最优二叉搜索树
计算机算法试题(含答案)

计算机算法试题(含答案)算法设计与分析试卷一、填空题(20分,每空2分)1、算法的性质包括输入、输出、___、有限性。
2、动态规划算法的基本思想就将待求问题_____、先求解子问题,然后从这些子问题的解得到原问题的解。
3、设计动态规划算法的4个步骤:(1)找出____,并刻画其结构特征。
(2)_______。
(3)_______。
(4)根据计算最优值得到的信息,_______。
4、流水作业调度问题的johnson算法:(1)令N1=___,N2={i|ai>=bj};(2)将N1中作业依ai的___。
5、对于流水作业高度问题,必存在一个最优调度π,使得作业π(i)和π(i+1)满足Johnson不等式_____。
6、最优二叉搜索树即是___的二叉搜索树。
二、综合题(50分)1、当(a1,a2,a3,a4,a5,a6)=(-2,11,-4,13,-5,-2)时,最大子段和为∑ak(2<=k<=4)____(5分)2、由流水作业调度问题的最优子结构性质可知,T(N,0)=______(5分)3、最大子段和问题的简单算法(10分)int maxsum(int n,int *a,int & bestj){intsum=0;for (int i=1;i<=n;i++)for (int j=i;j<=n;j++)int thissum=0;for(int k=i;k<=j;k++)_____;if(thissum>sum){sum=thissum;______;bestj=j;}} return sum;}4、设计最优二叉搜索树问题的动态规划算法OptimalBinarysearchTree (15分)Void OptimalBinarysearchTree(int a,int n,int * * m, int* * w){for(int i=0;i<=n;i++) {w[i+1][i]=a[i]; m[i+1][i]=____;}for(int r=0;r<n;r++)< p="">for(int i=1;i<=n-r;i++){int j=i+r;w[i][j]=w[i][j-1]+a[j]+b[j];m[i][j]=______;s[i][j]=i;for(int k=i+1;k<=j;k++){int t=m[i][k-1]+m[k+1][j];if(_____) {m[i][j]=t; s[i][j]=k;}}m[i][j]=t; s[i][j]=k;}}5、设n=4, (a1,a2,a3,a4)=(3,4,8,10), (b1,b2,b3,b4)=(6,2,9,15) 用两种方法求4个作业的最优调度方案并计算其最优值(15分)三、简答题(30分)1、将所给定序列a[1:n]分为长度相等的两段a[1:n/2]和a[n/2+1:n],分别求出这两段的最大子段和,则a[1:n]的最大子段和有哪三种情形(10分)答:2、由0——1背包问题的最优子结构性质,可以对m(i,j)建立怎样的递归式 (10分)3、0——1背包求最优值的步骤分为哪几步(10分)参考答案:填空题:确定性分解成若干个子问题最优解的性质递归地定义最优值以自底向上的方式计算出最优值构造最优解 {i|ai<="" p="">依bi的非增序排序min{bπ(i),aπ(i+1)}≥min{bπ(i+1),aπ(i)}最小平均查找长度综合题:20 min{ai+T(N-{i},bi)}(1=<i<=n) 0="" besti="i" m[i+1][j]="" p="" t<m[i][j]<="" thissum+="a[k]">法一:min(ai,bj)<=min(aj,bi)因为 min(a1,b2)<=min(a2,b1)所以1→2 (先1后2)由 min(a1,b3)<=min(a3,b1)得1→3 (先1后3)同理可得:最后为1→3→4→2法二:johnson算法思想N1={1,3,4} N2={2}N11={1,3,4} N12={2}所以N11→N12得:1→3→4→2简答题:1 、(1)a[1:n]的最大子段和与a[1:n/2]的最大子段和相同。
动态规划-最优二叉搜索树

动态规划-最优⼆叉搜索树摘要: 本章介绍了⼆叉查找树的概念及操作。
主要内容包括⼆叉查找树的性质,如何在⼆叉查找树中查找最⼤值、最⼩值和给定的值,如何找出某⼀个元素的前驱和后继,如何在⼆叉查找树中进⾏插⼊和删除操作。
在⼆叉查找树上执⾏这些基本操作的时间与树的⾼度成正⽐,⼀棵随机构造的⼆叉查找树的期望⾼度为O(lgn),从⽽基本动态集合的操作平均时间为θ(lgn)。
1、⼆叉查找树 ⼆叉查找树是按照⼆叉树结构来组织的,因此可以⽤⼆叉链表结构表⽰。
⼆叉查找树中的关键字的存储⽅式满⾜的特征是:设x为⼆叉查找树中的⼀个结点。
如果y是x的左⼦树中的⼀个结点,则key[y]≤key[x]。
如果y是x的右⼦树中的⼀个结点,则key[x]≤key[y]。
根据⼆叉查找树的特征可知,采⽤中根遍历⼀棵⼆叉查找树,可以得到树中关键字有⼩到⼤的序列。
介绍了⼆叉树概念及其遍历。
⼀棵⼆叉树查找及其中根遍历结果如下图所⽰:书中给出了⼀个定理:如果x是⼀棵包含n个结点的⼦树的根,则其中根遍历运⾏时间为θ(n)。
问题:⼆叉查找树性质与最⼩堆之间有什么区别?能否利⽤最⼩堆的性质在O(n)时间内,按序输出含有n个结点的树中的所有关键字?2、查询⼆叉查找树 ⼆叉查找树中最常见的操作是查找树中的某个关键字,除了基本的查询,还⽀持最⼤值、最⼩值、前驱和后继查询操作,书中就每种查询进⾏了详细的讲解。
(1)查找SEARCH 在⼆叉查找树中查找⼀个给定的关键字k的过程与⼆分查找很类似,根据⼆叉查找树在的关键字存放的特征,很容易得出查找过程:⾸先是关键字k与树根的关键字进⾏⽐较,如果k⼤⽐根的关键字⼤,则在根的右⼦树中查找,否则在根的左⼦树中查找,重复此过程,直到找到与遇到空结点为⽌。
例如下图所⽰的查找关键字13的过程:(查找过程每次在左右⼦树中做出选择,减少⼀半的⼯作量)书中给出了查找过程的递归和⾮递归形式的伪代码:1 TREE_SEARCH(x,k)2 if x=NULL or k=key[x]3 then return x4 if(k<key[x])5 then return TREE_SEARCH(left[x],k)6 else7 then return TREE_SEARCH(right[x],k)1 ITERATIVE_TREE_SEARCH(x,k)2 while x!=NULL and k!=key[x]3 do if k<key[x]4 then x=left[x]5 else6 then x=right[x]7 return x(2)查找最⼤关键字和最⼩关键字 根据⼆叉查找树的特征,很容易查找出最⼤和最⼩关键字。
最优二叉树(哈夫曼树)的构建及编码

最优⼆叉树(哈夫曼树)的构建及编码参考:数据结构教程(第五版)李春葆主编⼀,概述1,概念 结点的带权路径长度: 从根节点到该结点之间的路径长度与该结点上权的乘积。
树的带权路径长度: 树中所有叶结点的带权路径长度之和。
2,哈夫曼树(Huffman Tree) 给定 n 个权值作为 n 个叶⼦结点,构造⼀棵⼆叉树,若该树的带权路径长度达到最⼩,则称这样的⼆叉树为最优⼆叉树,也称为哈夫曼树。
哈夫曼树是带权路径长度最短的树,权值较⼤的结点离根较近。
⼆,哈夫曼树的构建1,思考 要实现哈夫曼树⾸先有个问题摆在眼前,那就是哈夫曼树⽤什么数据结构表⽰? ⾸先,我们想到的肯定数组了,因为数组是最简单和⽅便的。
⽤数组表⽰⼆叉树有两种⽅法: 第⼀种适⽤于所有的树。
即利⽤树的每个结点最多只有⼀个⽗节点这种特性,⽤ p[ i ] 表⽰ i 结点的根节点,进⽽表⽰树的⽅法。
但这种⽅法是有缺陷的,权重的值需要另设⼀个数组表⽰;每次找⼦节点都要遍历⼀遍数组,⼗分浪费时间。
第⼆种只适⽤于⼆叉树。
即利⽤⼆叉树每个结点最多只有两个⼦节点的特点。
从下标 0 开始表⽰根节点,编号为 i 结点即为 2 * i + 1 和 2 * i + 2,⽗节点为 ( i - 1) / 2,没有⽤到的空间⽤ -1 表⽰。
但这种⽅法也有问题,即哈夫曼树是从叶结点⾃下往上构建的,⼀开始树叶的位置会因为⽆法确定⾃⾝的深度⽽⽆法确定,从⽽⽆法构造。
既然如此,只能⽤⽐较⿇烦的结构体数组表⽰⼆叉树了。
typedef struct HTNode // 哈夫曼树结点{double w; // 权重int p, lc, rc;}htn;2,算法思想 感觉⽐较偏向于贪⼼,权重最⼩的叶⼦节点要离根节点越远,⼜因为我们是从叶⼦结点开始构造最优树的,所以肯定是从最远的结点开始构造,即权重最⼩的结点开始构造。
所以先选择权重最⼩的两个结点,构造⼀棵⼩⼆叉树。
然后那两个最⼩权值的结点因为已经构造完了,不会在⽤了,就不去考虑它了,将新⽣成的根节点作为新的叶⼦节加⼊剩下的叶⼦节点,⼜因为该根节点要能代表整个以它为根节点的⼆叉树的权重,所以其权值要为其所有⼦节点的权重之和。
盘点常用的搜索树

盘点常⽤的搜索树树的典型应⽤有很多,⽐如计算机的⽂件系统就是⼀棵树,根⽬录就是根节点。
树的重要应⽤之⼀就是搜索树,搜索树通常分为⼆叉搜索树和多路搜索树。
⼆叉搜索树⼆叉搜索树是⼀颗有序的树,每个结点不⼩于其左⼦树任意结点的值,不⼤于右⼦树任意结点的值。
⼆叉搜索树还有⼀个有趣的特性,它的中序遍历得到的是有序数列。
⼆叉搜索树能提⾼搜索的效率,搜索次数最多是树的深度次,最少能到log(n)。
搜索树有搜索,插⼊,删除等操作。
搜索即搜索整棵树,查找是否有匹配的节点;还有搜索最⼤值和最⼩值操作,最⼤值在树的最右侧,最⼩值在最左侧,因此都很好实现。
treenode find(tree T,int val){ /*搜索操作*/if(T==NULL) return NULL;if(T->data > val)return find(T->left,val);else if(T->data < val)return find(T->right,val);elsereturn T;}插⼊,也是采⽤递归实现,插⼊的结点都放到了叶⼦节点。
treenode insert(tree T,int val){if(T==NULL) {T=(treenode)malloc(sizeof(struct node));T->data=val;T->right=T->left=NULL;}else if(T->data >= val)T->left = insert(T->left,val);elseT->right = insert(T->right,val);return T;}删除,这种操作⽐较复杂,因为可能会破坏BST的规则,需要进⾏调整。
删除操作分⼏种情况:1)当删除的结点是叶⼦节点,直接删除即可,如删除下图中的7结点;2)当删除⾮叶节点,且该节点只有⼀个⼦节点时,我们可以删除该节点,并让其⽗节点连接到它的⼦节点即可;如删除8结点,直接让5结点连接到7即可;3)当⾮叶节点,且有两个⼦节点时,可以删除该节点,然后抓出左⼦树中最⼤的元素(或者右树中最⼩的元素),来补充被删元素产⽣的空缺。
(陈慧南 第3版)算法设计与分析——第7章课后习题答案

③ 其余元素
w[0][2] q[2] p[2] w[0][1] 15
k 1: c[0][0] c[1][2] c[0][2] min k 2 : c[0][1] c[2][2] w[0][2] 22 r[0][2] 2
17000
s[0][2]
0
m[1][3]
min
k k
1: m[1][1] m[2][3] 2 : m[1][2] m[3][3]
p1 p2 p4 p1 p3 p4
10000
s[1][3]
2
m[1][3]
min
k k
0 : m[0][0] m[1][3] 1: m[0][1] m[2][3]
第七章课后习题
姓名:赵文浩 学号:16111204082 班级:2016 级计算机科学与技术 7-1 写出对图 7-19 所示的多段图采用向后递推动态规划算法求解时的计算过程。
3
1
3
1
6
5
0
2
6
6
3
4
4 6
5
2
7
8
3
2
8
5
2
7
解析:
V 5 cost(5,8) 0 d (5,8) 8
V4
cos t(4, 6) minc(6,8) cos t(5,8) 7 cos t(4, 7) minc(7,8) cos t(5,8) 3
k 1: c[0][0] c[1][3] c[0][3] min k 2 : c[0][1] c[2][3] w[0][3] 25
最优二叉树

哈夫曼编码的另一种表示: 1.00
0 0.40 0 g 0.21 1
1
b 0.19
0
0.28 0 0.17 1
0.60 1 e 0.32
0.11 0 1
0
1 d 0.07 0.06
h 0.10
哈夫曼编码树
a
0.05
0 f 0.03 1 c 0.02
练习题:设计哈夫曼编码,通信中可能有8种字符,其频率 分别为:0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11
0 d
1
0
i 0 a
1
1 n
Huffman编码结果:d=0, i=10, a=110, n=111 WPL=1bit×7+2bit×5+3bit(2+4)=35(小于等长码的WPL=36) 特征:每一码不会是另一码的前缀,译码时唯一,不会错! Huffman编码也称为前缀码
Huffman编码
哈夫曼编码的基本思想是——— 出现概率大的信息用短码,概率小的用长码
最佳判定方法
Y Y E Y D Y a<60 N a<70 N C Y B Y D 70a<80 N 80a<90 N 60a<70 N
a<80
N a<90 N A
Y
E
C
Y B
a<60
N A
(b)WPL=40x1+30x2+15x3+5x4+10x4=205
(a)WPL=10x4+30x4+40x3+15x2+5x1=315
void Select (HuffmanTree HT,int t,int&s1,int&s2) {//在HT[1...t]中选择parent为0且权值最小的两个结点,其 序号分别为s1和s2 int i, m, n; m=n=100000; for(i=1;i<=t;i++) {if(HT[i].parent==0&&(HT[i].weight<m||HT[i].weight<n)) if(m<n) { n=HT[i].weight ; s2=i ; } else { m=HT[i].weight ; s1=i ; } } if(s1>s2) //s1放较小的序号 {i=s1;s1=s2;s2=i;} }
算法分析与设计-屈婉玲-第6周

时间复杂度:O(n)
10
小结
• • • • • • 图像变位存储问题的建模 子问题边界的界定 递推方程及初值 伪码 标记函数与解的追踪 时间复杂度
最大子段和
最大子段和
问题:给定n个数(可以为负数)的序列
(a1, a2, ... , an) j ak } 求 max{0, 1max k i i jn
1
L0
4 2 3
L3
6 5
L4 L6 L5
2
L1 L2
二叉树的检索方法
1. 初始,x与根元素比较; 2. x < 根元素,递归进入左子树; 3. x > 根元素,递归进入右子树; 4. x = 根元素,算法停止,输出 x; 5. x 到叶结点算法停止,输出 x不在数组.
4 2 1
L0
x=3.5 6
255 255 255 255 255 255
1
2
S[5]=50 S[4]=42 S[3]=23
10
1×2+11
1 1 2
63 57 58
2
2×2+11
2
3×8+11
1
S[2]=19
10
4×8+11
1 1 2
62 66
2
S[1]=15
10
5×8+11
6×8+11
59
9
追踪解
算法 Traceback ( n , l ) 输入:数组 l 输出:数组 C 1. j ← 1 // j 为正在追踪的段数 2. while n ≠ 0 do 第 j段 3. C[ j ] ← l [n] 长度 4. n ← n- l [n] 5. j ← j + 1 C[ j ]:从后向前追踪的第 j段的长度
介绍二叉排序树的结构和特点

介绍二叉排序树的结构和特点二叉排序树,也称为二叉搜索树或二叉查找树,是一种特殊的二叉树结构,其主要特点是左子树上的节点都小于根节点,右子树上的节点都大于根节点。
在二叉排序树中,每个节点都存储着一个关键字,而且所有的关键字都不相同。
二叉排序树的结构如下:1.根节点:二叉排序树的根节点是整个树的起始点,其关键字是最大的。
2.左子树:根节点的左子树包含着小于根节点关键字的所有节点,且左子树本身也是一个二叉排序树。
3.右子树:根节点的右子树包含着大于根节点关键字的所有节点,且右子树本身也是一个二叉排序树。
二叉排序树的特点如下:1.有序性:二叉排序树的最重要特点是有序性。
由于左子树上的节点都小于根节点,右子树上的节点都大于根节点,所以通过中序遍历二叉排序树,可以得到一个有序的序列。
2.快速查找:由于二叉排序树是有序的,所以可以利用二叉排序树进行快速查找操作。
对于给定的关键字,可以通过比较关键字与当前节点的大小关系,逐步缩小查找范围,最终找到目标节点。
3.快速插入和删除:由于二叉排序树的有序性,插入和删除操作比较简单高效。
插入操作可以通过比较关键字的大小关系,找到合适的位置进行插入。
删除操作可以根据不同情况,分为三种情况处理:删除节点没有子节点、删除节点只有一个子节点和删除节点有两个子节点。
4.可以用于排序:由于二叉排序树的有序性,可以利用二叉排序树对一组数据进行排序。
将数据依次插入二叉排序树中,然后再通过中序遍历得到有序序列。
二叉排序树的优缺点如下:1.优点:(1)快速查找:通过二叉排序树可以提供快速的查找操作,时间复杂度为O(log n)。
(2)快速插入和删除:由于二叉排序树的有序性,插入和删除操作比较简单高效。
(3)可以用于排序:通过二叉排序树可以对一组数据进行排序,时间复杂度为O(nlog n)。
2.缺点:(1)受数据分布影响:如果数据分布不均匀,可能导致二叉排序树的高度增加,从而降低了查找效率。
(2)不适合大规模数据:对于大规模数据,二叉排序树可能会导致树的高度过高,从而影响了查找效率。
《计算机算法设计与分析》课程设计

《计算机算法设计与分析》课程设计用分治法解决快速排序问题及用动态规划法解决最优二叉搜索树问题及用回溯法解决图的着色问题一、课程设计目的:《计算机算法设计与分析》这门课程是一门实践性非常强的课程,要求我们能够将所学的算法应用到实际中,灵活解决实际问题。
通过这次课程设计,能够培养我们独立思考、综合分析与动手的能力,并能加深对课堂所学理论和概念的理解,可以训练我们算法设计的思维和培养算法的分析能力。
二、课程设计内容:1、分治法:(2)快速排序;2、动态规划:(4)最优二叉搜索树;3、回溯法:(2)图的着色。
三、概要设计:分治法—快速排序:分治法的基本思想是将一个规模为n的问题分解为k个规模较小的子问题,这些子问题互相独立且与原问题相同。
递归地解这些子问题,然后将各个子问题的解合并得到原问题的解。
分治法的条件:(1) 该问题的规模缩小到一定的程度就可以容易地解决;(2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质;(3) 利用该问题分解出的子问题的解可以合并为该问题的解;(4) 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
抽象的讲,分治法有两个重要步骤:(1)将问题拆开;(2)将答案合并;动态规划—最优二叉搜索树:动态规划的基本思想是将问题分解为若干个小问题,解子问题,然后从子问题得到原问题的解。
设计动态规划法的步骤:(1)找出最优解的性质,并刻画其结构特征;(2)递归地定义最优值(写出动态规划方程);(3)以自底向上的方式计算出最优值;(4)根据计算最优值时得到的信息,构造一个最优解。
●回溯法—图的着色回溯法的基本思想是确定了解空间的组织结构后,回溯法就是从开始节点(根结点)出发,以深度优先的方式搜索整个解空间。
这个开始节点就成为一个活结点,同时也成为当前的扩展结点。
在当前的扩展结点处,搜索向纵深方向移至一个新结点。
这个新结点就成为一个新的或节点,并成为当前扩展结点。
算法竞赛专题解析-四边形不等式优化

算法竞赛专题解析│四边形不等式优化01理论背景四边形不等式(quadrangleinequality)应用于DP优化,是一个古老的知识点。
它起源于Knuth(高纳德)1971年的一篇论文,用来解决最优二叉搜索树问题。
1980年,储枫(F.FrancesYao,姚期智的夫人)做了深入研究,扩展为一般性的DP优化方法,把一些复杂度O(n3)的DP问题,优化为O(n2)。
所以这个方法又被称为“Knuth-YaoDPSpeedupTheorem”。
02应用场合有一些常见的DP问题,通常是区间DP问题,它的状态转移方程是:dp[i][j]=min(dp[i][k]+dp[k+1][j]+w[i][j])其中i<=k<j,初始值dp[i][i]已知。
min()也可以是max(),见本篇第6小节的说明。
方程的含义是:(1)dp[i][j]表示从i状态到j状态的最小花费。
题目一般是求dp[1][n],即从起始点1到终点n的最小花费。
(2)dp[i][k]+dp[k+1][j]体现了递推关系。
k在i和j之间滑动,k有一个最优值,使得dp[i][j]最小。
(3)w[i][j]的性质非常重要。
w[i][j]是和题目有关的费用,如果它满足四边形不等式和单调性,那么用DP计算dp的时候,就能进行四边形不等式优化。
这类问题的经典的例子是“石子合并”,它的转移矩阵就是上面的dp[i][j],w[i][j]是从第i堆石子到第j堆石子的总数量。
石子合并题目描述:有n堆石子排成一排,每堆石子有一定的数量。
将n堆石子并成为一堆。
每次只能合并相邻的两堆石子,合并的花费为这两堆石子的总数。
经过n-1次合并后成为一堆,求总的最小花费。
输入:测试数据第一行是整数n,表示有n堆石子。
接下来的一行有n个数,分别表示这n堆石子的数目。
输出:总的最小花费。
输入样例:3245输出样例:17提示:样例的计算过程是:第一次合并2+4=6;第二次合并6+5=11;总花费6+11=17。
二叉树
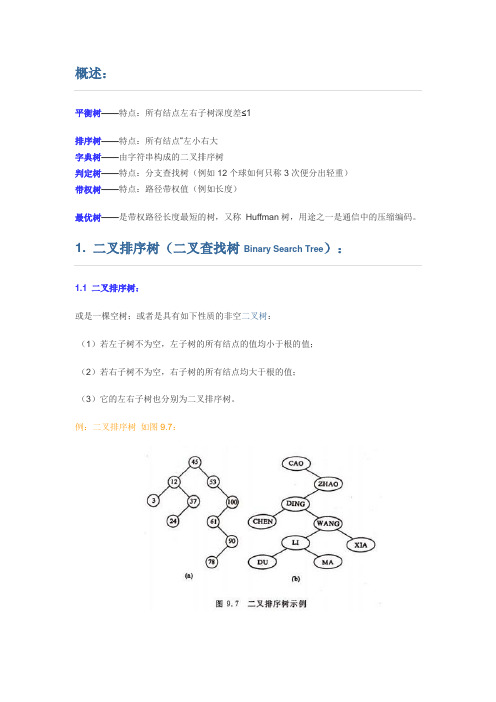
平衡树——特点:所有结点左右子树深度差≤1排序树——特点:所有结点―左小右大字典树——由字符串构成的二叉排序树判定树——特点:分支查找树(例如12个球如何只称3次便分出轻重)带权树——特点:路径带权值(例如长度)最优树——是带权路径长度最短的树,又称Huffman树,用途之一是通信中的压缩编码。
1.1 二叉排序树:或是一棵空树;或者是具有如下性质的非空二叉树:(1)若左子树不为空,左子树的所有结点的值均小于根的值;(2)若右子树不为空,右子树的所有结点均大于根的值;(3)它的左右子树也分别为二叉排序树。
例:二叉排序树如图9.7:二叉排序树的查找过程和次优二叉树类似,通常采取二叉链表作为二叉排序树的存储结构。
中序遍历二叉排序树可得到一个关键字的有序序列,一个无序序列可以通过构造一棵二叉排序树变成一个有序序列,构造树的过程即为对无序序列进行排序的过程。
每次插入的新的结点都是二叉排序树上新的叶子结点,在进行插入操作时,不必移动其它结点,只需改动某个结点的指针,由空变为非空即可。
搜索,插入,删除的复杂度等于树高,期望O(logn),最坏O(n)(数列有序,树退化成线性表).虽然二叉排序树的最坏效率是O(n),但它支持动态查询,且有很多改进版的二叉排序树可以使树高为O(logn),如SBT,AVL,红黑树等.故不失为一种好的动态排序方法.2.2 二叉排序树b中查找在二叉排序树b中查找x的过程为:1. 若b是空树,则搜索失败,否则:2. 若x等于b的根节点的数据域之值,则查找成功;否则:3. 若x小于b的根节点的数据域之值,则搜索左子树;否则:4. 查找右子树。
[cpp]view plaincopyprint?1.Status SearchBST(BiTree T, KeyType key, BiTree f, BiTree &p){2. //在根指针T所指二叉排序樹中递归地查找其关键字等于key的数据元素,若查找成功,3. //则指针p指向该数据元素节点,并返回TRUE,否则指针P指向查找路径上访问的4. //最好一个节点并返回FALSE,指针f指向T的双亲,其初始调用值为NULL5. if(!T){ p=f; return FALSE;} //查找不成功6. else if EQ(key, T->data.key) {P=T; return TRUE;} //查找成功7. else if LT(key,T->data.key)8. return SearchBST(T->lchild, key, T, p); //在左子树继续查找9. else return SearchBST(T->rchild, key, T, p); //在右子树继续查找10.}2.3 在二叉排序树插入结点的算法向一个二叉排序树b中插入一个结点s的算法,过程为:1. 若b是空树,则将s所指结点作为根结点插入,否则:2. 若s->data等于b的根结点的数据域之值,则返回,否则:3. 若s->data小于b的根结点的数据域之值,则把s所指结点插入到左子树中,否则:4. 把s所指结点插入到右子树中。
红黑树的使用案例

红黑树的使用案例红黑树是一种自平衡的二叉搜索树,它在许多应用中都有广泛的应用。
下面将列举一些使用红黑树的案例。
1. 数据库索引:数据库中的索引通常使用红黑树来实现。
红黑树能够在插入、删除和查找操作上保持较好的性能,因此非常适合作为数据库索引结构。
2. C++ STL中的map和set容器:map和set容器是C++标准模板库(STL)中的常用容器,它们的底层实现通常使用红黑树。
map容器实现了键值对的有序存储,set容器则实现了有序集合的存储。
3. Linux进程调度:Linux操作系统中的进程调度算法使用红黑树来管理进程的优先级。
红黑树能够高效地处理进程的插入和删除操作,并且能够按照优先级进行快速查找。
4. 文件系统:一些现代的文件系统(如NTFS、ZFS等)使用红黑树来管理文件的索引信息。
红黑树能够快速地定位文件的位置,提高文件系统的读写性能。
5. 路由表:网络路由器中的路由表通常使用红黑树来存储路由信息。
红黑树能够高效地查找最长匹配的路由条目,实现快速的数据包转发。
6. 平衡二叉搜索树的实现:红黑树是平衡二叉搜索树的一种实现方式,它能够在插入和删除操作后自动调整树的结构,保持树的平衡性。
因此,红黑树常常作为平衡二叉搜索树的基础实现。
7. 哈希表的实现:一些哈希表的实现中使用红黑树来解决哈希冲突。
当发生哈希冲突时,红黑树可以作为冲突解决的机制,将冲突的键值对存储在同一个桶中,并通过红黑树来管理桶内的键值对。
8. 软件缓存:一些软件缓存中使用红黑树来管理缓存的键值对。
红黑树能够按照键的顺序进行有序存储,并且能够高效地进行插入、删除和查找操作。
9. 任务调度:操作系统中的任务调度器通常使用红黑树来管理任务队列。
红黑树能够按照任务的优先级进行有序存储,并且能够快速地查找最高优先级的任务。
10. 编译器的符号表:编译器在进行词法分析和语法分析时,需要维护符号表来记录变量和函数的信息。
红黑树可以作为符号表的底层数据结构,提高符号表的插入和查找性能。
最优二叉树概念

最优二叉树概念1.树的路径长度树的路径长度是从树根到树中每一结点的路径长度之和。
在结点数目相同的二叉树中,完全二叉树的路径长度最短。
2.树的带权路径长度(Weighted Path Length of Tree,简记为WPL)结点的权:在一些应用中,赋予树中结点的一个有某种意义的实数。
结点的带权路径长度:结点到树根之间的路径长度与该结点上权的乘积。
树的带权路径长度(Weighted Path Length of Tree):定义为树中所有叶结点的带权路径长度之和,通常记为:其中:n表示叶子结点的数目w i和l i分别表示叶结点k i的权值和根到结点k i之间的路径长度。
树的带权路径长度亦称为树的代价。
3.最优二叉树或哈夫曼树在权为w l,w2,…,w n的n个叶子所构成的所有二叉树中,带权路径长度最小(即代价最小)的二叉树称为最优二叉树或哈夫曼树。
【例】给定4个叶子结点a,b,c和d,分别带权7,5,2和4。
构造如下图所示的三棵二叉树(还有许多棵),它们的带权路径长度分别为:(a)WPL=7*2+5*2+2*2+4*2=36(b)WPL=7*3+5*3+2*1+4*2=46(c)WPL=7*1+5*2+2*3+4*3=35其中(c)树的WPL最小,可以验证,它就是哈夫曼树。
注意:①叶子上的权值均相同时,完全二叉树一定是最优二叉树,否则完全二叉树不一定是最优二叉树。
②最优二叉树中,权越大的叶子离根越近。
③最优二叉树的形态不唯一,WPL最小。
哈夫曼算法哈夫曼首先给出了对于给定的叶子数目及其权值构造最优二叉树的方法,故称其为哈夫曼算法。
其基本思想是:(1)根据给定的n个权值w l,w2,…,w n构成n棵二叉树的森林F={T1,T2,…,T n},其中每棵二叉树T i中都只有一个权值为w i的根结点,其左右子树均空。
(2)在森林F中选出两棵根结点权值最小的树(当这样的树不止两棵树时,可以从中任选两棵),将这两棵树合并成一棵新树,为了保证新树仍是二叉树,需要增加一个新结点作为新树的根,并将所选的两棵树的根分别作为新根的左右孩子(谁左,谁右无关紧要),将这两个孩子的权值之和作为新树根的权值。
最优二叉树(哈夫曼树)

第八节最优二叉树(哈夫曼树)一、概念在具有n个带权叶结点的二叉树中,使所有叶结点的带权路径长度之和(即二叉树的带权路径长度)为最小的二叉树,称为最优二叉树(又称最优搜索树或哈夫曼树),即最优二叉树使(W k—第k个叶结点的权值;P k—第k个叶结点的带权路径长度)达到最小。
二、最优二叉树的构造方法假定给出n个结点ki(i=1‥n),其权值分别为Wi(i=1‥n)。
要构造以此n个结点为叶结点的最优二叉树,其构造方法如下:首先,将给定的n个结点构成n棵二叉树的集合F={T1,T2,……,Tn}。
其中每棵二叉树Ti中只有一个权值为wi的根结点ki,其左、右子树均为空。
然后做以下两步⑴在F中选取根结点权值最小的两棵二叉树作为左右子树,构造一棵新的二叉树,并且置新的二叉树的根结点的权值为其左、右子树根结点的权值之和;⑵在F中删除这两棵二叉树,同时将新得到的二叉树加入F 重复⑴、⑵,直到在F中只含有一棵二叉树为止。
这棵二叉树便是最优二叉树。
三、最优二叉树的数据类型定义在最优二叉树中非叶结点的度均为2,为满二叉树,因此采用顺序存储结构为宜。
如果带权叶结点数为n个,则最优二叉树的结点数为2n-1个。
Const n=叶结点数的上限;m=2*n-1;{最优二叉树的结点数}Typenode=record{结点类型}data:<数据类型>;{权值}prt,lch,rch,lth:0‥m;{父指针、左、右指针和路径长度}end;wtype=array[1‥n] of <数据类型> ;{n个叶结点权值的类型}treetype=array[1‥m] of node;{最优二叉树的数组类型}Var tree:treetype;{其中tree [1‥n]为叶结点,tree [n+1‥2n-1]为中间结点,根为tree [2n-1]}四、构造最优二叉树的算法。
最优二叉树规则

最优二叉树规则最优二叉树,也称为哈夫曼树,是一种特殊的二叉树结构,它的构建过程是基于一组权值的频率分布来进行的。
最优二叉树规则是指在构建最优二叉树时所遵循的一些基本规则,这些规则可以帮助我们更好地理解最优二叉树的构建过程,从而更好地应用它们来解决实际问题。
最优二叉树的构建过程最优二叉树的构建过程是基于一组权值的频率分布来进行的。
在构建最优二叉树时,我们需要按照以下步骤进行:1. 将所有的权值按照从小到大的顺序排列。
2. 选取两个权值最小的节点作为左右子节点,构建一个新的节点,其权值为这两个节点的权值之和。
3. 将新节点的权值插入到原来的序列中,并将原来的两个节点从序列中删除。
4. 重复步骤2和3,直到序列中只剩下一个节点为止。
最优二叉树规则在构建最优二叉树时,我们需要遵循以下规则:1. 权值越大的节点应该离根节点越近。
2. 在同一层次上,权值越小的节点应该在左边。
3. 在构建最优二叉树时,我们应该尽量使得树的深度最小。
这些规则的目的是为了使得最优二叉树的结构更加紧凑,从而减少树的深度,提高树的搜索效率。
在实际应用中,我们可以根据这些规则来构建最优二叉树,从而更好地解决实际问题。
最优二叉树的应用最优二叉树在实际应用中有着广泛的应用,例如在数据压缩、编码和解码、图像处理等领域中都有着重要的应用。
在数据压缩中,我们可以利用最优二叉树来构建哈夫曼编码,从而将数据压缩到最小的空间。
在编码和解码中,我们可以利用最优二叉树来实现高效的编码和解码算法。
在图像处理中,我们可以利用最优二叉树来实现图像的压缩和解压缩,从而减少图像的存储空间和传输带宽。
总结最优二叉树是一种特殊的二叉树结构,它的构建过程是基于一组权值的频率分布来进行的。
在构建最优二叉树时,我们需要遵循一些基本规则,例如权值越大的节点应该离根节点越近,权值越小的节点应该在左边等。
最优二叉树在实际应用中有着广泛的应用,例如在数据压缩、编码和解码、图像处理等领域中都有着重要的应用。
最优二叉查找树

最优⼆叉查找树最优⼆叉树也就是哈夫曼树,最优⼆叉树和最优⼆叉查找树是不⼀样的。
我们说⼀下他们的定义最优⼆叉树:给你n个节点,每⼀个节点有⼀个权值wi。
我们设⼀棵树的权值是所有节点的权值乘于每⼀个节点的深度,但是我们可以构造出来许多⼆叉树,我们称构造出来的那个权值最⼩的⼆叉树就是我们找的最优⼆叉树求解最优⼆叉树:(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有⼀个结点);(2) 在森林中选出两个根结点的权值最⼩的树合并,作为⼀棵新树的左、右⼦树,且新树的根结点权值为其左、右⼦树根结点权值之和;(3)从森林中删除选取的两棵树,并将新树加⼊森林;(4)重复(2)、(3)步,直到森林中只剩⼀棵树为⽌,该树即为所求得的哈夫曼树。
最优⼆叉查找树:给定n个节点的值key,假设x是⼆叉搜索树中的⼀个结点。
如果L是x的左⼦树的⼀个结点,那么L.key ≤ x.key。
如果R是x的右⼦树的⼀个结点,那么R.key ≥ x.key。
使⽤<key1,key2,key3....keyn>表⽰,且我们设定key1<key2<key3<keyn。
对于n个节点都有⼀个访问概率pi,使⽤<p1,p2,p3....pn>表⽰。
还有未找到访问点概率qi,我们使⽤<q0,q1,q2,q3....qn>表⽰。
例如访问到[-∞,key1)的概率是q0,访问到(key1,key2)的概率是q1,,,,访问到(keyn,∞)的概率是qn。
我们设定[-∞,key1)区间为d0,(key1,key2)区间为d1,,,,(keyn,∞)区间是dn。
所以是不会出现对于i,j(1<=i,j<=n)满⾜keyi==keyj的情况出现我们需要把2*n+1个节点放在⼀个⼆叉树上,其中n个节点是keyi,还有n+1个节点di。
最后形成的⼆叉树中叶节点肯定是di。
且∑n i=1pi+∑n i=0qi=1假定⼀次搜索的代价等于访问的结点数,也就是此次搜索找到的结点在⼆叉搜索树中的深度再加1。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include<stdio.h>
#include<stdlib.h>
#define max 9999
void OptimalBST(int,float*,float**,int**);
void OptimalBSTPrint(int,int,int**);
void main()
{
int i,num;
FILE *point;
//所有数据均从2.txt中获取,2.txt中第一个数据表示节点个数;从第二个数据开始表示各个节点的概率
point=fopen("2.txt","r");
if(point==NULL)
{
printf("cannot open 2.txt.\n");
exit(-1);
}
fscanf(point,"%d",&num);
printf("%d\n",num);
float *p=(float*)malloc(sizeof(float)*(num+1));
for(i=1;i<num+1;i++)
fscanf(point,"%f",&p[i]);
//创建主表;
float **c=(float**)malloc(sizeof(float*)*(num+2));
for(i=0;i<num+2;i++)
c[i]=(float*)malloc(sizeof(float)*(num+1));
//创建根表;
int **r=(int**)malloc(sizeof(int*)*(num+2));
for(i=0;i<num+2;i++)
r[i]=(int*)malloc(sizeof(int)*(num+1));
//动态规划实现最优二叉查找树的期望代价求解。
OptimalBST(num,p,c,r);
printf("该最优二叉查找树的期望代价为:%f \n",c[1][num]);
//给出最优二叉查找树的中序遍历结果;
printf("构造成的最优二叉查找树的中序遍历结果为:");
OptimalBSTPrint(1,4,r);
}
void OptimalBST(int num,float*p,float**c,int**r)
{
int d,i,j,k,s,kmin;
float temp,sum;
for(i=1;i<num+1;i++)//主表和根表元素的初始化
{
c[i][i-1]=0;
c[i][i]=p[i];
r[i][i]=i;
}
c[num+1][num]=0;
for(d=1;d<=num-1;d++)//加入节点序列
{
for(i=1;i<=num-d;i++)
{
j=i+d;
temp=max;
for(k=i;k<=j;k++)//找最优根
{
if(c[i][k-1]+c[k+1][j]<temp)
{
temp=c[i][k-1]+c[k+1][j];
kmin=k;
}
}
r[i][j]=kmin;//记录最优根
sum=p[i];
for(s=i+1;s<=j;s++)
sum+=p[s];
c[i][j]=temp+sum;
}
}
}
//采用递归方式实现最优根的输出,最优根都是保存在r[i][j]中的。
void OptimalBSTPrint(int first,int last,int**r)
{
int k;
if(first<=last)
{
k=r[first][last];
printf("%d ",k);
OptimalBSTPrint(first,k-1,r);
OptimalBSTPrint(k+1,last,r);
}
}。