算法分析(实验四)
算法实验报告结果分析

一、实验背景随着计算机科学技术的不断发展,算法作为计算机科学的核心内容之一,其重要性日益凸显。
为了验证和评估不同算法的性能,我们进行了一系列算法实验,通过对比分析实验结果,以期为后续算法研究和优化提供参考。
二、实验方法本次实验选取了三种常见的算法:快速排序、归并排序和插入排序,分别对随机生成的数据集进行排序操作。
实验数据集的大小分为10000、20000、30000、40000和50000五个级别,以验证算法在不同数据量下的性能表现。
实验过程中,我们使用Python编程语言实现三种算法,并记录每种算法的运行时间。
同时,为了确保实验结果的准确性,我们对每种算法进行了多次运行,并取平均值作为最终结果。
三、实验结果1. 快速排序快速排序是一种高效的排序算法,其平均时间复杂度为O(nlogn)。
从实验结果来看,快速排序在所有数据量级别下均表现出较好的性能。
在数据量较小的10000和20000级别,快速排序的运行时间分别为0.05秒和0.1秒;而在数据量较大的40000和50000级别,运行时间分别为0.8秒和1.2秒。
总体来看,快速排序在各个数据量级别下的运行时间均保持在较低水平。
2. 归并排序归并排序是一种稳定的排序算法,其时间复杂度也为O(nlogn)。
实验结果显示,归并排序在数据量较小的10000和20000级别下的运行时间分别为0.15秒和0.25秒,而在数据量较大的40000和50000级别,运行时间分别为1.5秒和2.5秒。
与快速排序相比,归并排序在数据量较小的情况下性能稍逊一筹,但在数据量较大时,其运行时间仍然保持在较低水平。
3. 插入排序插入排序是一种简单易实现的排序算法,但其时间复杂度为O(n^2)。
实验结果显示,插入排序在数据量较小的10000和20000级别下的运行时间分别为0.3秒和0.6秒,而在数据量较大的40000和50000级别,运行时间分别为8秒和15秒。
可以看出,随着数据量的增加,插入排序的性能明显下降。
实验四.多序列比对

实验四.多序列比对一.实验目的:在多序列分析中,多序列比对具有广泛的应用,是许多其他分析的基础和前提,比如进化发生分析、构建位置特异性打分矩阵、找到一致序列等,本实验的目的是熟悉多序列比对相关的操作和编辑方法。
二.实验基本要求:了解和熟悉多序列比对的原理和基本方法。
三.实验内容提要:1.使用CLUSTALW 算法,比对一组蛋白质序列,该序列属于RAD51‐RECA,在DNA 的复制阶段起重要作用,这些序列可以从NCBI genbank、Uniprot 等序列服务器获取,序列的索引号码为:P25454,P25453,P0A7G6,P48295。
将这些序列保存在一个文本文件。
如果查询到的序列不止一个的话,选择第一个。
a.练习使用EBI CLUSTALW(/Tools/msa/clustalw2/);b. 将序列数据拷贝复制到窗口中;c. 采用默认参数进行比对;回答:clustalw 算法的基本原理?2. 在BAliBASE 网站查找一组蛋白质:1csy。
这些蛋白质的一致性为20‐40%,属于BAliBASE 参考序列1。
正确的比对结果网址如下:http://bips.u‐strasbg.fr/en/Products/Databases/BAliBASE/ref1/test1/1csy_ref1.html这一序列名称分别为p43405, p62994, p23727, p27986.获取这4条序列的fasta 格式,放在一个文本文件中,选择ebi网站上(/Tools/msa/)的至少四个多序列比对工具(如MAFFT、MUSCLE、CLUSTALW、Clustal Omega、T‐Coffee、DbClustal)进行分析。
三.实验结果:1.使用CLUSTALW 算法进行比对2A.获取4条序列信息:B.打开/Tools/msa/建立引导树,在引导树的指导下运用CLUSTALW 算法进行比对:五.回答问题:CLUSTALW 算法基本原理:首先进行所有序列之间的两两比较,计算出他们之间的分化距离矩阵;然后从分化距离矩阵中计算出作为指导多序列比较顺序的树状分枝图;最后根据树状图的分支关系,按照分化顺序逐个地把序列加入多序列比较过程。
算法与分析实验报告

算法与分析实验报告一、引言算法是现代计算机科学中的核心概念,通过合理设计的算法可以解决复杂的问题,并提高计算机程序的执行效率。
本次实验旨在通过实际操作和数据统计,对比分析不同算法的执行效率,探究不同算法对于解决特定问题的适用性和优劣之处。
二、实验内容本次实验涉及两个经典的算法问题:排序和搜索。
具体实验内容如下:1. 排序算法- 冒泡排序- 插入排序- 快速排序2. 搜索算法- 顺序搜索- 二分搜索为了对比不同算法的执行效率,我们需要设计合适的测试用例并记录程序执行时间进行比较。
实验中,我们将使用随机生成的整数数组作为排序和搜索的测试数据,并统计执行时间。
三、实验步骤1. 算法实现与优化- 实现冒泡排序、插入排序和快速排序算法,并对算法进行优化,提高执行效率。
- 实现顺序搜索和二分搜索算法。
2. 数据生成- 设计随机整数数组生成函数,生成不同大小的测试数据。
3. 实验设计- 设计实验方案,包括测试数据的规模、重复次数等。
4. 实验执行与数据收集- 使用不同算法对随机整数数组进行排序和搜索操作,记录执行时间。
- 多次重复同样的操作,取平均值以减小误差。
5. 数据分析与结果展示- 将实验收集到的数据进行分析,并展示在数据表格或图表中。
四、实验结果根据实验数据的收集与分析,我们得到以下结果:1. 排序算法的比较- 冒泡排序:平均执行时间较长,不适用于大规模数据排序。
- 插入排序:执行效率一般,在中等规模数据排序中表现良好。
- 快速排序:执行效率最高,适用于大规模数据排序。
2. 搜索算法的比较- 顺序搜索:执行时间与数据规模成线性关系,适用于小规模数据搜索。
- 二分搜索:执行时间与数据规模呈对数关系,适用于大规模有序数据搜索。
实验结果表明,不同算法适用于不同规模和类型的问题。
正确选择和使用算法可以显著提高程序的执行效率和性能。
五、实验总结通过本次实验,我们深入了解了不同算法的原理和特点,并通过实际操作和数据分析对算法进行了比较和评估。
实验四 基于CLUSTAL算法的多重序列比对分析

实验四基于CLUSTAL算法的多重序列比对分析1. CLUSTAL简介CLUSTAL是对核苷酸或蛋白质进行多序列比对的程序,也可以对来自不同物种的功能相同或相似的序列进行比对和聚类,通过构建系统发生树判断亲缘关系,并对序列在生物进化过程中的保守性进行估计。
CLUSTAL有CLUSTALX和CLUSTALW之分,CLUSTALW 是以命令行格式运行,CLUSTALX则通过窗口格式进行操作。
目前最新版本为CLUSTAL 1.83,均可以从ftp:///pub/software/下载。
这里我们主要介绍CLUSTAL W,从ftp直接下载DOS文件夹下的CLUSTAL W到本地磁盘解压,其中有两个exe文件,CLUSTALW.exe是进行多序列比对和生成亲缘树的程序,而njplotWIN95则是对CLUSTALW.exe运行结果进行察看的程序。
另外还有许多在线的Clustal W服务,例如:/Clustalw/2 . 本地运行Clustal WClustal W程序能自动识别输入的序列,通常当读入的序列字母85%以上为A、C、G、T、U或N时,则被认为是核苷酸序列,反之为蛋白质序列。
进行多序列比对时,要求所有输入的序列按顺序储存于一个文件中。
当有大量的序列文件时,可以在Unix操作系统下用cat file1.seqfile2.seq……>multiseq.seq命令合并成一个文件序列的储存格式必须为以下7种格式之一,他们分别是:NBRF/PRI、EMBL/SWISSPORT、Pearson(Fasta)、Clustal(*.aln)、GCG/MSF(Pileup)、GCG9/RSF和GDE,除了“-”和“.”外所有的非字母都将被忽略。
这里我们将不同来源的15条甲硫酰胺tRNA 合成酶的氨基酸序列,保存在单一文件multiseq.file中。
进入程序安装目录,双击CLUSTALW.exe文件,进入Clustal W的主菜单界面(见图1)。
算法设计与分析实验报告

实验一找最大和最小元素与归并分类算法实现(用分治法)一、实验目的1.掌握能用分治法求解的问题应满足的条件;2.加深对分治法算法设计方法的理解与应用;3.锻炼学生对程序跟踪调试能力;4.通过本次实验的练习培养学生应用所学知识解决实际问题的能力。
二、实验内容1、找最大和最小元素输入n 个数,找出最大和最小数的问题。
2、归并分类将一个含有n个元素的集合,按非降的次序分类(排序)。
三、实验要求(1)用分治法求解问题(2)上机实现所设计的算法;四、实验过程设计(算法设计过程)1、找最大和最小元素采用分治法,将数组不断划分,进行递归。
递归结束的条件为划分到最后若为一个元素则max和min都是这个元素,若为两个取大值赋给max,小值给min。
否则就继续进行划分,找到两个子问题的最大和最小值后,比较这两个最大值和最小值找到解。
2、归并分类使用分治的策略来将一个待排序的数组分成两个子数组,然后递归地对子数组进行排序,最后将排序好的子数组合并成一个有序的数组。
在合并过程中,比较两个子数组的首个元素,将较小的元素放入辅助数组,并指针向后移动,直到将所有元素都合并到辅助数组中。
五、源代码1、找最大和最小元素#include<iostream>using namespace std;void MAXMIN(int num[], int left, int right, int& fmax, int& fmin); int main() {int n;int left=0, right;int fmax, fmin;int num[100];cout<<"请输入数字个数:";cin >> n;right = n-1;cout << "输入数字:";for (int i = 0; i < n; i++) {cin >> num[i];}MAXMIN(num, left, right, fmax, fmin);cout << "最大值为:";cout << fmax << endl;cout << "最小值为:";cout << fmin << endl;return 0;}void MAXMIN(int num[], int left, int right, int& fmax, int& fmin) { int mid;int lmax, lmin;int rmax, rmin;if (left == right) {fmax = num[left];fmin = num[left];}else if (right - left == 1) {if (num[right] > num[left]) {fmax = num[right];fmin = num[left];}else {fmax = num[left];fmin = num[right];}}else {mid = left + (right - left) / 2;MAXMIN(num, left, mid, lmax, lmin);MAXMIN(num, mid+1, right, rmax, rmin);fmax = max(lmax, rmax);fmin = min(lmin, rmin);}}2、归并分类#include<iostream>using namespace std;int num[100];int n;void merge(int left, int mid, int right) { int a[100];int i, j,k,m;i = left;j = mid+1;k = left;while (i <= mid && j <= right) {if (num[i] < num[j]) {a[k] = num[i++];}else {a[k] = num[j++];}k++;}if (i <= mid) {for (m = i; m <= mid; m++) {a[k++] = num[i++];}}else {for (m = j; m <= right; m++) {a[k++] = num[j++];}}for (i = left; i <= right; i++) { num[i] = a[i];}}void mergesort(int left, int right) { int mid;if (left < right) {mid = left + (right - left) / 2;mergesort(left, mid);mergesort(mid + 1, right);merge(left, mid, right);}}int main() {int left=0,right;int i;cout << "请输入数字个数:";cin >> n;right = n - 1;cout << "输入数字:";for (i = 0; i < n; i++) {cin >> num[i];}mergesort(left,right);for (i = 0; i < n; i++) {cout<< num[i];}return 0;}六、运行结果和算法复杂度分析1、找最大和最小元素图1-1 找最大和最小元素结果算法复杂度为O(logn)2、归并分类图1-2 归并分类结果算法复杂度为O(nlogn)实验二背包问题和最小生成树算法实现(用贪心法)一、实验目的1.掌握能用贪心法求解的问题应满足的条件;2.加深对贪心法算法设计方法的理解与应用;3.锻炼学生对程序跟踪调试能力;4.通过本次实验的练习培养学生应用所学知识解决实际问题的能力。
C语言实验报告 实验四 参考答案
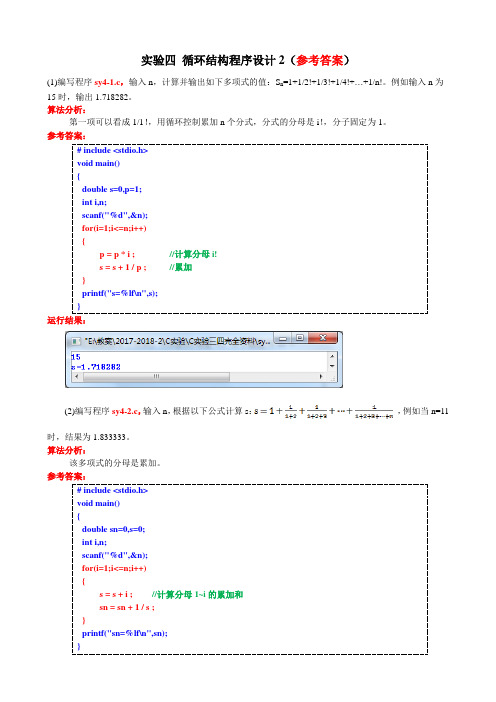
实验四循环结构程序设计2(参考答案)(1)编写程序sy4-1.c,输入n,计算并输出如下多项式的值:S n=1+1/2!+1/3!+1/4!+…+1/n!。
例如输入n为15时,输出1.718282。
算法分析:第一项可以看成1/1!,用循环控制累加n个分式,分式的分母是i!,分子固定为1。
参考答案:# include <stdio.h>void main(){double s=0,p=1;int i,n;scanf("%d",&n);for(i=1;i<=n;i++){p = p * i ; //计算分母i!s = s + 1 / p ; //累加}printf("s=%lf\n",s);}运行结果:(2)编写程序sy4-2.c,输入n,根据以下公式计算s:,例如当n=11时,结果为1.833333。
算法分析:该多项式的分母是累加。
参考答案:# include <stdio.h>void main(){double sn=0,s=0;int i,n;scanf("%d",&n);for(i=1;i<=n;i++){s = s + i ; //计算分母1~i的累加和sn = sn + 1 / s ;}printf("sn=%lf\n",sn);}运行结果:(3)编写程序sy4-3.c,计算3~n之间所有素数的平方根之和,要求:输入n,输出结果。
例如,输入n 的值是100,则输出结果是148.874270。
注意n应在2~100之间。
算法分析:穷举3~n之间的数找素数,若是素数则累加她的平方根。
参考答案:# include <stdio.h># include <math.h>void main(){int i,j,n,flag;double s=0;scanf("%d",&n);for(i=3;i<n;i++) //穷举3~n之间找素数{flag=1; //假设当前的i是素数,标志变量设为1for(j=2;j<i;j++) //穷举要判断是否是素数的i的除数,范围2~i-1if(i%j==0) //若i能被j整除,则不是素数{ flag=0; break; } //标志变量改为0,并终止循环if( flag == 1 )s = s + sqrt( i ); //若i是素数,则累加sqrt(i)}printf("s=%f\n",s);}运行结果:(4)编写程序sy4-4.c,根据以下公式求p的值,(m与n为两个正整数且m>n)。
算法设计与分析实验报告

算法设计与分析报告学生姓名学号专业班级指导教师完成时间目录一、课程内容 (3)二、算法分析 (3)1、分治法 (3)(1)分治法核心思想 (3)(2)MaxMin算法分析 (3)2、动态规划 (4)(1)动态规划核心思想 (4)(2)矩阵连乘算法分析 (5)3、贪心法 (5)(1)贪心法核心思想 (5)(2)背包问题算法分析 (6)(3)装载问题算法分析 (7)4、回溯法 (7)(1)回溯法核心思想 (7)(2)N皇后问题非递归算法分析 (7)(3)N皇后问题递归算法分析 (8)三、例子说明 (9)1、MaxMin问题 (9)2、矩阵连乘 (10)3、背包问题 (10)4、最优装载 (10)5、N皇后问题(非递归) (11)6、N皇后问题(递归) (11)四、心得体会 (12)五、算法对应的例子代码 (12)1、求最大值最小值 (12)2、矩阵连乘问题 (13)3、背包问题 (15)4、装载问题 (17)5、N皇后问题(非递归) (19)6、N皇后问题(递归) (20)一、课程内容1、分治法,求最大值最小值,maxmin算法;2、动态规划,矩阵连乘,求最少连乘次数;3、贪心法,1)背包问题,2)装载问题;4、回溯法,N皇后问题的循环结构算法和递归结构算法。
二、算法分析1、分治法(1)分治法核心思想当要求解一个输入规模为n,且n的取值相当大的问题时,直接求解往往是非常困难的。
如果问题可以将n个输入分成k个不同子集合,得到k个不同的可独立求解的子问题,其中1<k≤n, 而且子问题与原问题性质相同,原问题的解可由这些子问题的解合并得出。
那末,这类问题可以用分治法求解。
分治法的核心技术1)子问题的划分技术.2)递归技术。
反复使用分治策略将这些子问题分成更小的同类型子问题,直至产生出不用进一步细分就可求解的子问题。
3)合并技术.(2)MaxMin算法分析问题:在含有n个不同元素的集合中同时找出它的最大和最小元素。
实验四 图的遍历算法

实验四图的遍历算法4.1.实验的问题与要求1.如何对给定图的每个顶点各做一次且仅做一次访问?有哪些方法可以实现图的遍历?2.如何用这些算法解决实际问题?3.熟练掌握图的基本存储方法4.熟练掌握图的两种搜索路径的遍历方法5.掌握有关图的操作算法并用高级语言实现4.2.实验的基本思想和基本原理和树的遍历类似,图的遍历也是从某个顶点出发,沿着某条搜索路径对图中每个顶点各做一次且仅做一次访问。
它是许多图的算法的基础。
遍历常用两种方法:深度优先搜索遍历;广度优先搜索遍历4.2.1 深度优先搜索(Depth-First Traversal)深度优先搜索是一种递归的过程,正如算法名称那样,深度优先搜索所遵循的搜索策略是尽可能“深”地搜索图。
在深度优先搜索中,对于最新发现的顶点,如果它还有以此为起点而未探测到的边,就沿此边继续下去。
当结点v的所有边都己被探寻过,搜索将回溯到发现结点v有那条边的始结点。
这一过程一直进行到已发现从源结点可达的所有结点为止。
如果还存在未被发现的结点,则选择其中一个作为源结点并重复以上过程,整个进程反复进行直到所有结点都被发现为止。
1.图的深度优先遍历的递归定义假设给定图G的初态是所有顶点均未曾访问过。
在G中任选一顶点v 为初始出发点(源点),则深度优先遍历可定义如下:首先访问出发点v,并将其标记为已访问过;然后依次从v出发搜索v的每个邻接点w。
若w未曾访问过,则以w为新的出发点继续进行深度优先遍历,直至图中所有和源点v有路径相通的顶点(亦称为从源点可达的顶点)均已被访问为止。
若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点作为新的源点重复上述过程,直至图中所有顶点均已被访问为止。
图的深度优先遍历类似于树的前序遍历。
采用的搜索方法的特点是尽可能先对纵深方向进行搜索。
这种搜索方法称为深度优先搜索(Depth-First Search)。
相应地,用此方法遍历图就很自然地称之为图的深度优先遍历。
数值分析实验(4)

页脚内容1实验四 数值积分与数值微分专业班级:信计131班 姓名:段雨博 学号:2013014907 一、实验目的1、熟悉matlab 编程。
2、学习数值积分程序设计算法。
3、通过上机进一步领悟用复合梯形、复合辛普森公式,以及用龙贝格求积方法计算积分的原理。
二、实验题目 P1371、用不同数值方法计算积分049xdx =-⎰。
(1)取不同的步长h .分别用复合梯形及复合辛普森求积计算积分,给出误差中关于h 的函数,并与积分精确值比较两个公式的精度,是否存在一个最小的h ,使得精度不能再被改善?(2)用龙贝格求积计算完成问题(1)。
三、实验原理与理论基础1.1复合梯形公式及其复合辛普森求解[]()()()11101()()222n n n k k k k k h h T f x f x f a f x f b --+==⎡⎤=+=++⎢⎥⎣⎦∑∑误差关于h 的函数:()()212n b a R fh f η-''=-页脚内容2复合辛普森公式:()()()()111/201426n n n k k k k h S f a f x f x f b --+==⎡⎤=+++⎢⎥⎣⎦∑∑误差关于h 的函数:()()441802n n b a h R f I S f η-⎛⎫=-=- ⎪⎝⎭1.2龙贝格求积算法:龙贝格求积公式是梯形法的递推化,也称为逐次分半加速法,它是在梯形公式、辛普森公式和柯特斯公式之间的关系的基础上,构造出一种计算积分的方法,同时它有在不断增加计算量的前提下提高误差的精度的特点。
计算过程如下:(1)取0,k h b a ==-,求:()()()[]()00.,.2hT f a f b k a b =+→⎡⎤⎣⎦令k 1记为区间的二分次数 (2)求梯形值02k b a T -⎛⎫⎪⎝⎭即按递推公式12102122n n n k k h T T f x -+=⎛⎫=+ ⎪⎝⎭∑计算0k T .(3)求加速值,按公式()()()111444141m m k k k mm m m m T T T +--=---逐个求出T 表的地k 行其余各元素()()1,2,,k j j T j k -=(4)若()()001k k T T ε--<(预先给定的精度),则终止计算,并取()()0;1k T I k k ≈+→否则令转(2)继续计算。
数值分析实验四(Lagrange插值)

《数值分析》实验报告实验编号:实验四课题名称:Lagrange插值一、算法介绍对Lagrange型的n次插值多项式,先构造n+1个插值节点x[0],x[1],…,x[n]上的n次插值基函数对任一点xi所对应的插值基函数l[i](x)=[(x-x[0])…(x-x[i-1])(x-x[i+1])…(x-x[n])]/[(x[i]-x[0])…(x[i]-x[i-1])(x[i]-x[i+1 ])…(x[i]-x[n])],其中i=0,1,2,…,n。
有了这n+1个n次插值基函数,n次Lagrange 型插值多项式就容易写出来了,表达式为:f(x)=y[1]*l[1](x)+y[2]*l[2](x)+…+y[n]*l[n](x)。
此程序中n=10。
二、程序代码// testView.cpp : implementation of the CTestView class//#include "stdafx.h"#include "test.h"#include "testDoc.h"#include "testView.h"#ifdef _DEBUG#define new DEBUG_NEW#undef THIS_FILEstatic char THIS_FILE[] = __FILE__;#endif/////////////////////////////////////////////////////////////////////////////// CTestViewIMPLEMENT_DYNCREATE(CTestView, CView)BEGIN_MESSAGE_MAP(CTestView, CView)//{{AFX_MSG_MAP(CTestView)// NOTE - the ClassWizard will add and remove mapping macros here.// DO NOT EDIT what you see in these blocks of generated code!//}}AFX_MSG_MAP// Standard printing commandsON_COMMAND(ID_FILE_PRINT, CView::OnFilePrint)ON_COMMAND(ID_FILE_PRINT_DIRECT, CView::OnFilePrint)ON_COMMAND(ID_FILE_PRINT_PREVIEW, CView::OnFilePrintPreview)END_MESSAGE_MAP()/////////////////////////////////////////////////////////////////////////////// CTestView construction/destructionCTestView::CTestView(){// TODO: add construction code here}CTestView::~CTestView(){}BOOL CTestView::PreCreateWindow(CREATESTRUCT& cs){// TODO: Modify the Window class or styles here by modifying // the CREATESTRUCT csreturn CView::PreCreateWindow(cs);}/////////////////////////////////////////////////////////////////////////////// CTestView drawingvoid CTestView::OnDraw(CDC* pDC){CTestDoc* pDoc = GetDocument();ASSERT_V ALID(pDoc);// TODO: add draw code for native data hereint i,j,k;double x,y,p_x,p_y,l,xx[100],f[100],F[100],sum,p_sum;CPen MyPen,*OldPen;pDC->SetViewportOrg(400,400); //定义坐标原点for(i=-500;i<500;i++){pDC->SetPixel(0,i,RGB(0,0,0));pDC->SetPixel(i,0,RGB(0,0,0)); //画出坐标}pDC->TextOut(-210,5,"-1");pDC->TextOut(196,5,"1");//原函数MyPen.CreatePen(PS_SOLID,1,RGB(255,0,0));//定义画笔颜色OldPen=pDC->SelectObject(&MyPen);x=-1.0,y=1/(1+25*x*x);p_x=x*200;p_y=-y*200;pDC->MoveTo(p_x,p_y);for (x=-1.0;x<=1.0;x+=0.0001){y=1/(1+25*x*x);p_x=x*200;p_y=-y*200;pDC->LineTo(p_x,p_y);}pDC->SelectObject(OldPen);MyPen.DeleteObject();//Lagrange插值x=-1.0;MyPen.CreatePen(PS_SOLID,1,RGB(0,255,0));OldPen=pDC->SelectObject(&MyPen);for(i=0;i<=10;i++){f[i]=1/(1+25*x*x);xx[i]=x;x+=0.2;}x=-1.0;y=1/(1+25*x*x);p_x=x*200,p_y=-y*200; //将x和y坐标各放大200倍pDC->MoveTo(p_x,p_y);for(k=0;k<=1000;k++){sum=0;for(i=0;i<=10;i++){l=1;for(j=0;j<=10;j++){if(i!=j)l=l*(x-xx[j])/(xx[i]-xx[j]);}sum+=f[i]*l;}p_x=x*200;p_y=-sum*200;pDC->LineTo(p_x,p_y);x+=0.002;}pDC->SelectObject(OldPen);MyPen.DeleteObject();}/////////////////////////////////////////////////////////////////////////////// CTestView printingBOOL CTestView::OnPreparePrinting(CPrintInfo* pInfo){// default preparationreturn DoPreparePrinting(pInfo);}void CTestView::OnBeginPrinting(CDC* /*pDC*/, CPrintInfo* /*pInfo*/){// TODO: add extra initialization before printing}void CTestView::OnEndPrinting(CDC* /*pDC*/, CPrintInfo* /*pInfo*/){// TODO: add cleanup after printing}/////////////////////////////////////////////////////////////////////////////// CTestView diagnostics#ifdef _DEBUGvoid CTestView::AssertValid() const{CView::AssertValid();}void CTestView::Dump(CDumpContext& dc) const{CView::Dump(dc);}CTestDoc* CTestView::GetDocument() // non-debug version is inline{ASSERT(m_pDocument->IsKindOf(RUNTIME_CLASS(CTestDoc)));return (CTestDoc*)m_pDocument;}#endif //_DEBUG/////////////////////////////////////////////////////////////////////////////// CTestView message handlers三、运算结果截屏红色的曲线为原函数图像,绿色曲线为Lagerange插值多项式函数对应的图像四、算法分析上述图像中绿色的曲线为Lagrange插值多项式所对应的图像,通过观察可见函数图像在靠近区间端点的地方出现了Runge现象。
《-C语言程序设计》实验指导书

《C语言程序设计》实验指导书课程编号:课程名称:C语言程序设计•实验学时:44一、本实验课的性质、任务与tl的本实验课目的是使学生掌握C语言编程的常用方法,熟悉该语言中的语法、词法规则,为以后进行软件开发和学习后继专业课程打下基础。
通过学习能够运用c语言中的各个知识点编写能完成一定功能的程序。
训练学生进行复杂程序设计的技能和培养良好程序设计的习惯,其重要程度决不亚于知识的传授。
把高级语言的学习与程序设计.上机实践紧密地结合起来,以提高学生能灵活运用新的知识分析问题和解决问题的能力。
二、本实验课所依据的课程基本理论本实验课基于C语言的语法和词法规则、数据的表示及算法的处理,而语法及算法正是高级语言程序设计的主要研究对象。
《C语言程序设计》的主要任务是:C语言是一种应用广泛结构化程序设计语言,本课程介绍c语言的基本概念.基本语法和编程方法,重点描述C语言的结构化的特征,并通过本课程的学习,使学生掌握一定的结构化程序设计的知识,以及用C语言编写程序的能力。
三、实验类型与要求在做每个实验之前,让学生对本次实验相关的内容进行预习、算法设计、流程图的设计、编写程序,做好实验的准备工作;写出预习报告,画出流程图, 要求独立完成。
说明:1>实验类型:设计性;2、实验要求:必做。
四、每组人数与实验学时数每组1人,实验学时数44学时。
五、考核方式与评分办法实验总成绩二出勤情况"0%+实验报告*20%+平时*30%+实验表现*40%六、本实验课配套教材或实验指导书谭浩强.C程序设计.北京:清华大学出版社,2006年3月第3版谭浩强.C程序设计题解与上机指导.北京:清华大学出版社,2006年3月第3版谭浩强.C程序设计试题汇编.北京:清华大学出版社,2006年3月第2版夏宽理.C语言程序设计.北京:中国铁道出版社,2006年2月第1版夏宽理.C语言程序设计上机指导与习题解答.北京:中国铁道出版社,2006年2月第1 版王士元・C高级实用程序设计.北京:清华大学出版社,1996年1月第1版七、实验报告要求在机器上交作业,每次实验成绩分为优、良、及格、不及格,未参加的为0分。
实验报告

合肥师范学院实验报告册2016/ 2017 学年第 1 学期系别计算机学院实验课程算法设计与分析专业软件工程班级一班姓名杨文皇学号1310421071指导教师程敏实验一:分治算法一、实验目的1、理解分治策略的基本思想;2、掌握用分治法解决问题的一般技巧。
二、实验内容利用分治算法在含有n个不同元素的数组a[n]中同时找出它的最大的两个元素和最小的两个元素,编写出完整的算法,并分析算法的时间复杂度。
三、实验源程序。
1、算法设计思想利用分治法思想,n个不同元素的数组不断进行划分,化为若干个个子问题,其与原问题形式相;解决子问题规模较小而容易解决则直接解决:即当n的规模为只有一个或两个,三个或四个;否则再继续直至更小的子问题:即当n的规模大于四时。
将已求得的各个子问题的解,逐步合并原问题的解:即将左右两边求得的子问题进行比较,在四个数据中的得到两个最大(最小)值。
为了简化空间,采用了对每一个小规模问题的排序,以及合并原问题时,对四个数据进行排序,获得当前或合并的最大(最小)值2、算法实现#include<iostream>using namespace std;int a[10]={4,5,6,2,3,9,8,13,1};int b[4];int sort(int i,int j){int temp,k;for(;i<j;i++){for(k=i;k<j;k++)if(a[k]>a[k+1]){temp=a[k];a[k]=a[k+1];a[k+1]=temp;}}return 0;}int sort1(int lmin1,int lmin2,int rmin1,int rmin2){int i,j,temp;b[0]=lmin1;b[1]=lmin2;b[2]=rmin1;b[3]=rmin2;for(i=0;i<=1;i++)for(j=i;j<=3;j++){if(b[i]>b[j]){temp=b[i];b[i]=b[j];b[j]=temp;}}return 0;}int maxmin(int i,int j,int &fmin1,int &fmin2,int &fmax1,int &fmax2) {int mid;int lmin1,lmin2,lmax1,lmax2;int rmin1,rmin2,rmax1,rmax2;if(i==j || i==j-1){sort(i,j);fmin1=a[i];fmin2=a[i];fmax1=a[j];fmax2=a[j];}elseif(i==j-2 || i==j-3){sort(i,j);fmin1=a[i];fmin2=a[i+1];fmax1=a[j-1];fmax2=a[j];}else{mid=(i+j)/2;maxmin(i,mid,lmin1,lmin2,lmax1,lmax2);maxmin(mid+1,j,rmin1,rmin2,rmax1,rmax2);sort1(lmin1,lmin2,rmin1,rmin2);fmin1=b[0];fmin2=b[1];sort1(lmax1,lmax2,rmax1,rmax2);fmax1=b[2];fmax2=b[3];}return 0;}int main(){int fmin1,fmin2,fmax1,fmax2;int i;maxmin(0,8,fmin1,fmin2,fmax1,fmax2);cout<<endl;cout<<"该组数据为:";for(i=0;i<=8;i++)cout<<a[i]<<" ";cout<<endl<<endl<<"最小值是:"<<fmin1<<",第二小值是:"<<fmin2<<endl;cout<<endl<<"第二大值是:"<<fmax1<<",最大值是:"<<fmax2<<endl<<endl;return 0;}3、程序结果4、算法分析用T(n)元素表示数,则导出的递推关系式是:在理想的情况下,即每一小规模的子问题中的数据都是递增序列,则:当n<=4时,T(n)=1; 当n>4时,T(n)= T(n/2)+ T(n/2)(均向下取整);在非理想情况下,即每一小规模的子问题中的数据都是递减序列,则:当n=1时,T(n)=1;当n=2时,T(n)=2;当n=3时,T(n)=3;当n=4时,T(n)=6;当n>4时,T(n)= T(n/2)+ T(n/2)(均向下取整)+12。
实验四拉格朗日法插值

实验四用VC显示一定范围的确定函数及拉格朗日法插值得到的逼近函数的图像学院:计算机与信息工程学院班级: 计算机科学与技术师范汉班学号: 20081121107姓名: 黄志强指导老师: 马季驌算法分析:本程序运用计算机图形学的基本绘图函数进行画点绘图。
SetPixel(int(x+0.5),int (f(x)+0.5),colorref);我们剩下的工作就是求出f(x) 的各种插值逼近函数(原函数已经给出)的。
任务要求做三个近似函数:拉格朗日插值近似,分段线性插值近似,和Hermite分段三点二次插值。
本程序的算法核心是用程序实现形式较为繁杂的插值函数的表示。
拉格朗日插值函数的形式为在插值点处的函数值于二次插值基函数的线性组合;程序实现细则如下。
源代码:插值基函数double CMyView::L(int i, double x){double m=1;int j;for(j=0;j<N;j++){if(j==i)continue;m=m*(x-cx[j])/(cx[i]-cx[j]);}return m;}拉格朗日逼近函数(插值基函数与原函数在形值点处的线性组合)double CMyView::fai(double x){int i;double y=0;for(i=0;i<N;i++){y+=f(cx[i])*L(i,x);//L(i,x)有累积效应出错}return y;}结果截图:原函数图像拉格朗日插值函数图像拉格朗日插值函数图像与原函数图像的对照结果分析:拉格朗日插值逼近函数由于使用了10 个形值点,插值函数的次数高达9,函数的稳定性差产生了非常严重的荣格现象。
算法设计与分析实验报告

本科实验报告课程名称:算法设计与分析实验项目:递归与分治算法实验地点:计算机系实验楼110专业班级:物联网1601 学号:2016002105 学生姓名:俞梦真指导教师:郝晓丽2018年05月04 日实验一递归与分治算法1.1 实验目的与要求1.进一步熟悉C/C++语言的集成开发环境;2.通过本实验加深对递归与分治策略的理解和运用。
1.2 实验课时2学时1.3 实验原理分治(Divide-and-Conquer)的思想:一个规模为n的复杂问题的求解,可以划分成若干个规模小于n的子问题,再将子问题的解合并成原问题的解。
需要注意的是,分治法使用递归的思想。
划分后的每一个子问题与原问题的性质相同,可用相同的求解方法。
最后,当子问题规模足够小时,可以直接求解,然后逆求原问题的解。
1.4 实验题目1.上机题目:格雷码构造问题Gray码是一个长度为2n的序列。
序列无相同元素,每个元素都是长度为n的串,相邻元素恰好只有一位不同。
试设计一个算法对任意n构造相应的Gray码(分治、减治、变治皆可)。
对于给定的正整数n,格雷码为满足如下条件的一个编码序列。
(1)序列由2n个编码组成,每个编码都是长度为n的二进制位串。
(2)序列中无相同的编码。
(3)序列中位置相邻的两个编码恰有一位不同。
2.设计思想:根据格雷码的性质,找到他的规律,可发现,1位是0 1。
两位是00 01 11 10。
三位是000 001 011010 110 111 101 100。
n位是前n-1位的2倍个。
N-1个位前面加0,N-2为倒转再前面再加1。
3.代码设计:}}}int main(){int n;while(cin>>n){get_grad(n);for(int i=0;i<My_grad.size();i++)cout<<My_grad[i]<<endl;My_grad.clear();}return 0;}运行结果:1.5 思考题(1)递归的关键问题在哪里?答:1.递归式,就是如何将原问题划分成子问题。
霍夫曼算法实验报告

一、实验目的1. 理解霍夫曼算法的基本原理和过程。
2. 掌握霍夫曼算法的编程实现。
3. 分析霍夫曼算法的复杂度和性能。
二、实验原理霍夫曼算法是一种贪心算法,用于数据压缩。
其基本思想是根据字符出现的频率,构造出一棵最优二叉树,从而得到最优的编码方案。
霍夫曼算法的步骤如下:1. 统计每个字符的出现频率。
2. 将频率相同的字符视为一类,按照频率从小到大排序。
3. 将排序后的字符中频率最小的两个字符合并成一个新字符,新字符的频率为两个字符频率之和。
4. 将新字符插入到排序后的字符中,并重新排序。
5. 重复步骤3和4,直到只剩下一个字符为止。
6. 根据合并的顺序,从根节点到叶子节点的路径上,将0和1分别赋给路径,形成每个字符的霍夫曼编码。
三、实验内容1. 编写程序实现霍夫曼算法。
2. 对给定的字符集进行编码和解码。
3. 分析霍夫曼算法的复杂度和性能。
四、实验步骤1. 编写程序,统计字符集的频率。
2. 根据频率构造最优二叉树。
3. 根据最优二叉树生成霍夫曼编码。
4. 编写解码程序,根据霍夫曼编码解码字符。
5. 测试程序,分析霍夫曼算法的复杂度和性能。
五、实验结果与分析1. 实验结果(1)霍夫曼编码示例假设字符集为:{a, b, c, d, e, f},频率分别为:{4, 2, 3, 5, 7, 8}。
(2)霍夫曼编码根据霍夫曼算法,得到以下编码:a: 0b: 10c: 110d: 1110e: 1111f: 100(3)解码根据霍夫曼编码,解码结果为:{a, b, c, d, e, f}。
2. 实验分析(1)复杂度分析霍夫曼算法的时间复杂度为O(nlogn),其中n为字符集的长度。
这是因为算法需要构建一个最优二叉树,而构建最优二叉树的时间复杂度为O(nlogn)。
(2)性能分析霍夫曼编码具有较好的压缩效果,其平均编码长度较其他编码方法短。
当字符集中字符的频率差异较大时,霍夫曼编码的压缩效果更明显。
六、实验总结通过本次实验,我们掌握了霍夫曼算法的基本原理和编程实现,分析了算法的复杂度和性能。
《算法设计与分析》课程实验报告 (分治法(三))

《算法设计与分析》课程实验报告实验序号:04实验项目名称:实验4 分治法(三)一、实验题目1.邮局选址问题问题描述:在一个按照东西和南北方向划分成规整街区的城市里,n个居民点散乱地分布在不同的街区中。
用x 坐标表示东西向,用y坐标表示南北向。
各居民点的位置可以由坐标(x,y)表示。
街区中任意2 点(x1,y1)和(x2,y2)之间的距离可以用数值∣x1−x2∣+∣y1−y2∣度量。
居民们希望在城市中选择建立邮局的最佳位置,使n个居民点到邮局的距离总和最小。
编程任务:给定n 个居民点的位置,编程计算邮局的最佳位置。
2.最大子数组问题问题描述:对给定数组A,寻找A的和最大的非空连续子数组。
3.寻找近似中值问题描述:设A是n个数的序列,如果A中的元素x满足以下条件:小于x的数的个数≥n/4,且大于x的数的个数≥n/4 ,则称x为A的近似中值。
设计算法求出A的一个近似中值。
如果A中不存在近似中值,输出false,否则输出找到的一个近似中值4.循环赛日程表问题描述:设有n=2^k个运动员要进行网球循环赛。
现要设计一个满足以下要求的比赛日程表:每个选手必须与其他n-1个选手各赛一次,每个选手一天只能赛一次,循环赛一共进行n-1天。
二、实验目的(1)进一步理解分治法解决问题的思想及步骤(2)体会分治法解决问题时递归及迭代两种不同程序实现的应用情况之差异(3)熟练掌握分治法的自底向上填表实现(4)将分治法灵活于具体实际问题的解决过程中,重点体会大问题如何分解为子问题及每一个大问题涉及哪些子问题及子问题的表示。
三、实验要求(1)写清算法的设计思想。
(2)用递归或者迭代方法实现你的算法,并分析两种实现的优缺点。
(3)根据你的数据结构设计测试数据,并记录实验结果。
(4)请给出你所设计算法的时间复杂度的分析,如果是递归算法,请写清楚算法执行时间的递推式。
四、实验过程(算法设计思想、源码)1.邮局选址问题(1)算法设计思想根据题目要求,街区中任意2 点(x1,y1)和(x2,y2)之间的距离可以用数值∣x1−x2∣+∣y1−y2∣度量。
先来先服务调度算法实验四分析报告

操作系统实验四设计先来先服务进程调度模拟算法实验提示:进程个数至少5个以上(动态),也可让用户动态输入,每个进程由一个进程控制块来标识,进程控制块的内容根据情况自己设计,但至少要有进程名、进程状态、到达时间、估计运行时间信息;设计一个先进先出队列和系统时间,调度时,总是选择队列头部(到达时间最早)的进程;当进程到达时间小于系统时间时,进程执行,当在当前时间没有到达的进程时,可安排延时来模拟闲逛进程。
由于本实验为模拟实验,所以被选中调度进程并不实际启动运行,而仅执行按估计运行时间延时,并输出进程的开始和结束运行信息模拟进程的运行,而且省去进程的现场保护和现场恢复工作。
在所设计的程序中应有显示或打印语句,能显示或打印就绪队列中的进程、正运行进程的进程名、开始运行时间、结束运行时间等,给出各进程的周转时间和平均周转时间。
实验要求:实验报告中要给出流程图和源程序,源程序中要附有详细的注释,给出程序运行时的输入值和运行结果总结收获或对该题的改进意见和见解。
流程图:源程序:输入值:ID 进程名到达时间服务时间1 A2 32 B3 43 C4 5运行结果:总结收获:通过本次实验,我了解到如果早就绪的进程排在就绪队列的前面,迟就绪的进程排在就绪队列的后面,那么先来先服务总是把当前处于就绪队列之首的那个进程调度到运行状态。
也就说,它只考虑进程进入就绪队列的先后,而不考虑它的下一个CPU周期的长短及其他因素。
FCFS算法简单易行,是一种非抢占式策略,但性能却不大好。
先来先服务的调度算法:最简单的调度算法,既可以用于作业调度,也可以用于程序调度,当作业调度中采用该算法时,系统将按照作业到达的先后次序来进行调度,优先从后备队列中,选择一个或多个位于队列头部的作业,把他们调入内存,分配所需资源、创建进程,然后放入“就绪队列”,直到该进程运行到完成或发生某事件堵塞后,进程调度程序才将处理机分配给其他进程。
有利于长作业(进程)而不利于短作业(进程)和CPU 繁忙型作业(进程)而不利于I/O繁忙型作业(进程)。