s30.690.610.510.370.950.440.040.750.410.020.650.42赤狐V u l p e s v u l p e s30.690.610.510.370.950.440.040.750.410.020.650.42野猪S u s s c r o f a29.460.630.540.390.950.470.010.720.430.040.630.39家马E q u u s c a b a l l u s34.270.570.470.360.880.420.060.690.390.080.610.35黑猩猩P a n t r o g l o d y t e s36.470.570.500.360.830.430.100.660.360.100.570.29家猫F e l i s c a t u s31.520.620.520.400.950.460.020.710.430.040.650.41绵羊O v i s a r i e s32.580.600.510.370.910.440.040.700.410.060.630.38山羊C a p r a h i r c u s33.170.590.510.360.900.430.050.700.400.070.620.38斑马鱼D a n i o r e r i o52.800.510.520.380.610.450.170.410.330.290.480.152.4乌苏里貉与其他物种M C3R基因基于R S C U 值的比较分析由表5可知,在各个物种中均偏好使用(R S C U值>1)的密码子有16个,均以G/C结尾,它们共编码除苯丙氨酸(P h e)㊁甘氨酸(G l y)㊁蛋氨酸/甲硫氨酸(M e t)㊁脯氨酸(P r o)㊁色氨酸(T r p)及终止密码子外的15种氨基酸,其中蛋氨酸/甲硫氨酸㊁色氨酸由于仅由1种密码子编码,因此不具有偏好性(R S C U值为1)㊂同时还发现有21个密码子在各个物种中使用度均较低(R S C U值<1),这些密码子第3位碱基多为A/T㊂通过比较得知,某些密码子仅在某种动物中使用度较高,如编码丙氨酸(A l a)的C G A和编码甘氨酸(G l y)的G G A仅在原鸡和斑马鱼中使用度较高;编码丙氨酸(A l a)的G C G仅在家猫中使用度较高;编码丙氨酸(A l a)的G C T㊁编码亮氨酸(L e u)的C T T㊁编码精氨酸(A r g)的A G A和C G T㊁编码丝氨酸(S e r)的A G T仅在斑马鱼中使用度较高;编码苏氨酸(T h r)的A C T仅在原鸡中使用度较高㊂表5不同物种M C3R基因的R S C U值T a b l e5R S C Uv a l u e o f M C3R g e n e i nd i f f e r e n t s p e c i e s氨基酸A m i n o a c i d s密码子C o d o n s物种S p e c i e s 12345678910111213141516丙氨酸A l a G C A0.140.500.290.141.110.520.500.140.1400.430.590.130.140.291.24G C C2.622.672.572.622.002.432.332.762.762.932.432.672.252.482.431.24G C G0.830.500.570.830.220.170.670.830.830.670.710.441.130.830.570.41G C T0.410.330.570.410.670.870.500.280.280.400.430.300.500.550.711.10 45314期李鑫等:乌苏里貉M C3R基因密码子偏好性分析续表氨基酸A m i n o a c i d s密码子C o d o n s物种S p e c i e s 12345678910111213141516半胱氨酸C y s T G C2.001.671.652.001.411.781.892.002.002.001.671.671.781.651.651.26 T G T00.330.3500.590.220.110000.330.330.220.350.350.74天冬氨酸A s p G A C2.002.001.752.001.271.712.002.002.002.001.711.782.002.001.751.75G A T000.2500.730.2900000.290.22000.250.25谷氨酸G l u G A A0.440.440.220.440.750.220.250.220.220.220.440.360.250.220.220.86G A G1.561.561.781.561.251.781.751.781.781.781.561.641.751.781.781.14苯丙氨酸P h e T T C2.001.571.802.001.481.902.002.002.001.801.821.461.891.801.900.75 T T T00.430.2000.520.100000.200.180.540.110.200.100.25甘氨酸G l y G G A00.330.7301.33000000.360.8600.730.731.20G G C2.773.002.182.770.892.772.462.772.772.182.552.572.292.182.181.20G G G1.230.670.731.230.890.921.231.231.231.821.090.571.710.730.731.20G G T000.3600.890.310.310000000.360.360.40组氨酸H i s C A C2.002.001.802.001.781.782.002.002.002.001.802.002.002.002.001.56C A T000.2000.220.2200000.2000000.44异亮氨酸I l e A T A0.110.100.210.110.49000.110.1100.090.0900.230.210.23A T C2.132.612.462.891.472.742.912.892.893.002.822.632.902.652.681.85A T T00.290.3201.050.260.090000.090.280.100.120.110.92赖氨酸L y s A A A00.40000.890.400.4000000.250000.50A A G2.001.602.002.001.111.601.602.002.002.002.001.752.002.002.001.50亮氨酸L e u C T A0.44000.440.290.1500.290.29000.130.14000.52C T C1.902.401.401.902.051.901.692.052.051.872.342.172.291.671.671.70C T G3.663.153.913.661.763.373.853.663.663.873.073.193.573.913.911.57C T T000.4200.440.150.15000.130.150.1300.140.141.30T T A00000.4400000000000.13T T G00.450.2801.020.440.31000.130.440.3800.280.280.78蛋氨酸/甲硫氨酸M e t A T G1.001.001.001.001.001.001.001.001.001.001.001.001.001.001.001.00天冬氨酸A s n A A C2.001.601.502.001.231.631.882.002.001.861.501.602.001.631.631.50A A T00.400.500.000.770.380.13000.140.500.4000.380.380.50脯氨酸P r o C C A0.731.230.670.360.500.290.570.730.730.250.731.070.270.330.670.86C C C2.551.541.672.551.001.431.432.552.552.502.551.601.872.002.000.29C C G0.360.310.670.731.000.570.860.360.360.750.360.271.331.000.671.14C C T0.361.401.000.361.501.711.140.360.360.500.361.070.530.670.671.71谷氨酰胺G l n C A A00.500.290000.2900000.6000.290.290.22C A G2.001.501.712.002.002.001.712.002.002.002.001.402.001.711.711.78精氨酸A r g A G A00000.7500000000001.50A G G1.332.672.001.331.502.672.671.331.331.332.672.000.672.002.000.50C G A0000000000000000.50C G C2.002.002.672.001.502.001.332.002.002.672.672.002.002.672.672.00C G G2.001.331.332.001.501.331.332.002.002.000.672.002.671.331.330C G T0.67000.670.7500.670.670.670000.67001.50丝氨酸S e r A G C2.872.352.642.872.362.001.502.872.873.003.003.003.123.123.121.33A G T00.520.4800.640.440.6400000.430001.11T C A00.260.2401.2900000.230.460.6400.240.240.445531中 国 畜 牧 兽 医51卷续表氨基酸A m i n o a c i d s密码子C o d o n s 物种S p e c i e s 12345678910111213141516T C C 2.091.572.162.090.862.002.572.092.091.381.151.291.682.162.160.89T C G 0.780.780.480.780.2100.210.780.781.150.230.430.960.480.480.22T C T 0.260.5200.260.641.561.070.260.260.231.150.210.24002.00苏氨酸T h rA C A00.27000.220.29000.310.4700.31A C C 3.433.473.693.432.222.863.143.433.434.003.083.293.433.433.382.15A C G 0.29000.570.220.570.860.290.2900.3100.570.290.310.62A C T 0.290.270.3101.330.2900.290.2900.310.2400.290.310.92缬氨酸V a lG T A 0.130.1300.130.3000.140.120.1200.150.120.1400.53G T C 2.131.942.382.001.191.781.432.182.182.181.851.942.212.632.500.74G T G 1.751.551.501.881.781.781.711.701.701.702.001.581.661.381.502.21G T T00.390.1300.740.440.71000.120.000.3600.53色氨酸T r pT G G 1.001.001.001.001.001.001.001.001.001.001.001.001.001.001.001.00酪氨酸T y r T A C 2.002.001.452.001.171.601.642.002.002.001.821.832.002.002.001.56T A T000.5500.830.400.360000.180.17000.44终止密码子T A A 003.0000000003.003.000E n d c o d o nT A G 3.003.0003.0003.003.003.003.0003.003.003.00003.00T G A03.00003.000001,乌苏里貉;2,人;3,牛;4,犬;5,原鸡;6,小鼠;7,大鼠;8,北极狐;9,赤狐;10,野猪;11,家马;12,黑猩猩;13,家猫;14,绵羊;15,山羊;16,斑马鱼1,N y c t e r e u t e s p r o c y o n o i d e s ;2,H o m o s a p i e n s ;3,B o s T a u r u s ;4,C a n i s l u p u s f a m i l i a r i s ;5,G a l l u s g a l l u s ;6,M u s m u s c u l u s ;7,R a t t u s n o r v e g i c u s ;8,V u l p e s l a g o p u s ;9,V u l p e s v u l p e s ;10,S u s s c r o f a ;11,E q u u s c a b a l l u s ;12,P a n t r o g l o d y t e s ;13,F e l i s c a t u s ;14,O v i s a r i e s ;15,C a pr a h i r c u s ;16,D a n i o r e r i o 2.5 N e u t r a l i t y -pl o t 分析为了评估M C 3R 基因密码子使用的突变压力和自然选择程度,本研究进行了G C 12和G C 3s 之间的中性绘图分析,结果显示,M C 3R 基因密码子G C 12和G C 3s 之间相关系数为0.2439,统计分析也显示两者无显著相关(P >0.05);线性回归曲线斜率为0.1061,表明突变压力占选择力的10.61%,自然选择占89.39%(图1)㊂图1 N e u t r a l i t y -p l o t 分析曲线F i g .1 N e u t r a l i t y -p l o t a n a l ys i s c u r v e 2.6 E N c -pl o t 分析E N c 与G C 3s 的相关分析结果显示,16个物种的M C 3R 基因均分布在标准曲线以下或附近,其中原鸡M C 3R 基因离标准曲线最为接近(图2)㊂图2 E N c -P l o t 关联分析曲线F i g .2 E N c -P l o t c o r r e l a t i o n a l a n a l yt i c c u r v e 2.7 P R 2-pl o t 分析为了进一步确定突变和选择对密码子偏好性的影响,本研究进行了奇偶偏好性分析,结果显示,65314期李 鑫等:乌苏里貉M C 3R 基因密码子偏好性分析2个轴以0.5为中心,将图分成4个象限,所有物种M C 3R 基因均分布在中心纵轴左边,且大部分物种的基因分布在左下象限,即密码子第3个位置上C ㊁T 碱基出现的频率高于G ㊁A 碱基;少量分布在左上象限,即C ㊁A 碱基出现的频率高于G ㊁T 碱基(图3)㊂2.8 聚类分析系统进化树结果显示,乌苏里貉㊁犬分支与赤狐㊁北极狐分支聚为一类,绵羊㊁山羊分支与牛聚为一类,人和黑猩猩属同一分支,大鼠和小鼠属同一分支(图4);基于R S C U 值的聚类与系统进化树结果一致,其中乌苏里貉在系统进化上虽与其他犬科动物聚为一类,但在密码子使用度上与人㊁黑猩猩及家马更为相近(图5)㊂图3 P R 2-p l o t 分析结果F i g .3 P R 2-p l o t a n a l ys i s r e s u l ts 各分支节点处的值为自展值,表示该分支的可信度T h e v a l u e a t e a c hb r a n c hn o d e i s ab o o t s t r a p v a l u e ,i n d i c a t i n g t h e c o n f i d e n c e o f t h eb r a n c h 图4 不同物种M C 3R 基因C D S 区系统进化树F i g .4 P h y l o g e n e t i c t r e e o f M C 3R g e n eC D S i nd i f f e r e n t s pe c i e s 3 讨 论密码子使用偏好性被认为是翻译选择和突变压力这2个进化过程间非常复杂的平衡结果[34],普遍存在于各种生物中㊂分析不同物种的密码子偏好特征和变异,有助于了解物种的遗传结构和进化趋势[35-36]㊂众所周知,密码子第3位的碱基改变不会导致氨基酸改变,而密码子第1或2位的碱基改变则会导致氨基酸改变,影响其功能;与第1和2位相比,第3位碱基暴露的选择压力较小㊂因此,基于G C 3s 的研究在阐明各种生物密码子趋势中起着关键作用[14]㊂G C ㊁G C 3s 是对密码子在碱基使用上表现出偏好性的重要反应参数,当G C 和G C 3s 均>0.5时,说明该基因倾向于使用G ㊁C 的程度高㊂在本研究中,除原鸡外,各个物种M C 3R 基因C D S 区的G C ㊁G C 3s 均>0.5,说明M C 3R 基因在各物种中偏好使用G ㊁C 的程度高,且密码子偏好以G /C 结尾㊂原鸡G C 3s >0.5,但G C<0.5,说明原鸡M C 3R 基因密码子A ㊁T 含量高,但密码子第3位的G ㊁C 含量高㊂因此,在同义密码子第3位碱基分布上,各物种表现出相同的分布趋势G C 3s >G C 1s >G C 2s (G C 3s >0.5),且G 3s +C 3s >A 3s +T 3s㊂7531中 国 畜 牧 兽 医51卷每个长方形代表一个密码子的R S C U 值,颜色强度代表了不同R S C U 值E a c h r e c t a n g l e r e p r e s e n t e d t h eR S C Uv a l u e o f o n e c o d o n ,a n d t h e c o l o r i n t e n s i t y r e p r e s e n t e dd i f f e r e n tR S C Uv a l u e s 图5 不同物种M C 3R 基因密码子R S C U 值的聚类分析F i g .5 C l u s t e r i n g a n a l y s i s o f M C 3R c o d o nR S C Uv a l u e s i nd i f f e r e n t s pe c i e s R S C U 是反映密码子使用偏好的重要参数,当R S C U 值>1时,说明使用度较高;当R S C U 值=1时,说明不具有偏好性;当R S C U 值<1时,说明使用度较低[37]㊂本研究发现,乌苏里貉M C 3R 基因R S C U 值>1的密码子有25个,分别是G C C ㊁T G C ㊁G A C ㊁G A G ㊁T T C ㊁G G C ㊁G G G ㊁C A C ㊁A T C ㊁A A G ㊁C T C ㊁C T G ㊁A A C ㊁C C C ㊁C A G ㊁A G G ㊁C G C ㊁C G G ㊁A G C ㊁T C C ㊁A C C ㊁G T C ㊁G T G ㊁T A C 及T A G ,全部以G /C 结尾,且用法频率值和用法分值也相对较高,提示可能为M C 3R 基因的偏好密码子㊂各个物种间R S C U 值比较发现,除共同偏好使用的16个密码子,使用度均较低的21个密码子,以及编码蛋氨酸/甲硫氨酸㊁脯氨酸的密码子外,其余密码子在使用度上表现出了显著的种间差异㊂E N c 是反映密码子使用偏好程度的典型参数,E N c 值越小偏好性越强,基因表达量也越高[38]㊂E N c 取值范围为20~61,E N c 值=20表示每个氨基酸只使用一个密码子;E N c 值=61表示每个氨基酸随机使用密码子,一般认为E N c 值ɤ35的基因具有很强的密码子偏好[39]㊂本研究计算得出,乌苏里貉的E N c 值<35,说明M C 3R 基因的密码子偏好性较强,在乌苏里貉中具有较高的表达量;与其他物种相比,乌苏里貉与犬的E N c 值差异最小,两者还具有相同的F o p 和CB I 值,此外,乌苏里貉与北极85314期李鑫等:乌苏里貉M C3R基因密码子偏好性分析狐㊁赤狐在这些指标上差异也相对较小,说明这些物种均具有较强的密码子偏好性,推断可能与同为犬科动物有关㊂值得注意的是,乌苏里貉与家猫在E N c值的差异仅次于犬,两者F o p和C B I值的差异也仅次于其他犬科动物,与系统发育树上貉等犬科动物与家猫聚为一支相符,导致这种情况出现的原因可能是两者均属食肉目动物㊂密码子使用偏好受多种因素影响,包括基因碱基组成㊁基因长度㊁基因表达水平㊁t R N A丰度㊁氨基酸疏水性㊁芳香性㊁突变和选择等,其中突变和选择是影响密码子使用偏好的最重要因素[40-41]㊂N e u t r a l i t y-p l o t分析是研究3个密码子位置之间碱基使用模式的常用方法㊂同义密码子的突变一般为密码子第3位的碱基突变,而位于第1或2位的碱基突变则为非同义突变[42];应用N e u t r a l i t y-p l o t分析能够阐明密码子3个位置之间的相关性,以确定密码子偏好性上是否存在选择性突变,并量化自然选择和突变压力的程度[43]㊂本研究中,G C12与G C3s的相关性不显著,表明不同密码子位置的碱基组成不存在差异,且回归曲线趋近于0,说明M C3R基因密码子偏好性受自然选择影响更大㊂E N c-p l o t是分析密码子使用偏好影响因素的常用方法,如果一个基因的密码子偏好性形成受到突变的显著影响,其点的分布应在标准曲线上或附近;如果受自然选择的影响较大,则点应分布在离标准曲线较远的地方[44]㊂E N c-p l o t分析结果表明,除原鸡外,其他物种密码子偏好性受自然选择影响更大,而原鸡受突变影响更大㊂P R2-p l o t分析用来说明突变和选择压力对密码子使用偏差的影响,如果密码子使用偏好主要是由于突变偏好,则G和C(A和T)应按比例使用在密码子第3位;另一方面,如果自然选择占主导地位,则G和C(A和T)的使用并不一定会成比例[45]㊂本研究中,所有物种M C3R基因密码子第3位置偏好使用G㊁C,且C3s>G3s;除以G/C结尾的密码子外,A/T结尾的密码子中大部分物种T3s>A3s,少量物种A3s>T3s,说明在M C3R基因C D S区密码子第3位上,A T和G C间存在密码子使用不平衡,自然选择是导致这种情况出现的主要因素㊂综上所述,16个物种M C3R基因密码子偏好性形成,均为自然选择影响更大㊂在分子水平上,某些在进化过程中的生物学现象能用密码子偏好性来说明㊂基于不同物种的R S C U值,本研究构建了不同物种间关系的热图,发现基于R S C U值的不同物种间聚类与基于序列的进化关系有相似的结果,大部分亲缘关系相近的物种在密码子使用模式上也聚为一类㊂这与赵禹等[46]研究结果基本一致,在进化过程中,亲缘关系相近的物种密码子偏好性也相似,说明物种在密码子使用上具有保守性㊂值得注意的是,乌苏里貉在系统进化树上虽与犬聚为一支,但在密码子使用偏好性上与人㊁黑猩猩及家马聚为一类,这可能是因为单基因突变造成其密码子使用偏性发生较大变化,从而呈现出与真实的分类地位不同[47]㊂由此可得,虽然密码子偏好性有种属差异,但其他因素如基因结构㊁长度及碱基组成等也会对其偏好性产生影响;为异源基因高效表达提供宿主时,亲缘关系近的物种不一定适合作为最佳宿主㊂本研究通过对乌苏里貉M C3R基因密码子的偏好性进行分析,并与其他15个物种进行比较,了解了不同物种间的遗传进化关系,为今后开展M C3R基因异源高效表达工作提供了理论依据㊂4结论M C3R基因在各物种中偏好使用以G/C结尾的密码子,且M C3R基因密码子使用均存在一定偏好性,自然选择是导致偏好性产生的主要影响因素;密码子使用偏好具有种属特异性,亲缘关系近的物种密码子使用特征具有相似性,但因受多种因素影响,同一种属物种基因的密码子使用偏好性也会出现差异㊂参考文献(R e f e r e n c e s):[1]付晶,宁方勇,魏来,等.鹌鹑M C3R基因的S N P s及其与生长和屠体性状的相关研究[J].中国家禽,2011,33(20):13-17.F U J,N I NG F Y,W E I L,e t a l.S i n g l e n u c l e o t i d ep o l y m o r p h i s m s o f q u a i l m e l a n o c o r t i n-3r e c e p t o r(M C3R)g e n e a n d i t s a s s o c i a t i o n a n a l y s i s w i t hg r o w t ha n d s l a u g h t e r t r a i t s[J].C h i n aP o u l t r y,2011,33(20):13-17.(i nC h i n e s e)[2] Y A N I K T,D U R HA N S T.S p e c i f i c f u n c t i o n s o fm e l a n o c o r t i n-3r e c e p t o r(M C3R)[J].J o u r n a lC l i n i c a lR e s e a r c h i nP e d i a t r i cE n d o c r i n o l o g y,2023,15(1):1-6.[3] B R U N N E RL,N I C K H P,C UM I N F,e t a l.L e p t i n i sa p h y s i o l o g i c a l l y i m p o r t a n t r e g u l a t o r o f f o o di n t a k e[J].I n t e r n a t i o n a l J o u r n a l o f O b e s i t y a n dR e l a t e d M e t a b o l i cD i s o r d e r s,1997,21(12):1152-1160.[4] C H E HA BFF.L e p t i na s a r e g u l a t o r o f a d i p o s em a s sa n d r e p r o d u c t i o n[J].T r e n d s P h a r m a c o l o g i c a l9531中国畜牧兽医51卷S c i e n c e s,2000,21(8):309-314.[5] B E N O I TS,S C HWA R T Z M,B A S K I N D,e t a l.C N Sm e l a n o c o r t i n s y s t e mi n v o l v e m e n t i nt h er e g u l a t i o no ff o o d i n t a k e[J].H o r m o n e s a n d B e h a v i o r,2000,37(4):299-305.[6] H O G G A R D N,H U N T E R L,D U N C A N J S,e t a l.R e g u l a t i o no fa d i p o s et i s s u el e p t i ns e c r e t i o nb y a l p h a-m e l a n o c y t e-s t i m u l a t i n g h o r m o n e a n d a g o u t i-r e l a t e dp r o t e i n:F u r t h e r e v i d e n c e o f a n i n t e r a c t i o nb e t w e e n l e p t i na n dt h e m e l a n o c o r t i ns i g n a l l i n g s y s t e m[J].J o u r n a lo fM o l e c u l a rE n d o c r i n o l o g y,2004,32(1):145-153. [7]付晶,宁方勇,潘宝丽,等.鹌鹑M C3R基因多态性与体重关系的研究[J].中国家禽,2010,32(22):21-24.F U J,N I NG F Y,P A N B L,e t a l.R e l a t i o n s h i pb e t w e e n m e l a n oc o r t i n-3r e c e p t o r g e n e a nd b o d yw e i g h t i n q u a i l s[J].C h i n aP o u l t r y,2010,32(22):21-24.(i nC h i n e s e)[8]杜鹏,巴彩凤,周艳彬,等.比格犬黑皮质素受体3基因A167T对体质量性状的影响[J].中国组织工程研究与临床康复,2010,14(15):2740-2743.D U P,B A C F,Z H O U Y B,e t a l.E f f e c t s o fm e l a n o c o r t i n-3r e c e p t o r g e n e A167T o n t h e b o d yw e i g h t t r a i to fB e a g l ed o g s[J].J o u r n a l o f C l i n i c a lR e h a b i l i t a t i v e T i s s u e E n g i n e e r i n g R e s e a r c h,2010,14(15):2740-2743.(i nC h i n e s e)[9]张轶博,巴彩凤.M C3R和M C4R基因多态性位点与犬体型性状的关系[J].中国兽医学报,2013,33(4):627-629.Z HA N G Y B,B A C F.R e l a t i o n s h i p b e t w e e n M C3Ra n d M C4R g e n e p o l y m o r p h i s ma n db o d y s i z e t r a i t s i nd o g s[J].C h i ne s eJ o u r n a lV e t e r i n a r y S c i e n c e,2013,33(4):627-629.(i nC h i n e s e)[10] B U T L E R A A,K E S T E R S O N R A,K H O N G K,e t a l.A u n i q u em e t a b o l i cs y n d r o m ec a u s e so b e s i t y i nt h e m e l a n o c o r t i n-3r e c e p t o r-d e f i c i e n t m o u s e[J].E n d o c r i n o l o g y,2000,141(9):3518-3521.[11] C H E N AS,MA R S H DJ,T R UM B A U E R M E,e t a l.I n a c t i v a t i o n o f t h e m o u s e m e l a n o c o r t i n-3r e c e p t o rr e s u l t si ni n c r e a s e df a tm a s sa n dr e d u c e dl e a nb o d ym a s s[J].N a t u r e G e n e t i c s,2000,26(1):97-102. [12]李鑫,李伟,刘洁,等.乌苏里貉M C3R蛋白的生物信息学分析[J].黑龙江畜牧兽医,2023,14:119-124.L IX,L I W,L I U J,e t a l.B i o i n f o r m a t i c sa n a l y s i so fM C3R p r o t e i n i n U s s u r i r a c c o o n d o g s[J].H e i l o n g j i a n g A n i m a l S c i e n c e a n d V e t e r i n a r yM e d i c i n e,2023,14:119-124.(i nC h i n e s e)[13] B E HU R A S K,S E V E R S O N D W.C o m p a r a t i v ea n a l y s i s o f c o d o n u s a g eb i a s a n dc od o n c o n te x tp a t t e r n s b e t w e e n D i p t e r a n a n d H y m e n o p t e r a ns e q u e n c e d g e n o m e s[J].P u b l i c L i b r a r y o f S c i e n c eO n e,2012,7(8):e43111.[14] B A R B HU I Y APA,U D D I N A,C HA K R A B O R T YS.A n a l y s i s o f c o m p o s i t i o n a l p r o p e r t i e s a n dc o d o nu s a g eb i a so fm i t oc h o nd r i a l C Y B ge n e i n A n u r a u r o d e l a a n dG y m n o p h i o n a[J].G e n e,2020,751:144762.[15] C HU D,W E IL.D i r e c t i nv i v o o b s e r v a t i o no ft h ee f f e c t o fc o d o n u s a g e b i a s o n g e n e e x p r e s s i o ni nA r a b i d o p s i s h y b r i d s[J].J o u r n a l o f P l a n tP h y s i o l o g y,2021,265:153490.[16] F R A N Z O G,T U C C I A R O N E C M,L E G N A R D I M,e t a l.Ef f e c t o fg e n o m e c o m p o s i t i o na n d c o d o nb i a s o nI n f e c t i o u s b r o n c h i t i s v i r u s e v o l u t i o n a n d a d a p t a t i o n t ot a r g e t t i s s u e s[J].B M CG e n o m i c s,2021,22(1):244.[17] H I AF,T A K E U C H IO.T h e e f f e c t s o f c o d o nb i a s a n do p t i m a l i t y o n m R N A a n d p r o t e i n r e g u l a t i o n[J].C e l l u l a r a n d M o l e c u l a rL i f eS c i e n c e s,2021,78(5):1909-1928.[18] U D D I N A,M A Z U M D E R T H,C H O U D H U R Y M N,e t a l.C o d o nb i a s a n d g e n e e x p r e s s i o n o fm i t o c h o n d r i a lN D2g e n ei n C h o r d a t e s[J].B i o i n f o r m a t i o n,2015,11(8):407-412.[19] B I S WA S K K,P A L C H O U D HU R Y S,C HA K R A B O R T YP,e t a l.C o d o nu s a g eb i a s a n a l y s i so fC i t r u st r i s t e z av i r u s:H i g h e rc o d o na d a p t a t i o nt oC i t r u s r e t i c u l a t a h o s t[J].V i r u s e s,2019,11(4):331.[20] L A B E L L A A L,O P U L E N T ED A,S T E E N W Y KJL,e t a l.V a r i a t i o n a n d s e l e c t i o n o n c o d o n u s a g e b i a sa c r o s sa n e n t i r es ub p h y l u m[J].P u b l i cL i b r a r y o fS c i e n c eG e n e t i c s,2019,15(7):e1008304.[21] K O K A T EP P,T E C H TMA N N S M,W E R N E R T.C o d o nu s a g eb i a sa n dd i n u c l e o t i d e p r e f e r e n c ei n29D r o s o p h i l a s p e c i e s[J].G3-G e n e s G e n o m e s G e n e t i c s(B e t h e s d a),2021,11(8):j k a b191.[22] HU O X,L I U S,L IY,e t a l.A n a l y s i so f s y n o n y m o u sc od o n u s a ge of t r a n s c r i p t o m e d a t a b a s e i n R h e u mp a l m a t u m[J].J o u r n a lo f L i f e&E n v i r o n m e n t a lS c i e n c e s,2021,9:10450.[23] H U G A B O O M M,H A T M A K E R EA,L A B E L L A AL,e t a l.E v o l u t i o na n d c o d o nu s a g e b i a s o fm i t o c h o n d r i a la n dn u c l e a r g e n o m e s i n A s p e r g i l l u s s e c t i o n f l a v i[J].G3-G e n e sG e n o m e sG e n e t i c s(B e t h e s d a),2023,13(1):j k a c285.[24]马建青,杨清芳,宋占锋,等.绵羊骨代谢相关基因V D R密码子偏好性分析[J].中国畜牧兽医,2022,49(8):2888-2898.MAJQ,Y A N G Q F,S O N G Z F,e t a l.A n a l y s i so fc od o n u s a ge b i a s of V D Rg e n e r e l a t e d t o b o n em e t a b o l i s m i n O v i s a r i e s[J].C h i n a A n i m a l0631。
密码子偏好性分析

摘 要 脂多糖结合蛋白(lipopolysaccharide-binding protein, LBP)是机体识别革兰氏阴性菌内毒素并启 动免疫反应的关键因子。为了了解 LBP 基因的密码子使用特性,为其选择合适的受体动物以及最佳外源 表达系统提供依据,本研究运用 CHIPS、CUSP 和 CodonW 在线程序分析自主电子克隆的猪(Sus scrofa) LBP 基因(GenBank 登录号: NM-001128435.1)的密码子偏好性,并与猪 8 种抗病相关基因、模式生物基因 组以及其他物种 LBP 基因相比较。结果表明,猪 LBP 基因大部分偏好使用以 G/C 结尾的密码子,27 种偏 好密码子(相对使用度(RSCU)>1)中偏好性较强的有 GCC、CAC、CTG 和 TCC(RSCU≥2),而猪 8 种抗病 相关基因有 23 种偏好密码子,全部以 G/C 结尾,并且偏好性较强的密码子有 GCC、ATC、CTG 和 GTG;通 过比较 14 种动物的 LBP 基因密码子偏好性,发现 14 个物种的 LBP 基因表达水平一般,并且都偏好以 G/C 结尾的密码子;聚类分析发现,偶蹄目猪与 2 种食肉目动物(猫(Felis catus)和狗(Canis))聚为一类,与系统 分类关系不一致;在密码子的使用频率上,猪 LBP 基因与小鼠(Mus musculus)基因组的差异小于大肠杆菌 (Escherichia coli)和酵母菌(Saccharomyces)等 2 种模式生物基因组,故小鼠更适合作为该 LBP 基因的外源表 达宿主。本研究结果为 LBP 基因在动物遗传改良中选择合适的受体动物、选择最佳的外源表达系统以及 提高其表达水平提供一定的理论依据。 关键词 猪,脂多糖结合蛋白基因(LBP),密码子偏好性
密码子实用差异分析

密码子使用分析软件:
1.对分析序列的顺序没有要求,把要分析都装在一个文件里面,每个序列的格式都是fasta 格式。
高表达的基因的确定,是根据CAI、CBI、NC的值来确定的;具体解释如下:
密码子适应指数(Codon Adaptation Index,CAI),密码子适应指数常用于基因表达水平的测量。
此值为0~1,越接近1表示基因的表达水平越高。
密码子偏爱指数(codonbiasindex)CBI反应了一个具体基因中高表达优越密码子的组分情况.对目的宿主自身的基因,该指数和Nc值有很好的相关性,但在实际工作中可以更明确地反映外源基因在目的宿主中可能的表达情况,故而得到广泛应用.计算公式如
下:CBI=(Nopt-Nran)/(Ntot-Nran),Nopt代表优越密码子在该基因中出现次数之和;Nran代表氨基酸序列不变,所有同义密码子随机出现时优越密码子的出现次数之和;Ntot代表了优越密码子对应的氨基酸在基因中出现的次数之和.
密码子有效数(effectivenumberofcodons)Nc反映的是一个基因中所用到的密码子种类的多少,其数值一般在20~61之间.考虑到不同基因的长短和氨基酸组分不同,有关计算时引入了处理以消除这一影响,故Nc数值不是整数且可能大于61,已知高表达基因其密码子偏爱程度也大,从而Nc值较小;低表达基因则含有较多种类的稀有密码子,Nc值也较大,所以,当前普遍通过比较Nc来确定内源基因表达量的相对高低.Nc值越小,对应的内源基因往往表达量也越高,有关工作已证明了这一方法的可行性.。
密码子偏好性分析..

手段 ,通过比较核基因编码的核糖体蛋白和线粒体基 因编码的核糖体蛋白上密码子使用模式的差异来预测 未知蛋白的基因所在基因组位置。
(二)通过密码子使用偏好性的研究, 可以判定一些最优
密码子,针对这些密码子设计基因工程表达载体可以提高目 的基因的表达量 。 (三)利用密码子使用偏好性和某种功能的关联程度对某些 未知功能基因进行预测利用已知的密码子偏好知识对未知表 达水平 的 基 因 进行 判 定 初步判断该基因的表达水平高或 低。 (四)利用编码区和非编码区的基因组特征差异进行全基因 组扫描,发现新基因。 密码子使用偏性的影响因素:
其中,n表示这个密码子所代表的氨基酸的同义密码子种类数目(1<n6), 戈代表第i个密码子的出现次数。RSCU是衡量密码子偏性较直观的一个参数。
密码子适应指数( Codon adaption index , CAI ) 该指数以一组具高表达水平的基因为参考 , 测量某一个基因的密码子偏 好情况和这些高表达基因密码子偏好情况的接近程度 , 如果一个基因完 全使用高表达基因中所用的密码子 , 则其 C AI 值为 1 。目前这个指数已 被广泛用来预测基 因 的 表 达 水平。
进行查询
如只需要基因序列而不需要详细信息,则需点击TASTA
如需进行图文分析,则点击Graphics
计算同义密码子相对使用度(Relative synonymous codon
usage, RSCU) 在genebank中取出序列后,用codonw进行在线分析
结果如下:
利用cusp计算密码子Franction和Frequency。 Franction:各个密码子在编码该氨基酸的密码子中所占的比例。 Frequency:该密码子在编码总基因密码子中出现的频率。
紫九牛叶绿体基因组密码子偏好性分析

紫九牛叶绿体基因组密码子偏好性分析作者:郭松梁湘兰黄青青卢祥严其伟张鹏覃逸明来源:《广西植物》2022年第08期摘要:為确定瑶药紫九牛叶绿体基因组密码子的使用模式及其成因,该研究以紫九牛叶绿体基因组50条蛋白质编码序列为研究对象,利用Codon W 1.4.2和在线软件CUSP和Chips 分析其密码子偏好性。
结果表明:(1)RSCU>1的密码子有29个,其中有28个以A/U结尾,说明叶绿体基因组的同义密码子中偏好以A/U结尾。
(2)紫九牛叶绿体基因组密码子的GC含量GC1(47.38%)>GC2(39.81%)>GC3(29.60%),ENC值大于45的有40个,说明紫九牛叶绿体基因组存在较弱的偏性。
(3)中性绘图分析和ENC-plot分析说明了紫九牛叶绿体基因组密码子的偏好性既受到选择的作用,又受到突变因素的影响。
(4)通过构建的高低基因表达库最终确定了15个最优密码子,分别为UUG、AUU、GUU、GUA、UCU、 CCU、ACU、ACA、GCU、CAA、AAC、GAA、UGU、CGU和GGU。
该研究为紫九牛叶绿体基因组的确定以及遗传多样性分析提供了依据。
关键词:紫九牛,叶绿体基因组,密码子,偏好性分析,最优密码子中图分类号: Q75文献标识码: A文章编号: 1000-3142(2022)08-1426-07Codon usage bias in the chloroplast genomeof Ventilago leiocarpaGUO Song LIANG Xianglan HUANG Qingqing LU XiangYAN Qiwei ZHANG Peng QIN Yiming( 1. College of Food and Biochemical Engineering, Guangxi Science & Technology Normal University, Laibin 546119, Guangxi,China; 2. Key Laboratory for Research and Development of Characteristic Yao Medicine Resources,Guangxi Science & Technology Normal University, Laibin 546119, Guangxi, China )Abstract: To determine the codon usage pattern of chloroplast genome of Ventilago leiocarpa,a total of 50 selected protein-coding sequences were analyzed using Codon W 1.4.2 and online softwares of CUSP and Chips. The results were as follows:(1) There were 29 codons with RSCU > 1, and 28 of them ended with A/U, indicating that synonymous codons in chloroplast genome tend to end with A/U. (2) GC content of codon in chloroplast genome of V. leiocarpa was GC1(47.38%) > GC2 (39.81%) > GC3(29.60%), and there were 40 with ENC value greater than 45, which indicates that there is weak bias in chloroplast genome of V. leiocarpa. (3)Neutral mapping analysis and ENC-plot analysis demonstrated that the codon preference of chloroplast genome of V. leiocarpa was affected by both selection and mutation factors. (4)Through the constructed high and low gene expression libraries, 15 optimal codons were finally determined, which were UUG, AUU, GUU, GUA, UCU, CCU, ACU, ACA, GCU,CAA, AAC, GAA, UGU, CGU and GGU. The present study took some basis for the determination of chloroplast genome and genetic diversity analysis of V. leiocarpa.Key words: Ventilago leiocarpa, chloroplast genome, codon, usage bias analysis,optimal codons密码子是联结生物体内遗传物质和蛋白质翻译的纽带(谢平,2017;柳燕杰等,2020),在生物体内起着重要作用。
密码子偏性分析精品资料

2.1有效密码子数与GC含量
获得9676个CDS作为分析样本,经CodonW1.4.2软件分析获得全基因组共计9981条基因的4497467个密码子,密码子中不同位置GC含量不同,其中第2位的GC含量较低,为42%,第1位和第3位的GC含量差异较小,分别为57.8%和56.8%,GC平均含量为52.2%。
2.3相对同义密码子使用度
RSCU值反映的是密码子在编码同义氨基酸间的相对概率,当同义密码子对应氨基酸的使用频率相同,则相对密码子使用度就是1。当密码子的使用频率相对较高时则相对密码子使用度大于1(高频密码子),反之当密码子的使用频率相对较低时则相对密码子使用度小于1[9]。普通羊肚菌中RSCU值大于等于1的密码子总共35个,其中以G或C结尾的25个,占71.4%;以A或T结尾的10个,占28.6%(表1)。
1材料与方法
1.1标本
普通羊肚菌(M.conica)于2015年5月采自云南省昆明市禄劝县轿子山,标本经上海市农业科学院转基因环境安全评价实验室提取基因组DNA,交由上海派森诺生物公司测序,并将ITS序列提交到NCBI网站进行BLAST比对后鉴定为普通羊肚菌。
1.2CDS获得
将样品的基因组DNA构建采用C语言编写程序剔除序列长度小于300bp(氨基酸数量小于100)CDS作为分析样本[5]。
密码子偏性分析
摘要:
采用CodonW1.4.2软件和CUSP程序,以普通羊肚菌全基因组蛋白质编码序列为对象,解析了该菌的有效密码子数、密码子3个位点的GC含量、相对同义密码子使用度和高表达优越密码子。结果表明:普通羊肚菌全基因组密码子第2位密码子的GC含量明显低于第1位和第3位,第3位密码子与第1位含量差异不大,分别为57.8%和56.8%,RSCU值大于等于1的密码子总共35个,其中以G或C结尾的25个,占71.4%,确定了25个高表达优越密码子。
原核表达密码子偏好 概述及解释说明

原核表达密码子偏好概述及解释说明1. 引言1.1 概述原核表达密码子偏好是指原核生物在蛋白质合成过程中对编码氨基酸的密码子选择存在一定规律性。
密码子是由三个核苷酸组成的序列,用于编码不同的氨基酸。
在原核生物中,有些密码子被广泛使用,而其他密码子则较少使用。
这种密码子偏好现象引发了科学家们的兴趣,并且对研究人员揭示了一些有关遗传信息传递机制和生物进化的重要见解。
1.2 文章结构本文将以以下几个部分来描述原核表达密码子偏好。
首先,在第2部分中,我们将概述原核表达密码子偏好的基本概念和背景知识。
然后,在第3部分中,我们将解释说明影响原核表达密码子偏好的主要原因和机制。
接下来,在第4部分中,我们将通过实例分析具体介绍常见原核生物中的密码子偏好现象及其解释。
最后,在第5部分中,我们将总结原核表达密码子偏好的特点并展望该领域未来的研究方向。
1.3 目的本文旨在深入探讨原核表达密码子偏好的现象和机制,并通过实例分析加深对该领域的理解。
了解原核表达密码子偏好对我们揭示细胞功能和进化过程具有重要意义。
同时,本文也希望能够促进对密码子偏好研究领域的发展,为未来的研究提供新的思路和方向。
2. 原核表达密码子偏好概述:2.1 什么是原核表达密码子偏好原核生物中的基因编码信息通过密码子来进行转录和翻译,密码子是由三个核苷酸组成的序列,每个密码子对应着一个氨基酸。
然而,在同一种原核生物的基因组中,对于某些氨基酸来说,并非所有可能的密码子都被等概率地使用。
相反,原核生物存在一种选择性地使用某些密码子来编码特定氨基酸的现象,这就是原核表达密码子偏好。
2.2 密码子的定义和功能在DNA或RNA序列中,每三个连续的核苷酸被称为一个密码子。
根据遗传密码表,不同的密码子对应着不同的氨基酸,起到了翻译基因信息为蛋白质序列的作用。
2.3 原核生物中密码子使用的规律性原核生物在使用密码子时并非随机选择,而是存在一定程度上的规律性。
具体而言,原核生物中较为常见或者富集的密碼雙取决于其所编码氨基酸出现频率及其它影响因素。
酵母密码子偏好表
密码子表密码子酿酒酵母密码子偏好表UUU 26.1(170666) UCU 23.5(153557) UAU 18.8(122728) UGU 8.1( 52903) UUC 18.4(120510) UCC 14.2( 92923) UAC 14.8( 96596) UGC 4.8( 31095) UUA 26.2(170884) UCA 18.7(122028) UAA 1.1( 6913) UGA 0.7( 4447) UUG 27.2(177573) UCG 8.6( 55951) UAG 0.5( 3312) UGG 10.4( 67789)CUU 12.3( 80076) CCU 13.5( 88263) CAU 13.6( 89007) CGU 6.4( 41791) CUC 5.4( 35545) CCC 6.8( 44309) CAC 7.8( 50785) CGC 2.6( 16993) CUA 13.4( 87619) CCA 18.3(119641) CAA 27.3(178251) CGA 3.0( 19562) CUG 10.5( 68494) CCG 5.3( 34597) CAG 12.1( 79121) CGG 1.7( 11351)AUU 30.1(196893) ACU 20.3(132522) AAU 35.7(233124) AGU 14.2( 92466) AUC 17.2(112176) ACC 12.7( 83207) AAC 24.8(162199) AGC 9.8( 63726) AUA 17.8(116254) ACA 17.8(116084) AAA 41.9(273618) AGA 21.3(139081) AUG 20.9(136805) ACG 8.0( 52045) AAG 30.8(201361) AGG 9.2( 60289)GUU 22.1(144243) GCU 21.2(138358) GAU 37.6(245641) GGU 23.9(156109) GUC 11.8( 76947) GCC 12.6( 82357) GAC 20.2(132048) GGC 9.8( 63903) GUA 11.8( 76927) GCA 16.2(105910) GAA 45.6(297944) GGA 10.9( 71216) GUG 10.8( 70337) GCG 6.2( 40358) GAG 19.2(125717) GGG 6.0( 39359)酸性氨基酸:天冬氨酸、谷氨酸碱性氨基酸:赖氨酸、精氨酸、组氨酸目录[隐藏]∙ 1 基本結構∙ 2 分類∙ 3 理化特性∙ 4 胺基酸的化學結構∙ 5 胺基酸列表∙ 6 基本氨基酸∙7 必需氨基酸∙8 次要编码氨基酸∙9 其它胺基酸∙10 參考資料[化學主題首頁甘氨酸Glycine丙氨酸Alanine缬氨酸Valine亮胺酸Leucine異亮氨酸Isoleucine苯丙氨酸Phenylalanine色氨酸Tryptophan酪氨酸Tyrosine天冬氨酸 Asparticacid组氨酸Histidine天冬酰胺Asparagine谷(麩)氨酸Glutamic acid赖氨酸Lysine谷(麩)氨酰胺Glutamine甲硫氨酸Methionine精氨酸Arginine丝氨酸Serine苏氨酸Threonine半胱氨酸Cysteine脯氨酸 ProlineG Gly Glycine甘氨酸 親水性75.07 6.06 2.35 9.78 沒有旋光性A Ala Alanine丙氨酸 疏水性89.09 6.11 2.35 9.87V Val Valine纈氨酸 疏水性117.15 6.00 2.39 9.74L Leu Leucine亮氨酸 疏水性131.17 6.01 2.33 9.74I Ile Isoleucine異亮氨酸疏水性 131.17 6.05 2.32 9.76F Phe Phenylalanine 苯丙氨酸疏水性 165.19 5.49 2.20 9.31W Trp Tryptophan色氨酸 疏水性204.23 5.89 2.46 9.41Y Tyr Tyrosine酪氨酸 疏水性181.19 5.64 2.20 9.21 10.46 D Asp Aspartic acid 天冬酸133.10 2.85 1.99 9.90 3.90氨酸性 H His Histidine組氨酸鹼性 155.16 7.60 1.80 9.33 6.04N Asn Asparagine天冬酰胺親水性 132.12 5.41 2.14 8.72E Glu Glutamic acid 穀氨酸酸性 147.13 3.15 2.10 9.47 4.07K Lys Lysine赖氨酸鹼性 146.19 9.60 2.16 9.06 10.54Q Gln Glutamine穀氨酰胺親水性 146.15 5.65 2.17 9.13M Met Methionine甲硫氨酸疏水性 149.21 5.74 2.13 9.28 蛋白質合成時第一個胺基酸 可能在轉譯過程被移除R Arg Arginine精氨酸鹼性 174.20 10.76 1.82 8.99 12.48S Ser Serine絲氨酸 親水性105.09 5.68 2.19 9.21T Thr Threonine苏氨酸 親水性119.12 5.60 2.09 9.10C Cys Cysteine半胱氨酸親水性 121.16 5.05 1.92 10.70 8.37 P Pro Proline脯氨酸 疏水性 115.13 6.30 1.95 10.64 可結束蛋白質折疊結構。
密码子数据库及密码子偏好性分析软件

密码子数据库及密码子偏好性分析软件题记:转基因研究中经常要进行基因的异源表达,在翻译过程中,受体物种对外源基因密码子的翻译效率对表达有非常大的制约。
因此,利用相应的生物信息学数据库及软件对目标序列进行受体物种的密码子偏好性分析将有助于完成对转基因效率的评价,适当选择合适的受体物种进行高效、可行的表达。
人物,阅读前,让我们感谢下列科学家,是他们为基因异源高效表达提供有价值参考。
Yasukazu Nakamura博士:The First Laboratory for Plant Gene Research,Kazusa DNA Research Institute 开发Codon Usage Database(生物密码子表的利用情况统计)。
PrimerX:编写了Codon Usage Analyzer在线密码子统计表处理软件(/cgi-bin/codon.cgi),它使得对密码子的统计用图表的形式显示出来,更加的直观可读。
Morris Maduro博士:针对E. coli开发了E. coli Codon Usage Analyze 。
目前的版本为2.1。
Thomas Schödl:开发设计的以图形形式对异源基因表达的密码子使用分析软件(Graphical codon usage analyser),用以帮助异源基因表达时对异源基因进行改造,以适应受体物种,避免由于翻译时密码子使用情况的限制使受体物种对外源基因表达产生负面影响。
内容:一:密码子使用统计数据库Codon Usage Database(.jp/codon/ 是由植物基因研究第一实验室(The First Laboratory for Plant Gene Research)Kazusa DNA Research Institute的Yasukazu Nakamura博士开发的生物密码子表的利用情况统计。
数据来源于GenBank 的DNA 序列数据库,是GenBank 的Codon Usage Tabulated 数据库在WWW模式下的扩展和整合。
密码子使用偏好性量化方法研究

密码子使用偏好性量化方法研究摘要在基因组学水平上研究密码子使用偏性模式、成因并分析进化过程中的选择压力在基因组学研究中有重要意义。
文章概述了目前提出的密码子使用偏性的量化方法及实现原理。
目前研究发现:有些量化密码子偏性的方法受高表达基因参考数据集未完全注释的限制,不同密码子位置对变异和选择的影响不同,以及不同密码子位置处GC 含量和嘌呤含量的贡献不同。
由此展望密码子偏性量化方法发展方向为:需要设计不需要相关参考基因集合先验知识的密码子使用偏性量化方法;考虑不同位置处背景核苷酸组成的密码子使用偏性的量化方法;同时考虑基因表达水平的密码子使用偏性量化方法。
最后,归纳了目前可用的密码子使用偏性的量化工具和数据库。
关键词同义密码子, 密码子使用偏性, 背景核苷酸, GC3, 高表达基因密码子使用偏性是指在不同物种间或同一物种内的基因翻译过程中,某些密码子的使用次数多于其它同义密码子的现象。
密码子使用偏性现象在许多物种中广泛存在。
在基因组学水平上研究密码子使用偏性模式、成因并分析进化过程中的选择压力在基因组学研究中有重要意义。
分子进化研究表明:密码子使用偏性在基因组中广泛存在,对基因组进化有极深的影响(Sharp and Matassi, 1994)。
并且密码子与氨基酸的关系影响到细胞的蛋白质组分的变化,即分子机制的变化(Xiao and Yu, 2007)。
同时,密码子使用偏性的有效衡量对相关基因功能的推断很重要。
最近的研究表明某些特殊同义密码子的使用也能影响蛋白质的折叠和错误折叠(Tsai et al., 2008;Marin, 2008)。
基因组内不同基因具有不同的密码子使用偏性,变异、选择和随机漂移是形成物种间密码子使用偏性的三个主要原因(Bulmer, 1991; Palidwor et al., 2010Supek et al., 2010 ; Shah and Gilchrist, 2011)。
不同植物FERONIA基因密码子使用偏好性分析
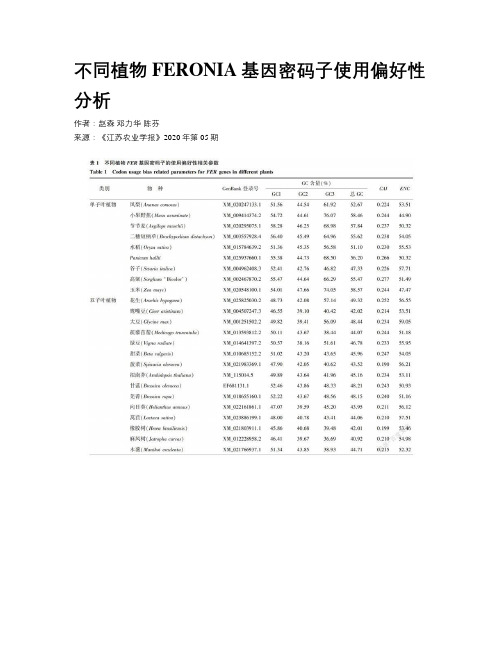
不同植物FERONIA基因密码子使用偏好性分析作者:赵森邓力华陈芬来源:《江苏农业学报》2020年第05期摘要:为了了解植物FERONIA(FER)基因在长期进化过程中所形成的密码子使用模式及它们之间的亲缘关系,采用Codon W、CUSP在线程序和SPSS等分析软件对不同植物的FER基因密码子进行碱基组成分析、对应性分析、PR2-Plot分析、中性绘图分析和ENC-Plot 分析并进行聚类分析。
结果表明,单子叶植物FER基因密码子的平均G+C含量高于双子叶植物,且单子叶植物偏好使用以G/C结尾的密码子,而双子叶植物偏好使用以A/T结尾的密码子。
对应性分析结果显示,在单子叶植物、双子叶植物中,向量轴1(Axis 1)可解释的变异分别占总变异的42.25%、28.56%。
在单子叶植物中,Axis 1与总G+C含量、GC3含量、G3含量、C3含量呈极显著正相关(P<0.01),而在双子叶植物中则呈极显著负相关(P<0.01)。
不同的碱基组成是单子叶植物和双子叶植物形成密码子使用偏好性的重要原因。
PR2-Plot分析结果、中性绘图结果和ENC-Plot分析结果表明,自然选择是形成植物FER基因密码子使用偏好性的主要驱动力。
基于编码序列(Coding sequence,CDS)构建的系统进化树比基于同义密码子相对使用度(RSCU)得出的聚类分析结果更接近传统的分类结果。
本研究结果可为进一步开展植物分子进化和基因工程研究奠定基础。
关键词:FERONIA基因;密码子使用偏好性;分子进化中图分类号:Q754;Q755文献标识码:A文章编号:1000-4440(2020)05-1073-09Abstract:To understand the usage pattern of codons formed in the long-term evolutionary process of FERONIA (FER) genes in plants and their genetic relationships, base composition analysis, correspondence analysis, PR2-Plot analysis, neutral plotting analysis and ENC-Plot analysis on FER gene codons of different plants were conducted by using Codon W, on line program of CUSP and analysis software like SPSS, and the cluster analysis was conducted. The results showed that the average content of G and C in FER gene codons of monocots was higher than that of dicots, and the monocots preferred G/C ending codons while dicots preferred A/T ending codons. The results of correspondence analysis showed that, Axis 1 accounted for 42.25% and 28.56% of the total variation in monocots and dicots respectively. Axis 1 presented significantly positive correlation (P<0.01) with contents of total G+C, GC3, G3 and C3 in monocots,while in dicots the correlation between Axis 1 and contents of total G+C, GC3, G3, C3 was significantly negative respectively. Different nucleotide composition is the important reason in the formation of codon usage preference in monocots and dicots. Results of PR2-Plot analysis, neutral plotting analysis as well as ENC-Plot analysis showed that, natural selection was the main driving force in the forming of codon usage preference of FER genes in plants. Phylogenetic tree constructed by coding sequence (CDS) was more similar with traditional classification results than the phylogenetic tree constructed by relative synonymous codon usage (RSCU). The results can lay foundation for further research on molecular evolution and gene engineering.Key words:FERONIA gene;codon usage preference;molecular evolution根據中心法则,遗传信息流的方向是从DNA经RNA到蛋白质,密码子则是生物体内核酸信息和蛋白质信息相互沟通的桥梁。
向日葵全基因组NBS抗病基因密码子使用偏好性分析

刘 洋,路 妍,景 岚.向日葵全基因组NBS抗病基因密码子使用偏好性分析[J].江苏农业科学,2021,49(10):43-47.doi:10.15889/j.issn.1002-1302.2021.10.008向日葵全基因组NBS抗病基因密码子使用偏好性分析刘 洋,路 妍,景 岚(内蒙古农业大学园艺与植物保护学院,内蒙古呼和浩特010019) 摘要:为分析了解向日葵(HelianthusannuusL.)核苷酸结合位点(nucleotidebindingsite,简称NBS)型抗病基因编码时各密码子的使用情况,以向日葵全基因组NBS型抗病基因的255条基因序列为来源,利用CodonW软件对每个基因序列进行密码子统计分析。
结果表明,向日葵NBS型抗病基因使用A/T(U)结尾的密码子占比大于G/C结尾的密码子,且有效密码子数(effectivenumberofcodon,简称ENC)平均值为51.40,整体偏好性较弱,但第3位碱基偏好使用以A/T(U)结尾的密码子。
从同义密码子相对使用频率(relativesynonymouscodonwusage,简称RSCU)分析得到第3位为A、T结尾的密码子占密码子总数(RSCU>1)的比例最高。
ENC-GC3s分布图表明,碱基突变是影响密码子偏好性的关键因素。
同时相关性分析结果还表明,ENC与A3s、T3s呈极显著负相关关系,多种不同分析都印证了向日葵NBS型抗病基因序列偏好于以A/T(U)结尾的密码子。
分析向日葵NBS型抗病基因密码子偏好性,通过优化密码子来提高NBS抗病基因在向日葵中的表达,可为向日葵分子改造和抗病育种提供理论依据。
关键词:向日葵;NBS抗病基因;密码子偏好性;密码子相关参数;相关性分析 中图分类号:S565.501;Q943.2 文献标志码:A 文章编号:1002-1302(2021)10-0043-05收稿日期:2020-09-15基金项目:国家自然科学基金(编号:31760509);内蒙古自然科学基金(编号:2020MS03046)。
刺猬线粒体基因组密码子偏好性分析

收稿日期:2023-05-05作者简介:韩君(1988—),男,黑龙江哈尔滨人,硕士,工程师,研究方向为生物信息学与多组学数据分析。
刺猬线粒体基因组密码子偏好性分析韩君(北京康仁堂药业有限公司,北京101301)摘要:为利用分子技术探究刺猬皮等组织作为中药使用的机制,促进远东刺猬分子进化研究。
以远东刺猬线粒体全基因组序列为材料,从中筛选出长度大于300bp 的非重复编码序列(CDS )12条,利用CodonW1.4.2、SPSS 25.0和Excel 2007等软件分析其密码子偏好性。
结果显示:密码子第3位的碱基平均GC 含量为24.30%;有效密码子数目(ENC )分布范围为31.83~50.67,平均值为43.37;相对同义密码子使用度(RSCU )值>1.00的密码子共有32个,偏好以碱基A 或U (T )结尾。
中性绘图分析结果显示,GC 1和GC 2的平均值(GC 12)与GC 3之间的相关系数为0.443;ENC-plot 分析结果显示,多数基因在标准曲线附近聚集;对应性分析结果表明,第1~4个向量轴的贡献率分别为35.64%、16.22%、10.26%和9.13%,同义密码子第3位的GC 含量(GC3s )、ENC 与第1向量轴(Axis1)呈显著正相关;密码子适应指数(CAI )与Axis1呈负相关,最终确定CUA 、AUA 、GUU 、UCU 、CCC 、ACA 、GCU 、CAU 、AAA 、GAA 、UGA 、CGC 、GGC 和GGA 为最优密码子。
通过优化远东刺猬线粒体基因组密码子以及应用分子手段进行深入研究,有助于探究远东刺猬组织入药机制。
关键词:远东刺猬;线粒体;密码子;偏好性;中药中图分类号:S862;R282文献标志码:A文章编号:1001-0084(2023)04-0031-07Codon Preference Analysis on MitochondrialGenome of Erinaceus amurensisHAN Jun(Beijing Tcmages Pharmaceutical Co.,Ltd.,Beijing 101301,China )Abstract:Using molecular technique to explore the mechanism of hedgehog hide and other tissues applied astraditional Chinese medicine,and promote molecular evolution of Erinaceus amurensis in the Far East,taking the complete mitochondrial genome sequence of Erinaceus amurensis as the material,12non-repeating coding sequences (CDS)with a length greater than 300bp were selected as the research objects in this study,and their codon preference was analyzed by using CodonW1.4.2,SPSS 25.0,Excel 2007and other software.The average GC content of the third codon was 24.30%;the number of effective codons (ENC)ranged from 31.83to 50.67,with an average value of 43.37;and the relative synonymous codon usage (RSCU)value of 32codons was greater than 1.00,and the preference ends with either A or U (T).According to neutral plot analysis,the correlation coefficientbetween the average value (GC 12)of GC 1,and GC 2and GC 3was 0.443.In addition,ENC-plot analysis also revealed that most genes cluster near the standard curve;besides,the corresponding analysis showed that the contribution rates of the 1-4vector axes were 35.64%,16.22%,10.26%and 9.13%,respectively;and the GC content of the third synonymous codon (GC3s )and ENC were significantly positively correlated with the first vector axis (Axis1).In addition,the codon adaptation index (CAI)was negatively correlated with Axis1.Hence,it could finally beDOI:10.20041/ki.slbl.2023.04.006猬科在我国共有5个属7个种。
豇豆叶绿体基因组密码子使用偏好性分析

核农学报2023,37(6):1118~1129Journal of Nuclear Agricultural Sciences豇豆叶绿体基因组密码子使用偏好性分析仇学文李丹甘玉迪杨有新程柳洋徐梦怡吴才君 *(江西农业大学农学院,江西南昌330000)摘要:为了探究豇豆(Vigna unguiculata)叶绿体基因组密码子的使用模式,本研究从NCBI下载完整的豇豆叶绿体基因组序列,并对其进行结构分析。
利用CodonW和CUSP对筛选获得的50条可编码蛋白序列(CDS)进行分析,获得GC1、GC2、GC3、RSCU、CAI、CBI、Fop、ENc、RFSC等重要参数,并进行中性绘图、PR2-plot绘图、ENc-plot绘图以及对应分析、最优密码子分析和其他物种对比分析。
结果发现,豇豆叶绿体基因密码子更偏向以A或U(T)结尾,G和C在密码子各位置中的占比较低,平均值为36.31%;有效密码子数(ENc)的平均值为44.903,密码子偏好性较弱;GC1与GC2、GC3间均有相关性,表明碱基突变对密码子选择也有影响。
从中性绘图、PR2-plot绘图、ENc-plot绘图结果可以看出,豇豆叶绿体密码子使用偏好性同时受到了碱基突变与自然选择的影响。
本研究最终筛选出20个最优密码子,并将豇豆叶绿体基因组密码子使用频率与其他物种进行比较,发现豇豆与番茄在密码子使用频率上存在较高的相似度。
本研究结果为提高豇豆叶绿体外源基因的表达效率提供了参考依据。
关键词:豇豆;叶绿体;基因组;密码子;使用偏好性DOI:10.11869/j.issn.1000⁃8551.2023.06.1118生物体内的DNA序列表达与信息传递主要借助64个密码子进行,而大多数氨基酸有不止一个密码子对应,称为密码子的简并性[1]。
编码同一个氨基酸的多个密码子称为同义密码子,除色氨酸与蛋氨酸之外,其余18个氨基酸都有多个同义密码子。
而某些同义密码子被高频使用的现象被称为密码子使用偏好性(codon usage bias, CUB)[2]。
密码子偏好性
CAC (7.3)
CGC (14.0)
C
CUA (5.6)
CCA (9.1)
CAA (14.4)
CGA (4.8)
A
CUG (37.4)
CCG (14.5)
CAG (26.7)
CGG (7.9)
G
A
AUU (29.6)
ACU (13.1)
AAU (29.3)
AGU (13.2)
U
AUC (19.4)
GCA (15.8)
GAA (29.0)
GGA (16.5)
A
GUG (28.1)
GCG (7.4)
GAG (39.6)
GGG (16.5)
G
表2大肠杆菌密码子偏好性
第二位碱基(‰)
第三位碱基
U
C
A
G
第一位碱基
U
UUU (24.4)
UCU (13.1)
UAU (21.6)
UGU (5.9)
U
UUC (13.9)
Trp
W
UGG
酪氨酸
Tyrosine
Tyr
Y
UAU,UAC
缬氨酸
Valine
Val
V
GUU,GUC,GUA,GUG
起始密码子
AUG
终止密码子
UAG,UGA,UAA
U
GUC (13.1)
GCC (21.6)
GAC (17.9)
GGC (20.6)
C
GUA (13.1)
GCA (23.0)
GAA (35.1)
GGA (13.6)
A
GUG (19.9)
密码子使用偏好性参数汇总

研究密码子偏好性常用的参数1、相对同义密码子使用度(Relativ e Synonymous Codon Usage, RSCU )是指对于某一特定的密码子在编码对应氨基酸的同义密码子间的相对概率,它去除了氨基酸组成对密码子使用的影响。
如果密码子的使用没有偏好性,该密码子的RSCU值等于1,当某一密码子的RSCU值大于1时,代表该密码子为使用相对较多的密码子,反之亦然。
第i个氨基酸的第j个密码子的相对同义密码子使用度值的计算公式如下:公式中, X ij是编码第i个氨基酸的第j个密码子的出现次数, n i是编码第i个氨基酸的同义密码子的数量( 值为1~6) 。
研究中通常先利用高表达基因的RSCU值建立参考表格。
2、密码子适应指数(Codon Adaptation Index, CAI)可以根据已知高表达基因的序列来估计未知基因密码子使用的偏好性程度。
CAI的值在0~1之间, 如果越高则表明该基因的密码子使用偏好性越强。
CAI 值一般用来预测种内基因的表达水平( 但目前的研究发现对于单细胞生物比较适用, 而在哺乳动物中并不能用来表示基因表达水平), 又可以用来预测外源基因的表达水平。
w ij(The relative adaptiveness of a codon): 密码子相对适应度上式中RSCU imax、X imax分别指编码第i个氨基酸的使用频率最高的密码子的RSCU值和X值L是指基因中所使用的密码子数。
3、密码子偏好参数(Codon Preference Parameter, CPP)CPP的变化范围为0 ~ 18, 越接近18表示密码子被非随机使用的程度越高。
它对于基因编码区域总的碱基组成不敏感, 适于比较基因间或物种间密码子使用偏性的大小。
x ij是编码第i个氨基酸的第j个密码子的出现次数, n i是编码第i个氨基酸的同义密码子的数量( 值为2~6, n i= 1 的情况被排除)4、有效密码子数(Effective Number of Codon, ENC)ENC值的范围在20~ 61之间, 越靠近20偏性越强。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
研究密码子偏好性常用的参数
1、相对同义密码子使用度(Relativ e Synonymous Codon Usage, RSCU )
是指对于某一特定的密码子在编码对应氨基酸的同义密码子间的相对概率,它去除了氨基酸组成对密码子使用的影响。
如果密码子的使用没有偏好性,该密码子的RSCU值等于1,当某一密码子的RSCU值大于1时,代表该密码子为使用相对较多的密码子,反之亦然。
第i个氨基酸的第j个密码子的相对同义密码子使用度值的计算公式如下:
公式中, X ij是编码第i个氨基酸的第j个密码子的出现次数, n i是编码第i个氨基酸的同义密码子的数量( 值为1~6) 。
研究中通常先利用高表达基因的RSCU值建立参考表格。
2、密码子适应指数(Codon Adaptation Index, CAI)
可以根据已知高表达基因的序列来估计未知基因密码子使用的偏好性程度。
CAI的值在0~1之间, 如果越高则表明该基因的密码子使用偏好性越强。
CAI 值一般用来预测种内基因的表达水平( 但目前的研究发现对于单细胞生物比较适用, 而在哺乳动物中并不能用来表示基因表达水平), 又可以用来预测外源基因的表达水平。
w ij(The relative adaptiveness of a codon): 密码子相对适应度
上式中RSCU imax、X imax分别指编码第i个氨基酸的使用频率最高的密码子的RSCU值和X值
L是指基因中所使用的密码子数。
3、密码子偏好参数(Codon Preference Parameter, CPP)
CPP的变化范围为0 ~ 18, 越接近18表示密码子被非随机使用的程度越高。
它对于基因编码区域总的碱基组成不敏感, 适于比较基因间或物种间密码子使用偏性的大小。
x ij是编码第i个氨基酸的第j个密码子的出现次数, n i是编码第i个氨基酸的同义密码子的数量( 值为2~6, n i= 1 的情况被排除)
4、有效密码子数(Effective Number of Codon, ENC)
ENC值的范围在20~ 61之间, 越靠近20偏性越强。
此值是描述密码子使用偏离随机选择的
程度( 并不是某个特殊密码子的使用频率与其他密码子的比较), 能反映密码子家族中同义密码子非均衡使用的偏好程度。
已知高表达基因其密码子偏爱程度也大,从而ENC 值较小; 低表达基因则含有较多种类的稀有密码子, ENC值也较大, 所以, 当前普遍通过比较ENC来确定内源基因表达量的相对高低。
ENC值越小, 对应的内源基因往往表达量也越高。
n 表示基因中所使用的密码子总数, k为同义密码子数量, p i是第i个密码子的使用频率( n i/ n ) 。
ENC值会受到基因氨基酸组成和基因长短的影响。
5、最优密码子使用频率(Frequency of Optimal Codons, FOP)
最优密码子是指在某物种高表达基因中使用频率最高的密码子, 也有人将一个氨基酸的最优密码子定义为具有最大数量的带有其反密码子tRNA 基因的密码子; FOP 是种特异性的, 而且最优密码子的确定需要一组基因序列以及相应的表达信息。
计算公式如下:
下标s代表“simple ”, n i表示基因g中密码子i的数量; N为基因g中的密码子总数, 但是用这一方法计算的FOP值受氨基酸组成的影响; 为了克服这一缺点人们改进了计算方法:
公式中的syn(i)表示密码子i编码的氨基酸对应的同义密码子数量。
上式整理后可得:
公式中,可见FOP成为了氨基酸使用频率为加权系数的最优密码子
的RSCU值加权平均值。
6、密码子偏爱指数(Codon Bias Index, CBI )
反应了一个具体基因中高表达优越密码子的组分情况。
对目的宿主自身的基因, 该指数和ENC值有很好的相关性, 但在实际工作中可以更明确地反映外源基因在目的宿主中可能的表达情况, 故而得到广泛应用。
计算公式如下:
N opt代表优越密码子在该基因中出现次数之和; N ran代表氨基酸序列不变,所有同义密码子随机出现时优越密码子的出现次数之和;N tot代表了优越密码子对应的氨基酸在基因中出现的次数之和。
7、G+C含量
一般认为G+C含量越高,密码子的偏好性就可能就越强!其含量可以通过一些软件进行编程进行求出,比如说使用perl语言。
8、GC3S
第三位上的各种碱基的含量,在蛋白质的合成过程中同义密码子的使用概率并不相同,而同义密码子的主要差别体现在第三位碱基上。
9、Kyte和Doolittle
计算每一个氢基酸的疏水指数,然后进行算术平均。
(可参考文献:Translational selection shapes codon usage in the GC-rich genomes of Chlamydomonas reinhardtii)
10、对应分析(correspondence analysis, COA)
在对基因密码子使用概率分析时,将每一条基因作为一个对象,相对密码子使用度作为变量采用59个同义密码子[去除编码蛋氨酸(M)的密码子AUG和编码色氨酸(W)的密码子UGG以及3个终止密码子的RSCU值对其密码子使用偏性进行分析基因间的距离规定为同义密码子相对使用度的欧拉平方距离。
对于基因a与基因b,其密码子使用距离的计算公式为::
11、AT偏移(AT-skew)
定义为整个基因组DNA序列的(A - T)/(A + T)的比值。
通过计算AT偏移可分析整个基因组中A、T的变化趋势。
12、高表达优越密码子(High-expression Codon ,HE)
参考文献:Expression pattern and , surprisingly , gene length shape codon usage in Caenorhabditis, Drosophila, and Arabi-dopsis1
13、高频密码子(High-frequency Codon)
参考文献:High-frequency codon analysis and its application in codon analysis of tobacco
另外,还有GRAVY值(反映蛋白质的疏水性对密码子使用偏好的影响)、Aromo值(反映芳香族蛋白质对密码子使用偏好的影响)等。