SPSS数据库建立操作过程指南
第01节如何建立SPSS数据文件

第01节如何建立SPSS数据文件SPSS(Statistical Package for the Social Sciences)是一种专业的统计分析软件,被广泛应用于社会科学、市场调研以及其他领域的数据分析中。
建立SPSS数据文件是使用SPSS进行数据分析的第一步,本文将介绍如何建立SPSS数据文件的步骤。
1. 确定数据变量在建立SPSS数据文件之前,首先需要确定好需要收集和记录的各个数据变量。
数据变量包括各种观测指标或测量项目,可以是数值型、顺序型或名义型的变量。
2. 打开SPSS软件双击打开SPSS软件,进入SPSS统计分析界面。
3. 创建新数据文件在SPSS界面的主菜单栏选择"File" -> "New" -> "Data",或者直接点击工具栏上的新建数据文件图标。
弹出新建数据文件对话框。
4. 设定数据文件属性在新建数据文件对话框中,可以设置数据文件的属性,包括数据文件名、存储位置、数据文件类型等。
根据需要填写相应信息,并确定保存位置和数据文件类型。
5. 定义数据变量在数据视图窗口中,可以依次定义各个数据变量。
点击数据视图窗口中的第一个空白格,输入第一个数据变量的名称,并按下"Tab"键移动到下一个格子中。
在下一个格子中选择适当的数据类型(如数值型、字符型等)并输入数据,然后按下"Tab"键继续定义下一个数据变量。
依此类推,逐个定义好所有的数据变量。
6. 设定数据值标签在数据视图窗口中,还可以对特定的数据变量设定数据值标签。
选中某个数据变量所在的格子,点击菜单栏中的"Variable View",在弹出的对话框中输入该变量的数据值标签。
7. 保存数据文件在完成所有数据变量的定义后,点击菜单栏中的"File" -> "Save",选择保存数据文件。
【SPSS】二、数据库的建立及数据的导入

File菜单小结: 需要掌握的功能
12
还帮我们发现错误。 5. 记录的快速定位:go to cases 6. 快速改变变量排列次序:选中相应的变量名,拖动
5
2. 数据录入及编辑技巧(续)
7. 变量标签的快速查看:将鼠标置于列标头上,可显示变量 标签。
8. 变量属性的快速查看:将鼠标置于列标头上,双击变量, 可查看变量属性。
9. 变量信息的批量查阅:
9
1. 导入Excel数据
• 例1: 导入 血磷1.xls 和 血磷2.xls • 例2: 导入 核电操纵员心理和神经测评数据.xls • 练习:导入exp362文件。
10
2. 导入文本格式数据
• 例1 SDS .txt中是五名病人SDS得分数据,使用文本导入向导导入该 文件。
• 例2 使用文本导入向导导入xuelin. txt文件。 • 练习:使用文本导入向导导入exp356.txt文件。
略。
4
2. 数据录入及编辑技巧
1. 变量排列:变量排列顺序与问卷一致,按行输入 2. 快速定义成批变量:复制、粘贴变量,再使用label和
values定义标签,可以成倍提高工作速度。 3. 快速查找异常值、极端值:Sort descending, sort
ascending 4. 充分利用变量值标签:view:value labels,不仅好看,
Utilities
Variables
File
Display Data File Information
6
3. 数据的保存
File
Save
File
Save as
7
二、数据的导入
8
SPSS可以导入的数据类型
spss数据文件的建立与操作

在Variable View中,定义变量的属性。
SPSS中的变量有十个属性:
变量名(Name)
变量类型(Type)
变量宽度(Width) 小数点的位数(Decimals)
变量名标签(Label) 变量值标签(Values)
1.1 数据文件的特点 1.2 定义变量 1.3 录入数据 1.4 外部数据的导入
1.1 数据文件的特点
SPSS数据文件是一种有结构的数据文件,它由数据 结构和数据内容两部分组成,其中结构部分用于定 义数据类型、宽度、缺失值等,而内容才是我们具 体要分析的数据。
SPSS数据文件的扩展名是.sav
通过一个例子理解数据文件的横向合并。
【例】将数据transform3.sav中的变量添加到 transform.sav中。
在菜单栏中选择Data | Merge Files | Add Variables命令
关于合并后的数据文件中的数据 按 哪 种 方 式 提 供 , SPSS有 三 个 选 项可供选择: 1.Both files provide cases: 是 SPSS默 认 的 方 式 , 指 合 并 后 的 数据由原来的两个数据文件共同 提供,即由原来两个数据文件中 的记录共同组成合并后的数据文 件。
在SPSS中,能使用定类尺度的数据可以是数值型,也可以是字符型变 量。必须符合穷尽和互斥的原则。穷尽的原则就是指每个个体都必须 能归为一个类别,互斥的原则是指每个个体都只能归为一个类别。
相应变量为定类变量或(无序)分类变量。
Ordinal
定序尺度是对事物之间等级或顺序差别的一种测度。 定序尺度的特点是可以测度类别差,还可以测度次序差
spss操作一 数据库建立与数据整理

• 1. 建立数据库 • 2. 数据文件的编辑于转换
– 数据编辑
• 数据排序 • 选择个案子集 • 数据分类汇总
– 变量编辑
• 根据已有变量建立新变量 • 产生分组变量
建立数据库
• 建立SPSS数据文件
– 定义变量
• 变量名、类型、长度、小数点位数、标签、值标签、宽度、测 量尺度
– 数据的输入与保存
操作练习1——定义变量与数据输入 建立“身高体重”数据库 变量:学号、性别、身高、体重 记录:全班同学
数据保存
数据保存
数据的编辑与转化——排序
• 操作要求:请按照体重排序
数据的编辑与转化——排序
• 操作要求:请按照体重排序
数据的编辑与转化——排序
• 操作要求:请按照体重排序
数据的编辑与转化——选择个案子集
• 操作要求:选择男生个案
数据的编辑与转化——选择个案子集
• 操作要求:选择男生个案
数据的编辑与转化——选择个案子集
• 操作要求:选择男生个案
数据的编辑与转化——选择个案子集
• 操作要求:选择男生个案
数据的编辑与转化——数据分类汇总
• 操作要求:对男女生的身高提体重进行分类汇总
产生分组变量
产生分组变量
产生分组变量
产生分组变量
数据合并1
数据合并1
数据合并1
数据合并1数据合并2来自 数据合并2数据合并2
数据合并2
练习
• 成绩数据库
– 对男女生的各个成绩进行分类汇总 – 将各个成绩分为59分一下,60-69分,70-79分, 80-89分,90-100分,共五段
数据的编辑与转化——数据分类汇总
SPSS基础、数据集的建立(69页)

生成新的变量
可视离散化 给观测排秩
数据:某时某地区学龄儿童体检表
1.发现重复数据
例如:请问数据中有无重复数据
数据表内重复12例,占11.3%
2.选择数据---按条件选择
例如:选择1年级学生数据进行分析
ØDATA Select Cases
设定条件:选择 年级为1者
2.选择数据---按条件选择
(3)数据录入
(4)数据保存
SPSS的数据 格式(*.sav) 可存为.xls
1.2 读入外部数据文件
表1 常用SPSS可以直接打开的数据类型
数据标识
数据类型
SPSS Statistics(*.sav) SPSS各版本的数据文件
Excel(*.xls, *.xlsx, *.xlsm)
Excel各版本的数据文 件
加分析例数; 2.两个数据文件的变量不同,但却有相同的例
数,合并的目的是增加变量。
7.数据合并
例如:把数据集“data2a”和“data2b”合并为一个数据集 (增加数据例数的合并)
7.数据合并
增加数据例数的合并
两个数据表不 一致的变量
合并后的数据 集中的变量
7.数据合并
增加数据例数的合并
数据合并
没有被选择的 数据不进入后 面的统计分析
3. 对观测进行排序
例如:对“data1-2.sav”数据按照“身高”进行排序
3. 对观测进行排序
按“身高” 排序后
4. 查找数据
举例:请查找数据中第10条观测。
(1)直接切换到某例
举例:请查找数据中姓名为“刘冰”者的数据。
(2)查找变量的数据值
4. 查找数据
数统 据计 转分 换析
spss数据库的建立

第四章 数据库建立
16/18
☆ 量化研究與統計分析…….
排序题处理
• 点选分析→复选题分析→定义集合
第四节
第四章 数据库建立
17/18
☆ 量化研究與統計分析…….
Time for rest
Chapter 4 is done here.. See you later!
第四章 数据库建立
18/18
第四章 数据库建立
2/18
☆ 量化研究與統計分析…….
SPSS资料建档程序
• 资料编辑视窗
– 直接进入变量检视工作表,以便进行变项定义
輸入變 項名稱
選擇變 數類型
設定 格式
輸入 註解
設定遺 漏值
顯示變項測 量格式類型
第一节
第四章 数据库建立
3/18
☆ 量化研究與統計分析…….
资料设定步骤
(一)输入变项名称 (二)选择适当变量型态 (三)输入注解 (四)输入数值注解 (五)设定遗漏值 (六)选定格式 (七)设定测量尺度
變項名稱與標籤
變項格式與遺漏值
變項數值與標籤
第一节
第四章 数据库建立
9/18
☆ 量化研究與統計分析…….
其他档案的转入
• EXCEL档案读入
EXCEL视窗 SPSS视窗
第二节
第四章 数据库建立
10/18
☆ 量化研究與統計分析…….
由文字档(ASCII档案,.dat)读入
文字汇入精灵
第二节
第四章 数据库建立
第三节
第四章 数据库建立
12/18
☆ 量化研究與統計分析…….
复选题分析 (multiple response analysis)
spss中录入数据的基本步骤有

SPSS中录入数据的基本步骤有SPSS(Statistical Product and Service Solutions)是一种数据分析软件,常用于统计学和社会科学研究中的数据分析。
在使用SPSS进行数据分析之前,需要首先将数据录入到SPSS中。
本文将详细介绍SPSS中录入数据的基本步骤,以帮助读者快速掌握数据录入的技巧。
步骤一:创建数据集在使用SPSS录入数据之前,首先需要创建一个新的数据集。
可以通过打开SPSS软件并选择“File”菜单中的“New”选项来创建新的数据集。
在打开的对话框中,可以选择数据集的名称和存储位置等信息,并选择数据类型。
SPSS支持多种数据类型,包括数字、字符串、日期等。
根据需要选择相应的数据类型,并点击“OK”按钮,即可创建一个新的数据集。
步骤二:定义变量在录入数据之前,需要定义各个变量的名称和属性。
变量是用来存储数据的容器,可以理解为数据集中的列。
在SPSS中,可以选择“Variable View”选项卡,进入变量定义界面。
在该界面中,可以添加新的变量,并为每个变量指定名称、标签、数据类型、缺失值等属性。
在定义变量时,需要根据数据的实际情况选择合适的数据类型,并设置相应的属性,以确保数据的准确性和一致性。
步骤三:录入数据定义完变量之后,就可以开始录入数据了。
在SPSS的数据编辑界面中,可以选择“Data View”选项卡,进入数据录入模式。
在该模式下,可以逐行录入数据。
对于每个变量,需要在相应的单元格中输入数据。
可以使用键盘输入数据,按“Tab”键或方向键可以快速切换到下一个单元格。
在录入数据时,可以使用各种符号和字符进行数据转换和标记,以便后续的数据分析和处理。
步骤四:检查数据在完成数据录入之后,需要仔细检查数据的准确性和完整性。
可以通过查看数据集的统计信息、频数分布和描述性统计等方式来检查数据。
SPSS提供了丰富的数据分析工具,可以帮助用户对数据进行质量控制和错误检测。
第二讲 SPSS之数据输入与建立

3.1 定义变量名(续)
变量命名必须惟一,不能有两个相同的变量 名。 在SPSS中不区分大小写。例如,HXH、hxh或 Hxh对SPSS而言,均为同一变量名称。图2-3 定义变量类型对话框 SPSS的保留字(Reserved Keywords)不能 作为变量的名称,如ALL、AND、WITH、OR等。
图2-1 变量定义视图窗口
3.1 定义变量名
SPSS默认的变量为Var00001、Var00002等,用户也 可以根据自己的需要来命名变量。SPSS变量的命名 和一般的编程语言一样,有一定的命名规则,具体 内容如下。 变量名必须以字母、汉字或字符@开头,其他字符 可以是任何字母、数字或_、@、#、$等符号。 变量最后一个字符不能是句号。 变量名总长度不能超过64个字符(即32个汉字)。 不能使用空白字符或其他特殊字符(如“!”、 “?”等)。
3.2 定义变量类型
点击类型,弹出下图所示的对话框,在对话 框中选择合适的变量类型并单击“OK”按钮, 即可。一般对于填写数字的变量默认数值型, 且默认宽度为8,小数为2;对于填写文字的 变量选择字符串。
3.3 定义变量标签
标签:表示该变量所表示的实际含义。 在标签栏中,输入相应含义即可,应与调查 问卷中的问题保持一致。
练习
根据自己收集的调研问卷,建立数据库模板 并输入数据。
第三节:变量定义
1.在spss数据录入前,要建立统一的录入模 板,也就是变量集合,首先要将问卷包含的 变量全部录入到spss数据库中。 2.定义变量即要定义变量名,变量类型,变 量宽度和小数位数,变量标签,值(即编码 过程),缺失值定义,显示宽度,对齐方式, 度量标准和角色。 3.操作:打开空白数据库→点击“变量视 图”→变量定义窗口
统计学SPSS软件简介和操作指南课件

age
年龄(岁)
实测值
pathsi 病理肿瘤大小(cm) 实测值,99表示缺失值 ze
lnpos 阳性腋下淋巴结(个数)
实测值
histgr ad
组织学分级
分1,2,3级,4缺失值
pr
孕酮受体状况
0阴性;1阳性;2缺失值
time
生存时间(月)
实测值
(一)数据编码
▪ 1. 定义变量名(variable) 原则如下: (1)变量名的长度不能多于8个字符
加选 显 权择 示
病标 例签
数据编辑窗的菜单栏和快捷图标栏(病例,即观察单位,case)
பைடு நூலகம் 数据的整理
▪ 在菜单命令 Data实现 1. 排序(Sort Cases)
练习:将例中的数据按生存时间time从 小到大排序,观察到什么?
2. 选择观察单位(Select Cases) 练习:将例中阳性腋下淋巴结个数lnpos 为0,(无腋下淋巴结转移)同时孕酮受 体er为1(阳性)的观察单位选择出来。 观察到什么?
1、鼠标形状与操作说明
➢光标形状
箭头形用于选项。 沙漏斗表示电脑正在运算中。 I字形用于文书处理中光标的移动。 手指形用于选择名词解释。
➢单击:常用光标的定位或选项。 ➢双击:常用运行某种过程。 ➢拖曳:表示标识了某一范围。
2、SPSS启动
(1)在桌面双击.SPSS13.0图标 (2)从菜单选择:开始程序 ▪ SPSS for Windows ▪ SPSS13.0 for Windows ( 3 ) 在 资 源 管 理 器 中 双 击 SPSSWIN.exe
数据的转换
▪ 在菜单命令 Transform实现
1.生成新变量
SPSS知识1:数据文件的建立

知识1:数据文件的建立一、数据库的建立-数据录入:数据编码(Variable view)——定义数据项的变量名(变量名可为拼音、英文缩写、汉字;变量名不能使用SPSS的保留字,如and等;SPSS不区分大小写字母);定义数据项的变量标签(可以定义可以不定义);定义变量取值的变量值标签(离散变量才需要:分类和等级资料;如男为1,女为0;)。
定义变量(Variable view)——变量名所在行需要对变量进行定义,如type列的变量类型为数值型(选numeric);如measure列的资料类型(scale,定量变量;ordinal,分类变量;nominal,等级变量)。
数据输入(data view)——纵向录入(回车),横向录入(tab);上下、左右;任意输入。
二、数据文件的读入:读入途径:file→open→data(look in,files of type,file name三个途径查找文件)。
原始数据首次常用有2种:一种是SPSS直接输入,二是其他数据文件(如Excel)导入。
注:其他数据文件导入数据后需要对数据进行编辑,转化为SPSS能识别的语言。
(数据分析,文字只能识别不能分析)三、数据文件的存储:存储途径:File→save as(保留原始数据)/save(不保存原始数据)。
数据存储方式有2种:一是保存为SPSS数据文件(键入文件名,save 即可;格式为:文件名.sav),二是保存为其他格式的数据文件(键入文件名,save as type选择,save即可;格式:如文件名.xls)。
四、根据已存在的变量建立新变量1、对数据进行重新编码(recode)→资料等级化/数据分组(频度分布表和直方图前提)。
SPSS操作:transform→recode into different variables…↓2、使用SPSS函数建立新变量(略)注:毕业论文:问卷调查表——数据录入(很少的数据可以仅用SPSS 软件,多的数据专门学习使用epidata录入数据)。
SPSS操作实验手册

SPSS试验操作指导手册(2023版)2.SPSS数据整顿2.1 SPSS数据文献旳建立SPSS数据文献旳建立可以运用【File(文献)】菜单中旳命令来实现。
详细来说, SPSS提供了四种创立数据文献旳措施:●新建数据文献【File(文献)】→【New(新建)】→【Data(数据)】命令;●直接打开已经有数据文献【File(文献)】→【Open (打开)】→【Data(数据)】命令;●使用数据库查询;【File(文献)】→【Open Database(打开数据库)】→【New Query(新建查询)】命令, 弹出【Database Wizard(数据库向导)】对话框●从文本向导导入数据文献。
【File(文献)】→【Read Text Data(打开文本数据)】命令, 弹出【Open Data(打开数据)】对话框实例分析: 股票指数旳导入文献2-1.xls是上证指数从2023年1月4日至2023年10月16 日旳数据资料, 包括了开盘价、当日最高价、当日最低价和收盘价等选项, 请将该数据导入至SPSS中。
2.2 SPSS数据文献旳属性一种完整旳SPSS文献构造包括变量名称、变量类型、变量名标签、变量值标签等内容。
注意: SPSS数据文献中旳一列数据称为一种变量, 每个变量都应有一种变量名。
SPSS数据文献中旳一行数据称为一条个案或观测量(Case)2.2.1 实例分析: 员工满意度调查表旳数据属性设计1.实例内容为了提高员工旳工作积极性, 完善企业各方面管理制度, 并到达有旳放矢旳目旳, 某企业决定对我司员工进行不记名调查, 但愿理解员工对企业旳满意状况。
请根据该企业设计旳员工满意度调查题目(行政人事管理部分)旳特点, 设计该调查表数据在SPSS旳数据属性。
2.实例操作详细环节如下文献(2-2.sav.)Step01: 打开SPSS中旳Data View窗口, 录入或导入原始调查数据。
Step02:选择菜单栏中旳【File(文献)】→【Save (保留)】命令, 保留数据文献, 以免丢失。
第二章-建立与编辑SPSS数据文件

数
据
编
值标签的作用是对变量取值的含
辑
窗
义进行说明,这对间断变量特别重
口
要。在变量视图中单击【值】列的
建
立
单元格,旁边会出现 按钮,单
数
击该按钮,将打开【值标签】对话
据
文
框,如图2-4所示。
件
11
图2-4 【值标签】对话框
第 一、定义变量的规则 一 节
通 过
在【值】编辑框中输入数字,在【标签】编辑框中输入数字对应的文字说明,然后单
数
据
度量数据的数值间不仅能区分高低大小,还能明确数值间的差距大小。例如,
文 件
变量“身高”,身高为170 cm的个体与身高为160 cm的个体身高相差10 cm,
身高为160 cm的个体与身高为150 cm的个体身高也相差10 cm。
18
第 二、数据的录入 一 节
通
过
数
据
在变量视图中定义好变量
编 辑
立
数
首要的一步便是定义变量。
据
文
件
4
第 一、定义变量的规则 一 节
通
过
数
打开SPSS数据文件后,单
据 编
击数据编辑窗口左下角的
辑
【变量视图】按钮,可以切
窗 口
换到变量视图,来定义和显
建
示变量,如图2-1所示。
立
数
据
文
件
5
图2-1 数据编辑窗口中的变量视图
第 一、定义变量的规则 一 节
通
定义变量即指定变量的名称和其他各种属性。变量视图中包括名称、类型、宽度、小数、
据
(5)单击【值】列下方对应的单元格,并
SPSS数据库建立操作过程指南
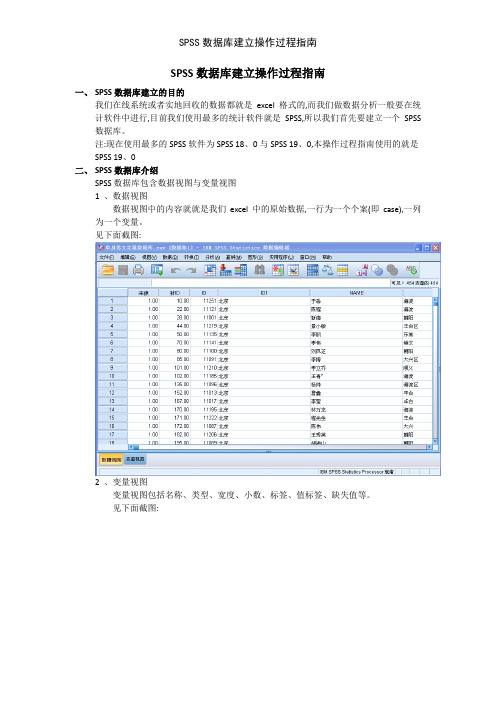
SPSS数据库建立操作过程指南一、SPSS数据库建立的目的我们在线系统或者实地回收的数据都就是excel格式的,而我们做数据分析一般要在统计软件中进行,目前我们使用最多的统计软件就是SPSS,所以我们首先要建立一个SPSS 数据库。
注:现在使用最多的SPSS软件为SPSS 18、0与SPSS 19、0,本操作过程指南使用的就是SPSS 19、0二、SPSS数据库介绍SPSS数据库包含数据视图与变量视图1 、数据视图数据视图中的内容就就是我们excel中的原始数据,一行为一个个案(即case),一列为一个变量。
见下面截图:2 、变量视图变量视图包括名称、类型、宽度、小数、标签、值标签、缺失值等。
见下面截图:1)名称即变量名,变量名必须以字母、汉字或字符@开头,其她字符可以就是任何字母、数字或_、@、#、$等符号;变量最后一个字符不能就是句号;不能使用空白字符或其她特殊字符(如“!”、“?”等)。
变量名一般用题号表示,变量名不能有重复的。
2)类型即变量类型,一般为数值型与字符型,选择性的题目最好设为数值型的,如果设为字符型的,空白的数据不默认缺失,而就是瞧做有答案的数据,在分析的时候也会出来空白的百分比,这样得到的每个选项的百分比会有偏差。
开放题以及半开放题的变量类型默认就是字符型的,不能改为数值型的,否则会使数据缺失。
3)宽度即数据的列宽。
4)标签为变量标签,一般用题目或选项表示,单选题一般用题目表示,多选题一般用选项表示。
5)值标签为单选题的每个选项代表的含义。
6)缺失值默认为无,我们可设1-3个离散数值为缺失值,也可设一个范围加一个离散值为缺失值。
设为缺失值的数值在分析的时候不会出现。
一个完整的SPSS数据库包括:变量名、数据、变量标签、值标签、多选集三、SPSS数据库建立的几大步骤(一)步骤列表1、多选题有其她请注明的先在它前面插入一列,并将有文字说明的case赋值为12、对照问卷改变量名,并附标签。
最新spss数据库的建立与编辑

• 如果表中全部是数据,则全选。 • 如果表中有文本,则与EXCEL相同
导入外部文件数据
• TXT 文件 • EXCEL文件
五、数据整理(data)
• 概念
– 数据整理是对原始数据中的变量或个体进行
• 增加 • 删除 • 排序 • 倒置(较少使用,不做介绍。) • 合并 • 加权
变量类型
• 数值型变量 • 字符型变量
变量名定义原则
• 唯一性 • 首字符不能是数字 • 变量名不能使用键盘上的#、¥、%等 • 变量名不能使用系统内部保留字,all 、
and 、by 、with 、not 、eq等 • 变量名不能以“.”结尾
四、数据录入、编辑
• 在完成变量定义后,单击左下方的data view标签,激活数据表。即可录入。
1、插入或删除(变量或个体)
插 Data 入
Data
Insert case Insert variable
删 单击行首或变量名,即可定义一行或一列,然 除 后即可删除一个体或一变量。
如果发现这是一种错误操作,可通过选择edit---undo 进行恢复。
2、个体排序(data --- sort case)
• If condition is satisfied:按给定条件选 择个体。
– If :是条件按钮,激活对话框。
• Random sample of cases:随机选择个 体
– Sample:随机样本按钮,激活对话框。
• Based on time or case range:在某范 围内选择人全部个体。
•数值‘0’表示源工作数据的个体,数值“1”表示 av的纵向合并
V1.sav
1第一讲 spss数据文件的建立和管理

• • • •
第四列为宽度 第五列为小数 第六列为标签,就是变量的中文名 第七列为值,就是变量的取值名
• 第八列为缺失值。就是填答问卷的人没有填答的问题, 或者填答错误的问题
4.3多选题的输入技巧
• 多选项二分法
– 就是把该变量拆分,因为每个选项只有两种可 能,要么被选中,要么不被选中,选中的为1, 未选中的为0,就是有多少个选项,就变成多 少个二分的变量。 – 如,你到城市打工的目的是什么?(可多选)
• 1、赚钱养家2、改变生活3、想开眼界4、纯粹跟风
– 那么我们就可以拆分为四个变量
• 1、北京大学2、清华大学3、中国人民大学4、北京理工大学5、北京 师范大学6、北京外国语大学
– 我们可以把志愿分为三类,每一类只有选一个学校,这时候,就 把多项选择题变成了单选题 – V901你的第一志愿是:
• 1、北京大学2、清华大学3、中国人民大学4、北京理工大学5、北京 师范大学6、北京外国语大学
• 纵向合并数据文件
– 同一个课题的问卷,分给多个人同时输入,然后把它合 并为一个整个数据。 – 点击菜单中的数据(data) 合并文件(merge file) 添加个案(add case)
• 横向合并数据文件
– 如果同一个课题的问卷,一部分人输问卷中的前十个变 量,一部分输中间十个变量,另一部分人输最后十个变 量,最后要把他们合并成一个数据库,就设计到纵向合 并数据文件。 – 点击菜单中的数据(data) 合并文件(merge file) 添加变量(add variables)
• • • • 你到城市打工是为了赚钱养家吗?1是 0 不是 你到城市打工是为了改变生活吗?1是 0 不是 你到城市打工是为了想开眼界吗?1是 0 不是 你到城市打工是为了纯粹跟风吗?1是 0 不是
第二章 SPSS数据文件的建立和管理

显示格式非常多 有效数值前带$以逗点 为分割符 12343 $12343
Custom Currency String
变量标签与变量值标签
变量标签(Variable Labels)
为为进一步描述变量所表示的意义,特别是当 变量名不能充分描述变量所表述的意义时。
变量值标签 (Value Labels)
三、数据的剪切、
二、插入与删除观 测量
1.插入观测量 单击行头,然后选择 菜单data-cases,或者 单击右键出现左侧对 话框, 单击Insert Case 2.删除观测量 单击行头,然后选择 菜单edit-clear,或者单 击右键出现左侧对话 框, 单击clear,或者直 接按del键。
复制
职工号 001 002
工资 1212 1001
职称 高级 初级
年龄 30 32
职工号 020 021
工资 1311 1120
职称 高级 高级
性别 男 女
职工号 001 002 020 021
工资 1212 1001 1311 1120
职称 高级 初级 高级 高级
年龄 30 32
性别
source 01 1 1
变量标签
no 编号 1 2 3 4 5
06/30/1987 2.80 12/15/1982 3.90 04/21/1993 3.00 11/07/1991 3.35 05/21/1993 2.56
欧阳德仪 初中 程德忠 不详
练习2:
将数据文件“纵向合并.sav”纵向合并到例题1数 据中,要求排除“母亲文化”变量,指定数据来 源变量,形成新的数据文件。
no
编号 6
name
educ
birth
数据创建与数据预处理SPSS Statistics

数据创建与数据预处理SPSS Statistics数据创建和数据预处理是进行数据分析的重要步骤。
在SPSS Statistics中,有许多功能和工具可以帮助我们进行数据创建和数据预处理,使数据具备可靠性和可用性。
本文将详细介绍如何使用SPSS Statistics进行数据创建和数据预处理。
一、数据创建数据创建是指根据研究目的和需求,将原始数据转化为可用于统计分析的数据形式。
在SPSS Statistics中,我们可以通过以下几种方式进行数据创建:1. 手动输入数据:如果数据量较小,我们可以直接在SPSS Statistics中手动输入数据。
打开SPSS Statistics软件后,选择"数据"菜单下的"输入数据"选项,然后根据数据的变量类型和取值范围逐个输入数据。
2. 导入外部数据:如果数据量较大或已经存在于其他文件中,我们可以将数据导入SPSS Statistics进行数据创建。
SPSS Statistics支持导入多种格式的数据文件,如Excel、CSV等。
选择"文件"菜单下的"打开"选项,然后选择相应的数据文件进行导入。
3. 数据变换:在数据创建过程中,我们还可以进行数据变换,如计算新的变量、合并数据集等。
SPSS Statistics提供了丰富的数据变换功能,如计算变量、合并文件、排序等。
选择"转换"菜单下的相应选项,然后按照提示进行操作。
二、数据预处理数据预处理是指在进行数据分析之前,对原始数据进行清洗和整理,以提高数据的质量和可靠性。
在SPSS Statistics中,我们可以使用以下方法进行数据预处理:1. 缺失值处理:在实际数据收集过程中,可能会存在一些缺失值。
SPSS Statistics提供了多种处理缺失值的方法,如删除含有缺失值的样本、替换缺失值为均值或中位数等。
选择"转换"菜单下的"缺失值处理"选项,然后选择相应的方法进行处理。
SPSS数据库建立操作过程指南

SPSS数据库建立操作过程指南D1)名称即变量名,变量名必须以字母、汉字或字符@开头,其他字符可以是任何字母、数字或_、@、#、$等符号;变量最后一个字符不能是句号;不能使用空白字符或其他特殊字符(如“!”、“?”等)。
变量名一般用题号表示,变量名不能有重复的。
2)类型即变量类型,一般为数值型和字符型,选择性的题目最好设为数值型的,如果设为字符型的,空白的数据不默认缺失,而是看做有答案的数据,在分析的时候也会出来空白的百分比,这样得到的每个选项的百分比会有偏差。
开放题以及半开放题的变量类型默认是字符型的,不能改为数值型的,否则会使数据缺失。
3)宽度即数据的列宽。
4)标签为变量标签,一般用题目或选项表示,单选题一般用题目表示,多选题一般用选项表示。
5)值标签为单选题的每个选项代表的含义。
6)缺失值默认为无,我们可设1-3个离散数值为缺失值,也可设一个范围加一个离散值为缺失值。
设为缺失值的数值在分析的时候不会出现。
一个完整的SPSS数据库包括:变量名、数据、变量标签、值标签、多选集一、S PSS数据库建立的几大步骤(一)步骤列表1、多选题有其他请注明的先在它前面插入一列,并将有文字说明的case赋值为12、对照问卷改变量名,并附标签。
(在excel中进行)3、将改过变量名的excel合格数据导入spss,导之前要把变量名下面的一行(即标签)删除。
注意保存spss数据库。
4、将之前赋好的标签贴到spss数据库中,然后观察一下数值型变量类型是否正确,不正确的改正。
5、用spss语句为单选题赋值标签,多选题定义多选集(一般都是二分法)。
(二)具体步骤2、对照问卷改变量名,并附标签。
改变量名的目的:一是,便于分析,二是,别人使用该数据库时也能明白每个变量的含义。
方法:将原始数据的第一行和第二行(即原始变量名和标签)转置粘贴到一个新的excel sheet表格中,在原变量名和标签中间插入两列,对照原始标签和问卷改变量名并赋标签,对于不同的题目类型,变量名和标签有所不同。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS数据库建立操作过程指南
一、SPSS数据库建立的目的
我们在线系统或者实地回收的数据都是excel格式的,而我们做数据分析一般要在统计软件中进行,目前我们使用最多的统计软件是SPSS,所以我们首先要建立一个SPSS数据库。
注:现在使用最多的SPSS软件为SPSS 18.0和SPSS 19.0,本操作过程指南使用的是SPSS 19.0
二、SPSS数据库介绍
SPSS数据库包含数据视图和变量视图
1 、数据视图
数据视图中的内容就是我们excel中的原始数据,一行为一个个案(即case),一列为一个变量。
见下面截图:
2 、变量视图
变量视图包括名称、类型、宽度、小数、标签、值标签、缺失值等。
见下面截图:
1)名称即变量名,变量名必须以字母、汉字或字符@开头,其他字符可以是任何字母、数字或_、@、#、$等符号;变量最后一个字符不能是句号;不能
使用空白字符或其他特殊字符(如“!”、“?”等)。
变量名一般用题号表示,变量名不能有重复的。
2)类型即变量类型,一般为数值型和字符型,选择性的题目最好设为数值型的,如果设为字符型的,空白的数据不默认缺失,而是看做有答案的数据,在
分析的时候也会出来空白的百分比,这样得到的每个选项的百分比会有偏
差。
开放题以及半开放题的变量类型默认是字符型的,不能改为数值型
的,否则会使数据缺失。
3)宽度即数据的列宽。
4)标签为变量标签,一般用题目或选项表示,单选题一般用题目表示,多选题一般用选项表示。
5)值标签为单选题的每个选项代表的含义。
6)缺失值默认为无,我们可设1-3个离散数值为缺失值,也可设一个范围加一个离散值为缺失值。
设为缺失值的数值在分析的时候不会出现。
一个完整的SPSS数据库包括:
变量名、数据、变量标签、值标签、多选集
三、SPSS数据库建立的几大步骤
(一)步骤列表
1、多选题有其他请注明的先在它前面插入一列,并将有文字说明的case赋值为1
2、对照问卷改变量名,并附标签。
(在excel中进行)
3、将改过变量名的excel合格数据导入spss,导之前要把变量名下面的一行(即标签)删除。
注意保存spss数据库。
4、将之前赋好的标签贴到spss数据库中,然后观察一下数值型变量类型是否正确,不正确的改正。
5、用spss语句为单选题赋值标签,多选题定义多选集(一般都是二分法)。
(二)具体步骤
2、对照问卷改变量名,并附标签。
改变量名的目的:一是,便于分析,二是,别人使用该数据库时也能明白每个变量的含义。
方法:将原始数据的第一行和第二行(即原始变量名和标签)转置粘贴到一个新的excel sheet表格中,在原变量名和标签中间插入两列,对照原始标签和问卷改变量名并赋标签,对于不同的题目类型,变量名和标签有所不同。
2.1 对于单选题:
变量名一般用题号表示,标签一般用题目(即原始标签)表示。
例:一个单选题的题目为:S2、您的年龄是?(单选)
那么它的变量名即为S2,标签为S2、您的年龄是?(单选)
变量名可以用原始标签按符号“、”分列得到,不需手动的输入或复制粘贴。
2.2 对于多选题
一个选项是一个变量,它的变量名一般用题号+下划线+选项序号表示,标签用选项内容表示。
例:一个多选题的题目为:
S4、请问在近一个月内,您在超市购买过以下哪些类别的食品?(可多选)
选项内容为
1、糖果类(如硬糖、口香糖、奶糖等)
2、乳制品类(液态牛奶、奶粉、奶酪等)
3、烘焙面点类(小面包、蛋糕、铜锣烧等)
4、方便食品类(方便面、速冻食品、罐头等)
5、调味品类(盐、味精、酱油等)
6、饮料类(碳酸饮料、果汁、绿茶等)
第一个选项“糖果类(如硬糖、口香糖、奶糖等)”它的原始变量名为:N901
糖果类(如硬糖、口香糖、奶糖等),改过之后的变量名为S4_1,标签为糖果
类(如硬糖、口香糖、奶糖等),这个标签可用mid公式由原始变量名提取得到,
即:MID(B4,5,LEN(B4)-4) ,B4为原始变量名所在的单元格,5为提取的起始
位置,LEN(B4)-4为提取的长度,由于选项内容的长度不固定,而选项前面的
长度是固定的,所以我们用这个字符窜的长度减去前面的长度表示需要提取的
长度。
2.3对于矩阵单选、矩阵多选
矩阵单选、矩阵多选相当于多个单选题和多个多选题,我们可以在题号后面加一个字母区分开,具体见excel“变量对应”sheet表。
5、用spss语句为单选题赋值标签,多选题定义多选集(一般都是二分法)。
5.1为单选题赋值标签
单选题赋值标签有两种方法:
1)我们可以手动的输入选项为每个单选题赋值标签,在值处输入选项序号,标签处输入选项内容,然后点击添加,输入完所有选项后点击确定即可。
见下面截图:
但是这种方法不适合多个选项,对于多个选项的单选题,我们可以用语法:
2)在spss数据库中点击文件—新建---语法,然后在语法中输入value labels以及变量名,然后将选项的值和内容复制到语法中,注意值在前面,内容在后面,可以先复制到excel中,调整好后再复制到语法中,例如:
value labels S1
1 河南
2 山东
3 安徽
4 浙江
5 其他.
S1为变量名,1 河南等为选项的值及内容
注意:语法中不能有“/”,可将“/”替换为“\”。
5.2 多选题定义多选集
1)在spss中点击分析—表---多响应集
2)打开定义多重响应集窗口,将一个题的所有选项变量拖到集合中的变量框中(注多选题有其他请注明的只需将“其他”变量拖进变量框中,“其他请注明”的变量不用拖进去。
3)选择变量编码:如果数据为0、1两种值,则选择二分法,计数值为1,如果数据为1、2、3、4...(选项的值)则选择类别。
一般的多选题都为二分法,开放题编码后的变量为类别。
4)输入集名称和集标签,这个类似单选题的变量名和标签,即集名称为多选题的题号,集标签为多选题的题目内容。
5)点击添加
6)定义下一个多选集的时候,可以点击刚定义过的多选集,将它的变量拖出去,重新选择新的变量,并改集名称和集标签,这样做的目的是方便找到变量而且变量编码不须重新选择(如果数据类型相同)
7)定义完所有多选集后点击确定即可,点击粘贴即可将语法保存下来。
见下面截图:。