《Hadoop大数据开发实战》教学教案—07Hive
Hadoop大数据开发基础教案Hadoop介绍教案

Hadoop大数据开发基础教案Hadoop介绍教案第一章:Hadoop概述1.1 课程目标了解Hadoop的定义、发展历程及应用场景掌握Hadoop的核心组件及其作用理解Hadoop在大数据领域的优势1.2 教学内容Hadoop的定义与发展历程Hadoop的核心组件:HDFS、MapReduce、YARN Hadoop的应用场景与优势1.3 教学方法讲解与案例分析相结合互动提问,巩固知识点1.4 课后作业简述Hadoop的发展历程及其在大数据领域的优势。
第二章:HDFS(分布式文件系统)2.1 课程目标掌握HDFS的架构与工作原理了解HDFS的优势与局限性掌握HDFS的常用操作命令2.2 教学内容HDFS的架构与工作原理HDFS的优势与局限性HDFS的常用操作命令:hdfs dfs, hdfs dfsadmin2.3 教学方法讲解与实践操作相结合案例分析,理解HDFS的工作原理2.4 课后作业利用HDFS命令练习文件的与。
第三章:MapReduce编程模型3.1 课程目标掌握MapReduce的基本概念与编程模型理解MapReduce的运行原理与执行过程学会使用MapReduce解决大数据问题3.2 教学内容MapReduce的基本概念:Mapper、Reducer、Shuffle与Sort MapReduce的编程模型:Map阶段、Shuffle阶段、Reduce阶段MapReduce的运行原理与执行过程3.3 教学方法讲解与编程实践相结合剖析经典MapReduce案例,理解编程模型3.4 课后作业编写一个简单的MapReduce程序,实现单词计数功能。
第四章:YARN(资源管理器)4.1 课程目标掌握YARN的基本概念与架构了解YARN的工作原理与调度策略掌握YARN的资源管理与优化方法4.2 教学内容YARN的基本概念与架构YARN的工作原理与调度策略YARN的资源管理与优化方法4.3 教学方法讲解与案例分析相结合实操演练,掌握YARN的资源管理方法4.4 课后作业分析一个YARN集群的资源使用情况,提出优化方案。
Hadoop大数据开发基础教案Hadoop基础操作教案

一、Hadoop简介1. 教学目标:(1)了解Hadoop的起源、发展历程和应用场景;(2)掌握Hadoop的核心组件及其作用;(3)了解Hadoop的生态体系。
2. 教学内容:(1)Hadoop的起源和发展历程;(2)Hadoop的核心组件:HDFS、MapReduce、YARN;(3)Hadoop的生态体系:Hive、HBase、Spark等。
3. 教学方法:(1)采用讲解、案例演示相结合的方式进行教学;(2)引导学生通过课后资料了解Hadoop的发展历程和应用场景;(3)组织学生讨论Hadoop的核心组件及其作用。
4. 教学资源:(1)PPT课件;(2)课后资料:Hadoop相关论文、博客等。
5. 教学环节:(1)介绍Hadoop的起源和发展历程;(2)讲解Hadoop的核心组件及其作用;(3)介绍Hadoop的生态体系;(4)案例演示:Hadoop的基本操作;(5)课后作业:深入了解Hadoop的应用场景。
二、HDFS分布式文件系统1. 教学目标:(1)了解HDFS的架构和原理;(2)掌握HDFS的基本操作;(3)了解HDFS的优缺点。
2. 教学内容:(1)HDFS的架构和原理;(2)HDFS的基本操作:文件、文件、文件权限管理等;(3)HDFS的优缺点。
3. 教学方法:(1)采用讲解、案例演示相结合的方式进行教学;(2)引导学生通过课后实践掌握HDFS的基本操作;(3)组织学生讨论HDFS的优缺点。
4. 教学资源:(1)PPT课件;(2)课后实践:搭建HDFS集群,进行文件操作。
5. 教学环节:(1)讲解HDFS的架构和原理;(2)演示HDFS的基本操作;(3)介绍HDFS的优缺点;(4)课后实践:搭建HDFS集群,进行文件操作;(5)课后作业:总结HDFS的使用经验和注意事项。
三、MapReduce编程模型1. 教学目标:(1)了解MapReduce的原理和流程;(2)掌握MapReduce的基本编程方法;(3)了解MapReduce的优缺点。
《Hadoop大数据开发实战》教学教案(全)

《Hadoop大数据开发实战》教学教案(第一部分)一、教学目标1. 理解Hadoop的基本概念和架构2. 掌握Hadoop的安装和配置3. 掌握Hadoop的核心组件及其作用4. 能够搭建简单的Hadoop集群并进行基本的操作二、教学内容1. Hadoop简介1.1 Hadoop的定义1.2 Hadoop的发展历程1.3 Hadoop的应用场景2. Hadoop架构2.1 Hadoop的组成部分2.2 Hadoop的分布式文件系统HDFS2.3 Hadoop的计算框架MapReduce3. Hadoop的安装和配置3.1 Hadoop的版本选择3.2 Hadoop的安装步骤3.3 Hadoop的配置文件解读4. Hadoop的核心组件4.1 NameNode和DataNode4.2 JobTracker和TaskTracker4.3 HDFS和MapReduce的运行原理三、教学方法1. 讲授法:讲解Hadoop的基本概念、架构和组件2. 实践法:引导学生动手实践,安装和配置Hadoop,了解其运行原理3. 讨论法:鼓励学生提问、发表观点,共同探讨Hadoop的应用场景和优缺点四、教学准备1. 教师准备:熟悉Hadoop的安装和配置,了解其运行原理2. 学生准备:具备一定的Linux操作基础,了解Java编程五、教学评价1. 课堂参与度:学生提问、回答问题的积极性2. 实践操作:学生动手实践的能力,如能够独立完成Hadoop的安装和配置3. 课后作业:学生完成课后练习的情况,如编写简单的MapReduce程序4. 综合评价:结合学生的课堂表现、实践操作和课后作业,综合评价学生的学习效果《Hadoop大数据开发实战》教学教案(第二部分)六、教学目标1. 掌握Hadoop生态系统中的常用组件2. 理解Hadoop数据存储和处理的高级特性3. 学会使用Hadoop进行大数据处理和分析4. 能够运用Hadoop解决实际的大数据问题七、教学内容1. Hadoop生态系统组件7.1 YARN的概念和架构7.2 HBase的概念和架构7.3 Hive的概念和架构7.4 Sqoop的概念和架构7.5 Flink的概念和架构(可选)2. Hadoop高级特性8.1 HDFS的高可用性8.2 HDFS的存储策略8.3 MapReduce的高级特性8.4 YARN的资源管理3. 大数据处理和分析9.1 Hadoop在数据处理中的应用案例9.2 Hadoop在数据分析中的应用案例9.3 Hadoop在机器学习中的应用案例4. Hadoop解决实际问题10.1 Hadoop在日志分析中的应用10.2 Hadoop在网络爬虫中的应用10.3 Hadoop在图像处理中的应用八、教学方法1. 讲授法:讲解Hadoop生态系统组件的原理和应用2. 实践法:引导学生动手实践,使用Hadoop进行数据处理和分析3. 案例教学法:分析实际应用案例,让学生了解Hadoop在不同领域的应用九、教学准备1. 教师准备:熟悉Hadoop生态系统组件的原理和应用,具备实际操作经验2. 学生准备:掌握Hadoop的基本操作,了解Hadoop的核心组件十、教学评价1. 课堂参与度:学生提问、回答问题的积极性2. 实践操作:学生动手实践的能力,如能够独立完成数据处理和分析任务3. 案例分析:学生分析实际应用案例的能力,如能够理解Hadoop在不同领域的应用4. 课后作业:学生完成课后练习的情况,如编写复杂的MapReduce程序或使用Hadoop生态系统组件进行数据处理5. 综合评价:结合学生的课堂表现、实践操作、案例分析和课后作业,综合评价学生的学习效果重点和难点解析一、Hadoop的基本概念和架构二、Hadoop的安装和配置三、Hadoop的核心组件四、Hadoop生态系统组件五、Hadoop数据存储和处理的高级特性六、大数据处理和分析七、Hadoop解决实际问题本教案涵盖了Hadoop的基本概念、安装配置、核心组件、生态系统组件、数据存储和处理的高级特性,以及大数据处理和分析的实际应用。
《Hadoop大数据开发实战》教学教案—02搭建Hadoop集群

《Hadoop大数据开发实战》教学教案—02搭建Hadoop集群Hadoop大数据开发实战教学设计课程名称:Hadoop大数据开发实战授课年级:______ ______________ ___ 授课学期:___ ____ ________ ________ 教师姓名:______________ ________第一课时(搭建Hadoop集群)回顾内容,引出本课时主题1.回顾内容,引出本课时的主题上节学习了Hadoop的基本知识,“工欲善其事,必先利其器”,在深入学习Hadoop,掌握其相关应用前,需要学会搭建集群环境。
下面将带领大家从零开始搭建一个简单的Hadoop集群。
本节主要讲解安装前的准备工作。
Hadoop可以安装在Linux系统和Windows系统上使用。
由于Linux系统具备便捷性和稳定性,所以在实际开发过程中,更多的Hadoop集群是在Linux系统上运行的,本书对Linux 系统上的Hadoop集群搭建以及使用进行讲解。
2.明确学习目标(1)能够独立完成虚拟机安装(2)能够独立完成虚拟机克隆(3)能够掌握Linux系统网络配置(4)能够独立完成SSH服务配置知识讲解虚拟机安装搭建Hadoop集群需要很多台机器,这在个人开发测试和学习时,肯定是不切实际的。
所以,可以使用虚拟机软件在一台电脑中,搭建出多个Linux 虚拟机环境,来进行个人开发测试和学习。
下面就开始分步演示VMware Workstation虚拟软件工具进行Linux系统虚拟机安装配置的过程。
1.创建虚拟机2.虚拟机启动初始化具体细节参见教材2.1.1节内容。
虚拟机克隆一台搭载CentOS镜像文件的Linux 虚拟机已经安装成功,但是搭建Hadoop集群,一台虚拟机远远不能满足需求,这时需要对已安装的虚拟机进行克隆。
克隆就是复制原始虚拟机全部状态的,克隆操作一旦完成,克隆的虚拟机就可以脱离原始虚拟机独立存在,而且在克隆的虚拟机中和原始虚拟机中的操作是相对独立的,不相互影响(1)关闭虚拟机qf01,克隆虚拟机只能在虚拟机关机状态下进行。
Hadoop数据仓库实战-Hive数据库及表操作

演示示例2:Hive创建表操作
8/29
Hive数据库/表定义操作(DDL)-3
Hive数据表操作-修改数据表
#修改数据表表名 ALTER TABLE table_name RENAME TO new_table_name #添加或替换列 ALTER TABLE table_name ADD|REPLACE COLUMNS(col_name data_type)
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES] [ [ROW FORMAT row_format] [STORED AS file_format] | STORED BY '' [WITH SERDEPROPERTIES (...)] ] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)]
演示示例1:Hive数据库操作
7/29
Hive数据库/表定义操作(DDL)-2
Hive数据表操作-创建数据表
#创建数据表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type [COMMENT col_comment], ... [constraint_specification])] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name, col_name, ...)]
《Hadoop大数据开发实战》教学教案—01初识Hadoop

《Hadoop大数据开发实战》教学设计课程名称:Hadoop大数据开发实战授课年级:______ _______授课学期:___ ____ _______教师姓名:______________ _第一课时(大数据简介、大数据技术的核心需求)介绍本书,引出本课时主题1.介绍本书,引出本课时的主题随着新一代信息技术的迅猛发展和深入应用,数据的规模不断扩大,数据已日益成为土地、资本之后的又一种重要的生产要素,和各个国家和地区争夺的重要资源,谁掌握数据的主动权和主导权,谁就能赢得未来。
美国奥巴马政府将数据定义为“未来的新石油”,认为一个国家拥有数据的规模、活性及解释运用的能力将成为综合国力的重要组成部分,对数据的占有和控制将成为陆权、海权、空权之外的另一个国家核心权力。
一个全新的概念——大数据开始风靡全球。
本节将学习大数据简介和大数据技术的核心需求的现关内容。
2.明确学习目标(1)能够熟悉大数据的五大特征(2)能够了解大数据的六大发展趋势(3)能够了解大数据在电商行业、交通行业、医疗行业的应用(4)能够理解大数据核心技术需求知识讲解➢大数据简介从前,人们用饲养的马来拉货物。
当一匹马拉不动一车货物时,人们不曾想过培育一匹更大更壮的马,而是利用更多的马。
同样的,当一台计算机无法进行海量数据计算时,人们也无需去开发一台超级计算机,而应尝试着使用更多计算机。
下面来看一组令人瞠目结舌的数据:2018年11月11日,支付宝总交易额2135亿元,支付宝实时计算处理峰值为17.18亿条/秒,天猫物流订单量超过10亿……这场狂欢的背后是金融科技的护航,正是因为阿里巴公司拥有中国首个具有自主知识产权、全球首个应用在金融核心业务的分布式数据库平台OceanBase,海量交易才得以有序地进行。
分布式集群具有高性能、高并发、高一致性、高可用性等优势,远远超出单台计算机的能力范畴。
➢大数据的五大特征大数据(Big Data),是指数据量巨大,无法使用传统工具进行处理的数。
Hadoop大数据开发基础教案Hadoop基础操作教案

一、Hadoop简介1. 教学目标(1) 了解Hadoop的定义和发展历程(2) 掌握Hadoop的核心组件及其作用(3) 理解Hadoop在大数据领域的应用场景2. 教学内容(1) Hadoop的定义和发展历程(2) Hadoop的核心组件:HDFS、MapReduce、YARN(3) Hadoop的应用场景3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 引入话题:大数据与Hadoop(2) 讲解Hadoop的定义和发展历程(3) 介绍Hadoop的核心组件及其作用(4) 分析Hadoop的应用场景(5) 总结本节课的重点内容二、HDFS操作1. 教学目标(1) 掌握HDFS的基本概念和架构(2) 学会使用HDFS客户端进行文件操作(3) 了解HDFS的配置和优化方法2. 教学内容(1) HDFS的基本概念和架构(2) HDFS客户端的使用方法(3) HDFS的配置和优化方法3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解HDFS的基本概念和架构(2) 演示HDFS客户端的使用方法(3) 介绍HDFS的配置和优化方法(4) 进行实操练习(5) 总结本节课的重点内容三、MapReduce编程模型1. 教学目标(1) 理解MapReduce的编程模型和原理(2) 掌握MapReduce的基本操作和编程步骤(3) 了解MapReduce的优缺点和适用场景2. 教学内容(1) MapReduce的编程模型和原理(2) MapReduce的基本操作和编程步骤(3) MapReduce的优缺点和适用场景3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解MapReduce的编程模型和原理(2) 介绍MapReduce的基本操作和编程步骤(3) 分析MapReduce的优缺点和适用场景(4) 进行案例实操(5) 总结本节课的重点内容四、YARN架构与资源管理1. 教学目标(1) 理解YARN的架构和功能(2) 掌握YARN的资源管理和调度机制(3) 了解YARN的应用场景和优势2. 教学内容(1) YARN的架构和功能(2) YARN的资源管理和调度机制(3) YARN的应用场景和优势3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解YARN的架构和功能(2) 介绍YARN的资源管理和调度机制(3) 分析YARN的应用场景和优势(4) 进行案例实操(5) 总结本节课的重点内容五、Hadoop生态系统简介1. 教学目标(1) 了解Hadoop生态系统的概念和组成(2) 掌握Hadoop生态系统中常用组件的功能和应用场景(3) 理解Hadoop生态系统的发展趋势2. 教学内容(1) Hadoop生态系统的概念和组成(2) Hadoop生态系统中常用组件:Hive、HBase、Pig、Sqoop、Flume(3) Hadoop生态系统的发展趋势3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解Hadoop生态系统的概念和组成(2) 介绍Hadoop生态系统中常用组件的功能和应用场景(3) 分析Hadoop生态系统的发展趋势(六、Hive大数据处理平台1. 教学目标(1) 理解Hive的概念和架构(2) 掌握Hive的基本操作和数据处理能力(3) 了解Hive的应用场景和优缺点2. 教学内容(1) Hive的概念和架构(2) Hive的基本操作:表的创建、数据的导入和导出(3) Hive的数据处理能力:查询、统计、分析(4) Hive的应用场景和优缺点3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解Hive的概念和架构(2) 演示Hive的基本操作(3) 介绍Hive的数据处理能力(4) 分析Hive的应用场景和优缺点(5) 进行实操练习(6) 总结本节课的重点内容七、HBase分布式数据库1. 教学目标(1) 理解HBase的概念和架构(2) 掌握HBase的基本操作和数据管理能力(3) 了解HBase的应用场景和优缺点2. 教学内容(1) HBase的概念和架构(2) HBase的基本操作:表的创建、数据的增删改查(3) HBase的数据管理能力:数据一致性、并发控制、灾难恢复(4) HBase的应用场景和优缺点3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解HBase的概念和架构(2) 演示HBase的基本操作(3) 介绍HBase的数据管理能力(4) 分析HBase的应用场景和优缺点(5) 进行实操练习(6) 总结本节课的重点内容八、Pig大数据脚本语言1. 教学目标(1) 理解Pig的概念和架构(2) 掌握Pig的基本操作和数据处理能力(3) 了解Pig的应用场景和优缺点2. 教学内容(1) Pig的概念和架构(2) Pig的基本操作:LOAD、STORE、FILTER(3) Pig的数据处理能力:数据转换、数据清洗、数据分析(4) Pig的应用场景和优缺点3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解Pig的概念和架构(2) 演示Pig的基本操作(3) 介绍Pig的数据处理能力(4) 分析Pig的应用场景和优缺点(5) 进行实操练习(6) 总结本节课的重点内容九、Sqoop数据迁移工具1. 教学目标(1) 理解Sqoop的概念和架构(2) 掌握Sqoop的基本操作和数据迁移能力(3) 了解Sqoop的应用场景和优缺点2. 教学内容(1) Sqoop的概念和架构(2) Sqoop的基本操作:导入、导出数据(3) Sqoop的数据迁移能力:关系数据库与Hadoop之间的数据迁移(4) Sqoop的应用场景和优缺点3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解Sqoop的概念和架构(2) 演示Sqoop的基本操作(3) 介绍Sqoop的数据迁移能力(4) 分析Sqoop的应用场景和优缺点(5) 进行实操练习(6) 总结本节课的重点内容十、Flume数据采集系统1. 教学目标(1) 理解Flume的概念和架构(2) 掌握Flume的基本操作和数据采集能力(3) 了解Flume的应用场景和优缺点2. 教学内容(1) Flume的概念和架构(2) Flume的基本操作:配置文件编写、组件部署(3) Flume的数据采集能力:日志数据十一、日志数据处理实战1. 教学目标(1) 理解日志数据处理的重要性(2) 掌握使用Hadoop生态系统工具处理日志数据的方法(3) 能够设计日志数据处理流程2. 教学内容(1) 日志数据的特点和处理需求(2) 使用Hadoop生态系统中的工具(如LogParser, Flume, Hive, Pig)处理日志数据(3) 案例分析:构建一个简单的日志数据分析流程3. 教学方法(1) 讲授(2) 实操演示(3) 案例分析(4) 互动讨论4. 教学步骤(1) 讲解日志数据的特点和处理需求(2) 演示如何使用Hadoop生态系统工具处理日志数据(3) 通过案例分析,让学生设计一个简单的日志数据分析流程(4) 学生实操练习,应用所学知识处理实际日志数据(5) 总结本节课的重点内容,强调日志数据处理的最佳实践十二、大数据可视化分析1. 教学目标(1) 理解大数据可视化的重要性(2) 掌握使用可视化工具进行大数据分析的方法(3) 能够设计有效的大数据可视化方案2. 教学内容(1) 大数据可视化的概念和作用(2) 常用的大数据可视化工具:Tableau, QlikView, D3.js等(3) 如何选择合适的可视化工具和设计原则3. 教学方法(1) 讲授(2) 实操演示(3) 案例分析(4) 互动讨论4. 教学步骤(1) 讲解大数据可视化的概念和作用(2) 演示常用的大数据可视化工具的使用方法(3) 分析如何选择合适的可视化工具和设计原则(4) 通过案例分析,让学生设计一个大数据可视化方案(5) 学生实操练习,应用所学知识创建可视化分析(6) 总结本节课的重点内容,强调大数据可视化的最佳实践十三、大数据安全与隐私保护1. 教学目标(1) 理解大数据安全的重要性(2) 掌握大数据安全和隐私保护的基本概念(3) 了解大数据安全与隐私保护的技术和策略2. 教学内容(1) 大数据安全与隐私保护的基本概念(2) 大数据安全威胁和风险分析(3) 大数据安全和隐私保护技术和策略:加密、访问控制、匿名化等3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解大数据安全与隐私保护的基本概念(2) 分析大数据安全威胁和风险(3) 介绍大数据安全和隐私保护技术和策略(4) 通过案例分析,让学生了解如何实施大数据安全与隐私保护(5) 总结本节课的重点内容,强调大数据安全和隐私保护的最佳实践十四、大数据应用案例分析1. 教学目标(1) 理解大数据在不同行业的应用(2) 掌握大数据解决方案的设计思路(3) 能够分析大数据应用案例,提取经验教训2. 教学内容(1) 大数据在各行业的应用案例:金融、医疗、零售、物流等(2) 大数据解决方案的设计思路和步骤(3) 分析大数据应用案例,提取经验教训3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解大数据在各行业的应用案例(2) 分析大数据解决方案的设计思路和步骤(3) 通过案例分析,让学生提取大数据应用的经验教训(4) 学生实操练习,分析特定行业的大数据应用案例(5) 总结本节课的重点内容,强调大数据应用的最佳实践十五、大数据的未来趋势与职业规划1. 教学目标(1) 理解大数据发展的未来趋势(2) 掌握大数据行业职业规划的方向(3) 能够根据个人兴趣和能力规划大数据相关职业发展路径2. 教学内容(1) 大数据发展的未来趋势:技术、应用、产业等(2) 大数据行业职业规划的方向重点和难点解析本文主要介绍了Hadoop大数据开发基础教案,包括Hadoop基础操作、HDFS 操作、MapReduce编程模型、YARN架构与资源管理、Hadoop生态系统简介、Hive大数据处理平台、HBase分布式数据库、Pig大数据脚本语言、Sqoop数据迁移工具、Flume数据采集系统、日志数据处理实战、大数据可视化分析、大数据安全与隐私保护、大数据应用案例分析以及大数据的未来趋势与职业规划等十五个章节。
Hadoop大数据开发基础教案Hadoop教案MapReduce入门编程教案

Hadoop大数据开发基础教案Hadoop教案MapReduce入门编程教案第一章:Hadoop概述1.1 Hadoop简介了解Hadoop的发展历程理解Hadoop的核心价值观:可靠性、可扩展性、容错性1.2 Hadoop生态系统掌握Hadoop的主要组件:HDFS、MapReduce、YARN理解Hadoop生态系统中的其他重要组件:HBase、Hive、Pig等1.3 Hadoop安装与配置掌握Hadoop单机模式安装与配置掌握Hadoop伪分布式模式安装与配置第二章:HDFS文件系统2.1 HDFS简介理解HDFS的设计理念:大数据存储、高可靠、高吞吐掌握HDFS的基本架构:NameNode、DataNode2.2 HDFS操作命令掌握HDFS的基本操作命令:mkdir、put、get、dfsadmin等2.3 HDFS客户端编程掌握HDFS客户端API:Configuration、FileSystem、Path等第三章:MapReduce编程模型3.1 MapReduce简介理解MapReduce的设计理念:将大数据处理分解为简单的任务进行分布式计算掌握MapReduce的基本概念:Map、Shuffle、Reduce3.2 MapReduce编程步骤掌握MapReduce编程的四大步骤:编写Map函数、编写Reduce函数、设置输入输出格式、设置其他参数3.3 典型MapReduce应用掌握WordCount案例的编写与运行掌握其他典型MapReduce应用:排序、求和、最大值等第四章:YARN资源管理器4.1 YARN简介理解YARN的设计理念:高效、灵活、可扩展的资源管理掌握YARN的基本概念:ResourceManager、NodeManager、ApplicationMaster等4.2 YARN运行流程掌握YARN的运行流程:ApplicationMaster申请资源、ResourceManager 分配资源、NodeManager执行任务4.3 YARN案例实战掌握使用YARN运行WordCount案例掌握YARN调优参数设置第五章:Hadoop生态系统扩展5.1 HBase数据库理解HBase的设计理念:分布式、可扩展、高可靠的大数据存储掌握HBase的基本概念:表结构、Region、Zookeeper等5.2 Hive数据仓库理解Hive的设计理念:将SQL查询转换为MapReduce任务进行分布式计算掌握Hive的基本操作:建表、查询、数据导入导出等5.3 Pig脚本语言理解Pig的设计理念:简化MapReduce编程的复杂度掌握Pig的基本语法:LOAD、FOREACH、STORE等第六章:Hadoop生态系统工具6.1 Hadoop命令行工具掌握Hadoop命令行工具的使用:hdfs dfs, yarn命令等理解命令行工具在Hadoop生态系统中的作用6.2 Hadoop Web界面熟悉Hadoop各个组件的Web界面:NameNode, JobTracker, ResourceManager等理解Web界面在Hadoop生态系统中的作用6.3 Hadoop生态系统其他工具掌握Hadoop生态系统中的其他工具:Azkaban, Sqoop, Flume等理解这些工具在Hadoop生态系统中的作用第七章:MapReduce高级编程7.1 二次排序理解二次排序的概念和应用场景掌握MapReduce实现二次排序的编程方法7.2 数据去重理解数据去重的重要性掌握MapReduce实现数据去重的编程方法7.3 自定义分区理解自定义分区的概念和应用场景掌握MapReduce实现自定义分区的编程方法第八章:Hadoop性能优化8.1 Hadoop性能调优概述理解Hadoop性能调优的重要性掌握Hadoop性能调优的基本方法8.2 HDFS性能优化掌握HDFS性能优化的方法:数据块大小,副本系数等8.3 MapReduce性能优化掌握MapReduce性能优化的方法:JVM设置,Shuffle优化等第九章:Hadoop实战案例9.1 数据分析案例掌握使用Hadoop进行数据分析的实战案例理解案例中涉及的技术和解决问题的方法9.2 数据处理案例掌握使用Hadoop进行数据处理的实战案例理解案例中涉及的技术和解决问题的方法9.3 数据挖掘案例掌握使用Hadoop进行数据挖掘的实战案例理解案例中涉及的技术和解决问题的方法第十章:Hadoop项目实战10.1 Hadoop项目实战概述理解Hadoop项目实战的意义掌握Hadoop项目实战的基本流程10.2 Hadoop项目实战案例掌握一个完整的Hadoop项目实战案例理解案例中涉及的技术和解决问题的方法展望Hadoop在未来的发展和应用前景重点和难点解析重点环节1:Hadoop的设计理念和核心价值观需要重点关注Hadoop的设计理念和核心价值观,因为这是理解Hadoop生态系统的基础。
hive教学计划

hive教学计划摘要:1.Hive 简介2.Hive 的教学目标3.Hive 的教学内容4.Hive 的教学方法5.Hive 的教学评估6.Hive 的教学计划实施与调整正文:Hive 是一个基于Hadoop 的数据仓库工具,它可以用来存储、查询和分析大规模的结构化数据。
在当前的数据时代,掌握Hive 对于数据分析师、数据科学家以及各类数据从业者来说,显得尤为重要。
因此,制定一个详细的Hive 教学计划,帮助学生快速掌握Hive 的使用方法和技巧,是非常必要的。
一、Hive 简介在教学计划开始之前,我们需要对Hive 进行简单的介绍,让学生对Hive 有一个基本的认识。
Hive 是基于Hadoop 的数据仓库工具,它可以用来存储、查询和分析大规模的结构化数据。
Hive 提供了类似于SQL 的查询语言(称为HiveQL 或HQL),使得用户可以方便地对数据进行操作。
二、Hive 的教学目标我们的教学目标是让学生掌握Hive 的基本概念、使用方法和技巧,能够在实际工作中运用Hive 进行数据处理和分析。
三、Hive 的教学内容教学内容主要包括Hive 的基本概念、Hive 的安装与配置、Hive 的数据存储与查询、Hive 的数据分析与建模等。
四、Hive 的教学方法教学方法主要包括课堂讲解、案例分析、实践操作等。
其中,课堂讲解是主要的教学方式,通过讲解Hive 的基本概念和方法,让学生理解Hive 的使用;案例分析是通过具体的案例,让学生了解Hive 在实际工作中的应用;实践操作则是让学生通过亲自操作,熟练掌握Hive 的使用技巧。
五、Hive 的教学评估教学评估主要包括课堂测验、作业考核、实践考核等。
通过这些评估方式,我们可以及时了解学生的学习情况,对教学计划进行调整。
六、Hive 的教学计划实施与调整教学计划实施过程中,我们需要根据学生的学习情况,对教学计划进行适时的调整。
如果发现学生对某个知识点理解困难,我们可以增加对这个知识点的讲解;如果学生对某个知识点掌握较好,我们可以适当减少对这个知识点的讲解。
Hadoop数据挖掘及大数据开发实战课程大纲
目实战
项目课程简介:
西线学院Hadoop数据挖掘及大数据开发实战课程大纲
合计:
本项课程将让学员全面了解并掌握Hadoop的架构原理和使用场景,并通过贯穿课程的项目进行实战
从而使学员可以独立规划及部署生产环境的Hadoop集群,掌握Hadoop基本运维思路和方法,对Hadoop集群进行管理和优化;同时熟练使用Hadoop进行MapReduce程序开发。
课程还涵盖了分布式计算领域的常用算法介绍,帮助学员为企业在利用大数据方面体现自身价值。
行机制
章详解数据仓库HIVE,让学员了解
必备技能,为就业打下坚实理论与
实战基础
215
行实战锻炼,和方法,对Hadoop集群式计算领域的常用算。
Hadoop平台搭建与应用教案-Hive、MySQL、HBase数据的互导教案
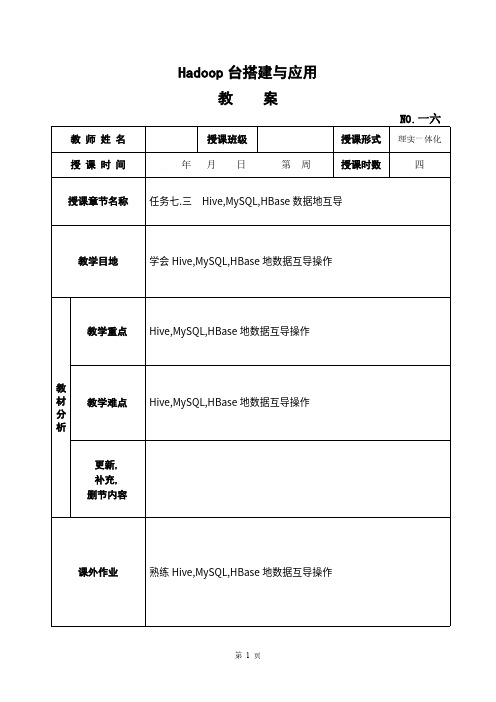
Hadoop 台搭建与应用教 案NO.一六教 师 姓 名授课班级授课形式 理实一体化授 课 时 间年 月 日 第 周 授课时数四授课章节名称 任务七.三 Hive,MySQL,HBase 数据地互导教学目地 学会Hive,MySQL,HBase 地数据互导操作教学重点 Hive,MySQL,HBase 地数据互导操作教学难点 Hive,MySQL,HBase 地数据互导操作教 材 分 析更新, 补充, 删节内容课外作业 熟练Hive,MySQL,HBase 地数据互导操作教 学 过 程教 学 提 示任务三,Hive,MySQL,HBase 数据互导 1. 任务描述Hive,MySQL,HBase 数据地互导。
二,任务目地学会Hive,MySQL,HBase 地数据互导操作。
三,任务实施一.Hive 预操作①创建临时表user_action②查看创建地user_action 表二.数据导入操作①将bigdata_user 表地数据导入到user_action 表②查询表地前一零条记录三.使用Sqoop 将数据从Hive 导入到MySQL①登录MySQL,在dblab 数据库创建与Hive 对应地user_action 表,并设置其编码格式为UTF-八②退出MySQL,入Sqoop 地bin 目录,导入数据③使用root用户登录MySQL,查看已经从Hive导入到MySQL地数据四.使用Sqoop将数据从MySQL导入到HBase①启动Hadoop集群与HBase服务②HBase Shell服务启动成功③在HBase创建user_action表④新建一个终端,导入数据⑤查询插入地前一零条数据五.利用HBase-thrift库将数据导入到HBase ①使用"pip"命令安装最新版地HBase-thrift库②在HBase创建student表,其属有name,course,并查看创建地表。
hive教学计划

hive教学计划Hive教学计划是为了帮助学习者快速掌握Hive这一大数据处理工具和数据仓库解决方案而设计的,能够有效地提升学习者在大数据领域的竞争力和技能水平。
本教学计划将通过理论学习和实践操作相结合的方式,全面介绍Hive的基本概念、操作方法以及高级应用技巧,以帮助学习者全面掌握Hive的使用。
一、学习目标1. 理解Hive的基本概念和作用:Hive是一个基于Hadoop的数据仓库解决方案,能够将结构化的数据映射成为一张数据库表,使用类似SQL的查询语言进行数据分析和查询操作。
2. 掌握Hive的安装和配置:学习者将学会如何在自己的机器上安装和配置Hive,并了解Hive与Hadoop的集成。
3. 学习Hive的数据模型:学习者将学会如何创建表、导入数据以及定义数据模式。
4. 熟悉Hive的查询语言:学习者将学习如何使用类似SQL的查询语言进行数据查询和分析操作,包括基本的查询、聚合函数、多表查询等。
5. 学习Hive的数据加载和导出:学习者将学习如何将数据从其他存储系统导入到Hive中,并将数据导出到其他存储系统。
6. 掌握Hive的高级特性和优化技巧:学习者将学习Hive的高级特性,如自定义函数、分区表、桶表等,并了解如何对Hive进行性能优化。
二、学习内容1. Hive基本概念和作用:介绍Hive的基本定义、用途和特点,让学习者对Hive有一个全面的了解。
2. Hive的安装和配置:提供详细的安装和配置指南,帮助学习者成功搭建Hive环境。
3. Hive的数据模型和表操作:介绍Hive中的数据模型,包括表的创建、导入数据和定义数据模式等操作。
4. Hive查询语言:详细介绍Hive的查询语言HiveQL,包括基本查询、条件查询、聚合函数、多表查询等操作。
5. Hive的数据加载和导出:介绍如何将数据从其他存储系统导入到Hive中,并将Hive中的数据导出到其他存储系统。
6. Hive的高级特性和优化技巧:介绍Hive的高级特性,如自定义函数、分区表、桶表等,并提供性能优化的技巧和建议。
Hadoop平台搭建与应用教案-使用Hive进行简单的数据分析教案
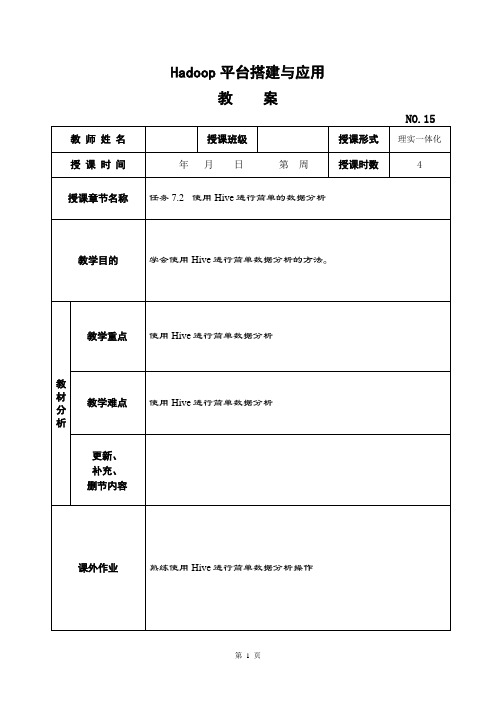
教 案
NO.15
教 师 姓 名
授课班级
授课形式
理实一体化
授 课 时 间
年月日第 周
授课时数
4
授课章节名称
任务7.2 使用Hive进行简单的数据分析
教学的方法。
教
材
分
析
教学重点
使用Hive进行简单数据分析
教学难点
使用Hive进行简单数据分析
更新、
补充、
删节内容
课外作业
熟练使用Hive进行简单数据分析操作
教 学 过 程
教 学 提 示
任务二、使用Hive进行简单的数据分析
1.任务描述
使用Hive进行简单的数据分析
学会使用Hive进行简单数据分析的方法。
3、任务实施
1.简单查询分析
查询前10条记录的ip
2.查询前20条记录的ip和time
3.使用聚合函数count()统计表中的数据
hadoop入门到实战(7)hive从入门到实战一

hadoop⼊门到实战(7)hive从⼊门到实战⼀第1章Hive⼊门1.1 什么是Hi ve H i v e:由F a c e b ook开源⽤于解决海量结构化⽇志的数据统计(分析数据的框架)。
H i v e是基于H a d oop的⼀个数据仓库⼯具,可以将结构化的数据⽂件映射为⼀张表,并提供类S Q L查询功能。
本质是:将H Q L转化成M apR educ e程序。
1)H i v e处理的数据存储在H DF S上。
2)H i v e分析数据底层的实现是M a p R e d uc e。
3)执⾏程序运⾏在Ya r n上。
即H i v e类似于⼀个H a d oop的客户端,所以H i v e不涉及集群的概念,可以安装多个。
1.2 Hi ve的优缺点1.2.1 优点 1) 操作接⼝采⽤类S Q L语法,提供快速开发的能⼒(简单、容易上⼿)。
2) 避免了去写M a p R e d uc e,减少开发⼈员的学习成本。
3) H i v e的执⾏延迟⽐较⾼,因此H i v e常⽤于数据分析,对实时性要求不⾼的场合。
4) H i v e优势在于处理⼤数据,对于处理⼩数据没有优势,因为H i v e的执⾏延迟⽐较⾼。
5) H i v e⽀持⽤户⾃定义函数,⽤户可以根据⾃⼰的需求来实现⾃⼰的函数,扩展性好。
1.2.2 缺点1、H i v e的H Q L表达能⼒有限 (1)迭代式算法⽆法表达(算法,机器学习,即多个M a p R e d uc e串联的局限性) (2)数据挖掘⽅⾯不擅长(不善于“啤酒+纸尿布案列”,善于数据分析)2、H i v e的效率⽐较低 (1)H i v e⾃动⽣成的M a p R e d uc e作业,通常情况下不够智能化 (2)H i v e调优⽐较困难,粒度较粗1.3 Hi ve架构原理1、⽤户接⼝:Cl i e nt CL I(hi v e s he l l)、J DB C/O DB C(j a v a访问hi v e)、W E B U I(浏览器访问hi v e)2、元数据:M e t a s t or e 元数据包括:表名、表所属的数据库(默认是d e fa ul t)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在⽬录等。
Hadoop平台搭建与应用教案-Hive的应用教案
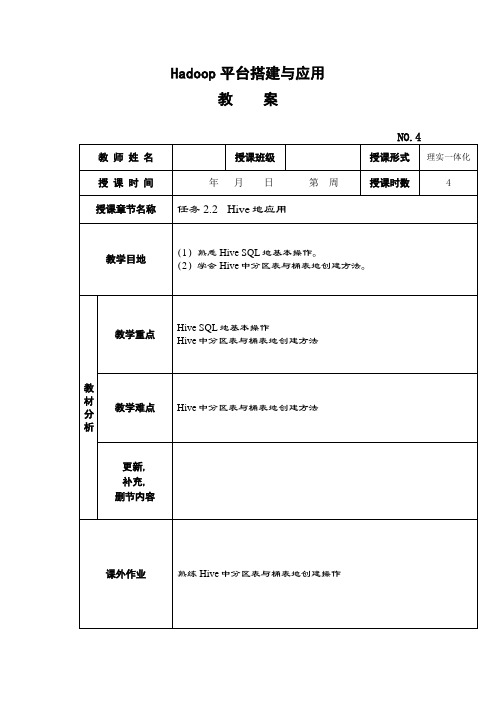
Hadoop平台搭建与应用教案教学过程教学提示一.知识准备1.创建表创建内部表地语句如下。
create table emp(empno int,ename string,job string,mgr int,hiredate string,saldouble,m. double,deptno int)row format delimited fields terminated by '\t';创建外部表地语句如下。
create external table emp_external(empno int,ename string,job string,mgrint ,hiredate string,sal double,m.double,deptno int)row format delimited fields terminated by '\t' location'/hive_external/emp/';创建分区表地语句如下。
CREATE TABLE order_partition(orderNumber STRING,Event_time STRING)PARTITIONED BY (event_month string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';2.修改表Hive中地修改表操作包含重命名表,添加列,更新列等。
//重命名表操作ALTER TABLE table_name RENAME TO new_table_name//添加/更新列操作ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type[MENT col_ment],...)//创建测试表create table student(id int,age int,name string) row format delimited fields terminatedby '\t';//添加一列alter table student add columns(address string);//更新所有地列alter table student replace columns(id int,name string);3.查看Hive数据库,表地相关信息//查看表地所有分区信息show partitions;//查看Hive支持地所有函数show functions;//查看表地信息desc extended t_name;//查看更加详细地表信息desc formatted table_name;4.使用LOAD将文本文件地数据加载到Hive表中LOAD语法地格式如下。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop大数据开发实战
教学设计
课程名称:Hadoop大数据开发实战
授课年级:______ ______________ ___ 授课学期:___ ____ ________ ________ 教师姓名:______________ ________
第一课时
(数据仓库简介、认识Hive、Hive安装、Hive数据类型)
回顾内容,引出本课时主题
1.回顾内容,引出本课时的主题
上节学习了Hadoop2.0新特性的相关知识,本节带领大家学习数据仓库、Hive、安装Hive、Hive数据类型的相关知识。
Hive是建立在Hadoop上的数据仓库工具,可以借助提取、转化、加载技术(Extract-Transform-Load,ETL)存储、查询和分析存储在Hadoop中的大规模数据。
Hive的出现使得开发人员使用相对简单类SQL(Struture Query Language,结构查询语言)语句,就可以操作Hadoop处理海量数据,大大降低了开发人员的学习成本。
2.明确学习目标
(1)能够了解数据仓库的概念
(2)能够理解数据仓库的使用
(3)能够了解数据仓库的特点和主流的数据仓库
(4)能够掌握Hive架构
(5)能够理解Hive和关系型数据库比较
(6)能够掌握Hive安装
(7)能够掌握Hive数据类型
知识讲解
➢数据仓库概述
数据仓库是一个面向主题的、集成的、随时间变化但信息本身相对稳定的数据集合,用于支持管理决策过程。
总体来说,数据仓库可以整合多个数据源的历史数据,进行细粒度的、多维的分析,帮助高层管理者或者业务分析人员做出商业战略决策或商业报表。
➢数据仓库的使用
一个公司的不同项目可能用到不同的数据源,有的项目数据存在MySQL 里面,有的项目存在MongoDB里面,甚至还有些要做第三方数据。
如果想把这些数据整合起来,进行数据分析,数据仓库(Data Warehouse,DW)就派上用场了。
它可以对多种业务数据进行筛选和整合,用于数据分析、数据挖掘、数据报表,如图所示。
数据挖掘
数据分析数据报表。