分组函数3解读
excel分组统计函数

excel分组统计函数Excel分组统计函数Excel是一款功能强大的办公软件,广泛应用于数据分析、图表制作等业务领域。
对于数据处理来说,Excel的分组统计函数是一种非常实用的工具,它能够在工作表中对数据进行分类、求和、计数等操作,方便我们对大量数据进行分析、展现和比较。
本文将介绍Excel中的几种分组统计函数,帮助读者更好地使用Excel进行数据分析。
一、SUMIF函数SUMIF函数是一种常用的分组统计函数,它能够根据一定的条件来计算符合条件的数值之和。
其语法为:SUMIF(range, criteria, [sum_range])其中,range表示要进行计算的数据范围,criteria表示要匹配的条件,可以是一个单独的数值,也可以是一个字符串或单元格引用,[sum_range]表示要进行求和的数值范围。
例如,我们要计算A列中满足“女性”条件的数据之和,可以使用SUMIF函数:= SUMIF(A2:A10, "女性", B2:B10)这个公式将返回A列中匹配“女性”条件的数值之和,即2400。
二、COUNTIF函数COUNTIF函数是一种统计某个条件出现的次数的函数,与SUMIF函数类似,其语法为:COUNTIF(range, criteria)其中,range表示要进行计算的数据范围,criteria表示要匹配的条件,可以是一个单独的数值,也可以是一个字符串或单元格引用。
例如,我们要计算A列中满足“女性”条件的数据出现的次数,可以使用COUNTIF函数:= COUNTIF(A2:A10, "女性")这个公式将返回A列中匹配“女性”条件的数据出现的次数,即2。
三、AVERAGEIF函数AVERAGEIF函数是一种计算符合条件的数值平均值的函数,其语法与SUMIF函数类似,其语法为:AVERAGEIF(range, criteria, [average_range])其中,range表示要进行计算的数据范围,criteria表示要匹配的条件,可以是一个单独的数值,也可以是一个字符串或单元格引用,[average_range]表示要进行平均值计算的数值范围。
group lasso的定义公式

group lasso的定义公式Group Lasso 是一种用于特征选择和稀疏建模的正则化技术,通常用于线性回归和相关的机器学习任务。
它通过对特征进行分组,以鼓励模型在每个特征组内选择一组相关的特征,并对不同的特征组应用不同的L1正则化,以实现特征选择和稀疏性。
Group Lasso 的数学定义如下:假设有m 个训练样本,n 个特征,以及k 个特征组(也称为分组)。
我们用X 表示一个m×n 的特征矩阵,其中每一行代表一个训练样本,每一列代表一个特征。
另外,我们用β 表示一个n 维的系数向量,表示特征的权重。
Group Lasso 的目标函数通常由两部分组成:数据拟合项(Least Squares Term):这是最小化拟合数据误差的部分,通常用平方误差(Least Squares)或其他回归损失函数来表示。
它的目标是使模型能够拟合训练数据。
Group L1 正则化项:这是对系数向量β进行正则化的部分,它鼓励特征在特定的分组内共享权重,从而实现特征选择和稀疏性。
Group L1 正则化通常表示为各个特征组的L1 范数之和。
Group Lasso 的数学目标函数可以表示为:minimize: 1/2m * ||Y - Xβ||² + λ * Σᵢ||βᵢ||₂其中:Y 是目标变量的向量(m 维度)。
X 是特征矩阵(m×n 维度)。
β是待学习的系数向量(n 维度)。
λ是控制正则化强度的超参数。
βᵢ表示特征组i 内的系数向量。
Σᵢ表示对所有特征组i 进行求和。
||.||₂表示L2 范数(Euclidean 范数)。
1/2m 是归一化因子,用于确保数据拟合项的尺度与正则化项相匹配。
通过调整λ 的值,可以控制正则化的强度,从而影响模型选择哪些特征组以及在每个特征组内选择哪些特征。
这使得Group Lasso 成为一种强大的特征选择技术,尤其适用于具有分组特征的问题,如图像处理、生物信息学和自然语言处理。
excel 随机分组函数

excel 随机分组函数摘要:1.介绍Excel 随机分组函数2.随机分组函数的语法和参数3.随机分组函数的使用方法和示例4.总结随机分组函数的作用和应用场景正文:Excel 随机分组函数是一种在Excel 中实现随机分组的函数,可以帮助用户实现对数据进行随机分组,从而实现更加公平的分组。
在Excel 中,随机分组函数主要包括“RAND()”和“RANDBETWEEN()”函数。
1.介绍Excel 随机分组函数Excel 随机分组函数是一种在Excel 中实现随机分组的函数,可以帮助用户实现对数据进行随机分组,从而实现更加公平的分组。
在Excel 中,随机分组函数主要包括“RAND()”和“RANDBETWEEN()”函数。
2.随机分组函数的语法和参数- RAND() 函数:语法:`=RAND()`参数:无返回值:返回一个大于等于0 且小于1 的随机数。
- RANDBETWEEN() 函数:语法:`=RANDBETWEEN(bottom, top)`参数:- bottom:必需参数,指定随机数的最小值(包括)。
- top:必需参数,指定随机数的最大值(不包括)。
返回值:返回一个指定范围内的随机整数。
3.随机分组函数的使用方法和示例- 使用RAND() 函数:示例:`=RAND()`,返回一个大于等于0 且小于1 的随机数。
- 使用RANDBETWEEN() 函数:示例:`=RANDBETWEEN(1, 10)`,返回一个介于1 和10 之间的随机整数。
4.总结随机分组函数的作用和应用场景随机分组函数在Excel 中有着广泛的应用,尤其是在需要实现随机分组的情况下。
例如,在进行抽奖活动时,可以使用随机分组函数来实现随机抽奖;在进行问卷调查时,可以使用随机分组函数来实现随机抽样。
sql 分组函数

SQL分组函数在SQL中,分组函数(Group Functions)是一类用于对数据进行聚合操作的函数。
它们将多个行作为输入,根据指定的条件对这些行进行分组,并对每个分组应用聚合函数来计算结果。
这些函数通常用于SELECT语句的SELECT子句或HAVING子句中。
SQL中的常见分组函数包括:COUNT、SUM、AVG、MAX和MIN。
下面将详细介绍每个函数的定义、用途和工作方式。
1. COUNT函数COUNT函数用于计算表中满足指定条件的行数。
它可以接受一个参数,也可以不带参数。
如果不带参数,则返回表中所有行的数量。
定义:COUNT(expression)用途:•计算表中满足指定条件的行数。
•统计某列非空值的数量。
•与GROUP BY子句一起使用时,可以统计每个分组中满足条件的行数。
工作方式:•如果不带参数,则返回表中所有行的数量。
•如果带有参数,则返回满足条件的行数。
示例:-- 返回表中所有行的数量SELECT COUNT(*) FROM table_name;-- 返回某列非空值的数量SELECT COUNT(column_name) FROM table_name;-- 统计每个部门有多少员工SELECT department, COUNT(*) FROM employees GROUP BY department;2. SUM函数SUM函数用于计算表中满足指定条件的行的某一列的总和。
它只能用于数值型数据。
定义:SUM(expression)用途:•计算表中满足指定条件的行的某一列的总和。
•与GROUP BY子句一起使用时,可以计算每个分组中某一列的总和。
工作方式:•返回满足条件的行中某一列值的总和。
示例:-- 计算表中所有行的某一列值的总和SELECT SUM(column_name) FROM table_name;-- 计算每个部门员工工资总和SELECT department, SUM(salary) FROM employees GROUP BY department;3. AVG函数AVG函数用于计算表中满足指定条件的行的某一列值的平均值。
高中数学排列组合中的“分组分配”问题详解

高中数学排列组合中的“分组分配”问题详解
数学好教师 2020-02-06
不同种元素
分组问题
将n个不同元素按照某些条件分成k组,称为分组问题。
分组问题有平均分组、不平均分组、和部分平均分组三种情况。
1. 平均分组
1
2. 不平均分组
2
3. 部分平均分组
3
分配问题:
如果把不同的元素分配给几个不同对象,并且每个不同对象可接受的元素个数没有限制,那么实际上是先分组后分配的问题,即分组方案数乘以不同对象数的全排列数。
所以针对分配问题,需要遵守的原则是:先分组,后分配
同种元素
分组问题:
1
分配问题:
对于同种元素的分配问题,通常有两种解法:常规法和隔板法
常规法:
隔板法:
常规法:
隔板法:
经典练习题
1:将五位老师分到三个学校任教,每个学校至少分一位老师,总共有多少种分法。
(答案:150种)
2:有4个不同小球放入4个不同盒子,其中有且只有一个盒子留空,有多少种不同放法?(答案:144种)
3:7个人参加义务劳动,选出6个人,分成2组,每组都是3个人,有多少种不同分法?(答案:70种)
4:10个三好学生名额分到7个班级,每个班级至少一个名额,有多少种不同分配方案?(答案:84种)
5:现有7个完全相同的小球,将它们全部放入编号为1,2,3的三个盒子中
(1)若每个盒子至少放一个球,共有多少种不同的放法?(答案:15种)
(2)若允许出现空盒,共有多少种不同的放法?(答案:36种)
6:现有12个相同的小球,将它们全部放入编号为1,2,3,4的四个盒子中,要求每个盒子中的小球个数不小于其编号数,问不同的放法有多少种?(答案:10种)。
python 的分组函数

python 的分组函数Python的分组函数是指在Python编程语言中,用于将数据集合按照特定的规则进行分组的函数。
分组函数在数据处理和分析中起着非常重要的作用,可以帮助我们更加高效地处理和分析大量的数据。
一、groupby函数groupby函数是Python中最常用的分组函数之一,它可以根据指定的键对数据进行分组。
在使用groupby函数之前,首先需要导入itertools模块。
1. 函数原型:itertools.groupby(iterable, key=None)2. 参数解释:iterable:可迭代对象,表示要进行分组的数据集合。
key:可选参数,表示用于分组的键,可以是一个函数或者是一个属性名。
3. 返回值:返回一个迭代器,每个元素都是一个包含分组键和分组对象的元组。
4. 示例代码:```import itertoolsdata = [1, 1, 2, 2, 3, 3, 4, 5, 5]groups = itertools.groupby(data)for key, group in groups:print(key, list(group))```以上代码将输出:```1 [1, 1]2 [2, 2]3 [3, 3]4 [4]5 [5, 5]```二、pandas的groupby函数pandas是Python中用于数据分析的重要库,它提供了更高级的分组函数,可以方便地对数据进行分组和聚合操作。
1. 函数原型:DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)2. 参数解释:by:用于分组的列名、函数或者多列名的列表。
axis:指定按照哪个轴进行分组,默认为0表示按照行进行分组。
level:指定分组的层级。
离散数学-03

定理3-3 设有函数f:A→B和g:B→C,那么:
(4)gf是内射,则f是内射,g可以不是。 a1 a2 a3 f b1 b2 b3 b4 g c1 c2 c3 c4
浙江大学 信息学院 信电系 电子信息技术与系统研究所 宋牟平
(5)gf是满射,则g是满射,f可以不是。 a1 a2 a3 f b1 b2 b3 b4 g c1 c2 c3
浙江大学 信息学院 信电系 电子信息技术与系统研究所 宋牟平
另外,从映射的角度看,a称为b的源,b称为a的像。
a1 a2 a5 a3 a4 b1 b2 b3 b6 b4 b5
浙江大学 信息学院 信电系 电子信息技术与系统研究所 宋牟平
函数f:A→B D f ⊆A 注意,函数的定义有三个要点: (1)函数是关系。 (2)像的唯一性。一个像源不能对应两个像,但一个像可以对应两个像源。 对于b1,b2∈B,若存在a1,a2∈A,使b1=f(a1),b2=f(a2),则b1≠b2必有 a1≠a2,或a1=a2必有b1=b2。 Rf ⊆B
a1 a2 a4 a3
浙江大学 信息学院 信电系 电子信息技术与系统研究所 宋牟平
b1 b2 b3 b6
b4 b5
a5
不是函数,像不唯一。 (3)定义域中任意一个像源都有像。
a1 a2 a4 a3 a5 b1 b2 b3 b6 b4 b5
不是函数,a5没有像。
例
A=I,B=N,定义函数 f=|2i|+1 (i∈I)
定义3-2 函数相等:设有两个函数f:A→B和g:C→D,若A=C,B=D,且对一切 的a∈A,都有f(a)=g(a),则称 f=g。
浙江大学 信息学院 信电系 电子信息技术与系统研究所 宋牟平
定义3-3 扩充与限制:设有函数f:A→B和g:S→B,如果S⊆A,且对一切的 a∈S,都有g(a)=f(a),称g是f在S上的限制,f是g在A上的扩充。 例 函数g:Z→N,定义为 g(z)=2z+1 则g是前例定义的函数f在Z上的限制,而f是g在I上的扩充。 例 A到B的所有函数构成的集合,即函数族, BA={f | f:A→B} 集合A到B能定义多少函数?设#A=m,#B=n,则函数的数目为 #(BA)=(#B)#A =nm 集合A到B能定义多少关系?2#A×#B=2m×n个。
分组函数python

分组函数python分组函数是编程中常用的一种函数,它可以将数据按照特定的条件进行分类和分组。
在Python中,我们可以使用内置的函数或者第三方库来实现分组函数的功能。
本文将介绍Python中常用的分组函数及其用法,帮助读者更好地理解和运用这些函数。
一、groupby函数groupby函数是Python内置的一个分组函数,它可以根据指定的键对数据进行分组。
具体用法如下:groupby(iterable[, key])其中,iterable表示要进行分组的数据集,可以是列表、元组、字符串等可迭代对象;key是一个函数,它接受一个参数并返回一个用于分组的键。
如果不指定key,默认使用元素本身作为键。
groupby函数返回一个迭代器,它包含了分组后的数据。
我们可以通过遍历迭代器来获取分组后的数据。
示例代码如下:```from itertools import groupbydata = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]groups = groupby(data)for key, group in groups:print(key, list(group))```运行结果如下:```1 [1]2 [2, 2]3 [3, 3, 3]4 [4, 4, 4, 4]```在这个例子中,我们将列表data进行了分组,按照相同的元素进行了分类。
可以看到,输出结果中每个元素都和它所属的分组一起打印出来了。
二、pandas库中的分组函数除了内置的groupby函数,我们还可以使用第三方库pandas中的分组函数来进行更复杂的分组操作。
pandas是一个强大的数据处理和分析库,它提供了丰富的函数和方法来处理数据。
下面我们来介绍pandas中常用的分组函数:groupby、agg、transform和apply。
1. groupby函数pandas中的groupby函数与内置的groupby函数类似,但它提供了更多的功能和选项。
分组排序函数——row_number()

分组排序函数——row_number()1、MySQL8.0以上版本用法1:无分组排序Row_number() OVER(ORDER BY 字段 DESC)例如:Row_number() OVER(ORDER BY 学生成绩 DESC)表示不分班级,所有学生的成绩从高到低排序用法2:分组排序ROW_NUMBER() OVER(PARTITION BY 字段1 ORDER BY 字段2 DESC)表示根据字段1分组,在分组内部根据字段2排序,这个函数计算的值就表示每组内部排序后的顺序编号例如:ROW_NUMBER() OVER(PARTITION BY 班级 ORDER BY 学生成绩 DESC)表示根据“班级”分组,在每个“班级”内部根据“学生成绩”排序,这个函数计算的值就表示每组内部排序后的顺序编号解释:ROW_NUMBER( ) 起到了编号的功能partition by 将相同数据进行分区order by 使得数据按一定顺序排序2、MySQL5.7版本用法1:无分组排序例如:计算销售人员的销售额,结果按从高到低排序,查询结果中要包含销售的排名SET @rank := 0;SELECTA.*,@rank := @rank + 1 AS rankFROM( SELECT sales_name, sum( sales ) FROM spm_orderGROUP BY sales_nameORDER BY sum( sales ) DESC ) A用法2:分组排序例:计算销售人员在不同城市的销售额;要求:结果根据销售人员在不同城市的销售额进行分组排序(降序),并且查询结果要包含分组排名SET @r := 0,@type := '';SELECT@r :=CASE WHEN @type = a.sales_name THEN@r + 1 ELSE 1END AS rowNum,@type := a.sales_name AS type,a.*FROM( SELECT sales_name, city, sum( sales ) FROM spm_orderGROUP BY sales_name, cityORDER BY sales_name, sum( sales ) DESC ) a;。
高中数学排列组合中的模型探究-----分组分配问题

高中数学排列组合中的模型探究-----分组分配问题分组分配问题是高中数学排列组合学习中的常见问题,是学习重点也是难点,本文就排列组合中具体的分组分配问题进行归类,浅析求解方法。
一、明确分组、分配问题的含义将n个不同元素依据条件分成m组(或是m堆)是分组问题,辨别的关键要点是任意交换一种分组的两个组员,结果是同一种情况,组和组的地位之间没有区别;分组问题有平均分组、部分平均分组和不平均分组三种情况。
将n个不同元素依据条件分给m个不同对象(或是去处),称为分配问题,分配问题又分为定向分配和不定向分配两种问题;分组问题和分配问题是有区别的,前者在分好组后,任意交换两个组员,结果是同一种情况,后者因为去向不同,交换成员后是算不同的情况,可区分的,对于后者常常先分组后排列。
二、不同元素的分组、分配问题(一)平均分组、分配问题例1 六本不同的书,求在下列条件下各有多少种不同的分配方法?(1)分为三组,每组两本.(2)分给三个人,每人两本.(3)甲两本、乙两本、丙两本.【分析】(1)分组与顺序无关,是组合问题。
分法是=15(种),为什么要除以?我们不妨把六本不同的书设为a,b,c,d,e,f六个号码,由分步乘法计数原理可以找出两种具体的分法为:(a,b) (c,d) (e,f)与(a,b) (e,f) (c,d),实际这两种分法是同一种分法,只是后面两组出现的先后有区别,但是分好组后最终的结果是同一种结果。
究其原因实际上是在运用分步乘法计数原理的时候加入先后顺序,也就是相当于三个组员间排列了。
因此还应取消三个组员间排列的顺序,即除以三个组员的全排列数,所以最终的分组方法数为=15(种)。
(2)此组题属于分配中的不定向分配问题。
由于分配给三人,同一本书给不同的人是不同的分法,所以是排列问题。
实际上可看作“分为三组,再将这三组分给甲、乙、丙三人”,因此只要将分组方法数再乘以,即=90(种),(3)由于分配给三人,每人分2本是一定的,属分配问题中的定向分配问题,由分步乘法计数原理得出:有=90(种),(二)部分的平均分组、分配问题例2 六本不同的书,求在下列条件下各有多少种不同的分配方法?(1)分为三组,一组四本,另外两组各一本.(2)分给三个人,一人四本、另两人各一本.(3)甲四本、乙一本、丙一本.【分析】(1)是分组问题,分组方法是=15(种),为什么要除以?跟例题1的一样,其中两组本数都是一本,由分步乘法计数原理的时候这两组有了一先一后挑选的顺序,也就是相当于这两本书在第二次和第三次分到组里去的过程中排列了,所以要除以这两个成员间的排列数,而与四本书的那一组,由于书的本数不一样,不可能重复,所以最终分法是=15(种)。
因式分解之分组分解法

因式分解之分组分解法【知识精读】分组分解法并不是一种独立的因式分解的方法,分组分解法的原则是分组后可以直接提公因式,或者可以直接运用公式。
使用这种方法的关键在于分组适当,而在分组时,必须有预见性。
能预见到下一步能继续分解。
而“预见”源于细致的“观察”,分析多项式的特点,恰当的分组是分组分解法的关键。
注意问题提示:(1)分组分解法主要应用于四项以上的多项式的因式分解。
(2)分析题时仍应首先考虑公因式的提取,公式法的应用,其次才考虑分组。
(3)分组方法的不同,仅仅是因为分解的手段不同,各种手段的目的都是把原多项式 进行因式分解。
常见分组方法方法一:分组后能提取公因式1.按字母分组例如:分解因式:ax+ay+bx+by 可以按某一字母为准分组,若按含有字母a 的分为一组, 含有字母b 的分为一组,即ax+ay+bx+by=(ax+ay)+(bx+by)=a(x+y)+b(x+y),这样就产生了公因式(x+y)。
2.按系数分组例如:分解因式:a 2-ab+3b-3a ,我们观察到前两项的系数之比和后两项系数之比恰好 相等,即1:(-1)=3:(-3),则a 2-ab+3b-3a=(a 2-ab)-(3a-3b)=a(a-b)-3(a-b)。
3.按次数分组例如:分解因式:x 3+x 2+x-y 3-y 2-y ,此多项式有两个三次项,有两个两次项,有两个一次项,按次数分组为:(x 3-y 3)+(x 2-y 2)+(x-y)方法二:分组后能运用公式例如:x 2-2xy+y 2-z 2可以把前三项作为一组,它是一个完全平方式,可以分解为(x-y)2。
而(x-y)2-z 2又是平方差形式的多项式,还可以继续分解。
方法三:重新分组例如:分解因式4x 2+3y-x(3y+4),此多项式必须先去括号,进行重新分组。
4x 2+3y-x(3y+4)=4x 2+3y-3xy-4x=(4x 2-4x)+(3y-3xy)=4x(x-1)-3y(x-1)=(4x-3y)(x-1)。
统计学随机分组公式

统计学随机分组公式全文共四篇示例,供读者参考第一篇示例:统计学中的随机分组公式是实验设计和数据分析中非常重要的一部分。
通过随机分组,我们可以确保实验组和对照组之间的差异是由实验处理而不是其他因素造成的。
在统计学中,随机分组可以帮助降低因为个体差异带来的偏差,使得研究结果更具有说服力和可信度。
下面我们将介绍一些常用的随机分组公式及其应用。
一、简单随机分组公式简单随机分组是一种最基本的随机分组方法,其公式为:n!/(m!(n-m)!)n表示总体样本量,m表示实验组的样本量。
在简单随机分组中,每个个体有相同的几率被分到实验组或对照组中。
通过这种方法,可以避免人为干扰和偏见,使得实验的结果更具有代表性和可靠性。
N= N1+N2+...+NkN表示总体样本量,N1、N2、...、Nk分别表示不同层次的样本量。
在分层随机分组中,我们可以根据不同特征对样本进行分层,然后在每一层次中进行随机分组。
这种方法可以有效控制混杂因素的影响,提高实验的准确性和可信度。
k=N/mN表示总体样本量,m表示实验组的样本量,k表示每隔k个体一个实验组样本。
在系统随机分组中,我们可以按照某种规律选择实验组样本,然后将剩余的个体分配到对照组中。
这种方法可以减少随机性带来的误差,同时保持实验的随机性和客观性。
n!(2m)!随机分组是实验设计和数据分析中至关重要的一环,通过合理选择和应用随机分组方法,我们可以有效地控制实验中的各种干扰因素,确保研究结果的可信度和科学性。
希望本文介绍的随机分组公式能够帮助读者更好地理解和应用统计学中的随机分组方法,为科学研究提供更加有力的支持。
【字数超过要求】第二篇示例:统计学中的随机分组是指将研究对象随机地分配到实验组和对照组中,以消除实验结果的偏倚及误差,从而得到更加客观和准确的实验结论。
随机分组是一种常用的实验设计方法,可以有效地降低实验结果的干扰因素,使实验结果更加具有代表性和可靠性。
在进行实验研究时,科研人员需要根据研究目的和实验设计要求来确定研究对象的分组方式。
数学分组分解法知识点总结

初中数学学问点:因式分解 下面是对数学中因式分解内容的学问讲解,盼望同学们仔细学习。 因式分解 因式分解定义:把一个多项式化成几个整式的积的形式的变形叫 把这个多项式因式分解。
魏
第3页共4页
本文格式为 Word 版,下载可任意编辑
④结果按数单字母单项式多项式顺序排列 ⑤相同因式写成幂的形式 ⑥首项负号放括号外 ⑦括号内同类项合并。
魏
第4页共4页
因式分解要素:①结果必需是整式②结果必需是积的形式③结果是 等式④
因式分解与整式乘法的关系:m(a+b+c) 公因式:一个多项式每项都含有的公共的因式,叫做这个多项式各 项的公因式。 公因式确定方法:①系数是整数时取各项最大公约数。②相同字母 取最低次幂③系数最大公约数与相同字母取最低次幂的积就是这个多 项式各项的公因式。 提取公因式步骤: ①确定公因式。②确定商式③公因式与商式写成积的形式。 分解因式留意; ①不准丢字母 ②不准丢常数项留意查项数 ③双重括号化成单括号
二二分法:
= -(x^2-2xy+y^2)+1
ax+ay+bx+by
= 1-(x-y)^2
=(ax+ay)+(bx+by)
= (1+x-y)(1-x+y)
=a(x+y)+b(x+y)
温馨提示:大家看过初二数学学问点之分组分解法,通过试题的
=(a+b)(x+y)
练习可bx 和 by 分一组,利用乘法安排律,两两
初中数学学问点总结:平面直角坐标系
离散数学 第三章 函数

于是我们有 χA′(x)=1- χA(x) χA∩B(x)= χA(x) .χB(x) χA∪B(x)= χA(x) +χB(x) - χA∩B(x)
16
离散数学
A⊆B⇔(∀x∈X)(χA(x) ≤χB(x)) A=B⇔(∀x∈X)(χA(x) =χB(x)) A=∅⇔(∀x∈X)(χA(x) =0) A=X⇔(∀x∈X)(χA(x) =1) 。 例11.谓词的特征函数:设P是X上的谓词,我们定义P的 特征函数 χP :X→{0,1} 如下
14
离散数学
设f ,g是由X到Y的两个函数,f ,g :X→Y,则 f = g ⇔ (∀x∈X)(f(x) = g(x) ) 。 定义3.运算(operation) 定义 对于任何自然数n≥1,n元运算f是一个从n维叉积Xn到 X的函数。 即 f :Xn →X 。 一般说来,运算具有以下两个特点: (1)定义较一般函数特殊; (2)易可操作性; 特别地,一元运算 f :X→X; 二元运算 f :X × X→X。 例9.集合的余运算 ′ :2X → 2X 是一元运算; 集合的交,并运算 ∩ ,∪ :2X × 2X → 2X 是二元运算。
1 χP(x)= 0 当P(x)为真时 当P(x)为假时
于是我们有 χ¬P(x)=1- χP(x) χP∧Q(x)= χP(x) .χQ(x) χP∨Q(x)= χP(x) +χQ(x) - χP∧Q(x)
17
离散数学
(P⇒Q)⇔(∀x∈X)(χP(x)≤χQ(x)) (P⇔Q)⇔(∀x∈X)(χP(x)=χQ(x)) F⇔(∀x∈X)(χF(x) =0) T⇔(∀x∈X)(χT(x) =1) 。
。
函数分组的使用方法

函数分组的使用方法
函数分组是一种将函数按照功能进行分组的方法,使得代码更加清晰易懂、易于维护。
以下是使用函数分组的一些方法:
1. 按照功能进行分组
将相同功能的函数放置在同一个函数组内。
例如,所有与用户登录相关的函数可以放在一个名为“用户登录”的函数组内。
2. 分组命名
对于不同的函数组,可以给它们命名以便于区分。
例如,与用户管理相关的函数组可以称为“用户管理”,与订单管理相关的函数组
可以称为“订单管理”。
3. 维护代码风格一致性
在分组时,应该遵循一定的代码风格,例如函数名的命名规范、注释的规范等等。
这样有助于提高代码的可读性和可维护性。
4. 提高代码的可重用性
通过将相关函数放在同一个函数组内,可以提高代码的可重用性。
例如,在开发一个新的功能时,可以直接使用之前已经编写过的函数组,而不必重新编写代码。
5. 优化代码结构
使用函数分组可以使代码结构更加清晰明了。
在需要修改某个功能时,可以更快地找到相关函数组,并且更容易修改。
总之,使用函数分组可以提高代码的可维护性、可读性和可重用性。
在编写代码时,应该根据功能进行分组,并遵循一定的代码风格。
分组分解法(教学课件)

典例讲析
例2:因式分解:⑵ a 2ab b c
2 2 2
解:原式= (a b) c
2
2
(a b c)(a b c)
如果把一个多项式分组后各组都 能分解因式,且在各组分解后,各组之 间又能继续分解因式,那么,这个多项 式就可以用分组分解法分解因式.
1.若 ,则
∴(a-3)2+(b+1)2=0
∴a=3,b=-1
练习3:因式分解
1、a b a b 1
2 2
2
2
2
a b 1 b 1
2 2
2
b 1 a 1
2
b 1b 1a 1a 1
分解因式要分解到不能继续分解因 式为止.
练习:因式分解
2、x 6 xy 9 y 9 y 3x
2 2
x 6 xy 9 y 3x 9 y
2 2
x 3 y 3x 3 y
2
,则
1.若
x 3 y x 3 y 3
小结:
如果一个多项式各项既没有公因式, 又不能直接运用公式,但把一个多项 式分组后各组都能分解因式,且在各 组分解后,各组之间又能继续分解因 式,那么这个多项式就可以用分组分 解法分解因式. 用分组分解法分解因式,一定要想想 分组后能否继续进行分解因式.
2
解:原式= a(a b) c(a b)
(a b)(a c)
这个多项式各项既没有公因式,又不能 直接运用公式,所以设法把原多项式的前 两项与后两项分成两组,在前两项提出a, 后两项提出c,发现两组都含有因式(a-b), 再继续用提取公因式法分解因式分组. 这种分解因式的方法叫做分组分解法.
excel 分组函数

excel 分组函数
Excel中的分组函数有很多种,以下是其中的几种:
1. 求和函数SUM:用于计算一定区域内数值的总和,语法为
=SUM(选定的数值区域)。
2. 平均数函数AVERAGE:用于计算一定区域内数值的平均数,语法为=AVERAGE(选定的数值区域)。
3. 计数函数COUNT:用于计算一定区域内数值的个数,语法为=COUNT(选定的数值区域)。
4. 最大值函数MAX:用于计算一定区域内数值的最大值,语法为=MAX(选定的数值区域)。
5. 最小值函数MIN:用于计算一定区域内数值的最小值,语法为=MIN(选定的数值区域)。
6. 计数非空函数COUNTA:用于计算一定区域内非空单元格的个数,语法为=COUNTA(选定的区域)。
7. 计数空单元格函数COUNTBLANK:用于计算一定区域内空单元格的个数,语法为=COUNTBLANK(选定的区域)。
以上这些函数可以用于数据的统计和分析,让用户轻松地获取所需的信息,并快速作出决策。
rank分组排序函数

Rank分组排序函数详解1. 定义Rank分组排序函数是一种用于对数据进行排序和分组的函数。
它可以将数据按照指定的规则进行排名,并将排名相同的数据分为一组。
2. 用途Rank分组排序函数主要用于以下几个方面:2.1 数据排名Rank函数可以根据指定的排序规则对数据进行排名,从而确定每个数据在整个数据集中的位置。
通过排名,我们可以了解每个数据相对于其他数据的大小关系。
2.2 数据分组Rank函数还可以将具有相同排名的数据归为一组。
这样做有助于我们对具有共同特征或属性的数据进行统计和分析。
2.3 数据筛选通过将数据按照排名进行排序,我们可以轻松筛选出前几位或后几位的数据,从而找出最大值、最小值或其他特定范围内的值。
3. 工作方式Rank分组排序函数通常包括以下几个步骤:3.1 数据排序首先,Rank函数会根据指定的排序规则对原始数据进行排序。
常见的排序规则包括升序(从小到大)和降序(从大到小)。
3.2 排名计算然后,Rank函数会计算每个数据在排序后的数据集中的排名。
排名通常从1开始,表示该数据在整个数据集中的位置。
3.3 分组划分接下来,Rank函数会根据排名将具有相同排名的数据归为一组。
这样可以方便后续对每个分组进行统计和分析。
3.4 结果输出最后,Rank函数会将排序后的结果和分组信息输出。
通常,输出结果包括原始数据、排名和分组标识等信息。
4. 常见的Rank分组排序函数4.1 RANK()RANK()函数是一种常见的Rank分组排序函数,在SQL语言中被广泛使用。
它可以根据指定的排序规则对数据进行排名,并返回每个数据在整个数据集中的排名。
示例:SELECT column1, RANK() OVER (ORDER BY column2 DESC) as rankingFROM table;上述示例代码中,RANK()函数将根据column2列的值进行降序排列,并返回每个column1列的值在整个表格中的排名。
单项式分组法

单项式分组法
单项式分组法是一种在代数学中常用的方法,用于将多项式中的单项式按照指定规则进行分类和组合。
这种方法可以简化多项式的运算和求解过程,提高计算效率。
首先,我们来了解一下什么是单项式。
单项式是指只包含一个变量的代数式,通常由一个系数和一个或多个变量的乘积组成。
比如,3x、5y^2、2xy等都是单项式。
在进行单项式的分组时,我们需要根据单项式中的变量和指数来进行分类。
例如,对于多项式3x^2y+5xy^2-7x^2y^2+4xy,我们可以按照变量和指数的组合将其分为三组:第一组包含指数为2的x和变量y的项,即3x^2y和-7x^2y^2;第二组包含指数为1的x和变量y的项,即5xy^2和4xy;第三组中只包含变量x的项,即0x。
通过单项式分组,我们可以更清晰地看到多项式中各个单项式的特点和规律,进而简化计算过程。
例如,在上述例子中,我们可以分
别对每一组内的单项式进行合并和运算,得到简化后的多项式为3x^2y-7x^2y^2+9xy^2。
单项式分组法还可以应用于解决一些代数学中的问题。
例如,在因式分解中,我们可以通过单项式分组来找出共同的因子,从而简化多项式的表达式。
此外,单项式分组法也有助于我们更好地理解和应用代数学中的规则和定律。
通过观察和分析单项式的组合方式,我们可以发现其中的模式和特点,提高我们对代数学的认识和学习效果。
总之,单项式分组法是一种在代数学中非常有用的方法,可以帮助我们简化多项式的运算和求解过程,提高计算效率。
通过合理的分类和组合,我们可以更好地理解和应用代数学中的规则和定律,进一步提升我们的数学能力。
利用数形结合解决关于min{f(x),g(x)}, max{f(x),g(x)}的问题
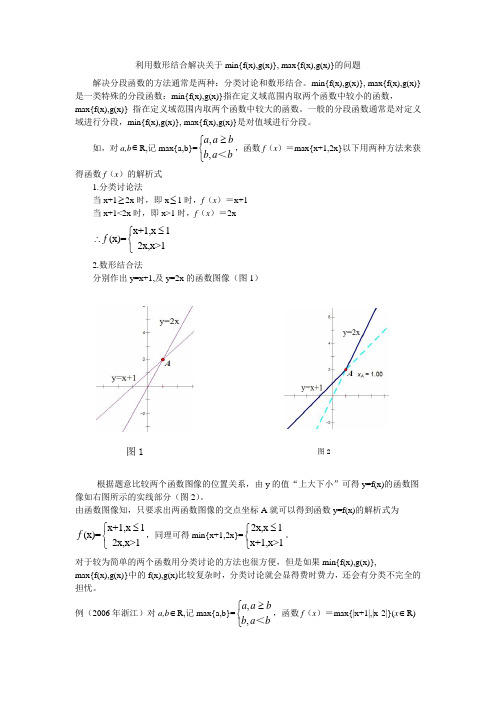
利用数形结合解决关于min{f(x),g(x)}, max{f(x),g(x)}的问题解决分段函数的方法通常是两种:分类讨论和数形结合。
min{f(x),g(x)}, max{f(x),g(x)}是一类特殊的分段函数:min{f(x),g(x)}指在定义域范围内取两个函数中较小的函数,max{f(x),g(x)} 指在定义域范围内取两个函数中较大的函数。
一般的分段函数通常是对定义域进行分段,min{f(x),g(x)}, max{f(x),g(x)}是对值域进行分段。
如,对a,b ∈R,记max{a,b}=⎩⎨⎧≥ba b ba a <,,,函数f (x )=max{x+1,2x}以下用两种方法来获得函数f (x )的解析式1.分类讨论法当x+1≥2x 时,即x ≤1时,f (x )=x+1 当x+1<2x 时,即x>1时,f (x )=2xx+1,x 1(x)=2x,x>1f ≤⎧∴⎨⎩ 2.数形结合法分别作出y=x+1,及y=2x 的函数图像(图1)根据题意比较两个函数图像的位置关系,由y 的值“上大下小”可得y=f(x)的函数图像如右图所示的实线部分(图2)。
由函数图像知,只要求出两函数图像的交点坐标A 就可以得到函数y=f(x)的解析式为x+1,x 1(x)=2x,x>1f ≤⎧⎨⎩,同理可得min{x+1,2x}=2x,x 1x+1,x>1≤⎧⎨⎩。
对于较为简单的两个函数用分类讨论的方法也很方便,但是如果min{f(x),g(x)},max{f(x),g(x)}中的f(x),g(x)比较复杂时,分类讨论就会显得费时费力,还会有分类不完全的担忧。
例(2006年浙江)对a,b ∈R,记max{a,b}=⎩⎨⎧≥b a b ba a <,,,函数f (x )=max{|x+1|,|x-2|}(x ∈R)图1图2的最小值是( )(A)0 (B)12 (C) 32(D)3 作出两函数的图像(图3)为如图所示的实线部分,则令|x+1|=|x-2|,即可求出点A 的横坐 标为12,所以f (x )的最小值为32。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
HAVING 子句
SELECT FROM GROUP BY HAVING department_id, MAX(salary) employees department_id MAX(salary)>10000 ;
嵌套组函数
显示各部门平均工资的最大值
SELECT MAX(AVG(salary)) FROM employees GROUP BY department_id;
GROUP BY 子句
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
SELECT AVG(salary) FROM employees GROUP BY department_id ;
使用多个列分组
EMPLOYEES
使用多个列 进行分组
…
在GROUP BY子句中包含多个列
SELECT department_id dept_id, job_id, SUM(salary) FROM employees GROUP BY department_id, job_id ;
使用 HAVING 过滤分组: 1. 行已经被分组。 2. 使用了组函数。 3. 满足HAVING 子句中条件的分组将被显示。
SELECT FROM [WHERE [GROUP BY [HAVING [ORDER BY column, group_function table condition] group_by_expression] group_condition] column];
非法使用组函数
所有包含于SELECT 列表中,而未包含于组函数中的列都 必须包含于 GROUP BY 子句中。
SELECT department_id, COUNT(last_name) FROM employees; SELECT department_id, COUNT(last_name) * ERROR at line 1: ORA-00937: not a single-group group function GROUP BY 子句中缺少列
非法使用组函数
• 不能在 WHERE 子句中使用组函数。 • 可以在 HAVING 子句中使用组函数。
SELECT FROM WHERE GROUP BY department_id, AVG(salary) employees AVG(salary) > 8000 department_id;
WHERE
AVG(salary) > 8000 * ERROR at line 3: ORA-00934: group function is not allowed here
WHERE 子句中不能使用组函数
过滤分组
EMPLOYEES
部门最高工资 比 10000 高的 部门
…
过滤分组: HAVING 子句
总
结
通过本章学习,您已经学会: • 使用组函数:avg(),sum(),max(),min(),count() • 在查询中使用 GROUP BY 子句。 • 在查询中使用 HAVING 子句。
SELECT FROM [WHERE [GROUP BY [HAVING [ORDER BY column, group_function(column) table condition] group_by_expression] group_condition] column];