建立动态链表
《C语言》章节列表

第1章程序设计和C语言1第2章算法——程序的灵魂16第3章最简单的C程序设计——顺序程序设计第4章选择结构程序设计85第5章循环结构程序设计114第6章利用数组处理批量数据1426.1怎样定义和引用一维数组1426.1.1怎样定义一维数组1436.1.2怎样引用一维数组元素1446.1.3一维数组的初始化1456.1.4一维数组程序举例1466.2怎样定义和引用二维数组1486.2.1怎样定义二维数组1496.2.2怎样引用二维数组的元素1506.2.3二维数组的初始化1516.2.4二维数组程序举例1526.3字符数组1546.3.1怎样定义字符数组1546.3.2字符数组的初始化1556.3.3怎样引用字符数组中的元素1556.3.4字符串和字符串结束标志1566.3.5字符数组的输入输出1596.3.6使用字符串处理函数1616.3.7字符数组应用举例165习题168第7章用函数实现模块化程序设计1707.1为什么要用函数1707.2怎样定义函数1727.2.1为什么要定义函数1727.2.2定义函数的方法1737.3调用函数1747.3.1函数调用的形式1747.3.2函数调用时的数据传递1757.3.3函数调用的过程1777.3.4函数的返回值1787.4对被调用函数的声明和函数原型1797.5函数的嵌套调用1827.6函数的递归调用1847.7数组作为函数参数1927.7.1数组元素作函数实参1937.7.2数组名作函数参数1947.7.3多维数组名作函数参数1977.8局部变量和全局变量1997.8.1局部变量1997.8.2全局变量2007.9变量的存储方式和生存期2047.9.1动态存储方式与静态存储方式2047.9.2局部变量的存储类别2057.9.3全局变量的存储类别2087.9.4存储类别小结2127.10关于变量的声明和定义2147.11内部函数和外部函数2157.11.1内部函数2157.11.2外部函数215习题218第8章善于利用指针2208.1指针是什么2208.2指针变量2228.2.1使用指针变量的例子2228.2.2怎样定义指针变量2238.2.3怎样引用指针变量2248.2.4指针变量作为函数参数2268.3通过指针引用数组2308.3.1数组元素的指针2308.3.2在引用数组元素时指针的运算2318.3.3通过指针引用数组元素2338.3.4用数组名作函数参数2378.3.5通过指针引用多维数组2458.4通过指针引用字符串2558.4.1字符串的引用方式 2558.4.2字符指针作函数参数2598.4.3使用字符指针变量和字符数组的比较263 8.5指向函数的指针2668.5.1什么是函数指针2668.5.2用函数指针变量调用函数2668.5.3怎样定义和使用指向函数的指针变量268 8.5.4用指向函数的指针作函数参数2708.6返回指针值的函数2748.7指针数组和多重指针2778.7.1什么是指针数组 2778.7.2指向指针数据的指针2808.7.3指针数组作main函数的形参2828.8动态内存分配与指向它的指针变量2858.8.1什么是内存的动态分配2858.8.2怎样建立内存的动态分配2858.8.3void指针类型 2878.9有关指针的小结288习题291第9章用户自己建立数据类型2939.1定义和使用结构体变量2939.1.1自己建立结构体类型2939.1.2定义结构体类型变量 2959.1.3结构体变量的初始化和引用2979.2使用结构体数组3009.2.1定义结构体数组3009.2.2结构体数组的应用举例3019.3结构体指针3039.3.1指向结构体变量的指针3039.3.2指向结构体数组的指针3049.3.3用结构体变量和结构体变量的指针作函数参数306 9.4用指针处理链表3099.4.1什么是链表 3099.4.2建立简单的静态链表3109.4.3建立动态链表3119.4.4输出链表3159.5共用体类型3179.5.1什么是共用体类型3179.5.2引用共用体变量的方式3189.5.3共用体类型数据的特点3199.6使用枚举类型3239.7用typedef声明新类型名326习题330第10章对文件的输入输出33110.1C文件的有关基本知识33110.1.1什么是文件33110.1.2文件名33210.1.3文件的分类33210.1.4文件缓冲区33310.1.5文件类型指针33310.2打开与关闭文件33510.2.1用fopen函数打开数据文件33510.2.2用fclose函数关闭数据文件33710.3顺序读写数据文件33810.3.1怎样向文件读写字符33810.3.2怎样向文件读写一个字符串34110.3.3用格式化的方式读写文件34410.3.4用二进制方式向文件读写一组数据34510.4随机读写数据文件34910.4.1文件位置标记及其定位34910.4.2随机读写 35210.5文件读写的出错检测353习题354第11章常见错误分析355附录370附录A在Visual C++ 6.0环境下运行C程序的方法370附录B常用字符与ASCII代码对照表377附录CC语言中的关键字378附录D运算符和结合性378附录EC语言常用语法提要380附录FC库函数384参考文献390第4章选择结构程序设计854.1选择结构和条件判断854.2用if语句实现选择结构874.2.1用if语句处理选择结构举例874.2.2if语句的一般形式 894.3关系运算符和关系表达式914.3.1关系运算符及其优先次序914.3.2关系表达式924.4逻辑运算符和逻辑表达式924.4.1逻辑运算符及其优先次序934.4.2逻辑表达式944.4.3逻辑型变量964.5条件运算符和条件表达式974.6选择结构的嵌套1004.7用switch语句实现多分支选择结构1024.8选择结构程序综合举例106习题112第5章循环结构程序设计1155.1为什么需要循环控制1155.2用while语句实现循环1165.3用do…while语句实现循环1185.4用for 语句实现循环1215.5循环的嵌套1255.6几种循环的比较1265.7改变循环执行的状态1265.7.1用break语句提前终止循环1275.7.2用continue语句提前结束本次循环1285.7.3break语句和continue语句的区别1295.8循环程序举例132习题141第6章利用数组处理批量数据1436.1怎样定义和引用一维数组1436.1.1怎样定义一维数组1446.1.2怎样引用一维数组元素1456.1.3一维数组的初始化1466.1.4一维数组程序举例1476.2怎样定义和引用二维数组1496.2.1怎样定义二维数组1506.2.2怎样引用二维数组的元素1516.2.3二维数组的初始化1526.2.4二维数组程序举例1536.3字符数组1556.3.1怎样定义字符数组1556.3.2字符数组的初始化1566.3.3怎样引用字符数组中的元素156 6.3.4字符串和字符串结束标志1576.3.5字符数组的输入输出1606.3.6使用字符串处理函数1626.3.7字符数组应用举例166习题169第7章用函数实现模块化程序设计171 7.1为什么要用函数1717.2怎样定义函数1737.2.1为什么要定义函数1737.2.2定义函数的方法1747.3调用函数1757.3.1函数调用的形式1757.3.2函数调用时的数据传递1767.3.3函数调用的过程1787.3.4函数的返回值1797.4对被调用函数的声明和函数原型181 7.5函数的嵌套调用1837.6函数的递归调用1857.7数组作为函数参数1937.7.1数组元素作函数实参1937.7.2数组名作函数参数1957.7.3多维数组名作函数参数1987.8局部变量和全局变量2007.8.1局部变量2007.8.2全局变量2017.9变量的存储方式和生存期2057.9.1动态存储方式与静态存储方式205 7.9.2局部变量的存储类别2067.9.3全局变量的存储类别2097.9.4存储类别小结2137.10关于变量的声明和定义2157.11内部函数和外部函数2167.11.1内部函数2167.11.2外部函数216习题219第8章善于利用指针2218.1指针是什么2218.2指针变量2238.2.1使用指针变量的例子2238.2.2怎样定义指针变量2248.2.3怎样引用指针变量2258.2.4指针变量作为函数参数2278.3通过指针引用数组2328.3.1数组元素的指针2328.3.2在引用数组元素时指针的运算2338.3.3通过指针引用数组元素2348.3.4用数组名作函数参数2398.3.5通过指针引用多维数组2478.4通过指针引用字符串2578.4.1字符串的引用方式 2578.4.2字符指针作函数参数2618.4.3使用字符指针变量和字符数组的比较265 8.5指向函数的指针2688.5.1什么是函数指针2688.5.2用函数指针变量调用函数2688.5.3怎样定义和使用指向函数的指针变量270 8.5.4用指向函数的指针作函数参数2728.6返回指针值的函数2768.7指针数组和多重指针2798.7.1什么是指针数组 2798.7.2指向指针数据的指针2828.7.3指针数组作main函数的形参2848.8动态内存分配与指向它的指针变量2878.8.1什么是内存的动态分配2878.8.2怎样建立内存的动态分配2878.8.3void指针类型 2898.9有关指针的小结290习题293第9章用户自己建立数据类型2959.1定义和使用结构体变量2959.1.1自己建立结构体类型2959.1.2定义结构体类型变量 2979.1.3结构体变量的初始化和引用2999.2使用结构体数组3029.2.1定义结构体数组3029.2.2结构体数组的应用举例3049.3结构体指针3059.3.1指向结构体变量的指针3059.3.2指向结构体数组的指针3069.3.3用结构体变量和结构体变量的指针作函数参数3089.4用指针处理链表3119.4.1什么是链表 3119.4.2建立简单的静态链表3129.4.3建立动态链表3139.4.4输出链表3179.5共用体类型3199.5.1什么是共用体类型3199.5.2引用共用体变量的方式3209.5.3共用体类型数据的特点3219.6使用枚举类型3259.7用typedef声明新类型名328习题332第10章对文件的输入输出33310.1C文件的有关基本知识33310.1.1什么是文件33310.1.2文件名33410.1.3文件的分类33410.1.4文件缓冲区33510.1.5文件类型指针33510.2打开与关闭文件33710.2.1用fopen函数打开数据文件33710.2.2用fclose函数关闭数据文件33910.3顺序读写数据文件34010.3.1怎样向文件读写字符34010.3.2怎样向文件读写一个字符串34310.3.3用格式化的方式读写文件34610.3.4用二进制方式向文件读写一组数据34710.4随机读写数据文件35110.4.1文件位置标记及其定位35110.4.2随机读写 35410.5文件读写的出错检测355习题356第11章常见错误分析374附录390附录A在Visual C++ 6.0环境下运行C程序的方法390 附录CC语言中的关键字398附录D运算符和结合性398附录EC语言常用语法提要400附录FC库函数404参考文献410。
动态数据结构

动态数据结构在计算机科学的广袤世界中,数据结构就如同建筑的基石,为各种程序和算法的高效运行提供了坚实的支撑。
而在众多的数据结构类型中,动态数据结构以其独特的灵活性和适应性,成为了应对复杂问题和不断变化需求的得力工具。
那么,究竟什么是动态数据结构呢?简单来说,动态数据结构是一种可以在运行时根据需要动态地改变其大小、结构或者内容的数据结构。
与静态数据结构不同,静态数据结构在创建时就确定了其大小和结构,并且在程序运行期间不能轻易改变。
而动态数据结构能够根据数据的增减、操作的需求等因素,自动地调整自身以适应变化,从而更有效地利用内存空间和提高程序的性能。
动态数组就是一种常见的动态数据结构。
想象一下,你有一个盒子,一开始你不知道要往里面放多少东西,所以你先准备了一个较小的盒子。
但随着你要放入的物品越来越多,这个小盒子装不下了。
这时候,动态数组就发挥作用了,它会自动给你一个更大的盒子,把原来的东西都搬过去,然后让你继续放新的物品。
这种自动扩容的特性使得动态数组在处理不确定数量的数据时非常方便。
比如,在一个用户输入数据的程序中,你无法提前知道用户会输入多少个数字,使用动态数组就能够轻松应对这种情况。
链表也是一种重要的动态数据结构。
它由一系列节点组成,每个节点包含数据和指向下一个节点的链接。
链表的最大优点是插入和删除操作非常高效。
如果要在一个已经存在的链表中间插入一个新节点,只需要修改几个链接指针就可以完成,而不需要像在数组中那样移动大量的数据。
这使得链表在需要频繁进行插入和删除操作的场景中表现出色,比如实现一个任务队列或者一个浏览器的历史记录。
栈和队列也是常见的动态数据结构。
栈就像一个只能从一端进出的筒子,遵循“后进先出”的原则。
想象一下叠盘子,最后放上去的盘子会最先被拿走,这就是栈的工作方式。
队列则像排队买票的队伍,遵循“先进先出”的原则,先到的人先得到服务。
栈和队列在很多算法和程序中都有广泛的应用,比如函数调用的实现就用到了栈,而操作系统中的任务调度可能会用到队列。
Python列表与链表的区别详解

Python列表与链表的区别详解⽬录python 列表和链表的区别列表的实现机制链表链表与列表的差异python 列表和链表的区别python 中的 list 并不是我们传统意义上的列表,传统列表——通常也叫作链表(linked list)是由⼀系列节点来实现的,其中每个节点都持有⼀个指向下⼀节点的引⽤。
class Node:def __init__(self, value, next=None):self.value = valueself.next = next接下来,我们就可以将所有的节点构造成⼀个列表了:>>> L = Node("a", Node("b", Node("c", Node("d"))))>>> L.next.next.value'c'这是⼀个所谓的单向链表,双向链表的各节点中还需要持有⼀个指向前⼀个节点的引⽤但 python 中的 list 则与此有所不同,它不是由若⼲个独⽴的节点相互引⽤⽽成的,⽽是⼀整块单⼀连续的内存区块,我们通常称之为“数组”(array),这直接导致了它与链表之间的⼀些重要区别。
例如如果我们要按既定的索引值对某⼀元素进⾏直接访问的话,显然使⽤数组会更有效率。
因为,在数组中,我们通常可以直接计算出⽬标元素在内存中的位置,并对其进⾏直接访问。
⽽对于链表来说,我们必须从头开始遍历整个链表。
但是具体到 insert 操作上,情况⼜会有所不同。
对于链表⽽⾔,只要知道了要在哪⾥执⾏ insert 操作,其操作成本是⾮常低的,⽆论该列表中有多少元素,其操作时间⼤致上是相同的。
⽽数组就不⼀样了,它每次执⾏ insert 操作都需要移动插⼊点右边的所有元素,甚⾄在必要的时候,我们可能还需要将这些列表元素整体搬到⼀个更⼤的数组中去。
也正因如此,append 操作通常会采取⼀种被称为动态数组或‘向量'的指定解决⽅案,其主要想法是将内存分配的过⼤⼀些,并且等到其溢出时,在线性时间内再次重新分配内存。
c语言动态链表代码

c语言动态链表代码动态链表是一种数据结构,它可以动态地增加或删除节点。
链表中的每个节点包含两个部分:数据和指向下一个节点的指针。
与数组不同,链表的大小可以根据需要增加或减少,因为它使用动态内存分配。
2. 动态链表的优点动态链表具有以下优点:(1)可以动态地增加或删除节点。
(2)在插入或删除元素时,不需要移动其他元素。
(3)不需要预先分配空间。
3. 动态链表的基本操作动态链表的基本操作包括:创建链表、插入节点、删除节点和遍历链表。
(1)创建链表:创建一个空链表,即一个头节点。
(2)插入节点:在链表中插入一个新节点。
(3)删除节点:从链表中删除一个节点。
(4)遍历链表:按照链表的顺序遍历每个节点。
4. C语言动态链表代码以下是一个简单的C语言动态链表代码,演示了链表的基本操作。
```c#include <stdio.h>#include <stdlib.h>// 定义节点结构体struct Node {int data;struct Node *next;};// 创建链表struct Node *createList() {struct Node *head = (struct Node *) malloc(sizeof(struct Node));head->next = NULL;return head;}// 插入节点void insertNode(struct Node *head, int data) {struct Node *p = (struct Node *) malloc(sizeof(struct Node));p->data = data;p->next = head->next;head->next = p;}// 删除节点void deleteNode(struct Node *head, int data) {struct Node *p = head;while (p->next != NULL) {if (p->next->data == data) {struct Node *q = p->next;p->next = q->next;free(q);return;}p = p->next;}}// 输出链表void printList(struct Node *head) { struct Node *p = head->next;while (p != NULL) {printf('%d ', p->data);p = p->next;}printf('');}// 主函数int main() {struct Node *head = createList();insertNode(head, 1);insertNode(head, 2);insertNode(head, 3);printList(head);deleteNode(head, 2);printList(head);return 0;}```以上代码创建了一个包含头节点的空链表,然后插入了三个节点,最后输出了链表。
C语言中指针链表学习

C语言中指针链表的学习探讨摘要:指针链表是一种最简单也是最常用的动态数据结构,它是对动态获得的内存进行组织的一种结构。
本文通过教学实践,通过图示法从基本概念的理解入手,并深入讲解动态链表的建立,插入和删除,在教学过程中起到了良好的效果。
关键词:动态;链表中图分类号:tp311.12c语言中存储数据的结构用的最普遍的是数组,包括简单类型的数组,指针数据和结构体数组等,但是他们在实际应用中,会因为实现定义过大的数组容量而造成内存的浪费,或者因为保守的预测分配而满足不了实际使用的要求,这时就需要另一种方法来解决这个问题,这就是动态数据结构和动态分配内存技术。
链表就是这样一种最简单的动态数据结构。
那么如何让学生能够很好的学习并掌握它,本人就近几年的教学过程中经过探讨,采用了图示法进行教学,效果很好。
1 基本概念的理解1.1 指针的理解(1)指针与简单变量。
通过图1所示理解指针与简单变量的关系,当把变量i的地址存入指针变量p1后,就可以说这个指针指向了该变量。
如需要指向下一个元素,只需要指针往后移动即可!1.2 结构体的理解(1)结构体类型。
结构体类型是一种专门组织和处理复杂关系的数据结构,是一种自定义类型。
同一个数据对象由于应用不同定义的类型也有所不同。
比如处理学生的信息,可以有很多种方式:结构体中的成员名可增,可减,形成新的结构体类型。
(2)结构体变量与数组。
以上是结构体类型的定义,变量定义方式有三种,这里不一一举例,可根据自己的个人习惯选择不同的定义方式。
比如上面两个类型,分别定义简单变量,可这样定义:struct student s1,s2; struct stu s3,s4;如定义数组,结合前面所学数组的知识,可这样定义:struct student s[10]; struct stu s1[20];2 指针链表掌握了前面指针和结构体的知识内容,对于指针链表的理解和掌握是非常重要的。
2.1 指针链表的定义这里主要讲解单项链表结点的结构体类型的定义,对于初学者掌握了这种定义,对于以后学习更为复杂的链表知识的理解是很有帮助的。
链表的特点及适合的应用场景。

链表的特点及适合的应用场景一、链表的特点1. 链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
2. 链表可以动态地分配内存,因此可以根据需要随时插入或删除节点,而不需要提前分配固定大小的内存空间。
3. 链表可以实现随机访问,但相对于数组,它的查找效率较低,因为需要从头节点开始遍历直到找到目标节点。
4. 链表不需要连续的内存空间,可以存储在任意位置,因此更灵活,可以节省内存空间。
二、链表的适合的应用场景1. 链表适合需要频繁插入或删除节点的场景。
由于链表的节点可以动态分配内存,因此可以在不同位置高效地插入或删除节点,这在一些需要频繁更新数据的场景中非常有用。
2. 链表适合处理大数据集合的场景。
在处理大规模数据集合时,链表的灵活性可以节省内存空间,并且可以随时根据需要进行扩展或收缩。
3. 链表适合实现队列或栈相关的算法。
由于链表的结构与队列和栈的特性相似,因此链表可以很好地用来实现这些数据结构,例如使用链表实现队列可以实现高效的入队和出队操作。
三、结论链表是一种灵活的数据结构,具有动态分配内存、高效的插入与删除操作的特点,适合处理需要频繁更新的数据集合和实现队列、栈等算法。
在实际应用中,程序员可以根据具体的应用场景选择合适的数据结构,充分发挥链表的优势,提高程序的效率和性能。
链表是一种非常重要的数据结构,在计算机科学领域中被广泛应用。
它的特点决定了它在某些特定的场景下具有独特的优势和适用性。
接下来,将继续探讨链表的特点及其适用的更多应用场景。
四、链表的特点进一步解析1. 动态性链表是一种动态数据结构,可以动态分配内存空间以存储数据,并且可以随时增加或删除节点,而不需要提前分配固定大小的空间。
这种动态性使得链表在处理实时更新的数据时表现出色,比如实时数据监控、上线游戏中玩家位置的更新等。
在生活中,如果需要管理一些动态变化的数据,比如列车的乘客名单、音乐播放列表等,链表也能很好地胜任。
C++链表的创建与操作

c++链表的创建与操作我们知道,数组式计算机根据事先定义好的数组类型与长度自动为其分配一连续的存储单元,相同数组的位置和距离都是固定的,也就是说,任何一个数组元素的地址都可一个简单的公式计算出来,因此这种结构可以有效的对数组元素进行随机访问。
但若对数组元素进行插入和删除操作,则会引起大量数据的移动,从而使简单的数据处理变得非常复杂,低效。
为了能有效地解决这些问题,一种称为“链表”的数据结构得到了广泛应用。
1.链表概述链表是一种动态数据结构,他的特点是用一组任意的存储单元(可以是连续的,也可以是不连续的)存放数据元素。
链表中每一个元素成为“结点”,每一个结点都是由数据域和指针域组成的,每个结点中的指针域指向下一个结点。
Head是“头指针”,表示链表的开始,用来指向第一个结点,而最后一个指针的指针域为NULL(空地址),表示链表的结束。
可以看出链表结构必须利用指针才能实现,即一个结点中必须包含一个指针变量,用来存放下一个结点的地址。
实际上,链表中的每个结点可以用若干个数据和若干个指针。
结点中只有一个指针的链表称为单链表,这是最简单的链表结构。
再c++中实现一个单链表结构比较简单。
例如,可定义单链表结构的最简单形式如下 struct Node{int Data; Node *next; };这里用到了结构体类型。
其中,*next是指针域,用来指向该结点的下一个结点;Data是一个整形变量,用来存放结点中的数据。
当然,Data可以是任何数据类型,包括结构体类型或类类型。
在此基础上,我们在定义一个链表类list,其中包含链表结点的插入,删除,输出等功能的成员函数。
class list{Node *head; public:list(){head=NULL;}void insertlist(int aDate,int bDate); //链表结点的插入 void Deletelist(int aDate); //链表结点的删除 void Outputlist(); //链表结点的输出 Node*Gethead(){return head;} };2.链表结点的访问由于链表中的各个结点是由指针链接在一起的,其存储单元文笔是连续的,因此,对其中任意结点的地址无法向数组一样,用一个简单的公式计算出来,进行随机访问。
一元多项式计算与链表 概述及解释说明

一元多项式计算与链表概述及解释说明1. 引言1.1 概述在计算机科学和数学领域,一元多项式计算是一个重要的问题。
一元多项式是指包含一个未知数的多项式,它由各个项的系数和指数决定。
而链表作为一种常见的数据结构,具有灵活性和高效性,可以应用于各种问题的解决中。
1.2 文章结构本文将首先对一元多项式计算进行介绍,包括多项式的定义与表示方法、多项式加法运算以及多项式乘法运算。
然后,我们将详细探讨链表的概念、特点以及链表在一元多项式计算中的应用。
接下来,将通过实例演示来解释一元多项式计算,并说明链表结构在多项式计算中的优势。
最后,我们将分享解决一元多项式计算问题时相关的考虑事项与技巧,并对研究内容进行总结,并展望其可能的拓展方向。
1.3 目的本文旨在向读者介绍和解释一元多项式计算与链表之间的关系,并探讨链表在该问题中所起到的作用。
通过深入了解一元多项式及其计算方法,以及链表数据结构原理和应用场景,读者将能够更好地理解一元多项式的计算过程,并了解链表在提高计算效率和灵活性方面的重要作用。
同时,通过分享解决问题时的考虑事项与技巧,本文还有助于读者在实际应用中更好地利用链表结构来解决一元多项式计算问题。
2. 一元多项式计算:2.1 多项式定义与表示方法:一元多项式是由若干个单项式构成的代数表达式。
一个单项式由系数和指数组成,通常可以表示为a*x^b的形式,其中a为系数,x为未知数,b为指数。
而一个多项式则是由多个单项式相加得到。
在计算机中,可以用数组或链表来表示一元多项式。
使用数组时,每个元素可以存储一个单项式的系数和指数;而使用链表时,则可以将每个单项式作为节点存储在链表中。
2.2 多项式加法运算:两个多项式相加时,需要将同一个指数的单项式进行合并并对系数进行相加。
具体步骤如下:- 将两个多项式中所有的不同指数提取出来形成一个集合。
- 遍历集合中的每个指数,在两个多项式中查找该指数对应的单项式。
- 如果某个多项式不存在该指数的单项式,则该指数对应的系数为空。
C高级程序设计(二)

• 如 : int *p[3];
– –
//指针数组
for(I=0;I<3;I++) p[I]=(int *)malloc(sizeof(int));
• 动态申请一块链表
– struct student * head, * p; – len= sizeof (struct student); – p= (struct student *) malloc( len);
C高级程序设计(二)
讲授: 陈礼民 浙江中医学院 计算机系 2005-4
目录:
• • • • • • • §4 , 结构: 结构, 指针和函数 联合: 链表: § 5, 文件 § 6. 程序员考试编程 § 7. 学生成绩管理系统
§4 , 结构:
• 数组,结构,联合是三种主要构造型数据类型, • 数组: 同一类型的数组集合 • 结构: 不同类型的数据集合; • 联合: 可以在不同的时间内拥不同类型和不 同长度的成员变量
– ex d,*p; – void input( ex d); – input (d); – printf( “%d %f %s”, d.a, d.b, d.c); –}
//答案??
• void input( ex t)
– int i; – t.a=3; – t.b=4.5; – gets(t.c);
• 2.输入 用for() • 关键语句: • scanf("%s",stu[i].num); • scanf("%s",stu[i].name); • for(j=0;j<3;j++) • scanf("%d",&stu[i].score[j]);
vb6数据结构

VB6数据结构简介VB6(Visual Basic 6)是一种基于事件驱动的编程语言,由微软公司开发。
VB6提供了丰富的数据结构,用于存储和组织数据。
数据结构在编程中起着至关重要的作用,它们可以帮助我们有效地管理和操作数据。
本文将深入探讨VB6中常用的数据结构,包括数组、集合、字典和链表。
数组数组是一种线性数据结构,用于存储相同类型的数据。
在VB6中,可以使用数组来存储一组数据,并通过索引来访问和修改其中的元素。
VB6中的数组有两种类型:静态数组和动态数组。
静态数组静态数组在声明时需要指定数组的大小,大小是固定的,不能改变。
例如,声明一个包含10个整数的静态数组可以使用以下语句:Dim numbers(9) As Integer动态数组动态数组的大小可以根据需要进行动态调整。
在VB6中,可以使用ReDim语句来重新调整数组的大小。
例如,声明一个动态数组可以使用以下语句:Dim numbers() As IntegerReDim numbers(9)多维数组VB6还支持多维数组。
多维数组可以是二维、三维甚至更高维度的。
声明一个二维数组可以使用以下语句:Dim matrix(9, 9) As Integer集合集合是一种动态数据结构,用于存储不同类型的数据。
在VB6中,可以使用集合来存储和操作一组对象。
集合提供了方便的方法来添加、删除和遍历元素。
创建集合可以使用Collection关键字来声明一个集合变量。
例如:Dim myCollection As CollectionSet myCollection = New Collection添加元素可以使用Add方法向集合中添加元素。
例如:myCollection.Add "Apple"myCollection.Add "Banana"myCollection.Add "Orange"删除元素可以使用Remove方法从集合中删除元素。
C语言结构体变量与链表知识总结

结构体与链表11.1 结构体类型的定义结构体是由C语言中的基本数据类型构成的、并用一个标识符来命名的各种变量的组合,其中可以使用不同的数据类型。
1.结构体类型的定义Struct结构体名{ 类型标识符1 成员名1;类型标识符2 成员名2;……类型标识符n 成员名n;};Struct结构体名——结构体类型名2.关于结构体类型的说明:(1)“struct 结构体名”是一个类型名,它和int、float等作用一样可以用来定义变量。
(2)结构体名是结构体的标识符不是变量名,也不是类型名。
(3)构成结构体的每一个类型变量称为结构体成员,它像数组的元素一样,单数组中元素以下标来访问,而结构体是按结构体变量名来访问成员的。
(4)结构体中的各成员既可以属于不同的类型,也可以属于相同的类型。
(5)成员也可以是一个结构体类型,如:Struct date{Int month;Int day;Int year;};Struct person{Float num;Char name[20];Char sex;Int age;Struct date birthday;Char address[10];};11.2 结构体类型变量11.2.1 结构体类型变量的定义1.先定义结构体类型,再定义结构体变量形式:Struct 结构体名{类型标识符1 成员名1;类型标识符2 成员名2;……类型标识符n 成员名n;};Struct 结构体名变量名表;例如:Struct student{char name[20];Char sex;Int age;Float score;};Struct student stu1,stu2;2.在定义结构体类型的同时定义变量形式:Struct 结构体名{类型标识符1 成员名1;类型标识符2 成员名2;……类型标识符n 成员名n;}变量名表;例如:Struct student{Char name[20];Char sex;Int age;Float score;}stu1,stu2;3.用匿名形式直接定义结构体类型变量形式:Struct{类型标识符1 成员名1;类型标识符2 成员名2;……类型标识符n 成员名n;}变量名表;例如:StructChar naem[20];Char sex;Int age;Float score;}stu1,stu2;11.2.2 结构体变量的使用结构体是一种新的数据类型,因此结构体变量也可以像其它类型的变量一样赋值、运算,不同的是结构体变量以成员作为基本变量。
数据结构与算法知识点必备

数据结构与算法知识点必备一、数据结构知识点1. 数组(Array)数组是一种线性数据结构,它由相同类型的元素组成,通过索引访问。
数组的特点是随机访问速度快,但插入和删除操作较慢。
常见的数组操作包括创建、访问、插入、删除和遍历。
2. 链表(Linked List)链表是一种动态数据结构,它由节点组成,每一个节点包含数据和指向下一个节点的指针。
链表的特点是插入和删除操作快,但访问速度较慢。
常见的链表类型包括单向链表、双向链表和循环链表。
3. 栈(Stack)栈是一种后进先出(LIFO)的数据结构,只能在栈顶进行插入和删除操作。
常见的栈操作包括入栈(push)和出栈(pop)。
4. 队列(Queue)队列是一种先进先出(FIFO)的数据结构,只能在队尾插入元素,在队头删除元素。
常见的队列操作包括入队(enqueue)和出队(dequeue)。
5. 树(Tree)树是一种非线性数据结构,由节点和边组成。
树的特点是层次结构、惟一根节点、每一个节点最多有一个父节点和多个子节点。
常见的树类型包括二叉树、二叉搜索树、平衡二叉树和堆。
6. 图(Graph)图是一种非线性数据结构,由节点和边组成。
图的特点是节点之间的关系可以是任意的,可以有环。
常见的图类型包括有向图、无向图、加权图和连通图。
7. 哈希表(Hash Table)哈希表是一种根据键(key)直接访问值(value)的数据结构,通过哈希函数将键映射到数组中的一个位置。
哈希表的特点是查找速度快,但内存消耗较大。
常见的哈希表操作包括插入、删除和查找。
二、算法知识点1. 排序算法(Sorting Algorithms)排序算法是将一组元素按照特定顺序罗列的算法。
常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序。
2. 查找算法(Search Algorithms)查找算法是在一组元素中寻觅特定元素的算法。
常见的查找算法包括线性查找、二分查找和哈希查找。
数据结构中链表及常见操作

链表1 定义链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。
由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
在计算机科学中,链表作为一种基础的数据结构可以用来生成其它类型的数据结构。
链表通常由一连串节点组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向明上一个或下一个节点的位置的链接("links")。
链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的访问往往要在不同的排列顺序中转换。
而链表是一种自我指示数据类型,因为它包含指向另一个相同类型的数据的指针(链接)。
链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。
链表有很多种不同的类型:单向链表,双向链表以及循环链表。
2 结构2.1 单向链表链表中最简单的一种是单向链表,它包含两个域,一个信息域和一个指针域。
这个链接指向列表中的下一个节点,而最后一个节点则指向一个空值。
一个单向链表的节点被分成两个部分。
第一个部分保存或者显示关于节点的信息,第二个部分存储下一个节点的地址。
单向链表只可向一个方向遍历。
链表最基本的结构是在每个节点保存数据和到下一个节点的地址,在最后一个节点保存一个特殊的结束标记,另外在一个固定的位置保存指向第一个节点的指针,有的时候也会同时储存指向最后一个节点的指针。
一般查找一个节点的时候需要从第一个节点开始每次访问下一个节点,一直访问到需要的位置。
请简述顺序表和链表的概念、特点及优缺点。

请简述顺序表和链表的概念、特点及优缺点。
顺序表和链表是两种基本的数据结构,用于存储具有相同类型的数据元素。
它们有许多共同点,例如都可以存储多个元素,并且都可以通过插入、删除和查找元素的方式访问和操作它们。
但是,它们也有一些不同之处,例如顺序表有一个固定的大小,而链表可以动态增长和缩小。
概念:顺序表是一种线性数据结构,其中元素按照一定顺序依次排列。
每个元素都有一个指向下一个元素的指针,称为下标。
顺序表的特点是没有链表的循环结构,元素之间是直接相连的。
顺序表常用于存储整数、字符和数组等具有相同类型的数据。
链表是一种非线性数据结构,其中元素通过指针相互连接。
每个元素都包含一个指向下一个元素的指针,称为下标。
链表的特点是可以存储多个元素,并且可以通过插入、删除和查找元素的方式访问和操作它们。
链表的缺点是内存占用较大,并且不能进行插入和删除的元素在顺序表中可以方便地操作。
特点:顺序表的特点包括:1. 顺序排列:顺序表的元素按照一定顺序依次排列。
2. 固定大小:顺序表的元素个数和大小都是固定的。
3. 下标:每个元素都有一个下标,用于指示该元素的位置。
4. 存储多个元素:顺序表可以存储多个具有相同类型的数据元素。
5. 线性结构:每个元素直接相连,没有循环结构。
链表的特点包括:1. 动态增长:链表可以动态增长和缩小,以适应不同的存储需求。
2. 链式结构:每个元素都包含一个指向下一个元素的指针,称为下标。
3. 可以存储多个元素:链表可以存储多个具有相同类型的数据元素。
4. 指针操作:链表的每个节点都可以使用指针进行访问和操作。
5. 循环结构:链表的循环结构可以通过手动添加节点来避免,但是在某些情况下可能会导致链表过长。
优缺点:顺序表的优点包括:1. 高效性:顺序表的插入、删除和查找操作都非常快,因为它只需要访问下标即可。
2. 固定大小:顺序表的元素个数和大小都是固定的,不需要额外的内存空间。
3. 简单性:顺序表的操作非常简单,易于理解和实现。
C语言程序设计C教案_92
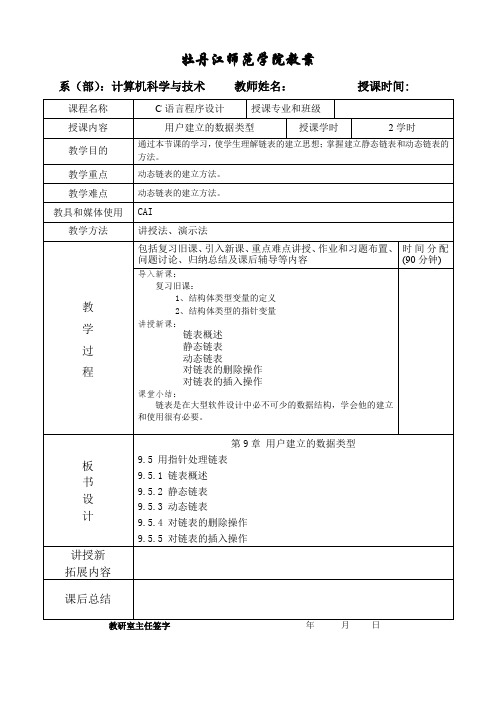
系(部):计算机科学与技术教师姓名:授课时间:
课程名称
C语言程序设计
授课专业和班级
授课内容
用户建立的数据类型
授课学时
2学时
教学目的
通过本节课的学习,使学生理解链表的建立思想;掌握建立静态链表和动态链表的方法。
教学重点
动态链表的建立方法。
教学难点
动态链表的建立方法。
教具和媒体使用
CAI
教学方法
讲授法、演示法
教
学
过
程
包括复习旧课、引入新课、重点难点讲授、作业和习题布置、问题讨论、归纳总结及课后辅导等内容
时间分配(分钟)
导入新课:
复习旧课:
1、结构体类型变量的定义
2、结构体类型的指针变量
讲授新课:
链表概述
静态链表
动态链表
对链表的删除操作
对链表的插入操作
课堂小结:
链表是在大型软件设计中必不可少的数据结构,学会他的建立和使用很有必要。
板
书
设
计
第9章用户建立的数据类型
9.5用指针处理链表
9.5.1链表概述
9.5.2静态链表
9.5.3动态链表
9.5.4对链表的删除操作
9.5.5对链表的插入操作
讲授新
拓展内容
课后总结
教研室主任签字年月日
尾插法建表

尾插法建表尾插法是一种常用的链表建表方法,它可以快速构建一个具有动态长度的链表。
在尾插法建表中,我们通过依次读入数据,并将其插入到链表的尾部,从而逐渐构建出完整的链表结构。
1. 算法原理尾插法建表的算法原理非常简单直观:1.创建一个空链表,用头指针head指向链表的头节点。
2.读取第一个数据,并创建一个新节点node。
3.如果链表为空,则将node作为第一个节点,即将head指向node。
4.如果链表不为空,则找到当前链表最后一个节点last,并将last的next指针指向node。
5.将node作为新的最后一个节点,并更新last为node。
6.重复步骤2-5,直到读取完所有数据。
2. 代码实现下面是使用Python语言实现尾插法建表的示例代码:class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextdef createLinkedList(nums):head = ListNode()last = headfor num in nums:node = ListNode(num)last.next = nodelast = nodereturn head.next3. 示例假设我们要使用尾插法建立一个包含4个节点的链表,数据依次为1、2、3、4。
nums = [1, 2, 3, 4]head = createLinkedList(nums)# 打印链表while head:print(head.val)head = head.next输出结果为:12344. 时间复杂度分析尾插法建表的时间复杂度为O(n),其中n为链表的长度。
这是因为每个数据都需要进行一次插入操作,而每次插入操作的时间复杂度是O(1)。
因此,整个建表过程的时间复杂度就是O(n)。
5. 空间复杂度分析尾插法建表的空间复杂度为O(n),其中n为链表的长度。
数据结构lst

数据结构lst1. 引言本文档主要介绍了一种常用的数据结构——链表(Linked List),简称LST。
链表是一种线性表,由一系列结点组成,每个结点包含数据域和指针域。
数据域用于存储数据元素,指针域用于存储下一个结点的地址。
链表具有动态分配、插入和删除操作高效等特点,广泛应用于计算机科学和软件工程领域。
2. 链表的基本概念2.1 结点链表的每个元素称为结点(Node),结点包含两个部分:数据域和指针域。
•数据域:用于存储数据元素,例如整数、字符串等。
•指针域:用于存储下一个结点的地址。
2.2 链表链表是由一系列结点组成的数据结构,可以分为单向链表、双向链表和循环链表等。
•单向链表:每个结点只包含一个指针域,指向下一个结点。
•双向链表:每个结点包含两个指针域,分别指向前一个结点和下一个结点。
•循环链表:链表的最后一个结点的指针指向第一个结点,形成一个环。
3. 链表的操作链表的操作主要包括创建、插入、删除和遍历等。
3.1 创建链表创建链表的常见方法有带头结点和不带头结点两种。
•带头结点的链表:头结点是一个特殊的结点,不存储数据元素,其指针域指向第一个数据结点。
•不带头结点的链表:直接从第一个数据结点开始创建。
3.2 插入结点插入结点是指在链表中插入一个新的结点,插入位置可以是链表的头部、中间或尾部。
•插入头部:在新结点的数据域存储要插入的数据元素,指针域指向原头结点,然后将新结点设置为头结点。
•插入中间:找到插入位置的前一个结点,将新结点的数据域存储要插入的数据元素,指针域指向原链表中的下一个结点,然后将原链表中的下一个结点插入到新结点之后。
•插入尾部:找到链表的最后一个结点,将新结点的数据域存储要插入的数据元素,指针域指向最后一个结点的下一个结点,然后将新结点添加到链表的末尾。
3.3 删除结点删除结点是指在链表中删除一个已存在的结点。
•删除头部:找到原头结点的下一个结点,将其设置为新的头结点。
•删除中间:找到要删除的结点的前一个结点,将前一个结点的指针指向要删除结点的下一个结点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
n--;
}
else printf("找不到该节点\n");
end:
return(head);
}
SWPA *insert(SWPA *head,SWPA *newdate)
{
SWPA *p0,*p,*pt;
unsigned long RESULT;
struct node *next;
}SWPA;
int n=0;
SWPA *creat(void)
{
SWPA *head=NULL;
SWPA *p,*pt;
p=pt=(SWPA *)malloc(LEN);
if(NULL!=p)
}
n++;
return(head);
}
void main(void)
{
SWPA *head,*p0;
long RESULT;
head=creat();
pri(head);
printf("请输入要删除的RESULT:\n");
scanf("%04x",&RESULT);
while(p->RESULT!=NULL&&p->next!=NULL)
{
pt=p;
p=p->next;
}
if(p->RESULT==NULL)
{
if(head==p)
head=p->next;
else
pt->next=p->next;
}
if(p0->RESULT<=p->RESULT)
{
if(p==head)
head=p0;
else
pt->next=p0;
p0->next=p;
}
else
{p->next=p0;p0->next=NULL;}
pt=p;
p=(SWPA *)malloc(LEN);
if(NULL!=p) scanf("%x,%x,%04x,%04x",&p->DMACH32,&p->DMACL16,&p->ETHTYPE,&p->RESULT);
else printf("is NULL\n");
while(0!=RESULT)
{
head=del(head,RESULT);
pri(head);
printf("请输入要删除的RESULT:\n");
scanf("%04x",&RESULT);
}
printf("请输入要插入的RESULT:\n");
p0=(SWPA *)malloc(LEN);
scanf("%x,%x,%04x,%04x",p0->DMACH32,p0->DMACL16,p0->ETHTYPE,p0->RESULT);
if(NULL!=p0)
while(0!=p0->RESULT)
{
head=insert(head,p0);
p=head;
p0=newdate;
if(NULL==head)
{head=p0;p0->next=NULL;}
else
{
while((p0->RESULT>p->RESULT)&&(NULL!=p->next))
{
pt=p;
p=p->next;
#include "stdafx.h"
#include<malloc.h>
#define NULL 0
#define LEN sizeof(SWPA)
typedef struct node
{
unsigned int DMACH32;
unsigned short DMACL16;
unsigned short ETHTYPE;
pri(head);
printf("请输入要插入的RESULT:\n");
p0=(SWPA *) malloc(LEN);
scanf("%x,%x,%04x,%04x",p0->DMACH32,p0->DMACL16,p0->ETHTYPE,p0->RESULT);
}
pt->next=NULL;
}
return(head);
}
void pri(SWPA *head)
{
if(NULL!=head)
do
{
printf("%x,%x,%04x,%04x",DMACH32,DMACL16,ETHTYPE,RESULT);
{
scanf("%x,%x,%04x,%04x",&p->DMACH32,&p->DMACL16,&p->ETHTYPE,&p->RESULT);
while(0!=p->RESULT)
{ n++;
if(1==n) head=p;
else pt->next=p;
head=head->next;
}while(NULL!=head);
}
SWPA *del(SWPA *head,long RESULT)
{
SWPA *p,*pt;
if(NULL==head)
{printf("is NULL\n");goto end;}
p=head;
}
} Байду номын сангаас