第15章 文字标签库与多国语言使用
文字标签库与多国语言使用
第十五章文字标签库与多国语言使用文字标签库一般使用在需要多国语言的环境中,使用者可以依照实际需要预先建立文字标签库的内容。
在需要使用文字的场合,只需由文字标签库中挑选需要的标签即可,系统在运作时也会依照设定,显示当时使用语言相对应的文字。
EB8000同时支持8种不同语言的文字显示。
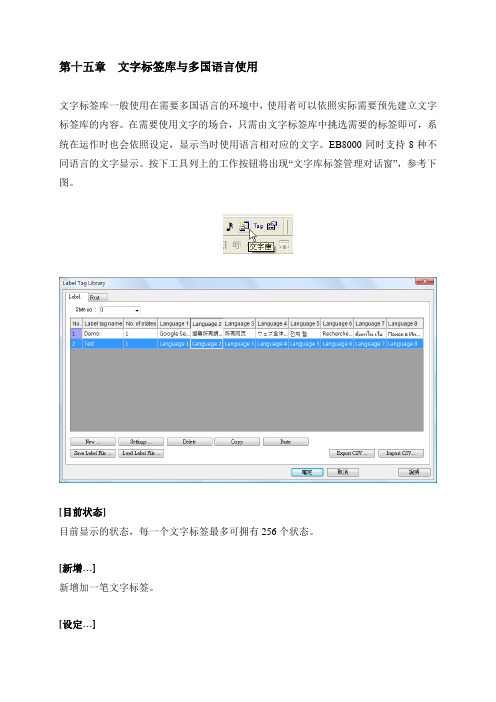
按下工具列上的工作按钮将出现“文字库标签管理对话窗”,参考下图。
[目前状态]目前显示的状态,每一个文字标签最多可拥有256个状态。
[新增…]新增加一笔文字标签。
[设定…]更改文字标签的内容。
[删除]删除特定的文件标签。
[输出]使用CSV格式将此文字标签库的所有内容输出到特定位置。
此功能不支持Unicode。
[汇入]将已存在的且为CSV格式的文字标签库加到目前的画面规划档(MTP)。
此功能不支持Unicode。
在“文字标签库管理对话窗”中可以看出目前已经存在两个标签“Demo”与“Test”,其中“Demo”所包含的8种语文分别为:英文、繁体中文、简体中文、日文、韩文、法文、泰文、俄文等。
文字标签库的字型选择不同语言可选择不同的字型,参考下图。
[字体][字体]设定页用来设定在使用多国文字时,各种语文所使用的字型。
[备注]每种字型的注释。
文字标签库的建立下面说明如何建立这些项目。
首先,打开“文字标签库管理对话窗”后按下[新增…],即可出现下图的对话窗,正确设定后按下确认键。
[标签名]文字标签的名称,此范例将标签命名为“Pump Alarm”。
[状态数]文字标签所拥有的状态。
完成此步骤后可以发现已存在一个新的标签“Pump Alarm”,并拥有两个状态,参考下图。
最后,选择“Pump Alarm”并按下[设定…],即可使用下图的对话窗设定相关语言的内容。
文字标签库的使用当文字标签库存在已定义完成的标签,在组件的[标签]设定页中可以勾选[使用文字标签库],并且在[标签]的项目中可以发现目前这些标签。
选择这些标签后可以发现[内容]中所显示为文字标签的内容,并且所使用的字型也为文字标签库的内容。
标记语言

第四篇标记语言从用于文档和图书管理的鼻祖SGML,到描述网页的万维网基石HTML,再到集万千宠爱于一身的数据描述和交换标准XML,标记语言在当今的信息社会中起着举足轻重的作用。
标记语言的蓬勃发展,得益于超文本标记语言HTML的意外成功;而标记语言的无限未来,则有赖于可扩展标记语言XML的广泛应用。
本来只能显示文本信息的超文本标记语言HTML,由于图形与多媒体界面浏览器的引进和脚本语言的出现,发展成为可以包含各种多媒体信息的动态超媒体标记语言DHTML(这大大推动了万维网和因特网的普及与应用)。
现在网页变成了典型的多媒体数据的集成工具,万维网因此成为了多媒体技术的最主要应用之一。
可扩展标记语言XML的发布,使标记语言从一种主要是描述网页的简单工具,发展到可以描述各类数据、并能够进行各种数据交换的万能工具,从而成为了信息表示、存储、处理和交换的核心技术。
本篇首先给出超文本和超媒体的基本概念,然后讨论标记语言的功能与演化,重点介绍HTML、JavaScript和XML的基本内容。
通过对这些知识的学习,可以为网页编辑与自动生成、Web服务器编程和XML应用打下良好的基础。
本篇包含如下4章:●第15章超文本与标记语言●第16章HTML●第17章JavaScript●第18章XML入门第15章超文本与标记语言超文本(hypertext)又叫超媒体(hypermedia)是将各种信息节点链接在一起的一种网状逻辑结构。
标记语言(ML = Markup Language)又叫置标语言,是一套标识文档的内容、结构和格式的语法规则,源于出版印刷部门对文档格式的排版标注。
随着万维网(WWW = World Wide Web,又叫环球网,常简称为Web)的发展,超文本标记语言(HTML = HyperText Markup Language)得到广泛应用,其超文本功能可将多种媒体元素集成和链接在一起,是表达多媒体信息的有力工具。
在Office 2010中使用其它国家语言

在Office 2010中使用其它国家语言
出处:驱动之家作者:萧萧日期:2009-07-30
关键字:Office
随着区域和语言间交流协作的越来越密切,一些问题也随之产生,对于很多人来说使用非母语语言不是一件轻松的事,微软表示,本着解决这一问题的目的,Office 2010进一步完善了多语言功能以便帮助用户处理一些简单的任务。
1、文本和文档翻译
Word 2010中的翻译选项中提供了“翻译文档”、“翻译选定文本”、“Mini 翻译器”。
全文档翻译:“翻译文档”功能使用了微软基于浏览器的Bing翻译器来提供同步逐字翻译。
Mini翻译器:当用户选中一个单词或短语时Mini翻译器为弹出悬浮翻译框,为用户提供来自字典、词典的定义,该悬浮翻译框也允许用户进行相关操作,比如复制翻译后的文本、对选中单词进行朗读等。
翻译选定文本:用户可以从右键菜单中选择翻译选定文本,并在右侧的搜索面板中查看结果。
2、屏幕顶端(ScreenTip)语言
使用ScreenTip功能用户可以查看其它语言版本的页面显示组件,比如按钮、菜单、对话框,而不用安装传统的语言包。
3、语言参数设置
Office 2010提供了一种全新的Office客户端环境自定义界面,用户现在可以在一个创投中轻松地查看自己安装了哪些语言、访问键盘布局对话框和Office在线工具。
第15章JSP标准标签库JSTL_core_luo

什么是JSTL
为了实现页面无脚本,还要借aServerPages Standard Tag Library)JSP标准标签库
JSTL 的优点
提供一组标准标签
可用于编写各种 动态 JSP 页面
用于访问数据库
JSTL组成
JSTL是由5个不同的功能的标签库组成的。在 JSTL1.1规范中,为5个标签库分别指定了不同的 URI,并对标签库的前缀做出了规定:
如果只在当前Web应用程序中使用,可以将这两个文件放到WEBINF\lib目录下。
另外还有一个standard-examples.war文件在下载的zip包 内。这是JSTL的例子程序。将此文件放到Tomcat的 webapps目录下,打开IE,输入 http://localhost:8080/standard-examples/ 就可以了。
index.jsp: <a href="servlet/StuSer">使用mvc模式 调用servlet获得bean的值,在输出到 jsp用el表达式获得</a>
C_out_1.jsp <%@ page contentType="text/html;charset=GBK"%> <%@ taglib uri="/jsp/jstl/core" prefix="c"%> <html> <body> <hr> <c:set value="刘丽" var="userName" scope="session"/> <c:out value="${userName}"/> <hr> <c:set var="password" scope="session"> yjhgmy </c:set> <c:out value="${password}"/> <hr> <c:out value="${}"/> <c:out value="${st.age}"/> </body> </html>
Office高级应用_成都信息工程大学中国大学mooc课后章节答案期末考试题库2023年

Office高级应用_成都信息工程大学中国大学mooc课后章节答案期末考试题库2023年1.如果在单元格A1中输入了1,则区域E1:E5中的公式{=if($A$1=1,$B$1:$B$5, $C$1:$C$5)}的计算结果为______。
参考答案:区域$B$1:$B$5的值2.在PowerPoint演示文稿中,不可以使用的对象是______。
参考答案:书签3.可以在PowerPoint内置主题中设置的内容是______。
参考答案:字体、颜色和效果4.如果需要在一个演示文稿的每页幻灯片左下角相同位置插入学校的校徽图片,则最优的操作方法是______。
参考答案:打开幻灯片母板视图,将校徽图片插入在母板中5.自定义动画时,以下不正确的说法是______。
参考答案:动画设置后,先后顺序不可改变6.改变演示文稿外观可以通过______。
参考答案:另外三项都对7.幻灯片母版设置可以起到______的作用。
参考答案:统一整套幻灯片的风格8.在空白幻灯片中无法直接插入______。
参考答案:文字9.演示文稿中每张幻灯片都是基于某种______创建的,它预定义了新建幻灯片的各种占位符布局情况。
参考答案:版式10.在PowerPoint中,可以创建某些______,在幻灯片放映时单击它们,就可以跳转到特定的幻灯片或运行一个嵌入的演示文稿。
参考答案:按钮11.在Excel2010中,工作表被删除后,下列说法正确的是______。
参考答案:数据被删除,而且无法通过撤消的方法来恢复12.使用"自动填充"方法输入数据时,若在A1输出2,A2输入4,然后选中A1:A2区域,再拖动填充柄至A10,则A1:A10区域内各单元格的数据为______。
参考答案:2,4,6,8, (20)13.一个工作薄里最多可以含有______张工作表。
参考答案:25514.在Excel中,一行与一列相交构成一个______。
参考答案:单元格15.某区域由A1,A2,A3,B1,B2,B3六个单元格组成。
说明书的多语种版本管理

说明书的多语种版本管理随着全球化的进展,越来越多的产品开始在国际市场上销售。
为了满足不同国家和地区的消费者需求,跨国企业需要为其产品开发多语种版本的说明书。
这些说明书的多语种版本管理变得至关重要,以确保准确传达产品的信息,提供良好的使用体验,并遵守法规和法律要求。
一、需求分析在制定多语种版本管理计划之前,首先需要进行需求分析。
这包括确定目标市场、语种需求、翻译质量要求以及法规和法律要求。
通过仔细分析这些因素,可以确定需要翻译和管理的语言数量和工作量。
二、翻译团队选择选择专业、熟悉产品的翻译团队至关重要。
翻译团队应具备良好的语言能力、翻译经验和专业知识。
他们应该理解产品的特性和使用方法,并能准确传达产品信息。
此外,确保翻译团队能够按时完成翻译任务,并具备适应快速变化的市场需求的能力。
三、翻译工具和技术为了提高翻译质量和效率,可以使用翻译工具和技术。
计算机辅助翻译工具(CAT)可以帮助翻译人员管理术语库、翻译记忆库和一致性检查工具。
此外,机器翻译和自动语音识别等技术也可以应用于一些简单和标准化的说明书翻译。
四、术语管理在多语种版本管理过程中,术语管理是非常重要的。
确保在不同语言的说明书中使用一致的术语可以提高产品的专业性和可理解性。
可以建立术语库来管理术语,并在翻译过程中进行术语的一致性检查。
五、版本控制和更新随着产品的改进和市场需求的变化,说明书需要不断进行更新。
为了确保不同语言版本的一致性,需要建立有效的版本控制机制。
每次更新都应该记录并通知相关翻译团队,以便进行及时的翻译和更新。
六、审核和审校在完成翻译工作后,说明书需要进行审核和审校。
审核和审校的目的是确保翻译准确无误、符合专业规范,并适应目标市场的文化和法律要求。
可以邀请来自目标市场的专业人士参与审核和审校过程,以确保语言和内容的质量。
七、文档管理为了方便多语种版本的管理,建议建立一个完善的文档管理系统。
文档管理系统应具备方便快捷的搜索、检索和更新功能,以便随时更新和发布多语种版本的说明书。
viewme-um004_-zh-e说明书

(完整版)GAMS用户手册(中文翻译第2-15章)(可编辑修改word版)

目录第二章GAMS 指南 (2)2.1引言 (2)2.2GAMS 模型的结构 (4)2.3集合 (6)2.4数据 (7)2.4.1清单数据输入 (7)2.4.2表格数据输入 (8)2.4.3直接赋值数据输入 (8)2.5变量 (9)2.6 方程 (10)2.6.1方程声明 (10)2.6.2GAMS 的求和符号(乘积符号) (11)2.6.3方程定义 (11)2.7目标函数 (13)2.8模型和求解语句 (13)2.9显示语句 (14)2.10 .lo,.l,.up,.m 数据库 (14)2.10.1变量边界和初始值的赋值 (14)2.10.2最优值的转化和显示 (15)2.11 GAMS 输出 (16)2.11.1 复写 (16)2.11.2错误信息 (18)2.11.3引用地图 (20)2.11.4方程清单 (21)2.11.5模型统计数据 (22)2.11.6状态报告 (22)2.11.7解报告 (23)2.12 总结 (24)第三章GAMS 程序 (26)3.1 引言 (26)3.2GAMS 程序的结构 (26)3.2.1GAMS 输入的格式 (26)3.2.2GAMS 语句的分类 (27)3.2.3GAMS 程序的组织 (27)3.3数据类型和定义 (28)3.4语言项 (29)3.4.1 字符 (29)3.4.2保留词 (29)3.4.3标识符(Identifiers) (30)3.4.4 标签 (30)3.4.5 文本 (31)3.4.6 数字 (31)3.4.7 分隔符 (32)3.4.8 注释 (32)3.5 小结 (33)第四章集合定义 (34)4.1 引言 (34)4.2简单集合 (34)4.2.1 语法 (34)4.2.2集合名称 (34)4.2.3集合元素 (35)4.2.4相关文本 (36)4.2.5作为集合元素的序列 (36)4.2.6多集合声明 (37)4.3别名语句:一个集合多个名称 (37)4.4子集合和定义域检查 (38)4.5多维集合 (39)4.5.1一对一映射 (39)4.5.2多对多映射 (40)4.6 小结 (41)第五章数据输入:参数,标量和表格 (42)5.1 引言 (42)5.2 标量 (42)5.2.1 语法 (42)5.2.2 例子 (42)5.3 参数 (43)5.3.1 语法 (43)5.3.2 例子 (43)5.3.3 高维数据参数 (44)5.4 表格 (44)5.4.1 语法 (45)5.4.2 例子 (45)5.4.3 续表 (46)5.4.4超过两维的表格 (46)5.4.5浓缩表格 (47)5.4.6处理长行表格 (48)5.5 Acronyms (48)5.5.1 语法 (48)5.5.2 示例 (49)5.6 小结 (49)第六章参数的数据处理 (50)6.1 引言 (50)6.2赋值语句 (50)6.2.1标量赋值 (50)6.2.2指数化赋值 (50)6.2.3在赋值中直接采用标签 (51)6.2.4子集上的赋值 (51)6.2.5控制指数的相关问题 (51)6.2.6赋值中扩展值域的标识符 (52)6.2.7赋值中的Acronyms (52)6.3表达式 (52)6.3.1标准算术运算 (52)6.3.2指数化运算 (53)6.3.3 函数 (54)6.3.4 扩展值域算法和错误处理 (55)6.4 小结 (56)第七章变量 (57)7.1 引言 (57)7.2变量声明 (57)7.2.1 语法 (57)7.2.2变量类型 (58)7.2.3变量声明的方式 (58)7.3变量属性 (59)7.3.1变量的边界 (59)7.3.2定值变量 (59)7.3.3变量的活动水平 (60)7.4显示语句和赋值语句中的变量 (60)7.4.1对变量属性进行赋值 (60)7.4.2赋值语句中的变量属性 (60)7.4.3显示变量属性 (61)7.5 小结 (62)第八章方程 (63)8.1 引言 (63)8.2方程声明 (63)8.2.1 语法 (63)8.2.2 例子 (63)8.3方程定义 (64)8.3.1 语法 (64)8.3.2 例子 (64)8.3.3标量方程 (65)8.3.4指数化方程 (65)8.3.5在方程中明确使用标签 (65)8.4方程定义中的表达式 (66)8.4.1方程定义中的算术算子 (66)8.4.2方程定义中的函数 (66)8.4.3避免方程中的无定义操作 (67)8.5方程的数据处理问题 (67)第九章模型和求解语句 (69)9.1 引言 (69)9.2模型语句 (69)9.2.1 语法 (69)9.2.2模型的分类 (70)9.2.3模型属性 (70)9.3求解语句 (71)9.3.1 语法 (72)9.3.2合法求解语句的要求 (72)9.3.3求解语句触发的行动 (72)9.4多个求解语句的程序 (73)9.4.1几个模型 (73)9.4.2敏感性分析和场景分析 (73)9.4.3非标准算法的迭代执行 (74)9.5让GAMS 获得新的求解模块 (75)第十章GAMS 输出 (76)10.1 引言 (76)10.2示例模型 (76)10.3编辑输出 (77)10.3.1输入文件的复写 (77)10.3.2符号引用地图 (79)10.3.3符号清单地图 (80)10.3.4单元素清单地图 (81)10.3.5实用的dollar($)控制指令 (82)10.4执行输出 (82)10.5求解语句生成的输出 (83)10.5.1方程清单 (83)10.5.2列清单 (84)10.5.3模型统计数据 (85)10.5.4求解摘要 (86)10.5.5求解模块报告 (89)10.5.6解清单 (89)10.5.7报告摘要 (91)10.5.8文件概要 (91)10.6错误报告 (91)10.6.1编辑错误 (92)10.6.2编辑时间错误 (93)10.6.3执行错误 (94)10.6.4求解错误 (94)10.7 小结 (95)第十一章条件表达式,赋值和方程 (96)11.1 引言 (96)11.2逻辑条件 (96)11.2.1作为逻辑条件的数值表达式 (96)11.2.2数值关系算子 (96)11.2.3逻辑算子 (97)11.2.4集合元素 (97)11.2.5包含Acronyms 的逻辑条件 (97)11.2.6逻辑条件的数值 (98)11.2.7混合逻辑条件――算子优先顺序 (98)11.2.8混合逻辑条件――例子 (99)11.3Dollar 条件 (99)11.3.1 例子 (99)11.3.2 嵌套dollar 条件 (99)11.4条件赋值 (100)11.4.1dollar 置于赋值语句左边 (100)11.4.2dollar 置于赋值语句右边 (101)11.4.3在指数化运算中过滤控制指数 (101)11.4.4过滤赋值语句中的集合 (102)11.5条件指数化运算 (103)11.5.1在指数化运算中过滤控制指数 (104)11.6条件方程 (105)11.6.1代数表达式中的dollar 算子 (105)11.6.2定义域的dollar 控制 (105)11.6.3过滤定义域 (106)第十二章动态集合 (107)12.1 引言 (107)11.2 动态集合的元素赋值 (107)11.2.1 语法 (107)11.2.2 例子 (107)12.2.3 多指数动态集合 (108)11.2.4 动态集合定义域上赋值语句 (108)12.2.5 定义在动态集合定义域上的方程 (108)12.3使用带有动态集合的dollar 控制 (109)12.3.1 赋值 (109)12.3.2 指数化运算 (109)12.3.3 方程 (110)12.3.4 通过动态集合过滤 (110)12.4集合运算 (111)12.4.1 并集 (111)12.4.2 交集 (111)12.4.3 补集 (111)12.4.4 差集 (111)12.5 小结 (112)第十三章作为序列的集合:有序集合 (113)13.1 引言 (113)13.3ord 和card (114)13.3.1ord 算子 (114)13.3.2Card 算子 (115)13.4lag 和lead 算子 (115)13.5赋值语句中的lags 和leads (116)13.5.1线性lag 和lead 算子――引用 (116)13.5.2线性lag 和lead 算子――赋值 (116)13.5.3循环lag 和lead 算子 (117)13.6方程中的lags 和leads (118)13.6.1线性lag 和lead 算子――定义域控制 (118)13.6.2线性lag 和lead 算子――引用 (119)13.6.3循环lag 和lead 算子 (119)13.7 小结 (120)第十四章显示语句 (121)14.1 引言 (121)14.2 语法 (121)14.3 例子 (121)14.4显示语句中的标签顺序 (122)14.4.1 例子 (123)14.5显示控制 (124)14.5.1全局显示控制 (124)14.5.2局部显示控制 (124)14.5.3生成列表格式数据的显示语句 (125)第十五章put 书写工具 (127)15.1 引言 (127)15.2 语法 (127)15.3 例子 (127)15.4输出文件 (129)15.4.1定义文件 (129)15.4.2赋值文件 (130)15.4.3关闭文件 (130)15.4.4添加内容到文件 (130)15.5页面格式 (131)15.6页面区域 (132)15.6.1访问不同的页面区域 (132)15.5.2 分页 (133)15.7定位页面指针 (133)15.8系统后缀 (133)15.9 输出项 (134)15.9.1 文本项 (134)15.9.2 数字项 (135)15.9.3 集合值项 (136)15.10.1字段对齐 (136)15.10.2字段宽度 (136)15.11局部输出项格式 (137)15.12额外的数字显示控制 (137)15.12.1 例子 (138)15.13指针控制 (139)15.13.1当前指针列 (139)15.13.2当前指针行 (140)15.13.3末行控制 (140)15.14分页控制 (141)15.15例外处理 (141)15.16与put 语句相关的错误来源 (141)15.16.1语法错误 (141)15.16.2put 错误 (142)15.17简单的电子数据表/数据库应用 (142)15.17.1 例子 (142)第二章GAMS 指南2.1 引言本书的介绍部分将给出一个详细的例子,介绍如何使用GAMS 来描述、求解和分析一个简单的小型优化问题。
CAD文件的多语言与国际化支持

CAD文件的多语言与国际化支持随着全球化的发展,国际交流和合作越来越频繁。
在设计领域,CAD(Computer-Aided Design,计算机辅助设计)软件成为了设计师不可或缺的工具。
为了满足不同国家和地区的用户需求,CAD软件需要提供多语言与国际化支持。
本文将探讨CAD文件的多语言与国际化支持的重要性及实现方式。
一、多语言支持的重要性CAD软件的多语言支持对于全球化市场来说至关重要。
随着全球市场的扩大,越来越多的设计师来自不同国家和地区,他们使用CAD软件进行设计工作。
因此,提供多语言支持可以帮助不同国家和地区的设计师更好地理解和使用CAD软件,提高工作效率。
此外,多语言支持还有助于促进各国之间的技术交流和合作。
设计是一个国际化的领域,不同国家和地区的设计师经常需要进行合作。
通过提供多语言支持,CAD软件可以消除语言障碍,促进各国设计师之间的交流和合作,推动全球设计行业的进步。
二、国际化支持的重要性除了多语言支持,CAD软件还需要提供国际化支持。
国际化是指将软件设计得能够适应不同地区、不同文化和不同习惯的需求。
CAD软件的国际化支持包括适应不同国家和地区的单位制度、尺寸标准、文件编码等。
CAD软件的国际化支持能够帮助用户更好地适应本地化工作环境。
以单位制度为例,不同国家和地区使用的单位制度可能不同,比如英制、公制等。
CAD软件应该能够根据用户的需求自动切换单位制度,避免用户在设计过程中频繁转换单位,提高工作效率。
此外,CAD软件还需要考虑到不同地区的尺寸标准和文件编码。
比如,欧洲和北美的尺寸标准可能存在差异,CAD软件应该提供灵活的设置选项,满足不同地区的尺寸需求。
同时,文件编码也是国际化支持的关键,CAD软件应该支持各种国际编码,确保文件在不同地区的交流和共享。
三、实现多语言与国际化支持的方式实现CAD文件的多语言与国际化支持可以采取以下几种方式:1. 界面本地化:将CAD软件的界面翻译成不同语言,使用户可以以其母语进行操作。
熟悉NLTK的基本概念与使用方法

熟悉NLTK的基本概念与使用方法自然语言工具包(NLTK)是一个用于在Python中处理人类语言数据的库。
它提供了许多用于文本分析和自然语言处理(NLP)的工具和功能。
本文将带您熟悉NLTK的基本概念和使用方法。
1.安装和导入要开始使用NLTK,首先需要安装它。
在命令行中运行以下命令:```pip install nltk```安装完成后,可以通过以下方式导入库:```pythonimport nltk```2.语料库NLTK提供了大量的语料库,其中包括文本、词汇和句子数据。
可以使用这些语料库来进行文本分析和NLP任务。
要查看它们的列表,可以运行以下命令:```pythonprint(nltk.corpus.__file__)```在运行上述命令后,将显示语料库所在的目录。
3.文本预处理在进行文本分析之前,通常需要对文本进行一些预处理。
NLTK提供了一些常用的文本预处理功能,如分词、去除停用词、词形还原和词性标注等。
- 分词(Tokenization):将文本分割成单个的词或标记。
可以使用NLTK的`word_tokenize(`函数进行分词。
```pythonfrom nltk.tokenize import word_tokenizetext = "Hello, how are you?"tokens = word_tokenize(text)print(tokens)```输出结果为:['Hello', ',', 'how', 'are', 'you', '?']- 去除停用词(Stopwords Removal):去除文本中常见的无意义词汇,如“a”、“the”、“in”等。
可以使用NLTK的`stopwords.words(`函数获取停用词列表,并在分词后去除它们。
```pythonfrom nltk.corpus import stopwordsstopwords = set(stopwords.words('english'))filtered_tokens = [token for token in tokens iftoken.lower( not in stopwords]print(filtered_tokens)```输出结果为:['Hello', ',', '?']- 词形还原(Stemming and Lemmatization):将单词还原为它们的基本形式。
python langid 使用方法

python langid 使用方法【原创实用版3篇】目录(篇1)1.介绍 Python 的 langid 库2.展示如何安装和使用 langid 库3.详述 langid 库的功能和应用场景正文(篇1)【1.介绍 Python 的 langid 库】Python 的 langid 库是一个用于识别语言的第三方库。
它可以自动识别文本的语种,并返回对应的语言代码。
这对于涉及到跨语言处理的应用开发非常有用,例如,在机器翻译、文本分类、舆情分析等领域均有广泛的应用。
【2.展示如何安装和使用 langid 库】要使用 langid 库,首先需要安装它。
在命令行中输入以下命令即可完成安装:```pip install langid```安装完成后,可以开始编写代码来使用 langid 库。
以下是一个简单的例子:```pythonfrom langid import detecttext = "你好,世界!"result = detect(text)print(result)```运行以上代码,将会输出如下结果:```{"lang": "zh-CN", "prob": 0.9999999999999999}```其中,`lang`表示识别出的语言代码,`prob`表示识别的准确率。
【3.详述 langid 库的功能和应用场景】langid 库的主要功能是识别文本的语言,并返回对应的语言代码。
它支持包括中文、英文、法文、日文等在内的 50 多种语言的识别。
除了识别单个文本的语言,langid 库还提供了批量识别的功能,可以同时对多个文本进行语言识别。
这使得它在处理大量跨语言文本时,具有更高的效率。
目录(篇2)1.介绍 Python 的 langid 库2.展示如何安装和使用 langid 库3.详述 langid 库的功能和应用场景正文(篇2)【1.介绍 Python 的 langid 库】Python 的 langid 库是一个非常实用的自然语言处理库,它可以帮助开发者快速地识别文本的语言。
药品说明书和标签管理规定(培训课件)ppt概要

第三章 药品的标签
其他有关规定:
(1)同一药品生产企业生产的同一药品,药品规格和包装规格 均相同的,其标签的内容、格式及颜色必须一致;药品规格 或者包装规格不同的,其标签应当明显区别或者规格项明显 标注。
(2)同一药品生产企业生产的同一药品,分别按处方药与非处 方药管理的,两者的包装颜色应当明显区别。
(4)除因包装尺寸的限制而无法同行书写的,不得分行书 写。
第四章 药品名称和注册商标的使用
有关规定:
(1)药品商品名称不得与通用名称同行书写,其字体和颜 色不得比通用名称更突出和显著,其字体以单字面积计不 得大于通用名称所用字体的二分之一。
(2)药品说明书和标签中禁止使用未经注册的商标以及其 他未经国家食品药品监督管理局批准的药品名称。
• 适应症或者功能主治、用法用量、不良反应、禁忌、注意 事项不能全部注明的,应当标出主要内容并注明“详见说明 书”字样。
第三章 药品的标签
两种特殊标签:
• 用于运输、储藏的包装的标签: 注明药品通用名称、规格、 贮藏、生产日期、产品批号、有效期、批准文号、生产企业
• 原料药的标签:注明药品名称、贮藏、生产日期、产品批号、 有效期、执行标准、批准文号、生产企业,同时还需注明包 装数量以及运输注意事项等必要内容。
(4)包含药品不良反应信息,详细注明药品不良反应。 (5)药品说明书核准日期和修改日期应当在说明书中醒目标
示。
第三章 药品的标签
定义:
• 药品的标签:是指药品包装上印有或者贴有的内容,分为内 标签和外标签。
• 内标签:直接接触药品的包装的标签。 • 外标签:内标签以外的其他包装的标签。
第三章 药品的标签
第一章 总则
(4)第六条 药品说明书和标签中的文字应当清晰易辨, 标识应当清楚醒目,不得有印字脱落或者粘贴不牢等现象, 不得以粘贴、剪切、涂改等方式进行修改或者补充。
如何解决多标签文本分类问题在深度学习中的应用方法

如何解决多标签文本分类问题在深度学习中的应用方法深度学习在自然语言处理领域取得了很大的突破,特别是在文本分类任务中的应用方面。
而多标签文本分类问题的解决对于许多实际应用场景来说,显得尤为重要。
本文将介绍几种在深度学习中解决多标签文本分类问题的应用方法。
1. One-hot 编码和多输出模型在多标签文本分类问题中,首先要进行的是标签的编码。
通常使用的方法是One-hot 编码,即将每个标签转化为一个二进制向量,其中只有一个元素为 1,其余元素为 0。
这样可以保证每个标签都有独立的输出。
在模型架构方面,可以使用多输出模型来解决多标签分类问题。
多输出模型是一种特殊的深度学习模型,可以在同一个网络中同时预测多个输出。
每个输出对应一个标签,通过对应标签的损失函数来计算误差并进行反向传播。
这样的模型结构可以有效地解决多标签问题。
2. 使用循环神经网络(RNN)循环神经网络是一种能够处理序列数据的神经网络模型,在文本分类任务中表现出色。
对于多标签文本分类问题,可以使用循环神经网络模型来对文本进行编码,并输出相应的标签。
在循环神经网络中,可以使用 LSTM(长短期记忆网络)或 GRU(门控循环单元)等变种来进行建模。
这些模型能够捕捉文本中的上下文信息,并较好地处理序列数据。
通过使用多个隐藏层和双向循环神经网络,还可以提高模型的性能。
3. 使用卷积神经网络(CNN)卷积神经网络是一种能够有效提取高维特征的深度学习模型,对于图像分类任务广泛应用。
然而,CNN 在文本分类中也有很好的表现,特别是在处理卷积核尺寸相对较小的情况下。
对于多标签文本分类问题,可以使用卷积神经网络进行序列建模。
通过将文本表示为嵌入矩阵,然后使用具有不同卷积核大小的卷积层来提取不同大小的特征。
最后,将提取的特征连接起来,并通过全连接层来进行标签分类。
4. 多模态深度学习在一些应用场景中,文本分类问题可能有多个输入源,例如文本和图像。
这时,可以使用多模态深度学习方法来解决多标签分类问题。
学会使用前端国际化库提供多语言支持(九)

学会使用前端国际化库提供多语言支持在当今全球化的社会中,越来越多的企业和开发者开始关注多语言支持。
作为前端开发者,学会使用前端国际化库提供多语言支持,可以为我们的应用程序增加更大的灵活性和可访问性。
本文将介绍什么是前端国际化库,为什么要使用它以及如何使用它来实现多语言支持。
什么是前端国际化库?前端国际化库是一种用于在前端应用程序中实现多语言支持的工具。
它能够根据用户的地理位置、语言偏好等信息,自动切换应用程序的显示语言。
通过使用前端国际化库,开发者可以轻松地在应用程序中添加多语言支持,而不需要手动编写大量的条件语句或硬编码翻译。
为什么要使用前端国际化库?首先,前端国际化库可以提高用户体验。
当用户可以在自己熟悉的语言中使用应用程序时,他们更容易理解和使用应用程序的功能。
这样可以减少用户的迷惑和不必要的学习成本,从而提高用户的满意度和使用率。
其次,前端国际化库可以降低开发和维护成本。
通过使用国际化库,开发者只需要维护一个统一的语言文件,而不需要为每种语言编写不同的代码。
这样可以显著减少开发时间和工作量,同时也减少了后期维护的难度。
最后,前端国际化库可以帮助应用程序更好地适应不同的市场。
随着互联网的普及,应用程序不再局限于特定的国家或地区。
通过提供多语言支持,应用程序可以更容易地进入全球市场,吸引更多的用户和潜在客户。
如何使用前端国际化库来实现多语言支持?首先,需要选择一个合适的前端国际化库。
市面上有许多成熟的国际化库可供选择,如React Intl、vue-i18n、Angular Translate 等。
开发者可以根据自己的需求和技术栈选择适合自己的库。
其次,需要准备多语言资源文件。
多语言资源文件包括了应用程序中所有需要翻译的文本内容,如按钮文字、标签、提示信息等。
开发者可以将这些文本内容根据语言分类保存在不同的文件中,以便后续使用。
接下来,需要在应用程序中引入和配置国际化库。
不同的库有不同的引入和配置方式,开发者可以根据官方文档进行操作。
VSCode多语言支持助力国际化应用开发

VSCode多语言支持助力国际化应用开发在当今全球化的社会中,国际化应用开发变得越来越重要。
随着各种语言和文化的交流和融合,开发者需要为他们的应用程序提供多语言支持,以便吸引全球用户。
在这方面,Visual Studio Code(简称VSCode)作为一款功能强大的开发工具,为开发者提供了许多实用的功能和插件,极大地方便了国际化应用开发的过程。
一、多语言文件支持在国际化应用开发中,最重要的一点是能够为不同的语言提供相应的翻译文本。
VSCode通过提供多语言文件支持,使得开发者可以轻松管理和编辑这些翻译文本。
1. JSON文件格式VSCode使用JSON文件格式来存储和管理多语言文本。
这种格式简洁清晰,易于理解和编辑。
开发者可以根据需要创建不同语言的JSON文件,并在其中添加对应的翻译文本。
例如,可以创建一个名为en.json的文件来存储英语的翻译文本,创建一个名为zh.json的文件来存储中文的翻译文本。
2. 快捷键支持为了进一步提高开发效率,VSCode还为多语言文件提供了快捷键支持。
开发者可以使用快捷键来快速切换不同语言的文件,并进行编辑。
这样,他们可以更方便地查看和修改不同语言的翻译文本,提高国际化应用开发的效率。
二、国际化插件支持除了多语言文件支持外,VSCode还提供了各种实用的插件,帮助开发者更好地进行国际化应用开发。
1. 多语言代码高亮VSCode的多语言插件可以根据不同语言的特性对代码进行高亮显示。
这对于开发者来说非常有用,因为他们可以更清楚地了解不同语言的代码结构和语法规则,更容易进行相应的国际化处理。
2. 自动翻译功能VSCode的自动翻译插件可以根据开发者选择的语言自动翻译文本。
这样,开发者不需要手动查找翻译文本,减少了开发时间和工作量。
同时,自动翻译功能可以提高翻译的准确性和一致性,确保应用程序的质量。
3. 国际化调试支持VSCode还提供了国际化调试插件,帮助开发者调试和测试国际化应用程序。
15.文字标签库与多国语言使用

EasyBuilder Pro V6.00.01目录第十五章文字标签库与多国语言使用 (1)15.1 概要 (1)15.2 文字标签库管理 (1)15.3 文字标签库的建立 (2)15.4 文字标签库的使用 (3)15.5 多国语言的使用 (4)第十五章文字标签库与多国语言使用本章节说明如何建立与使用文字标签库。
15.1 概要当需要在工程文件中使用多国语言时,需先建立文字标签库后,再从中选择需要的标签。
HMI在运行时会依照语言模式的设定,于工程文件中显示所选择语言模式相对应的文字。
EasyBuilder Pro同时支持24种不同语言的文字显示。
本章节将说明如何建立文字标签库并使用多国语言。
15.2 文字标签库管理按下工具栏上的“工程文件” » “文字标签”即可进入“文字标签库”对话框,如下图所示。
设定描述语言数量设定本工程文件所使用的语言数量。
当前状态一个文字标签最多可拥有256个状态(0 ~ 255)。
状态数量将受“语言数量”使用的限制,若使用1 ~ 3个语言,每个语言最多可有256个状态,若使用4个以上的语言数量,则可用768去除以语言数量后,即可得到最多状态数。
例如: 语言数量为24,则768/24 = 32 (状态数)。
新增新增一笔文字标签。
设定设定所选择的文字标签内容。
导出文字库文件保存所有文字标签为.lbl 格式文件。
导入文字库文件将现存文字标签.lbl 文件导入文字标签库。
导出为EXCEL文件保存所有文字标签为.csv, .xls 或.xlsx 格式文件。
导入EXCEL文件将现存文字标签.csv, .xls 或.xlsx 文件导入文字标签库。
Note导入或导出Excel文件均不支持Unicode。
15.3 文字标签库的建立请依照以下步骤建立文字标签库。
1.开启“文字标签库” » “新增”。
定义文字标签的名称并设定文字标签所要表现的状态数。
2.按下“确定”后会显示一个新的空白标签,选择该标签后按“设置”即可编辑标签内容。
超文本标记语言 计算机编程语言

超文本标记语言计算机编程语言超文本标记语言(Hypertext Markup Language,简称HTML)是一种用于创建网页的标准标记语言。
它是一种计算机编程语言,用于描述网页的结构和内容。
HTML使用标记来定义文本和其他元素的结构和样式,使其能够在浏览器中正确显示。
HTML的语法简单易懂,基本上是由一系列的标记组成。
每个标记都由尖括号包围,其中包括一个起始标记和一个结束标记。
起始标记用来定义元素的开始,结束标记用来定义元素的结束。
在两个标记之间,可以插入文本、图像、链接、表格等元素,以便构建丰富多样的网页。
HTML的标记语言使用的是英文单词或者单词的缩写,例如,`<head>`标记用来定义文档的头部,包括标题、样式和脚本等信息。
`<body>`标记用来定义文档的主体部分,包括文本、图像、链接等内容。
`<p>`标记用来定义段落,`<h1>`到`<h6>`标记用来定义标题的级别,`<a>`标记用来定义链接,等等。
除了基本的标记外,HTML还提供了许多其他的标记和属性,用于控制文本的样式、布局和行为。
例如,可以使用`<b>`标记来加粗文本,使用`<i>`标记来斜体文本,使用`<table>`标记来创建表格,使用`<img>`标记来插入图像,等等。
通过合理使用这些标记和属性,可以实现丰富多样的网页效果。
HTML不仅可以创建静态网页,还可以与其他技术结合,实现动态交互效果。
例如,可以使用JavaScript编程语言来控制HTML元素的行为和样式,可以使用CSS样式表来定义网页的外观和布局。
通过这些技术的结合,可以实现网页的动态更新、表单验证、响应式布局等功能。
HTML的标准由万维网联盟(World Wide Web Consortium,简称W3C)制定和维护。
W3C不断更新和完善HTML标准,以适应不断变化的互联网环境。
多标签文本分类原理

多标签文本分类原理
多标签文本分类是指将一个文本分配到多个标签中的任务。
与传统的单标签文本分类不同,多标签文本分类可以更准确地描述文本的内容和特征,因此在许多领域中得到了广泛的应用。
多标签文本分类的原理是基于机器学习算法,通过对大量已标注的文本数据进行训练,建立一个分类模型,然后将未标注的文本数据输入到模型中,根据模型的预测结果将其分配到多个标签中。
常用的机器学习算法包括朴素贝叶斯、支持向量机、决策树等。
多标签文本分类的应用非常广泛,例如在社交媒体中,可以将用户发布的内容分配到多个标签中,以便更好地推荐相关内容和广告;在电子商务中,可以将商品描述分配到多个标签中,以便更好地进行搜索和推荐;在医疗领域中,可以将病历分配到多个标签中,以便更好地进行诊断和治疗。
多标签文本分类的实现需要考虑以下几个方面:
1. 数据预处理:包括文本清洗、分词、去除停用词等,以便提取文本的特征。
2. 特征提取:将文本转换为向量表示,常用的方法包括词袋模型、TF-IDF等。
3. 模型训练:选择合适的机器学习算法,对已标注的文本数据进行
训练,建立分类模型。
4. 模型评估:使用测试数据对模型进行评估,包括准确率、召回率、F1值等指标。
5. 模型应用:将未标注的文本数据输入到模型中,根据模型的预测结果将其分配到多个标签中。
多标签文本分类是一种非常有用的技术,可以帮助我们更好地理解和分析文本数据,为各个领域的应用提供支持。
VSCode多语言支持

VSCode多语言支持随着全球化和跨国合作的不断深入发展,多语言支持变得越来越重要。
在软件开发领域,提供多语言支持可以使开发人员更加便利地进行跨语言开发和国际化。
作为一款广受欢迎的集成开发环境,Visual Studio Code(简称VSCode)在多语言支持方面也积极不断地进行更新和改进。
1. 背景介绍随着全球互联网的迅猛发展和跨国合作的广泛开展,软件开发不再局限于某一特定的语言环境。
开发人员需要能够流畅地切换不同的编程语言,并进行跨语言的调试和测试。
传统的开发环境通常只支持一种或少数几种特定的编程语言,这给开发人员带来了很大的不便。
2. 优势与功能VSCode通过其强大的多语言支持功能,帮助开发人员更加便捷地处理跨语言开发的需求。
具体包括以下几个方面:2.1 语法高亮VSCode内置了丰富的语法高亮插件,可以根据不同的编程语言自动识别并高亮显示代码。
同时,开发人员也可以根据需要自定义不同的颜色主题,以满足个性化的需求。
2.2 代码智能提示VSCode通过集成各种插件和扩展功能,可以为开发人员提供智能的代码提示功能。
在编辑代码的过程中,VSCode会根据当前的上下文环境和已有的代码库,自动提供合适的代码补全建议,加快开发速度并减少潜在的错误。
2.3 跨语言调试VSCode支持跨语言的调试功能,开发人员可以在同一个界面下进行不同编程语言的断点设置和调试操作。
这意味着开发人员不再需要频繁切换不同的开发环境,可以更加高效地进行跨语言调试和测试。
2.4 插件生态系统VSCode拥有庞大的插件生态系统,开发人员可以根据自己的需求自由选择和安装各种扩展功能。
这些插件包括但不限于代码格式化、版本控制、代码统计、自动化测试等,极大地拓展了开发人员的工作能力和便利性。
3. 使用说明在使用VSCode进行多语言开发时,可以按照以下步骤进行配置和操作:3.1 安装VSCode首先,用户需要下载并安装适用于自己操作系统的VSCode软件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第十五章文字标签库与多国语言使用
文字标签库一般使用在需要多国语言的环境中,使用者可以依照实际需要预先建立文字标签库的内容。
在需要使用文字的场合,只需由文字标签库中挑选需要的标签即可,系统在运作时也会依照设定,显示当时使用语言相对应的文字。
EB8000同时支持8种不同语言的文字显示。
按下工具列上的工作按钮将出现“文字库标签管理对话窗”,参考下图。
[目前状态]
目前显示的状态,每一个文字标签最多可拥有256个状态。
[新增…]
新增加一笔文字标签。
[设定…]
更改文字标签的内容。
[删除]
删除特定的文件标签。
[输出]
使用CSV格式将此文字标签库的所有内容输出到特定位置。
此功能不支持Unicode。
[汇入]
将已存在的且为CSV格式的文字标签库加到目前的画面规划档(MTP)。
此功能不支持Unicode。
在“文字标签库管理对话窗”中可以看出目前已经存在两个标签“Demo”与“Test”,其中“Demo”所包含的8种语文分别为:英文、繁体中文、简体中文、日文、韩文、法文、泰文、俄文等。
文字标签库的字型选择
不同语言可选择不同的字型,参考下图。
[字体]
[字体]设定页用来设定在使用多国文字时,各种语文所使用的字型。
[备注]
每种字型的注释。
文字标签库的建立
下面说明如何建立这些项目。
首先,打开“文字标签库管理对话窗”后按下[新增…],即可出现下图的对话窗,正确设定后按下确认键。
[标签名]
文字标签的名称,此范例将标签命名为“Pump Alarm”。
[状态数]
文字标签所拥有的状态。
完成此步骤后可以发现已存在一个新的标签“Pump Alarm”,并拥有两个状态,参考下图。
最后,选择“Pump Alarm”并按下[设定…],即可使用下图的对话窗设定相关语言的内容。
文字标签库的使用
当文字标签库存在已定义完成的标签,在组件的[标签]设定页中可以勾选[使用文字标签库],并且在[标签]的项目中可以发现目前这些标签。
选择这些标签后可以发现[内容]中所显示为文字标签的内容,并且所使用的字型也为文字标签库的内容。
多国语文的使用
当组件的文字内容要求表现出多国语文的效果时,除了需使用文字标签外,也需搭配系统保留缓存器[LW9134]的使用。
[LW9134]的有效可设定值范围为0~7,不同的数据对应到需显示的语言种类,下文一个简单的范例,说明如何使用多国语文。
首先建立一个文字组件,它的文字设定内容如下,可清楚看出此时使用文字标签。
下一步再建立一个数值输入组件,地址设定内容如下。
可清楚看出此时所使用的地址为系统保留缓存器[LW9134]。
此时画面的仿真效果如下图,当我们更改[LW9134]的内容时,即可更换文字组件所显示的内容。