【八斗学院】5.5 MapReduce是如何对错误进行处理的?(错误处理机制)
简述mapreduce的运行流程

简述mapreduce的运行流程MapReduce是一种用于在大规模数据集上并行计算的模型,它由Google 公司提出并应用于分布式计算领域。
MapReduce的核心思想是将计算任务拆分为多个阶段,并在多台计算机上进行并行计算,从而提高计算效率。
本文将从MapReduce的基本概念开始,逐步解释其运行流程。
一、MapReduce概述MapReduce模型将计算任务分为两个阶段:Map(映射)和Reduce(归约)。
Map阶段将输入数据集划分为多个子集,并为每个子集生成一组键-值对。
Reduce阶段将相同键的键-值对进行归约操作,生成最终结果。
在MapReduce中,计算任务的执行由一个主节点(称为JobTracker)和多个工作节点(称为TaskTracker)协同完成。
二、任务提交阶段1.生成任务:用户向计算集群提交一个MapReduce任务,并指定输入数据集的路径、Map函数、Reduce函数等信息。
提交任务后,JobTracker 为该任务生成一个唯一的任务ID,并将任务添加到待处理任务列表中。
2.任务划分:JobTracker根据输入数据的大小和计算资源的可用情况,将任务划分为若干个MapTask和ReduceTask,并将它们分配给相应的TaskTracker进行处理。
3.任务分配:JobTracker根据与各个TaskTracker之间的网络延迟和负载情况等因素,将MapTask和ReduceTask分配给合适的TaskTracker。
任务分配过程相对复杂,需要考虑多个因素,以实现负载均衡和最大化计算资源的利用率。
三、Map阶段1.数据划分:每个Map任务在启动时,首先从数据源中读取输入数据集。
输入数据集通常被划分为多个等大小的数据块,每个数据块由单独的Map 任务处理。
2.Map函数执行:每个Map任务将输入数据块作为输入,并根据用户定义的Map函数对数据进行处理。
Map函数将输入数据转换为一组键-值对,并将它们输出到本地磁盘上的临时输出文件中。
mapreduce数据处理原理

MapReduce数据处理原理1. 概述MapReduce是一种用于大规模数据处理的编程模型,由Google首先提出并应用于分布式计算中。
它通过将大规模数据集划分为小的子集,并在多个计算节点上同时进行处理,从而实现高效的数据处理。
MapReduce的核心思想是将复杂的数据处理任务分解成简单的、可并行执行的任务。
2. 基本原理MapReduce模型基于两个基本操作:Map和Reduce。
下面将详细介绍这两个操作以及它们在数据处理中的作用。
2.1 Map操作Map操作是将输入数据集中的每个元素进行转换,并生成一个键值对集合作为输出。
具体来说,Map操作接受一个键值对作为输入,经过转换后输出一个新的键值对。
在Map操作中,用户需要自定义一个Map函数,该函数接受输入键值对作为参数,并根据具体需求进行转换操作。
在词频统计任务中,用户可以定义一个Map函数来将输入文本切分成单词,并为每个单词生成一个键值对(单词,1)。
2.2 Reduce操作Reduce操作是将经过Map操作后生成的键值对集合按照键进行分组,并对每个组进行聚合计算。
具体来说,Reduce操作接受一个键和与该键相关联的一组值作为输入,经过聚合计算后输出一个新的键值对。
在Reduce操作中,用户需要自定义一个Reduce函数,该函数接受输入键和与之相关联的值集合作为参数,并根据具体需求进行聚合计算。
在词频统计任务中,用户可以定义一个Reduce函数来对每个单词出现的次数进行累加。
2.3 数据流MapReduce模型通过Map和Reduce操作将数据流划分为三个阶段:输入阶段、中间阶段和输出阶段。
在输入阶段,原始数据集被划分成多个小的数据块,并分配给不同的计算节点进行处理。
每个计算节点上的Map操作并行处理自己分配到的数据块,并生成中间结果。
在中间阶段,所有计算节点上生成的中间结果被按照键进行分组,相同键的结果被发送到同一个Reduce操作所在的计算节点。
mapreduce的shuffle机制

标题:探秘MapReduce的Shuffle机制:数据传输的关键环节在现代大数据处理领域,MapReduce框架已经成为一种常见的数据处理模式,而其中的Shuffle机制则是整个数据传输过程中的关键环节。
本文将深入探讨MapReduce的Shuffle机制,从简单到复杂、由浅入深地介绍其原理、作用和优化方法,让我们一起来揭开这个神秘的面纱。
1. Shuffle机制的基本概念在MapReduce框架中,Shuffle机制是指在Mapper阶段产生的中间结果需要传输给Reducer节点进行后续处理的过程。
简单来说,就是将Map阶段的输出结果按照特定的方式进行分区、排序和分组,然后传输给对应的Reducer节点。
这一过程包括数据分区、数据传输和数据合并三个关键步骤,是整个MapReduce任务中耗时和开销较大的部分。
2. Shuffle机制的作用和重要性Shuffle机制在MapReduce框架中起着至关重要的作用。
它决定了数据传输的效率和速度,直接影响整个任务的执行时间。
Shuffle过程的优化可以减少网络开销和磁盘IO,提升整体系统的性能。
而且,合理的Shuffle策略还能够减少数据倾斜和提高任务的容错性。
对Shuffle机制的深入理解和优化,对于提高MapReduce任务的执行效率和性能有着非常重要的意义。
3. Shuffle机制的具体实现方式在实际的MapReduce框架中,Shuffle机制的实现涉及到数据的分区、排序和分组等具体细节。
其中,数据分区决定了数据如何被划分到不同的Reducer节点;数据传输则涉及了数据的网络传输和磁盘读写操作;数据合并则是在Reducer端对来自不同Mapper的数据进行合并和排序。
不同的MapReduce框架会采用不同的Shuffle实现方式,如Hadoop使用的是基于磁盘的Shuffle,而Spark则采用了内存计算的Shuffle优化。
4. Shuffle机制的优化方法为了提高MapReduce任务的执行效率和性能,研究人员和工程师们提出了许多针对Shuffle机制的优化方法。
MapReduce工作原理

MapReduce工作原理1 MapReduce原理(一)1.1 MapReduce编程模型MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
简单地说,MapReduce 就是"任务的分解与结果的汇总"。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。
一个Hadoop集群中只有一台JobTracker。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
1.2 MapReduce处理过程在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。
这两个阶段分别用两个函数表示,即map函数和reduce函数。
map函数接收一个<key,value>形式的输入,然后同样产生一个<key,value>形式的中间输出,Hadoop函数接收一个如<key,(list of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key,value>形式的。
一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。
【八斗学院】5.4 MapReduce工作原理详解

MapReduce 工作原理详解来源:八斗学院我们通过Client 、JobTrask 和TaskTracker 的角度来分析MapReduce 的工作原理:首先在客户端(Client )启动一个作业(Job ),向JobTracker 请求一个Job ID 。
将运行作业所需要的资源文件复制到HDFS 上,包括MapReduce 程序打包的JAR 文件、配置文件和客户端计算所得的输入划分信息。
这些文件都存放在JobTracker 专门为该作业创建的文件夹中,文件夹名为该作业的Job ID 。
JAR 文件默认会有10个副本(mapred.submit.replication 属性控制);输入划分信息告诉了JobTracker 应该为这个作业启动多少个map 任务等信息。
JobTracker 接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map 任务,并将map 任务分配给TaskTracker 执行。
对于map 和reduce 任务,TaskTracker 根据主机核的数量和内存的大小有固定数量的map 槽和reduce 槽。
这里需要强调的是:map 任务不是随随便便地分配给某个TaskTracker 的,这里就涉及到上面提到的数据本地化(Data-Local )。
TaskTracker 每隔一段时间会给JobTracker 发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map 任务完成的进度等信息。
当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。
当JobClient 查询状态时,它将得知任务已完成,便显示一条消息给用户。
如果具体从map 端和reduce 端分析,可以参考上面的图片,具体如下:Map 端流程:1) 每个输入分片会让一个map 任务来处理,map 输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M ,由io.sort.mb 属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent 属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
mapreduce的介绍及工作流程

mapreduce的介绍及工作流程MapReduce是一种用于大规模数据处理的编程模型和计算框架。
它可以有效地处理大规模数据集,提供了分布式计算的能力,以及自动化的数据分片、任务调度和容错机制。
本文将介绍MapReduce的基本概念、工作流程以及其在大数据处理中的应用。
一、MapReduce的基本概念MapReduce的基本概念分为两个部分:Map和Reduce。
Map用于对输入数据进行初步处理,将输入数据分解成若干个<key, value>对。
Reduce则对Map的输出进行聚合操作,生成最终的结果。
MapReduce的输入数据通常是一个大型数据集,可以是文件、数据库中的表或者其他形式的数据源。
输入数据被划分为若干个数据块,每个数据块由一个Map任务处理。
Map任务将输入数据块转化为若干个中间结果,每个中间结果都是一个<key, value>对。
Reduce任务负责对Map任务的输出进行进一步处理,将具有相同key的中间结果进行聚合操作,生成最终的结果。
Reduce任务的输出结果通常是一个<key, value>对的集合。
二、MapReduce的工作流程MapReduce的工作流程可以简单概括为以下几个步骤:输入数据的划分、Map任务的执行、中间结果的合并与排序、Reduce任务的执行、最终结果的输出。
1. 输入数据的划分:输入数据被划分成若干个数据块,在分布式环境下,每个数据块都会被分配到不同的节点上进行处理。
数据块的大小通常由系统自动设置,以保证每个Map任务的负载均衡。
2. Map任务的执行:每个Map任务独立地处理一个数据块,将输入数据转化为若干个中间结果。
Map任务可以并行执行,每个任务都在独立的节点上运行。
Map任务的输出中间结果被存储在本地磁盘上。
3. 中间结果的合并与排序:Map任务输出的中间结果需要在Reduce任务执行之前进行合并和排序。
mapreduce的工作原理

mapreduce的工作原理MapReduce是一种用于大规模数据处理的编程模型和软件框架。
它最初由Google设计用于支持其Web搜索服务,后来成为了Apache Hadoop项目的核心组件之一。
MapReduce的工作原理是通过将大规模数据集分解成小块,然后在集群中并行处理这些小块数据,最终将结果合并起来得到最终的输出。
MapReduce的工作原理可以分为两个阶段,Map阶段和Reduce阶段。
在Map阶段,输入的数据被切分成若干个小的数据块,然后由多个Map任务并行处理这些数据块。
每个Map任务会将输入数据经过特定的处理逻辑,生成中间结果。
这些中间结果会根据它们的键被分发到不同的Reduce任务上去处理。
在Reduce阶段,这些中间结果会被合并、排序,然后再由多个Reduce任务并行处理,最终生成最终的输出结果。
MapReduce的工作原理中,Map任务和Reduce任务是并行执行的,它们之间的通信是通过分布式文件系统来进行的。
在Map阶段,每个Map任务只处理自己负责的数据块,不需要和其他Map任务进行通信。
在Reduce阶段,每个Reduce任务也只处理自己负责的中间结果,不需要和其他Reduce任务进行通信。
这种并行处理和通信机制使得MapReduce能够有效地处理大规模数据,并且具有很好的可扩展性。
MapReduce的工作原理还涉及到容错机制。
在MapReduce中,每个任务的执行都可能会出现错误,比如计算节点宕机、网络故障等。
为了保证整个任务的执行不受影响,MapReduce框架会对任务进行监控,并在出现错误时重新执行失败的任务。
这种容错机制保证了MapReduce在处理大规模数据时的可靠性和稳定性。
总的来说,MapReduce的工作原理是通过并行处理和分布式计算来实现对大规模数据的高效处理。
它将复杂的数据处理任务分解成简单的计算任务,并通过分布式计算框架来实现并行处理和通信,从而实现了对大规模数据的高效处理和分析。
【Hadoop】MapReduce笔记(二):MapReduce容错,任务失败处理

【Hadoop】MapReduce笔记(⼆):MapReduce容错,任务失败处理典型问题:Hadoop如何判断⼀个任务失败?失败了怎么做?分析:实际情况下,⽤户代码存在软件错误、进程崩溃、机器故障等都会导致失败。
Hadoop判断的失败有不同级别类型,针对不同级别的失败有不同的处理对策,这就是MapReduce的容错机制。
下⾯是⼏个不同级别失败的分类:⼀、任务失败分为3种情况:Task失败、⼦进程JVM退出、超时检测被关闭。
1.任务失败。
最常见的是Map或Reduce任务的失败,即写的本⾝MR代码导致失败。
发⽣Map或Reduce失败的时候,⼦任务JVM进程会在退出之前向上⼀级TaskTracker发送错误报告。
错误报告最后悔记录在⽤户的错误⽇志⾥⾯,TaskTracker会将此次task attempt标记为failed,释放⼀个任务槽slot⽤来运⾏另⼀个任务。
2. ⼦进程JVM突然退出。
可能由于JVM的bug导致,从⽽导致MapReduce⽤户代码执⾏失败。
在这种情况下,TaskTracker 会监控到进程以便退出,并将此次尝试标记为“failed”失败。
3. 关闭了超时连接(把超时timeout设置成0)。
所以长时间运⾏的任务永不会被标记failed。
在这种情况下,被挂起的任务永远不会释放其所占⽤的任务槽slot,并随时间推移会降低整个集群的性能。
⼆、TaskTracker失败正常情况下,TaskTracker 会通过⼼跳向 JobTracker 通信,如果发⽣故障,⼼跳减少, JobTracker 会将TaskTracker 从等待任务调度的池中移除,安排上⼀个成功运⾏的 Map 任务返回。
主要有两种情况:1.Map 阶段的情况。
如果属于未完成的作业,Reduce 阶段⽆法获取本地 Map 输出的⽂件结果,任务都需要重新调度和执⾏,只要是Map阶段失败必然是重新执⾏这个任务。
2.Reduce 阶段的情况。
mapreduce的实现机制

MapReduce是一种分布式计算框架,可以用于大规模数据处理,它的实现机制主要包括以下几个方面。
1. 数据分片在MapReduce中,数据会被分成多个数据块,并且这些数据块会被复制到不同的节点上。
这样做的目的是为了提高数据的可靠性,同时也可以避免单节点故障导致的数据丢失。
2. Map阶段在Map阶段中,每个节点会同时执行Map函数,将输入的数据块转换为键值对的形式。
Map函数的输出结果会被分配到不同的Reducer节点上,这里需要注意的是,Map函数的输出结果必须是无状态的,即输出结果只能依赖于输入参数,而不能依赖于其他状态信息。
3. Shuffle阶段在Shuffle阶段中,Map函数的输出结果按照键的哈希值进行排序,并将相同键的值归并到一起。
这个过程需要消耗大量的网络带宽和磁盘I/O,因此Shuffle阶段是整个MapReduce计算中的瓶颈之一。
4. Reduce阶段在Reduce阶段中,每个Reducer节点会对Map函数输出结果中相同键的数据进行聚合操作。
Reduce函数的输入参数由Map函数输出结果中相同键的数据组成,而Reduce函数的输出结果是最终结果,MapReduce框架会将所有Reducer节点的输出结果合并为一个最终结果。
5. 容错机制在分布式计算中,可能会出现节点故障、网络异常等问题,这些问题会导致数据丢失或者计算结果错误。
因此,MapReduce框架需要具备一定的容错机制,比如在Shuffle阶段中,如果某个节点的输出结果没有及时到达目标节点,MapReduce框架会自动重新发送数据。
6. 优化策略为了提高MapReduce计算的性能和效率,MapReduce框架还可以采用多种优化策略,比如合并小文件、增加Map和Reduce的任务并行度、调整数据分片大小等。
总的来说,MapReduce框架通过数据分片、Map函数、Shuffle 阶段、Reduce函数等组件的协同工作,实现了大规模数据的分布式处理。
mapreduce的处理流程

MapReduce的处理流程介绍M a pR ed uc e是一种分布式计算框架,被广泛应用于大数据处理。
本文将介绍M ap Re du ce的处理流程,包括分为M ap阶段和R ed uc e阶段。
Ma p阶段M a p阶段是Ma pR ed uc e处理过程的第一阶段,它将输入数据切分成若干个小的数据块,并将每个数据块交给不同的Ma pp er节点进行处理。
数据切分在M ap阶段,输入数据会被切分成多个数据块,每个数据块的大小由系统配置决定。
数据切分的目的是将输入数据拆分成更小的子任务,方便并行处理。
M a p函数的执行每个Ma pp er节点会执行用户定义的M ap函数,对其分配到的数据块进行处理。
M ap函数接收输入数据作为参数,处理后产生一组键值对。
中间结果的输出M a pp er节点会将处理后的键值对输出到临时文件中,这些中间结果会被保存在分布式文件系统中。
中间结果的格式为(ke y,va lu e),其中k e y是键,va lu e是与键相关联的值。
Reduc e阶段R e du ce阶段是M ap Re d uc e处理过程的第二阶段,它将Ma p阶段输出的中间结果进行合并和排序,并将相同键的值进行汇总处理。
中间结果的归并R e du ce阶段开始时,中间结果会被归并到不同的Re du ce r节点上,每个Re du ce r节点会处理一部分键值对。
R e d u c e函数的执行每个Re du ce r节点会执行用户定义的Re d uc e函数,对其分配到的键值对进行处理。
R edu c e函数接收键和与之相关的一组值作为输入,处理后产生最终的输出。
输出结果的写入R e du ce函数处理完毕后,最终结果会被写入到输出文件中。
输出文件的格式由用户定义的输出格式决定。
总结M a pR ed uc e的处理流程主要包括Ma p阶段和R ed uc e阶段。
在Ma p阶段,输入数据被切分并由不同的M ap pe r节点进行处理。
mapreduce数据处理原理

MapReduce数据处理原理一、概述在大数据时代,数据处理变得越来越重要。
MapReduce是一种经典的数据处理模型,它以其高效、可扩展和容错等特点被广泛应用于分布式数据处理。
本文将详细介绍MapReduce的原理,包括其基本概念、流程、组成部分以及实现方式等。
二、MapReduce基本概念MapReduce是一种将大规模数据集并行处理的编程模型。
它由两个阶段组成,即Map阶段和Reduce阶段。
在Map阶段中,原始数据被切分成若干个小数据块,然后通过Map函数进行处理;在Reduce阶段中,Map阶段的输出被分类整理并传递给Reduce函数进行进一步处理。
下面我们将详细介绍MapReduce的基本概念。
2.1 Map函数Map函数是MapReduce的核心部分之一。
它接收一个输入键值对,将其转换为若干个中间键值对。
通常情况下,Map函数的输入是一行文本,输出是零个或多个中间结果。
2.2 Reduce函数Reduce函数是MapReduce的另一个核心部分。
它接收同一个键的多个值,并将它们聚合为一个或多个结果。
Reduce函数的输入是一个键和与该键相关的一个或多个值,输出是最终的结果。
2.3 MapReduce过程MapReduce过程由Map阶段和Reduce阶段组成。
首先,在Map阶段中,原始数据被切分成若干个小数据块,每个小数据块由一个Map任务处理。
然后,Map任务对每个小数据块分别执行Map函数,生成中间键值对。
接着,在Reduce阶段中,中间结果被分类整理,并根据键进行排序。
每个键及其相关的值被传递给一个或多个Reduce任务,Reduce任务通过Reduce函数将多个值聚合为一个或多个结果。
三、MapReduce过程详解3.1 数据划分在MapReduce过程中,原始数据被划分成若干个小数据块,每个小数据块由一个Map任务处理。
数据划分的目的是将原始数据分解成多个小块,使得每个Map任务可以并行处理自己的数据。
mapreduce 工作原理

mapreduce 工作原理MapReduce 是一种用于大数据处理的编程模型,它可以将大任务分解成小任务,然后在不同的计算节点上并行执行。
MapReduce 设计出来的初衷就是要处理大数据,它的分布式处理能力和可伸缩性使得它成为了云计算时代的一个重要组成部分。
MapReduce 的基本工作原理是将大规模数据集分成很多小的数据块,然后依次对每一个数据块进行处理,最后将每个子任务的处理结果合并起来形成最终的结果。
MapReduce 模型分为两个阶段:Map 阶段和 Reduce 阶段。
Map 阶段中,MapReduce 模型将输入数据集分成若干个大小相等的数据块,然后为每个数据块启动一个 Map 任务,将该数据块输入到Map 函数中进行处理。
Map 函数会将每个输入的键值对经过一系列转换后输出成一系列新的键值对。
这些新的键值对会被分类和排序,最终输出到 Reduce 阶段进行处理。
Reduce 阶段中,MapReduce 模型将所有 Map 任务输出的键值对进行聚合和排序,并且将具有相同 key 值的键值对输出到同一个Reduce 任务中进行处理。
Reduce 函数将所有输入的键值对按照 key 值进行聚合,并且将聚合后的结果输出到一个新的文件中。
MapReduce 模型的优势在于其高可伸缩性和高容错性。
由于每个Map 任务之间互不干扰,也因为 Map 函数之间没有任何交互,所以MapReduce 模型可以非常容易地进行并行化处理。
同时为了解决可能存在的某些节点发生故障,MapReduce 模型通过持久化所有任务处理过程的数据以进行容错处理。
总之,MapReduce 模型是处理大数据的一个非常好的方法。
该模型将输入数据集拆分成几个小数据块,然后为每个数据块启动一个Map 任务,最终将 Map 任务的输出结果输入到 Reduce 函数中聚合处理,最后得到最终的结果。
该模型的可伸缩性和容错性都是很好的,使得它成为了当前大数据处理的一个非常好的解决方案。
mapreduce的原理

MapReduce的原理介绍MapReduce是一种用于大规模数据处理的编程模型,最初由Google提出并应用于分布式计算系统。
它的设计目标是简化并发处理大规模数据集的过程,通过将数据分割成多个块,然后在多个计算节点上进行并行处理,最后将结果合并返回。
在本文中,我们将深入探讨MapReduce的原理及其工作机制。
MapReduce的基本原理MapReduce模型包含两个主要步骤:Map和Reduce。
Map任务将输入数据拆分成一系列独立的片段,并为每个片段生成键值对。
Reduce任务则将Map任务生成的键值对进行合并和聚合,生成最终的结果。
Map任务Map任务是并行处理的第一步,它的输入是原始数据集,输出是一系列键值对。
Map任务通常由多个计算节点并行执行,每个节点处理输入数据的一个片段。
Map 任务的执行过程可以分为以下几个步骤:1.输入数据划分:原始数据集被划分成多个片段,每个片段被分配给一个Map任务。
2.记录解析:Map任务对输入数据进行解析,并将其转换成键值对的形式。
键值对的格式由具体的应用决定。
3.中间结果存储:Map任务将生成的键值对存储在本地磁盘上或内存中的缓冲区中。
这些中间结果将在Reduce任务中使用。
4.分区:Map任务根据键的哈希值将键值对分配到不同的Reduce任务上。
这样可以确保具有相同键的键值对被发送到同一个Reduce任务进行处理。
Reduce任务Reduce任务是并行处理的第二步,它的输入是Map任务生成的键值对,输出是最终的结果。
Reduce任务的执行过程可以分为以下几个步骤:1.分组:Reduce任务根据键对键值对进行分组,将具有相同键的键值对放在一起。
2.排序:Reduce任务对每个组内的键值对进行排序,以便更方便地进行后续的聚合操作。
3.聚合:Reduce任务对每个组内的键值对进行聚合操作,生成最终的结果。
聚合操作可以是求和、求平均值、计数等。
4.结果输出:Reduce任务将最终的结果写入输出文件或存储系统中。
mapreduce 的工作机制

MapReduce 是一种用于处理大规模数据的并行计算框架。
它的工作机制主要包括分布式计算、数据划分、映射函数和归约函数等关键步骤。
下面将详细介绍 MapReduce 的工作机制。
一、分布式计算1. MapReduce 使用分布式计算来处理大规模数据。
它将数据划分成多个块,并在不同的计算节点上并行处理这些数据块。
2. 分布式计算可以充分利用集裙中的计算资源,加快数据处理速度,并提高系统的容错能力。
3. 分布式计算还可以有效地处理数据的并行化计算,提高计算效率。
二、数据划分1. 在 MapReduce 中,数据会被划分成多个输入对。
2. 每个输入对包括一个键和一个值。
键用来唯一标识数据,值则是数据的实际内容。
3. 数据划分可以根据键来实现,这样相同键的数据会被划分到同一个计算节点上进行处理。
三、映射函数1. 映射函数是 MapReduce 中的一个重要环节。
它负责将数据划分成多个键值对,并为每个键值对生成一个中间键值对。
2. 映射函数会对每个数据块进行处理,并输出多个中间键值对。
这些中间键值对由键和相应的值组成。
3. 映射函数的输出将作为归约函数的输入,用于后续的数据处理。
四、归约函数1. 归约函数是 MapReduce 中的另一个重要环节。
它负责对映射函数的输出进行处理,并生成最终的结果。
2. 归约函数会根据键将中间键值对进行聚合,然后对每个键值对执行归约操作。
3. 归约函数的输出就是最终的处理结果,可以将结果保存到文件系统中。
五、MapReduce 的工作流程1. 当一个 MapReduce 任务被提交时,首先会将输入数据划分成多个数据块,然后将这些数据块分配到不同的计算节点上。
2. 每个节点上都会运行映射函数来处理数据块,并生成中间键值对。
然后这些中间键值对会被发送到不同的节点上进行归约操作。
3. 各个节点上的归约函数会对中间键值对进行聚合,生成最终的处理结果。
通过以上介绍,可以看出 MapReduce 的工作机制主要包括分布式计算、数据划分、映射函数和归约函数等关键步骤。
【原创】MapReduce运行原理和过程
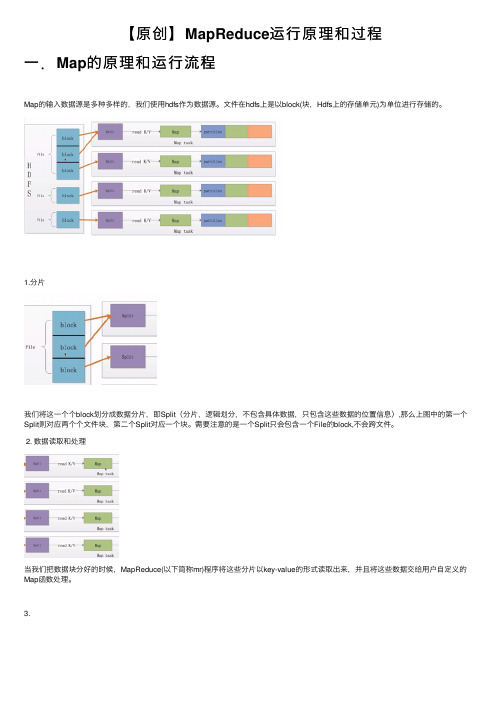
【原创】MapReduce运⾏原理和过程⼀.Map的原理和运⾏流程Map的输⼊数据源是多种多样的,我们使⽤hdfs作为数据源。
⽂件在hdfs上是以block(块,Hdfs上的存储单元)为单位进⾏存储的。
1.分⽚我们将这⼀个个block划分成数据分⽚,即Split(分⽚,逻辑划分,不包含具体数据,只包含这些数据的位置信息),那么上图中的第⼀个Split则对应两个个⽂件块,第⼆个Split对应⼀个块。
需要注意的是⼀个Split只会包含⼀个File的block,不会跨⽂件。
2. 数据读取和处理当我们把数据块分好的时候,MapReduce(以下简称mr)程序将这些分⽚以key-value的形式读取出来,并且将这些数据交给⽤户⾃定义的Map函数处理。
3.⽤户处理完这些数据后同样以key-value的形式将这些数据写出来交给mr计算框架。
mr框架会对这些数据进⾏划分,此处⽤进⾏表⽰。
不同颜⾊的partition矩形块表⽰为不同的partition,同⼀种颜⾊的partition最后会分配到同⼀个reduce节点上进⾏处理。
Map是如何将这些数据进⾏划分的?默认使⽤Hash算法对key值进⾏Hash,这样既能保证同⼀个key值的数据划分到同⼀个partition中,⼜能保证不同partition的数据梁是⼤致相当的。
总结:1.⼀个map指挥处理⼀个Split2.map处理完的数据会分成不同的partition3.⼀类partition对应⼀个reduce那么⼀个mr程序中 map的数量是由split的数量决定的,reduce的数量是由partiton的数量决定的。
⼆.ShuffleShuffle,翻译成中⽂是混洗。
mr没有排序是没有灵魂的,shuffle是mr中⾮常重要的⼀个过程。
他在Map执⾏完,Reduce执⾏前发⽣。
Map阶段的shuffle数据经过⽤户⾃定的map函数处理完成之后,数据会放⼊内存中的环形缓冲区之内,,他分为两个部分,数据区和索引区。
mapreduce架构工作原理

mapreduce架构工作原理MapReduce是一种用于大规模数据处理的并行计算模型,由谷歌公司提出,旨在解决海量数据的高效处理和分析问题。
本文将介绍MapReduce架构的工作原理。
一、MapReduce概述MapReduce采用了分而治之的思想,将大规模数据集分割成若干小数据块,并将这些数据块分布在集群中的多个计算节点上。
每个计算节点上有一个或多个Map和Reduce任务运行,通过分布式计算实现数据的并行处理。
二、Map阶段Map阶段是MapReduce任务的第一个阶段,主要负责数据的切割、映射和本地合并。
具体步骤如下:1. 输入数据切割:将输入数据集切割成若干个等大小的数据块,每个数据块称为一个Input Split。
2. Mapper映射:将每个Input Split交给对应的Mapper任务进行处理。
Mapper任务读取Input Split中的数据,根据预定义的映射函数对数据进行处理,生成中间结果。
3. 中间结果本地合并:在Map阶段的最后,每个Mapper任务将生成的中间结果按照键值进行排序和本地合并,减少数据的传输量。
三、Shuffle阶段Shuffle阶段是MapReduce任务的中间阶段,主要负责对Map阶段输出的中间结果进行重新划分和排序,以便进行Reduce操作。
具体步骤如下:1. 分区:将Map阶段输出的中间结果按照预定义的分区函数进行划分,将相同分区键值对应的结果发送到同一个Reduce任务进行处理。
2. 排序:每个Reduce任务接收到来自不同Mapper任务的中间结果后,对这些结果按照键值进行排序,以便进行后续的合并操作。
3. 合并:相同键值对应的中间结果将在Shuffle阶段进行合并,以减少后续Reduce阶段的数据传输量。
四、Reduce阶段Reduce阶段是MapReduce任务的最后一个阶段,主要负责对Shuffle阶段输出的中间结果进行汇总和计算,生成最终的结果。
mapreduce的执行原理

mapreduce的执行原理MapReduce是一种用于处理大规模数据的计算模型,由Google公司首次提出。
它将一个大的数据集分解成若干份小数据集,并在各个计算节点上进行并行处理,最后将处理结果进行合并,以达到快速处理海量数据的目的。
本文将从MapReduce的执行原理入手,进行详细阐述。
1. 输入数据拆分:MapReduce首先需要将整个输入数据集划分成若干个小数据片段,并为每个数据片段分配一个容器来存储Map函数的输出结果。
这个过程是由MapReduce框架的Master节点完成的。
2. Map阶段:Map阶段是MapReduce的第一阶段。
在这个阶段中,MapReduce将输入数据分散到各个计算节点上,并且在每个节点上执行Map函数。
Map函数会将输入数据映射到键值对的形式,输出中间结果,以供后续的Reduce程序进行处理。
Map函数可以有多个,每个Map函数都是独立执行的。
Map函数执行的时候不需要通信,这也是Map阶段的一个特点。
3. Shuffle阶段:Shuffle阶段是MapReduce的第二阶段,也是整个计算过程中最关键的一步。
在这个阶段中,MapReduce会将Map函数的输出结果按照Key进行排序,并将相同Key的记录集中起来。
这个过程是由MapReduce框架的Shuffle节点完成的。
Shuffle阶段的目的是将所有具有相同Key的值都放在同一个Reducer中。
4. Reduce阶段:Reduce阶段是MapReduce的最后一个阶段。
在这个阶段中,Reduce函数会接收到来自Map阶段的中间结果,并将相同Key的结果进行合并,并输出最终结果。
Reduce函数可以有多个,但是每个Reduce函数的输入数据都是相同的Key所对应的结果集。
Reduce函数执行的时候需要通信以及同步。
5. 输出结果:最后,MapReduce框架将所有Reduce函数的输出结果合并在一起,并将结果输出到指定的位置。
第5讲MapReduce的工作机制

2:获取Job ID和Job工作目录(但还没创建) JobID jobId = jobSubmitClient.getNewJobId(); //获取Job ID //根据jobId获取Job工作目录(但还没创建) Path submitJobDir = new Path(jobStagingArea, jobId.toString()); //将获取的Job工作目录设置到job的mapreduce.job.dir属性中 jobCopy.set("mapreduce.job.dir", submitJobDir.toString()); /* 最终目录一般呈现类似这种形式: /tmp/hadoop/mapred/staging/用户名/.staging/job_201408161410_0001/ */
MapReduce作业执行- 作业提交
JobClient的copyAndConfigureFiles(JobConf job, Path submitJobDir, short replication) 的定义为: ... // Retrieve command line arguments placed into the JobConf by GenericOptionsParser. String files = job.get("tmpfiles"); String libjars = job.get("tmpjars"); String archives = job.get("tmparchives"); // Create a number of filenames in the JobTracker's fs namespace FileSystem fs = submitJobDir.getFileSystem(job); //获取jt文件系统对象 LOG.debug("default FileSystem: " + fs.getUri()); if (fs.exists(submitJobDir)) { //submitJobDir不能事先存在 throw new IOException("Not submitting job. Job directory " + submitJobDir +" already exists!! This is unexpected.Please check what's there in" +" that directory"); } submitJobDir = fs.makeQualified(submitJobDir); //获取文件系统访问权限对象 FsPermission mapredSysPerms =newFsPermission(JobSubmissionFiles.JOB_DIR_PERMISSION); FileSystem.mkdirs(fs, submitJobDir, mapredSysPerms); //这时才创建submitJobDir
mapreduce的原理

mapreduce的原理
MapReduce是一个用于大规模数据处理的分布式编程模型和算法。
它的原理是将大规模数据分为若干个小的数据块,然后将这些小数据块分配给不同的计算节点进行处理,最后将这些处理结果合并在一起。
MapReduce的核心思想是将数据处理问题分解成两个独立的任务:Map任务和Reduce任务。
Map任务是将原始数据分解成一系列的key-value对,然后对每个key-value 对进行独立的处理。
Map任务的输出结果是一系列的中间结果,这些中间结果包含了key-value对的聚合信息,可以作为Reduce任务的输入数据。
Reduce任务是将Map任务的中间输出结果进行合并和聚合,生成最终的结果。
Reduce任务的输出结果通常是一个文件或者数据库记录,或者是一些统计信息。
MapReduce的核心算法是排序和分组,Map任务和Reduce任务都需要对数据进行排序和分组操作。
MapReduce的优势在于它能够自动化地处理数据的分布式计算、数据管理和错误处理等一系列问题,使得数据处理变得更加高效和可靠。
总之,MapReduce是一种在分布式计算环境下进行大规模数据处理的方法,它通过将数据分解成若干数据块并分布到不同的计算节点上进行处理,最终将处理结果聚合起来得到最终的结果。
map reduce 原理

map reduce 原理MapReduce原理MapReduce是一种大规模数据处理框架,由Google首先提出,其主要思想是将计算任务分解成许多小的任务,再将这些小任务分配给不同的计算节点,最后将结果合并得到最终结果。
MapReduce的核心思想是分而治之,将一个大问题分解成许多小问题,再将这些小问题分配给多个节点进行并行计算,最终将结果合并得到最终结果。
MapReduce的基本工作流程可以分为两个阶段:Map阶段和Reduce 阶段。
在Map阶段中,系统会将输入数据分割成多个小块,每个小块由一个Map任务处理。
Map任务的输入是一组键值对,其输出也是一组键值对。
在Map任务中,用户需要自定义一个map函数,将输入的键值对转换为中间键值对。
这些中间键值对会被排序后分配给Reduce任务处理。
在Reduce阶段中,系统会将中间键值对按照键进行分组,每组由一个Reduce任务处理。
Reduce任务的输入是一组具有相同键的中间键值对,其输出也是一组键值对。
在Reduce任务中,用户需要自定义一个reduce函数,将输入的中间键值对合并为最终结果。
MapReduce的优点在于其良好的可扩展性和容错性。
由于MapReduce 将计算任务分解成多个小任务并行计算,因此可以轻松地扩展计算能力,提高处理大规模数据的效率。
同时,由于MapReduce采用了数据冗余和任务备份等机制,即使某个节点出现故障,计算任务也能够在其他节点上继续执行,从而保证了计算任务的容错性。
除了基本的Map和Reduce操作外,MapReduce框架还提供了许多其他操作,包括Combiner、Partitioner、InputFormat和OutputFormat等。
其中,Combiner操作可以在Map任务输出中间结果之前对其进行合并,从而减少Reduce任务的输入数据量;Partitioner操作可以将中间结果按照特定规则分配给Reduce任务;InputFormat和OutputFormat操作可以分别处理输入和输出数据的格式,支持多种不同的数据源和数据格式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
MapReduce是如何对错误进行处理的?(错误处理机
制)
来源:八斗学院
MapReduce任务执行过程中出现的故障可以分为两大类:硬件故障和任务执行失败引发的故障。
一、硬件故障
在Hadoop Cluster中,只有一个JobTracker,因此,JobTracker本身是存在单点故障的。
如何解决JobTracker的单点问题呢?我们可以采用主备部署方式,启动JobTracker 主节点的同时,启动一个或多个JobTracker备用节点。
当JobTracker主节点出现问题时,通过某种选举算法,从备用的JobTracker节点中重新选出一个主节点。
机器故障除了JobTracker错误就是TaskTracker错误。
TaskTracker故障相对较为常见,MapReduce通常是通过重新执行任务来解决该故障。
在Hadoop集群中,正常情况下,TaskTracker会不断的与JobTracker通过心跳机制进行通信。
如果某TaskTracker出现故障或者运行缓慢,它会停止或者很少向JobTracker发送心跳。
如果一个TaskTracker在一定时间内(默认是1分钟)没有与JobTracker通信,那么JobTracker会将此TaskTracker从等待任务调度的TaskTracker集合中移除。
同时JobTracker会要求此TaskTracker上的任务立刻返回。
如果此TaskTracker任务仍然在mapping阶段的Map任务,那么JobTracker会要求其他的TaskTracker重新执行所有原本由故障TaskTracker执行的Map任务。
如果任务是在Reduce阶段的Reduce任务,那么JobTracker会要求其他TaskTracker重新执行故障TaskTracker未完成的Reduce任务。
比如:一个TaskTracker已经完成被分配的三个Reduce任务中的两个,因为Reduce任务一旦完成就会将数据写到HDFS上,所以只有第三个未完成的Reduce需要重新执行。
但是对于Map任务来说,即使TaskTracker完成了部分Map,Reduce仍可能无法获取此节点上所有Map 的所有输出。
所以无论Map任务完成与否,故障TaskTracker上的Map任务都必须重新执行。
二、任务执行失败引发的故障
在实际任务中,MapReduce作业还会遇到用户代码缺陷或进程崩溃引起的任务失败等情况。
用户代码缺陷会导致它在执行过程中抛出异常。
此时,任务JVM进程会自动退出,并向TaskTracker父进程发送错误消息,同时错误消息也会写入log文件,最后TaskTracker将此次任务尝试标记失败。
对于进程崩溃引起的任务失败,TaskTracker的监听程序会发现进程退出,此时TaskTracker也会将此次任务尝试标记为失败。
对于死循环程序或执行时间太长的程序,由于TaskTracker没有接收到进度更新,它也会将此次任务尝试标记为失败,并杀死程序对应的进程。
在以上情况中,TaskTracker将任务尝试标记为失败之后会将TaskTracker自身的任务计数器减1,以便想JobTracker申请新的任务。
TaskTracker也会通过心跳机制告诉JobTracker本地的一个任务尝试失败。
JobTracker接到任务失败的通知后,通过重置任务状态,将其加入到调度队列来重新分配该任务执行(JobTracker会尝试避免将失败的任务再次分配给运行失败的TaskTracker)。
如果此任务尝试了4次(次数可以进行设置)仍没有完成,就不会再被重试,此时整个作业也就失败了。