数据库技术大会DTCCPostgreSQL和MySQL的存储层深度解析5精品PPT课件
MySQL和PostgreSQL的比较

PostgreSQL主要优势:1. PostgreSQL完全免费,而且是BSD协议,如果你把PostgreSQL改一改,然后再拿去卖钱,也没有人管你,这一点很重要,这表明了PostgreSQL数据库不会被其它公司控制。
oracle数据库不用说了,是商业数据库,不开放。
而MySQL数据库虽然是开源的,但现在随着SUN 被oracle公司收购,现在基本上被oracle公司控制,其实在SUN被收购之前,MySQL中最重要的InnoDB引擎也是被oracle公司控制的,而在MySQL中很多重要的数据都是放在InnoDB引擎中的,反正我们公司都是这样的。
所以如果MySQL的市场范围与oracle数据库的市场范围冲突时,oracle公司必定会牺牲MySQL,这是毫无疑问的。
2. 与PostgreSQl配合的开源软件很多,有很多分布式集群软件,如pgpool、pgcluster、slony、plploxy等等,很容易做读写分离、负载均衡、数据水平拆分等方案,而这在MySQL 下则比较困难。
3. PostgreSQL源代码写的很清晰,易读性比MySQL强太多了,怀疑MySQL的源代码被混淆过。
所以很多公司都是基本PostgreSQL做二次开发的。
4. PostgreSQL在很多方面都比MySQL强,如复杂SQL的执行、存储过程、触发器、索引。
同时PostgreSQL是多进程的,而MySQL是线程的,虽然并发不高时,MySQL处理速度快,但当并发高的时候,对于现在多核的单台机器上,MySQL的总体处理性能不如PostgreSQL,原因是MySQL的线程无法充分利用CPU的能力。
目前只想到这些,以后想到再添加,欢迎大家拍砖。
PostgreSQL与oracle或InnoDB的多版本实现的差别PostgreSQL与oracle或InnoDB的多版本实现最大的区别在于最新版本和历史版本是否分离存储,PostgreSQL不分,而oracle和InnoDB分,而innodb也只是分离了数据,索引本身没有分开。
PostgreSQL与MySQL对比(转载)

PostgreSQL与MySQL对⽐(转载)所有数据库对⽐可以参考:原⽂地址:⽐较版本:PostgreSQL 11 VS MySQL5.7(innodb引擎) Oracle官⽅社区版版权情况:PostgreSQL 11(免费开源)、MySQL5.7 Oracle官⽅社区版(免费开源)1. CPU限制PGSQL没有CPU核⼼数限制,有多少CPU核就⽤多少MySQL能⽤128核CPU,超过128核⽤不上2. 配置⽂件参数PGSQL⼀共有255个参数,⽤到的⼤概是80个,参数⽐较稳定,⽤上个⼤版本配置⽂件也可以启动当前⼤版本数据库MySQL⼀共有707个参数,⽤到的⼤概是180个,参数不断增加,就算⼩版本也会增加参数,⼤版本之间会有部分参数不兼容情况3. 第三⽅⼯具依赖情况PGSQL只有⾼可⽤集群需要依靠第三⽅中间件,例如:patroni+etcd、repmgrMySQL⼤部分操作都要依靠percona公司的第三⽅⼯具(percona-toolkit,XtraBackup),⼯具命令太多,学习成本⾼,⾼可⽤集群也需要第三⽅中间件,官⽅MGR集群还没成熟4. ⾼可⽤主从复制底层原理PGSQL物理流复制,属于物理复制,跟SQL Server镜像/AlwaysOn⼀样,严格⼀致,没有任何可能导致不⼀致,性能和可靠性上,物理复制完胜逻辑复制,维护简单MySQL主从复制,属于逻辑复制,(sql_log_bin、binlog_format等参数设置不正确都会导致主从不⼀致)⼤事务并⾏复制效率低,对于重要业务,需要依赖 percona-toolkit的pt-table-checksum和pt-table-sync⼯具定期⽐较和修复主从⼀致主从复制出错严重时候需要重搭主从MySQL的逻辑复制并不阻⽌两个不⼀致的数据库建⽴复制关系5. 从库只读状态PGSQL系统⾃动设置从库默认只读,不需要⼈⼯介⼊,维护简单MySQL从库需要⼿动设置参数super_read_only=on,让从库设置为只读,super_read_only参数有bug,链接:6. 版本分⽀PGSQL只有社区版,没有其他任何分⽀版本,PGSQL官⽅统⼀开发,统⼀维护,社区版有所有功能,不像SQL Server和MySQL有标准版、企业版、经典版、社区版、开发版、web版之分国内外还有⼀些基于PGSQL做⼆次开发的数据库⼚商,例如:Enterprise DB、瀚⾼数据库等等,当然这些只是⼆次开发并不算独⽴分⽀MySQL由于历史原因,分裂为三个分⽀版本,MariaDB分⽀、Percona分⽀、Oracle官⽅分⽀,发展到⽬前为⽌各个分⽀基本互相不兼容Oracle官⽅分⽀还有版本之分,分为标准版、企业版、经典版、社区版7. SQL特性⽀持PGSQLSQL特性⽀持情况⽀持94种,SQL语法⽀持最完善,例如:⽀持公⽤表表达式(WITH查询)MySQLSQL特性⽀持情况⽀持36种,SQL语法⽀持⽐较弱,例如:不⽀持公⽤表表达式(WITH查询)关于SQL特性⽀持情况的对⽐,可以参考:8. 主从复制安全性PGSQL同步流复制、强同步(remote apply)、⾼安全,不会丢数据PGSQL同步流复制:所有从库宕机,主库会罢⼯,主库⽆法⾃动切换为异步流复制(异步模式),需要通过增加从库数量来解决,⼀般⽣产环境⾄少有两个从库⼿动解决:在PG主库修改参数synchronous_standby_names ='',并执⾏命令: pgctl reload ,把主库切换为异步模式主从数据完全⼀致是⾼可⽤切换的第⼀前提,所以PGSQL选择主库罢⼯也是可以理解MySQL增强半同步复制,mysql5.7版本增强半同步才能保证主从复制时候不丢数据mysql5.7半同步复制相关参数:参数rpl_semi_sync_master_wait_for_slave_count 等待⾄少多少个从库接收到binlog,主库才提交事务,⼀般设置为1,性能最⾼参数rpl_semi_sync_master_timeout 等待多少毫秒,从库⽆回应⾃动切换为异步模式,⼀般设置为⽆限⼤,不让主库⾃动切换为异步模式所有从库宕机,主库会罢⼯,因为⽆法收到任何从库的应答包⼿动解决:在MySQL主库修改参数rpl_semi_sync_master_wait_for_slave_count=09. 多字段统计信息PGSQL⽀持多字段统计信息MySQL不⽀持多字段统计信息10. 索引类型PGSQL多种索引类型(btree , hash , gin , gist , sp-gist , brin , bloom , rum , zombodb , bitmap,部分索引,表达式索引)MySQLbtree 索引,全⽂索引(低效),表达式索引(需要建虚拟列),hash 索引只在内存表11. 物理表连接算法PGSQL⽀持 nested-loop join 、hash join 、merge joinMySQL只⽀持 nested-loop join12. ⼦查询和视图性能PGSQL⼦查询,视图优化,性能⽐较⾼MySQL视图谓词条件下推限制多,⼦查询上拉限制多13. 执⾏计划即时编译PGSQL⽀持 JIT 执⾏计划即时编译,使⽤LLVM编译器MySQL不⽀持执⾏计划即时编译14. 并⾏查询PGSQL并⾏查询(多种并⾏查询优化⽅法),并⾏查询⼀般多见于商业数据库,是重量级功能MySQL有限,只⽀持主键并⾏查询15. 物化视图PGSQL⽀持物化视图MySQL不⽀持物化视图16. 插件功能PGSQL⽀持插件功能,可以丰富PGSQL的功能,GIS地理插件,时序数据库插件,向量化执⾏插件等等MySQL不⽀持插件功能17. check约束PGSQL⽀持check约束MySQL不⽀持check约束,可以写check约束,但存储引擎会忽略它的作⽤,因此check约束并不起作⽤(mariadb ⽀持)18. gpu 加速SQLPGSQL可以使⽤gpu 加速SQL的执⾏速度MySQL不⽀持gpu 加速SQL 的执⾏速度19. 数据类型PGSQL数据类型丰富,如 ltree,hstore,数组类型,ip类型,text类型,有了text类型不再需要varchar,text类型字段最⼤存储1GBMySQL数据类型不够丰富20. 跨库查询PGSQL不⽀持跨库查询,这个跟Oracle 12C以前⼀样MySQL可以跨库查询21. 备份还原PGSQL备份还原⾮常简单,时点还原操作⽐SQL Server还要简单,完整备份+wal归档备份(增量)假如有⼀个三节点的PGSQL主从集群,可以随便在其中⼀个节点做完整备份和wal归档备份MySQL备份还原相对不太简单,完整备份+binlog备份(增量)完整备份需要percona的XtraBackup⼯具做物理备份,MySQL本⾝不⽀持物理备份时点还原操作步骤繁琐复杂22. 性能视图PGSQL需要安装pg_stat_statements插件,pg_stat_statements插件提供了丰富的性能视图:如:等待事件,系统统计信息等不好的地⽅是,安装插件需要重启数据库,并且需要收集性能信息的数据库需要执⾏⼀个命令:create extension pg_stat_statements命令否则不会收集任何性能信息,⽐较⿇烦MySQL⾃带PS库,默认很多功能没有打开,⽽且打开PS库的性能视图功能对性能有影响(如:内存占⽤导致OOM bug)23. 安装⽅式PGSQL有各个平台的包rpm包,deb包等等,相⽐MySQL缺少了⼆进制包,⼀般⽤源码编译安装,安装时间会长⼀些,执⾏命令多⼀些MySQL有各个平台的包rpm包,deb包等等,源码编译安装、⼆进制包安装,⼀般⽤⼆进制包安装,⽅便快捷24. DDL操作PGSQL加字段、可变长字段类型长度改⼤不会锁表,所有的DDL操作都不需要借助第三⽅⼯具,并且跟商业数据库⼀样,DDL操作可以回滚,保证事务⼀致性MySQL由于⼤部分DDL操作都会锁表,例如加字段、可变长字段类型长度改⼤,所以需要借助percona-toolkit⾥⾯的pt-online-schema-change⼯具去完成操作将影响减少到最低,特别是对⼤表进⾏DDL操作DDL操作不能回滚25. ⼤版本发布速度PGSQLPGSQL每年⼀个⼤版本发布,⼤版本发布的第⼆年就可以上⽣产环境,版本迭代速度很快PGSQL 9.6正式版推出时间:2016年PGSQL 10 正式版推出时间:2017年PGSQL 11 正式版推出时间:2018年PGSQL 12 正式版推出时间:2019年MySQLMySQL的⼤版本发布⼀般是2年~3年,⼀般⼤版本发布后的第⼆年才可以上⽣产环境,避免有坑,版本发布速度⽐较慢MySQL5.5正式版推出时间:2010年MySQL5.6正式版推出时间:2013年MySQL5.7正式版推出时间:2015年MySQL8.0正式版推出时间:2018年26. returning语法PGSQL⽀持returning语法,returning clause ⽀持 DML 返回 Resultset,减少⼀次 Client <-> DB Server 交互MySQL不⽀持returning语法27. 内部架构PGSQL多进程架构,并发连接数不能太多,跟Oracle⼀样,既然跟Oracle⼀样,那么很多优化⽅法也是相通的,例如:开启⼤页内存MySQL多线程架构,虽然多线程架构,但是官⽅有限制连接数,原因是系统的并发度是有限的,线程数太多,反⽽系统的处理能⼒下降,随着连接数上升,反⽽性能下降⼀般同时只能处理200 ~300个数据库连接28. 聚集索引PGSQL不⽀持聚集索引,PGSQL本⾝的MVCC的实现机制所导致MySQL⽀持聚集索引29. 空闲事务终结功能PGSQL通过设置 idle_in_transaction_session_timeout 参数来终⽌空闲事务,⽐如:应⽤代码中忘记关闭已开启的事务,PGSQL会⾃动查杀这种类型的会话事务MySQL不⽀持终⽌空闲事务功能30. 应付超⼤数据量PGSQL不能应付超⼤数据量,由于PGSQL本⾝的MVCC设计问题,需要垃圾回收,只能期待后⾯的⼤版本做优化MySQL不能应付超⼤数据量,MySQL⾃⾝架构的问题31. 分布式演进PGSQLHTAP数据库:cockroachDB、腾讯Tbase分⽚集群: Postgres-XC、Postgres-XLMySQLHTAP数据库:TiDB分⽚集群:各种各样的中间件,不⼀⼀列举32. 数据库的⽂件名和命名规律PGSQLPGSQL在这⽅⾯做的⽐较不好,DBA不能在操作系统层⾯(停库状态下)看清楚数据库的⽂件名和命名规律,⽂件的数量,⽂件的⼤⼩⼀旦操作系统发⽣⽂件丢失或硬盘损坏,⾮常不利于恢复,因为连名字都不知道PGSQL表数据物理⽂件的命名/存放规律是:在⼀个表空间下⾯,如果没有建表空间默认在默认表空间也就是base⽂件夹下,例如:/data/base/16454/3599base:默认表空间pg_default所在的物理⽂件夹16454:表所在数据库的oid3599:就是表对象的oid,当然,⼀个表的⼤⼩超出1GB之后会再⽣成多个物理⽂件,还有表的fsm⽂件和vm⽂件,所以⼀个⼤表实际会有多个物理⽂件由于PGSQL的数据⽂件布局内容太多,⼤家可以查阅相关资料当然这也不能全怪PGSQL,作为⼀个DBA,时刻做好数据库备份和容灾才是正道,做介质恢复⼀般是万不得已的情况下才会做MySQL数据库名就是⽂件夹名,数据库⽂件夹下就是表数据⽂件,每个表都有对应的frm⽂件和ibd⽂件,存储元数据和表/索引数据,清晰明了,做介质恢复或者表空间传输都很⽅便33. 权限设计PGSQLPGSQL在权限设计这块是⽐较坑爹,抛开实例权限和表空间权限,PGSQL的权限层次有点像SQL Server,db=》schema=》object要说权限,这⾥要说⼀下Oracle,⽤Oracle来类⽐在ORACLE 12C之前,实例与数据库是⼀对⼀,也就是说⼀个实例只能有⼀个数据库,不像MySQL和SQL Server⼀个实例可以有多个数据库,并且可以随意跨库查询⽽PGSQL不能跨库查询的原因也是这样,PGSQL允许建多个数据库,跟ORACLE类⽐就是有多个实例(之前说的实例与数据库是⼀对⼀)⼀个数据库相当于⼀个实例,因为PGSQL允许有多个实例,所以PGSQL单实例不叫⼀个实例,叫集簇(cluster),集簇这个概念可以查阅PGSQL的相关资料PGSQL⾥⾯⼀个实例/数据库下⾯的schema相当于数据库,所以这个schema的概念对应MySQL的database注意点:正因为是⼀个数据库相当于⼀个实例,PGSQL允许有多个实例/数据库,所以数据库之间是互相逻辑隔离的,导致的问题是,不能⼀次对⼀个PGSQL集簇下⾯的所有数据库做操作必须要逐个逐个数据库去操作,例如上⾯说到的安装pg_stat_statements插件,如果您需要在PGSQL集簇下⾯的所有数据库都做性能收集的话,需要逐个数据库去执⾏加载命令⼜例如跨库查询需要dblink插件或fdw插件,两个数据库之间做查询相当于两个实例之间做查询,已经跨越了实例了,所以需要dblink插件或fdw插件,所以道理⾮常简单权限操作也是⼀样逐个数据库去操作,还有⼀个就是PGSQL虽然像SQL Server的权限层次结构db=》schema=》object,但是实际会⽐SQL Server要复杂⼀些,还有就是新建的表还要另外授权在PGSQL⾥⾯,⾓⾊和⽤户是⼀样的,对新⼿⽤户来说有时候会傻傻分不清,也不知道怎么去⽤⾓⾊,所以PGSQL在权限设计这⼀块确实⽐较坑爹MySQL使⽤mysql库下⾯的5个权限表去做权限映射,简单清晰,唯⼀问题是缺少权限⾓⾊user表db表host表tables_priv表columns_priv表34. 发展历史PGSQL在1995年,开发⼈员Andrew Yu和Jolly Chen在Postgres中添加了⼀个SQL(Structured Query Language,结构化查询语⾔)翻译程序,该版本叫做Postgres95,在开放源代码社区发放。
PostgreSQL数据库介绍

PostgreSQL是什么
PostgreSQL的发布遵从经典的 BSD 版权。它允许用户不限目的地使用 PostgreSQL,甚至你可以销售 PostgreSQL 而不含源代码也可以,唯一的限制 就是你不能因软体自身问题而向我们追诉法律责任,另外就是要求所有的软体拷 贝中须包括以下版权声明。下面就是我们所使用的BSD版权声明内容:
PostgreSQL发展历程
PostgreSQL是什么
伯克利的 POSTGRES 项目:
Michael Stonebraker 领导的 POSTGRES 项目是由防务高级研究项目局( DARPA), 陆军研究办公室(ARO),国家科学基金(NSF), 以及 ESL, Inc 共同赞助的。POSTGRES 的实现始于 1986 年, 第一个"演示性"系统在 1987 年便可使用了, 并且在 1988 年的 ACM-SIGMOD 大会上展出。在 1989 年六 月发布了版本 1给一些外部的用户使用。用于源代码维护的时间日益增加 占用了 太多本应该用于数据库研究的时间, 为了减少支持的负担,伯克利的 POSTGRES 项目在版本 4.2 时正式终止。
Postgres8.X:
可以在windows下运行,事务保存点功能,改变字段的类型,表空间
即时恢复: 即时恢复允许对服务器进行连续的备份。你既可以恢复到失败那个点 ,也可以恢复到以前的任意事务。
新的 Perl 服务器端编程语言
PostgreSQL9.X
HOT standby功能
PostgreSQL版权是什么?
PostgreSQL 是自由免费的,并且所有源代码都可以获得。
PostgreSQL 的开发队伍主要为志愿者,他们遍布世界各地并通过互联网进行联 系,这是一个社区开发项目,它不被任何公司控制。
如何使用MySQL实现分布式数据库架构

如何使用MySQL实现分布式数据库架构引言在当今互联网时代,海量的数据处理和存储是一个无法回避的问题。
分布式数据库架构就是为了解决单一数据库无法满足高并发、高可用和数据安全性需求而产生的一种解决方案。
MySQL作为最常用的关系型数据库管理系统,也可以通过一些技术手段实现分布式架构。
本文将介绍如何使用MySQL实现分布式数据库架构,探讨其原理和实施方法。
一、分布式数据库架构原理概述分布式数据库架构是将数据分散存储在不同的物理节点上,通过网络进行通信协作,实现数据的共享和处理。
其主要原理包括数据分片、数据一致性和查询路由。
1. 数据分片数据分片是指将数据库的数据按照一定规则划分为多个片段,分散存储在多个节点上。
一般可以按照数据的某个字段进行分片,如根据用户ID进行取模分片。
数据分片可以提高数据库的并发处理能力和数据存储能力,减轻单个节点的压力。
2. 数据一致性数据一致性是分布式数据库架构中必须要解决的问题。
由于数据存储在不同的节点上,节点之间可能出现数据不一致的情况,例如数据写入后没有及时同步到其他节点。
常见的解决方案有强一致性和最终一致性。
强一致性要求数据在多个节点间是同步的,即读取数据时各节点返回的结果一致;最终一致性则容许数据在多个节点间存在一定的延迟,但最终数据会达到一致的状态。
3. 查询路由查询路由是指根据查询条件将查询请求发送到相应的数据库节点上。
在分布式数据库架构中,不同的节点可能存储不同的数据分片,因此需要智能地将查询路由到合适的节点上。
常见的查询路由策略有基于哈希的路由和基于区间的路由。
哈希路由将查询条件进行哈希计算后,将查询请求定向到相应的节点上;区间路由则根据数据分片的范围判断查询请求应该发送到哪个节点。
二、MySQL分布式数据库架构实践在实践中,可以使用MySQL Proxy、MySQL Cluster或者自定义中间件等技术手段实现MySQL分布式数据库架构。
下面将重点介绍两种常见的实践方法:MySQL Proxy和MySQL Cluster。
mysql数据库的基本原理

MySQL数据库基本原理解析1. 什么是MySQL数据库?MySQL是一个开源的关系型数据库管理系统,广泛应用于Web应用程序的后台数据存储。
它是最流行的开源数据库之一,被许多大型网站和应用程序使用。
MySQL是由瑞典的MySQL AB公司开发的,现在属于Oracle公司。
MySQL数据库以其高性能、可靠性和易用性而闻名。
它支持多种操作系统,包括Windows、Linux和Mac OS等。
MySQL采用了客户端-服务器模型,其中客户端和服务器可以在同一台计算机上,也可以在不同的计算机上。
2. MySQL数据库的基本原理MySQL数据库的基本原理涉及以下几个方面:2.1 数据库架构MySQL数据库采用了经典的客户端-服务器架构。
服务器负责存储和管理数据,客户端负责与服务器进行通信,并发送查询和命令。
MySQL服务器包含以下组件:•连接处理器:处理客户端请求的连接和断开连接。
•查询处理器:解析和优化客户端发送的SQL查询语句。
•存储引擎:负责数据的存储和检索。
2.2 存储引擎MySQL数据库支持多种存储引擎,每个存储引擎都有不同的特性和用途。
常用的存储引擎有InnoDB、MyISAM、Memory等。
存储引擎负责管理数据的存储和检索。
它定义了数据的物理结构、索引方式和并发控制机制。
不同的存储引擎对事务支持、并发性能和数据完整性等方面有不同的特点。
2.3 数据库对象MySQL数据库中的数据是以表的形式组织的。
表由多个行和列组成,每个列都有一个特定的数据类型。
表可以包含索引,以加快数据的检索速度。
除了表,MySQL数据库还支持其他对象,如视图、存储过程、触发器等。
这些对象可以帮助开发人员更好地组织和管理数据。
2.4 数据库操作MySQL数据库支持丰富的操作,包括数据的插入、更新、删除和查询等。
•插入操作:将新的数据行插入到表中。
•更新操作:修改表中的现有数据行。
•删除操作:从表中删除数据行。
•查询操作:从表中检索数据行。
彻底搞懂MySql及其底层原理(更新中...)
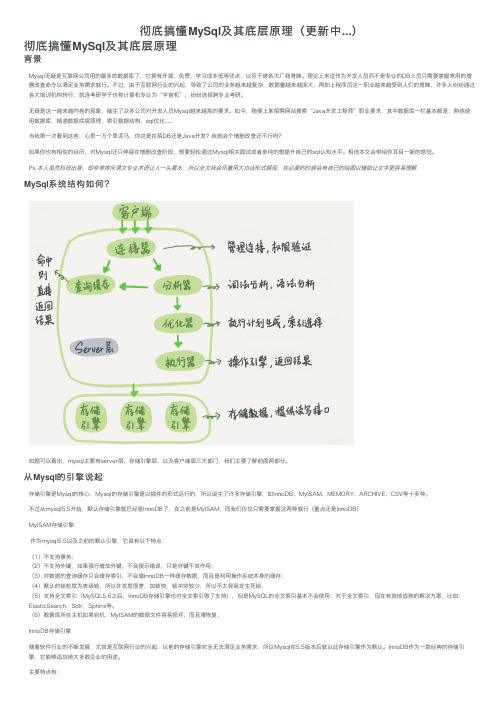
彻底搞懂MySql及其底层原理(更新中...)彻底搞懂MySql及其底层原理背景Mysql⽆疑是互联⽹公司⽤的最多的数据库了,它拥有开源、免费、学习成本低等优点,以⾄于被各⼤⼚商青睐。
理论上来说作为开发⼈员⽽不是专业的DB⼈员只需要掌握常⽤的增删改查命令以满⾜业务需求就⾏。
不过,由于互联⽹⾏业的兴起,导致了公司的业务越来越复杂,数据量越来越庞⼤,再加上程序员这⼀职业越来越受到⼈们的青睐,许多⼈纷纷通过各⼤培训机构转⾏,就连考研学⼦也称计算机专业为“宇宙机”,纷纷选择跨专业考研。
⽆疑是这⼀越来越内卷的现象,催⽣了众多公司对开发⼈员Mysql越来越⾼的要求。
如今,随便上某招聘⽹站搜索“Java开发⼯程师”职业要求,其中数据库⼀栏基本都是:熟练使⽤数据库,精通数据底层原理,索引数据结构,sql优化......当我第⼀次看到这些,⼼⾥⼀万个草泥马,你这是在招DB还是Java开发?我就会个增删改查还不⾏吗?如果你也有相似的经历,对Mysql还只停留在增删改查阶段,想要轻松通过Mysql相关⾯试或者单纯的想提升⾃⼰的sql认知⽔平。
相信本⽂会带给你⽿⽬⼀新的感觉。
Ps 本⼈虽然科班出⾝,却⾮常排斥满⽂专业术语让⼈⼀头雾⽔,所以全⽂我会尽量⽤⼤⽩话形式展现,在必要的时候会有⾃⼰的绘图以辅助让⽂字更容易理解MySql系统结构如何?如题可以看出,mysql主要有server层、存储引擎层、以及客户端层三⼤部门,我们主要了解前⾯两部分。
从Mysql的引擎说起存储引擎是Mysql的核⼼,Mysql的存储引擎是以插件的形式运⾏的,所以诞⽣了许多存储引擎,如InnoDB、MyISAM、MEMORY、ARCHIVE、CSV等⼗多种。
不过从mysql5.5开始,默认存储引擎就已经是InnoDB了,在之前是MyISAM,⽽我们仅仅只需要掌握这两种就⾏(重点还是InnoDB)MyISAM存储引擎:作为mysql5.5以及之前的默认引擎,它具有以下特点:(1)不⽀持事务;(2)不⽀持外键,如果强⾏增加外键,不会提⽰错误,只是外键不其作⽤;(3)对数据的查询缓存只会缓存索引,不会像InnoDB⼀样缓存数据,⽽且是利⽤操作系统本⾝的缓存;(4)默认的锁粒度为表级锁,所以并发度很差,加锁快,锁冲突较少,所以不太容易发⽣死锁;(5)⽀持全⽂索引(MySQL5.6之后,InnoDB存储引擎也对全⽂索引做了⽀持),但是MySQL的全⽂索引基本不会使⽤,对于全⽂索引,现在有其他成熟的解决⽅案,⽐如:ElasticSearch,Solr,Sphinx等。
PostgreSQL与MySql比较

PostgreSQL与MySql比较修改历史记录目录1.MYSQL与POSTGRESQL对比一 (3)2.MYSQL与POSTGRESQL对比二 (11)2.1两者不同的背景 (11)2.2M Y SQL的主要优点 (11)2.3P OSTGRE SQL的主要优点: (13)2.4M Y SQL和P OSTGRE SQL选择 (14)3.MYSQL与POSTGRESQL对比三 (14)3.1历史对比 (15)3.2P OSTGRE SQL特性和功能 (15)3.3M Y SQL特性和功能 (16)3.4社区为王 (17)3.5共享许可 (17)3.6小结 (17)1. MySQL与PostgreSQL对比一PostgreSQL由于是类似Oracle的多进程框架,所以能支持高并发的应用场景,这点与Oracle数据库很像,所以把Oracle DBA转到PostgreSQL数据库上是比较容易的,毕竟PostgreSQL数据库与Oracle数据库很相似。
同时,PostgreSQL数据库的源代码要比MySQL数据库的源代码更容易读懂,如果团队的C语言能力比较强的话,就能在PostgreSQL数据库上做开发,比方说实现类似greenplum的系统,这样也能与现在的分布式趋势接轨。
为了说明PostgreSQL的功能,我下面简要对比一下PostgreSQL数据库与MySQL 数据库之间的差异:我们先借助Jametong翻译的"从Oracle迁移到Mysql之前必须知道的50件事",看一看如何把Oracle转到MySQL中的困难:1. 对子查询的优化表现不佳.2. 对复杂查询的处理较弱3. 查询优化器不够成熟4. 性能优化工具与度量信息不足5. 审计功能相对较弱6. 安全功能不成熟,甚至可以说很粗糙.没有用户组与角色的概念,没有回收权限的功能(仅仅可以授予权限).当一个用户从不同的主机/网络以同样地用户名/密码登录之后,可能被当作完全不同的用户来处理.没有类似于Oracle的内置的加密功能.7. 身份验证功能是完全内置的.不支持LDAP,Active Directory以及其它类似的外部身份验证功能.8. Mysql Cluster可能与你的想象有较大差异.9. 存储过程与触发器的功能有限.10. 垂直扩展性较弱.11. 不支持MPP(大规模并行处理).12. 支持SMP(对称多处理器),但是如果每个处理器超过4或8个核(core)时,Mysql的扩展性表现较差.13. 对于时间、日期、间隔等时间类型没有秒以下级别的存储类型.14. 可用来编写存储过程、触发器、计划事件以及存储函数的语言功能较弱.15. 没有基于回滚(roll-back)的恢复功能,只有前滚(roll-forward)的恢复功能.16. 不支持快照功能.17. 不支持数据库链(database link).有一种叫做Federated的存储引擎可以作为一个中转将查询语句传递到远程服务器的一个表上,不过,它功能很粗糙并且漏洞很多.18. 数据完整性检查非常薄弱,即使是基本的完整性约束,也往往不能执行。
详解MySQL数据库安全配置

详解MySQL数据库安全配置.MySQL 是完全网络化的跨平台关系型数据库系统,同时是具有客户机/服务器体系结构的分布式数据库管理系统。
MySQL 是完全网络化的跨平台关系型数据库系统,同时是具有客户机/服务器体系结构的分布式数据库管理系统。
它具有功能强、使用简便、管理方便、运行速度快、安全可靠性强等优点,用户可利用许多语言编写访问MySQL 数据库的程序,特别是与php更是黄金组合,运用十分广泛。
由于MySQL是多平台的数据库,它的默认配置要考虑各种情况下都能适用,所以在我们自己的使用环境下应该进行进一步的安全加固。
作为一个MySQL的系统管理员,我们有责任维护MySQL数据库系统的数据安全性和完整性。
MySQL数据库的安全配置必须从两个方面入手,系统内部安全和外部网络安全,另外我们还将简单介绍编程时要注意的一些问题以及一些小窍门。
系统内部安全首先简单介绍一下MySQL数据库目录结构。
MySQL安装好,运行了mysql_db_install脚本以后就会建立数据目录和初始化数据库。
如果我们用MySQL源码包安装,而且安装目录是/usr/local/mysql,那么数据目录一般会是/usr/local/mysql/var。
数据库系统由一系列数据库组成,每个数据库包含一系列数据库表。
MySQL是用数据库名在数据目录建立建立一个数据库目录,各数据库表分别以数据库表名作为文件名,扩展名分别为MYD、MYI、frm的三个文件放到数据库目录中。
MySQL的授权表给数据库的访问提供了灵活的权限控制,但是如果本地用户拥有对库文件的读权限的话,攻击者只需把数据库目录打包拷走,然后拷到自己本机的数据目录下就能访问窃取的数据库。
所以MySQL所在的主机的安全性是最首要的问题,如果主机不安全,被攻击者控制,那么MySQL的安全性也无从谈起。
其次就是数据目录和数据文件的安全性,也就是权限设置问题。
从MySQL主站一些老的binary发行版来看,3.21.xx版本中数据目录的属性是775,这样非常危险,任何本地用户都可以读数据目录,所以数据库文件很不安全。
《数据库的存储结构》课件

通过优化查询语句,减少数 据检索量,提高查询效率。
1
索引优化
合理使用索引,加速数据检 索速度,减少数据库的I/O操
作。
分区优化
将大表分成小表,提高查询 和管理效率。
并行处理优化
通过多线程或多进程方式, 同时处理多个查询请求,提 高数据库的整体性能。
数据库的安全保护
用户权限管理
对不同用户设置不同的权 限级别,限制对数据的访 问和修改。
数据库的作用
数据库是信息系统的核心组成部分, 主要用于存储、检索、更新和管理大 量数据,满足各种应用的需求。
数据库的类型
关系型数据库
基于关系模型的数据库,通过表 和列来组织数据,使用SQL语言 进行数据操作。
非关系型数据库
不基于关系模型的数据库,如键 值存储、文档存储、列存储等, 具有灵活的数据模型和可伸缩性 。
非关系型数据库的设计原则
面向数据类型设计
根据实际需求选择合适的数据类型,如字符 串、整数、日期等。
数据冗余最小化
通过合理的数据结构设计,减少数据冗余, 提高数据一致性和可靠性。
数据分区
将数据按照一定规则分区存储,提高数据访 问效率和可扩展性。
数据副本
设置数据副本,提高系统的可用性和容错性 。
非关系型数据库的管理和维护
增量备份与全量备份
根据需要选择不同的备份方式, 全量备份完整覆盖数据,增量备 份只备份发生变动的部分。
恢复方法
在数据丢失或损坏时,能够快 速恢复到正常状态,减少损失 。
THANKS FOR WATCHING
感谢您的观看
《数据库的存储结构》ppt课件
目录
• 数据库概述 • 数据库的存储结构 • 关系型数据库 • 非关系型数据库 • 数据库的优化和安全
postgres数据库mvcc实现原理

postgres数据库mvcc实现原理PostgreSQL是一种开源的关系型数据库管理系统,它使用了MVCC (多版本并发控制)来实现并发控制。
MVCC是一种在数据库中实现并发控制的技术,它允许多个事务同时访问同一数据,而不会相互干扰。
在MVCC中,每个事务都可以看到一个独立的版本,这个版本是由数据库系统自动维护的。
MVCC的实现原理是将每个事务的修改操作都存储在一个单独的版本中。
每个版本都有一个唯一的事务ID和时间戳,用来标识这个版本是哪个事务修改的,以及修改的时间。
当一个事务需要读取数据时,它会读取最新的版本,如果需要修改数据,则会创建一个新的版本,并将修改操作写入这个版本中。
在MVCC中,每个事务都有一个可见性规则,用来确定它可以看到哪些版本。
这个规则是根据事务的启动时间和提交时间来确定的。
如果一个事务的启动时间早于某个版本的时间戳,但提交时间晚于这个版本的时间戳,则这个事务可以看到这个版本。
如果一个事务的启动时间晚于某个版本的时间戳,则这个事务不能看到这个版本。
MVCC的实现还需要解决一些问题,比如如何处理并发修改和如何回收不再使用的版本。
为了解决并发修改的问题,MVCC使用了锁和版本链。
当一个事务需要修改数据时,它会先获取一个锁,然后创建一个新的版本,并将修改操作写入这个版本中。
当事务提交时,它会释放锁,并将新版本添加到版本链中。
如果有多个事务同时修改同一数据,它们会竞争锁,只有一个事务能够获得锁并修改数据,其他事务需要等待。
为了回收不再使用的版本,MVCC使用了垃圾回收机制。
当一个事务提交时,它会将所有早于它启动时间的版本标记为可回收。
当数据库需要空间时,它会扫描版本链,将所有可回收的版本删除,并释放相应的空间。
总之,MVCC是一种在数据库中实现并发控制的技术,它允许多个事务同时访问同一数据,而不会相互干扰。
在MVCC中,每个事务都可以看到一个独立的版本,这个版本是由数据库系统自动维护的。
PostgreSQL--内核分析--数据存储系统

2数据缓冲区和数据存储层之间的接口2.1 存储访问接口层位于buffer下层的代码,是数据存储层,但数据缓冲区和数据存储层之间,有一个接口存在,位于src/backend/storage/smgr;这一接口,规定了数据缓冲区和数据存储层之间如何交互,如何发生关联。
PG的结构良好,很多层之间,可以很好的分离,这点也体现在了本文所讲述的接口之间。
接口层,通过抽象,规定了两层之间,发生关联的点;通过定义这些关联的点动作和出入口参数,完整描述了接口层的概貌。
在数据缓冲区的文档中,讲述了ReadBufferExtended函数极其调用的ReadBuffer_common 子函数中,可能都涉及的、类似smgrXXX函数的调用,如smgrread,这是buf层的函数发现buf中没有相应的数据可向数据访问层提供,则buf管理器直接向数据库存储层要求IO,使得被要求的数据能够进入buf。
关键数据结构如下:typedef struct f_smgr{void (*smgr_init) (void); /* may be NULL */void (*smgr_shutdown) (void); /* may be NULL */void (*smgr_close) (SMgrRelation reln, ForkNumber forknum);void (*smgr_create) (SMgrRelation reln, ForkNumber forknum,bool isRedo);bool (*smgr_exists) (SMgrRelation reln, ForkNumber forknum);void (*smgr_unlink) (RelFileNodeBackend rnode, ForkNumber forknum,bool isRedo);void (*smgr_extend) (SMgrRelation reln, ForkNumber forknum,BlockNumber blocknum, char *buffer, bool skipFsync);void (*smgr_prefetch) (SMgrRelation reln, ForkNumber forknum,BlockNumber blocknum);void (*smgr_read) (SMgrRelation reln, ForkNumber forknum,BlockNumber blocknum, char *buffer);void (*smgr_write) (SMgrRelation reln, ForkNumber forknum,BlockNumber blocknum, char *buffer, bool skipFsync);BlockNumber (*smgr_nblocks) (SMgrRelation reln, ForkNumber forknum);void (*smgr_truncate) (SMgrRelation reln, ForkNumber forknum,BlockNumber nblocks);void (*smgr_immedsync) (SMgrRelation reln, ForkNumber forknum);FileSeek //文件操作的相关封装FileTruncate //文件操作的相关封装PathNameOpenFile另外,LRU相关结构如下:typedef struct vfd{int fd; /* current FD, or VFD_CLOSED if none */unsigned short fdstate; /* bitflags for VFD's state */ResourceOwner resowner; /* owner, for automatic cleanup */File nextFree; /* link to next free VFD, if in freelist */File lruMoreRecently; /* doubly linked recency-of-use list */File lruLessRecently;off_t seekPos; /* current logical file position */char *fileName; /* name of file, or NULL for unused VFD *//* NB: fileName is malloc'd, and must be free'd when closing the VFD */int fileFlags; /* open(2) flags for (re)opening the file */int fileMode; /* mode to pass to open(2) */} Vfd;4数据存储在存储层,需要考虑对象规模如何存储等问题。
DB2、MySQL 和 PostgreSQL 体系结构

MySQL实例与DB2数据库相似。
MySQL和PostgreSQL数据库可以几乎每周都进行特性修改,但是DB2中的特性实现和修改要经过非常仔细的计划,这是因为有众多的业务依赖于使用DB2产品。请注意,在本文中我们使用MySQL 5.1、PostgreSQL 8.0.3和DB2 V8.2进行比较,所以在阅读本文时请考虑到这一点。
在默认情况下分配一个缓冲池,并可以使用CREATE BUFFERPOOL命令添加其他缓冲池。默认的页大小在创建数据库时决定,可以是4、8、16或32K。
数据库连接
客户机使用CONNECT或USE语句连接数据库,这时要指定数据库名,还可以指定用户id和密码。使用角色管理数据库中的用户和用户组。
客户机使用connect语句连接数据库,这时要指定数据库名,还可以指定用户id和密码。使用角色管理数据库中的用户和用户组。
图1、图2和图3是MySQL、PostgreSQL和DB2的体系结构图。我们在阅读一些文档之后竭尽我们的能力绘制出MySQL和PostgreSQL的体系结构图。如果您发现不符合实际情况的地方,请告诉我们,我们会进行纠正。
MySQL
MySQL使用一种基于线程的体系结构,而PostgreSQL和DB2采用基于进程的体系结构。正如在图1中看到的,一个MySQL实例可以管理许多数据库。一个实例中的所有MySQL数据库共享一个公用的系统编目,INFORMATION_SCHEMA。
图4. DB2数据库管理器(实例)和数据库共享内存体系结构
特性对比
表1对比了MySQL、PostgreSQL和DB2特性。这不是一个完整的列表,但是对比了最常用的特性。
表1. MySQL、PostgreSQL和DB2特性对比
postgresql(pg)数据库简介-new数据库

postgresql(pg)数据库简介-new数据库1.什么是PostgreSqlPostgreSQL是⼀个功能强⼤的开源对象关系型数据库系统,他使⽤和扩展了SQL语⾔,并结合了许多安全存储和扩展最复杂数据⼯作负载的功能。
PostgreSQL的起源可以追溯到1986年,作为加州⼤学伯克利分校POSTGRES项⽬的⼀部分,并且在核⼼平台上进⾏了30多年的积极开发。
PostgresSQL凭借其经过验证的架构,可靠性,数据完整性,强⼤的功能集,可扩展性以及软件背后的开源社区的奉献精神赢得了良好的声誉,以始终如⼀地提供⾼性能和创新的解决⽅案。
PostgreSQL在所有主要操作系统开始使⽤PostgreSQL从未如此简单。
2.为什么要使⽤PostgreSQLPostgreSql提供了许多功能,旨在帮助开发⼈员构建应⽤程序,管理员保护数据完整性并且构建容错环境,并帮助你管理数据,⽆论数据集的⼤⼩。
除了免费和开源之外,Postgre SQL还具有⾼度的可扩展性。
例如,你可以定义⾃⼰的数据类型,构建⾃定义SQL函数(此sql函数在另⼀篇帖⼦讨论:点此跳转),甚⾄可以编写来⾃不同编程语⾔的代码,⽽不需要重新编译数据库。
PostgreSql试图符合SQL标准,在这种标准中,这种⼀致性不会与传统特性相⽭盾,或者可能导致糟糕的架构决策。
⽀持SQL标准所需的许多功能,但是有时候语法或者功能略有不同。
随着时间的推移,可以预期进⼀步向⼀致性迈进。
从2018年10⽉发布的11版本开始,PostgreSQL符合SQL:2011核⼼⼀致性的179个强制性功能中的⾄少160个,在此之前,没有任何关系型数据库符合此标准的完全符合。
3.下⾯是PostgreSQL中的各种功能介绍数据类型1.基本类型:Integer, Numeric, String, Boolean2.结构类型:Date/Time, Array, Range, UUID3.⽂档类型:JSON/JSONB, XML, Key-value(Hstore)4.⼏何类型:Point, Line, Circle, Polygon5.⾃定义类型:Composite, Custom Types数据的完整性1.唯⼀性,不为空2.主键3.外键4.排除约束5.显式锁定,咨询锁定并发性,性能1.索引2.⾼级索引3.复杂的查询计划期/优化器4.交互5.多版本并发控制(MVCC)6.读取查询的并⾏化和构建B树索引7.表分区8.Sql标准中定义的所有事物隔离级别,包括Serializable9.即时表达式汇编(JIT)可靠性,灾难恢复1.预写⽇志(WAL)2.复制:异步,同步,逻辑3.时间点恢复(pitr),主动备⽤4.表空间安全性1.⾝份验证:GSSAPI, SSPI, LDAP, SCRAM-SHA-256, 证书等2.强⼤的访问控制系统3.列和⾏级安全性可扩展性1.存储的功能和程序2.程序语⾔:PL/PGSQL, Perl, Python (more)3.外部数据包装器:使⽤标准SQL接⼝连接到其他数据库或流4.许多提供附加功能的扩展,包括PostGIS国际化,⽂本搜索1.⽀持国际字符集,例如通过ICU校对2.全⽂检索对⽐Mysql1.PostgreSQL的稳定性极强,Innodb等引擎在崩溃、断电之类的灾难场景下抗打击能⼒有了长⾜的进步,然⽽很多Mysql⽤户都遇到过Server级的数据库丢失的场景---Mysql系统库是MyISAM的,相较⽽⾔,PG数据库在这⽅⾯要好⼀些。
超详细的MySQL工作原理体系结构

超详细的MySQL工作原理体系结构了解MySQL(超详细的MySQL工作原理体系结构)•1.MySQL体系结构•2.MySQL内存结构•3.MySQL文件结构•4.innodb体系结构一、了解MySQL前你需要知道的引擎是什么:MySQL中的数据用各种不同的技术存储在文件(或者内存)中。
这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。
通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
当我们理解了引擎这个概念,自然而然就知道引擎层的作用就提供各种不同引擎给你选择,然后用你选出来的引擎去处理sql语句二、MySQL体系结构MySQL 最重要、最与众不同的特性是它的存储引擎架构,这种架构的设计将查询处理(Query Processing)及其他系统任务(Server Task)和数据的存储/提取相分离。
这种处理和存储分离的设计可以在使用时根据性能、特性,以及其他需求来选择数据存储的方式。
由图,可以看出MySQL最上层是连接组件。
下面服务器是由连接池、管理工具和服务、SQL接口、解析器、优化器、缓存、存储引擎、文件系统组成。
•用户:进行数据库连接的人。
•支持接口:是第三方语言提供和数据库连接的接口,常见的有jdbc,odbc,c的标准api函数等等。
•管理工具和服务:系统管理和控制工具,例如备份恢复、Mysql 复制、集群等(见图)•连接层:提供与用户的连接服务,用于验证登录服务。
—> 连接池:由于每次建立建立需要消耗很多时间,连接池的作用就是将这些连接缓存下来,下次可以直接用已经建立好的连接,提升服务器性能。
•服务层:完成大多数的核心服务功能。
有sql接口,解析器parser,优化器optimizer,查询缓存 cache/buffer 。
—>SQL接口:接受用户的SQL命令,并且返回用户需要查询的结果。
比如select * from就是调用SQL Interface—>解析器: SQL命令传递到解析器的时候会被解析器验证和解析。
mysql 数据结构读写原理

mysql 数据结构读写原理
MySQL是一种关系型数据库管理系统,它使用了B+树数据结构来存储和管理数据。
读取数据:
1. 用户发出查询请求,查询语句被发送到MySQL服务器。
2. MySQL服务器解析查询语句,确定要查询的表和字段,并通过查询优化器生成查询计划。
3. 查询优化器分析查询条件,并根据索引的选择性和成本估算选择最佳的索引来加速查询。
4. MySQL服务器使用B+树索引结构来定位到符合查询条件的数据行。
B+树索引是一种多层次的树结构,其中叶子节点存储了实际的数据行,而非叶子节点存储了指向下一层节点的指针。
5. 一旦找到了符合查询条件的数据行,MySQL服务器将其返回给用户。
写入数据:
1. 用户发出写入请求,写入语句被发送到MySQL服务器。
2. MySQL服务器解析写入语句,并确定要写入的表和字段。
3. 如果表定义了主键或唯一索引,MySQL服务器会检查写入的数据是否有冲突。
如果有冲突,写入操作会被拒绝。
4. MySQL服务器将写入的数据行插入到对应的表中。
如果表定义了索引,MySQL会更新相应的索引数据。
5. 当写入操作完成后,MySQL服务器将写入结果返回给用户。
总结:
MySQL使用B+树数据结构来进行数据的存储和索引,通过查询优化器生成查询计划来加速查询操作。
对于写入操作,MySQL会检查数据的合法性,并将数据插入到对应的表和索引中。
这样,MySQL能够高效地读取和写入数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
64-bits 数据库的个数
表的个数 单表的容量
PostgreSQL 无限制 无限制 无限制
MySQL 无限制 无限制(InnoDB限制40亿张表) 理论上无限制(受限于OS)
11
2.1 存储层,我们看重什么?
文件大小受操作系统限制
12
2.1 存储层,我们看重什么?
单表比较 比较项
每个表的数据文件个数 单个文件最大尺寸 单个文件初始大小 文件在外存的形式
1 存储结构 2 运行信息
2.2 看的见的文件仅仅是文件吗? --PostgReSQL
存储结构包括了元 信息和用户的数据 1 存储结构 2 运行信息
运行信息与数据 库的功能相对应
2.2 看的见的文件仅仅是文件吗? --PostgReSQL
用户 SQL
cReate tablespace ts_a (…) cReate table t_a (…) …
MySQL 单表容量示例:
受操作系统影响 , 单表容量就是外存文件大小
实例
X 易的相册库: 150 亿记录, 分布在 8 个实例节点上, 单表接近 20 亿的记录, 单表 350G 的存储量
X 浪 60 亿单表的记录, 单表容量超过 1T
MySQL 依赖脱机配置参数 配置 系统表空间的容量 , 使用不方便且 IO 低效: innodb_data_ = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
tablespace ts_a... select … fRom t_a...
数据缓存区
系统表
pg_tablesapce pg_class pg_attRibutes
Reltablespace + Rel ( + ReltoastRelid )
外存,文件系统: 目录 - 表空间 -+ 文件名 ......
1 系统数据 2 用户数据
2.2 看的见的文件仅仅是文件吗? --MySQL
用户 SQL
参数控制表空间
innodb_ cReate table t_a (…) …
select … fRom t_a...
InnoDB
If (…) { ... }
FoR (int i=1, i<100,i++) { … }
PostgreSQL 无数个 默认1G
自动扩展到单个文件最大
MySQL 1个 受OS限制 自动扩展 存储层,我们看重什么?
PostgreSQL 单表容量示例:
单表 2GB*(1024*100 个文件 ) = 200TB/ 表空间 ( 64-bits 机器,实际上限为 2 的 64 次方 ) 次方)
存储介质
18
2.2 看的见的文件仅仅是文件吗? --PostgReSQL
文件中存放
系统运行信息、元 数据、用户数据
表空间级的存储能 力没有限制
没有管理 IO 依赖操作系统
单个文件大小有限 但表的数据量没限制
深度挖掘
19
2.2 看的见的文件仅仅是文件吗? --MySQL
2.2 看的见的文件仅仅是文件吗? --MySQL
2
1
存储与计算 , 引领数据处理的发展
2
PostgReSQL pk MySQL :存储层对比
2.1
存储层,我们看重什么?
2.2
看的见的文件仅仅是文件吗?
2.3
看不见的管理者:表空间?
3
PostgReSQL 和 MySQL 存储层的优化
3
1 存储与计算 , 引领数据处理的发展
?
什么引领着 数什么在引领着数据处理技术的发展
存储与计算的需求 引领 发展 什么在引领着数据处理技术的发展
2 PostgReSQL pk MySQL : 存储层对比
2.1 存储层,我们看重什么? 2.2 看的见的文件仅仅是文件吗? 2.3 看不见的管理者:表空间?
7
2.1 存储层,我们看重什么? 存储层,三大能力 1 IO 能力 2 稳定性 3 存储能力力
8
2.1 存储层,我们看重什么?
存储层,三大能力 ---IO 能力
比较项
PostgreSQL
MySQL
数据管理单位 页(默认8k)
区(每区默认1M,一次可分配1--4个)
物理读写单位
页
页
读数据到缓存区
读数据到缓存区
使用方式
预读(Read-Ahead)
多范围读(Multi-RangeRead)
9
2.1 存储层,我们看重什么?
存储层,三大能力 --- 稳定能力
PostgreSQL 与 MySQL
都能长期稳定运行,包括存储系统长期的稳定运行
MySQL:
Facebook/Google/ 淘宝 ...
PostgreSQL: 腾讯 /Fujitsu/Cisco/NTT Data...
.
10
2.1 存储层,我们看重什么?
存储层,三大能力 --- 存储能力
4
两个时代,五个阶段
存储的目的是为了计算
分布式数据库 : 分布式实时计算
第一代 Haddop 生态园 : 分布式非实时计算
武新
分布式文件系统 : 对大数据存储
阶段 5 阶段 4
数据库 : 既存储又计算
文件系统 : 只存储无计算
阶段 2
阶段 1
单机时代
阶段 3
多机协作时代
5
1 存储与计算 , 引领数据处理的发展
14
2.2 看的见的文件仅仅是文件吗?
用户 SQL
cReate tablespace ts_a (...)
cReate table t_a (…) … tablespace ts_a...
路径 目录 + 文件名
外存 数据的存储
数据库
PostgReSQL/MySQL/..., 神秘的盒子 ?
15
2.2 看的见的文件仅仅是文件吗? --PostgReSQL
PostgreSQL 和 MySQL 存储层深度解析
@ 2014-04-11
1
1
一名数据技术的学习者、实践者
2
书籍 : 《数据库查询优化器的艺术:原理解析与 SQL 性能优化》
3
微博: @ 那海蓝蓝
4
博客 :
5
邮箱 : database_XX@
6
方向 : 数据库( PostgReSQL,MySQL.etc )
数据缓存区
外存,文件系统: t_a.fRm t_a.ibd ............
存储介质
22
2.2 看的见的文件仅仅是文件吗? --MySQL
stoRage\innobase\include\fil0fil.h:
内部存储时,页的类型,部分定义:
系统运行信息与数据存放在一起
#define FIL_PAGE_INDEX