UDF中的数据类型
UDF教程

第五章 UDF其他应用领域
5.1 UDF并行化处理(1)
UDF的并行化:并行化处理后UDF串行和并行都可以运行
5.1 UDF并行化处理(1)
5.1 UDF并行化处理(1)
1.预处理 2.循环
3.同步化
4.Node与host之间的数据传输
5.1 UDF并行化处理(1)
1.预处理
5.1 UDF并行化处理(1)
3.2 梯度宏
单元标量及存储器宏
C_UDSI(c,t,i) C_UDSI_G(c,t,i) C_UDSI_M1(c,t,i) C_UDSI_M2(c,t,i) C_UDSI_DIFF(c,t,i) C_UDMI(f,t,i) F_UDMI(f,t,i)
F_UDSI(f,t,i)
3.2 梯度宏
3.3 UDS实例讲解(1)
5.8 UDF在动网格中的应用(3)
独立控制每个节点,用于边界和流体区域,不允许remesh 不允许连接改变,每个时间步都会调用
5.9 UDF在动网格中的应用(4)
5.9 UDF在动网格中的应用(4)
5.10 动网格UDF实例(1)
5.11 动网格UDF实例(2)
5.12 动网格UDF实例(3)
2.1 DEFINE_PROFILE宏
2.2 实例讲解
入口温度:300K 层流 不可压缩
2.3 DEFINE_SOURCE宏
不需要循环语句
2.4 实例讲解(2)
2.5 DEFINE_INIT宏
只在默认初始化后执行一次,一般用作 初始化自定义
2.6 DEFINE_ADJUST宏
每次迭代开始时调用,与迭代执行次数相同
1.4 代码实例讲解
1.4 代码实例讲解
UDF中的数据类型
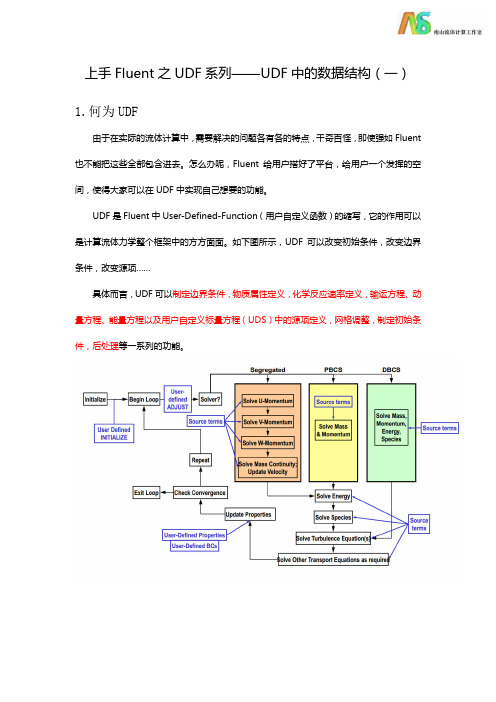
上手Fluent之UDF系列——UDF中的数据结构(一) 1.何为UDF由于在实际的流体计算中,需要解决的问题各有各的特点,千奇百怪,即使强如Fluent 也不能把这些全部包含进去。
怎么办呢,Fluent给用户搭好了平台,给用户一个发挥的空间,使得大家可以在UDF中实现自己想要的功能。
UDF是Fluent中User-Defined-Function(用户自定义函数)的缩写,它的作用可以是计算流体力学整个框架中的方方面面。
如下图所示,UDF可以改变初始条件,改变边界条件,改变源项……具体而言,UDF可以制定边界条件,物质属性定义,化学反应速率定义,输运方程、动量方程、能量方程以及用户自定义标量方程(UDS)中的源项定义,网格调整,制定初始条件,后处理等一系列的功能。
2.UDF中的数据类型数据结构的概念便于我们去找到我们需要的变量,首先要找到变量,才能修改它,去定义它,去计算它。
UDF中的数据主要采用Thread的概念,Thread代表了一系列cell(体积单元),face (面),与node(节点)的集合。
举例Domain *d; d 代表指向domain的thread类型指针Thread *t; t代表一般的thread类型指针cell t _t c; c 代表cell thread 类型变量face_t f; f 代表face thread 类型变量Node *node; node代表指向节点的thread类型指针首先,domain是以上的以几何概念划分的thread当中最高的层次。
domain 是针对phase来设定的,一般在单相流中,domain_id为1,该domain包含了所有区域的不同层次的数据结构,在多相流当中,则更为复杂,这个问题容我们下次再谈。
Cell,face,node都比较好理解,是一种几何上、维度上的划分。
最后简单谈谈怎么基于这些thread指针或者变量来进行操作:1.获取相应变量:我们可以得到相应thread的面积,体积,质心,以及密度、压力、温度、速度等等等等2.遍历操作:我们可以对domain,cell,face进行遍历操作,比如遍历一个cell thread中所有的face等等等等3.如何定义、赋予一个thread指针:采用get_domain,lookup_thread等宏来获得读到这里,可能还有疑问,比如我们设了一些边界条件,怎么得到这些边界条件的thread呢?且看下回分解参考文献:1.《ANSYS Fluent UDF Manual 15.0》2.《ANSYS UDF培训》。
用户自定义函数UDF中文详细讲解

边界温度分布
左侧温度分布
下面温度分布
场温度分布
UDF编写-用C语言
注释 /* 这是刘某人讲课示范用的程序 */ 数据类型 Int:整型 Long:长整型 Real:实数 Float:浮点型 Double:双精度 Char:字符型
UDF解释函数在单精度算法中定义real类型为float型,在双精度算法宏定义 real为double型。因为解释函数自动作如此分配,所以使用在UDF中声明所有 的float和double数据变量时使用real数据类型是很好的编程习惯。
Profile处理要点
(和一般计算一样设置求解器,模型等)
Define-Profile-Read
(数据) Define-BoundaryCondition-所需设置的面 -Thermal-Temperature-Temp t (和一般计算一样,设置其它边值条件、初 值条件及求解与结果检查等)
温度分布
Profile处理
((Temp point 26) (x 0.00E-03 2.00E-03 4.00E-03 6.00E-03 8.00E-03 1.00E-02 1.20E-02 1.40E-02 1.60E-02 1.80E-02 2.00E-02 2.20E-02 2.40E-02 2.60E-02 2.80E-02 3.00E-02 3.20E-02 3.40E-02 3.60E-02 3.80E-02 4.00E-02 4.20E-02 4.40E-02 4.60E-02 4.80E-02 5.00E-02 ) (y 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 0.00E+00 ) (t 3.49E+02 3.50E+02 3.50E+02 3.47E+02 3.46E+02 3.44E+02 3.41E+02 3.39E+02 3.36E+02 3.33E+02 3.31E+02 3.28E+02 3.26E+02 3.24E+02 3.22E+02 3.20E+02 3.19E+02 3.18E+02 3.17E+02 3.16E+02 3.16E+02 3.16E+02 3.15E+02 3.15E+02 3.15E+02 3.15E+02 ))
UDF总结

UDF使用技巧1、查找相应的函数的时候,可以现在word里面找到相应的函数名字,然后依次去中文帮助文档、英文帮助文档和网页帮助文档,看看详细解释并找找是否有相应的例子。
2、打个比方来说,thread就是公路,连接的cell和face,cell和face就相当于公路上汽车停靠的站点,cell_t这个面向的是单元,而face_t面向的是边或者面(二维或三维)在fluent循环过程中,一般是用thread作线程检索,而cell或者face作检索过程中位置(相当于指示位置的参数)参数的指示3、对于UDF来说,积分就是做加法,把通过面上每个网格的质量流量相加4、cell和face的区别,什么时候用cell,什么时候用face?5、1. begin, end_c_loop macro is used for looping over all the cells in particular thread for serial processing.2. For parallel processing, the cells inside a partition can be categorized as interior and exterior cells.3. The macros begin, end_c_loop_int; begin, end_c_loop_ext and begin, end_c_loop_all are used for looping over interior, exterior and all the cells (in a partition) respectively.4. In parallel simulations, both begin, end_c_loop and begin, end_c_loop_all macros will do the same job.5. For faces the looping macro in parallel are begin, end_f_loop_int; begin, end_f_loop_ext and begin, end_f_loop for looping over interior, boundary and all faces respectively. For all practical purpose, the user need not separate the interior and boundary faces of a partition. Hence, begin, end_f_loop_int and begin, end_f_loop_ext macros are rarely used.实际问题1、DEFINE_UDS_UNSTEADY中的apu包括的函数是不是不包括当前时刻的变量,而su包含前一时刻的变量,所以用了C_STORAGE_R存储前一时刻的变量。
UDF使用指南-1

UDF有多种功能,如:定制边界条件,定义材料属性,定义表面和体积反应率,定义Fluent 输运方程中的源项,用户自定义标量输运方程UDS中的源项扩散率函数等。
一、UDF基础1、Fluent的求解次序了解fluent的求解过程有助于理解UDF的调用过程,确定在给定的任意时间内哪些数据是当前的和有效的。
对于不同的求解器,其求解次序是不一样的。
在分离式求解器求解过程中,用户定义的初始化函数(使用DEFINE_INIT定义的)在迭代循环开始之前执行。
然后迭代循环开始执行用户定义的调整函数(使用DEFINE_ADJUST定义的)。
接着,求解守恒方程,顺序是从动量方程和后来的压力修正方程到与特定计算相关的附加标量方程。
守恒方程之后,属性被更新(包含用户定义属性)。
这样,如果模型涉及气体定律,这时,密度将随更新的温度(和压力、物质质量分数)而被更新,进行收敛或者附加要求的迭代的检查、循环或者继续或者停止。
在耦合求解器求解过程中,用户定义的初始化函数(使用DEFINE_INIT定义的)在迭代循环开始之前执行;然后迭代循环开始执行用户定义的调整函数(使用DEFINE_ADJUST定义的);接着,Fluent求解连续、动量和(适合的地方)能量的控制方程及相关的物质输运或矢量方程。
其余的求解步骤与分离式求解器相同。
2、Fluent网格拓扑①单元(cell):区域被分割成的控制体积②单元中心(cell center):Fluent中数据存储的地方③面(face):单元(二维或三维)的边界④边(edge):面(三维)的边界⑤节点(node):网格点⑥单元线索(cell thread):在其中分配了材料数据和源项的单元组⑦面线索(face thread):在其中分配了边界数据的面组⑧节点线索(node thread):节点组⑨区域(domain):由网格定义的所有节点、面和单元线索的组合3、Fluent的数据类型在编写UDF时,除了可以使用C语言数据类型外,还可以直接使用Fluent指定的与求解器数据相关的数据类型。
UDF的宏用法及相关算例

7 自定义函数(UDF)7.1,概述用户自定义函数(User-Defined Functions,即UDFs)可以提高FLUENT程序的标准计算功能。
它是用C语言书写的,有两种执行方式:interpreted型和compiled型。
Interpreted型比较容易使用,但是可使用代码(C语言的函数等)和运行速度有限制。
Compiled型运行速度快,而且也没有代码使用范围的限制,但使用略为繁琐。
我们可以用UDFs来定义:a)边界条件b)源项c)物性定义(除了比热外)d)表面和体积反应速率e)用户自定义标量输运方程f)离散相模型(例如体积力,拉力,源项等)g)代数滑流(algebraic slip)混合物模型(滑流速度和微粒尺寸)h)变量初始化i)壁面热流量j)使用用户自定义标量后处理边界条件UDFs能够产生依赖于时间,位移和流场变量相关的边界条件。
例如,我们可以定义依赖于流动时间的x方向的速度入口,或定义依赖于位置的温度边界。
边界条件剖面UDFs用宏DEFINE_PROFILE定义。
有关例子可以在5.1和6.1中找到。
源项UDFs可以定义除了DO辐射模型之外的任意输运方程的源项。
它用宏DEFINE_SOURCE 定义。
有关例子在5.2和6.2中可以找到。
物性UDFs可用来定义物质的物理性质,除了比热之外,其它物性参数都可以定义。
例如,我们可以定义依赖于温度的粘性系数。
它用宏DEFINE_PROPERTY定义,相关例子在6.3中。
反应速率UDFs用来定义表面或体积反应的反应速率,分别用宏DEFINE_SR_RA TE和DEFINE_VR_RATE定义,例子见6.4。
离散相模型用宏DEFINE_DPM定义相关参数,见5.4。
UDFs还可以对任意用户自定义标量的输运方程进行初始化,定义壁面热流量,或计算存贮变量值(用用户自定义标量或用户自定义内存量)使之用于后处理。
相关的应用见于5.3,5.5,5.6和5.7。
FLUENT udf中文资料ch10

第10章应用举例10.1 边界条件10.2源项10.3物理属性10.4反应速率(Reacting Rates)10.5 用户定义标量(User_Defined Scalars)10.1边界条件这部分包含了边界条件UDFs的两个应用。
两个在FLUENT中都是作为解释式UDFs被执行的。
10.1.1涡轮叶片的抛物线速度入口分布要考虑的涡轮叶片显示在Figure 10.1.1中。
非结构化网格用于模拟叶片周围的流场。
区域从底部周期性边界延伸到顶部周期性边界,左边是速度入口,右边是压力出口。
Figure 10.1.1: The Grid for the Turbine Vane Example常数x速度应用于入口的流场与抛物线x速度应用于入口的流场作了比较。
当采用分段线性分布的型线的应用是有效的对边界型线选择,多项式的详细说明只能通过用户定义函数来完成。
常数速度应用于流场入口的结果显示在Figure 10.1.2和Figure 10.1.3中。
当流动移动到涡轮叶片周围时初始常速度场被扭曲。
Figure 10.1.2: Velocity Magnitude Contours for a Constant Inlet x VelocityFigure 10.1.3: Velocity Vectors for a Constant Inlet x Velocity现在入口x速度将用以下型线描述:这里变量y在人口中心是0.0,在顶部和底部其值分别延伸到0745。
这样x速.0度在入口中心为20m/sec,在边缘为0。
UDF用于传入入口上的这个抛物线分布。
C源代码(vprofile.c)显示如下。
函数使用了Section 5.3中描述的Fluent提供的求解器函数。
/***********************************************************************//* vprofile.c *//* UDF for specifying steady-state velocity profile boundary condition *//***********************************************************************/#include "udf.h"DEFINE_PROFILE(inlet_x_velocity, thread, position){real x[ND_ND]; /* this will hold the position vector */real y;face_t f;begin_f_loop(f, thread){F_CENTROID(x,f,thread);y = x[1];F_PROFILE(f, thread, position) = 20. - y*y/(.0745*.0745)*20.;}end_f_loop(f, thread)}函数,被命名为inlet_x_velocity,使用了DEFINE_PROFILE定义并且有两个自变量:thread 和position。
SQLSERVER用户自定义函数(UDF)深入解析

SQLSERVER⽤户⾃定义函数(UDF)深⼊解析本⽂内容概要:1. UDF 概念、原理、优缺点、UDF 的分类2. 详细讲述3种 UDF 的创建、调⽤⽅法以及注意事项3. UDF 的实践建议基本原理:UDF:user-defined functions,⽤户⾃定义函数的简称。
UDF 是⼀个例程,它接受参数、执⾏操作并返回该操作的结果。
根据定义,结果可以是标量值(单个)或表。
UDF 的优点:1. UDF 可以把复杂的逻辑嵌⼊到查询中。
UDF 可以为复杂的表达式创建新函数。
2. UDF 可以运⽤在⼀个表达式或 SELECT 语句的 FROM ⼦句中,并且还可以绑定到架构。
此外,UDF 还可以接受参数。
UDF 有助于实施⼀致性和可重⽤性。
UDF 的缺点:该函数⼀旦误⽤会产⽣潜在的性能问题。
必须针对WHERE⼦句的每⼀⾏执⾏的任何函数,不管是⽤户定义的函数还是系统函数,都将减慢执⾏速度。
UDF 的类型:UDF 主要有 3 种类型(SQL Server Management Studio 把内联表值函数与多语句表值函数放到了⼀个组中):1. 标量函数2. 内联表值函数3. 多语句表值函数⼀、标量函数标量函数是返回⼀个具体值的函数。
函数可以接收多个参数、执⾏计算然后返回⼀个值。
返回值通过RETURN命令返回。
⽤户定义的函数中的每个可能代码路径都以RETURN命令结尾。
标量函数可以运⽤于 SQL Server 中的任何表达式,甚⾄在 CHECK 约束的表达式中也可以使⽤(但不推荐这种⽤法)。
函数限制标量函数必须是确定性的,也就是说标量函数必须反复地为相同的输⼊参数返回相同的值。
因此,如newid()函数和rand()函数不允许出现在标量函数中。
不允许⽤户定义标量函数更新数据库、调⽤存储过程或调⽤DBCC命令,唯⼀的例外是可以更新表变量。
⽤户定义函数不能返回BLOB(⼆进制⼤型对象)数据,如text、next、timestamp和image数据类型变量。
UDF使用指南-1
UDF有多种功能,如:定制边界条件,定义材料属性,定义表面和体积反应率,定义Fluent 输运方程中的源项,用户自定义标量输运方程UDS中的源项扩散率函数等。
一、UDF基础1、Fluent的求解次序了解fluent的求解过程有助于理解UDF的调用过程,确定在给定的任意时间内哪些数据是当前的和有效的。
对于不同的求解器,其求解次序是不一样的。
在分离式求解器求解过程中,用户定义的初始化函数(使用DEFINE_INIT定义的)在迭代循环开始之前执行。
然后迭代循环开始执行用户定义的调整函数(使用DEFINE_ADJUST定义的)。
接着,求解守恒方程,顺序是从动量方程和后来的压力修正方程到与特定计算相关的附加标量方程。
守恒方程之后,属性被更新(包含用户定义属性)。
这样,如果模型涉及气体定律,这时,密度将随更新的温度(和压力、物质质量分数)而被更新,进行收敛或者附加要求的迭代的检查、循环或者继续或者停止。
在耦合求解器求解过程中,用户定义的初始化函数(使用DEFINE_INIT定义的)在迭代循环开始之前执行;然后迭代循环开始执行用户定义的调整函数(使用DEFINE_ADJUST定义的);接着,Fluent求解连续、动量和(适合的地方)能量的控制方程及相关的物质输运或矢量方程。
其余的求解步骤与分离式求解器相同。
2、Fluent网格拓扑①单元(cell):区域被分割成的控制体积②单元中心(cell center):Fluent中数据存储的地方③面(face):单元(二维或三维)的边界④边(edge):面(三维)的边界⑤节点(node):网格点⑥单元线索(cell thread):在其中分配了材料数据和源项的单元组⑦面线索(face thread):在其中分配了边界数据的面组⑧节点线索(node thread):节点组⑨区域(domain):由网格定义的所有节点、面和单元线索的组合3、Fluent的数据类型在编写UDF时,除了可以使用C语言数据类型外,还可以直接使用Fluent指定的与求解器数据相关的数据类型。
generic udf 类型

generic udf 类型
在大多数UDF(用户定义的函数)系统中,有几种常见的类型可以被认为是“通用的”。
以下是其中一些类型:
1. String-related UDF(字符串相关的UDF):这些函数通常用于处理字符串数据,如字符串连接、分割、替换、转换大小写等操作。
2. Numeric UDF(数值型的UDF):这些函数用于执行数学运算,如加法、减法、乘法、除法以及其他数值转换操作。
3. Date and Time UDF(日期和时间的UDF):这些函数用于处理日期和时间相关的操作,如日期格式化、日期计算、日期比较等。
4. Aggregate UDF(聚合的UDF):这些函数用于执行聚合操作,如求和、平均、最小值、最大值等。
5. Conversion UDF(转换的UDF):这些函数用于数据类型转换,如将字符串转换为数字、将数字转换为字符串等。
以上只是通用UDF类型的一些示例,实际上还有许多其他类型的UDF,可以根据具体需求进行扩展和自定义。
genericudf 与 普通的udf 函数 -回复

genericudf 与普通的udf 函数-回复标题:深入理解GenericUDF与普通UDF函数的区别与应用在大数据处理和分析中,用户定义的函数(User Defined Function,简称UDF)扮演着至关重要的角色。
它们允许开发者根据特定的需求定制数据处理逻辑,极大地提升了数据处理的灵活性和效率。
在Hadoop生态系统中,主要有两种类型的UDF:普通UDF和GenericUDF。
本文将详细解析这两种UDF的区别,并通过实例一步步展示其应用。
一、普通UDF普通UDF是Hive中最基本的自定义函数类型。
它主要用于处理单个数据行或列,并返回一个单一的结果。
普通UDF需要开发者实现evaluate()方法,该方法接受一个或多个参数,并返回一个结果。
以下是一个简单的普通UDF示例,该函数接收一个字符串参数并返回其长度:javaimport org.apache.hadoop.hive.ql.exec.UDF;public class StringLengthUDF extends UDF {public int evaluate(String str) {if (str == null) {return 0;}return str.length();}}在这个例子中,我们定义了一个名为StringLengthUDF的类,它继承了UDF基类。
然后我们实现了evaluate()方法,该方法接受一个字符串参数,并返回其长度。
二、GenericUDF相比于普通UDF,GenericUDF提供了更大的灵活性和可扩展性。
GenericUDF可以处理多种数据类型,并且可以返回复杂的数据结构。
在GenericUDF中,开发者需要实现initialize()、getReturnType()和evaluate()方法。
以下是一个简单的GenericUDF示例,该函数接收两个整数参数并返回它们的和:javaimport org.apache.hadoop.hive.ql.udf.generic.GenericUDF; importorg.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; importorg.apache.hadoop.hive.serde2.objectinspector.primitive.Primitive ObjectInspectorFactory;importorg.apache.hadoop.hive.serde2.objectinspector.primitive.IntObjectI nspector;public class AddUDF extends GenericUDF {private IntObjectInspector intOI1;private IntObjectInspector intOI2;Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {if (arguments.length != 2) {throw new UDFArgumentException("AddUDF accepts exactly 2 arguments");}if (!(arguments[0] instanceofIntObjectInspector) !(arguments[1] instanceof IntObjectInspector)) {throw new UDFArgumentException("Both arguments should be of int type");}this.intOI1 = (IntObjectInspector) arguments[0];this.intOI2 = (IntObjectInspector) arguments[1];returnPrimitiveObjectInspectorFactory.javaIntObjectInspector;}Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {int arg1 = intOI1.get(arguments[0].get());int arg2 = intOI2.get(arguments[1].get());return arg1 + arg2;}Overridepublic String getDisplayString(String[] children) {return "add(" + children[0] + ", " + children[1] + ")";}}在这个例子中,我们定义了一个名为AddUDF的类,它继承了GenericUDF基类。
UDFudf中的C语言

第二章.UDF的C语言基础本章介绍了U DF的C语言基础2.1引言2.2注释你的C代码2.3FLUEN T中的C数据类型2.4常数2.5变量2.6自定义数据类型2.7强制转换2.8函数2.9数组2.10指针2.11声明2.12常用C操作符2.13C库函数2.14用#define实现宏置换2.15用#includ e实现文件包含2.16与FOR TRAN比较2.1引言本章介绍了C语言的一些基本信息,这些信息对处理FLUE NT的UD F很有帮助。
本章首先假定你有一些编程经验而不是C语言的初级介绍。
本章不会介绍诸如whi le-do循环,联合,递归,结构以及读写文件的基础知识。
如果你对C语言不熟悉可以参阅C语言的相关书籍。
2.2注释你的C代码熟悉C语言的人都知道,注释在编写程序和调试程序等处理中是很重要的。
注释的每一行以“/*”开始,后面的是注释的文本行,然后是“*/”结尾如:/* This is how I put a commen t in my C progra m */2.3FLUEN T的C数据类型FLUENT的UDF解释程序支持下面的C数据类型:Int:整型Long:长整型Real:实数Float:浮点型Double:双精度Char:字符型注意:UDF解释函数在单精度算法中定义real类型为flo at型,在双精度算法宏定义re al为do uble型。
因为解释函数自动作如此分配,所以使用在U DF中声明所有的fl oat和d ouble数据变量时使用rea l数据类型是很好的编程习惯。
2.4常数常数是表达式中所使用的绝对值,在C程序中用语句#define来定义。
最简单的常数是十进制整数(如:0,1,2)包含小数点或者包含字母e的十进制数被看成浮点常数。
hive udf 参数

hive udf 参数一、概述HiveUDF(用户自定义函数)是一种允许用户自定义数据处理的函数,可以在Hive查询中作为表达式使用。
通过创建和使用HiveUDF,用户可以扩展Hive的功能,实现更复杂的数据处理任务。
在创建HiveUDF时,参数是一个重要的组成部分,它们决定了函数的执行方式和行为。
二、参数类型HiveUDF的参数可以是输入参数、输出参数和可变参数。
输入参数是函数接收的输入数据,输出参数是函数产生的结果,而可变参数是指函数可以接收任意数量的参数。
三、参数说明1.输入参数:输入参数用于定义函数需要处理的数据。
输入参数的类型、数量和数据格式取决于具体的函数需求。
常见的输入参数类型包括基本数据类型(如INT、STRING等)和结构化数据类型(如数组、表等)。
2.输出参数:输出参数用于存储函数处理后的结果。
输出参数的类型和数量取决于函数的实现,通常会根据实际需求进行定义。
3.可变参数:可变参数允许函数接收任意数量的参数。
在调用函数时,可以传递任意数量的输入值给可变参数,函数会将这些值作为数组或列表处理。
4.命名规范:参数的命名应该遵循一定的规范,以便于阅读和理解。
常见的命名规范包括使用驼峰式命名法(如param1、param2等)和明确描述参数类型和用途(如input_array、output_result等)。
四、参数设置与使用创建HiveUDF时,需要指定参数的类型、名称、默认值等。
在函数定义中,可以使用逗号分隔的参数列表来指定输入和输出参数。
对于可变参数,可以使用通配符(*)来表示任意数量的参数。
在调用HiveUDF时,可以通过在查询中直接使用函数名和参数列表来指定参数。
例如,假设有一个名为my_udf的函数,有两个输入参数p1和p2,可以通过以下方式调用该函数:```sqlSELECTmy_udf(p1,p2)FROMmy_table;```这将从my_table中选择数据,并使用my_udf函数处理p1和p2两个参数。
enum()在udf中的用法

一、引言enum()是一种在udf(用户自定义函数)中常用的函数,它的作用是将一个集合中的元素转化为枚举类型,并对这些枚举类型进行操作和计算。
在实际的数据处理中,enum()经常用于数据清洗、数据转换等操作,能够提高代码的可读性和执行效率。
本文将详细介绍enum()在udf中的用法。
二、enum()函数的基本用法1. enum()函数的语法在udf中,enum()函数的基本语法如下:enum(collection)其中,collection是一个集合,可以是数组、列表或者其他数据结构。
2. enum()函数的功能enum()函数的主要功能是将一个集合中的元素转化为枚举类型。
枚举类型是一种特殊的数据类型,它将每个元素映射为一个唯一的整数值,可以方便地对元素进行索引和操作。
3. enum()函数的返回值enum()函数的返回值是一个枚举类型的对象,可以使用这个对象进行各种操作,比如查找、比较、排序等。
三、enum()函数在udf中的具体应用1. enum()函数在数据清洗中的应用在数据清洗的过程中,经常需要将一些非数值型的数据转化为数值型,方便后续的计算和分析。
这时就可以使用enum()函数将数据转化为枚举类型,然后进行数据清洗和转换。
2. enum()函数在数据转换中的应用在数据转换的过程中,可能需要对某些数据进行排序、分组等操作。
enum()函数可以将数据转化为枚举类型,然后利用枚举类型的特性进行各种操作。
3. enum()函数在特征工程中的应用在机器学习和数据分析中,特征工程是至关重要的一环。
enum()函数可以将原始数据转化为枚举类型的特征,然后用于模型的训练和测试。
四、enum()函数的优点和注意事项1. enum()函数的优点enum()函数能够提高代码的可读性,将非数值型的数据转换为数值型,方便后续的处理和分析。
enum()函数能够提高代码的执行效率,对枚举类型的操作通常比对原始数据的操作更快速。
udf介绍
ccli I C. 刊陀剖J " cell I c. Thread 气 cc lJ I c. Th rcad .1 ccH 1 c, Thre时" cell I c. Thread
0\.
1111 illî(; 盈 I毛"
""ih~ 盈!I-'
h
.w 宙由结 11、力
uv;1ì 昭雄 fl\};
..... m u..娃 l:k h
C_DP(c,I)lij C_U(C ,I)
u }j 1"1 的迫度
c
V(c咽。
|νh 向的速度
F
..,舍
UDF -f金周指南
219
锁线
名称(.戴}
..度提望
通固值
C \\'(C.I) C YI(C ,I. i) C_K(c ,t) C_O(CI) ,
ccll I c, Th~oo 叫 cC'1I t c. Th read -" illt i ce lJ I C, 丁、四ad -. ccll t c. Thre斟, "
FI Ul' nl ~鸟'民 "m 乌实例分析
名称(..的
,锺鬓噩
返回锺
绍'"
C
DVDY(c.叶
ccll I C. 丁nread -, ccll , c , Thn:四川 ccU I c. Thread çell t c‘刊陀,d
叫 气
".i.t. IQ:t-; \'
WÁ血地品.)
Ií 向的呼散
C_DVDZ(c,l)
(J 求解酷的量附巾
uf 以应用 l 灰 8-1 巾 除了'1'兀恪压力 (C 町的 所
udf学习

Udf概述输运方程FLUENT求解器建立在有限容积法的基础上,将计算域离散为有限数目的控制体或是单元。
网格单元是FLUENT中基本的计算单元,这些单元的守恒特征必须保证。
也就是说普通输运方程,例如质量、动量、能量方程的积分形式可以应用到每个单元:∂∂t ∫ρϕdV+∮ρϕV∙dA=∮Γ∇ϕ∙dA+∫SϕdVVAAV此处,ϕ是描述普通输运数量的变量,根据所求解的输运方程可取不同的值。
下面是输运方程中可求解ϕ的子集守恒与否需要知道通过单元边界的通量。
因此需要计算出单元和面上的属性值。
单元(cell)、面(face)、区域(zone)和线(thread)单元和面组成区域,区域可以由模型和区域的物理特征来标定,同时规定了计算域的物理组成。
如入口面域的单元面可以被指定为velocity-inlet。
线(thread)是FLUENT数据结构的内部名称,可被用来指定一个区域。
Thread结构可作为数据储存器来使用,这些数据对于它所表示的单元和面来说是公用的。
宏DEFINE_宏是用来定义UDF的,简单说,它是Fluent和UDF程序的一个接口。
只有通过宏,才能实现UDF与Fluent中信息的交互。
宏分为三类:通用、离散相和多相、动网格。
常用宏介绍:1、DEFINE_ADJUST该宏定义的函数在每一步迭代开始前执行。
利用它修改流场变量。
在执行该宏定义的函数时,它的参数domain传递给处理器,说明该函数是作用于整个流场的网格区域。
2、DEFINE_DIFFUSIVITY利用该宏定义函数修改组分扩散系数或者用户自定义标量输运方程的扩散系数。
其中c代表单元网格,t是指向网络的指针,i表示第i种组分或第i个用户自定义标量(传递给处理器)。
函数返回real型数据。
3、DEFINE_INIT用以初始化流场变量,他在fluent默认的初始化之后执行。
作用区域为全场,无返回值。
4、DEFINE_ON_DEMAND定义函数不是在计算中有fluent自动调用,二是根据需要手工调用运行。
UDF总结
UDF使用技巧1、查找相应的函数的时候,可以现在word里面找到相应的函数名字,然后依次去中文帮助文档、英文帮助文档和网页帮助文档,看看详细解释并找找是否有相应的例子。
2、打个比方来说,thread就是公路,连接的cell和face,cell和face就相当于公路上汽车停靠的站点,cell_t这个面向的是单元,而face_t面向的是边或者面(二维或三维)在fluent循环过程中,一般是用thread作线程检索,而cell或者face作检索过程中位置(相当于指示位置的参数)参数的指示3、对于UDF来说,积分就是做加法,把通过面上每个网格的质量流量相加4、cell和face的区别,什么时候用cell,什么时候用face?5、1. begin, end_c_loop macro is used for looping over all the cells in particular thread for serial processing.2. For parallel processing, the cells inside a partition can be categorized as interior and exterior cells.3. The macros begin, end_c_loop_int; begin, end_c_loop_ext and begin, end_c_loop_all are used for looping over interior, exterior and all the cells (in a partition) respectively.4. In parallel simulations, both begin, end_c_loop and begin, end_c_loop_all macros will do the same job.5. For faces the looping macro in parallel are begin, end_f_loop_int; begin, end_f_loop_ext and begin, end_f_loop for looping over interior, boundary and all faces respectively. For all practical purpose, the user need not separate the interior and boundary faces of a partition. Hence, begin, end_f_loop_int and begin, end_f_loop_ext macros are rarely used.实际问题1、DEFINE_UDS_UNSTEADY中的apu包括的函数是不是不包括当前时刻的变量,而su包含前一时刻的变量,所以用了C_STORAGE_R存储前一时刻的变量。
ODPS_ele—UDFPythonAPI

ODPS_ele—UDFPythonAPI⾃定义函数(UDF)UDF全称User Defined Function,即⽤户⾃定义函数。
ODPS提供了很多内建函数来满⾜⽤户的计算需求,同时⽤户还可以通过创建⾃定义函数来满⾜不同的计算需求。
UDF在使⽤上与普通的类似。
在ODPS中,⽤户可以扩展的UDF有三种,分别是:UDF 分类 | 描述User Defined Scalar Function 通常也称之为UDF⾃定义函数,准确的说是⽤户⾃定义标量函数 (User Defined Scalar Function)。
UDF的输⼊与输出是⼀对⼀的关系,即读⼊⼀⾏数据,写出⼀条输出值。
UDAF(User Defined Aggregation Function)⾃定义聚合函数,其输⼊与输出是多对⼀的关系,即将多条输⼊记录聚合成⼀条输出值。
可以与 SQL中的Group By语句联⽤。
具体语法请参考。
UDTF(User Defined Table Valued Function)⾃定义表函数,是⽤来解决⼀次函数调⽤输出多⾏数据场景的,也是唯⼀能返回多个字段的⾃定义函数。
⽽UDF及UDAF只能⼀次计算输出⼀条返回值。
注解UDF⼴义的说法代表了⾃定义标量函数,⾃定义聚合函数及⾃定义表函数三种类型的⾃定义函数的集合。
狭义来说,仅代表⽤户⾃定义标量函数。
⽂档会经常使⽤这⼀名词,请读者根据⽂档上下⽂判断具体含义。
受限环境ODPS UDF的Python版本为2.7,并以沙箱模式执⾏⽤户代码,即代码是在⼀个受限的运⾏环境中执⾏的,在这个环境中,被禁⽌的⾏为包括:读写本地⽂件启动⼦进程启动线程使⽤socket通信其他系统调⽤基于上述原因,⽤户上传的代码必须都是纯Python实现,C扩展模块是被禁⽌的。
此外,Python的标准库中也不是所有模块都可⽤,涉及到上述功能的模块都会被禁⽌。
具体标准库可⽤模块说明如下:1. 所有纯Python实现(不依赖扩展模块)的模块都可⽤2. C实现的扩展模块中下列模块可⽤1. 部分模块功能受限。
对一个简单解释型udf程序的详细解释

对一个简单解释型u d f 程序的详细解释-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN对一个简单解释型udf程序的详细解释#include ""/*是一个头文件,如果不写的话就不能使用fluent udf中的宏,函数等*/ DEFINE_PROFILE(pressure_profile, t, i)/*是一个宏,本例中用来说明进口压力与垂直坐标变量(还可以是其他的变量)的关系。
pressure_profile 是函数名,可随意指定。
t的数据类型是Thread *t ,t表示指向结构体thread(这里的thread表示边界上所有的网格面的集合)的指针。
i的数据类型是Int,表示边界的位置或者说是什么每个循环内对位置变量(这里应该是质心的纵坐标)设置的数值标签*/{real x[ND_ND];/* 定义了质心的三维坐标,数据类型为real*/real y;/*定义了一个变量y, 数据类型为real */face_t f;/*定义了一个变量f, 数据类型为face_t,也就是网格面的意思,即f代表一个网格单元的网格面 */begin_f_loop(f, t)/*表示遍寻网格面,它的意思是说在计算的时候,要扫描所定义边界的所有网格面,对每个网格面都要赋值,值存储在F_PROFILE(f, t, i)中*/{F_CENTROID(x,f,t);/*一个函数,它的意思是读取每个网格面质心的二维坐标,并赋值给x。
x 为名称,接收三维坐标值。
f为网格面(因为这里只是取的面的二维坐标,所以为f,如果是网格单元的话,这里就为c)。
t为指向结构体thread(这里的thread表示边界上所有的网格面的集合)的指针*/y = x[1];/*把质心的三维坐标的纵坐标的数值赋给y*/F_PROFILE(f, t, i) = - y*y/(.0745*.0745)*;/*赋给每个网格面的数值与网格质心纵坐标的关系。
udf语法

udf语法UDF语法是一种用于定义用户自定义函数的语法规则,它可以让用户根据自己的需求定义自己的函数,从而实现更加灵活和个性化的计算。
在本文中,将介绍UDF语法的基本结构和用法,并给出一些示例来帮助读者更好地理解和应用UDF语法。
一、UDF语法的基本结构UDF语法的基本结构包括函数名、参数列表和函数体。
函数名是用户定义的函数的名称,可以是任意合法的标识符;参数列表是函数的输入参数,用于接收外部传入的数据;函数体是函数的具体实现逻辑,用于处理参数并返回计算结果。
二、UDF语法的用法1. 定义函数名在UDF语法中,函数名是用户自定义的,可以根据实际需求起一个合适的名称。
一般来说,函数名应该具有描述性,能够清晰地表达函数的功能。
2. 定义参数列表参数列表是函数的输入参数,用于接收外部传入的数据。
参数列表由多个参数组成,每个参数由参数类型和参数名组成。
参数类型可以是任意合法的数据类型,包括整型、浮点型、字符串型等。
参数名是用户自定义的,用于在函数体中引用参数的值。
3. 定义函数体函数体是函数的具体实现逻辑,用于处理参数并返回计算结果。
函数体由一系列语句组成,可以包括赋值语句、条件语句、循环语句等。
在函数体中,可以使用参数名引用参数的值,也可以使用其他变量进行计算和操作。
三、UDF语法的示例为了更好地理解和应用UDF语法,下面给出一些示例:1. 计算两个数的和函数名:add参数列表:int a, int b函数体:return a + b2. 判断一个数是否为偶数函数名:isEven参数列表:int num函数体:if (num % 2 == 0) return true; else return false; 3. 计算一个数的阶乘函数名:factorial参数列表:int n函数体:int result = 1; for (int i = 1; i <= n; i++) { result *= i; } return result;通过以上示例,我们可以清楚地看到UDF语法的基本结构和用法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
上手Fluent之UDF系列——UDF中的数据结构(一) 1.何为UDF
由于在实际的流体计算中,需要解决的问题各有各的特点,千奇百怪,即使强如Fluent 也不能把这些全部包含进去。
怎么办呢,Fluent给用户搭好了平台,给用户一个发挥的空间,使得大家可以在UDF中实现自己想要的功能。
UDF是Fluent中User-Defined-Function(用户自定义函数)的缩写,它的作用可以是计算流体力学整个框架中的方方面面。
如下图所示,UDF可以改变初始条件,改变边界条件,改变源项……
具体而言,UDF可以制定边界条件,物质属性定义,化学反应速率定义,输运方程、动量方程、能量方程以及用户自定义标量方程(UDS)中的源项定义,网格调整,制定初始条件,后处理等一系列的功能。
2.UDF中的数据类型
数据结构的概念便于我们去找到我们需要的变量,首先要找到变量,才能修改它,去定义它,去计算它。
UDF中的数据主要采用Thread的概念,Thread代表了一系列cell(体积单元),face (面),与node(节点)的集合。
举例
Domain *d; d 代表指向domain的thread类型指针
Thread *t; t代表一般的thread类型指针
cell t _t c; c 代表cell thread 类型变量
face_t f; f 代表face thread 类型变量
Node *node; node代表指向节点的thread类型指针
首先,domain是以上的以几何概念划分的thread当中最高的层次。
domain 是针对phase来设定的,一般在单相流中,domain_id为1,该domain包含了所有区域的不同层次的数据结构,在多相流当中,则更为复杂,这个问题容我们下次再谈。
Cell,face,node都比较好理解,是一种几何上、维度上的划分。
最后简单谈谈怎么基于这些thread指针或者变量来进行操作:
1.获取相应变量:我们可以得到相应thread的面积,体积,质心,以及密度、压力、温度、速度等等等等
2.遍历操作:我们可以对domain,cell,face进行遍历操作,比如遍历一个cell thread中所有的face等等等等
3.如何定义、赋予一个thread指针:采用get_domain,lookup_thread等宏来获得
读到这里,可能还有疑问,比如我们设了一些边界条件,怎么得到这些边界条件的thread呢?
且看下回分解
参考文献:
1.《ANSYS Fluent UDF Manual 15.0》
2.《ANSYS UDF培训》。