第2章_SPSS数据文件的建立和管理
SPSS统计分析- 第2章 数据文件建立和管理

4.读取“*.txt”数据文件
现需将“人居收入.txt”文件中的数据读入SPSS,如图所示: (1) 打开“数据编辑器”对话框,选择“文件”|“打开文本数据”命令,打 开“打开数据”对话框。选择文本文件,单击“打开”按钮,打开“文本导入向 导”对话框,如图所示:
(2) 在“您的文本文件与 预定义的格式匹配吗? ” 选项组中选择 “ 是 ” 单选 按钮,可单击“浏览” 按 钮,选择已预定义好的 格式;单击 “ 否 ” 则需要 建立一个新格式。
2.1.1 打开定义变量视图
• 按前一章所述打开SPSS主界面,视图切换标签处单击“变 量视图”,即打开“变量视图”窗口,如图所示。在该视 图可对变量的以下属性进行定义:名称、类型、宽度、小 数、标签、值、缺失、列、对齐、度量标准和角色。
2.1.2 定义变量名称
• 在“变量视图”变量栏的“名称”栏中定义变量名称,用 户可根据数据需要或个人习惯进行定义,如果不对变量进 行定义,系统将自动默认变量名为var00001、var00002、 var00003等。一般根据变量的实质意义来命名,例如:年 龄、性别、年级等变量,可用Age,Gender,Grade命名,也 可用中文意义命名,但当出现变量数量较大时,一般使用 流水编号,即防混淆又方便。虽然变量可根据用户的需求 自行编辑,但仍有其需共同遵循的原则: • 若用英文命名,变量名首字必须为英文字母,其后方可接 数字、英文字母、@等。若用中文命名,则可直接使用。 • 不可使用空格和特殊字符(如键盘上的!、#、$、%、&、 ^、*、(、)、?等字符)。
(9) 之后进入下一步,如图所示。在“变量之间有哪些分隔符?”中,可根据 文本数据中变量间的分隔符,可选择“制表符”、 “空格”、“逗号 ”、“分号” 和“其他”复选框。在“文本限定符是什么?”中,可选择“无”、“单引号”、“ 双引号”和“其他”单选按钮,一般默认为“无”,选择完毕后单击“下一步” 。
SPSS数据文件的建立和管理实验报告
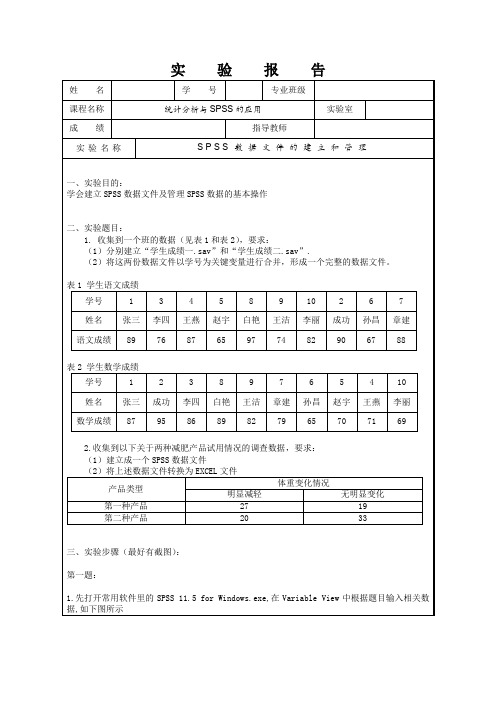
第二题:
1.先打开常用软件里的SPSS 11.5 for Windows.exe,在Variable View中根据题目输入相关数据,如下图所示
2.在Data View中根据题目输入相关数据,结果如下图所示
3.对这个表格进行保存,并且命名为“减肥产品.sav”
3.选中“Match cases on key variables in sorted files”,将“学号”放入“Key Variables”中,结果如下所示
第二题:
因为题中要求将数据文件转换为EXCEL文件,所以通过【File】→【Save As】可实现
输入文件名“减肥产品”,再修改保存类型,选择EXCEL保存类型,即可得到升序排列,结果如下图所示
3.对第一个表格进行保存,并且命名为“学生成绩一.sav”
4.重新打开一个表格,在Variable View中根据题中要求输入数据,如下图所示
5.在Data View中先输入数据,再选中“学号”一列,选择升序排列,结果如下图所示
表1学生语文成绩
学号
1
3
4
5
8
9
10
2
6
7
姓名
张三
李四
王燕
赵宇
白艳
王洁
李丽
成功
孙昌
章建
语文成绩
89
76
87
65
97
74
82
90
67
88
表2学生数学成绩
学号
1
2
3
8
9
7
6
5
4
10
姓名
张三
成功
SPSS02数据与数据文件

类
型
算术函数
数量
13
Statistical Functions
String Functions Date and Time Functions Logical Functions Probability Density Functions Tail Probability Functions Cumulative Distribution Functions Inverse Distribution Functions
五、数据文件的操作
(三)观测量的加权 1、数据描述 为研究抽烟与肺癌的关系,随机采访了45个 正常人和55个肺癌患者,并对是否吸烟进 行了记录,数据见“抽烟与肺癌关系.sav” 2、SPSS加权操作 点击菜单“数据-加权个案”,将左侧人数变 量选入右侧频率变量
五、数据文件的操作
(三)观测量的加权 3、进一步分析 点击菜单“分析-描述统计-交叉表”进行分析
随机变量函数
转换函数 缺失值函数
24
2 4
返回
上机练习
分布类型的检验方法
用SPSS建立n=20,π=0.2,0.5,0.8的二项 分布,并作线形图。 var0001更名为x,输入0~20。 转换-计算变量 : 目标变量 数字表达式 binomial0.2 = Pdf.BINOM(x,20,0.2)
总长度 7 9
小数位数 2 2
返回
变量标签和变量值标签
变量 Gender 变量标签 性别 变量值 f m Height 身高 1 2 3 男 女 <=1.49m 1.50~1.59m 1.60~1.69m 变量值标签
4
5
1.70~1.79m
>=1.80m
实验二SPSS数据录入与编辑

实验二SPSS数据录入与编辑SPSS数据录入与编辑一、引言SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,广泛应用于社会科学、市场调研、医学研究等领域。
在进行数据分析之前,首先需要将原始数据录入到SPSS软件中,并进行必要的数据编辑。
本文将详细介绍SPSS数据录入和编辑的标准格式。
二、数据录入1. 打开SPSS软件并创建新的数据文件。
在SPSS软件界面上方的菜单栏中,选择"File" -> "New" -> "Data",创建一个新的数据文件。
2. 定义变量名称和属性。
在数据文件中,每一列代表一个变量。
在第一行录入变量的名称,确保名称准确且易于理解。
在第二行录入变量的属性,包括变量的测量类型(如数值型、字符型、日期型等)和宽度(即变量所占的字符数)。
3. 逐行录入数据。
从第三行开始,逐行录入数据。
确保每一列的数据与对应的变量匹配,避免录入错误。
4. 保存数据文件。
在菜单栏中选择"File" -> "Save",保存数据文件。
建议将文件保存为SPSS的标准格式(.sav)。
三、数据编辑1. 缺失值处理。
在数据录入过程中,可能会出现一些数据缺失的情况。
可以使用SPSS软件提供的缺失值标记来表示缺失数据。
在数据文件中,将缺失值用特定的数值或符号表示,方便后续的数据分析。
2. 数据清洗。
数据清洗是指对数据进行筛选、排除异常值、修正错误等操作,以保证数据的质量和准确性。
可以使用SPSS软件提供的数据筛选、变量计算、数据转换等功能进行数据清洗。
3. 数据转换。
在进行数据分析之前,有时需要对数据进行转换,以满足分析的需求。
例如,可以进行数据归一化、对数变换、指标构建等操作。
SPSS软件提供了丰富的数据转换函数和操作,可以根据需求进行相应的数据转换。
第01节如何建立SPSS数据文件

第01节如何建立SPSS数据文件SPSS(Statistical Package for the Social Sciences)是一种专业的统计分析软件,被广泛应用于社会科学、市场调研以及其他领域的数据分析中。
建立SPSS数据文件是使用SPSS进行数据分析的第一步,本文将介绍如何建立SPSS数据文件的步骤。
1. 确定数据变量在建立SPSS数据文件之前,首先需要确定好需要收集和记录的各个数据变量。
数据变量包括各种观测指标或测量项目,可以是数值型、顺序型或名义型的变量。
2. 打开SPSS软件双击打开SPSS软件,进入SPSS统计分析界面。
3. 创建新数据文件在SPSS界面的主菜单栏选择"File" -> "New" -> "Data",或者直接点击工具栏上的新建数据文件图标。
弹出新建数据文件对话框。
4. 设定数据文件属性在新建数据文件对话框中,可以设置数据文件的属性,包括数据文件名、存储位置、数据文件类型等。
根据需要填写相应信息,并确定保存位置和数据文件类型。
5. 定义数据变量在数据视图窗口中,可以依次定义各个数据变量。
点击数据视图窗口中的第一个空白格,输入第一个数据变量的名称,并按下"Tab"键移动到下一个格子中。
在下一个格子中选择适当的数据类型(如数值型、字符型等)并输入数据,然后按下"Tab"键继续定义下一个数据变量。
依此类推,逐个定义好所有的数据变量。
6. 设定数据值标签在数据视图窗口中,还可以对特定的数据变量设定数据值标签。
选中某个数据变量所在的格子,点击菜单栏中的"Variable View",在弹出的对话框中输入该变量的数据值标签。
7. 保存数据文件在完成所有数据变量的定义后,点击菜单栏中的"File" -> "Save",选择保存数据文件。
SPSS数据分析教程-2-数据文件的建立和管理

最新课件
14
数据的输入操作(2)
ID号(id) 性别(sex):1:男; 2:女
1, 2, 1, 2, 2, 1, 2, 1, 1, 1, 2, 2
身高(height)
76,59,67,65,63,72,70,68,69,74,68,63
参加活动以前的体重(before)
185 113 145 156 109 191 155 165 175 180 135 118
如果一个文件中的某个个案在另一个文件中找不到 个案来匹配,则该个案于第二个文件的变量上的取 值为缺失值。反之亦然。
如果一个文件中的某个个案在另一个文件中找到两 个或者两个以上的个案来匹配,则该个案只取第二 个文件中第一个相匹配的个案来连接。反之亦然。
最新课件
38
合并变量示意图:一对一
最新课件
39
最新课件
3
本章学习目标
理解信息、数据与数据处理的基本概念; 了解SPSS数据编辑器的特点,熟悉SPSS的变
量视图和数据视图,掌握SPSS常用的工具按 钮;
掌握数据录入SPSS软件的方法;
掌握把电子表格、数据库、文本文件等格式的 数据文件读入SPSS软件的方法;
掌握SPSS数据集的数据字典; 学习合并两个数据文件的方法; 明确分割SPSS数据文件的方法。
分析的目的是比较不同收益类型客户的概要特征。
最新课件
42
先按照关键变量“orgntype”(客户工作单 位的类型)进行合并文件。选择【数据】→ 【排序个案】 ,首先按照关键变量
“orgntype”排序。
然后选择【数据】→【合并文件】→【添加变 量】 进行合并。
最新课件
43
2.7 数据的拆分
实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构

实验一SPSS数据文件的建立和管理一.实验目的1.掌握spss数据的结构和定义方法;2.掌握spss数据的录入与编辑:数据的录入、数据的定位、插入和删除一个个案、插入和删除一个变量、数据的移动、复制和删除;3.掌握spss数据的保存,保存为excel文件格式和spss文件格式;4.掌握读取excel文件格式和txt文件格式的数据;5.掌握spss数据文件的纵向与横向的合并。
二.实验基本方法1. spss数据的结构和定义方法操作步骤:参阅教材第24页。
2. spss数据的录入与编辑操作步骤:(1)数据的录入:参阅教材第29页。
(2)数据的定位:参阅教材第30页。
(3)插入和删除一个个案:参阅教材第31页。
(4)插入和删除一个变量:参阅教材第31页。
(5)数据的移动、复制和删除:参阅教材第32页。
3. spss数据的保存操作步骤:参阅教材第33页。
4. 读取excel文件格式和txt文件格式的数据操作步骤:参阅教材第35页。
5. spss数据文件的纵向与横向的合并操作步骤:(1)纵向合并数据文件:参阅教材第40页。
(2)横向合并数据文件:参阅教材第42页。
三.实验内容(一)验证性实验(1)教材第25页“关于居民储户调查问卷的spss变量的设计”(2)教材第38页“职工基本情况数据的纵向合并和横向合并”(二)实践性实验(1)针对“零散数据”文件夹中的若干excel数据和txt数据,将其转换为spss的数据文件,要求转换为spss数据后,根据变量的类型正确定义数据结构。
(2)针对“经管学院考试成绩”文件夹中的数据,首先,通过spss软件将“成绩1”和“成绩2”的excel文档打开,并保存为相同文件名的spss数据文件。
要求:spss读取excel的变量名,数据结构定义准确。
其次,利用横向合并的功能,将“成绩1”和“成绩2”进行合并,并存为“三次考试成绩汇总表.sav”的文件。
最后,将“三次考试成绩汇总表.sav”的文件保存一份txt本文数据和excel文件数据。
spss数据文件的建立与操作

在Variable View中,定义变量的属性。
SPSS中的变量有十个属性:
变量名(Name)
变量类型(Type)
变量宽度(Width) 小数点的位数(Decimals)
变量名标签(Label) 变量值标签(Values)
1.1 数据文件的特点 1.2 定义变量 1.3 录入数据 1.4 外部数据的导入
1.1 数据文件的特点
SPSS数据文件是一种有结构的数据文件,它由数据 结构和数据内容两部分组成,其中结构部分用于定 义数据类型、宽度、缺失值等,而内容才是我们具 体要分析的数据。
SPSS数据文件的扩展名是.sav
通过一个例子理解数据文件的横向合并。
【例】将数据transform3.sav中的变量添加到 transform.sav中。
在菜单栏中选择Data | Merge Files | Add Variables命令
关于合并后的数据文件中的数据 按 哪 种 方 式 提 供 , SPSS有 三 个 选 项可供选择: 1.Both files provide cases: 是 SPSS默 认 的 方 式 , 指 合 并 后 的 数据由原来的两个数据文件共同 提供,即由原来两个数据文件中 的记录共同组成合并后的数据文 件。
在SPSS中,能使用定类尺度的数据可以是数值型,也可以是字符型变 量。必须符合穷尽和互斥的原则。穷尽的原则就是指每个个体都必须 能归为一个类别,互斥的原则是指每个个体都只能归为一个类别。
相应变量为定类变量或(无序)分类变量。
Ordinal
定序尺度是对事物之间等级或顺序差别的一种测度。 定序尺度的特点是可以测度类别差,还可以测度次序差
第二章 SPSS数据文件的建立和管理

(2)删除一条个案:即删除数据编辑窗口中的某条个案。 ★在要删除的个案号码上单击左键,于是待删除的个案数 据全部反色显示。 ★单击右键,从弹出菜单中选择 cut选项。
3、插入和删除一个变量 (1)插入一个新变量:即在数据编辑窗口的某个变量前插 入一个新变量。 ★ 将当前数据单元确定在某变量上 ★选择菜单: 编辑 -> 插入变量
一行为一个个案
一列为一个变量
二、计数数据的组织方式 有时所采集的数据不是原始的调查问卷数据,而是经过分 组汇总后的计数数据。 在研究职称和年龄的关系时汇总得到如表所示的数据。其 中职称的分组值分别为1~4,年龄段的分组值为1~3。 职称 教授(1) 副教授(2) 讲师(3) 助教(4) 年龄段 35岁以下(1) 36~49岁(2) 50岁以上(3) 0 10 20 35 15 20 10 2 8 1 1 0
例 有两份关于职工基本情况的SPSS数据文件,文件名分别 为“职工数据.sav”和“追加职工.sav”。两份数据文件中的 数据项不尽相同,且同一数据项的变量名也不完全一致。现需 要将这两份数据合并到一起。
纵向合并数据文件的基本操作步骤
1、在数据编辑窗口中打开一个需要合并的SPSS数据文件。 2、选择菜单: 数据 -> 合并文件 -> 添加个案
基本操作步骤如下: (1)选择菜单: 文件 -> 打开 -> 数据 (2)选择数据文件的类型,并输入数据文件名。
注意:
如果读入的是Excel格式文件,SPSS默认将它的所有 数据读到SPSS数据编辑窗口中,也可以指定读取工作表中某 个区域内的数据(A5:B10,表示仅读取以A5单元为左上角 ,B10单元为右下角的矩形区域内的数据)。工作表上的一 行数据为SPSS的个案。如果Excel工作表文件第一行或指定 读取区域内的第一行上存储了变量名信息,则应选择读取变 量名选项。
SPSS复习资料

第一章SPSS统计分析系统软件简介1)SPSS的几种基本运行方式:①菜单操作方式:这种方法图形用户界面友好、操作简单、形象直观,能够一步步引导用户完成对数据的描述和模型的建立。
②程序运用方式:是在Syntax编辑窗口输入程序。
也可以用任何文本编辑器中输入,也可以在相应菜单操作的对话框中,用“Paste”按钮可以把相应的操作转化为Syntax语言。
选择所有的语法命令行,单击“Run”运行程序。
或者在SPSS的语法编辑器窗口输入语法。
③ Include运行方式:在编写Syntax命令中,如果要调用其他语法文件时,除了复制粘贴现有的资源外,还可以用Include的命令。
④ Production Facility方式:Production Facility生产作业方式提供了以自动化方式运行SPSS Statistics 的功能。
2)SPSS界面提供的五个窗口:①数据编辑窗口:这个窗口主要用来处理数据和定义数据字典,它分为两个视图。
一个是用来显示数据的数据视图(数据视图用来显示数据集中的记录或个案),另外一个是变量视图(变量视图的功能是定义数据集的数据字典)。
②结果管理窗口:也称为结果视图或者结果浏览器,该窗口用于存放SPSS软件的分析结果。
分为左边目录区,是SPSS分析结果的目录;右边是内容区,显示与目录相应的内容。
③结果编辑窗口:是编辑分析结果的窗口。
选中要编辑的内容,双击或者点击右键选择“编辑内容”,选中的图形就会出现在“图表编辑器”中,可以开始编辑。
④语法编辑窗口:语法编程方式,能够完成窗口操作所能完成的所有任务,还可以完成许多窗口操作所不能完成的其他工作。
在这个窗口中,还可以调用开源软件R中的任何程序。
⑤脚本窗口:是用Sax Basic 语言编写的程序。
脚本可以使SPSS内部操作自动化,可以自定义结果格式,可以连接VB和VBA应用程序。
第二章数据文件的建立和管理1)数据管理的特点:数据编辑器的每一行数据称为一个个案,每一列数据代表个体属性,即变量。
单元一 SPSS数据文件的建立和管理

第一节 SPSS的发展及使用基础
(二)SPSS数据结构的基本方式
(2)计数数据的组织方式
第二节 SPSS的数据结构和定义方法
(一)变量名
变量名是变量访问和分析的唯一标识。
变量命名原则:
SPSS 变量名由不多于64(32个汉字)个字符组成;首字母是字母或汉字也可以是@字符;不能使用?,!和*;注意不能以下划线_和圆点“.”作为变量名的最后一个字符;
第一节 SPSS的发展及使用基础
(二)SPSS数据结构的基本方式
第一节 SPSS的发展及使用基础
(二)SPSS数据结构的基本方式
在计数数据的组织方式中,数据编辑窗口中的一行为变量的一个分组(或多变量交叉分组下的一个分组)。所有行囊括了该变量的所有分组情况(或多变量交叉下的所有分组情况)。数据编辑器窗口中的一列仍为一个变量,代表某个问题(或者某个方面的特征)以及相应的计数结果。
第五节 数据文件合并
数据文件合并的介绍
(2)横向合并-案例
职工数据和职工奖金数据的合并
①打开“职工数据.sav”②选择菜单【数据】→ 【合并文件】 → 【添加变量】
学 业 进 步!
基本操作步骤如下:
【文件】→【导入数据】→【文本数据】
(二)使用导向导入其他格式的数据
第五节 数据文件合并
数据文件合并的介绍
当数据量较大时,经常会把一份大的数据分成几个小的部分,分别录入,录入完毕后, 就必须将若干个小的数据文件合并起来。数据文件的合并分为纵向合并和横向合并。
(1)纵向合并
将一个SPSS数据文件的内容追加到当前数据编辑器窗口中数据的后面,依据两份数据文件中的变量名进行数据对接。
字符串型简称字符串(R),是SPSS中较常用的数据类型,它有由一串字符组成。如职工号码、姓名、地址等变量都可以定义为字符串数据。
SPSS统计分析方法及应用01-01-01

咨询公司发现这一秘密的手段就是我们课程的关联分析 和频数分析。没有数据挖掘,这一信息将永不见天日!
电信:呼叫指纹识别 银行:逾期贷款、呆滞贷款 证券公司:上市公司是否被特别处理(ST)。 以上例子使用的工具,都是利用统计分析理论和方法研 制的软件系统。行业名称:数据分析、经济分析、数据挖掘
1994-1998年间,SPSS公司兼并了多家从事统计分析软 件研发的公司,对这一市场进行了整合,软件名称也改为: 统计产品与服务解决方案(Statistical Product and Service Solutions),最新版本SPSS17。
3) SPSS的应用领域
现在的SPSS统计分析软件在全球拥有26万家以上的用户, 广泛应用于通信、医疗、银行、证券、保险、军事、商业、 教育、科研和政府等社会的各个领域,是当今世界最流流行 的软件之一。见识
4) 变量值标签
在调查问卷中的选项中,答案经常是英文字母,例如学
历:A,初中以下;B,高中;C,大专…。在数据集中存储
02:20:10
河北工大廊坊分校经济系周玉江
25
是这些英文字母,让人很难读懂和理解。 SPSS可以定义变量值标签,对变量的值进行说明和解释。
在数据集中既可以浏览变量的值,也可以浏览变量值标签; 输出结果也是如此,十分方便。
钮都处于休眠状态。
02:20:10
河北工大廊坊分校经济系周玉江
26
变量的值
变量值标签
02:20:10
河北工大廊坊分校经济系周玉江
27
(2) 删除或修改变量值标签的对应关系
单击列表框中要删除的标签,这时标签的值重新显示在 标签Lable文本框中,在值Value文本框输入原来对应的值, 【Remove】按钮被激活,可以将对应关系移去。
Spss考试基本要求及大纲分析2
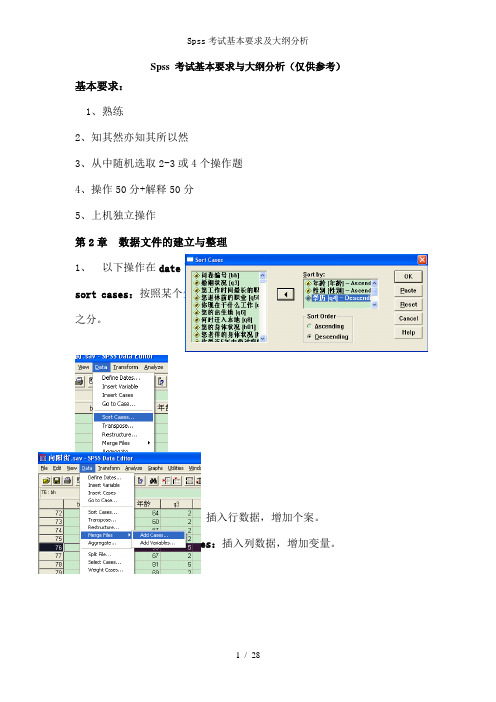
Spss 考试基本要求与大纲分析(仅供参考)基本要求:1、熟练2、知其然亦知其所以然3、从中随机选取2-3或4个操作题4、操作50分+解释50分5、上机独立操作第2章数据文件的建立与整理1、以下操作在date下完成:sort cases:按照某个分组变量排列数据,分类整理,有升序和降序排列之分。
Merge files >add cases:插入行数据,增加个案。
>add variables:插入列数据,增加变量。
2、split file:Data→Split File (文件拆分) 命令,打开Split File 对话框。
3、select cases:Data→Select Cases (选择个案)命令,打开Select Cases对话框。
执行后,会产生一个“~$”的变量,凡被选中的满足条件的个案,该变量对应的值为1(其值标签为Selected),否则为0 (值标签为Not Selected),并在个案序号列上将未选中的划上斜线“/”作为标记。
未选中的个案将在接着进行的统计分析中暂时被关闭。
按照设置的选择条件,选中个案。
点击if condition is satisfied选择性别xb,点击下方的表达式,让它=1.ok运行。
系统将自动产生一个名为“filter_$”的变量,凡被选中的满足条件的个案,该变量对应的值为1(其值标签为Selected),否则为0 (值标签为Not Selected),并在个案序号列上将未选中的划上斜线“/”作为标记。
未选中的个案将在接着进行的统计分析中暂时被关闭。
按照设置的选择条件,选中个案。
4、weight cases:Data→Weight cases (个案加权)命令,打开Weight cases 对话框。
对话框中单选项Do not weight cases (不对个案加权)为系统默认选项;第二个单选项为Weight cases by (对个案加权),选择此项时激活Frequency variable (频数) 矩形框,从源变量列表中选择一个加权变量移入此框中,单击OK,该数据文件的权变量便定义好了。
SPSS数据分析实例详解

第一章 SPSS概览--数据分析实例详解1.1 数据的输入和保存1.1.1 SPSS的界面1.1.2 定义变量1.1.3 输入数据1.1.4 保存数据1.2 数据的预分析1.2.1 数据的简单描述1.2.2 绘制直方图1.3 按题目要求进行统计分析1.4 保存和导出分析结果1.4.1 保存文件1.4.2 导出分析结果欢迎加入SPSS使用者的行列,首先祝贺你选择了权威统计软件中界面最为友好,使用最为方便的SPSS来完成自己的工作。
由于该软件极为易学易用(当然还至少要有不太高的英语水平),我们准备在课程安排上做一个新的尝试,即不急于介绍它的界面,而是先从一个数据分析实例入手:当你将这个例题做完,SPSS的基本使用方法也就已经被你掌握了。
从下一章开始,我们再详细介绍SPSS各个模块的精确用法。
我们教学时是以SPSS 10.0版为蓝本讲述的--什么?你还在用7.0版!那好,由于10.0版在数据管理的界面操作上和以前版本有较大区别,本章我们将特别照顾一下老版本,在数据管理界面操作上将按9.0及以前版本的情况讲述,但具体的统计分析功能则按10.0版本讲述。
没关系,基本操作是完全一样的。
好,说了这么多废话,等急了吧,就让我们开始吧!希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。
例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)?患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87让我们把要做的事情理理顺:首先要做的肯定是打开计算机(废话),然后进入瘟98或瘟2000(还是废话,以下省去废话2万字),在进入SPSS后,具体工作流程如下:1.将数据输入SPSS,并存盘以防断电。
SPSS基础教程讲解

SPSS基础教程讲解SPSS基础⽬录第⼀章SPSS简介1.1 SPSS概述1.2 SPSS窗⼝1、数据编辑窗⼝(data editor)2、输出窗⼝(Viewer)3.程序编辑窗⼝1.3SPSS系统参数的设置1.3.1 Options选择对话框1.3.2通⽤参数设置1.3.3结果输出窗⼝参数设置1.3.4 Currency窗⼝参数设置第⼆章数据⽂件的编辑与管理2.1 建⽴与保存数据⽂件2.1.1定义新变量1变量名(Name):2.变量类型(Type)3变量长度(Width):4变量⼩数点占位(Decimal):5变量标签(Lable):6变量值标签(Values):7缺失值的定义⽅式(Missing):8变量的显⽰宽度(Columns):9变量显⽰的对齐⽅式(Align)10变量的度量⽅式(Measure):2.1.2数据的输⼊2.1.3数据的保存2.2读如其他格式的数据⽂件例2.2.1读⼊EXCEL数据⽂件student.xls,并保存为同名的SPSS数据集student.sav 2.3 File菜单中的其他条⽬2.4数据⽂件的编辑2.4.1单元值的查找2.4.2增加或删除⼀个观测2.4.3分析数据的排序2.4.4分析数据集的转置2.4.5选取数据的观测⼦集2.4.6分析数据归类分组汇总2.4.7缺失值的替代2.5数据变量的操作2.5.1增加或删除⼀个变量2.5.2从原有变量构造新变量2.5.3数据排秩2.5.4产⽣计数变量2.5.5数据重新编码2.5.6产⽣⾃动分组变量2.5.7变量集的定义和使⽤2.6 数据⽂件的合并与拆分2.6.1数据⽂件的纵向合并2.6.2数据⽂件的横向合并2.6.3数据⽂件的拆分第⼀章SPSS简介1.1 SPSS概述Statistical package for Social Science,社会科学统计软件包是⼀个组合式软件包,它集数据整理、分析过程、结果输出等功能于⼀⾝,是世界上著名的统计分析软件之⼀。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
11
统计数据的计量尺度 (Measure)
• 三类计量尺度
定距尺度(Scale):连续或离散型数据,大小比较 有意义,差有意义,差之比有意义 定序尺度(Ordinal):没有内在固有大小或高低顺 序,大小比较有意义 定类尺度(Nominal):没有内在固有大小或高低顺 序 定比尺度:等价,大小比较有意义,差有意义,差 之比有意义,值之比也有意义
2
2014-8-4
2.1
SPSS数据文件
• SPSS数据文件的特点
• SPSS数据文件的组织方式
– 原始数据的组织方式
• 列:变量,行:个案 • 例:住房状况调查.sav
– 数据文件包括:数据结构和数据内容 – 分别在变量视图和数据视图中编辑 – 扩展名为:.sav
– 计数(分组)数据的组织方式
• 列:变量,行:一个分组 • 例:教工分组数据.sav变量值标签的作用与变量名标签相同 • 可利用菜单命令: View\Value Labels 显示(或关闭)变量值标签
2014-8-4
第二章 SPSS数据文件的建立和管理
10
缺失值(Missing)
• 用户缺失值 • 系统缺失值
2014-8-4
第二章 SPSS数据文件的建立和管理
• 变量名应与其代表的数据的含义相对应 • 如使用缩写形式的变量名,应定义标签
2014-8-4
第二章 SPSS数据文件的建立和管理
7
变量名标签(Label)
• 变量标签用于帮助对变量含义的理解 • 变量标签使输出分析结果更具可读性
2014-8-4
第二章 SPSS数据文件的建立和管理
8
SPSS的数据类型(Type)
2014-8-4
第二章 SPSS数据文件的建立和管理
12
2.3 SPSS数据的录入 与编辑
• SPSS数据的录入 • SPSS数据的编辑
– 数据的定位
• 按个案号码自动定位 • 按变量值自动定位
– 插入和删除一条个案 – 插入和删除一个变量 – 数据的移动、复制和删除
2014-8-4
第二章 SPSS数据文件的建立和管理
• 数值型
– – – – – 标准型(Numeric) 科学记数型(Scientific Notation) 逗号型(Comma) 圆点型(Dot) 美元符号型(Dollar)
• 字符型(String) • 日期型(Date)
2014-8-4
第二章 SPSS数据文件的建立和管理
9
变量值标签(Values)
14
2.4
– – – –
SPSS数据的保存
• SPSS支持的数据格式
SPSS格式 Excel格式 dbf格式 文本格式
• 保存SPSS数据的基本操作
2014-8-4
第二章 SPSS数据文件的建立和管理
15
2.5 读取其他格式 的数据文件
• 直接读取其他格式的数据文件 • 使用文本向导读取文本文件 • 使用数据库向导读入数据库文件
2014-8-4
第二章 SPSS数据文件的建立和管理
16
2.6 SPSS数据文件的合并
• 纵向合并(Data\Merge File\Add Cases)
– 打开一个文件(工作文件) – 执行命令并选择另一文件(合并文件) – 选定新文件的变量
• Variables in New Working Data File显示已配对的变量 或选入的非配对变量 • Unpaired Variables显示两个文件中非配对变量,可单独 选入,也可配对选入 • 可定义个案来源变量(Indicate case source as variable)
2014-8-4
第二章 SPSS数据文件的建立和管理
3
2.2 SPSS的数据结构 和定义方法
• • • • • 变量名(Name) 数据类型(Type) 列宽(Width) 小数位(Decimals) 变量名标签(Label) • 变量值标签 (Values) • 显示列数(Columns) • 对齐方式(Align) • 缺失值(Missing) • 计量尺度(Measure)
• 包含两个文件的所有个案 • 只包含当前工作文件的个案 • 只包含合并文件中的个案
– 点击OK执行横向合并
2014-8-4
第二章 SPSS数据文件的建立和管理
18
第2章练习
• P55 练习题 • 1. 2. 4. 5. 6.
2014-8-4
第二章 SPSS数据文件的建立和管理
19
2014-8-4
第二章 SPSS数据文件的建立和管理
5
数据类型
小数位
变量值 标签
显式列数
变量名
列宽
变量名 标签
缺失值
对齐方式 计量尺度
2014-8-4
第二章 SPSS数据文件的建立和管理
6
SPSS数据的变量名 (Name)
• 变量名是变量访问和分析的唯一标志 • 变量名定义规则:
– 以英文字母开头,不超过8个字符 – 不能使用!、?、*及保留字
统计分析与SPSS的应用
第2章 SPSS数据文件 的建立和管理
主要内容
• • • • • • 2.1 2.2 2.3 2.4 2.5 2.6 SPSS数据文件 SPSS数据的结构和定义方法 SPSS数据的录入与编辑 SPSS数据的保存 读取其他格式的数据文件 SPSS数据文件的合并
第二章 SPSS数据文件的建立和管理
– 点击OK执行合并
2014-8-4
第二章 SPSS数据文件的建立和管理
17
2.6
– – – –
SPSS数据文件的合并
• 横向合并(Data\Merge File\Add Variables)
打开一个文件(工作文件) 执行命令并选择另一文件(合并文件) 选择变量 选择关键变量:从Excluded Variables选择一个 变量到Key Variables中(两文件需要事先按关键变 量排序) – 指定合并方式