CUFFT_Library_3.0
LCF文件使用说明
Codewarrior 2.10是飞思卡尔32位汽车级单片机Qorriva 系列的编译器,与之前版本2.8、2.9完全兼容。
许多新用户对codewarrior 链接文件不是十分了解,本文将针对链接文件的常见问题以及段的定义进行介绍帮助用户快速了解和使用CodeWarrior 。
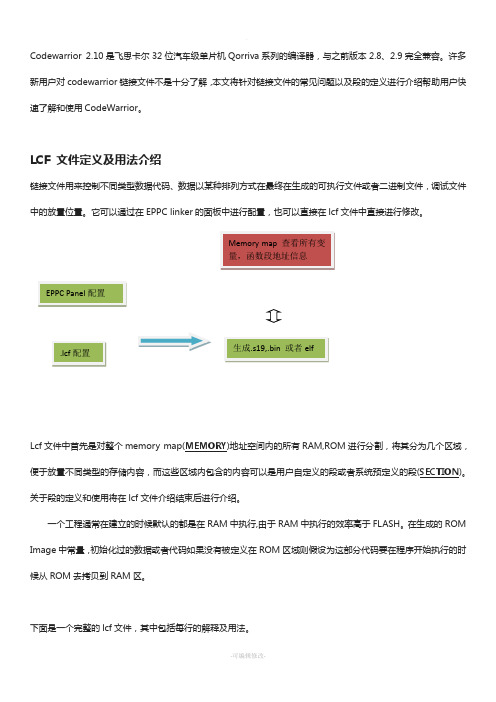
LCF 文件定义及用法介绍链接文件用来控制不同类型数据代码、数据以某种排列方式在最终在生成的可执行文件或者二进制文件,调试文件中的放置位置。
它可以通过在EPPC linker 的面板中进行配置,也可以直接在lcf 文件中直接进行修改。
Lcf 文件中首先是对整个memory map(MEMORY )地址空间内的所有RAM,ROM 进行分割,将其分为几个区域,便于放置不同类型的存储内容,而这些区域内包含的内容可以是用户自定义的段或者系统预定义的段(SECTION )。
关于段的定义和使用将在lcf 文件介绍结束后进行介绍。
一个工程通常在建立的时候默认的都是在RAM 中执行,由于RAM 中执行的效率高于FLASH 。
在生成的ROM Image 中常量,初始化过的数据或者代码如果没有被定义在ROM 区域则假设为这部分代码要在程序开始执行的时候从ROM 去拷贝到RAM 区。
下面是一个完整的lcf 文件,其中包括每行的解释及用法。
/* lcf file for MPC5604B M27V (debug RAM version) 文件的名字及对应单片机(RAM版本)*/ RAM版本和ROM版本的区别在于RAM版本不将程序下载到ROM中去,而在RAM中执行程序/* 512KB Flash, 32KB SRAM 单片机的FLASH和SRAM大小*/MEMORY下面是对单片机存储空间的定义,不同的段的起始地址,不能叠加地址空间{pseudo_rom:(仿真ROM区)org = 0x40000000, (开始地址)len = 0x00003000(长度)init: org = 0x40004000, len = 0x00001000 //初始化段所在位置exception_handlers: org = 0x40005000, len = 0x00001000 //中断向量所在地址internal_ram: org = 0x40006000, len = 0x00001800 //内部RAM的起始地址heap : org = 0x40007800, len = 0x00000400 /* Heap start */(堆的起始地址)stack : org = 0x40007C00, len = 0x00000400 /* Stack Start */ (栈的起始地址)}SECTIONS段的定义{GROUP : { // 它的定义需要遵从本例程方式”GROUP:{}” .“{}”中是内容部分.init : {} //.init段中所有内容。
uboot_JFFS2文件系统支持和U盘支持的使用备忘

一、U-Boot对JFFS2文件系统的支持我在include/configs/tekkaman2440.h 文件中添加了:#define CONFIG_CMD_JFFS2/*JFFS2 Support */#undef CONFIG_JFFS2_CMDLINE#define CONFIG_JFFS2_NAND 1#define CONFIG_JFFS2_DEVnand0"#define CONFIG_JFFS2_PART_SIZE 0x4c0000#define CONFIG_JFFS2_PART_OFFSET 0x40000/*JFFS2 Support */解释:CONFIG_CMD_JFFS2:使能对JFFS2相关命令的支持;[CONFIG_JFFS2_CMDLINE :若添加了此项定义,会加上对MTD勺支持。
但是要使用nand驱动,而不是nand_legacy驱动。
对于我这次移植改动会很大,所以暂不用;CONFIG_JFFS2_NAND:使能JFFS2 文件系统在NAND FLASHh的支持;CONFIG JFFS2 DEV :定义JFFS2文件系统所在的存储设备。
若对于NORFLASH为"nor0”; CONFIG_JFFS2_PART_SIZE :定义JFFS2文件系统分区大小。
CONFIG_JFFS2_PART_OFFSET定义JFFS2文件系统分区所在存储设备的起始偏移地址;U-Boot 还支持多分区的JFFS2文件系统,我还未做实验。
注意:即使是JFFS2 in NAND Flash,也不要使用\doc\README.JFFS2_NAND^介绍的CONFIG_JFFS2_NAND_DEVCONFIG_JFFS2_NAND_OFICONFIG_JFFS2_NAND_SIZEe配置,现在这些定义还未使用,是为以后的扩展设置的。
一开始我也被骗了。
配置好以上定义后,编译,下载到板子。
C Standard Library 参考手册说明书

About the T utorialC is a general-purpose, procedural, imperative computer programming language developed in 1972 by Dennis M. Ritchie at the Bell Telephone Laboratories to develop the Unix operating system.C is the most widely used computer language that keeps fluctuating at number one scale of popularity along with Java programming language which is also equally popular and most widely used among modern software programmers.The C Standard Library is a set of C built-in functions, constants and header files like <assert.h>, <ctype.h>,etc. This library will work as a reference manual for C programmers.AudienceThe C Standard Library is a reference for C programmers to help them in their projects related to system programming. All the C functions have been explained in a user-friendly way and they can be copied and pasted in your C projects.PrerequisitesA basic understanding of the C Programming language will help you in understanding the C built-in functions covered in this library.Copyright & DisclaimerCopyright 2014 by Tutorials Point (I) Pvt. Ltd.All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher.We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or inthistutorial,******************************************T able of ContentsAbout the Tutorial (i)Audience (i)Prerequisites (i)Copyright & Disclaimer (i)Table of Contents .................................................................................................................................... i i 1. C LIBRARY ─ <ASSERT.H> .. (1)Introduction (1)Library Macros (1)2. C LI BRARY ─ <CTYPE.H> (3)Introduction (3)Library Functions (3)Character Classes (24)3. C LIBRARY ─ <ERRNO.H> (26)Introduction (26)Library Macros (26)4. C LIBRARY ─ <FLOAT.H> (31)Introduction (31)Library Macros (31)5. C LIBRARY ─ <LIMITS.H> (34)Introduction (34)Library Macros (34)6. C LIBRARY ─ <LOCALE.H> (37)Introduction (37)Library Macros (37)Library Functions (38)Library Structure (42)7. C LIBRARY ─ <MATH.H> (45)Introduction (45)Library Macros (45)Library Functions (45)8. C LIBRARY ─ <SETJMP.H> (68)Introduction (68)Library Variables (68)Library Macros (68)Library Functions (70)9. C LIBRARY ─ <SIGNA L.H> (72)Introduction (72)Library Variables (72)Library Macros (72)Library Functions (73)10. C LIBRARY ─ <STDARG.H> (78)Introduction (78)Library Variables (78)Library Macros (78)11. C LIBRARY ─ <STDDEF.H> (83)Introduction (83)Library Variables (83)Library Macros (83)12. C LIBRARY ─ <STDIO.H> (87)Introduction (87)Library Variables (87)Library Macros (87)Library Functions (88)13. C LIBRARY ─ <STDLIB.H> (167)Introduction (167)Library Variables (167)Library Macros (167)Library Functions (168)14. C LIBRARY ─ <STRING.H> (205)Introduction (205)Library Variables (205)Library Macros (205)Library Functions (205)15. C LIBRARY ─ <TIME.H> (233)Introduction (233)Library Variables (233)Library Macros (234)Library Functions (234)C Standard Library 5IntroductionThe assert.h header file of the C Standard Library provides a macro called assert which can be used to verify assumptions made by the program and print a diagnostic message if this assumption is false.The defined macro assert refers to another macro NDEBUG which is not a part of <assert.h>. If NDEBUG is defined as a macro name in the source file, at the point where <assert.h> is included, the assert macro is defined as follows:Library MacrosFollowing is the only function defined in the header assert.h:void assert(int expression)DescriptionThe C library macro void assert(int expression) allows diagnostic information to be written to the standard error file. In other words, it can be used to add diagnostics in your C program. DeclarationFollowing is the declaration for assert() Macro.Parametersexpression -- This can be a variable or any C expression. If expression evaluates to TRUE, assert() does nothing. If expression evaluates to FALSE, assert() displays an1.C Standard Library6error message on stderr(standard error stream to display error messages and diagnostics) and aborts program execution.Return ValueThis macro does not return any value.ExampleThe following example shows the usage of assert() macro:Let us compile and run the above program in the interactive mode as shown below:C Standard Library 7IntroductionThe ctype.h header file of the C Standard Library declares several functions that are useful for testing and mapping characters.All the functions accepts int as a parameter, whose value must be EOF or representable as an unsigned char.All the functions return non-zero (true) if the argument c satisfies the condition described, and zero (false) if not.Library FunctionsFollowing are the functions defined in the header ctype.h:2.int isalnum(int c)DescriptionThe C library function void isalnum(int c)checks if the passed character is alphanumeric. DeclarationFollowing is the declaration for isalnum() function.Parametersc-- This is the character to be checked.Return ValueThis function returns non-zero value if c is a digit or a letter, else it returns 0.ExampleThe following example shows the usage of isalnum() function.9Let us compile and run the above program to produce the following result:int isalpha(int c)DescriptionThe C library function void isalpha(int c)checks if the passed character is alphabetic. DeclarationFollowing is the declaration for isalpha() function.Parametersc-- This is the character to be checked.Return ValueThis function returns non-zero value if c is an alphabet, else it returns 0.ExampleThe following example shows the usage of isalpha() function.11Let us compile and run the above program to produce the following result: int iscntrl(int c)DescriptionThe C library function void iscntrl(int c) checks if the passed character is a control character. According to standard ASCII character set, control characters are between ASCII codes 0x00 (NUL), 0x1f (US), and 0x7f (DEL). Specific compiler implementations for certain platforms may define additional control characters in the extended character set (above 0x7f).DeclarationFollowing is the declaration for iscntrl() function. Parametersc -- This is the character to be checked.Return ValueThis function returns non-zero value if c is a control character, else it returns 0.ExampleThe following example shows the usage of iscntrl() function.13Let us compile and run the above program to produce the following result:int isdigit(int c)DescriptionThe C library function void isdigit(int c)checks if the passed character is a decimal digit character.Decimal digits are (numbers): 0 1 2 3 4 5 6 7 8 9.14DeclarationFollowing is the declaration for isdigit() function.Parametersc-- This is the character to be checked.Return ValueThis function returns non-zero value if c is a digit, else it returns 0. ExampleThe following example shows the usage of isdigit() function.Let us compile and run the above program to produce the following result: int isgraph(int c)DescriptionThe C library function void isgraph(int c) checks if the character has graphical representation.The characters with graphical representations are all those characters that can be printed except for whitespace characters (like ' '), which is not considered as isgraph characters.DeclarationFollowing is the declaration for isgraph() function. Parametersc -- This is the character to be checked.Return ValueThis function returns non-zero value if c has a graphical representation as character, else it returns 0.ExampleThe following example shows the usage of isgraph() function.16Let us compile and run the above program to produce the following result:17int islower(int c)DescriptionThe C library function int islower(int c)checks whether the passed character is a lowercase letter.DeclarationFollowing is the declaration for islower() function.Parametersc-- This is the character to be checked.Return ValueThis function returns a non-zero value(true) if c is a lowercase alphabetic letter else, zero (false).ExampleThe following example shows the usage of islower() function.18Let us compile and run the above program to produce the following result: int isprint(int c)DescriptionThe C library function int isprint(int c) checks whether the passed character is printable. A printable character is a character that is not a control character.DeclarationFollowing is the declaration for isprint() function. Parametersc -- This is the character to be checked.19Return ValueThis function returns a non-zero value(true) if c is a printable character else, zero (false). ExampleThe following example shows the usage of isprint() function.20Let us compile and run the above program to produce the following result:int ispunct(int c)DescriptionThe C library function int ispunct(int c) checks whether the passed character is a punctuation character. A punctuation character is any graphic character (as in isgraph) that is not alphanumeric (as in isalnum).DeclarationFollowing is the declaration for ispunct() function.Parameters21c-- This is the character to be checked.Return ValueThis function returns a non-zero value(true) if c is a punctuation character else, zero (false). ExampleThe following example shows the usage of ispunct() function.22Let us compile and run the above program that will produce the following result:int isspace(int c)DescriptionThe C library function int isspace(int c) checks whether the passed character is white-space. Standard white-space characters are:23DeclarationFollowing is the declaration for isspace() function.Parametersc -- This is the character to be checked.Return ValueThis function returns a non-zero value(true) if c is a white-space character else, zero (false).24End of ebook previewIf you liked what you saw…Buy it from our store @ https://。
Infoprint 250 導入と計画の手引き 第 7 章ホスト

SUBNETMASK
255.255.255.128
Type of service...............: TOS
*NORMAL
Maximum transmission unit.....: MTU
*LIND
Autostart.....................:
AUTOSTART
*YES
: xx.xxx.xxx.xxx
: xx.xxx.xxx.xxx
*
(
)
IEEE802.3
60 1500
: xxxx
48 Infoprint 250
31. AS/400
IP
MTU
1
1
IPDS TCP
CRTPSFCFG (V3R2)
WRKAFP2 (V3R1 & V3R6)
RMTLOCNAME RMTSYS
MODEL
0
Advanced function printing............:
AFP
*YES
AFP attachment........................:
AFPATTACH
*APPC
Online at IPL.........................:
ONLINE
FORMFEED
*CONT
Separator drawer......................:
SEPDRAWER
*FILE
Separator program.....................:
SEPPGM
*NONE
Library.............................:
CUDA Fortran SC11 用户指南说明书

CUDA FortranSC11Dr. Justin Luitjens, NVIDIA CorporationCUDA Fortran/resources/cudafortran.htmMust either place inside a module or declare an explicit interfaceC Qualifier Fortran Attribute__global__ global __host__ host __device__ device __shared__ shared C Built-inFortranBuilt-in threadIdx.{xyz} threadIdx%{xyz} blockIdx.{xyz} blockIdx%{xyz} blockDim.{xyz} blockDim%{xyz} gridDim.{xyz} gridDim%{xyz}__syncthreads() call syncthreads() threadIdx & blockIdx are 1-basedFortran parameters are passed by reference by default!Kernel Loop Directive!$cuf kernel do(n) <<< grid, block >> !$cuf kernel do(2) <<< *, * >>>do j = 1, mdo i = 1, nd_a(i,j) = d_b(i,j) + d_c(i,j)end doend doReduction using CUF Kernels...sum = 0.0!$cuf kernel do <<<*,*>>>do i = 1, nsum = sum + a_d(i)end do...Compilationpgfortran.cuf .CUF-Mcuda=cc20-Mcuda=emu-Mcuda=cuda4.0 -Mcuda=fastmath __sinf())-Mcuda=nofma-Mcuda=maxregcount:<n>-Mcuda=ptxinfoExample: Hello Worldmodule hello containssubroutine mykernel() end subroutineend moduleprogram gpu_example use helloprint *, "Hello World!" call mykernel()end program module hellocontainsattributes(global)subroutine mykernel() end subroutineend moduleprogram gpu_exampleuse hellouse cudaforprint *, "Hello World!"call mykernel<<<1,1>>>()end programprogram vector_additionuse vectorAddinteger, allocatable:: a(:), b(:), c(:) integer:: NN=1000000allocate( a(N) , b(N) , c(N) )call initializeVector(a, N)call initializeVector(b, N)call add(N,a,b,c)deallocate( a(N), b(N), c(N) )end program program vector_additionuse vectorAdduse cudaforinteger, allocatable:: a(:), b(:), c(:)integer, device, allocatable:: d_a(:), d_b(:), d_c(:) integer:: NN=1000000allocate( a(N) , b(N) , c(N), d_a(N), d_b(N), d_c(N) )call initializeVector(a, N)call initializeVector(b, N)d_a = ad_b = bcall add<<<CEILING(N/512.0),512>>>(N,d_a,d_b,d_c) c = d_cdeallocate( a(N , b(N), c(N), d_a(N), d_b(N), d_c(N) ) end programmodule vectorAdd containssubroutine add(N, a, b, c) integer:: Ninteger:: a(N), b(N), c(N) integer:: idxdo idx = 1, Nc(idx) = a(idx) + b(idx) end doend subroutineend module module vectorAddcontainsattributes(global)subroutine add(N, a, b, c)integer, value:: Ninteger:: a(N), b(N), c(N)integer:: idxidx = threadIdx%x+(blockIdx%x-1)*blockDim%x if ( idx <= N ) thenc(idx) = a(idx) + b(idx)end ifend subroutineend moduleExample: Cuda Fortran Stencil 1D Kernel module stencil1dinteger, parameter:: RADIUS = 3intege r, parameter:: BLOCK_SIZE = 512containsattributes(global) subroutine stencil_1d(N, in, out)integer, value:: Ninteger:: in(N), out(N)integer, shared:: temp(BLOCK_SIZE + 2 * RADIUS) integer:: gidx, lidx, sum, offset! compute local and global indexgidx = threadIdx%x + (blockIdx%x-1) * blockDim%x lidx = threadIdx%x + RADIUS! load input into shared memorytemp(lidx) = in(gidx)if (threadIdx%x <= RADIUS) thentemp(lidx – RADIUS) = in(gidx – RADIUS)temp(lidx + BLOCK_SIZE) = in(gidx + BLOCK_SIZE) end if ! wait for all threadscall syncthreads()! sum out of shared memorysum = 0do offset = -RADIUS, RADIUSsum = sum + temp(lidx + offset) end do! write the sum to global memory out(gidx) = sumend subroutineend moduleCUDA Fortran/lit/whitepapers/pgicudaforug.pdf/resources/cudafortran.htmCUDA LibrariesSC11Dr. Justin Luitjens, NVIDIA CorporationCUDA Math Libraries /getcudaToday’s Goal/nvidia-gpu-computing-documentationcuFFT LibrarycuFFT Library FeaturescuFFT in 4 easy steps Step 1Step 2Step 3Step 4Example cuFFT Program#include <stdlib.h>#include <stdio.h>#include “cufft.h”#define NX 256#define NY 128int main() {cufftHandle plan;cufftComplex *idata, *odata;int i;cudaMalloc((void**)&idata, sizeof(cufftComplex)*NX*NY); cudaMalloc((void**)&odata, sizeof(cufftComplex)*NX*NY); /* initialize idata */… /* create a 2D FFT plan */cufftPlan2d(&plan, NX, NY, CUFFT_C2C);/* Use the CUFFT plan to transform the signal out of place. * Note: idata != odata indicates an out of place* transformation to CUFFT at execution time. */cufftExecC2C(plan, idata, odata, CUFFT_FORWARD);/* Inverse transform the signal in place */cufftExecC2C(plan, odata, odata, CUFFT_INVERSE);/* Destroy the CUFFT plan */cufftDestroy(plan);cudaFree(idata);cudaFree(odata);return 0}Check out the CUDA SDK for more examplesFFTs up to 10x Faster than MKL• cuFFT 4.1 on Tesla M2090, ECC on•MKL10.2.3,*******************************1D used in audio processing and as a foundation for 2D and 3D FFTs cuFFT-Single PrecisionCUFFT MKLcuFFT-Double PrecisionCUFFTMKLcuBLAS Library/nvidia-gpu-computing-documentationUsing cuBLAScublas.hCalling cuBLAS from C#include <stdlib.h>#include <stdio.h>#include “cublas.h”int main() {float *a, *b, *c, *d_a, *d_b, *d_c;int n=4096;int num_bytes=n*n*sizeof(float);/* initialize cublas */cublasInit();/* allocate memory */a=(float*)malloc(num_bytes);b=(float*)malloc(num_bytes);c=(float*)malloc(num_bytes);cublasAlloc(n*n, sizeof(float), (void**) & d_a); cublasAlloc(n*n, sizeof(float), (void**) & d_b); cublasAlloc(n*n, sizeof(float), (void**) & d_c); /* initialize matrices a and b on host */…/* copy matrices to device */cublasSetMatrix(n,n,sizeof(float), a, n, d_a, n);cublasSetMatrix(n,n,sizeof(float), b, n, d_b, n);/* perform multiplication */cublasSgemm(…N‟, …N‟, n, n, n, 1.0, d_a, n, d_b, n, 0.0, d_c, n); /* copy result back to the host */cublasGetMatrix( n, n, sizeof(float), d_c, n, c, n);/* free memory */cublasFree(d_a); cublasFree(d_b); cublasFree(d_c);free(a); free(b); free(c);/* shutdown cublas */cublasShutdown();return 0;}Calling cuBLAS from FORTRANSGEMM example (Thunking) program example_sgemm! Define 3 single precision matrices A, B, Creal, dimension(:,:),allocatable:: A(:,:),B(:,:),C(:,:)integer:: n=16allocate (A(n,n),B(n,n),C(n,n))! Initialize A, B and C…#ifdef CUBLAS! Call SGEMM in CUBLAS library using THUNKING interface (library takes care of! memory allocation on device and data movement)call cublas_SGEMM('n','n', n,n,n,1.,A,n,B,n,1.,C,n)#else! Call SGEMM in host BLAS librarycall SGEMM('n','n', n,n,n,1.,A,n,B,n,1.,C,n)#endifend program example_sgemmSGEMM example (Non-thunking) program example_sgemmreal, dimension(:,:),allocatable:: A(:,:),B(:,:),C(:,:)integer*8:: devPtrA, devPtrB, devPtrCinteger:: n=16, size_of_real=16allocate (A(n,n),B(n,n),C(n,n))call cublas_Alloc(n*n ,size_of_real, devPtrA)call cublas_Alloc(n*n, size_of_real, devPtrB)call cublas_Alloc(n*n, size_of_real, devPtrC)! Initialize A, B and C…! Copy data to GPUcall cublas_Set_Matrix(n, n, size_of_real, A, n, devPtrA, n)call cublas_Set_Matrix(n, n, size_of_real, B, n ,devPtrB, n)call cublas_Set_Matrix(n, n, size_of_real, C, n, devPtrC, n)! Call SGEMM in CUBLAS librarycall cublas_SGEMM('n', 'n', n, n, n, 1., devPtrA, n, devPtrB, n, 1., devPtrC, n)! Copy data from GPUcall cublas_Get_Matrix( n, n, size_of_real, devPtrC, n, C, n)call cublas_Free( devPtrA )call cublas_Free( devPtrB )call cublas_Free( devPtrC )end program example_sgemmuse cublascall saxpy(n, a_d, x_d, incx, y_d, incy)call cublasSaxpy(n, a_d, x_d, incx, y_d, incy)h istat = cublasSaxpy_v2(h, n, a_d, x_d, incx, y_d, incy)program cublasTestuse cublasimplicit nonereal, allocatable :: a(:,:),b(:,:),c(:,:)real, device, allocatable :: a_d(:,:),b_d(:,:),c_d(:,:)integer :: k=4, m=4, n=4real :: alpha=1.0, beta=2.0allocate(a(m,k), b(k,n), c(m,n), a_d(m,k), b_d(k,n), c_d(m,n))a = 1; a_d = ab = 2; b_d = bc = 3; c_d = ccall cublasSgemm('N', 'N', m , n, k, alpha, a_d, m, b_d, k, beta, c_d, m) c=c_ddeallocate(a, b, c, a_d, b_d, c_d)end program cublasTestcuBLAS Level 3 Performance• 4Kx4K matrix size• cuBLAS 4.1, Tesla M2090 (Fermi), ECC on•MKL10.2.3,*******************************>6x S G E M MS S Y M MS S Y R KS T R M MS T R S MC G E M MC S Y M MC S Y R KC T R M MC T R S MD GE M MD S Y M MD S Y R KD T R M MD T R S MZ G E M MZ S Y M MZ S Y R KZ T R M MZ T R S MSingle Complex Double Double ComplexS G E M MS S Y M MS S Y R KS T R M MS T R S MC G E M MC S Y M M C S Y R KC T R M MC T R S MD GE M MD S Y M MD S Y R KD T R M MD T R S MZ G E M MZ S Y M MZ S Y R KZ T R M MZ T R S MSingle Complex Double Double ComplexcuSPARSE: Sparse Linear Algebra Routines1.02.03.04.01.06.0 4.07.03.0 2.0 5.0cuSPARSE is up to 6x Faster than MKLPerformance may vary based on OS version and motherboard configuration * cuSPARSE 4.1, NVIDIA C2050 (Fermi), ECC on*MKL10.2.3,*******************************single-hybmv double-hybmv Complex-hybmv d-Complex-hybmv single-csrmv double-csrmv complex-csrmv d-complex-csrmvCURAND LibrarycuRAND: Random Number GenerationcuRAND PerformancePerformance may vary based on OS version and motherboard configurationcuRAND vs MKLDouble Precision, Uniform DistributioncuRAND vs MKLDouble Precision, Normal Distribution•cuRAND 4.1, Tesla M2090 (Fermi), ECC on•MKL10.2.3,*******************************Thrust: CUDA C++ Template LibraryquicklyThrust Example#include <thrust/host_vector.h>#include <thrust/device_vector.h>#include <thrust/sort.h>#include <cstdlib.h>int main(void){// generate 32M random numbers on the hostthrust::host_vector<int> h_vec(32 << 20);thrust::generate(h_vec.begin(), h_vec.end(), rand);// transfer data to the devicethrust::device_vector<int> d_vec = h_vec;// sort data on the device (846M keys per sec on GeForce GTX 480) thrust::sort(d_vec.begin(), d_vec.end());// transfer data back to hostthrust::copy(d_vec.begin(), d_vec.end(), h_vec.begin());return 0;}Thrust Algorithm PerformanceVarious Algorithms (32M int.) Speedup compared to Intel TBBThrust Various Algorithms (32M float.) Speedup compared to Intel TBBThrust• Thrust 4.1, cuBLAS 4.1, Tesla M2090 (Fermi), ECC on•*******************************NVIDIA Performance Primitives40x* NPP 4.1, NVIDIA M2090 (Fermi)*IPP6.1,*******************************Image Processing Primitivesmath.h: C99 floating-point library + extras•Basic(all IEEE-754 accurate for float, double, all rounding modes) •Exponentials•Trigonometry•Special functions•Utility•ExtrasNVIDIA CUDA LibrariesQuestions?。
freetype 用法

freetype 用法freetype是一个在计算机图形中广泛使用的开源字体引擎。
它提供了一种简单而强大的方法来将字体渲染到屏幕上,从而使开发人员能够在应用程序,游戏和其他图形项目中使用高质量的文本。
本文将介绍freetype的基本用法,并为您提供一步一步的指南。
第一步:安装freetype库要使用freetype,您首先需要在您的开发环境中安装该库。
您可以从freetype官方网站(第二步:初始化freetype库使用freetype之前,您需要初始化freetype库。
这可以通过调用`FT_Init_FreeType`函数来完成。
该函数将返回一个`FT_Library`对象,您将在后面的步骤中使用它来进行字体的加载和渲染操作。
以下是一个初始化freetype库的示例代码:c#include <ft2build.h>#include FT_FREETYPE_HFT_Library library;if (FT_Init_FreeType(&library)){初始化失败,处理错误}第三步:加载字体在渲染文本之前,您需要加载所需的字体。
freetype支持多种字体格式,包括TrueType和OpenType等常见格式。
您可以通过调用`FT_New_Face`函数来加载字体。
此函数接受字体文件的路径作为参数,并返回一个`FT_Face`对象,您将在后面的步骤中使用它来渲染文本。
以下是一个加载字体的示例代码:cFT_Face face;if (FT_New_Face(library, "path/to/font.ttf", 0, &face)){字体加载失败,处理错误}第四步:设置字体大小和字符间距在渲染文本之前,您需要设置字体的大小和字符间距。
要设置字体大小,您可以使用`FT_Set_Char_Size`函数或`FT_Set_Pixel_Sizes`函数。
第6章_TwinCAT库文件

6. TwinCAT库文件 (172)6.1. 温控库 (172)6.1.1. 简介 (172)6.2. 控制工具箱TcPlcControllerToolbox.lib (172)6.2.1. 滤波 (172)6.2.2. PID (174)6.2.3. PWM输出 (175)6.2.4. 设定点发生器SetpointGeneration (176)6.3. 调用Windows和TwinCA T功能的库TcUtility.lib (177)6.3.1. 调用Windows的功能 (177)6.3.2. 读取IP地址和修改注册表 (178)6.3.3. 启动和停止应用程序 (179)6.3.4. 内存操作 (180)6.3.5. 调用TwinCAT System Manager的功能 (181)6.3.6. BCD码转换 (181)6.4. EtherCAT主站和从站的控制TcEtherCAT.lib (182)6.4.1. EtherCAT状态切换 (182)6.4.2. EtherCAT从站的参数设置 (186)6.4.3. EtherCAT数据包统计 (190)6.4.4. EtherCAT诊断 (190)6.5. 其它有用的库 (190)第171页共1001 页2013-10-256.TwinCAT库文件6.1. 温控库例程及文档:“\配套文档\第6章_TwinCA T库文件\1 温控库\\温度库例子V1.1\说明”作者是倍福广州分公司的Swen Chen。
1,使用DEMO程序之前,请观看视频“\温度库例子V1.1\说明\温度库说明_Swen.exe”。
2,温控所需要的库文件在“\温度库例子V1.1\Lib\TcTempCtrl.lib”。
3,详细的温控库说明:“\温度库例子V1.1\说明\TcPlcLibTempControl.CHM”。
4,BECKHOFF的温控解决方案:“\配套文档\第6章_TwinCA T库文件\1 温控库\基于PC的温度控制解决方案.pdf”。
cufflinks输入输出文件分析

sort –k 3,3 –k 4,4n hits.sam > hits.sam.sortd
7. FPKMx8.01651样品x的基因FPKM
8. FPKMy 8.3514321样品y的基因FPKM
9.log2(FPKMy/FPKMx)0.06531fold
10.测试统计0.8665465寻找计算FPKM显著性差异
11.pvalue 0.389292
12. qvalue 0.985216FDR矫正p值
Isoforms.fpkm_tracking转录本FPKMs
Genes.fpkm_tracking Gene FPKMs,转录本每个基因的FPKM
cds.fpkm_tracking编码序列FPKMs.p_id,独立于tss_id
Tss_groups.fpkm_tracking初级转录本的FPKMs
Count tracking files
isoforms.count_tracking转录本计数
genes.count_tracking基因计数
cds.counቤተ መጻሕፍቲ ባይዱ_tracking编码序列计数
tss_groups.count_tracking初级转录本计数
Read group tracking files(读取组跟踪文件)
计算每个转录本,初级转录本每个重复基因的表达和片段的计数结果输出配一个重复文件。
Column编号column名字样品名描述
cuDLA API 参考手册.pdf_1701878184.765848说明书

API Reference ManualTable of Contents Chapter 1. Data Structures (1)cudlaDevAttribute (1)deviceVersion (1)unifiedAddressingSupported (1)cudlaExternalMemoryHandleDesc_t (1)extBufObject (2)size (2)cudlaExternalSemaphoreHandleDesc_t (2)extSyncObject (2)CudlaFence (2)fence (2)type (2)cudlaModuleAttribute (2)inputTensorDesc (3)numInputTensors (3)numOutputTensors (3)outputTensorDesc (3)cudlaModuleTensorDescriptor (3)cudlaSignalEvents (3)devPtrs (3)eofFences (3)numEvents (3)cudlaTask (4)inputTensor (4)moduleHandle (4)numInputTensors (4)numOutputTensors (4)outputTensor (4)signalEvents (4)waitEvents (4)cudlaWaitEvents (4)numEvents (4)preFences (5)Chapter 2. Data Fields (6)Chapter 1.Data StructuresHere are the data structures with brief descriptions:cudlaDevAttributecudlaExternalMemoryHandleDesccudlaExternalSemaphoreHandleDescCudlaFencecudlaModuleAttributecudlaModuleTensorDescriptorcudlaSignalEventscudlaTaskcudlaWaitEvents1.1. cudlaDevAttribute Union Reference Device attribute.uint32_t cudlaDevAttribute::deviceVersionDLA device version. Xavier has 1.0 and Orin has 2.0.uint8_tcudlaDevAttribute::unifiedAddressingSupported Returns 0 if unified addressing is not supported.1.2. cudlaExternalMemoryHandleDesc_tStruct ReferenceExternal memory handle descriptor.const void*cudlaExternalMemoryHandleDesc_t::extBufObjectA handle representing an external memory object.unsigned long long cudlaExternalMemoryHandleDesc_t::sizeSize of the memory allocation1.3. cudlaExternalSemaphoreHandleDesc_tStruct ReferenceExternal semaphore handle descriptor.const void*cudlaExternalSemaphoreHandleDesc_t::extSyncObjectA handle representing an external synchronization object.1.4. CudlaFence Struct ReferenceFence description.void *CudlaFence::fenceFence.cudlaFenceType CudlaFence::typeFence type.1.5. cudlaModuleAttribute UnionReferenceModule attribute.cudlaModuleTensorDescriptor*cudlaModuleAttribute::inputTensorDescReturns an array of input tensor descriptors.uint32_t cudlaModuleAttribute::numInputTensors Returns the number of input tensors.uint32_t cudlaModuleAttribute::numOutputTensors Returns the number of output tensors. cudlaModuleTensorDescriptor*cudlaModuleAttribute::outputTensorDescReturns an array of output tensor descriptors.1.6. cudlaModuleTensorDescriptor StructReferenceTensor descriptor.1.7. cudlaSignalEvents Struct Reference Signal events for cudlaSubmitTaskconst **cudlaSignalEvents::devPtrsArray of registered synchronization objects (via cudlaImportExternalSemaphore). CudlaFence *cudlaSignalEvents::eofFencesArray of fences pointers for all the signal events corresponding to the synchronization objects. uint32_t cudlaSignalEvents::numEventsTotal number of signal events.1.8. cudlaTask Struct ReferenceStructure of Task.const **cudlaTask::inputTensorArray of input tensors.cudlaModule cudlaTask::moduleHandlecuDLA module handle.uint32_t cudlaTask::numInputTensorsNumber of input tensors.uint32_t cudlaTask::numOutputTensorsNumber of output tensors.const **cudlaTask::outputTensorArray of output tensors.cudlaSignalEvents *cudlaTask::signalEventsSignal events.const cudlaWaitEvents *cudlaTask::waitEvents Wait events.1.9. cudlaWaitEvents Struct Reference Wait events for cudlaSubmitTask.uint32_t cudlaWaitEvents::numEventsTotal number of wait events.const CudlaFence *cudlaWaitEvents::preFences Array of fence pointers for all the wait events.Chapter 2.Data FieldsHere is a list of all documented struct and union fields with links to the struct/union documentation for each field:deviceVersioncudlaDevAttributedevPtrscudlaSignalEventseofFencescudlaSignalEventsextBufObjectcudlaExternalMemoryHandleDescextSyncObjectcudlaExternalSemaphoreHandleDescfenceCudlaFenceinputTensorcudlaTaskinputTensorDesccudlaModuleAttributemoduleHandlecudlaTasknumEventscudlaWaitEventscudlaSignalEventsnumInputTensorscudlaTaskcudlaModuleAttributenumOutputTensorscudlaTaskcudlaModuleAttributeoutputTensorcudlaTaskoutputTensorDesccudlaModuleAttributeData Fields preFencescudlaWaitEventssignalEventscudlaTasksizecudlaExternalMemoryHandleDesctypeCudlaFenceunifiedAddressingSupportedcudlaDevAttributewaitEventscudlaTaskNoticeThis document is provided for information purposes only and shall not be regarded as a warranty of a certain functionality, condition, or quality of a product. NVIDIA Corporation (“NVIDIA”) makes no representations or warranties, expressed or implied, as to the accuracy or completeness of the information contained in this document and assumes no responsibility for any errors contained herein. NVIDIA shall have no liability for the consequences or use of such information or for any infringement of patents or other rights of third parties that may result from its use. This document is not a commitment to develop, release, or deliver any Material (defined below), code, or functionality.NVIDIA reserves the right to make corrections, modifications, enhancements, improvements, and any other changes to this document, at any time without notice. Customer should obtain the latest relevant information before placing orders and should verify that such information is current and complete.NVIDIA products are sold subject to the NVIDIA standard terms and conditions of sale supplied at the time of order acknowledgement, unless otherwise agreed in an individual sales agreement signed by authorized representatives of NVIDIA and customer (“Terms of Sale”). NVIDIA hereby expressly objects to applying any customer general terms and conditions with regards to the purchase of the NVIDIA product referenced in this document. No contractual obligations are formed either directly or indirectly by this document.OpenCLOpenCL is a trademark of Apple Inc. used under license to the Khronos Group Inc.TrademarksNVIDIA and the NVIDIA logo are trademarks or registered trademarks of NVIDIA Corporation in the U.S. and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.Copyright© 2021-2021 NVIDIA Corporation & affiliates. All rights reserved.NVIDIA Corporation | 2788 San Tomas Expressway, Santa Clara, CA 95051。
Cstandardlibrary(c标准库)

C standard library(c标准库)<assert.h>: diagnosis<assert.h> defines only a macro assert with a reference, which is defined as follows:Void assert (int expression)The assert macro is used to add diagnostic features to a program, which can test a condition and possibly terminate the program. Execute statement:Assert (expression);When the expression is 0, a message is displayed at the terminal:Assertion failed: 0, file source file name, line line numberAbnormal program terminationThen invoke the abort to terminate the execution of the program.In <assert.h>, the macro assert is defined as conditional compilation, and if the macro NDEBUG is defined in the source file, the assert macro will be ignored even if the header file <assert.h> is included<ctype.h>: character class testingFunctions that define test characters are defined in headerfile <ctype.h>. In these functions, the arguments for each function are integer int, and each parameter is either EOF or char type. The list of standard functions defined in <ctype.h> is as follows:Functions defined in <ctype.h>Function definitionFunction brief introductionInt isalnum (int c)Check whether the characters are letters or numbersInt isalpha (int c)Check if the characters are lettersInt isascii (int c)Check if the character is ASCIIInt iscntrl (int c)Check that the character is a control characterInt isDigit (int c)Check that the characters are numeric charactersInt isgraph (int c)Check that the characters are printable charactersInt islower (int c)Check if the characters are lowercase lettersInt isprint (int c)Check that the characters are printable charactersInt ispunct (int c)Check if the characters are punctuation charactersInt isspace (int c)Check if the character is a space characterInt isupper (int c)Check if the characters are uppercase lettersInt isxdigit (int c)Check if the character is a sixteen digit numeric character Int toupper (int c)Converts lowercase letters to uppercase lettersInt tolower (int c)Converts uppercase letters to lower case lettersThese standard functions defined in <ctype.h>, and some commonly used nonstandard character processing functions, will be described in detail in the Eleventh chapter.<errno.h>: error handlingTwo constants, one variable, are defined in <errno.h>.1, EDOMIt represents the wrong code for mathematical domain errors.2, ERANGEIt represents an error code that results out of bounds.3, errnoThis is a variable that is set to indicate the type of error in the system call.<limits.h>: integer constantIn header file <limits.h>, some constants that represent integer sizes are defined. The following are the expressions and meanings of these constants, as shown in the followingtable.Character constants defined in <limits.h> character constantsValueMeaningCHAR_BITEightNumber of char typesCHAR_MAX255 or 127Char type maximumCHAR_MIN0 or -127Char type minimumINT_MIN-32767Int type minimumINT_MAXThirty-two thousand seven hundred and sixty-sevenInt type maximumLONG_MAXTwo billion one hundred and forty-seven million four hundred and eighty-three thousand six hundred and forty-sevenLong type maximumLONG_MIN-2147483647Long type minimumSCHAR_MAXOne hundred and twenty-sevenSigned char type maximumSCHAR_MIN-127Signed char type minimumSHRT_MAXThirty-two thousand seven hundred and sixty-seven Maximum value of type shortSHRT_MIN-32767The minimum value of the short typeUCHAR_MAXTwo hundred and fifty-fiveunsigned char类型最大值uint_max六万五千五百三十五unsigned int类型最大值ulong_max四十二亿九千四百九十六万七千二百九十五无符号长类型最大值ushrt_max六万五千五百三十五无符号短类型的最大值< H >:地域环境现场。
库说明

ANALOG.OLB是常用零件库:电阻、可变电阻、电容、可变电容、电解、电感、延迟线等共23个常用元件。
其中电感有脚号,其余无脚号。
BREAKOUT.OLB是48个模块的break库:进行蒙托卡诺和最坏情况统计分析时必须用此库中的电阻、电容及各种半导体器件。
ADC*break,Bbreak,C break,DAC*break,Dbreak,Jbreak,Kbreak,L break,Mbreak,POT有脚号的电位器、Qbreak,QdarBreakN达林顿,QdarBreakP达林顿,RAM8Kx1break,RAM8Kx8break,Rbreak,ROM32Kx8break,Sbreak,Wbreak,XFRM_NONLIN/CT-*,变压器3种,XFRM_NONLINEAR变压器4脚,ZbreakN。
Design Cache.OLB是绘制电路图时调用过的自动生成的模块库。
SOURCE.OLB是39个模块的数字信号库,各种电压源和电流源符号。
有电流、电池、电压和正弦信号。
SOURCSTM.OLB是8个模块的数字信号库。
当激励信号源的信号波形从/Pspice 中的StmEd模块设置时,则信号源符号应从SOURCSTM库调用。
SPECTAL.OLB是28个模块的特殊符号库,其中有CD4000_PWR。
PSPICE仿真库文件夹下有89个库文件(Orcad9.2.3也为89个,Orcad 9.2为7 9个)和一个\pspice\advanls目录,它的路径是:OrCAD_10.1\tools\capture \library\pspice,它们是:1_shot.olb是54、74、CD数字电路模块库:54L12.,74L*,74LS*,CD4*,B系列。
74ac.olb是74数字电路模块库:74AC*系列。
74act.olb是74ACT数字电路模块库:74ACT系列。
74als.olb是74ALS数字电路模块库:74ALS系列。
find_library用法

find_library用法find_library是一个在C++编程中常用的函数,它的作用是查找指定的库文件是否存在于系统中,并返回库文件的路径。
在本文中,我将详细介绍find_library函数的使用方法,以及如何在实际编程中正确使用它。
首先,让我们来了解一下find_library函数的语法。
它的语法非常简单,只需要提供一个参数,即要查找的库文件的名称。
find_library函数会搜索系统中的标准库路径,如果找到了匹配的库文件,则返回库文件的绝对路径;如果未找到,则返回一个空字符串。
在使用find_library函数之前,我们需要确保已经正确安装了目标库文件。
如果目标库文件是一个常见的系统库,那通常无需担心,因为操作系统通常会预装这些库文件。
但如果目标库文件是一个第三方库,那么我们需要先下载并安装它,才能在编程中使用。
接下来,让我们看一个简单的例子来演示find_library函数的用法。
假设我们想查找名为libcrypto的库文件。
我们可以在代码中使用以下语句来调用find_library函数:find_library("crypto")这里,我们将要查找的库文件名称作为find_library函数的参数传递。
如果系统中存在名为libcrypto的库文件,find_library函数将返回该库文件的绝对路径,否则将返回一个空字符串。
在使用find_library函数时,我们还可以使用一些可选参数来进行更精确的搜索。
例如,我们可以指定要搜索的库文件的路径列表,这样可以加快搜索速度。
我们可以使用以下语句来调用find_library函数:find_library("crypto" PATHS "/usr/local/lib" "/opt/lib")在上面的例子中,我们通过PATHS参数指定了两个路径:/usr/local/lib 和/opt/lib。
cufflinks的使用

cufflinks的使用一. 简介Cufflinks下主要包含cufflinks,cuffmerge,cuffcompare和cuffdiff等几支主要的程序。
主要用于基因表达量的计算和差异表达基因的寻找。
二. 安装Cufflinks下载网页。
1. 为了安装Cufflinks,必须有Boost C++ libraries。
下载Boost 并安装。
默认安装在/usr/local。
$ tar jxvf boost_1_53_0.tar.bz2$ cd boost_1_53_0$ ./bootstrap.sh$ sudo ./b2 install2.安装SAM tools。
下载SAM tools。
$ tar jxvf samtools-0.1.18.tar.bz2$ cd samtools-0.1.18$ make$ sudo su# mkdir /usr/local/include/bam# cp libbam.a /usr/local/lib# cp *.h /usr/local/include/bam/# cp samtools /usr/bin/3. 安装 Eigen libraries。
下载Eigen$ tar jxvf 3.1.2.tar.bz2$ cd eigen-eigen-5097c01bcdc4$ sudo cp -r Eigen/ /usr/local/include/4. 安装Cufflinks。
$ tar zxvf cufflinks-2.0.2.tar.gz$ cd cufflinks-2.0.2$ ./configure --prefix=/path/to/cufflinks/install --with-boost=/usr/local/ --with-eigen=/usr/local/include//Eigen/ $ make$ make install5. 可以直接下载Linux x86_64 binary。
NVIDIA CUDA 库和 CUDA Fortran 用户指南说明书

CUDA Libraries and CUDA FortranNVIDIA CUDA LibrariesNVIDIA CUDA Libraries—CUFFT —CUBLAS —CUSPARSE —Libm (math.h)—CURAND —NPP —Thrust —CUSPNVIDIA Libraries3rd Party LibrariesApplications CUDA C/FortranCUFFT LibraryCUFFT is a GPU based Fast Fourier Transform libraryCUFFT Library Features2357N= N1*N2N1N2N1N2T,T Cooley-TukeyCUFFT in 4 easy stepsCode example:/* Create a 2D FFT plan. *//* Use the CUFFT plan to transform the signal out of place. *//* Inverse transform the signal in place.Different pointers to input and output arrays implies out of place transformation */ /* Destroy the CUFFT plan. */CUBLAS LibraryCUBLAS FeaturesUsing CUBLASInterface to CUBLAS library is in cublas.hFunction naming conventioncublas + BLAS nameEg., cublasSGEMMError handlingCUBLAS core functions do not return errorCUBLAS provides function to retrieve last error recorded CUBLAS helper functions do return errorHelper functions:Memory allocation, data transferCalling CUBLAS from CCalling CUBLAS from FORTRANTwo interfaces:ThunkingAllows interfacing to existing applications without any changesDuring each call, the wrappers allocate GPU memory, copy source data from CPU memory space to GPUmemory space, call CUBLAS, and finally copy back the results to CPU memory space and deallocate theGPGPU memoryIntended for light testing due to call overheadNon-Thunking (default)Intended for production codeSubstitute device pointers for vector and matrix arguments in all BLAS functionsExisting applications need to be modified slightly to allocate and deallocate data structures in GPGPUmemory space (using CUBLAS_ALLOC and CUBLAS_FREE) and to copy data between GPU and CPUmemory spaces (using CUBLAS_SET_VECTOR, CUBLAS_GET_VECTOR, CUBLAS_SET_MATRIX, andCUBLAS_GET_MATRIX)SGEMM example (THUNKING) ! Define 3 single precision matrices A, B, C! Initialize A, B and C! Call SGEMM in CUBLAS library using THUNKING interface (library takes care of! memory allocation on device and data movement)! Call SGEMM in host BLAS librarySGEMM example (NON-THUNKING)! Initialize A, B and C! Copy data to GPU! Call SGEMM in CUBLAS library! Copy data from GPUGEMM PerformancecuBLAS 3.2, Tesla C2050 (Fermi), ECC on MKL10.2.3,********************Performance may vary based on OS version and motherboard configuration636775301295788039400100200300400500600700800900SGEMMCGEMMDGEMMZGEMMCUBLAS3.2MKL 4THREADSUsing CPU and GPU concurrentlyDGEMM(A,B,C) = DGEMM(A,B1,C1) U DGEMM(A,B2,C2)The idea can be extended to multi-GPU configuration and to handle huge matricesFind the optimal split, knowing the relative performances of the GPU and CPU cores on DGEMM(GPU)(CPU)Overlap DGEMM on CPU and GPU // Copy A from CPU memory to GPU memory devAstatus = cublasSetMatrix (m, k , sizeof(A[0]), A, lda, devA, m_gpu);// Copy B1 from CPU memory to GPU memory devBstatus = cublasSetMatrix (k ,n_gpu, sizeof(B[0]), B, ldb, devB, k_gpu);// Copy C1 from CPU memory to GPU memory devCstatus = cublasSetMatrix (m, n_gpu, sizeof(C[0]), C, ldc, devC, m_gpu);// Perform DGEMM(devA,devB,devC) on GPU// Control immediately return to CPUcublasDgemm('n', 'n', m, n_gpu, k, alpha, devA, m,devB, k, beta, devC, m);// Perform DGEMM(A,B2,C2) on CPUdgemm('n','n',m,n_cpu,k, alpha, A, lda,B+ldb*n_gpu, ldb, beta,C+ldc*n_gpu, ldc);// Copy devC from GPU memory to CPU memory C1status = cublasGetMatrix (m, n, sizeof(C[0]), devC, m, C, *ldc);Using CUBLAS, it is very easy to express the workflow in the diagramChanges to CUBLAS API in CUDA 4.0CUSPARSENew library for sparse basic linear algebraConversion routines for dense, COO, CSR and CSC formats Optimized sparse matrix-vector multiplication Building block for sparse linear solvers1.02.03.04.0y 1y 2y 3y 4α+ β1.0 6.04.07.03.02.05.0y 1y 2y 3y 4CUDA Libm featuresImprovements•Continuous enhancements to performance and accuracy CUDA 3.1erfinvf (single precision)accuracy5.43 ulp → 2.69 ulpperformance1.7x faster than CUDA 3.0CUDA 3.21/x (double precision)performance1.8x faster than CUDA 3.1Double-precision division, rsqrt(), erfc(), & sinh() are all >~30% faster on FermiCURAND LibraryLibrary for generating random numbersFeatures:XORWOW pseudo-random generatorSobol’ quasi-random number generatorsHost API for generating random numbers in bulkInline implementation allows use inside GPU functions/kernelsSingle-and double-precision, uniform, normal and log-normal distributionsCURAND Features/v08/i14/paperCURAND use 1.2.3.4.Example CURAND Program: Host APIExample CURAND Program: Run on CPUCURAND PerformanceCURAND 3.2, NVIDIA C2050 (Fermi), ECC onG i g a S a m p l e s / s e c o n dPerformance may vary based on OS version and motherboard configurationNVIDIA Performance Primitives (NPP)–C library of functions (primitives)–well optimized–low level API:–easy integration into existing code–algorithmic building blocks–actual operations execute on CUDA GPUs–Approximately 350 image processingfunctions–Approximately 100 signal processingfunctionsImage Processing PrimitivesThrust▪A template library for CUDA—Mimics the C++ STL▪Containers—Manage memory on host and device: thrust::host_vector<T>, thrust:device_vector<T>—Help avoid common errors▪Iterators—Know where data lives—Define ranges: d_vec.begin()▪Algorithms—Sorting, reduction, scan, etc: thrust::sort()—Algorithms act on ranges and support general types and operatorsThrust Example#include <thrust/host_vector.h>#include <thrust/device_vector.h>#include <thrust/sort.h>#include <cstdlib.h>// generate 32M random numbers on the host// transfer data to the device// sort data on the device (846M keys per sec on GeForce GTX 480)// transfer data back to hostAlgorithms—for_each, transform, gather, scatter…—reduce, inner_product, reduce_by_key…—inclusive_scan, inclusive_scan_by_key… —sort, stable_sort, sort_by_key…Thrust Algorithm Performance *Thrust4.0,NVIDIATeslaC2050(Fermi)******************Interoperability (from Thrust to C/CUDA) // allocate device vectordevice_vector int// obtain raw pointer to device vector’s memoryint raw_pointer_cast// use ptr in a CUDA C kernel// Note: ptr cannot be dereferenced on the host!Interoperability (from C/CUDA to Thrust)device_ptr// raw pointer to device memoryintvoid sizeof(int// wrap raw pointer with a device_ptrdevice_ptr int// use device_ptr in thrust algorithmsfill int// access device memory through device_ptr// free memoryThrust on Google CodeCUDA FortranPGI / NVIDIA collaborationSame CUDA programming model as CUDA-C with Fortran syntax Strongly typed –variables with device-type reside in GPUmemoryUse standard allocate, deallocateCopy between CPU and GPU with assignment statements:GPU_array = CPU_arrayKernel loop directives (CUF Kernels) to parallelize loops with device dataCUDA Fortran example use cudafordevicedim3! Use standard allocate for CPU and GPU arrays ! Move data with simple assignment! Call CUDA kernelblock_size=dim3(16,16,1)<<<grid_size, block_size>>>CUDA Fortran example attributes(global)value! Indices start from 1i = threadIdx%x+ (blockIdx%x -1) * blockDim%x j = threadIdx%y+ (blockIdx%y -1) * blockDim%y If ( i <= n .and. j<=m)end ifComputing πwith CUDA Fortranπ = 4 * (∑ red points)/(∑ points)Simple example:–Generate random numbers ( CURAND)–Compute sum using of kernel loop directive–Compute sum using two stages reduction with Cuda Fortran kernels –Compute sum using single stage reduction with Cuda Fortran kernel –AccuracyCUDA Libraries from CUDA Fortran!curandGenerateUniform(curandGenerator_t generator, float *outputPtr, size_t num);!pgi$ ignore_tr odata!curandGenerateUniformDouble(curandGenerator_t generator, double *outputPtr, size_t num);!pgi$ ignore_tr odataComputing with CUF kernel! Compute pi using a Monte Carlo methoduse cudafor ! CUDA Fortran runtimeuse curand! CURAND interfacepinneddevice! Define how many numbers we want to generate! Allocate arrays on CPU and GPU! Create pseudonumber generator! Set seed! Generate N floats or double on device ! Copy the data back to CPU to check result later ! Perform the test on GPU using CUF kernel!$cuf kernel do <<<*,*>>>! Perform the test on CPU! Check the results! Print the value of pi and the error! Deallocate data on CPU and GPU! Destroy the generatorComputingMismatch between CPU/GPU 78534862 78534859GPU accuracyFERMI GPUs are IEEE-754 compliant, both for single and double precision Support for Fused Multiply-Add instruction ( IEEE 754-2008)Results with FMA could be different*from results without FMAIn CUDA Fortran is possible to toggle FMA on/off with a compiler switch: -Mcuda=nofmaExtremely useful to compare results to “golden” CPU outputFMA is being supported in future CPUsCompute pi in single precision (seed=1234567 FMA disabled)Samples= 10000 Pi=3.16720009 Error= 0.2561E-01Samples= 100000 Pi=3.13919997 Error= 0.2393E-02Samples= 1000000 Pi=3.14109206 Error= 0.5007E-03Samples= 10000000 Pi=3.14106607 Error= 0.5267E-03Samples= 100000000 Pi=3.14139462 Error= 0.1981E-03*GPU results with FMA are identical to CPU if operations are done in double precisionReductions on GPU475911142531704163475911142531704163475911142531704163475911142531704163475911142531704163475911142531704163475911142531704163475911142531704163475911142531704163Level 0:8 blocks Level 1:1 block475911142531704163Parallel Reduction: Sequential Addressing1018-10-235-2-32701102123456788-21060937-2-3270110212348713130937-2-3270110212212013130937-2-327011021412013130937-2-32701102attributes(global)shared! Check if the point is inside the circle and increment local counter! Each block writes back its partial sum ! Local reduction per block! Compute the partial sums with 256 blocks of 512 threads! Compute the final sum with 1 block of 256 threadsattributes(globalshared! load partial sums in shared memory! First thread has the total sum, writes it back to global memory。
linux c fread实例 -回复

linux c fread实例-回复读取文件是编程中一个常见的操作,而在Linux环境下,可以使用C语言的fread函数来进行文件读取。
本文将以fread函数为例,详细介绍在Linux环境下如何使用该函数读取文件的步骤和注意事项。
首先,我们需要了解fread函数的基本用法。
fread函数主要用于从指定文件中读取数据,其函数原型如下:csize_t fread(void *ptr, size_t size, size_t count, FILE *stream);其中,参数ptr是用于存储读取数据的缓冲区地址,参数size表示每个数据项的字节数,参数count表示要读取的数据项的数量,参数stream表示要读取的文件流。
使用fread函数读取文件的一般步骤如下:1. 打开文件:在使用fread函数读取文件之前,需要先通过fopen函数打开要读取的文件。
fopen函数的返回值为一个指向文件的指针,我们可以将该指针传递给fread函数中的stream参数。
2. 检查文件是否打开成功:在调用fopen函数之后,需要对返回的文件指针进行判断,以确保文件是否成功打开。
如果文件打开失败,我们可以在程序中进行相应的错误处理。
3. 读取文件:使用fread函数进行文件读取操作。
在调用fread函数之前,我们需要准备一个足够大的缓冲区来存储读取到的数据。
缓冲区的大小可以根据实际需求进行调整。
读取数据时,需要指定每个数据项的字节数和要读取的数据项的数量。
读取到的数据将会被存储在缓冲区中。
4. 检查读取是否成功:在调用fread函数之后,需要对返回值进行判断,以确定读取操作是否成功。
如果读取失败,我们可以根据实际情况进行相应的错误处理。
5. 关闭文件:在读取完文件后,应该通过fclose函数关闭已打开的文件。
关闭文件对于程序的安全性和效率都非常重要。
如果文件未关闭,可能会对其他程序的文件操作造成干扰。
在使用fread函数读取文件时,还需要注意以下几点:1. 文件读取模式:在使用fopen函数打开文件时,需要指定文件读取模式。
libtool学习以及cross

libtool学习以及cross作者:Sam (甄峰)********************关于libtool部分,大量摘抄网络信息。
Sam在移植一些库和程序到嵌入式系统时,看到autoconfig就很头痛。
因为有时候它会出一些莫名其妙的问题。
尤其是在libtool部分。
今天在移植一个库到mipsel上时,又出问题了。
所以决定学学libtools.libtool作用:libtool 是一个通用库支持脚本(/usr/bin/libtool),将使用动态库的复杂性隐藏在统一、可移植的接口中。
可以在不同平台上创建并调用动态库,我们可以认为libtool是gcc的一个抽象,也就是说,它包装了gcc或者其他的任何编译器,用户无需知道细节,只要告诉libtool说我需要要编译哪些库即可,并且,它只与libtool文件打交道,例如lo、la为后缀的文件。
libtool生成一个抽象的后缀名为la高层库(其实是个文本文件),并将该库对其它库的依赖关系,都写在该la的文件中。
该文件中的dependency_libs记录该库依赖的所有库(其中有些是以.la 文件的形式加入的);libdir则指出了库的安装位置;library_names记录了共享库的名字;old_library记录了静态库的名字。
libtool使用方法:1. 编译为一个object文件:以BTX 为例:源文件为:BTX.c. 头文件在 ../include/BTX.h#libtool --mode=compile gcc -g -O -I../include -c BTX.c用gcc编译一切正常:mkdir .libsgcc -g -O -I../include -c BTX.c -fPIC -DPIC -o .libs/BTX.ogcc -g -O -I../include -c BTX.c -o BTX.o >/dev/null 2>&1#libtool --mode=compile mipsel_linux_gcc -g -O -I../include -c BTX.c显示需要--tag.libtool支持多语言,以下是语言与tag的对应:Language name Tag nameC CCC++ CXXJava GCJFortran 77 F77Windows Resource RC#libtool --mode=compile --tag=CC mipsel-linux-gcc -g -I../include -c BTX.c则正常了。
freetype编译

freetype编译1. 简介Freetype是一个开源的字体渲染引擎,它提供了一套用于解析和渲染字体文件的API。
通过编译freetype,我们可以获取到字体的轮廓信息,并进行渲染,从而实现文字在计算机屏幕或打印机上的显示。
2. freetype编译的准备工作在进行freetype编译之前,我们需要准备一些必要的工具和依赖库。
2.1 工具准备•编译器:我们需要一款支持C和C++的编译器,比如gcc或者clang。
•构建工具:我们可以使用make或者cmake来进行编译和构建。
•文本编辑器:为了方便修改配置文件和源代码,我们需要一款文本编辑器。
比如,vim或者sublime。
2.2 依赖库准备•zlib:freetype依赖zlib库来支持压缩和解压缩相关的操作。
我们可以通过源代码安装或者使用包管理器来获取zlib库。
•libpng:freetype还依赖libpng库来支持png格式的图片渲染。
同样,我们可以通过源代码安装或者使用包管理器来获取libpng库。
3. freetype编译步骤3.1 下载源代码首先,我们需要从freetype的官方网站上下载最新的源代码包。
可以通过以下命令:$ curl -O网址中的2.x.x是应替换为实际的版本号。
3.2 解压源代码解压刚下载的源代码包,可以通过以下命令:$ tar -zxvf freetype-2.x.x.tar.gz3.3 配置编译选项进入解压后的源代码目录,执行以下命令进行配置:$ ./configure --prefix=/usr/local/freetype上述命令中的--prefix选项指定了freetype的安装路径。
你可以根据自己的需要修改安装路径。
3.4 编译和安装配置完成后,使用以下命令编译和安装freetype:$ make$ sudo make install编译和安装过程可能需要一些时间,请耐心等待。
3.5 验证安装结果编译和安装完成后,我们可以通过以下命令来验证freetype是否成功安装:$ freetype-config --version如果安装成功,将会显示安装的版本号。
cufft用法

cufft用法CUFFT的用法CUFFT是NVIDIA提供的一个用于高性能傅立叶变换的库。
它被广泛应用于科学计算、数据分析和信号处理等领域。
本文将介绍CUFFT的基本用法,包括库的导入、数据准备、傅立叶变换和结果处理等方面。
一、CUFFT简介及安装CUFFT是CUDA的一部分,因此它需要与CUDA一起安装和使用。
CUDA是一种用于并行计算的平台和编程模型,适用于NVIDIA GPU。
要使用CUFFT,首先需要在系统中安装CUDA。
安装CUDA后,CUFFT库会自动包含在CUDA中。
使用CUFFT 时,只需在代码中引入相应的CUFFT头文件即可。
首先,在代码中添加以下代码:#include <cufft.h>这样就完成了CUFFT库的导入,接下来我们将学习如何使用它。
二、数据准备在进行傅立叶变换之前,我们需要准备好输入数据和输出数据的内存空间。
CUFFT支持单精度(float)和双精度(double)数据类型。
对于输入数据,可以使用CUDA的内存分配函数进行分配。
例如,使用以下代码可以分配一个长度为N的单精度浮点数数组:int N = 1024;float *input_data;cudaMalloc((void**)&input_data, N * sizeof(float));同样,我们还需要为傅立叶变换的结果分配内存空间。
可以使用以下代码来完成内存的分配:cudaMalloc((void**)&output_data, N * sizeof(cufftComplex));其中,cufftComplex是CUFFT库提供的一个数据类型,用于表示复数。
三、傅立叶变换准备好输入数据和输出数据后,我们可以开始进行傅立叶变换了。
CUFFT提供了几种不同的傅立叶变换函数,根据实际需求选择相应的函数即可。
以一维傅立叶变换为例,我们可以使用以下代码进行变换:cufftHandle plan;cufftPlan1d(&plan, N, CUFFT_R2C, 1);cufftExecR2C(plan, (cufftReal *)input_data, (cufftComplex*)output_data);首先,我们需要创建一个CUFFT变换句柄(cufftHandle)。
STM32固件库详解

STM32固件库详解.blogs./emouse/archive/2011/11/29/2268441.html1.1 基于标准外设库的软件开发1.1.1 STM32标准外设库概述STM32标准外设库之前的版本也称固件函数库或简称固件库,是一个固件函数包,它由程序、数据结构和宏组成,包括了微控制器所有外设的性能特征。
该函数库还包括每一个外设的驱动描述和应用实例,为开发者访问底层硬件提供了一个中间API,通过使用固件函数库,无需深入掌握底层硬件细节,开发者就可以轻松应用每一个外设。
因此,使用固态函数库可以大大减少用户的程序编写时间,进而降低开发成本。
每个外设驱动都由一组函数组成,这组函数覆盖了该外设所有功能。
每个器件的开发都由一个通用API (application programming interface 应用编程界面)驱动,API对该驱动程序的结构,函数和参数名称都进行了标准化。
ST公司2007年10月发布了V1.0版本的固件库,MDK ARM3.22之前的版本均支持该库。
2008年6月发布了V2.0版的固件库,从2008年9月推出的MDK ARM3.23版本至今均使用V2.0版本的固件库。
V3.0以后的版本相对之前的版本改动较大,本书使用目前较新的V3.4版本。
1.1.2 使用标准外设库开发的优势简单的说,使用标准外设库进行开发最大的优势就在于可以使开发者不用深入了解底层硬件细节就可以灵活规X的使用每一个外设。
标准外设库覆盖了从GPIO到定时器,再到CAN、I2C、SPI、UART和ADC等等的所有标准外设。
对应的C源代码只是用了最基本的C编程的知识,所有代码经过严格测试,易于理解和使用,并且配有完整的文档,非常方便进行二次开发和应用。
1.1.3 STM32F10XXX标准外设库结构与文件描述1. 标准外设库的文件结构在上一小节中已经介绍了使用标准外设库的开发的优势,因此对标准外设库的熟悉程度直接影响到程序的编写,下面让我们来认识一下STM32F10XXX的标准外设库。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CUDACUFFT LibraryPG-00000-003_V3.0February, 2010CUFFT Library PG-00000-003_V3.0Published byNVIDIA Corporation2701 San Tomas ExpresswaySanta Clara, CA 95050NoticeThis source code is subject to NVIDIA ownership rights under U.S. and international Copyright laws. This software and the information contained herein is PROPRIETARY and CONFIDENTIAL to NVIDIA and is being provided under the terms and conditions of a Non‐Disclosure Agreement. Any reproduction or disclosure to any third party without the express written consent of NVIDIA is prohibited.NVIDIA MAKES NO REPRESENTATION ABOUT THE SUITABILITY OF THIS SOURCE CODE FOR ANY PURPOSE. IT IS PROVIDED “AS IS” WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND. NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOURCE CODE, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY, NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE. IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOURCE CODE.U.S. Government End Users. This source code is a “commercial item” as that term is defined at 48 C.F.R.2.101 (OCT 1995), consisting of “commercial computer software” and “commercial computer software documentation” as such terms are used in 48 C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government only as a commercial end item. Consistent with 48 C.F.R.12.212 and 48 C.F.R. 227.7202‐1 through 227.7202‐4 (JUNE 1995), all U.S. Government End Users acquire the source code with only those rights set forth herein.TrademarksNVIDIA, CUDA, and the NVIDIA logo are trademarks or registered trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.Copyright© 2006–2010 by NVIDIA Corporation. All rights reserved.Table of ContentsCUFFT Library. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 CUFFT Types and Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 Type cufftHandle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 Type cufftResult . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 Type cufftReal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 Type cufftDoubleReal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 Type cufftComplex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 Type cufftDoubleComplex . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 CUFFT Transform Types. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 CUFFT Transform Directions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 Streamed CUFFT Transforms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 CUFFT API Functions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 Function cufftPlan1d(). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 Function cufftPlan2d(). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 Function cufftPlan3d(). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 Function cufftPlanMany(). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 Function cufftDestroy(). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 Function cufftExecC2C() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 Function cufftExecR2C() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 Function cufftExecC2R() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 Function cufftExecZ2Z() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 Function cufftExecD2Z() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 Function cufftExecZ2D() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 Function cufftSetStream() . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 Accuracy and Performance. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 CUFFT Code Examples. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 1D Complex-to-Complex Transforms. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 1D Real-to-Complex Transforms. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 2D Complex-to-Complex Transforms. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 2D Complex-to-Real Transforms. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 3D Complex-to-Complex Transforms. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 Batched 2D Complex-to-Complex Transforms. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21CUFFT Library This document describes CUFFT, the NVIDIA® CUDA™ Fast Fourier Transform (FFT) library. The FFT is a divide‐and‐conquer algorithm for efficiently computing discrete Fourier transforms of complex or real‐valued data sets, and it is one of the most important and widely used numerical algorithms, with applications that include computational physics and general signal processing. The CUFFT library provides a simple interface for computing parallel FFTs on an NVIDIA GPU, which allows users to leverage the floating‐point power and parallelism of the GPU without having to develop a custom, GPU‐based FFT implementation.FFT libraries typically vary in terms of supported transform sizes and data types. For example, some libraries only implement Radix‐2 FFTs, restricting the transform size to a power of two, while other implementations support arbitrary transform sizes. This version of the CUFFT library supports the following features:1D, 2D, and 3D transforms of complex and real‐valued dataBatch execution for doing multiple transforms of any dimension in parallel2D and 3D transform sizes in the range [2, 16384] in any dimension1D transform sizes up to 8 million elementsIn‐place and out‐of‐place transforms for real and complex dataDouble‐precision transforms on compatible hardware (GT200 and later GPUs)Support for streamed execution, enabling simultaneous computation together with data movementCUFFT Types and DefinitionsThe next sections describe the CUFFT types and transform directions:“Type cufftHandle” on page2“Type cufftResult” on page2“Type cufftReal” on page3“Type cufftDoubleReal” on page3“Type cufftComplex” on page3“Type cufftDoubleComplex” on page3“CUFFT Transform Types” on page3“CUFFT Transform Directions” on page5Type cufftHandletypedef unsigned int cufftHandle;is a handle type used to store and access CUFFT plans (see “CUFFTAPI Functions” on page6 for more information about plans). Forexample, the user receives a handle after creating a CUFFT plan anduses this handle to execute the plan.Type cufftResulttypedef enum cufftResult_t cufftResult;is an enumeration of values used exclusively as API function returnvalues. The possible return values are defined as follows:Return ValuesAny CUFFT operation is successful.CUFFT_INVALID_PLAN CUFFT is passed an invalid plan handle.CUFFT_ALLOC_FAILED CUFFT failed to allocate GPU memory.CUFFT_INVALID_TYPE The user requests an unsupported type.CUFFT_INVALID_VALUE The user specifies a bad memory pointer.CUFFT_INTERNAL_ERROR Used for all internal driver errors.CUFFT_EXEC_FAILED CUFFT failed to execute an FFT on the GPU.CUFFT_SETUP_FAILED The CUFFT library failed to initialize.Return Values (continued)The CUFFT library failed to shut down.CUFFT_INVALID_SIZE The user specifies an unsupported FFT size. Type cufftRealtypedef float cufftReal;is a single‐precision, floating‐point real data type.Type cufftDoubleRealtypedef double cufftDoubleReal;is a double‐precision, floating‐point real data type.Type cufftComplextypedef cuComplex cufftComplex;is a single‐precision, floating‐point complex data type that consists ofinterleaved real and imaginary components.Type cufftDoubleComplextypedef cuDoubleComplex cufftDoubleComplex;is a double‐precision, floating‐point complex data type that consists ofinterleaved real and imaginary components.CUFFT Transform TypesThe CUFFT library supports complex‐ and real‐data transforms. ThecufftType data type is an enumeration of the types of transform datasupported by CUFFT:typedef enum cufftType_t {CUFFT_R2C = 0x2a, // Real to complex (interleaved)CUFFT_C2R = 0x2c, // Complex (interleaved) to realCUFFT_C2C = 0x29, // Complex to complex, interleavedCUFFT_D2Z = 0x6a, // Double to double-complexCUFFT_Z2D = 0x6c, // Double-complex to doubleFor complex FFTs, the input and output arrays must interleave the realand imaginary parts (the cufftComplex type). The transform size ineach dimension is the number of cufftComplex elements. TheCUFFT_C2C constant can be passed to any plan creation function toconfigure a single ‐precision complex ‐to ‐complex FFT. Pass theCUFFT_Z2Z constant to configure a double ‐precision complex ‐to ‐complex FFT.For real ‐to ‐complex FFTs, the output array holds only the non ‐redundant complex coefficients. So for an N ‐element transform, theoutput array holds N/2+1 cufftComplex terms. For higher ‐dimensional real transforms of the form N0×N1×...×Nn , the lastdimension is cut in half such that the output data is N0×N1×...×(Nn/2+1) complex elements. Therefore, in order to perform an in ‐placeFFT, the user has to pad the input array in the last dimension to (Nn/2+1) complex elements or 2*(N/2+1) real elements. Note that thereal ‐to ‐complex transform is implicitly forward. Passing theCUFFT_R2C constant to any plan creation function configures a single ‐precision real ‐to ‐complex FFT. Passing the CUFFT_D2Z constantconfigures a double ‐precision real ‐to ‐complex FFT.The requirements for complex ‐to ‐real FFTs are similar to those for real ‐to ‐complex. In this case, the input array holds only the non ‐redundant,N/2+1 complex coefficients from a real ‐to ‐complex transform. Theoutput is simply N elements of type cufftReal . However, for an in ‐place transform, the input size must be padded to 2*(N/2+1) realelements. The complex ‐to ‐real transform is implicitly inverse. Passingthe CUFFT_C2R constant to any plan creation function configures asingle ‐precision complex ‐to ‐real FFT. Passing CUFFT_Z2D constantconfigures a double ‐precision complex ‐to ‐real FFT.For 1D complex ‐to ‐complex transforms, the stride between signals in abatch is assumed to be the number of cufftComplex elements in thelogical transform size. However, for real ‐data FFTs, the distancebetween signals in a batch depends on whether the transform is in ‐place or out ‐of ‐place. For in ‐place FFTs, the input stride is assumed tobe 2*(N/2+1) cufftReal elements or N/2+1 cufftComplex elements.CUFFT_Z2Z = 0x69 // Double-complex to double-complex} cufftType;For out‐of‐place transforms, input and output strides match the logicaltransform size (N) and the non‐redundant size (N/2+1), respectively.Starting with CUFFT version 3.0, batched transforms are supportedthrough the cufftPlanMany() function. Although this function takesinput parameters that specify input‐ and output‐data strides, inversion 3.0 data for each signal within the batch is assumed toimmediately follow that of the previous one (a stride of 1). CUFFT Transform DirectionsThe CUFFT library defines forward and inverse Fast FourierTransforms according to the sign of the complex exponential term: #define CUFFT_FORWARD -1#define CUFFT_INVERSE 1For higher‐dimensional transforms (2D and 3D), CUFFT performsFFTs in row‐major or C order. For example, if the user requests a 3Dtransform plan for sizes X, Y, and Z, CUFFT transforms along Z, Y, andthen X. The user can configure column‐major FFTs by simply changingthe order of the size parameters to the plan creation API functions.CUFFT performs un‐normalized FFTs; that is, performing a forwardFFT on an input data set followed by an inverse FFT on the resultingset yields data that is equal to the input scaled by the number ofelements. Scaling either transform by the reciprocal of the size of thedata set is left for the user to perform as seen fit.Streamed CUFFT TransformsExecution of a transform of a particular size and type may take severalstages of processing. A plan for the transform is generated, in whichCUFFT specifies the internal steps that need to be taken. These stepsmay include multiple kernel launches, memory copies, and so on.Every CUFFT plan may be associated with a CUDA stream. Once soassociated, all launches of the internal stages of that plan take placethrough the specified stream. Streaming of launches allows forpotential overlap between transforms and memory copies—see theNVIDIA CUDA Programming Guide for more information on streams. Ifno stream is associated with a plan, launches take place in stream 0(the default CUDA stream).CUFFT API FunctionsThe CUFFT API is modeled after FFTW (see ),which is one of the most popular and efficient CPU‐based FFTlibraries. FFTW provides a simple configuration mechanism called aplan that completely specifies the optimal—that is, the minimumfloating‐point operation (flop)—plan of execution for a particular FFTsize and data type. The advantage of this approach is that once theuser creates a plan, the library stores whatever state is needed toexecute the plan multiple times without recalculation of theconfiguration. The FFTW model works well for CUFFT becausedifferent kinds of FFTs require different thread configurations andGPU resources, and plans are a simple way to store and reuseconfigurations.The CUFFT library initializes internal data upon the first invocation ofan API function. Therefore, all API functions could return theCUFFT_SETUP_FAILED error code if the library fails to initialize.CUFFT shuts down automatically when all user‐created FFT plans aredestroyed. The CUFFT functions are as follows:“Function cufftPlan1d()” on page7“Function cufftPlan2d()” on page7“Function cufftPlan3d()” on page8“Function cufftPlanMany()” on page9“Function cufftDestroy()” on page10“Function cufftExecC2C()” on page10“Function cufftExecR2C()” on page11“Function cufftExecC2R()” on page12“Function cufftExecZ2Z()” on page13“Function cufftExecD2Z()” on page13“Function cufftExecZ2D()” on page14“Function cufftSetStream()” on page15Function cufftPlan1d()cufftResultcufftPlan1d( cufftHandle *plan, int nx, cufftType type,int batch );creates a 1D FFT plan configuration for a specified signal size and datatype. The batch input parameter tells CUFFT how many 1Dtransforms to configure.Inputplan Pointer to a cufftHandle objectnx The transform size (e.g., 256 for a 256-point FFT)type The transform data type (e.g., CUFFT_C2C for complex to complex)batch Number of transforms of size nxOutputContains a CUFFT 1D plan handle valueReturn ValuesCUFFT_SETUP_FAILED CUFFT library failed to initialize.CUFFT_INVALID_SIZE The nx parameter is not a supported size.CUFFT_INVALID_TYPE The type parameter is not supported.CUFFT_ALLOC_FAILED Allocation of GPU resources for the plan failed.CUFFT_SUCCESS CUFFT successfully created the FFT plan. Function cufftPlan2d()cufftResultcufftPlan2d( cufftHandle *plan, int nx, int ny,cufftType type );creates a 2D FFT plan configuration according to specified signal sizesand data type. This function is the same as cufftPlan1d() except thatit takes a second size parameter, ny, and does not support batching.Inputplan Pointer to a cufftHandle objectnx The transform size in the X dimension (number of rows)ny The transform size in the Y dimension (number of columns)type The transform data type (e.g., CUFFT_C2R for complex to real)Outputplan Contains a CUFFT 2D plan handle valueReturn ValuesCUFFT library failed to initialize.CUFFT_INVALID_SIZE The nx or ny parameter is not a supported size.CUFFT_INVALID_TYPE The type parameter is not supported.CUFFT_ALLOC_FAILED Allocation of GPU resources for the plan failed.CUFFT_SUCCESS CUFFT successfully created the FFT plan. Function cufftPlan3d()cufftResultcufftPlan3d( cufftHandle *plan, int nx, int ny, int nz,cufftType type );creates a 3D FFT plan configuration according to specified signal sizesand data type. This function is the same as cufftPlan2d() except thatit takes a third size parameter nz. :InputPointer to a cufftHandle objectnx The transform size in the X dimensionny The transform size in the Y dimensionnz The transform size in the Z dimensiontype The transform data type (e.g., CUFFT_R2C for real to complex)OutputContains a CUFFT 3D plan handle valueReturn ValuesCUFFT_SETUP_FAILED CUFFT library failed to initialize.CUFFT_INVALID_SIZE Parameter nx, ny, or nz is not a supported size.CUFFT_INVALID_TYPE The type parameter is not supported.CUFFT_ALLOC_FAILED Allocation of GPU resources for the plan failed.CUFFT_SUCCESS CUFFT successfully created the FFT plan.Function cufftPlanMany()cufftResultcufftPlanMany( cufftHandle *plan, int rank, int *n,int *inembed, int istride, int idist,int *onembed, int ostride, int odist,cufftType type, int batch );creates a FFT plan configuration of dimension rank, with sizesspecified in the array n. The batch input parameter tells CUFFT howmany transforms to configure in parallel. With this function, batchedplans of any dimension may be created.Input parameters inembed, istride, and idist and outputparameters onembed, ostride, and odist will allow setup of non‐contiguous input data in a future version. Note that for CUFFT 3.0,these parameters are ignored and the layout of batched data must beside‐by‐side and not interleaved. :Inputplan Pointer to a cufftHandle objectrank Dimensionality of the transform (1, 2, or 3)n An array of size rank, describing the size of each dimensioninembed Unused: pass NULListride Unused: pass 1idist Unused: pass 0onembed Unused: pass NULLostride Unused: pass 1odist Unused: pass 0type Transform data type (e.g., CUFFT_C2C, as per other CUFFT calls)batch Batch size for this transformOutputplan Contains a CUFFT plan handleReturn ValuesCUFFT library failed to initialize.CUFFT_INVALID_SIZE Parameter is not a supported size.CUFFT_INVALID_TYPE The type parameter is not supported.Function cufftDestroy()cufftResultcufftDestroy( cufftHandle plan );frees all GPU resources associated with a CUFFT plan and destroys theinternal plan data structure. This function should be called once a planis no longer needed to avoid wasting GPU memory.Function cufftExecC2C()cufftResultcufftExecC2C( cufftHandle plan, cufftComplex *idata,cufftComplex *odata, int direction );executes a CUFFT single ‐precision complex ‐to ‐complex transformplan as specified by direction . CUFFT uses as input data the GPUmemory pointed to by the idata parameter. This function stores theFourier coefficients in the odata array. If idata and odata are thesame, this method does an in ‐place transform.Allocation of GPU resources for the plan failed.CUFFT_SUCCESS CUFFT successfully created the FFT plan. Return Values (continued)Inputplan The cufftHandle object of the plan to be destroyed.Return ValuesCUFFT library failed to initialize.CUFFT_SHUTDOWN_FAILED CUFFT library failed to shut down.CUFFT_INVALID_PLAN The plan parameter is not a valid handle.CUFFT_SUCCESS CUFFT successfully destroyed the FFT plan. InputplanThe cufftHandle object for the plan to updateidata Pointer to the single-precision complex input data (in GPU memory) to transformodata Pointer to the single-precision complex output data (in GPU memory)direction The transform direction: CUFFT_FORWARD or CUFFT_INVERSEFunction cufftExecR2C()cufftResultcufftExecR2C( cufftHandle plan, cufftReal *idata,cufftComplex *odata );executes a CUFFT single ‐precision real ‐to ‐complex (implicitlyforward) transform plan. CUFFT uses as input data the GPU memorypointed to by the idata parameter. This function stores the non ‐redundant Fourier coefficients in the odata array. If idata and odataare the same, this method does an in ‐place transform (See “CUFFTTransform Types” on page 3 for details on real data FFTs.)Outputodata Contains the complex Fourier coefficientsReturn ValuesCUFFT library failed to initialize.CUFFT_INVALID_PLANThe plan parameter is not a valid handle. CUFFT_INVALID_VALUEThe i data , odata , and/or direction parameter is not valid. CUFFT_EXEC_FAILEDCUFFT failed to execute the transform on GPU. CUFFT_SUCCESS CUFFT successfully executed the FFT plan.InputThe cufftHandle object for the plan to update idataPointer to the single-precision real input data (in GPU memory) to transform odata Pointer to the single-precision complex output data (in GPU memory)OutputContains the complex Fourier coefficientsReturn ValuesCUFFT_SETUP_FAILEDCUFFT library failed to initialize.CUFFT_INVALID_PLAN The plan parameter is not a valid handle.CUFFT_INVALID_VALUE The i data and/or odata parameter is not valid.Function cufftExecC2R()cufftResultcufftExecC2R( cufftHandle plan, cufftComplex *idata,cufftReal *odata );executes a CUFFT single ‐precision complex ‐to ‐real (implicitly inverse)transform plan. CUFFT uses as input data the GPU memory pointed toby the idata parameter. The input array holds only the non ‐redundant complex Fourier coefficients. This function stores the realoutput values in the odata array. If idata and odata are the same, thismethod does an in ‐place transform. (See “CUFFT Transform Types”on page 3 for details on real data FFTs.)CUFFT failed to execute the transform on GPU.CUFFT_SUCCESS CUFFT successfully executed the FFT plan. Return Values (continued)InputplanThe cufftHandle object for the plan to update idataPointer to the single-precision complex input data (in GPU memory) to transform odata Pointer to the single-precision real output data (in GPU memory)OutputContains the real-valued output dataReturn ValuesCUFFT_SETUP_FAILEDCUFFT library failed to initialize.CUFFT_INVALID_PLANThe plan parameter is not a valid handle. CUFFT_INVALID_VALUEThe i data and/or odata parameter is not valid. CUFFT_EXEC_FAILEDCUFFT failed to execute the transform on GPU. CUFFT_SUCCESS CUFFT successfully executed the FFT plan.Function cufftExecZ2Z()cufftResultcufftExecZ2Z( cufftHandle plan,cufftDoubleComplex *idata,cufftDoubleComplex *odata, int direction );executes a CUFFT double ‐precision complex ‐to ‐complex transformplan as specified by direction . CUFFT uses as input data the GPUmemory pointed to by the idata parameter. This function stores theFourier coefficients in the odata array. If idata and odata are thesame, this method does an in ‐place transform.Function cufftExecD2Z()cufftResultcufftExecD2Z( cufftHandle plan, cufftDoubleReal *idata,cufftDoubleComplex *odata );executes a CUFFT double ‐precision real ‐to ‐complex (implicitlyforward) transform plan. CUFFT uses as input data the GPU memorypointed to by the idata parameter. This function stores the non ‐InputplanThe cufftHandle object for the plan to updateidata Pointer to the double-precision complex input data (in GPU memory) to transformodata Pointer to the double-precision complex output data (in GPU memory)direction The transform direction: CUFFT_FORWARD or CUFFT_INVERSE OutputContains the complex Fourier coefficientsReturn ValuesCUFFT_SETUP_FAILEDCUFFT library failed to initialize.CUFFT_INVALID_PLANThe plan parameter is not a valid handle. CUFFT_INVALID_VALUEThe i data , odata , and/or direction parameter is not valid. CUFFT_EXEC_FAILEDCUFFT failed to execute the transform on GPU. CUFFT_SUCCESS CUFFT successfully executed the FFT plan.redundant Fourier coefficients in the odata array. If idata and odataare the same, this method does an in ‐place transform (See “CUFFTTransform Types” on page 3 for details on real data FFTs.)Function cufftExecZ2D()cufftResultcufftExecZ2D( cufftHandle plan,cufftDoubleComplex *idata,cufftDoubleReal *odata );executes a CUFFT double ‐precision complex ‐to ‐real (implicitlyinverse) transform plan. CUFFT uses as input data the GPU memorypointed to by the idata parameter. The input array holds only thenon ‐redundant complex Fourier coefficients. This function stores thereal output values in the odata array. If idata and odata are the same,this method does an in ‐place transform. (See “CUFFT TransformTypes” on page 3 for details on real data FFTs.)InputThe cufftHandle object for the plan to update idataPointer to the double-precision real input data (in GPU memory) to transform odata Pointer to the double-precision complex output data (in GPU memory)OutputContains the complex Fourier coefficientsReturn ValuesCUFFT_SETUP_FAILEDCUFFT library failed to initialize.CUFFT_INVALID_PLANThe plan parameter is not a valid handle. CUFFT_INVALID_VALUEThe i data and/or odata parameter is not valid. CUFFT_EXEC_FAILEDCUFFT failed to execute the transform on GPU. CUFFT_SUCCESS CUFFT successfully executed the FFT plan.Inputplan The cufftHandle object for the plan to updateFunction cufftSetStream()cufftResultcufftSetStream( cufftHandle plan, cudaStream_t stream );associates a CUDA stream with a CUFFT plan. All kernel launchesmade during plan execution are now done through the associatedstream, enabling overlap with activity in other streams (for example,data copying). The association remains until the plan is destroyed orthe stream is changed with another call to cufftSetStream().idataPointer to the double-precision complex input data (in GPU memory) to transform odata Pointer to the double-precision real output data (in GPU memory)Outputodata Contains the real-valued output dataReturn ValuesCUFFT library failed to initialize.CUFFT_INVALID_PLANThe plan parameter is not a valid handle. CUFFT_INVALID_VALUEThe i data and/or odata parameter is not valid. CUFFT_EXEC_FAILEDCUFFT failed to execute the transform on GPU. CUFFT_SUCCESS CUFFT successfully executed the FFT plan. Input (continued)InputThe cufftHandle object to associate with the stream stream A valid CUDA stream created with cudaStreamCreate() (or 0 for the default stream)OutputContains the real-valued output dataReturn ValuesCUFFT_INVALID_PLAN The plan parameter is not a valid handle.CUFFT_SUCCESS The stream was successfully associated with the plan.。