多层前向神经网络的权值平衡算法
CNN算法中BP算法权重调整过程

CNN算法中权重调整过程详细推导卷积神经网络(CNN)训练的过程是:信号由输入层输入,经隐含层(至少一层),最后由输出层输出。
为了使得输出的结果与期望值间的误差最小,我们需要对每层的权重参数进行调整,调成的过程是:利用输出值与期望值之间的误差,由输出层经隐含层到输入层,进行每层的误差计算,这个过程其实就是反向传播网络BP(Back Propagation)的计算过程。
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
BP 学习网络能学习和存储大量的输入-输出模式映射关系,而事前无需揭示这种映射关系的数学方程。
它的学习规则是使用梯度下降法,通过反向传播不断调整网络的权重和阈值,使网络的误差平方和最小。
图1 神经网络示意图(这里没有添加偏置项)为了方便BP 算法推导,如图1所示,我们做了如下的定义: (1)我们定义输入是:n i x x x x X n i ==,],...,,...,,[21 (2)隐含层的输出是:l t x y y y Y l t ==,],...,,...,,[21(3)输出层是:mj o o o o O m j ==,],...,,...,,[21(4)输入层到隐含层的权重,我们定义:lt v v v v V l t ==,],...,,...,,[21线的颜色相同的权重一样,例如绿颜色的线权重是:1v )。
(5)隐含层到输出层的权重,我们定义:mj w w w w W m j ==,],...,,...,,[21下边讲的才是我们这部分的核心和重点,如何利用以上的定义,来描述图1所示的网络的工作过程。
在这里插入一个关于激活函数的定义,你肯定会问什么是激活函数,跟神经网络有什么关系?首先,激活函数是把激活的神经元的特征通过该函数把特征保存并映射出来,这里的保存特征,同时去除了数据中的一些冗余的信息,这是神经网络NN 解决非线性问题的关键。
多层神经网络

通过使用不同的激活函数,可以增加 网络的表达能力和学习能力,从而更 好地处理复杂的任务和数据。
03
前向传播算法
输入信号的前向传播过程
输入层接收外部输入信号
输出层产生最终结果
神经网络的输入层负责接收来自外部 的数据或信号,这些数据或信号可以 是图像、语音、文本等。
经过多层隐藏层的处理后,输出层产 生神经网络的最终输出结果,这个结 果可以是分类标签、回归值等。
说话人识别
多层神经网络可以用于说话人识别任务,识别语音信号的说话人身份。它在安全监控、语音认证等领域 有着重要的应用。
07
总结与展望
多层神经网络的优势与局限性
强大的表征学习能力
通过多层非线性变换,能够学习到输入数据的抽象特征表示 ,从而有效地解决复杂的模式识别问题。
泛化能力强
多层神经网络通过大量训练数据学习到的特征表示具有通用 性,可以应用于新的未见过的数据。
根据硬件资源和数据规模选择 合适的批处理大小,以充分利 用计算资源并加速训练过程。
正则化
使用L1、L2正则化或 Dropout等技术来防止过拟 合,提高模型的泛化能力。
优化器选择
根据任务类型和模型结构选择 合适的优化器,如SGD、 Adam等。
模型评估指标及优化方法
损失函数
根据任务类型选择合适 的损失函数,如均方误
04
反向传播算法
误差的反向传播过程
计算输出层误差
根据网络的实际输出和期 望输出,计算输出层的误 差。
反向传播误差
将输出层的误差反向传播 到隐藏层,计算隐藏层的 误差。
更新权重和偏置
根据隐藏层和输出层的误 差,更新网络中的权重和 偏置。
梯度下降法与权重更新规则
多层前向神经网络及其研究

第 2 卷第 3 1 期
20 0 6年 9月
柳
州
师
专
学
报
Vo . . 1 2l No 3
Ju a fL u h uT a h r olg o r l iz o e c esC l e n o e
S pt 0 6 e .2 0
而构造 出来 的系统可 以具有相当好的鲁棒性 ;5 多输入多输 出的结构模型 , () 可方便地用于多变量控 制系统 , 由于具有分布特
性, 所以多层神经网络的系统 特别适合 处理 比较 复杂 的问题 .
2 1 P神 经 网络 的基 本原 理 和 方 法 . B
多层前 向神经 网络的网络结构如图 1 所示 . 网络结构是 由输入层 、 输 出层和 隐层组成 , 中隐层 可以是 一层 , 其 也可 以是 多层 , 前层 至后层 节点 输入
8 8
维普资讯
吴 建生 , 虞继 敏 : 多层 前 向神经 网络及其 研究
mn ( ,,,) i  ̄ Eo
() t ’ [ /
() 多 ) t一 ]
单元有 一个单一 的输 出联接 , 这个输 出可 以根 据需 要被 分支成 希望个 数 的许 多并行 联接 , 且这 些并行联 接都 输 出相 同的信 号, 即相应处 理单元 的信号 , 号的大小 不因为分支 的多少 而变 化. 信 处理单元的输 出信号 可 以是任何需 要的数学模 型, 每个处 理单元 中进行 的操作必须是完全局部的. 神经 网络是 巨量信息并行处理和大规模 平行计算 的基 础 , 既是高度 非线性动力学 系统 , 它 又是 自适 应 系统 , 可用 来描述 认 知决策及控制 的智能行为 , 它具有存储和应用经验知识 的 自然 特性 , 它与人脑 相似之处 可以概括 为两 个方 面 : 一是 通过学 习从外部环境 中获取知识 ; 二是 内部神经元具有存储知识的能力. 2 近 O年来 , 神经 网络技术迅猛 发展 , 已经 在智能控制 、 式 模 识 别、 计算机视觉 、 非线性优化、 信号处理等方面取得巨大的成功和进展 , 现已成为人工智能研究的重要领域之一 . 。
BP神经网络原理及其在医学统计应用中的设计技巧
△通讯作者。
j j 5@综述B P 神经网络原理及其在医学统计应用中的设计技巧潍坊医学院卫生统计教研室(261042) 王俊杰 陈景武△ 人工神经网络作为智能信息处理的工具之一,有着很强的适应性、高度的容错性及强大的功能等优点,在医学统计中有着广阔的应用前景。
它是模仿人的大脑神经系统信息处理功能的智能化系统,由简单处理单元(神经元)联接构成的规模庞大的并行分布式处理器,根据其网络拓扑结构,可分为四种类型:(1)前向网络、有反馈的前向网络、层内互联前向网络和全互联或部分互联网络。
本文探讨的B P 神经网络(简称B P 网络)是指基于误差反向传播算法的多层前向网络,目前应用较广泛。
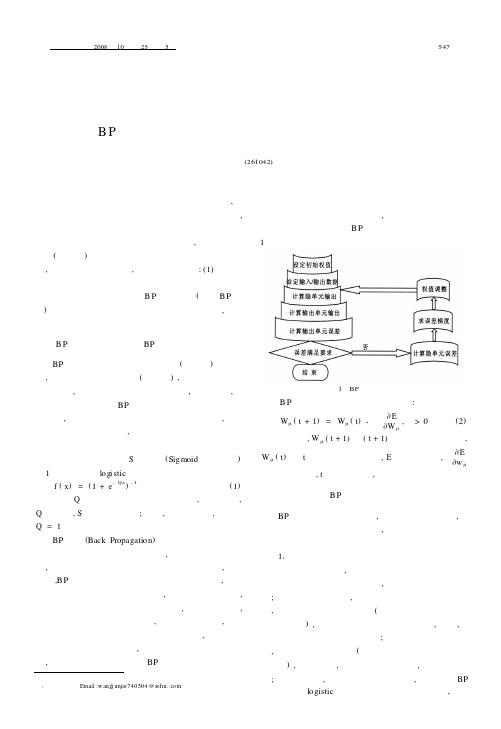
B P 网络的拓扑结构及BP 算法的基本原理BP 网络通常含有输入层、隐含层(中间层)和输出层,每层均包括多个神经元(即节点),输入层与输出层各有一层,隐含层根据需要可以设多层,也可不设,不含隐含层的称为单层BP 网络。
神经元之间通过权相互连接,前一层神经元只对下一层神经元起作用,同层神经元之间无相互作用,权值大小代表上一级神经元对下一级神经元的影响程度。
网络中作用于神经元的激励函数通常采用的是S 型函数(Sigmoid 可微函数)式1实际上就是logi stic 回归中概率的表达式。
f (x )=(1+e-Qx )-1(1)式中Q 为调节激励函数形式的参数,称增益值,Q 值越大,S 形曲线越陡峭;反之,曲线越平坦,通常取Q =1。
BP 算法(Back Propagation )是为了解决多层前向神经网络的权值调整而提出来的,也称为反向传播算法,即网络权值的调整规则是向后传播学习算法,具体来说,B P 算法是建立在梯度下降法的基础上的,学习过程由正向传播和反向传播组成,在正向传播过程中,输入信息由输入层经隐含层逐层处理,并传向输出层,如果输出层得不到期望的输出,则转入反向传播,逐层递归计算实际输入与期望输入的差即误差,将误差信号沿原来的连接通道返回,通过修改各层神经元的权值,最终使得误差信号最小。
基于微粒群算法的多层前馈神经网络

摘要 : 微粒群 算 法和神 经 网络 结合起 来 , 将 实现 了非线形模 型 的 辨 识 问题 和 P D 控 制 器 参 数优 化 I 问题 。仿真 实验表 明 : 粒 群 算 法在神 经 网络 控 制 微
及 非 线形模 型辨识 方 面的应 用具 有 可行 性 , 有 良 具
好 的应 用 前 景 。
设 在 m维 优 化 空 间 中 , 个 微 粒 组 成 的 种 由
群 , i 微 粒 的 当前 位 置 可 以表 示 为 X = ( , 第 个
0 引 言
神经 网络具 有 复杂 的 非线 形 映射 能力 、 大规 模 并行分 布处理 能力 n 。一个 3 前 向网络可 以逼 近 ] 层
1 微 粒群 算 法原 理
人 们 通过 对 动物 社会 行 为 的观 察 , 现在 群 体 发 中对 信 息 共 享 有 利 于 在 演 化 中 获 得 优 势 , a s J me
Ke n d n e y和 Ru sl E eh r sel b ra t以 此 为 基 础 提 出 了
P O算 法 。与其 它进 化算 法 类 似 , 也采 用 “ 体” S 它 群
维普资讯
基 于 微粒 群 算 法 的 多层 前 馈 神 经 网络
曾祥 光 , 玲 玲 张
( 南交通 大学峨眉校 区机 械 系, 川 峨 眉 6 4 0 ) 西 四 1 2 2
M u t — l y r Fe d o wa d Ne a e wo k Ba e n Pa tc e Swa m tm ia i n li— a e e f r r ur lN t r s d o r i l r Op i z to
法 寻优 速度快 、 全局 收敛 等特点 , 在一定 程度 上避免
bp算法原理

bp算法原理BP算法原理BP算法是神经网络中应用最广泛的一种学习算法,它的全称是“反向传播算法”,用于训练多层前馈神经网络。
BP算法基于误差反向传播原理,即先通过前向传播计算网络输出值,再通过反向传播来调整各个神经元的权重,使误差函数最小化。
BP算法的步骤如下:1. 初始化:随机初始化网络每个神经元的权重,包括输入层、隐藏层和输出层的神经元的权重。
2. 前向传播:将训练样本输送到输入层,通过乘积和运算得到每个隐藏层神经元的输出,再通过激活函数得到隐藏层神经元的实际输出值。
然后,将隐藏层的输出值输送到输出层,按照同样的方法计算输出层神经元的输出值。
3. 反向传播:通过误差函数计算输出层神经元的误差值,然后反向传播计算隐藏层神经元的误差值。
4. 权值调整:按照梯度下降法,计算误差对每个神经元的权重的偏导数,根据偏导数的大小来调整各个神经元的权重,使误差逐渐减小。
5. 重复步骤2~4,直到误差小到一定程度或者训练次数达到预定值。
其中,误差函数可以选择MSE(Mean Squared Error)函数,也可以选择交叉熵函数等其他函数,不同的函数对应不同的优化目标。
BP算法原理的理解需要理解以下几个方面:1. 神经元的输入和输出:神经元的输入是由上一层神经元的输出和它们之间的权重乘积的和,加上神经元的偏置值(常数)。
神经元的输出是通过激活函数把输入值转化为输出值。
2. 前向传播和反向传播:前向传播是按照输入层到输出层的顺序计算神经元的输出值。
反向传播是一种误差反向传播的过程,它把误差从输出层往回传递,计算出每个神经元的误差,然后调整各个神经元的权重来使误差逐渐减小。
3. 梯度下降法:梯度下降法是一种优化算法,根据误差函数的梯度方向来寻找误差最小的点。
BP算法就是基于梯度下降法来优化误差函数的值,使神经网络的输出结果逼近实际值。
综上所述,BP算法是一种常用的神经网络学习算法,它利用前向传播和反向传播的过程来调整神经元的权重,不断优化误差函数的值,从而使神经网络的输出结果更加准确。
人工神经网络多层前向网络及BP学习算法

y1
x1
x2
y2
xm
yp
xM
yP
i (1,2, , I ) j (1,2, , J )
神经元旳输入用u表达,鼓励输出用v表达,u, v旳上
标表达层,下标表达层中旳某个神经元,如
u
I i
表达I
层(即第1隐层)旳第i个神经元旳输入。设全部旳
神经元旳鼓励函数均用Sigmoid函数。设训练样本集
为X=[X1,X2,…,Xk,…,XN],相应任一训练样本: Xk= [xk1,xk2,…, kM]T,(k=1,2,…,N)旳实际输出为: Yk= [yk1, yk2,…,ykP]T,期望输出为dk= [dk1,dk2,…, dkP]T。 设n为迭代次数,权值和实际输出是n旳函数。
E(n) wij(n)
E(n) uJj (n)
uJj (n) wij(n)
E(n) uJj (n)
viI
(n)
设局部梯度为:
J j
(n)
E(n) uJj (n)
E(n) vJj (n) vJj (n) uJj (n)
vJj uJj
(n) (n)
f
'
(uJj
(n))
E(n)
1 2
P
ek2p(n)
p1
E(n)
vJj (n)
pP1ekp(n)evkJjp((nn))
pP1ekp(n)eukpPp((nn))uvJpP j ((nn))
e k( n p ) d k( n p ) y k( n p ) d k( n p ) f( u p P ( n ))
ekp(n) upP(n)
f
'
(upP(n))
多层前馈神经网络算法资料

从而求得节点6的输出:
例题
到此我们就完成了神经网络算法的一次计算,下面对该网络进 行更新操作。
例题
因为更新操作的顺序是从后往前的,首先对输出节点进行更新。先求 输出节点的误差Err6: 因为训练数据的 “正确答案”为1, 所以T6等于1。 权重进行更新操作:
偏倚进行更新操作:
例题
同理,可以对节点4、5进行更新操作,其误差计算方法与节点6不同:
回顾一下,更新操作是从后往前的,更新节点6更新了偏倚 以及 权重w46,w56。同理,更新节点4更新了 以及w14,w24,w34;更 新节点5。。。这样就完成了一次对于神经网络的更新。
ቤተ መጻሕፍቲ ባይዱ
关于更新操作的时机
一般训练数据有很多组,将所有训练数据进行一次计算+ 更新操作,叫做一次迭代。 每处理一个样本就进行一次更新叫做实例更新;处理完 所有训练数据后,再进行更新操作叫做周期更新。一般数学计算 中常常使用周期更新,用计算机实现时常常使用实例更新。实例 更新所需要的迭代次数较少,但计算量较大。 周期更新是将权重和偏倚的该变量 和 进行累 计,直到所有训练数据累计完成后,再进行一次更新操作。
实例演示
下面是我用神经网络算法实现的一个识别(正\负)奇(偶) 数的实例。
Add Your Company Slogan
Thank You!
多层前馈神经网络算法
王玉良
目录
1 2
神经网络算法基础知识 多层前馈神经网络
3
4
神经网络例题
神经网络实例演示
多层前馈神经网络结构图
隐藏层和输出层的节点被称作神经节点,神经网络的层 数为隐藏层数+输出层数。神经网络是全链接的,即每一个 节点和它下一层的每一个节点都有链接。
BP算法过程范文

BP算法过程范文BP算法是一种常用的神经网络算法,用于求解多层感知机模型的权值和阈值。
BP算法通过在输入层和输出层之间逐层传播误差,并利用梯度下降的方法来调整权值,从而实现模型的训练。
以下是BP算法的具体过程:1. 初始化:设定网络的结构,包括输入层、隐藏层和输出层的神经元数量,并设置随机初始权值和阈值。
同时设定学习率(learning rate)和最大迭代次数。
2.前向传播:将输入样本输入到网络中,依次计算每一层的神经元输出。
对于隐藏层和输出层的每一层,计算公式为:- 神经元输入:$net_j = \sum_{i=1}^{n} w_{ij} \cdot x_i +b_j$- 神经元输出:$out_j = f(net_j)$其中,$w_{ij}$是连接输入层与当前层的权值,$x_i$是输入层神经元的输出,$b_j$是当前层神经元的阈值,$f($是激活函数。
3.反向传播:计算输出层和隐藏层的误差。
对于输出层,误差计算公式为:- 输出层误差:$E_j = (y_j - out_j) \cdot f'(net_j)$其中,$y_j$是期望输出,$f'$是激活函数的导数。
对于隐藏层,误差计算公式为:- 隐藏层误差:$E_j = \sum_{k=1}^{K} (w_{kj} \cdot E_k) \cdot f'(net_j)$其中,$w_{kj}$是连接当前层与下一层的权值,$E_k$是下一层的误差。
4.更新权值和阈值:利用梯度下降的方法,根据误差大小调整权值和阈值。
对于连接输入层与隐藏层的权值更新公式为:- 权值更新:$w'_{ij} = w_{ij} + \eta \cdot x_i \cdot E_j$其中,$\eta$是学习率。
对于连接隐藏层与输出层的权值更新公式为:- 权值更新:$w'_{kj} = w_{kj} + \eta \cdot out_k \cdot E_j$对于隐藏层和输出层的阈值更新公式为:- 阈值更新:$b'_j = b_j + \eta \cdot E_j$5.重复迭代:重复2-4步骤,直至达到最大迭代次数或目标误差。
神经网络中的多层感知机算法

神经网络中的多层感知机算法神经网络是人工智能领域的重要分支之一,近年来取得了长足的发展。
其中,多层感知机算法是最为基础也最为广泛应用的一种神经网络结构。
本文将对多层感知机算法进行深入探讨,介绍其原理、应用及未来发展方向。
一、多层感知机算法的原理多层感知机算法是一种监督学习方法,其基本思想是利用人工神经元模拟人类大脑神经细胞之间的信息传递过程。
神经元之间通过权值连接进行信息传递,并加以激活函数进行处理,从而实现对于输入数据的分类、识别、预测等任务。
多层感知机模型通常由三部分构成:输入层、隐藏层和输出层。
输入层负责接收外部输入数据,并将其传递至隐藏层。
隐藏层主要是通过神经元之间的连接和激活函数实现数据的非线性映射。
输出层则是对隐藏层结果的加权组合,并通过激活函数输出最终结果。
在神经网络中,每个连接和每个神经元都有相应的权值,这些权值是通过训练集不断地调整得到的。
多层感知机算法的核心在于反向传播算法。
反向传播算法是一种通过梯度下降优化神经网络权值的方法。
它通过计算误差函数对权值进行迭代调整,从而实现神经网络的学习过程。
具体来说,反向传播算法的步骤包括前向传播、误差计算和反向传播三个过程。
其中前向传播是将样本数据输入网络中,经过每一层的处理,最终得到输出结果。
误差计算是将网络预测结果与实际结果进行比对,得到误差值。
反向传播则是根据误差值计算每个神经元的梯度,从而对权值进行更新。
二、多层感知机算法的应用多层感知机算法是深度学习领域中最基础也最常用的算法之一,其应用范围十分广泛。
以下是多层感知机算法在不同领域的应用举例:1. 图像分类与识别:针对不同类别的图片,分类算法可以将其分为不同的类别。
在这个过程中,多层感知机算法可以自动学习出特征,并通过反向传播算法优化参数,达到更加准确的结果。
2. 语音识别:语言处理领域中,多层感知机算法可以通过自适应模型、模型结构优化等方式,提升语音识别的整体准确率。
3. 自然语言处理:多层感知机算法可以学习单词与语义之间的关系,从而实现对句子和文本的情感分析、文本分类、语言翻译等任务。
多层前向网络及BP学习算法

输出层第p个神经元的误差信号为:
ekp (n) dkp (n) ykp (n)
定义神经元p的误差能量为:
1 2
ek2p
(n)
则输出层所有神经元的误差能量总和为:
E(n)
1 2
P
ek2p (n)
p 1
误差信号的反向传播过程:
(1)隐层J与输出层P之间的权值修正量
w jp
(n)
E(n) wjp (n)
(n)
J j
(n)viI
(n)
(3)与隐层I和隐层J之间的权值修正量推导 方法相同,输入层M上任一节点与隐层I上任 一节点之间权值的修正量为:
wmi (n) i (n)xkm (n) I
其中:
J
I i
(n)
f
'
(u
I i
(n))
J j
(n)wij
(n)
j 1
BP学习算法步骤
第一步:设置变量和参量 第个二较步小: 的初 随始 机化非,零赋值,给WnM=I0(0), WIJ (0), WJP (0),各一 第三步:随机输入样本Xk 第元四的步输: 入对信输号入u和样输本出X信k ,号前v 向计算BP网络每层神经 第Y转k五至(n)步第计: 八算由 步误期 ;差望不E(输满n)出足,d转判k和至断上第其一六是步步否求。满得足的要实求际,输若出满足
多层感知器
输入层
隐层
输出层
多层感知器
多层感知器同单层感知器相比具有四个明显的特点:
(1)除了输入输出层,多层感知器含有一层或多层隐 单元,隐单元从输入模式中提取更多有用的信息, 使网络可以完成更复杂的任务。
(2)多层感知器中每个神经元的激励函数是可微的
BP神经网络的简介

BP神经网络的发展在人工神经网络发展历史中,很长一段时间里没有找到隐层的连接权值调整问题的有效算法。
直到误差反向传播算法(BP算法)的提出,成功地解决了求解非线性连续函数的多层前馈神经网络权重调整问题。
BP (Back Propagation)神经网络,即误差反传误差反向传播算法的学习过程,由信息的正向传播和误差的反向传播两个过程组成。
输入层各神经元负责接收来自外界的输入信息,并传递给中间层各神经元;中间层是内部信息处理层,负责信息变换,根据信息变化能力的需求,中间层可以设计为单隐层或者多隐层结构;最后一个隐层传递到输出层各神经元的信息,经进一步处理后,完成一次学习的正向传播处理过程,由输出层向外界输出信息处理结果。
当实际输出与期望输出不符时,进入误差的反向传播阶段。
误差通过输出层,按误差梯度下降的方式修正各层权值,向隐层、输入层逐层反传。
周而复始的信息正向传播和误差反向传播过程,是各层权值不断调整的过程,也是神经网络学习训练的过程,此过程一直进行到网络输出的误差减少到可以接受的程度,或者预先设定的学习次数为止。
BP神经网络模型BP网络模型包括其输入输出模型、作用函数模型、误差计算模型和自学习模型。
(1)节点输出模型隐节点输出模型:Oj=f(∑Wij×Xi-qj) (1)输出节点输出模型:Yk=f(∑Tjk×Oj-qk) (2)f-非线形作用函数;q -神经单元阈值。
图1 典型BP网络结构模型(2)作用函数模型作用函数是反映下层输入对上层节点刺激脉冲强度的函数又称刺激函数,一般取为(0,1)内连续取值Sigmoid函数: f(x)=1/(1 e) (3)(3)误差计算模型误差计算模型是反映神经网络期望输出与计算输出之间误差大小的函数:(4)tpi- i节点的期望输出值;Opi-i节点计算输出值。
(4)自学习模型神经网络的学习过程,即连接下层节点和上层节点之间的权重矩阵Wij的设定和误差修正过程。
多层前向网络及BP学习算法

多层前向网络及BP学习算法多层前向网络(Multilayer Feedforward Network)是一种常用的人工神经网络结构,用于解决各种分类和回归问题。
它由多个层次组成,每一层都包含多个神经元(节点),并且每个神经元都与前一层的所有神经元相连。
\[z_{j}^{(l)} = \sum_{i=1}^{n^{(l-1)}}w_{ij}^{(l)}x_{i}^{(l-1)} + b_{j}^{(l)}\]\[x_{j}^{(l)}=f(z_{j}^{(l)})\]其中,\(z_{j}^{(l)}\) 是第 \(l\) 层的第 \(j\) 个神经元的加权和,\(w_{ij}^{(l)}\) 是第 \(l-1\) 层的第 \(i\) 个神经元到第 \(l\) 层的第 \(j\) 个神经元的权重,\(x_{i}^{(l-1)}\) 是第 \(l-1\) 层的第 \(i\) 个神经元的输出,\(b_{j}^{(l)}\) 是第 \(l\) 层的第 \(j\) 个神经元的偏置项,\(f(\cdot)\) 是激活函数。
在训练多层前向网络时,可以使用反向传播(Backpropagation)学习算法。
反向传播算法基于梯度下降法,通过计算损失函数对网络参数的偏导数,来更新参数以最小化损失函数。
反向传播算法的主要步骤如下:1.前向传播:将训练样本输入网络,逐层计算每个神经元的输出。
3.反向传播:逐层计算每个神经元的误差信号,从输出层开始向输入层反向传播。
4.更新参数:根据误差信号和学习率,更新每个神经元的权重和偏置项。
5.重复步骤1-4,直到达到收敛条件或达到最大迭代次数。
尽管多层前向网络和反向传播算法是非常优秀的模型和学习算法,但它们也面临一些挑战和限制。
例如,多层前向网络可能会陷入局部最优解,而非全局最优解。
反向传播算法可能因为梯度消失或梯度爆炸的问题而导致训练不稳定。
此外,对于大规模复杂的问题,网络的深度和规模可能需要很大的计算资源和训练时间。
多层前向神经网络权值初始化的研究进展

O 引 言
多层前 向神 经 网络 ( F M N—M hl e Fe— u iyr ed a
fradN tok 指 拓 扑结构 为 有 向无环 图 的前 向 ow r e r) w
网络, 包括 ML P网 、 P网 、 B B R F网. 一 种最 广泛 是
广泛的认为是最 有效地 提高训练速度 的方 法之
谢 富强等 : 前 向神经网络权值初始化 的研究进 展 多层
9 9
样本和网络结构本身 的特点选取初始权值. 主要 有基于样本特征提取 、 遗传和免疫 、 均匀设计 、 记 忆式 、 感受野型等算法.
11 随机取 值型 .
一
区, 加快 了收敛速度又部分解决了局部最优问题. 用 N— w法初始化权重与阈值的算式为
Ab ta t rp sd iiaiain meh d hc r h wn t c iv ey fs lann sr c :Po o e nt l t to s w ih ae s o o a he e v r a t e r ig i z o s e da d t e ra etep o a it f o a nmaaes g e td n 山i p p r her — p e n d ce s r b bl yo c lmii r u g s .I o h i l e s a e .t e
XI Fu q a g, E - in TANG a - e g Yi o g n ( col f o pt c ne n eh o g ,ahaU i rt, egagH nn 20 1C i ) Sho o C m u r i c dT cnl yN nu n e i H n n , u a 10 ,h a eS e a o v sy y 4 n
神经网络中的权重和偏置的调整方法

神经网络中的权重和偏置的调整方法神经网络是一种能够模拟人脑神经元工作方式的计算机系统,它使用一系列的层来进行信息处理,每层输入和输出被称为神经元,而两个神经元之间的相互作用则被称为连接。
这些连接中的每个连接都有一个特定的权重和一个偏置,权重和偏置的调整被认为是神经网络学习过程中最重要的步骤之一。
在本文中,我们将探讨神经网络中权重和偏置的调整方法,包括梯度下降法、带动量的梯度下降法和自适应学习率算法。
一、梯度下降法梯度下降法是一种最常见的神经网络权重和偏置调整方法。
该方法基于最小化代价函数(误差函数),以达到最佳的权重和偏置。
代价函数可以看做是一个反映模型预测结果和实际结果差距的评估指标。
通过构建代价函数,可以将神经网络学习问题转化为一个最优化问题,即在所有可能的权重和偏置的组合中找到使得代价函数最小的一组。
为了达到这个目标,我们需要不断地调整权重和偏置,使代价函数不断减小,这就是梯度下降法的基本原理。
具体而言,梯度下降法是通过计算代价函数关于权重和偏置的导数来进行调整。
在每次迭代中,将导数与一个常数乘积(即学习率)相乘,得到一个权重和偏置的调整量,从而将权重和偏置沿着其导数所指向的反方向更新。
二、带动量的梯度下降法梯度下降法虽然是一种基本的权重和偏置调整方法,但在实际应用中容易出现陷入局部最优解的问题。
为了克服这种问题,人们引入了带动量的梯度下降法。
带动量的梯度下降法对梯度下降法的基本原理做了改进,具体而言,它增加了一项表示上一次权重和偏置调整量的项,以此来“平滑”每次调整。
带动量的梯度下降法的公式如下:Δw(t)=η▽C/▽w(t)+αΔw(t-1)其中,Δw表示权重和偏置的调整量,η表示学习率,▽C/▽w 表示代价函数在当前权重和偏置处的梯度,α表示动量系数,Δw(t-1)表示上一次的权重和偏置调整量。
Δw(t)被更新后,就可以用来更新每个权重和偏置。
三、自适应学习率算法自适应学习率算法是指在梯度下降算法的基础上,每个权重和偏置都分别拥有自己的学习率。
神经网络作业-问题及答案

一 简述人工神经网络常用的网络结构和学习方法。
(10分)答:1、人工神经网络常用的网络结构有三种分别是:BP 神经网络、RBF 神经网络、Kohonen 神经网络、ART 神经网络以及Hopfield 神经网络。
人工神经网络模型可以按照网络连接的拓扑结构分类,还可以按照内部信息流向分类。
按照拓扑结构分类:层次型结构和互连型结构。
层次型结构又可分类:单纯型层次网络结构、输入层与输出层之间有连接的层次网络结构和层内有互联的层次网络结构。
互连型结构又可分类:全互联型、局部互联型和稀疏连接性。
按照网络信息流向分类:前馈型网络和反馈型网络。
2、学习方法分类:⑴.Hebb 学习规则:纯前馈网络、无导师学习。
权值初始化为0。
⑵.Perceptron 学习规则:感知器学习规则,它的学习信号等于神经元期望输出与实际输出的差。
单层计算单元的神经网络结构,只适用于二进制神经元。
有导师学习。
⑶.δ学习规则:连续感知学习规则,只适用于有师学习中定义的连续转移函数。
δ规则是由输出值与期望值的最小平方误差条件推导出的。
⑷.LMS 学习规则:最小均放规则。
它是δ学习规则的一个特殊情况。
学习规则与神经元采用的转移函数无关的有师学习。
学习速度较快精度较高。
⑸.Correlation 学习规则:相关学习规则,他是Hebb 学习规则的一种特殊情况,但是相关学习规则是有师学习。
权值初始化为0。
⑹.Winner-Take-All 学习规则:竞争学习规则用于有师学习中定义的连续转移函数。
权值初始化为任意值并进行归一处理。
⑺.Outstar 学习规则:只适用于有师学习中定义的连续转移函数。
权值初始化为0。
2.试推导三层前馈网络BP 算法权值修改公式,并用BP 算法学习如下函数:21212221213532)(x x x x x x x x f -+-+=,其中:551≤≤-x ,552≤≤-x 。
基本步骤如下:(1)在输入空间]5,5[1-∈x 、]5,5[2-∈x 上按照均匀分布选取N 个点(自行定义),计算)(21x x f ,的实际值,并由此组成网络的样本集;(2)构造多层前向网络结构,用BP 算法和样本集训练网络,使网络误差小于某个很小的正数ε;(3)在输入空间上随机选取M 个点(N M >,最好为非样本点),用学习后的网络计算这些点的实际输出值,并与这些点的理想输出值比较,绘制误差曲面;(4)说明不同的N 、ε值对网络学习效果的影响。
多层神经网络的优化方法

多层神经网络的优化方法引言神经网络已经成为了人工智能领域的一个很重要的分支,神经网络的应用越来越广泛,比如图像识别、语音识别等。
神经网络的优化是神经网络的关键,对神经网络的优化方法的研究成为了一个热门的话题。
本文将介绍多层神经网络的优化方法。
多层神经网络多层神经网络是一种由多个层次结构组成的神经网络,每个层次结构都由一些神经元(或节点)组成,每个节点都与这一层的所有节点相连。
多层神经网络的深度是指神经网络的层数,它越深,它的抽象能力和泛化能力就越好。
1、梯度下降法梯度下降法是一种最常用的优化方法,其基本思想是根据网络误差,通过计算误差函数对权值和阈值进行迭代计算,使得误差函数逐渐降低,最终找到函数的最小值点或者局部最优点。
梯度下降法可以分为批量梯度下降法、随机梯度下降法和小批量梯度下降法。
2、动量法动量法是基于梯度下降法的一种优化方法,它沿纵向方向增加一个动量项,这个动量项由前面迭代中的梯度累积得到。
动量项的加入,可以在搜索中避免陷入鞍点,加快训练的收敛速度。
3、自适应学习率优化方法自适应学习率优化方法是基于梯度下降法的一种优化方法,它可以自动地调整神经网络中每个权值的学习率。
这种方法可以使神经网络在训练过程中找到最优解。
4、正则化方法正则化方法是一种用来减少过拟合的技术,它可以通过在误差函数中增加一个正则化项来约束权值参数的取值范围。
常用的正则化方法有L1正则化和L2正则化。
5、Dropout方法Dropout方法是一种用来减少过拟合的技术,它可以在训练过程中随机地关闭一些神经元,让它们不参与到训练中去。
这种方法可以有效地防止过拟合,提高模型的泛化能力。
6、批标准化方法批标准化方法是一种优化方法,它可以通过对每层的输入进行标准化来解决训练速度下降和过拟合的问题。
这种方法可以使神经网络收敛速度更快,同时可以提高其泛化能力。
结论本文介绍了多层神经网络的优化方法,包括梯度下降法、动量法、自适应学习率优化方法、正则化方法、Dropout方法和批标准化方法。
unet权重计算

unet权重计算Unet权重计算是深度学习中的一个重要概念,用于计算神经网络中各个连接的权重。
在深度学习中,神经网络的权重是指用于调整神经元之间连接强度的参数。
权重的好坏直接影响到神经网络的性能和准确度。
Unet权重计算是指通过训练神经网络,不断调整神经网络中各个连接的权重,使得神经网络能够更好地拟合训练数据,并对未知数据进行准确预测。
在深度学习中,通常使用反向传播算法来更新权重。
反向传播算法通过计算损失函数对权重的梯度,然后根据梯度更新权重,使得损失函数下降,从而提高神经网络的性能。
Unet权重计算的过程可以简单描述为以下几个步骤:1. 初始化权重:在神经网络训练之前,需要对权重进行初始化。
通常可以使用随机数生成器来生成一个小的随机数作为初始权重。
2. 前向传播:通过前向传播算法,将输入数据输入到神经网络中,逐层计算神经元的输出。
前向传播过程中,权重起到的作用是对输入数据进行加权求和,并通过激活函数将结果转换为非线性的输出。
3. 计算损失函数:将神经网络的输出与真实标签进行比较,计算预测值与真实值之间的差距,这个差距通常使用损失函数来表示。
常用的损失函数包括均方误差、交叉熵等。
4. 反向传播:通过反向传播算法,计算损失函数对权重的梯度。
反向传播算法利用链式法则,将损失函数的梯度从输出层传递到输入层,逐层计算每个神经元对权重的梯度。
5. 更新权重:根据计算得到的权重梯度,使用优化算法(如随机梯度下降)来更新权重。
优化算法通过将权重沿着梯度的反方向进行微小调整,使得损失函数下降,神经网络的性能得到提升。
6. 重复训练:通过多次迭代训练,不断更新权重,使得神经网络能够更好地拟合训练数据,提高预测准确度。
Unet权重计算的关键是通过不断迭代训练,使得神经网络的权重逐渐调整到最优状态。
在训练过程中,需要注意避免过拟合和欠拟合的问题。
过拟合是指模型过于复杂,过度拟合了训练数据,导致在未知数据上的泛化能力较差。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
+ 1 )
d :(P
—
)荟 +
( 3 )
::一 ’ ( ’ y1
.=
, ∑ (
± =0 l
) ( 1 )
但仍 以 B P算法 为 主 . B 因 P算 法 本 质上 是一 种 梯 度法 , 如果
搜 索 步长 选 择 不 恰 当 , 敛 速 度 将 会 很 慢 , 易 于 陷人 局 部 极 收 且 小 点 . 此 , 多 研 究 者 提 出 了 改 进 的 算 法 , 要 是 围 绕 四 个 为 许 主 方 面 进 行 改 进 1 l( ) 进 学 习 率 参 数 调 节 方 法 , 学 习 率 :1 改 如
A s rc : T e i , v d B lmi m fmud a e ,u a ew r i c s d a d a l & meh d, i bt t a h mp, e P ag t o l ly r, rl t o k i d s u e n  ̄ - to e o h e n s s q t x r o e g t‘ f c D 0cel . 1 1w ih s e e tO . p 0 e so e r l r c 8 fn u a r r ii kt a a  ̄
b ln e aa c
t l }r i lI s
. i u t r t i aeta t a u ei r o 呼 S l i , t c t h ti h s a s p r m a o s ̄d o c
rt n rcs nc p aea d pe io c Ⅲd l tn ad B lo tm. h e rln t r nolew ihfsfrti a ̄ctm sas i I . i t tes d r P agrh T en ua e oi a i woks ltr hc t o s l i i l ds 1 l l i h h o cs
和计 算维 数带 来新 的 问题 . 易实 现 , 节参 数 也较 困难 本 不 调 文从 应用 角度 出发 , 出一种简 单有效 的方 法 , 大大地提 高 提 能
神 经 网络 的 收 敛 速 度 和 精 度 .
输人层 与第二层权 值 :
(o 1= ( ∑ +) )
t
r = ( wr ( , ∑ #) 2  ̄ 1 )
设 有 P 个 样 本 , 误 差 函 数 为 取
P 1 — l
.
-
专 . 一 蔷(;2 改变 激励 函数 , () 如把 S m i i o g d函数 修正 成分段 函数 ;3 权 值修 正方 法 , () 如动量项 法 、 顿法 ;4 牛 ()
K y wD s B loi m ; e r ln t u k; e e : P ag rt h , u a ew r w i , b l e ag f t n  ̄ a la t e i  ̄
1 引言
多层 前 向神 经网 络作为 一种 非线性 系统 的辨识 工具得 到
了 广 泛 的 应 用 , 前用 于 多 屉 前 向神 经 网 络 计 算 的 算 法 很 多 , 目
。 ) 采用梯 度 法 , 得到 每 一层 可 的权值 迭 代公 式 , 出层 与 第 二 输
层权值 :
图 I 多 层 前 向 神 经 网络
改变误 差 函数 . 如采 用 柯西 误 差估 计 器 的 £ = ∑ ∑ I[ + n 1
=I
【f f ] . £—o > 等 各种改进算法对提高 B 算法收敛和克服局部 P
:
( 4}
2 基于 B P算 法 的权 值 平 衡 法
2I B . P算法分析 多层 神经网络 的结 构如 图 1所示 ( 以三 层 网络 为 例 ) 输 , 入 矢量 为 0 . . , … I 层 之 间的权 为
浙 江 太 学 工 业 控 制 技 术 国 家 重 点 宴 验 室 , 江 杭 州 30 2 ) 浙 107
摘
要 : 对 前向多层 神经 网络 B P算 法 的改进 方法 作 了分 析 , 出 了一种新 的改进方 法——权 值 平衡算法 , 提 充分
发挥各权 值对 网络训 练 的作用 . 仿真结果 表明 , 新算法 与基 本 的 B P算 法相 比明显地提 高 了 网络 收敛速 度 和精度 , 对适
维普资讯
第 l期
2O O 2年 1 月
电
子
学
报
Ⅵ .0 3
№ I
AC E RO CA SI CA TA EL CT m NI
Jn a 2O 02
多层 前 向神 经 网络 的 权 值 平 衡 算 法
装浩 东, 宏 业 , 苏 褚 健
P od n , U Ho gy , HU Ja EI Ha — o g S n - e C in
( c № Lb I o*a 一 a r . l d ̄ d , r g 哪 、 ag u. h in 10 7  ̄ll) H n  ̄o g ea g3 02 ,Tba j
合运 用本算法 的神 经网络结 构作 了探 讨 . 关键词 : B P算法 ;神 经网络 ;权值 平衡 算法 中图分类 号 : T I P3 文献标 识 码 : A 文章 编号 : 07 -12( o2 l03 —3 322 1 2o )O 一190
W eg tB ln e Alo t m fMuta e u a t r ih aa c g r h o lly rNe r l i i Ne wo k