网页编码如何转换为UTF-8
网站编码统一为UTF-8的详细设置

| \xF0[\x90-\xBF][\x80-\xBF]{2} # planes 1-3
| [\xF1-\xF3][\x80-\xBF]{3} # planes 4-15
3.Javascript或Flash
js直接用记事本打开另存为选择UTF-8即可,
(一般用编辑软件如editplus、DW或者Notepad2打开再改编码都不行,在浏览器上打开中文仍然是乱码,尤其是在网上下载下来的js文件 )
-------------------------网站编码统一为UTF-8的详细设置------------------------------------------
一.用记事本打开文件,选另存为时,显示的是UTF-8,而不是ANSI或其他。
二.用编辑软件修改(如DW打开时候——修改——页面属性——标题/编码——UTF-8)
if($s0 == $str){
return 'utf-8';
}else{
return 'gbk';
}
}
而css中不写@charset "utf-8";那么在浏览器中打开,中文内容包括注释和中文字体都会是乱码,但对网站本身没有影响,
当然首先得用记事本或者其他编辑软件将其本身编码改为了utf-8)
5.xml
<?xml version="1.0" encoding="utf-8"?>
或者这样判断是不是utf-8
function is_utf8($string) {
在线编码转换的使用方法

在线编码转换的使用方法
一、输入源码
在进行在线编码转换之前,首先需要将需要进行转换的源码复制到剪贴板中,或者将源码文件上传到指定的位置。
二、选择目标编码
在选择目标编码时,用户可以根据需要选择不同的目标编码,如UTF-8、GBK等。
这些编码方式各有特点,用户可以根据实际情况进行选择。
例如,UTF-8是一种国际化的编码方式,支持多种语言字符,被广泛应用于网页和电子邮件等场景;而GBK则是一种简体中文字符集编码方式,适用于中文字符的编码。
三、开始转换
在选择好目标编码后,点击开始转换按钮,系统会自动将源码转换为对应的目标编码。
转换过程需要一定的时间,具体时间取决于源码的大小和复杂度。
四、查看转换结果
转换完成后,用户可以查看转换结果。
如果转换成功,用户可以直接复制转换后的代码进行使用;如果转换失败,用户需要检查源码是否正确,或者尝试选择其他的目标编码进行转换。
五、错误处理
在进行在线编码转换时,可能会遇到一些错误,如源码中含有无法识别的字符等。
此时,用户需要仔细检查源码,找出错误的原因并进行修复。
同时,系统也会给出相应的错误提示,帮助用户更好地解决问题。
如果遇到其他问题或困难,用户可以联系在线客服寻求帮助。
utf32编码表 转换成utf8

utf32编码表转换成utf8
在计算机编程中,常常需要处理不同编码的字符集。
UTF-32和UTF-8是两种常见的字符编码方式。
UTF-32是一种固定长度的编码方式,每个字符占据4个字节,可以表示所有的Unicode字符;而UTF-8是一种可变长度的编码方式,每个字符占据1到4个字节,适用于在有限的存储空间内表示Unicode字符。
在处理字符编码时,有时需要将UTF-32编码表转换成UTF-8编码表,以便更好地使用和显示Unicode字符。
UTF-32编码表转换成UTF-8编码表的过程可以通过以下步骤实现:
1. 对每个UTF-32编码的字符进行判断,确定其在UTF-8中所需占据的字节数。
UTF-8中一个字符占据1到4个字节,根据UTF-32编码表中的字符值,可以确定其在UTF-8中所需占据的字节数。
2. 根据所需占据的字节数,生成UTF-8编码。
UTF-8编码的生成方式为:对于占据n个字节的字符,第一个字节的前n位为1,第n+1位为0;后续n-1个字节的前两位均为10,后面6位用于表示该字符的Unicode码。
3. 将生成的UTF-8编码与原UTF-32编码表中的字符对应起来,形成新的UTF-8编码表。
UTF-32编码表转换成UTF-8编码表可以帮助程序员更好地处理和显示Unicode字符,使得多语言的支持更加便捷。
- 1 -。
将编码从GB2312转成UTF-8的方法汇总(从前台、程序、数据库)

将编码从GB2312转成UTF-8的⽅法汇总(从前台、程序、数据库)⼀个⽹站如果需要国际化,就需要将编码从GB2312转成UTF-8,其中有很多的问题需要注意,如果没有转换彻底,将会有很多的编码问题出现!主要有五个⽅⾯:⼀..HTML页⾯转UTF-8编码问题⼆.PHP页⾯转UTF-8编码问题三.MYSQL数据库使⽤UTF-8编码的问题四.JS相关的UTF-8编码问题五.FLASH相关的UTF-8编码问题⼀.HTML页⾯转UTF-8编码问题1.在后,之间有中⽂字符的话,显⽰的标题有可能是乱码!2.html⽂件编码问题:点击编辑器的菜单:“⽂件”->“另存为”,可以看到当前⽂件的编码,确保⽂件编码为:UTF-8,如果是ANSI,需要将编码改成:UTF-8。
3.HTML⽂件头BOM问题:将⽂件从其他的编码转换成UTF-8编码时,有时候会在⽂件的最开始加上⼀个BOM标签,在个BOM标签可能会导致浏览器在显⽰中⽂的时候出现乱码。
删除这个BOM标签的⽅法:1.可以⽤Dreamweaver打开⽂件,并重新保存,即可以去除BOM标签!2.可以⽤EditPlus打开⽂件,并在菜单“⾸选项”->“⽂件”->"UTF-8标识",设置为:“总是删除签名”,然后保存⽂件,即可以去除BOM标签!4.WEB服务器UTF-8编码问题:如果你按以上所列的步骤做了,还是有中⽂乱码问题,请检查你的所使⽤的WEB服务器的编码问题如果你使⽤的是Apache,请将配置⽂件⾥的:charset 设成:utf-8(这⾥仅列出⽅法,具体格式请参考apache的配置⽂件)。
如果你使⽤的是Nginx,请将nginx.conf⾥的:charset 设成 utf-8,具体找到 "charset gb2312;"或者类似的语句,改成:"charset utf-8;”。
⼆.PHP页⾯转UTF-8编码问题1.在代码开始出加⼊⼀⾏:header("Content-Type: text/html;charset=utf-8");2.PHP⽂件编码问题点击编辑器的菜单:“⽂件”->“另存为”,可以看到当前⽂件的编码,确保⽂件编码为:UTF-8,如果是ANSI,需要将编码改成:UTF-8。
dede模板GBK快速转换为UTF-8教程
dede模板GBK快速转换为UTF-8教程做外贸站的模板时,客户要求增加一个多语言界面,就是在现有的中文界面上新增英文,日文和韩文。
第一个想法就是在织梦后台新增几个这样的栏目,然后只要将模板做成其他的语言就可以调用了。
但是如果现有网站的织梦是gbk的,若想出现其他语言文字就必须转化成UTF-8的。
在此整理了一下一个比较不错的转换方式:1.备份网站的所有数据这一部分是很重要的,尤其是数据库的备份。
先织梦后台备份,然后再整站进行备份2.导出数据库文件并转换。
这一部分需要使用到PHPMyadmin。
我们在phpMyAdmin找到网站的数据库名,默认的数据表前缀为dede_,全选这些数据表,选择导出。
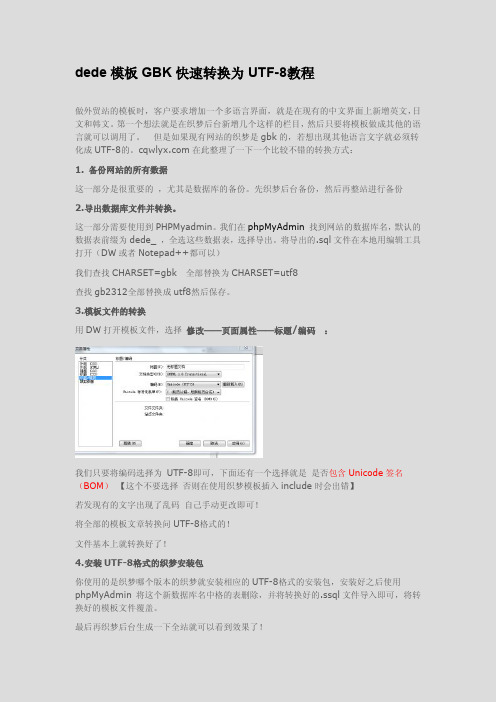
将导出的.sql文件在本地用编辑工具打开(DW或者Notepad++都可以)我们查找CHARSET=gbk全部替换为CHARSET=utf8查找gb2312全部替换成utf8然后保存。
3.模板文件的转换用DW打开模板文件,选择修改——页面属性——标题/编码:我们只要将编码选择为UTF-8即可,下面还有一个选择就是是否包含Unicode签名(BOM)【这个不要选择否则在使用织梦模板插入include时会出错】若发现有的文字出现了乱码自己手动更改即可!将全部的模板文章转换问UTF-8格式的!文件基本上就转换好了!4.安装UTF-8格式的织梦安装包你使用的是织梦哪个版本的织梦就安装相应的UTF-8格式的安装包,安装好之后使用phpMyAdmin将这个新数据库名中格的表删除,并将转换好的.ssql文件导入即可,将转换好的模板文件覆盖。
最后再织梦后台生成一下全站就可以看到效果了!。
curl utf8编码

curl utf8编码curl是一个流行的HTTP工具,用于发送和接收数据。
在处理包含非ASCII 字符的文本时,确保正确的编码和解码非常重要。
本文将介绍curl中utf8编码的使用方法。
一、UTF-8编码简介UTF-8(Unicode Transformation Format)是一种通用的字符编码标准,用于表示各种语言的字符。
UTF-8支持超过16位Unicode字符集的所有字符,包括非英语字符和特殊符号。
在curl中,使用UTF-8编码可以确保跨语言和平台的兼容性。
二、curl中的UTF-8编码设置1. 命令行参数:curl命令行工具支持使用特定的参数来指定编码格式。
例如,使用`--header`参数可以指定请求头部的编码方式。
例如,要设置请求头部的编码为UTF-8,可以使用以下命令:```arduinocurl --header "Content-Type: text/plain; charset=UTF-8" ...```2. 配置文件:curl的配置文件(`curl.conf`)也可以设置默认的编码格式。
在配置文件中添加以下行:```arduinodefault_charset = UTF-8```这将确保curl在默认情况下使用UTF-8编码发送请求。
三、解码响应数据当从服务器接收响应数据时,curl会自动检测响应头部的编码格式,并将其应用于响应体数据。
如果响应头部指定了UTF-8编码,那么curl会自动解码响应体数据为UTF-8格式。
您可以使用标准库函数或curl库函数来解码响应数据。
四、注意事项在使用curl进行跨语言和平台的数据传输时,确保正确处理编码和解码非常重要。
某些服务器可能使用不同的编码格式,因此您需要了解服务器的编码要求并相应地设置curl的参数。
另外,请注意处理可能的字符集转换错误,以确保数据的正确性和一致性。
五、结论curl是一个功能强大的HTTP工具,支持多种编码格式。
ucs2编码和utf8编码关系

UCS-2编码和UTF-8编码是两种常见的字符编码方式,它们在计算机领域起到了重要的作用。
本文将深入探讨UCS-2编码和UTF-8编码之间的关系。
1. UCS-2编码和UTF-8编码简介1.1 UCS-2编码UCS-2(Universal Character Set 2)是一种用于表示Unicode字符的编码方式。
它使用16位(2个字节)的编码空间,可以表示的字符范围为U+0000至U+FFFF。
在UCS-2编码中,每个字符都用两个字节进行表示,无论该字符的编码是否需要那么多位。
这种编码方式简单直观,适合于处理大部分常用字符。
1.2 UTF-8编码UTF-8(Unicode Transformation Format 8-bit)是一种变长的编码方式,可以以1至4个字节对Unicode字符进行编码。
它兼容ASCII字符集,对于ASCII字符只需用一个字节进行表示。
对于其他字符,UTF-8使用不同长度的字节来表示,确保可以表示全Unicode字符范围内的字符。
2. UCS-2编码和UTF-8编码的关系UCS-2编码和UTF-8编码都是用于表示Unicode字符的编码方式,它们之间有着紧密的联系。
2.1 兼容性UCS-2编码可以视为UTF-16编码的子集,因为UCS-2编码只能表示Unicode范围内的字符,而UTF-16编码可以表示更广泛的字符范围,包括Unicode扩展字符。
UTF-8编码则可以视为UCS-2编码和ASCII编码的子集,因为UTF-8可以表示UCS-2编码和ASCII编码范围内的所有字符。
2.2 字符编码方式UCS-2编码使用固定长度的两个字节对字符进行表示,每个字节的高位都为0。
而UTF-8编码则根据字符的范围使用不同长度的字节进行表示,每个字节的高位都包含了用于表示该字符所需的额外编码信息。
2.3 存储空间由于UCS-2编码使用固定长度的两个字节,无论是表示ASCII字符还是非ASCII字符,都需要两个字节的存储空间。
ucode编码规则

Ucode编码规则1. 简介Ucode是一种编码规则,用于将文本或数据转换为一系列可读的字符。
它被广泛应用于数据传输、存储和显示等领域。
Ucode编码规则的设计目标是简单、高效、可靠,并且能够兼容各种字符集。
2. 编码原理Ucode编码规则基于Unicode字符集,通过将Unicode字符映射到特定的可读字符来实现编码。
它采用了一种类似于Base64的算法,将每个Unicode字符转换为一个固定长度的Ucode字符。
具体而言,Ucode使用一个128个字符的可读字符集,每个Ucode字符由6位二进制数表示。
对于每个Unicode字符,先将其转换为UTF-8编码表示形式(如果不是UTF-8编码,则先进行转换),然后将UTF-8编码表示形式解析为一系列字节。
接下来,将这些字节转换为二进制数,并补齐到8位。
最后,取每6位连续的二进制数,并根据其值在可读字符集中找到对应的Ucode字符。
3. 编码步骤使用Ucode进行编码需要按照以下步骤进行:步骤1:准备待编码文本首先需要准备待编码的文本,可以是任意Unicode字符组成的字符串。
如果文本中包含非UTF-8编码的字符,则需要进行转换为UTF-8编码。
步骤2:将文本转换为UTF-8编码表示形式使用UTF-8编码将文本转换为字节序列。
UTF-8采用可变长度编码,根据Unicode 字符的不同范围,使用1到4个字节表示一个字符。
步骤3:将字节序列转换为二进制数将每个字节转换为二进制数,并补齐到8位。
例如,一个字节的十进制值为137,其二进制表示形式为10001001。
步骤4:拼接二进制数将所有字节对应的二进制数拼接在一起,得到一个长的二进制数序列。
步骤5:分割二进制数从左到右按照每6位划分二进制数序列,并且在最后不足6位时进行补0操作。
例如,1100010100111011会被划分为110001和010011和101100。
步骤6:映射Ucode字符根据每个6位二进制数所代表的十进制值,在128个可读字符集中找到对应的Ucode字符。
码制转换原理

码制转换原理
码制转换是指将一种编码方式转换为另一种编码方式的过程。
在计算机领域中,常见的编码方式有ASCII码、Unicode码、UTF-8等。
ASCII码是最早的字符编码方式,使用7位二进制来表示128个字符。
它包括基本的拉丁字母、数字、标点符号等。
如果需要表示更多字符,就需要使用多字节编码。
Unicode是一种字符集,它包含世界上几乎所有的字符,无论是哪个国家的文字、符号、图形等,都能找到对应的Unicode 码。
Unicode采用16位或32位的编码方式,可以表示超过65536个字符。
UTF-8是一种变长的Unicode转换格式,它能够用来表示Unicode标准中的任何字符。
UTF-8使用1到4个字节来表示一个字符,具体使用几个字节表示一个字符是根据字符的Unicode码大小来决定的。
UTF-8采用了一种自适应的编码方式,对于英文字符可以使用1个字节表示,对于汉字等字符使用更多字节表示,从而实现了较好的空间利用率和兼容性。
在进行码制转换时,需要将源编码的字符逐个提取,并根据目标编码的规则,将其转换成目标编码的对应字符。
对于ASCII 码到Unicode码的转换,可以直接通过查找对应关系完成;对于Unicode码到UTF-8的转换,需要根据UTF-8的编码规则逐个处理。
通过码制转换,可以在不同的编码方式之间实现互相转换和兼容,确保数据在不同平台、不同应用间能够正确地传输和解析。
码制转换在计算机领域中起着重要的作用,使得不同语言、不同文化的信息可以得到正确的处理和显示。
utf8编码互相转换 -回复

utf8编码互相转换-回复UTF-8编码互相转换是指将文本从UTF-8编码转换为其他编码,或从其他编码转换为UTF-8编码。
UTF-8是一种变长的编码方式,能够表示全球范围内的字符,它在网络传输和存储中被广泛使用。
本文将以UTF-8编码互相转换为主题,一步一步地回答如何进行转换的方法。
首先,我们需要先了解UTF-8编码的基本知识。
UTF-8编码是用于表示Unicode字符的一种变长编码方式,它能够表示从U+0000到U+10FFFF的所有字符。
UTF-8编码使用1到4个字节来表示一个字符,其中ASCII字符(U+0000到U+007F)使用1个字节表示,而其他字符使用2到4个字节表示。
一、将文本从UTF-8编码转换为其他编码:1. 确定目标编码:首先,我们需要确定要将UTF-8编码转换为的目标编码。
常见的目标编码包括UTF-16、UTF-32、GB2312、GBK等。
2. 使用编程语言提供的函数或库:大多数编程语言都提供了函数或库来进行编码转换。
例如,在Python中,可以使用`decode`函数将UTF-8编码的文本转换为其他编码,如下所示:pythonutf8_text = b'\xe4\xbd\xa0\xe5\xa5\xbd' # UTF-8编码的文本target_encoding = 'GBK' # 目标编码decoded_text = utf8_text.decode('utf-8').encode(target_encoding)这里首先使用`decode`函数将UTF-8编码的文本解码为Unicode字符串,然后再使用`encode`函数将Unicode字符串编码为目标编码。
3. 确认转换结果:转换完成后,可以使用目标编码来确认转换结果是否正确。
例如,可以将转换后的文本写入文件或发送到其他系统中,并确保目标系统能够正确解析该文本。
二、将文本从其他编码转换为UTF-8编码:1. 确定原始编码:首先,我们需要确定要将其他编码转换为UTF-8编码的原始编码。
utf8编码互相转换 -回复

utf8编码互相转换-回复UTF-8编码是一种用来在计算机系统中表示字符的方法,它是一种全球通用的字符编码标准。
互相转换指的是在不同的编码方式之间转换字符的过程。
本文将分步骤回答互相转换的实现方法,并探讨其重要性和应用领域。
首先,我们需要了解UTF-8编码的基本原理。
UTF-8编码使用可变长度来表示字符,最常见的字符使用一个字节进行编码,而其他字符则可能使用两个、三个甚至四个字节进行编码。
此编码方式通过将字符映射到不同的二进制序列来表示不同的字符。
在进行编码和解码时,我们需要使用一些工具和技术。
下面是一些常见的方法:1. Python的`encode()`和`decode()`方法:Python提供了内置的字符串方法来实现编码和解码功能。
使用`encode()`方法可以将字符串转换为特定编码方式的字节序列,而使用`decode()`方法则可以将字节序列转换回字符串。
2. 在命令行中使用`iconv`命令:`iconv`是一个命令行工具,用于在各种编码和字符集之间进行转换。
通过输入`iconv -f <源编码> -t <目标编码> <文件>`命令,可以将一个文件从源编码转换为目标编码。
3. 在文本编辑器中使用转换工具:许多文本编辑器提供了内置的编码转换工具,可以方便地将文本从一种编码方式转换为另一种编码方式。
例如,使用记事本的"另存为"功能可以选择不同的编码方式保存文件。
互相转换的实现方法主要包括以下几个步骤:1. 确定源编码和目标编码:在进行字符编码转换之前,我们需要确定要从哪种编码方式转换为另一种编码方式。
通常情况下,我们会将源编码确定为已知的编码方式,而目标编码则是我们想要转换成的编码方式。
2. 选择合适的工具和技术:根据实际需求,选择合适的工具和技术来进行字符编码转换。
比如,如果需要将一个文件从一种编码方式转换为另一种编码方式,可以使用`iconv`命令;如果只需在编程环境中进行编码转换,可以使用Python的`encode()`和`decode()`方法。
php utf8中文编码

php utf8中文编码在PHP中,UTF-8编码是一种常用的字符编码方式,它能够支持包括中文在内的多种语言字符。
在PHP中正确处理UTF-8编码的中文,对于网页的国际化、跨语言网站的开发和维护都非常重要。
一、UTF-8编码概述UTF-8编码是一种变长编码的字符集,它能够表示世界上几乎所有语言的字符。
UTF-8编码使用三个字节来表示中文字符,每个中文字符在UTF-8编码中占用三个字节。
这种编码方式使得中文字符在网页中能够得到更好的处理和显示。
二、PHP中的UTF-8编码处理在PHP中,处理UTF-8编码的中文需要使用正确的字符编码设置和函数。
以下是一些常用的PHP函数和设置:1.使用`header()`函数设置字符编码在网页的头部(`<head>`标签内)使用`header()`函数设置字符编码为UTF-8,以确保网页的字符集被正确识别和解析。
例如:```phpheader('Content-Type:text/html;charset=utf-8');```2.使用`mb_internal_encoding()`函数设置内部字符编码PHP内部使用一种字符编码方式来处理字符串,这个编码方式会影响到字符串的比较、连接、替换等操作。
使用`mb_internal_encoding()`函数可以设置内部字符编码为UTF-8。
例如:```phpmb_internal_encoding('UTF-8');```3.使用`mb_convert_encoding()`函数转换编码当需要将非UTF-8编码的字符串转换为UTF-8编码时,可以使用`mb_convert_encoding()`函数。
例如:```php$str=mb_convert_encoding($str,'UTF-8');```4.使用`iconv()`函数转换编码`iconv()`函数也可以用于字符串的编码转换,它支持更多的字符集和编码格式。
网页编码之GB2312、GBK与UTF-8的区别

⽹页编码之GB2312、GBK与UTF-8的区别⾸先,我们要明⽩,GB2312、GBK和UTF-8都是⼀种字符编码,除此之外,还有好多字符编码。
只是对于我们中国⼈的⽹站来说,⽤这三种编码⽐较多。
简单的说⼀下,为什么要⽤编码,在计算机内,储存⽂本信息⽤ASC II码,每⼀个字符对应着唯⼀的ASCII码。
最初计算机是由美国发明的,他们也⽤的是键盘和上⾯的字母,所以他们的字符ASCII好解决。
但是我们中国的就不同了,每个汉字要对应唯⼀的ASCII码。
这样,就出来了国家制定的字符编码标准:GB2312、GBK等。
其他国家,其他语⾔也有他们对应的编码标准。
GB 就是国标的意思,GB2312和GBK主要⽤于汉字的编码,⽽UTF-8是全世界通⽤的。
意思就是说,如果你的⽹页主要⾯对使⽤汉语的中国⼈的话,使⽤ GB2312和GBK⾮常好,⽂字储存体积要⼩,有⼀些优点。
如果你的⽹页要⾯向世界的话,你再⽤GB2312和GBK作为⽹页编码的话,有些电脑上的浏览器没有这种编码,你的⽹页汉字内容就会变成⽆法识别的乱码。
它们通常⽤在⽹页的meta标签内,例如:,表⽰这个页⾯使⽤的是GB2312编码。
这个信息是给浏览器看的,浏览器会优先考虑使⽤从⽹页头部提取出来的编码信息对⽹页进⾏解码。
当然,我们也可以强制浏览器使⽤某种编码解释⽹页,这样我们就看到了传说中的乱码。
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:GBK、GB2312--Unicode--UTF8UTF8--Unicode--GBK、GB2312对于⼀个⽹站、论坛来说,如果英⽂字符较多,则建议使⽤UTF-8节省空间。
不过现在很多论坛的插件⼀般只⽀持GBK。
如果是中⽂的⽹站推荐GB2312 GBK有时还是有点问题为了避免所有乱码问题,应该采⽤UTF-8,将来要⽀持国际化也⾮常⽅便 UTF-8可以看作是⼤字符集,它包含了⼤部分⽂字的编码。
ansi to utf-8 converter的用法

ansi to utf-8 converter的用法ANSI to UTF-8 Converter 是一种常用的工具,用于将文件从ANSI 编码转换为 UTF-8 编码。
ANSI 是一种旧的字符编码格式,而 UTF-8 则是一种更先进和通用的字符编码格式。
在某些情况下,我们可能需要将文件从 ANSI 转换为 UTF-8,以便在不同的系统和平台上正确显示和处理各种字符。
以下是使用 ANSI to UTF-8 Converter 的参考内容:1. 下载和安装:首先,你需要从可靠的来源下载 ANSI to UTF-8 Converter 工具。
在下载之前,请确保你使用的是受信任的网站。
安装过程与常规软件安装过程相似,通过双击安装程序并按照提示进行操作。
2. 打开 ANSI to UTF-8 Converter:安装完成后,你可以打开 ANSI to UTF-8 Converter 工具。
通常,该工具提供一个用户友好的界面,使用户可以直观地进行操作。
3. 选择要转换的文件:在 ANSI to UTF-8 Converter 界面中,你将看到一个“选择文件”或类似的选项。
通过单击这个选项,可以导航到计算机上的文件夹,然后选择要转换的 ANSI 编码文件。
4. 选择输出位置和文件名:之后,工具可能会要求你选择输出文件的位置和文件名。
你可以选择在相同的文件夹中保存输出文件,也可以选择其他位置。
请记住,确保文件名和位置符合你要求的标准。
5. 选择 UTF-8 编码:ANSI to UTF-8 Converter 工具通常允许你选择要将文件转换为的编码格式。
在这种情况下,你应该选择 UTF-8 编码。
6. 启动转换过程:一旦你完成了上述步骤,你可以单击“转换”或类似的按钮,启动转换过程。
转换过程可能需要一些时间,具体取决于文件的大小和你的计算机性能。
7. 等待转换完成:一旦转换过程开始,你需要等待工具完成转换。
在转换过程中,你通常可以看到进度条或一些其他指示器,以显示转换的进度。
ansi to utf-8 converter的用法

ansi to utf-8 converter的用法ANSI to UTF-8 Converter是一个常用的工具,用于将ANSI编码的文本文件转换为UTF-8编码。
ANSI是一种常见的字符编码方式,用于在英文环境下传输和存储文本数据,而UTF-8是一种Unicode的变长字符编码方式,适用于包含多种语言文字的文本数据。
以下是一些相关参考内容的描述和使用方法。
1. 工具简介和用途ANSI to UTF-8 Converter是一个用于转换文本编码的工具,它可以将ANSI编码的文本文件转换为UTF-8编码,以便在不同语言环境下正确地显示和处理文本数据。
2. 下载和安装ANSI to UTF-8 Converter可以从多个网站上下载。
下载后,双击运行安装程序并按照提示完成安装。
安装完成后,可以在计算机的应用程序列表或桌面上找到该工具的快捷方式。
3. 转换文本文件编码打开ANSI编码的文本文件,然后打开ANSI to UTF-8 Converter工具。
在工具界面上,可以看到一个浏览按钮或文本框,用于选择要转换的ANSI文本文件。
点击浏览按钮,选择要转换的文件,或手动输入文件路径到文本框中。
4. 设置输出文件路径在工具界面上,通常会有一个用于设置转换后输出文件路径的文本框或浏览按钮。
点击浏览按钮,选择输出文件的保存路径,或手动输入文件路径到文本框中。
注意,最好选择一个与原文件不同的路径,以免覆盖原文件。
5. 开始转换在工具界面上,可能会有一个开始转换或转换按钮。
点击该按钮,工具将开始将ANSI编码的文本文件转换为UTF-8编码。
转换过程需要时间,取决于原始文件的大小和计算机的性能。
6. 转换完成一旦转换完成,工具界面会显示转换成功的提示信息。
此时,可以在选择的输出文件路径中找到转换后的UTF-8编码文本文件。
打开该文件,可以确认文本编码已经成功转换。
7. 注意事项在使用ANSI to UTF-8 Converter时,需要注意以下几点:- 由于文件编码的转换是不可逆的操作,建议在转换前备份原始文件,以防止数据丢失。
ansi to utf-8 converter的用法

ansi to utf-8 converter的用法摘要:一、ansi to utf-8 converter 简介1.定义与作用2.应用场景二、ansi to utf-8 converter 的用法1.转换方法a.命令行转换b.图形界面转换2.注意事项a.文件格式兼容性b.编码设置三、ansi to utf-8 converter 的优势与局限1.优势a.提高文件兼容性b.方便传输与存储2.局限a.转换可能引发的问题b.不支持部分特殊字符正文:ansi to utf-8 converter 是一个将ansi 编码文件转换为utf-8 编码文件的工具,它可以提高文件的兼容性,使得文件在各种操作系统和设备上都能正常显示。
本篇文章将详细介绍ansi to utf-8 converter 的用法、优势与局限。
一、ansi to utf-8 converter 简介ansi to utf-8 converter 主要用于将ansi 编码的文件转换为utf-8 编码的文件。
ansi 编码是一种针对西欧字符集的编码方式,而utf-8 是一种全球通用的编码方式,能表示世界上几乎所有的字符。
因此,将ansi 编码文件转换为utf-8 编码文件可以提高文件的兼容性,使其在各种操作系统和设备上都能正常显示。
ansi to utf-8 converter 广泛应用于需要在不同设备、操作系统间传输或存储文件的场合,例如:在不同国家、地区间进行文件交流,或在网页上展示特殊字符等。
二、ansi to utf-8 converter 的用法要使用ansi to utf-8 converter,可以选择以下两种方法之一进行转换:1.命令行转换使用命令行工具,例如Windows 系统下的cmd 或PowerShell,输入以下命令:```iconv -f ansi -t utf-8 input.txt > output.txt```其中,input.txt 为需要转换的ansi 编码文件,output.txt 为转换后的utf-8 编码文件。
网页乱码问题当设置编码为utf-8乱码的解决方法

⽹页乱码问题当设置编码为utf-8乱码的解决⽅法
最近php写⽹页时,设置编码都是utf-8,但是恶⼼的是好多次出现乱码,我就头疼,终于抽了10分钟从⽹上把乱码的根源弄明⽩了,以后见了⽹页乱码问题不在害怕了,嘎嘎!!
utf-8是国际编码,包括汉字,建议都设置成utf-8,省⼼;
步主如下:
第⼀:定义⽹页显⽰编码。
如果不定义⽹页编码,那么我们浏览⽹页的时候,IE会⾃动识别⽹页编码,这就有可能会导致中⽂显⽰乱码了。
所以我们做⽹页的时候,都会⽤“<meta http-equiv=”Content-Type” content=”text/html; charset=utf-8″>”来定义⽹页编码。
第⼆:⽹页存储编码。
⼤家经常会忽略这个问题。
我们编辑⽹页时,不同的⼯具会默认⼀中编码格式,我们应该⽤utf-8格式编辑并保存,同时使⽤<meta http-equiv=”Content-Type” content=”text/html; charset=utf-8″>来使⽹页显⽰编码也为utf8,如果不⼀致就会导致乱码。
ps:php编程⽤到数据库时,数据库的编码也要⽤和⽹页显⽰的编码⼀致的编码格式,才能把数据库的内容显⽰在⽹页上,从⽽不出现乱码问题;
谢谢!。
vue 中文utf-8编码

vue 中文utf-8编码在Vue.js 项目中,默认情况下,Vue 文件和其他相关文件(如HTML 文件)都应该使用UTF-8 编码。
UTF-8 是一种可变长度的字符编码,它支持世界上几乎所有的字符。
确保你的Vue 项目文件都保存为UTF-8 编码的步骤如下:1. 编辑器设置:在你使用的代码编辑器中,通常有一个设置或保存文件时的选项,你可以选择将文件保存为UTF-8 编码。
确保设置中选择了"UTF-8" 或"UTF-8 without BOM"。
2. HTML 文件头部声明:在你的HTML 文件中,确保你有一个UTF-8 的字符集声明。
例如:```html<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Your Vue App</title></head><body><!-- Your Vue app content goes here --></body></html>```3. Vue 文件:对于Vue 单文件组件(.vue 文件),也要确保它们使用UTF-8 编码。
这通常是编辑器的默认设置,但你也可以在编辑器中手动检查并设置。
确保所有文件都是以UTF-8 编码保存,这有助于确保字符的正确显示,避免编码问题。
latin1转utf8算法

latin1转utf8算法在计算机领域中,编码就是将字符转换为计算机能够识别的二进制数据的过程。
在不同的编码方案中,字符与二进制数据的映射方式不同。
在网页或文本文件中,最常见的编码方式是Unicode编码。
Unicode编码是一种国际标准,可以用于表示世界上绝大部分语言的字符。
在Unicode编码中,每个字符都被赋予一个唯一的码点(Code Point),用十六进制数表示。
例如,字母A的码点是0041,汉字“好”的码点是597d。
但是,Unicode编码并不是一种具体的二进制编码方式,它只是规定了对应关系,具体的编码方式包括UTF-8, UTF-16等。
由于历史原因,有些数据库或文本文件中可能采用的是latin1编码。
为了统一字符集,需要将这些latin1编码转换为Unicode编码,进而转换为UTF-8编码。
这里简单介绍一下latin1转UTF-8算法:首先,我们需要明确一下UTF-8编码的规则。
UTF-8规定,一个字符的码点如果是0-127,则这个字符被编码为一个字节(即UTF-8编码和ASCII编码是一致的);如果码点是128-2047,则这个字符被编码为两个字节;如果码点是2048-65535,则这个字符被编码为三个字节;如果码点是65536-1114111,则这个字符被编码为四个字节。
我们现在需要将一个latin1编码的字符转换为UTF-8编码。
首先,我们需要确定这个字符对应的Unicode码点,即将latin1编码转换为Unicode码点。
然后,根据UTF-8编码的规则,将这个Unicode码点转换为UTF-8编码。
假设现在有一个latin1编码的字符,其十六进制表示为0x80,我们需要将它转换为UTF-8编码。
我们可以先将它转换为Unicode码点。
由于latin1编码只占用一个字节,所以这个字符的Unicode码点就是0x80,即十进制的128。
接下来,我们需要将这个Unicode码点转换为UTF-8编码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
UTF-8,这种编码解码在WEB开发中的意义用get方法传递中文时,必须经过编码的动作.进行编码时必须使用套件中的URLEncoder类型的encode类别方法,其语法:.URLEncoder.encode(字符串) 即:response.sendRedirect( "err.jsp?msg "+.URLEncoder.encode( "乱码 "))不过最好用变量而不要直接用中文:response.sendRedirect( "err.jsp?msg= "+vmsg);举个简单例子:text = "abcd ";url = "a.jsp?text= "+text;这样没有问题;但是当text = "abcd&edf "; 这样url就是 "a.jsp?text=abcd&edf " request.getParameter就获得abcd,剩余的就解析为另外一个参数edf所以需要对符号 "& "编码String value1= "123&中文 ";String enc= "UTF-8 ";String url= "Http://localhost:8080/forum.jsp?id= "+URLEncoder.encoder(value1,enc);如果没有进行URL编码,getParameter( "id ")的值为 "123 ";另外,假设服务器的Http URL encoding 是 "UTF-8 ", 而value1中含有中文。
那么,enc 也要是UTF-8。
才能正确显示中文。
java中的URLEncoder和URLDecoder类网页中的表单使用POST方法提交时,数据内容的类型是 application/x-www-form-urlencoded,这种类型会:1.字符"a"-"z","A"-"Z","0"-"9",".","-","*",和"_" 都不会被编码;2.将空格转换为加号 (+) ;3.将非文本内容转换成"%xy"的形式,xy是两位16进制的数值;4.在每个 name=value 对之间放置 & 符号。
*/URLEncoder类包含将字符串转换为application/x-www-form-urlencoded MIME 格式的静态方法。
web设计者面临的众多难题之一便是怎样处理不同操作系统间的差异性。
这些差异性能引起URL方面的问题:例如,一些操作系统允许文件名中含有空格符,有些又不允许。
大多数操作系统不会认为文件名中含有符号“#”会有什么特殊含义;但是在一个URL中,符号“#”表示该文件名已经结束,后面会紧跟一个fragment(部分)标识符。
其他的特殊字符,非字母数字字符集,它们在URL或另一个操作系统上都有其特殊的含义,表述着相似的问题。
为了解决这些问题,我们在URL中使用的字符就必须是一个ASCII字符集的固定字集中的元素,具体如下:1.大写字母A-Z2.小写字母a-z3.数字 0-94.标点符 - _ . ! ~ * ' (和 ,)诸如字符: / & ? @ # ; $ + = 和 %也可以被使用,但是它们各有其特殊的用途,如果一个文件名包括了这些字符( / & ? @ # ; $ + = %),这些字符和所有其他字符就应该被编码。
编码过程非常简单,任何字符只要不是ASCII码数字,字母,或者前面提到的标点符,它们都将被转换成字节形式,每个字节都写成这种形式:一个“%”后面跟着两位16进制的数值。
空格是一个特殊情况,因为它们太平常了。
它除了被编码成“%20”以外,还能编码为一个“+”。
加号(+)本身被编码为%2B。
当/ # = & 和?作为名字的一部分来使用时,而不是作为URL部分之间的分隔符来使用时,它们都应该被编码。
WARNING这种策略在存在大量字符集的异构环境中效果不甚理想。
例如:在U.S. Windows 系统中, é被编码为 %E9. 在 U.S. Mac中被编码为%8E。
这种不确定性的存在是现存的URI的一个明显的不足。
所以在将来URI的规范当中应该通过国际资源标识符(IRIs)进行改善。
</td> <td width="175" valign="top"> </td> </tr> </table>类URL并不自动执行编码或解码工作。
你能生成一个URL对象,它可以包括非法的ASCII和非ASCII字符和/或%xx。
当用方法getPath() 和toExternalForm( ) 作为输出方法时,这种字符和转移符不会自动编码或解码。
你应对被用来生成一个URL对象的字符串对象负责,确保所有字符都会被恰当地编码。
幸运的是,java提供了一个类URLEncoder把string编码成这种形式。
Java1.2增加了一个类URLDecoder它能以这种形式解码string。
这两个类都不用初始化:public class URLDecoder extends Objectpublic class URLEncoder extends Object一、URLEncoder在java1.3和早期版本中,类.URLEncoder包括一个简单的静态方法encode( ),它对string 以如下规则进行编码:public static String encode(String s)这个方法总是用它所在平台的默认编码形式,所以在不同系统上,它就会产生不同的结果。
结果java1.4中,这个方法被另一种方法取代了。
该方法要求你自己指定编码形式:public static String encode(String s, String encoding) throws UnsupportedEncodingException两种关于编码的方法,都把任何非字母数字字符转换成%xx(除了空格,下划线(_),连字符(?),句号(。
),和星号(*))。
两者也都编码所以的非ASCII字符。
空格被转换成一个加号。
这些方法有一点过分累赘了;它们也把“~”,“‘”,“()”转换成%xx,即使它们完全用不着这样做。
尽管这样,但是这种转换并没被URL规范所禁止。
所以web浏览器会自然地处理这些被过分编码后的URL。
两中关于编码的方法都返回一个新的被编码后的string,java1.3的方法encode( ) 使用了平台的默认编码形式,得到%xx。
这些编码形式典型的有:在 U.S. Unix 系统上的ISO-8859-1, 在U.S. Windows 系统上的Cp1252,在U.S. Macs上的MacRoman,和其他本地字符集等。
因为编码解码过程都是与本地操作平台相关的,所以这些方法是令人不爽的,不能跨平台的。
这就明确地回答了为什么在java1.4中这种方法被抛弃了,转而投向了要求以自己指定编码形式的这种方法。
尽管如此,如果你执意要使用所在平台的默认编码形式,你的程序将会像在java1.3中的程序一样,是本地平台相关的。
在另一种编码的方法中,你应该总是用UTF-8,而不是其他什么。
UTF-8比起你选的其他的编码形式来说,它能与新的web浏览器和更多的其他软件相兼容。
例子7-8是使用URLEncoder.encode( ) 来打印输出各种被编码后的string。
它需要在java1.4或更新的版本中编译和运行。
Example 7-8. x-www-form-urlencoded strings下面就是它的输出。
需要注意的是这些代码应该以其他编码形式被保存而不是以ASCII码的形式,还有就是你选择的编码形式应该作为一个参数传给编译器,让编译器能据此对源代码中的非ASCII字符作出正确的解释。
% javac -encoding UTF8 EncoderTest %java EncoderTestThis+string+has+spacesThis*string*has*asterisksThis%25string%25has%25percent%25signsThis%2Bstring%2Bhas%2BplusesThis%2Fstring%2Fhas%2FslashesThis%22string%22has%22quote%22marksThis%3Astring%3Ahas%3AcolonsThis%7Estring%7Ehas%7EtildesThis%28string%29has%28parentheses%29This.string.has.periodsThis%3Dstring%3Dhas%3Dequals%3DsignsThis&string&has&ersandsThis%C3%A9string%C3%A9has%C3%A9non-ASCII+characters特别需要注意的是这个方法编码了符号,“\” ,&,=,和:。
它不会尝试着去规定在一个URL中这些字符怎样被使用。
由此,所以你不得不分块编码你的URL,而不是把整个URL一次传给这个方法。
这是很重要的,因为对类URLEncoder最通常的用法就是查询string,为了和服务器端使用GET方法的程序进行交互。
例如,假设你想编码这个查询sting,它用来搜索AltaVista网站:pg=q&kl=XX&stype=stext&q=+"Java+I/O"&search.x=38&search.y=3这段代码对其进行编码:String query =URLEncoder.encode( "pg=q&kl=XX&stype=stext&q=+\"Java+I/O\"&search.x=38&search.y=3");System.o ut.println(query);不幸的是,得到的输出是:pg%3Dq&kl%3DXX&stype%3Dstext&q%3D%2B%22Java%2BI%2FO%22&search.x%3D38&search.y%3D3出现这个问题就是方法URLEncoder.encode( ) 在进行盲目地编码。