【原创】R语言逐步回归变量选择数据分析可视化案例报告 (附代码数据)
R语言线性回归案例数据分析可视化报告

R语言线性回归案例数据分析可视化报告摘要本报告使用R语言对线性回归案例数据进行可视化分析和解读。
通过使用R的多种库和函数,我们对数据进行清洗、探索、建模和可视化,并最终得出结论和建议。
一、数据来源和背景介绍本报告所使用的数据来源于一个在线购物平台的销售数据。
数据包含了产品的销售量、价格、类别、品牌等因素。
我们选取了一个特定类别的产品销售数据,使用R语言进行线性回归分析。
二、数据预处理1、数据清洗:我们首先对数据进行清洗,去除缺失值、异常值和重复值,确保数据的准确性和完整性。
2、数据探索:对数据进行初步探索,观察数据的分布和特征,为后续的模型建立提供参考。
3、数据编码:将类别变量进行编码,以便于模型处理。
三、线性回归模型建立使用R的lm()函数建立线性回归模型。
我们将销售量作为因变量,价格、类别、品牌等因素作为自变量。
通过拟合模型,得到模型的系数、截距和R方等指标。
四、模型评估和可视化1、模型评估:使用R的summary()函数对模型进行评估,观察模型的系数、标准误差、t值、p值等指标,判断模型的拟合程度和预测能力。
2、可视化:使用R的ggplot2库对数据进行可视化。
我们绘制了散点图、直方图、箱线图等图形,直观地展示了数据的分布和模型的拟合效果。
五、结论和建议通过分析,我们发现价格是影响销售量的重要因素。
在控制其他因素的情况下,价格每上升1个单位,销售量会下降20个单位。
我们还发现不同类别和品牌的产品对销售量的影响也有所不同。
根据这些结论,我们提出了一些针对不同产品的定价和营销策略建议。
六、展望与未来工作本报告仅对一个特定类别的产品销售数据进行了线性回归分析。
未来,我们可以进一步扩大数据集的范围,包括更多的产品类别和更长的时间序列数据。
我们还可以尝试使用其他回归模型或机器学习算法,以更准确地预测销售量和其他因素的关系。
多元线性回归分析数据可视化的R多元线性回归分析数据可视化在R语言中的重要性和应用场景在数据分析中,多元线性回归是一种常见的预测和分析方法,它可以帮助我们了解自变量和因变量之间的关系。
R语言线性回归数据分析案例可视化报告 (附代码数据)

R语言线性回归数据分析案例可视化报告从源下载数据集。
2.清理数据2.a放入数据列pimalm<-lm(class~npreg+glucose+bp+triceps+insulin+bmi+dia betes+age, data=pima)去除大p值的变量(p值> 0.005)Remove variables (insulin, age) with large p value (p value > 0.005) After the variables are dropped, the R-squared value remain about the same. This suggests the variables dropped do not have much effect on the model.Residual analysis shows almost straight line with distribution around zero. Due to this pattern, this model is not as robust.qqnorm(resid(pimalm), col="blue")qqline(resid(pimalm), col="red")The second dataset with much simpler variables. Although intuitively the variables both effect the output, the amount of effect by each variable is interesting. This dataset was examined to have a better sense of how multivariate regression will perform.allbacks.lm<-lm(weight~volume+area, data=allbacks) summary(allbacks.lm)qqnorm(resid(allbacks.lm), col="blue") qqline(resid(allbacks.lm), col="red")。
【原创】在R语言中实现Logistic逻辑回归数据分析报告论文(代码+数据)

咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog在R语言中实现Logistic逻辑回归数据分析报告来源:大数据部落|原文链接/?p=2652逻辑回归是拟合回归曲线的方法,当y是分类变量时,y = f(x)。
典型的使用这种模式被预测Ÿ给定一组预测的X。
预测因子可以是连续的,分类的或两者的混合。
R中的逻辑回归实现R可以很容易地拟合逻辑回归模型。
要调用的函数是glm(),拟合过程与线性回归中使用的过程没有太大差别。
在这篇文章中,我将拟合一个二元逻辑回归模型并解释每一步。
数据集我们将研究泰坦尼克号数据集。
这个数据集有不同版本可以在线免费获得,但我建议使用Kaggle提供的数据集,因为它几乎可以使用(为了下载它,你需要注册Kaggle)。
数据集(训练)是关于一些乘客的数据集合(准确地说是889),并且竞赛的目标是预测生存(如果乘客幸存,则为1,否则为0)基于某些诸如服务等级,性别,年龄等特征。
正如您所看到的,我们将使用分类变量和连续变量。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog数据清理过程在处理真实数据集时,我们需要考虑到一些数据可能丢失或损坏的事实,因此我们需要为我们的分析准备数据集。
作为第一步,我们使用该函数加载csv数据read.csv()。
确保参数na.strings等于c("")使每个缺失值编码为a NA。
这将帮助我们接下来的步骤。
training.data.raw < - read.csv('train.csv',header = T,na.strings = c(“”))现在我们需要检查缺失的值,并查看每个变量的唯一值,使用sapply()函数将函数作为参数传递给数据框的每一列。
sapply(training.data.raw,function(x)sum(is.na(x)))PassengerId生存的Pclass名称性别0 0 0 0 0 年龄SibSp Parch票价177 0 0 0 0 小屋着手687 2 sapply(training.data.raw,函数(x)长度(unique(x)))PassengerId生存的Pclass名称性别891 2 3 891 2 年龄SibSp Parch票价89 7 7 681 248 小屋着手148 4对缺失值进行可视化处理可能会有所帮助:Amelia包具有特殊的绘图功能missmap(),可以绘制数据集并突出显示缺失值:咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog可变机舱有太多的缺失值,我们不会使用它。
【原创】R语言线性回归案例数据分析可视化报告(附代码数据)

R语言线性回归案例数据分析可视化报告在本实验中,我们将查看来自所有30个职业棒球大联盟球队的数据,并检查一个赛季的得分与其他球员统计数据之间的线性关系。
我们的目标是通过图表和数字总结这些关系,以便找出哪个变量(如果有的话)可以帮助我们最好地预测一个赛季中球队的得分情况。
数据用变量at_bats绘制这种关系作为预测。
关系看起来是线性的吗?如果你知道一个团队的at_bats,你会习惯使用线性模型来预测运行次数吗?散点图.如果关系看起来是线性的,我们可以用相关系数来量化关系的强度。
.残差平方和回想一下我们描述单个变量分布的方式。
回想一下,我们讨论了中心,传播和形状等特征。
能够描述两个数值变量(例如上面的runand at_bats)的关系也是有用的。
从前面的练习中查看你的情节,描述这两个变量之间的关系。
确保讨论关系的形式,方向和强度以及任何不寻常的观察。
正如我们用均值和标准差来总结单个变量一样,我们可以通过找出最符合其关联的线来总结这两个变量之间的关系。
使用下面的交互功能来选择您认为通过点云的最佳工作的线路。
# Click two points to make a line.After running this command, you’ll be prompted to click two points on the plot to define a line. Once you’ve done that, the line you specified will be shown in black and the residuals in blue. Note that there are 30 residuals, one for each of the 30 observations. Recall that the residuals are the difference between the observed values and the values predicted by the line:e i=y i−y^i ei=yi−y^iThe most common way to do linear regression is to select the line that minimizes the sum of squared residuals. To visualize the squared residuals, you can rerun the plot command and add the argument showSquares = TRUE.## Click two points to make a line.Note that the output from the plot_ss function provides you with the slope and intercept of your line as well as the sum of squares.Run the function several times. What was the smallest sum of squares that you got? How does it compare to your neighbors?Answer: The smallest sum of squares is 123721.9. It explains the dispersion from mean. The linear modelIt is rather cumbersome to try to get the correct least squares line, i.e. the line that minimizes the sum of squared residuals, through trial and error. Instead we can use the lm function in R to fit the linear model (a.k.a. regression line).The first argument in the function lm is a formula that takes the form y ~ x. Here it can be read that we want to make a linear model of runs as a function of at_bats. The second argument specifies that R should look in the mlb11 data frame to find the runs and at_bats variables.The output of lm is an object that contains all of the information we need about the linear model that was just fit. We can access this information using the summary function.Let’s consider this output piece by piece. First, the formula used to describe the model is shown at the top. After the formula you find the five-number summary of the residuals. The “Coefficients” table shown next is key; its first column displays the linear model’s y-intercept and the coefficient of at_bats. With this table, we can write down the least squares regression line for the linear model:y^=−2789.2429+0.6305∗atbats y^=−2789.2429+0.6305∗atbatsOne last piece of information we will discuss from the summary output is the MultipleR-squared, or more simply, R2R2. The R2R2value represents the proportion of variability in the response variable that is explained by the explanatory variable. For this model, 37.3% of the variability in runs is explained by at-bats.output, write the equation of the regression line. What does the slope tell us in thecontext of the relationship between success of a team and its home runs?Answer: homeruns has positive relationship with runs, which means 1 homeruns increase 1.835 times runs.Prediction and prediction errors Let’s create a scatterplot with the least squares line laid on top.The function abline plots a line based on its slope and intercept. Here, we used a shortcut by providing the model m1, which contains both parameter estimates. This line can be used to predict y y at any value of x x. When predictions are made for values of x x that are beyond the range of the observed data, it is referred to as extrapolation and is not usually recommended. However, predictions made within the range of the data are more reliable. They’re also used to compute the residuals.many runs would he or she predict for a team with 5,578 at-bats? Is this an overestimate or an underestimate, and by how much? In other words, what is the residual for thisprediction?Model diagnosticsTo assess whether the linear model is reliable, we need to check for (1) linearity, (2) nearly normal residuals, and (3) constant variability.Linearity: You already checked if the relationship between runs and at-bats is linear using a scatterplot. We should also verify this condition with a plot of the residuals vs. at-bats. Recall that any code following a # is intended to be a comment that helps understand the code but is ignored by R.6.Is there any apparent pattern in the residuals plot? What does this indicate about the linearity of the relationship between runs and at-bats?Answer: the residuals has normal linearity of the relationship between runs ans at-bats, which mean is 0.Nearly normal residuals: To check this condition, we can look at a histogramor a normal probability plot of the residuals.7.Based on the histogram and the normal probability plot, does the nearly normal residuals condition appear to be met?Answer: Yes.It’s nearly normal.Constant variability:1. Choose another traditional variable from mlb11 that you think might be a goodpredictor of runs. Produce a scatterplot of the two variables and fit a linear model. Ata glance, does there seem to be a linear relationship?Answer: Yes, the scatterplot shows they have a linear relationship..1.How does this relationship compare to the relationship between runs and at_bats?Use the R22 values from the two model summaries to compare. Does your variable seem to predict runs better than at_bats? How can you tell?1. Now that you can summarize the linear relationship between two variables, investigatethe relationships between runs and each of the other five traditional variables. Which variable best predicts runs? Support your conclusion using the graphical andnumerical methods we’ve discussed (for the sake of conciseness, only include output for the best variable, not all five).Answer: The new_obs is the best predicts runs since it has smallest Std. Error, which the points are on or very close to the line.1.Now examine the three newer variables. These are the statistics used by the author of Moneyball to predict a teams success. In general, are they more or less effective at predicting runs that the old variables? Explain using appropriate graphical andnumerical evidence. Of all ten variables we’ve analyzed, which seems to be the best predictor of runs? Using the limited (or not so limited) information you know about these baseball statistics, does your result make sense?Answer: ‘new_slug’ as 87.85% ,‘new_onbase’ as 77.85% ,and ‘new_obs’ as 68.84% are predicte better on ‘runs’ than old variables.1. Check the model diagnostics for the regression model with the variable you decidedwas the best predictor for runs.This is a product of OpenIntro that is released under a Creative Commons Attribution-ShareAlike 3.0 Unported. This lab was adapted for OpenIntro by Andrew Bray and Mine Çetinkaya-Rundel from a lab written by the faculty and TAs of UCLA Statistics.。
【原创】R语言数据可视化分析报告(附代码数据)
Vis 3这个图形是用另一个数据集菱形建立的,也是内置在ggplot2包中的数据集。
library(ggthemes)
ggplot(diamonds)+geom_density(aes(price,fill=cut,color=cut),alpha=0.4,size=0.5)+labs(title='Diamond Price Density',x='Diamond Price (USD)',y='Density')+theme_economist()
library(ggplot2)
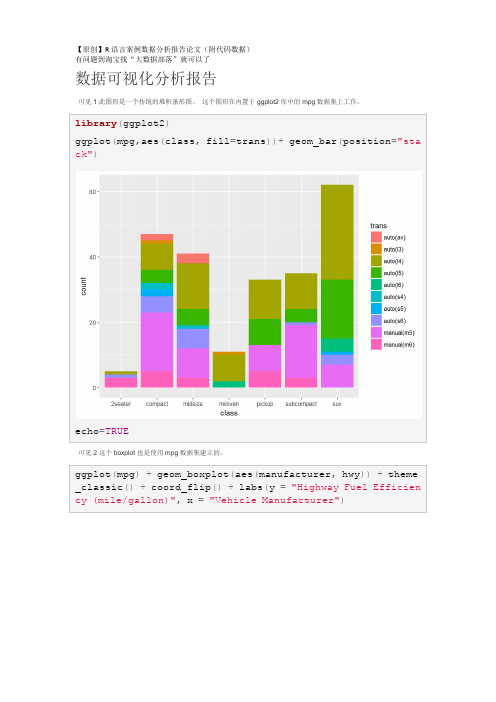
ggplot(mpg,aes(class,fill=trans))+geom_bar(position="stack")
echo=TRUE
可见2这个boxplot也是使用mpg数据集建立的。
ggplot(mpg)+geom_boxplot(aes(manufacturer,hwy))+theme_classic()+coord_flip()+labs(y="Highway Fuel Efficiency (mile/gallon)",x="Vehicle Manufacturer")
echo=TRUE
另外,我正在使用ggplot2软件包来将线性模型拟合到框架内的所有数据上。
ggplot(iris,aes(Sepal.Length,Petal.Length))+geom_point()+geom_smooth(method=lm)+theme_minimal()+theme(panel.grid.major=element_line(size=1),panel.grid.minor=element_line(size=0.7))+labs(title='relationship between Petal and Sepal Length',x='Iris Sepal Length',y='Iris Petal Length')
R语言回归模型项目分析报告论文(附代码数据)

回归模型项目分析报告论文(附代码数据)摘要该项目包括评估一组变量与每加仑(MPG)英里之间的关系。
汽车趋势大体上是对这个具体问题的答案的本质感兴趣:* MPG的自动或手动变速箱更好吗?*量化自动和手动变速器之间的手脉差异。
我们在哪里证实传输不足以解释MPG的变化。
我们已经接受了这个项目的加速度,传输和重量作为解释汽油里程使用率的84%变化的变量。
分析表明,通过使用我们的最佳拟合模型来解释哪些变量解释了MPG 的大部分变化,我们可以看到手册允许我们以每加仑2.97多的速度驱动。
(A.1)1.探索性数据分析通过第一个简单的分析,我们通过箱形图可以看出,手动变速箱肯定有更高的mpg结果,提高了性能。
基于变速箱类型的汽油里程的平均值在下面的表格中给出,传输比自动传输产生更好的性能。
根据附录A.4,通过比较不同传输的两种方法,我们排除了零假设的0.05%的显着性。
第二个结论嵌入上面的图表使我们看到,其他变量可能会对汽油里程的使用有重要的作用,因此也应该考虑。
由于simplistisc模型显示传播只能解释MPG变异的35%(AppendiX A.2。
)我们将测试不同的模型,我们将在这个模型中减少这个变量的影响,以便能够回答,如果传输是唯一的变量要追究责任,或者如果其他变量的确与汽油里程的关系更强传输本身。
(i.e.MPG)。
### 2.模型测试(线性回归和多变量回归)从Anova分析中我们可以看出,仅仅接受变速箱作为与油耗相关的唯一变量的模型将是一个误解。
一个更完整的模型,其中的变量,如重量,加速度和传输被考虑,将呈现与燃油里程使用(即MPG)更强的关联。
一个F = 62.11告诉我们,如果零假设是真的,那么这个大的F比率的可能性小于0.1%的显着性是可能的,因此我们可以得出结论:模型2显然是一个比油耗更好的预测值仅考虑传输。
为了评估我们模型的整体拟合度,我们运行了另一个分析来检索调整的R平方,这使得我们可以推断出模型2,其中传输,加速度和重量被选择,如果我们需要,它解释了大约84%的变化预测汽油里程的使用情况。
R语言可视化案例分析报告 附代码数据

4. 绘制一个散点图,ቤተ መጻሕፍቲ ባይዱ示体重和MPG之间的关系。
ggplot(mtcars,aes(x=wt,y=mpg))+
xlab("wt")+ylab("mpg")+
geom_point()+
geom_line()+
ggtitle("Relationship between 'wt' and 'mpg'")+
stat_smooth(method="loess",formula=y~x,size=1,col="red")
5. Design a visualization of your choice using the data and write a brief summary about why you chose that visualization.
显示mtcars中的每种齿轮类型的数量。
ggplot(data=mtcars,aes(x=gear))+geom_bar(stat="count")
3. .下一个显示了每个齿轮类型的堆积条形图
ggplot(mtcars,
aes(x=factor(cyl),fill=factor(gear)))+
xlab("Values of 'cyl'")+
R语言可视化案例分析报告
【原创】R语言回归案例报告附代码数据

data=read.table("clipboard",header=T)#在excel中选取数据,复制。
在R中读取数据apply(data,2,mean)#计算每个变量的平均值obs lnWAGE EDU WYEAR SCORE EDU_MO EDU_FA25.5000 2.5380 13.0200 12.6400 0.0574 11.5000 12.1000apply(data,2,sd) #求每个变量的标准偏差obs lnWAGE EDU WYEAR SCORE EDU_MO EDU_FA 14.5773797 0.4979632 2.0151467 3.5956890 0.8921353 3.1184114 4.7 734384cor(data)#求不同变量的相关系数可以看到wage和edu wyear score 有一定的相关关系plot(data)#求不同变量之间的分布图可以求出不同变量之间两两的散布图lm=lm(lnWAGE~EDU+WYEAR+SCORE+EDU_MO+EDU_FA,data=data)#对工资进行多元线性分析Summary(lm)#对结果进行分析可以看到各个自变量与因变量之间的线性关系并不显著,只有EDU变量达到了0.01的显著性水平,因此对模型进行修改,使用逐步回归法对模型进行修改。
lm2=step(lm,direction="forward")#使用向前逐步回归summary(lm2)可以看到,由于向前逐步回归的运算过程是逐个减少变量,从该方向进行回归使模型没有得到提升,方法对模型并没有很好的改进。
因此对模型进行修改,使用向前向后逐步回归。
lm3=step(lm,direction="both")#使用向前向后逐步回归Summary(lm3)从结果来看,该模型的自变量与因变量之间具有叫显著的线性关系,其中EDU变量达到了0.001的显著水平。
【原创】R语言案例数据分析可视化报告 (附代码数据)

R语言案例数据分析可视化报告这个问题集的目标是让你参与到R中的一些活动中,并且在欣赏数据可视化的重要性的同时进行一个深思熟虑的练习。
对于每个问题,创建一个代码块或文本响应,完成/回答所请求的活动或问题。
Questions计算每列的均值,方差和每对之间的相关性library(ggplot2)library(GGally)library(fBasics)## Loading required package: timeDate## Loading required package: timeSeries#### Rmetrics Package fBasics## Analysing Markets and calculating Basic Statistics## Copyright (C) 2005-2014 Rmetrics Association Zurich## Educational Software for Financial Engineering and Computational Science## Rmetrics is free software and comes with ABSOLUTELY NO WARRANTY.basicStats(data, ci = 0.95)## x1 x2 x3 x4 y1 y2## nobs 11.000000 11.000000 11.000000 11.000000 11.000000 11.000000## NAs 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000## Minimum 4.000000 4.000000 4.000000 8.000000 4.260000 3.100000## Maximum 14.000000 14.000000 14.000000 19.000000 10.840000 9.260000## 1. Quartile 6.500000 6.500000 6.500000 8.000000 6.315000 6.695000## 3. Quartile 11.500000 11.500000 11.500000 8.000000 8.570000 8.950000## Mean 9.000000 9.000000 9.000000 9.000000 7.500909 7.500909## Median 9.000000 9.000000 9.000000 8.000000 7.580000 8.140000## Sum 99.000000 99.000000 99.000000 99.000000 82.510000 82.510000## SE Mean 1.000000 1.000000 1.000000 1.000000 0.612541 0.612568## LCL Mean 6.771861 6.771861 6.771861 6.771861 6.136083 6.136024## UCL Mean 11.228139 11.228139 11.228139 11.228139 8.865735 8.865795## Variance 11.000000 11.000000 11.000000 11.000000 4.127269 4.127629 ## Stdev 3.316625 3.316625 3.316625 3.316625 2.031568 2.031657## Skewness 0.000000 0.000000 0.000000 2.466911 -0.048374 -0.978693## Kurtosis -1.528926 -1.528926 -1.528926 4.520661 -1.199123 -0.514319 ## y3 y4## nobs 11.000000 11.000000## NAs 0.000000 0.000000## Minimum 5.390000 5.250000## Maximum 12.740000 12.500000## 1. Quartile 6.250000 6.170000## 3. Quartile 7.980000 8.190000## Mean 7.500000 7.500909## Median 7.110000 7.040000## Sum 82.500000 82.510000## SE Mean 0.612196 0.612242## LCL Mean 6.135943 6.136748## UCL Mean 8.864057 8.865070## Variance 4.122620 4.123249## Stdev 2.030424 2.030579## Skewness 1.380120 1.120774## Kurtosis 1.240044 0.628751cor(data, use="complete.obs", method="kendall")## x1 x2 x3 x4 y1 y2## x1 1.00000000 1.00000000 1.00000000 -0.4264014 0.6363636 0.56363636 ## x2 1.00000000 1.00000000 1.00000000 -0.4264014 0.6363636 0.56363636 ## x3 1.00000000 1.00000000 1.00000000 -0.4264014 0.6363636 0.56363636 ## x4 -0.42640143 -0.42640143 -0.42640143 1.0000000 -0.4264014 -0.42640143 ## y1 0.63636364 0.63636364 0.63636364 -0.4264014 1.0000000 0.56363636 ## y2 0.56363636 0.56363636 0.56363636 -0.4264014 0.5636364 1.00000000 ## y3 0.96363636 0.96363636 0.96363636 -0.4264014 0.6000000 0.60000000 ## y4 -0.09090909 -0.09090909 -0.09090909 0.4264014 -0.1636364 -0.01818182 ## y3 y4## x1 0.96363636 -0.09090909## x2 0.96363636 -0.09090909## x3 0.96363636 -0.09090909## x4 -0.42640143 0.42640143## y1 0.60000000 -0.16363636## y2 0.60000000 -0.01818182## y3 1.00000000 -0.05454545## y4 -0.05454545 1.00000000ggcorr(data, geom = "blank", nbreaks = 5, label = TRUE,palette = "RdYlBu", hjust = .75)+geom_point(size = 10, aes(color = coefficient > 0, alpha = abs(coefficient) > 0.4)) +scale_alpha_manual(values = c("TRUE" = 0.25, "FALSE" = 0)) +guides(color = FALSE, alpha = FALSE)3.为每个x,yx,y数据对创建散点图。
r语言逐步logistic回归法代码

r语言逐步logistic回归法代码
逐步Logistic回归法是一种回归分析方法,它通过逐步选择自变量来优化模型的预测性能。
在R语言中,可以使用step函数来实现逐步回归。
以下是一个逐步Logistic回归的示例代码:
r# 导入必要的库
library(MASS)
# 构建Logistic回归模型
start_model <- glm(y ~ x1 + x2 + x3, data = your_data, family = binomial) # 进行逐步回归
step_result <- step(start_model, scope = list(lower = NULL, upper = NULL), direction = "both", trace = 0)
# 输出结果
summary(step_result)
在上述代码中,y是因变量,x1、x2、x3是自变量,your_data是数据框。
首先,我们使用glm函数构建了一个初始的Logistic回归模型。
然后,使用step函数进行逐步回归,其中scope参数定义了模型搜索的范围,direction参数指定了模型搜索的方向,trace参数控制了输出信息的详细程度。
最后,使用summary函数输出逐步回归的结果。
原创R语言线性回归案例数据分析可视化报告附代码数据

原创R语言线性回归案例数据分析可视化报告附代码数据在数据分析领域,线性回归是一种常用的数据建模和预测方法。
本文将使用R语言进行一个原创的线性回归案例分析,并通过数据可视化的方式呈现分析结果。
下面是我们的文本分析报告,同时包含相关的代码数据(由于篇幅限制,只呈现部分相关代码和数据)。
请您详细阅读以下内容。
1. 数据概述本次案例我们选用了一个关于房屋价格的数据集,数据包含了房屋面积、房间数量、地理位置等多个维度的信息。
我们的目标是分析这些因素与房屋价格之间的关系,并进行可视化展示。
2. 数据预处理在开始回归分析之前,我们需要对数据进行预处理,包括数据清洗和特征选择。
在这个案例中,我们通过删除空值和异常值来清洗数据,并选择了面积和房间数量两个特征作为自变量进行回归分析。
以下是示例代码:```R# 导入数据data <- read.csv("house_data.csv")# 清洗数据data <- na.omit(data)# 删除异常数据data <- data[data$area < 5000 & data$rooms < 10, ]# 特征选择features <- c("area", "rooms")target <- "price"```3. 线性回归模型建立我们使用R语言中的lm()函数建立线性回归模型,并通过summary()函数输出模型摘要信息。
以下是相关代码:```R# 线性回归模型建立model <- lm(data[, target] ~ ., data = data[, features])# 输出模型摘要信息summary(model)```回归模型摘要信息包含了拟合优度、自变量系数、截距等重要信息,用于评估模型的拟合效果和各个因素对因变量的影响程度。
【最新】R语言线性回归分析案例报告 附代码数据

R语言线性回归案例报告
R初始指令
安装“汽车”包:install.packages(“汽车”)加载库汽车
加载汽车中的数据:数据(Salaries,package =“car”)查看您的办公桌上的数据(屏幕):它所表示的薪水视图(帮助)和数据描述:help(薪水)变量的确切名称:名称(薪金)
考虑谁是定量和定性的变量
分散图
虽然有些变量不是量化的,但相反,它们是绝对的,例如秩序是有序的,我们将要制作离散图
考虑到图表,我们将运行变量之间的简单回归模型:“yrs.since.phd”“yrs.service”,但首先让我们来回顾一下变量之间的相关性。
因此,我们要确定假设正态性的相关系数
考虑到这两个变量之间的相关性高,解释结果
结果
因变量yrs.since.phd的选择是正确的,请解释为什么编写表单的模型:y = intercept + oendiente * x
解释截距和斜率
假设检验
根据测试结果,考虑到p值= 2e-16,是否拒绝了5%的显着性值的假设?斜率为零根据测试结果,考虑到p值= 2e-16,关于斜率的假设是否被拒绝了5%的显着性值?考虑到变量yrs.service在模型中是重要的模型和测试调整
考虑到R的平方值为0.827,你认为该模型具有良好的线性拟合?解释调整的R平方值考虑到验证数据与模型拟合的测试由F统计得到:1894在1和395 DF,p值:<2.2e-16认为模型符合调整? ##使用模型进行估计为变量x的以下值查找yrs.since.phd的估计值:
Graficas del modelo。
【原创】R语言线性回归 :多项式回归案例分析报告附代码数据

线性回归模型尽管是最简单的模型,但它却有不少假设前提,其中最重要的一条就是响应变量和解释变量之间的确存在着线性关系,否则建立线性模型就是白搭。
然而现实中的数据往往线性关系比较弱,甚至本来就不存在着线性关系,机器学习中有不少非线性模型,这里主要讲由线性模型扩展至非线性模型的多项式回归。
多项式回归多项式回归就是把一次特征转换成高次特征的线性组合多项式,举例来说,对于一元线性回归模型:一元线性回归模型扩展成一元多项式回归模型就是:一元多项式回归模型这个最高次d应取合适的值,如果太大,模型会很复杂,容易过拟合。
这里以Wage数据集为例,只研究wage与单变量age的关系。
> library(ISLR)> attach(Wage)> plot(age,wage) # 首先散点图可视化,描述两个变量的关系age vs wage可见这两条变量之间根本不存在线性关系,最好是拟合一条曲线使散点均匀地分布在曲线两侧。
于是尝试构建多项式回归模型。
> fit = lm(wage~poly(age,4),data = Wage) # 构建age的4次多项式模型>> # 构造一组age值用来预测> agelims = range(age)4次多项式回归模型从图中可见,采用4次多项式回归效果还不错。
那么多项式回归的次数具体该如何确定?在足以解释自变量和因变量关系的前提下,次数应该是越低越好。
方差分析(ANOVA)也可用于模型间的检验,比较模型M1是否比一个更复杂的模型M2更好地解释了数据,但前提是M1和M2必须要有包含关系,即:M1的预测变量必须是M2的预测变量的子集。
> fit.1 = lm(wage~age,data = Wage)> fit.2 = lm(wage~poly(age,2),data = Wage)。
R语言线性回归分析案例报告 附代码数据

R语言线性回归分析案例报告附代码数据线性回归是一种非常常见的预测和分析方法,它用于理解两个或更多变量之间的关系。
在本案例中,我们将使用R语言进行线性回归分析。
我们将从一个简单的数据集开始,然后逐步构建线性回归模型,并对其进行解释和评估。
首先,我们需要一份数据集。
在这个例子中,我们将使用R内置的“mtcars”数据集。
该数据集包含了32辆不同车型的汽车在不同速度下的发动机排量、马力、扭矩等数据。
接下来,我们将使用“lm”函数来拟合一个线性回归模型。
在这个例子中,我们将预测“mpg”变量(每加仑英里数),并使用“hp”(马力)和“wt”(车重)作为自变量。
输出结果会给出模型的系数、标准误差、t值、p值等信息。
我们可以根据这些信息来解释模型。
在这个例子中,我们的模型是“mpg = β0 + β1 * hp + β2 * wt”,其中“β0”是截距,“β1”和“β2”是系数。
根据输出结果,我们可以得出以下结论:1、马力每增加1个单位,每加仑英里数平均增加0.062个单位(β1的95%置信区间为[0.022, 0.102]);2、车重每增加1个单位,每加仑英里数平均减少0.053个单位(β2的95%置信区间为[-0.077, -0.030])。
接下来,我们将使用一些指标来评估模型的性能。
首先,我们可以使用R-squared(决定系数)来衡量模型对数据的解释能力。
R-squared 的值越接近1,说明模型对数据的解释能力越强。
接下来,我们将使用残差标准误差来衡量模型预测的准确性。
残差标准误差越小,说明模型的预测能力越强。
最后,我们将使用模型预测值与实际值之间的均方根误差(RMSE)来评估模型的预测能力。
RMSE越小,说明模型的预测能力越强。
通过线性回归分析,我们可以更好地理解变量之间的关系,并使用模型进行预测和分析。
在本案例中,我们使用R语言对“mtcars”数据集进行了线性回归分析,并使用各种指标评估了模型的性能。
【原创】 r语言逻辑回归模型分析报告附代码数据

逻辑回归模型回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与因变量y的关系。
最常见问题有如医生治病时的望、闻、问、切,之后判定病人是否生病或生了什么病,其中的望闻问切就是获取自变量x,即特征数据,判断是否生病就相当于获取因变量y,即预测分类。
最简单的回归是线性回归,在此借用Andrew NG的讲义,有如图1.a所示,X为数据点——肿瘤的大小,Y为观测值——是否是恶性肿瘤。
通过构建线性回归模型,如h θ (x)所示,构建线性回归模型后,即可以根据肿瘤大小,预测是否为恶性肿瘤h θ(x)≥.05为恶性,h θ (x)<0.5为良性。
Z i=ln(P i1−P i)=β0+β1x1+..+βn x n Zi=ln(Pi1−Pi)=β0+β1x1+..+βnxn数据描述用R语言做logistic regression,建模及分析报告,得出结论,数据有一些小问题,现已改正重发:改成以“是否有汽车购买意愿(1买0不买)”为因变量,以其他的一些项目为自变量,来建模分析,目的是研究哪些变量对用户的汽车购买行为的影响较为显著。
问题描述我们尝试并预测个人是否可以根据数据中可用的人口统计学变量使用逻辑回归预测是否有汽车购买意愿(1买0不买)。
在这个过程中,我们将:1.导入数据2.检查类别偏差3.创建训练和测试样本4.建立logit模型并预测测试数据5.模型诊断数据描述分析查看部分数据head(inputData)是否有汽车购买意愿.1买0不买. 区域城市人均地区生产总值.元.1 NA NA2 NA NA3 0 中部长沙 1078904 0 中部长沙 1078905 0 中部长沙 1078906 0 中部长沙 107890职工平均工资.元. 全市总人口.万人. 全市面积.平方公里.1 NA NA NA2 NA NA NA3 56383.16 662.8 118164 56383.16 662.8 118165 56383.16 662.8 118166 56383.16 662.8 11816全市人口密度.人.平方公里. 市区总人口.万人. 市区面积.平方公里.1 NA NA NA2 NA NA NA3 560.94 299.3 19104 560.94 299.3 19105 560.94 299.3 19106 560.94 299.3 1910市区人口密度.人.平方公里. 城市道路面积.万平方米. 公共汽.电.车车辆数.辆.1 NA NA NA2 NA NA NA3 1566.75 29964 1574 1566.75 2996 4 1575 1566.75 2996 4 1576 1566.75 2996 4 157公交客运总量.万人次. 出租汽车数.辆. 每万人拥有公共汽车.辆.1 NA NA NA2 NA NA NA3 73943 6915 13.894 73943 6915 13.895 73943 6915 13.896 73943 6915 13.89人均城市道路面积.平方米. 私人汽车保有量.辆. 地铁条数地铁长度1 NA NA NA NA2 NA NA NA NA3 10.01 1200000 0 04 10.01 1200000 0 05 10.01 1200000 0 06 10.01 1200000 0 0日平均温度.F.的平均值日最高温度.F.的最大值日最高温度.F.的平均值1 NA NA NA2 NA NA NA3 64.42 104 71.54 64.42 104 71.55 64.42 104 71.56 64.42 104 71.5日最低温度.F.的平均值日最低温度.F.的最小值日最高温低于0度天数1 NA NA NA2 NA NA NA3 57.3 26 04 57.3 26 05 57.3 26 06 57.3 26 0日最低温低于0度天数日最高温高于30度天数下雨天数住房数性别.1男2女.1 NA NA NA NA N A2 NA NA NA NA N A3 22 95 173 2 14 22 95 173 2 25 22 95 173 3 16 22 95 173 1 1年龄职业类型学生.1代表是.后同. 蓝领白领.粉领其他职业或无职业1 NA NA NA NA NA NA2 NA NA NA NA NA NA3 404 0 0 1 04 30 4 0 0 1 05 26 4 0 0 1 06 30 2 0 0 1 0电动自行车数量汽车数量摩托车数量有驾照司机数成人数儿童数在家1 NA NA NA2 NA NA NA3 1 1 0 1 2 1 54 2 1 1 2 2 1 55 1 1 1 1 2 1 56 3 0 1 0 3 0 5上学工作家庭收入行程出行时间 X 购买时间购买时间.1 购买时间.21 NA NA NA NA NA2 NA NA NA NA NA3 4 5 10.0 0.63 NA 2009 20114 2 11 20.0 0.25 NA 2009 2009 2008.0005 5 11 2.0 0.12 NA 2011 NA6 2 3 2.7 0.17 NA 2009 2011购买时间.3 购买时间.4 购买时间.5 购买时间.61 NA NA NA2 NA NA NA3 NA NA NA4 NA NA NA5 NA NA NA6 NA NA NA查看数据维度[1] 948 56对数据进行描述统计分析:是否有汽车购买意愿.1买0不买. 区域城市Min. :0.0000 东部 :414 安庆 : 371st Qu.:0.0000 南部 :122 青岛 : 27Median :0.0000 北部 :121 镇江 : 27Mean :0.2144 中部 : 81 柳州 : 263rd Qu.:0.0000 西北 : 74 唐山 : 26Max. :1.0000 西南 : 68 赤峰 : 24NA's :20 (Other): 68 (Other):781人均地区生产总值.元. 职工平均工资.元. 全市总人口.万人. 全市面积.平方公里. Min. : 17096 Min. :32183 Min. : 53.6 Min. : 761 1st Qu.: 36340 1st Qu.:41305 1st Qu.: 345.9 1st Qu.: 7615 Median : 54034 Median :48270 Median : 613.3 Median :12065 Mean : 63605 Mean :49529 Mean : 635.4 Mean :15970 3rd Qu.: 84699 3rd Qu.:54211 3rd Qu.: 759.7 3rd Qu.:16757 Max. :155690 Max. :93997 Max. :3358.4 Max. :90021。
【原创】R语言案例数据分析可视化报告 (附代码数据)

A study of the impact of storms and weather events in the United StatesDeborah5 de novembro de 2017Synopsis:In this report we aim to identify the storm and weather events more harmful to population health and with greate impacct on economy in the United States. The report analyses data from US. National Oceanic and Atmospheric Administration’s (NOAA) storm database since 1950 to 2011. Our overall hypothesis is that Tsunami is the most harmful event to population health and hurricane has the greatest impact on economy. To investigate this hypothesis, we had to adjust the events names and aggregate the data to calculate average impacts for each event. From these data, we confirmed our hypothesis.Data ProcessingFrom the U.S. National Oceanic and Atmo spheric Administration’s (NOAA) we obtained database on major storms and weather events in the United States, including when and where they occur, as well as estimates of any fatalities, injuries, and property damage. The data is from 1950 and end in November 2011.Reading in databaseWe first read in the data from the raw text file included in the zip archive. The data is a comma separated file (csv).After reading in the data we check the first few rows (there are 902,297) rows in this dataset.As we can see that are more unique events than permitted by National Weather Service Instruction (NWSI). For the rest of the analysis, we will reclassify some of the events so that most events perfectly matches the 48 permitted Storm Data Events. The following steps will be taken: - Replace “s” at the end of the event by “” - Replace “TSTM” by “THUNDERSTORM” - Replace “ING” at the end of a line by “” - Look for some part of the events name and replace it by the real event name - for example, there are many occurances of “THUNDERSTORM W” with many different continuations. So everytime there is this matche it will be replaced by “THUNDERSTORM WIND”.。
原创R语言多元统计分析介绍数据分析数据挖掘案例报告附代码

原创R语言多元统计分析介绍数据分析数据挖掘案例报告附代码R语言作为一种功能强大的数据分析工具,在数据挖掘领域得到了广泛的应用。
本文将介绍使用R语言进行多元统计分析的方法,并结合实际数据分析案例进行详细分析。
同时,为了便于读者学习和复现,也附上了相关的R代码。
一、多元统计分析简介多元统计分析是指同时考虑多个变量之间关系的统计方法。
在现实生活和研究中,往往会遇到多个变量相互关联的情况,通过多元统计分析可以揭示这些变量之间的联系和规律。
R语言提供了丰富的统计分析函数和包,可以方便地进行多元统计分析。
二、数据分析案例介绍我们选取了一份关于房屋销售数据的案例,来演示如何使用R语言进行多元统计分析。
该数据集包含了房屋的各种属性信息,如房屋面积、卧室数量、卫生间数量等,以及最终的销售价格。
我们的目标是分析这些属性与销售价格之间的关系。
首先,我们需要导入数据集到R中,并进行数据预处理。
预处理包括数据清洗、缺失值处理、异常值检测等。
R语言提供了丰富的数据处理函数和包,可以帮助我们高效地完成这些任务。
接下来,我们可以使用R语言的统计分析函数进行多元统计分析。
常用的多元统计分析方法包括主成分分析(PCA)、因子分析、聚类分析等。
这些方法可以帮助我们从众多的变量中找到重要的变量,对数据集进行降维和聚类,以便更好地理解数据和进行预测。
在本案例中,我们选择主成分分析作为多元统计分析的方法。
主成分分析是一种常用的降维技术,通过线性变换将原始变量转化为一组新的互相无关的变量,称为主成分。
主成分分析可以帮助我们发现数据中的主要模式和结构,从而更好地解释数据。
最后,我们可以通过可视化方法展示多元统计分析的结果。
R语言提供了丰富多样的数据可视化函数和包,可以生成各种图表和图形,帮助我们更直观地理解和传达数据分析的结果。
三、附录:R语言代码下面是进行多元统计分析的R语言代码。
需要注意的是,代码的具体实现可能会因数据集的不同而有所差异,请根据实际情况进行调整和修改。
R语言数据分析回归研究案例报告 附代码数据

x
}
数据
#load data
silence({
kb16=read_rds("data/Kirkegaard and Bjerrekær 2016 data.rds")
kb16_aggr=read_rds("data/Kirkegaard and Bjerrekær 2016 data aggr.rds")%>%
d_controls%<>%score_items(c("Samme antal indvandrere","Færre indvandrere","Negativt","Positivt",T))
names(d_controls)="control_"+1:5
d_controls%<>%map_df(as.logical)
## No exact match: Det tidligere Jugoslavien
## Best fuzzy match found: Det tidligere Jugoslavien -> Jugoslavien with distance 14.00
names(d_econ)=str_match(names(d_econ),"^[^:]+")%>%as.vector()%>%pu_translate()
#subset
d_prefs=d[pref_items]
d_econ=d[econ_items]
#sort variables by name function
【原创】R语言数据可视化分析报告

【原创】R语言数据可视化分析报告在当今数据驱动的时代,有效地理解和呈现数据变得至关重要。
R语言作为一种强大的数据分析和可视化工具,为我们提供了丰富的手段来探索数据中的模式、趋势和关系。
首先,让我们来谈谈为什么数据可视化如此重要。
想象一下面对一堆密密麻麻的数字表格,这不仅让人感到眼花缭乱,还很难从中快速获取有价值的信息。
而通过数据可视化,我们可以将复杂的数据转化为直观的图形和图表,使数据的特征和规律一目了然。
这有助于我们更快地发现问题、做出决策,以及向他人清晰地传达数据背后的故事。
R 语言在数据可视化方面具有众多优势。
它拥有丰富的绘图函数和包,能够满足各种不同的可视化需求。
比如说,“ggplot2”包就是一个非常强大且受欢迎的可视化工具。
接下来,我们通过一个实际的案例来看看 R 语言的数据可视化是如何工作的。
假设我们有一组关于某个城市不同区域房价的数据,包括房屋面积、卧室数量、房屋价格等信息。
首先,我们使用 R 语言读取数据。
这可以通过“readcsv()”或其他相应的函数来实现。
然后,我们可以使用简单的统计函数来了解数据的基本特征,比如均值、中位数、标准差等。
为了直观地展示房屋面积和价格之间的关系,我们可以使用“ggplot2”包创建一个散点图。
在代码中,我们指定 x 轴为房屋面积,y轴为价格,并添加一些美化的元素,比如标题、坐标轴标签等。
这样,我们就能清晰地看到面积和价格之间的大致趋势。
如果我们想进一步了解不同区域的房价分布情况,可以绘制箱线图。
通过箱线图,我们能够直观地比较各个区域房价的离散程度和中位数。
除了上述基本的图形,R 语言还能绘制更复杂的可视化图形,比如热力图。
如果我们有多个变量之间的相关性数据,热力图可以非常直观地展示这些相关性的强弱。
在进行数据可视化时,颜色的选择也非常重要。
合适的颜色搭配可以增强图形的可读性和吸引力。
同时,坐标轴的刻度和标签设置也需要精心考虑,以确保数据的展示清晰准确。
【最新】R语言分段回归 数据分析 案例报告(附代码数据)

R语言分段回归数据数据分析案例报告# 读取数据data=read.csv("artificial-cover.csv")# 查看部分数据head(data)## tree.cover shurb.grass.cover## 1 13.2 16.8## 2 17.2 21.8## 3 45.4 48.8## 4 53.6 58.7## 5 58.5 55.5## 6 63.3 47.2#######先调用spline包library ( splines )###########用lm拟合,主要注意部分是bs(age,knots=c(...))这部分把自变量分成不同部分fit =lm(tree.cover~bs(shurb.grass.cover ,knots =c(25 ,40 ,60) ),data=da ta )############进行预测,预测数据也要分区pred=predict (fit , newdata =list(shurb.grass.cover =data$shurb.grass. cover),se=T)#############然后画图plot(fit)# 可以构造一个相对复杂的 LOWESS 模型(span参数取小一些),然后和一个简单的模型比较,如:x<-data$shurb.grass.covery<-data$tree.coverplot(x,y,type="l",col=2)fit3 =loess(y ~x, span =0.2)fit4 =loess(y ~1 +x +I(x >30) +I((x -30) *(x >30)),span =1, degree =1)par(mar =c(4, 4, 0, 0), family ="serif", mgp =c(2, 1, 0))plot(x, y, pch =20, col ="darkgray")lines(x, fitted(fit3), lwd =2, col =2)lines(x, fitted(fit4), lwd =2, lty =2)library(ggplot2)## Warning: package 'ggplot2' was built under R version 3.3.3qplot(x, y) +geom_smooth() # 总趋势## `geom_smooth()` using method = 'loess'qplot(x, y, group = x >30) +geom_smooth() +theme(panel.background = element_rect(fill ='white', colour ='black')) # 按30前后分组## `geom_smooth()` using method = 'loess'# 其他数据# 读取数据data=read.csv("其他数据.csv")# 查看部分数据data=data[,1:4]head(data)## year Soil vegetation SEM ## 1 1999 -3.483724 -2.528836 2.681003 ## 2 1999 -3.452582 -2.418049 2.348640 ## 3 1999 -3.350827 -2.590552 2.696037 ## 4 1999 -3.740395 -2.933848 3.627112 ## 5 1999 -3.465906 -2.694211 2.333755 ## 6 1999 -3.381802 -2.788154 2.656276 #####因变量 Soil#######先调用spline包library ( splines )###########用lm拟合,主要注意部分是bs(age,knots=c(...))这部分把自变量分成不同部分fit =lm(Soil~bs(vegetation ,knots =c(-2 ,0 ,1) ),data=data )############进行预测,预测数据也要分区pred=predict (fit , newdata =list(vegetation =data$vegetation),se=T) #############然后画图plot(fit)# 可以构造一个相对复杂的 LOWESS 模型(span 参数取小一些),然后和一个简单的模型比较,如:x<-data$vegetationy<-data$Soilplot(x,y,type="l",col=2)fit3 =loess(y ~x, span =0.2)fit4 =loess(y ~1 +x +I(x >0) +I((x -0) *(x >0)),span =1, degree =1)par(mar =c(4, 4, 0, 0), family ="serif", mgp =c(2, 1, 0)) plot(x, y, pch =20, col ="darkgray")lines(x, fitted(fit3), lwd =2, col =2)lines(x, fitted(fit4), lwd =2, lty =2)library(ggplot2)qplot(x, y) +geom_smooth() +theme(panel.background =element_rect(fil l ='white', colour ='black')) # 按30前后分组## `geom_smooth()` using method = 'loess'# 总趋势qplot(x, y, group = x >0) +geom_smooth() +theme(panel.background =e lement_rect(fill ='white', colour ='black')) # 按30前后分组## `geom_smooth()` using method = 'loess'# 按0前后分组#####因变量 SEM#######先调用spline包library ( splines )###########用lm拟合,主要注意部分是bs(age,knots=c(...))这部分把自变量分成不同部分fit =lm(SEM~bs(vegetation ,knots =c(-2 ,0 ,1) ),data=data )############进行预测,预测数据也要分区pred=predict (fit , newdata =list(vegetation =data$vegetation),se=T) #############然后画图plot(fit)# 可以构造一个相对复杂的 LOWESS 模型(span 参数取小一些),然后和一个简单的模型比较,如:x<-data$vegetationy<-data$SEMplot(x,y,type="l",col=2)fit3 =loess(y ~x, span =0.2)fit4 =loess(y ~1 +x +I(x >0) +I((x -0) *(x >0)),span =1, degree =1)par(mar =c(4, 4, 0, 0), family ="serif", mgp =c(2, 1, 0)) plot(x, y, pch =20, col ="darkgray")lines(x, fitted(fit3), lwd =2, col =2)lines(x, fitted(fit4), lwd =2, lty =2)library(ggplot2)qplot(x, y) +geom_smooth()+theme(panel.background =element_rect(fill ='white', colour ='black')) # 按30前后分组## `geom_smooth()` using method = 'loess'# 总趋势qplot(x, y, group = x >0) +geom_smooth() +theme(panel.background =e lement_rect(fill ='white', colour ='black')) # 按30前后分组## `geom_smooth()` using method = 'loess'# 按0前后分组NA。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
R语言逐步回归变量选择数据分析可视化案例报告
介绍
所有可能的回归
所有子集回归检验潜在自变量集合的所有可能的子集。
如果有K个潜在的自变量(除了常数),那么就有2k2k不同的子集被测试。
例如,如果您有10个候选自变量,则要测试的子集数为210210个,即1024个,如果有20个候选变量,则该数为220220个,超过100万个。
model <-lm(mpg ~disp +hp +wt +qsec, data = mtcars)
ols_all_subset(model)
## # A tibble: 15 x 6
## Index N Predictors `R-Square` `Adj. R-Square` `Mallow's Cp`
## <int><int><chr><chr><chr><chr>
## 1 1 1 wt 0.75283 0.74459 12.48094
## 2 2 1 disp 0.71834 0.70895 18.12961
## 3 3 1 hp 0.60244 0.58919 37.11264
## 4 4 1 qsec 0.17530 0.14781 107.06962
## 5 5 2 hp wt 0.82679 0.81484 2.36900
## 6 6 2 wt qsec 0.82642 0.81444 2.42949
## 7 7 2 disp wt 0.78093 0.76582 9.87910
## 8 8 2 disp hp 0.74824 0.73088 15.23312
## 9 9 2 disp qsec 0.72156 0.70236 19.60281
## 10 10 2 hp qsec 0.63688 0.61183 33.47215
## 11 11 3 hp wt qsec 0.83477 0.81706 3.06167
## 12 12 3 disp hp wt 0.82684 0.80828 4.36070
## 13 13 3 disp wt qsec 0.82642 0.80782 4.42934
## 14 14 3 disp hp qsec 0.75420 0.72786 16.25779
## 15 15 4 disp hp wt qsec 0.83514 0.81072 5.00000
model <-lm(mpg ~disp +hp +wt +qsec, data = mtcars)
k <-ols_all_subset(model)
plot(k)
.最佳子集回归
选择在满足一些明确的客观标准时做得最好的预测变量的子集,例如具有最大R2值或最小MSE,model <-lm(mpg ~disp +hp +wt +qsec, data = mtcars)
ols_best_subset(model)
## Best Subsets Regression
## ------------------------------
## Model Index Predictors
## ------------------------------
## 1 wt
## 2 hp wt
## 3 hp wt qsec
## 4 disp hp wt qsec
## ------------------------------
##
## Subsets Regression Summary ##
--------------------------------------------------------------------------------------------------------------------
-----------
## Adj. Pred ## Model R-Square R-Square R-Square C(p) AIC SBIC SBC MSEP FPE HSP APC
##
--------------------------------------------------------------------------------------------------------------------
-----------
## 1 0.7528 0.7446 0.7087 12.4809 166.0294 74.2916 170.4266 9.8972 9.8572 0.3199 0.2801
## 2 0.8268 0.8148 0.7811 2.3690 156.6523 66.5755 162.5153 7.4314 7.3563 0.2402 0.2091
## 3 0.8348 0.8171 0.782 3.0617 157.1426 67.7238 164.4713 7.6140 7.4756 0.2461 0.2124
## 4 0.8351 0.8107 0.771 5.0000 159.0696 70.0408 167.8640 8.1810 7.9497 0.2644 0.2259
##
--------------------------------------------------------------------------------------------------------------------
-----------
## AIC: Akaike Information Criteria
## SBIC: Sawa's Bayesian Information Criteria
## SBC: Schwarz Bayesian Criteria
## MSEP: Estimated error of prediction, assuming multivariate normality。